A New Approach to Line Simplification Based on Image Processing: A Case Study of Water Area Boundaries



Abstract
:1. Introduction
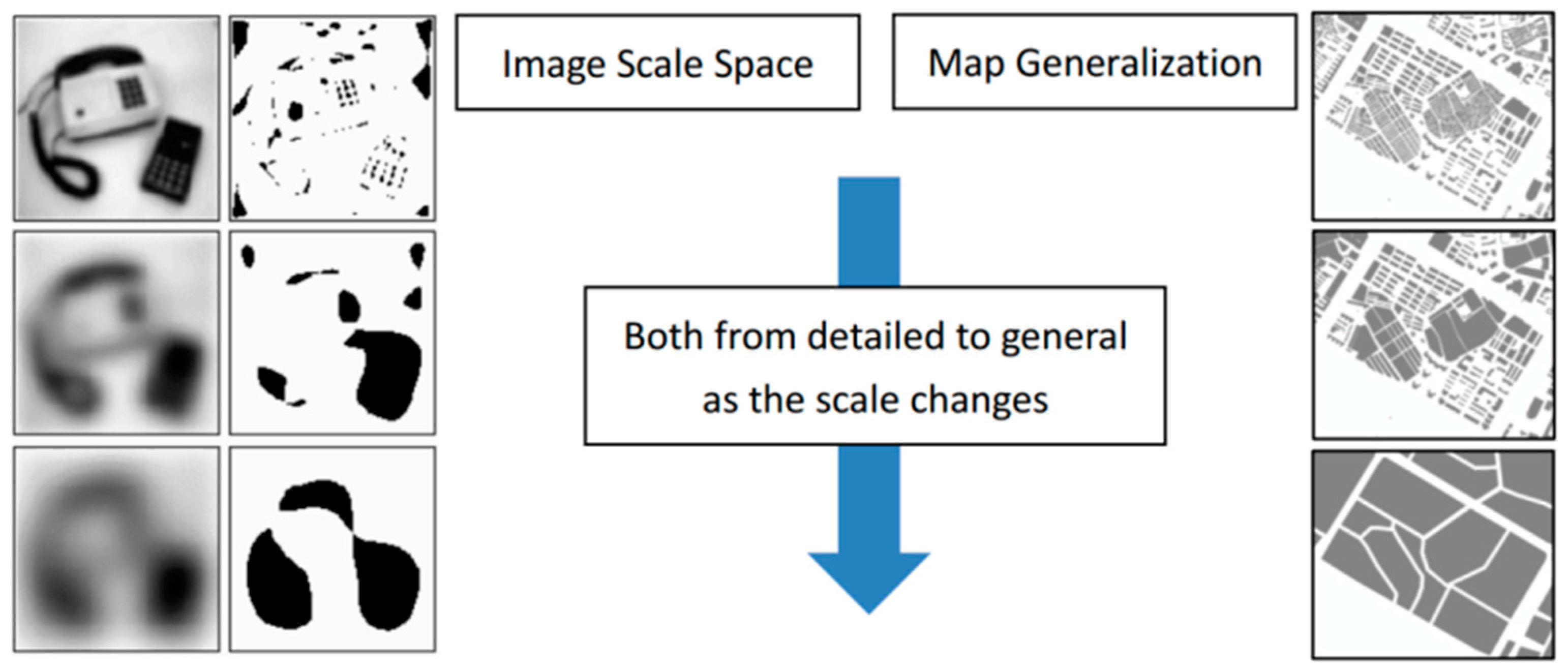
2. Scale Space and Map Generalization
3. Methodologies for Line Simplification
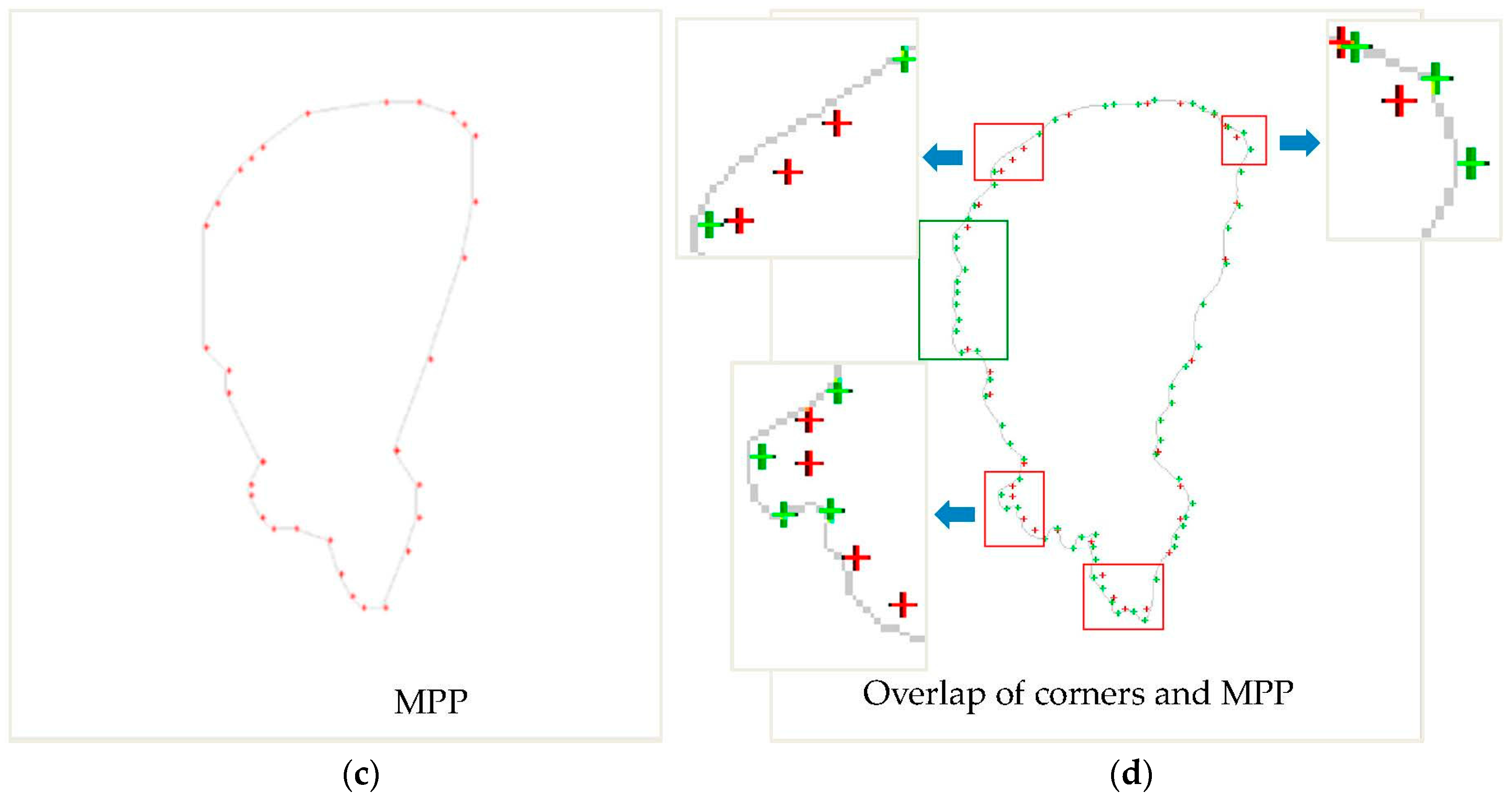
3.1. Classification and Detection of Corners
- (1)
- To obtain the binary edges, the method of Canny edge detection [55] is applied.
- (2)
- Edge contours are extracted from the edge map as described in the CSS method.
- (3)
- After the edge contours are extracted, the curvature of each contour is computed at a small scale to obtain the true corners. If the absolute curvature of a point is the local maximum, it can be treated as a corner candidate.
- (4)
- Classification of corner points. According to the mean curvature within a region of support, an adaptive threshold is calculated. The round corner is marked by comparing the adaptive threshold with the curvature of corner candidates. According to a dynamically recalculated region of support, the angles of the corner candidates should also be calculated, and any false corners will be eliminated. As a result, the corners can be divided into three types: acute and right corners, round corners, and obtuse corners.
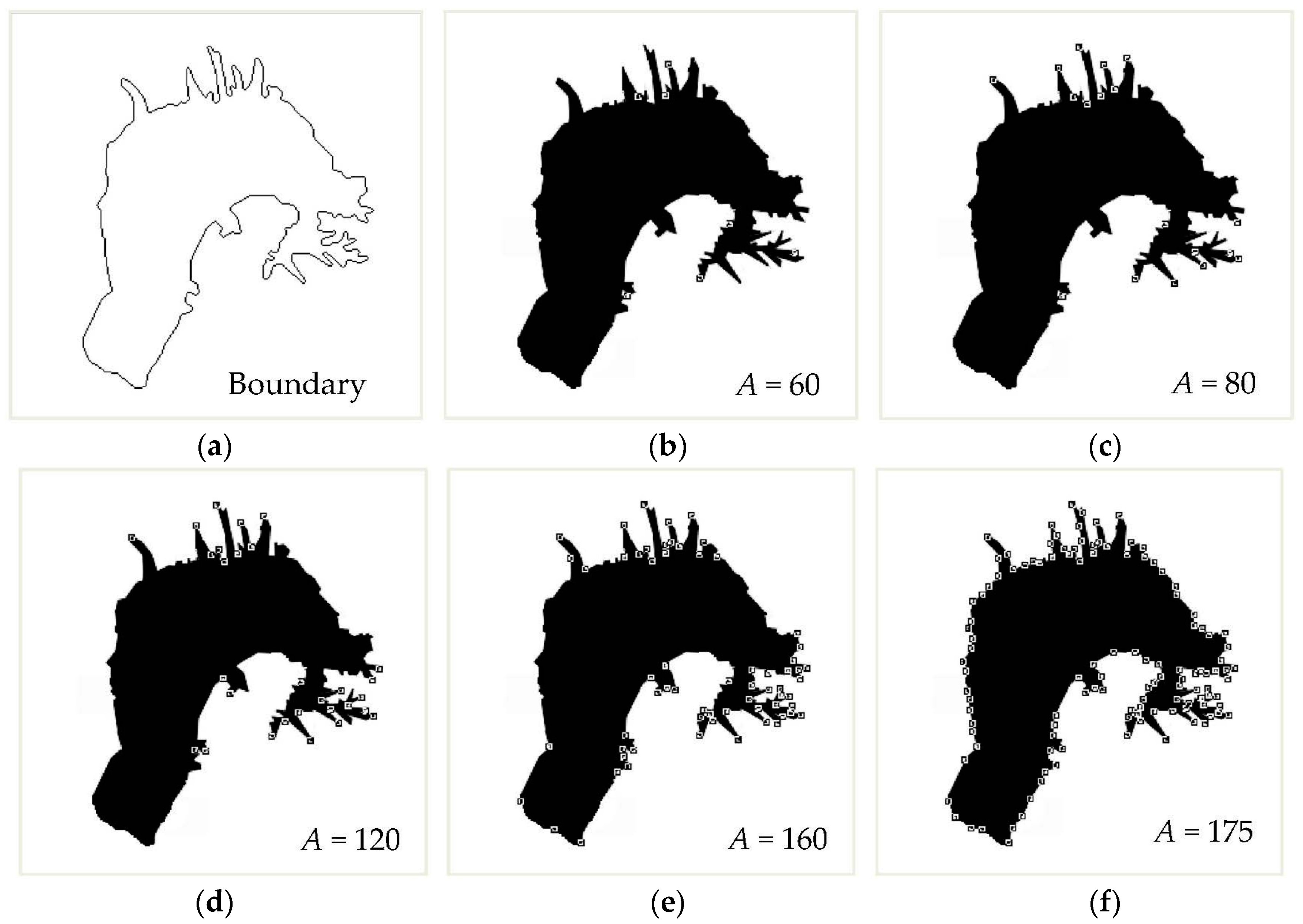
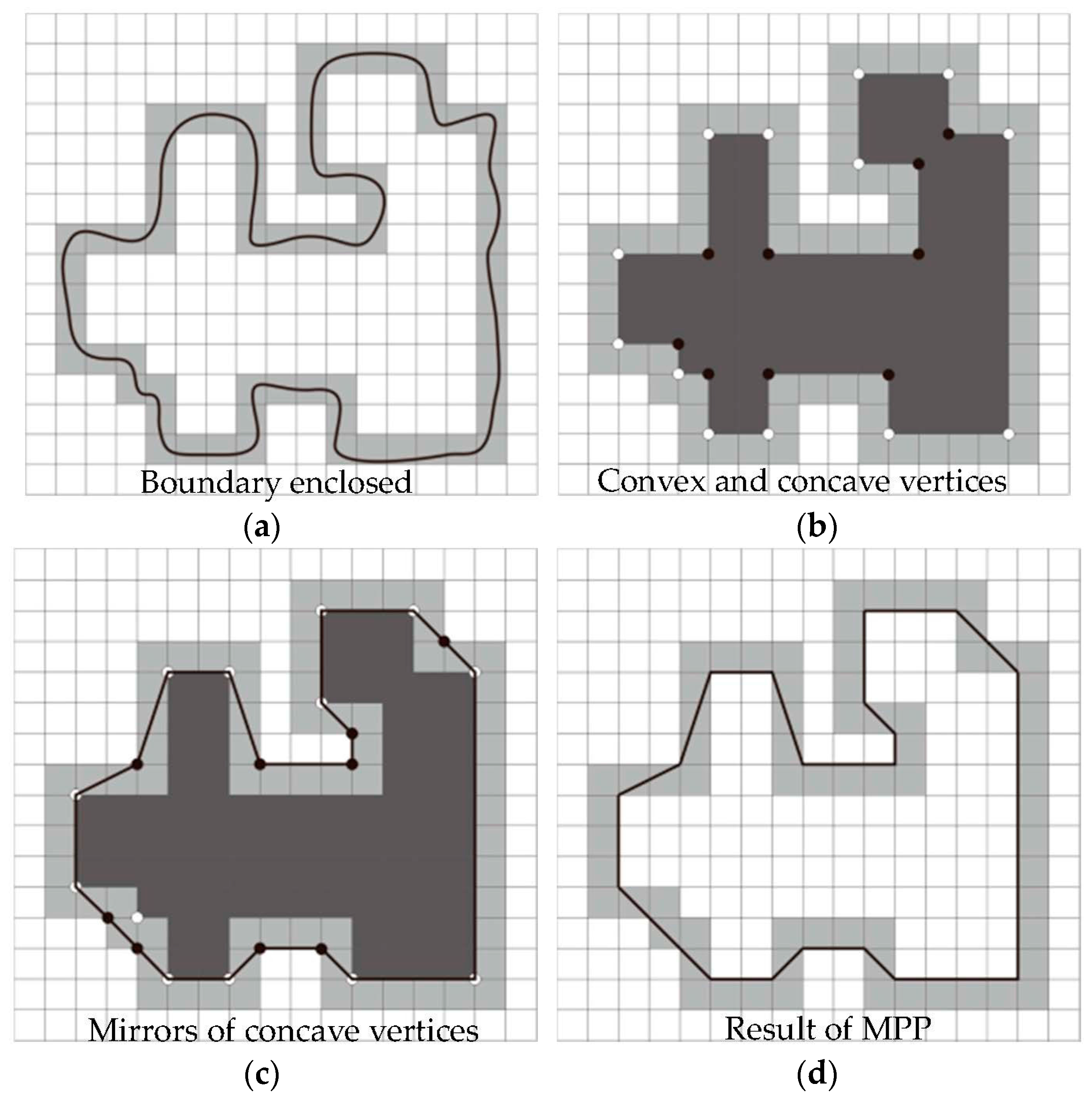
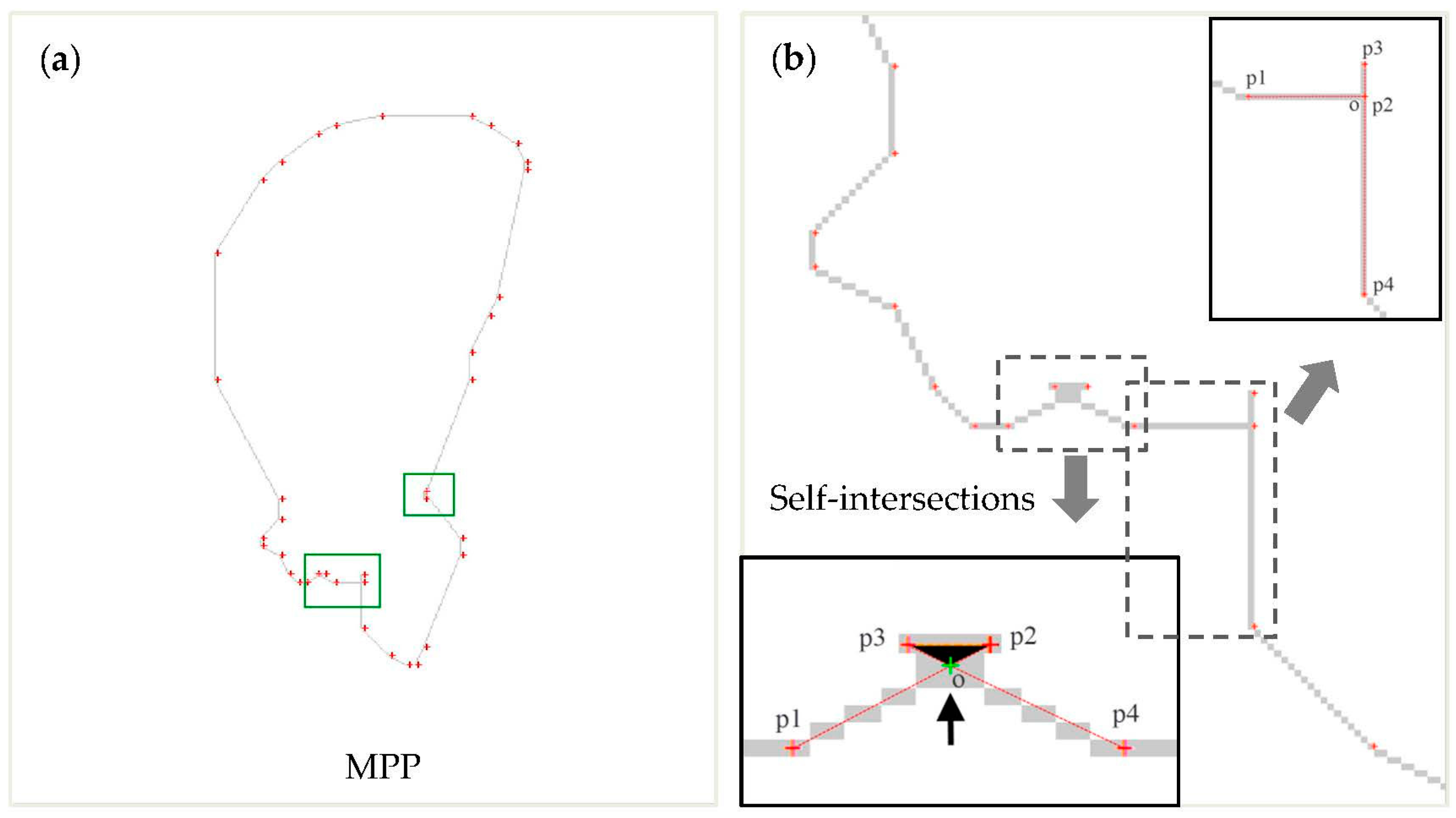
3.2. Calculation of a Minimum-Perimeter Polygon
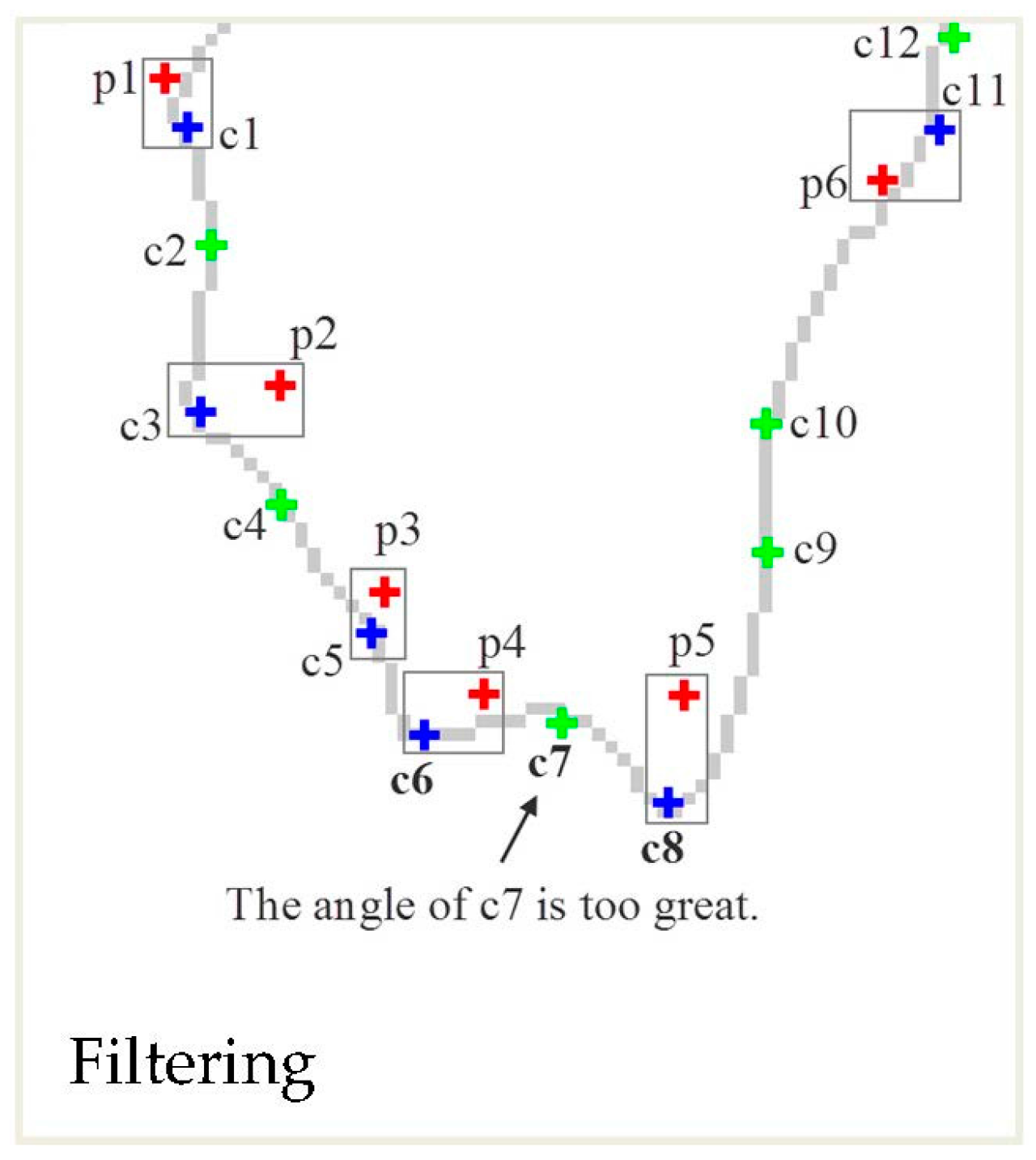
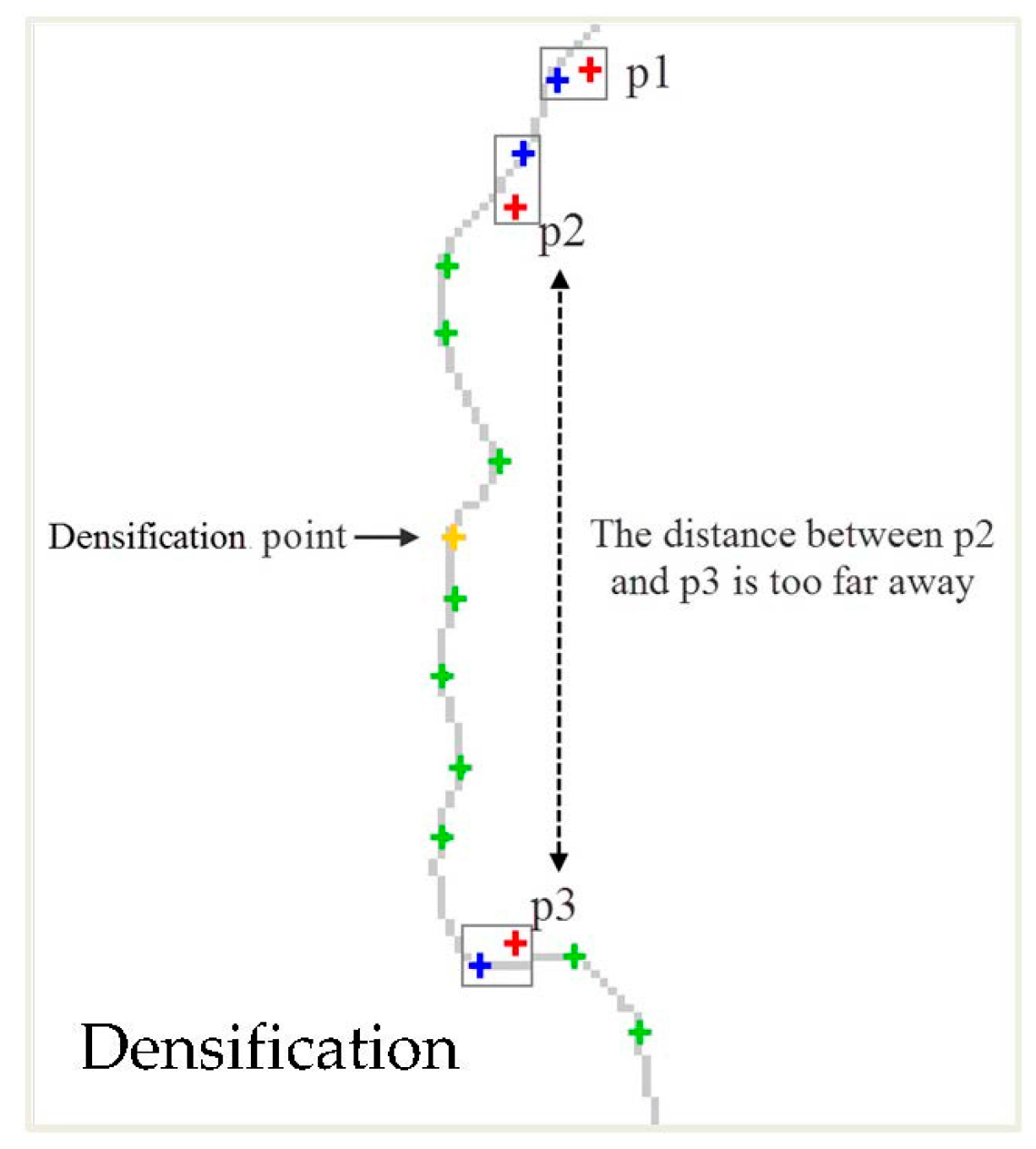
3.3. Simplification of a Polygonal Boundary
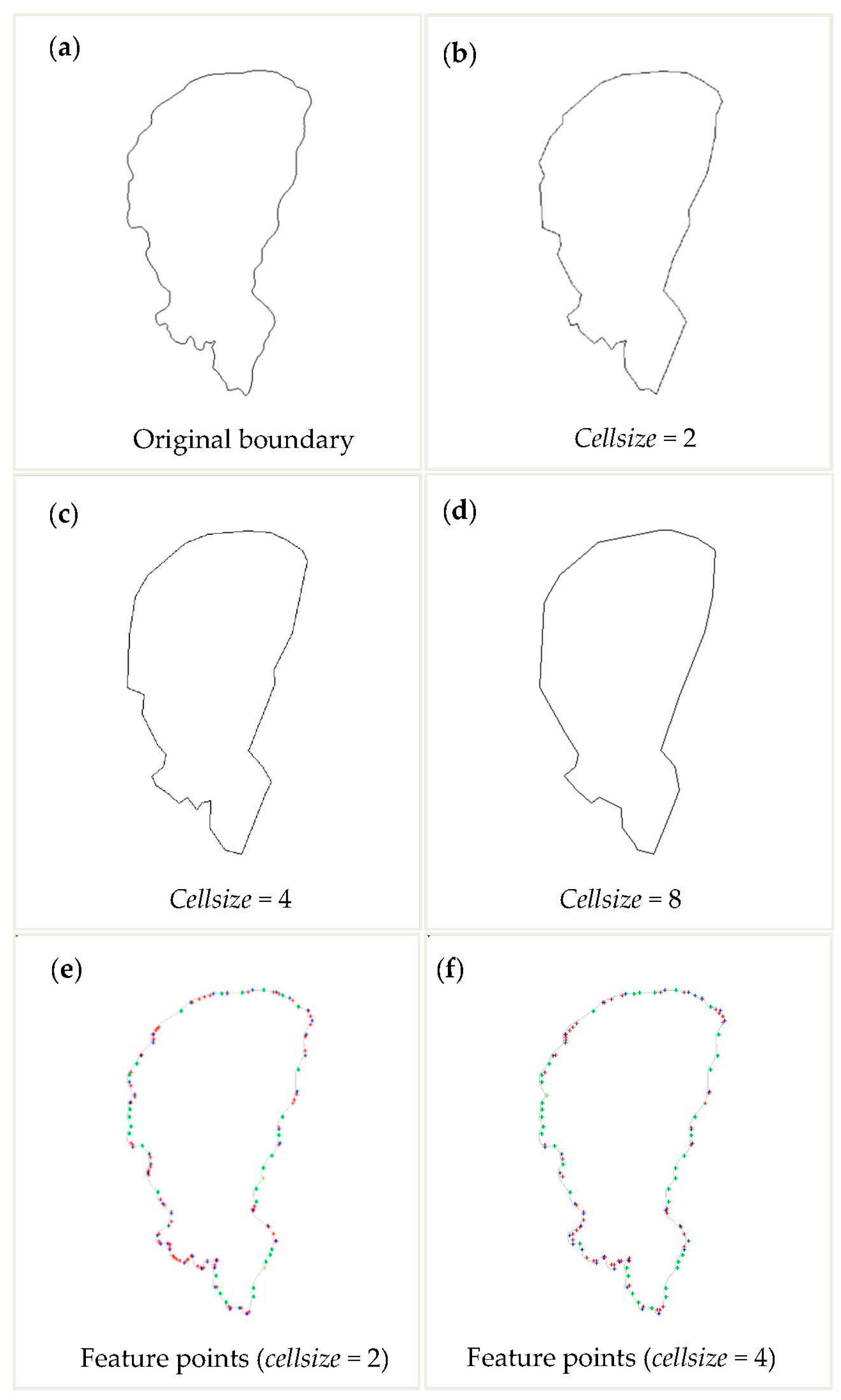
4. Experiments and Evaluations
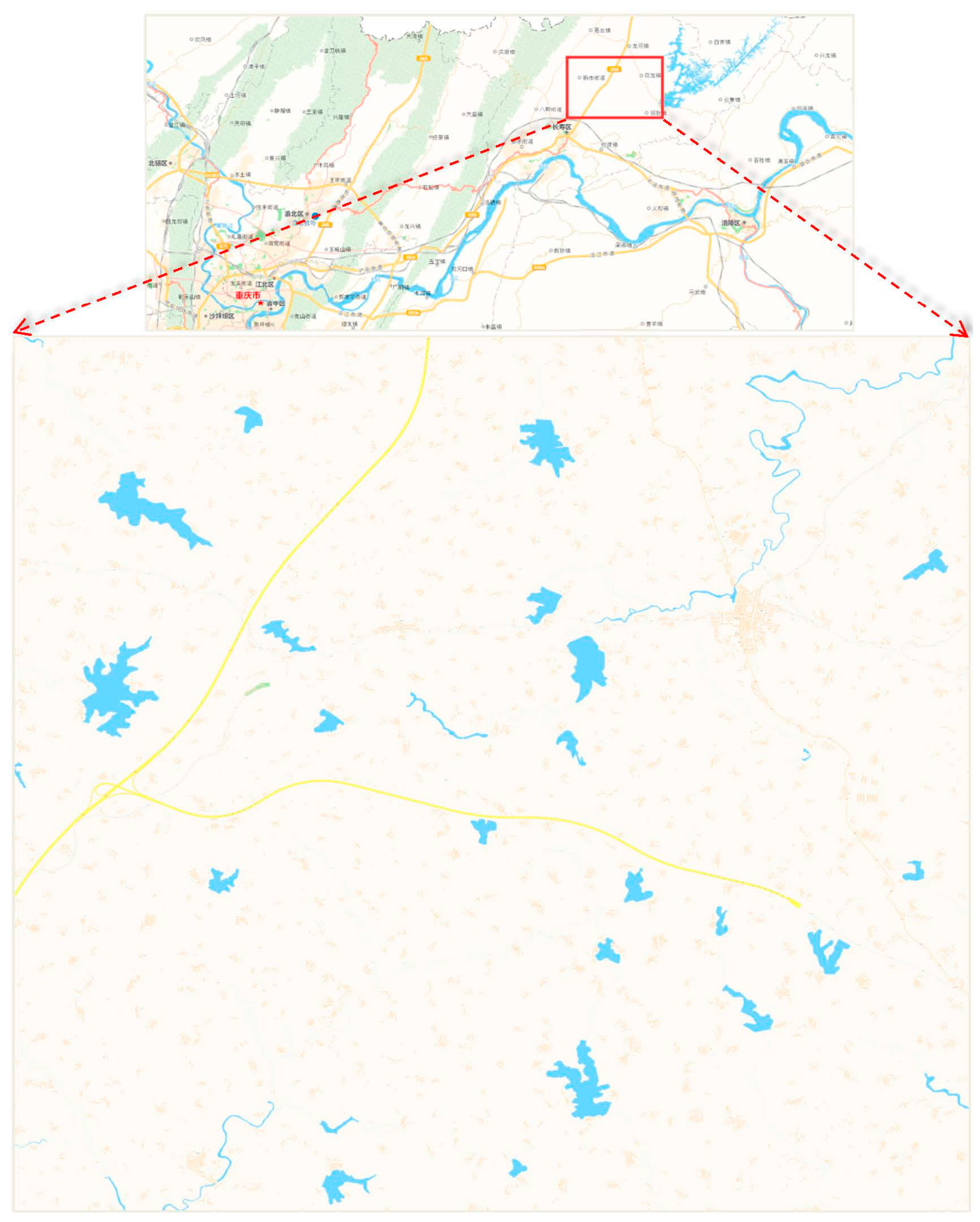
4.1. Study Area
4.2. Results and Analysis
- (1)
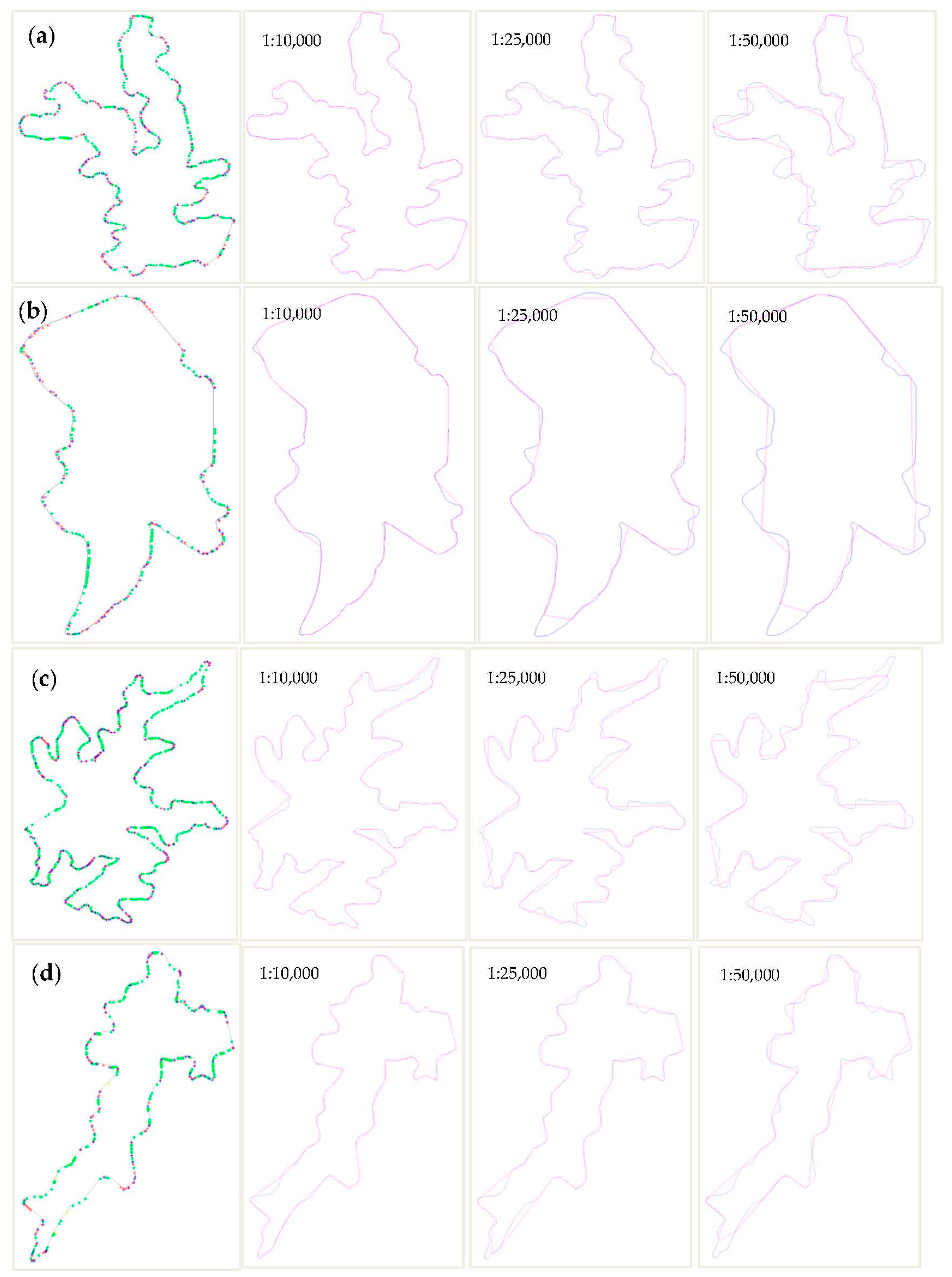
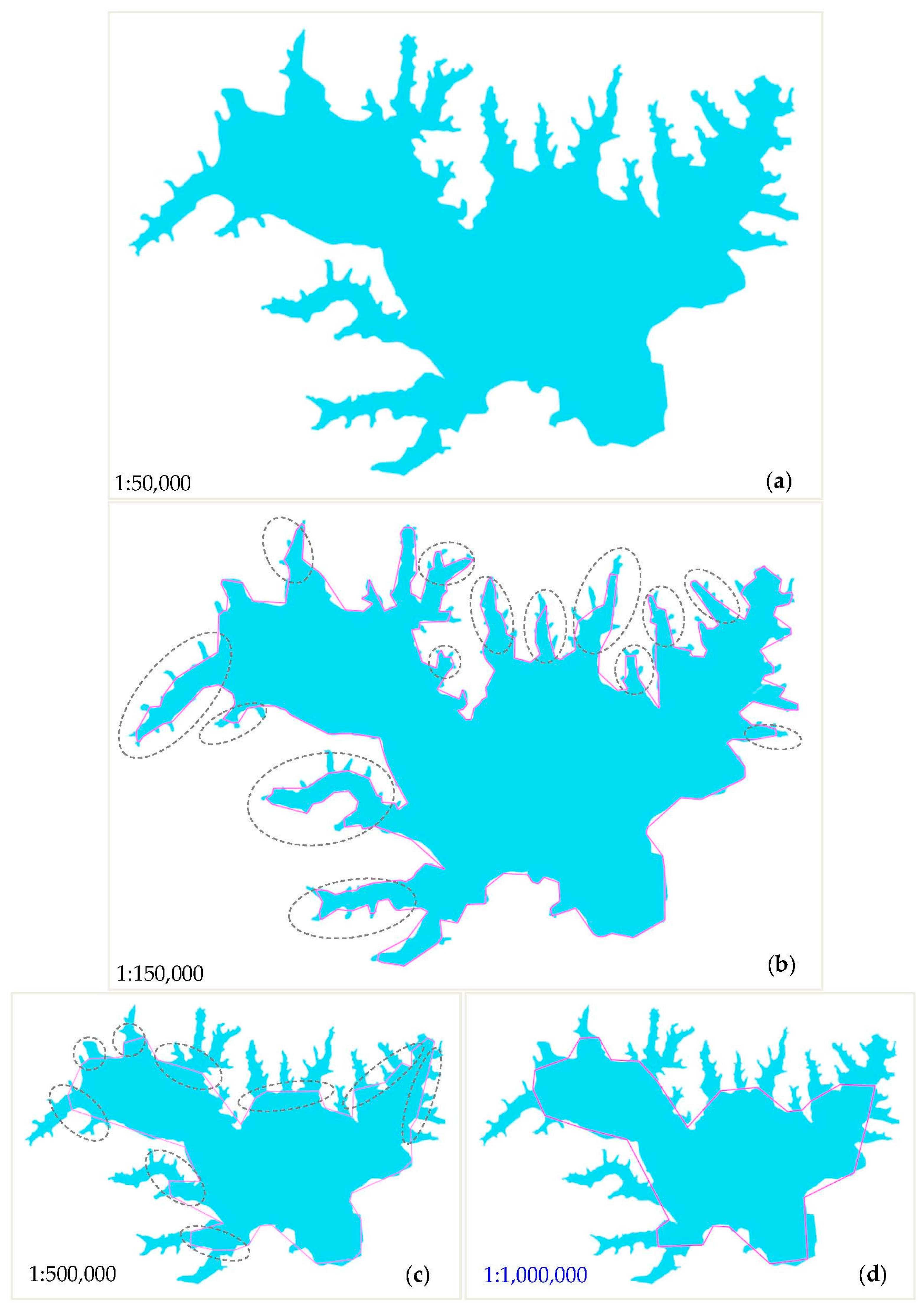
- The proposed BIP method can be effectively used for polygonal boundary simplification of water areas at different scales. The BIP method for the simplification of water areas aligns with people’s visual processes. With an increase in visual distance, i.e., as the scale becomes smaller, the small parts of an object will appear invisible. The invisible parts should be abandoned in the process of simplification. As shown in Figure 14, the black polygons are the results of simplification using the DP and WM algorithms, and the pink polygons are the results of simplification using the proposed BIP method. The smaller part of the polygon marked with the black dotted box can be removed using our method because this part is too small to be seen when the scale is small. The same areas are conserved using the DP and WM algorithms, and this type of simplification is unreasonable as we can hardly see these areas at the small scale.
- (2)
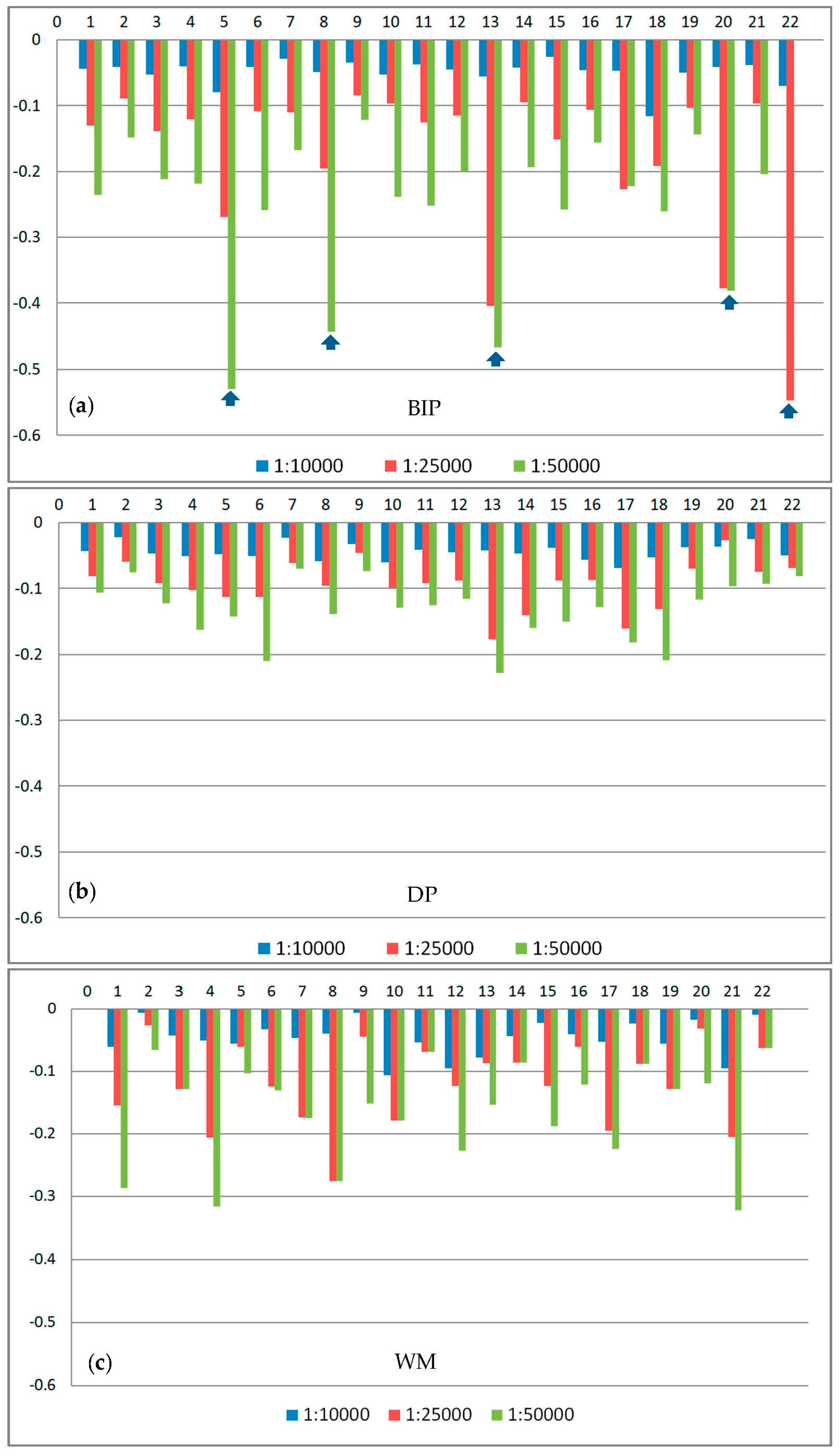
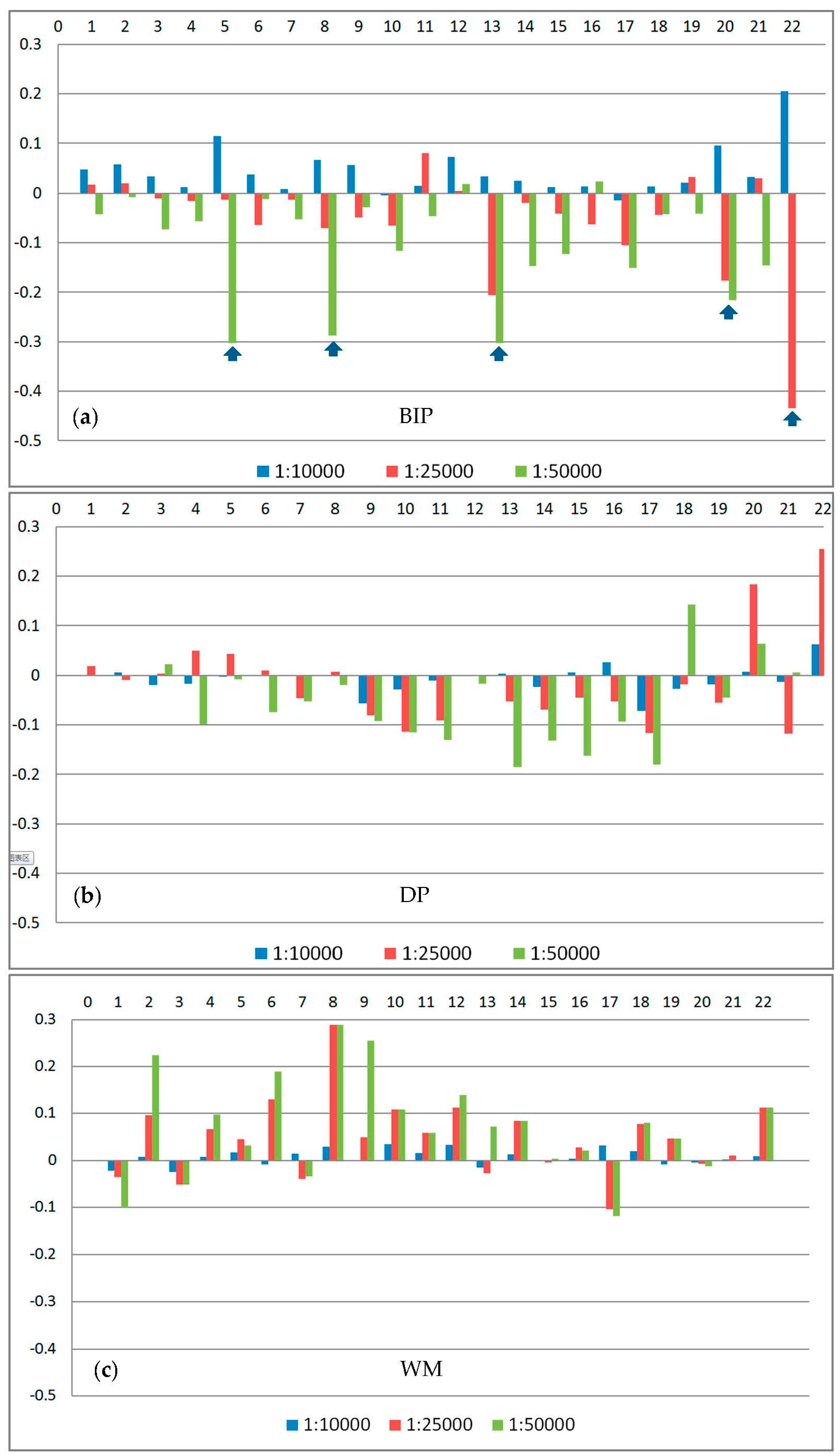
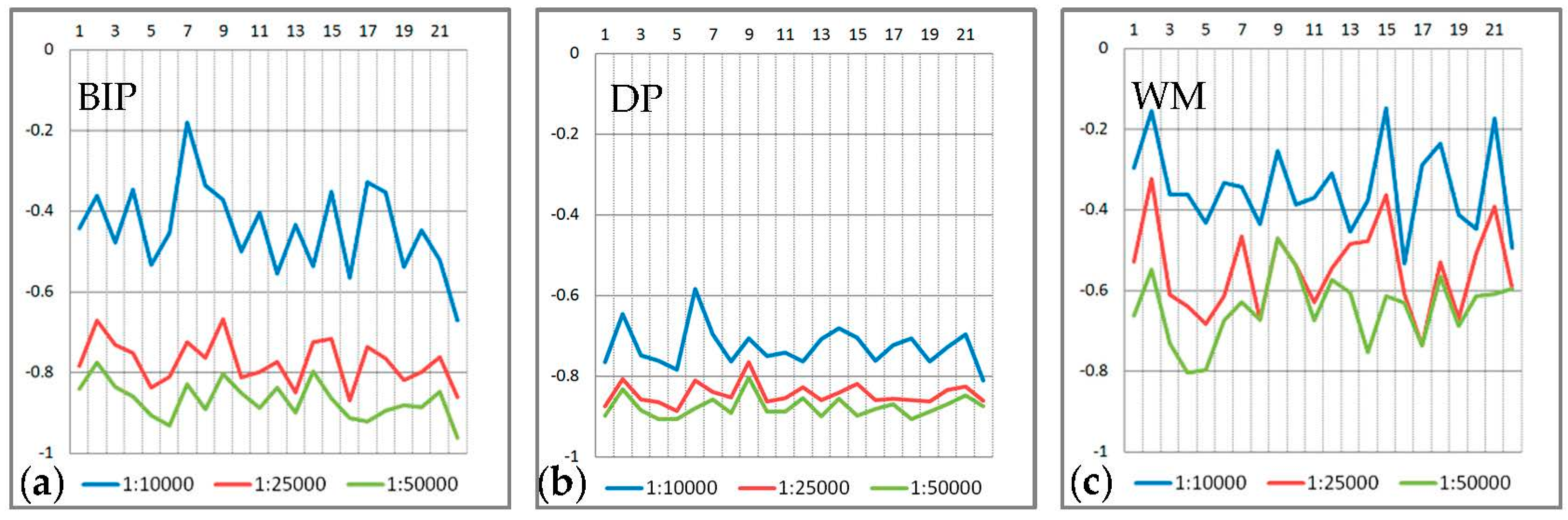
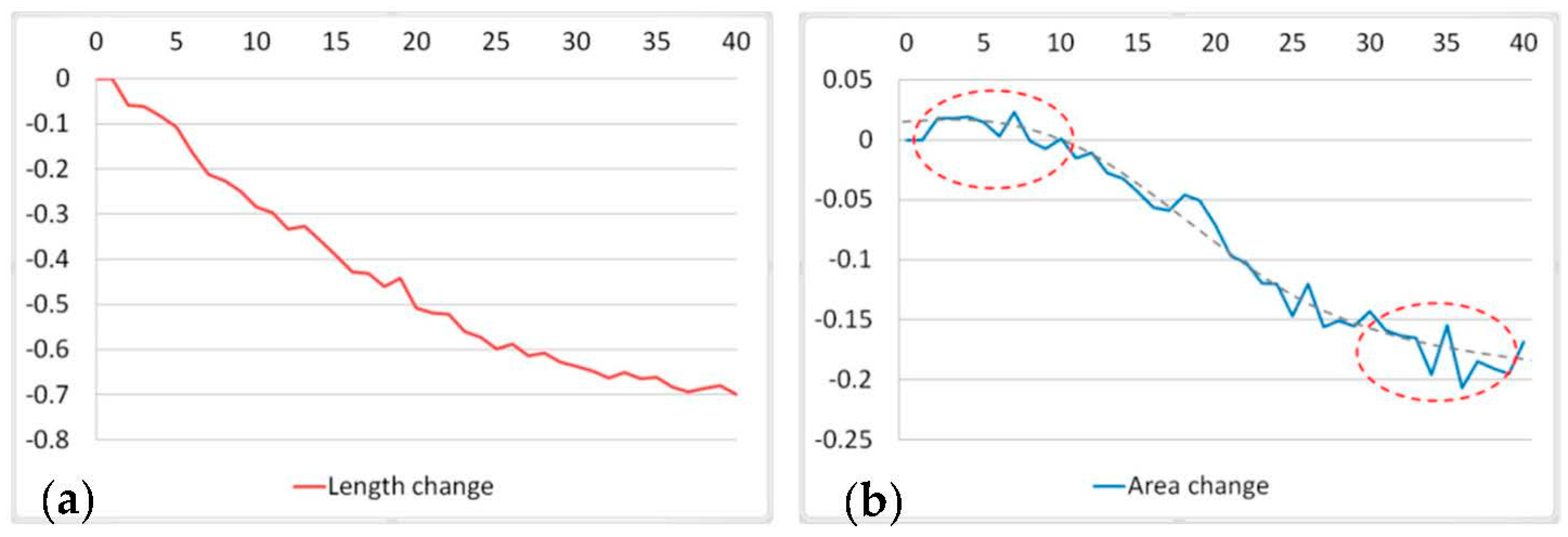
- The changes in length resulting from the proposed BIP method are slightly larger than those resulting from the DP and WM methods. With a decrease in scale, the changes in length increase for the three methods. As shown in Table 4, the average per cent changes in the perimeters at scales 1:25,000 and 1:50,000 are −0.176 and −0.253, respectively, for the BIP method. The corresponding per cent changes for the DP method are −0.094 and −0.133, respectively. However, there is an interesting phenomenon in Figure 15, which shows the detailed changes in the perimeter of each object at three scales. As shown in Figure 15, five lakes have remarkable changes in their perimeters because of characteristics based on the visual processes of the BIP method, as described in the above Section 2. In other words, removing the invisible parts leads to significant changes in the perimeters. The changes in the area between the original and simplified boundaries follow the same rule, as shown in Figure 16.
- (3)
- Figure 17 shows the comparison of changes in the number of points. The average per cent change in the number of points of the proposed method is −0.442 at the largest scale. With an increase in cellsize, the per cent change increases. The average per cent change in the number of points is −0.869 at the smallest scale. Overall, the point reduction ratio of the proposed method at the three scales is lower than the DP method, but higher than the WM methods. Additionally, as shown in Table 4, since the BIP method uses the image data to perform simplification, the execution time of the proposed method is longer than the other two methods.
- (4)
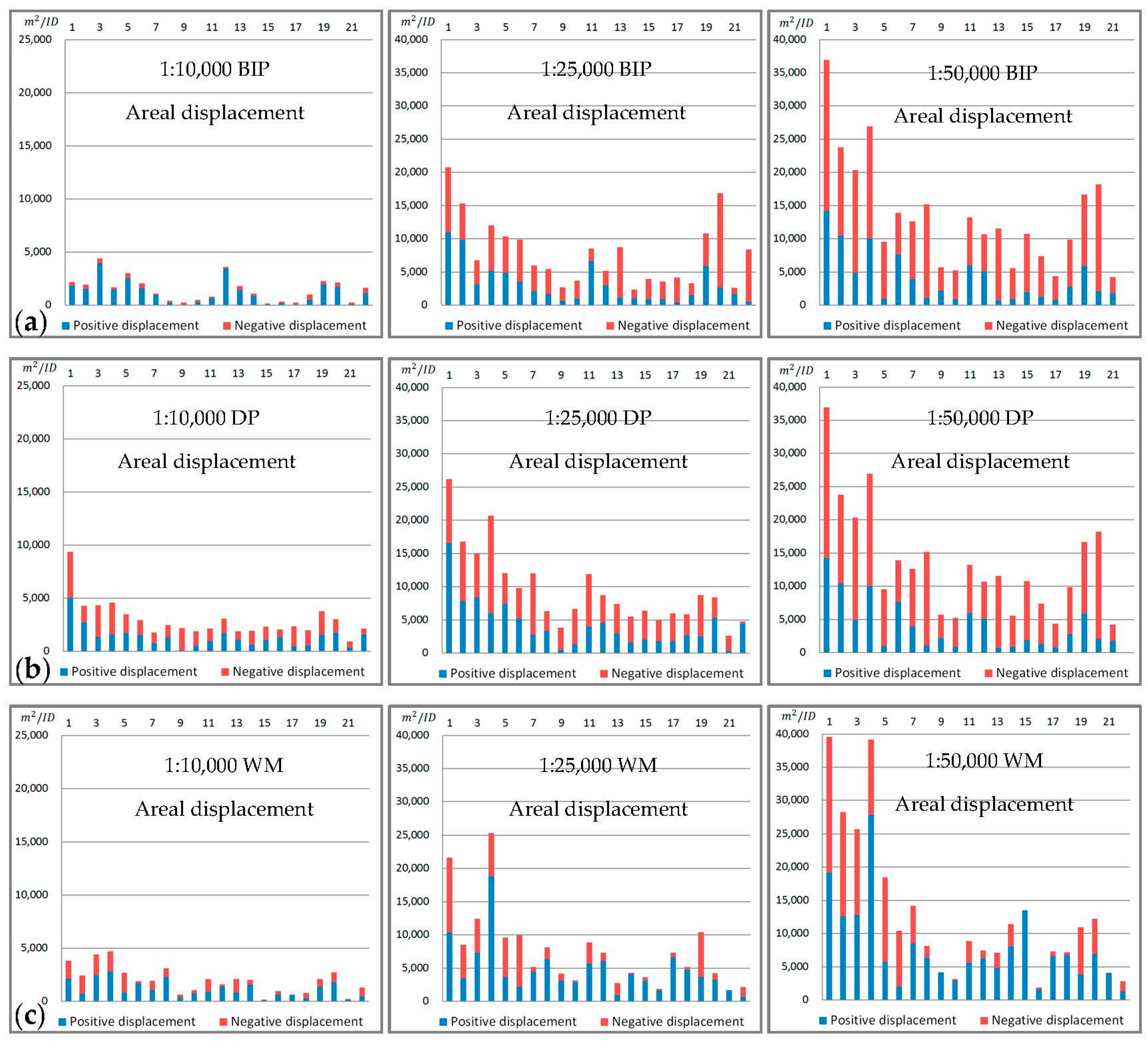
- We also use the areal displacement [60] to measure the location accuracy. As shown in Figure 18 and Table 5, the average areal displacement of the BIP method at the three scales is smaller than that of the DP method. In addition, the average areal displacement of the BIP method at scales of 1:10,000 (1494 m2) is smaller than that of the WM method (1974 m2). However, the average areal displacement of the BIP method at scales of 1:25,000 and 1:50,000 (7918 m2 and 13,468 m2, respectively) is larger than that of the WM method (7628 m2 and 13,362 m2, respectively). Thus, the location accuracy of the proposed method at the three scales is better than that of the DP method, but close to the WM method.
4.3. A Case of Hierarchical Simplification Using the BIP Method
5. Conclusions
- (1)
- The proposed BIP method can be effectively used for polygonal boundary simplification of water areas at different scales. By using the method of corner detection based on CSS, the local features of the water areas are maintained.
- (2)
- The proposed BIP simplification method aligns with people’s visual processes. As long narrow parts (as shown in Figure 14a) usually attach around water areas, the BIP method can remove the invisible long, narrow parts when the scale decreases by the definition of the minimum visibility (mv) of a feature. Therefore, this method is especially suitable for simplifying the boundary of water areas at larger scales.
- (3)
- In comparison with the DP and WM methods, the length and area change of the proposed method is slightly larger at three scales, and the maximum average percentage difference of length at the three scales is only 0.06%, and the maximum average percentage difference of area at the three scales is only 0.05%. The location accuracy resulting from the proposed BIP method is better than that form the DP method, but close to the WM method.
- (4)
- Given that the proposed BIP method can more accurately remove the details that humans do not need at larger scales, the point reduction ratio of the proposed BIP method at the three scales is lower than the DP method, but higher than the WM method. Additionally, since the BIP method uses the image data to perform simplification, the execution time of the BIP method is longer than the other two methods.
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Ai, T.; Ke, S.; Yang, M.; Li, J. Envelope generation and simplification of polylines using Delaunay triangulation. Int. J. Geogr. Inf. Sci. 2017, 31, 297–319. [Google Scholar] [CrossRef]
- Ratschek, H.; Rokne, J.; Leriger, M. Robustness in GIS algorithm implementation with application to line simplification. Int. J. Geogr. Inf. Sci. 2001, 15, 707–720. [Google Scholar] [CrossRef]
- Mitropoulos, V.; Xydia, A.; Nakos, B.; Vescoukis, V. The Use of Epsilon-convex Area for Attributing Bends along A Cartographic Line. In Proceedings of the 22nd International Cartographic Conference, La Coruña, Spain, 9–16 July 2005. [Google Scholar]
- Qian, H.; Zhang, M.; Wu, F. A new simplification approach based on the Oblique-Dividing-Curve method for contour lines. ISPRS Int. J. Geo-Inf. 2016, 5, 153. [Google Scholar] [CrossRef]
- Ai, T. The drainage network extraction from contour lines for contour line generalization. ISPRS J. Photogramm. Remote Sens. 2007, 62, 93–103. [Google Scholar] [CrossRef]
- Ai, T.; Zhou, Q.; Zhang, X.; Huang, Y.; Zhou, M. A simplification of ria coastline with geomorphologic characteristics reserved. Mar. Geodesy 2014, 37, 167–186. [Google Scholar] [CrossRef]
- Lang, T. Rules for the robot draughtsmen. Geogr. Mag. 1969, 42, 50–51. [Google Scholar]
- Douglas, D.H.; Peucker, T.K. Algorithms for the reduction of the number of points required to represent a digitized line or its caricature. Can. Cartogr. 1973, 10, 112–122. [Google Scholar] [CrossRef]
- Li, Z.L.; Openshaw, S. Algorithms for automated line generalization based on a natural principle of objective generalization. Int. J. Geogr. Inf. Syst. 1992, 6, 373–389. [Google Scholar] [CrossRef]
- Visvalingam, M.; Whyatt, J.D. Line generalization by repeated elimination of points. Cartogr. J. 1993, 30, 46–51. [Google Scholar] [CrossRef]
- Wang, Z.; Muller, J.C. Line generalization based on analysis of shape characteristics. Cartogr. Geogr. Inf. Sci. 1998, 25, 3–15. [Google Scholar] [CrossRef]
- Jiang, B.; Nakos, B. Line Simplification Using Self-organizing Maps. In Proceedings of the ISPRS Workshop on Spatial Analysis and Decision Making, Hong Kong, China, 3–5 December 2003. [Google Scholar]
- Zhou, S.; Jones, C. Shape-aware Line Generalisation with Weighted Effective Area. In Developments in Spatial Data Handling; Springer: Berlin, Germany, 2004; pp. 369–380. [Google Scholar]
- Raposo, P. Scale-specific automated line simplification by vertex clustering on a hexagonal tessellation. Cartogr. Geogr. Inf. Sci. 2013, 40, 427–443. [Google Scholar] [CrossRef]
- Gökgöz, T.; Sen, A.; Memduhoglu, A.; Hacar, M. A new algorithm for cartographic simplification of streams and lakes using deviation angles and error bands. ISPRS Int. J. Geo-Inf. 2015, 4, 2185–2204. [Google Scholar] [CrossRef]
- Samsonov, T.E.; Yakimova, O.P. Shape-adaptive geometric simplification of heterogeneous line datasets. Int. J. Geogr. Inf. Sci. 2017, 31, 1485–1520. [Google Scholar] [CrossRef]
- Dyken, C.; Dæhlen, M.; Sevaldrud, T. Simultaneous curve simplification. J. Geogr. Syst. 2009, 11, 273–289. [Google Scholar] [CrossRef]
- Saalfeld, A. Topologically consistent line simplification with the Douglas-Peucker algorithm. Cartogr. Geogr. Inf. Sci. 1999, 26, 7–18. [Google Scholar] [CrossRef]
- Mustafa, N.; Krishnan, S.; Varadhan, G.; Venkatasubramanian, S. Dynamic simplification and visualization of large maps. Int. J. Geogr. Inf. Sci. 2006, 20, 273–320. [Google Scholar] [CrossRef]
- Nöllenburg, M.; Merrick, D.; Wolff, A.; Benkert, M. Morphing polylines: A step towards continuous generalization. Comput. Environ. Urban Syst. 2008, 32, 248–260. [Google Scholar] [CrossRef]
- Park, W.; Yu, K. Generalization of Digital Topographic Map Using Hybrid Line Simplification. In Proceedings of the ASPRS 2010 Annual Conference, San Diego, CA, USA, 26–30 April 2010. [Google Scholar]
- Ai, T.; Zhang, X. The Aggregation of Urban Building Clusters Based on the Skeleton Partitioning of Gap Space. In The European Information Society: Leading the Way with Geo-Information; Springer: Berlin/Heidelberg, Germany, 2007; pp. 153–170. [Google Scholar]
- Stanislawski, L.V.; Raposo, P.; Howard, M.; Buttenfield, B.P. Automated Metric Assessment of Line Simplification in Humid Landscapes. In Proceedings of the AutoCarto 2012, Columbus, OH, USA, 16–18 September 2012. [Google Scholar]
- Nakos, B.; Gaffuri, J.; Mustière, S. A Transition from Simplification to Generalisation of Natural Occurring Lines. In Proceedings of the 11th ICA Workshop on Generalisation and Multiple Representation, Montpelier, France, 20–21 June 2008. [Google Scholar]
- Mustière, S. An Algorithm for Legibility Evaluation of Symbolized Lines. In Proceedings of the 4th InterCarto Conference, Barnaul, Russia, 1–4 July 1998; pp. 43–47. [Google Scholar]
- De Bruin, S. Modelling positional uncertainty of line features by accounting for stochastic deviations from straight line segments. Trans. GIS 2008, 12, 165–177. [Google Scholar] [CrossRef]
- Veregin, H. Quantifying positional error induced by line simplification. Int. J. Geogr. Inf. Sci. 2000, 14, 113–130. [Google Scholar] [CrossRef]
- Stoter, J.; Zhang, X.; Stigmar, H.; Harrie, L. Evaluation in Generalisation. In Abstracting Geographic Information in a Data Rich World; Burghardt, D., Duchêne, C., Mackaness, W., Eds.; Springer: Cham, Switzerland, 2014; pp. 259–297. [Google Scholar]
- Chrobak, T.; Szombara, S.; Kozoł, K.; Lupa, M. A method for assessing generalized data accuracy with linear object resolution verification. Geocarto Int. 2017, 32, 238–256. [Google Scholar] [CrossRef]
- McMaster, R.B. The integration of simplification and smoothing algorithms in line generalization. Can. Cartogr. 1989, 26, 101–121. [Google Scholar] [CrossRef]
- Bose, P.; Cabello, S.; Cheong, O.; Gudmundsson, J.; Van Kreveld, M.; Speckmann, B. Area-preserving approximations of polygonal paths. J. Discret. Algorithms 2006, 4, 554–566. [Google Scholar] [CrossRef]
- Buchin, K.; Meulemans, W.; Renssen, A.V.; Speckmann, B. Area-preserving simplification and schematization of polygonal subdivisions. ACM Tran. Spat. Algorithms Syst. 2016, 2, 1–36. [Google Scholar] [CrossRef]
- Tong, X.; Jin, Y.; Li, L.; Ai, T. Area-preservation simplification of polygonal boundaries by the use of the structured total least squares method with constraints. Trans. GIS 2015, 19, 780–799. [Google Scholar] [CrossRef]
- Stum, A.K.; Buttenfield, B.P.; Stanislawski, L.V. Partial polygon pruning of hydrographic features in automated generalization. Trans. GIS 2017, 21, 1061–1078. [Google Scholar] [CrossRef]
- Arcelli, C.; Ramella, G. Finding contour-based abstractions of planar patterns. Pattern Recognit. 1993, 26, 1563–1577. [Google Scholar] [CrossRef]
- Kolesnikov, A.; Fränti, P. Polygonal approximation of closed discrete curves. Pattern Recognit. 2007, 40, 1282–1293. [Google Scholar] [CrossRef]
- Prasad, D.K.; Leung, M.K.H. Polygonal representation of digital curves. In Digital Image Processing; Stefan, G.S., Ed.; InTech: Vienna, Austria, 2012; pp. 71–90. [Google Scholar]
- Ray, K.S.; Ray, B.K. Polygonal approximation of digital curve based on reverse engineering concept. Int. J. Image Graph 2013, 13, 1350017. [Google Scholar] [CrossRef]
- Witkin, A.P. Scale space filtering. In Proceedings of the 8th International Joint Conference Artificial Intelligence, Karlsruhe, Germany, 8–12 August 1983; pp. 1019–1022. [Google Scholar]
- Lindeberg, T. Scale-space theory: A basic tool for analyzing structures at different scales. J. Appl. Stat. 1994, 21, 225–270. [Google Scholar] [CrossRef]
- Babaud, J.; Witkin, A.P.; Baudin, M.; Duda, R.O. Uniqueness of the Gaussian kernel for scale-space filtering. IEEE Trans. Pattern Anal. Mach. Intell. 1986, 1, 26–33. [Google Scholar] [CrossRef]
- Li, Z. Digital map generalization at the age of the enlightenment: A review of the first forty years. Cartogr. J. 2007, 44, 80–93. [Google Scholar] [CrossRef]
- Fung, G.S.K.; Yung, N.H.C.; Pang, G.K.H. Vehicle shape approximation from motion for visual traffic surveillance. In Proceedings of the IEEE 4th International Conference on Intelligent Transportation Systems, Oakland, CA, USA, 25–29 August 2001; pp. 608–613. [Google Scholar] [Green Version]
- Serra, B.; Berthod, M. 3-D model localization using high-resolution reconstruction of monocular image sequences. IEEE Trans. Image Process. 1997, 61, 175–188. [Google Scholar] [CrossRef] [PubMed]
- Manku, G.S.; Jain, P.; Aggarwal, A.; Kumar, A.; Banerjee, L. Object Tracking Using Affine Structure for Point Correspondence. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Juan, Puerto Rico, 17–19 June 1997; pp. 704–709. [Google Scholar]
- Kitchen, L.; Rosenfeld, A. Gray level corner detection. Pattern Recognit Lett. 1982, 1, 95–102. [Google Scholar] [CrossRef]
- Smith, S.M.; Brady, J.M. SUSAN—A new approach to low-level image processing. Int. J. Comput. Vis. 1997, 23, 45–78. [Google Scholar] [CrossRef]
- Rosenfeld, A.; Johnston, E. Angle detection on digital curves. IEEE Trans. Comput. 1973, 100, 875–878. [Google Scholar] [CrossRef]
- Liu, H.C.; Srinath, M.D. Corner detection from chain-code. Pattern Recognit 1990, 23, 51–68. [Google Scholar] [CrossRef]
- Chabat, F.; Yang, G.Z.; Hansell, D.M. A corner orientation detector. Image Vis. Comput. 1999, 17, 761–769. [Google Scholar] [CrossRef]
- Rattarangsi, A.; Chin, R.T. Scale-based detection of corners of planar curves. In Proceedings of the 10th International Conference on Pattern Recognition, Atlantic City, NJ, USA, 16–21 June 1990; pp. 923–930. [Google Scholar]
- Mokhtarian, F.; Suomela, R. Robust image corner detection through curvature scale space. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 1376–1381. [Google Scholar] [CrossRef]
- Mokhtarian, F. Enhancing the Curvature Scale Space Corner Detector. In Proceedings of the Scandinavian Conference on Image Analysis, Bergen, Norway, 11–14 June 2001; pp. 145–152. [Google Scholar]
- Mokhtarian, F.; Mackworth, A.K. A theory of multi-scale curvature-based shape representation for planar curves. IEEE Trans. Pattern Anal. Mach. Intell. 1992, 14, 789–805. [Google Scholar] [CrossRef]
- He, X.C.; Yung, N.H. Corner detector based on global and local curvature properties. Opt. Eng. 2008, 47, 057008. [Google Scholar] [CrossRef] [Green Version]
- Sklansky, J.; Chazin, R.L.; Hansen, B.J. Minimum-perimeter polygons or digitized silouettes. IEEE Trans. Comput. 1972, 100, 260–268. [Google Scholar] [CrossRef]
- Gonzalez, R.C.; Woods, R.E. Digital Image Processing, 3rd ed.; Prentice Hall: Upper Saddle River, NJ, USA, 2008; pp. 803–807. [Google Scholar]
- Shen, Y.; Ai, T. A hierarchical approach for measuring the consistency of water areas between multiple representations of tile maps with different scales. ISPRS Int. J. Geo-Inf. 2017, 6, 240. [Google Scholar] [CrossRef]
- Muller, J.C. Fractal and automated line generalization. Cartogr. J. 1987, 24, 27–34. [Google Scholar] [CrossRef]
- McMaster, R.B. A statistical analysis of mathematical measures for linear simplification. Am. Cartogr. 1986, 13, 103–116. [Google Scholar] [CrossRef]























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cellsize (pixel) | Number of Corner Points | Number of MPP Points | Number of Simplified Points | Length Change (%) | Area Change (%) |
|---|---|---|---|---|---|
| 2 | 74 | 78 | 43 | −0.036 | 0.006 |
| 4 | 74 | 55 | 35 | −0.046 | −0.001 |
| 8 | 74 | 33 | 30 | −0.082 | −0.005 |
| Object | Scale | Number of Corner Points | Number of MPP Points | Number of Simplified Points |
|---|---|---|---|---|
| a | 1:10,000 | 487 | 189 | 162 |
| 1:25,000 | 487 | 75 | 67 | |
| 1:50,000 | 487 | 43 | 38 | |
| b | 1:10,000 | 198 | 86 | 72 |
| 1:25,000 | 198 | 29 | 28 | |
| 1:50,000 | 198 | 18 | 17 | |
| c | 1:10,000 | 668 | 218 | 194 |
| 1:25,000 | 668 | 88 | 80 | |
| 1:50,000 | 668 | 62 | 56 | |
| d | 1:10,000 | 315 | 101 | 85 |
| 1:25,000 | 315 | 51 | 49 | |
| 1:50,000 | 315 | 35 | 34 |
| Scale | Cellsize | mv | Original Resolution |
|---|---|---|---|
| 1:10,000 | 10 pixels | 1.194 mm | 1 pixel = 1.194 m |
| 1:25,000 | 30 pixels | 1.432 mm | 1 pixel = 1.194 m |
| 1:50,000 | 50 pixels | 1.194 mm | 1 pixel = 1.194 m |
| Methods | Scales | Changes in Perimeter Length (%) | Changes in Area (%) | Changes in the Number of Points (%) | Parameter Settings | Execution Time (s) |
|---|---|---|---|---|---|---|
| BIP | 1:10,000 | −0.047 | 0.044 | −0.442 | 10 pixels | 4.3 s |
| DP | 1:10,000 | −0.045 | −0.008 | −0.727 | 6 m | 0.2 s |
| WM | 1:10,000 | −0.047 | 0.007 | −0.346 | 20 m | 0.8 s |
| BIP | 1:25,000 | −0.176 | −0.055 | −0.774 | 30 pixels | 3.7 s |
| DP | 1:25,000 | −0.094 | −0.014 | −0.844 | 15 m | 0.1 s |
| WM | 1:25,000 | −0.119 | 0.048 | −0.549 | 40 m | 0.6 s |
| BIP | 1:50,000 | −0.253 | −0.103 | −0.869 | 50 pixels | 2.8 s |
| DP | 1:50,000 | −0.133 | −0.052 | −0.876 | 25 m | 0.1 s |
| WM | 1:50,000 | −0.164 | 0.068 | −0.645 | 50 m | 0.3 s |
| Scale | BIP | DP | WM |
|---|---|---|---|
| 1:10,000 | 1494 m2 | 2946 m2 | 1974 m2 |
| 1:25,000 | 7918 m2 | 9570 m2 | 7628 m2 |
| 1:50,000 | 13,468 m2 | 13,842 m2 | 13,362 m2 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shen, Y.; Ai, T.; He, Y. A New Approach to Line Simplification Based on Image Processing: A Case Study of Water Area Boundaries. ISPRS Int. J. Geo-Inf. 2018, 7, 41. https://doi.org/10.3390/ijgi7020041
Shen Y, Ai T, He Y. A New Approach to Line Simplification Based on Image Processing: A Case Study of Water Area Boundaries. ISPRS International Journal of Geo-Information. 2018; 7(2):41. https://doi.org/10.3390/ijgi7020041
Chicago/Turabian StyleShen, Yilang, Tinghua Ai, and Yakun He. 2018. "A New Approach to Line Simplification Based on Image Processing: A Case Study of Water Area Boundaries" ISPRS International Journal of Geo-Information 7, no. 2: 41. https://doi.org/10.3390/ijgi7020041
APA StyleShen, Y., Ai, T., & He, Y. (2018). A New Approach to Line Simplification Based on Image Processing: A Case Study of Water Area Boundaries. ISPRS International Journal of Geo-Information, 7(2), 41. https://doi.org/10.3390/ijgi7020041