1. Introduction
With the development of information technology and the popularization of the Internet, large amounts of data are constantly being generated. Thus, big data, which was defined by Viktor Mayer-Schonberger in 2008 and is a product of this era, has attracted increasing attention from researchers [
1,
2]. Big data can be defined as large volumes of highly varied data that are generated, captured, and processed at high velocity and have five traits that begin with the letter V, specifically: volume, velocity, variety, value, and veracity [
1,
3,
4]. Big data has gained significant impetus as a breakthrough technological development in nearly all fields, such as government administration, commercial operations, and scientific research [
5,
6,
7].
Many countries such as the USA, the UK, Canada, and Japan are committed to the development and application of multi-source government big data, which represents an important field of application of big data techniques [
8,
9]. Such data have both a wide range of data sources and are supplied in various data formats [
10,
11]. These data can be analyzed and explored to produce valuable knowledge, which can help to improve governance. Furthermore, multi-source government big data is the foundation of the development of smart cities [
11,
12,
13]. However, the application of these data is presently insufficient. Specifically, most multi-source government big data are only browsed and queried because an efficient means of processing large amounts of unstructured data, which include text-based, spatial, and multimedia data, is lacking [
4]. In addition, there is a shortage of applications of data processing and analysis techniques. Moreover, government big data are scattered among different departments without centralized management, organization, or fusion [
14].
In view of these three problems, many studies have been carried out. First, big data processing is a complete technical chain that includes data storage, calculation, and analysis [
15,
16]. Thus, previous studies have focused mainly on these three directions. In terms of data storage, the relational database management system (RDBMS) was proposed early (E.F. Codd, 1970); the NoSQL (Not Only Structured Query Language) is a currently popular approach for large and distributed data management and database design that first appeared in 1998 and was proposed a second time by Eric Evans in 2009; and a new type of distributed database (HBase) has been introduced to store and manage structured and unstructured big data (Fay Chang, 2006). In terms of calculations using data, Hadoop MapReduce, which is a distributed parallel computing framework for big data, was used in early studies (Apache Software Foundation, 2005). With the promotion of big data applications and increased diversity in the modes of computing used (which mainly involve stream calculations, graph calculations, and interactive calculations), many newly distributed parallel computing frameworks, such as Spark (UC Berkeley AMP lab, in the USA, 2009) and GraphLab (CMU, Select, 2010), have been developed [
15]. These computing frameworks broaden the modes of computing used and their efficiency is much greater. In terms of data analysis and mining, many machine learning and parallel deep learning algorithms (Hinton, 2006) have been developed to solve problems that arise in practical applications, including image recognition, natural language processing, and social network analysis. Additionally, some government data analysis methods are being applied in various departments. Many scholars use decision trees to assist in land management governance, use cluster analysis to explore the trends of urban economic development, and use statistical regression or machine learning to reveal and predict the spatiotemporal distributions of air quality (e.g., PM 2.5). Furthermore, government data management platforms have been established in many cities. These platforms can aggregate data resources from various municipal departments, so as to realize centralized management and data sharing. However, compared with the massive amounts of government data, the current application research remains inadequate. This situation leads to the wasted data sources [
4,
5].
To broaden the applications of multi-source government data, this paper focuses on those applications in construction project management using various kinds of data fusion methods and the multi-criteria decision aiding (MCDA) analytic hierarchy process (AHP). Currently, given the impetus supplied by electronic government affairs, the correlation of attributes of government data is implemented in most e-government systems [
17,
18]. However, the correlation of text-based and spatial data is still in its infancy at the application level. The MCDA is also widely used in other fields: Shirley Chua Jin Lin explored the procurement strategies of the government (2015); Eylem Koc and Hasan Arda Burhan explored the location selection of commercial circles (2015); Lakshmi Tulasi and Ramakrishna Rao explored resource allocation in project scheduling (2014); Li Hongxian and Mohamed Al-Hussein explored risk identification and the assessment of modular construction (2013); and Wang Xiaodi and Peng Xiuyan explored the evaluations of educational equipment efficiency factors (2011) [
19,
20,
21,
22,
23]. However, MCDA has rarely been applied in urban construction and supervision.
To address this problem, this paper examines a practical application of the fusion of multi-source big government data to urban construction and supervision in Tianjin, China. Various data from different departments, such as the urban planning and urban construction departments and the environmental protection bureau, are used to assess the degree to which construction projects satisfy the relevant legal requirements. Specifically, this study combines the three modes of data fusion. We use a text correlation method, correlated attributes, and a spatial correlation method to calculate the degrees of correlation of a project name and location description, construction unit, and spatial intersection. In addition, this study applies the multi-criteria decision aiding (MCDA) analytic hierarchy process (AHP) to calculate the correlations of every construction segment within individual projects. We note that a construction project can be separated into several segments, according to its degree of completion [
24]. Moreover, we develop a new method that is based on the results of the AHP to calculate the correlations between different construction projects. If the correlation is lower than some threshold, which is set based on experience, it means that the construction project or segment does not satisfy the relevant legal requirements. The application of multi-source government data in construction supervision and the quantitative calculation of data correlations will broaden the horizons of this field and provide key insight for use by the construction supervision department.
3. Results and Discussion
3.1. Description of Construction Project Cases
To apply the abovementioned method to actual construction projects using multi-source government data, two construction project cases are introduced to calculate the degree of correlation of different approval items within individual construction projects and between different construction projects. The selected approval items and a qualitative evaluation of the degree of correlation between the factors of two construction projects are listed in
Table 3.
3.2. Calculation of the Degree of Correlation of the Approval Items in a Single Construction Project
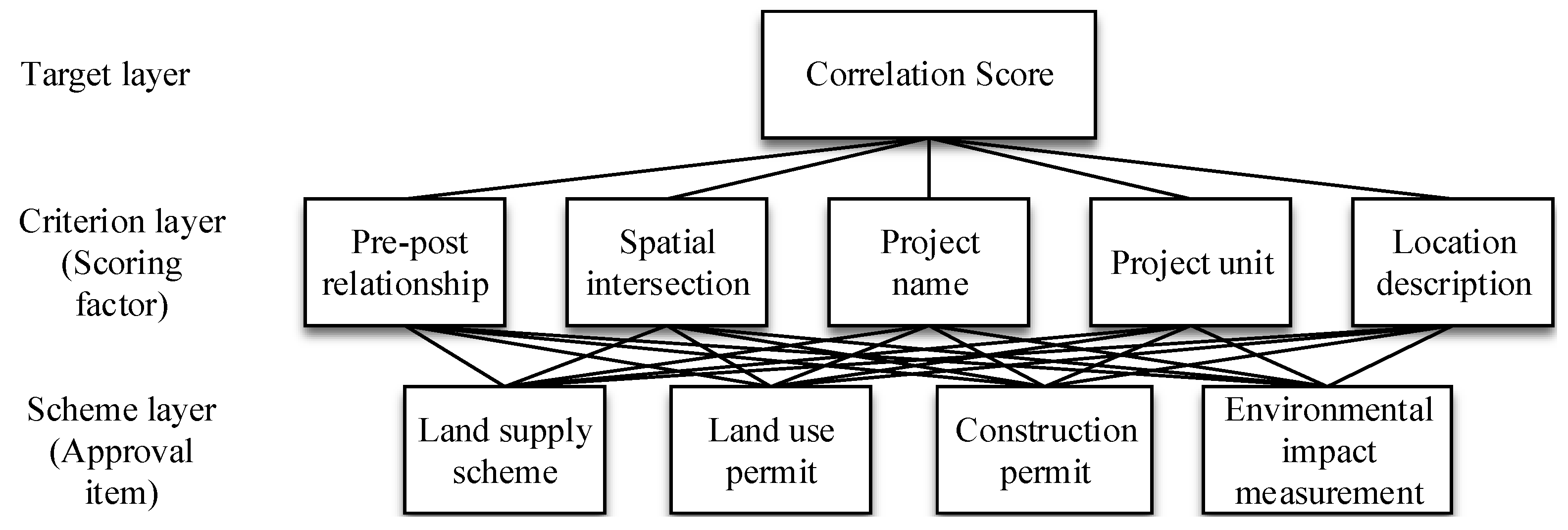
1. Hierarchical Single Arrangement
The priority is to determine the values of the correlation factors in the criterion layer. These values are determined and screened from the approval data of the construction projects based on the experience of the experts, which has a significant effect on the correlation scores. In this study, five correlation factors (pre-post relationships, spatial intersection, the project name, the project unit, and the location description) are grouped to form the criterion layer in the analytic hierarchy model. Some approval items, such as the land supply scheme, the land use permit, the construction permit, and the environmental protection measures of a project, play major roles in the entire construction project. Thus, these approval items are assigned to elements in the scheme layer. On this basis, these factors are organized into a complete hierarchical structure that conveys the subordinate relationships and correlations. The AHP model is layered. Although the upper layer is affected by the correlation factors of the middle layer and the approval items of the bottom layer, the factors within a given layer are independent. The AHP model for Tianjin is shown in
Figure 3.
Note that each correlation factor in the criterion layer is connected with the different approval items of the scheme layer, and the factors in the upper layers are clearly related and subordinated to those of the lower layers. To calculate and quantitatively represent the importance of the elements in the scheme layer to the correlation factors in the criterion layer, pairs of the correlation factors in the criterion layer are compared with each other to construct a comparison matrix. Based on the comparison of pairs of factors, the results are scaled in the judgment matrix.
Table 4 shows the judgment matrix that reflects the results of comparing the correlation factors.
Note that the project unit is the weakest of the five factors, and pre-post relationships represent the strongest factor. The weights of each correlation factor in the criterion layer can be calculated. The normalized weights of the five correlation factors corresponding to the maximum eigenvalue are , and the CR is 0.004 << 0.1. These results demonstrate that the comparison matrix displays complete consistency. Moreover, the pre-post relationships are shown to have the greatest effect on the calculated degree of correlation among the approval items in a construction project. When arranged in descending order according to their weights, the remaining factors are a spatial intersection, the project name, the location description, and the project unit.
2. Hierarchical Total Arrangement
The purpose of this section is to calculate the degree of correlation among different approval items within a single project. This study selects four approval items, which are mentioned in
Figure 2. Specifically, they are the land supply scheme, the land use permit, the construction permit, and the environmental impact assessment. Note that each correlation factor has a fourth-order comparison matrix, and each matrix shows the real correlation among the four approval items. For example, the comparison matrix of the pre-post relationships for construction project A is as follows (the other comparison matrices are provided in the
Supplementary Materials):
All the results are shown in
Table 5, including the maximum eigenvalues and the corresponding eigenvectors of the two construction projects.
The hierarchical total arrangement, that is, the degree of correlation among different approval items in a single construction project, can be calculated according to this table. The results are shown in
Table 6.
Overall, land use is the approval item with the highest degree of correlation for both construction projects. This result indicates that the approval data of the construction projects are relatively complete for this approval item, and this item has a relatively high probability of satisfying the relevant legal requirements. Thus, the supervision of construction projects should be strengthened in the other approval items.
3.3. Calculation of the Degree of Correlation Among Different Construction Projects
The purpose of this section is to calculate the degree of correlation among different construction projects. As a result of the curse of dimensionality, it is impossible to use the AHP to calculate the degree of correlation among different construction projects. The new approach has been introduced to solve the problem, and the details of this approach are provided in
Section 2.3.2. This study selects two construction projects and calculates the correlation matching degree of these projects separately. For example, on the basis of the pre-post relationships comparison matrix, the quantitative representation of the correlation matching degree of this factor in construction project A is as follows (the other comparison matrices are shown in the
Supplementary Materials):
The correlation scores of the two construction projects are shown in
Table 7, according to all the comparison matrices with quantitative representations of the correlation matching degree and the weight of each factor.
The result shows that project B has higher correlation scores than project A. Pre-post relationships (SB = 14.4 versus SA = 9.6) and spatial intersection (SB = 16.1 versus SA = 12.1) are the main factors that determine their scores. Specifically, the description of pre-post relationships in construction project B is more consistent than that of construction project A. In addition, the spatial relationship is nearly coincident among the four approval items in construction project B, whereas the area of spatial intersection is less than 50% or even less in construction project A.
3.4. The Calculation of the General Degree of Correlation of Typical Approval Items and Complete Construction Projects
This study calculates the degree of correlation of 30,996 typical approval items and 7749 construction projects.
Table 8 shows the results, including the matching correlation rate and the matching accuracy, and
Table 9 shows the same results for the complete construction projects. Note that the resulting matching correlation rates are calculated using data uploaded by different departments, and the resulting matching accuracies are counted on a per-investigation basis. In addition, the thresholds of the degree of correlation for approval items and construction projects have been set to 0.55 and 28.0, respectively, based on practical experience.
The overall degree of correlation of typical approval items and different construction projects is satisfactory (higher than 70%). Two of the approval items, the land supply scheme and the land use permit, have high matching correlation rates and matching accuracies. The former values are approximately 90%, whereas the latter values even exceed 95% because the data for both of these approval items are complete and are less likely to change than those of the others. Moreover, given the decline in the quality of construction project approval data and the increase in illegal construction projects, the general degree of correlation of complete construction projects in 2016 is lower than that in 2015. These results indicate that the quality of construction project approval data should be improved, and the level of construction project supervision must be increased.
The experiments reported in
Section 3.1,
Section 3.2,
Section 3.3 and
Section 3.4 demonstrate the core concepts used in the calculation of the degree of correlation; namely, the calculation of the degree of correlation of typical approval items within individual construction projects using AHP and the calculation of the degree of correlation among different construction projects using the new approach presented here. The two forms of the degree of correlation can be calculated using these two methods. The results provide useful suggestions for the supervision of construction projects.
However, our methods have several implicit flaws. The quantification of all of the factors considered in calculating both forms of the degree of correlation is subjective. In addition, this paper does not consider other relevant factors such as project progress and the project principal.
4. Conclusions
The fusion of multi-source government data has been applied to urban construction and supervision to assess the supervision degree and the legitimacy of construction projects in Tianjin. This study broadens the horizons of the fusion of government data and provides some suggestions to the construction supervision department.
The AHP and a new degree of correlation algorithm are used to calculate the correlation scores between the different approval items within individual construction projects and among different projects, respectively. The results show about 80% correlation for the construction projects and their approval items, which is relatively high.
Future work based on this study will include three main parts. First, the degree of correlation algorithm should be modified to improve the accuracy of the degree of correlation matching of construction projects. Second, the fusion of multi-source government data should be extended to fields including environmental protection, urban planning, and public safety. Third, a multi-source big government data computing framework such as Hadoop or Spark should be established to accelerate the calculation process.

 ,
, 




{kind=link}
{kind=link}
{kind=link}