Mining Individual Similarity by Assessing Interactions with Personally Significant Places from GPS Trajectories

Abstract
:1. Introduction
- (1)
- We present a framework for mining individual similarity. The novelty of the proposed similarity measurement, called the ISM-PSP, lies in exploring both the spatial distribution and temporal signatures of individuals’ significant visits. Unlike existing similarity approaches, we go beyond simply emphasizing the sequential aspects of individuals’ movements.
- (2)
- We propose that two individuals’ significant visits can be compared only when they are identical in their semantic aspects. In contrast to many previous works, which have addressed commonly interesting places and their functionality for the general public, we determine the semantics of individually significant places from the perspectives of personal behavior. Specifically, when extracting the semantics of significant places, we consider places of both personal and public interest. We interpret the semantics of personal places of interest based on the temporal distribution of a person’s presence, and determine the semantics of public places of interest using public geographic databases.
- (3)
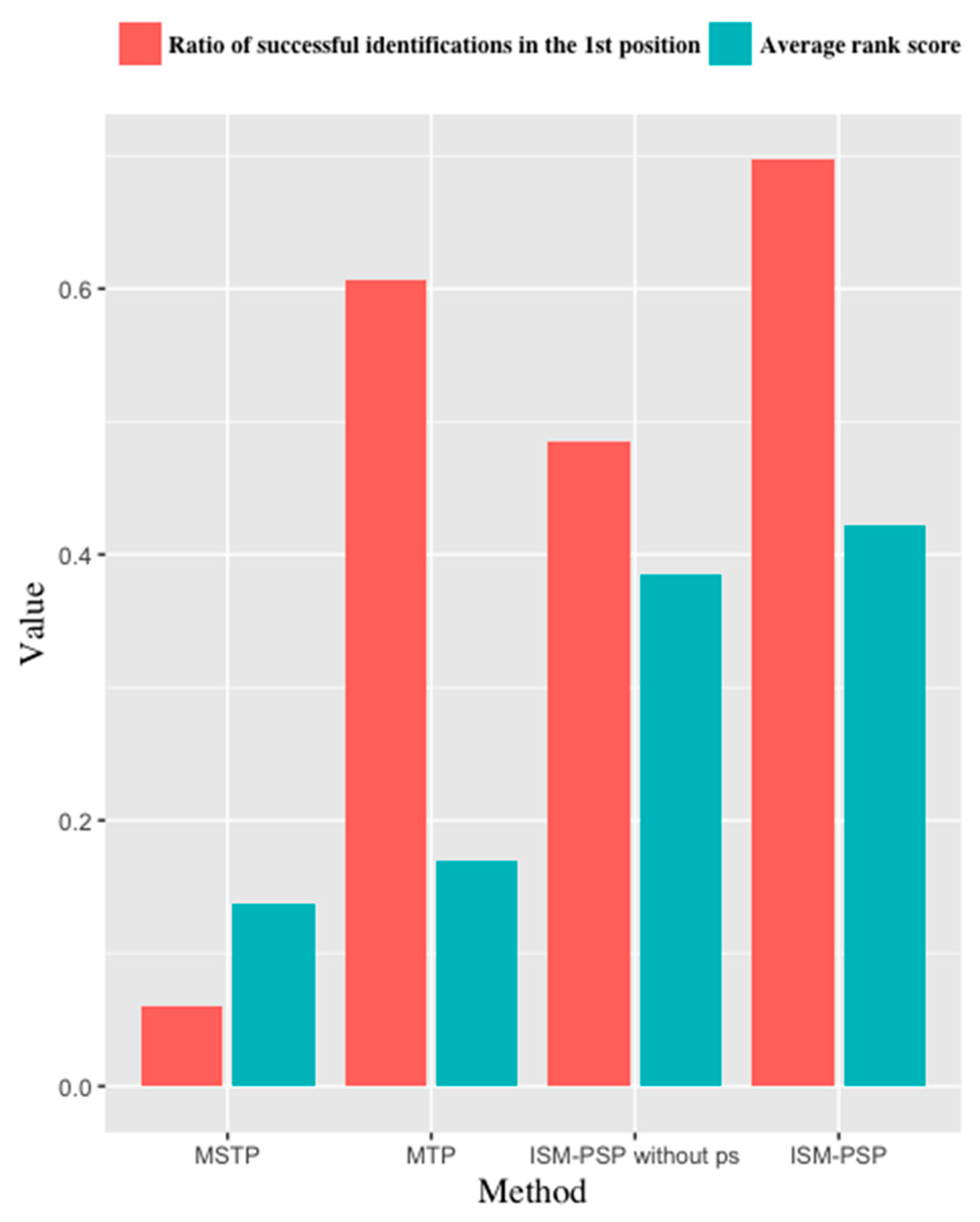
- We conduct several experiments using the real-world Geolife dataset. The results show that the proposed ISM-PSP outperforms previous works in its ability to differentiate between individuals. It presents a high ratio of finding identical individuals, while maintaining a low number of false identifications and can be used to generate meaningful groups of individuals. In addition, a comparison of the ISM-PSP results with and without personal meaning illustrates the insufficiency of many previous works, in which only visits to public places have been considered when mining individual similarity.
2. Related Work
2.1. Significant Place Semantics Extraction
2.2. User Similarity Measurement
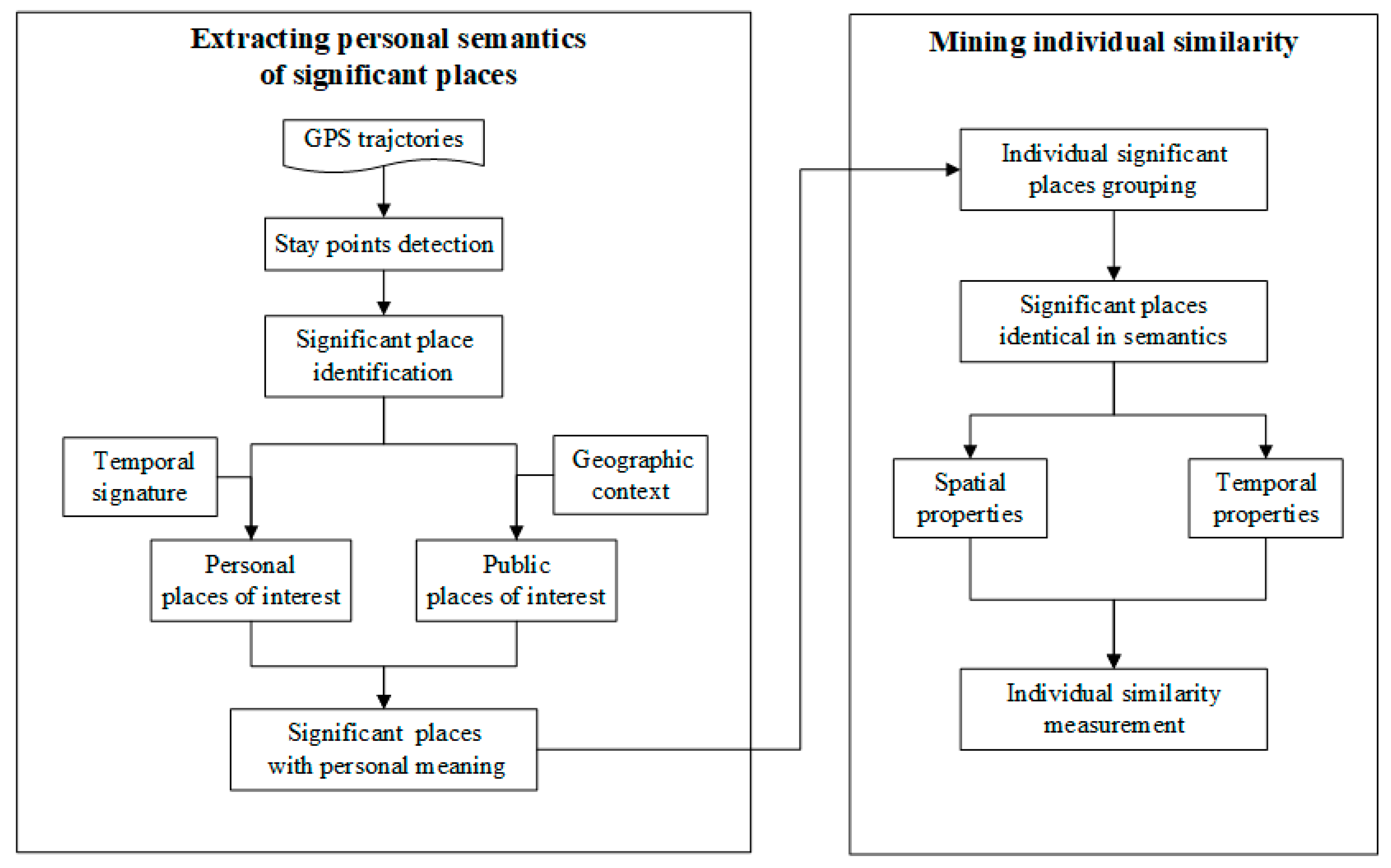
3. Proposed Framework
3.1. Overview
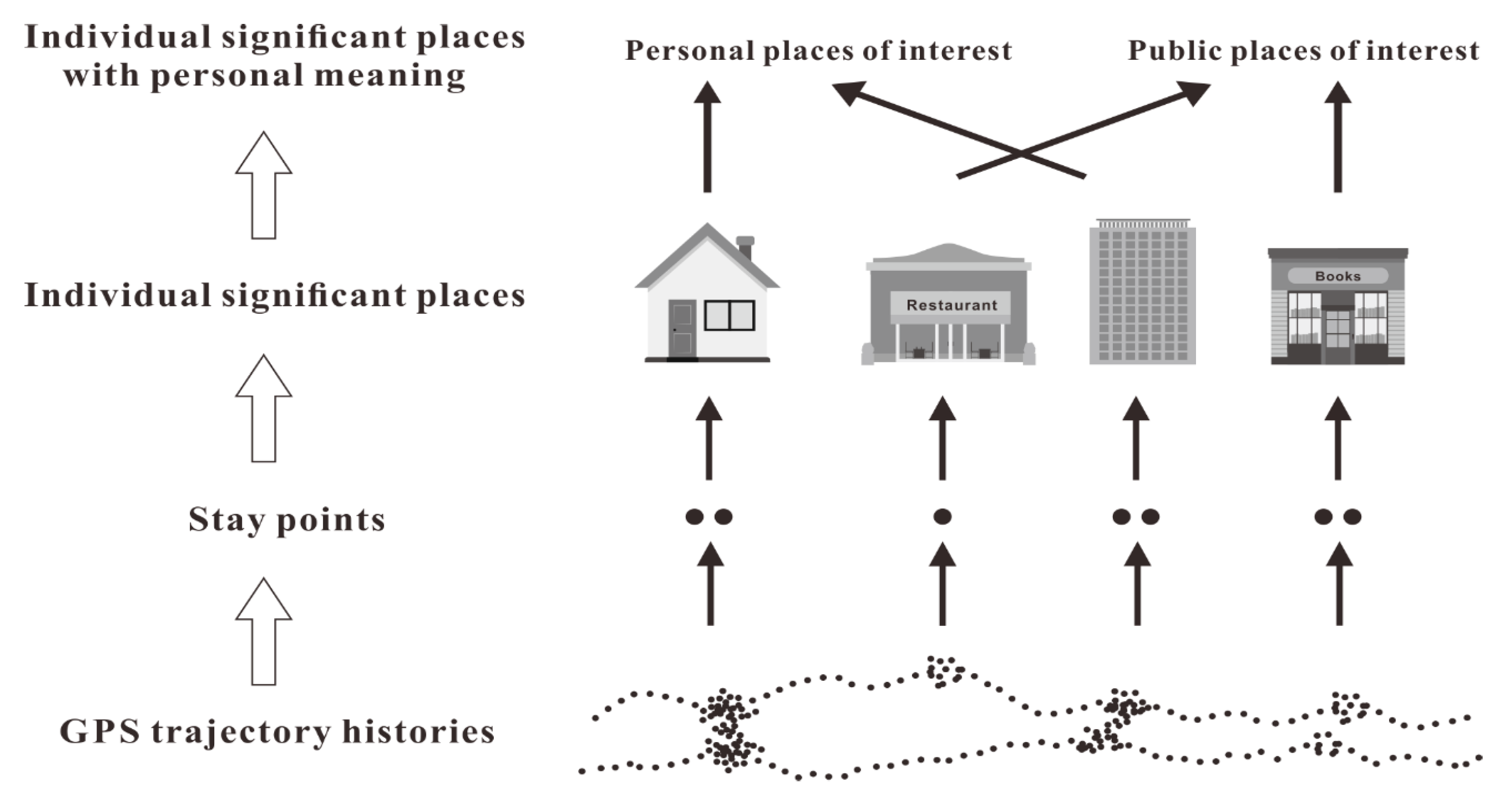
3.2. Extracting the Semantics of Personally Significant Places
| Algorithm 1. PersonalSemanticExtraction (TH, STI, POI). |
| Input: TH: The set of individuals’ trajectories TH = {THi| 1 ≤ i ≤ |I|} STI: The set of standard time intervals STI = {STIps} POI: The set of points of interest |
| Output: SPps: The set of individuals’ significant places with personal meaning SPps = {1 ≤ i ≤ |I|} |
| Foreach i∈I do si = ∅; // stay points of i Foreach Ti∈THi do |
| si .Add(StayPointDetection(Ti, θtime, θdistance)); SPi = OPTICS(si, r, MinPts); // obtain significant places from stay points PeSPi = MatchPe(SPi, STI, ε); // identify semantics of personal places of interest SPi = SPi − PeSPi; PuSPi = MatchPu(SPi, POI); // identify semantics of public places of interest SPpsi = PeSPi ∪ PuSPi; SPps.Add(SPpsi); Return SPps; |
3.2.1. Identification of Individual Significant Places
3.2.2. Semantic Interpretation of Individual Significant Places
3.3. Mining Individual Similarity
| Algorithm 2. IndividualSimilarityMeasurement (TH, SPps). |
| Input: TH: The set of individuals’ trajectories TH = {THi|1 ≤ i ≤ |I|} SPps: The set of individuals’ significant places with personal meaning SPps = {1 ≤ i ≤ |I|} |
| Output: SimMatrix: Individual similarity matrix |
| Foreach a∈ I do = GetPersonalSemantics(); PS = ; // personal semantics Foreach b∈ I do = GetPersonalSemantics(); PS = PS ∪ ; SimMatrix(a,b) = 0; Foreach ps∈ PS do Simspatial (a,b) = CalSpatialSim(a,b); Simtemporal (a,b) = CalTemporalSim(a,b); Simps (a,b) = w1* Simspatial (a,b) + w2* Simtemporal (a,b); SimMatrix(a,b) += wps * Simps(a,b); |
| Return SimMatrix; |
3.3.1. Grouping Individual Significant Places
3.3.2. Measuring Individual Similarity
4. Experiments
4.1. Dataset
4.1.1. GPS Trajectory Dataset
4.1.2. POI Dataset
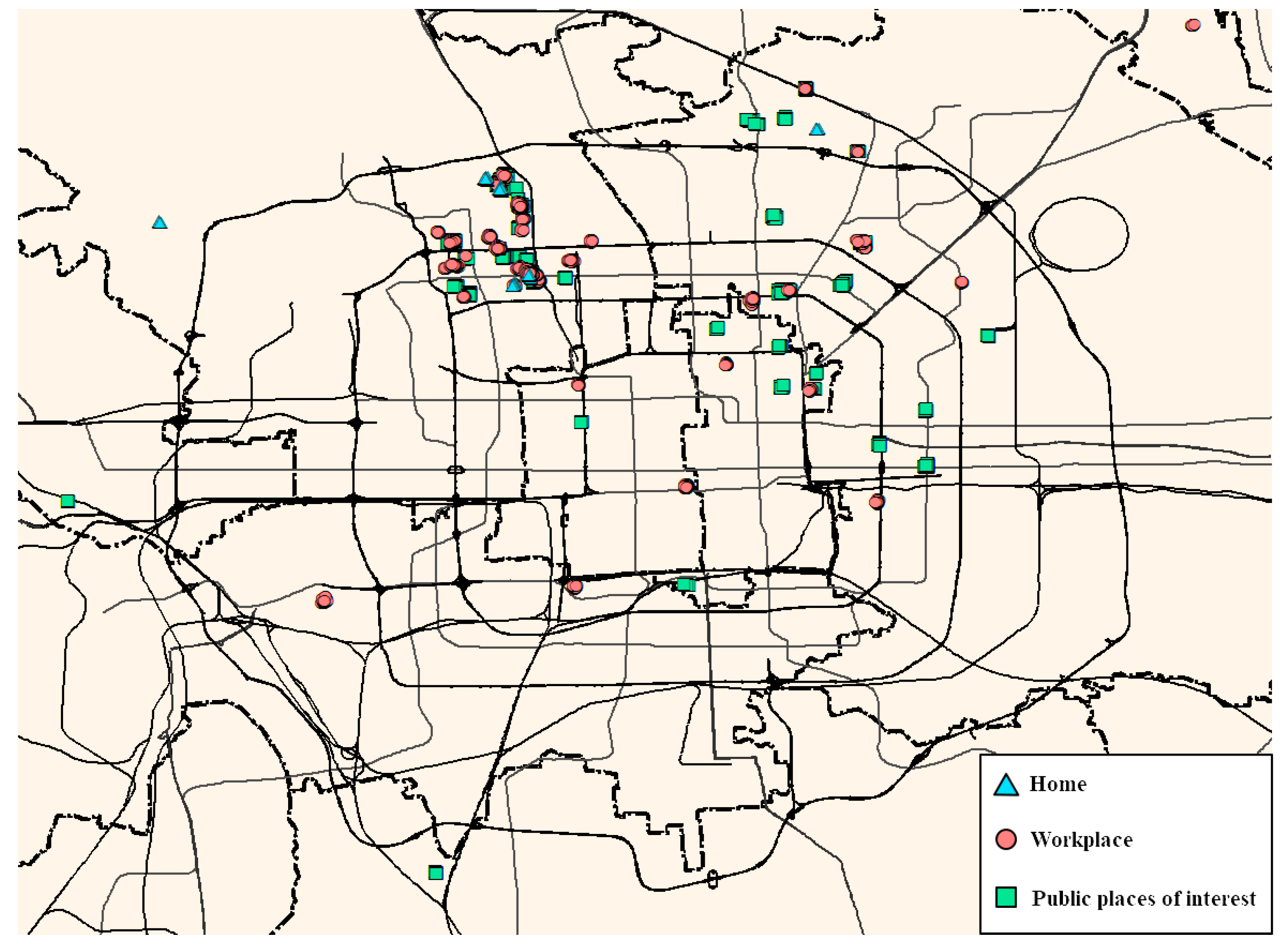
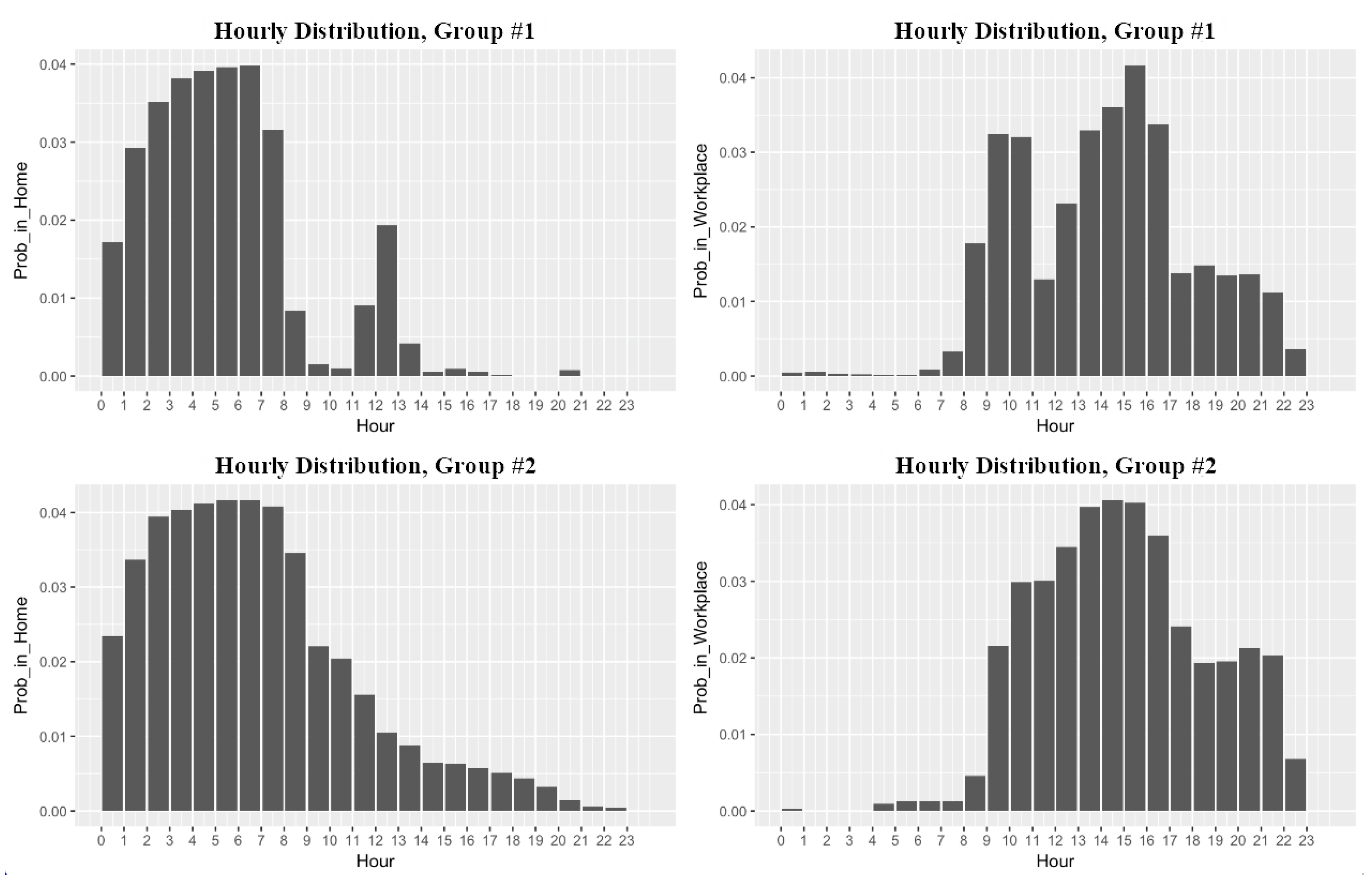
4.2. Semantics Extraction of Significant Places
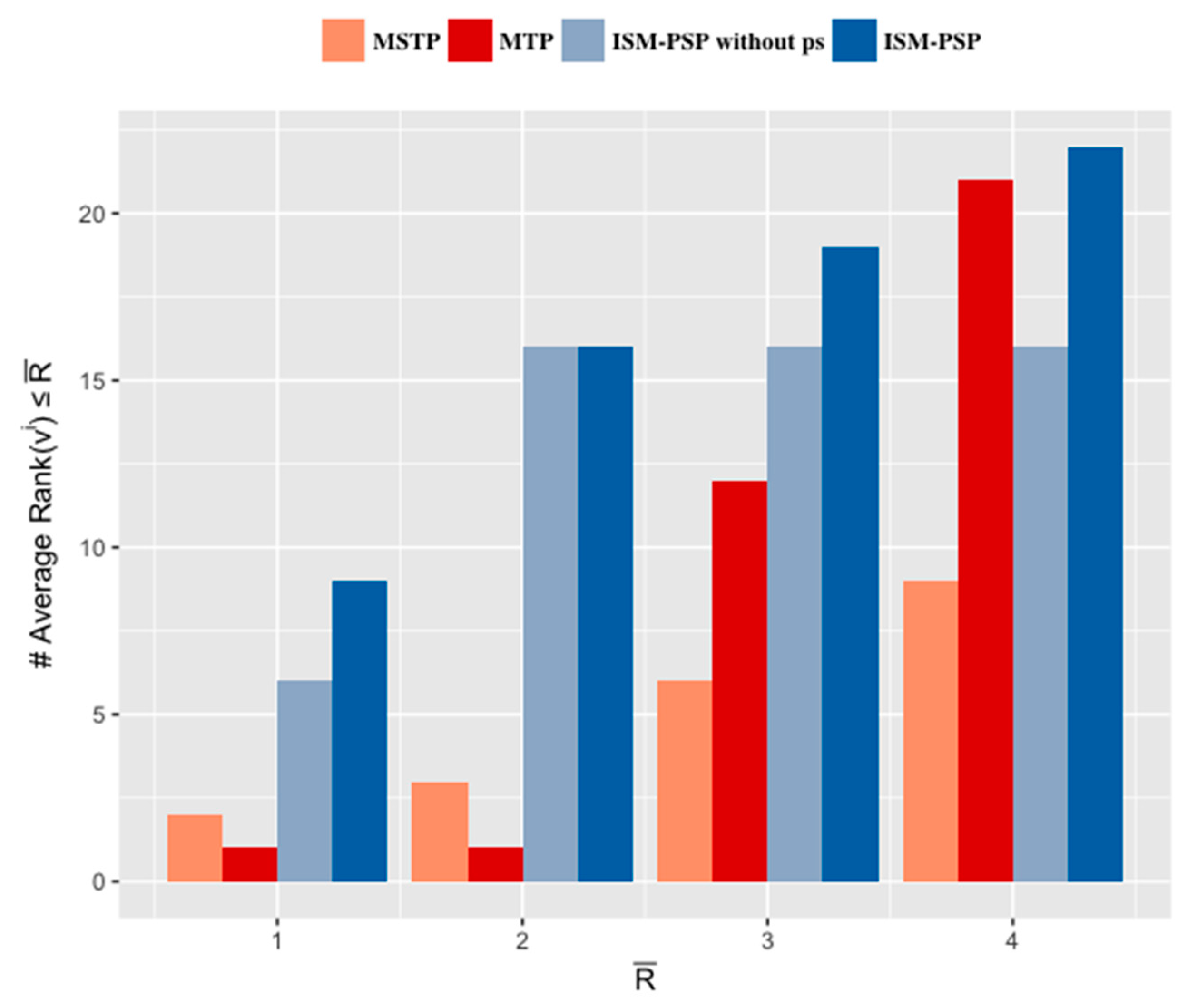
4.3. Comparative Analysis of Individual Similarity Measurements
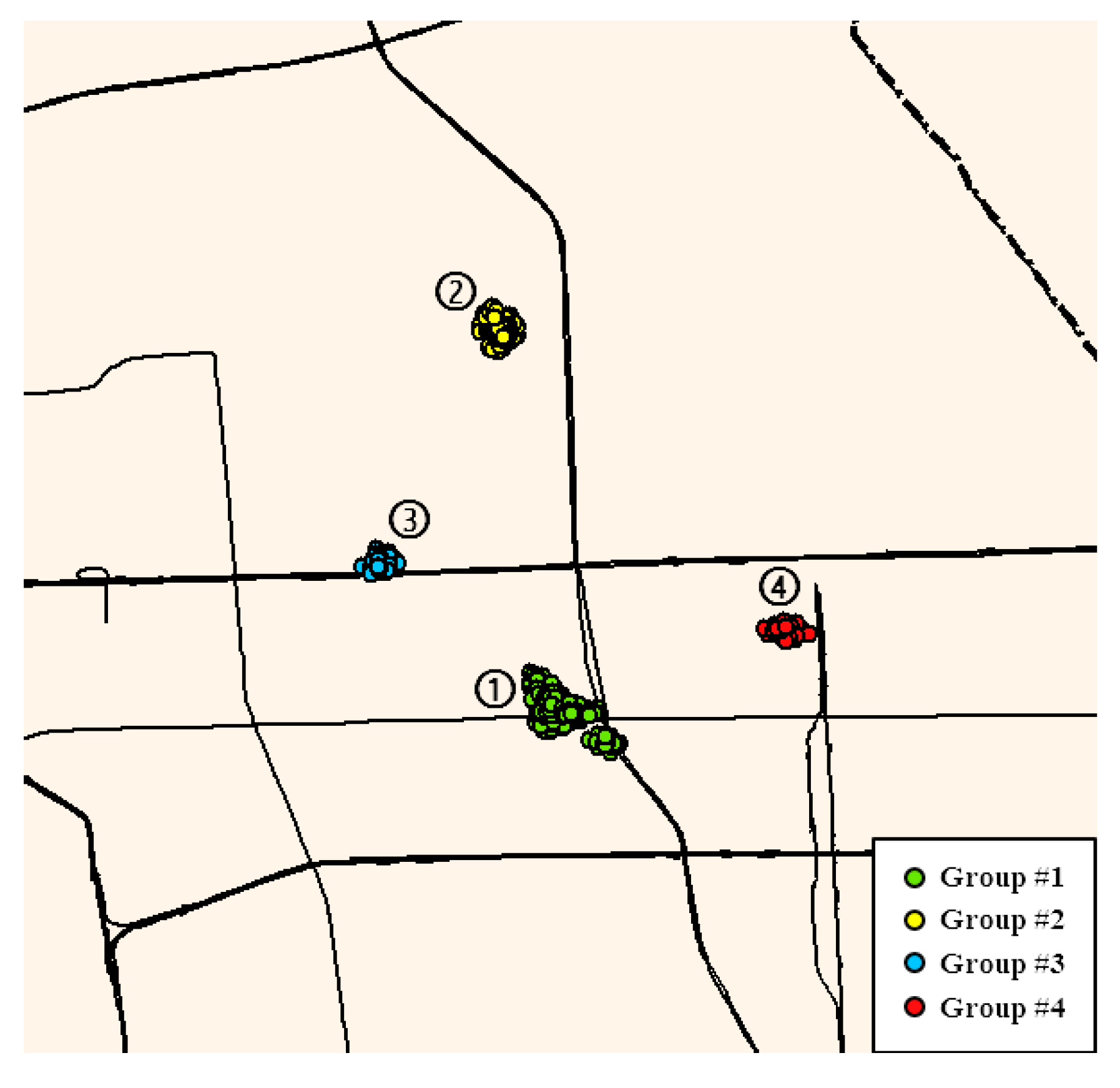
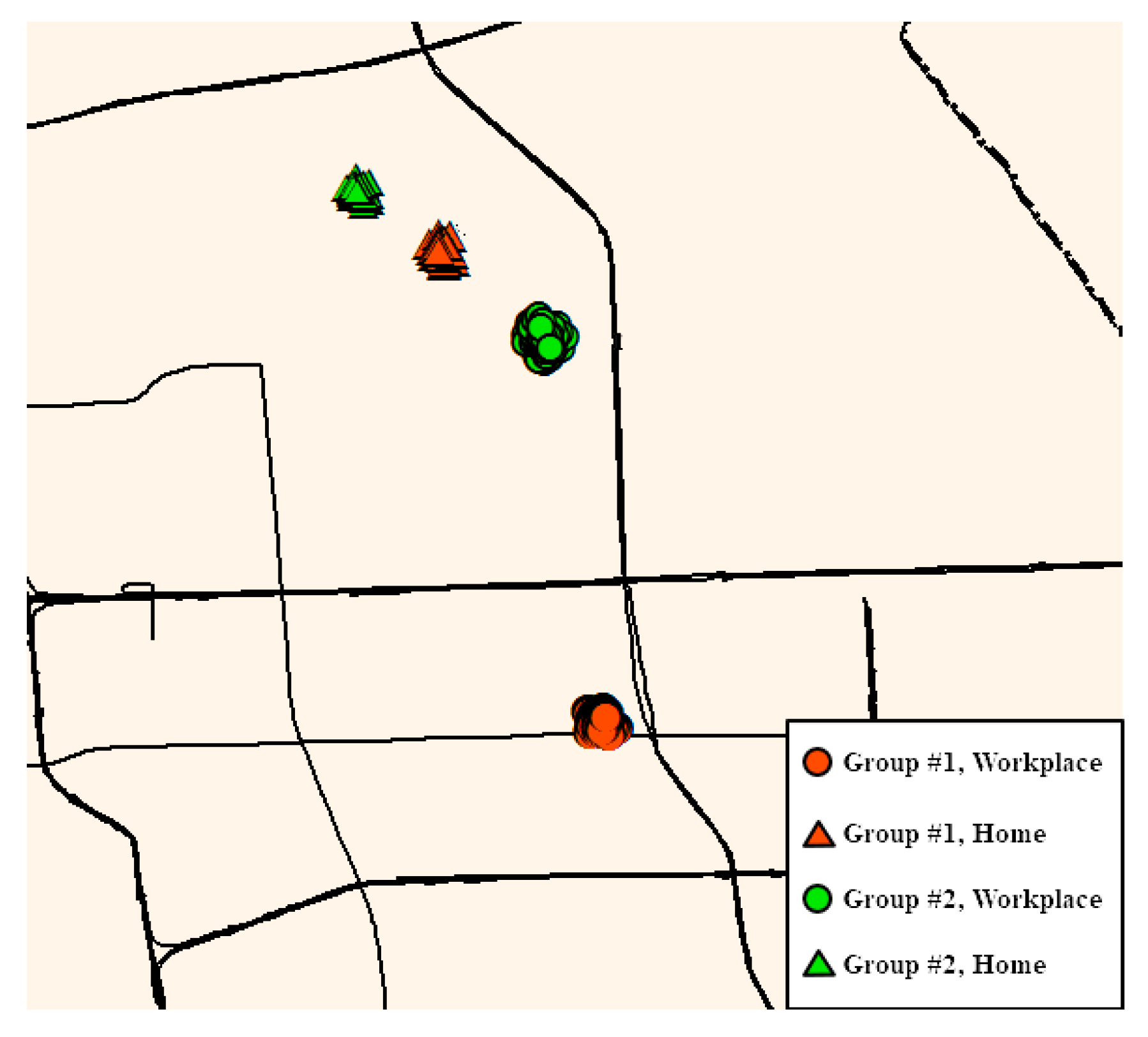
4.4. Grouping Individuals
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Yuan, Y.; Raubal, M. Measuring similarity of mobile phone user trajectories—A spatio-temporal edit distance method. Int. J. Geogr. Inf. Sci. 2014, 28, 496–520. [Google Scholar] [CrossRef]
- Andrienko, G.L.; Andrienko, N.V. Extracting patterns of individual movement behaviour from a massive collection of tracked positions. In Proceedings of the Workshop on Behaviour Monitoring and Interpretation, Bremen, Germany, 10 September 2007; pp. 1–16. [Google Scholar]
- Ye, Y.; Zheng, Y.; Chen, Y.; Feng, J.; Xie, X. Mining Individual Life Pattern Based on Location History. In Proceedings of the Tenth International Conference on Mobile Data Management: Systems, Services and Middleware, Taipei, Taiwan, 18–20 May 2009; pp. 1–10. [Google Scholar]
- Kang, C.; Gao, S.; Xiao, Y.; Yuan, Y.; Liu, Y.; Ma, X. Analyzing and geo-visualizing individual human mobility patterns using mobile call records. In Proceedings of the 2010 18th International Conference on Geoinformatics, Beijing, China, 18–20 June 2010. [Google Scholar]
- Zheng, Y.; Zhang, L.Z.; Ma, Z.X.; Xie, X.; Ma, W.Y. Recommending friends and locations based on individual location history. ACM Trans. Web 2011, 5. [Google Scholar] [CrossRef]
- Zhu, L.; Xu, C.Q.; Guan, J.F.; Zhang, H.K. SEM-PPA: A semantical pattern and preference-aware service mining method for personalized point of interest recommendation. J. Netw. Comput. Appl. 2017, 82, 35–46. [Google Scholar] [CrossRef]
- Trasarti, R.; Guidotti, R.; Monreale, A.; Giannotti, F. Myway: Location prediction via mobility profiling. Inf. Syst. 2017, 64, 350–367. [Google Scholar] [CrossRef]
- Xiao, X.; Zheng, Y.; Luo, Q.; Xie, X. ST-DMQL: A Semantic Trajectory Data Mining Query Language. J. Ambient Intell. Humaniz. Comput. 2014, 5, 3–19. [Google Scholar] [CrossRef]
- Ying, J.J.-C.; Lu, E.H.-C.; Lee, W.-C.; Weng, T.-C.; Tseng, V.S. Mining user similarity from semantic trajectories. In Proceedings of the 2nd ACM SIGSPATIAL International Workshop on Location Based Social Networks, San Jose, CA, USA, 2 November 2010; ACM: New York, NY, USA, 2010; pp. 19–26. [Google Scholar]
- Liu, Y.; Seah, H.S. Points of interest recommendation from gps trajectories. Int. J. Geogr. Inf. Sci. 2015, 29, 953–979. [Google Scholar] [CrossRef]
- Zhu, L.; Xu, C.; Guan, J.; Yang, S. Finding top-k similar users based on trajectory-pattern model for personalized service recommendation. In Proceedings of the 2016 IEEE International Conference on Communications Workshops (ICC), Kuala Lumpur, Malaysia, 23–27 May 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 553–558. [Google Scholar]
- Liu, J.; Wolfson, O.; Yin, H. Extracting semantic location from outdoor positioning systems. In Proceedings of the 7th International Conference on Mobile Data Management, (MDM 2006), Nara, Japan, 10–12 May 2006; IEEE: Los Alamitos, CA, USA, 2006; p. 73. [Google Scholar]
- Comito, C.; Falcone, D.; Talia, D. Mining human mobility patterns from social geo-tagged data. Pervasive Mob. Comput. 2016, 33, 91–107. [Google Scholar] [CrossRef]
- Spaccapietra, S.; Parent, C.; Damiani, M.L.; de Macedo, J.A.; Porto, F.; Vangenot, C. A conceptual view on trajectories. Data Knowl. Eng. 2008, 65, 126–146. [Google Scholar] [CrossRef] [Green Version]
- Parent, C.; Spaccapietra, S.; Renso, C.; Andrienko, G.; Andrienko, N.; Bogorny, V.; Damiani, M.; Gkoulalas-Divanis, A.; Macedo, J.; Pelekis, N.; et al. Semantic trajectories modeling and analysis. ACM Comput. Surv. (CSUR) 2013, 45, 1–32. [Google Scholar] [CrossRef]
- Yan, Z.; Chakraborty, D.; Parent, C.; Spaccapietra, S.; Aberer, K. Semitri: A framework for semantic annotation of heterogeneous trajectories. In Proceedings of the 14th International Conference on Extending Database Technology, Uppsala, Sweden, 21–24 March 2011; ACM: New York, NY, USA, 2011; pp. 259–270. [Google Scholar]
- Cao, X.; Cong, G.; Jensen, C.S. Mining significant semantic locations from GPS data. Proc. VLDB Endow. 2010, 3, 1009–1020. [Google Scholar] [CrossRef]
- Papandrea, M.; Jahromi, K.K.; Zignani, M.; Gaito, S.; Giordano, S.; Rossi, G.P. On the properties of human mobility. Comput. Commun. 2016, 87, 19–36. [Google Scholar] [CrossRef]
- Alvares, L.; Bogorny, V.; Kuijpers, B.; de Macedo, J.; Moelans, B.; Vaisman, A. A model for enriching trajectories with semantic geographical information. In Proceedings of the 15th Annual ACM International Symposium on Advances in Geographic Information Systems, Seattle, WA, USA, 7–9 November 2007; ACM: New York, NY, USA, 2007; pp. 1–8. [Google Scholar]
- Bogorny, V.; Kuijpers, B.; Alvares, L.O. ST-DMQL: A semantic trajectory data mining query language. Int. J. Geogr. Inf. Sci. 2009, 23, 1245–1276. [Google Scholar] [CrossRef]
- Xiao, X.; Zheng, Y.; Luo, Q.; Xie, X. Finding similar users using category-based location history. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; ACM: New York, NY, USA, 2010; pp. 442–445. [Google Scholar]
- Spinsanti, L.; Celli, F.; Renso, C. Where you stop is who you are: Understanding people’s activities by places visited. In Proceedings of the Behaviour Monitoring and Interpretation (BMI) Workshop, Karlsruhe, Germany, 21 September 2010; pp. 38–52. [Google Scholar]
- Ye, M.; Janowicz, K.; Mülligann, C.; Lee, W.-C. What you are is when you are: The temporal dimension of feature types in location-based social networks. In Proceedings of the 19th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Chicago, IL, USA, 1–4 November 2011; ACM: New York, NY, USA, 2011; pp. 102–111. [Google Scholar]
- Shen, J.N.; Cheng, T. A framework for identifying activity groups from individual space-time profiles. Int. J. Geogr. Inf. Sci. 2016, 30, 1785–1805. [Google Scholar] [CrossRef]
- Andrienko, G.; Andrienko, N.; Fuchs, G.; Raimond, A.-M.O.; Symanzik, J.; Ziemlicki, C. Extracting semantics of individual places from movement data by analyzing temporal patterns of visits. Presented at the 21st ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems (ACM SIGSPATIAL GIS 2013), Orlando, FL, USA, 5–8 November 2013; ACM: New York, NY, USA, 2013; pp. 9–16. [Google Scholar]
- Li, Q.; Zheng, Y.; Xie, X.; Chen, Y.; Liu, W.; Ma, W.-Y. Mining user similarity based on location history. In Proceedings of the 16th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Irvine, CA, USA, 5–7 November 2008; ACM: New York, NY, USA, 2008; pp. 1–10. [Google Scholar]
- Chen, X.; Pang, J.; Xue, R. Constructing and comparing user mobility profiles. ACM Trans. Web (TWEB) 2014, 8, 1–25. [Google Scholar] [CrossRef]
- Mazumdar, P.; Patra, B.K.; Lock, R.; Korra, S.B. An approach to compute user similarity for GPS applications. Knowl.-Based Syst. 2016, 113, 125–142. [Google Scholar] [CrossRef]
- Lv, M.; Chen, L.; Chen, G. Mining user similarity based on routine activities. Inf. Sci. 2013, 236, 17–32. [Google Scholar] [CrossRef]
- González, M.C.; Hidalgo, C.A.; Barabási, A.-L. Understanding individual human mobility patterns. Nature 2008, 453, 779–782. [Google Scholar] [CrossRef] [PubMed]
- Song, C.; Koren, T.; Wang, P.; Barabási, A. Modelling the scaling properties of human mobility. Nat. Phys. 2010, 6, 818–823. [Google Scholar] [CrossRef]
- Furtado, A.S.; Kopanaki, D.; Alvares, L.O.; Bogorny, V. Multidimensional similarity measuring for semantic trajectories. Trans. GIS 2016, 20, 280–298. [Google Scholar] [CrossRef]
- Palma, A.; Bogorny, V.; Kuijpers, B.; Alvares, L. A clustering-based approach for discovering interesting places in trajectories. In Proceedings of the 2008 ACM Symposium on Applied Computing, Fortaleza, Brazil, 16–20 March 2008; ACM: New York, NY, USA, 2008; pp. 863–868. [Google Scholar]
- Rocha, J.A.M.R.; Times, V.C.; Oliveira, G.; Alvares, L.O.; Bogorny, V. DB-SMoT: A direction-based spatio-temporal clustering method. In Proceedings of the 2010 5th IEEE International Conference Intelligent Systems (IS), London, UK, 7–9 July 2010; pp. 114–119. [Google Scholar]
- Zheng, Y.; Zhang, L.; Xie, X.; Ma, W.-Y. Mining interesting locations and travel sequences from GPS trajectories. In Proceedings of the 18th International Conference on World Wide Web, Madrid, Spain, 20–24 April 2009; ACM: New York, NY, USA, 2009; pp. 791–800. [Google Scholar]
- Huang, G.; He, J.; Zhou, W.; Huang, G.-L.; Guo, L.; Zhou, X.; Tang, F. Discovery of stop regions for understanding repeat travel behaviors of moving objects. J. Comput. Syst. Sci. 2016, 82, 582–593. [Google Scholar] [CrossRef]
- Ankerst, M.; Breunig, M.M.; Kriegel, H.-P.; Sander, J. Optics: Ordering points to identify the clustering structure. In Proceedings of the 1999 ACM SIGMOD International Conference on Management of Data, Philadelphia, PA, USA, 31 May–3 June 1999; Volume 28, pp. 49–60. [Google Scholar]
- Liu, Y.; Liu, X.; Gao, S.; Gong, L.; Kang, C.G.; Zhi, Y.; Chi, G.H.; Shi, L. Social sensing: A new approach to understanding our socioeconomic environments. Ann. Assoc. Am. Geogr. 2015, 105, 512–530. [Google Scholar] [CrossRef]
- Lin, D. An information-theoretic definition of similarity. In Proceedings of the Fifteenth International Conference on Machine Learning, Madison, WI, USA, 24–27 July 1998; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1998; pp. 296–304. [Google Scholar]
- Huang, W.; Li, S.; Liu, X.; Ban, Y. Predicting human mobility with activity changes. Int. J. Geogr. Inf. Sci. 2015, 29, 1569–1587. [Google Scholar] [CrossRef]
- Gabrielli, L.; Rinzivillo, S.; Ronzano, F.; Villatoro, D. From tweets to semantic trajectories: Mining anomalous urban mobility patterns. In Citizen in Sensor Networks; Springer: Cham, Switzerland, 2014; pp. 26–35. [Google Scholar]
- Steiger, E.; Westerholt, R.; Resch, B.; Zipf, A. Twitter as an indicator for whereabouts of people? Correlating twitter with uk census data. Comput. Environ. Urban Syst. 2015, 54, 255–265. [Google Scholar] [CrossRef]
- Steiger, E.; Resch, B.; Zipf, A. Exploration of spatiotemporal and semantic clusters of twitter data using unsupervised neural networks. Int. J. Geogr. Inf. Sci. 2016, 30, 1694–1716. [Google Scholar] [CrossRef]
- Gao, S.; Janowicz, K.; Couclelis, H. Extracting urban functional regions from points of interest and human activities on location-based social networks. Trans. GIS 2017, 21, 446–467. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Place Semantics | a’s Significant Places | b’s Significant Places |
|---|---|---|
| Home | ||
| Workplace | ||
| Restaurant | , | |
| Bookstore | , | |
| Shopping mall |
| Type ID | Type | Count |
|---|---|---|
| 1 | Shopping | 72,370 |
| 2 | Restaurant | 52,567 |
| 3 | Education | 21,224 |
| 4 | Hotel | 15,272 |
| 5 | Sports | 10,557 |
| 6 | Life service | 9035 |
| 7 | Entertainment | 784 |
| 8 | Healthcare | 115 |
| Total | 181,924 |
| Type ID | Type | Count |
|---|---|---|
| 1 | Shopping | 11 |
| 2 | Restaurant | 14 |
| 3 | Education | 13 |
| 4 | Hotel | 5 |
| 5 | Sports | 5 |
| 6 | Life service | 2 |
| Total | 50 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, M.; Cheng, C.; Chen, B. Mining Individual Similarity by Assessing Interactions with Personally Significant Places from GPS Trajectories. ISPRS Int. J. Geo-Inf. 2018, 7, 126. https://doi.org/10.3390/ijgi7030126
Yang M, Cheng C, Chen B. Mining Individual Similarity by Assessing Interactions with Personally Significant Places from GPS Trajectories. ISPRS International Journal of Geo-Information. 2018; 7(3):126. https://doi.org/10.3390/ijgi7030126
Chicago/Turabian StyleYang, Mengke, Chengqi Cheng, and Bo Chen. 2018. "Mining Individual Similarity by Assessing Interactions with Personally Significant Places from GPS Trajectories" ISPRS International Journal of Geo-Information 7, no. 3: 126. https://doi.org/10.3390/ijgi7030126
APA StyleYang, M., Cheng, C., & Chen, B. (2018). Mining Individual Similarity by Assessing Interactions with Personally Significant Places from GPS Trajectories. ISPRS International Journal of Geo-Information, 7(3), 126. https://doi.org/10.3390/ijgi7030126