Population Synthesis Handling Three Geographical Resolutions


Abstract
:1. Introduction
2. Materials and Methods
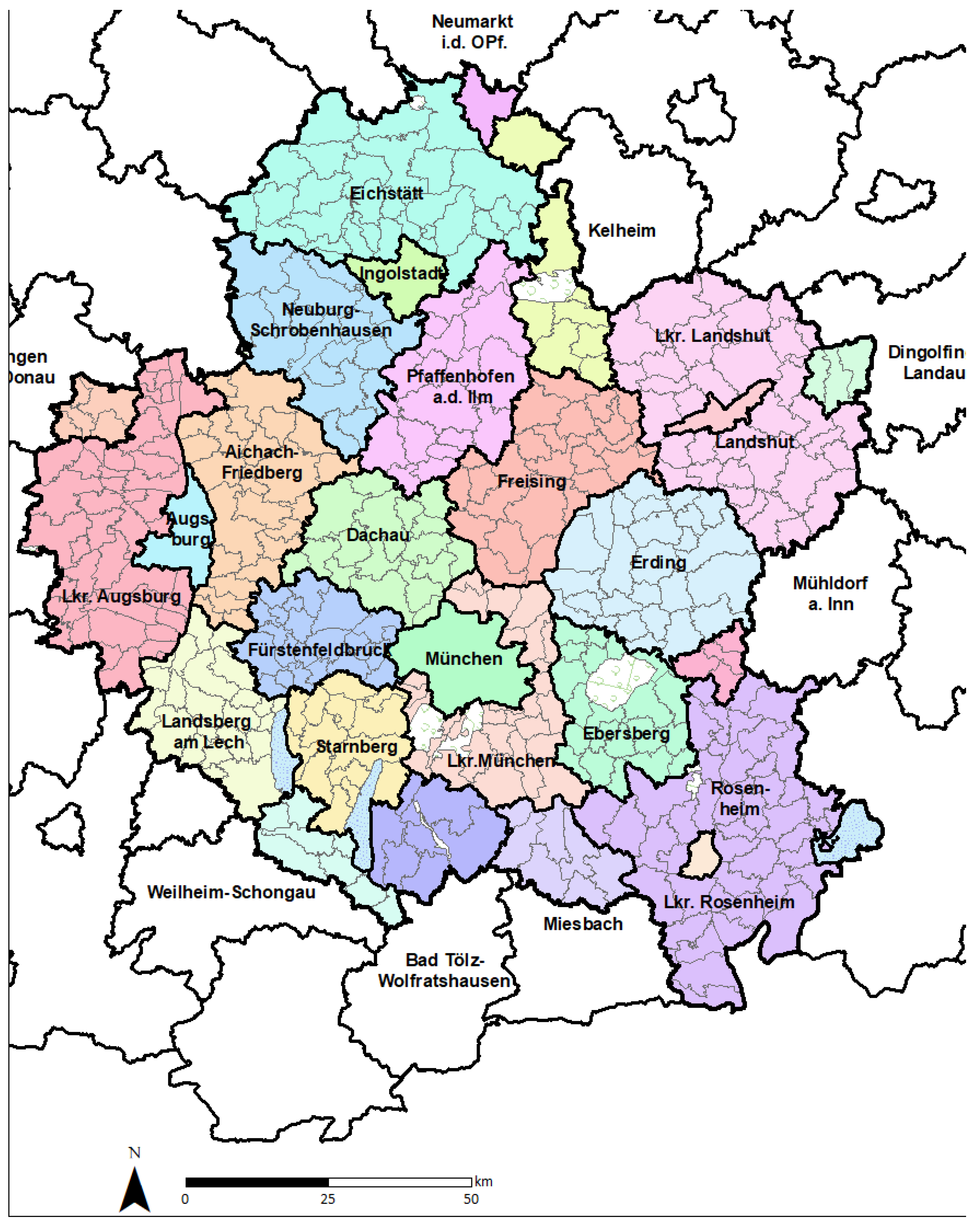
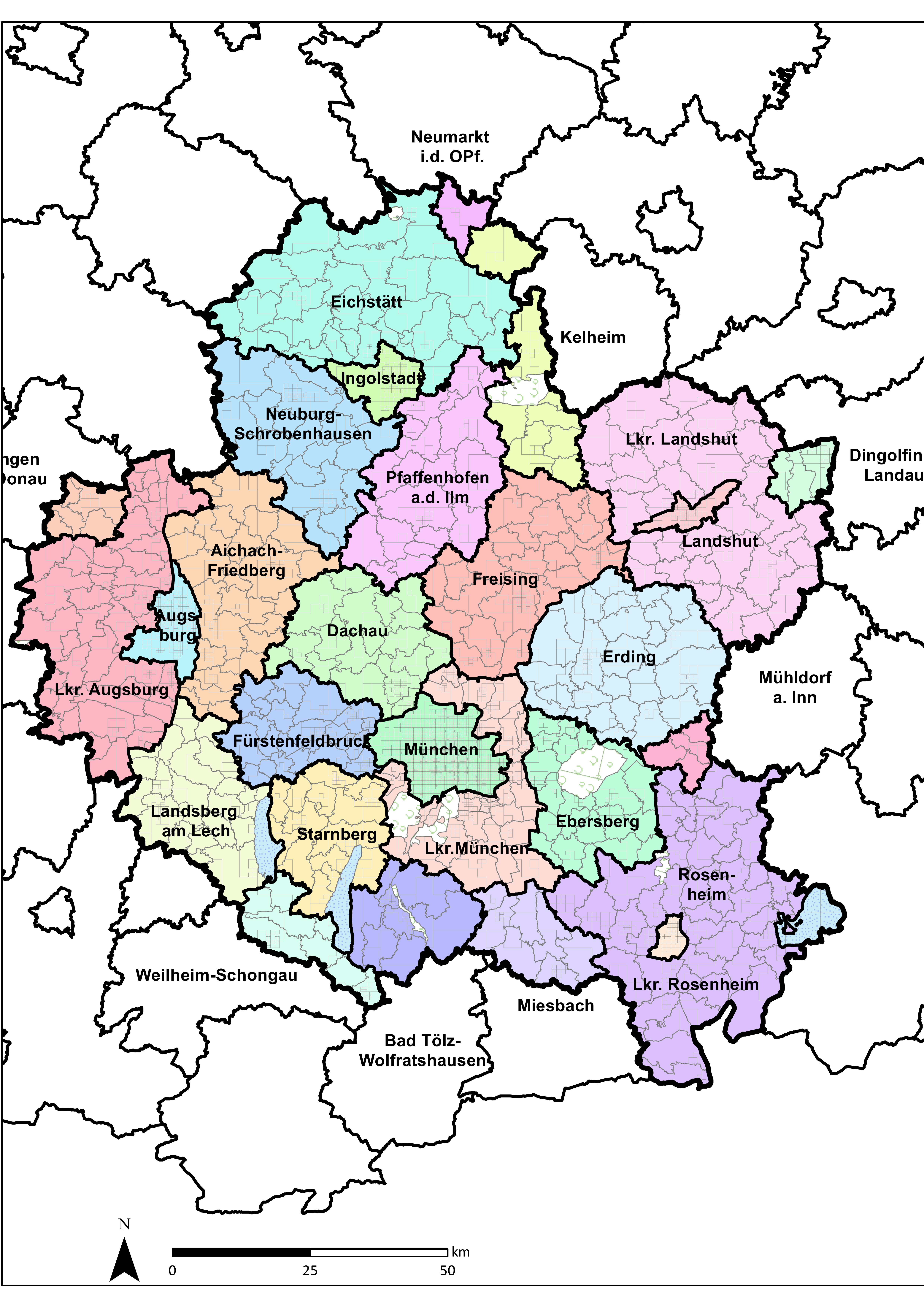
2.1. Selecting Geographical Resolution and Scales of Analysis
2.2. Optimization: IPU with Three Geographical Resolutions
2.3. Allocation: Monte Carlo Sampling
2.4. Application
3. Results
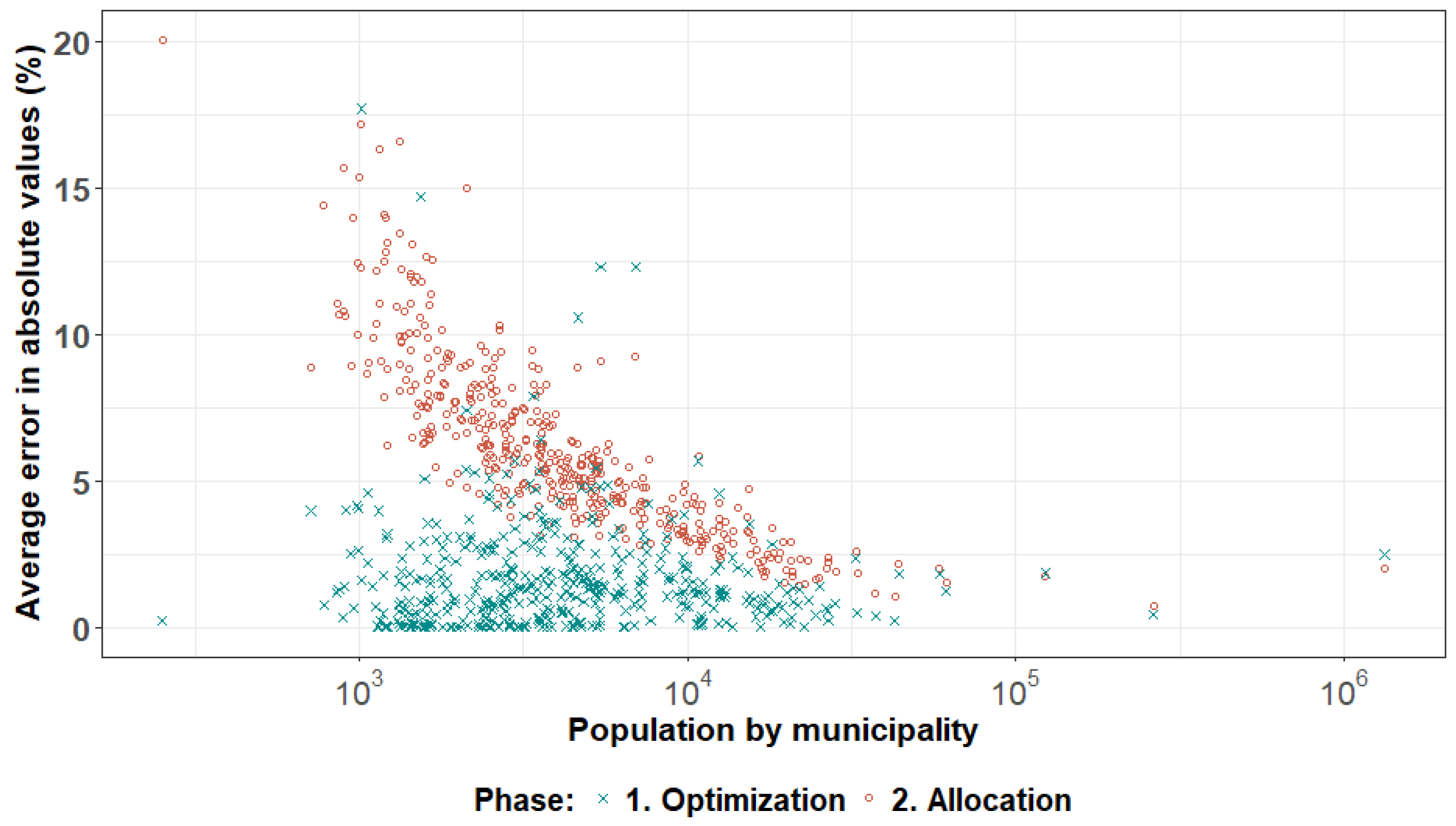
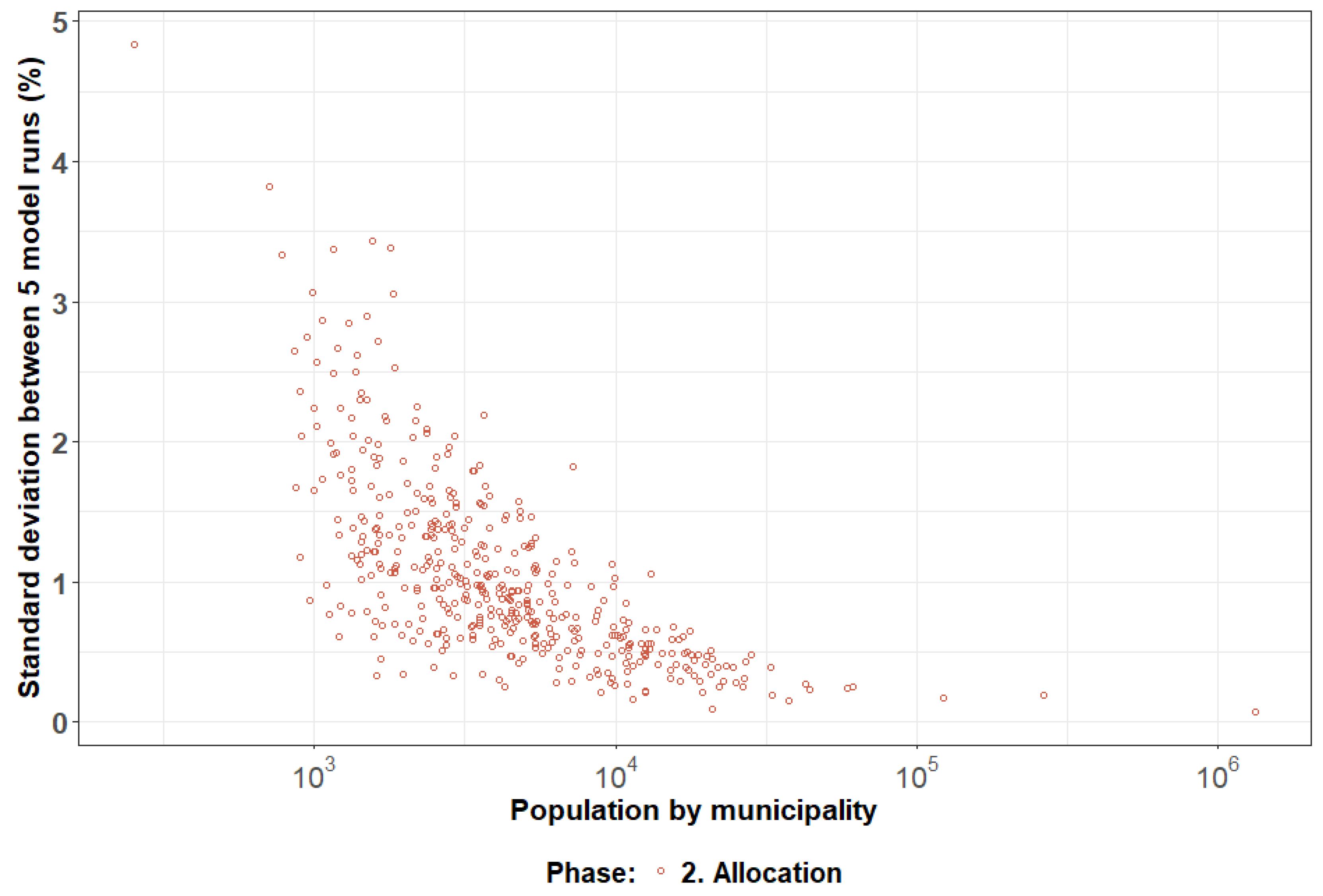
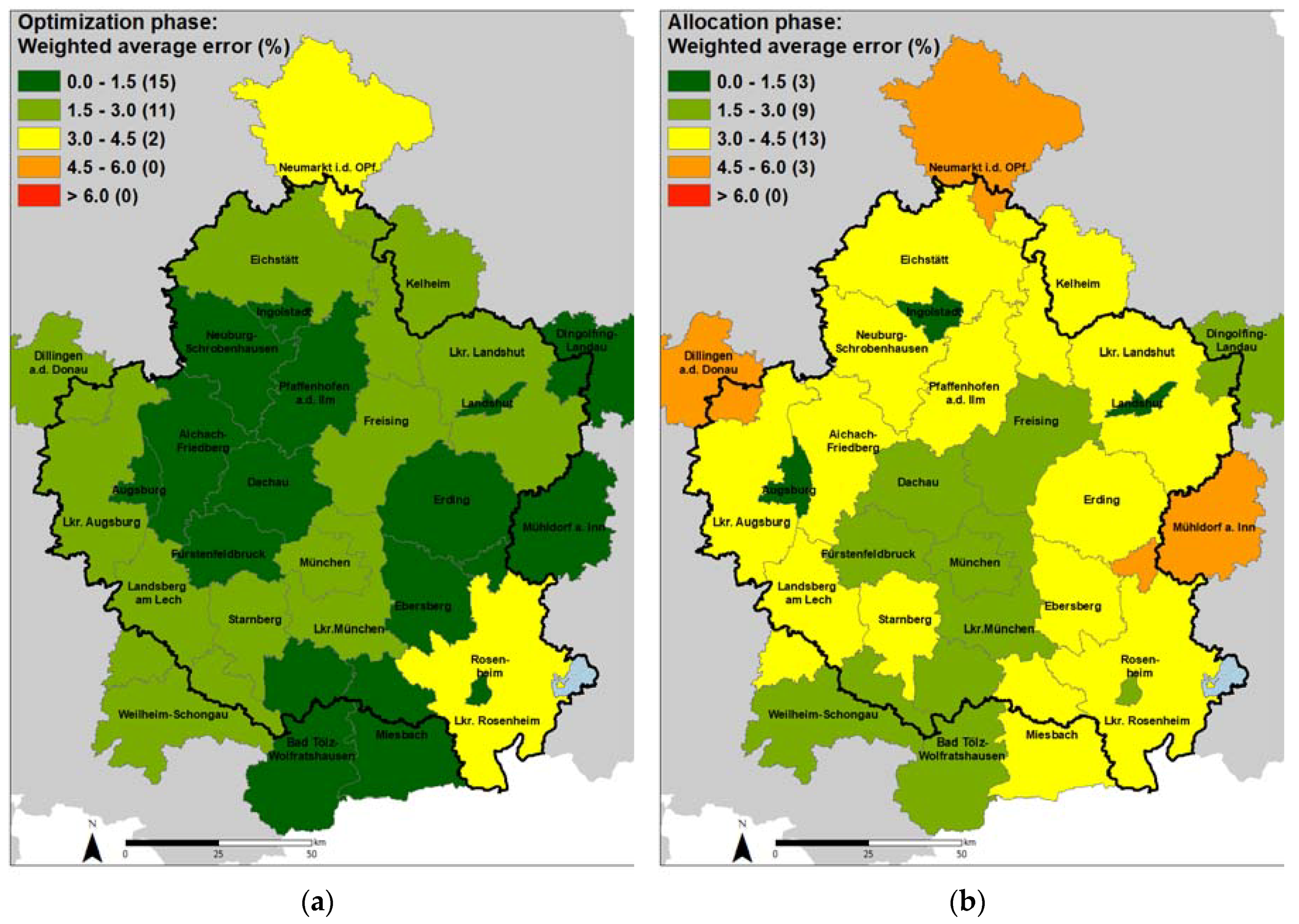
3.1. By Geographical Resolution
3.2. By Attribute
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Ref. | Optimization Procedure 1 | Allocation Procedure |
|---|---|---|---|
| TRANSIMS | [1] | IPF for hh and pp | Monte Carlo |
| CEMDAP | [3] | IPF for hh and pp | Monte Carlo with replacement |
| ILUMASS | [4] | Microsimulation for hh and pp, IPF for dd and jj | Monte Carlo |
| PopSynWin | [5,13] | IPF for hh and pp | Monte Carlo |
| ILUTE | [6,7,36,48] | IPF for hh and families with sparse list | Conditioned Monte Carlo |
| ALBATROSS | [8] | IPF with relation matrix at pp level and IPF for hh | Monte Carlo |
| Zhu and Ferreira | [11] | Two step IPF for hh and pp | Monte Carlo |
| FSUTMS | [9] | IPF | Monte Carlo |
| Lovelace et al. | [14] | IPF for pp | Monte Carlo |
| Whitworth et al. | [15] | IPF with spatial microsimulation | Monte Carlo |
| Bar-Gera et al. | [22] | IPF, entropy maximization | Monte Carlo |
| Barthelemy and Toint | [23] | IPF, entropy maximization | Monte Carlo for household head |
| PopSyn | [10] | IPF, entropy maximization | Monte Carlo |
| Rose et al. | [16] | IPF, entropy maximization | Monte Carlo |
| PopGen | [12,13,20,21,32] | IPU | Monte Carlo |
| Fournier et al. | [17] | IPF, integerization, IPU | Monte Carlo |
| Mueller and Axhausen | [49] | Hierarchical IPF | Monte Carlo |
| Ryan et al. | [50] | Combinatorial optimization | With fitting |
| Synthesizer | [26] | Combinatorial optimization | With fitting |
| Farooq et al. | [27] | Full or Partial conditionals using discrete choice models | Monte Carlo Markov chains |
| Saadi et al. | [19,28] | Partial conditionals using Hidden Markov Models | Monte Carlo |
| Saadi et al. | [28] | Partial conditionals using Hidden Markov Models | Monte Carlo |
| SILC | [31] | Multinomial regression model | Monte Carlo |
| Agenter | [30,33] | Multinomial regression model | Choice modeling |
| Model | Ref. | Application | Geographical Resolutions | Household Attributes | Person Attributes | Dwelling Attributes |
|---|---|---|---|---|---|---|
| TRANSIMS | [1] | Bay Area | Local | Size | - | - |
| CEMDAP | [3] | Dallas/Forth Worth MA | Target area | Family, type, children, size, zone | Gender, age, race | - |
| TriLat | [4] | Netanya, 159,000 persons 50,000 households | Zones | Size, workers, income, cars | Age, gender, religion, education, workplace | - |
| ILUMASS | [4] | Dortmund, 2.6 M persons in 1.1 M households | Zones | Size, workers, income, cars | Age, gender, religion, education, workplace | Type, tenure, size, quality, rent |
| PopSynWin | [5] | Chicago, 1.5 M persons in 0.5 M households | Block groups | Size, income, workers, zone | Gender, age, ethnicity | - |
| PopSynWin | [13] | Melbourne, 4 M persons in 1.4 M households | Census zones | Type, size, cars | Gender, age, employment | - |
| ILUTE | [6,7,36,48] | Toronto, 3.4 M persons 1.1 M households | Census tracts | Size | Gender, Income, age by family, age by labor, age by education, education by labor, occupation | Type, tenure, size, age, rooms, families |
| ALBATROSS | [8] | The Netherlands, 6.4M households | Zones and regions | HH type, region and density | Gender, age, employment | - |
| FSUTMS | [9] | Florida state 87,800 persons in 23,000 households | Census tracts | Workers, income, cars, size, structure | Age, gender, ethnicity, working hours, citizenship | Size, tenure |
| Zhu and Ferreira | [11] | Singapore | TAZ | Size, income, workers | Age, gender, ethnicity | Type |
| Whitworth et al. | [15] | Wales | MSOAs | - | Age by sex, employment, quals, health, region | Tenure |
| Lovelace et al. | [14] | South Yorkshire | Area code | - | Age by gender, travel mode, distance to work, income | - |
| Rose et al. | [16] | Bangladesh, 150 M persons | Fit to division and estimate district | - | Age by gender by school attendance female occupation, average size of household, electricity, tenure status, rural/urban, division | - |
| Bar-Gera et al. | [22] | Maricopa county | Type, size, income | Gender, age, ethnicity | - | |
| Barthelemy and Toint | [23] | Belgium, 10 M persons in 4.3 M households | Districts | Type, children, other adults | Age, gender, activity, education, driving license | - |
| PopSyn | [10] | Maricopa, 4 M persons | County, TAZ, MAZ | Size, type, income, workers | Age | - |
| PopGen | [20] | Maricopa county, 5.4 M persons, 2.0 M households, 0.1 M quarters | Block groups | Type, size, income | Gender, age, ethnicity | - |
| PopGen | [21] | Baltimore metro council | County, PUMA, TAZ | Size, income, workers | Age, employment | - |
| PopGen | [32] | Sydney, 4.9 M persons 1.8 M households | TAZ | Type, size, cars | Age, gender, employment | Type |
| PopGen | [12] | Southern California 17 M persons 5.5 M households | TAZ | Family, head age, size, type, children, income | Age, gender, ethnicity | - |
| PopGen | [13] | Melbourne, 4 M persons 1.4 M households | Census tracts | Type, size, cars | Gender, age, employment | - |
| Mueller and Axhausen | [49] | Switzerland, 7 M persons 3.1 M households | Municipality | Size, type, children, age of head, age oldest child, age youngest child | Age, gender, foreigner, marital status, education, workplace location, commute mode | - |
| Fournier et al. | [17] | Boston, 4.6 M persons in 1.7 M households | Census tracts | Size, cars, income, race | Gender, age, work hours, school enrollment, relationship, travel time, industry, occupation | Type |
| Synthesizer | [26] | California STDM, 33.9 M persons, 11.5 M households 0.8 M group quarters | TAZ | Size, income, cars, resident | Age, occupation, grade level | Type |
| Farooq et al. | [27] | Brussels, 1.2 M households | Regions | Size, workers, children, cars, education, income | - | - |
| Farooq et al. | [27] | Switzerland | Sectors | Household size | Age, gender, education | - |
| Saadi et al. | [19,29] | Belgium | Municipality | - | Age, gender, education, travel distance, profession | - |
| Saadi et al. | [28] | Belgium | Municipality | - | Age, gender, socio-professional status, working time expenditure, public transport subscription, driver license | - |
| SILC | [31] | Austria, 10 M persons 3.8 M households | Region | Size, region, urbanization | Age, gender, employment | - |
| Agenter | [30,33] | Beijing | TAZ | Income, size, parcel ID, distance to center | Age, gender, marriage, education, occupation | - |
| (a) Main routine, to be repeated for each county Require: Reference sample H in frequency matrix Require: County C control totals Require: Municipalities mi control totals Require: Boroughs bj control totals Require: Initial set of weights wbh(0) Ensure: Set of weights wbh for each borough b of the county and each household h from the reference sample H obeying all control totals wbh ← wbh(0) for all h H while convergence not reached do wbh ← County IPU (H, wbh, ) wbh ← Municipality IPU (H, wbh, ) wbh ← Borough IPU (H, wbh, ) Check convergence return wbh |
| (b) Subroutine County IPU Require: Households h from the reference sample H in frequency matrix Require: County c control totals … Require: Attributes at the county level α1, α2, … Require: Boroughs bj of the county C Require: Current set of weights wbh Ensure: Improved set of weights wbh that fits control totals at the county level For all attributes α at the county level do For all boroughs b of the county C return wbh |
| (c) Subroutine Municipality IPU Require: Households h from the reference sample H in frequency matrix Require: Municipalities mi control totals Require: Attributes at the municipality level β1, β2, … Require: Boroughs bk of the municipality mi Require: Current set of weights wbh Ensure: Improved set of weights wbh that fits control totals at the municipality level For all attributes β at the municipality level do For all municipalities m within the county do For all boroughs b of the municipality do return wbh |
| (d) Subroutine Borough IPU Require: Households h from the reference sample H in frequency matrix Require: Boroughs bi control totals Require: Attributes at the borough level γ1, γ2, … Require: Boroughs bk of the county c Require: Current set of weights wbh Ensure: Improved set of weights wbh that fits control totals at the borough level For all attributes γ at the borough level do For all boroughs b within the county do return wbh |
| (e) Subroutine Check convergence Require: Households h from the reference sample H in frequency matrix Require: County c control totals … Require: Attributes at the county level α1, α2, … Require: Municipalities mi control totals Require: Attributes at the municipality level β1, β2, … Require: Boroughs bi control totals Require: Attributes at the borough level γ1, γ2, … Require: Boroughs bk of the county c Require: Current set of weights wbh Require: Previous average error in absolute value Require: Threshold for the average error in absolute value Require: Threshold for difference between two iterations Require: Maximum number of iterations Ensure: Check for stopping criteria based on the average error in absolute value and iteration i For all attributes α at the county level do For all boroughs b within the county do For all attributes β at the municipality level do For all municipalities m within the county do For all boroughs b within the municipality do For all attributes γ at the borough level do For all boroughs b within the county do If stop If stop If stop return stop or continue |
References
- Beckman, R.J.; Baggerly, K.A.; McKay, M.D. Creating synthetic baseline populations. Transp. Res. Part A Policy Pract. 1996, 30, 415–429. [Google Scholar] [CrossRef]
- Müller, K.; Axhausen, K.W. Population synthesis for microsimulation: State of the art. In Proceedings of the 90th Annual Meeting of the Transportation Research Board, Washington, DC, USA, 23–27 January 2011; p. 21. [Google Scholar]
- Guo, J.Y.; Bhat, C.R. Population Synthesis for Microsimulating Travel Behavior. Transp. Res. Rec. J. Transp. Res. Board 2007, 2014, 92–101. [Google Scholar] [CrossRef]
- Moeckel, R. Creating a synthetic Population. In Proceedings of the 8th International Conference on Computers in Urban Planning and Urban Management (CUPUM), Sendai, Japan, 27–29 May 2003; pp. 1–18. [Google Scholar]
- Auld, J.A.; Mohammadian, A. Efficient Methodology for Generating Synthetic Populations with Multiple Control Levels. Transp. Res. Rec. J. Transp. Res. Board 2010, 2175, 138–147. [Google Scholar] [CrossRef]
- Salvini, P.; Miller, E.J. ILUTE: An operational prototype of a comprehensive microsimulation model of urban systems. Netw. Spat. Econ. 2005, 5, 217–234. [Google Scholar] [CrossRef]
- Pritchard, D.R.; Miller, E.J. Advances in population synthesis: Fitting many attributes per agent and fitting to household and person margins simultaneously. Transportation (Amst.) 2012, 39, 685–704. [Google Scholar] [CrossRef]
- Arentze, T.A.; Timmermans, H.; Hofman, F. Creating Synthetic Household Propulations: Problems and Approach. Transp. Res. Rec. J. Transp. Res. Board 2007, 2014, 85–91. [Google Scholar] [CrossRef]
- Srinivasan, S.; Ma, L.; Yathindra, K. Procedure for Forecasting Household Characteristics for Input to Travel-Demand Models; Final Report Project TRC-FDOT-64011-2008; Transportation Research Center, The University of Florida: Gainesville, FL, USA, 2008. [Google Scholar]
- Vovsha, P.; Hicks, J.E.; Paul, B.M.; Livshits, V.; Maneva, P.; Jeon, K. New Features of Population Synthesis. In Proceedings of the 94th Annual Meeting on Transportation Research Board, Washington, DC, USA, 11–15 January 2015; pp. 1–20. [Google Scholar]
- Zhu, Y.; Ferreira, J. Synthetic Population Generation at Disaggregated Spatial Scales for Land Use and Transportation Microsimulation. Transp. Res. Rec. J. Transp. Res. Board 2014, 2429, 168–177. [Google Scholar] [CrossRef]
- Pendyala, R.M.; Bhat, C.R.; Goulias, K.G.; Paleti, R.; Konduri, K.C.; Sidharthan, R.; Hu, H.-H.; Huang, G.; Christian, K.P. Application of Socioeconomic Model System for Activity-Based Modeling: Experience from Southern California. Transp. Res. Rec. J. Transp. Res. Board 2012, 2303, 71–80. [Google Scholar] [CrossRef]
- Jain, S.; Ronald, N.; Winter, S. Creating a Synthetic Population: A Comparison of Tools. In Proceedings of the 3rd Conference Transportation Reserch Group, Kolkata, India, 17–20 December 2015. [Google Scholar]
- Lovelace, R.; Ballas, D.; Watson, M. A spatial microsimulation approach for the analysis of commuter patterns: From individual to regional levels. J. Transp. Geogr. 2014, 34, 282–296. [Google Scholar] [CrossRef]
- Whitworth, A.; Carter, E.; Ballas, D.; Moon, G. Estimating uncertainty in spatial microsimulation approaches to small area estimation: A new approach to solving an old problem. Comput. Environ. Urban Syst. 2017, 63, 50–57. [Google Scholar] [CrossRef]
- Rose, A.N.; Nagle, N.N. Validation of spatiodemographic estimates produced through data fusion of small area census records and household microdata. Comput. Environ. Urban Syst. 2017, 63, 38–49. [Google Scholar] [CrossRef]
- Fournier, N.; Christofa, E.; Akkinepally, A.P. An integration of population synthesis methods for agent-based microsimulation. In Proceedings of the Annual Meeting of the Transportation Research Board, Washington, DC, USA, 13–17 January 2018. [Google Scholar]
- Deming, W.E.; Stephan, F. On a least squares adjustment of a sampled frequency table when the expected marginal totals are known. Ann. Math. Stat. 1940, 11, 427–444. [Google Scholar] [CrossRef]
- Saadi, I.; Mustafa, A.; Teller, J.; Cools, M. Mitigating the Error Rate of an IPF-Based Population Synthesis Approach by Incorporating more Heterogeneity into the Initial Seed. In Proceedings of the 96th Annual Meeting of the Transportation Research Board, Washington, DC, USA, 8–12 January 2017. [Google Scholar]
- Ye, X.; Konduri, K.; Pendyala, R.; Sana, B.; Waddell, P. A Methodology to Match Distributions of Both Household and Person Attributes in the Generation of Synthetic Populations. In Proceedings of the 88th Annual Meeting of the Transportation Research Board, Washington, DC, USA, 11–15 January 2009. [Google Scholar]
- Konduri, K.; You, D.; Garikapati, V.M.; Pendyala, R. Application of an Enhanced Population Synthesis Model that Accommodates Controls at Multiple Geographic Resolutions. In Proceedings of the 95th Annual Meeting of the Transportation Research Board, Washington, DC, USA, 10–14 January 2016. [Google Scholar]
- Bar-Gera, H.; Konduri, K.; Sana, B.; Ye, X.; Pendyala, R. Estimating Survey Weights with Multiple Constraints using Entropy Optimization Methods. In Proceedings of the 88th Annual Meeting of the Transportation Research Board, Washington, DC, USA, 11–15 January 2009. [Google Scholar]
- Barthelemy, J.; Toint, P.L. Synthetic Population Generation Without a Sample. Transp. Sci. 2012, 1655, 1–14. [Google Scholar] [CrossRef]
- Müller, K.; Axhausen, K.W. Multi-level Fitting Algorithms for Population Synthesis; IVT, ETH Zürich: Zurich, Switzerland, 2012. [Google Scholar]
- Casati, D.; Müller, K.; Fourie, P.J.; Erath, A.; Axhausen, K.W. Synthetic population generation by combining a hierarchical, simulation-based approach with reweighting by generalized raking. In Proceedings of the 94th Annual Meeting of the Transportation Research Board, Washington, DC, USA, 11–15 January 2015. [Google Scholar]
- Abraham, J.E.; Stephan, K.J.; Hunt, J.D. Population Synthesis Using Combinatorial Optimization at Multiple Levels. In Proceedings of the 91st Annual Meeting of the Transportation Research Board, Washington, DC, USA, 22–26 January 2012. [Google Scholar]
- Farooq, B.; Bierlaire, M.; Hurtubia, R.; Flötteröd, G. Simulation based Population Synthesis. Transp. Res. Part B Methodol. 2013, 58, 243–263. [Google Scholar] [CrossRef]
- Saadi, I.; Mustafa, A.; Teller, J.; Cools, M. Forecasting travel behavior using Markov Chains-based approaches. Transp. Res. Part C Emerg. Technol. 2016, 69, 402–417. [Google Scholar] [CrossRef]
- Saadi, I.; Mustafa, A.; Teller, J.; Farooq, B.; Cools, M. Hidden Markov Model-based population synthesis. Transp. Res. Part B Methodol. 2016, 90, 1–21. [Google Scholar] [CrossRef]
- Long, Y.; Shen, Z. Disaggregating heterogeneous agent attributes and location. Comput. Environ. Urban Syst. 2013, 42, 14–25. [Google Scholar] [CrossRef]
- Alfons, A.; Filzmoser, P.; Hulliger, B.; Kraft, S.; Ralf, M.; Templ, M. Synthetic Data Generation of SILC Data Version: 2011; Deliverable 6.2 Project FP7–SSH–2007–217322; AMELI: Vienna, Austria, 2011. [Google Scholar]
- Lim, P.P.; Gargett, D. Population Synthesis for Travel Demand Forecasting. In Proceedings of the 36th Australasian Transport Research Forum (ATRF), Brisbane, Australia, 2–4 October 2013; pp. 1–14. [Google Scholar]
- Long, Y.; Shen, Z. Population spatialization and synthesis with open data. In Geospatial Analysis to Support Urban Planning in Beijing; Springer: Cham, Switzerland, 2015; pp. 115–131. ISBN 9783319193410. [Google Scholar]
- Müller, K.; Axhausen, K.W. Preparing the Swiss Public-Use Sample for generating a synthetic population of Switzerland. In Proceedings of the 12th Swiss Transport Research Conference, Monte Veritá, Switzerland, 2–4 May 2012. [Google Scholar]
- Auld, J.A.; Mohammadian, A.; Wies, K. Population Synthesis with Subregion-Level Control Variable Aggregation. J. Transp. Eng. 2009, 135, 632–639. [Google Scholar] [CrossRef]
- Salvini, P.; Miller, E.J. ILUTE: An Operational Prototype of a Comprehensive Microsimulation Model of ILUTE: An Operational Prototype of a Comprehensive Microsimulation Model of Urban Systems. In Proceedings of the 10th International Conference on Travel Behaviour Research, Lucerne, Switzerland, 10–15 August 2003. [Google Scholar]
- Molloy, J.; Moeckel, R. Automated design of gradual zone systems. Open Geospat. Data Softw. Stand. 2017, 2, 19. [Google Scholar] [CrossRef]
- Statistische Ämter des Bundes und der Länder Zensus 2011. Available online: https://www.zensus2011.de/DE/Home/home_node.html (accessed on 12 September 2016).
- Statistisches Bundesamt GENESIS-Online Datenbank. Available online: https://www-genesis.destatis.de/genesis/online (accessed on 12 September 2016).
- Eurostat 2011 Census Hub. Available online: https://ec.europa.eu/CensusHub2 (accessed on 19 September 2016).
- Landeshauptstadt München—Kommunalreferat—GeodatenService Indikatorenatlas München. Available online: https://www.muenchen.de/rathaus/Stadtinfos/Statistik/Indikatoren-und-Monatszahlen/Indikatorenatlas.html (accessed on 16 October 2017).
- Statistisches Bundesamt. Datenhandbuch zum Mikrozensus. Scientific Use File 2011; Statistisches Bundesamt: Bonn, Germany, 2013.
- Moeckel, R. Constraints in household relocation: Modeling land-use/transport interactions that respect time and monetary budgets. J. Transp. Land Use 2017, 10, 211–228. [Google Scholar] [CrossRef]
- Moeckel, R.; Nagel, K. Maintaining Mobility in Substantial Urban Growth Futures. Transp. Res. Procedia 2016, 19, 70–80. [Google Scholar] [CrossRef]
- Horni, A.; Nagel, K.; Axhausen, K.W. The Multi-Agent Transport Simulation MATSim; Ubiquity Press: London, UK, 2016. [Google Scholar]
- Xu, Z.; Glass, K.; Lau, C.L.; Geard, N.; Graves, P.; Clements, A. A Synthetic Population for Modelling the Dynamics of Infectious Disease Transmission in American Samoa. Sci. Rep. 2017, 7, 16725. [Google Scholar] [CrossRef] [PubMed]
- Leyk, S.; Buttenfield, B.P.; Nagle, N. Uncertainty in demographic small area estimate. In Proceedings of the 9th International Symposium on Spatial Accuracy Assessment, Leicester City, UK, 20–23 July 2010. [Google Scholar]
- Pritchard, D.R.; Miller, E.J. Advances in Agent Population Synthesis and Application in an Integrated Land Use/Transportation Model. In Proceedings of the 88th Annual Meeting of the Transportation Research Board, Washington, DC, USA, 11–15 January 2009. [Google Scholar]
- Müller, K.; Axhausen, K.W. Hierarchical IPF: Generating a synthetic population for Switzerland. In Proceedings of the 51st New Challenges for European Regions and Urban Areas in a Globalised World, Barcelona, Spain, 30 August–3 September 2011. [Google Scholar]
- Ryan, J.; Maoh, H.; Kanaroglou, P. Population synthesis: Comparing the major techniques using a small, complete population of firms. Geogr. Anal. 2009, 41, 181–203. [Google Scholar] [CrossRef]






| Attribute | Categories | Geographical Resolution(s) | ||
|---|---|---|---|---|
| Type | Name | Number | Description | |
| Household | Total | 1 | Sum of households | Municipality and borough |
| Household size | 5 | 1, 2, 3, 4, 5+ | Municipality | |
| Household size | 1 | 1 | Borough | |
| Household with children | 1 | Household with person(s) younger than 18 years old | Borough | |
| Person | Total | 1 | Population | Municipality and borough |
| Age by gender | 34 | Male/Female + age (under 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, over 80) | Municipality | |
| Age | 4 | Under 5, 17, 64, over 65 | Borough | |
| Gender | 2 | Male (reference), female | Borough | |
| Nationality | 2 | German (reference), foreigner | Municipality and borough | |
| Employment status by gender | 2 | Male/Female + employed | Municipality and borough | |
| Dwelling | Tenure status | 2 | Owned, rent | Municipality |
| Dwelling living space (m2) | 5 | Less than 60, 61–80, 81–100, 101–120, more than 120 | County | |
| Building size by construction year | 8 | Smaller/Larger (2 or less dwellings in the building, 3 or more dwellings in the building) + construction year (before 1948, 1949–1990, 1991–2000, after 2001) | County | |
| Attribute | Weighted Average Error (%) and Standard Deviation (%) | |
|---|---|---|
| Optimization Phase | Allocation Phase | |
| Total | 0.0 [-] | 0.0 [0.00] |
| Size: 1 | 0.1 [-] | 1.5 [0.08] |
| Size: 2 | 0.2 [-] | 1.5 [0.08] |
| Size: 3 | 0.3 [-] | 2.2 [0.12] |
| Size: 4 | 0.7 [-] | 2.8 [0.10] |
| Size: 5+ | 0.6 [-] | 3.8 [0.11] |
| Attribute | Weighted Average Error (%) and Standard Deviation (%) | |
|---|---|---|
| Optimization Phase | Allocation Phase | |
| Tenure status: owned | 0.7 [-] | 1.4 [0.09] |
| Tenure status: rented | 0.2 [-] | 1.3 [0.05] |
| Living space: <60 sqm | 0.1 [-] | 1.4 [0.08] |
| Living space: 60–80 sqm | 0.1 [-] | 0.6 [0.08] |
| Living space: 80–100 sqm | 0.1 [-] | 1.2 [0.20] |
| Living space: 100–120 sqm | 0.1 [-] | 1.5 [0.12] |
| Living space: >120 sqm | 0.2 [-] | 1.4 [0.09] |
| Smaller building constructed before 1948 | 0.2 [-] | 2.1 [0.22] |
| Smaller building constructed 1949–1990 | 0.1 [-] | 1.3 [0.16] |
| Smaller building constructed 1991–2000 | 0.2 [-] | 1.8 [0.38] |
| Smaller building constructed after 2001 | 0.3 [-] | 1.6 [0.11] |
| Larger building constructed before 1948 | 0.2 [-] | 1.4 [0.33] |
| Larger building constructed 1949–1990 | 0.1 [-] | 0.6 [0.07] |
| Larger building constructed 1991–2000 | 0.1 [-] | 1.2 [0.29] |
| Larger building constructed after 2001 | 0.0 [-] | 0.8 [0.09] |
| Attribute | Male | Female | All | |||
|---|---|---|---|---|---|---|
| Phase O | Phase A | Phase O | Phase A | Phase O | Phase A | |
| Total persons | 1.9 * | 1.9 * | 2.1 * | 2.2 * | 2.0 [-] | 2.0 [-] |
| Workers | 0.6 [-] | 1.8 [0.06] | 0.9 [-] | 2.3 [0.05] | 0.7 * | 1.8 * |
| Foreigners | - | - | - | - | 0.7 [-] | 4.6 [0.12] |
| Age: <4 years old | 2.3 [-] | 6.5 [0.18] | 2.8 [-] | 6.9 [0.45] | 2.4 * | 4.9 * |
| Age: 5–9 years old | 2.7 [-] | 6.9 [0.27] | 2.6 [-] | 6.8 [0.32] | 2.5 * | 5.0 * |
| Age: 10–14 years old | 3.0 [-] | 6.9 [0.32] | 2.8 [-] | 6.5 [0.26] | 2.7 * | 4.7 * |
| Age: 15–19 years old | 2.7 [-] | 6.2 [0.25] | 3.1 [-] | 7.0 [0.36] | 2.8 * | 5.1 * |
| Age: 20–24 years old | 1.9 [-] | 5.1 [0.26] | 1.4 [-] | 5.5 [0.55] | 1.6 * | 4.2 * |
| Age: 25–29 years old | 1.3 [-] | 4.5 [0.13] | 1.3 [-] | 4.5 [0.24] | 1.3 * | 3.2 * |
| Age: 30–34 years old | 1.7 [-] | 4.2 [0.24] | 2.1 [-] | 4.7 [0.12] | 1.8 * | 3.3 * |
| Age: 35–39 years old | 2.2 [-] | 4.4 [0.11] | 2.8 [-] | 4.9 [0.15] | 2.4 * | 3.8 * |
| Age: 40–44 years old | 2.0 [-] | 4.1 [0.19] | 2.9 [-] | 4.6 [0.15] | 2.3 * | 3.3 * |
| Age: 45–49 years old | 2.0 [-] | 3.7 [0.17] | 2.4 [-] | 3.9 [0.15] | 2.1 * | 3.3 * |
| Age: 50–54 years old | 1.8 [-] | 3.7 [0.13] | 1.9 [-] | 3.5 [0.14] | 1.8 * | 2.9 * |
| Age: 55–59 years old | 1.3 [-] | 3.6 [0.10] | 1.7 [-] | 3.8 [0.28] | 1.5 * | 3.1 * |
| Age: 60–64 years old | 1.2 [-] | 3.8 [0.16] | 1.5 [-] | 4.1 [0.23] | 1.3 * | 3.1 * |
| Age: 65–69 years old | 2.0 [-] | 4.6 [0.30] | 2.0 [-] | 5.0 [0.20] | 1.9 * | 3.8 * |
| Age: 70–74 years old | 1.7 [-] | 4.3 [0.33] | 2.3 [-] | 4.9 [0.29] | 1.9 * | 4.1 * |
| Age: 75–79 years old | 2.4 [-] | 6.0 [0.32] | 2.0 [-] | 5.4 [0.35] | 2.1 * | 4.8 * |
| Age: >80 years old | 1.5 [-] | 5.5 [0.27] | 2.0 [-] | 5.4 [0.18] | 1.7 * | 4.2 * |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Moreno, A.T.; Moeckel, R. Population Synthesis Handling Three Geographical Resolutions. ISPRS Int. J. Geo-Inf. 2018, 7, 174. https://doi.org/10.3390/ijgi7050174
Moreno AT, Moeckel R. Population Synthesis Handling Three Geographical Resolutions. ISPRS International Journal of Geo-Information. 2018; 7(5):174. https://doi.org/10.3390/ijgi7050174
Chicago/Turabian StyleMoreno, Ana Tsui, and Rolf Moeckel. 2018. "Population Synthesis Handling Three Geographical Resolutions" ISPRS International Journal of Geo-Information 7, no. 5: 174. https://doi.org/10.3390/ijgi7050174
APA StyleMoreno, A. T., & Moeckel, R. (2018). Population Synthesis Handling Three Geographical Resolutions. ISPRS International Journal of Geo-Information, 7(5), 174. https://doi.org/10.3390/ijgi7050174