Metaphor Representation and Analysis of Non-Spatial Data in Map-Like Visualizations



Abstract
:1. Introduction
2. Related Research
3. Methods
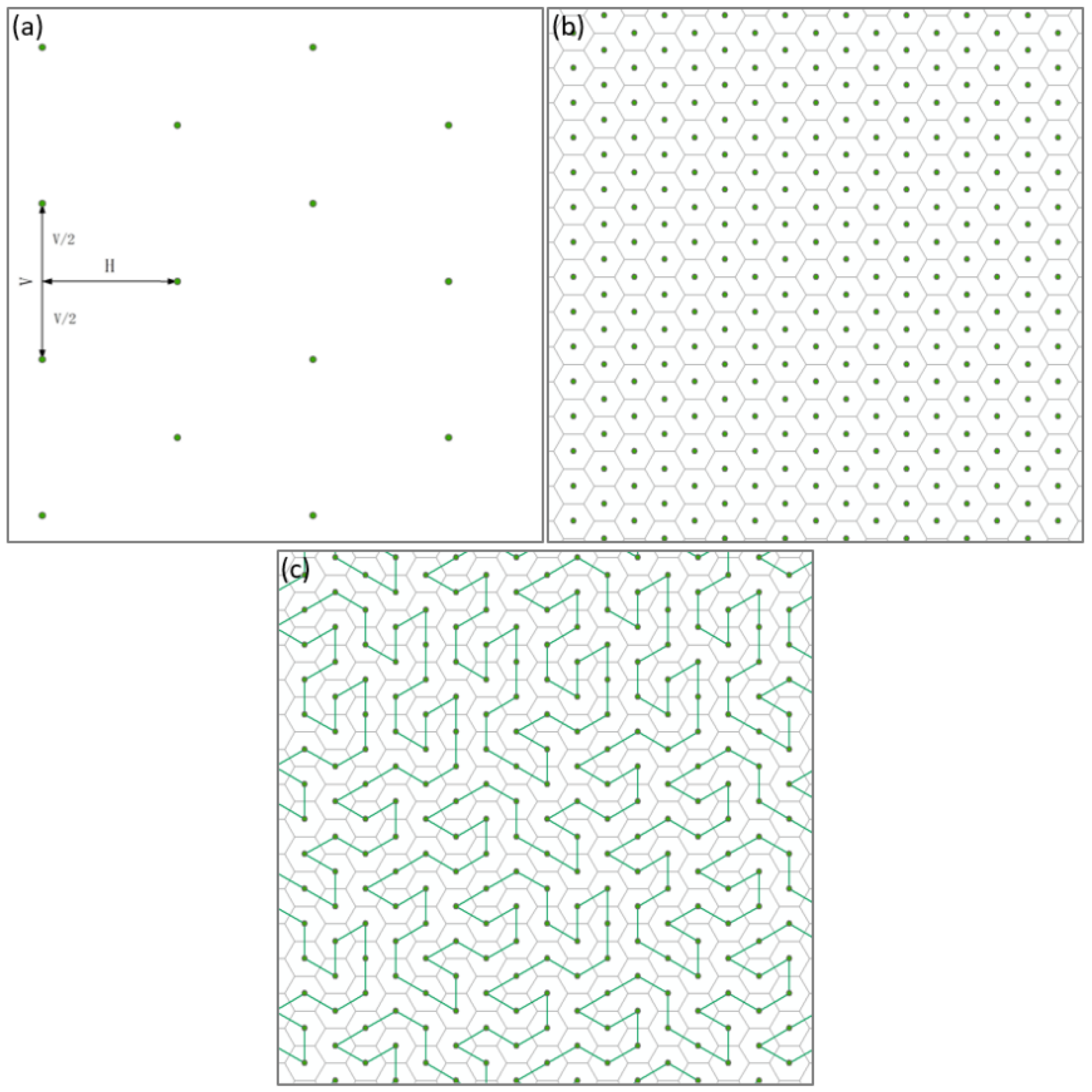
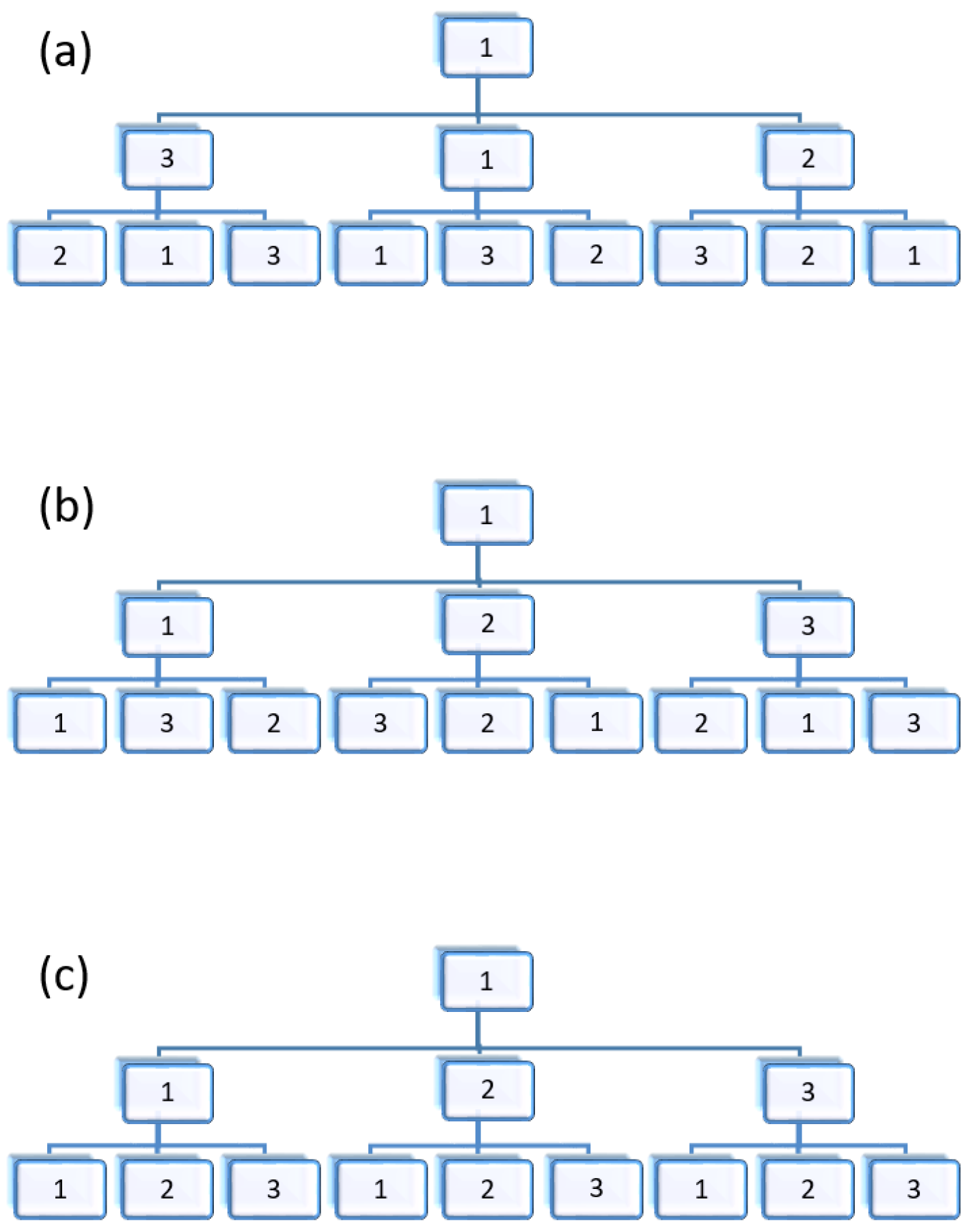
3.1. Map Frame Construction
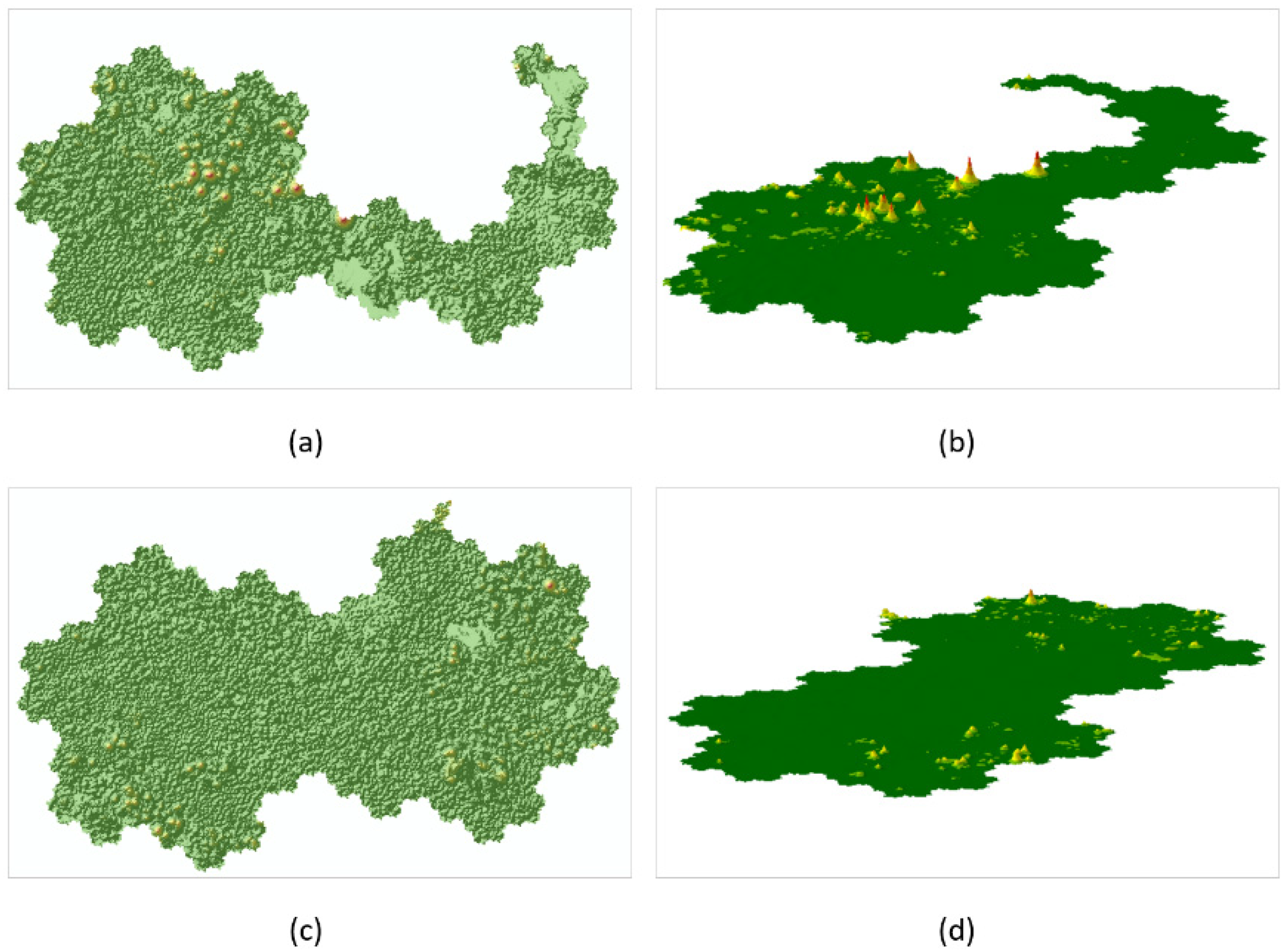
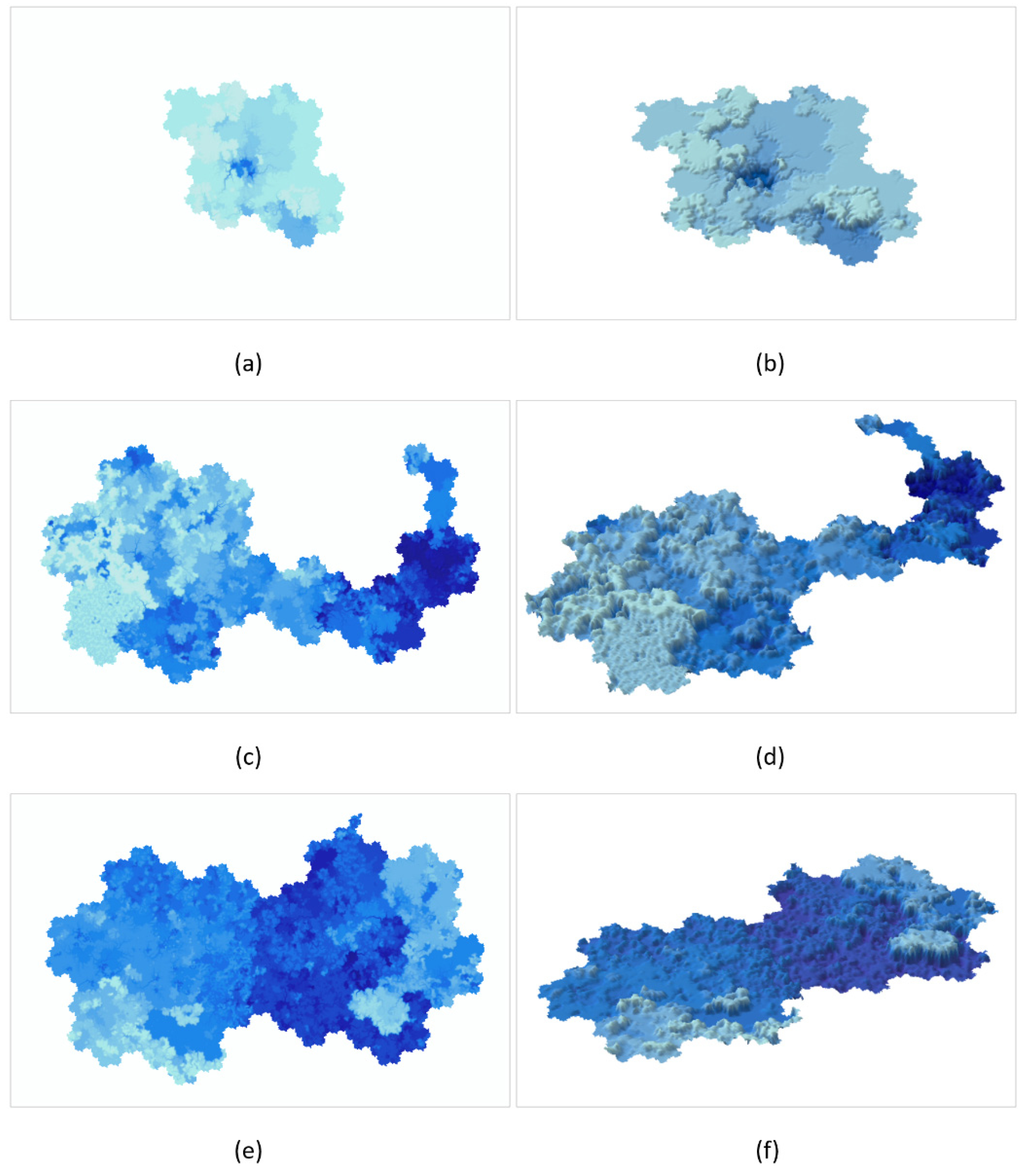
3.2. Virtual Terrain Expression
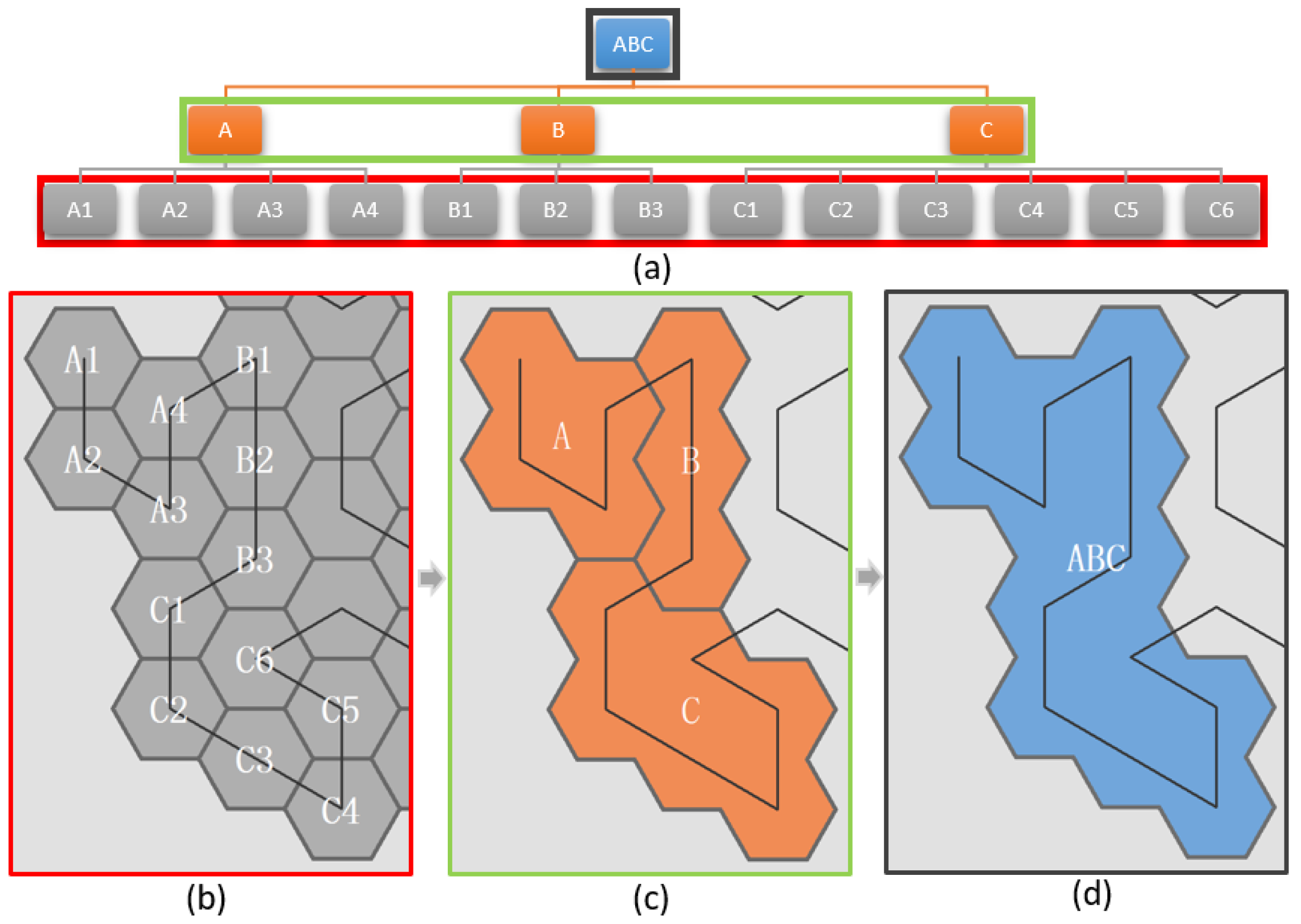
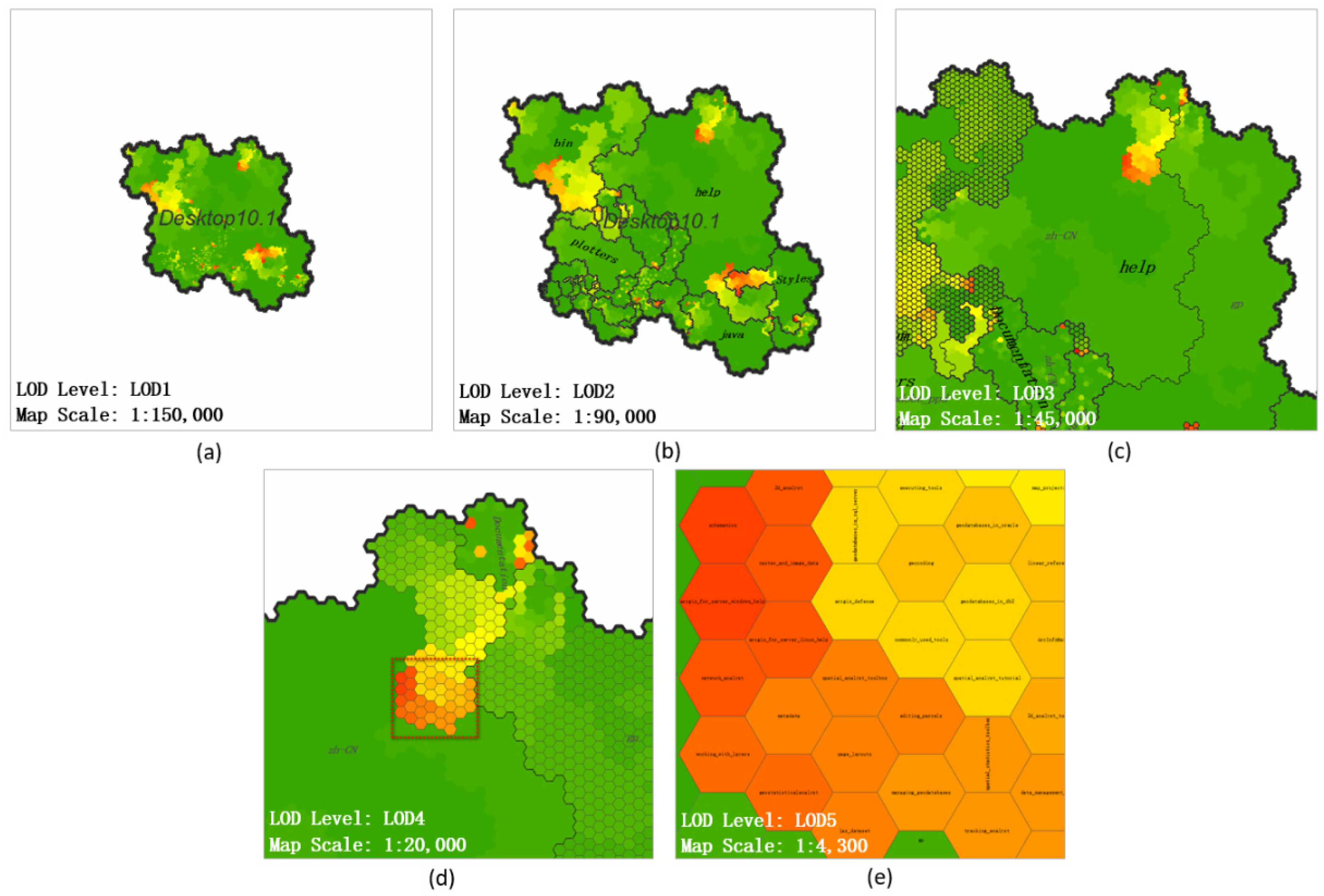
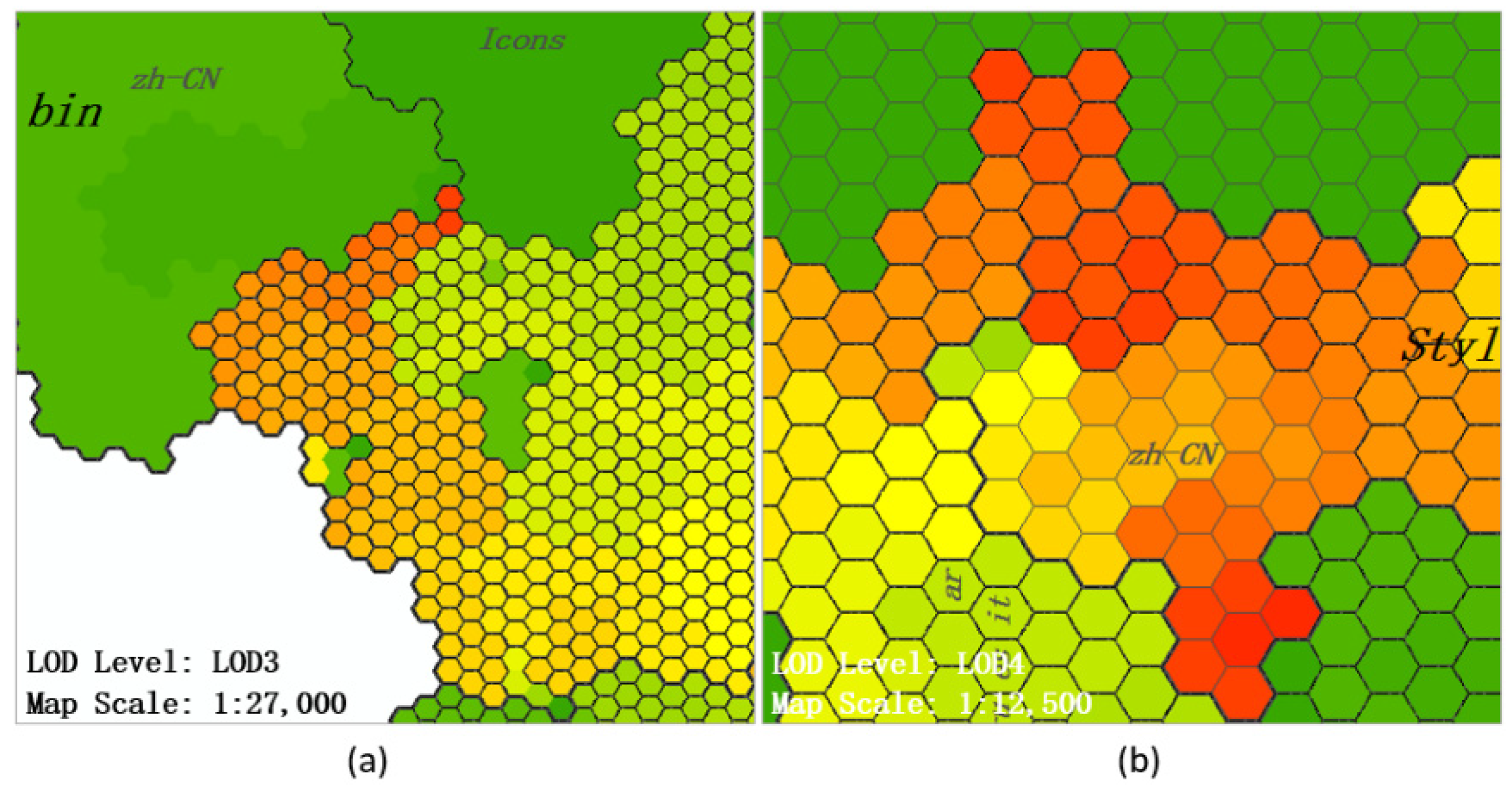
3.3. Multi-Scale Analysis of a Map
4. Experiment and Discussion
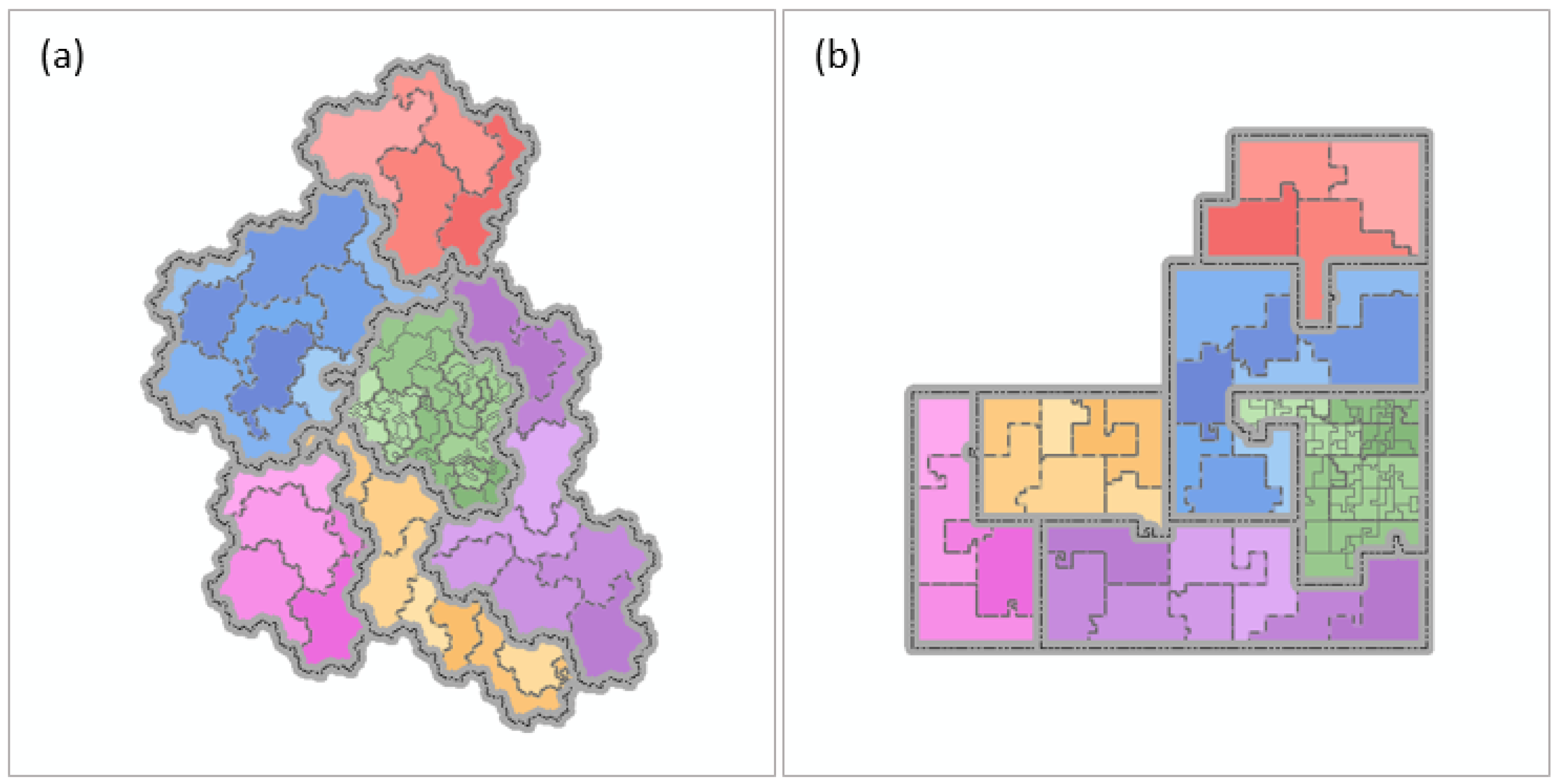
4.1. Diversified Expressions of Maps
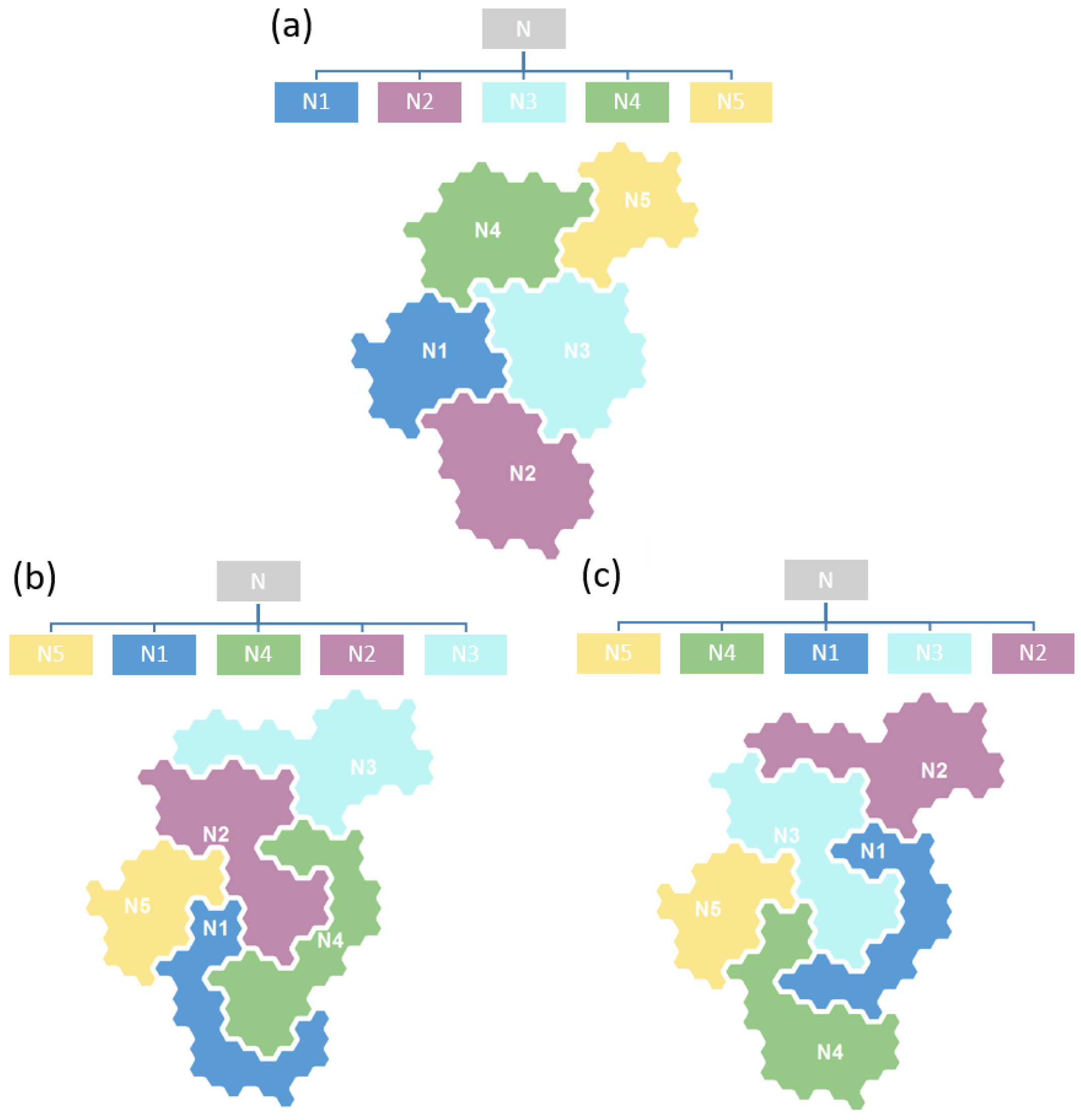
4.2. Multi-Scale Map Analysis
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Dodge, M.; Kitchin, R. Atlas of Cyberspace; Addison-Wesley: Boston, MA, USA, 2001. [Google Scholar]
- Skupin, A.; Fabrikant, S.I. Spatialization. In The Handbook of Geographical Information Science; Wilson, J.P., Fotheringham, A.S., Eds.; Blackwell Publishing: Malden, MA, USA, 2008; pp. 61–79. [Google Scholar]
- Skupin, A.; Buttenfield, B.P. Spatial metaphors for visualizing information spaces. In Proceedings of the ACSM/ASPRS Annual Convention and Exhibition, Seattle, WA, USA, 7–10 April 1997; pp. 116–125. [Google Scholar]
- Lakoff, G.; Johnson, M. Metaphors We Live by; University of Chicago Press: Chicago, IL, USA, 2008. [Google Scholar]
- Skupin, A. From metaphor to method: Cartographic perspectives on information visualization. In Proceedings of the IEEE Symposium on Information Visualization, Salt Lake City, UT, USA, 9–10 October 2000; pp. 91–97. [Google Scholar]
- Blades, M.; Blaut, J.M.; Darvizeh, Z.; Elguea, S.; Sowden, S.; Soni, D.; Spencer, C.; Stea, D.; Surajpaul, R.; Uttal, D. A cross-cultural study of young children’s mapping abilities. Trans. Inst. Br. Geogr. 1998, 23, 269–277. [Google Scholar] [CrossRef]
- Kraak, M.-J.; Ormeling, F.J. Cartography: Visualization of Spatial Data; Routledge: Abingdon, UK, 2013. [Google Scholar]
- Ai, T.; Ke, S.; Yang, M.; Li, J. Envelope generation and simplification of polylines using Delaunay triangulation. Int. J. Geogr. Inf. Sci. 2017, 31, 297–319. [Google Scholar] [CrossRef]
- Piaget, J.; Inhelder, B. The Child’s Conception of Space. Am. J. Sociol. 1956, 5, 490. [Google Scholar]
- Spiess, E.; Baumgartner, U.; Arn, S.; Vez, C. Topographic Maps—Map Graphics and Generalisation; Swiss Society of Cartography: Wabern, Switzerland, 2002. [Google Scholar]
- Brock, A.M.; Truillet, P.; Oriola, B.; Picard, D.; Jouffrais, C. Interactivity Improves Usability of Geographic Maps for Visually Impaired People. Hum. Comput. Interact. 2015, 30, 156–194. [Google Scholar] [CrossRef] [Green Version]
- Fabrikant, S.I.; Skupin, A. Cognitively plausible information visualization. In Exploring Geovisualization; Dykes, J., MacEachren, A.M., Kraak, M.-J., Eds.; Elsevier: New York, NY, USA, 2005; pp. 667–690. [Google Scholar]
- Montello, D.R.; Fabrikant, S.I.; Ruocco, M.; Middleton, R.S. Testing the first law of cognitive geography on point-display spatializations. In Proceedings of the International Conference on Spatial Information Theory, Kartause Ittingen, Switzerland, 24–28 September 2003; Kuhn, W., Worboys, M., Timpf, S., Eds.; 2003; Volume 2825, pp. 316–331. [Google Scholar]
- Fabrikant, S.I.; Montello, D.R.; Ruocco, M.; Middleton, R.S. The distance–similarity metaphor in network-display spatializations. Cartogr. Geogr. Inf. Sci. 2004, 31, 237–252. [Google Scholar] [CrossRef]
- Fabrikant, S.I.; Montello, D.R.; Mark, D.M. The distance-similarity metaphor in region-display spatializations. IEEE Comput. Graph. Appl. 2006, 26, 34–44. [Google Scholar] [CrossRef] [PubMed]
- Tobler, W.R. Computer Movie Simulating Urban Growth In Detroit Region. Econ. Geogr. 1970, 46, 234–240. [Google Scholar] [CrossRef]
- Fabrikant, S.I.; Montello, D.R. The effect of instructions on distance and similarity judgements in information spatializations. Int. J. Geogr. Inf. Sci. 2008, 22, 463–478. [Google Scholar] [CrossRef]
- Skupin, A. A cartographic approach to visualizing conference abstracts. IEEE Comput. Graph. Appl. 2002, 22, 50–58. [Google Scholar] [CrossRef]
- Cao, N.; Lin, Y.-R.; Gotz, D. UnTangle Map: Visual Analysis of Probabilistic Multi-Label Data. IEEE Trans. Vis. Comput. Graph. 2016, 22, 1149–1163. [Google Scholar] [CrossRef] [PubMed]
- Wattenberg, M. A note on space-filling visualizations and space-filling curves. In Proceedings of the IEEE Symposium on Information Visualization, Minneapolis, MN, USA, 23–25 October 2005; pp. 181–186. [Google Scholar]
- Auber, D.; Huet, C.; Lambert, A.; Renoust, B.; Sallaberry, A.; Saulnier, A. GosperMap: Using a Gosper Curve for Laying Out Hierarchical Data. IEEE Trans. Vis. Comput. Graph. 2013, 19, 1820–1832. [Google Scholar] [CrossRef] [PubMed]
- Biuk-Aghai, R.P.; Yang, M.; Pang, P.C.-I.; Ao, W.H.; Fong, S.; Si, Y.-W. A map-like visualisation method based on liquid modelling. J. Vis. Lang. Comput. 2015, 31, 87–103. [Google Scholar] [CrossRef]
- Yang, M.; Biuk-Aghai, R.P. Enhanced Hexagon-Tiling Algorithm for Map-Like Information Visualisation. In Proceedings of the 8th International Symposium on Visual Information Communication and Interaction, Tokyo, Japan, 24–26 August 2015; pp. 137–142. [Google Scholar]
- Gansner, E.R.; Hu, Y.; Kobourov, S.G. Visualizing Graphs and Clusters as Maps. IEEE Comput. Graph. Appl. 2010, 30, 54–66. [Google Scholar] [CrossRef] [PubMed]
- Gronemann, M.; Jünger, M. Drawing clustered graphs as topographic maps. In Proceedings of the International Symposium on Graph Drawing, Redmond, WA, USA, 19–21 September 2012; pp. 426–438. [Google Scholar]
- Fried, D.; Kobourov, S.G. Maps of Computer Science. In Proceedings of the 2014 IEEE Pacific Visualization Symposium, Yokohama, Japan, 4–7 March 2014; pp. 113–120. [Google Scholar]
- Lu, M.; Chen, S.; Lai, C.; Lin, L.; Yuan, X. Frontier of Information Visualization and Visual Analytics in 2016. J. Vis. 2017, 20, 667–686. [Google Scholar] [CrossRef]
- Chen, S.; Chen, S.; Wang, Z.; Liang, J.; Yuan, X.; Cao, N.; Wu, Y. D-Map: Visual Analysis of Ego-centric Information Diffusion Patterns in Social Media. In Proceedings of the 2016 IEEE Conference on Visual Analytics Science and Technology, Baltimore, MD, USA, 23–28 October 2016; pp. 41–50. [Google Scholar]
- Chen, S.; Chen, S.; Lin, L.; Yuan, X.; Liang, J.; Zhang, X. E-map: A visual analytics approach for exploring significant event evolutions in social media. In Proceedings of the IEEE Conference on Visual Analytics Science&Technology (VAST), Phoenix, AZ, USA, 1–6 October 2017. [Google Scholar]
- Cao, N.; Shi, C.; Lin, S.; Lu, J.; Lin, Y.-R.; Lin, C.-Y. TargetVue: Visual Analysis of Anomalous User Behaviors in Online Communication Systems. IEEE Trans. Vis. Comput. Graph. 2016, 22, 280–289. [Google Scholar] [CrossRef] [PubMed]
- Carr, D.B.; Olsen, A.R.; White, D. Hexagon Mosaic Maps for Display of Univariate and Bivariate Geographical Data. Cartogr. Geogr. Inf. Syst. 1992, 19, 228–236. [Google Scholar] [CrossRef]
- Birch, C.P.D.; Oom, S.P.; Beecham, J.A. Rectangular and hexagonal grids used for observation, experiment and simulation in ecology. Ecol. Model. 2007, 206, 347–359. [Google Scholar] [CrossRef]
- Coppola, D.M.; Purves, H.R.; McCoy, A.N.; Purves, D. The distribution of oriented contours in the real word. Proc. Natl. Acad. Sci. USA 1998, 95, 4002–4006. [Google Scholar] [CrossRef] [PubMed]
- Carr, D.B. Looking at Large Data Sets Using Binned Data Plots; Pacific Northwest Labortary: Richland, WA, USA, 1990. [Google Scholar]
- Carr, D.B.; Littlefield, R.J.; Nicholson, W.L.; Littlefield, J.S. Scatterplot Matrix Techniques for Large-N. J. Am. Stat. Assoc. 1987, 82, 424–436. [Google Scholar] [CrossRef]
- Ai, T.; Cheng, X.; Liu, P.; Yang, M. A shape analysis and template matching of building features by the Fourier transform method. Comput. Environ. Urban Syst. 2013, 41, 219–233. [Google Scholar] [CrossRef]
- Ortiz, M.J. Visual Rhetoric: Primary Metaphors and Symmetric Object Alignment. Metaphor Symb. 2010, 25, 162–180. [Google Scholar] [CrossRef]
- Chalmers, M. Using a landscape metaphor to represent a corpus of documents. In Proceedings of the European Conference on Spatial Information Theory, Marciana Marina, Italy, 19–22 September 1993; pp. 377–390. [Google Scholar]
- Weber, G.H.; Bremer, P.-T.; Pascucci, V. Topological landscapes: A terrain metaphor for scientific data. IEEE Trans. Vis. Comput. Graph. 2007, 13, 1416–1423. [Google Scholar] [CrossRef] [PubMed]
- Fabrikant, S.I.; Montello, D.R.; Mark, D.M. The Natural Landscape Metaphor in Information Visualization: The Role of Commonsense Geomorphology. J. Am. Soc. Inf. Sci. Technol. 2010, 61, 253–270. [Google Scholar] [CrossRef]
- Brandes, U.; Willhalm, T. Visualization of Bibliographic Networks with a Reshaped Landscape Metaphor. In Proceedings of the Symposium on Data Visualisation, Barcelona, Spain, 27–29 May 2002; pp. 159–164. [Google Scholar]
- Tory, M.; Swindells, C.; Dreezer, R. Comparing Dot and Landscape Spatializations for Visual Memory Differences. IEEE Trans. Vis. Comput. Graph. 2009, 15, 1033–1039. [Google Scholar] [CrossRef] [PubMed]
- Haverkort, H.; van Walderveen, F. Locality and bounding-box quality of two-dimensional space-filling curves. Comput. Geom. Theory Appl. 2010, 43, 131–147. [Google Scholar] [CrossRef]
- Montello, D.R.; Golledge, R. Scale and detail in the cognition of geographic information. In Proceedings of the Specialist Meeting of Project Varenius, Santa Barbara, CA, USA, 14–16 May 1998. [Google Scholar]
- Fabrikant, S.I. Evaluating the usability of the scale metaphor for querying semantic spaces. In Proceedings of the International Conference on Spatial Information Theory, Morro Bay, CA, USA, 19–23 September 2001; pp. 156–172. [Google Scholar]
- Shneiderman, B. The eyes have it: A task by data type taxonomy for information visualizations. In The Craft of Information Visualization; Elsevier: New York, NY, USA, 2003; pp. 364–371. [Google Scholar]
- Szewranski, S.; Kazak, J.; Sylla, M.; Swiader, M. Spatial Data Analysis with the Use of ArcGIS and Tableau Systems. In Rise of Big Spatial Data; Ivan, I., Singleton, A., Horak, J., Inspektor, T., Eds.; Springer: Berlin, Germany, 2017; pp. 337–349. [Google Scholar]
- Wickramasuriya, R.; Ma, J.; Berryman, M.; Perez, P. Using geospatial business intelligence to support regional infrastructure governance. Knowl. Based Syst. 2013, 53, 80–89. [Google Scholar] [CrossRef]
- Safadi, M.; Ma, J.; Wickramasuriya, R.; Daly, D.; Perez, P.; Kokogiannakis, G. Mapping for the future: Business intelligence tool to map regional housing stock. Procedia Eng. 2017, 180, 1684–1694. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| LOD Level | Map Scale | Newly Emerging Map Slice |
|---|---|---|
| LOD1 | 1:150,000 | map slice of level 1 |
| LOD2 | 1:100,000 | map slice of level 2 |
| LOD3 | 1:50,000 | map slice of level 3 |
| LOD4 | 1:25,000 | map slice of level 4 |
| LOD5 | 1:10,000 | map slice of level 5 |
| … | … | … |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xin, R.; Ai, T.; Ai, B. Metaphor Representation and Analysis of Non-Spatial Data in Map-Like Visualizations. ISPRS Int. J. Geo-Inf. 2018, 7, 225. https://doi.org/10.3390/ijgi7060225
Xin R, Ai T, Ai B. Metaphor Representation and Analysis of Non-Spatial Data in Map-Like Visualizations. ISPRS International Journal of Geo-Information. 2018; 7(6):225. https://doi.org/10.3390/ijgi7060225
Chicago/Turabian StyleXin, Rui, Tinghua Ai, and Bo Ai. 2018. "Metaphor Representation and Analysis of Non-Spatial Data in Map-Like Visualizations" ISPRS International Journal of Geo-Information 7, no. 6: 225. https://doi.org/10.3390/ijgi7060225
APA StyleXin, R., Ai, T., & Ai, B. (2018). Metaphor Representation and Analysis of Non-Spatial Data in Map-Like Visualizations. ISPRS International Journal of Geo-Information, 7(6), 225. https://doi.org/10.3390/ijgi7060225