1. Introduction
The spatial pattern of crops is the manifestation of agricultural production activities on land use and the efficient usage of natural resources and scientific field management [
1,
2]. With the growth of populations and the reduction of arable land, timely and accurate mapping of the spatial distribution of crops is an important foundation for growth monitoring, yield estimation, disaster assessment, grain production macro-control, and agricultural trade regulation [
3,
4]. The spatial patterns are also the evidence that allows relevant departments to promptly formulate agricultural policies to guarantee food security [
5].
For a long time, the traditional approach for obtaining crop planting area was based on sampling surveys and step-by-step summaries [
6]. However, this process is labor intensive and uses a large quantity of material resources, and the accuracy is greatly affected by a variety of subjective and objective factors [
7,
8].
Remote sensing data play an important role in many fields, such as air temperature estimation [
9], land cover monitoring [
10,
11], fire incidence assessment [
12], drought prediction [
13], and monitoring of crop distribution [
14,
15]. However, due to technological and budget constraints, space-borne sensors must compromise among spatial resolution, temporal resolution, and repeat periods [
16], and data from any single sensor cannot fully reflect the spatiotemporal crop patterns [
17,
18], which generally presents a complex spatiotemporal heterogeneity [
19]. For example, a single medium or high spatial resolution remote sensing sensor usually has a long repeat cycle and has a limited potential for capturing the entire growth period of the crop [
2,
20]; the probability of acquiring high quality remote sensing data (cloud cover <10%) is less than 10% because of the influence of cloud contamination [
21] on Landsat series with a 16-day repeat period. On the other hand, a single sensor with high temporal resolution can provide temporally dense data for the monitoring of large-scale vegetation [
22,
23], but its coarse spatial resolution data generally have a poor ability to describe the spatial heterogeneity [
24,
25,
26]; one example is the moderate resolution imaging spectroradiometer (MODIS). Hence, few sensors currently provide high spatial and temporal resolution remote sensing data for mapping the complexity and diversity of crop planting structures and farmland fragmentation.
Remote sensing spatiotemporal fusion models have been developed to merge high spatial resolution data with high temporal resolution data to produce high spatiotemporal resolution data, which can be used to identify crop distributions with high accuracy [
27,
28]. Researchers have used the original normalized difference vegetation index (NDVI) or time series derived from the spatial and temporal adaptive reflectance fusion model (STARFM) [
29], which is the most widely used model, to study land cover classification or crop classification extraction through the supervised classification method [
30,
31,
32,
33,
34,
35,
36]. However, researchers often pair Landsat and MODIS in their studies [
37]. Here, we were interested in whether more kinds of sensor data can be used to provide more data for the target with the STARFM and accurately extract crop classifications.
In this study, we attempted to extend the NDVI time series from the ZY-3 satellite data, which are very suitable for crop monitoring [
38], by combining the Landsat 8 Operational Land Imager (OLI) and HJ-1A/B charge coupled device (CCD) data, which have 30-m spatial resolution, through the STARFM. The support vector machine (SVM) and random forest (RF) algorithms are two widely used classifiers in the remote sensing community [
33,
36] and are used for crop classification in this study. The additional purposes of this study are to investigate the effect of the NDVI time series density on the classification accuracy by the two classifiers and to explore the feasibility of obtaining the optimal time period of wheat recognition for the NDVI fusion and classification by using the RF classifier.
3. Method
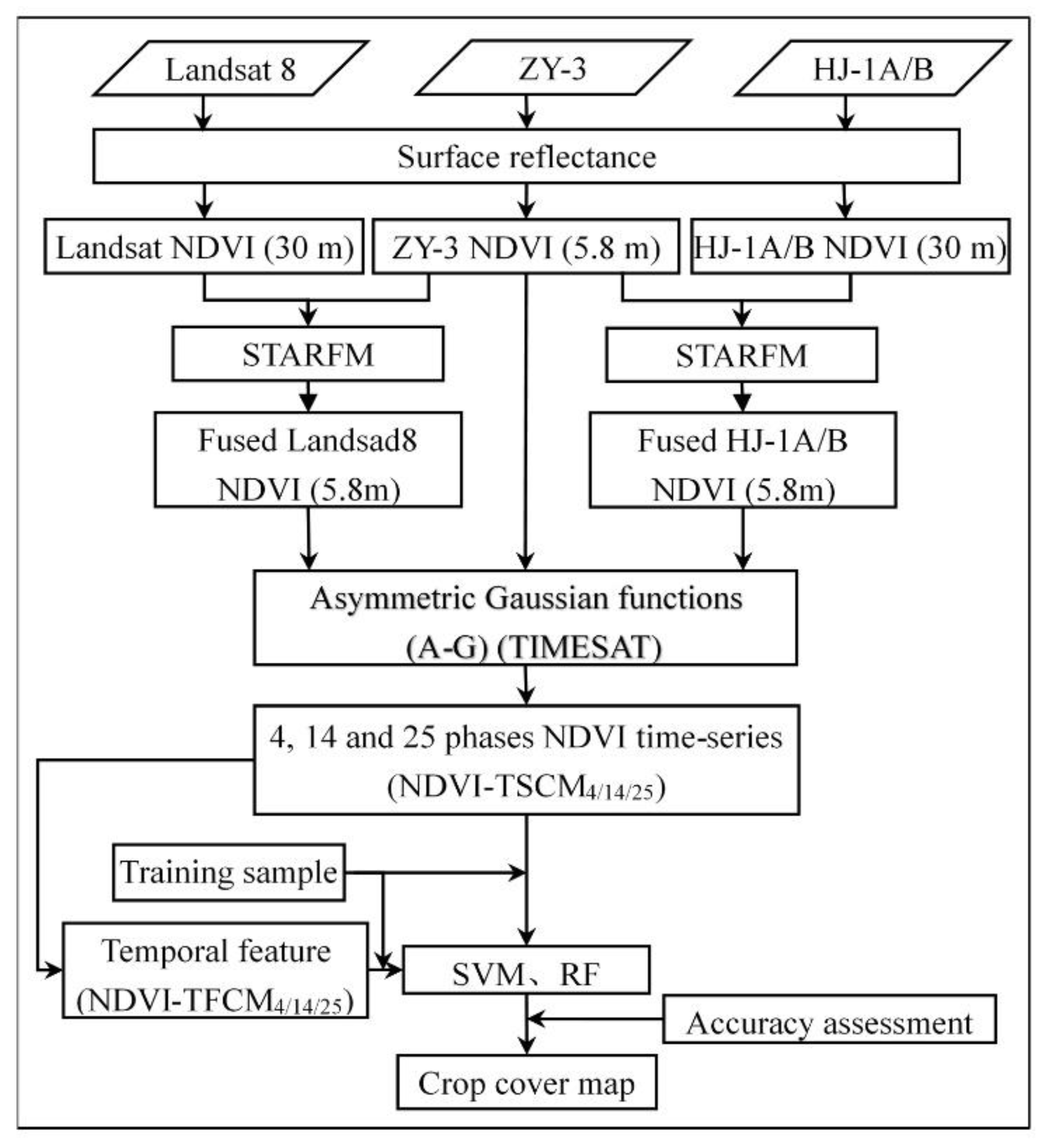
Figure 2 presents the flowchart of this study. First, all remote sensing data were clipped to the same region. The NDVI was calculated using red and near infrared (NIR) bands. Then, the time series of the Landsat 8 and HJ-1A/B NDVIs were fused with the ZY-3 NDVI using STARFM [
29]. To reduce the effect of noise on the vegetation data, the fused NDVI time series was filtered by Time-series Satellite data Analysis Tool (TIMESAT). Finally, the NDVI time series and its corresponding temporal features were used to classify crops using the SVM and RF, respectively, and to evaluate the accuracy of the classification results.
3.1. STARFM
The STARFM is based on one pair of images comprising one medium-resolution reflectance image (M) and one high-resolution reflectance image (L) as the reference date (tk), and then blends the differences (L-M) with another medium spatial resolution reflectance image (M) from the prediction date (t0) to predict the corresponding high spatial resolution reflectance image (L). Under the assumption that the surface reflectance difference does not change over time, a weighted averaging method is used with a moving window centered at the target pixel to reduce the boundary influence of the adjacent pixels. The surface reflectance of the target pixel is predicted by selecting the spectrally similar and cloudless pixels in the moving window as follows:
where
w is the size of the moving window,
is the center pixel of the moving window at date
t0,
is the predicted reflectance value of the high spatial resolution value,
M (
xi,yj,t0) is the medium spatial resolution reflectance value at date
t0, and
L(
xi,yj,tk) and
M (
xi,yj,tk) represent the high and medium spatial resolution reflectance values, respectively, at the base date
tk. The weight
Wijk,, which determines how much each similar pixel contributes to the surface reflectance of the target pixel, is decided by the spectral difference, temporal difference, and location difference after the normalization processing [
16,
29].
3.2. NDVI Time Series and A-G Filter
The NDVI time series is usually continuous and smooth, and can reflect the growth process of the vegetation, but remote sensing data are influenced by various factors in the acquisition process [
36]. They will cause the NDVI time series to fluctuate irregularly and may influence the trend analysis and the temporal feature extraction of the NDVI time series [
39]. Therefore, it is necessary to filter the noise from the NDVI time series to improve the data quality. The TIMESAT software includes three filtering methods, i.e., asymmetric Gaussian functions (A-G), the double logistic function method (D-L), and the Savitzky–Golay method (S-G). The A-G filtering method has the highest fidelity to the original data [
40,
41]; therefore, it is more suitable for processing the NDVI time series of the grassland, farmland, and other vegetation types [
41,
42,
43]. Accordingly, this study adopted A-G to remove the noise from the NDVI time series.
3.3. Extracting Temporal Features from NDVI Time Series
The NDVI time series can appropriately reflect the growth of vegetation and contains the information used to distinguish vegetation types [
44,
45], such as the seasonal and phenological changes. The NDVI time series can represent the seasonal and annual variations in crop growth (i.e., periodic variations from planting, seedling emergence, maturity at harvest) [
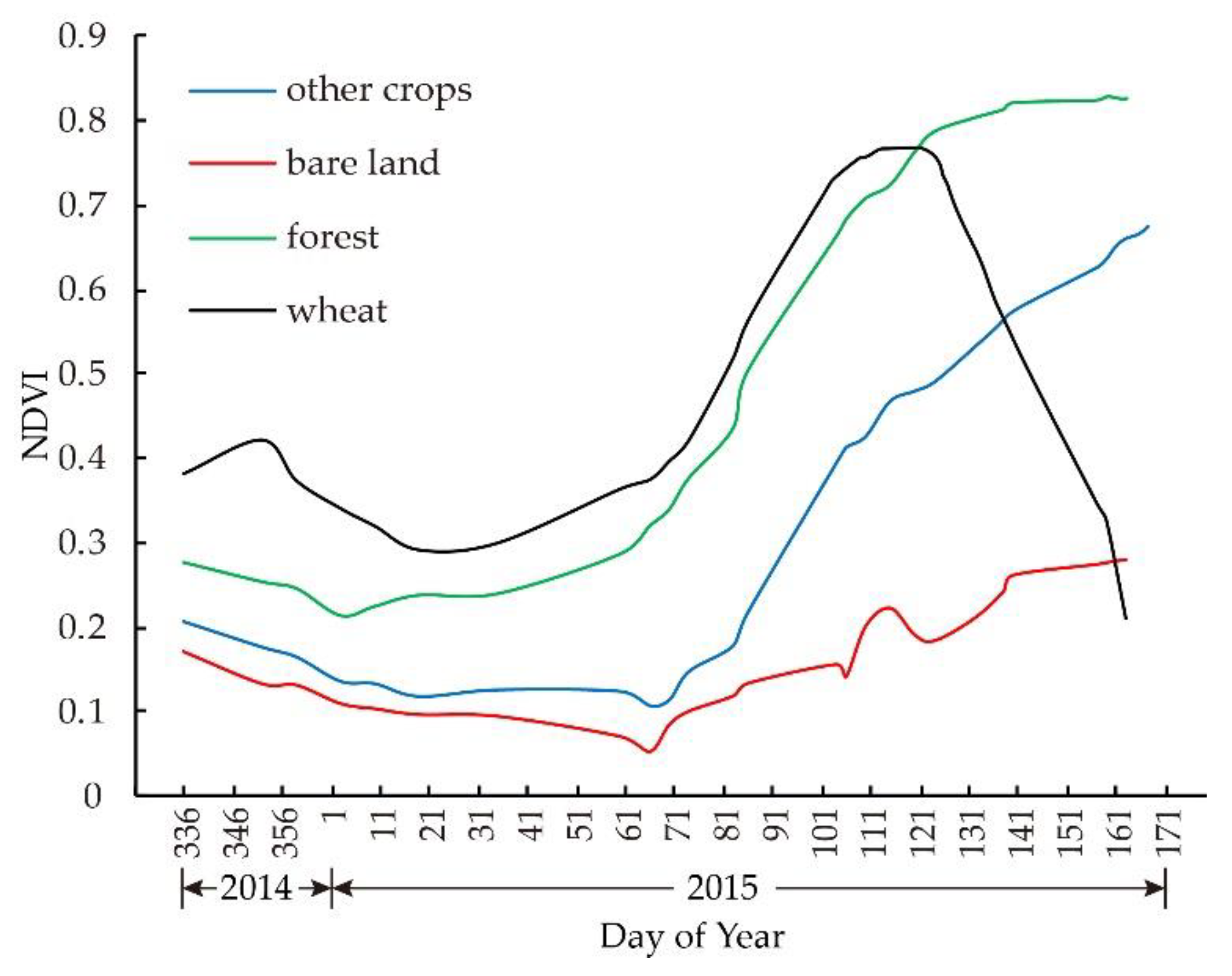
36]. For winter wheat, there were two peaks in the NDVI curve during the growth period (
Figure 3). The first is in early December. After the sowing period, the NDVI of winter wheat increased gradually and reached the first peak, while the NDVI of other vegetation decreased gradually with decreasing temperature. At this stage, the time-NDVI slope of wheat was greater than zero, while that of other vegetation was less than zero. The second occurred between late April and early May. The biomass of winter wheat increased rapidly after rising and jointing, and the NDVI also increased. By early May, the NDVI value reached its maximum, forming a second peak. Then, the leaves gradually withered, and the NDVI gradually decreased, and the curve slope of NDVI was less than zero. However, the curve slope of the NDVI of other vegetation was greater than zero, and the NDVI was still increasing. The change characteristics of the NDVI curve are an important basis for identifying winter wheat.
The three NDVI time series were constructed from 4 ZY-3 NDVIs, 14 ZY-3+Landsat 8 fused NDVIs, and 25 ZY-3+Landsat 8+HJ-1A/B fused NDVIs. The original or fused NDVI time series were not a good choice for land cover classification and could reduce the accuracy of the classification model due to their large amount of redundant information [
46]. Therefore, to eliminate the redundant information of the high-dimensional data [
30], six temporal features were extracted from the denoised 4, 14, and 25 NDVI time series for classification, including the maximum, minimum, mean, standard deviation, time-accumulated NDVI, and the time of maximum value.
3.4. SVM and RF
The SVM has a unique advantage for analyzing nonlinear local minima with small sample sizes and high dimensional pattern recognition problems [
47]. It is widely used in land cover classification [
48], identification of forest types [
49,
50], and crop monitoring [
51], and has achieved higher classification accuracy compared with traditional supervised classification methods [
32]. The LIBSVM package (provided by
http://www.csie.ntu.edu.tw/~cjlin/libsvm) provides multiple SVM classifiers to support multilevel classification and the function of cross-validated models [
52].
In this study, we used the default SVM classifier (C-SVC) [
52] for crop classification. The kernel functions used in the SVM are generally linear, polynomial, radial basis (RBF) and sigmoidal functions, which directly affect the performance of the classification model. Generally, the number of training data points is much higher than the number of features, and an optimal result can be obtained using the nonlinear kernel function. Therefore, we use the RBF kernel function. At the same time, with the grid search and k-fold cross validation methods, the variable pair (such as γ and the penalty parameter C) with the highest cross-validation accuracy were selected as the optimal global parameters [
52].
The random forest (RF) classifier is a flexible and easy-to-use machine learning algorithm. Its essence is the ensemble learning method, which is widely used in land cover classification [
33], biomass estimation [
53], cloud detection [
54], and species classification [
55]. Please refer to Breiman [
56] for the detailed introduction to the RF. Crop mapping was carried out using RF in the EnMAP-Box tools provided by the German Environmental Mapping and Analysis Program [
57].
The NDVI time series with 4, 14, and 25 phases and the corresponding temporal features were combined into six kinds of classifying input vectors, which were termed the NDVI time series classification models (NDVIS/R-TSCM4, NDVIS/R-TSCM14, and NDVIS/F-TSCM25) and the temporal feature classification models (NDVIS/R-TFCM4, NDVIS/R-TFCM14, and NDVIS/F-TFCM25).
3.5. Accuracy Validation
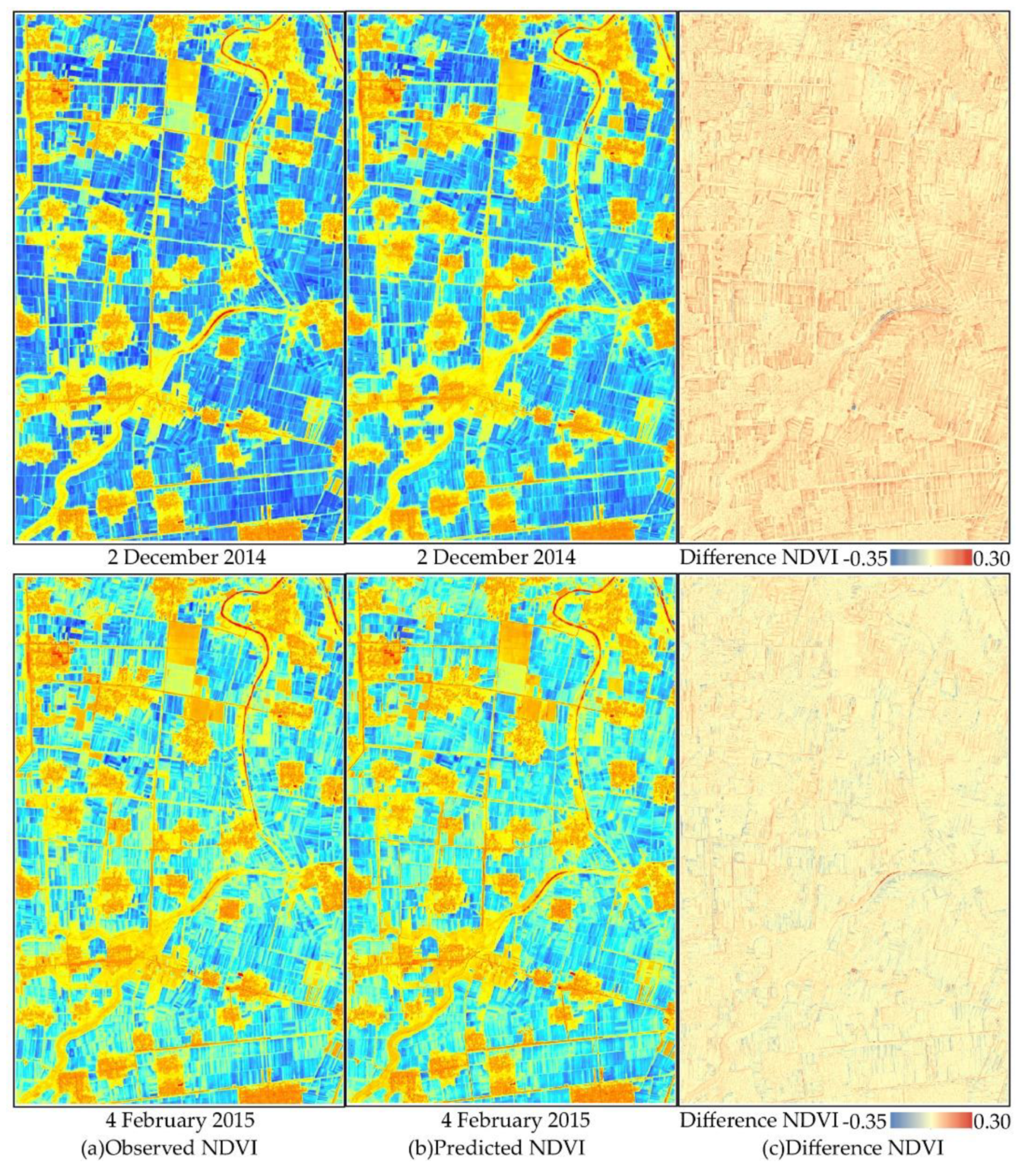
The NDVIs predicted by STARFM were qualitatively and quantitatively evaluated with the observed NDVIs. The quantitative indexes including the determination coefficients (R
2), root mean square error (RMSE), average absolute difference (AAD), average difference (AD) [
29,
58,
59], and standard deviation (SD).
The quantitative evaluation indexes, including the confusion matrix, kappa coefficient, overall accuracy, producer accuracy, user accuracy [
60], and the true skill statistic (TSS) [
61], were calculated using randomly selected sample pixels to evaluate the classification accuracies of NDVIS/R-TSCM4/14/25 and NDVIS/R-TFCM4/14/25. In addition, the statistical areas of the different classification results were also compared.
Combining ground surveys with land-cover type information in the region, we selected 8 kinds of land cover. This process was finished with the help of Google Earth tools and ground survey points. The numbers of wheat and non-wheat sample pixels were 882 and 1333, respectively (
Table 2). These samples were selected using a random stratified sampling method to make them representative of the study area. Sixty-five percent of the samples were randomly selected for training, and the other 35% were selected for validation.
5. Discussion
According to the classification results, increasing the NDVI temporal phase of NDVI-TFCM and NDVI-TSCM can help to improve the classification accuracy. The reason may be that the NDVI temporal phases increased from 4 to 14 and then to 25, which meant an increase in the image acquisition frequency and a decrease in the time gap between adjacent NDVIs in the study period. This helped to improve the accuracy of crop type identification. Moreover, the temporal information can help determine the growth characteristics of vegetation more accurately, which is also helpful for crop classification, especially for the identification of vegetation types [
31,
63].
Although MODIS has the advantages of a short revisit period and open access data, compared with the ZY-3 data, its highest spatial resolution is only 250 m, and the mixed pixel phenomenon is very severe. Thus, it is unsuitable to combine MODIS with ZY-3 data to meet the refinement requirements of regional monitoring for condensed areas and small acreage [
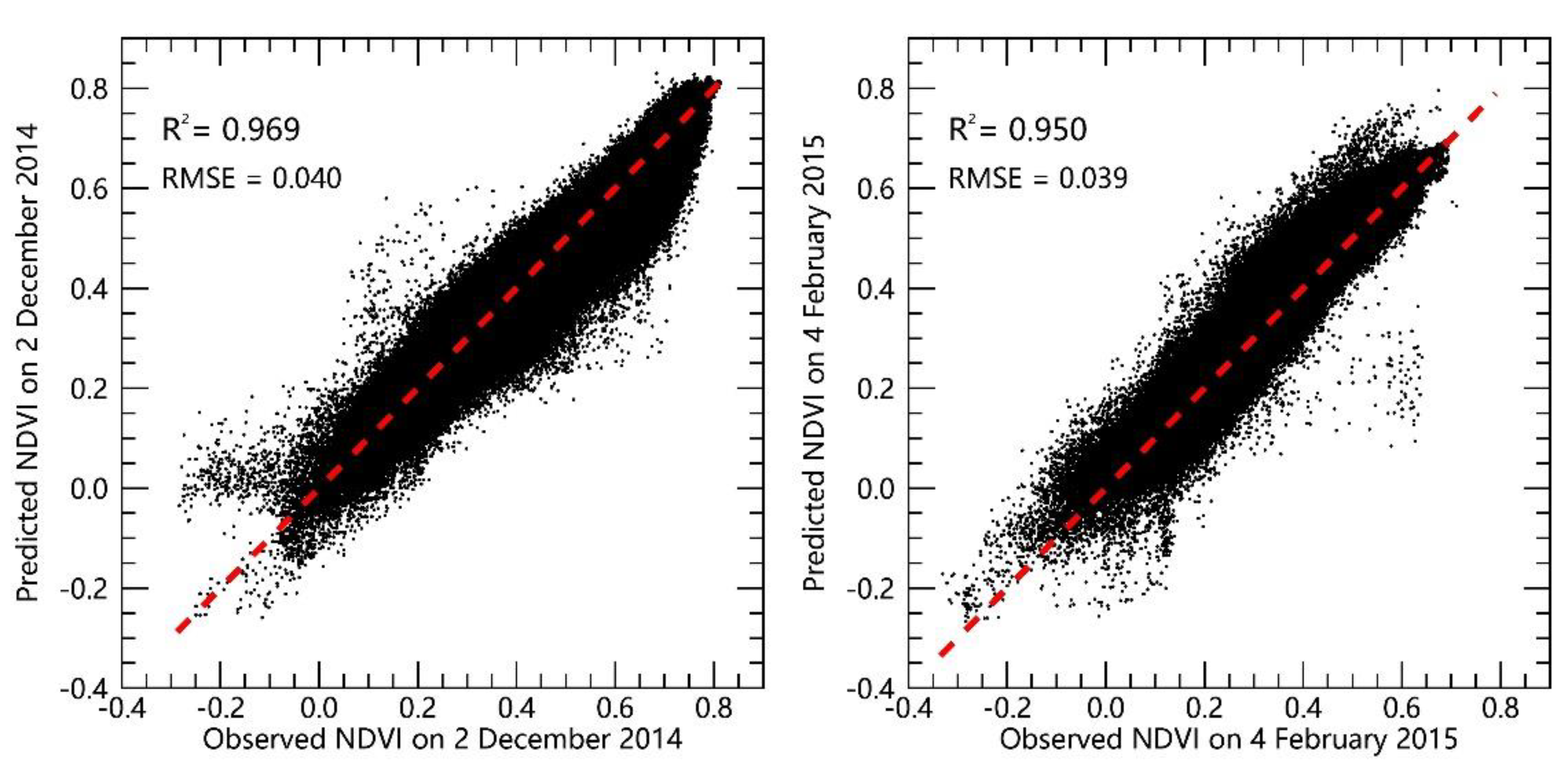
36]. However, the Landsat 8 and HJ-1A/B data with 30-m spatial resolution can better reflect the spatial heterogeneity in the crop distribution than can MODIS. Therefore, they are more suitable to be combined with the ZY-3 data. Considering that the availability and quality of the Landsat 8 data are better than those of the HJ-1A/B data, we chose the Landsat 8 as the main data source and the HJ-1A/B as an auxiliary data source to provide temporal change information for ZY-3. By evaluating the fusion results, the STARFM can effectively predict the unavailable ZY-3 NDVIs caused by long recursive cycles (59 days) and cloud contamination. The constructed ZY-3-like NDVI time series data were fine enough to detect small objects and regional heterogeneity with spatial scales less than 30 m.
In this study, the accuracies of the fusion results were also affected by the following factors: 1) the qualities of the ZY-3, Landsat 8 and HJ-1A/B data. 2) During the study period, considerable changes with a spatial scale of less than 30 m took place in vegetation growth; however, Landsat 8 and HJ-1A/B data cannot capture such changes. Thus, errors were introduced into the fused images. 3) STARFM was proposed for reflectance fusion, so when it was directly used in the NDVI fusion, some deviations may have been produced. 4) Due to the interference of atmospheric conditions and other factors, such as the bidirectional reflectance distribution function, after a series of image processing, some noise may be introduced into NDVI images inadvertently. Therefore, avoiding noise introduction will also improve the accuracy of fusion results.
In recent years, an increasing number of nonparametric classifiers have been developed, which would be preferable for use in improving classification accuracy in future studies. High spatial resolution images, such as GF-1/2, can be used with the mentioned method for land cover classification. Thus, the combination of the spatiotemporal fusion model and the advanced classification model can play an important role in regional forest cover mapping, land cover mapping, and the identification of crop types.
6. Conclusions
The research in this study showed that multisource sensor data can be used for crop classification after spatiotemporal fusion and that the data source was not limited by the sensor platform, which provides a flexible choice for data sources. The classification accuracy with the NDVI temporal features vector was not necessarily higher than that using the NDVI time series itself, which was related to the selection of the classifier. With the increase in the NDVI phases from 4 to 14 and then to 25, the classification accuracy with the use of NDVI-TSCM and NDVI-TFCM were both improved. The classification accuracy with NDVI-TSCM was higher than that with NDVI-TFCM under the RF classifier, while it had the opposite trend under the SVM. With the increase in the NDVI temporal phase, the classification accuracy was gradually improved. If the added NDVI phases were not in the optimal time period for wheat recognition, the classification accuracy was not greatly improved. In addition, this study can provide a good reference for the selection of the optimal time ranges of base image pairs for spatiotemporal fusion methods for high accuracy mapping of crops, and help avoid excessive data collection and processing.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}