A Twitter Data Credibility Framework—Hurricane Harvey as a Use Case



Abstract
:1. Introduction
2. Literature Review
2.1. Information Extraction from Social Media in Disaster Situation
2.2. Quality and Trust for Crowdsourcing Data in Emergency Management
3. Methodology
3.1. Twitter Reclassification Using Predefined Keywords
3.2. Event Identification
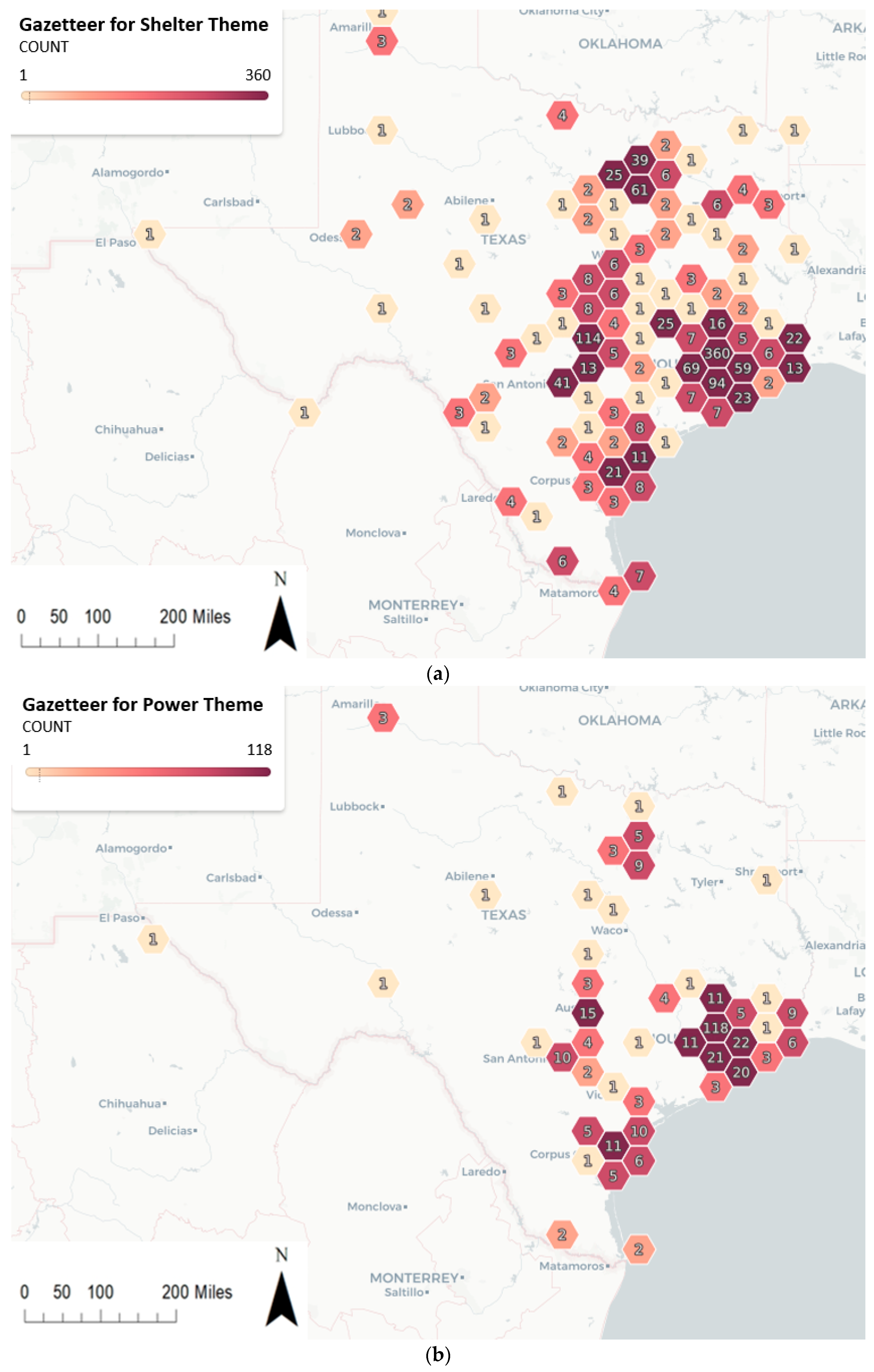
3.2.1. Location Extraction and Local Gazetteer Construction
3.2.2. Gazetteer Merging
- Duplicated locations are identified through a coordinate check. If different expressions have the same coordinates after geocoding, these are merged.
- After a coordinate check, a road-name match, similar to the first step, is applied based on the road names acquired after the geocoding process as extracted place names do not have addresses before geocoding. If one road name has 75% or higher similarity score with another after standard name format and the zip codes are the same, these locations are merged. The similarity score is calculated based on the Jaro Distance score for a string match (jellyfish python package [32]). For example, because “X High School” is an 81% match to “X School” and is higher than 75%, these two are merged if they also share the same zip code.
3.2.3. Space–Time Event Identification
3.3. Event-Based Credibility (EBC) Schema
4. Data and Credibility Analysis
4.1. Hurricane Harvey Twitter Dataset
4.2. Data Preprocessing
4.3. Event-Based Credibility Analysis
4.3.1. Local Gazetteer Construction
4.3.2. Event Identification
4.3.3. Credibility Score Calculation
5. Case-Study Results of Credibility Scores for Hurricane Harvey
5.1. Spatial Reliability
5.2. Temporal Trend
5.3. Social Impacts
5.4. Low Credibility Validation
6. Conclusions
6.1. Limitations
6.2. Future Developments
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- 2017 Atlantic hurricane season. Wikipedia. 2018. Available online: https://en.wikipedia.org/wiki/2017_Atlantic_hurricane_season (accessed on 7 December 2018).
- Murthy, D.; Gross, A.J. Social media processes in disasters: Implications of emergent technology use. Soc. Sci. Res. 2017, 63, 356–370. [Google Scholar] [CrossRef] [PubMed]
- Tim, Y.; Pan, S.L.; Ractham, P.; Kaewkitipong, L. Digitally enabled disaster response: The emergence of social media as boundary objects in a flooding disaster. Inf. Syst. J. 2017, 27, 197–232. [Google Scholar] [CrossRef]
- Yu, M.; Yang, C.; Li, Y. Big Data in Natural Disaster Management: A Review. Geosciences 2018, 8, 165. [Google Scholar] [CrossRef]
- Huang, Q.; Xiao, Y. Geographic Situational Awareness: Mining Tweets for Disaster Preparedness, Emergency Response, Impact, and Recovery. ISPRS Int. J. Geo-Inf. 2015, 4, 1549–1568. [Google Scholar] [CrossRef] [Green Version]
- Middleton, S.E.; Middleton, L.; Modafferi, S. Real-Time Crisis Mapping of Natural Disasters Using Social Media. IEEE Intell. Syst. 2014, 29, 9–17. [Google Scholar] [CrossRef]
- Tsou, M.-H.; Jung, C.-T.; Allen, C.; Yang, J.-A.; Han, S.Y.; Spitzberg, B.H.; Dozier, J. Building a Real-Time Geo-Targeted Event Observation (Geo) Viewer for Disaster Management and Situation Awareness. In Proceedings of the Advances in Cartography and GIScience; Peterson, M.P., Ed.; Springer International Publishing: Cham, Switzerland, 2017; pp. 85–98. [Google Scholar]
- Reuter, C.; Kaufhold, M.-A. Fifteen years of social media in emergencies: A retrospective review and future directions for crisis Informatics. J. Conting. Crisis Manag. 2018, 26, 41–57. [Google Scholar] [CrossRef]
- Collins, M.; Neville, K.; Hynes, W.; Madden, M. Communication in a disaster—The development of a crisis communication tool within the S-HELP project. J. Decis. Syst. 2016, 25, 160–170. [Google Scholar] [CrossRef]
- Goodchild, M.F. Citizens as sensors: The world of volunteered geography. GeoJournal 2007, 69, 211–221. [Google Scholar] [CrossRef]
- Goodchild, M.F.; Li, L. Assuring the quality of volunteered geographic information. Spat. Stat. 2012, 1, 110–120. [Google Scholar] [CrossRef]
- Chae, J.; Thom, D.; Bosch, H.; Jang, Y.; Maciejewski, R.; Ebert, D.S.; Ertl, T. Spatiotemporal social media analytics for abnormal event detection and examination using seasonal-trend decomposition. In Proceedings of the 2012 IEEE Conference on Visual Analytics Science and Technology (VAST), Seattle, WA, USA, 14–19 October 2012; pp. 143–152. [Google Scholar]
- Benson, E.; Haghighi, A.; Barzilay, R. Event Discovery in Social Media Feeds. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; Association for Computational Linguistics: Stroudsburg, PA, USA, 2011; Volume 1, pp. 389–398. [Google Scholar]
- Ritter, A.; Mausam; Etzioni, O.; Clark, S. Open Domain Event Extraction from Twitter. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; ACM: New York, NY, USA, 2012; pp. 1104–1112. [Google Scholar]
- Becker, H.; Naaman, M.; Gravano, L. Beyond Trending Topics: Real-World Event Identification on Twitter. In Proceedings of the Fifth International Conference on Weblogs and Social Media, Barcelona, Catalonia, Spain, 17–21 July 2011. [Google Scholar]
- Imran, M.; Elbassuoni, S.; Castillo, C.; Diaz, F.; Meier, P. Practical Extraction of Disaster-relevant Information from Social Media. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; ACM: New York, NY, USA, 2013; pp. 1021–1024. [Google Scholar]
- Discovering Health Topics in Social Media Using Topic Models. Available online: https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0103408 (accessed on 7 December 2018).
- Chae, J.; Thom, D.; Jang, Y.; Kim, S.; Ertl, T.; Ebert, D.S. Public behavior response analysis in disaster events utilizing visual analytics of microblog data. Comput. Graph. 2014, 38, 51–60. [Google Scholar] [CrossRef]
- Resch, B.; Usländer, F.; Havas, C. Combining machine-learning topic models and spatiotemporal analysis of social media data for disaster footprint and damage assessment. Cartogr. Geogr. Inf. Sci. 2018, 45, 362–376. [Google Scholar] [CrossRef]
- Contextual Enrichment of Remote-Sensed Events with Social Media Streams. Available online: https://dl.acm.org/citation.cfm?id=2984063 (accessed on 7 December 2018).
- Pouyanfar, S.; Chen, S.-C. Automatic Video Event Detection for Imbalance Data Using Enhanced Ensemble Deep Learning. Int. J. Semant. Comput. 2017, 11, 85–109. [Google Scholar] [CrossRef]
- Gupta, A.; Kumaraguru, P. Credibility Ranking of Tweets during High Impact Events. In Proceedings of the 1st Workshop on Privacy and Security in Online Social Media, Lyon, France, 17 April 2012; ACM: New York, NY, USA, 2012; pp. 2:2–2:8. [Google Scholar]
- Senaratne, H.; Mobasheri, A.; Ali, A.L.; Capineri, C.; Haklay, M. (Muki) A review of volunteered geographic information quality assessment methods. Int. J. Geogr. Inf. Sci. 2017, 31, 139–167. [Google Scholar] [CrossRef]
- Hovland, C.I.; Janis, I.L.; Kelley, H.H. Communication and Persuasion; Psychological Studies of Opinion Change; Communication and Persuasion; Psychological Studies of Opinion Change; Yale University Press: New Haven, CT, USA, 1953. [Google Scholar]
- Mendoza, M.; Poblete, B.; Castillo, C. Twitter Under Crisis: Can We Trust What We RT? In Proceedings of the First Workshop on Social Media Analytics, Washington, DC, USA, 25–28 July 2010; ACM: New York, NY, USA, 2010; pp. 71–79. [Google Scholar]
- Rice, M.T.; Paez, F.I.; Rice, R.M.; Ong, E.W.; Qin, H.; Seitz, C.R.; Fayne, J.V.; Curtin, K.M.; Fuhrmann, S.; Pfoser, D.; et al. Quality Assessment and Accessibility Applications of Crowdsourced Geospatial Data: A Report on the Development and Extension of the George Mason University Geocrowdsourcing Testbed; George Mason University: Fairfax, VA, USA, 2014. [Google Scholar]
- Qin, H.; Rice, R.M.; Fuhrmann, S.; Rice, M.T.; Curtin, K.M.; Ong, E. Geocrowdsourcing and accessibility for dynamic environments. GeoJournal 2016, 81, 699–716. [Google Scholar] [CrossRef]
- Qin, H. Link to External Site, This Link Will Open in a New Window Modeling Accessibility through Geocrowdsourcing. Ph.D. Thesis, George Mason University, Fairfax County, VA, USA, 2017. [Google Scholar]
- Castillo, C.; Mendoza, M.; Poblete, B. Predicting information credibility in time-sensitive social media. Internet Res. 2013, 23, 560–588. [Google Scholar] [CrossRef]
- Shelton, T.; Poorthuis, A.; Graham, M.; Zook, M. Mapping the data shadows of Hurricane Sandy: Uncovering the sociospatial dimensions of ‘big data’. Geoforum 2014, 52, 167–179. [Google Scholar] [CrossRef]
- Get Started|Geocoding API. Available online: https://developers.google.com/maps/documentation/geocoding/start (accessed on 7 December 2018).
- Jellyfish 0.5.6—Jellyfish 0.5.6 Documentation. Available online: https://jellyfish.readthedocs.io/en/latest/ (accessed on 7 December 2018).
- Gao, S.; Li, L.; Li, W.; Janowicz, K.; Zhang, Y. Constructing gazetteers from volunteered Big Geo-Data based on Hadoop. Comput. Environ. Urban Syst. 2017, 61, 172–186. [Google Scholar] [CrossRef] [Green Version]
- Abdelhaq, H.; Sengstock, C.; Gertz, M. EvenTweet: Online Localized Event Detection from Twitter. Proc. VLDB Endow. 2013, 6, 1326–1329. [Google Scholar] [CrossRef]
- Kulldorff, M.; Athas, W.F.; Feurer, E.J.; Miller, B.A.; Key, C.R. Evaluating cluster alarms: A space-time scan statistic and brain cancer in Los Alamos, New Mexico. Am. J. Public Health 1998, 88, 1377–1380. [Google Scholar] [CrossRef] [PubMed]
- Kulldorff, M.; Heffernan, R.; Hartman, J.; Assunção, R.; Mostashari, F. A Space–Time Permutation Scan Statistic for Disease Outbreak Detection. PLoS Med. 2005, 2, e59. [Google Scholar] [CrossRef] [PubMed]
- SaTScan—Software for the Spatial, Temporal, and Space-Time Scan Statistics. Available online: https://www.satscan.org/ (accessed on 9 February 2019).
- Phillips, M.E. Hurricane Harvey Twitter Dataset. Twitter. 2017. Available online: https://digital.library.unt.edu/ark:/67531/metadc993940/ (accessed on 7 December 2018).
- Laylavi, F.; Rajabifard, A.; Kalantari, M. A Multi-Element Approach to Location Inference of Twitter: A Case for Emergency Response. ISPRS Int. J. Geo-Inf. 2016, 5, 56. [Google Scholar] [CrossRef]
- PostgreSQL: The World’s Most Advanced Open Source Database. Available online: https://www.postgresql.org/ (accessed on 7 December 2018).
- Welcome to Goose3’s Documentation!—Goose3 3.1.6 Documentation. Available online: https://goose3.readthedocs.io/en/latest/ (accessed on 7 December 2018).
- Houston Mayor Opens Toyota Center as Additional Shelter for Harvey Evacuees. Available online: https://weather.com/storms/hurricane/news/houston-convention-center-hundreds-refuge-harvey (accessed on 7 December 2018).
- City opening George, R. Brown, Multiservice Centers as Shelters|khou.com. Available online: https://www.khou.com/article/weather/tropics/city-opening-george-r-brown-multiservice-centers-as-shelters/468175978 (accessed on 7 December 2018).
- Taylor, B. Ben Taub Hospital Being Evacuated Due to Flooding, Power Outages. Available online: https://www.click2houston.com/news/ben-taub-hospital-being-evacuated-due-to-flooding-power-outages (accessed on 7 December 2018).
- Flood Event Viewer. Available online: https://stn.wim.usgs.gov/fev/#HarveyAug2017 (accessed on 20 February 2019).
- Gephi—The Open Graph Viz Platform. Available online: https://gephi.org/ (accessed on 7 December 2018).
- St. John Barned-Smith, Reporter, Houston Chronicle—Houston Chronicle. Available online: https://www.houstonchronicle.com/author/st-john-barned-smith/ (accessed on 7 December 2018).
- Houston Local News, Weather, Headlines, Sports, Business, and Entertainment—The Houston Chronicle at Chron.com—Houston Chronicle. Available online: https://www.chron.com/ (accessed on 7 December 2018).
- Associated Press News. Available online: https://apnews.com (accessed on 7 December 2018).
- News, A.B.C. ABC News. Available online: https://abcnews.go.com (accessed on 7 December 2018).
- Blank, G. The Digital Divide among Twitter Users and Its Implications for Social Research. Soc. Sci. Comput. Rev. 2017, 35, 679–697. [Google Scholar] [CrossRef]
- Ballatore, A.; De Sabbata, S. Charting the Geographies of Crowdsourced Information in Greater London. In Proceedings of the Geospatial Technologies for All; Mansourian, A., Pilesjö, P., Harrie, L., van Lammeren, R., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 149–168. [Google Scholar]
- Yang, C.; Huang, Q.; Li, Z.; Liu, K.; Hu, F. Big Data and cloud computing: Innovation opportunities and challenges. Int. J. Digit. Earth 2017, 10, 13–53. [Google Scholar] [CrossRef]
- Li, C.; Sun, A. Fine-grained Location Extraction from Tweets with Temporal Awareness. In Proceedings of the 37th International ACM SIGIR Conference on Research & Development in Information Retrieval, Gold Coast, Queensland, Australia, 6–11 July 2014; ACM: New York, NY, USA, 2014; pp. 43–52. [Google Scholar]
- Li, R.; Lei, K.H.; Khadiwala, R.; Chang, K.C. TEDAS: A Twitter-based Event Detection and Analysis System. In Proceedings of the 2012 IEEE 28th International Conference on Data Engineering, Washington, DC, USA, 1–5 April 2012; pp. 1273–1276. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Theme | Keywords |
|---|---|
| Sheltering | hotel, housing, shelter |
| Casualty | dead, death, death toll, drowned, kill |
| Damage | catastrophe, collapse, damage, damaged, damaging, debris, destroy, destroyed, destruct, destructed, destructing, destruction, destroying, devastate, devastation, rip off, ruin, ruined, ruining, wreck, wrecking |
| Flood | flood, flooded, flooding, spill over, surge overflow, under water, underwater, wash away, washing away, water over the roof, water overflow, water rushing, drown |
| Power/Electricity | black out, blackout, coned, dark, darker, downed electrical wires, POWER down, POWER not expected, POWER off, POWER out, POWER outage, goodbye POWER, knock out POWER, lose POWER, losing POWER, lost POWER, no POWER, noPOWER, off the grid, powerless, shut off POWER, taken POWER, transformer exploding, transformer explosion, w/o POWER, wait POWER return, without POWER, without power |
| tw_road | tw_place | url_road | url_place | Tcreate | TID |
|---|---|---|---|---|---|
| *R 601 Delany Rd | #P Abundant Life Christian Center | 2017-08-25 10:08:51 p.m. | 901280250784514048 | ||
| *R Texas Coastal Bend | *R Texas Coastal Bend | #P Rockport Fulton High School | 2017-08-26 11:48:28 a.m. | 901486512914804738 | |
| *R 3300 Poteet Dr | #P Poteet High School | 2017-08-25 08:55:51 p.m. | 901261879120715777 | ||
| *R 5 Dallas Fort | *R San Antonio Fort | #P Bailey Hutchison Convention Center | 2017-08-30 03:04:34 p.m. | 902985413991727104 |
| Cluster | Neighbors | loc_credit | rt_credit | loc_credits | rt_credits |
|---|---|---|---|---|---|
| 6594 | #P Ben Taub Hospital, #P Houston Ben Taub Hospital, #P Ben Taub hospital, #P Nevertheless Ben Taub hospital | 6.5 | 38 | {0.5,0.5,0.5,0.5,0.5…} | {0,1,27,0,0,0,8…} |
| 34 | #P Texas A M university, #P Texas A M University, #P TEXAS A M UNIVERSITY, *R Smith College Station | 11.5 | 59 | {0.5,0.5,0.5,0.5,1…} | {4,2,12,11,0,11,9…} |
| 11 | *R The Galveston Ferry, #P Galveston Island Beach, #P The Galveston Island Beach, #P Stewart Beach | 14 | 97 | {0.5,0.5,0.5,0.5…} | {1,3,0,35,4,1,2,0,2…} |
| 162 | *R College Station, *R Bryan College Station, *R COLLEGE STATION, #P College Station, #P Bryan College Station, #P COLLEGE STATION | 1 | 0 | {1} | {0} |
| TID | Content | loc_credit | rt_credit |
|---|---|---|---|
| 901869361501274112 | Not much rain in College Station for the time being but the wind is picking up. Hopefully we won’t lose power #Harvey | 1 | 0 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, J.; Yu, M.; Qin, H.; Lu, M.; Yang, C. A Twitter Data Credibility Framework—Hurricane Harvey as a Use Case. ISPRS Int. J. Geo-Inf. 2019, 8, 111. https://doi.org/10.3390/ijgi8030111
Yang J, Yu M, Qin H, Lu M, Yang C. A Twitter Data Credibility Framework—Hurricane Harvey as a Use Case. ISPRS International Journal of Geo-Information. 2019; 8(3):111. https://doi.org/10.3390/ijgi8030111
Chicago/Turabian StyleYang, Jingchao, Manzhu Yu, Han Qin, Mingyue Lu, and Chaowei Yang. 2019. "A Twitter Data Credibility Framework—Hurricane Harvey as a Use Case" ISPRS International Journal of Geo-Information 8, no. 3: 111. https://doi.org/10.3390/ijgi8030111
APA StyleYang, J., Yu, M., Qin, H., Lu, M., & Yang, C. (2019). A Twitter Data Credibility Framework—Hurricane Harvey as a Use Case. ISPRS International Journal of Geo-Information, 8(3), 111. https://doi.org/10.3390/ijgi8030111