A Novel Dynamic Dispatching Method for Bicycle-Sharing System

Abstract
:1. Introduction
- (1)
- The spatial distribution of bike-sharing changes with time. In order to understand the situation of bike-sharing, Zhou et al. [5] analyzed the correlation of origin-destination (OD) flows by visualizing the large-scale movement data of the bicycle’s origin-destination. Wang et al. [6] applied time series analysis to activity patterns, a hierarchical clustering algorithm using Dynamic Time Warping distances as features, and visualization on station-based data, and then employed a random forest algorithm to analyze the factors affecting bike-sharing. They use two-dimensional visualization to show the status of bike-sharing at a certain moment. However, a disadvantage of these methods is the lack of a 3D model to analyze the trend of bike-sharing with time.
- (2)
- Currently, the dynamic scheduling method of bike-sharing is affected by many factors, especially depending on the relationship between the stations. Therefore, the division of the inflow/outflow stations is very important. For instance, Feng et al. [7] proposed a hierarchical traffic prediction model for predicted bike check-out/in number of each station cluster. Ouyang et al. [8] develop CompetitiveBike, a system to predict the particular contest among bike-sharing apps leveraging multi-source data. It utilizes Random Forest model to forecast the future competitiveness. However, the clustering methods used in these prediction models are hard clustering; that is, directly classifying a station into a cluster and ignoring the possibility that it may belong to other clusters.
- Tri-G is proposed to realize the visualization of global information to facilitate management. This method uses a three-dimensional model to show the dynamic movement of the bike-sharing, which takes the stations’ transition patterns and geographical locations into consideration in an iterative approach.
- The prediction algorithm has been improved. This article introduces a method of soft clustering (GMM), which is to analyze the possibility that a certain station belongs to any clusters. It is more regular and easier to predict than that at an individual station. This method integrates multiple similarities to be predicted based on historical periods. In addition, Tri-G has real-time performance because it runs online.
- This method is verified through experiments with real data from New York City, so as to provide ideas for urban governance. The results indicate that Tri-G shows better performance than other methods.
2. Related Work
3. Definitions and Framework
3.1. The Definition of Concept
3.2. Framework
4. Details Implementation
4.1. The Implementation of STG Visualization

4.2. Prediction Methods
- (1)
- For the convenience of users, stations in a cluster should be geographically close to each other. Therefore, for users near their starting point or destination but with no bicycle available, it is acceptable to walk to another station in the same cluster to use the bicycle.
- (2)
- Since it is necessary to predict the net flow between clusters, in order to improve its accuracy, it is hoped that stations in a cluster should have an actual flow similar to all clusters.
4.2.1. Cluster Method
4.2.2. GBRT
5. Experiments and Suggestions
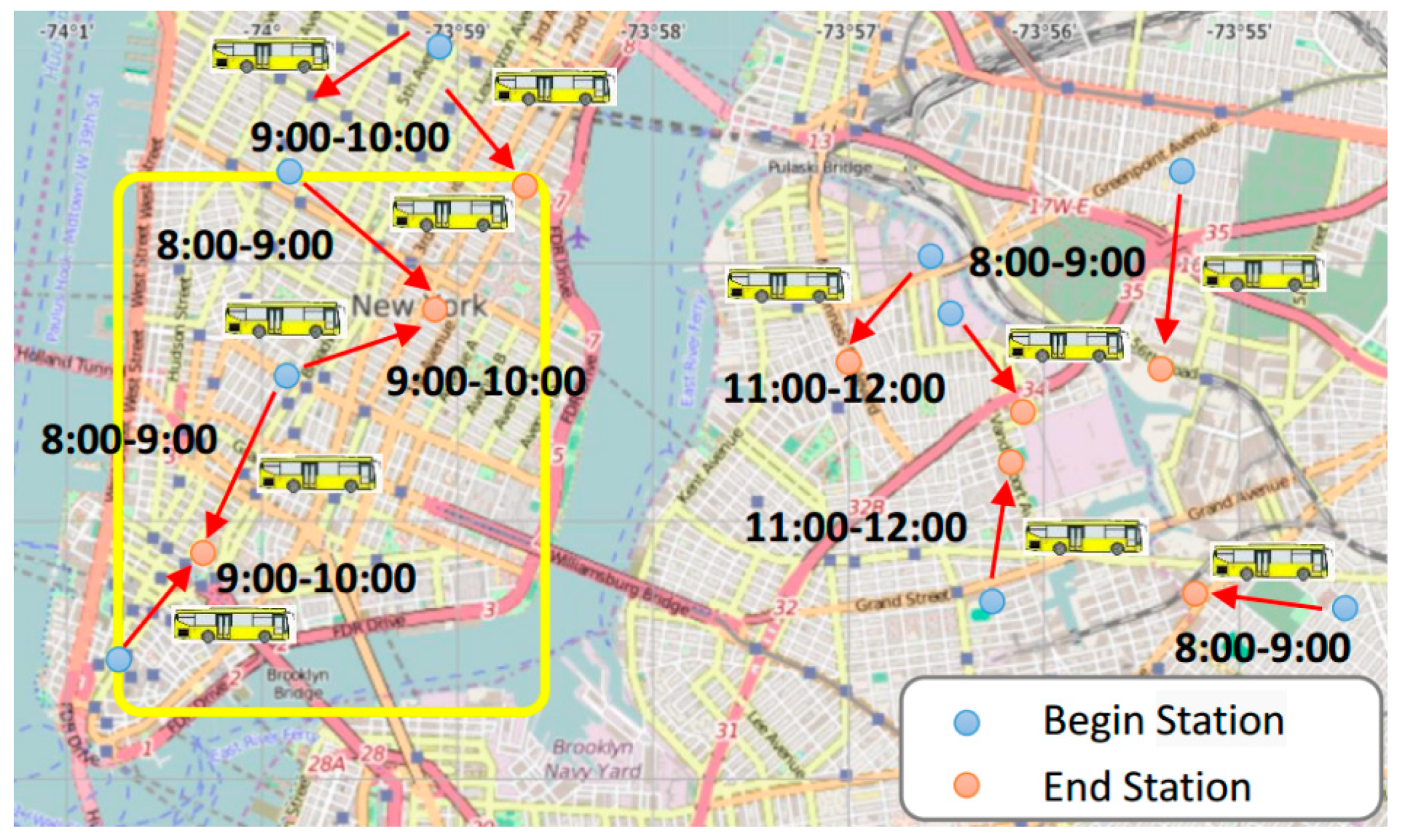
5.1. Building a Spatiotemporal Map Based on the New York Dataset
5.2. Prediction Results
5.2.1. Preparations
5.2.2. Experimental Results
5.3. Suggestions
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- China Exports its Bike-Sharing Revolution to the US, the World. Available online: https://www.stuff.co.nz/world/asia/96478393/china-exports-its-bikesharing-revolution-to-the-us-the-world (accessed on 4 September 2017).
- Van der Spek, S.C.; Scheltema, N. The importance of bicycle parking management. Res. Transp. Bus. Manag. 2015, 15, 39–49. [Google Scholar] [CrossRef]
- Boldrini, C.; Incaini, R.; Bruno, R. Relocation in car sharing systems with shared stackable vehicles: Modelling challenges and outlook. In Proceedings of the 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, Japan, 16–19 October 2017; pp. 1–8. [Google Scholar]
- Larsen, J. Bicycle parking and locking: Ethnography of designs and practices. Mobilities 2017, 12, 53–75. [Google Scholar] [CrossRef]
- Zhou, Z.; Meng, L.; Tang, C.; Zhao, Y.; Guo, Z.; Hu, M.; Chen, W. Visual abstraction of large scale geospatial origin-destination movement data. IEEE Trans. Vis. Comput. Graph. 2019, 25, 43–53. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Wu, J.; Li, W. Research on the mode and driving mechanism of public bicycles in small and medium-sized cities. J. Earth Inf. Sci. 2019, 21, 25–35. [Google Scholar]
- Feng, S.; Chen, H.; Du, C.; Li, J.; Jing, N. A hierarchical demand prediction method with station clustering for bike sharing system. In Proceedings of the 2018 IEEE Third International Conference on Data Science in Cyberspace (DSC), Guangzhou, China, 18–21 June 2018; pp. 829–836. [Google Scholar]
- Ouyang, Y.; Guo, B.; Lu, X.; Han, Q.; Guo, T.; Yu, Z. Competitivebike: Competitive analysis and popularity prediction of bike-sharing apps using multi-source data. IEEE Trans. Mob. Comput. 2018. [Google Scholar] [CrossRef]
- Rathore, M.M.; Ahmad, A.; Paul, A.; Rho, S. Urban planning and building smart cities based on the internet of things using big data analytics. Comput. Netw. 2016, 101, 63–80. [Google Scholar] [CrossRef]
- Alam, M.; Rayes, A.; He, X.; Atiquzzaman, M.; Lloret, J.; Tsang, K.F. Guest editorial introduction to the special issue on dependable wireless vehicular communications for intelligent transportation systems (its). IEEE Trans. Intell. Transp. Syst. 2018, 19, 949–952. [Google Scholar] [CrossRef]
- Faghih-Imani, A.; Hampshire, R.; Marla, L.; Eluru, N. An empirical analysis of bike sharing usage and rebalancing: Evidence from barcelona and seville. Transp. Res. Part A Policy Pract. 2017, 97, 177–191. [Google Scholar] [CrossRef]
- Gleason, R.; Miskimins, L. Exploring Bicycle Options for Federal Lands: Bike Sharing, Rentals and Employee Fleets; TRB: Washington, DC, USA, 2012. [Google Scholar]
- Shaheen, S.; Martin, E.; Cohen, A. Public Bikesharing and Modal Shift Behavior: A Comparative Study of Early Bikesharing Systems in North America. Int. J. Transp. 2013, 1, 2–18. [Google Scholar] [CrossRef]
- Shaheen, S.A. Public Bikesharing in North America: Early Operator and User Understanding. Available online: https://rosap.ntl.bts.gov/view/dot/24566 (accessed on 5 January 2019).
- Otero, I.; Nieuwenhuijsen, M.; Rojas-Rueda, D. Health impacts of bike sharing systems in Europe. Environ. Int. 2018, 115, 387–394. [Google Scholar] [CrossRef] [PubMed]
- DeMaio, P. Bike-sharing: History, impacts, models of provision, and future. J. Public Transp. 2009, 12, 3. [Google Scholar] [CrossRef]
- Camm, J.D.; Chorman, T.E.; Dill, F.A.; Evans, J.R.; Sweeney, D.J.; Wegryn, G.W. Blending or/ms, judgment, and GIS: Restructuring P&G’s supply chain. Interfaces 1997, 27, 128–142. [Google Scholar]
- Xu, J.; Yao, J.; Wang, L.; Ming, Z.; Wu, K.; Chen, L. Narrowband internet of things: Evolutions, technologies, and open issues. IEEE Internet Things J. 2018, 5, 1449–1462. [Google Scholar] [CrossRef]
- Sun, Y.; Mobasheri, A. Utilizing crowdsourced data for studies of cycling and air pollution exposure: A case study using strava data. Int. J. Environ. Res. Public Health 2017, 14, 274. [Google Scholar] [CrossRef] [PubMed]
- Yan, Y.; Tao, Y.; Xu, J.; Ren, S.; Lin, H. Visual analytics of bike-sharing data based on tensor factorization. J. Vis. 2018, 21, 495–509. [Google Scholar] [CrossRef]
- Yang, Z.; Chen, J.; Hu, J.; Shu, Y.; Cheng, P. Mobility modeling and data-driven closed-loop prediction in bike-sharing systems. IEEE Trans. Intell. Transp. Syst. 2019. [Google Scholar] [CrossRef]
- Zhang, Y.; Wen, H.; Qiu, F.; Wang, Z.; Abbas, H. Ibike: Intelligent public bicycle services assisted by data analytics. Future Gener. Comput. Syst. 2019, 95, 187–197. [Google Scholar] [CrossRef]
- Huang, F.; Qiao, S.; Peng, J.; Guo, B. A bimodal gaussian inhomogeneous poisson algorithm for bike number prediction in a bike-sharing system. IEEE Trans. Intell. Transp. Syst. 2018. [Google Scholar] [CrossRef]
- Olfert, C. Urban Planning, Architecture and Bike Trails; Sa & B Mag Sustainable Architecture & Building, Janam Publications Inc.: Toronto, ON, Canada, 2009. [Google Scholar]
- Jiang, J.J. Bike Your City: Planning and Designing Cycling Infrastructure in the Urban Environment. Master’s Thesis, Victoria University of Wellington, Wellington, New Zealand, 2012. [Google Scholar]
- Silva, V.; Harder, H. Urban Design Interventions towards a Bike Friendly City; Trafikdage: Aalborg, Denmark, 2013. [Google Scholar]
- Zheng, Y. Methodologies for cross-domain data fusion: An overview. IEEE Trans. Big Data 2015, 1, 16–34. [Google Scholar] [CrossRef]
- Ahillen, M.; Mateo-Babiano, D.; Corcoran, J. Dynamics of bike sharing in washington, dc and brisbane, australia: Implications for policy and planning. Int. J. Sustain. Transp. 2016, 10, 441–454. [Google Scholar] [CrossRef]
- He, B.; Zhang, Y.; Chen, Y.; Gu, Z. A simple line clustering method for spatial analysis with origin-destination data and its application to bike-sharing movement data. ISPRS Int. J. Geo-Inf. 2018, 7, 203. [Google Scholar] [CrossRef]
- Shen, S.; Wei, Z.Q.; Sun, L.J.; Su, Y.Q.; Wang, R.C.; Jiang, H.M. The shared bicycle and its network—internet of shared bicycle (IOSB): A review and survey. Sensors 2018, 18, 2581. [Google Scholar] [CrossRef] [PubMed]
- Hong, L.; Zheng, Y.; Yung, D.; Shang, J.; Zou, L. Detecting urban black holes based on human mobility data. In Proceedings of the 23rd SIGSPATIAL International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 3–6 November 2015; p. 35. [Google Scholar]
- Cuadros-Vargas, A.J.; Nonato, L.G.; Tejada, E.; Ertl, T. Generating segmented tetrahedral meshes from regular volume data for simulation and visualization applications. In Proceedings of the Computat. Model. Objects Presented Images (CompIMAGE), Niagara Falls, NY, USA, 21–23 September 2018; pp. 141–146. [Google Scholar]
- Rostami, S.; Creemers, S.; Leus, R. Precedence theorems and dynamic programming for the single-machine weighted tardiness problem. Eur. J. Oper. Res. 2019, 272, 43–49. [Google Scholar] [CrossRef]
- Riding the Bike-Share Boom: The Top Five Components of a Successful System. Available online: https://www.itdp.org/2014/03/25/riding-the-bike-share-boom-the-top-five-components-of-a-successful-system/ (accessed on 25 March 2014).
- Vogel, P.; Mattfeld, D.C. Strategic and operational planning of bike-sharing systems by data mining—A case study. In International Conference on Computational Logistics; Springer: Berlin/Heidelberg, Germany, 2011; pp. 127–141. [Google Scholar]
- Windmeijer, F. A finite sample correction for the variance of linear efficient two-step GMM estimators. J. Econ. 2005, 126, 25–51. [Google Scholar] [CrossRef]
- Gebru, I.D.; Alameda-Pineda, X.; Forbes, F.; Horaud, R. Em algorithms for weighted-data clustering with application to audio-visual scene analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 2402–2415. [Google Scholar] [CrossRef] [PubMed]
- Zhang, K.; Gonzalez, R.; Huang, B.; Ji, G. Expectation–maximization approach to fault diagnosis with missing data. IEEE Trans. Ind. Electron. 2015, 62, 1231–1240. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Data. Available online: http://www.citibikenyc.com/system-data (accessed on 4 September 2017).
- Cai, Q.; Liu, J. Hierarchical Clustering of Bipartite Networks Based on Multiobjective Optimization. IEEE Trans. Netw. Sci. Eng. 2018. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Station | Inflow | Outflow | Actual Flow | Mark Stations |
|---|---|---|---|---|
| 231 | 35 | 21 | +14 | -- |
| 343 | 57 | 73 | −16 | -- |
| 25 | 102 | 37 | +65 | blue |
| 78 | 12 | 78 | −66 | red |
| 512 | 33 | 172 | −139 | red |
| Setting | Build STG Index | Mesh Grid | Merge Grids |
|---|---|---|---|
| d = | 0.27 s | 4.18 s | 0.33 s |
| Baseline | HA | ARMA | GBRT | |
|---|---|---|---|---|
| Methods | ||||
| RMLSE | GC | 37.7% | 36.3% | 38.2% |
| BC | 36.5% | 35.2% | 36.5% | |
| GMM | 36.4% | 35.2% | 36.3% | |
| ER | GC | 34.7% | 34.0% | 30.9% |
| BC | 35.2% | 34.4% | 30.9% | |
| GMM | 35.1% | 34.2% | 30.8% |
| Baseline | HA | ARMA | GBRT | |
|---|---|---|---|---|
| Methods | ||||
| RMLSE | GC | 38.7% | 37.1% | 38.6% |
| BC | 37.2% | 35.4% | 36.9% | |
| GMM | 37.1% | 35.3% | 36.8% | |
| ER | GC | 35.3% | 34.6% | 31.1% |
| BC | 35.5% | 34.6% | 31.4% | |
| GMM | 35.1% | 34.4% | 31.0% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mao, D.; Hao, Z.; Wang, Y.; Fu, S. A Novel Dynamic Dispatching Method for Bicycle-Sharing System. ISPRS Int. J. Geo-Inf. 2019, 8, 117. https://doi.org/10.3390/ijgi8030117
Mao D, Hao Z, Wang Y, Fu S. A Novel Dynamic Dispatching Method for Bicycle-Sharing System. ISPRS International Journal of Geo-Information. 2019; 8(3):117. https://doi.org/10.3390/ijgi8030117
Chicago/Turabian StyleMao, Dianhui, Zhihao Hao, Yalei Wang, and Shuting Fu. 2019. "A Novel Dynamic Dispatching Method for Bicycle-Sharing System" ISPRS International Journal of Geo-Information 8, no. 3: 117. https://doi.org/10.3390/ijgi8030117
APA StyleMao, D., Hao, Z., Wang, Y., & Fu, S. (2019). A Novel Dynamic Dispatching Method for Bicycle-Sharing System. ISPRS International Journal of Geo-Information, 8(3), 117. https://doi.org/10.3390/ijgi8030117