1. Introduction
Moving objects [
1] (MOs) are objects (e.g., cars, trucks, pedestrians) whose spatial features change continuously in time. The data produced by MOs (e.g., by using attached devices like GPSs and smartphones) can be analyzed in many ways, for example, to discover mobility patterns [
2]. This is called mobility data analysis, a technique that is currently used in many related fields, like traffic management, transportation, car pooling applications, smart cities, etc.
The increasing availability of MO data has triggered the interest in mobility data analysis, which has been growing steadily year after year. Moving object data generally come in the form of long sequences of spatiotemporal coordinates . To facilitate analysis, these sequences are split into smaller portions of movement, called trajectories. Trajectories can be represented in two possible ways. A continuous trajectory represents the movement track of an object by means of a sequence of spatiotemporal points occurring within a certain interval, together with interpolation functions that allow computing the (approximate) position of the object at any instant. A discrete trajectory contains only a sequence of spatiotemporal points but no interpolation function can be defined.
Moving object databases are databases that store the positions of MOs at any point in time. Although these databases are appropriate for querying, for example, current movement, by means of queries like “which taxis are within ten minutes from Brussels Central Station”, they do not support, per se, complex analytical queries such as “For each month, list the total number of buses running at a speed higher than 60 km per hour for more than 40% of their total route.” For this, integration with, for example, data warehousing technologies, is needed, yielding the notion of mobility data warehouses. These are data warehouses that contain MO data that can be analyzed in conjunction with other kinds of data (e.g., spatial data), for instance, a road network, altitude data, and the kind.
To represent MOs, the definition of appropriate data types is needed. The notion of temporal type refers to a collection of data types that capture the evolution over time of base types and spatial types. For instance, temporal integers may be used to represent the evolution in the number of employees in a department. Analogously, a temporal point may represent the evolution in time of the position of a vehicle, reported by a GPS device, which would yield a temporal geometry of type point. Over these kind of data types, MO databases can be implemented. Thus, MobilityDB was developed (the demo of this database can be accessed at
http://demo.mobilitydb.eu/, where also the manual with a full description of the data types is available). MobilityDB is a MO database (MOD), that builds on PostGIS (the spatial extension of PostgreSQL), that extends the type system of PostgreSQL and PostGIS with abstract data types (ADTs), in order to represent MO data. These ADTs are based on the notion of temporal types and their associated operations.
1.1. Mobility Data Warehouses
Conventional databases are used to support the day-to-day operations in an organization. The operations over these databases are usually denoted as online transactional processing (OLTP). To support data analysis, the notion of data warehousing was developed. A data warehouse (DW) collects large amounts of data from various data sources and reduces them to a form that can be used to analyze the behavior of an organization. DWs are based on the multidimensional model, which represents data as facts that can be analyzed along a collection of dimensions, composed of levels conforming aggregation hierarchies. The multidimensional model builds on the data cube abstraction, where the axes of the cubes are the dimensions, and the cells contain measure values. Typically, DWs are exploited by means of the online analitycal processing (OLAP) technique, which consists of a collection of operations that manipulate the data cube. The most popular OLAP operations are roll-up, which aggregates measure data along a dimension up to a certain aggregation level; drill-down, which is the inverse of the former; slice, which drops a dimension from the cube; and dice, which selects a sub-cube that satisfies a boolean condition.
Spatial data can represent geographic objects (e.g., mountains, cities), geographic phenomena (e.g., temperature, precipitation), etc. Similarly to conventional databases, spatial databases are typically used for operational applications in many different domains, rather than to support data analysis tasks. Spatial DWs (SDWs), on the other hand, combine spatial databases features and DW technologies, to provide more sophisticated data analysis, visualization, and manipulation capabilities. Thus, a SDW is a DW that is capable of representing, storing, and manipulating spatial data. Usually, to represent the extent of a spatial object, spatial data types are used. A SDW can thus take advantage of the operations associated with spatial data types, to allow queries like “give me the total number of theaters within one kilometer from my current position”.
Most DWs (either spatial or not) assume that only facts evolve in time. However, dimension data, like for instance, the category of a product, may also change across time. The most popular approach for tackling this issue is based on the notion of slowly changing dimensions [
3]. An alternative approach for this issue is based on the concept of temporal databases. Built-in temporal semantics allow these kinds of databases to manage time-varying information. The combination of spatial and temporal databases and DWs leads to the notion of spatiotemporal DWs. Since MO are in essence spatiotemporal, adding MO data to a DW leads to the notion of mobility DWs. This is, in a nutshell, the problem addressed by this paper: modeling and querying mobility DWs by means of adding temporal types to spatial DWs.
1.2. Contributions and Motivation
The authors of this paper had previously defined the notion of spatiotemporal queries as queries that can be expressed by Klug’s relational algebra with aggregation, extended with spatial and moving types [
4]. Based on this, the authors defined
spatiotemporal DWs as DWs that support spatiotemporal queries. The classification in the referred work helps to characterize the different kinds of DW systems in terms of their expressiveness, and it is used in the discussion below.
Many efforts have been published under the concept of trajectory data warehouses [
5,
6,
7]. These works basically propose storing, in the DW fact tables, aggregate measures (like the number of cars in a given latitude-longitude range), segments of trajectories, or spatiotemporal points, probably together with semantic information. It is therefore clear that these approaches do not qualify as trajectory or, equivalently, spatiotemporal DWs (according to the classification in [
4]), since they do not support spatiotemporal queries, given that they do not include moving data types. For example, storing aggregate measures [
6], does not allow queries like “total distance covered by all cars in Brussels”. Instead, they allow expressing queries like “average number of cars in downtown Brussels on Sunday mornings”. These approaches conform, in some sense, traditional spatial DWs. The other proposals (although implementations are not yet reported), aim at querying semantic trajectories, for example “total number of persons going from restaurants to theaters”. Even in the case where spatiotemporal points are stored, these represent the raw trajectories rather than moving types, and thus everything must be solved using relational operations. On the other hand, there are systems that implement MO databases, typically
Secondo and Hermes. However, these systems are not aimed at building mobility DWs, therefore, implementing a mobility DW based on them is not a trivial task.
Section 6 further elaborates on the discussion above.
The work presented in this paper extends and dramatically improves existing trajectory DW proposals. The implementation of MobilityDB gives the possibility of defining MOs as measures in a DW fact table. Integrating relational warehouse data with MO data allows realizing the notion of spatiotemporal queries defined in [
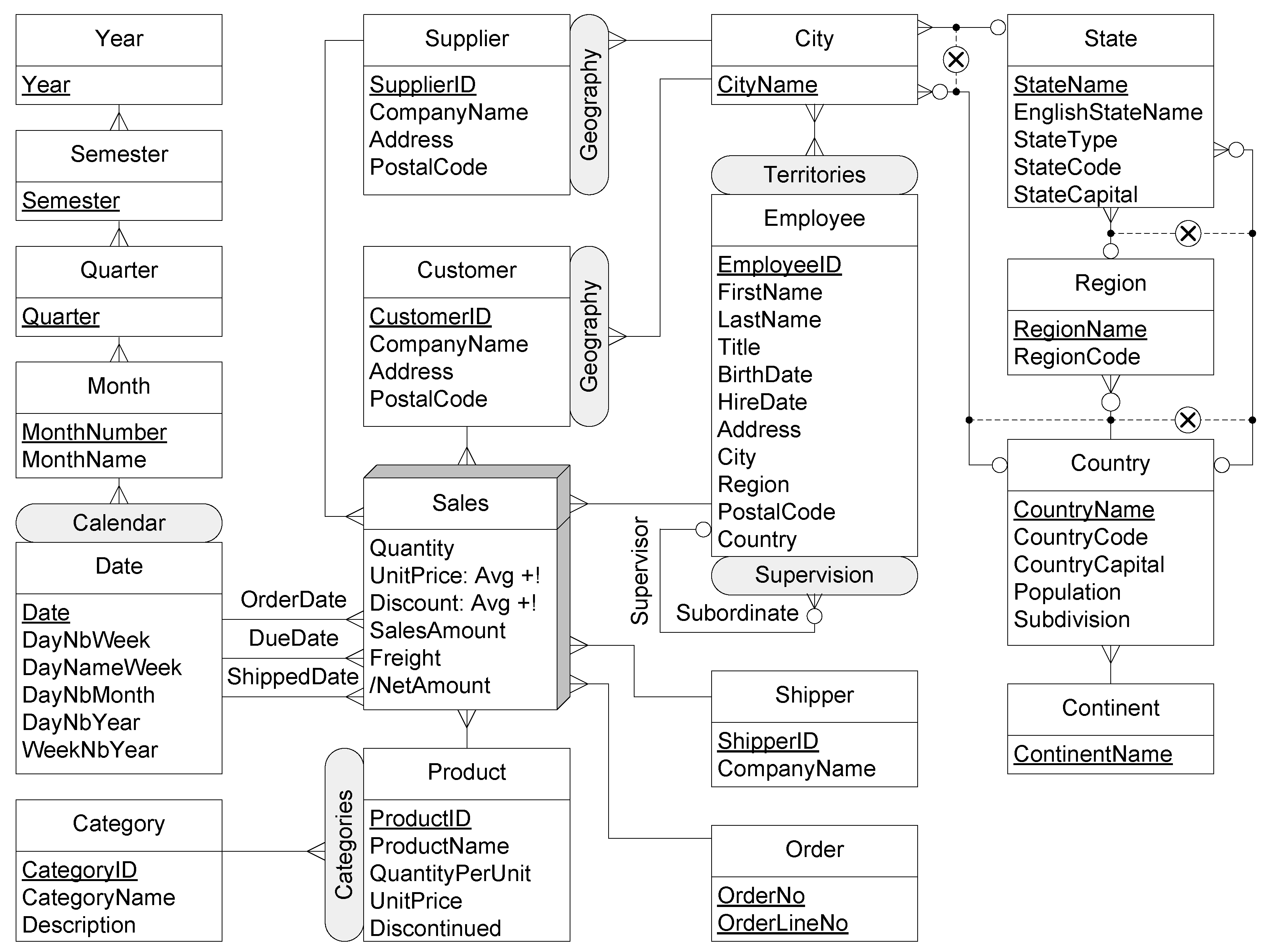
4], as this paper will show through a collection of comprehensive examples. The resulting DW is called Mobility DW. In addition, the problem of conceptual and logical modeling of mobility DWs is also covered here. Throughout this paper, the well-known Northwind DW [
8], extended with MO and spatial data, is used as a running example.
Note that although the work presented here is based on a centralized PostgresSQL database management system (DBMS), there are ongoing efforts to develop parallel version of this DBMS, from which MobilityDB (and therefore, the mobility DW studied in this paper) can benefit. Further, in a Big Data scenario, horizontal scalability is crucial. This has encouraged the development of a horizontally-scalable version of Postgres, called Postgres-XL,
https://www.postgres-xl.org, which can handle mixed workloads, which include OLTP and OLAP queries, GIS queries, OLTP transactions, and so on. Last, but not least, the approach presented here can be extended to big data hadoop-based environments that are currently available,
http://spatialhadoop.cs.umn.edu,
http://esri.github.io/gis-tools-for-hadoop.
1.3. Paper Organization
In
Section 2, the notion of temporal types is defined and explained.
Section 3 describes the implementation of temporal types in MobilityDB.
Section 4 studies the modeling of mobility DWs, also providing a background on DW design, for the non-expert readers, while
Section 5 presents a comprehensive set of queries to illustrate how a mobility DW can be exploited.
Section 6 discusses related work and compares such work against the present proposal, and
Section 7 concludes the paper.
2. Background: Temporal Types
To make this paper self-contained, this section presents some basic concepts on temporal types. Many of the concepts and operations can be found in [
1,
8]. However, to develop MobilityDB, new operations had been defined, and are also explained here. Also, a syntax for these temporal types is introduced here.
Temporal types are functions that map time instants to values from a domain. They are implemented by means of applying a constructor
temporal(·). For example, a value of type
temporal(integer) is a continuous function
f : instant → integer. Analogously, a temporal boolean is a function mapping instants to boolean values. In temporal databases terminology, several notions for time can be defined. The most popular ones are valid time and transaction time [
9]. The former represents the time period during which a database fact is valid in the modeled reality. The latter is the time period during which a fact stored in the database is considered to be true. These are orthogonal concepts. In the remainder, valid time is considered.
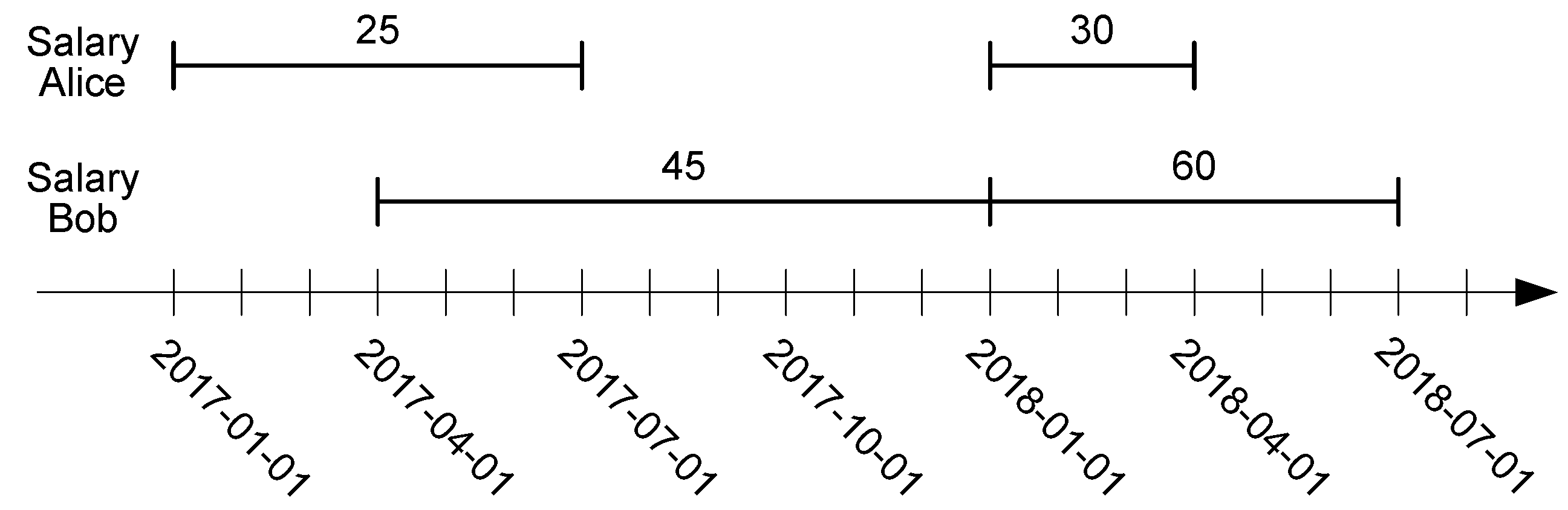
Temporal types may be undefined during certain time periods. For example, in
Figure 1, Alice’s salary is undefined between 1 July 2017 and 1 January 2018 (e.g., because she took a six-month leave), and this is denoted ‘⊥’. As a convention, closed-open intervals are used.
2.1. Classes of Operations on Temporal Types
Temporal types are associated with different kinds of operations, described next.
Projection over domain and range. Operations of this kind are, for example, GetTime and GetValues, which return, respectively, the domain and range of a temporal type.
Interaction with domain and range. Example of operations of this kind are AtTimestamp, AtTimestampSet, AtPeriod, and AtPeriodSet, which restrict the function to a given timestamp (set) or period (set). Operations StartTimestamp and StartValue return, respectively, the first timestamp at which the function is defined and the corresponding value. The operations EndTimestamp and EndValue are analogous. The operations AtValue and AtRange restrict the temporal type to a value or to a range of values in the range of the function. The operations AtMin and AtMax restrict the function to the instants when its value is minimal or maximal, respectively.
Example 1. The functions GetTime(SalaryAlice) and GetValues(SalaryAlice) return, respectively, {[2017-01-01, 2017-07-01), [2018-01-01, 2018-04-01)} and {25, 30}. Further, AtTimestamp(SalaryAlice, 2017-07-15) returns ‘⊥’, since Alice’s salary is undefined at that date. The operation StartTimestamp(SalaryAlice) returns 2017-01-01, while AtValue(SalaryAlice, 25) and AtValue(SalaryAlice, 35) return, respectively, a temporal real with value 20@[2017-01-01, 2017-07-01) and ‘⊥’, because no salary with value 35 exists.
Temporal aggregation. These kinds of operations are crucial to mobility data analysis. Three basic operations take as argument a temporal integer or real and return a real value namely: Integral, that returns the area under the curve defined by the function, Duration, which returns the duration of the temporal extent over which the function is defined, and Length, which returns the length of the curve defined by the function. From these operations, other derived operations can be defined, such as TWAvg, TWVariance, or TWStDev. The operation TWAvg computes the time-weighted average of a temporal value, taking into account the duration in which the function takes a value. TWVariance and TWStDev compute the variance and the standard deviation of a temporal type. Finally, MinValue and MaxValue return, respectively, the minimum and maximum value taken by the function. These can be obtained by Min(GetValues(·)) and Max(GetValues(·)) where Min and Max are the classic operations over numeric values.
Example 2. In the example above, TAvg(SalaryAlice) would yield a value of 26.66, given that Alice had a salary of 25 during 181 days and a salary of 30 during 90 days.
Lifting. This class represents the generalization of the operations on nontemporal types to temporal types [
10]. An operation for nontemporal types is lifted to allow any of the arguments to be replaced by a temporal type, and returns a temporal type. For example, the “less than” (<) operation has lifted versions (denoted by
#<) where one or both of its arguments can be temporal types, yielding a temporal boolean. Intuitively, the result is computed at each instant using the nonlifted operation. When two temporal values are defined on different temporal extents, the result of a lifted operation can be defined either over the intersection of both extents or the union of them. In the remainder, for the lifted operations, the first option is assumed.
Example 3. In Figure 1, the comparison SalaryAlice < SalaryBob results in a temporal boolean with value true@{[2017-04-01, 2017-07-01), [2018-01-01, 2018-04-01)}.
Lifted aggregation operations are such that the aggregate function is computed at each time instant, and the result is defined over the union of all the extents.
Figure 2 shows an exampe of a lifted average for the two salaries in
Figure 1.
2.2. Temporal Types over Spatial Data
Temporal types can be also defined over spatial data types, not only over basic types like integers or reals. For example, the trajectory of a truck can be represented using a
temporal(point) type. Analogously to what was explained above, this type would be a continuous function
f : instant → point. Some of the operations described in
Section 2.1 are explained next for the spatial case. The example in
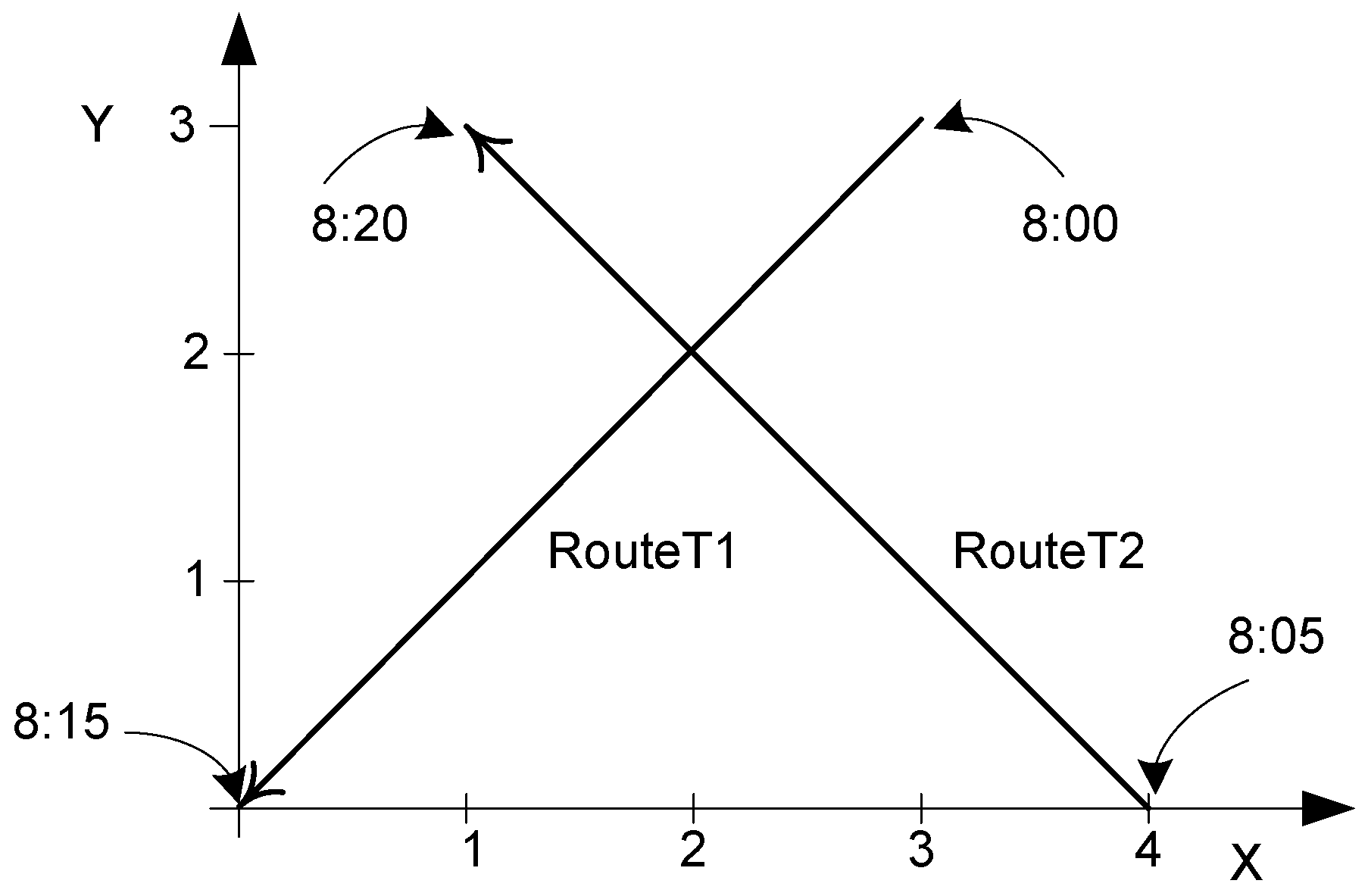
Figure 3 shows two temporal points
RouteT1 and
RouteT2 that represent the delivery routes of two trucks
T1 and
T2 on a particular day. It can be seen that, for instance, truck
T1 took 15 min to go from point (3, 3) to point (0, 0), while truck
T2 took 15 min to go from point (4, 0) to point (1, 3). A constant speed between consecutive pairs of points is assumed.
An operation called
Trajectory, projects a temporal geometry into the plane. In the example,
Trajectory(RouteT1) results in the leftmost line in
Figure 3, without any temporal information. Note that the projection of a temporal point into the plane may consist in points and lines.
As an example of an operation of the class addressing the interaction with domain and range (as in
Section 2.1) for the spatial case, the
AtGeometry operation restricts the temporal point to a given geometry. For example, if
Polygon denotes a polygon defined as follows
Polygon((0 0, 0 2, 2 2, 2 0, 0 0)), then
AtGeometry(RouteT1, Polygon) will return the value
RouteT1 restricted to the period [8:05, 8:15].
Analogously to the non-spatial case, all operations over nontemporal spatial types are lifted. For example, the
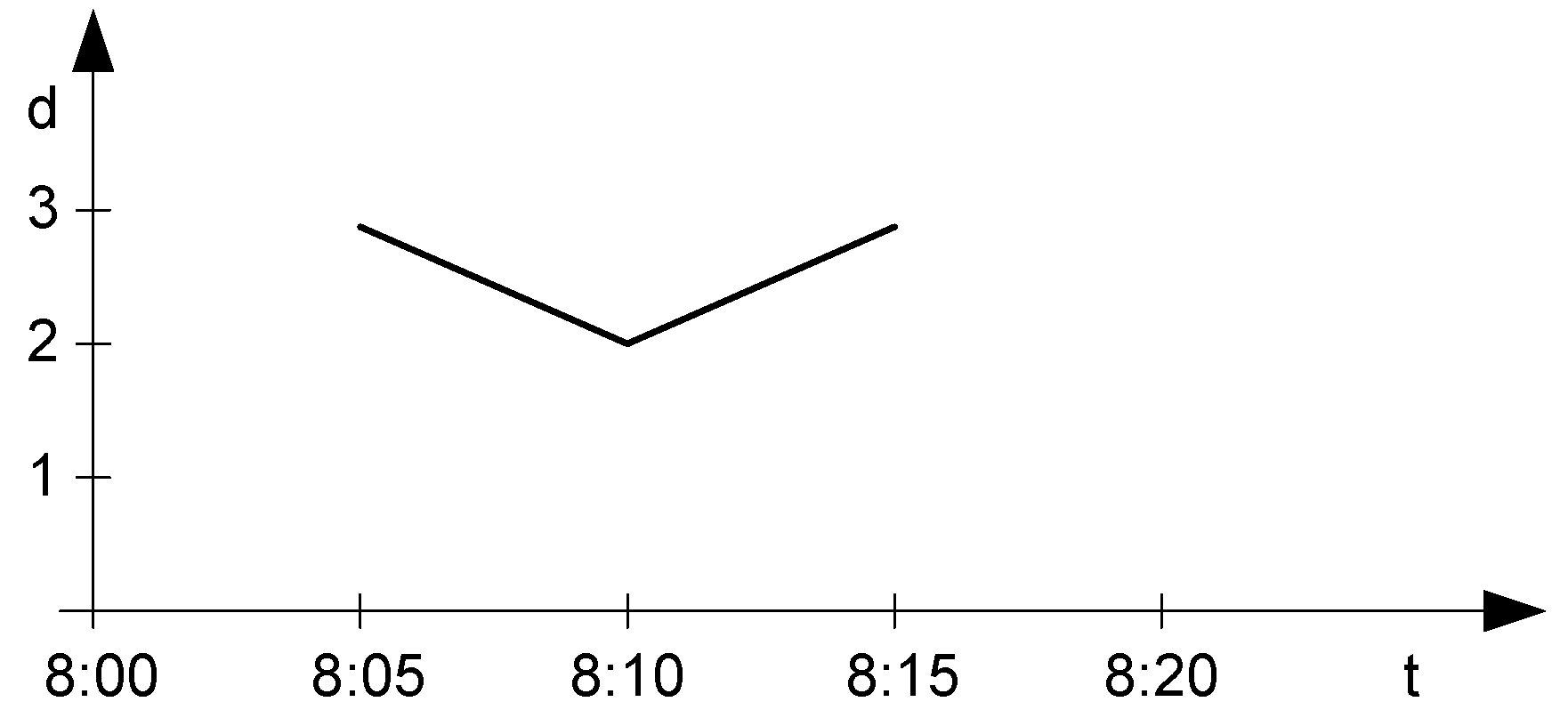
Distance function has lifted versions where one or both of its arguments can be temporal points and the result is a temporal real. In the example,
Distance(RouteT1, RouteT2) returns a temporal real shown in
Figure 4, where, for instance, the value evolves from
@8:05 to
2@8:10 to
@8:15. Note that in this case, the distance function has been approximated by a linear function.
Lifted topological operations return a temporal boolean. Examples of such operators are TIntersects, TDWithin, and TContains. For example, TIntersects(RouteT1, RouteT2) returns a temporal boolean with value false@[8:05, 8:15] since the two trucks were never at the same point at any instant of their route. Similarly, TDWithin(RouteT1, RouteT2, 2) returns a temporal boolean with value {false@[8:05, 8:10), true@[8:10, 8:10], false@(8:10, 8:15]} since the two trucks were only at a distance of two at 8:10. Finally, if Polygon is defined as above, then TContains(Polygon, RouteT1) will return a temporal boolean with value {false@[8:00, 8:05), true@[8:05, 8:15]}.
To conclude, several operations compute the rate of change for points. Operation Speed yields the usual concept of speed of a temporal point at any instant as a temporal real. Operation Direction returns the direction of the movement, that is, the angle between the x-axis and the tangent to the trajectory of the moving point. Finally, the Turn operation yields the change of direction at any instant.
5. Querying the Mobility Data Warehouse in SQL and MobilityDB
In order to express queries to the Northwind mobility DW, the temporal types and their associated operations as defined in
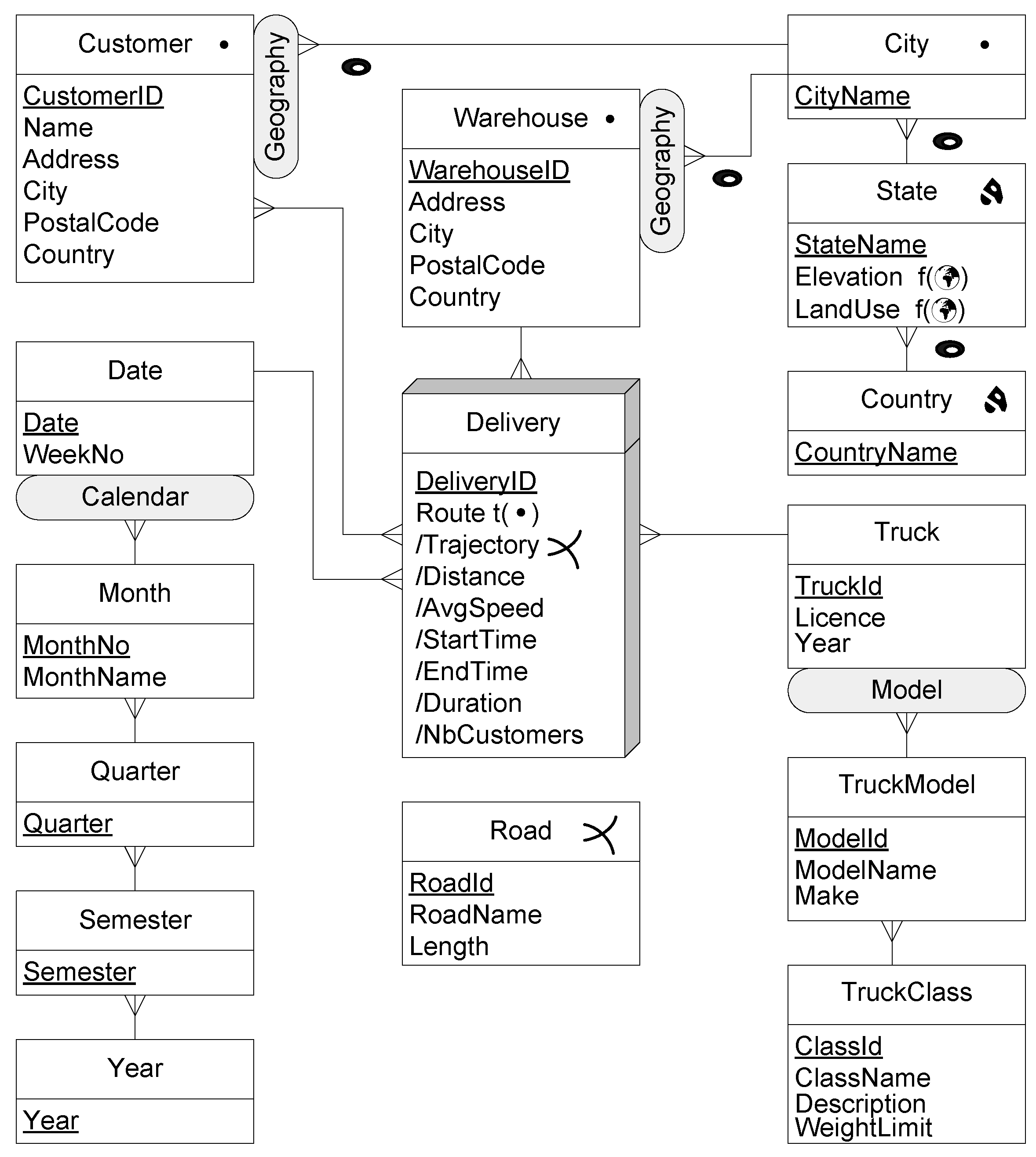
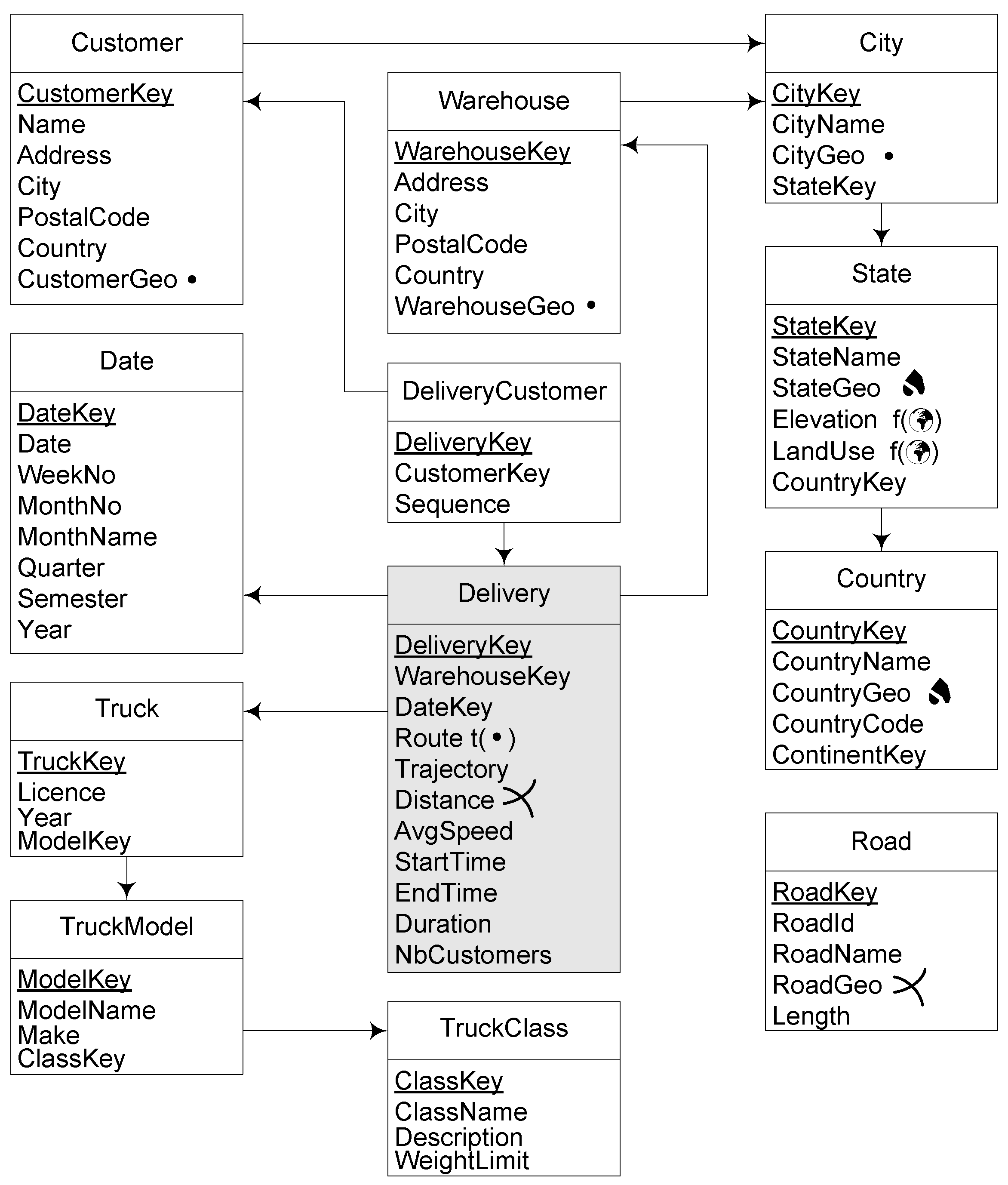
Section 3 are used. The mobility DW depicted in
Figure 7 is used as an example. Queries were targeted for Belgium, in which the administrative divisions corresponding to states are called provinces. In what follows, the functions that are prefixed by
ST_ are PostGIS functions, while the functions not prefixed (e.g.,
length) are the temporal extensions from MobilityDB. The queries below are aimed at highlighting the advantages of defining MO data as a measure rather than the typical solution of defining static segments of trajectories as measures [
5,
6,
7]. Therefore, the queries combine typical OLAP operations, like
Roll-up,
Slice, and
Dice, with operations on MOs (in this case, the trucks that perform the deliveries. For each query, the operations involved are explained, to remark the wide variety of queries that the model and implementation allow.
Query 1 (Roll-up + slice + distance). List the total distance traveled by trucks, per make and month.
This query involves aggregation along the Date and Truck dimensions, slicing out all other dimensions, and the computation of the distance travelled by the MOs.
SELECT M.Make, DT.Year, DT.MonthNumber, SUM(length(D.Route))FROM Delivery D, Truck T, TruckModel M, Date DTWHERE D.TruckKey = T.TruckKey AND T.ModelKey = M.ModelKey ANDD.DateKey = DT.DateKeyGROUP BY M.Make, DT.Year, DT.MonthNumberORDER BY M.Make, DT.Year, DT.MonthNumber
Also, the query uses the function length to compute the distance traveled by each delivery, and then aggregates the distances per truck make and month in the usual way.
An analysis of this query makes it clear the advantage of the approach presented here, with respect to the approaches that segment the trajectories in order to provide a relational representation of a trajectory. The latter would require, for example, to compute the length of each segment individually (see [
8], Chapter 12, for a detailed explanation), and also joining each segment with other dimension tables. Further, proposals that partition the space into a grid, precomputing aggregated measures for each cell in the grid (see
Section 6), of course cannot express this query, neither any of the queries in the next examples. Also, even though MO databases like
Secondo and Hermes (also see
Section 6) could of course address the MO part of the queries, integrating them into a system to perform OLAP operations is far from being trivial. Therefore, it can be seen that the mobility DW approach based on MobilityDB takes the best of both worlds, bridging the gap between them. The explanation above applies to all queries that are discussed below in this section, thus, it will not be repeated to avoid redundancy.
Query 2 (Roll-up + slice + dice + duration). List the average duration per day of deliveries starting with a customer located in the province of Namur.
This query requires aggregation along the Date dimension, a Roll-up operation over the Customer dimension, a Dice operation to select the province of Namur at the State level, and the computation of the duration of the time spanned by the deliveries. Finally, all dimensions but Date are sliced out.
SELECT DT.Date, AVG(duration(D.Route))
FROM Delivery D, DeliveryCustomer DC, Customer C, State S, Date DT
WHERE D.DeliveryKey = DC.DeliveryKey AND DC.Sequence = 1 AND
DC.CustomerKey = C.CustomerKey AND C.StateKey = S.StateKey AND
S.Name = ’Namur’ AND D.DateKey = DT.DateKey
GROUP BY DT.Date
ORDER BY DT.Date
The query selects the first customer visited by a delivery using the attribute Sequence, and verifies that she is located in the province of Namur. Then, it uses function duration to compute the duration of the delivery. Finally, the query computes the average of the durations per day.
Query 3 (Roll-up + slice + dice + spatial + duration). For each month, compute the number of deliveries such that their route intersects the province of Namur for more than 20 min.
The query performs a roll-up operation along the Date and Customer dimensions, a Dice operation to select the province of Namur at the State level, a spatial operation to compute the intersection, and the computation of the duration of the time spanned by the deliveries within the province. Finally, all dimensions but Date are sliced out.
SELECT T.Year, T.MonthNumber, COUNT(*)
FROM Delivery D, Date T, State S
WHERE D.DateKey = T.DateKey AND S.Name = ’Namur’ AND D.Route && S.Geom AND
duration(atGeometry(D.Route, S.Geom)) >= interval ’20 min’
GROUP BY T.Year, T.MonthNumber
ORDER BY T.Year, T.MonthNumber
This query uses the function atGeometry to restrict the route of the delivery to the geometry of the province of Namur. Then, function duration computes the time spent within the province and verifies that this duration is at least of 20 min. Remark that this duration of 20 min may not be continuous. Finally, the count of the selected deliveries is performed as usual.
The term D.Route && S.Geom is optional and it is included to enhance query performance. It verifies, using an index, that the spatio-temporal bounding box of the delivery projected over the spatial dimension intersects with the bounding box of the geometry. In this way, the atGeometry function is only applied to the deliveries satisfying the bounding box condition.
Query 4 (Roll-up + slice + dice + spatial + duration). Same as the previous query but with the condition that the route intersects the province of Namur for more than consecutive 20 min.
The operations involved here are similar to the ones in the previous query. The queries differ in the way in which they compute the duration. Again, this is only possible when measures are actually represented as MOs.
SELECT DT.Year, DT.MonthNumber, COUNT(*)
FROM Delivery D, Date DT, State S,
unnest(periods(getTime(atGeometry(D.Route, S.Geom)))) P
WHERE D.DateKey = DT.DateKey AND S.Name = ’Namur’ AND
D.Route && S.Geom AND duration(P) >= interval ’20 min’
GROUP BY DT.Year, DT.MonthNumber
ORDER BY DT.Year, DT.MonthNumber
As in the previous query, the function atGeometry restricts the route of the delivery to the province of Namur. This results in a route that may be discontinuous in time, because the route may enter and leave the province. The query uses the function getTime to obtain the set of periods of the restricted delivery, represented as a periodSet value. The function periods converts the latter value into an array of periods, and the PostgreSQL function unnest expands this array to a set of rows, each row containing a period P. Then, it is possible to verify that the duration of one of the periods P has at least 20 min.
Query 5 (Roll-up + slice + distance + speed). For each month, compute the total number of deliveries that traveled at least 50 km at a speed higher than 100 km/h.
The operations involved in this query are: a Roll-up along the Date dimension, and the computation of the distance and speed functions on the MO data. Finally, slicing is performed to drop all dimensions but Date.
SELECT DT.Year, DT.MonthNumber, COUNT(*)
FROM Delivery D, Date DT
WHERE D.DateKey = DT.DateKey AND length(atPeriodSet(D.Route,
getTime(atRange(speed(Route) * 3.6, ’[100,infinity]’)))) / 1000 > 50
GROUP BY DT.Year, DT.MonthNumber
ORDER BY DT.Year, DT.MonthNumber
The query uses the function speed to obtain a temporal float representing the speed of the route at each instant, expressed in units per second, depending on the spatial reference system, which in our case is meters per second. This temporal value is then transformed into kilometers per hour by multiplying it by 3.6. The function atRange restricts the speed to the float range [100, infinity]. The getTime function computes the set of periods during which the delivery travels at more than 100 km/h. The function atPeriodSet restricts the delivery to these periods and the length function computes the distance traveled by the restricted deliveries, expressed in meters, which is then converted to kilometers and compared against the value 50.
Query 6 (Temporal aggregation). For each speed range of 20 km/h, give the total distance traveled by all trucks within that range.
This is a typical temporal aggregation query, as explained below. That is, operations over MOs are performed over the measure, without involving the dimensions. Only the fact table is used here.
WITH Ranges AS (
SELECT I AS RangeID, floatrange(((I-1)*20), I*20) AS Range
FROM generate_series(1,10) I )
SELECT R.Range, SUM(length(atPeriodSet(D.Route,
getTime(atRange(speed(D.Route) * 3.6, R.Range)))) / 1000)
FROM Delivery D, Ranges R
WHERE atRange(speed(D.Route) * 3.6, R.Range) IS NOT NULL
GROUP BY R.RangeID, R.Range
ORDER BY R.RangeID
This idea of this query is to allow having an overall view of the speed behaviour of the entire fleet of delivery trucks. The temporary table Ranges stores the ranges , , …. In the main query, the speed of the route, obtained in meters per second, is transformed into kilometers per hour. Then, the function atRange restricts the route to the portions having a given speed range. The time periods comprising the restricted route are obtained with the getTime function. The overall route is restricted then to the obtained time periods with the function atPeriodSet, the distance traveled at the given speed range is obtained with the length function, and all the distances for all trucks at the given time range are obtained with the SUM aggregation function.
Query 7 (Slice + spatial). Compute the number of deliveries that traversed at least two states.
The OLAP operation here is a Slice, to drop all dimensions. The rest of the query involves spatial operations to perform intersections between the MOs’ trajectories and the State dimension level. Note that, in fact, the intersection is performing a “climbing” along the geographic dimension, skipping the intermediate levels in the hierarchy.
SELECT COUNT(*)
FROM Delivery D, State S1, State S2
WHERE S1.StakeyKey <> S2.StateKey AND
ST_Intersects(trajectory(D.Route), S1.Geom) AND
ST_Intersects(trajectory(D.Route), S2.Geom)
This query projects the route of the delivery to the spatial dimension using the function trajectory, which results in a geometry. The query then tests that the trajectory of the route intersects two states using the PostGIS function ST_Intersects.
Query 8 (Slice + distance + duration). List the pairs of deliveries that traveled at less than one kilometer from each other during more than half an hour. Again, the OLAP operation here is a Slice, to drop all dimensions. Only the Delivery fact is kept. Then, computations on the temporal types are performed.
SELECT D1.DeliveryKey, D2.DeliveryKey
FROM Delivery D1, Delivery D2
WHERE D1.DeliveryKey <> D2.DeliveryKey AND duration(getTime(
atValue(tdwithin(D1.Route, D2.Route, 1000), TRUE))) > ‘20 min’
The function tdwithin is the temporal version of the PostGIS function ST_DWithin. It returns a temporal boolean which is true during the periods when the two routes are within the specified distance from each other. The function atValue restricts the temporal boolean to the periods when its value is true, and the function getTime obtains these periods. Finally, the query uses the duration function to obtain the corresponding interval and verifies that it is greater than 20 min.
The next example query involves the LandUse continuous field.
Query 9 (Roll-up + slice + spatial (raster) + distance + duration). Compute the average duration of the deliveries that started in a residential area and ended in an industrial area on 1 February 2017.
The OLAP operations are a slice, to drop all dimensions but Date and Customer, and a roll-up over the Customer (only up to the bottom level) and Date dimensions. Spatial operations over raster data are also performed. Finally, also computations on the temporal types are performed.
SELECT AVG(duration(D.Route))
FROM Delivery D, Date T, DeliveryCustomer DC1, DeliveryCustomer DC2,
Customer C1, Customer C2, City Y1, City Y2, State S1, State S2
WHERE D.DateKey = T.DateKey AND D.Date = ’2017-02-01’ AND
D.DeliveryKey = DC1.DeliveryKey AND DC1.Sequence = 1 AND
D.DeliveryKey = DC2.DeliveryKey AND DC2.Sequence = D.NbCustomers AND
DC1.CustomerKey = C1.CustomerKey AND
DC2.CustomerKey = C2.CustomerKey AND
C1.CityKey = Y1.CityKey AND C2.CityKey = Y2.CityKey AND
Y1.StateKey = S1.StateKey AND Y2.StateKey = S2.StateKey AND
ST_Intersects(C1.CustomerGeo,AtValue(S1.LandUse, ’Residential’)) AND
ST_Intersects(C2.CustomerGeo,AtValue(S2.LandUse, ’Industrial’))
The query starts by selecting the deliveries of the given date. It also selects, using the bridge table DeliveryCustomer, the first and last customers served by the delivery. Then, the query obtains the state of these customers with the subsequent joins. Further, the function AtValue restricts the land use fields of the corresponding states to the values of type residential or industrial. Finally, the function ST_Intersects ensures that the start and end locations of the delivery are included in the restricted fields. Notice that, in PostGIS, the ST_Intersects predicate can compute not only if two geometries intersect, but also if a geometry and a raster intersect.
Note that the query above does not involve temporal data since it neither mentions a temporal geometry such as measure Route, nor a temporal field such as Temperature. The next query involves both temporal attributes, and combines a field and a trajectory.
Query 10 (Slice + spatial (raster) + distance). List the deliveries that have traveled along more than 50 km of roads at more than 1000 m of altitude.
A slice is performed to drop all dimensions. Spatial operations over raster data (in this case, representing elevation) are performed. Finally, computations on the temporal types are also performed.
SELECT D.DeliveryNumber
FROM Delivery D
WHERE ( SELECT SUM(ST_Length(ST_Intersection(Trajectory(D.Route),
AtRange(S.Elevation, ’[1000,infinity)’)).geom))
FROM State S
WHERE ST_Intersects(Trajectory(D.Route), S.StateGeo) ) > 50,000
For each delivery, using the function ST_Intersects, the inner query verifies that the route of the delivery and the geometry of the state intersect. Then, the elevation field of the state is restricted to the range of values higher than 1000 m with function AtRange. The function ST_Intersection computes the intersection of the trajectory of the route and the restricted field, and the length of this route is computed with the function ST_Length. The SUM aggregate function is then used to calculate the sum of the lengths of all the obtained routes for all states, and finally the outer query verifies that this sum is greater than 50 km.
Discussion on Performance
Since the paper is oriented to show the features of the mobility data warehousing approach, it is focused on highlighting the expressiveness that MO data adds to the classic and spatial data warehousing approaches. Therefore, a thorough evaluation of query performance is outside the scope of this work. Nevertheless, this section reports a preliminary evaluation, developed as follows. The mobility DW depicted in
Figure 7 was implemented over a PostgresSQL relational database. Delivery data (the MO data in attribute
Route of the fact table
Delivery) had been produced using the data generator of the BerlinMOD benchmark for moving objects
http://dna.fernuni-hagen.de/secondo/BerlinMOD/BerlinMOD.html. However, since the BerlinMOD benchmark targets the city of Berlin, the geographic hierarchy has been dropped, and the references to the
State dimension had been replaced by a
Borough dimension, both in the schema and in the queries. The evaluation was performed with 520 delivery tuples. The minimum, maximum, and average length of the deliveries are 96, 4632, and 1870, respectively, therefore, this would be approximately equivalent in size to a “normalized” fact table of one million records. There rest of the data are based on the Northwind database. Thus, the table
Customer contains 1430 tuples, and there are seven warehouses and 100 trucks. Queries 1–8 were run (Queries 9 and 10 were not run, since they include raster data just as an example), changing, as mentioned, the references to the
State with references to the
Borough. For example, Query 3 now reads:
SELECT T.Year, T.MonthNumber, COUNT(*)
FROM Delivery D, Date T, Borough B
WHERE D.DateKey = T.DateKey AND S.Name = ’Mitte’ AND D.Route && B.Geom AND
duration(atGeometry(D.Route, B.Geom)) >= interval ’20 min’
GROUP BY T.Year, T.MonthNumber
ORDER BY T.Year, T.MonthNumber
Analogously, Query 4 reads, for these experiments:
SELECT DT.Year, DT.MonthNumber, COUNT(*)
FROM Delivery D, Date DT, Borough B,
unnest(periods(getTime(atGeometry(D.Route, B.Geom)))) P
WHERE D.DateKey = DT.DateKey AND B.Name = ’Mitte’ AND
D.Route && B.Geom AND duration(P) >= interval ’20 min’
GROUP BY DT.Year, DT.MonthNumber
ORDER BY DT.Year, DT.MonthNumber
Table 1 shows the results obtained in these tests. Queries were run several times to eliminate the influence of cold caching (that is, hot chache is assumed). Further, once this influence was eliminated, execution times were the same for each run, therefore just the average value was reported in the table, since the differences between runs were negligible. It can be seen that the queries that took longer were the ones that included spatial operations.
Of course, these results are not pretended to be conclusive, but suggest that the addition of MOs as fact measures in a warehouse adds query expressiveness. Also, existing proposals segment trajectories (see
Section 6) require a “normalization” of the trajectory representation, which is costly due to the number of joins that queries like the ones presented here would require. This is not needed when trajectories are represented as MOs. In addition, note that the DW is implemented using standard object-relational technologies (in this case, PostgresSQL and PostGIS). Therefore, the effect of the inclusion of MOs can also be inferred from an evaluation of the implementation of the temporal types. This is available in the MobilityDB demo site, at URL
http://demo.mobilitydb.eu/, where the system runs over the BerlinMOD benchmark data (the queries in such demo do not include warehouse data, they are purely MO queries). It can be observed on the demo site that typical MO queries run very fast over the benchmark, although this is not reported in this paper. Developing a benchmark to perform a comprehensive set of experiments is outside the scope of this paper, and is planned as future work (
Section 7).
6. Related Work
Trajectory DWs are strongly related to spatial databases and DWs. The main features of PostGIS, the OGC-based extension to PostgresSQL can be found in [
12]. Also, the spatial extension of the MultiDim model presented here was based on the spatial data types of MADS [
13], a spatiotemporal conceptual model. The notion of spatial OLAP (SOLAP) was introduced in [
14], and it is reviewed in [
15]. Other relevant work on SOLAP can be found in [
16,
17,
18].
In order to support spatio-temporal data, a data model and associated query language for MO data were needed. This is achieved in
Secondo http://dna.fernuni-hagen.de/secondo/ [
19], a MO database system developed at the FernUniversität in Hagen, based on the model of Güting et al. [
1]. Along similar lines, Hermes is a MOD introduced by Pelekis et al. [
20]. The Hermes system is described in [
21]. In spite of their ability to handle MO data, neither
Secondo, nor Hermes, are oriented toward addressing the problem of mobility DWs. Among other reasons, integrating both prototypes into existing relational databases is not straightforward. Hermes, for example, extends Oracle through a so-called cartridge with the MO types. However, to build an application on top of the database the application developer must write a source program (for example, in Java), and embed PL/SQL scripts that invoke object constructors and methods from Hermes.
Secondo is as packed system, therefore, integration with existing databases is even more complicated. On the contrary, being coded in the “C” programming language (like PostgresSQL), MobilityDB seamlessly extends the PostGIS library with temporal data types, not requiring any additional software architecture. Thus, building a mobility DW with MobilityDB turns out to be a natural extension of a spatial relational DW. On the downside, MobilityDB at this time only supports moving points, while
Secondo and Hermes provide (although limited) support to other MOs. However, for traffic analysis, moving points are the most used kind of MOs. The data type system of the temporal types presented in this paper follows the approach of [
1]. Also, an SQL extension for spatiotemporal data is proposed in [
22].
The work by Orlando et al. [
6] introduces the concept of trajectory DWs, aimed at providing the infrastructure needed to deliver advanced reporting capabilities and facilitating the use of mining algorithms on aggregate data. This work is based on the Hermes system. A relevant feature of this proposal is the treatment given to the extraction, transformation and loading (ETL) process, which transforms the raw location data and loads it to the trajectory DW. However, regarding mobility analysis, this proposal does not address MO data. Measures in this trajectory DW are related with the number of MO present in a cell defined by spatiotemporal coordinates. Therefore, queries that can be addressed using this DW are of the form “compute the number of cars between latitudes
and
, and longitudes
and
, on 3 November 2018”. However, actual mobility analysis queries like the ones presented in
Section 5 cannot be addressed. Also, the authors themselves state in their proposal that MO data analysis remains outside the TDW.
Along similar lines, Wagner et al. [
7] proposed the Mob-Warehouse, a conceptual to support mobility analysis using a TDW. The authors propose to enrich trajectory data with semantic information about the domain. The paper is based on the previously defined notion of semantic trajectory [
23]. Unlike the model presented in [
6], where the measures are pre-aggregated (e.g., number of cars in a cell), in this model the measures are at the finest detail level. No implementation details are given, and MO operations are not addressed. Instead, the proposal is aimed at analyzing semantic trajectories, as the example queries provided suggest.
Based on [
7,
23], and the work on semantic trajectories, another model for TDWs is proposed in [
5], accounting for semantic information. In this case, again, MO data are only partially considered. MO trajectories are partitioned into segments, to which semantic information is associated. No implementation is described, and the authors report than experiments are being carried out, suggesting that the segments in the fact table are not that efficient, which is certainly expected given that many joins are required to reconstruct a trajectory from such segments.
Note that the proposal presented in the present paper does not exclude semantic information. On the contrary, semantic information about MOs can be naturally included in the mobility DW proposed here, and, in fact, this is what dimensions are defined for. Also, all of the features of the proposals above are supported by the model described in this paper (e.g., segmentation, pre-aggregation, semantic information).
An overall perspective of the state of the art in mobility data management can be found in [
2,
24,
25,
26]. A survey on spatiotemporal data warehousing, OLAP, and mining is given in [
27]. A discussion about the meaning of spatiotemporal data warehousing is given in [
4]. Also, mobility DWs are discussed in [
28,
29,
30]. Analysis tools for mobility DWs can be found in [
31]. Finally, a survey on spatiotemporal aggregation is given in [
32], while a survey on trajectory aggregation is provided in [
33].










{kind=link}
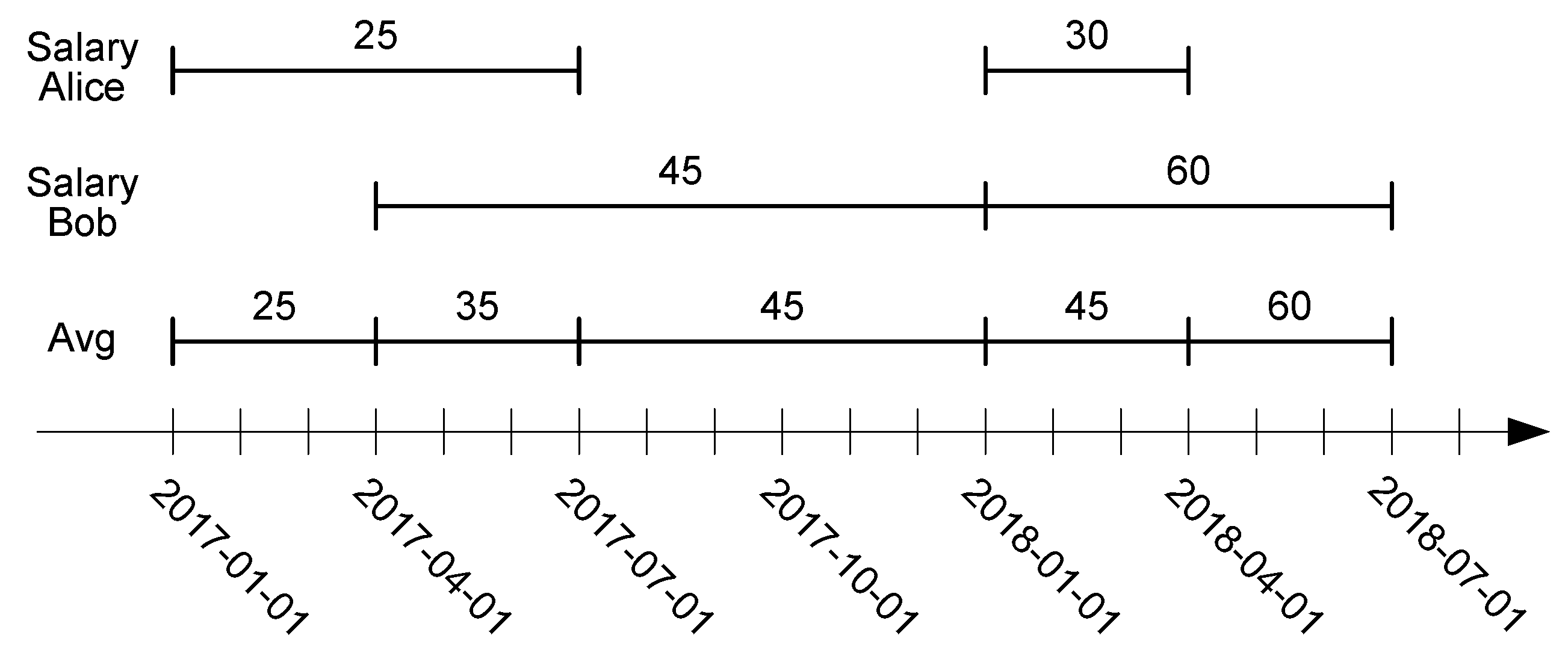{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}