Eigenvector Spatial Filtering-Based Logistic Regression for Landslide Susceptibility Assessment

Abstract
:1. Introduction
2. Study Area and Data
2.1. Study Area
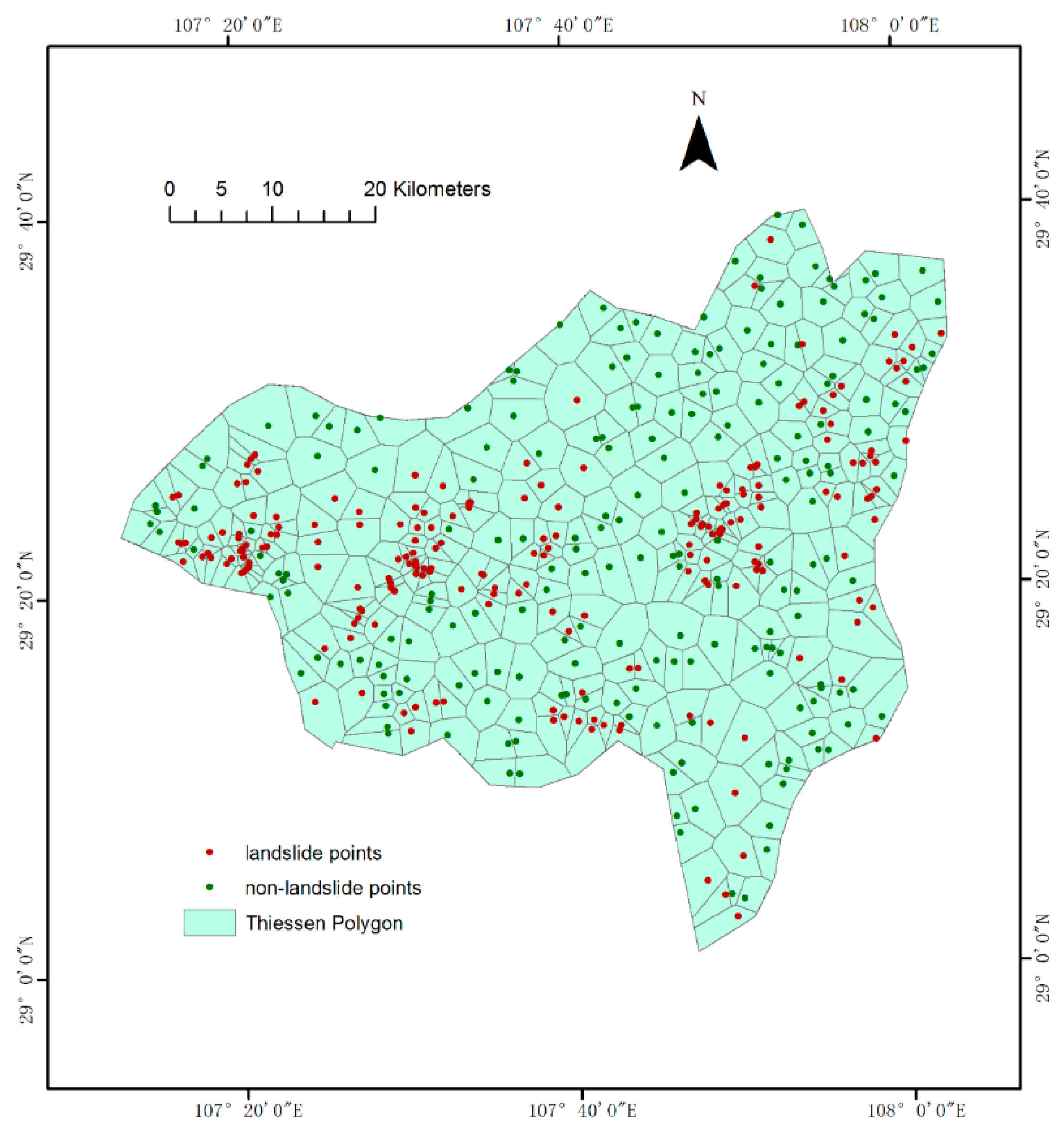
2.2. Landslide Inventory Map
2.3. Landslide Predisposing Factors
3. Methods
3.1. Generation of Landslide Dataset
3.2. Multicollinearity Analysis
3.3. Eigenvector Spatial Filtering Based on Logistic Regression Modeling
3.4. Model Validation
4. Results and Discussion
4.1. Model Construction
4.2. Model Evaluation and Comparison
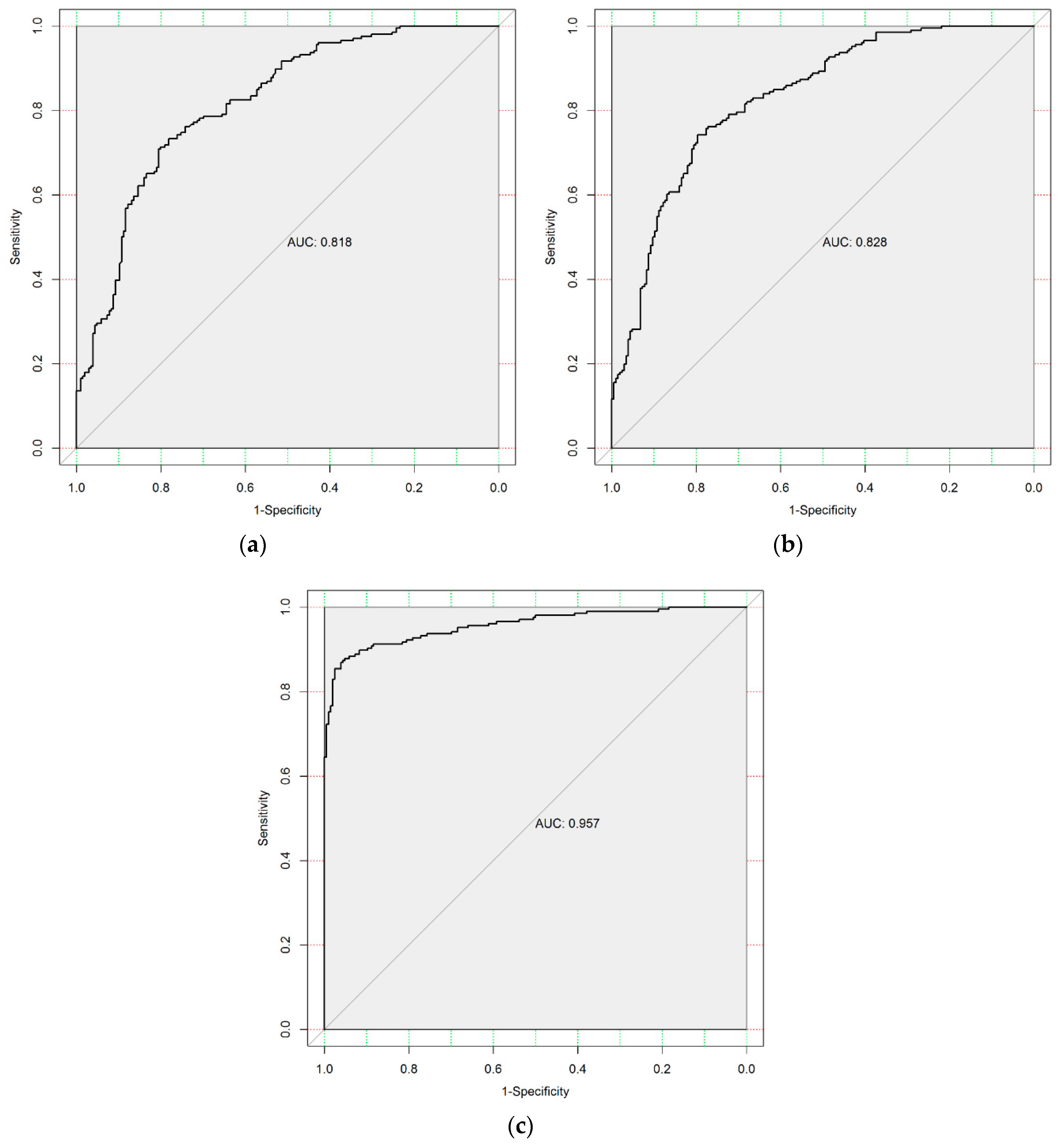
4.2.1. Model Performance
4.2.2. Detection of Spatial Autocorrelation of Residuals
4.2.3. Cross Validation
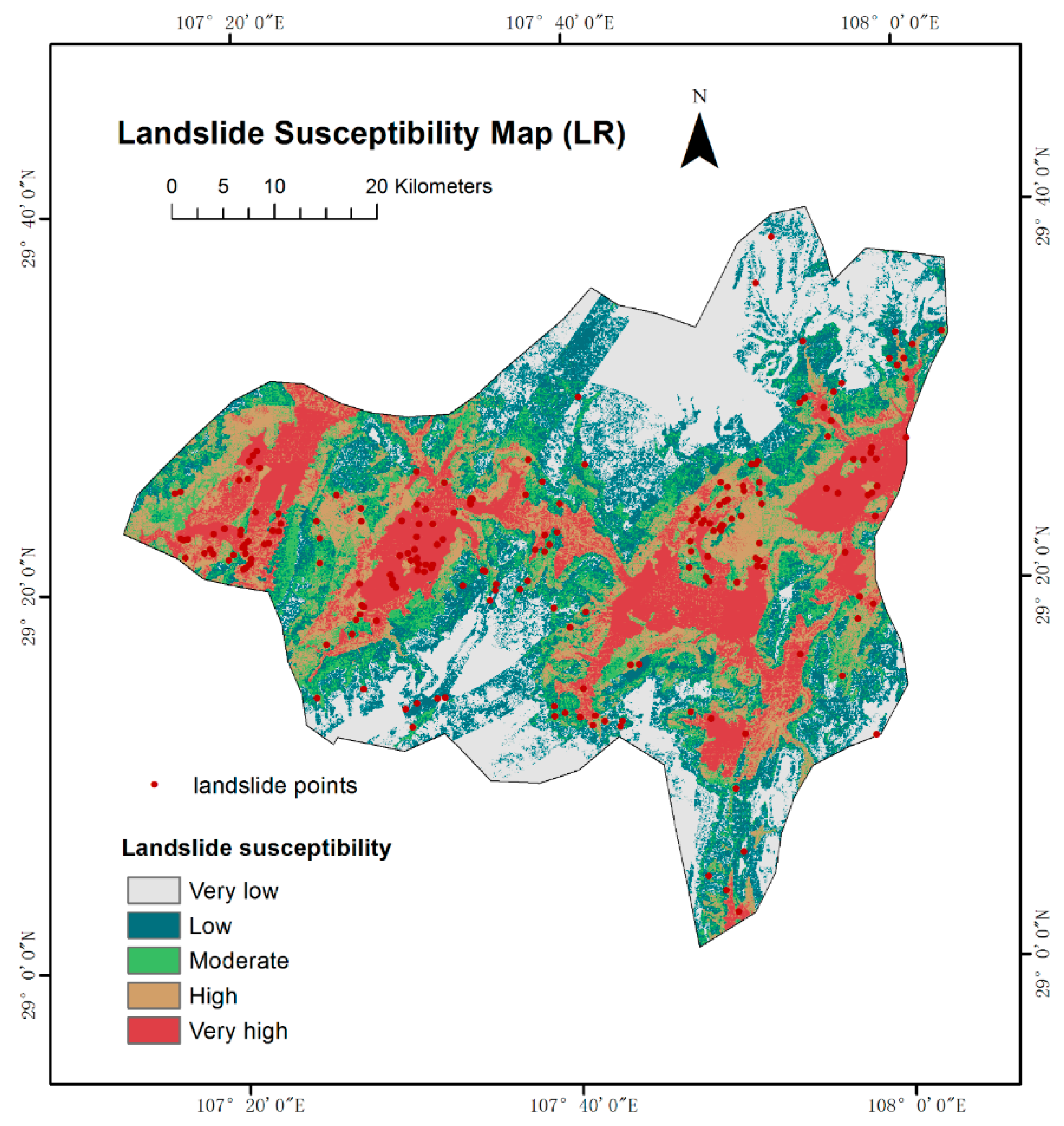
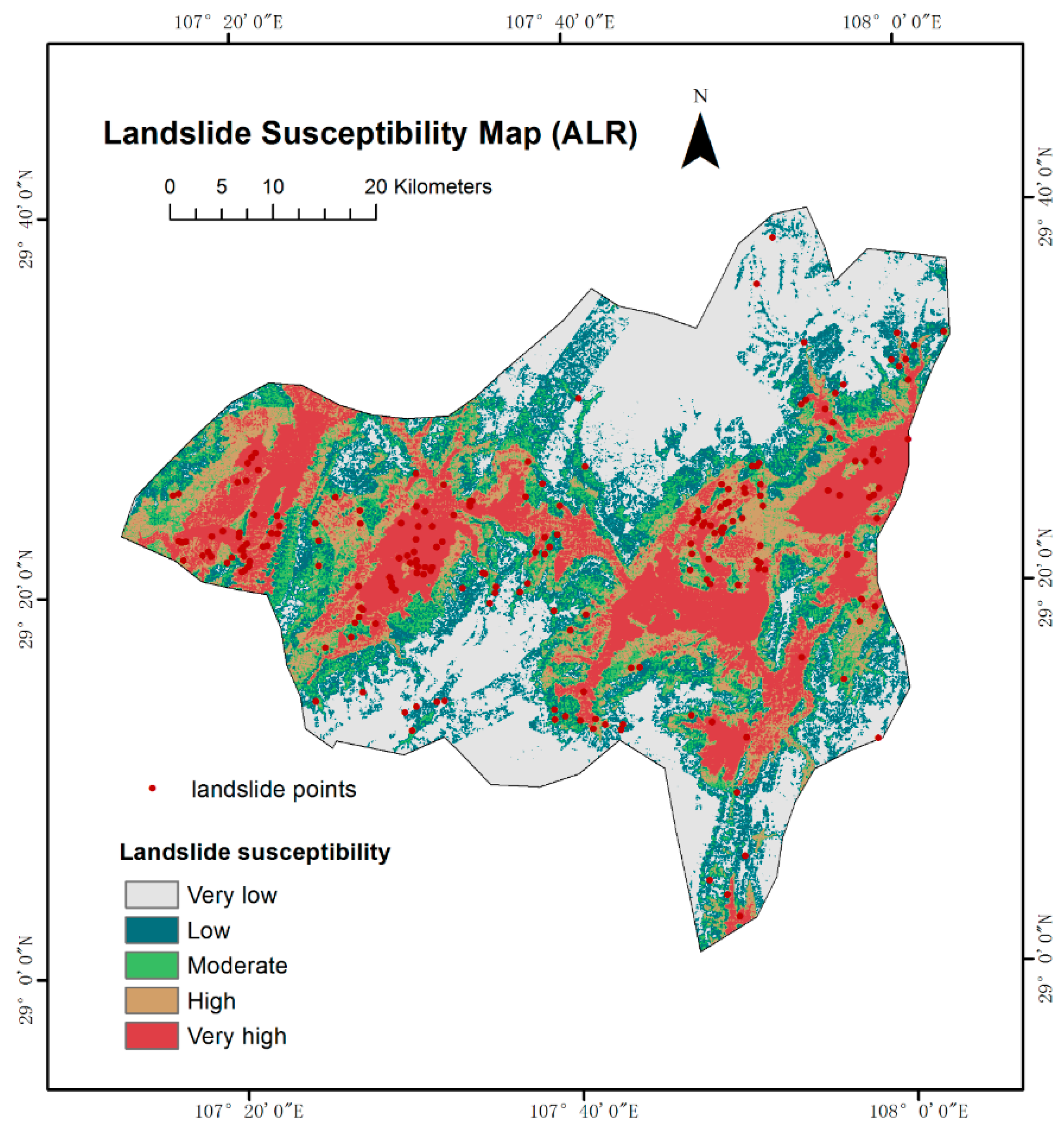
4.3. Landslide Susceptibility Mapping
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Dai, F.C.; Lee, C.F.; Ngai, Y.Y. Landslide risk assessment and management: An overview. Eng. Geol. 2002, 64, 65–87. [Google Scholar] [CrossRef]
- Bai, S.B.; Wang, J.; Lü, G.N.; Zhou, P.G.; Hou, S.S.; Xu, S.N. GIS-based logistic regression for landslide susceptibility mapping of the Zhongxian segment in the Three Gorges area, China. Geomorphology 2010, 115, 23–31. [Google Scholar] [CrossRef]
- Atkinson, P.M.; Massari, R. Generalised linear modelling of susceptibility to landsliding in the central apennines, italy. Comput. Geosci. 1998, 24, 373–385. [Google Scholar] [CrossRef]
- Budimir, M.E.A.; Atkinson, P.M.; Lewis, H.G. A systematic review of landslide probability mapping using logistic regression. Landslides 2015, 12, 419–436. [Google Scholar] [CrossRef] [Green Version]
- Che, V.B.; Kervyn, M.; Suh, C.E.; Fontijn, K.; Ernst, G.G.J.; Marmol, M.A.D.; Trefois, P.; Jacobs, P. Landslide susceptibility assessment in Limbe (SW Cameroon): A field calibrated seed cell and information value method. Catena 2012, 92, 83–98. [Google Scholar] [CrossRef]
- Ba, Q.; Chen, Y.; Deng, S.; Wu, Q.; Yang, J.; Zhang, J. An Improved Information Value Model Based on Gray Clustering for Landslide Susceptibility Mapping. ISPRS Int. J. Geo Inf. 2017, 6, 18. [Google Scholar] [CrossRef]
- Ba, Q.; Chen, Y.; Deng, S.; Yang, J.; Li, H. A comparison of slope units and grid cells as mapping units for landslide susceptibility assessment. Earth Sci. Inform. 2018, 11, 373–388. [Google Scholar] [CrossRef]
- Lee, S.; Pradhan, B. Landslide hazard mapping at Selangor, Malaysia using frequency ratio and logistic regression models. Landslides 2007, 4, 33–41. [Google Scholar] [CrossRef]
- Zhang, G.; Cai, Y.; Zheng, Z.; Zhen, J.; Liu, Y.; Huang, K. Integration of the Statistical Index Method and the Analytic Hierarchy Process technique for the assessment of landslide susceptibility in Huizhou, China. Catena 2016, 142, 233–244. [Google Scholar] [CrossRef]
- Fan, X.Y.; Qiao, J.P.; Chen, Y.B. Application of analytic hierarchy process in assessment of typical landslide danger degree. J. Nat. Disasters 2004, 13, 72–76. [Google Scholar]
- Lee, S.; Ryu, J.H.; Won, J.S.; Park, H.J. Determination and application of the weights for landslide susceptibility mapping using an artificial neural network. Eng. Geol. 2004, 71, 289–302. [Google Scholar] [CrossRef]
- Zare, M.; Pourghasemi, R.H.; Vafakhah, M.; Pradhan, B. Landslide susceptibility mapping at Vaz Watershed (Iran) using an;artificial neural network model: A comparison between multilayer;perceptron (MLP) and radial basic function (RBF) algorithms. Arab. J. Geosci. 2013, 6, 2873–2888. [Google Scholar] [CrossRef]
- Xu, C.; Dai, F.; Xu, X.; Yuan, H.L. GIS-based support vector machine modeling of earthquake-triggered landslide susceptibility in the Jianjiang River watershed, China. Geomorphology 2012, 145–146, 70–80. [Google Scholar] [CrossRef]
- Brenning, A. Spatial prediction models for landslide hazards: Review, comparison and evaluation. Nat. Hazards Earth Syst. Sci. 2005, 5, 853–862. [Google Scholar] [CrossRef]
- Lee, S. Application of logistic regression model and its validation for landslide susceptibility mapping using GIS and remote sensing data. Int. J. Remote Sens. 2005, 26, 1477–1491. [Google Scholar] [CrossRef]
- Yilmaz, I. Landslide susceptibility mapping using frequency ratio, logistic regression, artificial neural networks and their comparison: A case study from Kat landslides (Tokat—Turkey). Comput. Geosci. 2009, 35, 1125–1138. [Google Scholar] [CrossRef]
- Akgun, A. A comparison of landslide susceptibility maps produced by logistic regression, multi-criteria decision, and likelihood ratio methods: A case study at İzmir, Turkey. Landslides 2012, 9, 93–106. [Google Scholar] [CrossRef]
- Tobler, W.R. A Computer Movie Simulating Urban Growth in the Detroit Region. Econ. Geogr. 1970, 46, 234–240. [Google Scholar] [CrossRef]
- Getis, A. A History of the Concept of Spatial Autocorrelation: A Geographer’s Perspective. Geogr. Anal. 2010, 40, 297–309. [Google Scholar] [CrossRef]
- Erener, A.; Düzgün, H. Improvement of statistical landslide susceptibility mapping by using spatial and global regression methods in the case of More and Romsdal (Norway). Landslides 2010, 7, 55–68. [Google Scholar] [CrossRef]
- Getis, A. Screening for spatial dependence in regression analysis. Pap. Reg. Sci. Assoc. 1990, 69, 69–81. [Google Scholar] [CrossRef]
- Getis, A. Spatial Filtering in a Regression Framework: Examples Using Data on Urban Crime, Regional Inequality and Government Expenditures; Springer: Berlin, Germany, 2010; pp. 172–185. [Google Scholar]
- Griffith, D.A. A linear regression solution to the spatial autocorrelation problem. J. Geogr. Syst. 2000, 2, 141–156. [Google Scholar] [CrossRef]
- Getis, A.; Griffith, D.A. Comparative Spatial Filtering in Regression Analysis. Geogr. Anal. 2002, 34, 130–140. [Google Scholar] [CrossRef]
- Ayalew, L.; Yamagishi, H.; Marui, H.; Kanno, T. Landslides in Sado Island of Japan: Part II. GIS-based susceptibility mapping with comparisons of results from two methods and verifications. Engi. Geol. 2005, 81, 432–445. [Google Scholar] [CrossRef]
- Wang, Q.; Wang, D.; Yong, H.; Wang, Z.; Zhang, L.; Guo, Q.; Wei, C.; Sang, M. Landslide Susceptibility Mapping Based on Selected Optimal Combination of Landslide Predisposing Factors in a Large Catchment. Sustainability 2015, 7, 16653–16669. [Google Scholar] [CrossRef] [Green Version]
- Dai, F.C.; Lee, C.F. Landslide characteristics and slope instability modeling using GIS, Lantau Island, Hong Kong. Geomorphology 2002, 42, 213–228. [Google Scholar] [CrossRef]
- Eeckhaut, M.V.D.; Reichenbach, P.; Guzzetti, F.; Rossi, M. Combined landslide inventory and susceptibility assessment based on different mapping units: An example from the Flemish Ardennes, Belgium. Nat. Hazards Earth Syst.Sci. NHESS Discuss. NHESSD 2009, 9, 507–521. [Google Scholar] [CrossRef]
- Pourghasemi, H.R.; Pradhan, B.; Gokceoglu, C. Application of fuzzy logic and analytical hierarchy process (AHP) to landslide susceptibility mapping at Haraz watershed, Iran. Nat. Hazards 2012, 63, 965–996. [Google Scholar] [CrossRef]
- Wang, Q.; Li, W.; Wu, Y.; Pei, Y.; Xie, P. Application of statistical index and index of entropy methods to landslide susceptibility assessment in Gongliu (Xinjiang, China). Environ. Earth Sci. 2016, 75, 599. [Google Scholar] [CrossRef]
- Schaefer, R.L. Alternative estimators in logistic regression when the data are collinear. J. Stat. Comput. Simul. 1986, 25, 75–91. [Google Scholar] [CrossRef]
- Miles, J. Tolerance and Variance Inflation Factor; John Wiley and Sons: Hoboken, NJ, USA, 2005; pp. 2055–2056. [Google Scholar]
- Allison, P.D. Logistic Regression Using the SAS System: Theory and Application; SAS Publishing: Cary, NC, USA, 1999. [Google Scholar]
- Griffith, D.A.; Peresneto, P.R. Spatial modeling in ecology: The flexibility of eigenfunction spatial analyses. Ecology 2006, 87, 2603–2613. [Google Scholar] [CrossRef]
- Griffith, D.A. Spatial Autocorrelation and Spatial Filtering; Springer: Berlin/Heidelberg, Germany, 2013; pp. 633–635. [Google Scholar]
- Thayn, J.B.; Simanis, J.M. Accounting for Spatial Autocorrelation in Linear Regression Models Using Spatial Filtering with Eigenvectors. Ann. Assoc. Am. Geogr. 2013, 103, 47–66. [Google Scholar] [CrossRef]
- Dormann, C.; McPherson, J.; Araújo, M.; Bivand, R.; Bolliger, J.; Carl, G.; Wilson, R. Methods to Account for Spatial Autocorrelation in the Analysis of Species Distributional Data: A Review. Ecography 2007, 30, 609–628. [Google Scholar] [CrossRef]
- Atkinson, P.M.; Massari, R. Autologistic modelling of susceptibility to landsliding in the Central Apennines, Italy. Geomorphology 2011, 130, 55–64. [Google Scholar] [CrossRef]
- Augustin, N.H.; Ma, B.S.M. An autologistic model for the spatial distribution of wildlife. J. Appl. Ecol. 1996, 33, 339–347. [Google Scholar] [CrossRef]
- Hong, H.; Pradhan, B.; Xu, C.; Bui, D.T. Spatial prediction of landslide hazard at the Yihuang area (China) using two-class kernel logistic regression, alternating decision tree and support vector machines. Catena 2015, 133, 266–281. [Google Scholar] [CrossRef]
- Frattini, P.; Crosta, G.; Carrara, A. Techniques for evaluating the performance of landslide susceptibility models. Eng. Geol. 2010, 111, 62–72. [Google Scholar] [CrossRef]
- García-Rodríguez, M.J.; Malpica, J.A.; Benito, B.; Díaz, M. Susceptibility assessment of earthquake-triggered landslides in El Salvador using logistic regression. Geomorphology 2008, 95, 172–191. [Google Scholar] [CrossRef] [Green Version]
- Peng, C.Y.J.; Lee, K.L.; Ingersoll, G.M. An introduction to logistic regression analysis and reporting. J. Educ. Res. 2002, 96, 3–14. [Google Scholar] [CrossRef]
- Tiefelsdorf, M. The Saddlepoint Approximation of Moran’s I’s and Local Moran’s Ii’s Reference Distributions and Their Numerical Evaluation. Geogr. Anal. 2002, 34, 187–206. [Google Scholar] [CrossRef]
- Bengio, Y.; Grandvalet, Y. Bias in Estimating the Variance of K-Fold Cross-Validation; Springer: New York, NY, USA, 2005; pp. 75–95. [Google Scholar]
- Fushiki, T. Estimation of Prediction Error by Using K-fold Cross-Validation; Kluwer Academic Publishers: Berlin/Heidelberg, Germany, 2011; pp. 137–146. [Google Scholar]
- Yang, J.; Chen, Y.; Chen, M.; Yang, F.; Yao, M. A Segmented Processing Approach of Eigenvector Spatial Filtering Regression for Normalized Difference Vegetation Index in Central China. ISPRS Int. J. Geo Inf. 2018, 7, 330. [Google Scholar] [CrossRef]
- Murakami, D.; Griffith, D.A. Eigenvector Spatial Filtering for Large Data Sets: Fixed and Random Effects Approaches. Geogr. Anal. 2019, 51, 23–49. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Factors | Class | Landslide Area (Ai) | Landslide Area Ratio (Ai/A) | Class Area Ratio (Si/S) | Frequency Ratio (R) |
|---|---|---|---|---|---|
| Elevation | 1 | 141.28 | 0.22 | 0.09 | 2.6 |
| 2 | 172.36 | 0.27 | 0.11 | 2.52 | |
| 3 | 90.14 | 0.14 | 0.13 | 1.12 | |
| 4 | 121.63 | 0.19 | 0.14 | 1.37 | |
| 5 | 34.78 | 0.05 | 0.14 | 0.4 | |
| 6 | 75.56 | 0.12 | 0.13 | 0.91 | |
| 7 | 0.96 | 0 | 0.12 | 0.01 | |
| 8 | 0 | 0 | 0.08 | 0 | |
| 9 | 0 | 0 | 0.07 | 0 | |
| Slope | 1 | 37.99 | 0.06 | 0.11 | 0.54 |
| 2 | 213.74 | 0.34 | 0.16 | 2.08 | |
| 3 | 148.79 | 0.23 | 0.18 | 1.29 | |
| 4 | 102.71 | 0.16 | 0.17 | 0.96 | |
| 5 | 56.79 | 0.09 | 0.14 | 0.64 | |
| 6 | 39.98 | 0.06 | 0.11 | 0.6 | |
| 7 | 28.02 | 0.04 | 0.07 | 0.6 | |
| 8 | 4.66 | 0.01 | 0.04 | 0.17 | |
| 9 | 4.03 | 0.01 | 0.02 | 0.37 | |
| Aspect | 1 | 0 | 0 | 0 | 0 |
| 2 | 42.65 | 0.07 | 0.1 | 0.64 | |
| 3 | 96.65 | 0.15 | 0.12 | 1.27 | |
| 4 | 122.45 | 0.19 | 0.15 | 1.31 | |
| 5 | 73.95 | 0.12 | 0.15 | 0.76 | |
| 6 | 79.07 | 0.12 | 0.1 | 1.18 | |
| 7 | 69.47 | 0.11 | 0.11 | 0.98 | |
| 8 | 58.72 | 0.09 | 0.13 | 0.71 | |
| 9 | 93.75 | 0.15 | 0.13 | 1.13 | |
| Curvature | 1 | 0 | 0 | 0 | 0 |
| 2 | 1.75 | 0 | 0.02 | 0.16 | |
| 3 | 46.02 | 0.07 | 0.07 | 1.04 | |
| 4 | 174.59 | 0.27 | 0.21 | 1.29 | |
| 5 | 303.37 | 0.48 | 0.4 | 1.19 | |
| 6 | 79.75 | 0.13 | 0.21 | 0.61 | |
| 7 | 28.06 | 0.04 | 0.07 | 0.62 | |
| 8 | 2.47 | 0 | 0.02 | 0.21 | |
| 9 | 0.7 | 0 | 0 | 0.45 | |
| Distance to Road | 1 | 303.55 | 0.48 | 0.28 | 1.71 |
| 2 | 145.05 | 0.23 | 0.24 | 0.95 | |
| 3 | 75.04 | 0.12 | 0.18 | 0.66 | |
| 4 | 87.33 | 0.14 | 0.12 | 1.1 | |
| 5 | 16.4 | 0.03 | 0.08 | 0.32 | |
| 6 | 1.34 | 0 | 0.05 | 0.04 | |
| 7 | 2.7 | 0 | 0.02 | 0.17 | |
| 8 | 0.5 | 0 | 0.01 | 0.06 | |
| 9 | 4.8 | 0.01 | 0.01 | 0.81 | |
| Distance to Railway | 1 | 122.16 | 0.19 | 0.17 | 1.11 |
| 2 | 193.82 | 0.3 | 0.18 | 1.7 | |
| 3 | 139.24 | 0.22 | 0.16 | 1.4 | |
| 4 | 102.95 | 0.16 | 0.14 | 1.16 | |
| 5 | 39.85 | 0.06 | 0.11 | 0.55 | |
| 6 | 19.87 | 0.03 | 0.09 | 0.34 | |
| 7 | 11.73 | 0.02 | 0.07 | 0.25 | |
| 8 | 0.45 | 0 | 0.05 | 0.01 | |
| 9 | 6.64 | 0.01 | 0.03 | 0.37 | |
| Distance to River | 1 | 260.26 | 0.41 | 0.25 | 1.65 |
| 2 | 107.62 | 0.17 | 0.22 | 0.76 | |
| 3 | 148.41 | 0.23 | 0.18 | 1.27 | |
| 4 | 41.76 | 0.07 | 0.12 | 0.54 | |
| 5 | 57.58 | 0.09 | 0.08 | 1.12 | |
| 6 | 8.26 | 0.01 | 0.06 | 0.22 | |
| 7 | 10.68 | 0.02 | 0.04 | 0.46 | |
| 8 | 1.24 | 0 | 0.03 | 0.06 | |
| 9 | 0.9 | 0 | 0.02 | 0.08 | |
| Distance to Fault | 1 | 44.5 | 0.07 | 0.16 | 0.44 |
| 2 | 42.93 | 0.07 | 0.17 | 0.4 | |
| 3 | 66.51 | 0.1 | 0.15 | 0.71 | |
| 4 | 142.69 | 0.22 | 0.13 | 1.78 | |
| 5 | 144.28 | 0.23 | 0.11 | 2.05 | |
| 6 | 68.69 | 0.11 | 0.1 | 1.06 | |
| 7 | 63.92 | 0.1 | 0.09 | 1.15 | |
| 8 | 58.06 | 0.09 | 0.07 | 1.38 | |
| 9 | 5.13 | 0.01 | 0.04 | 0.23 | |
| Precipitation | 1 | 7.88 | 0.01 | 0.02 | 0.63 |
| 2 | 7.01 | 0.01 | 0.06 | 0.18 | |
| 3 | 18.02 | 0.03 | 0.14 | 0.2 | |
| 4 | 92.97 | 0.15 | 0.14 | 1.03 | |
| 5 | 92.69 | 0.15 | 0.17 | 0.88 | |
| 6 | 239.65 | 0.38 | 0.17 | 2.16 | |
| 7 | 114.66 | 0.18 | 0.18 | 1 | |
| 8 | 57.63 | 0.09 | 0.1 | 0.89 | |
| 9 | 6.2 | 0.01 | 0.02 | 0.54 | |
| Lithology | 1 | 98.33 | 0.15 | 0.48 | 0.32 |
| 2 | 131.2 | 0.21 | 0.16 | 1.31 | |
| 3 | 7.45 | 0.01 | 0 | 3.95 | |
| 4 | 2.14 | 0 | 0 | 1.76 | |
| 5 | 6.18 | 0.01 | 0 | 7.36 | |
| 6 | 195.11 | 0.31 | 0.2 | 1.57 | |
| 7 | 36.02 | 0.06 | 0.01 | 4.78 | |
| 8 | 11.5 | 0.02 | 0 | 7.95 | |
| 9 | 148.78 | 0.23 | 0.14 | 1.63 | |
| NDVI | 1 | 15.8 | 0.02 | 0.06 | 0.41 |
| 2 | 32.84 | 0.05 | 0.08 | 0.68 | |
| 3 | 77.74 | 0.12 | 0.09 | 1.29 | |
| 4 | 63.21 | 0.1 | 0.12 | 0.81 | |
| 5 | 127.43 | 0.2 | 0.14 | 1.45 | |
| 6 | 123.43 | 0.19 | 0.15 | 1.26 | |
| 7 | 135.46 | 0.21 | 0.15 | 1.38 | |
| 8 | 57.2 | 0.09 | 0.13 | 0.69 | |
| 9 | 3.6 | 0.01 | 0.07 | 0.08 |
| Landslide Predisposing Factor | TOL | VIF |
|---|---|---|
| Elevation | 0.827 | 1.209 |
| Slope | 0.97 | 1.031 |
| Aspect | 0.982 | 1.019 |
| Curvature | 0.966 | 1.036 |
| Distance to Road | 0.795 | 1.258 |
| Distance to Railway | 0.804 | 1.244 |
| Distance to River | 0.779 | 1.284 |
| Distance to Fault | 0.93 | 1.075 |
| Precipitation | 0.895 | 1.117 |
| Lithology | 0.952 | 1.05 |
| NDVI | 0.966 | 1.035 |
| NO. | Eigenvector |
|---|---|
| 1 | E3 |
| 2 | E1 |
| 3 | E5 |
| 4 | E8 |
| 5 | E4 |
| 6 | E13 |
| 7 | E9 |
| 8 | E21 |
| 9 | E36 |
| Independent Variables | Coefficient | p Value |
|---|---|---|
| Elevation | 1.3480 | <0.001 |
| Curvature | 1.1963 | 0.0637 |
| Distance to Fault | 1.2676 | <0.001 |
| NDVI | 0.8868 | 0.0826 |
| E3 | 49.9670 | <0.001 |
| E1 | 22.8224 | <0.001 |
| E5 | −16.1425 | <0.001 |
| E8 | −21.5564 | <0.001 |
| E4 | −9.6310 | 0.0185 |
| E13 | −14.5683 | <0.001 |
| E9 | −14.0375 | 0.0011 |
| E21 | 11.8195 | 0.0027 |
| E36 | 6.9485 | 0.0957 |
| Intercept | −4.9146 | <0.001 |
| Independent Variables | Coefficient | p Value |
|---|---|---|
| Elevation | 1.1109 | 6.25 × 10−13 |
| Curvature | 0.9087 | 0.0297 |
| Distance to Railway | 0.7154 | 0.0041 |
| Distance to Fault | 0.7324 | 0.0000 |
| NDVI | 0.6659 | 0.0343 |
| Intercept | −4.5507 | 2.18 × 10−11 |
| Model | AUC | Nagelkerke R2 | AIC |
|---|---|---|---|
| LR | 0.818 | 0.3907 | 440.31 |
| ALR (Autocov90) | 0.828 | 0.4075 | 426.86 |
| ALR (Autocov150) | 0.827 | 0.4053 | 427.83 |
| ALR (Autocov270) | 0.824 | 0.3987 | 430.77 |
| Independent Variables | Coefficient | p Value |
|---|---|---|
| Curvature | 0.7151 | 0.090 |
| Autocov90 | 5.2782 | <0.001 |
| Intercept | −3.3612 | <0.001 |
| Parameter | LR | ALR | ESFLR |
|---|---|---|---|
| TN | 157 | 160 | 191 |
| FN | 49 | 46 | 15 |
| FP | 55 | 52 | 24 |
| TP | 151 | 154 | 182 |
| Positive accuracy (%) | 73.30 | 74.76 | 88.35 |
| Negative accuracy (%) | 76.21 | 77.67 | 92.72 |
| Overall accuracy (%) | 74.76 | 76.21 | 90.53 |
| AUC | 0.818 | 0.828 | 0.957 |
| Nagelkerke R2 | 0.3907 | 0.4075 | 0.7810 |
| AIC | 440.31 | 426.86 | 236.08 |
| Model | Moran’s I | p Value |
|---|---|---|
| LR | 0.4104 | <0.001 |
| ALR | 0.3971 | <0.001 |
| ESFLR | 0.0270 | 0.1558 |
| Model | Training Dataset | Validation Dataset | ||||
|---|---|---|---|---|---|---|
| Negative Accuracy (%) | Positive Accuracy (%) | Overall Accuracy (%) | Negative Accuracy (%) | Positive Accuracy (%) | Overall Accuracy (%) | |
| LR | 77.24 | 73.25 | 75.24 | 76.74 | 72.69 | 74.70 |
| ALR_90 | 77.89 | 74.86 | 76.37 | 77.69 | 74.17 | 75.92 |
| ESFLR | 90.18 | 90.24 | 90.21 | 88.33 | 89.88 | 89.10 |
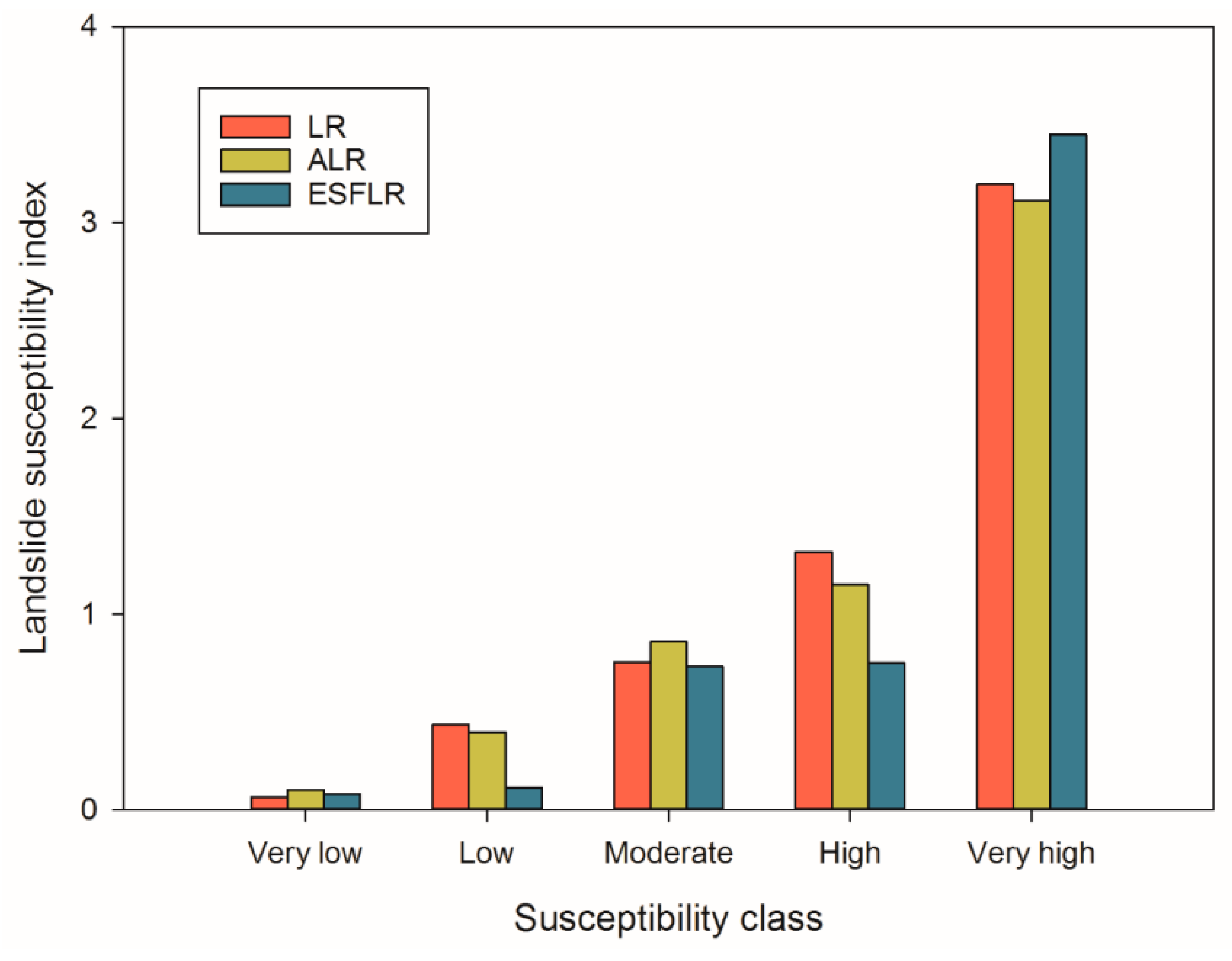
| Model | Susceptibility Class | Landslide | Landslide Area (m2) | % Landslide Covered (a) | % Area Covered (b) | Landslide Density (a/b) |
|---|---|---|---|---|---|---|
| LR | Very high | 90 | 3,561,500 | 55.94 | 17.51 | 3.19 |
| High | 47 | 1,254,800 | 19.71 | 14.96 | 1.32 | |
| Moderate | 34 | 837,650 | 13.16 | 17.42 | 0.76 | |
| Low | 29 | 596,200 | 9.36 | 21.65 | 0.43 | |
| Very low | 6 | 116,900 | 1.84 | 28.47 | 0.06 | |
| ALR | Very high | 101 | 3,947,200 | 61.99 | 19.92 | 3.11 |
| High | 41 | 955,350 | 15.00 | 13.05 | 1.15 | |
| Moderate | 30 | 763,400 | 11.99 | 13.95 | 0.86 | |
| Low | 25 | 474,200 | 7.45 | 18.75 | 0.40 | |
| Very low | 9 | 226,900 | 3.56 | 34.33 | 0.10 | |
| ESFLR | Very high | 148 | 4,937,650 | 77.55 | 22.48 | 3.45 |
| High | 27 | 585,700 | 9.20 | 12.27 | 0.75 | |
| Moderate | 14 | 531,800 | 8.35 | 11.45 | 0.73 | |
| Low | 6 | 116,600 | 1.83 | 15.98 | 0.11 | |
| Very low | 11 | 195,300 | 3.07 | 37.81 | 0.08 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, H.; Chen, Y.; Deng, S.; Chen, M.; Fang, T.; Tan, H. Eigenvector Spatial Filtering-Based Logistic Regression for Landslide Susceptibility Assessment. ISPRS Int. J. Geo-Inf. 2019, 8, 332. https://doi.org/10.3390/ijgi8080332
Li H, Chen Y, Deng S, Chen M, Fang T, Tan H. Eigenvector Spatial Filtering-Based Logistic Regression for Landslide Susceptibility Assessment. ISPRS International Journal of Geo-Information. 2019; 8(8):332. https://doi.org/10.3390/ijgi8080332
Chicago/Turabian StyleLi, Huifang, Yumin Chen, Susu Deng, Meijie Chen, Tao Fang, and Huangyuan Tan. 2019. "Eigenvector Spatial Filtering-Based Logistic Regression for Landslide Susceptibility Assessment" ISPRS International Journal of Geo-Information 8, no. 8: 332. https://doi.org/10.3390/ijgi8080332
APA StyleLi, H., Chen, Y., Deng, S., Chen, M., Fang, T., & Tan, H. (2019). Eigenvector Spatial Filtering-Based Logistic Regression for Landslide Susceptibility Assessment. ISPRS International Journal of Geo-Information, 8(8), 332. https://doi.org/10.3390/ijgi8080332