1. Introduction
According to the report of the United Nations Conference on Trade and Development [
1], transportation between seaports represents over 80% of global trade by volume. Therefore, maritime network analysis has attracted extensive interest, driven by purposes ranging from transportation network dynamic evaluation [
2,
3,
4,
5,
6] and outlier behavior detection [
7] to epidemic risk assessment [
8].
Ports are the most important ROIs (Regions of Interest) on oceans where commodities and passengers are exchanged between water and land, and they are nodes of the maritime transportation network. Therefore, the foundation of shipping network analysis is identifying the port calls of ships. To obtain OD (Origin-Destination) records, some previous work on maritime network analysis purchased them from shipping companies such as IHS Markit [
9], Clipper Data Ltd [
5] and LBH group [
10]. These purchased records generated by black boxes have unknown accuracy and only cover some large ships and some global ports. For example, the dataset collected by Haiying et al. [
10] covers the loading and discharging events across Australia, Brazil, China, India and South Africa of only 1486 dry-bulk vessels with capacities of 100,000 deadweight tonnes or more.
The requirement for transparency and wider coverage by researchers and policy makers has resulted in more and more work on maritime network analysis based on AIS (Automatic Identification System) data, which capture ships’ arrivals and departures automatically when their positions overlap with a port’s [
4,
11,
12]. In contrast to partial proprietary data from a port authority or shipping company, OD datasets generated based on AIS data broadcast by ships can cover wider areas and ships because AIS is a compulsory system. Besides, the quality of these OD records based on standard AIS data can be estimated and compared if researchers describe their port call detection methods in published work. The AIS [
13] is a self-reporting system installed on ships used to broadcast kinematic (dynamic), identity (static) and voyage-related information to nearby ships, base stations and satellites periodically, with 27 types of message in total. Ships of 300 gross tons and upwards on international voyages or 500 tons and upwards for cargos not in international waters and passenger vessels are required to fit AIS transceivers [
14]. The identity and voyage information in message types 5 and 24 is input manually and prone to error. For example, Abdallah et al. [
12] found that only 38% of the destination fields in AIS data match the ground truth, Abbas et al. [
15] discovered that some optional information fields of the AIS data such as destination are not updated in most cases, and 30% of ships were detected as displaying incorrect status information in a VTS (vessel traffic service)-based AIS study. On the other hand, compulsory information fields including SOG (Speed Over Ground), COG (Course Over Ground), Longitude and Latitude in kinematic messages (types 1, 2, 3, 9, 18, 19 and 27) of AIS data are generated by sensors such as GPS (Global Position System) automatically and are highly reliable; see
Table 1.
Although databases such as the World Port Index [
16] contain the locations of major ports and terminals worldwide, their boundaries are unknown; see
Table 2. To decide whether a ship is in port or not automatically, shipping companies such as Elane Inc. [
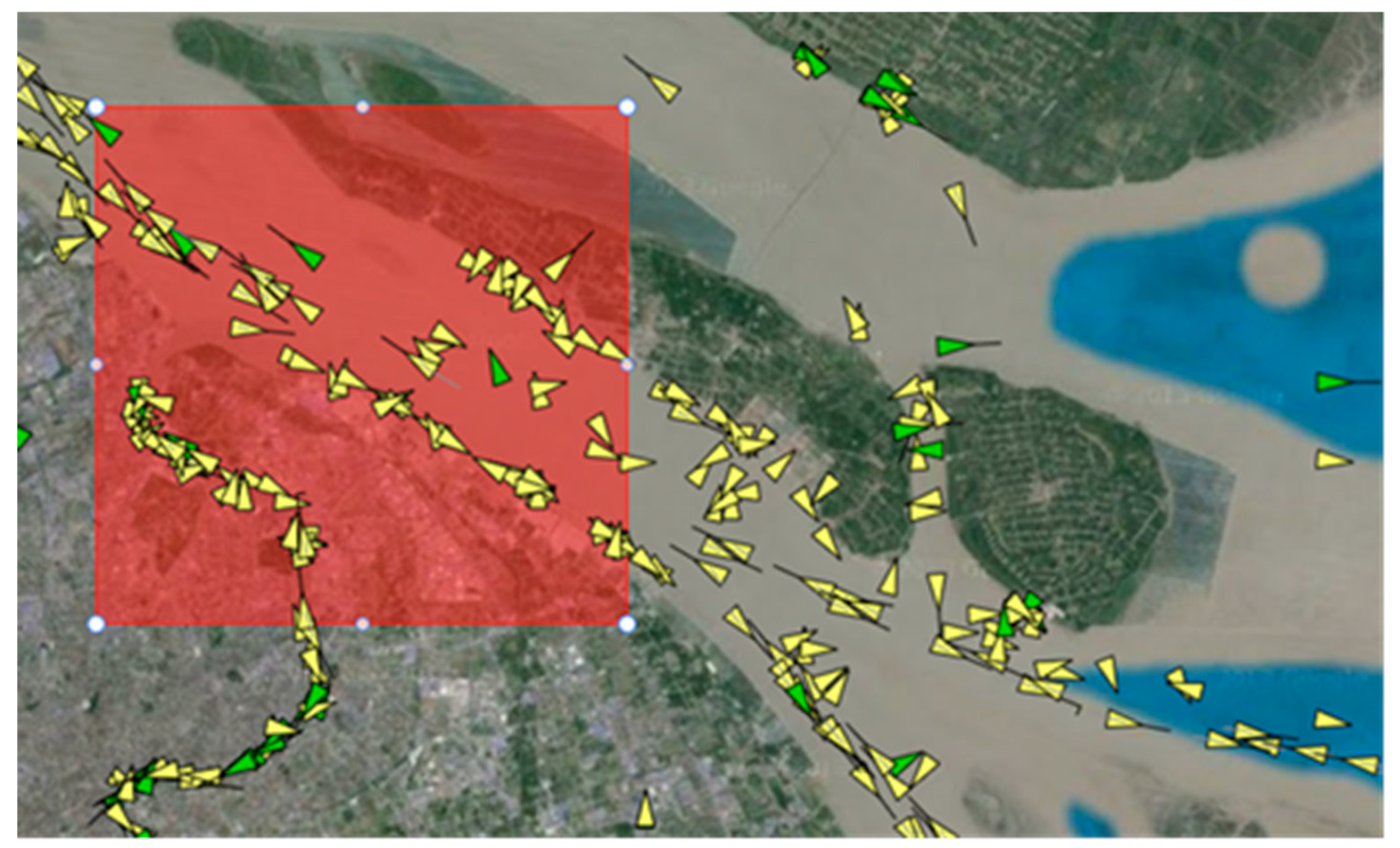
17] draw a rectangle for each port manually to represent its boundar, y as depicted in
Figure 1, which is too coarse and prone to error. Haiying Jia et al. [
4] decided whether a vessel was in port based on AIS data by setting the SOG threshold as 1 knot and distance threshold as 1 km, which is equivalent to representing each port as a circle with a radius of 1 km. For large ports such as Shanghai, which has coastlines on the order of about 100 km, this method will miss a large proportion of OD events. In the work of Hadzagic et al. [
18], each port was associated with a cell (0.25 degrees longitude by 0.25 degrees latitude), and a ship was considered as visiting a port if it was in the cell. As the extent of a cell was as large as about 20 km, ships passing by small ports would be taken as visiting the port mistakenly. In some other work [
2,
12,
19] on calculating port arrival events based on the intersection of port and vessel positions, details such as the values of the port radius or port boundary are not provided.
To improve the accuracy of port call identification based on trajectory data, we need to obtain a precise boundary for every port first. When studying a restricted area, consulting experts and authorities is a simple and effective method of obtaining detailed information about port areas. Vries et al. [
20] integrated geographical domain knowledge along the Dutch west coast provided by Rijkswaterstaat (part of the Dutch Ministry of Infrastructure and the Environment) to enhance stop region clustering and classification task performance. If global activities are under investigation, it is more efficient to extract port boundaries based on data mining—the number of berths in China alone is as large as 31,705 [
21]. In some previous work [
22,
23,
24,
25,
26], port extraction was achieved by clustering stationary points detected by speed gating. There are two problems in these spatial-clustering-based methods. The first one is the high false-positive rate. When a ship approaches a berth, at anchorage or fishing, its speed can be very low. A speed-gating-based method will have a high false-positive detection rate. The second problem is that the spatial resolution of clustered areas is too coarse for distinguishing waters, berths, anchorages, etc. The extent of a cluster is usually on the order of kilometers, containing berths, anchorages and wide waters at the same time. When a ship is inside a stop cluster area, it is unclear whether it is loading in the port or just passing by. To pick out berth-only stops, Zhihuan et al. [
8] excluded stops if their distances to the coastline were larger than 2 km. This method relies on data for global coastlines and may fail to exclude a large portion of anchorages due to the fixed value of the distance threshold.
This paper proposes a method of identifying the port calls of ships by uncertain reasoning with trajectory data, in
Section 2. Then, we describe the implementation of this method with global AIS data via C++ and present the results in
Section 3. Finally, we conclude the paper in
Section 4.
2. Materials and Methods
2.1. Overall Framework
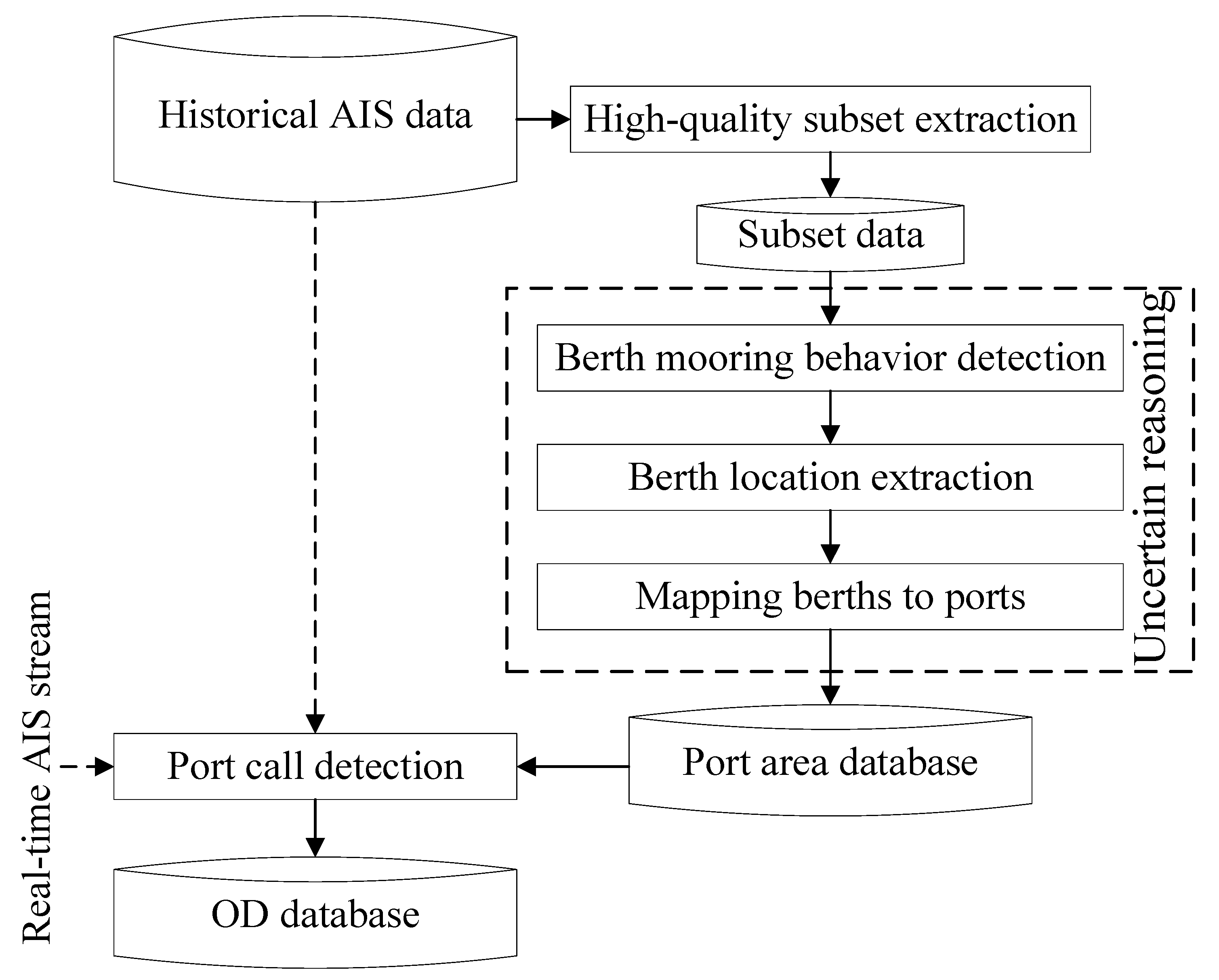
The overall framework of our method is depicted in
Figure 2. As the region of loading and unloading in a port is its berths, we represent each port as a set of berths. With a high-spatial-resolution representation of ports mined by uncertainty reasoning, the arrival and departure events can be detected when a ship’s position is inside one of these berths.
As we have described in
Section 1, there are 27 types of AIS messages, and only some of them contain trajectory data. Besides, some optional information fields in the message, such as navigational status and true heading, are not available or incorrect. For example, the value of true heading is available only when there is an electronic compass installed and connected to the AIS device. Therefore, we extracted a high-quality subset from historical AIS data first according to the integrity of the information fields. Then, we performed uncertain reasoning on these data to detect berth mooring behavior, which is equivalent to identifying port call events in this high-quality subset trajectory database. The positions of these berth mooring events were aggregated into berths and associated with ports, resulting in a high-resolution port area database. Finally, port call events in all the historical or real-time trajectory data could be identified easily by comparing a ship’s position with the port area database.
2.2. High-Quality Subset Historical Data Extraction
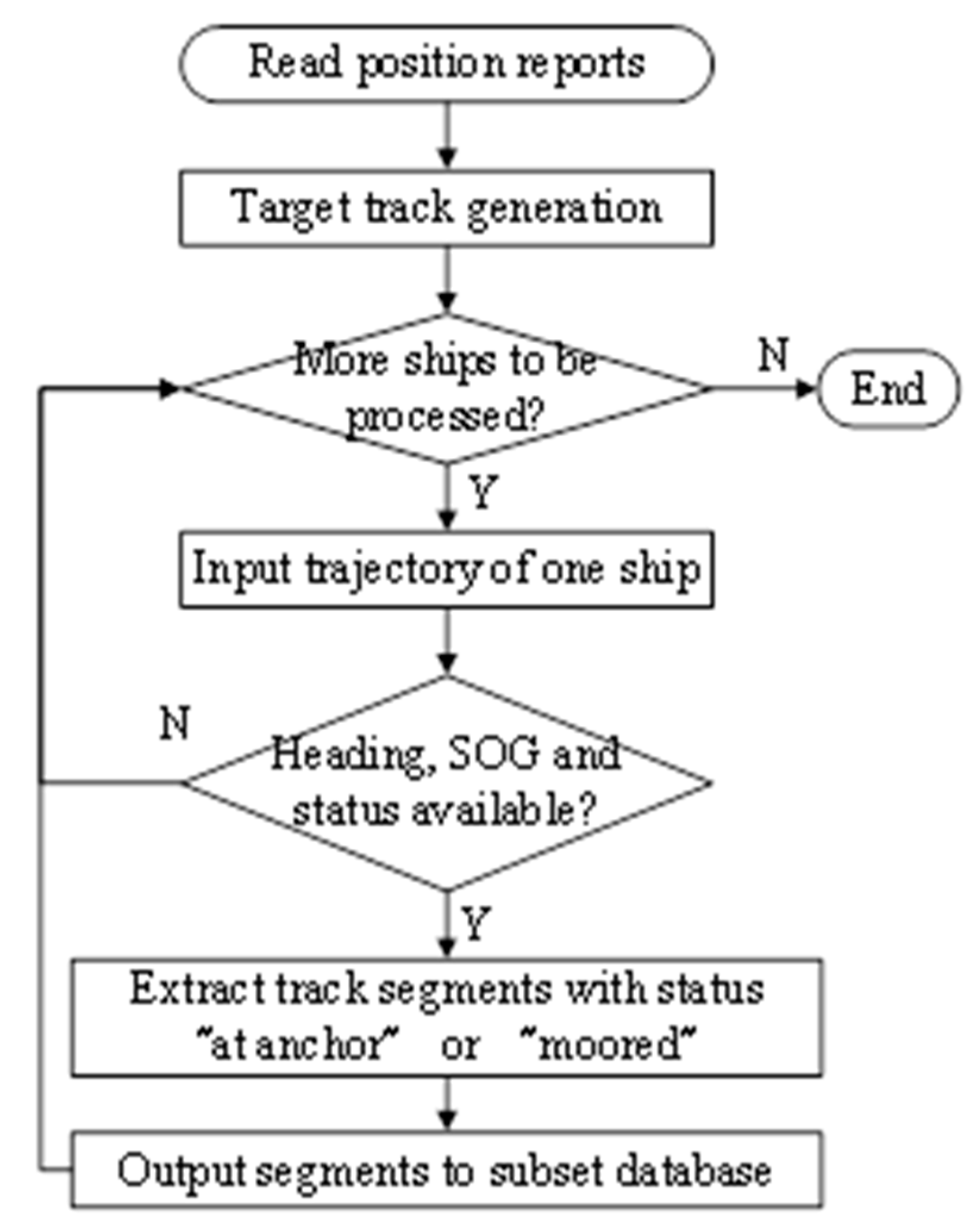
Before detecting the behavior of mooring alongside a berth, we extracted high-quality subset historical trajectory data as candidates; see
Figure 3. This process aims to lower the false-positive rate of the mooring behavior detection. Although a large proportion of the trajectory data were discarded, the false-negative rate of the berth location detection was still low due to the benefit of big data.
First of all, we read position reports from the historical AIS database. Although the MMSI (Maritime Mobile Service Identity) number in each position report is assumed to be a unique identifier for a ship, it is not always the case in reality because this information field can be input and modified manually. Our previous work [
27] found that MMSIs such as 123456789, 111111111, 999999999, 222222222, 100000000, 888888888, 413000000 and 808664168 had been shared by more than ten vessels worldwide. Therefore, we performed a target track association algorithm on the historical position data, as proposed in the previous paper [
27], and assigned each target a unique identifier, generating tracks as input for further processes.
Then, we input the trajectory data of each ship one by one, filtering out those trajectories without valid heading, SOG and navigational status information fields in the position reports. After that, we extracted track segments with navigational statuses “at anchor” or “moored” and output them into a subset database. The reason for incorporating records with the status “at anchor” was that this status was usually mixed up with “moored” in the reports, partially due to the fact that ships anchored outside the port before any berth was available and crews did not update the status field manually when they sailed the ship to berth afterwards. As the navigation status value in the record was not reliable, the true status was further verified by uncertain reasoning in the following steps.
2.3. Berth Mooring Behavior Detection
As we have described in the previous section, the inputs for berth behavior detection are high-quality subset historical track segments. The kinematic AIS data contained in these track segments have valid information fields such as true heading, SOG and navigational status, apart from highly reliable longitude and latitude values output from GPS sensors. Although the values of these information fields are valid, they may be incorrect. Therefore, we detected berth mooring behavior through the information fusion of position, heading and SOG, as described in this section.
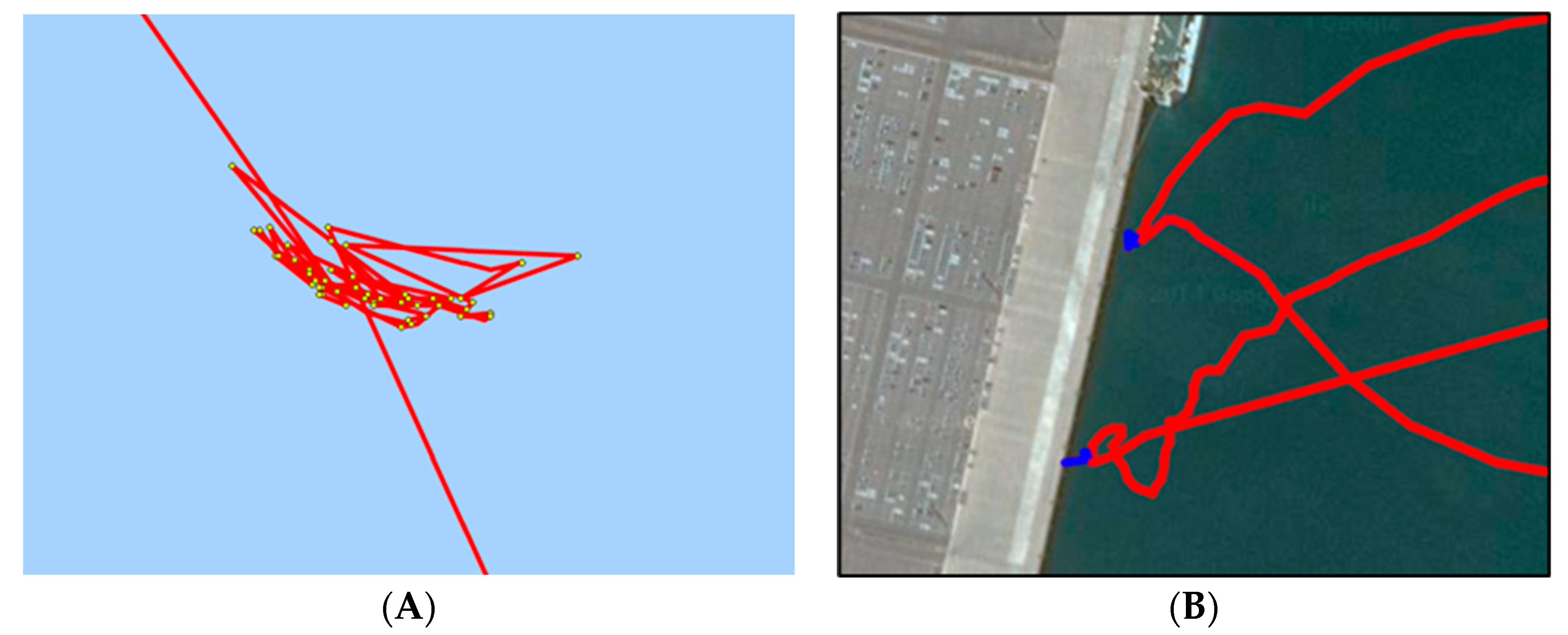
Due to positioning noise, wind, waves, tides, etc., the speed of a stopped ship is not always zero and its position is changing all the time; see
Figure 4. In addition, we need to distinguish anchoring from berth mooring behavior because the exchange of commodities and people between water and land happens only at berth. When a ship is moored alongside a berth, its movement is much lower than when it is anchored outside the port. As it takes time to load and unload, the mooring event lasts hours or days. Taking these factors into consideration, the berth mooring behavior was detected by fuzzy inference.
In fuzzy inference, the truth of any statement becomes a matter of a degree represented as a membership function. A membership function for a fuzzy set A on the universe of discourse X is defined as A(x): X → [0,1], where each element of X is mapped to a value between 0 and 1. This value, called the membership value or degree of membership, quantifies the grade of membership of the element in X to the fuzzy set A.
The membership that a track segment corresponds to berth mooring is calculated based on two fuzzy rules according to historical data analysis:
(1) IF a ship stayed within a small area for a long time, with a low speed and tiny heading variations, THEN it was moored alongside a berth;
(2) IF many AIS kinematic messages are included in this track segment, THEN the calculated heading variation and extent of area are precise.
Using the annotations in
Table 3, these two rules can be rewritten as:
(3) IF extent is small AND time is long AND speed is low AND stdev(heading) is tiny, THEN type is berth mooring;
(4) IF count is large THEN extent’ is approximately extent AND time’ is approximately time AND speed’ is approximately speed AND stdev(heading’) is approximately stdev(heading).
Combining these two rules, the following rule can be deduced:
(5) IF count is large AND extent’ is small AND time’ is long AND speed’ is low AND stdev(heading’) is tiny, THEN behavior is berth mooring.
We use S-membership functions and their complements to represent these increasing and decreasing notions in the fuzzy rule (5). The definition of the S-membership function is:
where a, b and c are real numbers satisfying a < b < c and b = (a + c)/2. After analyzing the historical tracks of ships mooring alongside berths, fuzzy sets in the fuzzy rule are defined as:
If the membership that a track segment
segi belongs to a berth calculated in the following equation is larger than 0, we classify it as berth mooring behavior.
2.4. Berth Location Extraction
With the mooring events detected, we extracted the locations of them and aggregated to ports for performing OD detection with other datasets.
First of all, we discretized space by partitioning the Earth’s surface into grids at a spatial resolution of 0.6 s longitude by 0.6 s latitude, finer than 20 m by 20 m anywhere. The unit of the longitude and latitude in AIS messages is 1/10,000 min, and the spatial resolution of a grid cell in this paper corresponds to 100 units.
The longitude and latitude of
celli,j span from −180° +
ix to −180° + (
i + 1)x and −90° +
jx to −90° + (
j + 1)x, respectively, where x is 0.6 s. After discretization, a track segment can be represented as one or multiple grid cells:
The membership that a grid cell belongs to a berth is calculated according to the mooring events located in it.
If no track segment has been located in a cell, then the membership is 0. After this step, we assigned a membership value to every grid cell on earth. Then, cells belonging to berths were picked out:
where
th is the threshold of the membership value, and we set its value as 0 in this paper. That is to say, a grid cell was regarded as belonging to a berth if its membership value to the fuzzy set Berth was larger than the threshold value.
2.5. Mapping Berths to Ports
After identifying grid cells belonging to berths, a port can be represented as a set of the berth grid cells nearest to it:
where N is the total number of ports worldwide and
is the distance between a port and a grid cell. The distance function is a combination of the geospatial and semantic distance:
where
dg is the geospatial distance along the Great Circle Route between the central position of the grid cell and port, and
ds is the semantic distance between them, which is defined as:
if (Country(port)!= Country(cell))
else if (Subdivision(port)!=Subdivision(cell))
else if (UNLocation(port)!=UNLocation(cell))
else
When a grid cell and a port belong to different countries, subdivisions or UNLocations [
28],
ds is empirically set as 100,000, 50,000 or 500 m, respectively.
To determine the semantic attributes of grid cells and ports, we matched them with the geographically nearest UN/LOCODE (United Nations Code for Trade and Transport Locations) [
28]. The UN/LOCODE is used by most major shipping companies, by freight forwarders and in the manufacturing industry around the world. In the preprocessing step, we deleted UN/LOCODE records whose statuses were RR (request rejected), UR (entry included on user’s request; not officially approved) and XX (entry that will be removed from the next issue of UN/LOCODE). In addition, multiple mistaken locations in China were picked out manually. Finally, we converted the format of the coordinates from a string (“0000lat 00000long”) to two numbers (longitude and latitude in degrees). The final dataset contained 76,000 locations; see
Figure 5.
To accelerate the matching, we divided the Earth’s surface into 360*180 containers at a spatial resolution of 1 degree latitude by 1 degree longitude. Then, 76,000 locations, 3685 ports and all the berth grids discovered were put into these containers, performing matching between objects in adjacent containers.
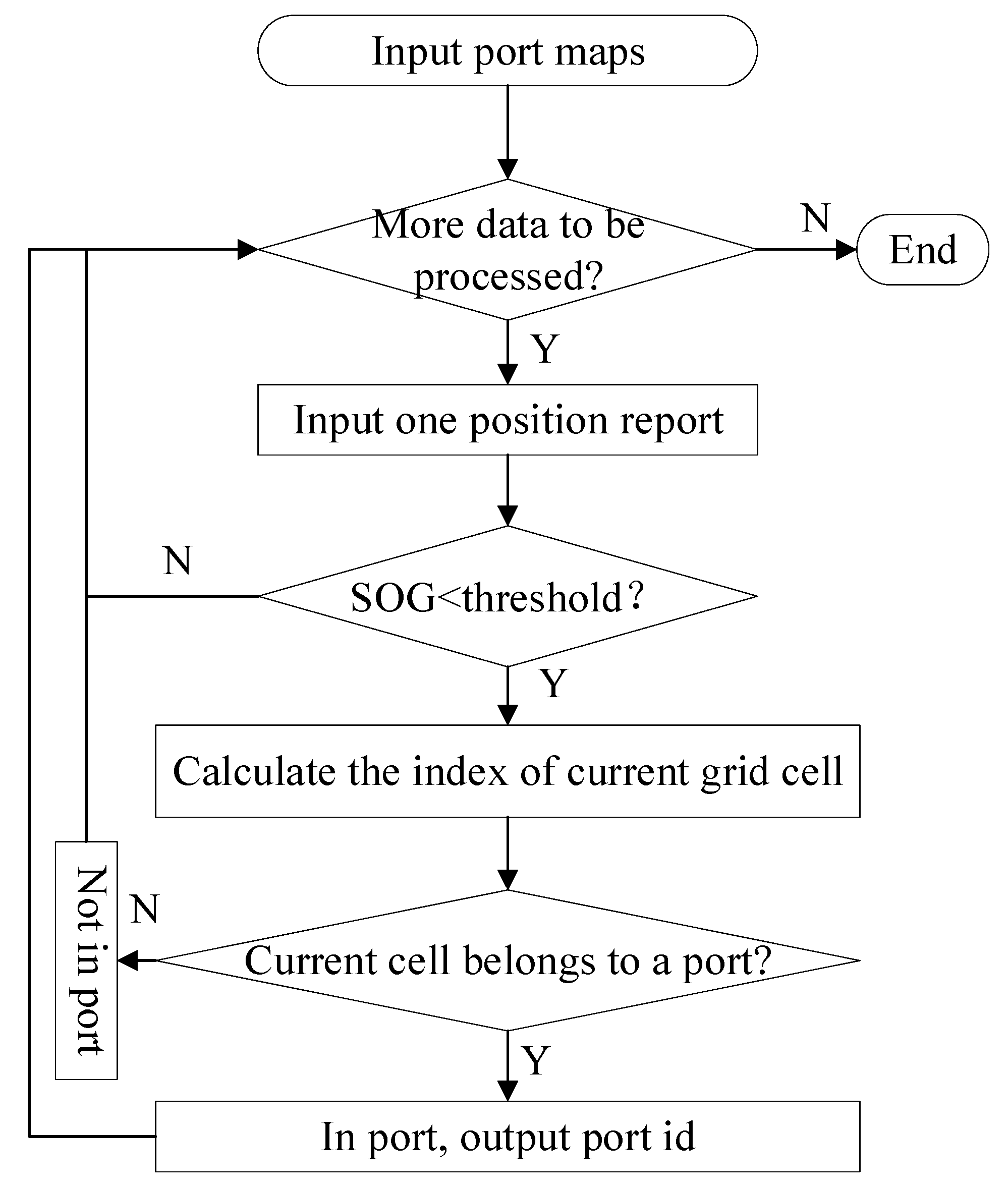
2.6. Port Call Detection
Each mooring event detected as described in
Section 2.3 corresponds to a port call in the high-quality subset historical data.
In addition, with a refined port map mined from the high-quality subset data, we could detect historical or real-time port call events by judging whether the position of a ship was inside a berth grid cell; see
Figure 6. First of all, we calculated the index of the grid cell that a low SOG position report resided in. Then, we iterated port maps to detect whether this grid cell belonged to any port. To speed up computing, we divided the Earth’s surface into 360*180 containers and only iterated ports in adjacent containers. Considering that the size of a ship may span dozens of cells and to reduce missed detection, we also compared multiple nearby grid cells with port maps.
3. Results
In this work, we used about 14 billion pieces of AIS dynamic data provided by the China Transport Telecommunications & Information Centre (CTTIC). These AIS records were from July 2015 to February 2016, spanning 8 months in total.
MySQL Community Server 5.6.24 was used to store the AIS data and the results of the port mapping. The MySQL Server and program for mooring behavior detection were run on two CentOS servers; each had 2 × Xeon E5 2620v2 CPUs, 16 × 8 GB DDR3 1600 MHz RAM and 8 × 3TB SAS disks. It took about 10 h to complete the task of extracting high-quality subset data, detecting OD events and mining global berths, including retrieving data and writing the results into the database. All these computing tasks were accomplished by C++ programs developed by our team. There were 202,238 grid cells whose memberships to berth were above zero; some of them are depicted in
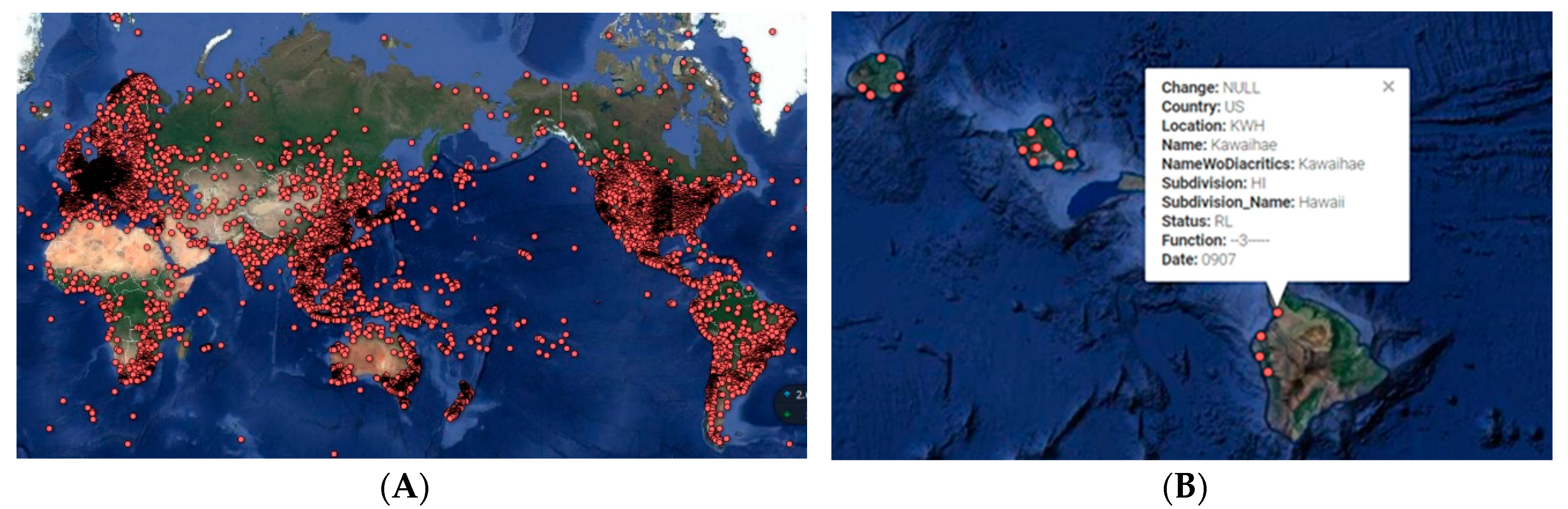
Figure 7. Each of these cells represents one or multiple historical port call events in the high-quality subset data. The matching between 202,238 grids and 3685 ports took 2.3 s.
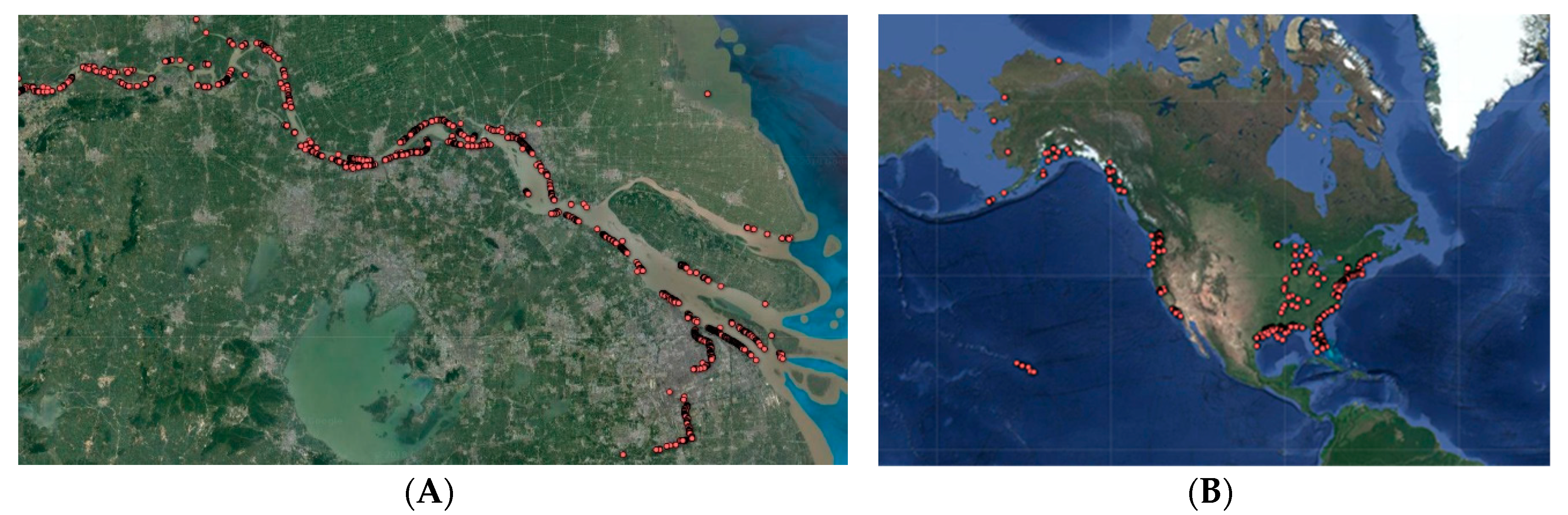
China’s combined navigable rivers are longer than any other country’s, at 126,300 km [
21]. The lower reaches of the Yangtze River (the third longest in the world) with the mined berth grid cells are demonstrated in the left of
Figure 7. After the berth-to-UN/LOCODE association, each berth grid had the attribute of country. In the right of
Figure 7, the distribution of ports in the US is depicted, with berths in Alaska correctly associated with the US rather than Canada, although they are closer to Canada by geospatial distance alone.
Tianjin is the largest port in North China, and Rotterdam is the largest port in Europe. The results of mapping them from historical port call events are shown in
Figure 8 and
Figure 9. It can be seen from these figures that our method has a high true-positive rate and a low false-positive rate for OD/berth detection, and the spatial resolution of the ports mined was high enough for OD detection based on the distance between a ship and a berth in the future.
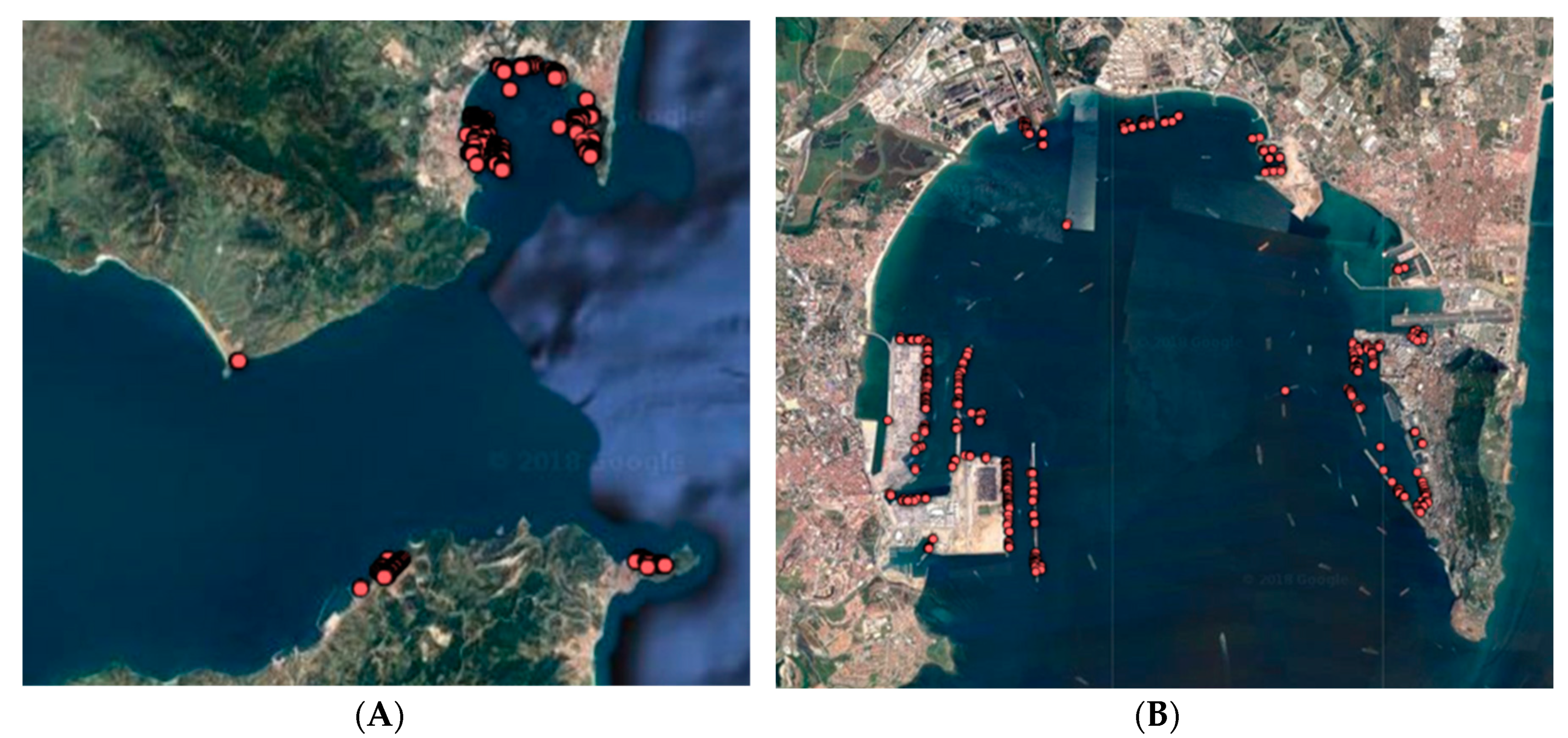
Pallotta et al. [
24] detected stationary points during a two-week period over the Strait of Gibraltar, and then clustered them into port and offshore platform objects using Density-Based Spatial Clustering of Applications with Noise (DBSCAN). The spatial resolution and extent of the clustered objects were on the order of kilometers, including both waters and anchorages outside the port. As a comparison, the spatial resolution and extent of the berths detected by our method over the same district were on the order of meters, as shown in
Figure 10. The precise positions of berths were detected, and the numbers of false-positive berth grid cells at sea were limited, which is the basis of accurate port call detection according to comparing positions only in the future.
4. Conclusions
The requirements for dataset transparency and wider coverage of researchers and policy makers has resulted in more and more work on maritime network analysis based on AIS data. To analyze ships’ transitions among ports from trajectory data automatically, the ranges of ports are needed by computer programs. Compared with remote-sensing-image-based methods, trajectory mining has the advantage of lower computational complexity and wider spatial coverage. Previous work usually detected ports by clustering stationary points into bounding polygons or drawing rectangles and circles manually. Ports discovered by this kind of method were coarse in extent and spatial resolution, resulting in low-precision port call detection.
In this paper, an uncertain reasoning method for mapping global ports from AIS data is proposed. The results show that this method has high precision in port call/berth detection, and the ports mapped fit well with satellite images. The spatial resolution of the port maps represented as grid cell sets is higher than 20 m, much finer than that of the extracted stationary areas in previous work, which was on the order of kilometers. Each berth grid cell depicted in this paper corresponds to one or multiple port call events in the high-quality subset historical data. Based on these detected berth grid cells, whether a ship is in port or not can be determined automatically and efficiently by comparing its position with nearby berths without uncertain reasoning in subsequent processes. The method described in this paper has already supported multiple studies on maritime transportation network analysis [
29,
30].
In this paper, 8 months of AIS data were used. Our future work would be to map global ports from a larger dataset, and take ships’ size into consideration, expecting fewer misdetections. After that, we plan to continue our work on analyzing ships’ transit among global ports by combining AIS data with the global ports mapped in this paper. By combining ships’ static information such as the ship type and size, the property of each berth and port can be determined. Based on this extracted contextual knowledge, anomaly detection can be performed.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}