Space-Time Hierarchical Clustering for Identifying Clusters in Spatiotemporal Point Data


Abstract
:1. Introduction
1.1. Background
1.2. Common Clustering Techniques
1.3. Hierarchical Clustering
2. Proposed Approach
2.1. Space–Time Hierarchical Clustering with Attributes
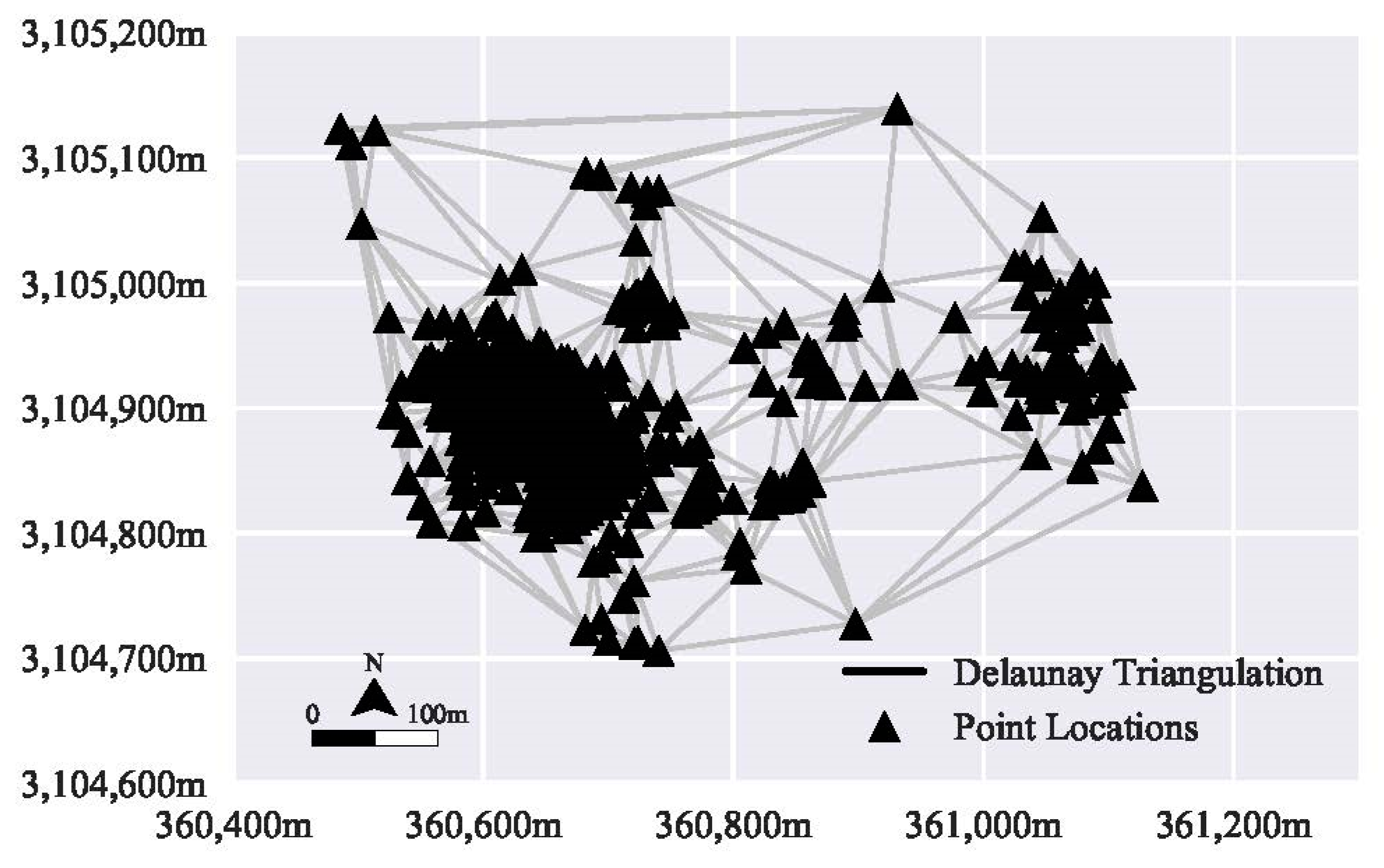
2.1.1. Calculations for Distance
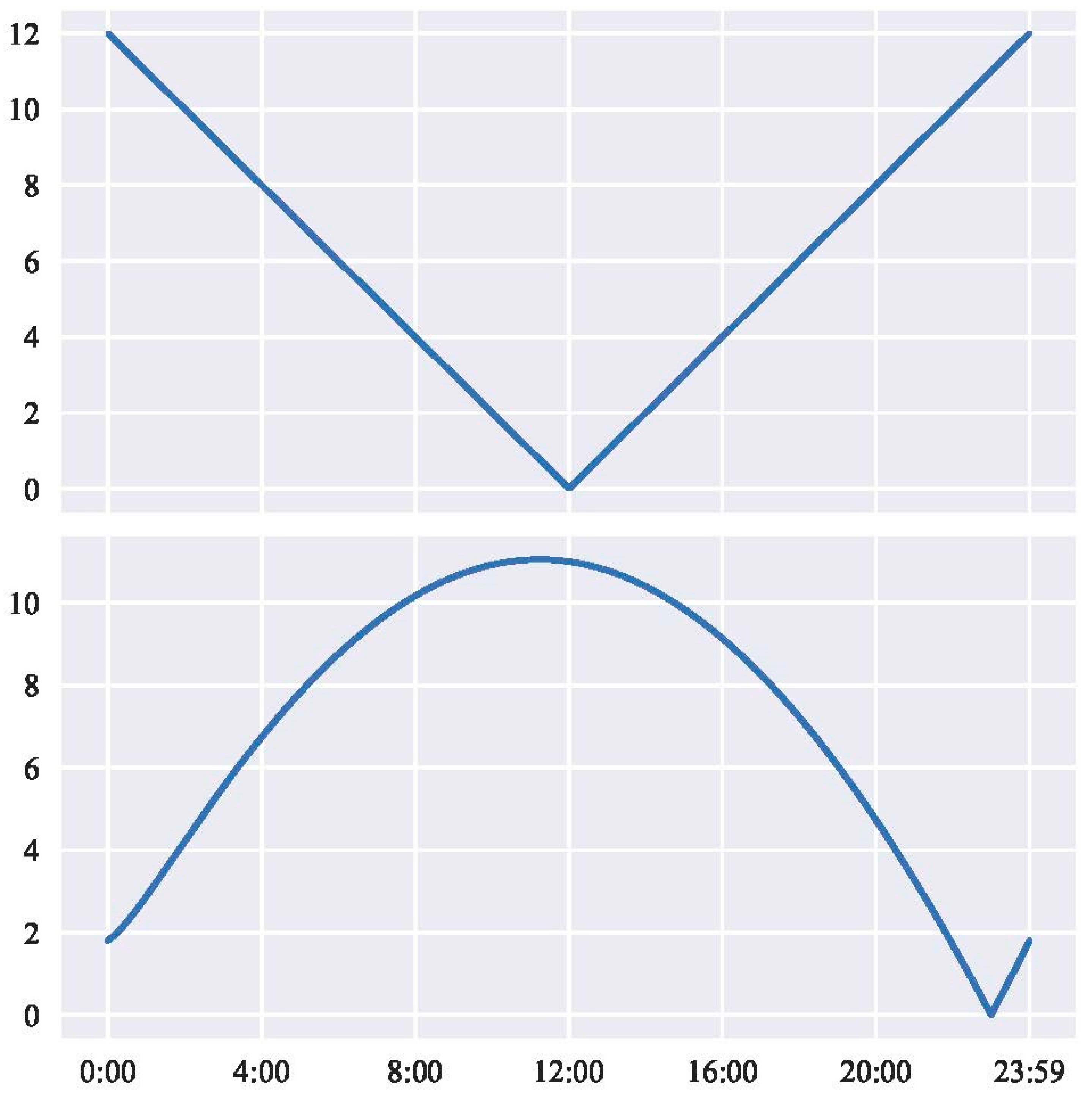
2.1.2. Calculations for Time
2.1.3. Calculations for Attribute Space
2.1.4. Implementation
2.2. Relation to Spatial Scale
3. Results
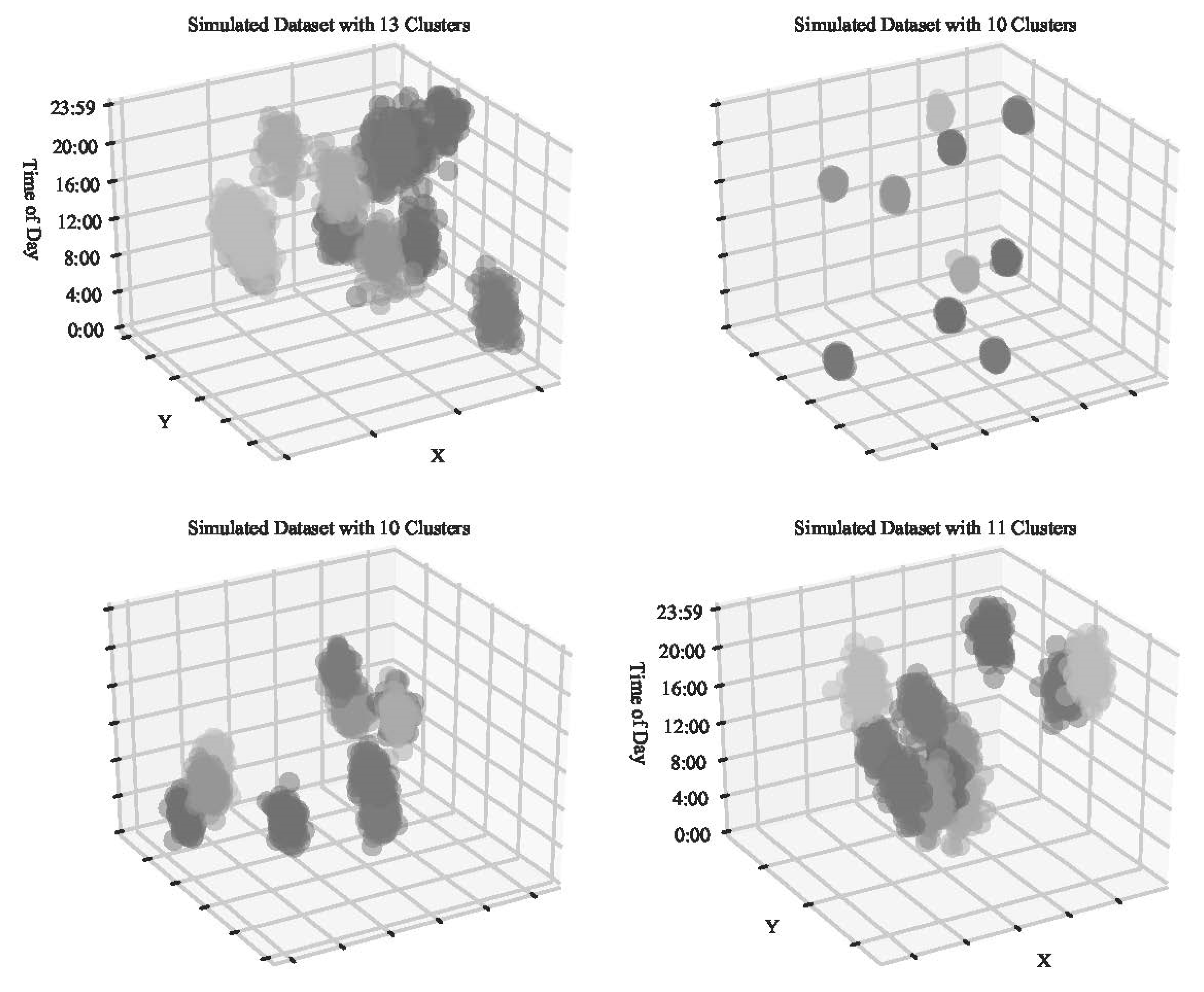
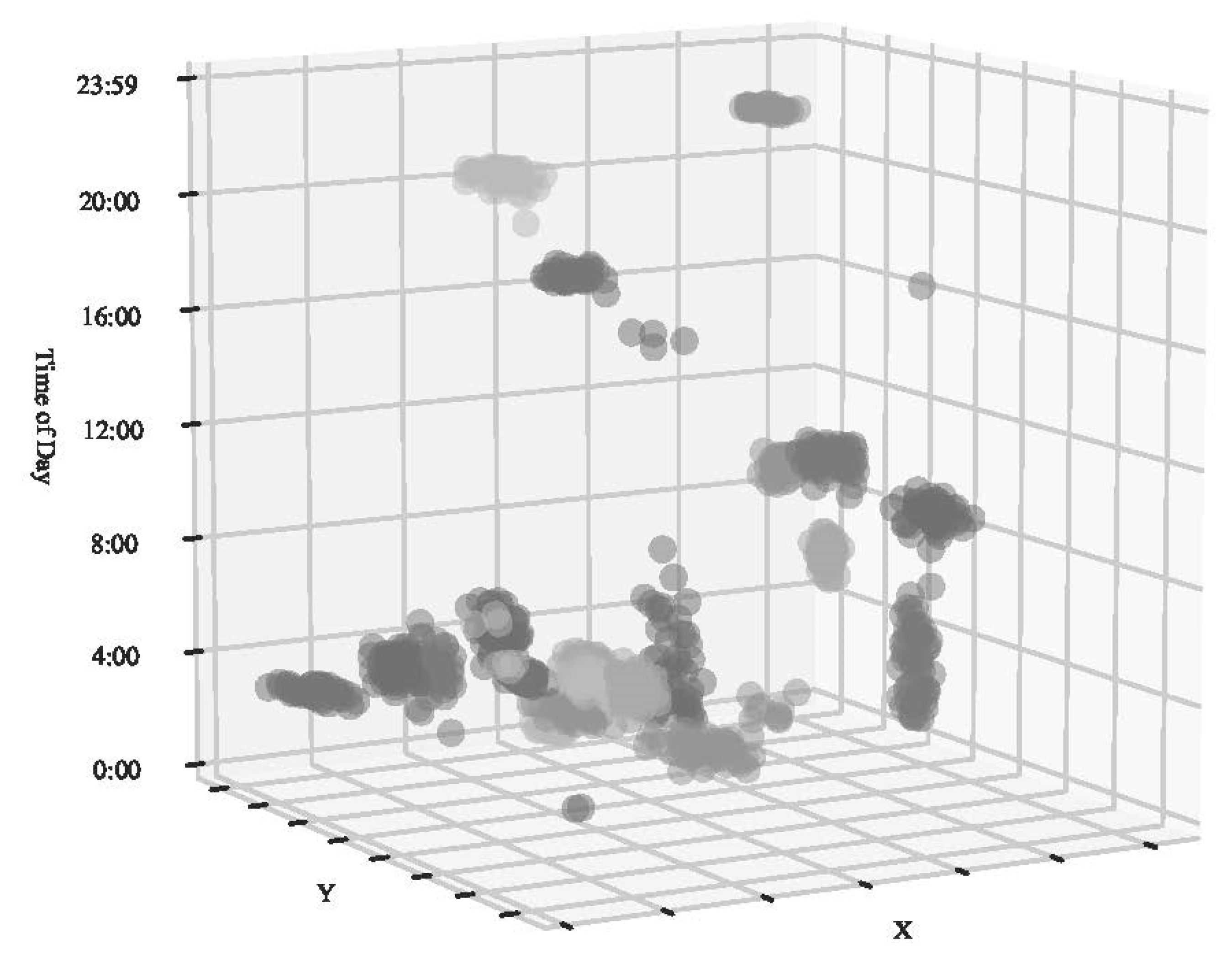
3.1. Simulations
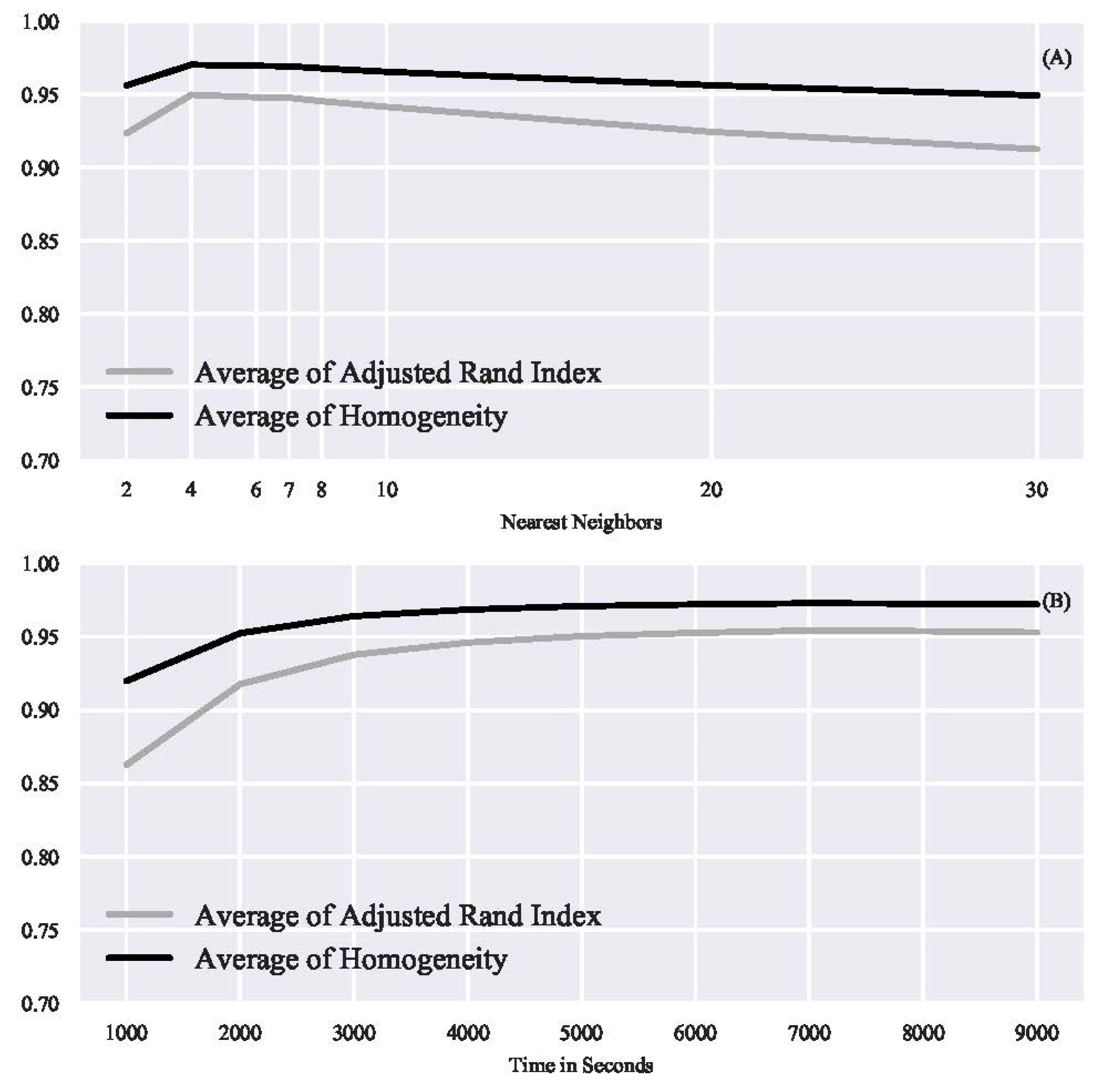
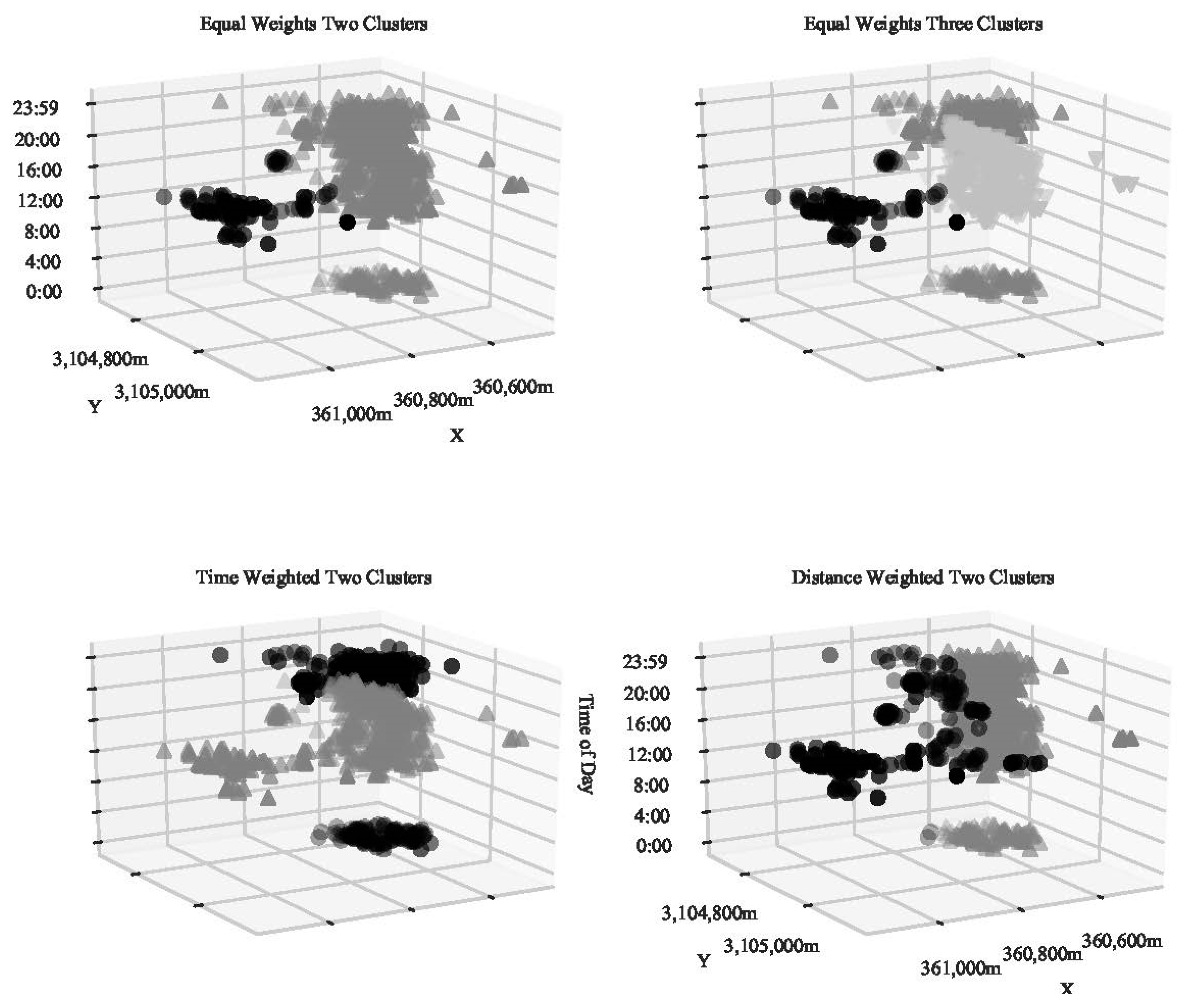
3.2. Comparison with Alternative Clustering Approaches
4. Discussion
Author Contributions
Funding
Conflicts of Interest
References
- Miller, H.J.; Han, J. (Eds.) Geographic Data Mining and Knowledge Discovery, 2nd ed.; CRC Press: Boca Raton, FL, USA, 2009; ISBN 978-1-4200-7397-3. [Google Scholar]
- Everitt, B.S.; Landau, S.; Leese, M.; Stahl, D. Hierarchical Clustering. In Cluster Analysis; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2011; pp. 71–110. ISBN 978-0-470-97781-1. [Google Scholar]
- Han, J.; Lee, J.-G.; Kamber, M. An overview of clustering methods in geographic data analysis. In Geographic Data Mining and Knowledge Discovery; Miller, H.J., Han, J., Eds.; Taylor and Francis: Abingdon, UK, 2009; pp. 149–187. [Google Scholar]
- Yamada, I.; Rogerson, P.A. An Empirical Comparison of Edge Effect Correction Methods Applied to K-function Analysis. Geogr. Anal. 2003, 35, 97–109. [Google Scholar]
- Mennis, J.; Guo, D. Spatial data mining and geographic knowledge discovery—An introduction. Comput. Environ. Urban Syst. 2009, 33, 403–408. [Google Scholar] [CrossRef]
- Zhang, T.; Wang, J.; Cui, C.; Li, Y.; He, W.; Lu, Y.; Qiao, Q. Integrating Geovisual Analytics with Machine Learning for Human Mobility Pattern Discovery. ISPRS Int. J. Geo-Inf. 2019, 8, 434. [Google Scholar] [CrossRef] [Green Version]
- Long, J.A. Modeling movement probabilities within heterogeneous spatial fields. J. Spat. Inf. Sci. 2018, 16, 85–116. [Google Scholar] [CrossRef]
- Miller, H.J. A Measurement Theory for Time Geography. Geogr. Anal. 2005, 37, 17–45. [Google Scholar] [CrossRef]
- Miller, H.J. Modelling accessibility using space-time prism concepts within geographical information systems. Int. J. Geogr. Inf. Syst. 1991, 5, 287–301. [Google Scholar] [CrossRef]
- Richter, K.-F.; Schmid, F.; Laube, P. Semantic trajectory compression: Representing urban movement in a nutshell. J. Spat. Inf. Sci. 2012, 3–30. [Google Scholar] [CrossRef]
- Okabe, A.; Yamada, I. The K-Function Method on a Network and Its Computational Implementation. Geogr. Anal. 2001, 33, 271–290. [Google Scholar] [CrossRef]
- Yamada, I.; Thill, J.-C. Comparison of planar and network K-functions in traffic accident analysis. J. Transp. Geogr. 2004, 12, 149–158. [Google Scholar] [CrossRef]
- Okabe, A.; Sugihara, K. Spatial Analysis Along Networks: Statistical and Computational Methods; John Wiley & Sons: Hoboken, NJ, USA, 2012; ISBN 978-1-119-96776-7. [Google Scholar]
- Lamb, D.S.; Downs, J.A.; Lee, C. The network K-function in context: Examining the effects of network structure on the network K-function. Trans. GIS. 2015, 20, 448–460. [Google Scholar] [CrossRef]
- Manson, S.M. Does scale exist? An epistemological scale continuum for complex human–environment systems. Geoforum 2008, 39, 776–788. [Google Scholar] [CrossRef]
- Goodchild, M.F. Citizens as sensors: The world of volunteered geography. GeoJournal 2007, 69, 211–221. [Google Scholar] [CrossRef] [Green Version]
- Richardson, D.B. Real-Time Space–Time Integration in GIScience and Geography. Ann. Assoc. Am. Geogr. 2013, 103, 1062–1071. [Google Scholar] [CrossRef] [PubMed]
- Miller, H.J.; Goodchild, M.F. Data-driven geography. GeoJournal 2015, 80, 449–461. [Google Scholar] [CrossRef]
- Miller, H.J. Activity-Based Analysis. In Handbook of Regional Science; Fischer, M.M., Nijkamp, P., Eds.; Springer: Berlin/Heidelberg, Germany, 2014; pp. 705–724. ISBN 978-3-642-23429-3. [Google Scholar]
- Ashbrook, D.; Starner, T. Using GPS to Learn Significant Locations and Predict Movement Across Multiple Users. Pers. Ubiquitous Comput 2003, 7, 275–286. [Google Scholar] [CrossRef]
- Andrienko, G.; Andrienko, N.; Bak, P.; Keim, D.; Wrobel, S. Visual Analytics of Movement; Springer: Berlin/Heidelberg, Germany, 2013; ISBN 978-3-642-37582-8. [Google Scholar]
- Birant, D.; Kut, A. ST-DBSCAN: An algorithm for clustering spatial–temporal data. Data Knowl. Eng. 2007, 60, 208–221. [Google Scholar] [CrossRef]
- Everitt, B.S.; Landau, S.; Leese, M.; Stahl, D. An Introduction to Classification and Clustering. In Cluster Analysis; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2011; pp. 1–13. ISBN 978-0-470-97781-1. [Google Scholar]
- Guo, D. Multivariate Spatial Clustering and Geovisualization. In Geographic Data Mining and Knowledge Discovery; Miller, H., Han, J., Eds.; CRC Press: Boca Raton, FL, USA, 2009; pp. 325–345. [Google Scholar]
- Kisilevich, S.; Mansmann, F.; Nanni, M.; Rinzivillo, S. Spatio-temporal clustering. In Data Mining and Knowledge Discovery Handbook; Maimon, O., Rokach, L., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 855–874. ISBN 978-0-387-09822-7. [Google Scholar]
- Wang, M.; Wang, A.; Li, A. Mining Spatial-temporal Clusters from Geo-databases. In Proceedings of the Advanced Data Mining and Applications: Second International Conference, ADMA 2006, Xi’an, China, 14–16 August 2006. [Google Scholar]
- Agrawal, K.P.; Garg, S.; Sharma, S.; Patel, P. Development and validation of OPTICS based spatio-temporal clustering technique. Inf. Sci. 2016, 369, 388–401. [Google Scholar] [CrossRef]
- Wardlaw, R.L.; Frohlich, C.; Davis, S.D. Evaluation of precursory seismic quiescence in sixteen subduction zones using single-link cluster analysis. Pure Appl. Geophys. 1990, 134, 57–78. [Google Scholar] [CrossRef]
- Andrienko, G.; Andrienko, N. Interactive Cluster Analysis of Diverse Types of Spatiotemporal Data. SIGKDD Explor Newsl 2010, 11, 19–28. [Google Scholar] [CrossRef]
- Oliveira, R.; Santos, M.Y.; Moura Pires, J. 4D+SNN: A Spatio-Temporal Density-Based Clustering Approach with 4D Similarity. In Proceedings of the 2013 IEEE 13th International Conference on Data Mining Workshops (ICDMW), Dallas, TX, USA, 7–10 December 2013; pp. 1045–1052. [Google Scholar]
- Bermingham, L.; Lee, I. A framework of spatio-temporal trajectory simplification methods. Int. J. Geogr. Inf. Sci. 2017, 31, 1128–1153. [Google Scholar] [CrossRef]
- Lee, J.-G.; Han, J.; Whang, K.-Y. Trajectory clustering: A partition-and-group framework. In Proceedings of the 2007 ACM SIGMOD International Conference on Management of Data, Beijing, China, 11–14 June 2007; pp. 593–604. [Google Scholar]
- Guo, N.; Shekhar, S.; Xiong, W.; Chen, L.; Jing, N. UTSM: A Trajectory Similarity Measure Considering Uncertainty Based on an Amended Ellipse Model. ISPRS Int. J. Geo-Inf. 2019, 8, 518. [Google Scholar] [CrossRef] [Green Version]
- Sokal, R.R.; Michener, C.D. A statistical method for evaluating systematic relationships. Univ. Kans. Sci. Bull. 1958, 38, 1409–1438. [Google Scholar]
- Downs, J.A.; Horner, M.W. Analysing infrequently sampled animal tracking data by incorporating generalized movement trajectories with kernel density estimation. Comput. Environ. Urban Syst. 2012, 36, 302–310. [Google Scholar] [CrossRef]
- McGuire, M.P.; Janeja, V.; Gangopadhyay, A. Mining sensor datasets with spatiotemporal neighborhoods. J. Spat. Inf. Sci. 2013. [Google Scholar] [CrossRef]
- Okabe, A.; Boots, B.; Sugihara, K.; Chiu, S.N. Spatial Tessellations: Concepts and Applications of Voronoi Diagrams; John Wiley & Sons: Hoboken, NJ, USA, 2009; ISBN 978-0-470-31785-3. [Google Scholar]
- Gibbons, A. Algorithmic Graph Theory; Cambridge University Press: New York, NY, USA, 1985; ISBN 9780521288811. [Google Scholar]
- Di Pierro, M. Annotated Algorithms in Python with Applications in Physics, Biology, and Finance; EXPERTS4SOLUTIONS: Chicago, IL, USA, 2013; ISBN 978-0-9911604-0-2. [Google Scholar]
- Huang, B.; Wu, Q.; Zhan, F.B. A shortest path algorithm with novel heuristics for dynamic transportation networks. Int. J. Geogr. Inf. Sci. 2007, 21, 625–644. [Google Scholar] [CrossRef]
- Ertoz, L.; Steinbach, M.; Kumar, V. A new shared nearest neighbor clustering algorithm and its applications. In Proceedings of the Workshop on Clustering High Dimensional Data and its Applications at 2nd SIAM International Conference on Data Mining, Arlington, VA, USA, 11–13 April 2002; pp. 105–115. [Google Scholar]
- Oliphant, T.E. Python for Scientific Computing. Comput. Sci. & Eng. 2007, 9, 10–20. [Google Scholar]
- Hagberg, A.A.; Schult, D.A.; Swart, P.J. Exploring network structure, dynamics, and function using NetworkX. In Proceedings of the 7th Python in Science Conference (SciPy2008), Pasadena, CA USA, 19–24 August 2008; pp. 11–15. [Google Scholar]
- McMaster, R.B.; Sheppard, E. Introduction: Scale and Geographic Inquiry. In Scale and Geographic Inquiry; Sheppard, E., McMaster, R.B., Eds.; Blackwell Publishing Ltd.: Malden, MA, USA, 2004; pp. 1–22. ISBN 978-0-470-99914-1. [Google Scholar]
- Levin, S.A. The Problem of Pattern and Scale in Ecology: The Robert H. MacArthur Award Lecture. Ecology 1992, 73, 1943–1967. [Google Scholar] [CrossRef]
- Fotheringham, A.S.; Wong, D.W.S. The Modifiable Areal Unit Problem in Multivariate Statistical Analysis. Environ. Plan. A 1991, 23, 1025–1044. [Google Scholar] [CrossRef]
- Kwan, M.-P. The Uncertain Geographic Context Problem. Ann. Assoc. Am. Geogr. 2012, 102, 958–968. [Google Scholar] [CrossRef]
- Kwan, M.-P. Algorithmic Geographies: Big Data, Algorithmic Uncertainty, and the Production of Geographic Knowledge. Ann. Am. Assoc. Geogr. 2016, 106, 274–282. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Hubert, L.; Arabie, P. Comparing partitions. J. Classif. 1985, 2, 193–218. [Google Scholar] [CrossRef]
- Rosenberg, A.; Hirschberg, J. V-Measure: A Conditional Entropy-Based External Cluster Evaluation Measure. In Proceedings of the EMNLP-CoNLL, Prague, Czech Republic, 28–30 June 2007; Volume 7, pp. 410–420. [Google Scholar]
- Pavlis, M.; Dolega, L.; Singleton, A. A Modified DBSCAN Clustering Method to Estimate Retail Center Extent. Geogr. Anal. 2017. [Google Scholar] [CrossRef]
- Downs, J.A.; Horner, M.W.; Hyzer, G.; Lamb, D.; Loraamm, R. Voxel-based probabilistic space-time prisms for analysing animal movements and habitat use. Int. J. Geogr. Inf. Sci. 2014, 28, 875–890. [Google Scholar] [CrossRef]
- Gao, P.; Kupfer, J.A.; Zhu, X.; Guo, D. Quantifying Animal Trajectories Using Spatial Aggregation and Sequence Analysis: A Case Study of Differentiating Trajectories of Multiple Species. Geogr. Anal. 2016, 48, 275–291. [Google Scholar] [CrossRef]
- Karypis, G.; Han, E.-H.; Kumar, V. Chameleon: Hierarchical clustering using dynamic modeling. Computer 1999, 32, 68–75. [Google Scholar] [CrossRef] [Green Version]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Clustering Classification | Description | Common Algorithms |
|---|---|---|
| Partitioning | Partitions the data into a user specified number of groups. Each point belongs to one group. Does not work well for irregularly shaped clusters. | k-means, k-medoids, clustering large applications based randomized search (CLARANS), and Expectation-Maximization (EM) algorithm. |
| Hierarchical | Decomposes data into a hierarchy of groups, each larger group contains a set of subgroups. Two methods: agglomerative (builds groups from the observation up), or divisive (start with a large group and separate). | Balanced iterative reducing and clustering using hierarchies (BIRCH), Chameleon, Ward’s Method, Nearest Neighbor, (Dendrograms are used to visualize the hierarchy). |
| Density-based | Useful for irregularly shaped clusters. Clusters grow based on a threshold for the number of objects in a neighborhood. | DBSCAN, ordering points to identify cluster structure (OPTICS) and density based clustering (DENCLUE), SNN |
| Grid-based | Region is divided in to a grid of cells, and clustering is performed on the grid structure. | statistical information grid (STING), WaveCluster, and clustering in quest (CLIQUE) |
| Method and Parameters | Clusters Selected or Identified | Homogeneity Score | Adjusted Random Index |
|---|---|---|---|
| Hierarchical Clustering with Euclidean Distance and average linkage | 20 | 0.79 | 0.59 |
| Space-Time Hierarchical clustering (Nearest Neighbors = 7, time scale = 3600) | 20 | 0.89 | 0.77 |
| Space-Time Hierarchical clustering (Nearest Neighbors = 7, time scale = 3600) | 15 | 0.83 | 0.65 |
| ST-DBSCAN (Spatial Threshold = 5000, Temporal Threshold = 3600, MinPts = 7 | 15 + Noise | 0.75 | 0.52 |
| ST-DBSCAN (Spatial Threshold = 8000, Temporal Threshold = 1800, MinPts = 1) | 20 + Noise | 0.85 | 0.66 |
| ST-DBSCAN (Spatial Threshold = 5000, Temporal Threshold = 3600, MinPts = 2) | 20 + Noise | 0.82 | 0.62 |
| DBSCAN (eps = 0.05, Minimum Samples = 2) | 20 + Noise | 0.85 | 0.67 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lamb, D.S.; Downs, J.; Reader, S. Space-Time Hierarchical Clustering for Identifying Clusters in Spatiotemporal Point Data. ISPRS Int. J. Geo-Inf. 2020, 9, 85. https://doi.org/10.3390/ijgi9020085
Lamb DS, Downs J, Reader S. Space-Time Hierarchical Clustering for Identifying Clusters in Spatiotemporal Point Data. ISPRS International Journal of Geo-Information. 2020; 9(2):85. https://doi.org/10.3390/ijgi9020085
Chicago/Turabian StyleLamb, David S., Joni Downs, and Steven Reader. 2020. "Space-Time Hierarchical Clustering for Identifying Clusters in Spatiotemporal Point Data" ISPRS International Journal of Geo-Information 9, no. 2: 85. https://doi.org/10.3390/ijgi9020085
APA StyleLamb, D. S., Downs, J., & Reader, S. (2020). Space-Time Hierarchical Clustering for Identifying Clusters in Spatiotemporal Point Data. ISPRS International Journal of Geo-Information, 9(2), 85. https://doi.org/10.3390/ijgi9020085