3.1. Dataset
Our initial dataset was obtained from the Kaggle [
23] dataset, which provides data scientists with a huge amount of data to train their machine learning models. It was collected by Bart de Cock in 2011 and is significantly bigger than the well-known Boston housing dataset [
24]. It contains 79 expressive variables, which demonstrate almost each feature of residential homes in Ames, Iowa, USA, during the period from 2006 to 2010. The dataset consists of both numeric and text data. The numeric data include information about the number of rooms, size of rooms, and the overall quality of the property. In contrast to numeric data, the text data is provided in words. The location of the house, type of materials used to build the house, and the style of the roof, garage, and fence are the examples of the text data.
Table 1 illustrates the description of the dataset.
The main reason for dividing the dataset into different types of data was that the text data had to be converted into numeric data with the one-hot encoding technique before training. We will describe this encoding method in the following data preprocessing section of our methodology. A total of 19 features have missing values out of a total of 80 features. The percentage of missing values is 16%.
3.2. Data Preprocessing
In this process, we transformed raw, complicated data into organized data. This consisted of several procedures from one-hot encoding to finding the missing and unnecessary data in the dataset. Several machine learning techniques can work with categorical data right away. For instance, a decision tree algorithm can operate with categorical data without the need of data transformation. However, numerous machine learning systems cannot work with labeled data. They need all variables (input and output) to be numeric. This can be regarded as a huge limitation of machine learning algorithms rather than hard limitations on the algorithms themselves. Therefore, if we have categorical data then we must convert it into numerical data. There are two common methods to create numeric data from categorical data:
one-hot encoding
integer encoding
In the case of the house location, the houses in the dataset may be located in three different cities: New York, Washington, and Texas. The city names need to be converted into numeric data. Firstly, each unique feature value is given an integer value; for instance, 1 is for “New York”, 2 is for “Washington”, and 3 is for “California”. For several attributes, this might be sufficient. This is because integers have an ordered connection with each other, which enables machine learning techniques to comprehend and harness that association. In contrast, categorical variables possess no ordinal relationship; therefore, integer encoding is not able to solve the issue. The use of such encoding and allowing the model to get the natural ordering between categories may have poor application or unanticipated outcomes. We provide the above-mentioned example of a toy dataset in
Table 2 and its integer encoding in
Table 3. It can be noticed that the ordering between categories results in a less precise prediction of the house price.
In order to solve the problem, we can use one-hot encoding. This is where the integer determined variable is removed and a new binary variable is added for each single integer value [
2]. As we mentioned, based on our data, we may face the situation where our model is confused by thinking that a column has the data with a certain order or hierarchy. However, it can be avoided by “one-hot encoding”, in which label encoded categorical data is split into numerous columns. The numbers are substituted by 1s and 0s, based on the values of the columns. In our case, we got three new columns, namely New York, Washington, and California. For the rows that have the first column value as New York, “1” will be assigned to the “New York” column, and the other two columns will get “0”s. Likewise, for rows that have the first column value as Washington, “1” will be assigned to the “Washington”, and the other two columns will have “0” and so on (see
Table 4). We used this type of encoding in the data preprocessing part.
In case of missing values, one-hot encoding converts missing values into zeros. Here is the example shown in
Table 5:
In above-given table, the third value is missing. When converting these categorical values into numeric, all non-missing values have one(s) in their corresponding ID rows. Missing values however, get zeros in respective ID rows. Now we will see the result of how one-hot encoding treats this value.
Thus, the third example gains only zeros as we see in
Table 6. Before selecting most correlated features and dealing with missing values, we convert these zeros again into missing values.
3.3. Feature Correlation
Feature selection is a vigorous sphere in computer science. It has been a productive research area since the 1970s in a number of fields, such as statistical pattern recognition, machine learning, and data mining [
25,
26,
27,
28,
29,
30,
31,
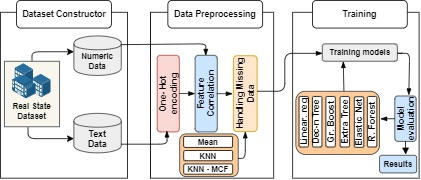
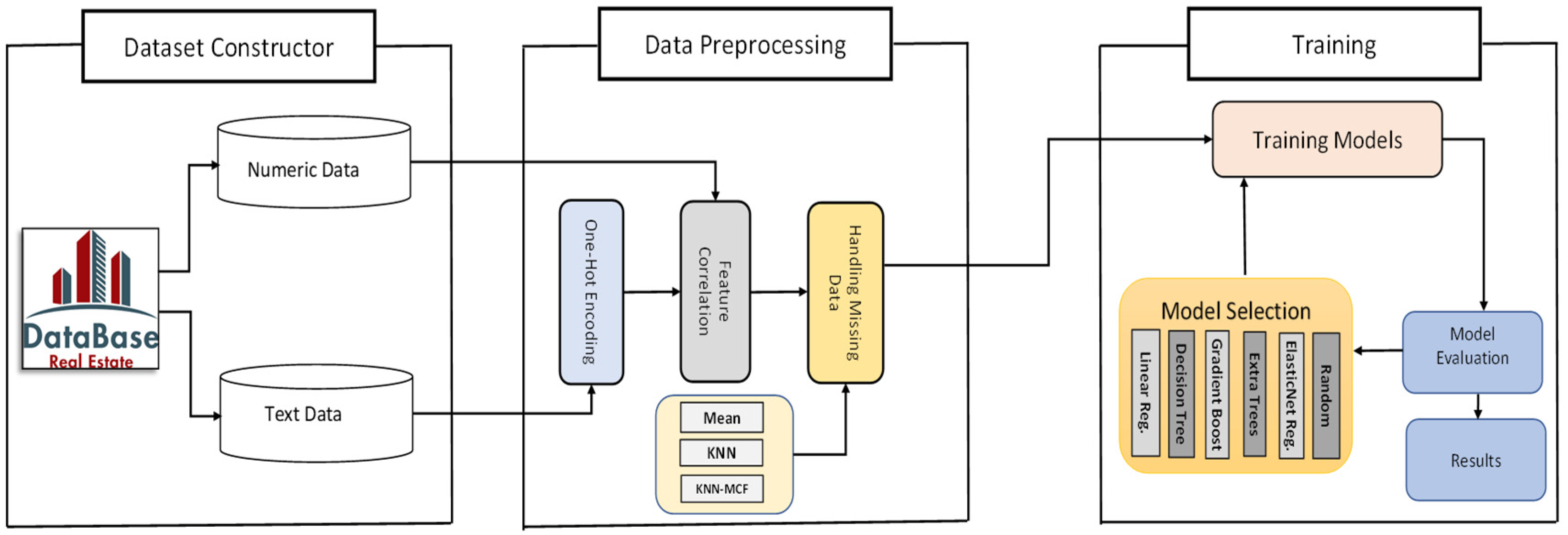
32]. The central suggestion in this work is to apply feature correlation to the dataset before dealing with the missing data by using the KNN algorithm. By doing so, we can illustrate an optimized K-nearest neighbor algorithm based on the most correlated features for the missing data imputation, namely KNN–MCF. First, we encoded the categorical data into numeric data, as described in the previous subsection. The next and main step was to choose the most important features related to the house prices in the dataset. The overall architecture of the model is illustrated in
Figure 1.
Then, we implemented three methods of handling missing data:
mean value of all non-missing observations,
KNN algorithm, and
KNN–MCF, which is the proposed algorithm for handling the missing data.
The accuracy of each model implemented in the training part improved after the application of the method. Now, we will explain the selection of the most important features. There are different methods for feature correlation. In this work, we used the correlation coefficient method for selecting the most important features. Let us assume that we have two features: a and b. The correlation coefficient between these two variables can be defined as follows:
Correlation coefficient:
where, Cov(a, b) is the covariance of a and b and Var(.) is the variance of one feature. The covariance between two features is calculated using the following formula:
In this formula:
—values of variable “a”
—mean (average) value of variable “a”
values of variable “b”
—mean (average) value of variable “b”
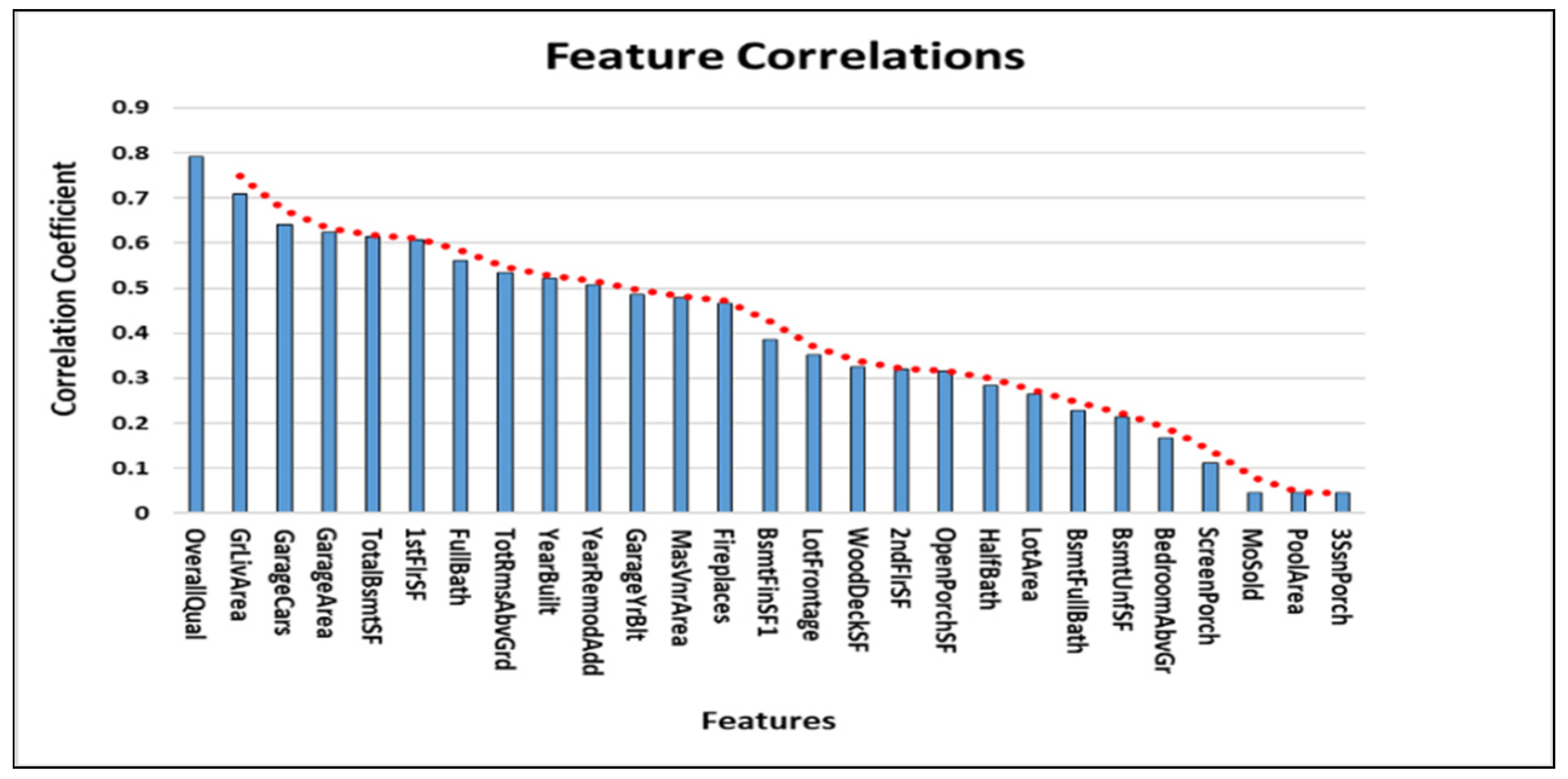
After implementing the above formula into the dataset, we obtained the result illustrated in
Figure 2.
It is evident that the attributes were ordered according to their correlation coefficient. The overall quality of the house and the total ground living area were the most important features of the dataset for predicting the house price. We trained a random forest algorithm with different values of the correlation coefficient. The accuracy on the training set was high with a huge number of features, while the performance on the test set was substantially lower due to the overfitting problem. In order to attain the perfect value of the correlation coefficient, we simulated the dataset in more detail and with greater precision.
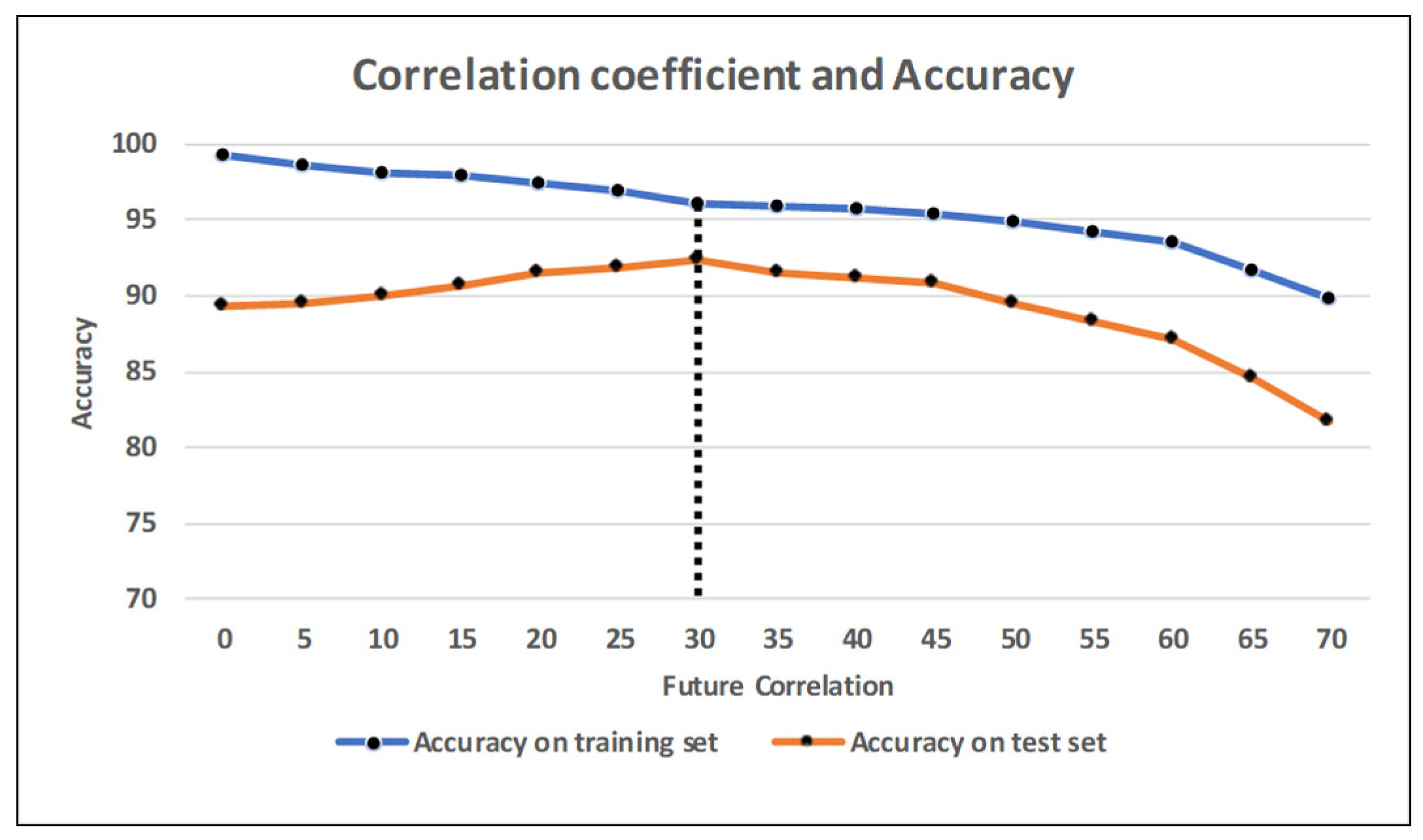
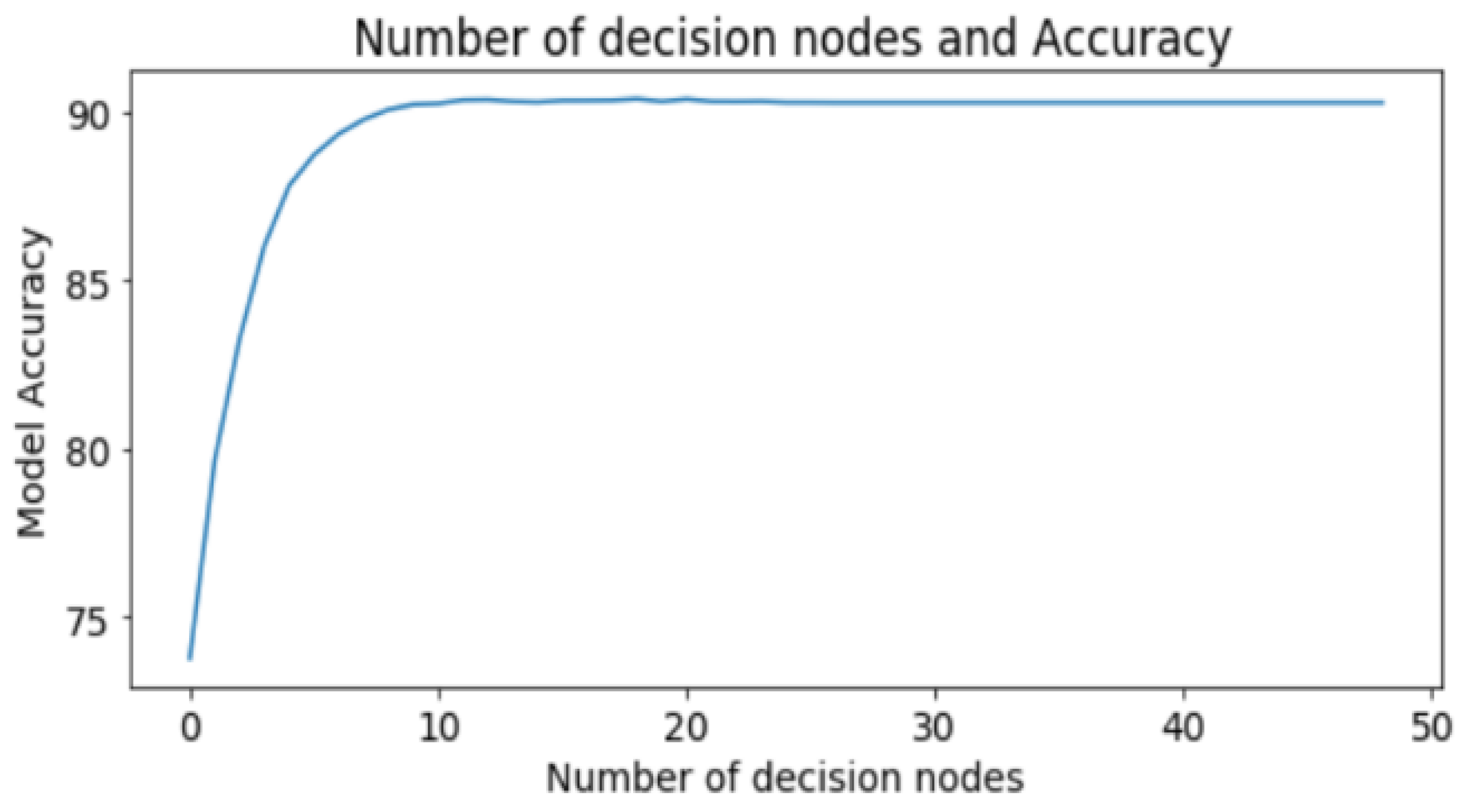
Figure 3 shows the significant relationship between the correlation coefficient and the accuracy of the model on both the training and the test subsets. The vertical axis demonstrates the accuracy percentage of the training and the test subsets. The horizontal axis represents the correlation coefficient over the given amount.
To make it clearer, take the first value, 0%, as an example. It denotes that we used all the 256 features while training and testing the model. The accuracy line illustrates the values of around 99% and 89% for the training and the test sets, respectively. The second value, 5%, denotes that we considered the attributes with a correlation coefficient of more than 5%. In this situation, the number of attributes in the training process declined to 180. Practically, the fewer the features for the training set, the lower the accuracy recorded. After training our model with the given number of features, the accuracy for training decreased, while the test set accuracy increased gradually as we tried to prevent our model from overfitting. The main purpose of this graph was to show the best value of the correlation coefficient for obtaining the ideal measure of accuracy.
Figure 3 shows that the best value was 30%. The dataset consisted of 45 features that fit this requirement.
Thus, we improved the accuracy of the model, as the use of few appropriate features is better for training the model than that of a huge amount of irrelevant and unnecessary data. Furthermore, we could prevent overfitting because the possibility of overfitting increases with a growth in the number of unrelated attributes.
3.4. Handling Missing Data
Several concepts to define the distance for KNNs have been described thus far [
6,
9,
10,
33,
34]. The distance measure can be computed by using the Euclidean distance. Suppose that the jth impute feature of x is absent in
Table 7. After calculating the distance from x to all the training examples, we chose its K closest neighbors from the training subset, as demonstrated in Equation (3).
The set in Equation (3) represents the K closest neighbors of x settled in the ascending order of their remoteness. Therefore, v
1 was the nearest neighbor of x. The K closest cases were selected by examining the distance with the non-missing inputs in the incomplete feature to be imputed. After its K nearest neighbors were chosen, the unknown value was imputed by an estimation from the jth feature values of A
x. The imputed value
was acquired by using the mean value of its K closest neighbors, if the jth feature was a numeric variable. One important change was to weight the impact of each observation based on its distance to x, providing a bigger weight to the closer neighbors (see Equation (4)).
The primary shortcoming of this method is that when the KNN impute studies the most alike samples, the algorithm uses the entire dataset. This restriction can be very serious for large databases [
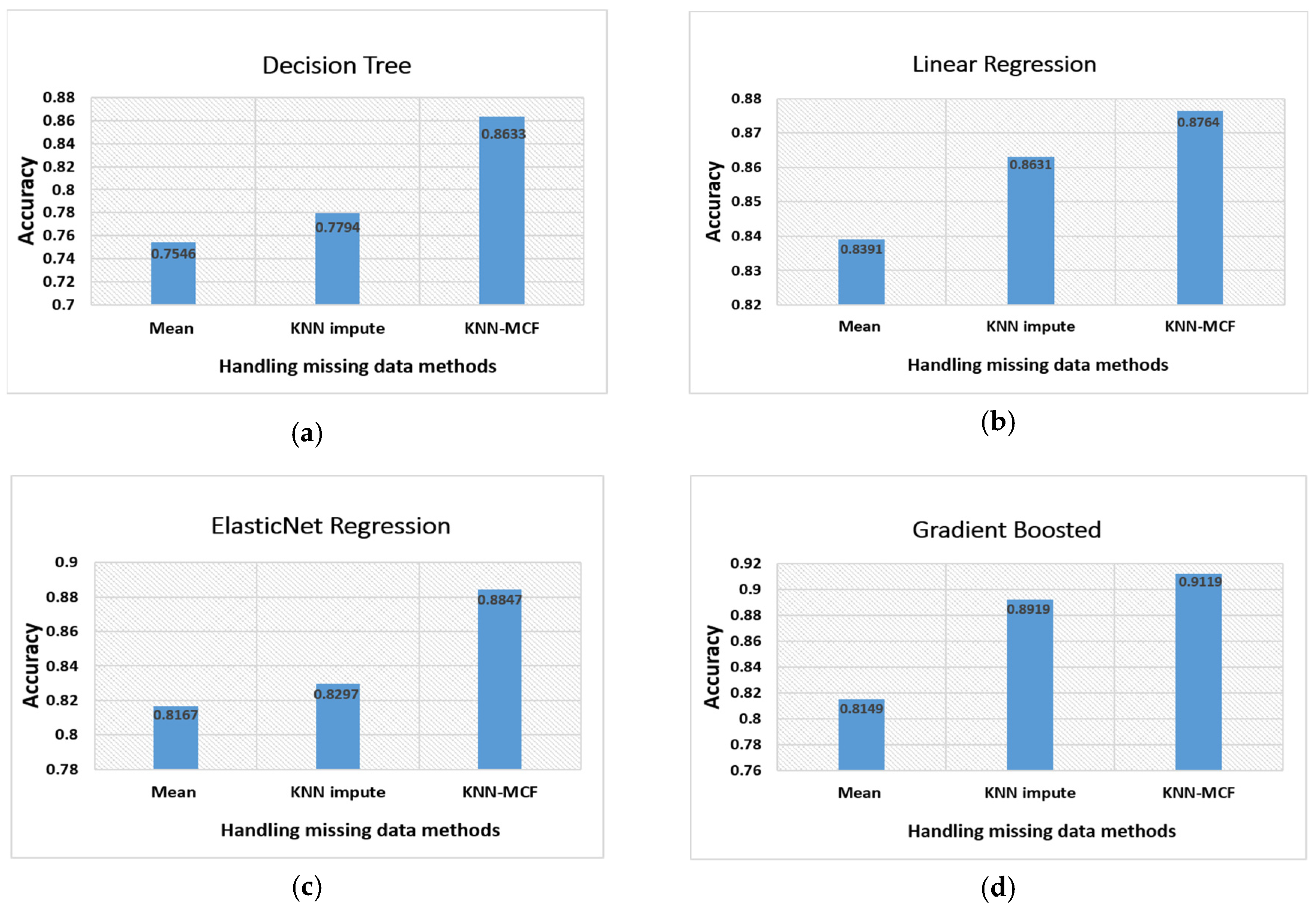
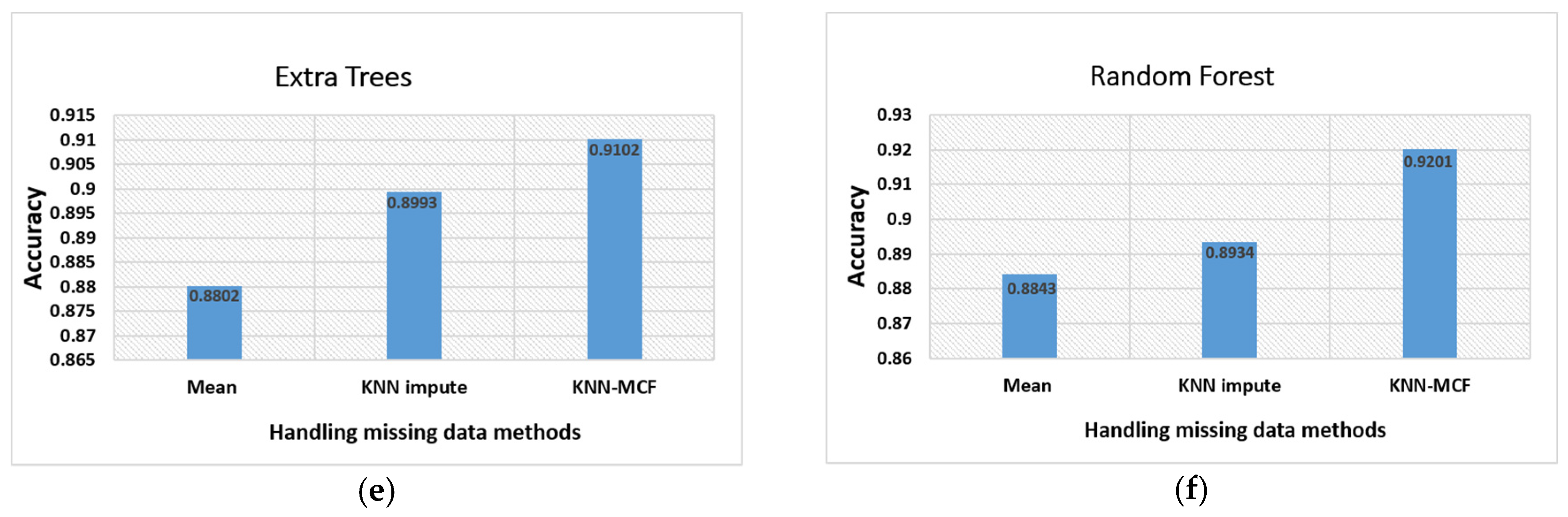
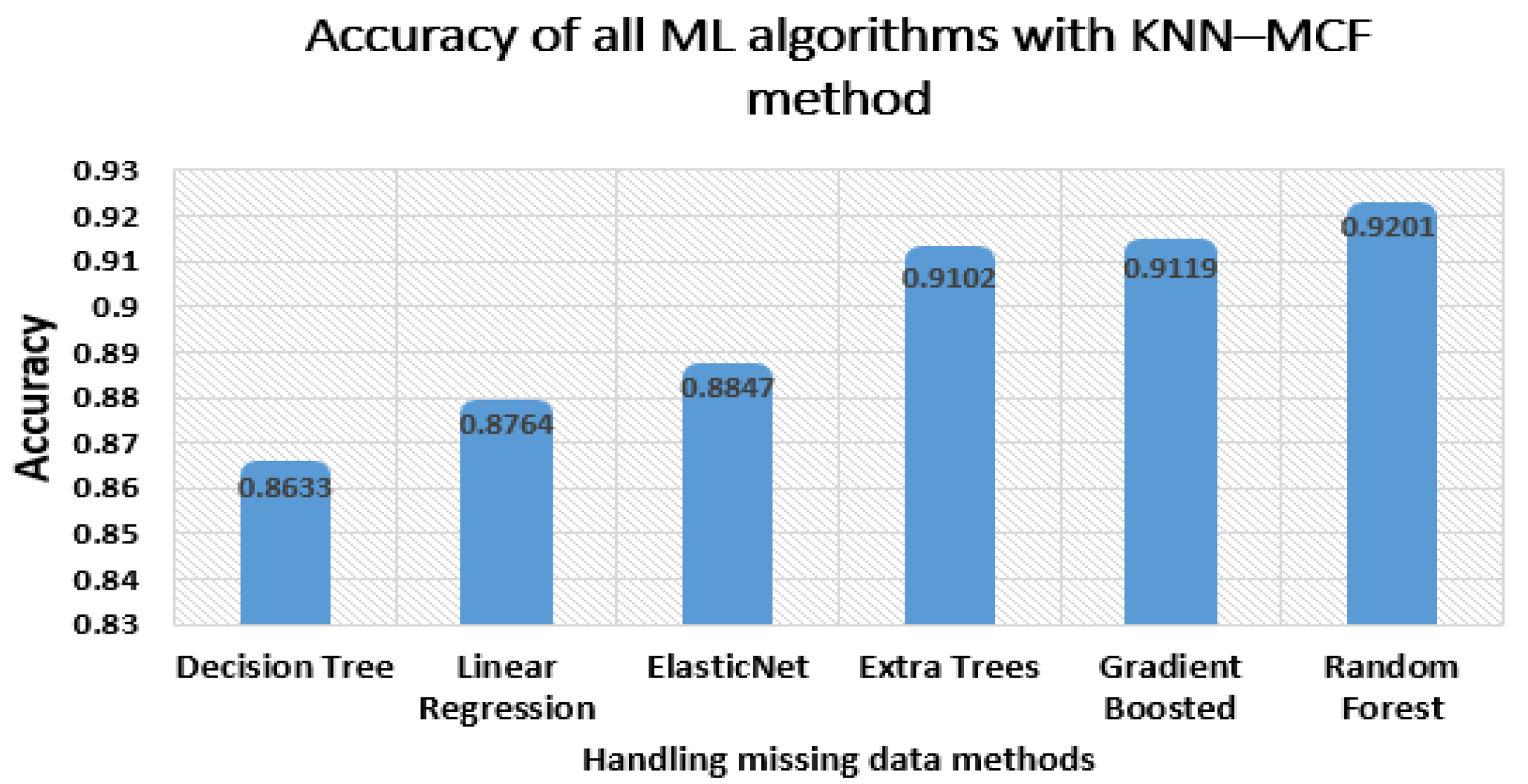
35]. The suggested technique implements the KNN–MCF method to find the missing values in large datasets. The key downside of using KNN imputation is that it can be severely degraded with high-dimensional data because there is little difference between the nearest and the farthest neighbors. Instead of using all the attributes, in this study, we used only the most important features selected by using Equations (1) and (2). The feature selection technique is typically used for several purposes in machine learning. First, the accuracy of the model can be improved, as the usage of a number of suitable features is better to train the model than the usage of a large number of unrelated and redundant data. The second and the most significant reason is dealing with the overfitting problem, since the possibility of overfitting is high with a growth of the number of irrelevant features. We used only 45 of the most important features for handling the missing data with our model. By doing so, we achieved the goal of avoiding the drawbacks of the KNN impute algorithm. To verify the proposed model, we applied three of the abovementioned methods of handling missing data, namely mean average, KNN, and KNN–MCF, to several machine learning-based prediction algorithms.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}