Exploiting Two-Dimensional Geographical and Synthetic Social Influences for Location Recommendation

Abstract
:1. Introduction
2. Related Work
3. Methods
3.1. Problem Statement
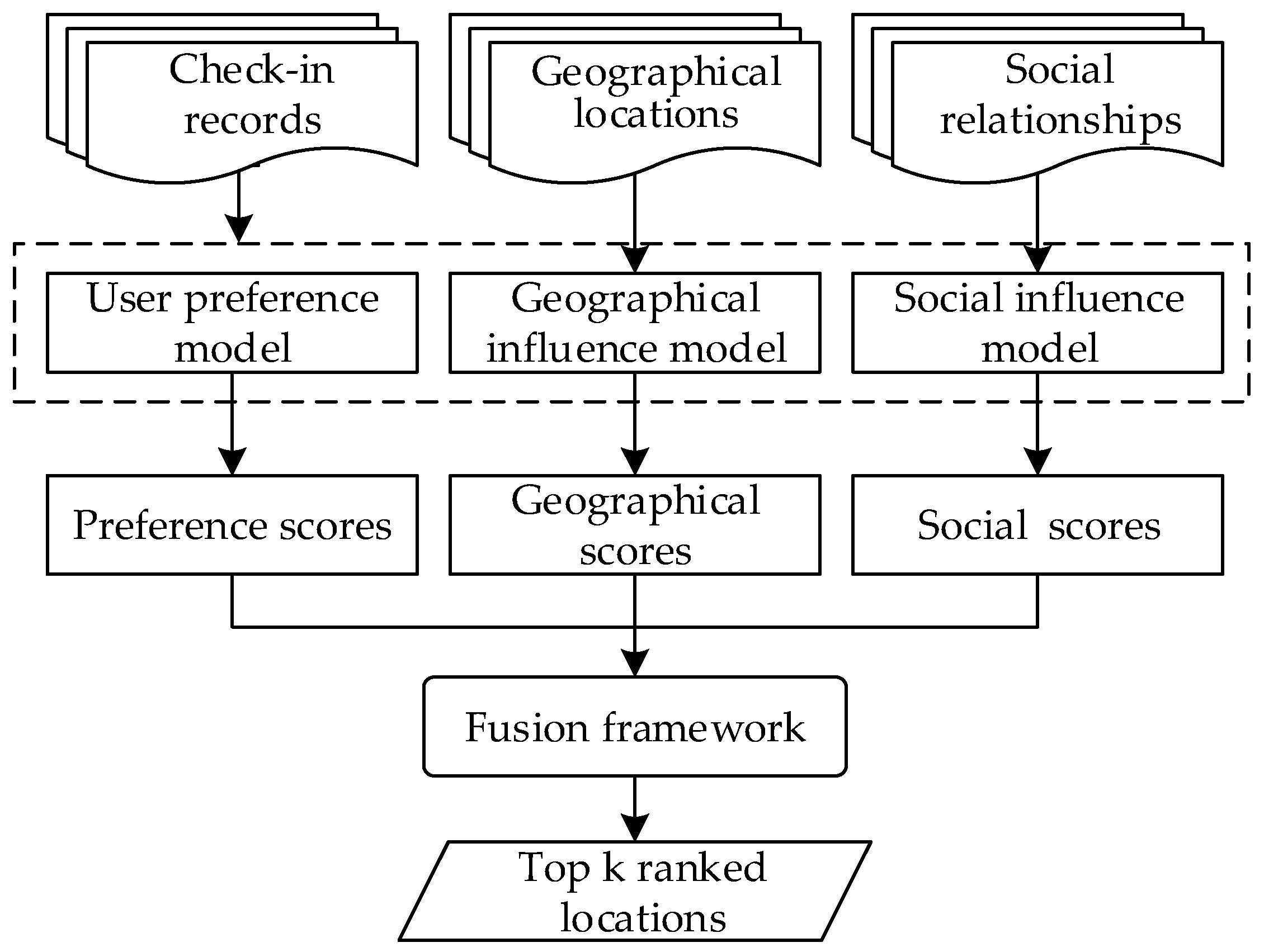
3.2. Geographical and Synthetic Social Influences (GeSso) Model
3.2.1. User Preference Model
3.2.2. Geographical Influence Model
3.2.3. Social Influence Model
3.2.4. Fusion Framework
4. Experiment Evaluation
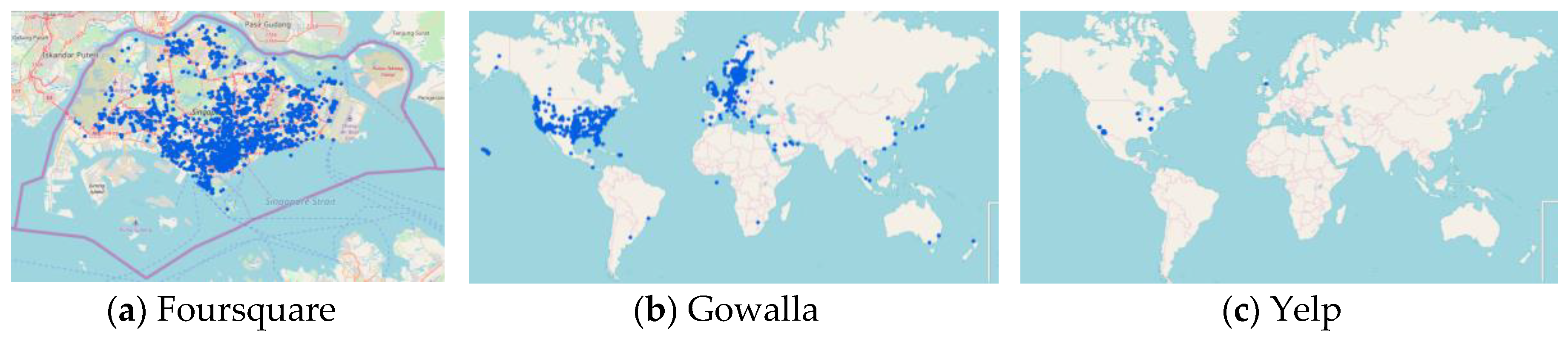
4.1. Dataset Description
4.2. Evaluated Recommendation Methods
- USG. USG is a unified location recommendation framework, which explores user preferences and geographical and social influences for location recommendation. It uses a sum rule to integrate user preferences and geographical and social influences [15].
- Lore. This method models sequential, geographical, and social influences for location recommendation. It uses an unweighted two-dimensional KDE model for geographical modeling [11]. The similarity between friends is computed based on the distance between residences. Because the residence locations are not available, we define users’ most frequently visited locations as their residences. It uses a product fusion rule to integrate different factors.
- GeoSoCa. This method models three types of contextual information, namely, geographical, social, and categorical information. It uses an adaptive weighted two-dimensional KDE model for geographical modeling [18].
- SCF. SCF is a social-based collaborative filtering method which makes location recommendations based on the Jaccard similarity between friends. The similarity between friends is computed based on the common friends. [37]
4.3. Performance Metrics
4.4. Experiment Settings
5. Results and Discussion
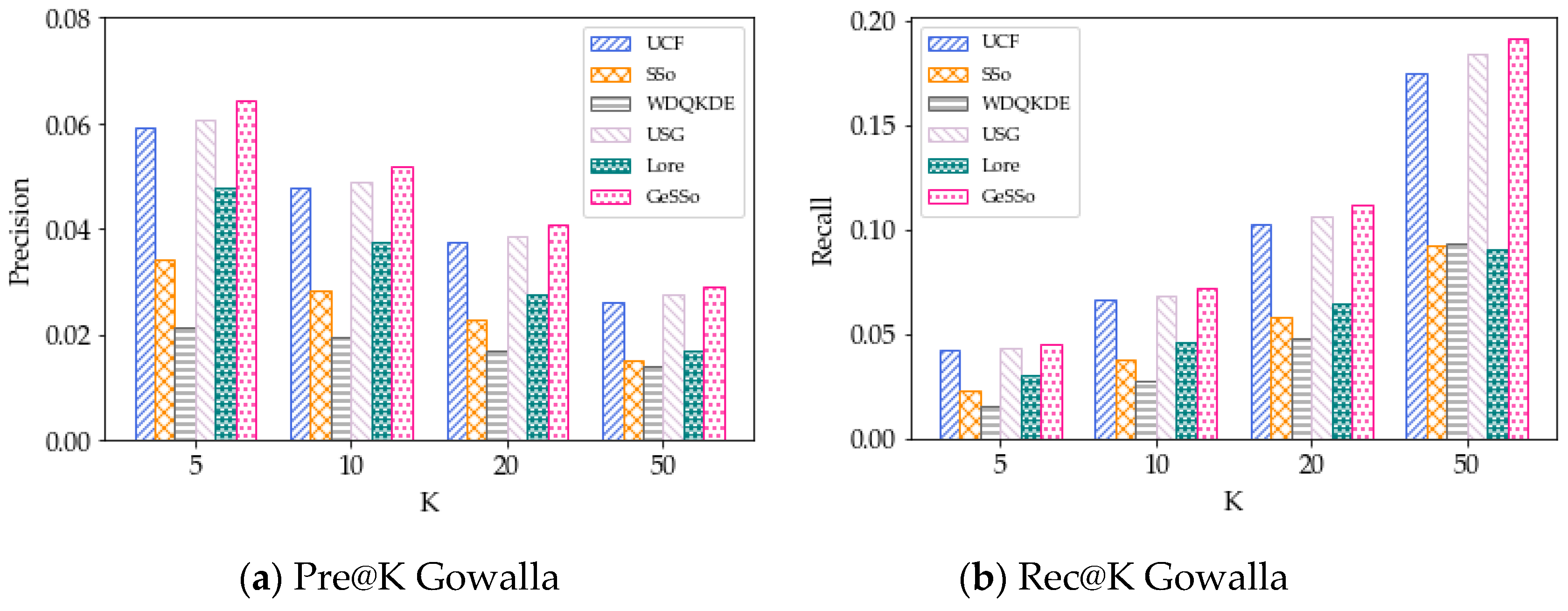
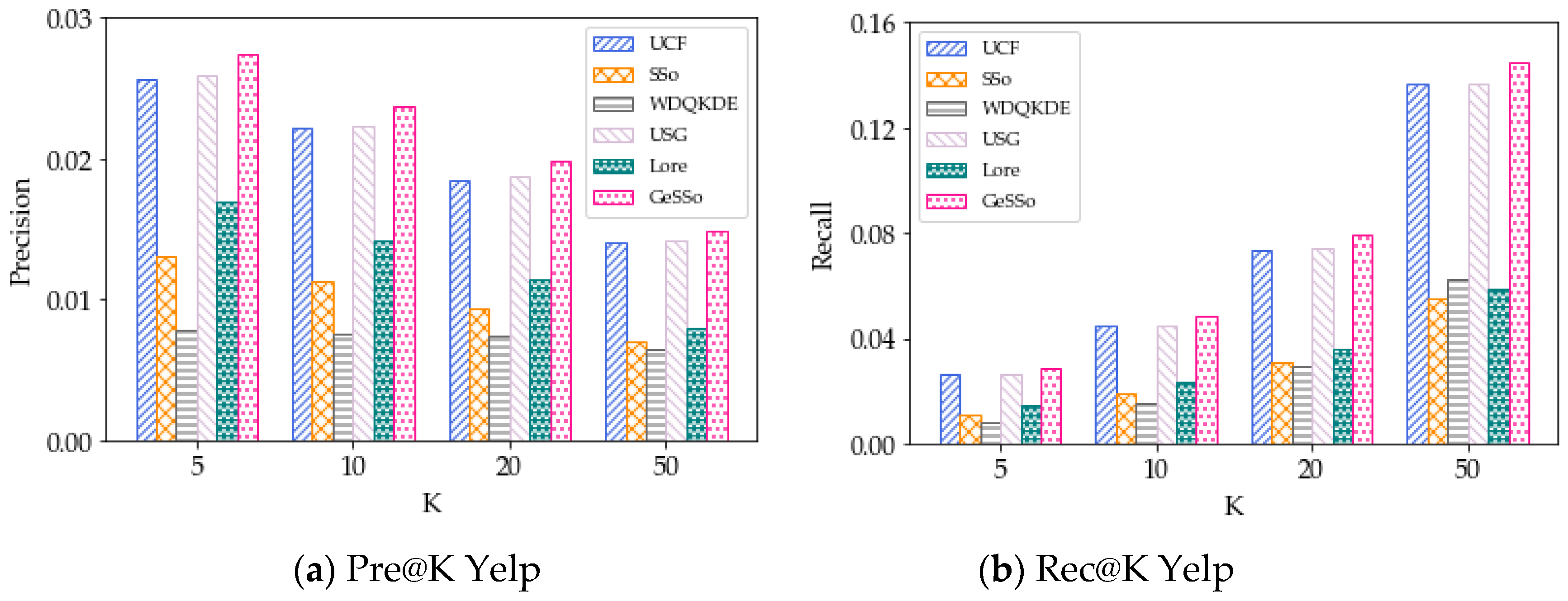
5.1. Overall Performance Results
5.2. Results for the Geographical Influence Methods
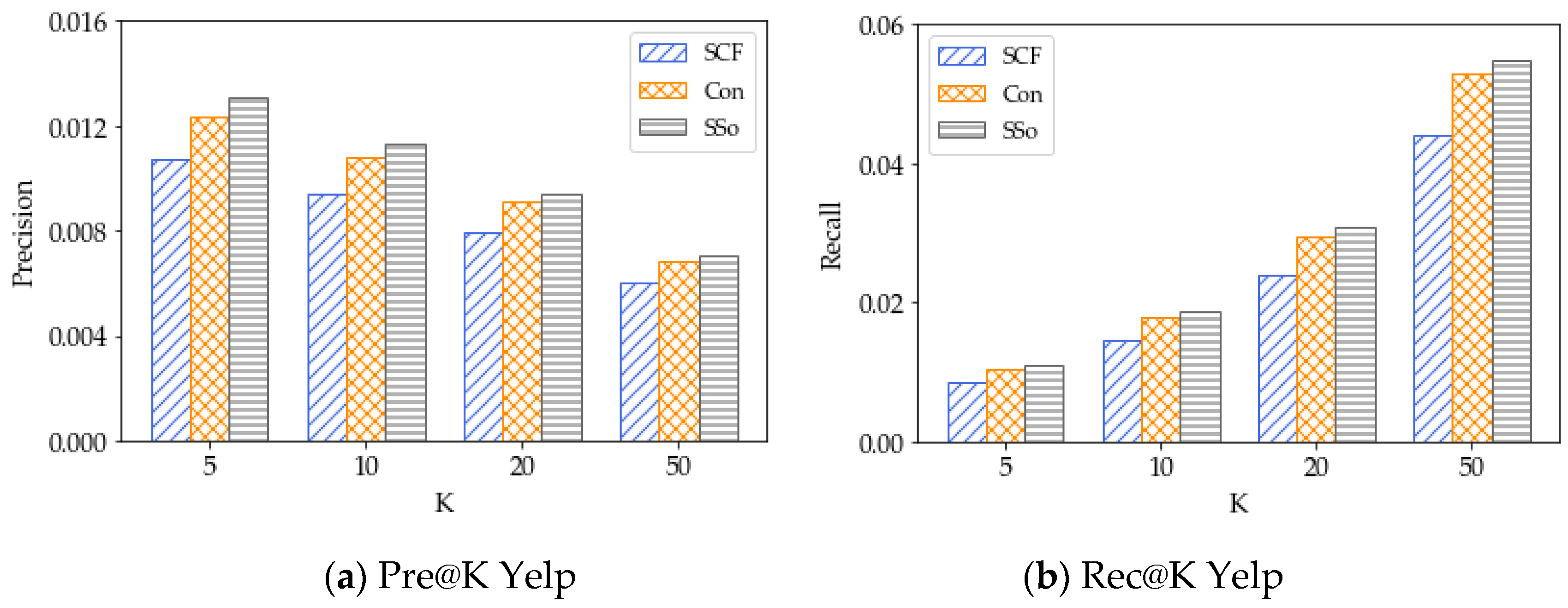
5.3. Results for Social Influence Methods
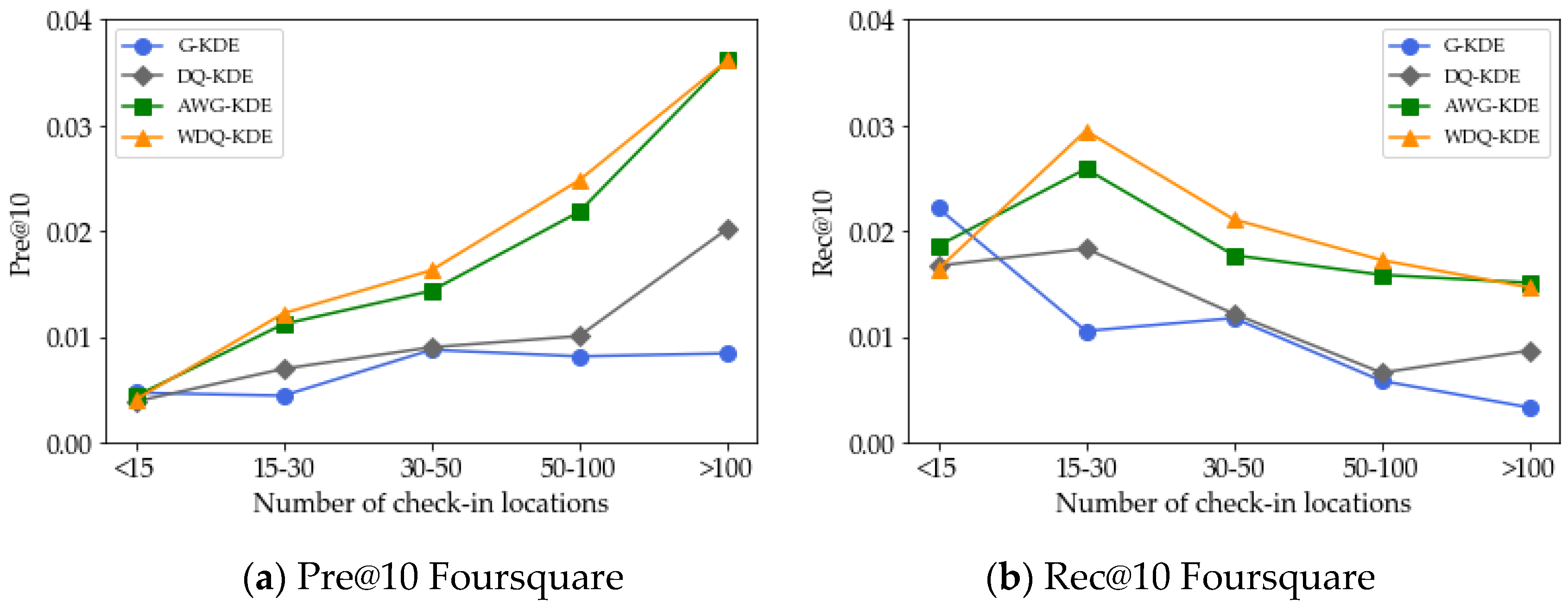
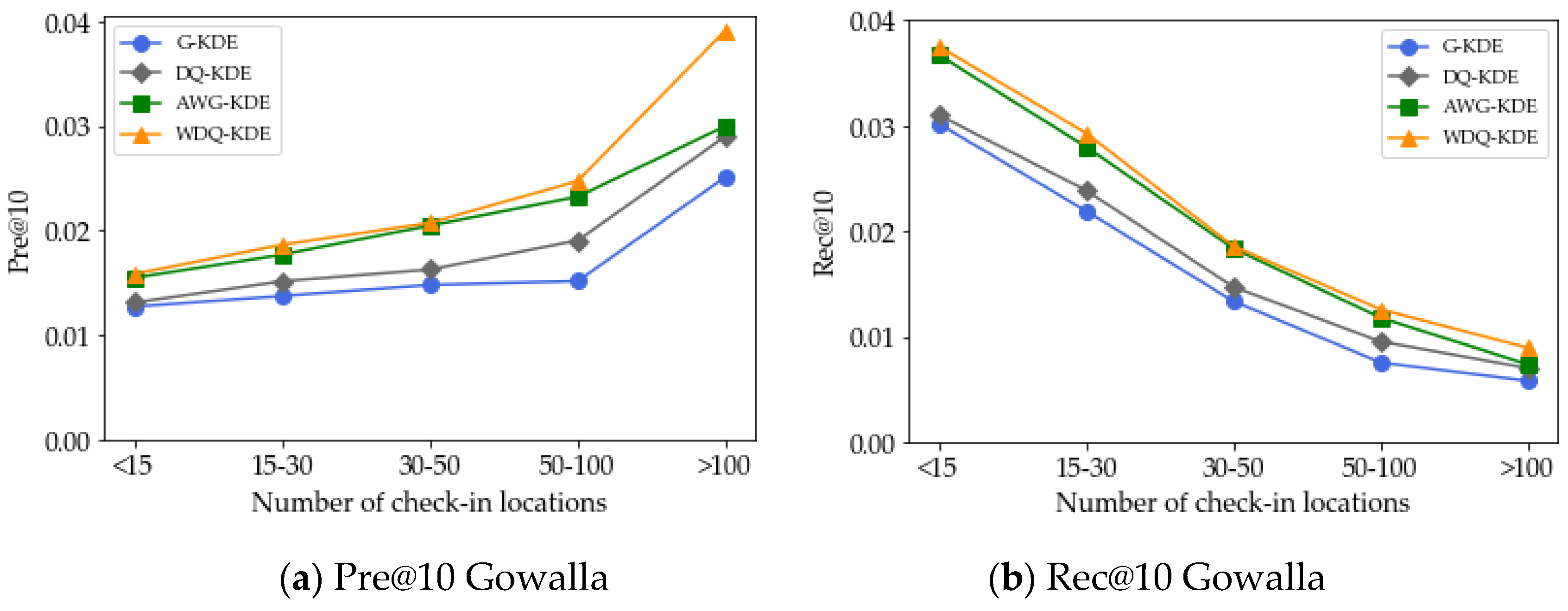
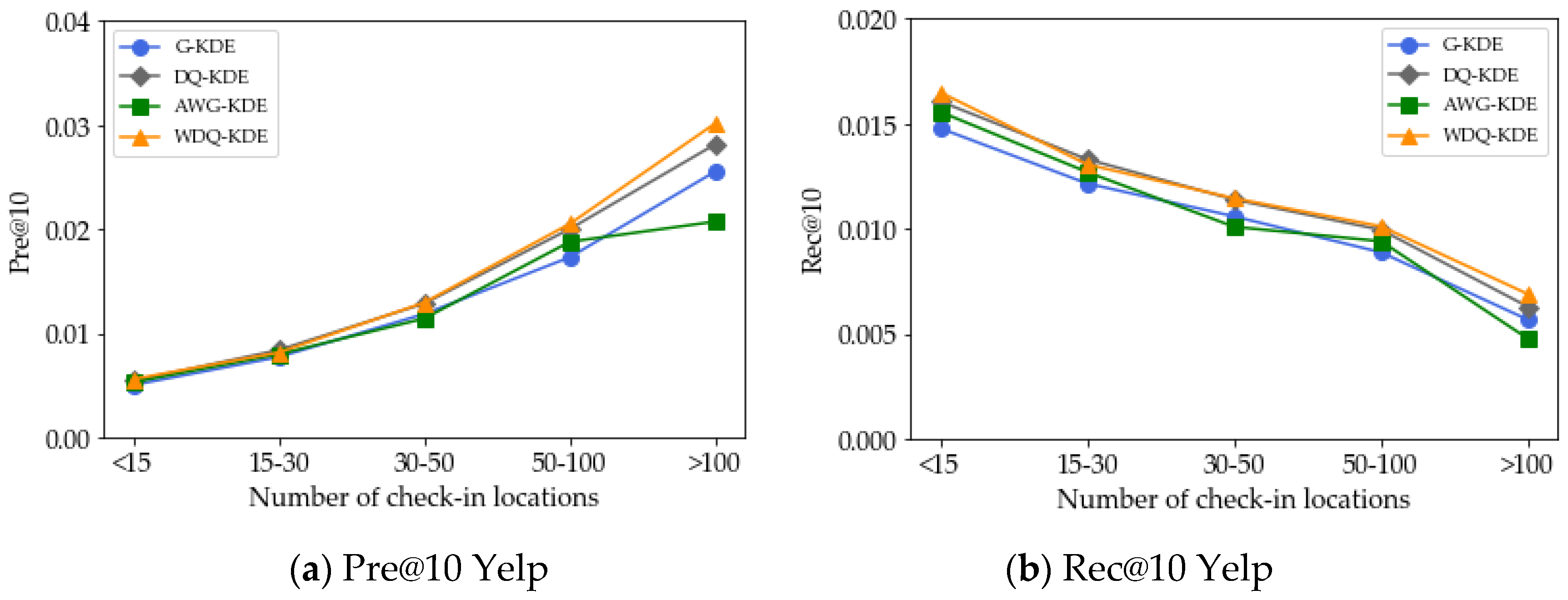
5.4. Effect of the Number of Check-in Locations
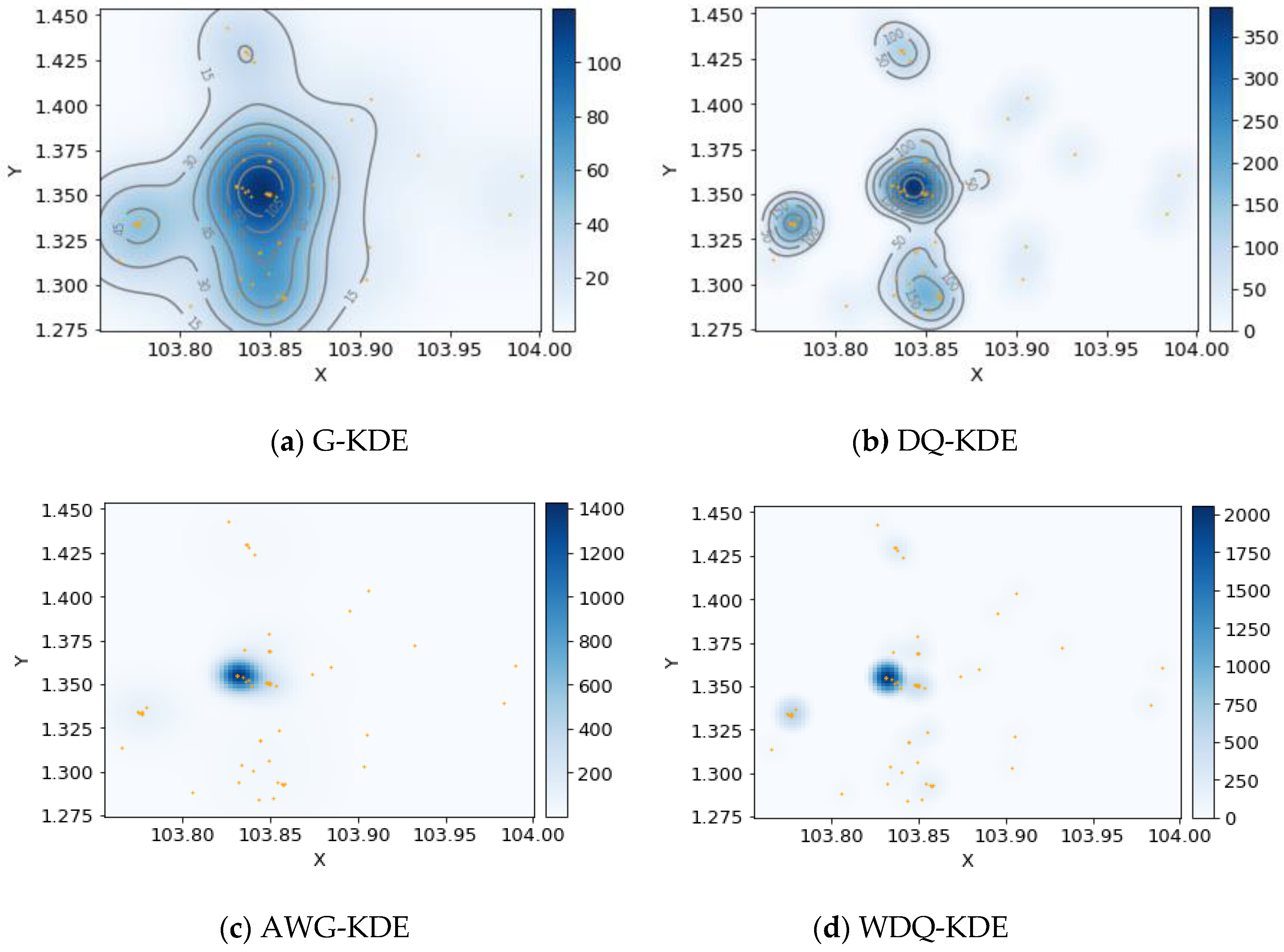
5.5. Effect of the Kernel Density Estimation Model
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Cai, L.; Xu, J.; Liu, J.; Pei, T. Integrating spatial and temporal contexts into a factorization model for POI recommendation. Int. J. Geogr. Inf. Sci. 2018, 32, 524–546. [Google Scholar] [CrossRef]
- Bao, J.; Zheng, Y.; Wilkie, D.; Mokbel, M. Recommendations in location-based social networks: A survey. Geoinformatica 2015, 19, 525–565. [Google Scholar] [CrossRef]
- Lu, Z.; Wang, H.; Mamoulis, N.; Tu, W.; Cheung, D. Personalized location recommendation by aggregating multiple recommenders in diversity. GeoInformatica 2017, 21, 1–26. [Google Scholar] [CrossRef]
- Aliannejadi, M.; Crestani, F. Personalized Context-Aware Point of Interest Recommendation. ACM Trans. Inf. Syst. (TOIS) 2018, 36, 1–28. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Pham, T.-A.N.; Cong, G.; Yuan, Q. An experimental evaluation of point-of-interest recommendation in location-based social networks. Proc. VLDB Endow. 2017, 10, 1010–1021. [Google Scholar] [CrossRef]
- Wang, F.; Meng, X.; Zhang, Y.; Zhang, C. Mining user preferences of new locations on location-based social networks: A multidimensional cloud model approach. Wirel. Netw. 2018, 24, 113–125. [Google Scholar] [CrossRef]
- Ogundele, T.J.; Chow, C.-Y.; Zhang, J.-D. SoCaST: Exploiting Social, Categorical and Spatio-Temporal Preferences for Personalized Event Recommendations. In Proceedings of the 2017 14th International Symposium on Pervasive Systems, Algorithms and Networks & 2017 11th International Conference on Frontier of Computer Science and Technology & 2017 Third International Symposium of Creative Computing (ISPAN-FCST-ISCC), Exeter, UK, 21–23 June 2017; pp. 38–45. [Google Scholar]
- Yu, X.; Pan, A.; Tang, L.-A.; Li, Z.; Han, J. Geo-Friends Recommendation in GPS-based Cyber-physical Social Network. In Proceedings of the 2011 International Conference on Advances in Social Networks Analysis and Mining, Kaohsiung, Taiwan, 25–27 July 2011; pp. 361–368. [Google Scholar]
- Shokeen, J.; Rana, C. A study on features of social recommender systems. Artif. Intell. Rev. 2020, 53, 965–988. [Google Scholar] [CrossRef]
- Liu, B.; Fu, Y.; Yao, Z.; Xiong, H. Learning geographical preferences for point-of-interest recommendation. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; pp. 1043–1051. [Google Scholar]
- Zhang, J.-D.; Chow, C.-Y.; Li, Y. LORE: Exploiting sequential influence for location recommendations. In Proceedings of the 22nd ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Dallas, TX, USA, 4–7 November 2014; pp. 103–112. [Google Scholar]
- Sun, Y.; Yin, H.; Ren, X. Recommendation in context-rich environment: An information network analysis approach. In Proceedings of the 26th International Conference on World Wide Web Companion, Perth, Australia, 3–7 April 2017; pp. 941–945. [Google Scholar]
- Ren, X.; Song, M.; Song, J. Context-Aware Point-of-Interest Recommendation in Location-Based Social Networks. Jisuanji Xuebao Chin. J. Comput. 2017, 40, 824–841. [Google Scholar]
- Cui, Q.; Tang, Y.; Wu, S.; Wang, L. Distance2Pre: Personalized Spatial Preference for Next Point-of-Interest Prediction. In Pacific-Asia Conference on Knowledge Discovery and Data Mining; Springer: Cham, Switzerland, 2019; pp. 289–301. [Google Scholar]
- Ye, M.; Yin, P.; Lee, W.-C.; Lee, D.-L. Exploiting geographical influence for collaborative point-of-interest recommendation. In Proceedings of the 34th international ACM SIGIR Conference on Research and Development in Information Retrieval, Beijing, China, 25–29 July 2011; pp. 325–334. [Google Scholar]
- Zhang, J.-D.; Chow, C.-Y. iGSLR: Personalized geo-social location recommendation: A kernel density estimation approach. In Proceedings of the 21st ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Orlando, FL, USA, 5–8 November 2013; pp. 334–343. [Google Scholar]
- Lian, D.; Zhao, C.; Xie, X.; Sun, G.; Chen, E.; Rui, Y. GeoMF: Joint geographical modeling and matrix factorization for point-of-interest recommendation. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 831–840. [Google Scholar]
- Zhang, J.-D.; Chow, C.-Y. GeoSoCa: Exploiting Geographical, Social and Categorical Correlations for Point-of-Interest Recommendations. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, Santiago, Chile, 9–13 August 2015; pp. 443–452. [Google Scholar]
- Zhang, J.-D.; Chow, C.-Y.; Li, Y. iGeoRec: A Personalized and Efficient Geographical Location Recommendation Framework. IEEE Trans. Serv. Comput. 2015, 8, 701–714. [Google Scholar] [CrossRef]
- Guo, H.; Li, X.; He, M.; Zhao, X.; Liu, G.; Xu, G. CoSoLoRec: Joint Factor Model with Content, Social, Location for Heterogeneous Point-of-Interest Recommendation. In International Conference on Knowledge Science, Engineering and Management; Springer: Cham, Switzerland, 2016; pp. 613–627. [Google Scholar]
- Zhang, J.-D.; Chow, C.-Y. TICRec: A Probabilistic Framework to Utilize Temporal Influence Correlations for Time-Aware Location Recommendations. IEEE Trans. Serv. Comput. 2016, 9, 633–646. [Google Scholar] [CrossRef]
- Gao, R.; Li, J.; Li, X.; Song, C.; Zhou, Y. A personalized point-of-interest recommendation model via fusion of geo-social information. Neurocomputing 2018, 273, 159–170. [Google Scholar] [CrossRef]
- Cheng, C.; Yang, H.; King, I.; Lyu, M.R. Fused matrix factorization with geographical and social influence in location-based social networks. Proc. Natl. Conf. Artif. Intell. 2012, 1, 17–23. [Google Scholar]
- Yuan, Q.; Cong, G.; Ma, Z.; Sun, A.; Thalmann, N.M. Time-aware point-of-interest recommendation. In Proceedings of the 36th International ACM SIGIR Conference on Research and Development in Information Retrieval, Dublin, Ireland, 28 July–1 August 2013; pp. 363–372. [Google Scholar]
- Yin, H.; Sun, Y.; Cui, B.; Hu, Z.; Chen, L. LCARS: A location-content-aware recommender system. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013. [Google Scholar]
- Zhang, J.-D.; Chow, C.-Y. CoRe: Exploiting the personalized influence of two-dimensional geographic coordinates for location recommendations. Inf. Sci. 2015, 293, 163–181. [Google Scholar] [CrossRef]
- Liu, Y.; Wei, W.; Sun, A.; Miao, C. Exploiting Geographical Neighborhood Characteristics for Location Recommendation. In Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management, Shanghai, China, 13–14 July 2017; pp. 739–748. [Google Scholar]
- Li, X.; Cong, G.; Li, X.-L.; Pham, T.-A.N.; Krishnaswamy, S. Rank-GeoFM: A Ranking based Geographical Factorization Method for Point of Interest Recommendation. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, Santiago, Chile, 9–13 August 2015; pp. 433–442. [Google Scholar]
- Ding, R.; Chen, Z. RecNet: A deep neural network for personalized POI recommendation in location-based social networks. Int. J. Geogr. Inf. Sci. 2018, 32, 1631–1648. [Google Scholar] [CrossRef]
- Zhao, P.; Zhu, H.; Liu, Y.; Xu, J.; Li, Z.; Zhuang, F.; Sheng, V.; Zhou, X. Where to Go Next: A Spatio-Temporal Gated Network for Next POI Recommendation. Proc. AAAI Conf. Artif. Intell. 2019, 33, 5877–5884. [Google Scholar] [CrossRef]
- Liu, Q.; Wu, S.; Wang, L.; Tan, T. Predicting the next location: A recurrent model with spatial and temporal contexts. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Kong, D.; Wu, F. HST-LSTM: A Hierarchical Spatial-Temporal Long-Short Term Memory Network for Location Prediction. In Proceedings of the 27th International Joint Conference on Artificial Intelligence and the 23rd European Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 2341–2347. [Google Scholar]
- Lian, D.; Zheng, K.; Ge, Y.; Cao, L.; Chen, E.; Xie, X. GeoMF++: Scalable Location Recommendation via Joint Geographical Modeling and Matrix Factorization. ACM Trans. Inf. Syst. 2018, 36, 1–29. [Google Scholar] [CrossRef]
- Guo, Q. Graph-based Point-of-interest Recommendation on Location-based Social Networks. Ph.D. Thesis, Nanyang Technological University, Singapore, 2019. [Google Scholar]
- Anagnostopoulos, A.; Kumar, R.; Mahdian, M. Influence and correlation in social networks. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008; pp. 7–15. [Google Scholar]
- Qiu, J.; Tang, J.; Ma, H.; Dong, Y.; Wang, K.; Tang, J. DeepInf: Modeling influence locality in large social networks. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, London, UK, 19–23 August 2018. [Google Scholar]
- Ma, H.; King, I.; Lyu, M.R. Learning to recommend with social trust ensemble. In Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Boston, MA, USA, 19–23 July 2009; pp. 203–210. [Google Scholar]
- Ma, H.; Zhou, T.C.; Lyu, M.R.; King, I. Improving Recommender Systems by Incorporating Social Contextual Information. ACM Trans. Inf. Syst. 2011, 29, 1–23. [Google Scholar] [CrossRef]
- Lak, P. A Novel Approach to Define and Model Contextual Features in Recommender Systems. In Proceedings of the 39th International ACM SIGIR Conference on Research and Development in Information Retrieval, Pisa, Italy, 17–21 July 2016; p. 1161. [Google Scholar]
- Konstas, I.; Stathopoulos, V.; Jose, J.M. On social networks and collaborative recommendation. In Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Boston, MA, USA, 19–23 July 2009; pp. 195–202. [Google Scholar]
- Chaney, A.J.; Blei, D.M.; Eliassi-Rad, T. A probabilistic model for using social networks in personalized item recommendation. In Proceedings of the 9th ACM Conference on Recommender Systems, Vienna, Austria, 16–20 September 2015; pp. 43–50. [Google Scholar]
- Wang, M.; Zheng, X.; Yang, Y.; Zhang, K. Collaborative filtering with social exposure: A modular approach to social recommendation. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Yang, B.; Lei, Y.; Liu, J.; Li, W. Social collaborative filtering by trust. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1633–1647. [Google Scholar] [CrossRef]
- Herlocker, J.L.; Konstan, J.A.; Borchers, A.; Riedl, J. An algorithmic framework for performing collaborative filtering. In Proceedings of the 22nd annual international ACM SIGIR conference on Research and development in information retrieval, Berkeley, CA, USA, 15–19 August 1999; pp. 230–237. [Google Scholar]
- Silverman, B.W. Density Estimation for Statistics and Data Analysis; CRC Press: Boca Raton, FL, USA, 1986. [Google Scholar]
- Ma, H.; Yang, H.; Lyu, M.R.; King, I. SoRec: Social recommendation using probabilistic matrix factorization. In Proceedings of the 17th ACM Conference on Information and Knowledge Management, Napa Valley, CA, USA, 26–30 October 2008; pp. 931–940. [Google Scholar]
- Cao, Y.; Li, Y. An intelligent fuzzy-based recommendation system for consumer electronic products. Expert Syst. Appl. 2007, 33, 230–240. [Google Scholar] [CrossRef]
- Yan, Y.; Feng, C.-C.; Wang, Y.-C. Utilizing fuzzy set theory to assure the quality of volunteered geographic information. GeoJournal 2017, 82, 517–532. [Google Scholar] [CrossRef]
- Vahidi, H.; Klinkenberg, B.; Yan, W. Trust as a proxy indicator for intrinsic quality of Volunteered Geographic Information in biodiversity monitoring programs. GISci. Remote Sens. 2018, 55, 502–538. [Google Scholar] [CrossRef]
- Yin, H.; Wang, W.; Wang, H.; Chen, L.; Zhou, X. Spatial-aware hierarchical collaborative deep learning for POI recommendation. IEEE Trans. Knowl. Data Eng. 2017, 29, 2537–2551. [Google Scholar] [CrossRef]
- Zhang, F.; Yuan, N.J.; Lian, D.; Xie, X.; Ma, W.-Y. Collaborative knowledge base embedding for recommender systems. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 353–362. [Google Scholar]
- Ma, H.; Zhou, D.; Liu, C.; Lyu, M.R.; King, I. Recommender systems with social regularization. In Proceedings of the Fourth ACM International Conference on Web Search and Data Mining, Hong Kong, China, 9–12 February 2011; pp. 287–296. [Google Scholar]
- Hosseini, S.; Yin, H.; Zhou, X.; Sadiq, S.; Kangavari, M.R.; Cheung, N.-M. Leveraging multi-aspect time-related influence in location recommendation. World Wide Web 2019, 22, 1001–1028. [Google Scholar] [CrossRef] [Green Version]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Meaning |
|---|---|
| Set of users in the LBSN | |
| Set of POIs in the LBSN | |
| Set of locations that user visited, | |
| Set of users having social relations with , | |
| Predicted probability of visiting given | |
| Actual rating of user for the visited location | |
| Predicted rating of user for the unvisited location | |
| Bandwidth, i.e., search radius |
| Dataset | Foursquare | Gowalla | Yelp |
|---|---|---|---|
| Number of users | 2321 | 18,737 | 30,887 |
| Number of POIs | 5596 | 32,510 | 18,995 |
| Number of check-ins | 194,108 | 1,278,274 | 860,888 |
| Average number of check-ins for a user | 83.63 | 68.22 | 27.87 |
| Average number of POIs for a user | 45.57 | 43.87 | 26.58 |
| Minimum number of check-ins for a user | 5 | 15 | 10 |
| Minimum number of users for a POI | 5 | 10 | 10 |
| Time span | 2010.08–2011.07 | 2009.01–2010.10 | 2004.10–2015.12 |
| Region | Singapore | World | Several cities |
| Density | 8.14*10−3 | 1.35*10−3 | 1.40*10−3 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, J.; Zhang, Z.; Liu, C.; Qiu, A.; Zhang, F. Exploiting Two-Dimensional Geographical and Synthetic Social Influences for Location Recommendation. ISPRS Int. J. Geo-Inf. 2020, 9, 285. https://doi.org/10.3390/ijgi9040285
Liu J, Zhang Z, Liu C, Qiu A, Zhang F. Exploiting Two-Dimensional Geographical and Synthetic Social Influences for Location Recommendation. ISPRS International Journal of Geo-Information. 2020; 9(4):285. https://doi.org/10.3390/ijgi9040285
Chicago/Turabian StyleLiu, Jiping, Zhiran Zhang, Chunyang Liu, Agen Qiu, and Fuhao Zhang. 2020. "Exploiting Two-Dimensional Geographical and Synthetic Social Influences for Location Recommendation" ISPRS International Journal of Geo-Information 9, no. 4: 285. https://doi.org/10.3390/ijgi9040285
APA StyleLiu, J., Zhang, Z., Liu, C., Qiu, A., & Zhang, F. (2020). Exploiting Two-Dimensional Geographical and Synthetic Social Influences for Location Recommendation. ISPRS International Journal of Geo-Information, 9(4), 285. https://doi.org/10.3390/ijgi9040285