
Forecasting Industrial Production Using Its Aggregated and Disaggregated Series or a Combination of Both: Evidence from One Emerging Market Economy



Abstract
:1. Introduction
2. Literature Review
3. Methodology
3.1. Time-Varying Parameters Autoregressive Model of First Order
3.2. UC with Stochastic Volatility
3.3. LASSO-Type Penalties
3.3.1. LASSO
3.3.2. AdaLASSO
3.3.3. WLadaLASSO
3.4. Exponential Smoothing
3.5. Autometrics Algorithm
3.6. Combination of Aggregated and Disaggregated Series
4. Data and Empirical Strategy
4.1. Empirical Strategy and Forecast Comparison
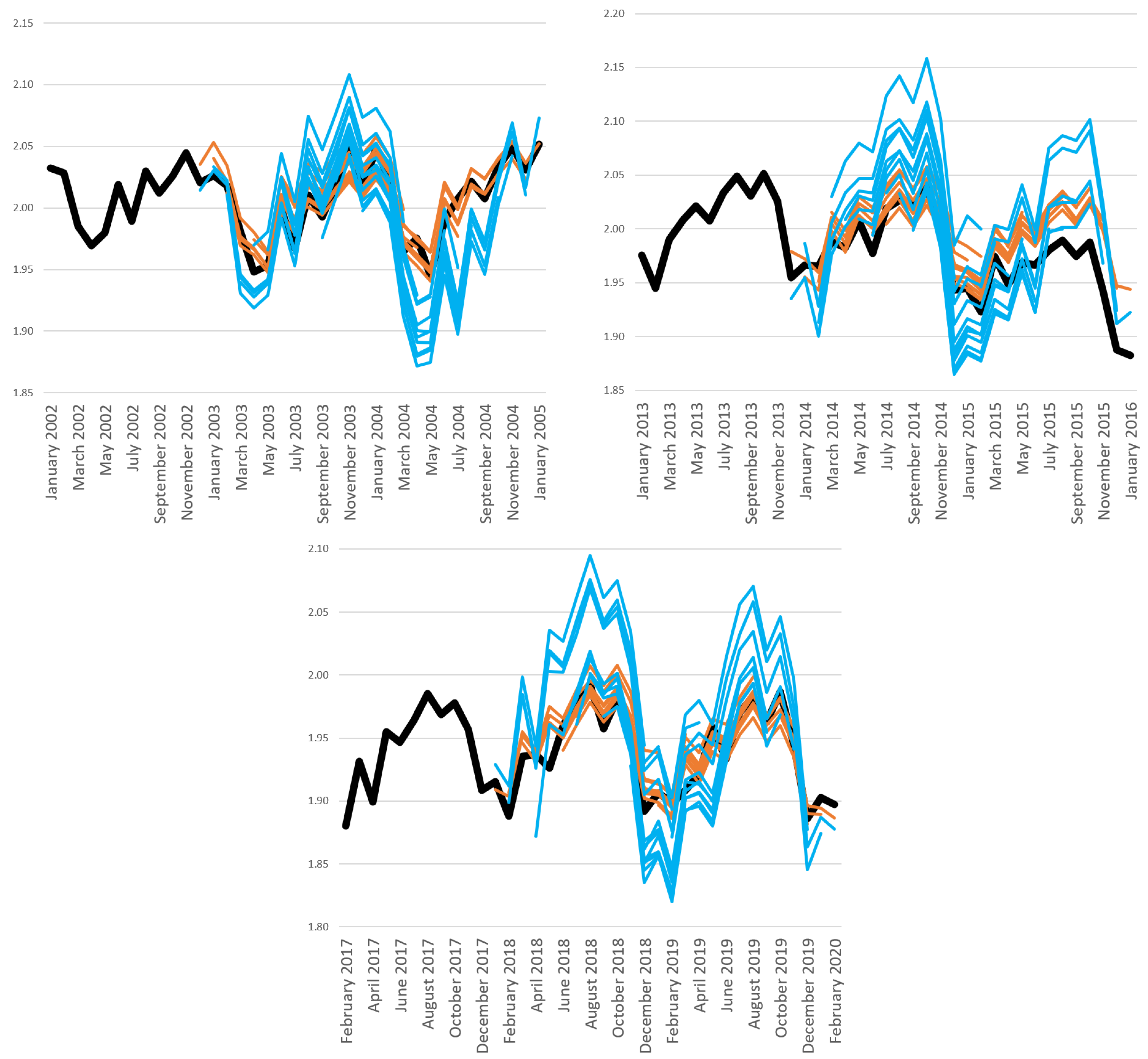
5. Results
Comparing the Forecast of the Disaggregated ETS Model with That of the Disaggregated WLadaLASSO
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Appendices for the Paper Forecasting Industrial Production Using Aggregated and Disaggregated Series or a Combination of Both: Evidence from One Emerging Market Economy
Appendix A.1. Detailing the Bayesian Estimation
- We obtain the lower Cholesky factorization .
- We draw .
- We determine from .
- We obtain .
- We repeat steps 2–4 independently N times.
Appendix A.2. Markov Chain Monte Carlo Method
- (1)
- We set the starting values for , where the superscript 0 represents the starting values.
- (2)
- We take draws and obtain a sample from the distribution of the conditional on the current values of :
- (3)
- We take draws obtaining a sample from the distribution of conditional on the current values of :
Appendix A.3. Detailing the Bayesian Estimation of UC-SV
Appendix A.4. Explanation of the 15 Types of ETS Models
Appendix A.5. Autometrics
Appendix A.6. Test of Forecast Accuracy between Models
Appendix A.7. Model Confidence Set—MCS
Appendix A.8. Forecast Encompassing Test
Appendix A.9. Multi-Horizon Forecast Comparison through Uniform and Average Superior Predictive Ability (SPA)
Appendix A.10. Tables Showing Descriptive Statistics and the Results for Forecast Accuracy between Models

{kind=link}
{kind=link}
| Mean | 0.0002 | 0.0023 |
| Standard deviation | 0.0283 | 0.0281 |
| Maximum | 0.0722 | 0.0754 |
| Minimum | −0.0850 | −0.0808 |
| First quartile | −0.0186 | −0.0134 |
| Third quartile | 0.0196 | 0.0201 |
| Models | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| −6.32 | −7.32 | −9.68 | −8.53 | −11.28 | −12.42 | −49.47 | −7.32 | −7.29 | −7.31 | −7.26 | −7.16 | |
| (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | |
| −6.31 | −7.36 | −9.69 | −8.60 | −11.36 | −12.43 | −48.81 | −7.32 | −7.29 | −7.30 | −7.26 | −7.15 | |
| (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | |
| −6.51 | −5.41 | −5.30 | −4.72 | −4.87 | −5.07 | −5.68 | −6.68 | −7.33 | −9.77 | −11.81 | −14.62 | |
| (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | |
| −6.03 | −5.31 | −4.88 | −3.81 | −3.94 | −4.07 | −4.72 | −5.55 | −6.58 | −10.42 | −11.00 | −13.60 | |
| (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | |
| −7.28 | −7.27 | −10.90 | −10.47 | −7.26 | −16.76 | −7.41 | −8.37 | −6.89 | −16.22 | −11.66 | −8.55 | |
| (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | |
| −6.86 | −7.30 | −11.08 | −10.44 | −7.38 | −14.97 | −7.46 | −8.39 | −6.97 | −15.83 | −11.91 | −8.47 | |
| (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | |
| - | −8.00 | −7.10 | −6.56 | −7.56 | −8.41 | −8.93 | −8.65 | −10.07 | −13.25 | −14.08 | −10.11 | −14.24 |
| (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | |
| - | −7.41 | −7.02 | −6.51 | −7.57 | −8.57 | −9.17 | −8.63 | −10.14 | −12.72 | −14.43 | −10.12 | −15.82 |
| (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | |
| 0.11 | −0.02 | −0.13 | −0.72 | −1.01 | −1.51 | −0.87 | −1.44 | −1.77 | −0.95 | −4.75 | −0.54 | |
| (0.54) | (0.49) | (0.45) | (0.24) | (0.16) | (0.07) | (0.19) | (0.08) | (0.04) | (0.17) | (0.00) | (0.29) | |
| −6.51 | −5.01 | −4.85 | −4.66 | −4.80 | −5.01 | −5.48 | −6.31 | −6.79 | −7.47 | −7.99 | −9.27 | |
| (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | |
| −6.76 | −4.85 | −4.71 | −4.08 | −3.97 | −4.03 | −4.83 | −5.14 | −5.84 | −8.97 | −8.53 | −8.04 | |
| (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | |
| −6.44 | −5.14 | −4.97 | −4.65 | −4.84 | −5.05 | −5.66 | −6.57 | −7.51 | −8.48 | −9.40 | −11.93 | |
| (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | |
| −6.35 | −4.93 | −4.84 | −4.54 | −4.62 | −4.81 | −5.27 | −6.05 | −8.88 | −14.46 | −12.65 | −8.70 | |
| (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | |
| −6.33 | −5.08 | −5.10 | −4.62 | −4.67 | −5.11 | −5.58 | −6.44 | −7.23 | −7.85 | −9.13 | −12.64 | |
| (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | |
| −6.46 | −5.06 | −4.96 | −4.54 | −4.53 | −4.71 | −5.11 | −5.98 | −8.86 | −13.08 | −11.52 | −9.12 | |
| (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | |
| −7.21 | −6.59 | −6.92 | −7.05 | −7.11 | −7.70 | −7.61 | −8.24 | −7.83 | −6.76 | −6.08 | −6.52 | |
| (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | |
| −5.82 | −6.48 | −6.90 | −5.76 | −5.39 | −5.26 | −5.71 | −4.88 | −5.67 | −5.13 | −4.41 | −4.95 | |
| (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | |
| −5.50 | −5.04 | −5.44 | −2.51 | −4.84 | −3.40 | −1.78 | −2.61 | −2.23 | −2.32 | −2.24 | −2.43 | |
| (0.00) | (0.00) | (0.00) | (0.01) | (0.00) | (0.00) | (0.04) | (0.01) | (0.01) | (0.01) | (0.01) | (0.01) | |
| −6.03 | −4.43 | −4.93 | −2.49 | −4.09 | −4.30 | −2.11 | −3.03 | −2.44 | −2.94 | −2.94 | −2.93 | |
| (0.00) | (0.00) | (0.00) | (0.01) | (0.00) | (0.00) | (0.02) | (0.00) | (0.01) | (0.00) | (0.00) | (0.00) | |
| −6.51 | −5.45 | −5.28 | −4.98 | −5.19 | −5.26 | −5.83 | −6.52 | −7.20 | −7.94 | −9.09 | −12.92 | |
| (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | |
| −7.27 | −6.68 | −7.11 | −7.35 | −7.42 | −7.62 | −7.50 | −7.82 | −7.26 | −6.52 | −6.06 | −6.16 | |
| (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | |
| −5.80 | −5.51 | −5.80 | −2.81 | −5.09 | −3.41 | −1.87 | −2.92 | −2.34 | −2.43 | −2.42 | −2.62 | |
| (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.03) | (0.00) | (0.01) | (0.01) | (0.01) | (0.01) | |
| −6.64 | −5.35 | −5.18 | −4.95 | −5.11 | −5.22 | −5.60 | −6.26 | −6.57 | −7.17 | −7.81 | −10.14 | |
| (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | |
| −7.25 | −7.49 | −10.72 | −10.59 | −7.37 | −15.25 | −7.52 | −8.37 | −6.97 | −14.25 | −10.91 | −46.46 | |
| (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | |
| - | −8.05 | −7.68 | −10.41 | −8.92 | −7.17 | −12.03 | −7.38 | −98.73 | −6.88 | −36.35 | −15.21 | −7.59 |
| (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | |
| −6.45 | −5.38 | −5.38 | −4.93 | −5.01 | −5.32 | −5.79 | −6.42 | −6.94 | −7.37 | −8.69 | −13.89 | |
| (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | |
| −8.72 | −6.76 | −8.05 | −8.56 | −9.75 | −10.65 | −11.82 | −10.42 | −17.75 | −27.30 | −7.47 | −7.35 | |
| (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | |
| −6.41 | −7.42 | −9.53 | −8.64 | −11.23 | −12.03 | −27.44 | −39.87 | −7.40 | −7.40 | −7.33 | −7.24 | |
| (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | |
| −6.52 | −5.57 | −5.38 | −5.15 | −5.31 | −5.33 | −5.85 | −6.50 | −6.89 | −7.28 | −8.07 | −10.05 | |
| (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | |
| −7.30 | −6.79 | −7.17 | −7.39 | −7.36 | −7.41 | −7.19 | −7.36 | −6.80 | −6.25 | −5.73 | −5.77 | |
| (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | |
| −5.62 | −5.51 | −5.84 | −2.83 | −5.00 | −3.29 | −1.86 | −2.93 | −2.27 | −2.39 | −2.38 | −2.58 | |
| (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.03) | (0.00) | (0.01) | (0.01) | (0.01) | (0.01) | |
| −6.62 | −5.47 | −5.26 | −5.13 | −5.25 | −5.31 | −5.57 | −6.21 | −6.31 | −6.61 | −7.07 | −8.56 | |
| (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | |
| −7.19 | −7.50 | −10.90 | −10.53 | −7.41 | −15.82 | −7.50 | −8.36 | −6.99 | −15.29 | −11.05 | −33.03 | |
| (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | |
| - | −8.02 | −7.73 | −10.41 | −8.87 | −7.15 | −12.00 | −7.36 | −8.15 | −6.90 | −56.69 | −15.26 | −7.55 |
| (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | |
| −6.47 | −5.48 | −5.47 | −5.09 | −5.12 | −5.37 | −5.79 | −6.38 | −6.65 | −6.81 | −7.74 | −10.51 | |
| (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | |
| −8.73 | −6.77 | −8.05 | −8.49 | −9.81 | −10.73 | −11.90 | −10.48 | −18.05 | −24.88 | −7.45 | −7.33 | |
| (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | |
| −6.39 | −7.45 | −9.65 | −8.63 | −11.27 | −12.35 | −36.83 | −7.41 | −7.38 | −7.36 | −7.31 | −7.24 | |
| (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | |
| −6.03 | −5.12 | −5.64 | −5.02 | −4.61 | −4.01 | −5.15 | −3.78 | −4.58 | −8.13 | −9.89 | −6.13 | |
| (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | |
| −6.22 | −4.68 | −5.37 | −6.21 | −4.71 | −4.53 | −5.62 | −4.41 | −6.58 | −5.69 | −6.00 | −5.82 | |
| (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | |
| −5.28 | −4.97 | −5.11 | −3.57 | −3.97 | −3.48 | −2.54 | −2.38 | −2.16 | −3.32 | −2.78 | −4.01 | |
| (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.01) | (0.01) | (0.02) | (0.00) | (0.00) | (0.00) | |
| −6.32 | −4.67 | −5.38 | −4.96 | −4.71 | −3.90 | −5.53 | −4.11 | −4.43 | −7.57 | −6.83 | −143.16 | |
| (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | |
| −6.81 | −5.82 | −6.27 | −8.09 | −8.86 | −5.51 | −17.62 | −17.02 | −10.96 | −16.10 | −7.21 | −7.43 | |
| (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | |
| - | −7.44 | −5.95 | −5.73 | −7.26 | −8.31 | −4.80 | −6.17 | −9.62 | −5.81 | −9.47 | −6.99 | −5.14 |
| (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | |
| −6.03 | −5.18 | −5.76 | −5.08 | −4.60 | −3.98 | −5.05 | −3.78 | −4.53 | −7.87 | −10.42 | −29.62 | |
| (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | |
| −8.81 | −6.38 | −7.76 | −7.98 | −8.62 | −8.05 | −11.81 | −23.83 | −6.83 | −7.60 | −7.16 | −7.60 | |
| (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | |
| −5.99 | −5.53 | −6.22 | −7.49 | −6.49 | −6.25 | −15.61 | −10.31 | −9.35 | −8.58 | −13.28 | −16.32 | |
| (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) |
| Horizon | ||
|---|---|---|
| 1 | 0.53 ** | 0.47 * |
| 2 | 0.48 | 0.52 |
| 3 | 0.41 | 0.59 |
| 4 | 0.22 | 0.78 * |
| 5 | −0.25 | 1.25 ** |
| 6 | −0.17 | 1.17 ** |
| 7 | 0.02 | 0.98 * |
| 8 | −0.08 | 1.08 ** |
| 9 | −0.51 | 1.51 *** |
| 10 | −0.01 | 1.01 ** |
| 11 | −0.97 | 1.97 *** |
| 12 | 0.09 | 0.91 * |
| 1 | Direct forecasts require estimating a separate time series model for each forecasting horizon; the only change between each model is the number of horizons ahead for the dependent variable. The recursive forecast is defined if we re-estimate the model for each period in the forecast evaluation sample and if we compute forecasts with the recursively estimated parameters. See pages 30 and 31 of Ghysels and Marcellino (2018) for a definition of a recursive forecast. |
| 2 | We considered an AR(13) model to approximate a multiplicative seasonality in which the non-seasonal part was the first-order autoregressive and the seasonal part was dependent on the previous year. |
| 3 | Stock and Watson (2007) assumed that , and that , or a mixture of two normal distributions, with with a probability 0.95 and with a probability 0.05. is the identity matrix of order 2, is a scalar parameter and controls the smoothness of the stochastic volatility process. |
| 4 | For comparison, Stock and Watson (2007) called the models (3) and (4) UC-SV, but the DGP for the SV was a random walk instead of the AR(1) model with a non-zero mean. This is the Stock and Watson (2007) formulation for UC-SV, which is unconventional. Their model implies that when the distribution of is a mixture of normal distributions, there is a heavy tail that is a characteristic of SV models. We think they used this model because they only estimated one parameter instead of six for two SVs: two constants in AR(1), two autoregressive parameters, and two variances. |
| 5 | In general, a model being congruent means not having a problem in the specifications based on tests of heteroskedasticity, autocorrelation, and normality, among others. A more detailed discussion is in the Appendix A.5. |
| 6 | These two sectors together have a 2.3% share in the industrial production index. |
| 7 | |
| 8 | The standard deviation of for industrial production in Brazil is about four times the standard deviation for the first difference in the logarithm of the non-seasonally adjusted US industrial production series for comparison. |
| 9 | A value-weighted portfolio means that the weight of a specific stock in a value-weighted portfolio is proportional to the market capitalization of this stock (Bhattacharya and Galpin 2011). |
| 10 | We compared the specifications of the selected ETS model that we obtained with the one from Hyndman et al. (2002). We considered the aggregated ETS model for simplification. Regarding the aggregated ETS model chosen for each of the 91 rolling windows, we determined that additive seasonality is more common, which differs from Hyndman et al. (2002), who found that most monthly series had multiplicative seasonality. Additive and additive dampened trends represent, respectively, 44% and 35% of the selected specifications in the 91 rolling windows. Hyndman et al. (2002) obtained a similar proportion of monthly series (with additive or additive dampened trends), which does not differ from what we obtained for the 91 rolling windows. So, we obtained a specification of the trend component for our case that was similar to the pattern reported by Hyndman et al. (2002), but our pattern differs in the case of the seasonality component (in relation to the authors). |
| 11 | We would like to acknowledge the comments by one of the referees. |
| 12 | The second statistic compares all of the models in pairs to obtain a set, but the computational process is more intense. |
References
- Aguiar, Mark, and Gita Gopinath. 2007. Emerging market business cycles: The cycle is the trend. Journal of Political Economy 115: 69–102. [Google Scholar] [CrossRef] [Green Version]
- Albert, Jim. 2009. Bayesian Computation with R. Berlin: Springer. [Google Scholar]
- Andrews, Donald W. K. 1991. Heteroskedasticity and autocorrelation consistent covariance matrix estimation. Econometrica: Journal of the Econometric Society 59: 817–58. [Google Scholar] [CrossRef]
- Barhoumi, Karim, Olivier Darné, and Laurent Ferrara. 2010. Are disaggregate data useful for factor analysis in forecasting French GDP? Journal of Forecasting 29: 132–44. [Google Scholar] [CrossRef] [Green Version]
- Barnett, Alina, Haroon Mumtaz, and Konstantinos Theodoridis. 2014. Forecasting UK GDP growth and inflation under structural change. a comparison of models with time-varying parameters. International Journal of Forecasting 30: 129–43. [Google Scholar] [CrossRef]
- Bhattacharya, Utpal, and Neal Galpin. 2011. The global rise of the value-weighted portfolio. Journal of Financial and Quantitative Analysis 46: 737–56. [Google Scholar] [CrossRef]
- Blake, Andrew P., and Haroon Mumtaz. 2017. Applied Bayesian Econometrics for Central Bankers. Technical Report. London: Bank of England. [Google Scholar]
- Borup, Daniel, and Erik Christian Montes Schütte. 2022. In search of a job: Forecasting employment growth using Google Trends. Journal of Business & Economic Statistics 40: 186–200. [Google Scholar]
- Bulligan, Guido, Roberto Golinelli, and Giuseppe Parigi. 2010. Forecasting monthly industrial production in real-time: From single equations to factor-based models. Empirical Economics 39: 303–36. [Google Scholar] [CrossRef]
- Carlo, Thiago Carlomagno, and Emerson Fernandes Marçal. 2016. Forecasting Brazilian inflation by its aggregate and disaggregated data: A test of predictive power by forecast horizon. Applied Economics 48: 4846–60. [Google Scholar] [CrossRef]
- Carstensen, Kai, Klaus Wohlrabe, and Christina Ziegler. 2011. Predictive ability of business cycle indicators under test: A case study for the Euro area industrial production. Journal of Economics and Statistics (Jahrbuecher fuer Nationaloekonomie und Statistik) 231: 82–106. [Google Scholar]
- Carter, Chris K., and Robert Kohn. 1994. On Gibbs sampling for state space models. Biometrika 81: 541–53. [Google Scholar] [CrossRef]
- Castle, Jennifer L., Jurgen A. Doornik, and David F. Hendry. 2011. Evaluating Automatic Model Selection. Journal of Time Series Econometrics 3: 1–33. [Google Scholar] [CrossRef] [Green Version]
- Castle, Jennifer L., Michael P. Clements, and David F. Hendry. 2015. Robust approaches to forecasting. International Journal of Forecasting 31: 99–112. [Google Scholar] [CrossRef] [Green Version]
- Chib, Siddhartha. 1995. Marginal likelihood from the Gibbs output. Journal of the American Statistical Association 90: 1313–21. [Google Scholar] [CrossRef]
- Chong, Yock Y., and David F. Hendry. 1986. Econometric evaluation of linear macro-economic models. The Review of Economic Studies 53: 671–90. [Google Scholar] [CrossRef]
- Clements, Michael P., and David F. Hendry. 1993. On the limitations of comparing mean square forecast errors. Journal of Forecasting 12: 617–37. [Google Scholar] [CrossRef]
- Diebold, Francis, and Roberto Mariano. 1995. Comparing predictive accuracy. Journal of Business & Economic Statistics 13: 253–63. [Google Scholar]
- Doornik, Jurgen A. 2008. Encompassing and Automatic Model Selection. Oxford Bulletin of Economics and Statistics 70: 915–25. [Google Scholar] [CrossRef]
- Doornik, Jurgen A., and David F. Hendry. 2022. Empirical Econometric Modellig—PcGive™ 16: Volume 1. London: Timberlake Consultants. [Google Scholar]
- Doornik, Jurgen A., Jennifer L. Castle, and David F. Hendry. 2020. Card forecasts for M4. International Journal of Forecasting 36: 129–34. [Google Scholar] [CrossRef]
- Elliott, Graham, and Allan Timmermann. 2008. Economic forecasting. Journal of Economic Literature 46: 3–56. [Google Scholar] [CrossRef]
- Epprecht, Camila, Dominique Guegan, Álvaro Veiga, and Joel Correa da Rosa. 2021. Variable selection and forecasting via automated methods for linear models: Lasso/adalasso and autometrics. Communications in Statistics-Simulation and Computation 50: 103–22. [Google Scholar] [CrossRef] [Green Version]
- Ericsson, Neil R. 1992. Parameter constancy, mean square forecast errors, and measuring forecast performance: An exposition, extensions, and illustration. Journal of Policy Modeling 14: 465–95. [Google Scholar] [CrossRef] [Green Version]
- Espasa, Antoni, Eva Senra, and Rebeca Albacete. 2002. Forecasting inflation in the european monetary union: A disaggregated approach by countries and by sectors. The European Journal of Finance 8: 402–21. [Google Scholar] [CrossRef] [Green Version]
- Faust, Jon, and Jonathan H. Wright. 2013. Forecasting inflation. In Handbook of Economic Forecasting. Amsterdam: Elsevier, vol. 2, pp. 2–56. [Google Scholar]
- Ghysels, Eric, and Massimiliano Marcellino. 2018. Applied Economic Forecasting Using Time Series Methods. Oxford: Oxford University Press. [Google Scholar]
- Giacomini, Raffaella. 2015. Economic theory and forecasting: Lessons from the literature. The Econometrics Journal 18: C22–C41. [Google Scholar] [CrossRef] [Green Version]
- Giacomini, Raffaella, and Barbara Rossi. 2010. Forecast comparisons in unstable environments. Journal of Applied Econometrics 25: 595–620. [Google Scholar] [CrossRef]
- Giacomini, Raffaella, and Clive W. J. Granger. 2004. Aggregation of space-time processes. Journal of Econometrics 118: 7–26. [Google Scholar] [CrossRef] [Green Version]
- Granger, Clive W. J. 1987. Implications of aggregation with common factors. Econometric Theory 3: 208–22. [Google Scholar] [CrossRef]
- Hansen, Peter R. 2005. A test for superior predictive ability. Journal of Business & Economic Statistics 23: 365–80. [Google Scholar] [CrossRef] [Green Version]
- Hansen, Peter R., Asger Lunde, and James M. Nason. 2011. The model confidence set. Econometrica 79: 453–97. [Google Scholar] [CrossRef] [Green Version]
- Harvey, David, Stephen Leybourne, and Paul Newbold. 1997. Testing the equality of prediction mean squared errors. International Journal of Forecasting 13: 281–91. [Google Scholar] [CrossRef]
- Harvey, David I., Stephen J. Leybourne, and Paul Newbold. 1998. Tests for forecast encompassing. Journal of Business & Economic Statistics 16: 254–59. [Google Scholar]
- Heinisch, Katja, and Rolf Scheufele. 2018. Bottom-up or direct? forecasting German GDP in a data-rich environment. Empirical Economics 54: 705–45. [Google Scholar] [CrossRef] [Green Version]
- Hendry, David F., and Bent Nielsen. 2007. Econometric Modeling: A Likelihood Approach. Princeton: Princeton University Press. [Google Scholar]
- Hendry, David F., and Kirstin Hubrich. 2011. Combining disaggregate forecasts or combining disaggregate information to forecast an aggregate. Journal of Business & Economic Statistics 29: 216–27. [Google Scholar]
- Hubrich, Kirstin. 2005. Forecasting Euro area inflation: Does aggregating forecasts by hicp component improve forecast accuracy? International Journal of Forecasting 21: 119–36. [Google Scholar] [CrossRef] [Green Version]
- Hyndman, Rob, Anne B. Koehler, J. Keith Ord, and Ralph D. Snyder. 2008. Forecasting with Exponential Smoothing: The State Space Approach. New York: Springer Science & Business Media. [Google Scholar]
- Hyndman, Robin John, and Yeasmin Khandakar. 2008. Automatic time series forecasting: The forecast package for R. Journal of Statistical Software 27: 1–22. [Google Scholar] [CrossRef] [Green Version]
- Hyndman, Rob J., Anne B. Koehler, J. Keith Ord, and Ralph D. Snyder. 2005. Prediction intervals for exponential smoothing using two new classes of state space models. Journal of Forecasting 24: 17–37. [Google Scholar] [CrossRef]
- Hyndman, Rob J., Anne B. Koehler, Ralph D. Snyder, and Simone Grose. 2002. A state space framework for automatic forecasting using exponential smoothing methods. International Journal of forecasting 18: 439–54. [Google Scholar] [CrossRef] [Green Version]
- Jacquier, Eric, Nicholas G. Polson, and Peter E. Rossi. 2002. Bayesian analysis of stochastic volatility models. Journal of Business & Economic Statistics 20: 69–87. [Google Scholar]
- Kapetanios, George, Massimiliano Marcellino, and Fabrizio Venditti. 2019. Large time-varying parameter vars: A nonparametric approach. Journal of Applied Econometrics 34: 1027–49. [Google Scholar] [CrossRef]
- Kock, Anders Bredahl, and Timo Teräsvirta. 2014. Forecasting performances of three automated modelling techniques during the economic crisis 2007–2009. International Journal of Forecasting 30: 616–31. [Google Scholar] [CrossRef]
- Kohn, David, Fernando Leibovici, and Håkon Tretvoll. 2021. Trade in commodities and business cycle volatility. American Economic Journal: Macroeconomics 13: 173–208. [Google Scholar] [CrossRef]
- Konzen, Evandro, and Flavio A. Ziegelmann. 2016. Lasso-type penalties for covariate selection and forecasting in time series. Journal of Forecasting 35: 592–612. [Google Scholar] [CrossRef]
- Kotchoni, Rachidi, Maxime Leroux, and Dalibor Stevanovic. 2019. Macroeconomic forecast accuracy in a data-rich environment. Journal of Applied Econometrics 34: 1050–72. [Google Scholar] [CrossRef]
- Kroese, Dirk P., and Joshua C. C. Chan. 2014. Statistical Modeling and Computation. Berlin: Springer. [Google Scholar]
- Lütkepohl, Helmut. 1984. Linear transformations of vector arma processes. Journal of Econometrics 26: 283–93. [Google Scholar] [CrossRef]
- Lütkepohl, Helmut. 1987. Forecasting Aggregated Vector ARMA Processes. New York: Springer Science & Business Media, vol. 284. [Google Scholar]
- Makridakis, Spyros, Evangelos Spiliotis, and Vassilios Assimakopoulos. 2020. The M4 competition: 100,000 time series and 61 forecasting methods. International Journal of Forecasting 36: 54–74. [Google Scholar] [CrossRef]
- Marcellino, Massimiliano, James H. Stock, and Mark W. Watson. 2003. Macroeconomic forecasting in the Euro area: Country specific versus area-wide information. European Economic Review 47: 1–18. [Google Scholar] [CrossRef]
- Martinez, Andrew B., Jennifer L. Castle, and David F. Hendry. 2022. Smooth robust multi-horizon forecasts. In Essays in Honor of M. Hashem Pesaran: Prediction and Macro Modeling. Bingley: Emerald Publishing Limited, pp. 143–65. [Google Scholar]
- Ord, John Keith, Anne B. Koehler, and Ralph D. Snyder. 1997. Estimation and prediction for a class of dynamic nonlinear statistical models. Journal of the American Statistical Association 92: 1621–29. [Google Scholar] [CrossRef]
- Park, Heewon, and Fumitake Sakaori. 2013. Lag weighted lasso for time series model. Computational Statistics 28: 493–504. [Google Scholar] [CrossRef]
- Pesaran, M. Hashem, Richard G. Pierse, and Mohan S. Kumar. 1989. Econometric analysis of aggregation in the context of linear prediction models. Econometrica: Journal of the Econometric Society 57: 861–88. [Google Scholar] [CrossRef]
- Picchetti, Paulo. 2018. Brazilian business cycles as characterized by CODACE. In Business Cycles in BRICS. Cham: Springer International Publishing, pp. 331–35. [Google Scholar] [CrossRef]
- Pretis, Felix, J. James Reade, and Genaro Sucarrat. 2018. Automated general-to-specific (GETS) regression modeling and indicator saturation for outliers and structural breaks. Journal of Statistical Software 86: 1–44. [Google Scholar] [CrossRef]
- Quaedvlieg, Rogier. 2021. Multi-horizon forecast comparison. Journal of Business & Economic Statistics 39: 40–53. [Google Scholar]
- Rapach, David E., Matthew C. Ringgenberg, and Guofu Zhou. 2016. Short interest and aggregate stock returns. Journal of Financial Economics 121: 46–65. [Google Scholar] [CrossRef]
- Rossi, Barbara, and Tatevik Sekhposyan. 2010. Have economic models’ forecasting performance for us output growth and inflation changed over time, and when? International Journal of Forecasting 26: 808–35. [Google Scholar] [CrossRef]
- Stock, James H., and Mark W. Watson. 2002. Macroeconomic forecasting using diffusion indexes. Journal of Business & Economic Statistics 20: 147–62. [Google Scholar]
- Stock, James H., and Mark W. Watson. 2007. Why has US inflation become harder to forecast? Journal of Money, Credit and Banking 39: 3–33. [Google Scholar] [CrossRef] [Green Version]
- Talagala, Thiyanga S., Rob J. Hyndman, and George Athanasopoulos. 2018. Meta-learning how to forecast time series. Monash Econometrics and Business Statistics Working Papers 6: 16. [Google Scholar]
- Tibshirani, Robert. 1996. Regression shrinkage and selection via the LASSO. Journal of the Royal Statistical Society: Series B (Methodological) 58: 267–88. [Google Scholar] [CrossRef]
- Van Garderen, Kees Jan, Kevin Lee, and M. Hashem Pesaran. 2000. Cross-sectional aggregation of non-linear models. Journal of Econometrics 95: 285–331. [Google Scholar] [CrossRef]
- Weber, Enzo, and Gerd Zika. 2016. Labour market forecasting in Germany: Is disaggregation useful? Applied Economics 48: 2183–98. [Google Scholar] [CrossRef]
- Zellner, Arnold, and Justin Tobias. 2000. A note on aggregation, disaggregation and forecasting performance. Journal of Forecasting 19: 457–65. [Google Scholar] [CrossRef]
- Zou, Hui. 2006. The adaptive Lasso and its Oracle properties. Journal of the American Statistical Association 101: 1418–29. [Google Scholar] [CrossRef] [Green Version]


| Abbreviation | Definition |
|---|---|
| AR(1) with disaggregated series | |
| AR(1) with aggregated series | |
| AR(13) with disaggregated series | |
| AR(13) with aggregated series | |
| TVP-AR(1) with disaggregated series | |
| TVP-AR(1) with aggregated series | |
| - | UC-SV with disaggregated series |
| - | UC-SV with aggregated series |
| ETS with disaggregated series | |
| ETS with aggregated series | |
| LASSO with disaggregated series | |
| LASSO with aggregated series | |
| adaLASSO with disaggregated series | |
| adaLASSO with aggregated series | |
| WLadaLASSO with disaggregated series | |
| WLadaLASSO with aggregated series | |
| Autometrics without outlier and with disaggregated series | |
| Autometrics without outlier and with aggregated series | |
| Autometrics with IIS dummy variables and with disaggregated series | |
| Autometrics with IIS dummy variables and with aggregated series | |
| Combination with LASSO to select and use adaLASSO forecasts | |
| Combination with LASSO to select and use forecasts | |
| Combination with LASSO to select and use forecasts | |
| Combination with LASSO to select and use LASSO forecasts | |
| Combination with LASSO to select and use TVP-AR(1) forecasts | |
| - | Combination with LASSO to select and use UC-SV forecasts |
| Combination with LASSO to select and use WLadaLASSO forecasts | |
| Combination with LASSO to select and use ETS forecasts | |
| Combination with LASSO to select and use AR(1) forecasts | |
| Combination with adaLASSO to select and use adaLASSO forecasts | |
| Combination with adaLASSO to select and use forecasts | |
| Combination with adaLASSO to select and use forecasts | |
| Combination with adaLASSO to select and use LASSO forecasts | |
| Combination with adaLASSO to select and use TVP-AR(1) forecasts | |
| - | Combination with adaLASSO to select and use UC-SV forecasts |
| Combination with adaLASSO to select and use WLadaLASSO forecasts | |
| Combination with adaLASSO to select and use ETS forecasts | |
| Combination with adaLASSO to select and use AR(1) forecasts | |
| Combination with Autometrics to select and use adaLASSO forecasts | |
| Combination with Autometrics to select and use forecasts | |
| Combination with Autometrics to select and use forecasts | |
| Combination with Autometrics to select and use LASSO forecasts | |
| Combination with Autometrics to select and use TVP-AR(1) forecasts | |
| - | Combination with Autometrics to select and use UC-SV forecasts |
| Combination with Autometrics to select and use WLadaLASSO forecasts | |
| Combination with Autometrics to select and use ETS forecasts | |
| Combination with Autometrics to select and use AR(1) forecasts |
| Models | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 4.01 | 4.12 | 4.22 | 4.28 | 4.31 | 4.33 | 4.34 | 4.33 | 4.32 | 4.33 | 4.33 | 4.33 | |
| 4.24 | 4.26 | 4.32 | 4.35 | 4.37 | 4.37 | 4.37 | 4.36 | 4.35 | 4.35 | 4.35 | 4.35 | |
| 1.21 | 1.41 | 1.51 | 1.59 | 1.65 | 1.68 | 1.70 | 1.71 | 1.72 | 1.72 | 1.73 | 1.73 | |
| 1.39 | 1.61 | 1.70 | 1.78 | 1.86 | 1.90 | 1.91 | 1.93 | 1.94 | 1.95 | 1.96 | 1.96 | |
| 5.27 | 5.29 | 5.70 | 5.96 | 6.05 | 6.12 | 6.11 | 6.08 | 5.94 | 5.74 | 5.52 | 5.30 | |
| 5.31 | 5.31 | 5.71 | 5.96 | 6.03 | 6.09 | 6.06 | 6.01 | 5.86 | 5.65 | 5.44 | 5.24 | |
| - | 5.02 | 7.51 | 8.34 | 8.81 | 9.13 | 9.35 | 9.50 | 9.62 | 9.70 | 9.73 | 9.77 | 9.80 |
| - | 4.97 | 7.44 | 8.29 | 8.77 | 9.08 | 9.31 | 9.47 | 9.59 | 9.66 | 9.70 | 9.74 | 9.77 |
| 0.16 | 0.19 | 0.21 | 0.21 | 0.22 | 0.22 | 0.22 | 0.22 | 0.22 | 0.22 | 0.22 | 0.22 | |
| 0.16 | 0.19 | 0.21 | 0.21 | 0.22 | 0.22 | 0.22 | 0.22 | 0.22 | 0.22 | 0.23 | 0.23 | |
| 1.25 | 1.40 | 1.49 | 1.58 | 1.64 | 1.67 | 1.69 | 1.70 | 1.71 | 1.72 | 1.74 | 1.75 | |
| 1.58 | 1.72 | 1.81 | 1.92 | 2.01 | 2.05 | 2.06 | 2.08 | 2.09 | 2.09 | 2.09 | 2.09 | |
| 1.25 | 1.40 | 1.49 | 1.57 | 1.63 | 1.66 | 1.68 | 1.70 | 1.71 | 1.72 | 1.74 | 1.75 | |
| 1.62 | 1.74 | 1.83 | 1.94 | 2.01 | 2.04 | 2.05 | 2.08 | 2.08 | 2.08 | 2.09 | 2.09 | |
| 1.24 | 1.38 | 1.47 | 1.55 | 1.60 | 1.63 | 1.66 | 1.67 | 1.69 | 1.70 | 1.71 | 1.72 | |
| 1.59 | 1.75 | 1.86 | 1.97 | 2.05 | 2.09 | 2.11 | 2.13 | 2.14 | 2.14 | 2.14 | 2.15 | |
| 1.78 | 1.76 | 1.76 | 1.79 | 1.81 | 1.81 | 1.81 | 1.81 | 1.82 | 1.82 | 1.82 | 1.83 | |
| 2.04 | 2.01 | 1.93 | 1.97 | 1.97 | 1.99 | 2.00 | 1.99 | 1.98 | 1.96 | 1.95 | 1.94 | |
| 2.00 | 2.06 | 2.27 | 2.94 | 2.72 | 2.56 | 2.60 | 2.51 | 2.50 | 2.45 | 2.45 | 2.42 | |
| 2.16 | 2.28 | 2.50 | 3.19 | 3.05 | 2.95 | 3.05 | 2.94 | 2.93 | 2.92 | 2.90 | 2.90 | |
| 1.27 | 1.42 | 1.51 | 1.60 | 1.66 | 1.70 | 1.72 | 1.74 | 1.76 | 1.77 | 1.79 | 1.81 | |
| 1.84 | 1.82 | 1.83 | 1.86 | 1.88 | 1.89 | 1.89 | 1.89 | 1.89 | 1.90 | 1.91 | 1.92 | |
| 1.97 | 2.03 | 2.26 | 2.76 | 2.58 | 2.46 | 2.50 | 2.42 | 2.41 | 2.38 | 2.37 | 2.35 | |
| 1.27 | 1.42 | 1.52 | 1.61 | 1.67 | 1.71 | 1.73 | 1.74 | 1.76 | 1.77 | 1.79 | 1.80 | |
| 4.89 | 4.93 | 5.30 | 5.56 | 5.64 | 5.71 | 5.70 | 5.67 | 5.53 | 5.35 | 5.15 | 4.96 | |
| - | 4.74 | 4.57 | 4.76 | 4.92 | 4.96 | 5.01 | 4.98 | 4.95 | 4.86 | 4.72 | 4.63 | 4.51 |
| 1.25 | 1.40 | 1.49 | 1.57 | 1.63 | 1.66 | 1.69 | 1.71 | 1.73 | 1.75 | 1.77 | 1.78 | |
| 3.22 | 2.68 | 2.52 | 2.44 | 2.40 | 2.36 | 2.34 | 2.32 | 2.31 | 2.30 | 2.30 | 2.29 | |
| 3.79 | 3.92 | 4.02 | 4.08 | 4.12 | 4.13 | 4.14 | 4.14 | 4.13 | 4.13 | 4.14 | 4.14 | |
| 1.29 | 1.44 | 1.53 | 1.61 | 1.67 | 1.70 | 1.73 | 1.75 | 1.77 | 1.79 | 1.81 | 1.82 | |
| 1.92 | 1.88 | 1.89 | 1.91 | 1.93 | 1.93 | 1.92 | 1.93 | 1.93 | 1.94 | 1.95 | 1.95 | |
| 2.05 | 2.10 | 2.34 | 2.86 | 2.67 | 2.55 | 2.59 | 2.50 | 2.50 | 2.46 | 2.45 | 2.43 | |
| 1.28 | 1.44 | 1.53 | 1.62 | 1.68 | 1.72 | 1.74 | 1.76 | 1.77 | 1.79 | 1.81 | 1.82 | |
| 4.98 | 5.03 | 5.42 | 5.69 | 5.78 | 5.85 | 5.84 | 5.81 | 5.67 | 5.48 | 5.28 | 5.08 | |
| - | 4.88 | 4.71 | 4.91 | 5.07 | 5.12 | 5.17 | 5.14 | 5.11 | 5.00 | 4.86 | 4.76 | 4.63 |
| 1.27 | 1.41 | 1.50 | 1.57 | 1.63 | 1.67 | 1.69 | 1.72 | 1.74 | 1.76 | 1.78 | 1.80 | |
| 3.18 | 2.65 | 2.49 | 2.42 | 2.38 | 2.34 | 2.32 | 2.30 | 2.29 | 2.28 | 2.28 | 2.27 | |
| 3.86 | 4.00 | 4.11 | 4.17 | 4.21 | 4.22 | 4.23 | 4.23 | 4.22 | 4.22 | 4.22 | 4.22 | |
| 1.48 | 1.63 | 1.71 | 1.81 | 1.94 | 2.04 | 2.06 | 2.07 | 2.12 | 2.14 | 2.12 | 2.12 | |
| 2.03 | 1.89 | 1.93 | 1.97 | 2.08 | 2.15 | 2.14 | 2.13 | 2.15 | 2.16 | 2.16 | 2.17 | |
| 1.98 | 1.90 | 1.97 | 2.38 | 2.32 | 2.28 | 2.24 | 2.19 | 2.23 | 2.21 | 2.24 | 2.20 | |
| 1.54 | 1.69 | 1.76 | 1.85 | 1.98 | 2.07 | 2.08 | 2.09 | 2.14 | 2.15 | 2.13 | 2.13 | |
| 4.63 | 4.29 | 4.32 | 4.37 | 4.42 | 4.55 | 4.53 | 4.57 | 4.54 | 4.40 | 4.29 | 4.20 | |
| - | 4.50 | 4.02 | 3.92 | 3.98 | 3.98 | 4.11 | 4.12 | 4.16 | 4.18 | 4.08 | 4.05 | 4.00 |
| 1.47 | 1.63 | 1.70 | 1.80 | 1.92 | 2.02 | 2.03 | 2.05 | 2.10 | 2.11 | 2.10 | 2.10 | |
| 3.81 | 3.22 | 3.03 | 2.93 | 2.85 | 2.80 | 2.78 | 2.75 | 2.76 | 2.74 | 2.73 | 2.71 | |
| 3.55 | 3.54 | 3.53 | 3.55 | 3.63 | 3.70 | 3.68 | 3.67 | 3.65 | 3.64 | 3.64 | 3.61 |
| Models | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| - | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| - | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 0.91 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | |
| 1.00 | 0.98 | 0.89 | 0.62 | 0.25 | 0.28 | 0.37 | 0.30 | 0.09 | 0.28 | 0.01 | 0.50 | |
| 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.01 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.01 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.02 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| - | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.02 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| - | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.01 | 0.00 | 0.00 | 0.00 | |
| 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| - | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Models | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.1 | *** | 1.1 | *** | 1.1 | *** | 1.1 | *** | 1.1 | *** | |
| 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.1 | *** | 1.1 | *** | 1.1 | *** | 1.1 | *** | 1.1 | *** | |
| 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | |
| 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | |
| 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.1 | *** | 1.1 | *** | |
| 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.1 | *** | 1.1 | *** | |
| - | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** |
| - | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** |
| 0.5 | * | 0.5 | 0.6 | 0.8 | * | 1.2 | ** | 1.2 | ** | 1.0 | * | 1.1 | ** | 1.5 | *** | 1.0 | ** | 2.0 | *** | 0.9 | * | |||
| 1.2 | *** | 1.3 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.3 | *** | 1.3 | *** | 1.3 | *** | 1.3 | *** | |
| 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.3 | *** | 1.3 | *** | 1.3 | *** | |
| 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.3 | *** | 1.3 | *** | 1.3 | *** | 1.3 | *** | |
| 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.3 | *** | 1.2 | *** | 1.2 | *** | 1.3 | *** | |
| 1.2 | *** | 1.3 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.3 | *** | 1.3 | *** | 1.3 | *** | 1.3 | *** | |
| 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | |
| 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | |
| 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.3 | *** | 1.2 | *** | |
| 1.1 | *** | 1.1 | *** | 1.1 | *** | 1.0 | *** | 1.2 | *** | 1.2 | *** | 1.1 | ** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | |
| 1.1 | *** | 1.1 | *** | 1.1 | *** | 1.0 | *** | 1.2 | *** | 1.2 | *** | 1.1 | *** | 1.2 | *** | 1.1 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | |
| 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | |
| 1.1 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | |
| 1.1 | *** | 1.1 | *** | 1.1 | *** | 1.0 | *** | 1.2 | *** | 1.2 | *** | 1.1 | ** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | |
| 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | |
| 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.1 | *** | 1.1 | *** | |
| - | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.1 | *** | 1.0 | *** | 1.1 | *** | 1.1 | *** | 1.1 | *** | 1.1 | *** |
| 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | |
| 1.1 | *** | 1.1 | *** | 1.1 | *** | 1.1 | *** | 1.2 | *** | 1.1 | *** | 1.1 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | |
| 1.1 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.1 | *** | 1.0 | *** | 1.1 | *** | 1.1 | *** | 1.1 | *** | 1.1 | *** | 1.1 | *** | 1.1 | *** | |
| 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | |
| 1.1 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | |
| 1.1 | *** | 1.1 | *** | 1.1 | *** | 1.0 | *** | 1.2 | *** | 1.2 | *** | 1.1 | ** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | |
| 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | |
| 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.1 | *** | 1.1 | *** | |
| - | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.1 | *** | 1.0 | *** | 1.1 | *** | 1.1 | *** | 1.1 | *** | 1.1 | *** |
| 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | |
| 1.1 | *** | 1.1 | *** | 1.1 | *** | 1.1 | *** | 1.2 | *** | 1.1 | *** | 1.1 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | |
| 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.0 | *** | 1.1 | *** | 1.0 | *** | 1.0 | *** | 1.1 | *** | 1.1 | *** | 1.1 | *** | 1.1 | *** | 1.1 | *** | |
| 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.3 | *** | 1.2 | *** | |
| 1.1 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | |
| 1.1 | *** | 1.1 | *** | 1.2 | *** | 1.1 | *** | 1.3 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | ** | 1.3 | *** | 1.2 | *** | 1.3 | *** | |
| 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.3 | *** | 1.2 | *** | |
| 1.1 | *** | 1.0 | *** | 1.0 | *** | 1.1 | *** | 1.1 | *** | 1.1 | *** | 1.1 | *** | 1.0 | *** | 1.1 | *** | 1.1 | *** | 1.1 | *** | 1.1 | *** | |
| - | 1.1 | *** | 1.0 | *** | 1.0 | *** | 1.1 | *** | 1.1 | *** | 1.1 | *** | 1.1 | *** | 1.0 | *** | 1.1 | *** | 1.1 | *** | 1.0 | *** | 1.1 | *** |
| 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.2 | *** | 1.3 | *** | 1.3 | *** | 1.2 | *** | |
| 1.1 | *** | 1.1 | *** | 1.1 | *** | 1.1 | *** | 1.1 | *** | 1.1 | *** | 1.1 | *** | 1.1 | *** | 1.1 | *** | 1.1 | *** | 1.1 | *** | 1.1 | *** | |
| 1.1 | *** | 1.1 | *** | 1.1 | *** | 1.1 | *** | 1.1 | *** | 1.1 | *** | 1.1 | *** | 1.1 | *** | 1.1 | *** | 1.1 | *** | 1.1 | *** | 1.1 | *** | |
| uSPA | aSPA | |||
|---|---|---|---|---|
| Models | t Statistics | p-Value | t Statistics | p-Value |
| 7.724 | 0.000 | 29.404 | 0.000 | |
| 7.758 | 0.000 | 29.522 | 0.000 | |
| 4.810 | 0.000 | 11.127 | 0.000 | |
| 4.768 | 0.000 | 9.783 | 0.001 | |
| 7.539 | 0.000 | 28.050 | 0.000 | |
| 7.431 | 0.000 | 28.734 | 0.000 | |
| - | 7.189 | 0.000 | 16.878 | 0.000 |
| - | 7.127 | 0.000 | 17.065 | 0.000 |
| −0.124 | 0.003 | 2.722 | 0.009 | |
| 4.731 | 0.000 | 11.025 | 0.000 | |
| 4.159 | 0.000 | 9.134 | 0.001 | |
| 4.830 | 0.000 | 11.240 | 0.001 | |
| 4.778 | 0.000 | 10.155 | 0.000 | |
| 4.773 | 0.000 | 11.284 | 0.000 | |
| 4.761 | 0.000 | 9.746 | 0.001 | |
| 6.549 | 0.000 | 14.215 | 0.000 | |
| 5.637 | 0.000 | 10.512 | 0.001 | |
| 2.455 | 0.000 | 4.659 | 0.002 | |
| 2.940 | 0.000 | 5.151 | 0.002 | |
| 5.077 | 0.000 | 11.562 | 0.000 | |
| 6.715 | 0.000 | 14.349 | 0.000 | |
| 2.576 | 0.000 | 5.090 | 0.001 | |
| 4.962 | 0.000 | 11.308 | 0.001 | |
| 7.518 | 0.000 | 28.717 | 0.000 | |
| - | 7.502 | 0.000 | 28.987 | 0.000 |
| 4.993 | 0.000 | 11.635 | 0.000 | |
| 6.934 | 0.000 | 20.147 | 0.000 | |
| 7.856 | 0.000 | 27.967 | 0.000 | |
| 5.229 | 0.000 | 11.606 | 0.000 | |
| 6.705 | 0.000 | 13.912 | 0.000 | |
| 2.556 | 0.000 | 5.033 | 0.001 | |
| 5.229 | 0.000 | 11.606 | 0.000 | |
| 7.510 | 0.000 | 29.496 | 0.000 | |
| - | 7.549 | 0.000 | 29.223 | 0.000 |
| 5.127 | 0.000 | 11.658 | 0.000 | |
| 6.917 | 0.000 | 20.114 | 0.000 | |
| 7.846 | 0.000 | 29.007 | 0.000 | |
| 3.805 | 0.000 | 10.468 | 0.000 | |
| 4.854 | 0.000 | 11.488 | 0.000 | |
| 3.103 | 0.000 | 6.388 | 0.001 | |
| 3.805 | 0.000 | 10.468 | 0.000 | |
| 5.941 | 0.000 | 15.168 | 0.000 | |
| - | 4.469 | 0.000 | 11.117 | 0.000 |
| 3.754 | 0.000 | 10.347 | 0.000 | |
| 6.832 | 0.000 | 19.809 | 0.000 | |
| 5.903 | 0.000 | 16.763 | 0.000 | |
| uSPA | aSPA | |||
|---|---|---|---|---|
| Horizons | t-Statistics | p-Value | t-Statistics | p-Value |
| 1 | −0.124 | 0.612 | −0.124 | 0.617 |
| 1,2 | −0.124 | 0.407 | −0.073 | 0.574 |
| 1,2,3 | −0.124 | 0.280 | 0.014 | 0.488 |
| 1,2,3,4 | −0.124 | 0.196 | 0.171 | 0.361 |
| 1,…,5 | −0.124 | 0.153 | 0.506 | 0.165 |
| 1,…,6 | −0.124 | 0.088 | 0.783 | 0.101 |
| 1,…,7 | −0.124 | 0.065 | 0.912 | 0.081 |
| 1,…,8 | −0.124 | 0.028 | 1.189 | 0.049 |
| 1,…,9 | −0.124 | 0.016 | 1.715 | 0.025 |
| 1,…,10 | −0.124 | 0.010 | 2.003 | 0.019 |
| 1,…,11 | −0.124 | 0.005 | 2.727 | 0.009 |
| 1,…,12 | −0.124 | 0.003 | 2.722 | 0.009 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
de Prince, D.; Marçal, E.F.; Valls Pereira, P.L. Forecasting Industrial Production Using Its Aggregated and Disaggregated Series or a Combination of Both: Evidence from One Emerging Market Economy. Econometrics 2022, 10, 27. https://doi.org/10.3390/econometrics10020027
de Prince D, Marçal EF, Valls Pereira PL. Forecasting Industrial Production Using Its Aggregated and Disaggregated Series or a Combination of Both: Evidence from One Emerging Market Economy. Econometrics. 2022; 10(2):27. https://doi.org/10.3390/econometrics10020027
Chicago/Turabian Stylede Prince, Diogo, Emerson Fernandes Marçal, and Pedro L. Valls Pereira. 2022. "Forecasting Industrial Production Using Its Aggregated and Disaggregated Series or a Combination of Both: Evidence from One Emerging Market Economy" Econometrics 10, no. 2: 27. https://doi.org/10.3390/econometrics10020027
APA Stylede Prince, D., Marçal, E. F., & Valls Pereira, P. L. (2022). Forecasting Industrial Production Using Its Aggregated and Disaggregated Series or a Combination of Both: Evidence from One Emerging Market Economy. Econometrics, 10(2), 27. https://doi.org/10.3390/econometrics10020027