
Heteroskedasticity of Unknown Form in Spatial Autoregressive Models with a Moving Average Disturbance Term

Abstract
:1. Introduction
2. Model Specification and Assumptions
3. Spatial Processes for the Disturbance Term

4. The MLE of and

5. The MLE of
- (1)
- For the SARMA(1,1) model, we have:
- (2)
- For the SARMA(0,1) model, where , we have .
- (3)
- For the SARMA(1,0) model, where , we have:
6. Monte Carlo Simulation
6.1. Design
6.2. Simulation Results
7. Conclusions
Appendix
A: Some Useful Lemmas
- (1)
- (2)
- (3)
- (4)
- (5)
B: Proof of Proposition 1
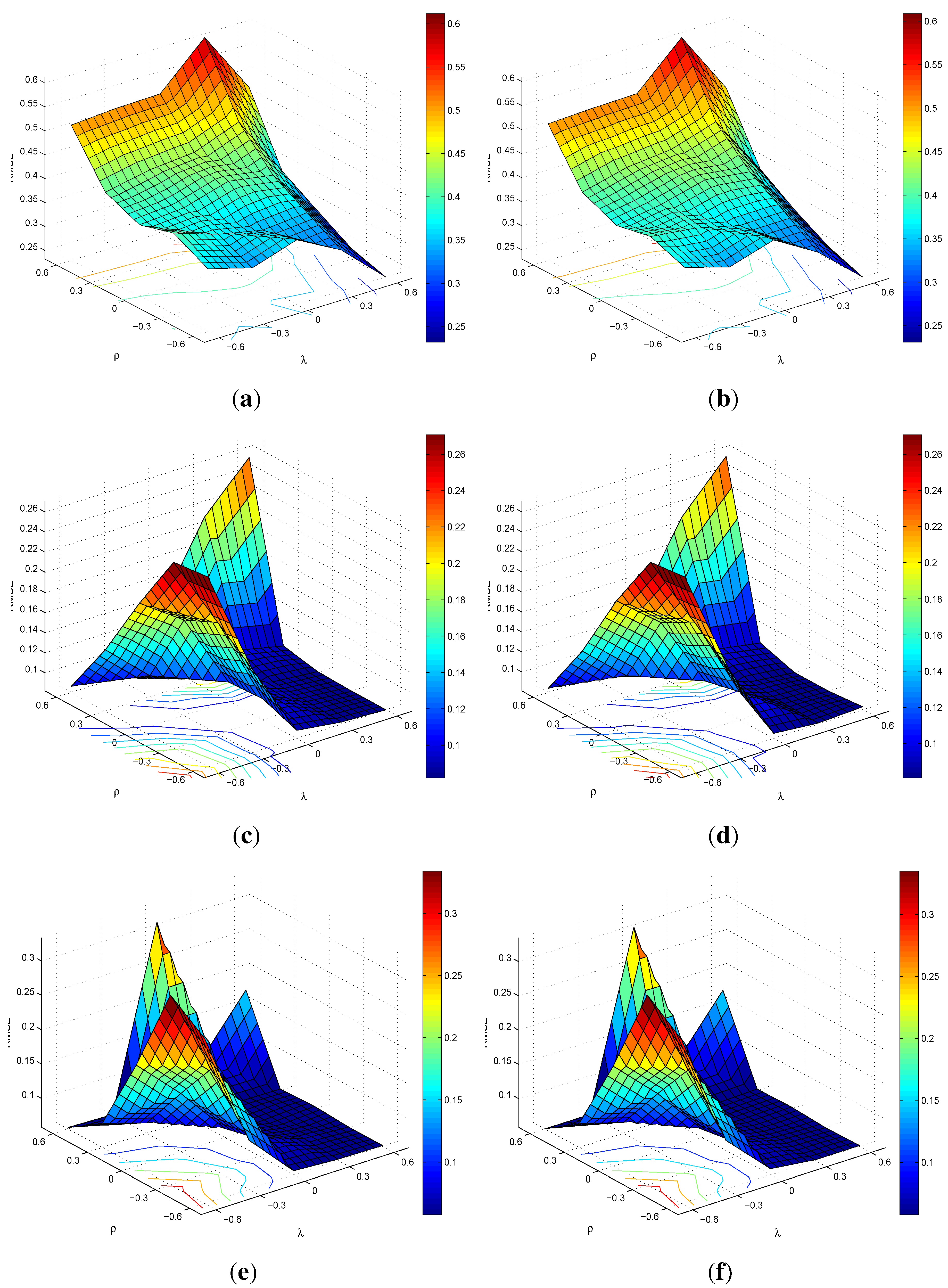
C: Simulation Results for SARMA(0,1)

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ρ | ||||||
|---|---|---|---|---|---|---|
| ρ | (Mean)[Bias](SE)[RMSE] | (Mean)[Bias](SE)[RMSE] | (Mean)[Bias](SE)[RMSE] | |||
| −0.6 | (0.987)[−0.013](0.209)[0.209] | (1.009)[0.009](0.218)[0.218] | (−0.405)[0.195](0.618)[0.648] | |||
| −0.3 | (1.000)[−0.000](0.211)[0.211] | (0.998)[−0.002](0.203)[0.203] | (−0.205)[0.095](0.630)[0.637] | |||
| 0.0 | (1.001)[0.001](0.214)[0.214] | (1.008)[0.008](0.229)[0.229] | (0.101)[0.101](0.565)[0.574] | |||
| 0.3 | (1.000)[0.000](0.217)[0.217] | (0.993)[−0.007](0.222)[0.222] | (0.434)[0.134](0.386)[0.409] | |||
| 0.6 | (0.996)[−0.004](0.212)[0.212] | (0.998)[−0.002](0.210)[0.210] | (0.710)[0.110](0.204)[0.232] | |||
| −0.6 | (1.006)[0.006](0.083)[0.083] | (0.995)[−0.005](0.082)[0.082] | (−0.652)[−0.052](0.377)[0.380] | |||
| −0.3 | (1.001)[0.001](0.083)[0.083] | (1.002)[0.002](0.084)[0.084] | (−0.354)[−0.054](0.388)[0.392] | |||
| 0.0 | (0.998)[−0.002](0.084)[0.084] | (1.002)[0.002](0.082)[0.082] | (0.007)[0.007](0.293)[0.293] | |||
| 0.3 | (1.005)[0.005](0.085)[0.085] | (0.998)[−0.002](0.080)[0.080] | (0.346)[0.046](0.189)[0.194] | |||
| 0.6 | (0.997)[−0.003](0.078)[0.078] | (1.002)[0.002](0.081)[0.081] | (0.652)[0.052](0.095)[0.108] | |||
| 1,000 | ||||||
| −0.6 | (1.000)[−0.000](0.058)[0.058] | (1.000)[0.000](0.059)[0.059] | (−0.682)[−0.082](0.284)[0.296] | |||
| −0.3 | (0.999)[−0.001](0.059)[0.059] | (0.998)[-0.002](0.058)[0.058] | (−0.342)[−0.042](0.274)[0.277] | |||
| 0.0 | (1.000)[−0.000](0.057)[0.057] | (1.004)[0.004](0.059)[0.059] | (0.010)[0.010](0.191)[0.191] | |||
| 0.3 | (0.998)[−0.002](0.058)[0.058] | (1.000)[0.000](0.058)[0.058] | (0.330)[0.030](0.125)[0.128] | |||
| 0.6 | (1.002)[0.002](0.057)[0.057] | (0.999)[−0.001](0.057)[0.057] | (0.630)[0.030](0.072)[0.078] | |||
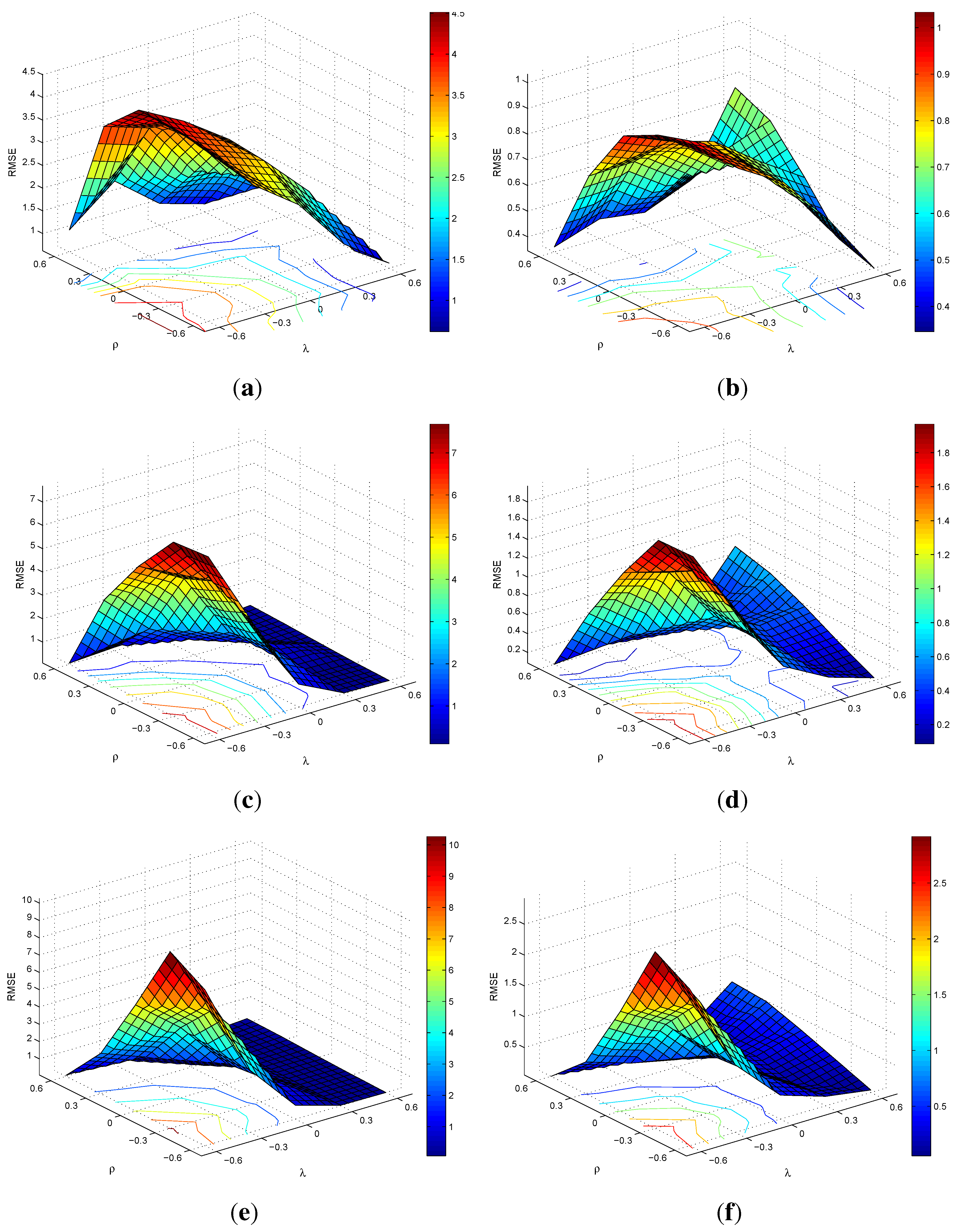
D: Simulation Results for SARMA(1,1)
| λ | ρ | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| λ | ρ | (Mean)[Bias](SE)[RMSE] | (Mean)[Bias](SE)[RMSE] | (Mean)[Bias](SE)[RMSE] | (Mean)[Bias](SE)[RMSE] | |||||
| −0.6 | −0.6 | (−1.583)[−0.983](4.262)[4.374] | (0.874)[−0.126](0.342)[0.364] | (0.898)[-0.102](0.350)[0.365] | (−0.273)[0.327](0.981)[1.034] | |||||
| −0.6 | −0.3 | (−1.790)[−1.190](4.346)[4.506] | (0.848)[−0.152](0.371)[0.401] | (0.847)[−0.153](0.361)[0.392] | (−0.178)[0.122](0.997)[1.004] | |||||
| −0.6 | 0.0 | (−1.794)[v1.194](4.355)[4.516] | (0.867)[−0.133](0.357)[0.381] | (0.865)[−0.135](0.353)[0.378] | (0.021)[0.021](0.934)[0.934] | |||||
| −0.6 | 0.3 | (−1.404)[−0.804](3.687)[3.773] | (0.839)[−0.161](0.379)[0.412] | (0.851)[−0.149](0.382)[0.410] | (0.264)[−0.036](0.709)[0.710] | |||||
| −0.6 | 0.6 | (−0.591)[0.009](1.108)[1.108] | (0.760)[−0.240](0.455)[0.515] | (0.760)[−0.240](0.455)[0.515] | (0.470)[−0.130](0.342)[0.366] | |||||
| −0.3 | −0.6 | (−0.907)[−0.607](3.275)[3.331] | (0.912)[−0.088](0.325)[0.337] | (0.907)[−0.093](0.324)[0.337] | (−0.259)[0.341](0.822)[0.890] | |||||
| −0.3 | −0.3 | (−1.132)[−0.832](3.497)[3.594] | (0.882)[−0.118](0.351)[0.370] | (0.881)[−0.119](0.362)[0.381] | (−0.136)[0.164](0.906)[0.920] | |||||
| −0.3 | 0.0 | (−1.335)[−1.035](3.840)[3.977] | (0.857)[−0.143](0.361)[0.388] | (0.861)[−0.139](0.367)[0.393] | (−0.005)[−0.005](0.861)[0.861] | |||||
| −0.3 | 0.3 | (−1.045)[−0.745](3.364)[3.445] | (0.840)[−0.160](0.399)[0.430] | (0.835)[−0.165](0.400)[0.433] | (0.220)[−0.080](0.709)[0.714] | |||||
| −0.3 | 0.6 | (−0.574)[−0.274](1.873)[1.893] | (0.768)[−0.232](0.466)[0.521] | (0.758)[−0.242](0.459)[0.519] | (0.436)[−0.164](0.390)[0.423] | |||||
| 0.0 | −0.6 | (−0.452)[−0.452](2.570)[2.609] | (0.904)[−0.096](0.354)[0.367] | (0.898)[−0.102](0.350)[0.365] | (−0.292)[0.308](0.721)[0.784] | |||||
| 0.0 | −0.3 | (−0.690)[−0.690](3.123)[3.199] | (0.903)[−0.097](0.337)[0.350] | (0.889)[−0.111](0.340)[0.358] | (−0.208)[0.092](0.772)[0.778] | |||||
| 0.0 | 0.0 | (−0.834)[−0.834](3.174)[3.282] | (0.841)[−0.159](0.383)[0.415] | (0.857)[−0.143](0.391)[0.416] | (−0.079)[−0.079](0.804)[0.808] | |||||
| 0.0 | 0.3 | (−0.450)[−0.450](2.131)[2.178] | (0.839)[−0.161](0.407)[0.438] | (0.838)[−0.162](0.412)[0.442] | (0.238)[−0.062](0.590)[0.593] | |||||
| 0.0 | 0.6 | (−0.278)[−0.278](1.068)[1.104] | (0.768)[−0.232](0.469)[0.523] | (0.763)[−0.237](0.463)[0.521] | (0.411)[−0.189](0.349)[0.397] | |||||
| 0.3 | −0.6 | (0.068)[-0.232](1.429)[1.448] | (0.938)[-0.062](0.311)[0.317] | (0.951)[-0.049](0.307)[0.311] | (−0.384)[0.216](0.543)[0.585] | |||||
| 0.3 | −0.3 | (-0.157)[-0.457](2.174)[2.221] | (0.903)[-0.097](0.344)[0.358] | (0.902)[-0.098](0.345)[0.359] | (−0.279)[0.021](0.623)[0.623] | |||||
| 0.3 | 0.0 | (−0.211)[-0.511](2.030)[2.094] | (0.867)[-0.133](0.376)[0.399] | (0.864)[-0.136](0.381)[0.404] | (−0.161)[-0.161](0.660)[0.679] | |||||
| 0.3 | 0.3 | (−0.203)[-0.503](2.007)[2.069] | (0.819)[-0.181](0.437)[0.473] | (0.813)[-0.187](0.432)[0.471] | (0.095)[-0.205](0.621)[0.654] | |||||
| 0.3 | 0.6 | (-0.022)[-0.322](0.735)[0.802] | (0.659)[-0.341](0.508)[0.612] | (0.657)[-0.343](0.503)[0.609] | (0.329)[-0.271](0.381)[0.468] | |||||
| 0.6 | −0.6 | (0.422)[−0.178](0.712)[0.733] | (0.981)[−0.019](0.231)[0.232] | (0.981)[−0.019](0.230)[0.231] | (−0.584)[0.016](0.346)[0.346] | |||||
| 0.6 | −0.3 | (0.376)[−0.224](0.580)[0.621] | (0.976)[−0.024](0.253)[0.254] | (0.965)[−0.035](0.255)[0.257] | (−0.511)[−0.211](0.329)[0.391] | |||||
| 0.6 | 0.0 | (0.270)[−0.330](0.842)[0.905] | (0.961)[−0.039](0.294)[0.296] | (0.945)[−0.055](0.292)[0.297] | (−0.412)[−0.412](0.386)[0.564] | |||||
| 0.6 | 0.3 | (0.152)[−0.448](1.345)[1.418] | (0.921)[−0.079](0.326)[0.335] | (0.920)[−0.080](0.335)[0.344] | (−0.286)[−0.586](0.415)[0.719] | |||||
| 0.6 | 0.6 | (0.159)[−0.441](0.767)[0.884] | (0.802)−0.198](0.436)[0.479] | (0.800)[−0.200](0.432)[0.476] | (−0.059)[−0.659](0.414)[0.779] |
| λ | ρ | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| λ | ρ | (Mean)[Bias](SE)[RMSE] | (Mean)[Bias](SE)[RMSE] | (Mean)[Bias](SE)[RMSE] | (Mean)[Bias](SE)[RMSE] | |||||
| −0.6 | −0.6 | (−3.051)[−2.451](7.286)[7.687] | (0.914)[−0.086](0.257)[0.271] | (0.911)[−0.089](0.256)[0.271] | (−1.040)[−0.440](1.921)[1.970] | |||||
| −0.6 | −0.3 | (−2.905)[−2.305](7.213)[7.572] | (0.916)[−0.084](0.253)[0.267] | (0.918)[−0.082](0.254)[0.267] | (−0.725)[−0.425](1.913)[1.960] | |||||
| −0.6 | 0.0 | (−1.771)[−1.171](5.677)[5.797] | (0.953)[−0.047](0.203)[0.208] | (0.949)[−0.051](0.204)[0.210] | (−0.123)[−0.123](1.427)[1.432] | |||||
| −0.6 | 0.3 | (−0.977)[−0.377](3.577)[3.597] | (0.985)[−0.015](0.142)[0.143] | (0.982)[−0.018](0.140)[0.141] | (0.303)[0.003](0.814)[0.814] | |||||
| −0.6 | 0.6 | (−0.667)[−0.067](0.139)[0.154] | (1.003)[0.003](0.088)[0.088] | (1.006)[0.006](0.085)[0.085] | (0.609)[0.009](0.087)[0.087] | |||||
| −0.3 | −0.6 | (−0.985)[−0.685](4.189)[4.244] | (0.979)[−0.021](0.163)[0.165] | (0.975)[−0.025](0.162)[0.164] | (−0.608)[−0.008](1.201)[1.201] | |||||
| −0.3 | −0.3 | (−1.513)[−1.213](5.164)[5.304] | (0.953)[−0.047](0.187)[0.193] | (0.960)[−0.040](0.189)[0.193] | (−0.577)[−0.277](1.472)[1.498] | |||||
| −0.3 | 0.0 | (−1.196)[−0.896](4.602)[4.689] | (0.972)[−0.028](0.174)[0.177] | (0.968)[−0.032](0.171)[0.174] | (−0.155)[−0.155](1.284)[1.293] | |||||
| −0.3 | 0.3 | (−0.457)[−0.157](1.797)[1.804] | (0.996)[−0.004](0.103)[0.103] | (0.994)[−0.006](0.102)[0.102] | (0.312)[0.012](0.449)[0.449] | |||||
| −0.3 | 0.6 | (−0.460)[−0.160](0.212)[0.266] | (1.000)[−0.000](0.082)[0.082] | (1.006)[0.006](0.082)[0.082] | (0.557)[−0.043](0.132)[0.139] | |||||
| 0.0 | −0.6 | (0.040)[0.040](1.086)[1.087] | (0.998)[−0.002](0.090)[0.090] | (0.998)[−0.002](0.086)[0.086] | (−0.371)[0.229](0.468)[0.521] | |||||
| 0.0 | −0.3 | (−0.220)[−0.220](2.089)[2.100] | (0.994)[−0.006](0.103)[0.103] | (0.994)[−0.006](0.109)[0.109] | (−0.333)[−0.033](0.703)[0.704] | |||||
| 0.0 | 0.0 | (−0.205)[−0.205](1.807)[1.819] | (0.996)[−0.004](0.101)[0.101] | (0.995)[−0.005](0.101)[0.101] | (−0.075)[−0.075](0.681)[0.685] | |||||
| 0.0 | 0.3 | (−0.077)[−0.077](0.731)[0.735] | (0.996)[−0.004](0.085)[0.085] | (0.998)[−0.002](0.087)[0.087] | (0.298)[−0.002](0.328)[0.328] | |||||
| 0.0 | 0.6 | (−0.153)[−0.153](0.253)[0.296] | (0.987)[−0.013](0.136)[0.137] | (0.989)[−0.011](0.135)[0.136] | (0.521)[−0.079](0.197)[0.213] | |||||
| 0.3 | −0.6 | (0.317)[0.017](0.140)[0.141] | (1.003)[0.003](0.084)[0.084] | (1.000)[0.000](0.082)[0.082] | (−0.430)[0.170](0.201)[0.263] | |||||
| 0.3 | −0.3 | (0.228)[−0.072](0.173)[0.188] | (1.003)[0.003](0.086)[0.086] | (0.998)[−0.002](0.083)[0.083] | (−0.323)[−0.023](0.272)[0.273] | |||||
| 0.3 | 0.0 | (0.137)[−0.163](0.715)[0.734] | (0.998)[−0.002](0.086)[0.087] | (0.997)[−0.003](0.086)[0.086] | (−0.174)[−0.174](0.408)[0.444] | |||||
| 0.3 | 0.3 | (0.199)[−0.101](0.211)[0.234] | (0.996)[−0.004](0.100)[0.100] | (0.996)[−0.004](0.100)[0.100] | (0.216)[−0.084](0.362)[0.372] | |||||
| 0.3 | 0.6 | (0.245)[−0.055](0.194)[0.202] | (0.961)[−0.039](0.211)[0.214] | (0.958)[−0.042](0.209)[0.213] | (0.587)[−0.013](0.205)[0.205] | |||||
| 0.6 | −0.6 | (0.545)[−0.055](0.086)[0.102] | (0.998)[−0.002](0.082)[0.082] | (1.000)[−0.000](0.084)[0.084] | (−0.652)[−0.052](0.102)[0.115] | |||||
| 0.6 | −0.3 | (0.486)[−0.114](0.082)[0.141] | (0.998)[−0.002](0.082)[0.082] | (1.001)[0.001](0.081)[0.081] | (−0.583)[−0.283](0.103)[0.301] | |||||
| 0.6 | 0.0 | (0.411)[−0.189](0.091)[0.209] | (1.000)[0.000](0.083)[0.083] | (0.997)[−0.003](0.081)[0.081] | (−0.490)[−0.490](0.124)[0.505] | |||||
| 0.6 | 0.3 | (0.324)[−0.276](0.088)[0.290] | (1.007)[0.007](0.089)[0.090] | (1.003)[0.003](0.092)[0.092] | (−0.344)[−0.644](0.200)[0.674] | |||||
| 0.6 | 0.6 | (0.288)[−0.312](0.159)[0.350] | (0.943)[−0.057](0.253)[0.259] | (0.941)[−0.059](0.253)[0.260] | (−0.070)[−0.670](0.387)[0.774] |
| λ | ρ | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| λ | ρ | (Mean)[Bias](SE)[RMSE] | (Mean)[Bias](SE)[RMSE] | (Mean)[Bias](SE)[RMSE] | (Mean)[Bias](SE)[RMSE] | |||||
| −0.6 | −0.6 | (−3.449)[−2.849](8.618)[9.077] | (0.907)[−0.093](0.283)[0.298] | (0.906)[−0.094](0.282)[0.297] | (−1.323)[−0.723](2.487)[2.590] | |||||
| −0.6 | −0.3 | (−4.151)[−3.551](9.648)[10.280] | (0.877)[−0.123](0.311)[0.334] | (0.880)[−0.120](0.312)[0.335] | (−1.135)[−0.835](2.798)[2.920] | |||||
| −0.6 | 0.0 | (−1.675)[−1.075](6.110)[6.204] | (0.957)[−0.043](0.201)[0.205] | (0.958)[−0.042](0.199)[0.204] | (−0.148)[−0.148](1.666)[1.672] | |||||
| −0.6 | 0.3 | (−0.650)[−0.050](2.400)[2.401] | (0.991)[−0.009](0.092)[0.093] | (0.991)[−0.009](0.093)[0.093] | (0.352)[0.052](0.568)[0.570] | |||||
| −0.6 | 0.6 | (−0.682)[−0.082](0.095)[0.126] | (1.007)[0.007](0.059)[0.060] | (1.007)[0.007](0.057)[0.058] | (0.595)[−0.005](0.054)[0.055] | |||||
| −0.3 | −0.6 | (−0.698)[−0.398](3.631)[3.653] | (0.983)[−0.017](0.128)[0.129] | (0.985)[−0.015](0.129)[0.129] | (−0.624)[−0.024](1.152)[1.153] | |||||
| −0.3 | −0.3 | (−1.691)[−1.391](6.083)[6.240] | (0.952)[−0.048](0.204)[0.210] | (0.954)[−0.046](0.204)[0.209] | (−0.704)[−0.404](1.839)[1.883] | |||||
| −0.3 | 0.0 | (−0.829)[−0.529](4.086)[4.120] | (0.981)[−0.019](0.141)[0.143] | (0.982)[−0.018](0.142)[0.143] | (−0.103)[−0.103](1.241)[1.245] | |||||
| −0.3 | 0.3 | (−0.385)[−0.085](1.415)[1.418] | (1.000)[−0.000](0.073)[0.073] | (0.999)[−0.001](0.074)[0.074] | (0.300)[−0.000](0.335)[0.335] | |||||
| −0.3 | 0.6 | (−0.476)[−0.176](0.169)[0.244] | (1.005)[0.005](0.058)[0.058] | (1.007)[0.007](0.058)[0.058] | (0.524)[−0.076](0.105)[0.130] | |||||
| 0.0 | −0.6 | (0.090)[0.090](0.866)[0.870] | (0.998)[−0.002](0.064)[0.064] | (1.000)[−0.000](0.067)[0.067] | (−0.361)[0.239](0.373)[0.443] | |||||
| 0.0 | −0.3 | (−0.096)[−0.096](1.508)[1.511] | (0.996)[−0.004](0.083)[0.083] | (0.995)[−0.005](0.078)[0.078] | (−0.323)[−0.023](0.575)[0.575] | |||||
| 0.0 | 0.0 | (−0.111)[−0.111](1.287)[1.291] | (0.997)[−0.003](0.071)[0.071] | (0.994)[−0.006](0.070)[0.070] | (−0.063)[−0.063](0.525)[0.529] | |||||
| 0.0 | 0.3 | (−0.074)[−0.074](0.181)[0.195] | (0.997)[−0.003](0.060)[0.060] | (0.999)[−0.001](0.060)[0.060] | (0.260)[−0.040](0.169)[0.174] | |||||
| 0.0 | −0.6 | (0.068)[−0.232](1.429)[1.448] | (0.938)[−0.062](0.311)[0.317] | (0.951)[−0.049](0.307)[0.311] | (−0.384)[0.216](0.543)[0.585] | |||||
| 0.3 | −0.6 | (0.342)[0.042](0.090)[0.099] | (1.000)[0.000](0.060)[0.060] | (1.001)[0.001](0.059)[0.059] | (−0.429)[0.171](0.118)[0.208] | |||||
| 0.3 | −0.3 | (0.251)[−0.049](0.111)[0.121] | (1.000)[−0.000](0.063)[0.063] | (1.004)[0.004](0.060)[0.061] | (−0.338)[−0.038](0.152)[0.157] | |||||
| 0.3 | 0.0 | (0.174)[−0.126](0.125)[0.178] | (1.001)[0.001](0.058)[0.058] | (0.998)[−0.002](0.059)[0.059] | (−0.188)[−0.188](0.229)[0.296] | |||||
| 0.3 | 0.3 | (0.225)[−0.075](0.145)[0.163] | (0.999)[−0.001](0.061)[0.061] | (0.999)[−0.001](0.058)[0.058] | (0.223)[−0.077](0.271)[0.281] | |||||
| 0.3 | 0.6 | (0.274)[−0.026](0.147)[0.149] | (0.996)[−0.004](0.097)[0.097] | (0.992)[−0.008](0.097)[0.097] | (0.609)[0.009](0.148)[0.148] | |||||
| 0.6 | −0.6 | (0.562)[−0.038](0.055)[0.067] | (1.002)[0.002](0.059)[0.059] | (1.000)[0.000](0.059)[0.059] | (−0.668)[−0.068](0.066)[0.095] | |||||
| 0.6 | −0.3 | (0.496)[−0.104](0.058)[0.119] | (1.002)[0.002](0.059)[0.059] | (1.000)[0.000](0.058)[0.058] | (−0.590)[−0.290](0.071)[0.299] | |||||
| 0.6 | 0.0 | (0.417)[−0.183](0.058)[0.192] | (0.998)[−0.002](0.062)[0.062] | (1.000)[0.000](0.061)[0.061] | (−0.495)[−0.495](0.072)[0.501] | |||||
| 0.6 | 0.3 | (0.324)[−0.276](0.061)[0.282] | (1.004)[0.004](0.060)[0.060] | (1.002)[0.002](0.060)[0.060] | (−0.372)[−0.672](0.114)[0.682] | |||||
| 0.6 | 0.6 | (0.320)[−0.280](0.176)[0.331] | (0.977)[−0.023](0.175)[0.177] | (0.975)[−0.025](0.176)[0.177] | (0.007)[−0.593](0.416)[0.725] |
E: Surface Plots of RMSEs for SARMA(1,1)


Acknowledgements
Conflicts of Interest
References
- R.P. Haining. “The moving average model for spatial interaction.” Trans. Inst. Br. Geogr. 3 (1978): 202–225. [Google Scholar] [CrossRef]
- L. Anselin. Spatial Econometrics: Methods and Models. New York, NY, USA: Springer, 1988. [Google Scholar]
- L.W. Hepple. Bayesian and Maximum Likelihood Estimation of the Linear Model with Spatial Moving Average Disturbances. Working Papers Series; Bristol, UK: School of Geographical Sciences, University of Bristol, 2003. [Google Scholar]
- B. Fingleton. “A generalized method of moments estimator for a spatial model with moving average errors, with application to real estate prices.” Empir. Econ. 34 (2008): 35–37. [Google Scholar] [CrossRef]
- B. Fingleton. “A generalized method of moments estimator for a spatial panel model with an endogenous spatial lag and spatial moving average errors.” Spat. Econ. Anal. 3 (2008): 27–44. [Google Scholar] [CrossRef]
- H.H. Kelejian, and I.R. Prucha. “A generalized spatial two-stage least squares procedure for estimating a spatial autoregressive model with autoregressive disturbances.” J. Real Estate Financ. Econ. 17 (1998): 1899–1926. [Google Scholar]
- H.H. Kelejian, and I.R. Prucha. “A generalized moments estimator for the autoregressive parameter in a spatial model.” Int. Econ. Rev. 40 (1999): 509–533. [Google Scholar] [CrossRef]
- D. Das, H.H. Kelejian, and I.R. Prucha. “Small sample properties of estimators of spatial autoregressive models with autoregressive disturbances.” Pap. Reg. Sci. 82 (2003): 1–26. [Google Scholar] [CrossRef]
- H.H. Kelejian, and I.R. Prucha. “Specification and estimation of spatial autoregressive models with autoregressive and heteroskedastic disturbances.” J. Econom. 157 (2010): 53–67. [Google Scholar] [CrossRef] [PubMed]
- X. Liu, L.F. Lee, and C.R. Bollinger. “An efficient GMM estimator of spatial autoregressive models.” J. Econom. 159 (2010): 303–319. [Google Scholar] [CrossRef]
- L.F. Lee. “Asymptotic distributions of quasi-maximum likelihood estimators for spatial autoregressive models.” Econometrica 72 (2004): 1899–1925. [Google Scholar] [CrossRef]
- L.F. Lee. “GMM and 2SLS estimation of mixed regressive, spatial autoregressive models.” J. Econom. 137 (2007): 489–514. [Google Scholar] [CrossRef]
- L.F. Lee, and X. Liu. “Efficient GMM estimation of high order spatial autoregressive models with autoregressive disturbances.” Econom. Theory 26 (2010): 187–230. [Google Scholar] [CrossRef]
- J.P. Lesage. “Bayesian estimation of spatial autoregressive models.” Int. Reg. Sci. Rev. 20 (1997): 113–129. [Google Scholar] [CrossRef]
- J. LeSage, and R.K. Pace. Introduction to Spatial Econometrics (Statistics: A Series of Textbooks and Monographs. London, UK: Chapman and Hall/CRC, 2009. [Google Scholar]
- L.W. Hepple. “Bayesian techniques in spatial and network econometrics: 1. Model comparison and posterior odds.” Environ. Plan. 27 (1995): 247–469. [Google Scholar]
- I.R. Prucha. “Instrumental variables/method of moments estimation.” In Handbook of Regional Science. Edited by M.M. Fischer and P. Nijkamp. Berlin, Germany: Springer Berlin Heidelberg, 2014, pp. 1597–1617. [Google Scholar]
- L.F. Lee. “The method of elimination and substitution in the GMM estimation of mixed regressive, spatial autoregressive models.” J. Econom. 140 (2007): 155–189. [Google Scholar] [CrossRef]
- B.H. Baltagi, and L. Liu. “An improved generalized moments estimator for a spatial moving average error model.” Econ. Lett. 113 (2011): 282–284. [Google Scholar] [CrossRef]
- M. Arnold, and D. Wied. “Improved GMM estimation of the spatial autoregressive error model.” Econ. Lett. 108 (2010): 65–68. [Google Scholar] [CrossRef]
- D.M. Drukker, P. Egger, and I.R. Prucha. “On two-step estimation of a spatial autoregressive model with autoregressive disturbances and endogenous regressors.” Econom. Rev. 32 (2013): 686–733. [Google Scholar] [CrossRef]
- X. Lin, and L.F. Lee. “GMM estimation of spatial autoregressive models with unknown heteroskedasticity.” J. Econom. 157 (2010): 34–52. [Google Scholar] [CrossRef]
- H.H. Kelejian, and D. Robinson. “A suggested method of estimation for spatial interdependent models with autocorrelated errors, and an application to a county expenditure model.” Pap. Reg. Sci. 72 (1993): 297–312. [Google Scholar] [CrossRef]
- J. Besag. “Spatial interaction and the statistical analysis of lattice systems.” J. R. Stat. Soc. Ser. B (Methodological) 36 (1974): 192–236. [Google Scholar]
- S. Richardson, C. Guihenneuc, and V. Lasserre. “Spatial linear models with autocorrelated error structure.” J. R. Stat. Soc. Ser. D (The Statistician) 41 (1992): 539–557. [Google Scholar] [CrossRef]
- L.W. Hepple. “Bayesian techniques in spatial and network econometrics: 2. Computational methods and algorithms.” Environ. Plan. 27 (1995): 615–644. [Google Scholar]
- B.D. Ripley. Spatial Statistics. Wiley Series in Probability and Statistics; Hoboken, New Jersey, USA: John Wiley & Sons, 2005. [Google Scholar]
- R. Haining. “Trend-Surface models with regional and local scales of variation with an application to aerial survey data.” Technometrics 29 (1987): 461–469. [Google Scholar]
- K.V. Mardia, and R.J. Marshall. “Maximum likelihood estimation of models for residual covariance in spatial regression.” Biometrika 71 (1984): 135–146. [Google Scholar] [CrossRef]
- L.W. Hepple. “A Maximum likelihood model for econometric estimation with spatial series.” In Theory and Practice in Regional Science. Edited by I. Masser. London papers in regional science 6; London, UK: Pion Limited, 1976. [Google Scholar]
- K.M. Abadir, and J.R. Magnus. Matrix Algebra. Econometric Exercises; New York, NY, USA: Cambridge University Press, 2005. [Google Scholar]
- L.F. Lee. “Identification and estimation of econometric models with group interactions, contextual factors and fixed effects.” J. Econom. 140 (2007): 333–374. [Google Scholar] [CrossRef]
- L.F. Lee, X. Liu, and X. Lin. “Specification and estimation of social interaction models with network structures.” Econom. J. 13 (2010): 145–176. [Google Scholar] [CrossRef]
- H.H. Kelejian, and I.R. Prucha. Specification and Estimation of Spatial Autoregressive Models with Autoregressive and Heteroskedastic Disturbances. College Park, MD, USA: Department of Economics, University of Maryland, 2007. [Google Scholar]
- R.K. Pace, J.P. LeSage, and S. Zhu. Spatial Dependence in Regressors and Its Effect on Performance of Likelihood-Based and Instrumental Variable Estimators, 30th Anniversary ed. Advances in Econometrics; Bingley, UK: Emerald Group Publishing Limited, 2012, Volume 30, pp. 257–295. [Google Scholar]
- O. Dogan, and T. Suleyman. GMM Estimation of Spatial Autoregressive Models with Autoregressive and Heteroskedastic Disturbances. Working Papers 001; New York, NY, USA: City University of New York Graduate Center, Ph.D. Program in Economics, 2013. [Google Scholar]
- 2See Kelejian and Prucha [9].
- 3For a definition and some properties of uniform boundedness, see Kelejian and Prucha [9].
- 4There are some other formulations for the parameter spaces in the literature. For details, see Kelejian and Prucha [9] and LeSage and Pace [15]. Note that the parameter spaces for and are not required to be compact. As shown in Equations (8a) and (8b), the MLE of these parameters is an OLS-type estimator; hence, boundedness is enough for the parameter spaces.
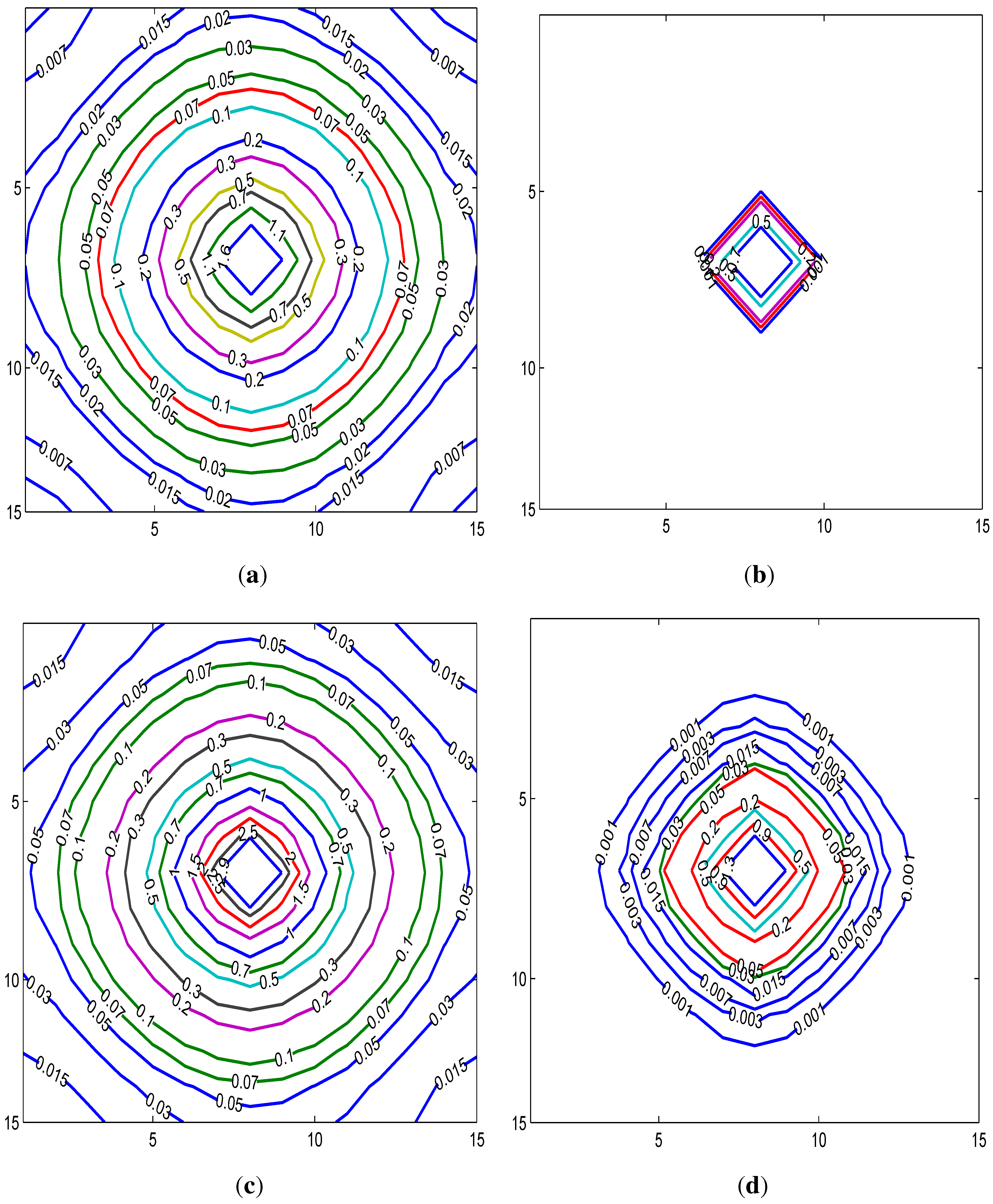
- 5For easy comparison, we set for SAR, for SMA, for SARAR(1,1) and for SARMA(1,1). The disturbance of the unit located at the center of the lattice is increased by three.
- 6, where is the Earth’s radius.
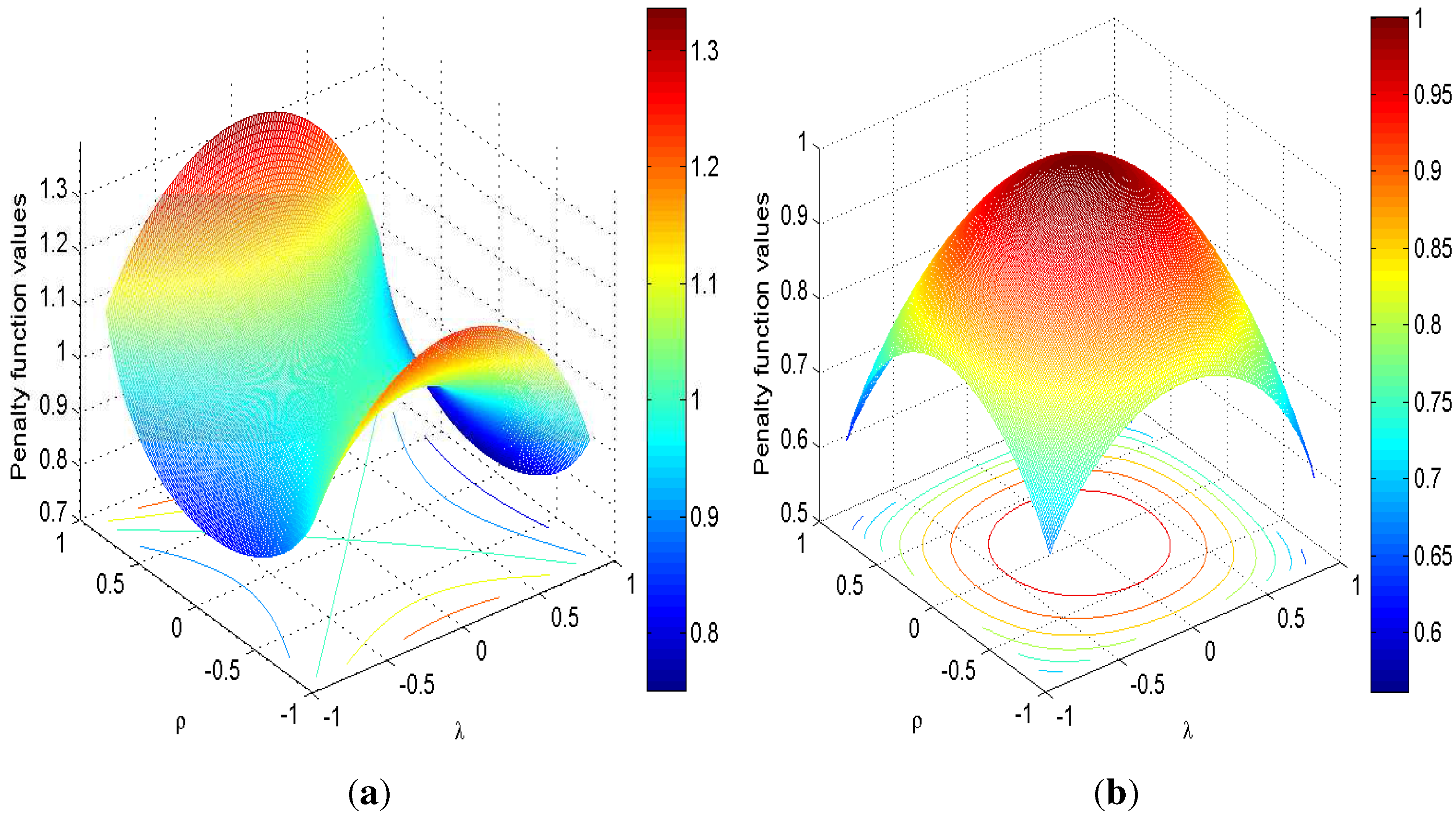
- 7For SARAR(1,1), the penalty function is .
- 8For these results, I use the derivative rule given by . For a proof, see (Abadir and Magnus [31], p. 372). Also note the commutative property of .
- 9Here, denotes the block diagonal matrix in which the diagonal blocks are matrices ofs.
- 10Note that .
© 2015 by the author; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Doğan, O. Heteroskedasticity of Unknown Form in Spatial Autoregressive Models with a Moving Average Disturbance Term. Econometrics 2015, 3, 101-127. https://doi.org/10.3390/econometrics3010101
Doğan O. Heteroskedasticity of Unknown Form in Spatial Autoregressive Models with a Moving Average Disturbance Term. Econometrics. 2015; 3(1):101-127. https://doi.org/10.3390/econometrics3010101
Chicago/Turabian StyleDoğan, Osman. 2015. "Heteroskedasticity of Unknown Form in Spatial Autoregressive Models with a Moving Average Disturbance Term" Econometrics 3, no. 1: 101-127. https://doi.org/10.3390/econometrics3010101
APA StyleDoğan, O. (2015). Heteroskedasticity of Unknown Form in Spatial Autoregressive Models with a Moving Average Disturbance Term. Econometrics, 3(1), 101-127. https://doi.org/10.3390/econometrics3010101