1. Introduction
This paper takes up a simple but nontrivial example of a situation that arises often in econometrics. An econometric model takes the form where y is a vector of outcomes, x is a vector or matrix of covariates or conditioning observables, β is an unknown parameter vector, and the functional form of p is the model specification. Due to the motivating economic theory, or by virtue of the interpretation of the model, β is a function of a more fundamental parameter vector θ, so that . The function need not be one-to-one. For purposes of motivation and interpretation θ is superior to β; indeed, this typically can best be accomplished in terms of θ. Examples can be found in most chapters of many econometrics textbooks, from the undergraduate to postgraduate levels. A generic case is the one in which θ expresses the underlying taste and/or technology state of a market or economy: neoclassical models of production and consumption and structural simultaneous equation macroeconometric models are two broad subcategories. The same is true in nonstructural settings like the many specific variants of linear state space models and factor models. And it is also true in the effort to provide economic interpretation of simple descriptive models like the one used here.
For a subjective Bayesian, this point has added force because a prior distribution that is substantive (by implication proper) must be expressed in terms of
θ, not
β. Bayesian econometrics now has a set of tools to address these nonlinear models, the most widely applied perhaps being Markov chain Monte Carlo (MCMC). This paper adds to this collection of tools the sequentially adaptive Bayesian learning algorithm (SABL). Given that there already exist multiple approaches, the question of why an additional approach naturally arises. There are several good answers to this question. The objective of this paper is to substantiate the answers, by both presenting the method and by illustrating its application to nonlinear models.
SABL provides a generic and robust approach to the nonlinear model problem as just stated. Compared with existing methods like MCMC it requires very little tuning and experimentation with the exact form of the algorithm (for example, specification of the variance matrix for the Metropolis random walk, burn-in and convergence decisions). In many cases, like the illustration here, no tuning or experimentation at all is required.
With a simple change of a single parameter, the SABL algorithm can be used for optimization as well as Bayesian inference. Here, that feature is used to compute maximum likelihood estimates and their associated asymptotic distribution. More generally, SABL can be used to attack a wide variety of optimization problems in economics.
SABL enables Bayesians to use almost any prior distribution and to modify conventional distribution by imposing constraints (illustrated here) or mixing with discrete distributions (not illustrated). It also provides numerical standard errors and accurate log marginal likelihood (marginal data density) approximations as by-products, neither of which is a focus of this paper.
In many cases SABL is faster and more accurate than any competing algorithm when executed in a conventional multicore CPU environment. That is the case for the illustration here.
The SABL algorithm is pleasingly parallel, and except for a computationally insignificant portion of the algorithm it is embarrassingly parallel. It is therefore well suited to execution on graphics processing units, and this facility is included in SABL.
This list is not intended to be exhaustive, but rather as motivation for the reader already steeped in Bayesian computational techniques to continue on.
The paper proceeds by introducing the nonlinear model used as a simple but realistic example,
Section 2.
Section 3 then provides an overview of SABL used for Bayesian inference, drawing on more extensive documentation for SABL that is readily available [
1]. This is followed by the illustrative example for Bayesian inference,
Section 4.
Section 5 takes up optimization in SABL, with a specific focus on maximum likelihood, and the illustration follows in
Section 6. There is a short concluding section.
The paper is written to convey an understanding of SABL and its application to the problem set forth in the next section. For full development of the immediate theory, refer to [
2,
3,
4]. For the underlying probability theory the single best self-contained reference is [
5].
2. Interpretation of the Third-Order Autoregression
The relationship of second-order stochastic difference equations to business cycle dynamics has been recognized at least since [
6]. In a model like
where
is the innovation (shock) for the stationary time series
, the associated characteristic polynomial is
. Let the roots of the polynomial be
and
. Stationarity is equivalent to
,
. If, in addition,
and
are a complex conjugate pair then the time series exhibits characteristic cycles in which the amplitude is
and the period is
where
denotes the principle branch in
. This is the technical essence of [
6] and now a standard part of graduate education.
Geweke [
7] applied a similar interpretation to the third-order stochastic difference equation (autogregression)
taking up the case with one real root
and a pair of complex conjugate roots
and
in the associated characteristic polynomial. That paper used the reparameterization
where the subscript
s denotes “secular” and
denotes “cyclical.” It continued to impose
, permitted
,
then being the explosive growth rate, as well as
, the rate of dampening in the transmission of
. The paper used a conventional improper prior distribution for
β and
and data from 19 OECD countries 1957–1983. It found posterior probabilities of explosive roots near 0, probabilities of complex pairs exceeding one-half for all countries, and probabilities that
over one-half for most countries.
The application here works directly with parameters that are much closer to the way that economists think about growth and business cycles than are the time series parameters and σ. This enables the economist to construct a substantive prior distribution and to readily understand the posterior distribution.
The work begins by replacing the amplitudes
and
with their corresponding half-lives. A damping amplitude
generates the sequence
, equivalent to the impulse response function in the first-order autoregression
. The corresponding half-life is the value
h for which
which implies
. Thus for the secular and cyclical components we have the inverse relations
mapping the secular half-life
to its amplitude
and the cyclical half-life
to its amplitude
. Writing the generating polynomial for the stochastic difference equation (
1)
with
, we obtain from (
2)
The domains of
and
are
. The domain of
p is
, the lower bound corresponding to using the principal branch of the function
in
in (
2). More fundamentally, there is an identification problem presented by aliasing: in any time series with one time unit between observations periodicities
all exhibit as period
p. A conventional way to resolve this problem is to require
, which also seems satisfactory for business cycles with annual data.
Thus, given the half-lives
and
and the period
p, (
3) followed by (
4) provides
. The mapping is continuous and has continuous derivatives of all orders. The other parameters of the model are
σ, which has straightforward economic interpretation, and
, which does not but is of little interest.
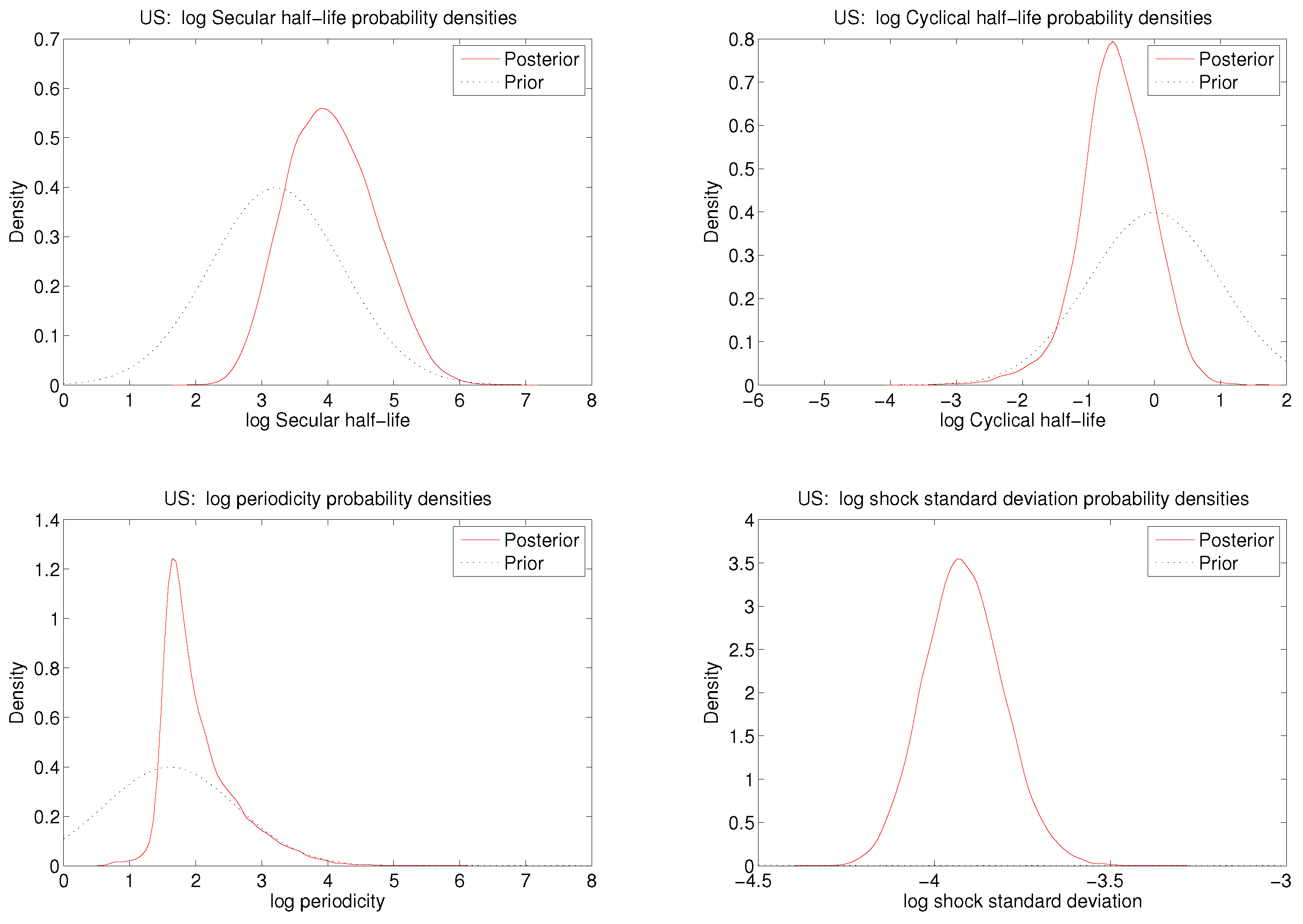
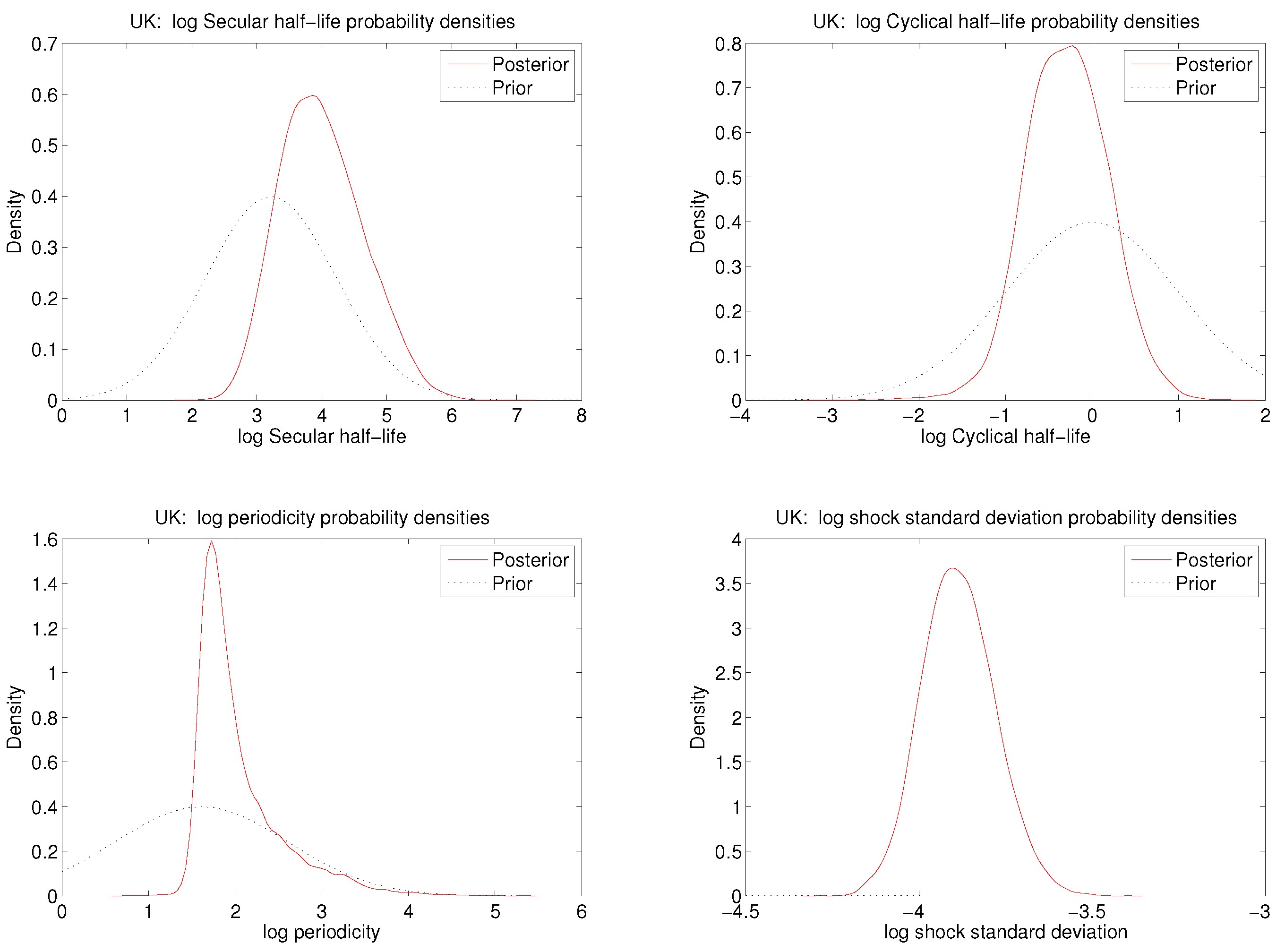
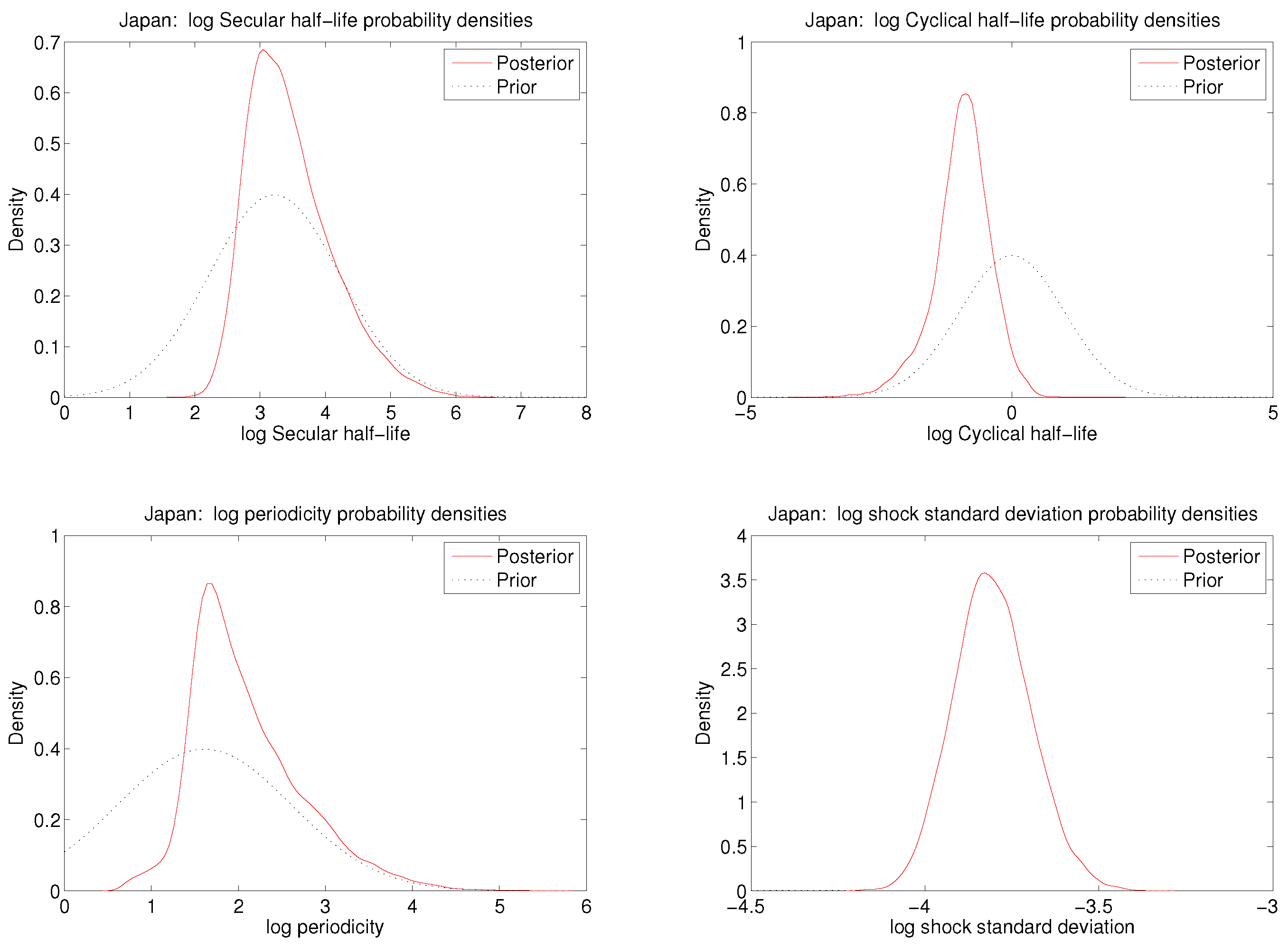
It is natural to express independent prior distributions for , , p, and σ: most economists could readily state some plausible and some implausible values for each—unlike the case with , and . The half-lives and periods are all measured in time units and the supports of the respective prior distributions must each be (a subset of) the positive half-line. Several well-known prior distributions qualify and can easily be used in the approach taken here. We will use a log-normal prior distribution for each, the distribution for being truncated below at . There are also several well-known prior distributions for σ; we again use a log normal prior. Finally, will be given a diffuse normal prior distribution.
The components
are mutually independent and normal in the prior distribution.
Section 4 discusses the specific choice of the distribution. The prior distribution is also used as a computational device for maximum likelihood, but the result is unaffected by the choice of prior so long as its support includes the maximizing argument of the likelihood function. Noting that the successive transformations (
2) to (
3) to (
4) are continuously differentiable of all orders, and considering the properties of the likelihood function for (
1), it is clear that if the likelihood function has a unique internal global mode, then there is a neighborhood of the mode in which the log-likelihood function is twice continuously differentiable with bounded third derivative. This familiar condition is important to a deep verification of the properties of the SABL maximum likelihood estimates in
Section 5 and
Section 6.
3. Bayesian Inference Using SABL
The SABL algorithm is a procedure for the controlled introduction of new information. It pertains to situations in which information can be represented as the probability distribution of a finite dimensional vector. SABL approximates this distribution by means of many (typically on the order of to ) alternative versions of the vector. These versions are called particles , reflecting some of SABL’s connections to the particle filtering literature. In the SABL algorithm particles undergo a sequence of transformations as information is introduced. With minor exceptions accounting for a negligible fraction of computing time in typical research applications, these transformations amount to identical instructions that operate on each particle in isolation. SABL is therefore a pleasingly parallel algorithm. This property is responsible for dramatic decreases in computing time for many research applications with GPU execution of SABL.
At its highest level the SABL algorithm looks like this:
In the sequential Monte Carlo literature each pass through the loop While ... End is known as a cycle, and we will use ℓ to index cycles. The three steps in each cycle are the correction (C) phase, the selection (S) phase, and the mutation (M) phase.
Let
denote the vector whose probability distribution represents information. Denote the particles by
, the double subscripts indicating the
J groups of
N particles each employed by SABL. Initially
θ has probability density
; extension beyond absolutely continuous distributions is easy, and this streamlines the notation. In SABL the particles initially are
In Bayesian inference
is a proper prior density and in optimization it is the probability density. It must be practical to sample from the initial distribution (
5) and to evaluate
.
Denote the density incorporating all the information by
. SABL requires that it be possible to evaluate a kernel
with the properties
In Bayesian inference the kernel
is the likelihood function,
where
T denotes sample size and
denotes the data.
Cycle
ℓ begins with the kernel
and ends with the kernel
. In the first and last cycles,
respectively. Correspondingly define
implying
The particles change in each cycle, and reflecting this let
denote the particles at the end of cycle
ℓ. The initial particles
have the common distribution (
5) and are independent. In succeeding cycles the particles
continue to be identically distributed but they are not independent. The theory underlying SABL, discussed further in this section and developed in detail by [
3,
4] drawing on sequential Monte Carlo theory, assures that the final particles
. This convergence in distribution takes place in
N, the number of particles per group. The result is actually stronger: the particles are ergodic in
N, meaning that for any function
g for which
exists,
with probability 1 in each group
.
A leading technical challenge in practical sequential Monte Carlo algorithms, which of course work with finite
N, is to limit the dependence amongst particles, and in particular to keep dependence from increasing from one cycle to the next to the point that the final distribution of particles is an unreliable representation of any distribution at all. A further technical challenge is to provide a measure of the accuracy of the approximation implicit in the left side of (
10) for finite
N that is itself reliable. The SABL algorithm and toolbox do both in a way that makes minimal demands on users. The remainder of this section provides some details.
3.1. C phase
For each cycle
ℓ define the weight function
The theory underlying the SABL algorithm requires that there exist an upper bound
, that is,
The
C phase determines
explicitly and thereby defines
and
Thus (
8) and (
11) imply
as well. In SABL the weight functions
are designed so that there exists
for which
, although the value of
L is in general not known at the outset.
One approach in designing the weight function is to use the functional form and determine a sequence of positive increments with . Thus at the end of cycle ℓ, where . This variant of the C phase is known as power tempering . The term originates in the simulated annealing literature in which is known as temperature and as the cooling schedule. Another approach originates in particle filtering and Bayesian inference: , where for a sample of size T. The increments are therefore . This variant of the C phase is known as data tempering.
The
C phase can be motivated informally by analogy to importance sampling, a long-established Monte Carlo simulation method, interpreting
as the kernel of the source density and
as the kernel of the target density. If it were the case that the particles
were independent and had common distribution indicated by the kernel density
, then
so long as
exists. The convergence is in
N, the number of particles per group.
The core of the argument for importance sampling is
This result does not apply strictly, here, because while the particles
are identically distributed, they are not independent and
is at best an approximation of the kernel density of the true common distribution of the particles
so long as
(as it must be in practice). But many of the practical concerns in importance sampling carry over. In particular, success lies in
being “well-conditioned”–loosely speaking, variation in
must not be too great. For example, difficulties arise when just a few weights
account for most of the sum. In this case the target density kernel
is represented almost entirely by a small number of particles and the approximation of
implicit in the left side of (
12) is poor.
The
C phase directly confronts the key question of how much information to introduce in cycle
ℓ: too little and
L will be larger than it need be; too much, and it becomes difficult for the other phases to convert ill-weighted particles from cycle
into particles from cycle
ℓ sufficiently independent that the representation of the distribution does not deteriorate from one cycle to the next into a state of gross unreliability. A conventional and effective way to monitor the quality of the weight function is by means of
relative effective sample size
The
effective sample size is an adjustment to the sample size (number of particles,
) that accounts for lack of balance in the weights, and relative effective size is its ratio to sample size.
In general is lower the more information is introduced in the C phase. This is always true for power tempering and as a practical matter is nearly always the case for data tempering. It suggests a strategy of introducing no further information after has attained or fallen below a target value . The target is usually reasonable. Practical experience shows that somewhat higher leads to more cycles but faster execution in the M phase, lower to fewer cycles but slower M phase execution, and as a result there is not much difference in execution time over the interval for .
Before any new information is introduced in the
C phase
. Data tempering entails iterations
in which iteration
s introduces
, updates
and computes the corresponding
. Iterations terminate the first time
. This procedure is well established, though much of the sequential Monte Carlo particle filtering literature introduces exactly one new observation per cycle. In neither approach does the algorithm control the amount of information introduced in the
C phase and therefore in each cycle. Indeed, routine applications of SABL demonstrate that unusual or outlying observations (e.g., asset returns for days or periods marked by financial crisis) can produce
with values much smaller than
, imply poor performance in the
S and
M phases, and generally compromise the efficiency of the algorithm.
Power tempering, discussed briefly at the start of this section, makes it possible in principle for the algorithm to control the introduction of information through the choice of the sequence of increments
. Precisely the same problem arises in simulated annealing approaches to optimization, which uses temperature, the inverse of power, and the problem is known as choice of the temperature reduction schedule. We return to this problem in
Section 5, because it has some closely related aspects that apply to optimization but not Bayesian inference. The solution developed there is subsequently used for both Bayesian inference and maximum likelihood estimation in
Section 4 and
Section 6.
3.2. S phase
The rest of cycle
ℓ starts with the weighted particles
from the end of the
C phase and produces unweighted particles
that that meet or exceed a mixing condition—a measure of lack of dependence described in the next section—at the end of the
M phase. The
S phase begins this process, removing weights by means of resampling. The principle behind resampling is to regard the weight function as the kernel of a discrete probability function defined over the particles and draw from this distribution with replacement. Hence the name selection phase. SABL performs this operation on each group of particles separately—that is, particles are always selected within groups and never across groups. This independence between the groups
is essential in (1) proving the convergence of the algorithm; (2) assessing the mixing condition in the
M phase; and (3) providing a numerical standard error for the approximation as discussed in
Section 3.4. Resampling produces unweighted particles denoted
.
The most elementary resampling method is to make
N independent and identically distributed draws from the multinomial distribution with argument
N and probabilities
This method is known as
multinomial resampling. An alternative method, known as
residual resampling, is to compute the same probabilities and collect an initial subsample of size
consisting of
copies of each particle
, where the function
is standard notation for what is variously known as the greatest whole integer, greatest integer not greater than, or floor function. Then draw the remaining
particles by means of multinomial resampling with probabilities
. Residual resampling results in lower dependence amongst the particles
than does multinomial resampling. For both methods there are central limit theorems that are essential to demonstrating convergence and interpreting numerical standard errors. There are other resampling methods that lead to even less dependence amongst the particles, but for these methods central limit theorems do not apply. These methods are all described in [
5].
The S phase is a simple but key part of the SABL algorithm. Resampling is also a key part of evolutionary (or, genetic) algorithms where it plays much the same role. The particles are for this reason sometimes called the children of the parent particles , and also to emphasize the fact that for each child there is a parent . Parents with larger weights are likely to have more children—it is not hard to work out the exact distribution of the number of children of a given parent for any one parent for multinomial resampling and then again for residual resampling. With both, the expected number of children, or fertility, of the parent is proportional to , a measure of the parent’s “success” in the environment of the information introduced in cycle ℓ.
3.3. M phase
If the algorithm were to continue in this way, the number of unique children would never increase and in general would decrease from cycle to cycle. Indeed, in the context of Bayesian inference it can be shown under mild regularity conditions that the number of unique particles converges almost surely to 1 as the number of observations increases.
The
M phase addresses this problem by creating diversity amongst sibling particles in a way that is faithful to the information kernel
. It does so using the same principle of invariance that is central to Markov chain Monte Carlo (MCMC) algorithms, drawing particles from a transition density
with the invariance property
The universe of invariant transition densities is large and manifest in the MCMC literature. Many of these transitions are model-specific, for example Gibbs sampling variants of MCMC. On the other hand a number of families of Metropolis-Hastings transitions apply quite generally and with problem-specific tuning of parameters can be computationally efficient.
SABL incorporates one of these variants, the Metropolis Gaussian random walk. The
M phase applies the Metropolis random walk repeatedly in steps
, each step generating a new set of particles
from the previous set
. Following the familiar arithmetic, candidate new particles are generated
and accepted with probability
In SABL is proportional to the sample variance of computed using all the particles. The factor of proportionality increases when the rate of candidate acceptance in the previous step exceeds a specified threshold and is decreased otherwise. This draws on established practice in MCMC and works well in this context. SABL incorporates variants of the basic Metropolis Gaussian random walk, as well, drawing on experience in the MCMC literature.
The objective of the M phase is to attain a degree of independence of the particles at the end of each cycle sufficient to render the final set of particles a reliable representation of the distribution implied by the probability density function . The idea behind M phase termination in SABL is to measure the degree of mixing (lack of dependence) amongst the particles at the end of each Metropolis step s of cycle ℓ, and terminate when this measure meets or exceeds a certain threshold.
In SABL mixing is measured by the average relative numerical efficiency (RNE) of a group of functions chosen specifically for this purpose in each model. The RNE of the SABL approximation of a posterior moment is a measure of its numerical accuracy relative to that achieved by a hypothetical simulation . The next section explains how this measure is constructed. In the M phase the RNE of the particles tends to increase with the number of steps s, though not monotonically.
A simple stopping rule for the M phase is to terminate the iterations of the Metropolis random walk when the average RNE of a group of functions first exceeds a stated threshold. In any application there are practical limits to the average RNE that can be achieved through these iterations, and so SABL imposes a limit on their number. Achieving greater independence of particles is especially important in the last cycle, because at the end of the M phase in that cycle the particles constitute the representation of . The SABL core default criterion is average RNE 0.4 with 100 maximum iterations in cycles and average RNE 0.9 with 300 maximum iterations in the final cycle L.
Mixing thoroughly is not the objective of the M phase. In MCMC that is essential in providing a workable representation of the distribution with kernel . In SABL the C and S phases take on this important task, whereas the function of the M phase is to place a lower bound on the dependence amongst particles.
3.4. Convergence and the Two-Pass Variant
of SABL
Durham and Geweke [
3] shows that bounded likelihood and existence of the relevant prior moment together sufficient for ergodicity. In all posterior simulators the assessment of numerical accuracy is based on a central limit theorem, which in this context takes the form
where
By itself (
15) is not enough: it is essential to compute or approximation
as well.
The theory developed in the sequential Monte Carlo literature provides a start. It posits a fixed pre-specified sequence of kernels
(see (
11)) and a fixed pre-specified sequence of
M phase transition densities
(see (
14)), together with side conditions (implied by bounded likelihood and the existence of prior moments), and proves (
15). For example, this is the framework set up in [
8] as well as the careful treatment in [
5]. But in any practical application the kernels
and transition densities
are adaptive, relying on information in the particles
or
, rather than fixed. The theory does not apply then because the kernels and transitions depend on the random particles, and the structure of this dependence is so complex as to preclude extension of the existing theory to this case—especially for the transition kernels
. Thus, this literature provides a theory of sequential Bayesian learning but not a theory of
sequentially adaptive Bayesian learning. It is universally recognized that some form of adaptation is required, for it is impossible to pre-specify kernels
and transition densities
that provide reliable approximations in tolerable time without knowing a great deal about the posterior distribution—which, of course, is the goal and not the starting point.
Durham and Geweke [
3] deals with this issue by creating the two-pass variant of the algorithm. The first pass is exactly as described in this section, with the addition that the kernels
and transitions
are saved. For the specific variants described in
Section 3.1 and
Section 3.3, this amounts to saving the sequence
or
from the
C phase and the doubly-indexed sequence of variance matrices
from the
M phase, but the idea generalizes to other variants of the
C and
M phases. The second pass re-executes the algorithm (with different seeds for the random number generator) and uses the kernels
and transitions
computed in the first pass, skipping the work required to compute these objects from the particles. The theory developed in the sequential Monte Carlo literature then applies directly to the second pass, because the kernels
and transitions
are in fact fixed in the second pass.
Experience thus far is that substantial differences between the first and second passes do not arise, and can only be made to do so by specifying imprudently small values of N. Thus in practice it suffices to use the two-pass algorithm only occasionally—perhaps at the inception of a research project when the general character of the model(s), data and sample size are known, and then again prior to communicating findings.
The sequential Monte Carlo literature provides abstract expressions for
in (
15) but no means of evaluating or approximating
. SABL provides the approximation using the particle groups. Consider the second pass of the two-pass algorithm where the convergence theory fully applies. In this setting there is no dependence of particles across groups. The
M phase and the
C phase are perfectly parallel: exactly the same operations applied to all the particles with no communication between particles. Resampling in the
S phase, which introduces dependence amongst particles, takes place entirely within groups so as not to compromise independence across groups. Therefore the approximations
of
are independent across the groups
. A central limit theorem (
15) applies within each group so long as
has finite second moment. Computing the cross-group mean
, a conventional estimate of
in (
15) is
and
the convergence in (
17) being in particles per group
N. In the limit
,
and
are independent.
The corresponding numerical variance estimate for
is
This should not be confused with the approximation of the posterior variance
. The
numerical standard error corresponding to (
18) is
. This is the measure of accuracy used in SABL. From (
17) the formal interpretation of numerical standard error is
. If particles within groups are independent then
, whereas if they are not then usually
, although
may occur and is more likely with smaller numbers of particle groups
J. The
relative numerical efficiency of the approximation
is
A useful interpretation of (
19) is that a hypothetical simulator with
would achieve the same accuracy with
particles.
This argument does not apply directly in the first pass because of the adaptation. In particular, recall that RNE is used in the M phase to assess mixing and determine the end of the sequence of iterations of the Metropolis random walk. This is an example of the complex feedback between particles and adaptation in the algorithm that has frustrated central limit theorems. This shortfall in theory is likely to persist. The two-pass procedure overcomes the problem and, moreover, provides the foundation for future variants of the algorithm without the overhead of establishing convergence for each variant.
5. Maximum Likelihood Using SABL
With minor modification of the
C phase, SABL handles global optimization problems as well as inference problems. This section provides a heuristic approach; for more formal motivation and technical details, see [
2] and [
4].
5.1. The Method
To begin, consider replacing the kernel
of
Section 3 with the kernel
with
. The corresponding probability density is now more concentrated than it was originally. The Bayesian annealing algorithm could proceed in precisely the same way but now terminating with
rather than
. Of course, the particles at that point would not correspond to a posterior distribution: such an interpretation would amount to an erroneous replication of the sample and additional
times. But everything stated in
Section 3 about approximation of the distribution with kernel
remains true for the distribution with kernel
.
Next consider what happens as
q moves to increasingly higher values, and to this end two properties of
are useful:
The kernel has a unique global mode ;
is twice continuously differentiable with bounded third derivative in a neighborhood of , and , a negative definite matrix.
In the applications in this paper is the likelihood function and similar conditions are invoked in standard limit theorems for posterior distributions and maximum likelihood estimators. The difference is that here the limit is rather than increasing sample size.
Recall that in cycle ℓ of the annealing variant of the SABL algorithm the exponent of becomes . Denote the variance matrix of particles at the end of this cycle by .
The following four implications follow, the first from the first property and the others from both. The first three are unsurprising given conventional results for the limits of posterior distributions and maximum likelihood estimators.
The probability distribution corresponding to the kernel converges in distribution to the point .
The probability distribution of converges in distribution .
Taking the limit first as the number of particles
N increases and then as the cycle
ℓ increases,
which is the asymptotic variance of the maximum likelihood estimator.
Taking limits in the same way, the power increase ratio
converges almost surely to
where
d is the dimension of
θ. Note that
ρ, the asymptotic power increase ratio, depends on
only through
d.
A strength of this approach is that there is no need to determine first and second derivatives, either analytically or by means of numerical differentiation. The only requirements are (a) verify properties 1 and 2 analytically, (b) derive the likelihood function, (c) code the evaluation of the log-liklelihood function, and (d) code nonlinear parameter transformations. For many applications these requirements become trivial if one is using a nonlinear parameterization of an existing model, thus avoiding (b) and (c). In particular this approach avoids analytical derivation and code testing for first or second derivatives, or numerical evaluation of derivatives, both of which can be time consuming, tedious and encounter arcane numerical problems.
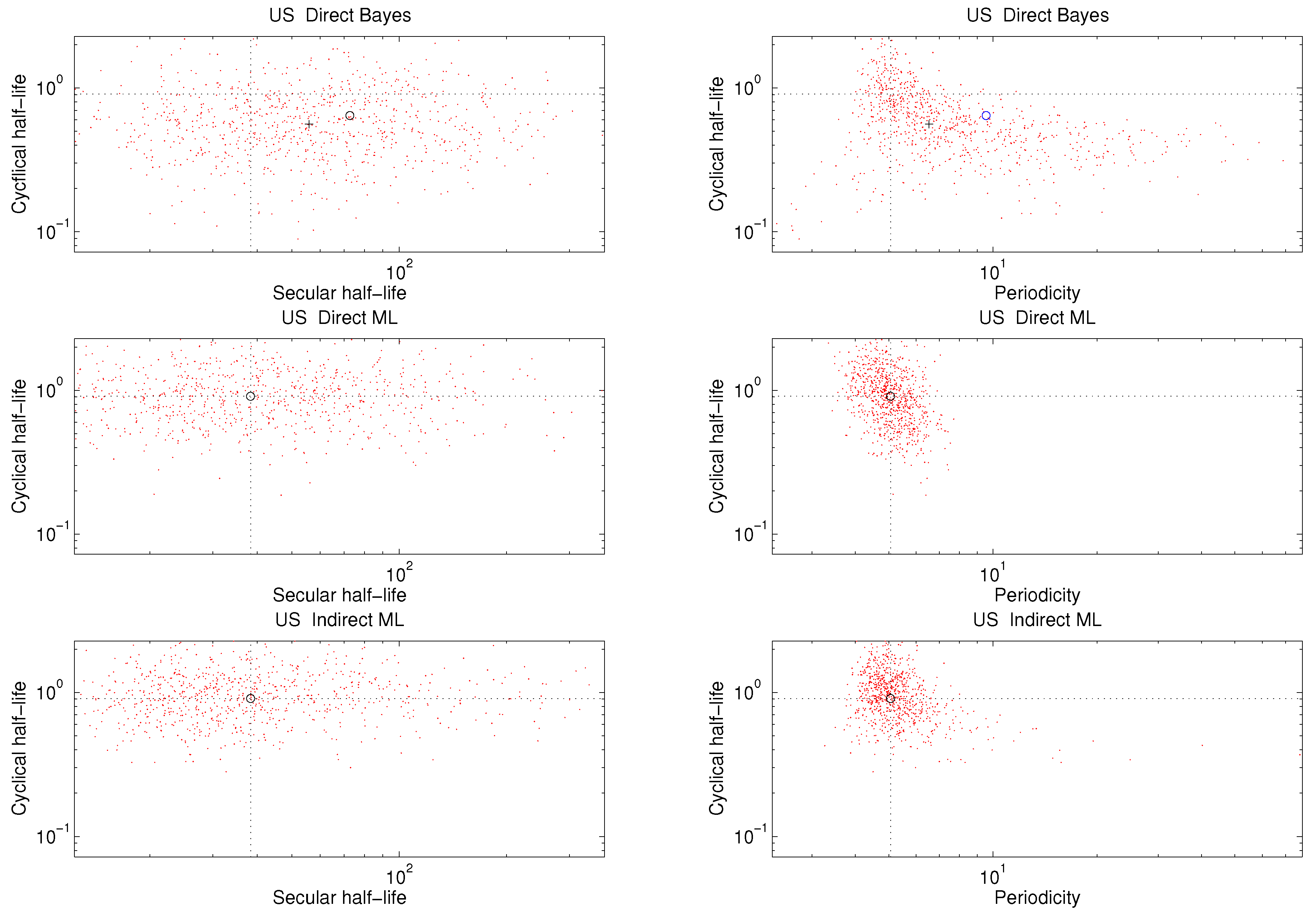
The results are insensitive to the prior distribution so long as the prior distribution provides support in a neighborhood of , the same condition invoked in the derivation of the asymptotic properties of posterior distributions. A practical consideration, here, is that as prior probability in this neighborhood decreases, becomes smaller and the number of cycles required to achieve a given concentration of particles becomes greater.
5.2. Convergence Criteria
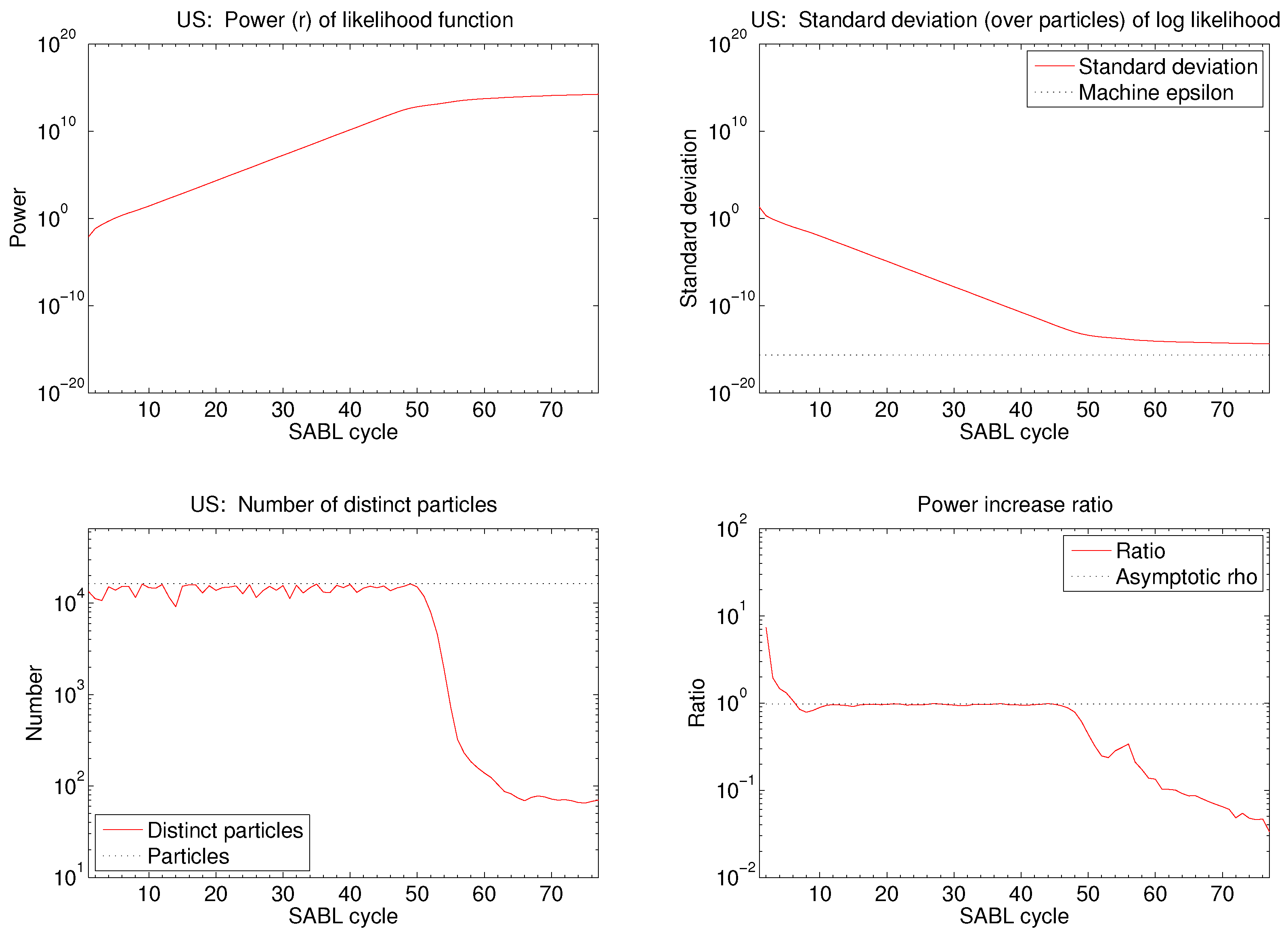
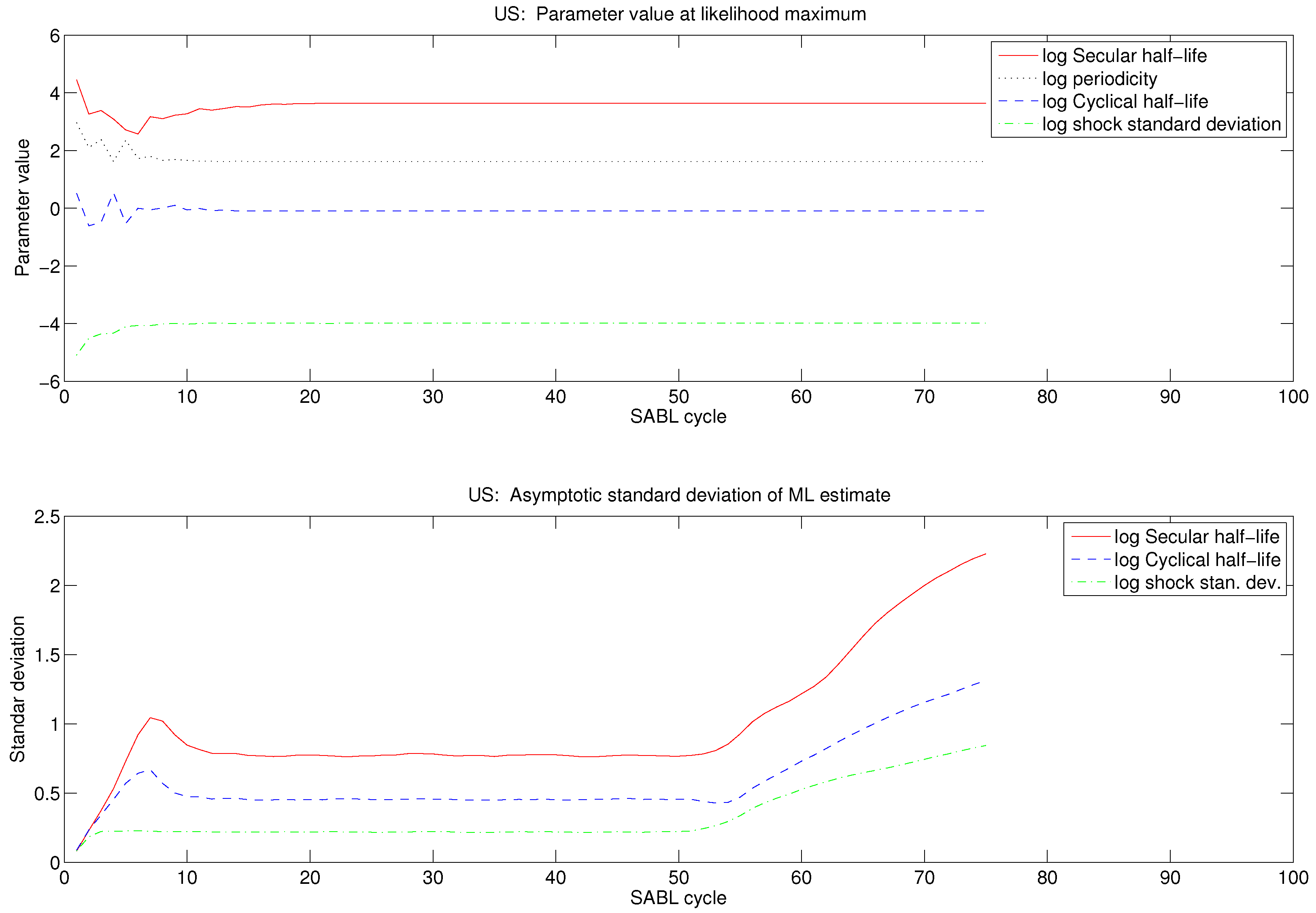
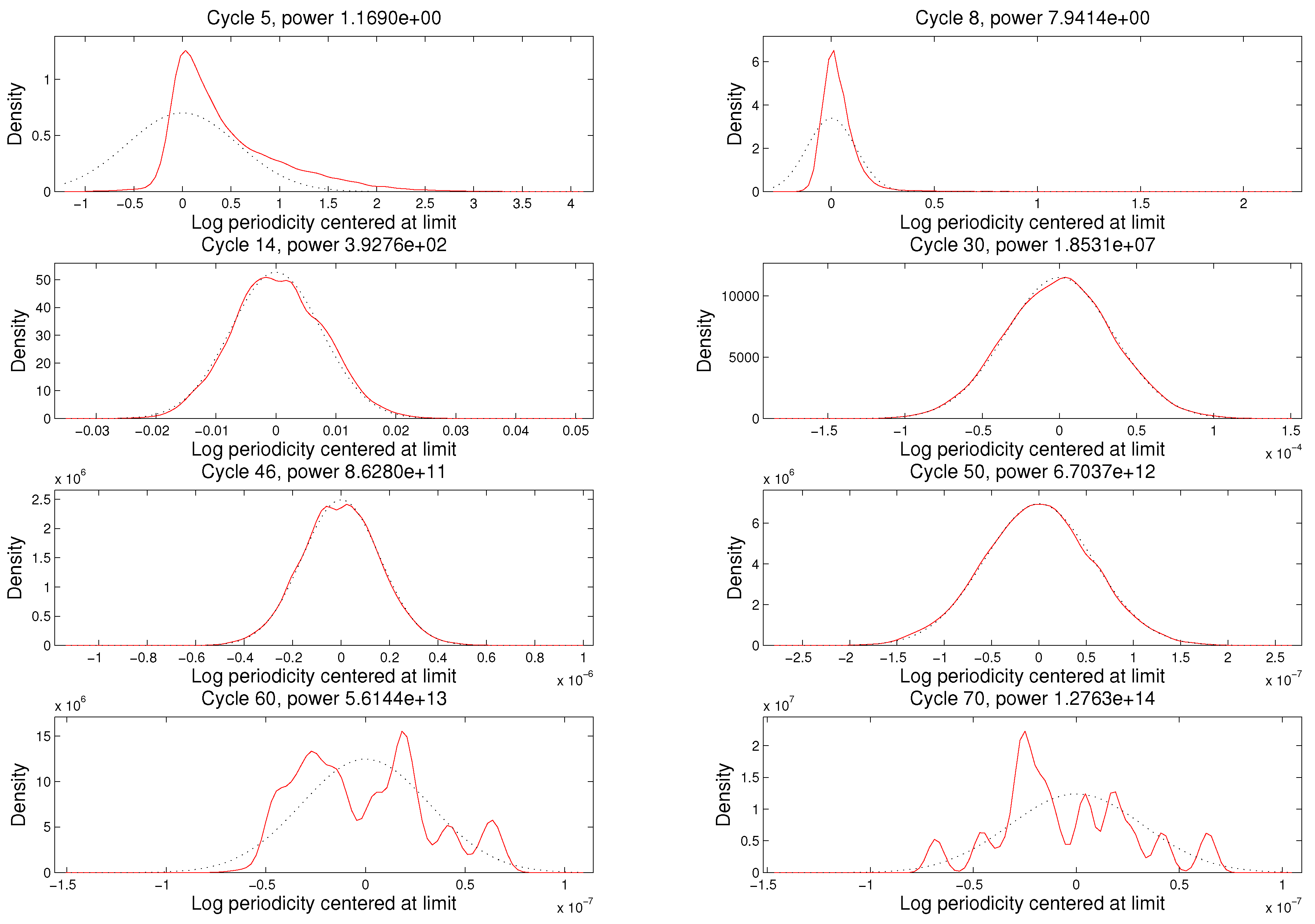
Important practical questions are SABL termination criteria and the cycle(s) ℓ whose particles are used to approximate using . Clearly the cycles chosen to approximate v must be cycles after the asymptotic power increase ratio has been closely attained, evidenced by fluctuations above and below ρ over a sequence of successive cycles. One may also wish to apply criteria for concentration of the distribution of the particles or the distribution of the objective . There seems no reason to continue beyond these points.
In fact, if cycles are allowed to continue, then eventually the algorithm encounters the limits of 64-bit arithmetic in distinguishing between values of
. The telltale evidence of this condition is that the evaluation of
at different particles
reflects the bits of the mantissa corresponding to lowest significance. Experience with examples like the one in this paper strongly suggests that the sequence of power increase ratios
exhibits three episodes, going to the limits of 64-bit arithmetic.
In the early cycles differs substantially from ρ. The most common pattern observed is that in the early cycles exceeds ρ, drifting downward toward ρ.
In the middle cycles fluctuates around ρ, fluctuations being smaller the larger the number of particles. With the default number of particles in the SABL software () fluctuations are less than 10% and commonly less than 5%. In these cycles the particles have a distribution that is hard to distinguish from multivariate normal.
In the later cycles
drops well below
ρ and fluctuates erratically. The reason is that variation in the particles is no longer dominated by the asymptotics outlined above: the limits of machine precision become increasingly important. (In the limit the distribution can become bizarre, as detailed in [
2]). The random walk Gaussian Metropolis steps in the
M phase are poorly suited to the the objective function now dominated by lower-order bit arithmetic, relative numerical efficiency is poor, and the particle distribution provides a poor source distribution in the
C phase, leading to smaller increases in power in each cycle.
These patterns are generally evident in a plot of as a function of cycles ℓ, in which the middle cycles exhibit as a nearly flat portion of an otherwise generally decreasing function of ℓ. Any one of the middle cycles is a natural point to harvest the asymptotic variance matrix of the maximum likelihood estimator, as described above. At this point it is also natural to take as the MLE . Experience suggests that the accuracy of the MLE, so computed, is well beyond the number of digits typically reported.
5.3. Relationship to the Simulated Annealing Literature
The technique of simulated annealing was introduced over 30 years ago [
10] and is now widely applied in science and engineering. Applications in statistics and econometrics are very rare and most econometricians do not include it in their suite of approaches to maximization problems. This is so despite the fact that [
11] demonstrated the method’s utility in that capacity in a
Journal of Econometrics paper that ranks 18th (out of thousands) by citation in the simulated annealing literature, and ninth in the citation rankings of articles in that journal. Almost all of the citations come from the science and engineering literature, very few from economics or statistics.
The simulated annealing literature also uses a sequence of increasing powers of the objective function, but casts the sequence as its inverse , known as temperature. Thus temperature decreases as the algorithm proceeds and this is responsible for its name. In the original version, and indeed most applications since, it may be regarded as a simple version of the SABL algorithm in which there is one particle and no S phase. Since there is no distribution of particles, neither the sequence of increasing powers in the C phase nor the variance in the Metropolis steps of the M phase can be constructed algorithmically as they are in SABL. Instead they must be provided directly by the user in each application.
Choosing a sequence of increasing powers (decreasing temperatures) that results in reasonable efficiency—or even works at all—has been a challenge. Typical applications, even by experienced practitioners, involve trial, error and tinkering with temperature reduction schedules. The choice of the variance matrix for the Metropolis step similarly must be tailored to each application, a procedure familiar to many Bayesian econometricians and statisticians who have used the Metropolis random walk for Bayesian inference. In simulated annealing, this variance matrix must be related systematically to temperature (power).
Very recently the simulated annealing literature has begun to adopt parallel chains of arguments–particles, in the terminology of this paper. Zhou and Chen [
12] is representative. I am not aware of any work in this literature that attempts to use the parallel chains to address the temperature reduction problem and the Metropolis variance matrix problem systematically. Thus the method still suffers from this very substantial overhead in application. Once acceptable solutions to these problems have been found by trial and error, none begins to approach the standard of computing the maximizing argument to the limits of machine precision attained by SABL. Geweke and Frischknecht [
2] draws an explicit comparison using the test problems in [
12], showing that SABL achieves machine precision with about the same number of floating point operations used in the methods of that paper, which in fact do not even determine the optimizing values to even three significant figures in all cases.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}