1. Introduction
We use a novel dynamic and arbitrary mixture of Gaussian Graphical Models (GGM) to describe sets of returns with complex relationships in a dynamic, nonstationary and nonparametric form and, at the same time, extract new nonparametric, nonstationary and dynamic alphas (excess returns) and betas (exposures to risk factors) of those returns. The procedure we follow builds on the formal mathematical model devised by [
1]. However, we adjust their approach to financial settings, by constructing an approach that will extract and construct implied nonparametric alphas and betas, which are key parameters of interest in financial applications. A simulation study will offer an initial insight to the level of outperformance of our approach against some traditionally used approaches. Additionally, we apply this procedure to hedge fund index data for the period January 1994 to June 2009, and find that our estimated alphas or excess returns are, on average, 0.75% per month. These alphas are 0.13% per month higher than those estimated applying OLS for the same period and, thus, our procedure uncovers that average hedge fund alphas could be underestimated when measured using OLS.
Our paper contributes to the existing literature mainly in two ways: first, it devises a new methodology to extract market dynamic alphas and betas, which is less bound to widely-extended assumptions on the parametric structure of returns. This approach is especially beneficial when the generating process is very dynamic with varying numbers of clusters (and series within clusters). Second, we provide information about clusters that can be used by allocators/decision-makers outside of the more traditional expected return/risk-reward settings (for example, through relation-in-distress measurements, which could allow allocators to reduce exposures in combinations of assets/funds that tend to cluster when volatilities rise or when returns drop, or increase exposures in combinations that tend to de-cluster when returns drop, increasing the level of expected “idiosyncracy-under-stress” when it’s most needed in the portfolio). Our approach allows for the joint modelling of multiple series both as dependent and independent sets of variables. Our methodology finds a natural application in problems where a set of variables is driven by another set of variables in a difficult-to-parametrize, non-stationary fashion.
Our application, hedge fund returns, can be seen as jointly driven by a set of factors, as opposed to fixed asset benchmarks, with exposures to those varying over time. Our results show much higher alphas to those considered through more traditional methods, indicating sufficiently relevant differences to consider this approach as one of non-marginal impact. These contrast with the alphas outlined in recent literature (see Titman and Tiu [
2], Mamaysky
et al. [
3], Ferson and Schadt [
4], Patton and Ramadorai [
5], for a recent review). Furthermore, our estimated alphas and betas exhibit very high volatility, particularly in periods which can be identified as times of stressful market events. This is in line with the existence of many dynamic drivers in this particular application, such as dynamic market conditions, dynamic internal fund allocations, shift in portfolio manager styles and exposures, as well as dynamics of liquidity parameters of the individual funds. These findings question the constant alpha and beta assumption implicit in some studies conducted to measure hedge fund performance, as well as in the dynamic (yet parametric) approaches presented in others like [
3]. Ours is more in line with a dynamic mixture model, with the mixtures viewed as the flexible, accomodating distributions to the different approaches to portfolio management and exposures of funds over time.
The question of investment performance measurement (in both absolute and relative terms) has received increasing attention by both academicians and practitioners. The hedge fund industry, the focus of our application, has grown rapidly during the past two decades, and institutional investors such as endowments and pension funds have gradually increased their allocations to hedge funds. According to Hedge Fund Research, the total number of funds around the world grew to around ten thousand and total assets under management (AUM) reached around 2 trillion US dollars by the end of 2013. The hedge fund industry was severely affected by the global financial crisis of 2008–2009, with the total number of funds and AUM dropping by around a third during the crisis, although they mostly recovered by the end of 2010. The analysis of their returns, however, is nontrivial as the underlying processes are both complex and dynamic. Hedge fund managers change their allocations, positions, and their styles over time. Risk or leverage limits are often imposed. Market events change the focus of specific managers and new managers come and go with different styles. Additionally, the alpha of different styles changes over time, with periods where some styles outperform/underperform others over arbitrary periods before they revert. Even within a hedge fund group/style, there will be much different approaches that will generate very different return series (for example, depending on the frequency at which they operate). As such, any modelling approach must be sufficiently flexible to account for these (and other) changes in the nature of the return process over time. We offer a flexible, nonstationary, nonparametric approach that borrows information across dynamic clusters, but, more importantly, makes neither parametric assumptions on the nature of the (dynamic) alphas and betas nor on their autocorrelation structure. This approach, although we focus on the Hedge Fund return application, is applicable to any set of return series where the dynamics are too complex and unknown to be modelled using parametric assumptions, yet a dynamic model is needed for all the key elements of the series (alphas, betas and clusters).
It is important to mention that the focus of this paper is mainly descriptive, rather than inferential. Due to the high variability and the dynamic nature of the series we model, and the cluster dependence on the drivers of the series, although inference is technically possible, our focus is on providing a better understanding of the returns. A more accurate understanding of alphas, betas and clustering styles will provide decision-makers with new sources of information. This information, although usable directly in the allocation process (through the alphas and betas), finds also a natural space indirectly through cluster analysis (for example, putting limits on combined weights assigned to series that have a high probability of clustering in distress periods).
The measurement of alpha, in the case hedge funds returns, as well as other complex return series, is complicated by their dynamic use of strategies that include long and short positions, as well as derivatives that result in very dynamic factor exposures against fixed benchmarks. This in turn generates non-linear returns that require tailored benchmarks. Furthermore, and according to [
6], risk exposures of hedge funds have also declined in response to the rising dominance of institutional investors replacing family offices and private individuals as the primary source of investor capital. These same authors argue that the rapid growth of hedge funds has been responsible for the decline in their performance between the 1990s and mid-2000s and that perhaps “all the low-hanging fruits have been picked.” This view questions the use of a constant, mean-reverting level for the alphas, and calls for non-stationary models for key paramers, such as the one proposed in this paper. Additionally, it is also questionable that betas to key factors can be stationary, especially as funds deploy new ways to exploit competitive advantages (for example, as funds/sectors move to trading in higher frequencies, betas of those funds to factors defined in lower frequencies may diminish).
When empirically tested, many of the approaches assume that the coefficients of the regressions are constant over time (or come from a constant distribution). If, in fact, these coefficients are time-varying and non-stationary, then the estimated parameters using these models would be unreliable. In the context of our application, as an example, [
7] propose to measure the conditional performance of hedge fund indices using a stochastic discount factor approach, which imposes fewer limitations on the behavior of underlying returns. They find that estimated alphas, which are found to be positive, are similar when hedge fund performance is measured assuming either of the following four cases: (i) an absolute return approach (e.g., Alpha =
); (ii) a single-factor, fixed-exposure approach (e.g., CAPM); (iii) a single-factor, linear time-varying exposure approach (e.g., Merton’s model); and (iv) an extension of Merton’s approach consisting of a multi-factor, linear time-varying exposure approach. This finding of similar estimated alphas regardless of the model used leads them to conclude that better models are needed to measure hedge fund performance. Our approach finds very different (across funds and over time) alphas and betas, which seems more in line with expectations of highly dynamic funds.
In a related prior approach, for a similar application, [
3] address the issue of time variation in mutual fund factor loadings and develop a Kalman filter model to test for market-timing ability; showing that even though the Kalman filter model does not appear to exhibit market-timing ability at the daily frequency, it does so at the monthly frequency. While we focus our application on monthly returns, the flexibility of the design accomodates via a non-parametric approach to estimate dependence between alphas, making it less reliant on a strong parametric link between them over time, like the one imposed by the Kalman filter. Although a special case of our model and with another application in mind, [
8] use a regime-switching beta model to measure dynamic risk exposures of hedge funds to various risk factors during different market volatility conditions. For interesting overlaps of our work with networks and graphical models please see [
9,
10].
Kosowski
et al. [
11] use Bayesian measures to estimate hedge fund alpha at the individual hedge fund level. These measures are based on the robust boostrap approach suggested by [
12], and the Bayesian framework of [
13]. They argue, in the same vein as [
14,
15,
16], that hedge fund performance measures do not follow parametric normal distributions because these funds hold derivatives such as options, because of the dynamic nature of their trading strategies, and also due to small sample problems. These features of hedge fund performance help explain their finding that Bayesian nonparametric measures yield superior performance predictability relative to alphas estimated when specific parametric models are assumed.
The Bayesian paradigm provides in the case aforementioned, as well as ours, a natural, flexible tool to the fast estimation of the quantities of interest. Our approach is especially amenable for cases where small sample sizes also hinder many alternative approaches due to the (random) large dimensionality of the problem. The implementation of a Bayesian approach for measuring hedge fund performance should not be surprising, because Bayesian measures have been traditionally used to help overcome the small-sample problem typical of hedge fund returns
1, making this also an area where our approach may become amenable.
Using a robust boostrap procedure, [
11] also find that hedge fund performance at the top cannot be explained solely by luck, that performance persists at annual horizons, and that OLS alphas of top hedge funds tend to be incorrectly estimated. It is worth noticing that the model used in [
11] is not only parametric in nature, and therefore exposed to model risk, but also stationary. On the contrary, the alphas, as well as the betas derived in our paper, are nonstationary and dynamic. To the best of our knowledge there is no previous work that employs a formal mathematical model to describe in a dynamic, nonstationary and nonparametric way multivariate returns against multivariate factors, and extract at the same time some new nonparametric, nonstationary and dynamic alphas and betas, under a clustering scheme for shrinking, and in a fully Bayesian approach.
Gaussian graphical models (GGMs), also called covariance selection models [
22], are popular tools for modeling dependence across observables. GGMs assume that the returns generated by different asset classes and/or investment vehicles follow a joint multivariate Gaussian distribution, and explore the pattern of partial correlations to understand how the different outcomes influence each other. Because observations are assumed to follow a (arbitrary mixture of) multivariate Gaussian distribution, absence of partial correlation corresponds to a zero in the appropriate entry of the precision (inverse covariance) matrix and indicates that the variables are conditionally independent. The conditional independence patterns inferred in this way can be represented using a graph where nodes correspond to variables and an edge is present between two variables if they are conditionally dependent, and absent otherwise.
GGMs are a natural alternative to
endogenous factor models as described in [
23,
24], which explain the joint multivariate outcome as a linear combination of a small number of unknown factors determined directly from the data being modeled
2. However, GGMs are particularly appealing over these endogenous factor models because they allow researchers to asses conditional rather than marginal independence, which in turn makes it straightforward to distinguish between direct and indirect interactions between the variables. GGMs have been successfully applied in finance and econometrics (for example, see [
1,
28,
29,
30,
31]), where they have been shown to provide interpretability and enhanced predictive performance. However, our extraction of cluster-implied alphas and betas adds a new layer of outputs to the existing literature, since they allow direct use of these parametric measures derived from a non-parametric setting.
The paper is organized as follows.
Section 2 presents the statistical methods we employ.
Section 3 offers sensitivity analysis and simulation exercises to compare our model to traditionally used models that pursue similar features of the data. In
Section 4 we describe the data used in the study, and the application through hedge fund returns.
Section 5 shows the main results obtained, while
Section 6 offers the results of estimating time-varying alphas and betas, as well as cluster analysis, using the infinite hidden Markov model (iHMM-GGM) proposed by [
1]. Finally, we outline our conclusions and potential extensions in
Section 7.
4. Data and Empirical Strategy
We use the monthly returns of the Credit Suisse First Boston Tremont Hedge Fund Indices (CSFB/TREMONT) for our study. The CSFB/TREMONT hedge fund indices, which are reported net of fees, are a family of asset-weighted hedge fund indices designed by Credit Suisse First Boston and Tremont, and includes more than 4500 hedge funds (both open and closed to new investors) from all over the world. To be included in the index, a hedge fund must have a minimum of 10 million dollars in assets under management, a history of at least twelve months, and audited financial statements. Hedge funds are grouped into the following nine categories: Convertible Arbitrage (CA), Short Bias (SB), Emerging Markets (EM), Equity Market Neutral (EMN), Event-Driven (ED), Fixed-Income (FI), Global Macro (GM), Long-Short Equity (LS), and Managed Futures (F). Recently, CSFB/TREMONT also added a Multi-Strategy (MS) hedge fund category. CSFB/TREMONT also calculates an index that is an average of all strategies (HF). A complete list of the hedge funds included in the CSFB/TREMONT database can be found on www.hedgeindex.com. Net asset value returns from this database are reported monthly. We use monthly data from January 1994 to June 2009. Most studies on hedge funds start in January 1994 because most databases do not contain information on funds that died before December 1993, thus giving rise to survivorship bias. As a clarification, this is not a forecasting exercise since we use all the data from January 1994 up to June 2009 to estimate our model.
The search for alpha requires the correct identification of betas. Different authors have proposed sets of common factors that can influence hedge fund returns. For example, among the first studies, [
47] considered 13 factors while [
48] considered eight factors. The works in [
2,
16,
48,
49,
50,
51] used stepwise regressions to identify the factors.
We use the seven factor model proposed by [
52]. This model has been extensively used in the hedge fund literature (for a recent review of the use of the model in the hedge fund literature see [
2]). The seven factors are: two equity oriented risk factors (a stock market factor and a firm size factor), two bond oriented risk factors (a bond market factor and a credit spread factor), and three trend-following risk factors (a bond trend-following risk factor, a currency trend-following risk factor, and a commodity trend-following risk factor).
The three trend-following risk factors mentioned above are the returns of portfolios of options on bonds, foreign currencies, and commodities, and were originally proposed by [
50]. These authors found that these portfolios, which are constructed as lookback straddles on bonds, currencies and commodities, produce high returns during large moves in equity markets
4. They also find that the returns of trend-following funds’ are sensitive to large shifts in world equity markets. The return series for these three trend factors were obtained from David Hsieh’s website:
https://faculty.fuqua.duke.edu/~dah7/HFData.htm The data for the other four factors was obtained from Datastream. Fung and Hsieh’s [
52] seven factor model following our notation is:
where
are the respective hedge fund index excess returns over 3-Month LIBOR rates for period t, and
, and where:
Stock market factor (SMF), measured as the monthly total return (price appreciation and cash dividends) of the Standard and Poor’s 500 Index.
Firm size factor (FSF), measured as the difference between monthly small cap total returns (price appreciation and cash dividends) on the Russell 2000 Index minus Large Cap monthly total returns (price appreciation and cash dividends) on the Standard and Poor’s 500 Index.
Bond market factor (BMF), measured as the monthly change (month-end to month-end) in the ten-year U.S. Treasury constant maturity yield.
Credit spread factor (CSF), measured as the monthly change in the Moody’s U.S. Baa yield minus the ten-year U.S. Treasury constant maturity yield.
Bond lookback straddle (BLS), measured as the return of a primitive trend following strategy bond lookback straddle and reported by David Hsieh in his website.
Currency lookback straddle (CULS), measured as the return of a primitive trend following strategy currency lookback straddle and reported by David Hsieh in his website.
Commodity lookback straddle (COLS), measured as the return of a primitive trend following strategy commodity lookback straddle and reported by David Hsieh in his website.
Table 2 suggests that hedge fund returns exhibit non-normal behavior since the empirical moments are very different (skewness and kurtosis) from those of a normal distribution. This is not a surprise, as it has been extensively documented in the hedge fund literature. There is a certain temporal dependence, judging by the AR(1) coefficients for those strategies that have a significant coefficient. The moments reflected in the table do not fit any of the usual distributions used in finance, and, therefore, a more flexible approach to the modeling of these returns seems appropriate. Finally, half of the Sharpe ratios are positive.
Table 3 presents summary statistics of the factors used to analyze hedge fund returns and suggests that the factors also exhibit non-normal behavior.
Table 4 presents the correlation matrix of the factors. Correlations are fairly low, and tend to be slightly negative between each of the first four factors and each of the three factors representing portfolios of lookback straddles.
5. Results
In this section, we comment on the main results obtained, bearing in mind that a number of disruptive market events were experienced during the period January 1994 to June 2009. Primarily among them are the sharp interest rate increase of early 1994, the Asian financial crisis of 1997–1998, the Russian default of 1998 and the ensuing collapse of Long Term Capital Management (LTCM), the end of the Internet bubble at the beginning of 2000, the terrorist attacks of September 2001, the corporate scandals of Enron and Worldcom in 2002, the bursting of the real estate bubble and the ensuing global financial crisis in 2007–2008. These stressful events would have most likely required hedge funds to alter their portfolios, thus causing their betas to shift over time.
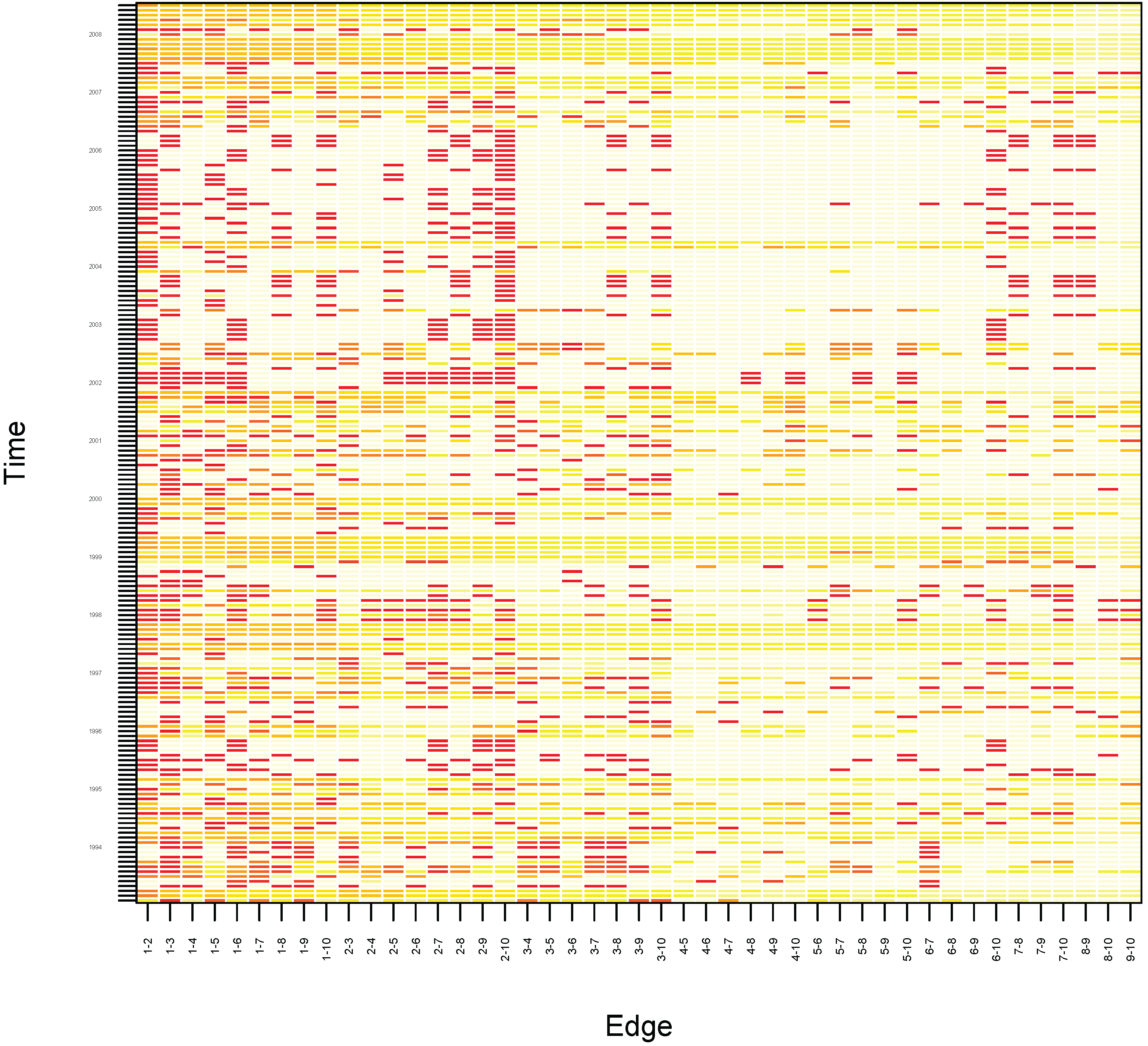
Figure 6 presents the Heatmap displaying the probability that two observations of edges of nine hedge fund strategy returns, the average for all strategies, and the seven factors from Fung and Hsieh’s [
52] model belong to the same cluster between January 1994 and June 2009. The figure shows very high probabilities (more than 80%) that the following edges of hedge fund strategies belong to the same cluster during most of the months of the period January 1994 to June 2009, particularly during the bull market periods of 1994–1999 and 2003–2007:
Short-bias and Event-Driven
Short-bias and Fixed-Income
Short-bias and Global Macro
Short-bias and Managed Futures
Emerging Markets and the bond market factor
Emerging Markets and the commodity lookback straddle
Event-Driven and the stock market factor
Event-Driven and the firm size factor
Event-Driven and the bond market factor
Fixed-Income and Managed Futures
Managed Futures and the firm size factor
Furthermore, and as expected, the probability that the Equity Market Neutral strategy and any other strategy belongs to the same cluster (except for the edge Equity Market Neutral and Short Bias during the second half of the sample period) is fairly low.
Fung and Hsieh [
52] had already identified two breakpoints in factor exposures by hedge funds (September 1998, the collapse of LTCM, and March 2000, the beginning of the end of the Internet and technology bubble of the 1990s). This is consistent with hedge funds changing their strategies through time, this is, with alphas and betas being time-varying. Agarwal
et al. [
21] and Fung
et al. [
53] also use these breakpoints in their studies. Interestingly, [
12] also report a structural break in the series of hedge fund returns in December of 2000.
The figure also illustrates that the global financial crisis of late 2008 (August through December), and the crisis experienced by financial markets in 1998 as a result of the Russian default and the LTCM debacle (September through November of that year) were two extraordinary events, because the probability that any two hedge fund strategies belonged to the same cluster was high, and almost the same for all the possible edges of hedge fund strategies during those two sub-periods, as can be seen by the lines of yellow/orange colors during those periods. This outlines the dangers from a risk management point of view of the presence of apparently uncorrelated groups of strategies or portfolios, that become highly correlated at periods of stress, due presumably to synchronized unwinding of positions across different strategies. These results also confirm the findings by [
52], who had already reported a structural break in hedge fund index returns in September of 1998.
In a related article, [
54] examine the extent to which hedge fund styles suffer from contagion. To that end, they use parametric and semi-parametric analysis and monthly hedge fund index data for the period 1990 to 2008. Contagion is defined as “correlation over and above what one would expect from economic fundamentals” (based on [
55]). They find that hedge fund returns that fall in the bottom 10% of a hedge fund style’s monthly returns, cluster across styles. They also suggest that liquidity shocks to a number of contagion channel variables help explain hedge fund contagion.
6. Time-Varying Alphas and Betas Estimated Using iHMM-GGM
In this section we ran the model of [
1] explained in
Section 2 for 120,000 iterations and having descarted the first 20,000. The pseudo-code for computing the alpha and beta for each t = 1,...,186 consists in the following steps:
For i = 1,...,120,000.
Generate a value for the number of clusters in iteration i.
Conditional on , label each data vector with a specific cluster so that for t = 1,...,186.
Construct and for t = 1,...,186 from the distribution .
For a given t, average over all clusters the values of and as and
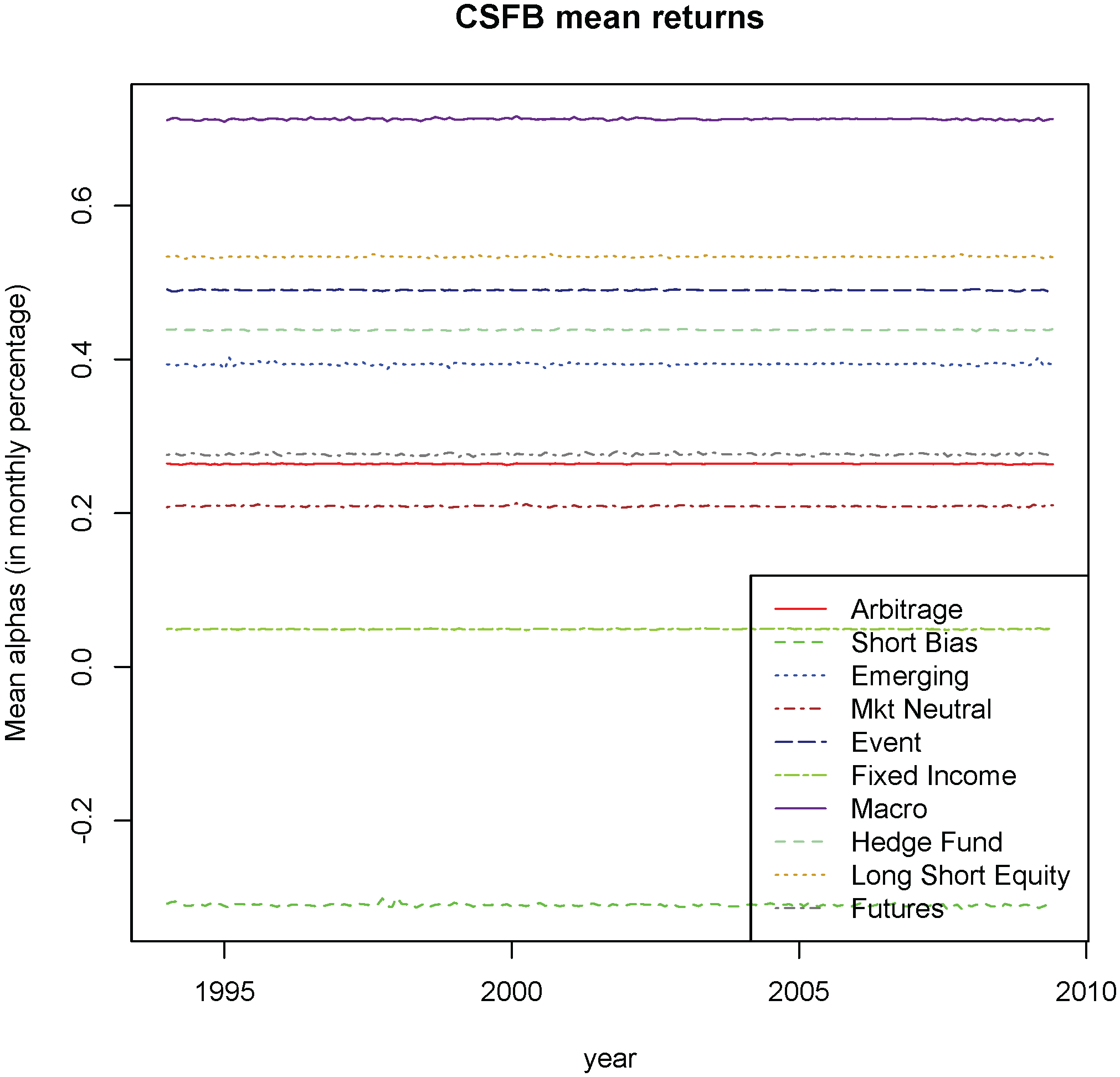
Figure 7 present the estimated mean alphas for each strategy from highest to lowest (in percent per month) and for the whole sample period: (1) Global Macro (1.02%); (2) Long/Short Equity (0.83%); (3) Event Driven (0.79%); (4) Emerging Markets (0.70%); (5) Managed Futures (0.58%); (6) Convertible Arbitrage (0.57%); (7) Equity Market Neutral (0.52%); (8) Fixed-Income (0.35%); and (9) Short-Bias (−0.02%).
Our results can be compared to those reported in a recent paper by [
56], who also used a similar sample period (January 1995 to December 2009
versus our sample period of January 1994 to June 2009), and also worked with Fung and Hsieh’s seven factor model, but based their study on data from individual hedge funds available in TASS (we used CSFB/Tremont hedge fund indices) to estimate alpha applying OLS regressions. Ibbotson
et al. [
56] found a positive alpha for all strategies, although it was only statistically significant for the following strategies: equity market neutral (annualized alpha equal to 2.38%), event driven (annualized alpha equal to 3.73%), fixed income (annualized alpha equal to 2.39%), and long/short equity (annualized alpha equal to 5.16%). The average hedge fund had a statistically significant alpha of 3.01% per year. In our study, average hedge fund alpha was substantially higher, around 0.75% per month or 9.4% when annualized.
We also computed the difference between our estimated iHMM-GGM time-varying alphas for the nine CSFB/TREMONT hedge fund strategies and the average for all strategies, and the alphas estimated using OLS regressions during the sample period. We found that for all hedge fund strategies, except for Short-Bias (−0.6% per month), Managed Futures (−0.08% per month), and Fixed-Income (−0.04% per month), the difference between our estimated iHMM-GGM time-varying alphas and the estimated alphas using OLS regressions was positive on average. The highest difference was for Emerging Markets and Long/Short, at around 0.25% per month for each. The average hedge fund had an alpha that was around 0.13% per month (1.6% per year) higher when estimated using our iHMM-GGM procedure and the estimated alphas using OLS regressions. This implies that, over the time period we are using, estimations of alpha using OLS regressions such as those conducted in most of the prior research could underestimate the true alpha generated by the average hedge fund belonging to these three strategies. In
Table 5 we report the standard deviations of the 186 time-varying alphas for each of the nine strategies and for the average of all strategies. It is important to notice that computing the standard deviation over the 186 time- varying alphas only makes sense if we assume that these 186 alphas are each independent and identically distributed, something that we have seen is not the case since they are likely to be time-varying and not identically distributed (given the fact that they come estimated from our iHMM-GMM model). However, we still decided to report the standard deviations to have an idea of the variability of the alphas over all the 186 periods.
Global macro strikes out as the strategy having the most volatile alpha, around twice the volatility of that for managed futures, the second most volatile strategy in terms of alpha. This finding may be explained, in part, by the effect on the performance of global macro that had extraordinary events such as those of September 1998, in which Long Term Capital Management, a hedge fund belonging to this strategy and one of the largest hedge funds at the time, collapsed. As expected, the volatility of alpha for equity market neutral and long-short hedge funds is relatively low. The average performance of these strategies, especially in the case of equity market neutral, is more predictable and stable. The volatilities of alpha for event driven, convertible arbitrage and fixed-income strategies are close to the average volatility of all strategies. The volatility of alpha for emerging markets, a strategy that is in many respects similar to global macro, and short-bias hedge funds were around the lowest.
Figure 8 shows the estimated iHMM-GGM monthly alpha for the Global Macro Strategy estimated using the seven factor model for the whole sample period. For illustrative purposes, we chose to present here these time-varying alphas only for one of the strategies, Global Macro, which, as was just explained, was found to have the most volatile alpha of the nine strategies. The figure shows the volatility exhibited by the alpha of Global Macro. This volatility of the alphas questions the constant alpha assumption implicit in the estimation through regression models. We also present, in
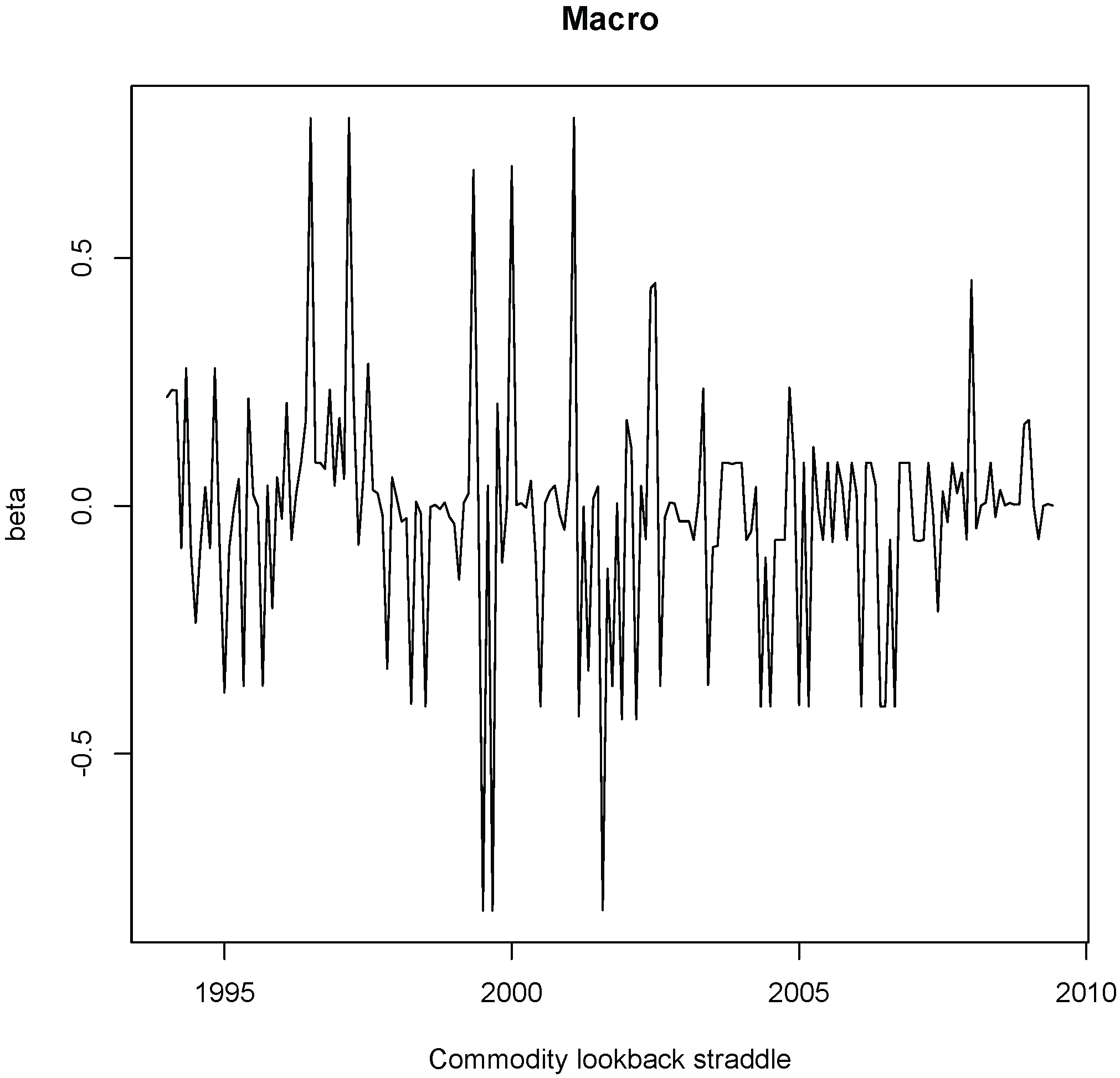
Figure 9, and for illustrative purposes, the estimated iHMM-GGM beta of the Global Macro Strategy with respect to one of the seven factors of Fung and Hsieh [
52], the commodity lookback straddle factor, using the whole sample period. It can be clearly observed the high volatility of beta for Global Macro with respect to this specific factor, particularly during the first half of the sample period.
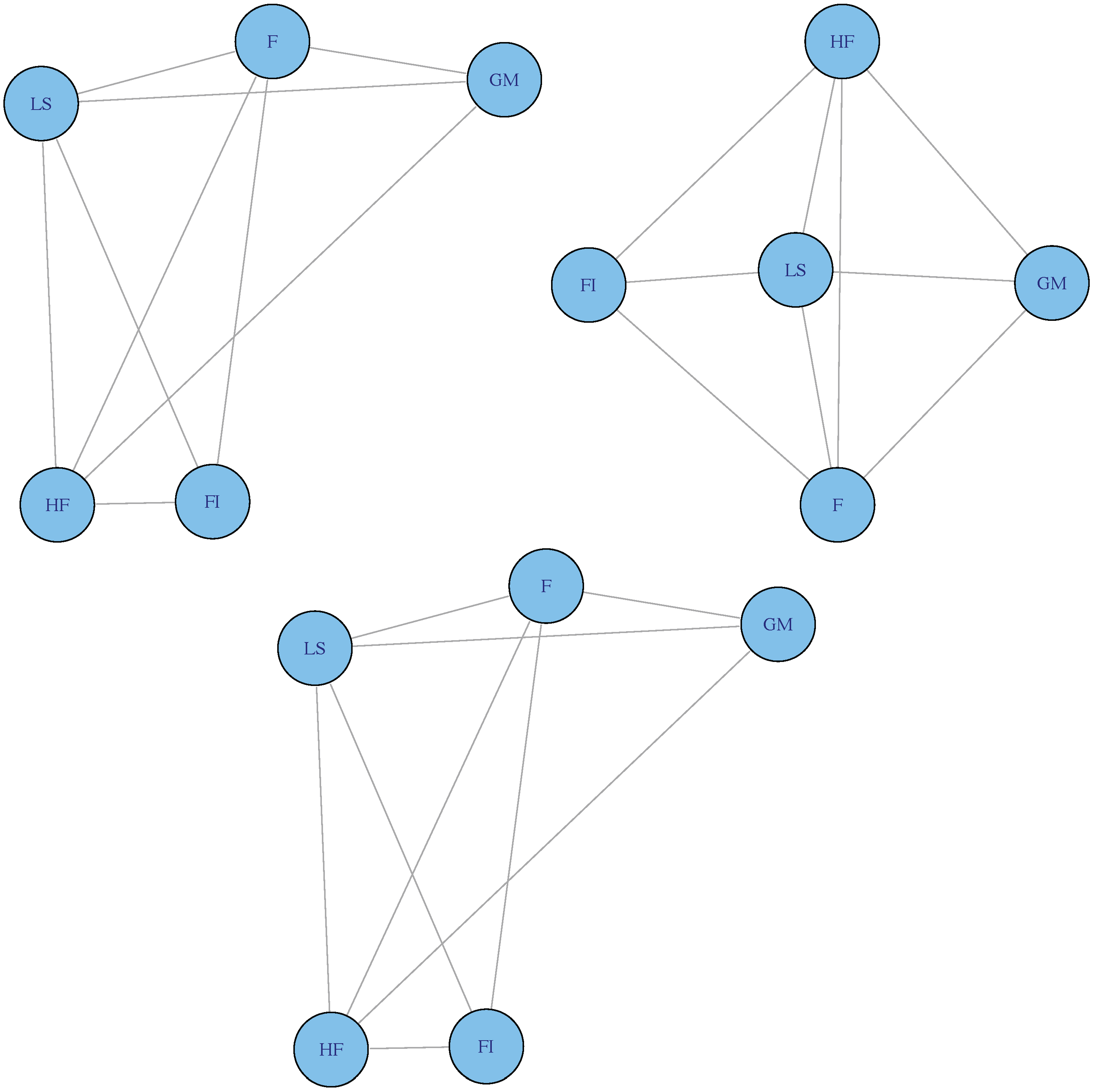
Figure 10 shows the graphical models associated to three critical time-points (months) during the sample: September 1998 (collapse of Long-Term Capital Management), March 2000 (beginning of the end of the 1990s bull market), and September 2008 (fall of Lehman Brothers and beginning of the global financial crisis). These graphs were built by adding any edge that had a greater than 80% posterior inclusion probability for the respective timepoint. It is striking to note that the three graphs are exactly the same, this is, they depict the same relation among four hedge fund strategies (global macro, fixed income, long/short and managed futures) and the average of the hedge fund indices for all strategies. The graphs suggest that in times of market crisis the aforementioned strategies belonged to the same cluster as they exhibited a high degree of covariation and dependence. Our findings from
Figure 10 could be very useful, for example, for funds of hedge funds (or any other allocators), as they indicate that in times of market distress hedge funds dedicated to these strategies may suffer heavy losses and, thus, allocators investing into these categories of hedge funds will not be as diversified as originally thought. We can compare our results to previous studies. For example, Khandani and Lo [
57], who also used CSFB/TREMONT hedge fund indices, documented that the global macro strategy had a correlation of only between 25% and 50% with both the long/short and the fixed income strategies between the following two sub-periods: April of 1994 to December of 2000, and January of 2001 to June of 2007; and that the fixed income strategy had a correlation of less than 25% with the long/short strategy during the same sub-periods. However,
Figure 10 strongly suggests that the global macro and fixed income strategies were both linked to the long/short strategy but not between them during those months of market stress, and that the managed futures strategy was linked to the other three strategies. In turn, [
57] also find, contrary to our results, a strong correlation (greater than 50%) between 29 pairs of hedge fund strategies and during the same sub-periods. Thus, our results may also uncover the dangers of inferring the benefits of diversifying into specific hedge funds styles in times of market crisis when using traditional correlation analysis. In sum, the understanding of the joint distribution of hedge fund styles under different clusters provides a portfolio view of their marginal impact and behavior. For example, if one identifies a crisis cluster and observes the inferred distribution of returns in that cluster, one may be able to construct a portfolio that weights funds more appropriately, not according to their Sharpe or other performance measures, but around the expected behavior of the distribution in times of crisis. Our findings are also important in the context of stress testing of portfolios during periods of market turmoil.
7. Conclusions and Extensions
We expand a novel statistical method to compute nonparametric dynamic alphas and betas, as well as returns clusters in a Bayesian fashion. This model provides a nonparametric, nonstationary, fully flexible approach to modelling sets of complex relationships between return series, regardless of the data generating process. We show through a simulation exercise that for both alpha and beta the estimation results based on the RMSE and MAD measures improve significantly upon popular statistical methods such as the regular OLS and DLMs, a special case of which being the Kalman filter. In a second exercise, we use hedge fund index returns from CSFB/Tremont for the period January 1994 to June 2009 and find that, using a Gaussian Graphical Model applied to Fung and Hsieh’s [
52] seven-factor model, our estimated alphas are, on average, 0.75% per month. The average alphas of global macro, long/short equity and event driven were above the average for all strategies. The other strategies still had positive alphas, except for short-bias, although their average alphas were below the average for all strategies. Our estimated average alphas for all strategies are 0.13% per month (1.6% per year) higher than the alphas for all strategies estimated through OLS for the same period and, thus, our methodology reveals that average hedge fund alpha could be underestimated when measured using OLS. Furthermore, our estimated alphas and betas exhibit high volatility, particularly in periods which can be identified as times of stressful market events. Consistent with previous research, hedge fund returns were found to be non-normal. We also found that estimated alphas for the global macro strategy were highly volatile. The alphas of equity market neutral, long/short equity and emerging markets exhibited the lowest volatilities of the nine strategies. These findings question the use of parametric and stationary (non dynamic) models to estimate alphas and betas. The Bayesian procedure that we use in this paper has as advantages that it describes hedge fund returns in a dynamic, nonstationary and nonparametric form and, at the same time, allows us to extract new nonparametric, nonstationary and dynamic alphas and betas.
The procedure for measuring alpha that we propose in this paper was applied at the index level. Future research should investigate whether the same conclusions hold when individual hedge fund data is used. The use of individual hedge fund data also facilitates the measurement of performance persistence by grouping outperforming and underperforming hedged funds in each strategy and measuring their subsequent performance. Another extension would be to apply our procedure using other risk factors besides those of Fung and Hsieh [
52] seven-factor model. In this regard, some authors have proposed specific factors for certain hedge fund strategies. For example, [
58] propose a risk factor model for hedge funds dedicated to the fixed-income strategy. Finally, [
21] document that mutual funds, which are catered mainly to small investors and are tightly regulated, as opposed to hedge funds, have recently begun offering funds that use trading strategies similar to those that are typical of hedge funds, as they include short sales and the use of derivatives, intended to take advantage of investment opportunities. These trading strategies should generate nonlinear payoffs and, thus, future research could also be extended to measuring mutual fund alpha using a more general procedure such as the one we propose here.
The focus of this paper has been on a descriptive approach to the returns for decision-makers. Future work will focus on forecasting, in cases where enough persistence exists in the series to provide sufficient structure. In this paper we do not presume that there is a stationary distribution to revert to, but instead a nonstationary process that reflects the less predictable characteristics of the returns.
One of the by-products of the methodology that we have presented in this paper is the time-varying probability that any two strategies belong to the same cluster. This information could be used by decision-makers in a number of different ways. For example, one approach would be through the understanding of the evolution of that relationship over time. However, another approach that could be more novel and meaningful, would be to analyze whether a set of strategies belong to the same cluster in key moments in time. Those key periods could be defined as periods with large negative returns, very large positive returns or any other particular feature that could be of relevance to the decision-maker, which in turn could help understand the relationship features between strategies with a higher granularity, as well as the expected marginal impact of additions to their portfolio in key periods. For example,
Figure 10 showed that the graphical representation of the relationship between four specific strategies and aggregate hedge fund indices is the same in three key periods of time (September of 1998, March of 2000, and September of 2008). Whether the decision-maker expects that relationship to exist or expects further independence during times of market stress is outside the scope of this paper. However, the availability of this by-product brings in itself a significant number of areas of future research, including the analysis of the dynamics of these graphical structures over time and their impact on portfolio construction.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}