1. Introduction
This paper revisits the approximation properties of the linear quantile regression under misspecification ([
1,
2,
3]). The quantile regression estimator, introduced by the seminal paper of Koenker and Bassett [
4], offers parsimonious summary statistics for the conditional quantile function and is computationally tractable. Since the development of the estimator, researchers have frequently used quantile regression, in conjunction with ordinary least squares regression, to analyse how the outcome variable responds to the explanatory variables. For example, to model wage structure in labour economics, Angrist, Chernozhukov, and Fernández-Val [
1] study returns to education at different points in the wage distribution and changes in inequality over time. A thorough review of recent developments in quantile regression can be found in [
5]. The object of interest of this paper is the quantile regression (QR) parameter that is the probability limit of the Koenker–Bassett estimator without assuming the true conditional quantile function to be linear. Two results are presented: a new interpretation and the semiparametric efficiency bound for the QR parameter.
The topic of interest is the conditional distribution function (CDF) of a continuous response variable
Y given the regressor vector
X, denoted as
. An alternative for the CDF is the conditional quantile function (CQF) of
Y given
X, defined as
for any quantile index
. Assuming integrability, the CQF minimizes the check loss function
where
is the set of measurable functions of
X,
is known as the check function and
is the indicator function. A linear approximation to the CQF is provided by the QR parameter
, which solves the population minimization problem
assuming the integrability and uniqueness of the solution, and
d is the dimension of
X. The QR parameter
provides a simple summary statistic for the CQF. The QR estimator introduced in [
4] is the sample analogue
for the random sample
on the random variables
. By the equivalent first-order condition, this estimator
is also the generalized method of moments (GMM) estimator based on the unconditional moment restriction ([
6,
7])
This paper focuses on the population QR parameter defined by (
1) or equivalently (
3).
If the CQF is modelled to be linear in the covariates
or
, the coefficient
satisfies the conditional moment restriction
almost surely. In the theoretical and applied econometrics literature, this linear QR model is often assumed to be correctly specified. Nevertheless, a well-known crossing problem arises: the CQF for different quantiles may cross at some values of
X, except when
is the same for all
τ. A logical monotone requirement is violated for
or its estimator to be weakly increasing in the probability index
τ given
X. The crossing problem for estimation could be treated by rearranging the estimator (for example, see [
8] and the references therein.
1). However, the crossing problem remains for the population CQF, suggesting that the linear QR model (
4) is inherently misspecified. That is, there is no
satisfying the conditional moment (
4) almost surely. Therefore, the parameter of interest in this paper is the QR parameter
defined by (
1) or (
3) without the linear CQF assumption in (
4). We can view
as the pseudo-true value of the linear QR model under misspecification. As the Koenker–Bassett QR estimator is widely used, it is important to understand the approximation nature of the estimand.
For the mean regression counterpart, ordinary least squares (OLS) consistently estimates the linear conditional expectation and minimizes mean-squared error loss for fitting the conditional expectation under misspecification. Chamberlain [
9] proves the semiparametric efficiency of the OLS estimator, which provides additional justification for the widespread use of OLS. The attractive features of OLS, interpretability and semiparametric efficiency, under misspecification, motivate my investigation of parallel properties in QR. I study how this QR parameter approximates the CQF and the CDF and calculate its semiparametric efficiency bound.
The first contribution of this paper is on how
minimizes the distribution approximation error, defined by
, under a mean-squared loss function. The first-order condition (
3) can be understood as the orthogonality condition of the covariates
X and the distribution approximation error in the projection model. I show that the QR parameter
minimizes the mean-squared distribution approximation error, inversely weighted by the conditional density function
. Angrist, Chernozhukov, and Fernández-Val [
1] (henceforth ACF) show that
minimizes the mean-squared quantile specification error, defined by
, using a weight primarily determined by the conditional density. ACF’s study, as well as my own results, suggests that QR approximates the CQF more accurately at points with more observations, but the corresponding CDF evaluated at the approximated point
is more distant from the targeted quantile level
τ. This trade-off is controlled by the conditional density, which is distinct from OLS approximating the conditional mean, because the distribution and quantile functions are generally nonlinear operators. This observation is novel and increases the understanding of how the QR summarizes the outcome distribution. A numerical example in
Figure 1 in
Section 4 illustrates this finding.
The second result is the semiparametric efficiency bound of the
. Chamberlain’s results in [
9] on the mean regression based on differentiable moment restrictions cannot be applied to semiparametric efficiency for QR, due to the lack of moment function differentiability in (
3). Although Ai and Chen [
10] provide general results for sequential moment restrictions containing unknown functions, which could cover the quantile regression setting, I calculate the efficiency bound accommodating regularity conditions specifically for the QR parameter
using the method of Severini and Tripathi [
11]. It follows that the misspecification-robust asymptotic variance of the QR estimator
in (
2) attains this bound, which means no regular
2 estimator for (
3) has smaller asymptotic variance than
. This result might be expected for an M-estimator, but, to my knowledge, the QR application has not been demonstrated and discussed rigorously in any publication. Furthermore, I calculate the efficiency bounds for jointly estimating QR parameters at a finite number of quantiles for both linear projection (
3) and linear QR (
4) models. Employing the widely-used method of Newey [
12], Newey and Powell [
13] find the semiparametric efficiency bound for
of the correctly-specified linear CQF in (
4). Note that the efficiency bounds for (
3) do not imply the bounds for (
4); nor does the converse hold.
In
Section 2, I discuss the interpretation of the misspecified QR model in terms of approximating the CDF and the CQF. The theorems for the semiparametric efficiency bounds are in
Section 3. In
Section 4, I discuss the parallel properties of QR and OLS. The paper is concluded by a review of some existing efficient estimators for linear projection model (
3) and linear QR model (
4).
2. Interpreting QR under Misspecification
Let
Y be a continuous response variable and
X be a
regressor vector. The quantile-specific residual is defined as the distance between the response variable and the CQF,
with the conditional density
at
or
at
for any
. This is a semiparametric problem in the sense that the distribution functions of
and
X, as well as the CQF, are unspecified and unrestricted other than by the following assumptions, which are standard in QR models. I assume the following regularity conditions, based on the conditions of Theorem 3 in ACF.
- (R1)
are independent and identically distributed on the probability space for each n;
- (R2)
the conditional density exists and is bounded and uniformly continuous in y, uniformly in x over the support of X;
- (R3)
is positive definite for all
, where
is uniquely defined in (
1);
- (R4)
for some ;
- (R5)
to be bounded away from zero.
The identification of the pseudo-true parameter
is assumed in (R3). The bounded conditional density function of the continuous response variable
Y given
X in (R2) is needed for the existence of the CQF for any
. The uniform continuity guarantees the existence and differentiability of the distribution function,
i.e.,
and
with probability one. (R4) is used for the asymptotic normality of
. The covariates
X are allowed to contain discrete components. (R5) guarantees that the objective function defined below in Equation (
6) is finite
, where
is the parameter of interest uniquely defined by Equation (
1).
The parameter of interest
is equivalent to solving
by applying the law of iterated expectations on Equation (
3). Equation (
5) states that
X is orthogonal to the distribution approximation error
. The following theorem interprets QR via a weighed mean-squared error loss function on the distribution approximation error.
Theorem 1. Assume (R1)–(R5). Then, solves the equationFurthermore, if is positive definite at , then is the unique solution to this problem (6). Proof of Theorem 1. The objective function in (6) is finite by the assumptions. Any fixed point would solve the first-order condition, .
By the law of iterated expectations, (3) implies the above first-order condition. Therefore, solves (6). When the second-order condition holds, i.e., is positive definite at ,
solves (6) uniquely. ☐
Theorem 1 states that is the unique fixed point to an iterated minimum distance approximation, with a weight of a function of X only. The mean-squared loss makes it clear how the linear function matches the CDF to the targeted probability of interest. The loss function puts more weight on points where the conditional density is small. As a result, the distribution approximation error is smaller at points with smaller conditional density.
Now, I discuss the approximation nature of QR based on the distributional approximation error and quantile specification error. ACF interpret QR as the minimizer of the weighted mean-squared error loss function for quantile specification error, defined as the deviation between the approximation point
and the true CQF
,
3
ACF define
in (
8) to be the importance weights that are the averages of the response variable over a line connecting the approximation point
and the true CQF. ACF note that the regressors contribute disproportionately to the QR estimate and the primary determinant of the importance weight is the conditional density.
Moreover, the first-order condition implied by (
7)
is a weighted orthogonal condition of the quantile specification error. A Taylor expansion provides intuition to connect the distribution approximation error and the quantile specification error:
by
. This observation implies the quantile specification error is smaller at points where the conditional density
is larger. On the other hand, the distribution approximation error is larger at points with larger
. Comparing with the OLS, where the mean operator is linear, the CDF and its inverse operator, the CQF, are generally nonlinear. The distribution approximation error can be interpreted as the distance after a nonlinear transformation by the CDF,
. A Taylor expansion linearizes the distribution function to the quantile specification error multiplied by the conditional density function. The conditional density plays a crucial role on weighting the distribution approximation error and the quantile specification error. The above discussion provides additional insights to how the QR parameter approximates the CQF and fits the CDF to the targeted quantile level.
Remark 1 (Mean-squared loss under misspecification)
. The linear function is the best linear approximation under the check loss function in (1). While is the least absolute derivations estimation, the QR parameter for is the best linear predictor for a response variable under the asymmetric loss function in (1). ACF note that the prediction under the asymmetric check loss function is often not the object of interest in empirical work, with the exception of the forecasting literature, for example [15]. For the mean regression counterpart, OLS consistently estimates the linear conditional expectation and minimizes mean-squared error loss for fitting the conditional expectation under misspecification. The robust nature of OLS also motivates research on misspecification in panel data models. For example, Galvao and Kato [16] investigate linear panel data models under misspecification. The pseudo-true value of the fixed effect estimator provides the best partial linear approximation to the conditional mean given the explanatory variables and the unobservable individual effect.4 4. Discussion and Conclusions
Misspecification is a generic phenomenon; especially in quantile regression (QR), the true conditional quantile function (CQF) might be nonlinear or different functions of the covariates at different quantiles.
Table 1 summarizes the parallel properties of QR and OLS. Under misspecification, the pseudo-true OLS coefficient can be interpreted as the best linear predictor of the conditional mean function,
, in the sense that the coefficient minimizes the mean-squared error of the linear approximation to the conditional mean. The approximation properties of OLS have been well studied (see, for example, [
22]). With respect to the QR counterpart, I present the inverse density-weighted mean-squared error loss function based on the distribution approximation error
. This result complements the interpretation based on the quantile specification error in [
1]. My results imply that the Koenker–Bassett estimator is semiparametrically efficient for misspecified linear projection models and correctly specified linear quantile regression models when
does not depend on
X. Alternatively, the smoothed empirical likelihood estimator using the unconditional moment restriction in [
23] has the same asymptotic distribution as the Koenker-Bassett estimator and, hence, attains the efficiency bound.
Table 1.
Summary properties of OLS and quantile regression (QR).
Table 1.
Summary properties of OLS and quantile regression (QR).
| | OLS | QR |
|---|
| | Linear Projection Model |
| objective minimized | | |
| (interpretation) | | |
| | | |
| unconditional moment | | |
| (interpretation) | | |
| | | |
| efficient estimators | | |
| | | (Koenker–Bassett) |
| | (OLS) | |
| asymptotic covariance | | |
| efficiency bounds | Chamberlain (1987) [9] | Theorem 2 |
| | Linear Regression Model |
| conditional moment | | |
| | | or |
| efficiency bounds | Chamberlain (1987) [9] | Newey and Powell (1990) [13] |
| homoscedasticity-type | | |
| condition | | |
| efficient estimators | OLS | Koenker–Bassett |
Under the linear quantile regression model, the Koenker–Bassett estimator consistently estimates the true
, although it is not semiparametrically efficient given heteroskedasticity. Researchers have proposed many efficient estimators for the correctly-specified linear quantile regression parameter, for example the one-step score estimator in [
13], the smoothed conditional empirical likelihood estimator in [
24] and the sieve minimum distance (SMD) estimator in [
25,
26]. However, for all of these estimators, the pseudo-true values under misspecification are different, and their interpretations have not been thoroughly studied. Therefore, the semiparametric efficiency bounds of these pseudo-true values are also different. For example, an unweighted SMD estimator converges to a pseudo-true value
that minimizes
.
6 The first-order condition is
, which is the unconditional moment used in [
13] for the semiparametrically efficient GMM estimator under correct specification. The conditional density weight is similar to the generalized least squares in the mean regression in that it uses a weight function of the conditional variance to construct an efficient estimator.
It is interesting to note that the pseudo-true value of the SMD estimator minimizes
. The distribution approximation error is weighted evenly over the support of
X for
, in contrast to the QR parameter, which is weighted more at points with smaller conditional density in Theorem 1. Therefore, the SMD estimator might have more desirable and reasonable approximation properties than QR. Nevertheless, the SMD estimator is computationally more demanding than the Koenker–Bassett estimator. A numerical example in
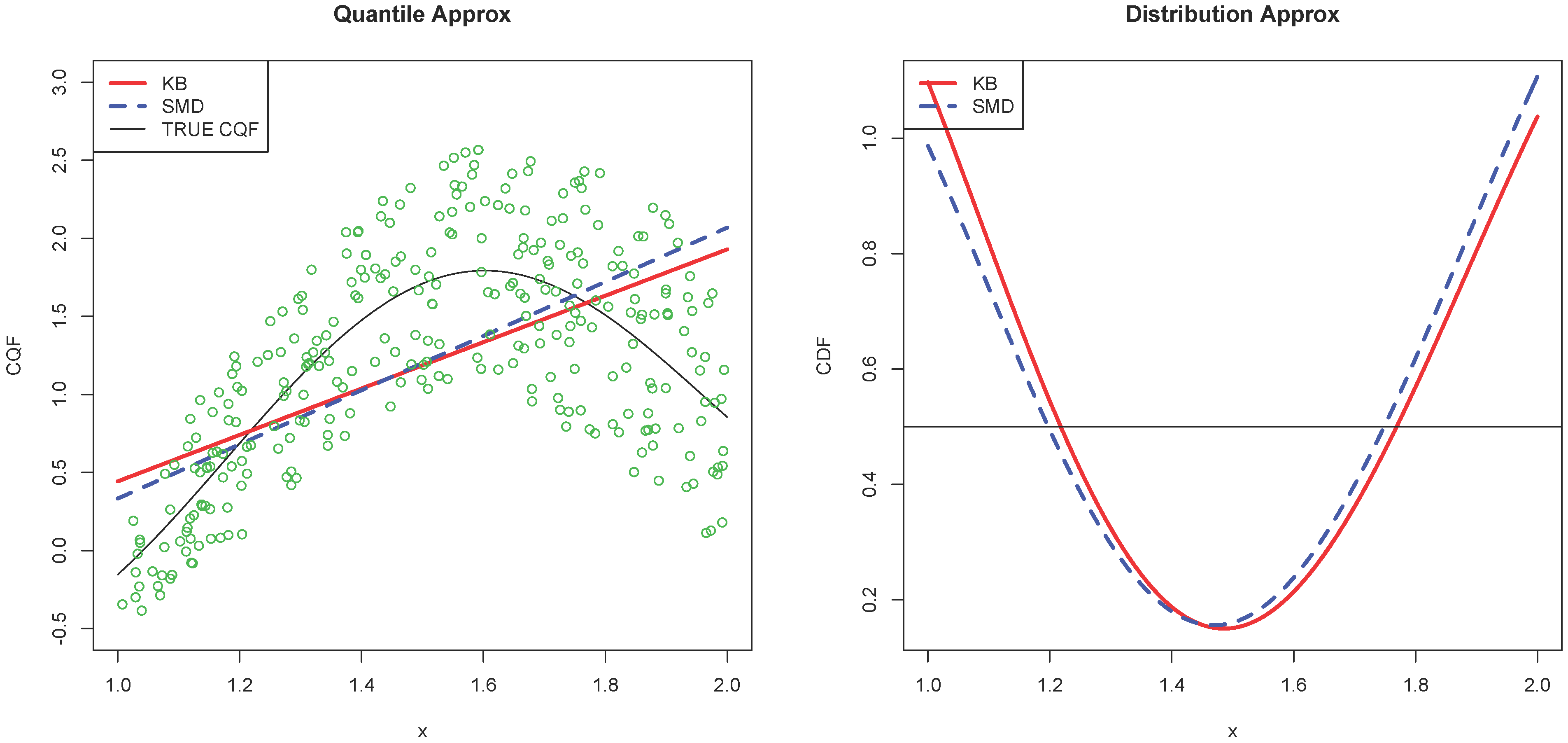
Figure 1 illustrates how the Koenker and Bassett (KB) and SMD estimators approximate the CQF and the CDF.
Figure 1.
This numerical example is constructed by
,
and
. Therefore,
,
and
. Set
for the median. The red solid line is for the QR parameter
defined in (
3) and estimated by the Koenker-Bassett (KB) estimator. The blue dashed line is the approximation by the SMD estimator
minimizing
. The approximations are
and
. The left panel shows the linear approximations
,
and the true CQF. The green circles are 300 random draws from the DGP. The right panel shows the corresponding CDFs
and
. For smaller
x where the conditional density is larger, the quantile specification error of SMD is smaller than that of KB in the left panel. For the distribution approximation error in the right panel, SMD weights more evenly over the support of
X, while KB has smaller distribution approximation error at larger
x with smaller density.
Figure 1.
This numerical example is constructed by
,
and
. Therefore,
,
and
. Set
for the median. The red solid line is for the QR parameter
defined in (
3) and estimated by the Koenker-Bassett (KB) estimator. The blue dashed line is the approximation by the SMD estimator
minimizing
. The approximations are
and
. The left panel shows the linear approximations
,
and the true CQF. The green circles are 300 random draws from the DGP. The right panel shows the corresponding CDFs
and
. For smaller
x where the conditional density is larger, the quantile specification error of SMD is smaller than that of KB in the left panel. For the distribution approximation error in the right panel, SMD weights more evenly over the support of
X, while KB has smaller distribution approximation error at larger
x with smaller density.
![Econometrics 04 00002 g001]()
This discussion leads to open-ended questions: What is an appropriate linear approximation or a meaningful summary statistic for the nonlinear CQF? How should economists measure the marginal effect of the covariates on the CQF? An approach that circumvents this problem is measuring the average marginal response of the covariates on the CQF directly. The average quantile derivative, defined as
where
is a weight function, offers such a succinct summary statistic ([
27]). Sasaki [
28] investigates the question that quantile regressions may misspecify true structural functions. He provides a causal interpretation of the derivative of the CQF, which identifies a weighted average of heterogeneous structural partial effects among the subpopulation of individuals at the conditional quantile of interest. Sasaki’s work adds economic content to this misspecified question. This paper complements the prior literature on understanding how the QR statistically summarizes the outcome distribution.



{kind=link}
