All articles published by MDPI are made immediately available worldwide under an open access license. No special
permission is required to reuse all or part of the article published by MDPI, including figures and tables. For
articles published under an open access Creative Common CC BY license, any part of the article may be reused without
permission provided that the original article is clearly cited. For more information, please refer to
https://www.mdpi.com/openaccess.
Feature papers represent the most advanced research with significant potential for high impact in the field. A Feature
Paper should be a substantial original Article that involves several techniques or approaches, provides an outlook for
future research directions and describes possible research applications.
Feature papers are submitted upon individual invitation or recommendation by the scientific editors and must receive
positive feedback from the reviewers.
Editor’s Choice articles are based on recommendations by the scientific editors of MDPI journals from around the world.
Editors select a small number of articles recently published in the journal that they believe will be particularly
interesting to readers, or important in the respective research area. The aim is to provide a snapshot of some of the
most exciting work published in the various research areas of the journal.
We consider a model in which an outcome depends on two discrete treatment variables, where one treatment is given before the other. We formulate a three-equation triangular system with weak separability conditions. Without assuming assignment is random, we establish the identification of an average structural function using two-step matching. We also consider decomposing the effect of the first treatment into direct and indirect effects, which are shown to be identified by the proposed methodology. We allow for both of the treatment variables to be non-binary and do not appeal to an identification-at-infinity argument.
This paper deals with nonparametric identification in a three-equation nonparametric model with discrete endogenous regressors. We provide conditions under which an average structural function (ASF) (e.g., [1]) is point identified and discuss how different treatment effects can be identified using our methods. Like [2,3], we use a Dynkin system approach, which is based on the idea of matching; the idea of matching was also used by [3,4] inter alia, albeit that our notion of matching is different from the commonly-used matching method in the treatment effect literature (e.g., [5]). The latter uses the matching idea to control for observed covariates, while our method matches on identified/estimable sets, i.e., elements of Dynkin systems, as will become apparent below.
To motivate the parameter of interest in this paper, consider the example of assessing the dynamic evolution of crime (e.g., [6]). The number of crimes, say murders, at time t is affected both by the number of crimes prior to time t and by the level of police activity (measured by, e.g., the number of police patrols) at time t. This example has a special triangular structure, because the number of police patrols at time t is in part a response to the number of crimes at time . The number of crimes is discrete, as is the number of police patrols. There are several potential endogeneity problems in this example, e.g., simultaneity between crimes and police activity at time t and unobserved heterogeneity due to changes in the neighborhood and its surroundings. We focus on the identification of the ASF, which in this example, corresponds to the mean number of crimes at time t that would occur if both the number of crimes at time and the number of police patrols were exogenously fixed. There are other objects of potential interest that can be identified with our identification strategy. For instance, one could instead fix the number of crimes at time , but allow the number of police patrols to respond to it endogenously. We can thus decompose the effect of the changes of the past number of crimes into a direct effect and an indirect effect: a high level of crime at time can create an environment in which crime thrives at time t (e.g., because criminals build up local knowledge, set up networks), but it also leads to an increased police presence, which reduces crimes at time t. We also discuss such decompositions in this paper.
The model that we study is similar to that in [3,4] and others in that we make and exploit a weak separability assumption. However, [4] specifically excludes the possibility of non-binary categorical endogenous regressors, imposes restrictive support conditions on the covariates and only deals with the two-equation case. The non-binary categorical regressor case is not discussed in (the published version of) [3], which further does not deal with the present, more complicated, three-equation model featuring two discrete endogenous regressors. In this paper, we show that the methodology developed in [3] can be used to study non-binary treatments with a double layer of endogeneity. There are other papers that have a three-equation model and/or allow for non-binary regressors (e.g., [7,8,9]), but the model or the object of interest is generally different.
There are many examples in which (a (semi)parametric version of) our structure has been used. We mention only a few. The work in [10] studies the effects of smoking on birth weight through the mechanism of gestation time. The work in [11] analyzes the effects of school type and class size on earnings and educational attainment. The work in [12] has a simpler dependence structure than the one used here. The work in [13] investigates labor market returns to community college attendance and four-year college education. The work in [14] considers the multi-stage nature of the adoption process of on-line banking services, where interruptions in the initial sign-up stage and in the later regular use stage are the treatments of interest. We further note that the double hurdle model of [15], which is used in much empirical work, is a special case of our model, albeit that the identification methods developed here are of limited use in Cragg’s specification.
The focus here is on point identification. There are several papers (e.g., [16,17,18]) that develop bounds on treatment effects in models that are similar to, but simpler than, the one in this paper using weaker monotonicity assumptions than are imposed here. As shown in [2], the Dynkin system approach can be used to obtain sharp bounds in an environment in which there is only partial identification. We do not pursue this possibility in the current paper.
Identification of parameters of interest in our paper proceeds in two steps. In the first step, we use the variation in the instrument for the treatment to infer what variation in the instrument for the intermediate endogenous variable would compensate exactly for variation in . Using this information, we can undo the effect of changing on . Provided that the instruments for and have sufficient variation, we can identify the structural function for this way. Using this first stage information along with variation in instruments for and , we infer what variation in the exogenous regressors in the outcome equation would compensate exactly for variation in both treatment and intermediate endogenous variable . Our paper differs from both [2,3,4] in that we have to use another level of matching in order to undo the effect of both and on the outcome . A critical component of our strategy is the existence of instruments for the endogenous regressors and and sufficient variation in the exogenous regressors in the outcome equation to allow us to compensate for variation in the endogenous regressors directly.
The Dynkin system approach is a natural scheme that allows one to collect and aggregate information contained in the data in a natural and thorough fashion through a recursion scheme1. Each combination of observables implies that the unobservable error terms belong to certain sets. From these sets, one can infer additional information through various operations on these sets. In this paper, we use a version of the Dynkin system approach, first used in [3], which exploits matching in addition to the union and difference operators used in [2]. Matching has been used frequently in the past. For instance, [20] used it to avoid support conditions in estimating weakly-separable nonparametric regression functions. The way we use matching in this paper is closer to [4], albeit that our procedure, as already mentioned, can be applied more generally.
Although the fact that the Dynkin system approach requires only weak covariate support restrictions is an attractive feature, this paper will instead focus on extending the use of the Dynkin system to more complicated situations, since the support restrictions issue was discussed at length in [3], albeit for the two-equation binary endogenous regressor case. Further, the Dynkin system mechanism can be used to study effects other than average partial effects, such as marginal treatment effects (e.g., [21]), but here, we focus on average partial effects.
The remainder of the paper is organized as follows. In Section 2, we lay out our model and discuss the objects we want to identify and the rationale for our desire to do so. Section 3 provides a rough description of the basic ideas underlying our identification approach. These ideas are formalized and illustrated using more complete examples in Section 4 and Section 5. Finally, Section 7 provides a brief sketch of how the identification methods proposed here could be implemented.
2. Model
Imposing weak separability in multiple places, we consider the model
where and are unknown functions. We assume that are known and that we observe . The unobservables and are scalar random variables; the dimension of is not restricted.
One feature in (1) is that and are excluded from the first and second equations, respectively. Our identification arguments will require that and be able to vary the and functions, respectively, but the fact that appears in the functions and do in the functions will be immaterial. Therefore, we will simply consider
for the sake of illustrational clarity. We now impose that , , and . This is without loss of generality in view of Assumption B below. The setup in (2) requires that the exogenous covariates appear only once in each equation2. It is straightforward to generalize our identification strategy to Model (1) at the expense of exposition. However, doing so would introduce additional notational complexity and requires more variations in and .
In the crime example discussed in the Introduction, would be the number of crimes this period, the number of police patrols and the number of crimes in the previous period. Then, represent observable exogenous neighborhood characteristics this period and last period, respectively. Finally, can contain variables that reflect the resources that the police can employ to combat crime, with the implicit assumption that such resources cannot be enhanced in the short term and can hence be treated as exogenous.
We now make several model assumptions. Let .
Assumption A. is independent of .
Assumption B.The distribution of is absolutely continuous with respect to the Lebesgue measure μ with support , and have marginal uniform distributions on .
Assumption C. is for all strictly monotonic in α.
Assumption A is strong, but can be relaxed to independence conditional on covariates, i.e., either covariates in addition to or elements of vector-valued . Moreover, if g is additively separable in , then Assumption A can be further weakened as explained below.
The second half of Assumption B constitutes a normalization. The first part is restrictive, but is difficult to avoid. Please note, however, that and are allowed to be dependent and that the support of given need not be .
Monotonicity is a common assumption in the nonparametric identification literature, but unlike, e.g., [22,23,24], Assumption C does not require monotonicity in the error term of the structural function g itself, but instead, it requires monotonicity of the (conditional) expectation3; a similar assumption can be found in [4]. For instance, an indicator function, such as , is allowed, as long as is continuously distributed, given and . However, the single index feature of the structural function is an essential feature of Assumption C. For the use of the Dynkin system idea to identify a structural function under a stronger form of monotonicity, see [2].
Both and are general ordered response variables, which are allowed to be endogenous. Instead of having one variable with support points, we have two treatment variables here4 that depend on two distinct error terms, and . As a result, if we tried to combine and into one variable with support points, the resulting random variable would not necessarily have the threshold crossing form that and have in our paper. This is because to have a treatment variable that has a threshold crossing form, and would have to be represented by a single unobservable, whose values could be ordered linearly. However, there does not generally exist such a one-to-one mapping. Without having a discrete treatment variable that has this threshold crossing form, the identification method given in [4] would not work. Since [3] also consider a single treatment variable with a threshold crossing form, the method in [3] would not work either. As a result, the model studied in this paper is not covered by the models studied in [3,4]. It is also more general than the double hurdle model of [15], Equations (5) and (6), albeit that our matching strategy for identification is of limited usefulness there5.
When discussing our assumptions, we mentioned that Assumption A could be weakened further if g is additively separable in . To be more specific, let and , where are scalar-valued random variables. Suppose that the outcome equation is given by
which is a form commonly applied by researchers. Then, Assumption A can be further weakened in the following way:
Assumption D.(i) , (ii) , (iii) is independent of conditional on and (iv) .
Under Assumption D, the outcome Equation (3) can be written as
and can be identified by running an OLS regression of on , since
where . Then, can be used to compensate for the effects of varying and in the outcome equation as long as .
To see why this weakening of Assumption A might be particularly useful, suppose that equals adult wages of an individual, treatment is whether a student is assigned to a small class or not and is an indicator for college attendance. This example is also considered in [25]. The instrument for is the educational intervention in the Project STAR experiment, in which early graders were randomized into small classes, and the instrument for could be the variation in tuition fees or distance to college; see, for instance, [13,26]. We still need a variable in the wage equation that is exogenous and that does not enter the other two equations. Under Assumption D, the exogeneity condition such a variable has to satisfy is considerably weaker than the one embodied in Assumption A. In particular, the individual’s age when adult wage is measured might be a reasonable candidate as the required .
In contrast to the existing literature, including [3,4], which mainly focuses on the effects of one endogenous variable while fixing other variables, our setting features multiple endogenous treatments with a triangular structure, which allows us to consider various causal parameters, such as direct and indirect (average) effects of the treatment variable . Below, we discuss such parameters and methods of identifying them, albeit that our main focus is on identifying the average structural function.
We now formally state the average structural function we analyze. Let . Thus, if , but if , then is the value would have taken if the same individual had . Therefore, is a typical counterfactual outcome variable, but with two indices instead of the usual one. The focus in this paper will be on the identification of
where are chosen by the researcher. We obtain identification of as a byproduct. Please note that is the ASF conditional on , when the treatments are exogenously fixed at and . For instance, could be the counterfactual mean earnings of a male worker () if he had both a college degree () and received on-the-job training (), or it could be the counterfactual mean birth weight for an infant if her mother had a normal gestation length () and smoked (). In the crime example, is the mean number of crimes at time t if current neighborhood characteristics are one and with both police patrols at time t and crime at for exogenous reasons.
The function ψ can be used to obtain many, but not all, causal effects of interest. Recall the dual binary treatment example involving college education and on-the-job training. Consider exogenously changing and fixing at a specified value . Then, one can identify the ceteris paribus effect of a change in college education status on earnings for a male worker with job training, i.e., . We call this an average partial treatment effect. Alternatively, we can define average joint treatment effects by looking at the causal effects on earnings for male workers of exogenously changing both college education and job training status, i.e., . One can aggregate up such effects across sexes, or indeed across job training statuses, e.g., , where is drawn from a suitable job training status distribution.
It should also be noted that our results can be further used to conduct a decomposition of direct and indirect effects for policy analysis. For instance, if the policy maker can only influence college education decisions, but not job training decisions directly, then an object of interest would be the effect of exogenously changing on a male worker’s mean earnings leaving to adjust according to the preferences of the worker and his employer, i.e., the parameter
where is the counterfactual value of when is exogenously fixed at d given 6. We call the left-hand side in (6) an average total treatment effect, which is decomposed into a direct effect and an indirect effect on the right-hand side7. Although the parameters in (6) are not represented by ψ, the methods we develop to identify ψ can be used to identify them, as we show in Section 6.
The fact that there are several causal parameters of potential interest arises both because there are multiple endogenous treatment variables and because of the triangular nature of the model. However, we do not believe that one parameter is generally more important than others, but the purpose and context of the policy question of interest should be taken into account. As explained in Section 6, identification of causal parameters, like (6), can be established by the matching method developed in this paper. Therefore, we focus on the identification of ψ (and ) in the main text to highlight the idea of matching, while we show in Section 6 that the identification of (6) can be obtained by the same methods.
3. Description
We now provide a broad and rough description of our identification strategy. We combine the idea of matching to that of set operations. Matching was also used in [3,4], inter alia. Indeed, our methodology shares some of the intuition with Jun, Pinkse, and Xu (2012) [3]: this will become clear as we proceed. However, due to the triangular structure, the procedure used in this paper is more complicated than that in [3]. The methodology in [3] covers the specification in [4] as a special case.
There are several unknown functions in our model: the ’s, ’s and α are important to identify ψ. The functions are identified directly from the data since is simply the probability that the number of crimes last period was no more than given that . Identification of the ’s is more involved, but is simpler than that of ψ. Therefore, we start with the functions.
Our method of identifying the ’s is related to the identification approaches in [3,4]. Indeed, if is binary and the joint support of is sufficiently rich, then our approach has the same intuition as that in [4]. For instance, we also ask what changes in police resources will offset the changes in police activity induced by changes in the number of past crimes. However, the method of [4] only applies to the case in which is binary. Below, we explain how matching is convenient when is binary and how our Dynkin system can be used to obtain identification if is not necessarily binary.
We start with the simple case, i.e., binary . Consider the problem of identifying . Note that for any value of z,
Note here that the inequality describes the event in which the potential status of given when is fixed at zero is equal to zero. There are two possibilities: either is actually equal to zero (the first right-hand side term in (7)) or it is not equal to zero (the second right-hand side term in (7)). The first right-hand side term in (7) can be inferred directly from the distribution of observables and is hence identified. This is where matching is useful. If we can find such that , then is the same event as . Therefore, the second term on the right-hand side of (7) equals
The question is how to find such . The work in [4] proposes finding for which the left-hand sides (and therefore, the right-hand sides) in the following equations are equal.
The equalities in (8) and (9) rely on the threshold structure of (which is binary for now). There are a few issues here. First, and must all be in the joint support . Second, this procedure only works if is binary.
Our Dynkin system approach is a systematic way of combining multiple such matches via set operations. For instance, when the support is limited, the Dynkin system approach provides chaining arguments: see [3] for details. When is not binary, it provides an extra layer of matching. For instance, suppose that can take three values: 0, 1 or 2. Then, like in (7), for any z,
The intuitive interpretation of the event is the same as before: the potential outcome of the variable when is fixed at zero is equal to zero. Therefore, the first term on the right-hand side is identified because it is equal to a conditional probability on observables. In the binary case, (7), we had one unknown right-hand side term; now, there are two. The second and third terms in (10) correspond to the cases where the realized value of equals one and two, respectively. Therefore, we need to find , such that . The method of [4] does not provide a solution: (8) is still valid, but (9) is not.
Our solution is to use an extra layer of matching in the ’s. To see how this works, suppose that the probability of having no more than one incidence of crime in the past given is matched to the probability of having no crime at all in the past given , i.e.,
Then, we have
which can be used in place of (9). In other words, if and only if the left-hand side in (12) equals the left-hand side in (8). The Dynkin system provides a general and systematic method of doing this.
Note that it is insufficient for the (conditional) probability of no crime in the past to vary with z. It now matters how much the conditional probabilities of crime vary with ; see (11). The above examples only a few features of the general Dynkin system approach. For instance, if the joint support of is limited, then identification can be obtained via the Dynkin system approach, but it will be more complicated than the procedure described above.
Identification of is substantially more complicated (even when and are both binary), but the basic idea is the same. We want to match the α function at different argument values, for which we need to combine matching ’s and matching of ’s. We now explain how this can be done.
To get a whiff of the basic premise, we focus on the simplest possible meaningful case, i.e., binary treatments and : our results in the remainder of the paper are general. Again, we will exploit only a few features of the general methodology. In particular, in this example, we assume that the joint support of is simply the product of the marginal supports, i.e., , which is unnecessary, as will become apparent later in the paper.
Define
Further, define
To understand the idea behind (13) and (14), please note that is the event that is equal to d, and the potential status of when is fixed at j is equal to s, conditional on . Therefore, it involves the counterfactual status of the variable. There are combinations of for which can be recovered directly from the joint distribution of observables, namely for given ,
Therefore, if
then
Equality (16) plays the same role as the first right-hand side term in (7) and (10). Indeed, note that can be decomposed as follows: for any ,
which is more complicated than, but similar to (7) and (10). An important complication is that, for instance, finding a value , such that , is insufficient to identify the second term on the right-hand side in (17) because itself also involves a counterfactual.
Resolving this complication requires that we pair this approach with the matching procedure for the functions, which we have explained above. For example, matching to ensures that , which implies that matching will indeed lead to identification of the second right-hand side term in (17). In the following example, we provide a graphical illustration to explain how to find such .
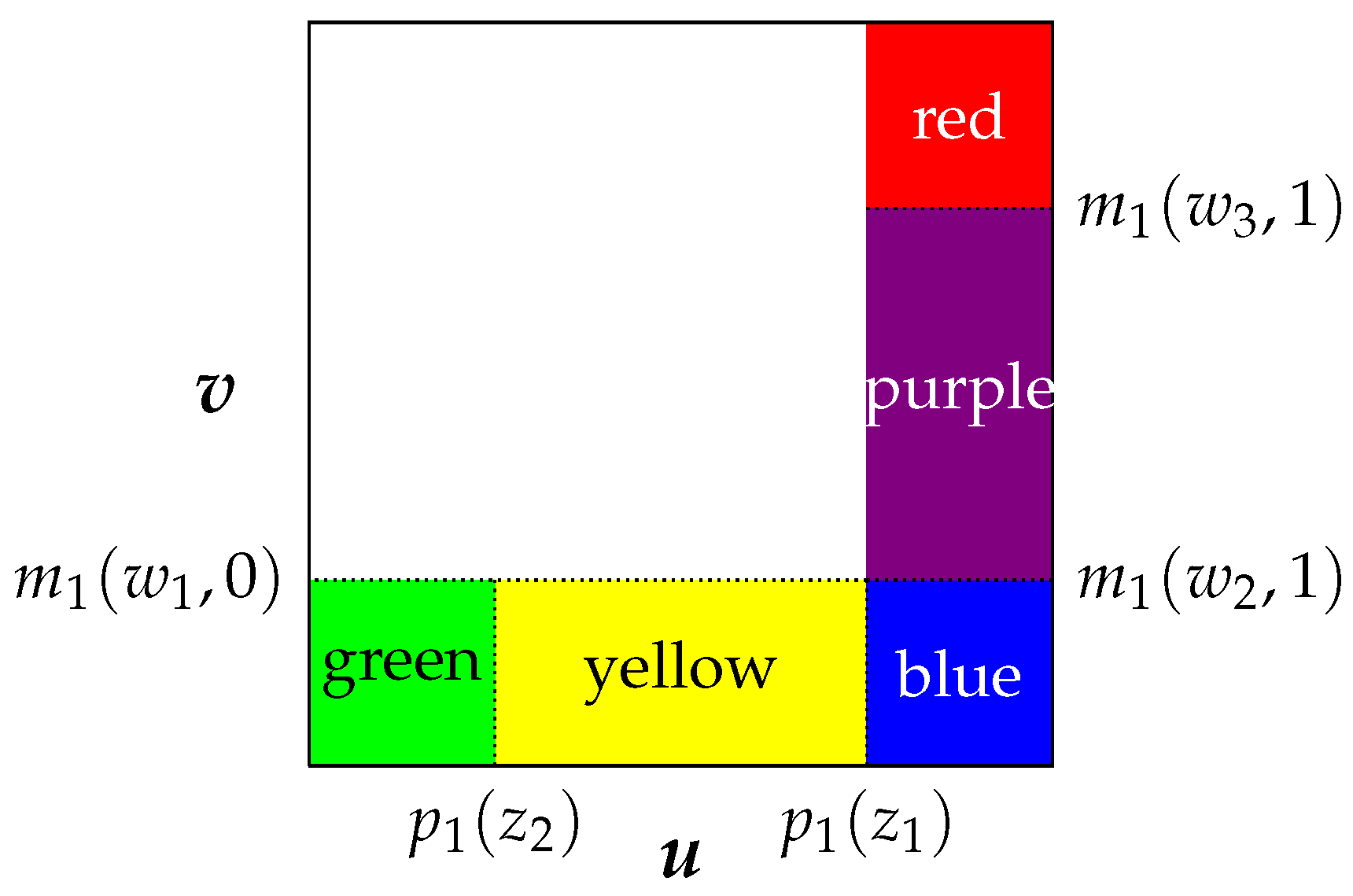
Example 1. Consider Figure 1 and suppose for now that the functions are identified and that the joint support of the covariates equals the product of their marginal supports. Let be values in their respective supports (i.e., ), such that and , as is depicted in Figure 1. Then, the following quantities are identified directly from the data.
Subtracting the first and third lines in (18) from the second and fourth lines, respectively, yields and , which are equal if and only if . Likewise, subtracting the third and sixth lines in (18) from the fifth and seventh lines allows one to verify whether . We can verify that analogously.
Figure 1.
Simple matching procedures.
Figure 1.
Simple matching procedures.
Once values are found, such that , can be computed as (for instance) the sum of , , and . ☐
Finally, we note that there exists an alternative, but not particularly attractive, possibility: identification-at-infinity. From (15), it should be apparent that if we can find a sequence , such that
then identification of obtains, since
However, such an identification-at-infinity argument is undesirable since it generally makes inefficient use of the data [27] and imposes extreme support restrictions. Therefore, we do not consider this possibility.
In the remainder of this paper, more general versions of the procedures sketched above are formally expressed in terms of a Dynkin system, and their power is illustrated using some concrete examples.
4. Identification of m
We now establish the identification of formally. Define8
Further, let be the support of conditional on and define
Then, is identified when because
We now show that is identified for a much broader class of sets than .
Definition 1. is the collection in the following iterative scheme. Let . Then, for all , consists of all sets , such that at least one of the following conditions is satisfied, where μ denotes the standard Lebesgue measure over .
(i)
;
(ii)
;
(iii)
;
(iv)
. ☐
The conditions in Definition 1 are similar to those in [3]. Note that depends on s because of Condition (iv). The importance of Condition (iv) will become apparent in Lemma 1 below. The main difference between [3] and what we have here for the identification of m is that the collection in Definition 1 now also has an argument s: identification of ψ is substantially more involved than that.
Note that is an increasing sequence of collections, such that is the infinite union of ’s.9 Note further that is indexed by , as well as d. If is the same for all w values, then the argument pursued in this section is simpler, but such support restrictions are undesirable, because they exclude the possibility that have elements in common, and they also preclude the situation in which certain combinations of values cannot occur.
All elements of are defined in terms of (combinations of) the unknown and functions. Hence, each element can be thought of as an unknown parameter. In Lemma 1, we show that all elements in are identified. Subsequently, we obtain a condition that is sufficient for identification of .
Lemma 1.Suppose that Assumptions A and B are satisfied.
Since is an increasing sequence of collections of sets and take finitely many values, Assumption E is satisfied when there exists a finite T, such that . Assumption E is testable, because for any finite t, all elements of are identified.
Theorem 1.If Assumptions A, B and E are satisfied then, is identified.
Assumption E involves conditions on the support of ; the class is mostly determined by the amount of variation available in given . For example, consider the simple case . Suppose that there exist , such that . Then, Assumption E is satisfied if the support of contains values with . Please note that even though does not contain a partition of , we have , and therefore, the matching mechanism (iv) in Definition 1 implies that contains a partition of .
Indeed, suppose that for some . Then, by (iv) in Definition 1, implies that . Therefore, not only , but also should be taken into account, which is particularly useful when . This reasoning suggests a simple sufficient condition, which we state as a corollary.
Corollary 1 (Sufficient conditions). Suppose that Assumptions A and B are satisfied and that . Suppose further that there exists a sequence , such that for all . Further, suppose that:
where each is a continuous function and is continuously distributed. Then, is identified.
Please note that Corollary 1 imposes restrictions on the relationship between and (for all values of j), but it does not require there to be a direct relationship between and . Indeed, the matching procedure can be chained in the sense that we can first establish equality of to , then uncover that , and so on.
To illustrate Corollary 1, consider the following example.
Example 2 (Ordered response). Suppose that for all and some and , , as would be the case in an ordered probit model. This is one of the least favorable cases for our procedure, since for all and , .
Therefore, condition (21) in Corollary 1 is satisfied if
To illustrate the idea of Theorem 1, we provide the following two fairly concrete examples. Let
which is identified provided that .
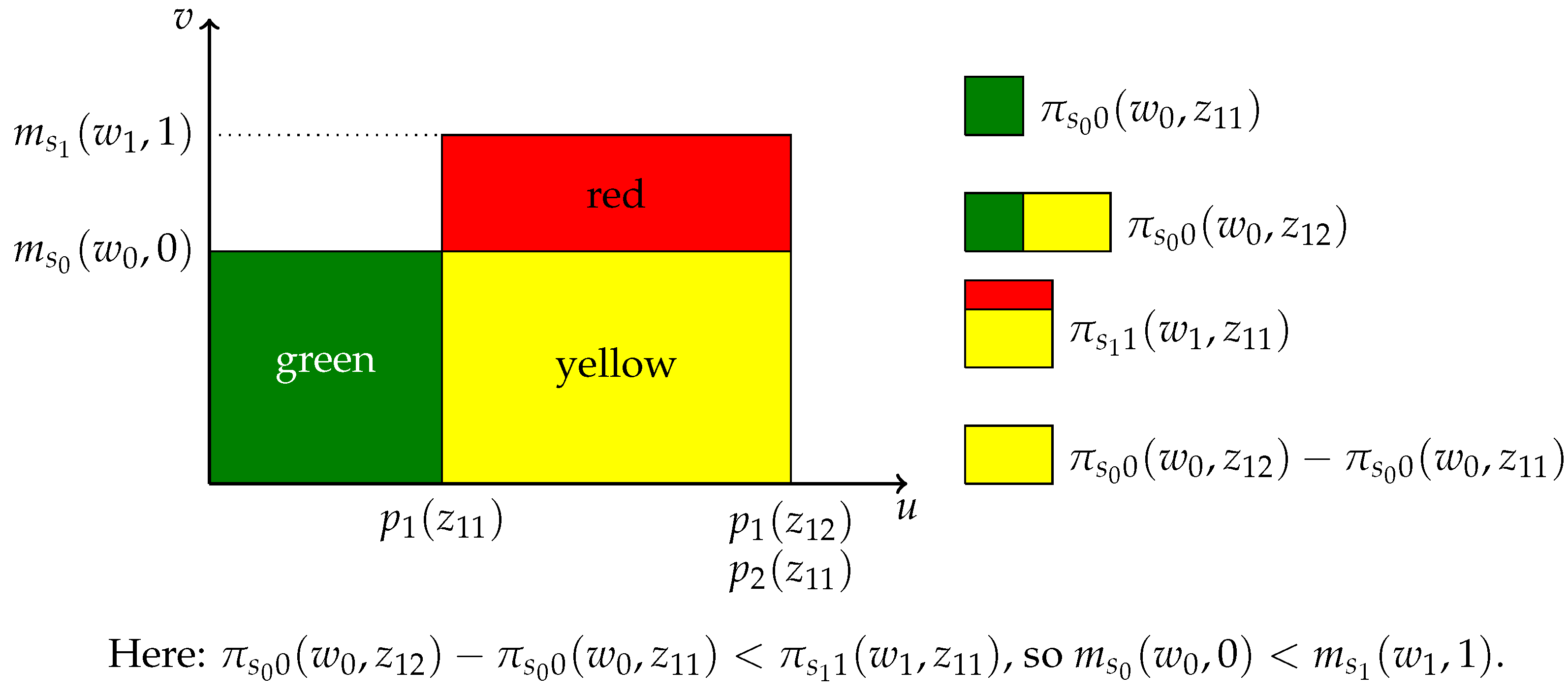
Example 3 (Uncovering that ). We verify whether for some candidate pair . Our approach is described below and illustrated in Figure 2, which assumes the existence of values , such that . It should be apparent from Figure 2 that if and only if the measure of the red area is zero.
Figure 2.
Verifying whether .
Figure 2.
Verifying whether .
The measures of the yellow area, the yellow plus the green area and the yellow plus the red area are identified directly from the data. The measure of the yellow area can then be learned as , and finally, the measure of the red area as .
The formal identification argument is as follows. First,
Using (i) and (ii) of Definition 1, it follows that . Thus,
are both identified; they are equal if and only if . ☐
In Example 3 it is implicitly assumed that and that . However, Theorem 1 does not require this. Indeed, if there exist , such that , and both and , then we can match with to obtain .
Example 4 (Verifying that ). We now turn to the task of verifying that once has been established. The procedure is illustrated in Figure 3 and described below, which presumes the existence of for which .
Again, the question is whether the measure of the red area equals zero. Pink, orange and yellow are directly identified, which allows us to deduce . Further, is identified, and hence, so is , which in turn implies the identification of red.
Figure 3.
Verifying whether given that .
Figure 3.
Verifying whether given that .
Formally, it follows from Example 3 that for all . Therefore, for sufficiently large t, . However, since , the equality of and can be verified using the set V. ☐
Once we have ascertained that , we can identify
since .
When the support of and is the Cartesian product of the marginals (as in these examples), Assumption E is reduced to the requirement that has sufficient variability and sufficiently rich support, as in Corollary 1.
5. Identification of ψ
We now turn to the identification of the main object of interest, i.e., , for which we use the fact that the m function is identified.
The role of κ is similar to that of the function θ in Section 4. Indeed, if A is a set of positive measure, then by Assumption C, if and only if . We start with the identification of κ.
Let be the support of conditional on . We define to be the collection of triples for which and are both identified. Formally, we let
Therefore, by Theorem 1 is a collection of nonempty rectangles whose corner points are all identified under Assumptions A and B. Moreover, for , is identified, because
We now extend to a larger class of sets K for which the identification of obtains.
Definition 2. is the collection in the following iterative scheme. Let . Then, for all , consists of all sets , such that at least one of the following four conditions is satisfied, where denotes the standard Lebesgue measure over .
(i)
;
(ii)
;
(iii)
;
(iv)
. ☐
The collection (like ) consists of sets defined in terms of the unknown functions, such that can be interpreted as a set of unknown parameters.
Lemma 2.Suppose that Assumptions A to C and E are satisfied.
(i)
For all , every is identified;
(ii)
is identified whenever and .
Assumption F..
Like for Assumption E, Assumption F equivalently requires that there be a finite T, such that .
Theorem 2.Suppose that Assumptions A to C and F are satisfied. Then, is identified.
Our method for identifying ψ is similar to our method for identifying m described in Section 4: is now generated from a collection of rectangles, not a collection of intervals. Further, if we can ascertain that , then implies that the two collections in fact coincide. This is particularly helpful when and .
We now state a set of sufficient conditions for the identification of .
Corollary 2 (Sufficient conditions). Suppose that there exists a sequence , such that for all . Further, suppose that . If are continuously distributed and that for some continuous functions ,
(i)
for and
(ii)
for and ,
Then, is identified.
Corollary 2 is a two-dimensional analog to Corollary 1.
We now consider a simple example that illustrates the basics of the machinery developed above. The example is limited relative to the theoretical results in several respects, which we discuss after the example.
Example 5. We will focus on the simplest interesting case, i.e., with covariate support . Because of the absence of support restrictions, we will use instead of in this example. Identification of is trivial, and identification of was discussed in Section 4, so the discussion below starts from the point at which identification of and has already been established.
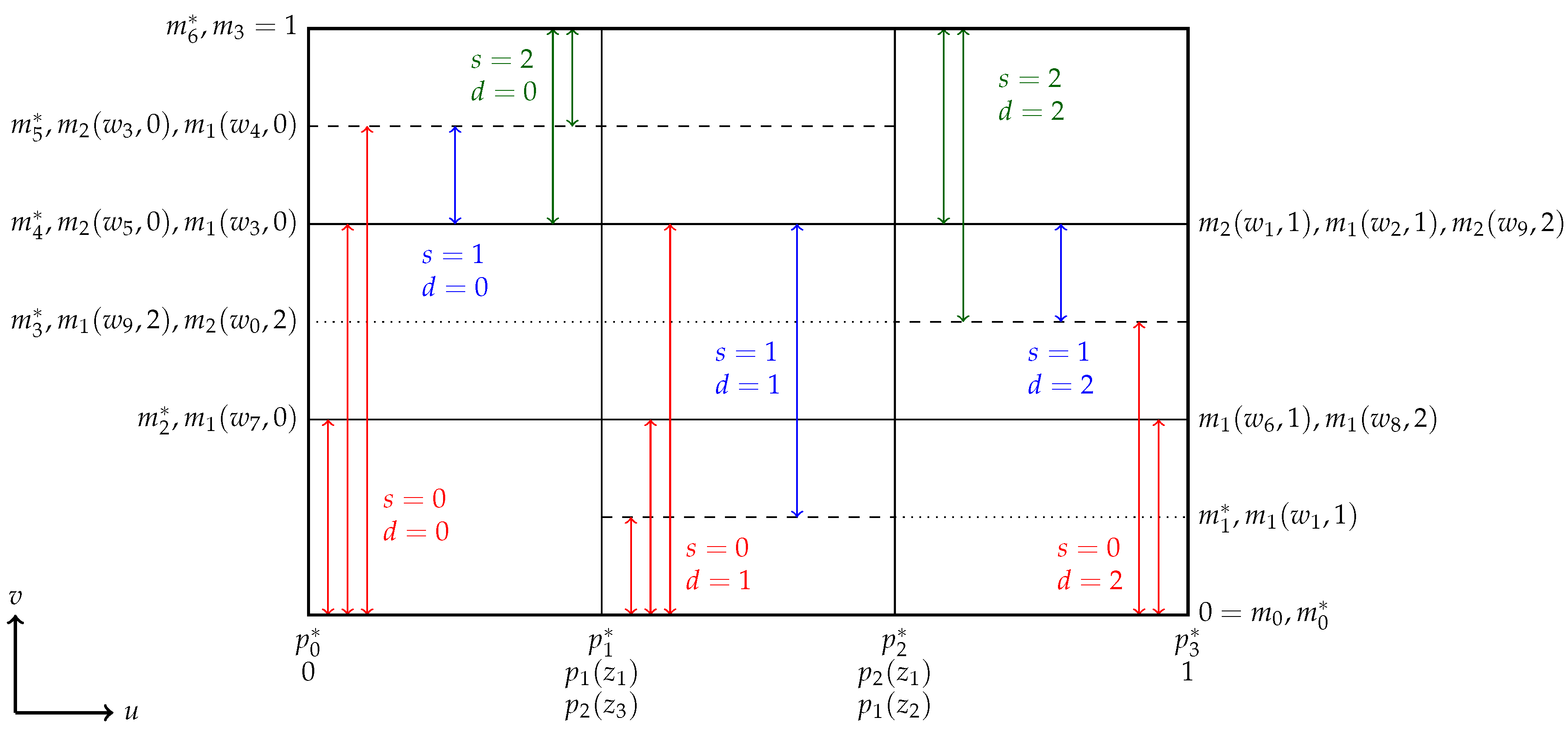
The example is illustrated in Figure 4, which depicts a situation in which is identified for all values of provided that varies sufficiently as a function of x. In the discussion below, we assume that there exists a , such that is the same for all values of s and d, such that the existence of the combinations in Figure 4 is sufficient. We show that for such , is the same for all values of , which implies that is an element of for all , which implies identification. From hereon, we use the shorthand notation to mean .
Figure 4.
Identification of ψ if .
Figure 4.
Identification of ψ if .
We start by showing that if . Let
Since , , and , it follows that . Likewise, using and , it follows that , which implies that , also. Therefore, , such that by the assumption on α made earlier in the example and Condition (iv) of Definition 2, .
We next show that . Now, , because . Further, implies that and, hence, that . Likewise, , such that . Consequently, , which (together with the assumption on α used in this example) implies that .
Given that , it follows that . Likewise, using , , and hence, , also. Repeating the same argument for results in , and hence, .
Finally, using , it follows that , and using , it can be deduced that , such that is identical for all .
To see that , note that each of the nine rectangles with solid boundaries in Figure 4 belongs trivially to some (e.g., ). Since the union of the nine rectangles is exactly and is the same for all , identification is hereby established. ☐
In the above example, it was shown that was the same for all values of . This is not necessary for the identification of . Indeed, all that is required is that ; it does not matter which combinations of pairs are matched with each other, as long as the Dynkin system generated by the union of their -sets includes as an element.
Example 5 is limited in several respects. First, the support of covariates was assumed to be the Cartesian product of the marginal supports and to be independent of . With support restrictions, the procedure to establish identification of would be similar, but more care should be taken in the selection of pairs to ensure that the support restrictions are satisfied. For instance, Figure 4 of Example 5 indicates that belongs to for a number of different values of j, but this condition can be relaxed in numerous ways.
Further, it was assumed that . With more than two categories, the essence of the identification procedure does not change, but Figure 4 would be messier. An essential ingredient of Example 5 is that there are values of for which and likewise for . This is analogous to Corollary 1. It should be pointed out that with more than three categories ( or ), it is not necessary for there to be a -value for which . Indeed, what is needed is for there to be a pair , such that . As mentioned earlier, such a chaining argument can be extended to any number of categories, i.e., one could obtain a set of sufficient conditions similar to those in Corollary 1.
6. Decomposing the Effect of
As mentioned in Section 2, it is possible to use the methodology developed in this paper to identify objects that are not based on ψ. In this section, we show that the average total effect and its decomposition in (6) is indeed identified by the same method. For this purpose, we will explain how to use the matches of the m and α functions, because we have already explained in detail how to achieve those matches and how Dynkin systems can help.
We focus on the special case with binary ; the general case is similar. We discuss the identification of
where is the counterfactual value of when is fixed at d given , i.e., . Therefore, (6) is now
We note that and ψ are different objects unless and are known to be independent11. However, the identification of can also be achieved using our matching procedure.
We focus on ; the other cases are similar. We have
The first term on the right-hand side can be identified by using . For the second term on the right-hand side, consider which can be written as
The method developed in the paper explains how to find and , such that and . Identification of the second term in (25) then follows from the fact that it is equal to
The first term in (25) can be dealt with similarly.
Given that is identified, the total, direct and indirect effects of in (24) are all identified.
7. Sketch of an Estimation Procedure
Below follows a sketch of a simple estimation procedure of . This procedure is provided to demonstrate how can be estimated, but in order to keep the sketch simple, we will make several assumptions, which are much stronger than those made in the identification portion of this paper. For instance, we shall assume that the joint support of is the Euclidean product of the marginal supports, that only take the values and that there is sufficient variation in to allow for the matches used. More complicated procedures can be devised that exploit some salient features of this paper (such as chaining) and lift such restrictions, but such procedures are beyond the scope of this paper, which primarily deals with identification. In earlier work [3], we provide rigorous results for an estimation procedure that does not impose a joint support assumption, albeit in a considerably simpler model than the one considered here.
We will moreover not be assuming the use of any particular nonparametric methodology. Most objects to be estimated can be expressed as conditional expectations (or probabilities), sometimes with estimated regressors. Some of these conditional expectations are then integrated with respect to one of the conditioning variables à la [28]. There are numerous important details in the theoretical development and empirical implementation of such methods, but these can by now be considered to be well established, and elaborate discussions thereof are available in various places in the literature. Hence, we do not discuss them here. Whenever an object is estimable by the standard nonparametric methodology (ENPM) we will so indicate.
7.1. Estimation of m
We commence our discussion with the estimation of . Please note that
where with
Once estimates of are available, are ENPM, and can then be estimated by integrating out over z in the spirit of [28].
Now, , which is ENPM. For the estimation of , it is helpful to introduce , which is ENPM given that . Since
they too are ENPM.
Finally, to obtain estimates of and , one can simply estimate
7.2. Estimation of ψ
We focus here on the estimation of for ; other combinations of can be handled analogously. Let . Please note that
Naturally, is ENPM. For and/or , other methods must be developed to estimate . We will focus on the case , where the other cases can be handled analogously and possibly (if or ) more easily.
Let
which is ENPM. Define
which is ENPM. Then, is equivalent to . Finally, is ENPM.
Acknowledgments
This paper is based on research supported by National Science Foundation Grant SES–0922127. We thank the Human Capital Foundation (http://www.hcfoundation.ru/en) and especially Andrey P. Vavilov for their support of the Center for Auctions, Procurements and Competition Policy (CAPCP, http://capcp.psu.edu) at Penn State University. We thank Andrew Chesher, Elie Tamer, Xavier d’Haultfoeuille, (other) participants of the 2010 Cowles foundation workshop and the 2012 conference by Centre Interuniversitaire de Recherche en Economie Quantitative (CIREQ) and Centre for Microdata Methods and Practice (CEMMAP), as well as the referees for their helpful comments.
Author Contributions
All of the authors made contributions to all parts of the paper.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix
A. Proofs
Proof of Lemma 1. We show both parts simultaneously and use transfinite induction: i.e., we will show: (i) that has a property; (ii) that if has the property, then has the property too; and (iii) that if for all t, has the property, then must have the property, as well. Please note that (iii) is trivial, because is an increasing sequence of sets, and therefore, . Therefore, we will establish (i) and (ii) below.
For all , any can be expressed as for some and is hence identified and satisfies , which is hence also identified.
Now, suppose that for arbitrary t and all , identification of has been established for all . We now establish identification of for any set and any .
Since , it must be the set in one of the four conditions in Definition 1. We verify identification in each of the four cases. First (i): if , then identification of both objects is trivial. Now (ii): since both and are differences between two identified objects, they are identified, also. The argument is analogous for (iii).
Finally, (iv): We know that where are such that there exists a set . Since all sets in and are identified, the existence and identification of such a set can be established. Further, and are both identified and equal if and only if . Given that belongs to , it is identified and so is , because it is known to equal , which is identified. ☐
Proof of Theorem 1. This follows from the fact that . ☐
Proof of Corollary 1. We use mathematical induction. Suppose that for some , it has been established that . By (21), there exists a for which . Now,
such that . ☐
Proof of Lemma 2. The proof is very similar to, but somewhat more complicated than, that of Lemma 1. We establish both parts simultaneously and again use transfinite induction, for which we note that .
For all , any can be expressed as for some for which . is hence identified and satisfies
which is hence also identified.
Now, suppose that for arbitrary t and all identification of has been established for all . We now establish identification of for any set and any .
Since , it must be the set in one of the four conditions in Definition 2. We verify identification in each of the four cases. First (i): if , then identification of both objects is trivial. Now (ii): since both and are differences between two identified objects, they are identified, also. The argument is analogous for (iii).
Finally (iv): We know that , where are such that there exists a set . Since all sets in and are identified, the existence and identity of such a set can be established. Further, and are both identified and equal if and only if by Assumption C. Given that belongs to , it is identified and so is , because it is equal to , which is identified. ☐
Proof of Theorem 2. When , we have . Apply the previous theorem. ☐
References
R.W. Blundell, and J.L. Powell. “Endogeneity in semiparametric binary response models.” Rev. Econ. Stud. 71 (2004): 655–679. [Google Scholar]
S. Jun, J. Pinkse, and H. Xu. “Tighter bounds in triangular systems.” J. Econom. 161 (2011): 122–128. [Google Scholar]
S.J. Jun, J. Pinkse, and H.Q. Xu. “Discrete endogenous variables in weakly separable models.” Econom. J. 15 (2012): 288–312. [Google Scholar]
E. Vytlacil, and N. Yildiz. “Dummy endogenous variables in weakly separable models.” Econometrica 75 (2007): 757–779. [Google Scholar] [CrossRef]
G.W. Imbens, and J.M. Wooldridge. “Recent Developments in the Econometrics of Program Evaluation.” J. Econ. Lit. 47 (2009): 5–86. [Google Scholar]
B. Jacob, L. Lefgren, and E. Moretti. “The dynamics of criminal behavior evidence from weather shocks.” J. Hum. Resour. 42 (2007): 489–527. [Google Scholar]
D. Black, and J. Smith. “How robust is the evidence on the effects of college quality? Evidence from matching.” J. Econom. 121 (2004): 99–124. [Google Scholar]
K. Imai, and D. van Dyk. “Causal inference with general treatment regimes.” J. Am. Stat. Assoc. 99 (2004): 854–866. [Google Scholar]
A. Lewbel. “Endogenous selection or treatment model estimation.” J. Econom. 141 (2007): 777–806. [Google Scholar]
C. Flores, and A. Flores-Lagunes. Identification and Estimation of Causal Mechanisms and Net Effects of a Treatment under Unconfoundedness. Discussion Paper, IZA Discussion Paper; Bonn, Germany: The Institute for the Study of Labor (IZA), 2009. [Google Scholar]
L. Dearden, J. Ferri, and C. Meghir. “The effect of school quality on educational attainment and wages.” Rev. Econ. Stat. 84 (2002): 1–20. [Google Scholar]
M. Lechner. “Identification and estimation of causal effects of multiple treatments under the conditional independence assumption.” In Econometric Evaluation of Labour Market Policies. Berlin, Germany: Springer Science and Business Media, 2001, pp. 43–58. [Google Scholar]
T.J. Kane, and C.E. Rouse. “Labor-market returns to two-and four-year college.” Am. Econ. Rev. 85 (1995): 600–614. [Google Scholar]
A. Lambrecht, K. Seim, and C. Tucker. “Stuck in the adoption funnel: The effect of interruptions in the adoption process on usage.” Mark. Sci. 30 (2011): 355–367. [Google Scholar] [CrossRef] [Green Version]
J.G. Cragg. “Some statistical models for limited dependent variables with application to the demand for durable goods.” Econometrica 39 (1971): 829–844. [Google Scholar] [CrossRef]
R. Chiburis. “Semiparametric bounds on treatment effects.” J. Econom. 159 (2010): 267–275. [Google Scholar]
I. Mourifié. Sharp Bounds on Treatment Effects. Discussion Paper; Québec, Canada: Université de Montréal, 2012. [Google Scholar]
A. Shaikh, and E. Vytlacil. “Partial identification in triangular systems of equations with binary dependent variables.” Econometrica 79 (2011): 949–955. [Google Scholar]
X. D’Haultfœuille, and P. Février. “Identification of nonseparable models with endogeneity and discrete instruments.” Econometrica 83 (2015): 1199–1210. [Google Scholar]
J. Pinkse. “Nonparametric Regression Estimation Using Weak Separability.” PA, USA: Pennsylvania State University, Unpublished work. 2001. [Google Scholar]
J. Heckman, and E. Vytlacil. “Structural equations, treatment effects, and econometric policy evaluation.” Econometrica 73 (2005): 669–738. [Google Scholar]
V. Chernozhukov, and C. Hansen. “An IV model of quantile treatment effects.” Econometrica 73 (2005): 245–261. [Google Scholar] [CrossRef]
A. Chesher. “Identification in nonseparable models.” Econometrica 71 (2003): 1405–1441. [Google Scholar]
G. Imbens, and W. Newey. “Identification and estimation of triangular simultaneous equations models without additivity.” Econometrica 77 (2009): 1481–1512. [Google Scholar]
M. Frölich, and M. Huber. “Direct and Indirect Treatment Effects: Causal Chains and Mediation Analysis with Instrumental Variables.” Discussion Paper, IZA Discussion Paper; Bonn, Germany: IZA, 2014. [Google Scholar]
D. Card. “The wage curve: A review.” J. Econ. Lit. 33 (1995): 785–799. [Google Scholar]
S. Khan, and E. Tamer. “Irregular identification, support conditions, and inverse weight estimation.” Econometrica 78 (2010): 2021–2042. [Google Scholar]
O. Linton, and W. Härdle. “Estimation of additive regression models with known links.” Biometrika 83 (1996): 529–540. [Google Scholar]
1.D’Haultfoeuille and Février (2015) [19] also uses a recursion scheme for the purpose of identification, but both their method and their model is different from ours.
2.We allow for the possibility that are random vectors containing common elements, e.g., and and , provided that at least one variable in each equation is excluded from the other equations.
3.Under additive separability of the error term, both types of monotonicity are satisfied.
4.We thank Elie Tamer for pointing this out.
5.Indeed, let be binary; let ; and let be independent uniform . Define . Then, for parameter vectors , and scale parameter , letting , , if , and , otherwise, reproduces the likelihoods in Equations (5) and (6), of [15]. We note however that our matching strategy will explicitly require that and can be varied separately.
6.Note that is generally not equal to because and are dependent.
7.A similar decomposition is studied by Frölich, M. and Huber, M. (2014) [25].
8.We use ⊂ as a generic symbol for the subset, where some other authors might distinguish between proper and non-proper subsets.
9.Please note that this is the infinite union of collections of sets, not the collection of infinite unions of sets. To see the difference, consider that , but . It is the latter concept that is used here.
10. is nonempty under the the conditions of Theorem 1.
Jun, S.J.; Pinkse, J.; Xu, H.; Yıldız, N.
Multiple Discrete Endogenous Variables in Weakly-Separable Triangular Models. Econometrics2016, 4, 7.
https://doi.org/10.3390/econometrics4010007
AMA Style
Jun SJ, Pinkse J, Xu H, Yıldız N.
Multiple Discrete Endogenous Variables in Weakly-Separable Triangular Models. Econometrics. 2016; 4(1):7.
https://doi.org/10.3390/econometrics4010007
Jun, S.J.; Pinkse, J.; Xu, H.; Yıldız, N.
Multiple Discrete Endogenous Variables in Weakly-Separable Triangular Models. Econometrics2016, 4, 7.
https://doi.org/10.3390/econometrics4010007
AMA Style
Jun SJ, Pinkse J, Xu H, Yıldız N.
Multiple Discrete Endogenous Variables in Weakly-Separable Triangular Models. Econometrics. 2016; 4(1):7.
https://doi.org/10.3390/econometrics4010007


{kind=link}
{kind=link}
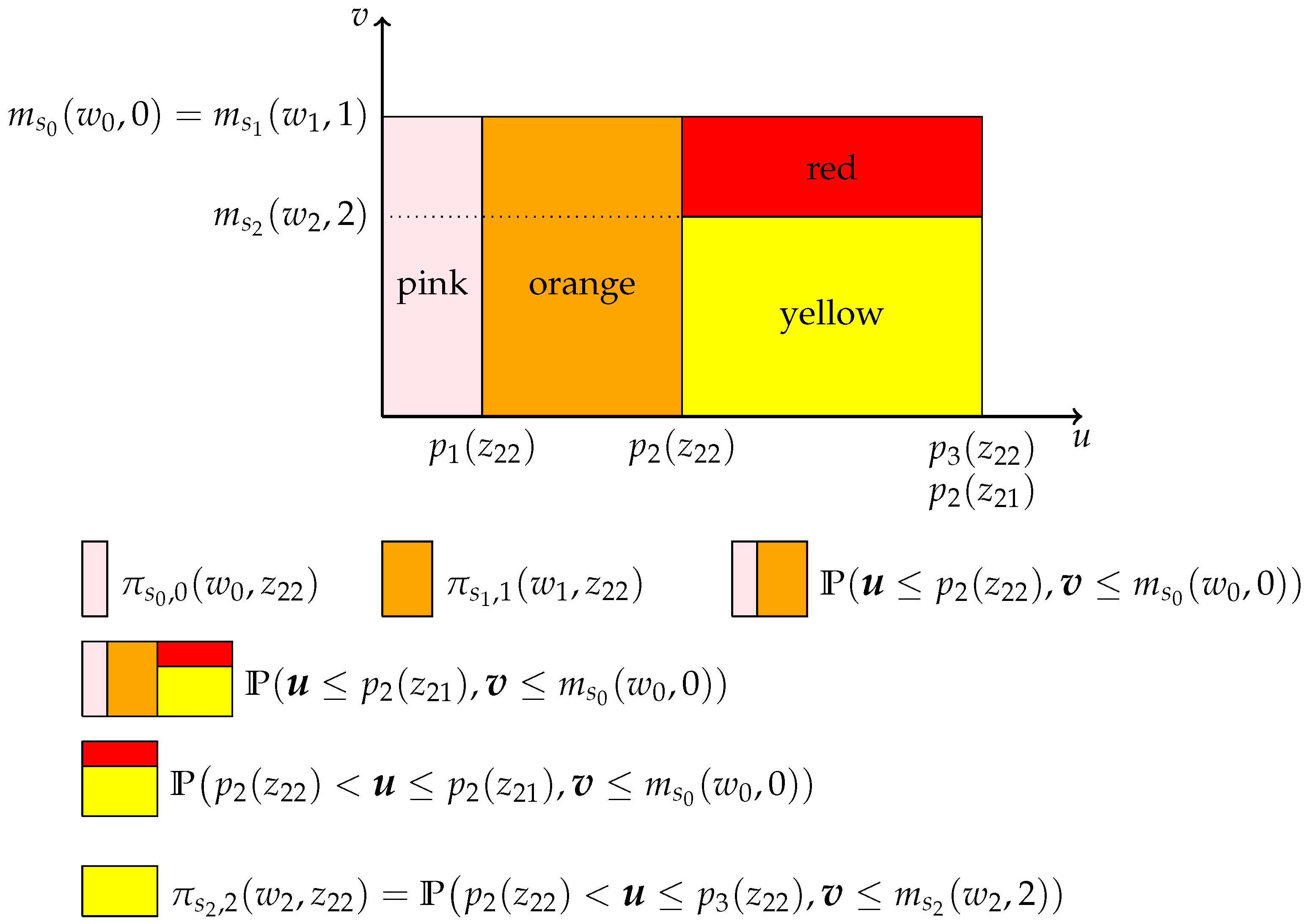{kind=link}
{kind=link}



