Econometric Fine Art Valuation by Combining Hedonic and Repeat-Sales Information

Abstract
:1. Introduction
2. Econometric Methods
2.1. Hedonic Models
2.2. Model Averaging
2.3. Combining Hedonic and Repeat-Sale Information
3. Empirical Predictions of Value at Auction
3.1. Model Elements
3.2. Forecast Evaluation
3.3. Predictive Results
- F1. OLS pooled, broad:
- F2. OLS individual artist, broad:
- F3. OLS individual artist, core:
- F4. Model average: where W contains various combinations of the variables contained in and , with data-based weights as described in Section 2.2.
- F5. OLS core (F3) + RSM: where is the forecast from F3 and is the repeat-sale estimate as given in Equation (5).
- F6. Model average (F4) + RSM: where is the forecast from F4 and is the repeat-sale estimate as given in Equation (5).
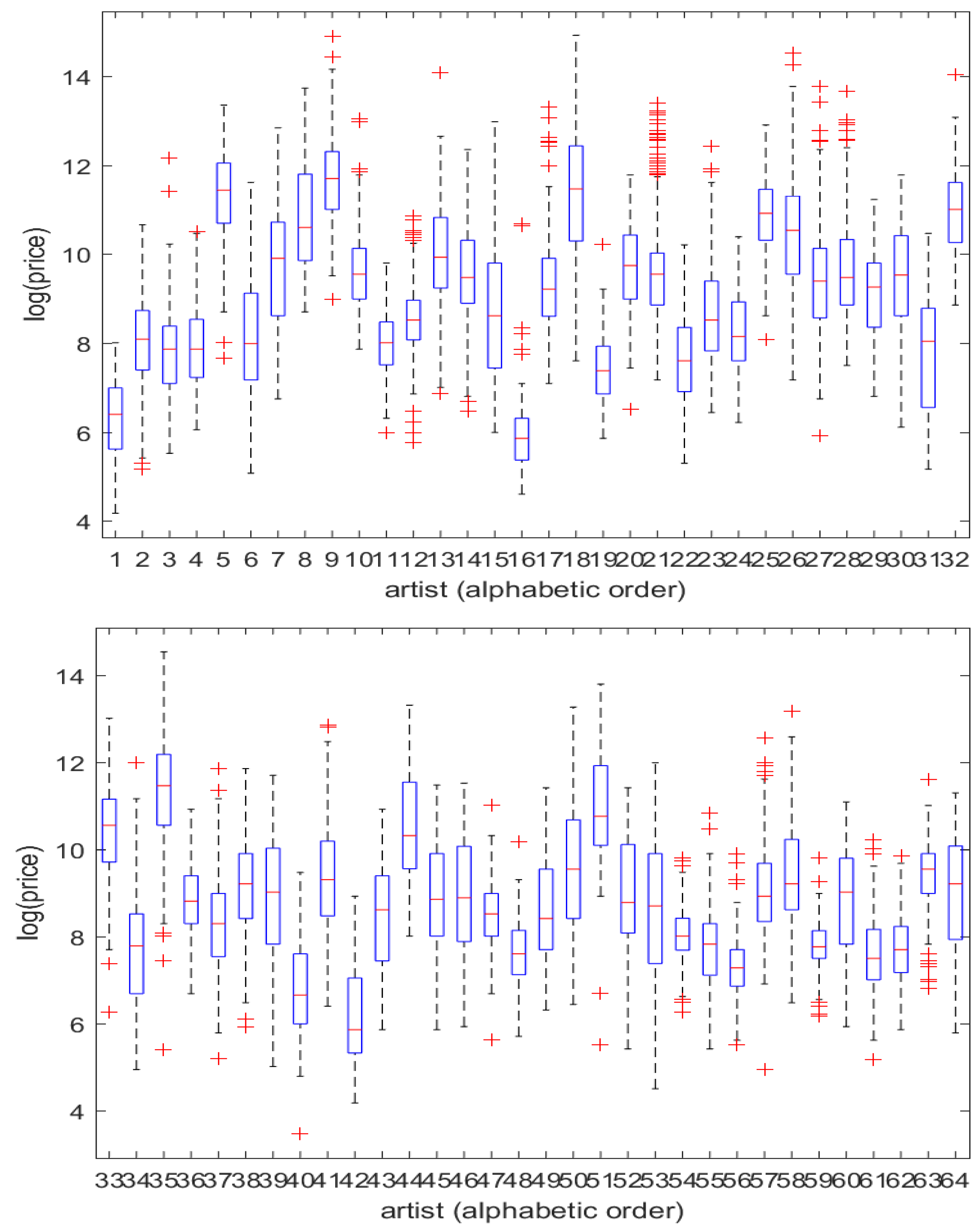
- Do pooled or individual-artist regressions produce the lower forecast loss? Table 2 summarizes this information.
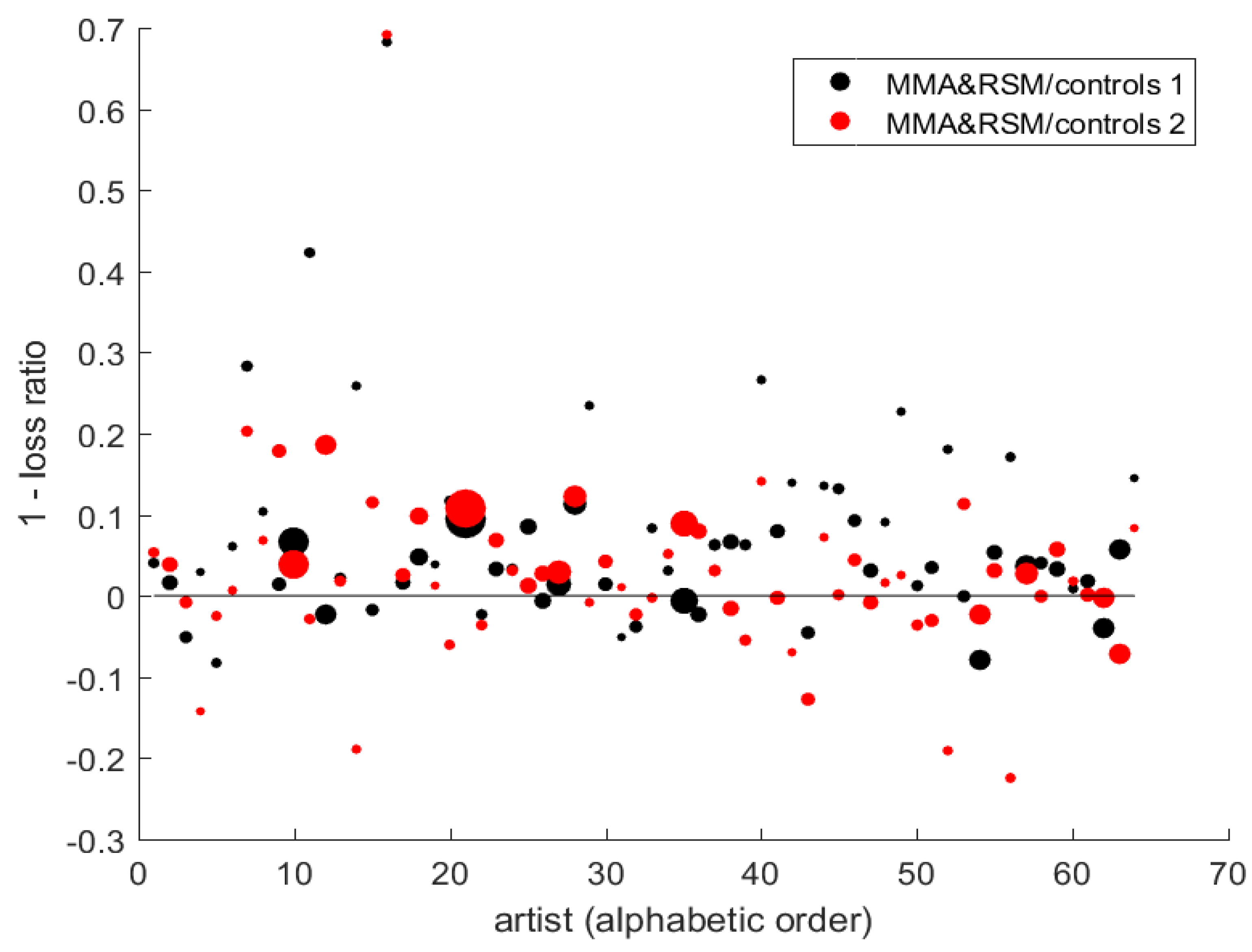
- Does incorporation of repeat-sale information offer potential further improvement? Table 3 treats the subset of cases in which repeat-sale information is available, compares estimated forecast losses, and gives tests of the null of equal forecast variance with and without repeat-sale information. Figure 2 displays, for each artist, performance of the hybrid model relative to two forms of hedonic model.
- What are the key observable factors that predict sale prices at auction?
4. Concluding Remarks
Author Contributions
Acknowledgments
Conflicts of Interest
Appendix A
References
- Accominotti, Fabien. 2009. Creativity from interaction: Artistic movements and the creativity careers of modern painters. Poetics 37: 267–94. [Google Scholar] [CrossRef]
- Arvin, B. Mak, and Marisa Scigliano. 2004. Hedonic prices in art and returns to art investment: Evidence from the Group of Seven at auction. Économie Appliquée 57: 137–62. [Google Scholar]
- Atukeren, Erdal, and Aylin Seckin. 2009. An analysis of the price dynamics between the Turkish and the international paintings markets. Applied Financial Economics 19: 1705–14. [Google Scholar] [CrossRef]
- Bates, J. M., and C. W. J. Granger. 1969. The combination of forecasts. Operational Research Quarterly 20: 451–68. [Google Scholar] [CrossRef]
- Campbell, H. 1970–1975. Canadian Art Auction Record 1969–1974. Toronto: Canadian Antiques and Fine Arts, Montreal: Bernard Amtmann, vols. 1–6. [Google Scholar]
- Campbell, H. 1980. Canadian Art Auctions, Sales, and Prices, 1976–1978. Don Mills: General. [Google Scholar]
- Clapp, John M., and Carmelo Giaccotto. 2002. Evaluating house price forecasts. Journal of Real Estate Research 24: 1–26. [Google Scholar]
- Clemen, Robert T. 1989. Combining forecasts: A review and annotated bibliography. International Journal of Forecasting 5: 559–83. [Google Scholar] [CrossRef]
- Diebold, Francis X., and Roberto Mariano. 1995. Comparing predictive accuracy. Journal of Business and Economic Statistics 13: 253–65. [Google Scholar]
- Galbraith, John W., and Douglas J. Hodgson. 2012. Dimension reduction and model averaging for estimation of artists’ age-valuation profiles. European Economic Review 56: 422–35. [Google Scholar] [CrossRef]
- Galenson, David W. 2000. The careers of modern artists. Journal of Cultural Economics 24: 87–112. [Google Scholar] [CrossRef]
- Galenson, David W. 2001. Painting Outside the Lines. Cambridge: Harvard University Press. [Google Scholar]
- Galenson, David W., and Bruce A. Weinberg. 2000. Age and quality of work: The case of modern American painters. Journal of Political Economy 108: 761–77. [Google Scholar] [CrossRef]
- Galenson, David W., and Bruce A. Weinberg. 2001. Creating modern art: The changing careers of painters in France from impressionism to cubism. American Economic Review 91: 1063–71. [Google Scholar] [CrossRef]
- Hansen, Bruce. 2007. Least squares model averaging. Econometrica 75: 1175–89. [Google Scholar] [CrossRef]
- Hellmanzik, Christiane. 2009. Artistic styles: Revisiting the analysis of modern artists’ careers. Journal of Cultural Economics 33: 201–32. [Google Scholar] [CrossRef]
- Hellmanzik, Christiane. 2010. Location matters: Estimating cluster premiums for prominent modern artists. European Economic Review 54: 199–218. [Google Scholar] [CrossRef]
- Hodgson, Douglas J. 2011. Age-price profiles for Canadian painters at auction. Journal of Cultural Economics 35: 287–308. [Google Scholar] [CrossRef]
- Hodgson, Douglas J., Barrett A. Slade, and Keith P. Vorkink. 2006. Constructing Commercial Indices: A semiparametric adaptive estimator approach. Journal of Real Estate Finance and Economics 32: 151–68. [Google Scholar] [CrossRef]
- Hodgson, Douglas J., and Keith Vorkink. 2004. Asset pricing theory and the valuation of Canadian paintings. Canadian Journal of Economics 37: 629–55. [Google Scholar] [CrossRef]
- Jiang, Liang, Peter C. B. Phillips, and Jun Yu. 2015. New methodology for constructing real estate prices applied to the Singapore residential market. Journal of Banking and Finance 61: S121–31. [Google Scholar] [CrossRef]
- Mallows, C. L. 1973. Some comments on Cp. Technometrics 15: 661–75. [Google Scholar]
- Meese, Richard A., and Nanacy E. Wallace. 1997. The construction of residential housing price indices: A comparison of repeat-sales, hedonic-regression, and hybrid approaches. Journal of Real Estate Finance and Economics 14: 51–73. [Google Scholar]
- Mincer, Jacob A. 1974. Schooling, Experience, and Earnings. New York: Columbia University Press. [Google Scholar]
- Shiller, Robert J. 2008. Derivatives Markets for Home Prices. NBER Working Paper w13962, National Bureau of Economic Research, Cambridge, MA, USA. [Google Scholar] [Green Version]
- Sotheby’s. 1975. Canadian Art at Auction, 1968–1975. Toronto: Sotheby’s. [Google Scholar]
- Sotheby’s. 1980. Canadian Art at Auction, 1975–1980. Toronto: Sotheby’s. [Google Scholar]
- Westbridge, A. R. 1981–2015. Canadian Art Sales Index, 1977–2014. Vancouver: Westbridge Publications Ltd. [Google Scholar]
| 1. | Galbraith and Hodgson (2012) also use model-average methods, as well as principal components, for the problem of estimating individual-artist age-valuation profiles; the quantities of interest are the parameters of a polynomial in the artist’s age. That paper does not consider the sale-price prediction problem. |
| 2. | Repeat sales occur when the same item is sold at least twice in the given sample data, so that an earlier sale may be used to predict the price of a later one. |
| 3. | Jiang et al. (2015) quote Shiller (2008) as follows: “there are too many possible hedonic variables that might be included, and if there are n possible hedonic variables, then there are possible sets of independent variables in a hedonic regression, often a very large number. One could strategically vary the list of included variables until one found the results one wanted.” Model averaging mitigates this problem, providing results based on objective criteria rather than the investigator’s selections. |
| 4. | The notation “e-x”, (e.g., e-05) means . |
| 5. | The notation “——–” indicates the full model with no excluded variables. “All core” means excluding height, width, area, age and age squared; “all medium, genre” means excluding all indicators for the materials with which the work was executed and all indicators for the genre. indicates the decline in when the particular group of variables is omitted from the model. |
| 6. | In the context of housing markets, forecasting models of the time dimension have been considered by, for example, Clapp and Giaccotto (2002). In many cases of both art and real estate, however, a valuation is made conditional on sales already observed in the current year, so that the time lag between price index update and sale is very small, and any deviation of the price process from a random walk should have correspondingly small effect. |
| 7. | Table 2 records bias, variance and loss function measures by method; in the second part of the table, the best (lowest) forecast loss is in bold for each measure. One large extreme outlier is removed for the individual broad OLS regression and equally-weighted model average, in Table 2 and Table 4 results involving either of these two methods; these methods are not competitive and so rankings are not affected, but removal of the outlier gives a more accurate impression of their typical performance. |
| 8. | The size of dot for each artist is proportional to individual sample size. Results from equally weighted model averages are relatively erratic and so are not depicted. |
| 9. | Table 4 gives Diebold–Mariano statistics for the null of no difference in forecast loss between various pairs of methods; the statistic as used here is the difference in the MSE’s of two forecasts divided by an estimate of the standard error of this difference and is asymptotically Because sales are not ordered within a year, we do not apply any correction for autocorrelation in the denominator. A positive value corresponds with lower mean-square forecast loss for the higher-numbered method. |



{kind=link}
{kind=link}
| (a) | ||
| Core Variable: | Coefficient | Std. Err. |
| height | 0.0166 | 5.9e-04 |
| width | 0.0167 | 5.7e-04 |
| area | −8.86e-05 | 4.7e-06 |
| artist age | −0.0037 | 3.5e-03 |
| artist age2 | −8.79e-05 | 3.2e-05 |
| (b) | ||
| Excluded Variables: | ||
| ——– | 0.783 | – |
| H,W, area | 0.709 | −0.075 |
| age, age2 | 0.773 | −0.010 |
| all core | 0.702 | −0.081 |
| all medium, genre | 0.776 | −0.008 |
| (a) | |||||
| Bias: | Variance: | ||||
| Method: | Pooled | Indiv. | Pooled | Indiv. | |
| OLS-broad | 0.063 | −0.124 | 0.675 | 0.598 | |
| OLS-core | — | −0.112 | — | 0.579 | |
| model avg | — | −0.128 | — | 0.546 | |
| OLS-core + RSM | — | −0.081 | — | 0.562 | |
| model avg + RSM | — | −0.096 | — | 0.533 | |
| (b) | |||||
| RMSE: | Linex: | ||||
| Method: | Pooled | Indiv. | Pooled | Indiv. | |
| OLS-broad | 0.824 | 0.783 | 0.087 | 0.0892 | |
| OLS-core | — | 0.769 | — | 0.0846 | |
| model avg | — | 0.750 | — | 0.0794 | |
| OLS-core + RSM | — | 0.754 | — | 0.0802 | |
| model avg + RSM | — | 0.736 | — | 0.0753 | |
| Method: | RMSE | vs. 1 | vs. 2 | vs. 3 | vs. 4 | vs. 5 | vs. 6 |
|---|---|---|---|---|---|---|---|
| 1. RSM only | 0.700 | 1.69 | 1.08 | 1.46 | 7.67 | 7.96 | |
| 2. OLS-broad | 0.659 | −2.96 | −2.36 | 5.35 | 5.64 | ||
| 3. OLS-core | 0.673 | 2.56 | 6.09 | 6.18 | |||
| 4. model avg. | 0.664 | 5.56 | 5.80 | ||||
| 5. OLS-core + RSM | 0.585 | 1.86 | |||||
| 6. Model avg + RSM | 0.582 |
| Method: | vs. 1 | vs. 2 | vs. 3 | vs. 4 | vs. 5 | vs. 6 |
|---|---|---|---|---|---|---|
| 1. pooled | 2.64 | 3.77 | 5.15 | 4.79 | 6.13 | |
| 2. OLS-broad | 1.88 | 6.04 | 3.68 | 7.90 | ||
| 3. OLS-core | 3.39 | 6.01 | 5.36 | |||
| 4. model avg. | −0.68 | 5.73 | ||||
| 5. OLS-core + RSM | 3.21 | |||||
| 6. Model avg + RSM |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Galbraith, J.W.; Hodgson, D.J. Econometric Fine Art Valuation by Combining Hedonic and Repeat-Sales Information. Econometrics 2018, 6, 32. https://doi.org/10.3390/econometrics6030032
Galbraith JW, Hodgson DJ. Econometric Fine Art Valuation by Combining Hedonic and Repeat-Sales Information. Econometrics. 2018; 6(3):32. https://doi.org/10.3390/econometrics6030032
Chicago/Turabian StyleGalbraith, John W., and Douglas J. Hodgson. 2018. "Econometric Fine Art Valuation by Combining Hedonic and Repeat-Sales Information" Econometrics 6, no. 3: 32. https://doi.org/10.3390/econometrics6030032
APA StyleGalbraith, J. W., & Hodgson, D. J. (2018). Econometric Fine Art Valuation by Combining Hedonic and Repeat-Sales Information. Econometrics, 6(3), 32. https://doi.org/10.3390/econometrics6030032