1. Introduction
The interaction of monetary policy and the stock market has been studied extensively with structural vector autoregressive (VAR) models. A central problem is the identification of the structural shocks. Nowadays, a range of different tools is available for identifying structural VARs (see
Kilian and Lütkepohl 2017). Therefore, different types of identifying restrictions for monetary policy and stock market shocks have been used. For example,
Bjørnland and Leitemo (
2009) considered a structural VAR model for the US, where long-run and short-run restrictions were combined to identify structural shocks. Such models were also used in the context of identification by heteroscedasticity (e.g.,
Lütkepohl and Netšunajev 2017a,
2017b;
Bertsche and Braun 2018). All these studies investigated the relation between monetary policy and the stock market in the US, but they ignored that the variables may be cointegrated. In the present study, we consider the relation between monetary policy and the stock market in Europe and explicitly account for possible cointegration of the variables involved.
European monetary policy is, of course, a central topic of empirical macroeconomics (e.g.,
Peersman and Smets 2001). There are also studies investigating explicitly the impact of monetary policy in Europe on the stock market.
Cassola and Morana (
2004) found that price-stabilizing monetary policy contributes to the stability of the stock market in the euro area.
Bredin et al. (
2009) performed an event study and found a negative relation between UK monetary policy and stock returns, but not between German monetary policy and stock returns.
Kholodilin et al. (
2009) used the approach of
Rigobon and Sack (
2004) and found heterogeneous relations between monetary policy and stock prices for different sectors, but the effect of an increase in the policy rate of the European Central Bank (ECB) on an aggregate stock index was reported to be negative.
Haitsma et al. (
2016) identified the ECB monetary policy shocks using an event-study approach and via heteroscedasticity following
Rigobon and Sack (
2004). Both identification methods yielded a negative relationship between unexpected changes in policy rates and stock returns.
Alessi and Kerssenfischer (
2016) estimated a structural factor model using euro area data and argued that the responses of stock returns to monetary policy are larger and quicker than in a conventional small-scale structural VAR. In a more recent study,
Fausch and Sigonius (
2018) used different techniques to investigate the relation between ECB monetary policy and German stock returns, including an event study, a VAR analysis—where monetary policy surprises are captured by a proxy variable—and a threshold VAR model. They found a negative relation between the ECB monetary policy and stock returns in the pre-crisis period.
In this study, we use a structural vector error correction model (VECM) identified through heteroscedasticity to investigate the relation between monetary policy and the stock market. The cointegration framework developed by Johansen and Juselius (see
Johansen and Juselius 1990;
Johansen 1991,
1995;
Juselius 2006) opens up a convenient way to impose restrictions on the long-run effects of structural shocks in structural VAR analysis, as shown by
King et al. (
1991). They used the Granger–Johansen representation of a VAR model (
Johansen 1995) to determine the long-run effects of their shocks, and the framework is easy to combine with identifying information obtained from the second-moment structure of the model (see
Lütkepohl and Velinov 2016 or
Kilian and Lütkepohl 2017, chp. 14). We use this framework in our empirical investigation.
We model the conditional heteroscedasticity in the data by a Markov-switching (MS) mechanism and find a cointegrated structural VAR model for which conventional identifying restrictions are in line with the second-moment structure of the data. The impulse responses are plausible and, in particular, production and price level go down after a contractionary monetary policy shock. Although the long-run impact of a monetary policy shock on stock prices is restricted to zero, such a shock is found to have a rather long-lasting negative impact on the stock market.
The structure of this study is as follows. In the next section, the basic structural VECM is presented and the model for the second moments is discussed in
Section 3. The empirical analysis is considered in
Section 4 and conclusions are presented in
Section 5. The
Appendix A provides details on the data sources.
2. Structural Vector Error Correction Models
The time series variables of interest are collected in the
vector
. The components of
may be integrated and cointegrated variables. We assume that all variables are stationary (
) or integrated of order one (
). Assuming a cointegration rank
r,
, our point of departure is the VECM form of a VAR model,
where
is the differencing operator such that
,
is a
constant intercept term,
is a
loading matrix of rank
r,
is a
cointegration matrix of rank
r, and
are
coefficient matrices (see also
Johansen 1995).
The reduced-form residuals are white noise, that is, is serially uncorrelated with mean zero but may have time-varying second moments. In other words, may be heteroscedastic or conditionally heteroscedastic. The structural shocks, denoted by , are obtained from the reduced-form residuals by a linear transformation or . The transformation matrix B is assumed to be such that the structural shocks are instantaneously uncorrelated. Hence, is a diagonal matrix.
Substituting
for
in (
1), the matrix
B is easily recognized as the matrix of impact effects of the structural shocks. Thus, imposing restrictions directly on the impact effects means putting restrictions on the elements of
B. Typically, zero restrictions are imposed on
B, which implies that certain variables do not respond instantaneously to a shock.
The long-run effects of the shocks are easily obtained through the Granger–Johansen representation (see
Johansen (
1995, Theorem 4.2)) of
corresponding to (
1),
where
is a stationary process,
contains deterministic terms, and
represents initial conditions. In (
3),
and
are
dimensional orthogonal complements of the
dimensional matrices
and
, respectively. If the cointegration rank
r is zero, the orthogonal complement matrices are replaced by
identity matrices so that the long-run effects matrix becomes
The corresponding long-run effects of the structural shocks are given by
. Since
and
have rank
r, their orthogonal complements have rank
, implying that
also has rank
, and the same holds for
because
B is an invertible matrix of full rank
K. For a given reduced-form matrix
, restrictions on
imply restrictions for
B and, hence, can help identify the structural shocks. The reduced rank of the long-run effects matrix implies that there can be at most
r shocks without any long-run effects, corresponding to
r columns of zeros of
. In other words, only
r shocks can be purely transitory. Another side effect of the reduced rank of
is, however, that simply counting zero restrictions is not enough to assess identification of the structural matrix
B, as we will see in our empirical application in
Section 4.
This setup for identifying structural shocks in VAR models was proposed by
King et al. (
1991). Introductory treatments are given by
Lütkepohl (
2005, chp. 9) and
Kilian and Lütkepohl (
2017, chp. 10). An advantage of the structural VECM setup is that only the cointegration rank is needed, which implies the rank of the long-run effects matrix
. Knowing that rank, the structural shocks can be properly specified through long-run restrictions. Typically the actual cointegration relations are not needed. Thus, pretesting for specific cointegration relations and even knowing the precise order of integration of specific variables is not necessary, as long as the cointegration rank is known.
There are a number of situations of special interest. For
, the matrix of long-run effects
is of full rank
K and, hence, cannot have zero columns. Thus, for
, all
K structural shocks have some long-run effects. If the cointegrating rank is zero, the VECM (
1) reduces to a VAR model in first differences,
for which the accumulated long-run effects on the
are known to be
The accumulated effects on the first differences are just the long-run effects on the levels
, of course. This case was considered by
Blanchard and Quah (
1989), and the estimation of the structural parameters, i.e., the
B matrix, is particularly easy for this case (e.g.,
Lütkepohl (
2005, chp. 9)).
If some of the components of
are
, the long-run effects matrix
and, hence, also
, has corresponding rows of zero elements because a stationary variable is not affected permanently by a shock. Formally, that can be seen by dividing up the vector
where all components of the
vector
are
and all components of the
vector
are
. In this case there exists a cointegration matrix of the form
where
is a
matrix and
denotes a
zero matrix. Thus, there exists an orthogonal complement of
such that
Hence, the last rows of are rows of zeros.
4. Monetary Policy and the Stock Market in Europe
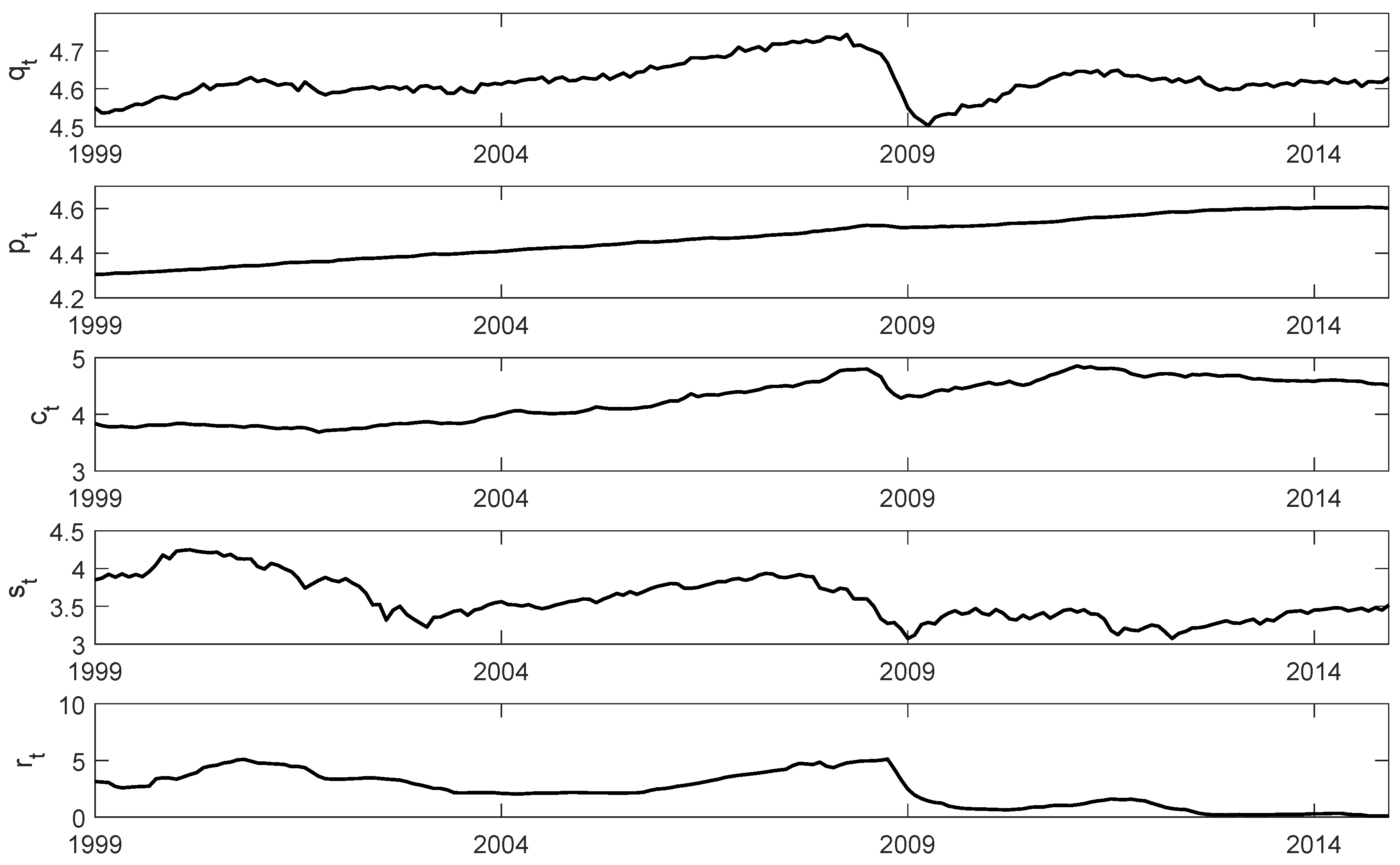
A five-dimensional VAR model for the euro area with variables
is considered, where
is the log of an industrial production index,
denotes the log of the harmonized index of consumer prices (HICP),
is a log non-energy commodity price index,
is the log of the real Euro Stoxx 50 stock price index, and
denotes the 3 month Euribor. The set of variables corresponds to the system used by
Bjørnland and Leitemo (
2009) for analysing the relation between monetary policy and the stock market in the US. We use monthly data for the period 1999M1–2014M12 and, hence, avoid the period of quantitative easing in the eurozone. Further details on the variables and data sources are given in the appendix, and the time series are plotted in
Figure 1.
Given the substantial impact of the financial crisis in 2008 following the collapse of Lehman Brothers, one may wonder whether a time-invariant VAR or VECM is appropriate for the full sample period. We have therefore fitted VAR(2) models for
, where all or some of the coefficients are allowed to vary over time. The time-variation is governed by a two-state MS mechanism. Some models are compared in
Table 1, using standard model selection criteria. The abbreviations used in
Table 1 follow those proposed by
Krolzig (
1997), that is, MSIAH stands for a VAR model with time-varying intercept, VAR slope coefficients, and error covariance matrix; MSIH abbreviates a model where only the intercept vector and the error covariance matrix are allowed to vary; and MSH signifies a model with time-invariant intercept and VAR slope coefficients but varying error covariance matrix. In all cases, two Markov states are used, which is indicated in parentheses behind the model abbreviation. A lag order of
is suggested by the Akaike information criterion (AIC), the Schwarz Criterion (SC), and the Hannan–Quinn criterion (HQ) (see
Lütkepohl (
2005, sct. 4.3)) for a time-invariant VAR process for the full sample period. Thus, in
Table 1, for example, VAR(2)-MSH(2) signifies a VAR model of order 2 with 2 possible error covariance regimes and time-invariant intercept and VAR slope coefficients. It turns out that such a model is favoured by the SC and HQ model selection criteria, while AIC favours a fully flexible model. Provided the quantitative easing period is excluded from the sample, it is reasonable to believe that the monetary policy regime has not changed. With that in mind, and taking into account the preferences of the SC and HQ criteria, we use the model with time-invariant intercepts and slope coefficients and allow for a time-varying error covariance matrix only in the following. We decompose the covariance matrices such that time-invariant impact effects and time-invariant impulse responses are identified.
Based on conventional ADF tests, all five variables are classified as
variables. Thus, there may be cointegration among the variables, which is worth taking into account in our structural analysis. Since the VAR(2)-MSH(2) model, and thus a model with conditional heteroscedasticity, was favoured in the previous analysis, we base tests for the cointegration rank on Johansen’s (1995) cointegration rank tests robustified for conditional heteroscedasticity by generating the
p-values with a wild bootstrap algorithm, as proposed by
Cavaliere et al. (
2010) and further investigated by
Cavaliere et al. (
2018). The results are presented in
Table 2 and suggest a cointegration rank of
if a 5% significance level is used. Thus, we consider a VECM(1) with one lag of the differenced variables (i.e.,
) and cointegration rank
for our structural analysis.
One advantage of imposing long-run restrictions on the long-run effects matrix
obtained via the Granger–Johansen representation is that we do not have to take a stand on the exact cointegration relations, we just need to know the cointegration rank of the model. Imposing only the rank restriction is also in line with the original ideas behind structural VAR modelling, which imposes as few restrictions as possible. In this context, it is perhaps worth mentioning that
Bjørnland and Leitemo (
2009) considered a system
for US data which effectively assumes that there is no cointegration between the variables
,
and
so that these variables can be included in first differences. Although we do not want to reconsider the issue for US data here, it may be worth checking whether a setup with
,
, and
instead of the levels variables can be used for European data as well, or whether the variables are potentially cointegrated. In
Table 3, we present the results of cointegration rank tests and find clear evidence of cointegration between
,
, and
. Thus, the precise model specification used by
Bjørnland and Leitemo (
2009) would be difficult to defend for our European data, and we use the VECM(1) model with cointegration rank
in the following. Another point worth emphasising is that this choice even accommodates the possibility that there are stationary variables in the model. For example, if there is a suspicion that the unit root tests have indicated unit roots just because of lack of power, this may be accommodated in our VECM setup as long as the cointegration tests indicate the cointegration rank adequately.
Based on the previous MS analysis we fit a volatility model of the type discussed in
Section 3 with two states of the Markov process. The model is referred to as a VECM(1)-MSH(2) in the following. Given our small sample size, considering more volatility states is unreasonable.
1 The AIC, HQ, and SC values of a VECM(1) model without allowing for heteroscedasticity and a VECM(1)-MSH(2) model are shown in
Table 4. They clearly signal that allowing for conditional heteroscedasticity improves the model fit. The values of all three model selection criteria are substantially smaller than the corresponding values for the model without heteroscedasticity. In other words, the second-moment structure may well provide useful identifying information for the structural shocks.
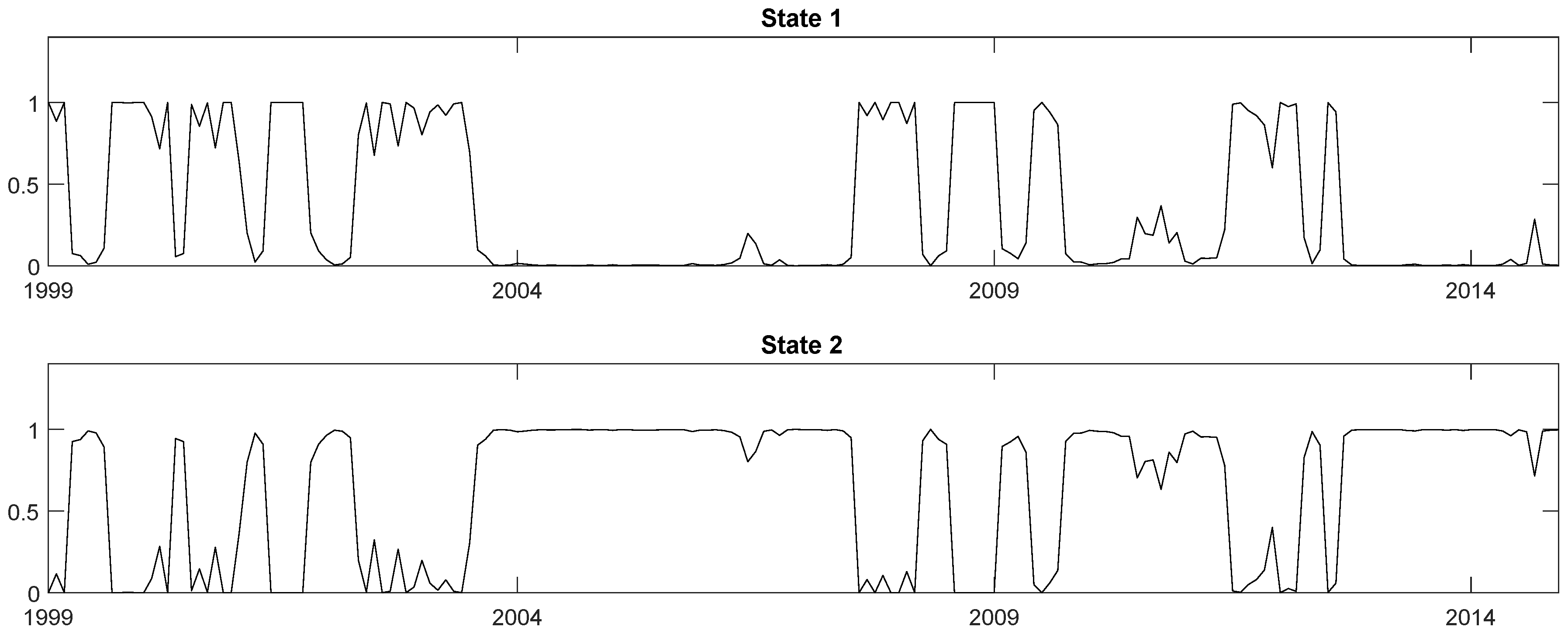
In
Figure 2, the smoothed state probabilities of the VECM(1)-MSH(2) model are presented. They show that the two volatility regimes change frequently throughout the sample period so that guessing the change points reliably would be difficult for a researcher. Hence, using a model which allows for endogenously assigned volatility changes is clearly an advantage over a model where the volatility states have to be prespecified by the researcher.
To explore the identification issue, we have to consider the diagonal elements of
, which represent the variances of the structural shocks in the second volatility state relative to the first state, as explained in
Section 3. They are displayed in
Table 5, together with estimated standard errors. Four of the five estimated relative variances of the structural shocks in the second state are smaller than 1. Hence, most structural shocks have smaller variance in the second than in the first state. In other words, the second state captures potentially periods of lower volatility. From
Figure 2, it can be seen that the first regime is associated with the period around the turn of the millennium, where the internet bubble burst, and with the period 2008/2009, where the financial crisis started. These events may have generated higher volatility in some of the structural shocks. Note, however, that at this point it is difficult to associate any of the shocks identified through heteroscedasticity with economic shocks of interest because the ordering of the shocks is arbitrary. Therefore, it is difficult to argue that specific economic shocks are more volatile in state 1.
For the identification of the shocks through heteroscedasticity, the diagonal elements of have to be distinct. Although the estimated diagonal elements are all distinct, the estimation uncertainty reflected in the standard errors is rather high and, hence, the true underlying quantities may not be distinct. This uncertainty in the estimates is not surprising given the relatively small sample size. However, some of the standard errors are quite small compared to the corresponding estimates of the relative variances, so it is reasonable to assume that at least some of the diagonal elements of are distinct. Thus, there is at least some identifying information in the second moments which may be sufficient to discriminate between competing conventional identification schemes. We emphasise that for this to hold, it is not necessary that all the are distinct.
We are primarily interested in a monetary policy shock and a stock market shock. Therefore, we place these shocks in the last two positions of , that is, . In other words, the stock market shock, , is the fourth shock, and the monetary policy shock, , is last. The other components of are left unspecified and represent other shocks to the economy.
We consider the two alternative identification schemes in
Table 6. Since we have a cointegration rank
, the rank of
is
. Thus, there can be two columns of zeros in the long-run effects matrix
. The first identification scheme in
Table 6 assumes that both the stock market shock and the monetary policy shock are purely transitory and, hence, do not have any long-run effects on any of the variables. The two shocks are distinguished by the assumption that
does not affect the commodity price index instantaneously, but only with some delay. Hence, there is a corresponding zero in the third row of
B. The long-run restrictions may be justified by the notion that the effects of monetary policy and stock market shocks should be transitory. In a conventional VAR analysis, effects of these shocks on the macroeconomic variables vanish over time (see
Christiano et al. 1999;
Bjørnland and Leitemo 2009). The restriction on the short-run effect is needed to distinguish the two shocks, which are both neutral in the long run, and it is part of the identification schemes used by
Christiano et al. (
1999),
Bjørnland and Leitemo (
2009), and others for US data. Note also that no restrictions are imposed on the first three columns of
B and
so that the first three shocks are identified purely by the volatility changes. Since we are not interested in them, we did not ensure that they have economic interpretations.
The second identification scheme is due to
Bjørnland and Leitemo (
2009), who used it for US data. They were also primarily interested in the last two shocks, and arbitrarily identified the first three shocks by imposing a recursive structure on their contemporaneous impact effects, which is seen by the recursive structure of the zero entries in the first three columns of
B. Again, the last shock is specified as monetary policy shock. It is assumed to have no long-run impact on stock prices, and this distinguishes the shock from the stock market shock. Both shocks are assumed to have no impact effects on industrial production, the price level, and the commodity price index. This assumption reflects the belief that these variables move slowly in response to
and
. There are no further long-run restrictions.
The two identification schemes differ not only in the way they identify the shocks of interest. While the first scheme relies primarily on long-run restrictions, the second scheme imposes most restrictions on the impact effects. Without heteroscedasticity, Scheme (1) is under-identified and the second scheme is just-identified. Thus, in the absence of heteroscedasticity, they cannot be compared with statistical tests without further assumptions. However, assuming that the shocks are already identified by the second-moment structure, the zero restrictions on B and are over-identifying and can be tested by standard likelihood ratio (LR) tests.
The results of such tests are presented in
Table 7, where the alternative is a model that is purely identified by heteroscedasticity and has no zero restrictions on
B or
. In addition to the value of the LR statistic, the assumed degrees of freedom of the
limiting distributions are presented on which the
p-values are based. For both tests, the number of degrees of freedom is determined under the assumption that the structural matrix
B is fully identified by heteroscedasticity. The number of degrees of freedom for testing Scheme (1) is 7 because, for
, the long-run effects matrix
has rank
and, hence, each column of zeros counts for three independent restrictions only. In other words, the columns of the matrix
can be represented as a linear combination of three basis vectors. A zero column is obtained if the basis vectors are multiplied by zero coefficients. Thus, each of the two columns of zeros is obtained by restricting the three weights of the basis vectors to zero. Hence, the 10 zero coefficients in the last two columns of the long-run effects matrix in Scheme (1) count for six restrictions only. In addition, there is one zero restriction on the impact effects matrix
B.
For Scheme (1), the
p-value of the LR test is less than 1%, so Scheme (1) is rejected at any conventional significance level. This also indicates that there must be identifying information in the second-moment structure because the
model is not identified by the zero restrictions alone. Thus, the heteroscedastic structure has identifying power. However, since the evidence of all relative variances being distinct in
Table 5 is weak, there is of course the possibility that the structure is only partially identified by heteroscedasticity. In that case, the degrees of freedom of the LR tests in
Table 7 may be smaller than assumed in the table, implying that the
p-values would be even smaller than those in the table.
Considering the second
p-value in
Table 7, Identification Scheme (2) cannot be rejected at a 1% level, although its
p-value is slightly below 5%, at least if a
distribution with 10 degrees of freedom is used as reference. This outcome is interesting because, in a related study based on identification through heteroscedasticity,
Lütkepohl and Netšunajev (
2017a) found strong evidence against the restrictions for the US. Admittedly, this evidence is based on a quite different sample period. Moreover,
Bertsche and Braun (
2018) did not confirm this result with a different volatility model. However,
Lütkepohl and Netšunajev (
2017b) also found an implausible reaction of the inflation rate to a monetary policy shock for the US. Thus, it is instructive to see the responses of the variables to the two shocks of interest for our European model when Identification Scheme (2) is used.
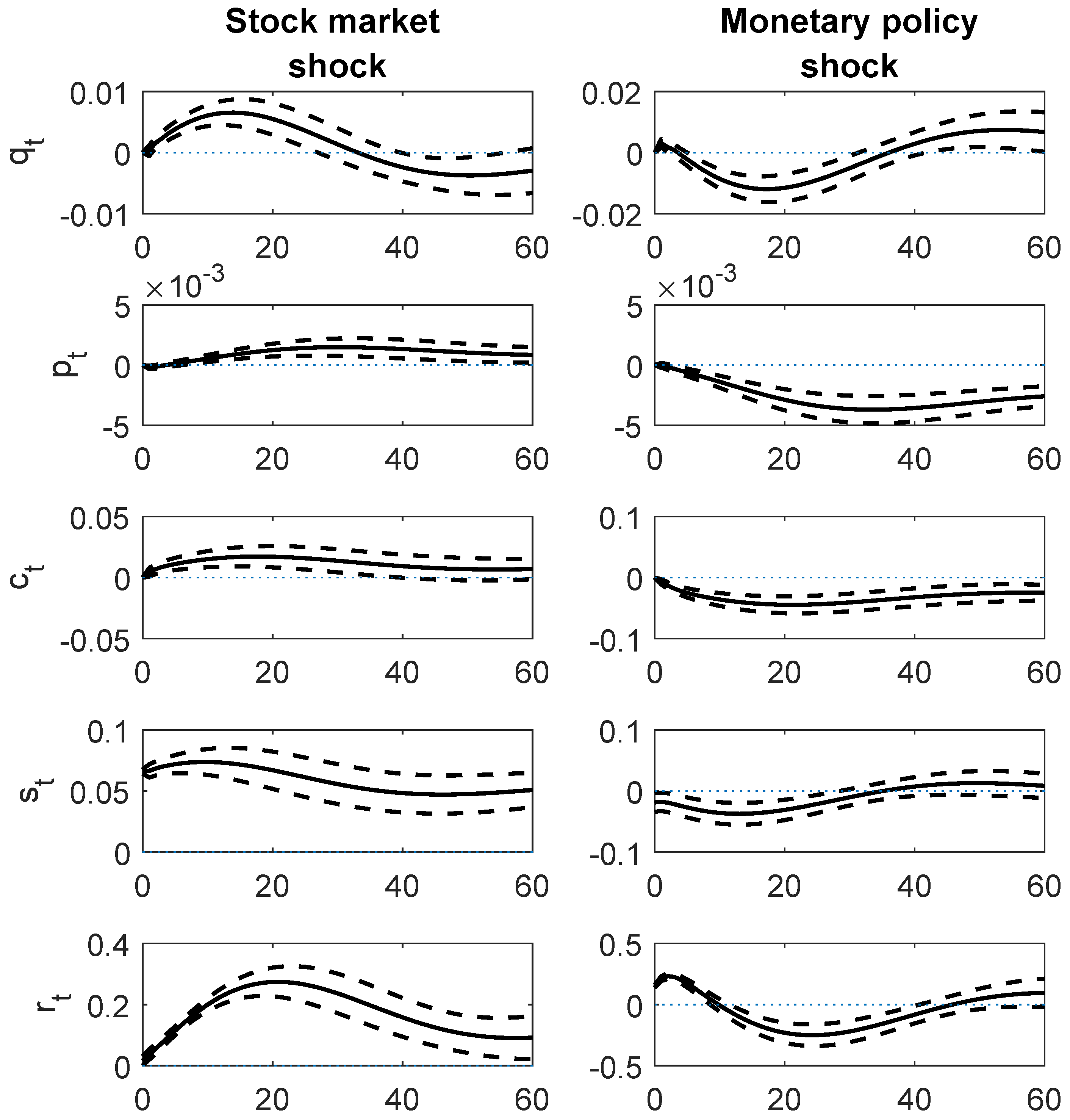
The estimated impulse responses with ± one standard error bootstrap confidence intervals are shown in
Figure 3. The confidence intervals have a 68% level in a Gaussian environment. The standard errors are estimated with a fixed-design wild bootstrap conditioning on the transition probabilities, as proposed in
Herwartz and Lütkepohl (
2014) and also used in
Lütkepohl and Netšunajev (
2017a).
The responses of the variables to both shocks are quite plausible. A stock market shock is followed by increases in all other variables, although these upswings occur with some delay. This is in line with the studies by
Bjørnland and Leitemo (
2009) and
Li et al. (
2010) for the US. The increase in output and inflation is consistent with the view that a rise in stock prices increases consumption (
Beaudry and Portier 2006) through a wealth effect and investment through a Tobin Q effect, thus inducing aggregate demand to increase. Due to nominal rigidities, prices react slowly, and inflation as well as commodity prices rise in the intermediate run. The response of the interest rate may be explained by the behaviour of an inflation-targeting central bank which is increasing interest rates to combat the inflationary pressure of a high aggregate demand.
A contractionary monetary policy shock, induced by an increase in the interest rate, reduces industrial production, the price level, and commodity prices with some delay. Similar to
Peersman and Smets (
2001) and
Ehrmann et al. (
2003), we do not find any price puzzle and observe long-run effects on prices. The shock leads to a long-lasting downturn of the stock index after a monetary policy tightening. This is in line with results of
Bjørnland and Leitemo (
2009) for the US, but the effect for the euro area is not as pronounced as in their study. Even though there is mixed evidence regarding the influence of monetary policy on industry- or country-level stock returns in Europe, most of the studies agree on a negative relation between ECB monetary policy and aggregate stock returns in the euro area (
Kholodilin et al. 2009;
Alessi and Kerssenfischer 2016;
Fausch and Sigonius 2018). Clearly, our results support those previous findings which show that the policy of the ECB has a substantial impact on the stock market in Europe.






{kind=link}
{kind=link}
{kind=link}