1. Introduction
Economic theories are often operationalized under linearity assumptions on the relationships between the underlying variables or joint normality assumptions on their distributions. Famous examples include the Capital Asset Pricing Model (CAPM) and Value at Risk models. Often, linearity and normality assumptions are needed in order to obtain analytical formulas and elegant characterizations of the phenomena of interest. However, such assumptions may lead to wrong conclusions when they are not valid. Recognizing these limits and observing the relatively high frequency of extreme economic events (e.g., financial crises and recessions), a body of the empirical literature in finance emphasizes the distributional characteristics of assets returns that do not reflect normality, in particular asymmetry and fat tails.
For example,
Harvey and Siddique (
1999,
2000) propose a model to estimate the conditional skewness and highlight the importance of taking this into account when analyzing the cross sectional properties of assets prices.
Christoffersen et al. (
2006) propose a framework to price options in the presence of conditional skewness.
Feunou and Tedongap (
2012) propose a stochastic volatility model with conditional skewness for assets prices and show that these distributional aspects are very important to explain how investors value options.
Gabaix (
2009,
2016) argues that stable laws approximate the distribution of many economic and financial variables fairly well while
Gabaix (
2011) proves that macroeconomic fluctuations can have granular origins. Indeed, Gabaix’s work draws attention on a more general issue, namely, the fact that the aggregation of independent phenomena does not always lead to the normal distribution as stipulated by the central limit theorem.
If non-normality is now well entrenched in the mind of academic researchers and financial risk managers, non-linearity has received much less attention in the literature. The joint normality of two random variables X and Y implies that is a linear function of X and that conversely is linear in Y. While a linear relation can still exist between X and Y without joint normality, a nonlinear relationship precludes joint normality. This shows that nonlinearity and non-normality are distinct concepts. Despite the availability of more and more complex computer solutions, linear relationships remain largely advocated for empirical inquiries in economics and finance. Prominent models that are based on linear relationships include the Arbitrage Pricing Theory (APT), Taylor rules and Keynesian consumption functions. Unfortunately, a linearity assumption may lead to wrongly falsifying a theory when the true unknown relationship of interest is nonlinear. Even after acknowledging that the relationship between two variables is nonlinear, finding the functional form that works best for the situation of interest may still be difficult.
In this paper, I propose an approach to measure the degree of nonlinearity of the relationship between two variables. For any pair , I define the exposure of Y to X as the expectation of Y given X. The relationship between X and Y is then said to be nonlinear if either Y is nonlinearly exposed to X or X is nonlinearly exposed to Y. Said differently, the relationship between X and Y is linear if and only if Y is linearly exposed to X and in turn X is linearly exposed to Y. Indeed, it is possible that be a linear function of X without being linear in Y. In this case, the linearity of is spurious as it is misleading about the true relationship between the two variables. Please note that the relationship between variables is approached in this paper from a predictive point of view rather than from a causal perspective. Knowing that the predictive relationship between X and Y is nonlinear is a good starting point for the search of the true underlying causal relationship.
The proposed measure for the degree of nonlinearity of the function , denoted , exploits the relative importance of the norms of the linear and nonlinear parts of in a functional space. The decomposition of into its linear and nonlinear part is done via a functional projection of onto a basis of orthogonal polynomials , where is a polynomial of order j and the orthogonality is defined with respect to a metrics . Upon observing that linear functions of X are loaded only on and , a function is said to be purely nonlinear when it is entirely loaded on the higher order polynomials . For any function of X, the value of always lies between 0 and 1, with 0 meaning that is linear in X and 1 meaning that is purely nonlinear as per the previous definition. The index is invariant to linear transformations of Y as well as to the addition of an independent noise to Y. It is not invariant to the choice of the metrics and it is therefore sensitive to transformations of X.
Unlike our proposed measure of nonlinearity, the Pearson
linear correlation coefficient measures the propensity of a random variable
Y of being replicated by a linear function of another variable
X. It always lies between
and
, with 1 meaning a perfectly linear and positive relationship, 0 the absence of linear relationship and
a perfectly linear and negative relationship. A linear correlation coefficient lying strictly between
and 1 indicates that a fit of
Y by a linear function of
X will not be perfect. This imperfection arises either from the dependence of
Y on random factors other than
X or from nonlinearity in the relationship between
Y and
X (or both). The linear correlation coefficient is smaller than 1 in absolute value when
X and
Y are bound by a deterministic but nonlinear relationship. In an effort to repair the limitations of the linear correlation, measures of nonlinear association (typically, based on ranks) have been proposed. Notably, we have the rank correlation coefficient of
Spearman (
1904), Kendall’s tau (
Kendall 1938,
1970), Goodman and Kruskal’s gamma (
Goodman and Kruskal 1954,
1959) and the quadrant count ratio (see
Holmes 2001). All rank correlation measures are designed to detect the strength of possibly nonlinear but monotonic relationships between
Y and
X. Unlike the linear correlation, a rank correlation coefficient equals 1 if for instance
and
if
(assuming
). However, like the linear correlation, a rank correlation coefficient can be non significant if the relationship between
X and
Y is non-monotonic.
The remainder of the paper is organized as follows.
Section 2 motivates the use of the nonlinearity index (
) proposed in this paper.
Section 3 presents the derivation of
.
Section 4 discusses the choice of the metrics
used to calculate
.
Section 5 examines the invariance properties of
.
Section 6 illustrates the calculation of
for simple functions and warns against coarse errors when choosing the metrics
.
Section 7 proposes a feasible estimator for
and shows its consistency.
Section 8 proposes three applications of our methodology. In the first application, I compute the nonlinearity index of a European option relatively to the underlying asset. It is found that the degree of nonlinearity of the option depends on its maturity and strike as well as on the volatility of the underlying asset. The second application underscores the importance of performing a nonlinearity diagnosis prior to designing a hedging strategy for a portfolio. In the third application, I analyze the nature of the relationship between the returns on the SP500 index and the associated risk as measured by the realized variance (RV). The empirical results are supportive of the existence of a nonlinear relationship between the expected return and the expected risk. The SP500 seems to be driven by two regimes, one regime in which the expected return is increasing in the expected risk and another regime in which the trade-off is negative. Within each regime, the return-risk trade-off is approximately linear.
Section 9 concludes. The mathematical proofs are gathered in
Appendix A.
3. Measuring Nonlinearity
Let the exposure of
Y to
X be given by:
where
X and
Y are scalar random variables and
is a possibly nonlinear function of
X. In assets pricing,
Y could be the risk premium on an asset and
X a measure of the risk for bearing that asset, in which case
describes a nonlinear risk-return trade-off. Alternatively,
Y can be viewed as an investors portfolio and
X the traditional market index. In the latter case,
would be reflecting a nonlinear exposure to the market stemming from a non-directional investment strategy. In macroeconomics,
Y could be the inflation rate and
X the unemployment rate, in which case
features a nonlinear Phillips curve. Finally,
could be an arbitrary process and
its lagged value in a nonlinear time series model.
My objective is to assess the extent of nonlinearity of
. Let the population linear regression of
Y onto
X be denoted by:
where
and
are real numbers. Please note that
coincides with the linear regression of
onto
X and that
coincides with
if and only if
Y can be represented as:
where
is linearly uncorrelated with
X. In the particular case where
is bivariate Gaussian,
and
are necessarily identical and
is normally distributed as well. That is, the joint Gaussianity of
is sufficient but not necessary for linearity.
With no loss of generality, I assume that
admits a series representation of the following form:
where
is a complete sequence of orthogonal polynomials over the support of
X under some metrics
, that is:
and
is the
tight range of
X, that is, the domain over which the values of
X are meaningful. For instance,
is a priori
for a price process and
for a log-return process.
is a polynomial of order
j and
. Please note that
satisfies (
5) if and only if:
See
Carrasco et al. (
2007) and the references therein. Upon knowing
, the metrics
can always be selected to meet the condition (
6).
Let the projection of
onto
under the metrics
be given by:
where:
and
denotes the scalar product under
. The function
is linear if and only if it is loaded only on the first two basis functions, that is:
where the first equality is deduced from (
5) and the last equality stems from (
4).
is nonlinear if and only if the residual of the projection of
onto
, i.e.,
, is not identically null. Therefore, the nonlinear part of
may be isolated as:
Based of this observation, a measure of the degree of nonlinearity of
is given by:
By construction,
if
is perfectly linear and
if
is fully loaded on the nonlinear basis functions. Hence,
always lies between 0 and 1 and is decreasing in the degree of linearity of
as measured by the ratio of the norms of
and
. Equivalent expressions of
are therefore given by:
Please note that
is not defined when
, just as the linear correlation coefficient between
Y and a constant does not exist.
The choice of the metrics is a crucial step of the methodology presented above. Indeed, the value of depends on the metrics used and a bad choice of metrics may lead to spuriously detect nonlinearity. This issue is discussed in the next section.
4. The Conditioning Information Set and the Suitable Choice of Metrics
Let
denote the conditioning information set, that is, the support of
X. A probability measure
on
is said to belong to Pearson’s family if and only if it satisfies:
For instance, letting
and
leads to:
which is the Gaussian probability distribution function on
. Likewise, letting
yields the uniform distribution on
while setting
(
) and
yields an exponential distribution on
. The Student, Gamma, Beta distributions are also special members of the Pearson family. See
Johnson et al. (
1994, pp. 15–25) and
Bontemps and Meddahi (
2012) for more details.
If a probability measure
defined on
belongs to the Pearson family, the sequence of orthogonal polynomials under
are given by Rodrigues’ formula (see
Askey 2005):
where
is the
nth order differentiation operator and
is a sequence of normalization factors that could be chosen so as to achieve specific purposes. That is, any sequence
given by (
14) satisfies:
Subsequently, we consider five cases that are representative of the situations that researchers will often face in practice.
Case 1: When
, a suitable choice of metrics is
. The corresponding orthogonal basis is given by Hermite polynomials:
where
is the derivative of
with respect to
x. In this case, the nonlinearity of
is given by:
where:
Case 2: When
, one may use
along with the corresponding orthogonal basis formed by Laguerre polynomials:
The nonlinearity of
is then given by:
where:
Case 3: If
X can realistically not fall below a given threshold
, one may consider defining the domain of
X as
. The corresponding Laguerre polynomials are obtained by noting that:
Hence for
,
is orthogonal to
with respect to
on
.
Case 4: When
, the simplest possible choice of metrics is uniform weighting function
. The corresponding orthogonal basis of functions consists of Legendre’s polynomials:
4 Case 5: For an arbitrary bounded domain
, we simply note that:
Hence, by letting
, it is straightforward to show that:
Hence, a suitable choice of basis functions when
is given by the sequence
. The measure of nonlinearity for this case is:
where:
The latter set up best suits for measuring nonlinearity on segments of the support of X.
Any metrics that follows the guideline described above will delivers a measure of nonlinearity that is reliable. This means that for an appropriately chosen metrics, the function under consideration is nonlinear as soon as is strictly positive. However, the interpretation of the result is “metrics specific”, meaning that is a relative measure of nonlinearity. While the degrees of nonlinearity of different functions obtained under different metrics cannot be compared, different functions sharing the same support can be compared under the same metrics.
5. Invariance Properties
Observe that has the flavor of the of a linear regression as it measures the “goodness-of-fit” of the functional projection of onto . Based on this observation, one is tempted to claim that shares all the invariance properties as an . However, such a statement is only partially true because of the dependence of on the metrics . The invariance properties of are discussed below.
Proposition 1. κ is invariant to a linear transformation of Y.
Proposition 1 establishes that the amount of nonlinearity remains the same under drifting and scaling of Y. Applied to a portfolio of financial assets, this property means that leverage does not affect the nonlinearity of a financial position. Another property shared by the is stated below.
Proposition 2. κ is invariant to the addition of a randomness ε to Y provided that ε is independent of X.
This property is rather interesting as it implies that may be used to diagnose linear models with additive error terms. Let us assume that X is the return on the market index and Y the return on the portfolio of an investor such that (i.e., we are assuming that the exposure of Y to X is perfectly linear). The strength of the exposure of Y to X is given by the linear correlation between Y and , that is, the square root of of the regression of Y onto X. Suppose the investor decides to implement a non-directional (i.e., market neutral) diversification strategy by changing Y into , where is independent of X. The exposure of the new position is given by , where and . The alpha of the new position may have increased of decreased depending on the value of and its beta is reduced by half. However, the nonlinearity of the new position as measured by is unaltered since remains linear in X.
The next proposition examines the consequence of an addition of a linear function of X to Y.
Proposition 3. If Y is nonlinearly exposed to X, Adding a linear function of X to Y does not necessarily decrease its degree of nonlinearity.
Indeed,
is not invariant to the addition of a linear function of
X to
Y. To understand this result in the context of the proposition (see the proof in
Appendix A for more details), suppose
is positive so that
. Then adding
to
Y exacerbates its nonlinearity if
a is negative and lies within the range
. The degree of nonlinearity decreases only if
or
. Alternatively, suppose
is negative so that
. Then adding
to
Y exacerbates its nonlinearity if
a is positive and lies within the range
. Otherwise, the nonlinearity of
Y decreases. Applied to portfolio choice, Proposition 3 implies that an asset that is linearly exposed to
X can be used to increase the nonlinearity of an already nonlinear position
Y. A sufficient condition for the addition of
to reduce the nonlinearity of
Y is that
a be of the same sign as
.
The property of highlighted by Proposition 3 is also shared by the linear correlation coefficient. Unlike the correlation coefficient however, the value of is sensitive to drifting and scaling of X.
Proposition 4. Let where a and b are some constants. Then the degree of nonlinearity of Y with respect to X under is equal to its degree of nonlinearity with respect to Z under .
The result of Proposition 4 stems from the fact that any transformation of X alters the metrics , which in turn invalidates the orthogonality of . It implies that the values of are not directly comparable across different choices of metrics, which is a drawback of the proposed methodology. However, this drawback is a minor one if is continuous and puts zero weights outside the support of X. Also, functions that are defined on the same domain may be compared under the same metrics provided that they all have finite norms.
6. Spurious Nonlinearity
This section illustrates how to compute
when
is known and in passing, underscores the importance of selecting the metrics
wisely. Indeed,
spurious nonlinearity may arise from a bad choice of metrics. To see this, let us consider the exponential function
, which also has the following representation:
It is tempting to claim based on (
24) that
. However, such a claim would be false since
and
have been defined as the coordinates of
in the basis formed by the orthogonal polynomials
. By noting that
for the exponential function, we let
so that
, where
are Hermite polynomials and:
This yields the following measure of nonlinearity:
Let us now consider
. This function is defined only for
and hence, its nonlinearity
should not be measured as though
x lies on the whole real line. For illustration purposes, let us ignore this warning by letting
. This leads to:
The measure of nonlinearity that results is:
which is quite excessive compared to what is obtained for the exponential. In reality, the nonlinearity calculated above is for the function given by:
which is distinct from
on
. The domain of
is the whole real line whereas the
tight domain of
is
. This explains why we obtain a spuriously high value of
.
Let us now account for the fact that the domain of
is
by letting
, where
are Laguerre polynomials. We obtain:
This yields:
which is more reasonable than previously.
7. Feasible Estimators
Upon observing a sample
of size
T from the joint distribution of
, the conditional expectation
can be estimated by the nonparametric method of
Nadaraya (
1964) and
Watson (
1964):
where
is a kernel function and
h is a bandwidth.
With the estimator
above in hand, the sample counterpart of
is:
where
with
if
,
if
and
if
. Given these choices of metrics, integrals of the form
can be solved analytically when
is a polynomial. For more complicated functions however, numerical quadratures should be used.
When
, the quadrature rule yields:
where
are Gauss-Hermite quadrature points associated with the weights
.
For the alternative metrics
, the quadrature rule becomes:
where
are Gauss-Laguerre quadrature points associated with the weights
.
Finally, for the natural metrics
, we have:
where
are Gauss-Legendre quadrature points associated with the weights
.
The quadrature rules above are designed such that they are exact when the integrand is a polynomial of order
. That is:
Thus, it is straightforward to show that:
where
. If
, the approximation error of
by a quadrature rule is:
Please note that the finiteness of the norm of
imposes that
. Furthermore,
is an approximation of
. Consequently, the approximation error (
42) converges to zero fast as
N increases (especially for
and
). This is a good news given that the expression of
only requires on
and
.
The next proposition states a consistency result for by assuming that its numerical approximation error is negligible.
Proposition 5. Assume that , where is a sequence of bandwidth satisfying as . Then we have: According to Proposition 5, any consistent estimator
of
may be plugged into (
30) to (32) to obtain a consistent estimator of
. Nonparametric estimators of type (
28) have been shown to be consistent under quite general settings (
Bierens 1987).
8. Applications
This section presents three applications of . The first subsection discusses the degree of nonlinearity of a European option with respect to the underlying asset. The second subsection discusses the optimal hedge ratio in the presence of nonlinearity. The third subsection presents an empirical example where the relationship between the risk and the returns on the SP500 index is analyzed.
8.1. How Nonlinear Are Put and Call Options?
This section examine the nonlinearity of the price of a European style option with respect to the underlying asset. This exercise is trivial in a sense as options generate nonlinear payoffs by construction. However, it is nevertheless useful as it gives us a pretext to compare the degree of nonlinearity of several functions under the same metrics and to further illustrate the importance of correctly selecting the metrics .
The payoff a European Call option at maturity is given by , where X is the price of the underlying asset and K is the strike.
If one ignores the fact that the support of
X is
and use
to compute the nonlinearity of
, then one obtains the following expressions:
where
is the standard normal cumulative distribution function. This suggests that
where
,
and
are given above. Evaluating this formula at
yields:
The value of
is clearly misleading since
is linear when
.
To avoid spurious nonlinearity, one uses
. We have:
Hence the nonlinearity of the payoff of an European Call is given by:
We see that the formula above now implies that
, consistently with the fact that
when
.
I now consider the payoff a Put option with strike
K, given by
. Having learned from the previous example, I set
and obtain:
The nonlinearity of the payoff of an European Put is given by:
Please note that for a Put,
when
. Hence, we expect to see
as
. Indeed, we have:
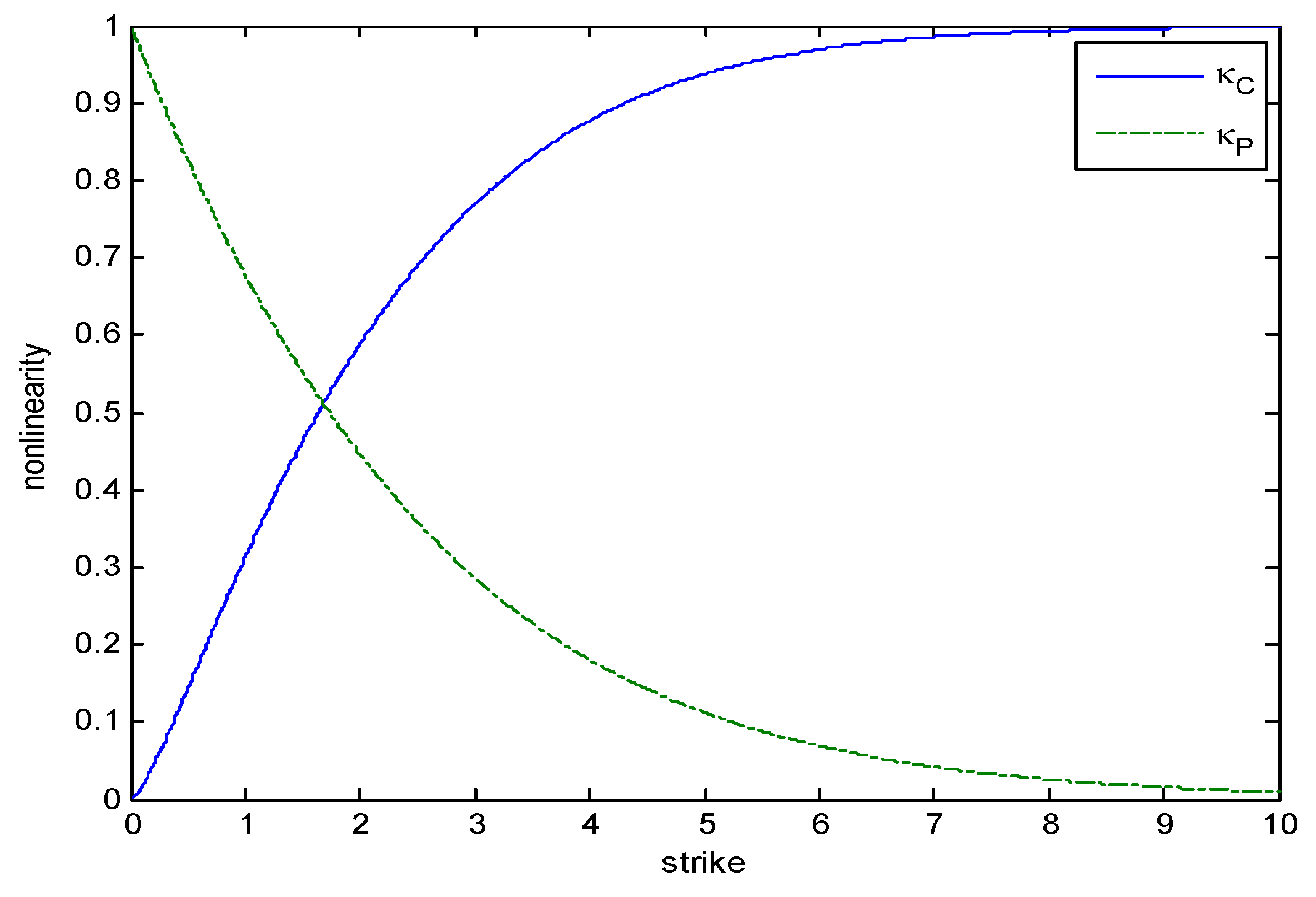
Figure 4 compares the nonlinearity of a the payoffs of a Call and a Put under the metrics
. As
K increases to infinity,
starts at
and converges to 1 whereas
at
and converges to zero
.
5 Over the course of its lifetime, the price of a Call as given by the Black-Scholes formula is:
where:
X is the price of the underlying asset,
K is the strike,
t is the current date,
T is the maturity and
is the spot volatility of
X.
The following quantities are needed in order to evaluate the nonlinearity of
as
K,
t and
vary:
These integrals cannot be computed in closed form. A numerical approximation based on Gauss-Laguerre rule yields:
where
are quadrature points associated with weights
. Hence,
For an European Put option, the price evolves according to:
The nonlinearity of this price with respect to the underlying asset is:
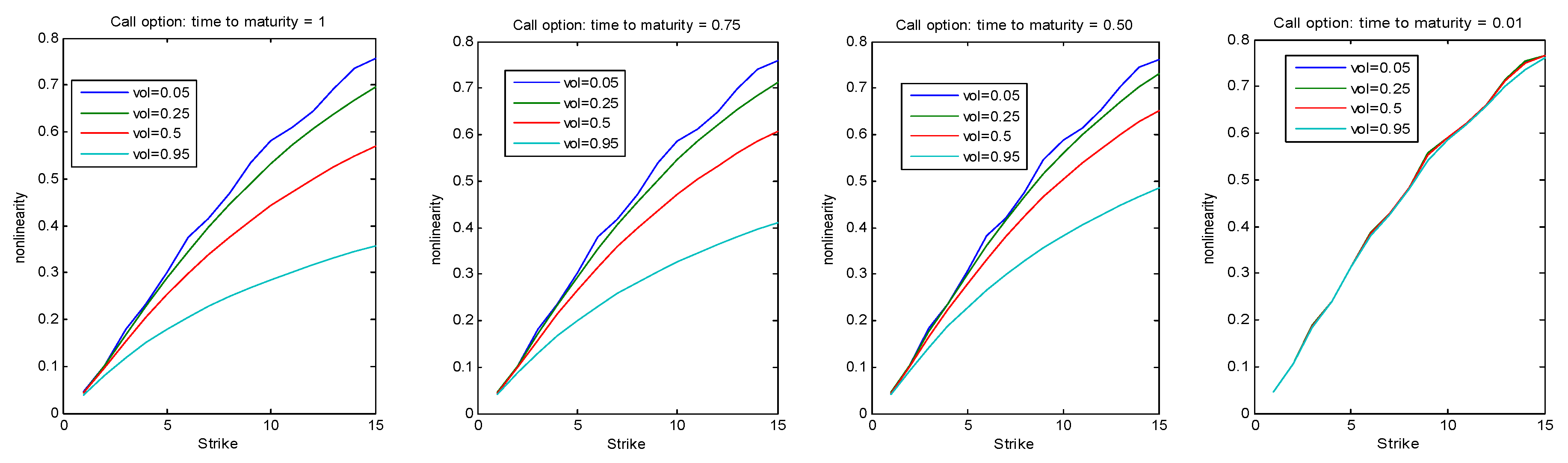
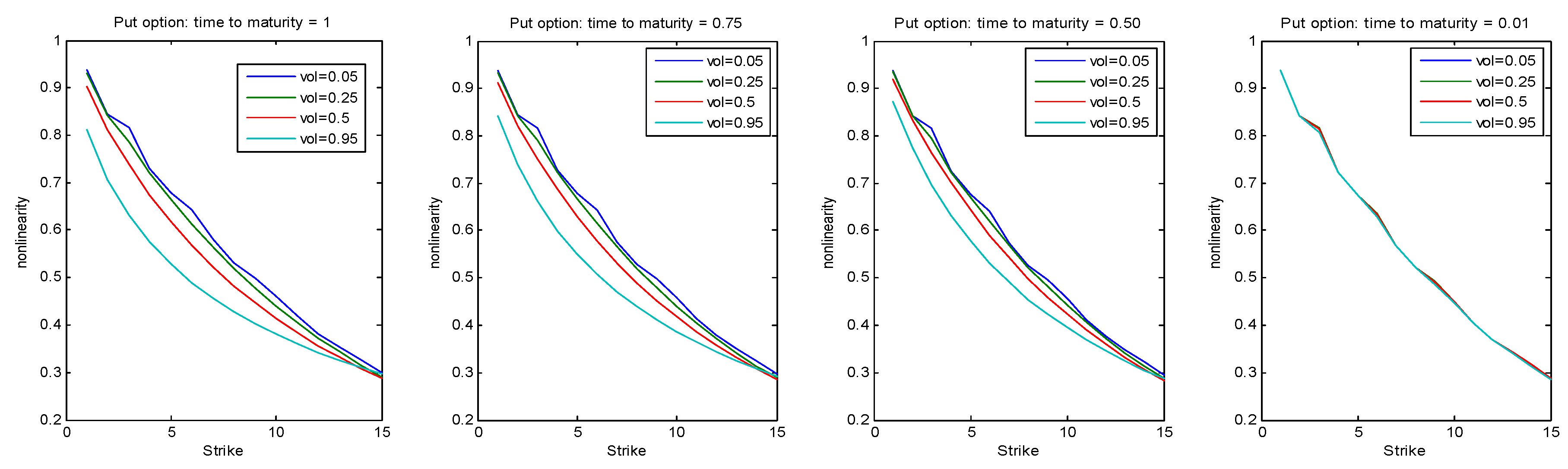
Figure 5 is drawn by assuming that
year,
,
and
. For a Call option (resp., Put options), nonlinearity increases (resp., decreases) in the strike
K for all values of volatility and time to maturity. For both types of options, the nonlinearity is decreasing in the volatility and time to maturity. The nonlinearity appears to be more sensitive in the volatility and time to maturity for a Call than for a Put.
8.2. Nonlinearity and Optimal Hedging
Assume that an investor wants to hold
units of a risk free asset (
) and
units of a risky asset (
) so as to hedge against the volatility of an asset
. This investor would form a hedge portfolio whose value is
. The hedging error is given by:
where
In practice, a perfect hedge that results in can rarely be achieved. Therefore, the best solution often consists of minimizing the variance of the hedging error with respect to the “hedge ratio” , which is the number of units of Asset to hold per unit of Asset . When is the payoff of an option and the price of the underlying asset, corresponds to the “delta” of the option (hence the expression “Delta Hedging”).
The optimal hedging problem boils down to the following minimization:
The optimal hedge ratio is given by
. However,
can be zero if
is nonlinearly exposed to
. In this case, one would wrongly conclude that Asset
is of no help for hedging against the fluctuations of
.
Now, suppose we have detected that
is nonlinear using the methodology proposed in this paper. A reasonable hedging strategy would therefore consist of first using state-of-the-art models to predict
as
and next linearizing
around this prediction to obtain:
An approximately optimal hedge ratio would then be given by:
This example underscores the importance of being aware of the presence of nonlinearity in assets returns for a sound portfolio risk management.
8.3. Empirical Application: Return-Risk Trade-Off on the SP500
In this section, I illustrate an empirical use of the measure of nonlinearity
by performing an analysis of the return-risk trade-off based on the
Merton’s (
1973) intertemporal capital asset pricing model (ICAPM). This model posits the following relation between the conditional expected return on the market index
and the conditional expected variance
:
where
is the risk free rate and
is the relative risk aversion coefficient of the representative agent. A multivariate version of the ICAPM is proposed in
Bollerslev et al. (
1988).
Ghysels et al. (
2005) employed a MIxed DAta Sampling (MIDAS) methodology to the CRSP value-weighted portfolio and concluded that “
there is a [positive] risk-return trade-off after all.” Previous studies who found a positive relationship between risk premium and expected risk include
French et al. (
1987) and
Campbell and Hentschel (
1992), in contrast with
Nelson (
1991) who find a negative relationship or
Glosten et al. (
1993) and
Harvey (
2001) whose conclusions are mixed.
Ghysels et al. (
2005) attributes the conflicting conclusions to differences in the models posited for the conditional variance.
Jacquier and Okou (
2014) suspect the differences in data frequencies to be responsible of the inconsistencies across findings. The empirical results of the current paper suggest that the controversy on the nature of the return-risk trade-off is mainly due to nonlinearity.
I consider estimating the following nonlinear version of the ICAPM:
If one assume that
and
are IID and Gaussian, Equations (
54) and (55) imply that:
As in the ICAPM, the conditional expected return
is increasing in conditional expected variance
. Unlike in the ICAPM, the relationship between the conditional expected return and the innovation on the log-variance process (
) is explicitly characterized. Namely, the conditional expected return is decreasing in the variance of
, as observed empirically by
French et al. (
1987). Finally, the market price of risk is a nonlinear function of the conditional expected variance.
I estimate the AR(1)
for the log-RV and compute the fitted values as
. These fitted values are the expected risk at time
t as perceived by investors at time
. The estimated coefficients are
(significant at
level) and
(significant at
level). The
of this regression is
and the estimated error variance is
.
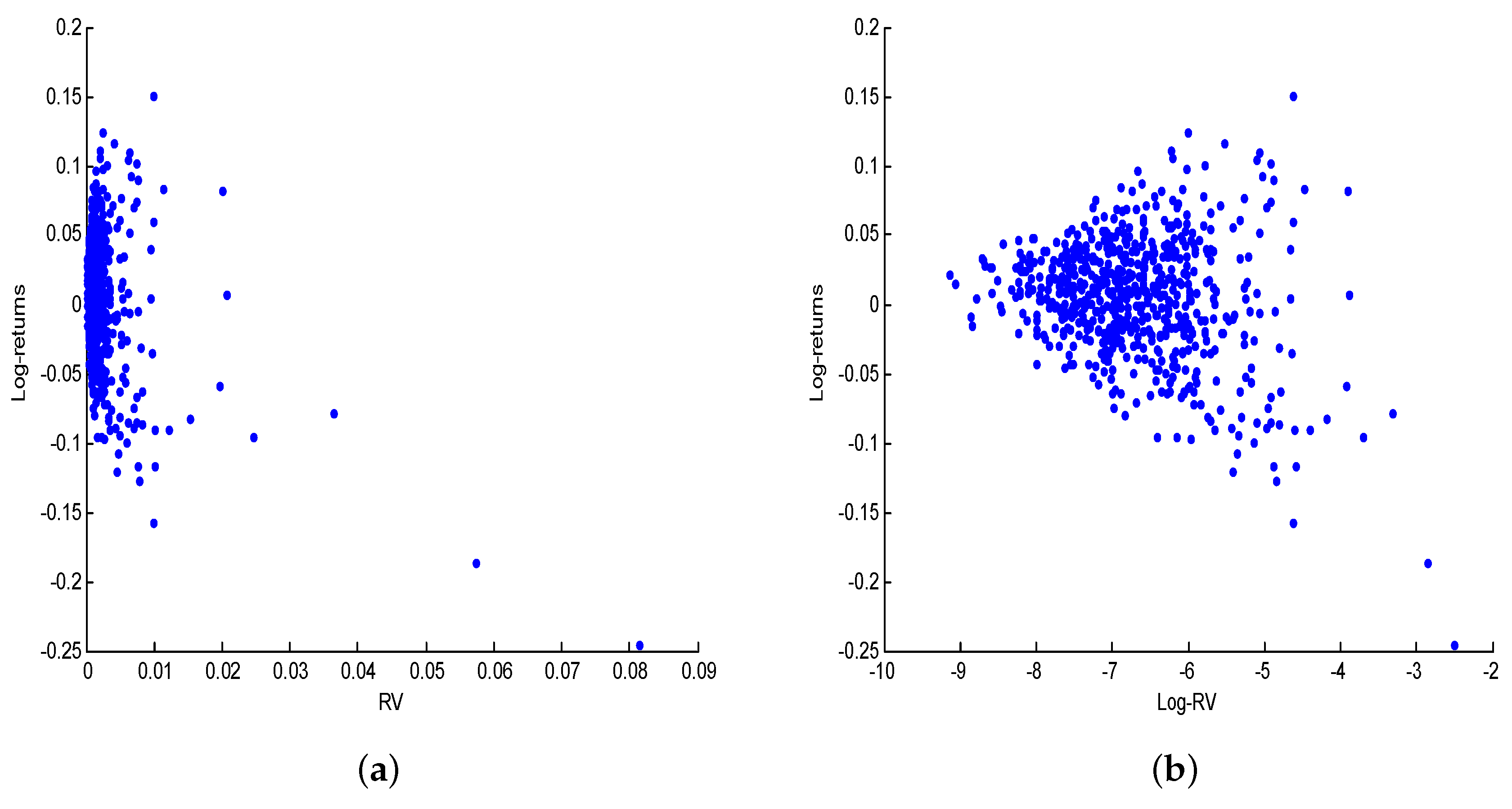
Figure 5a shows the scatter plot of
against
. Next, I regress the log-return
on
and a constant and compute the fitted values as
. This yields
and
. Neither of these coefficients is significant at
level and not surprisingly, the
of the regression is less than
. The poor fit provided but the linear regression of
onto
suggests that the relationship between these variable is nonlinear. This is confirmed by the nonparametric estimator of
shown by
Figure 2.
Figure 6a,b respectively show the estimated nonlinearity of
and
on increasing segments of the support of
and
. The scaling of the x-axis corresponds to the quantiles of the conditioning variable. For any pair
, the nonlinearity of
is computed on the segments
using the metrics
along with Gauss-Legendre’s polynomials, where:
For each
,
is obtained by spline interpolation based on
.
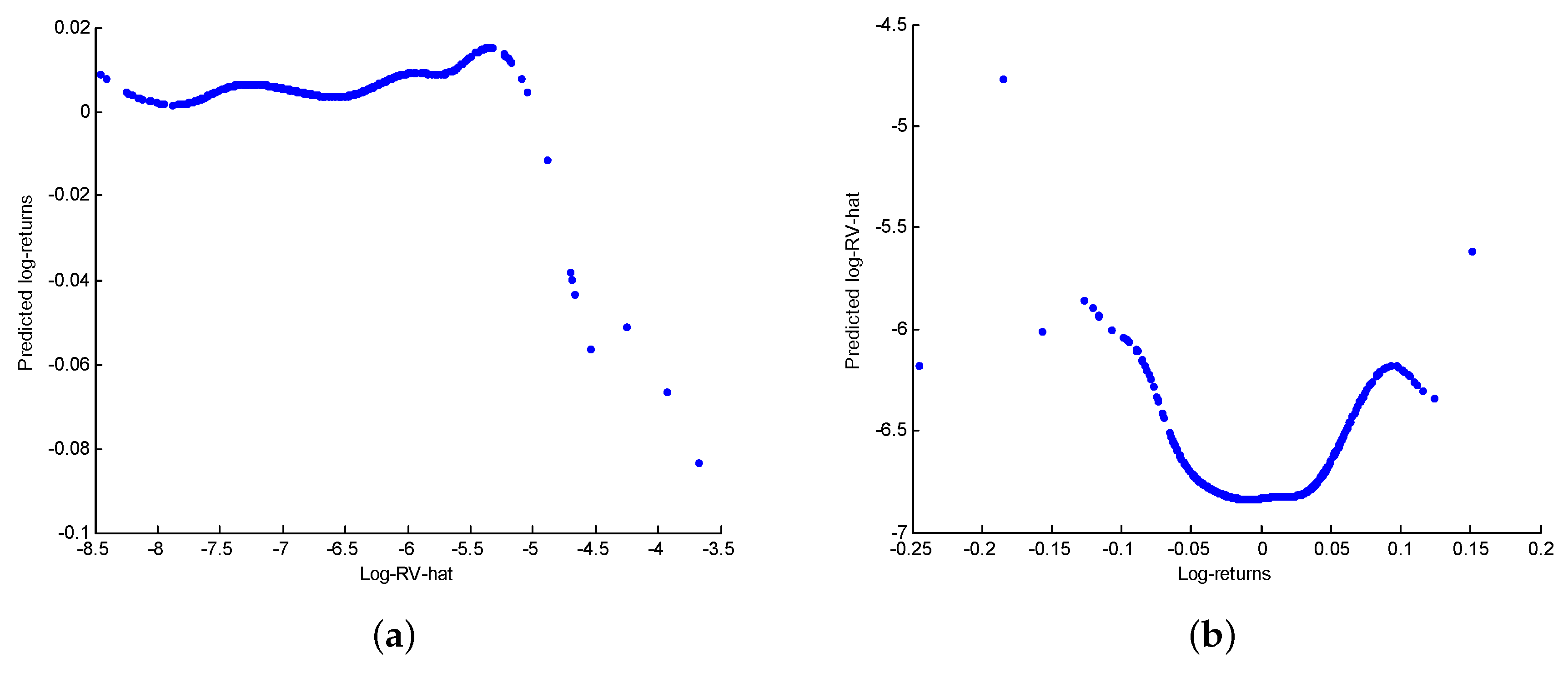
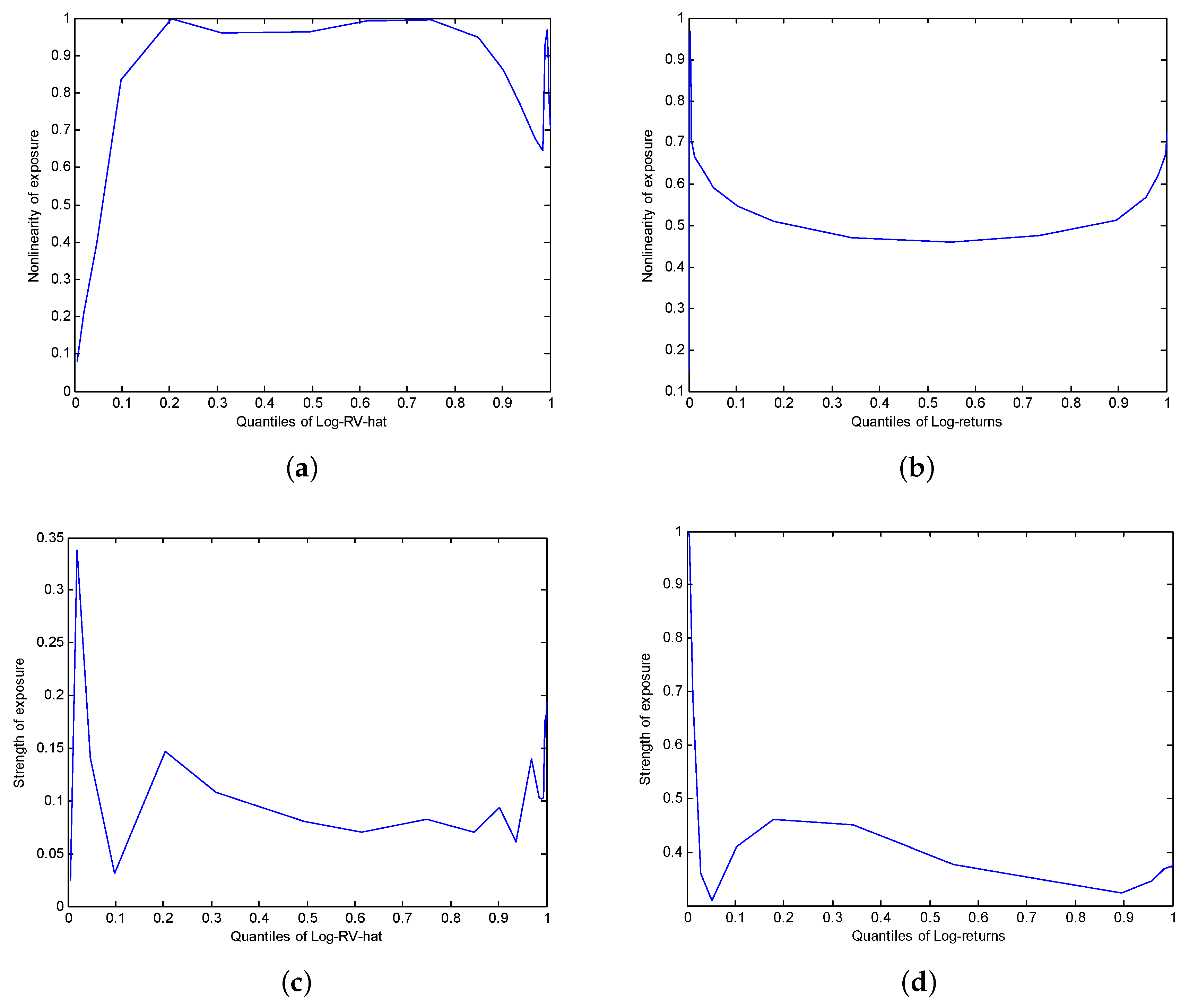
We see that the nonlinearity of increases fast and remains high after the 20th percentile of . By contrast, the nonlinearity of decreased on the first portion of the support of and increases steadily after the median. The point at which the nonlinearity of is minimized, , is a good candidate for the threshold of a piecewise linear model.
Figure 6c,d respectively show the strength of the exposure of
to
and
to
on increasing subsample of type
. The correlation of
and
approximately equals
on a large portion of the support of
while that of
and
is on average equal to
. This means that
fits
better than
fits
.
Acting on the fact that the
linearity of
reaches its
maximum at
, I estimate the following piecewise linear regression:
Let
denote the fitted values obtained from this piecewise linear regression.
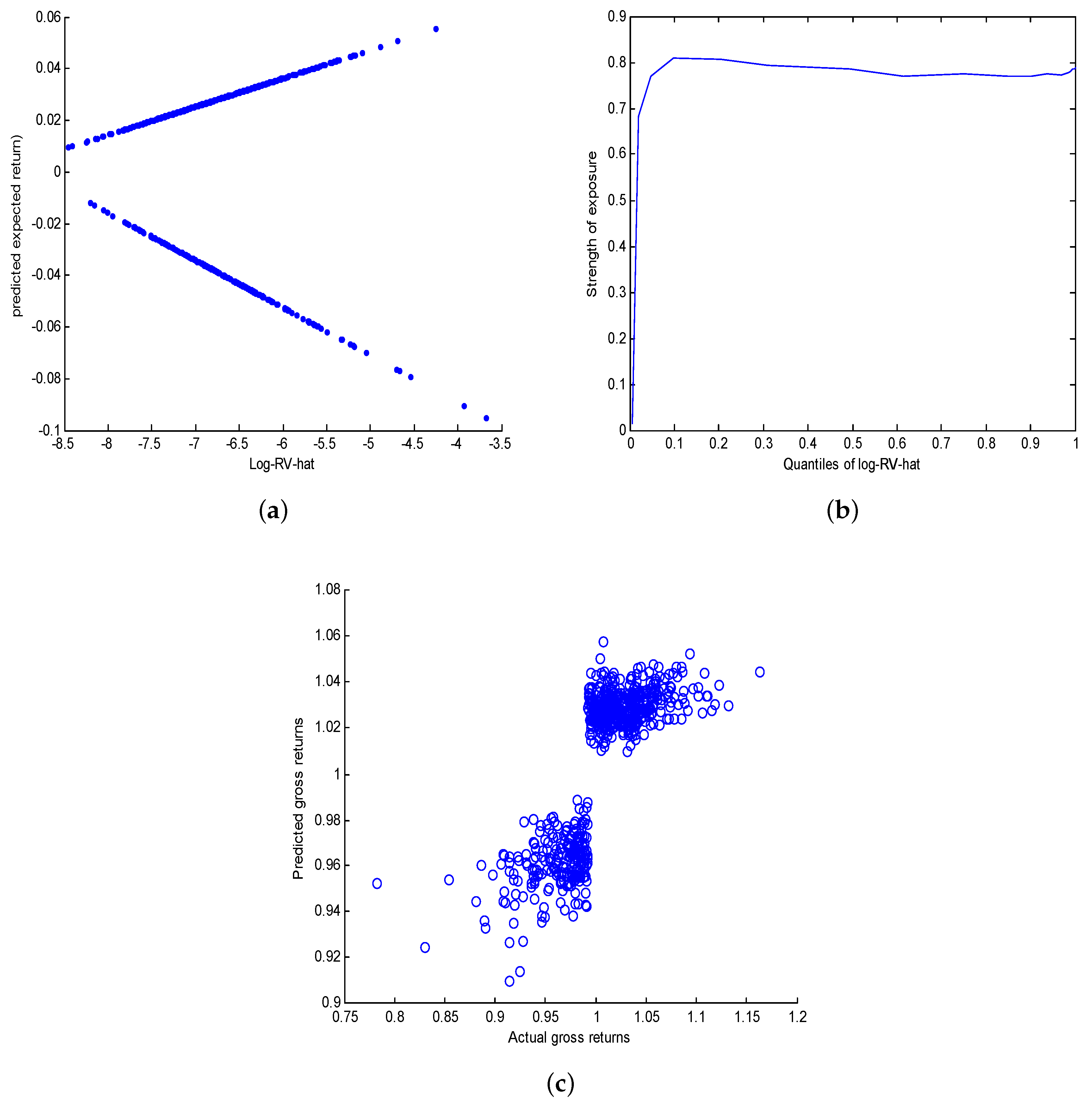
Figure 7a shows the fitted regression lines while
Figure 7b plots the linear correlation between
and
against the quantiles of
. The correlation between
and
reaches
at the 10th percentile and remains above
thereafter. This strong nonlinear relationship between log-returns and log-realized volatility is completely missed by the naive linear regression of
onto
.
The estimated regression lines are:
The estimated error variances are respectively
for the first regime and
for the second regime. Finally, the estimated nonlinear return-risk trade-offs are:
Based on the equation, the unconditional correlation between the actual gross-returns and their predictions shown on
Figure 7c is
.
A natural implication of these results is that option pricing models should at least account for the presence of regimes or parameter uncertainty in the distribution of the returns on the underlying asset. Our findings provide a strong empirical support for regime switching models in which volatility influences returns (as in
Duan et al. 2002), heteroskedastic mixture models or Bayesian models that naturally account for parameter uncertainty (e.g.,
Rombouts and Stentoft 2014,
2015).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








