Using the Entire Yield Curve in Forecasting Output and Inflation


Abstract
:1. Introduction
2. Supervising Factors
2.1. Factor Models
2.1.1. CI-Factor Model
2.1.2. CF-Factor Model
2.2. Singular Value Decomposition
2.3. Supervision
2.4. Example 1
| k = 1 | 24 | 1.8 |
| k = 2 | 36 | 3.6 |
| k = 3 | 36 | 8.2 |
| k = 4 | 24 | 25.0 |
| k = 5 | 0 | N/A |
3. Monte Carlo
3.1. Example 2
3.2. Example 3
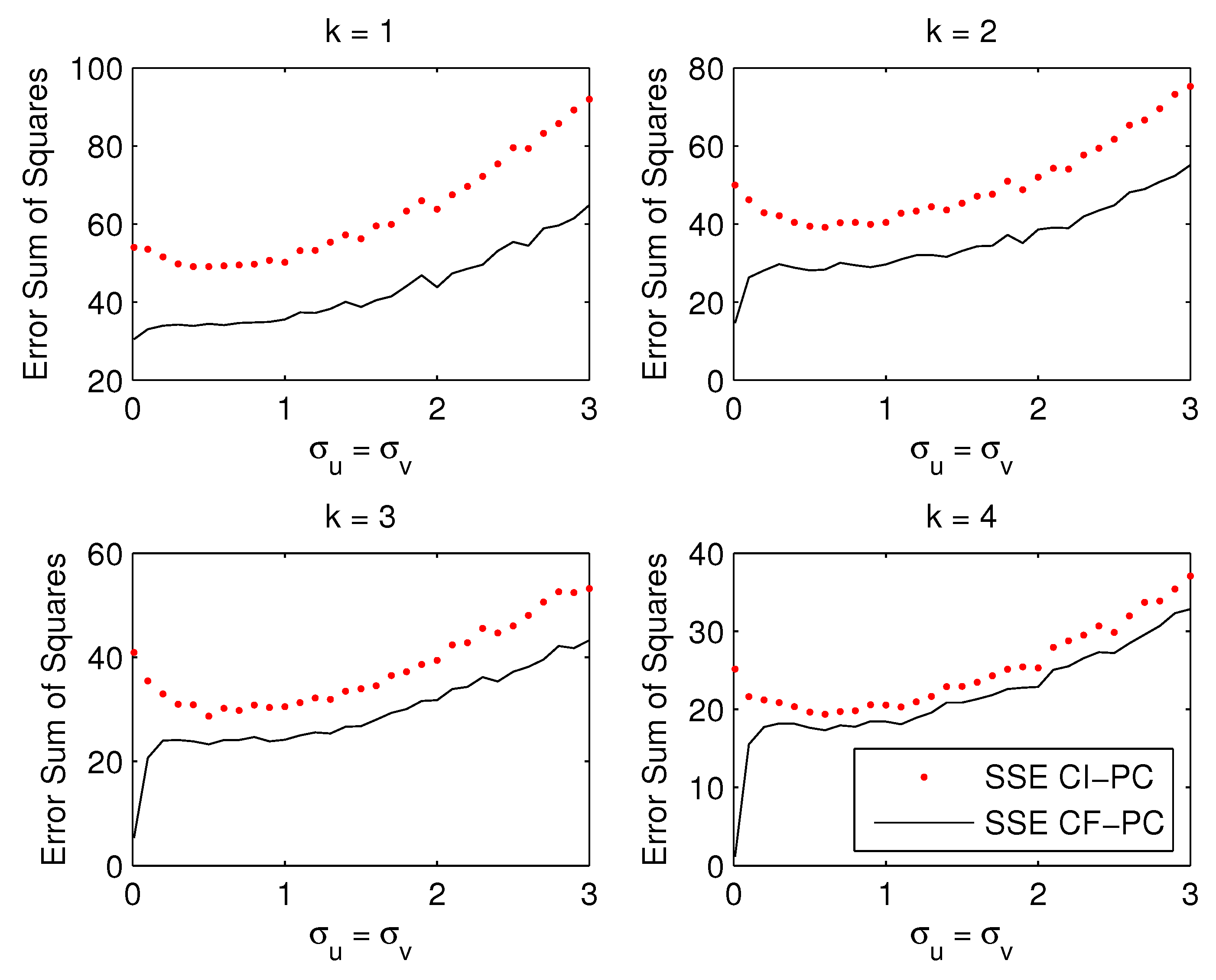
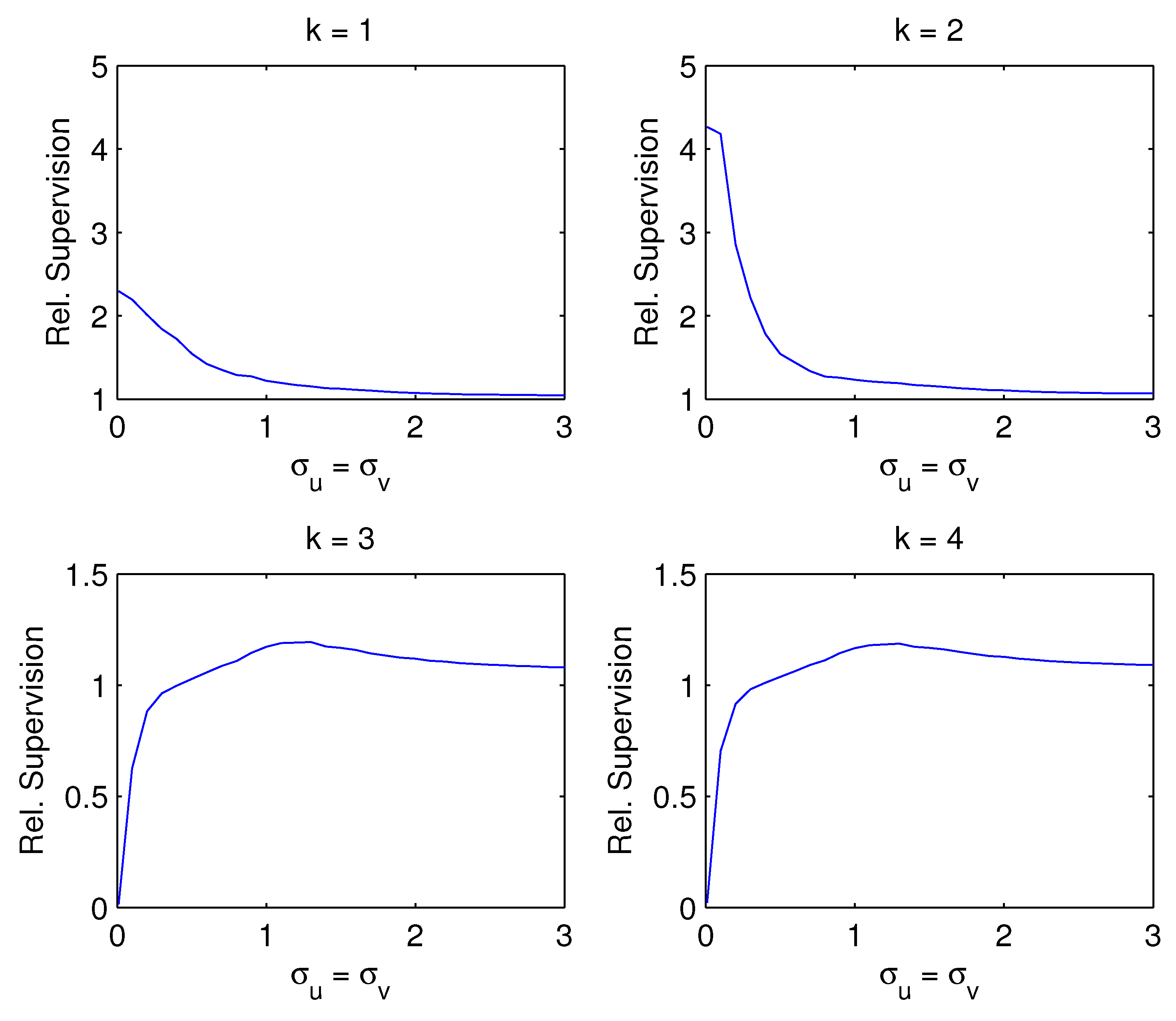
- Figure 2: If the number of estimated factors k is below the true number , as shown in top panels, the supervision becomes smaller with increasing noise. If the correct number of factors or more are estimated as in bottom panels, the advantage of supervision increases with the noise level , Even in this case when the CI-PC is the correct model ( supervision becomes larger as the noise increases.
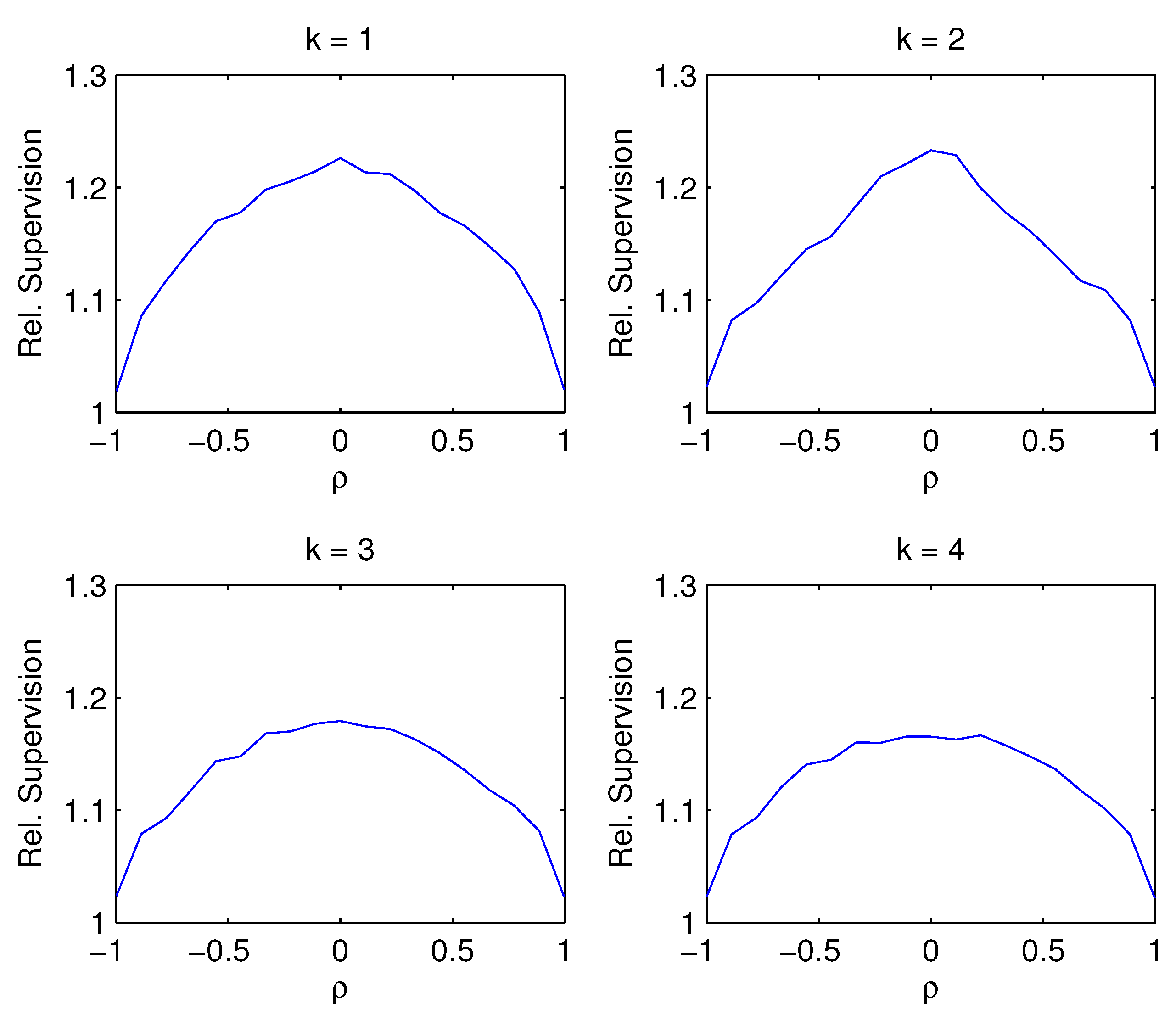
- Figure 3: The advantage of supervision is greatest when the contemporaneous correlation between predictors is minimal. For almost perfect correlation, the advantage of supervision disappears. This is true regardless of whether the correct number of factors is estimated or not. Intuitively, for near-perfect factor correlation, the difference between those factors that explain variation in the columns of X and those that explain variation in vanishes, and so supervision becomes meaningless.
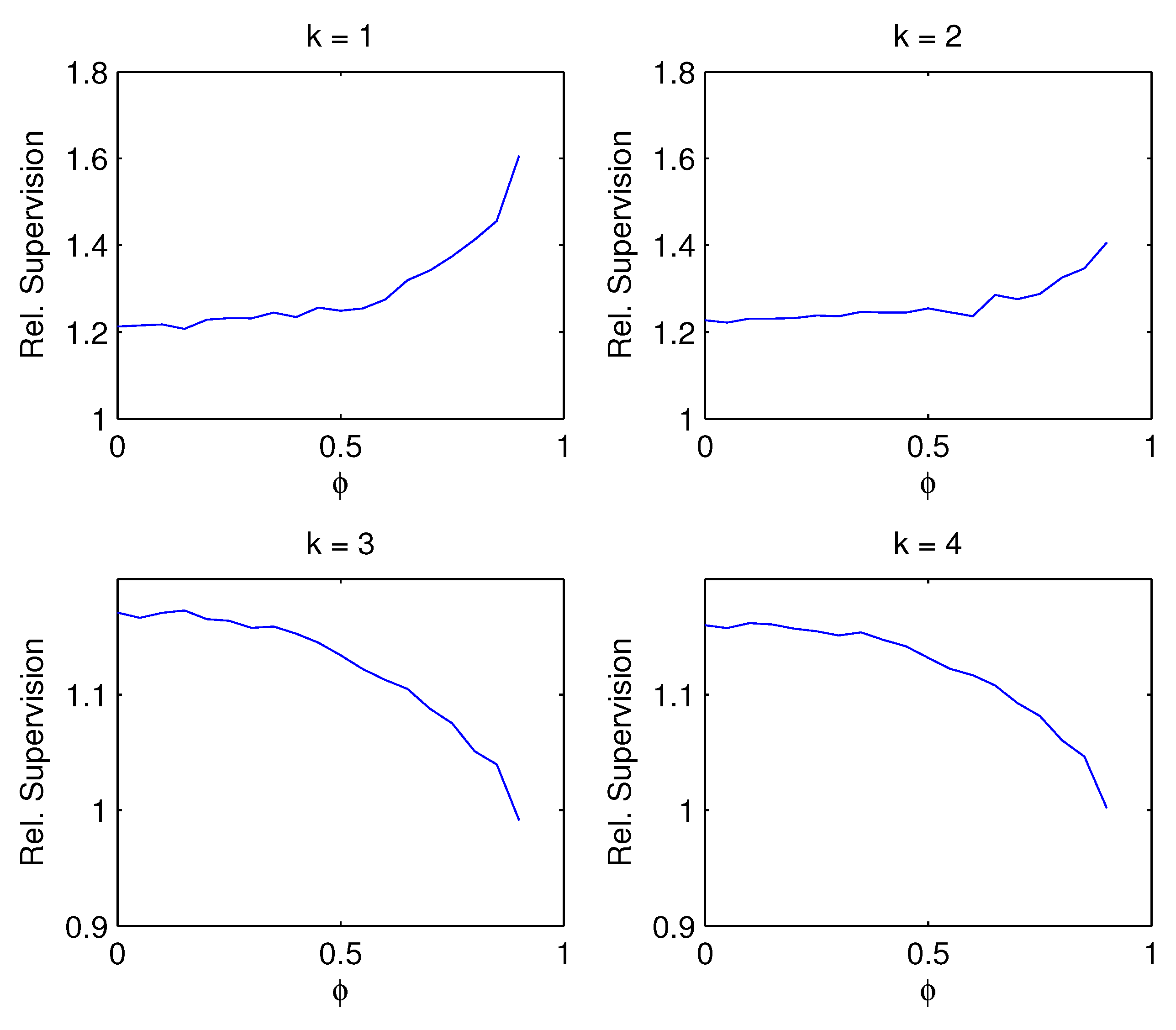
- Figure 4: If the correct number of factors or more are estimated , the advantage of supervision decreases with factor persistence . High persistence induces spurious contemporaneous correlation, and in this sense the situation is related to the result in No. 2. If the number of estimated factors is below the true number of factors , however, the advantage of supervision increases with factor persistence.
4. Supervising Nelson–Siegel Factors
4.1. Nelson–Siegel Components of the Yield Curve
4.2. CI-NS and CF-NS
4.2.1. NS Components of Predictors X (CI-NS)
4.2.2. NS Components of Forecasts (CF-NS)
5. Forecasting Output Growth and Inflation
5.1. Data
5.2. Out-of-Sample Forecasting
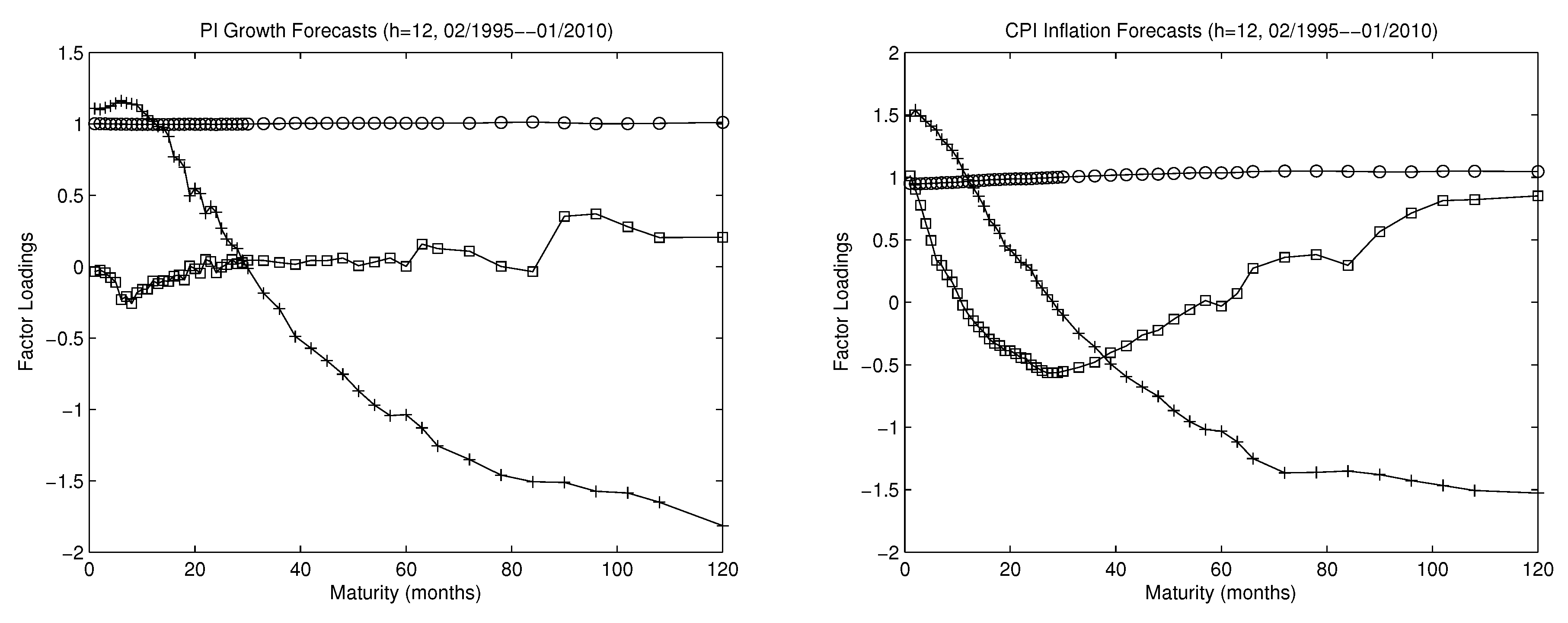
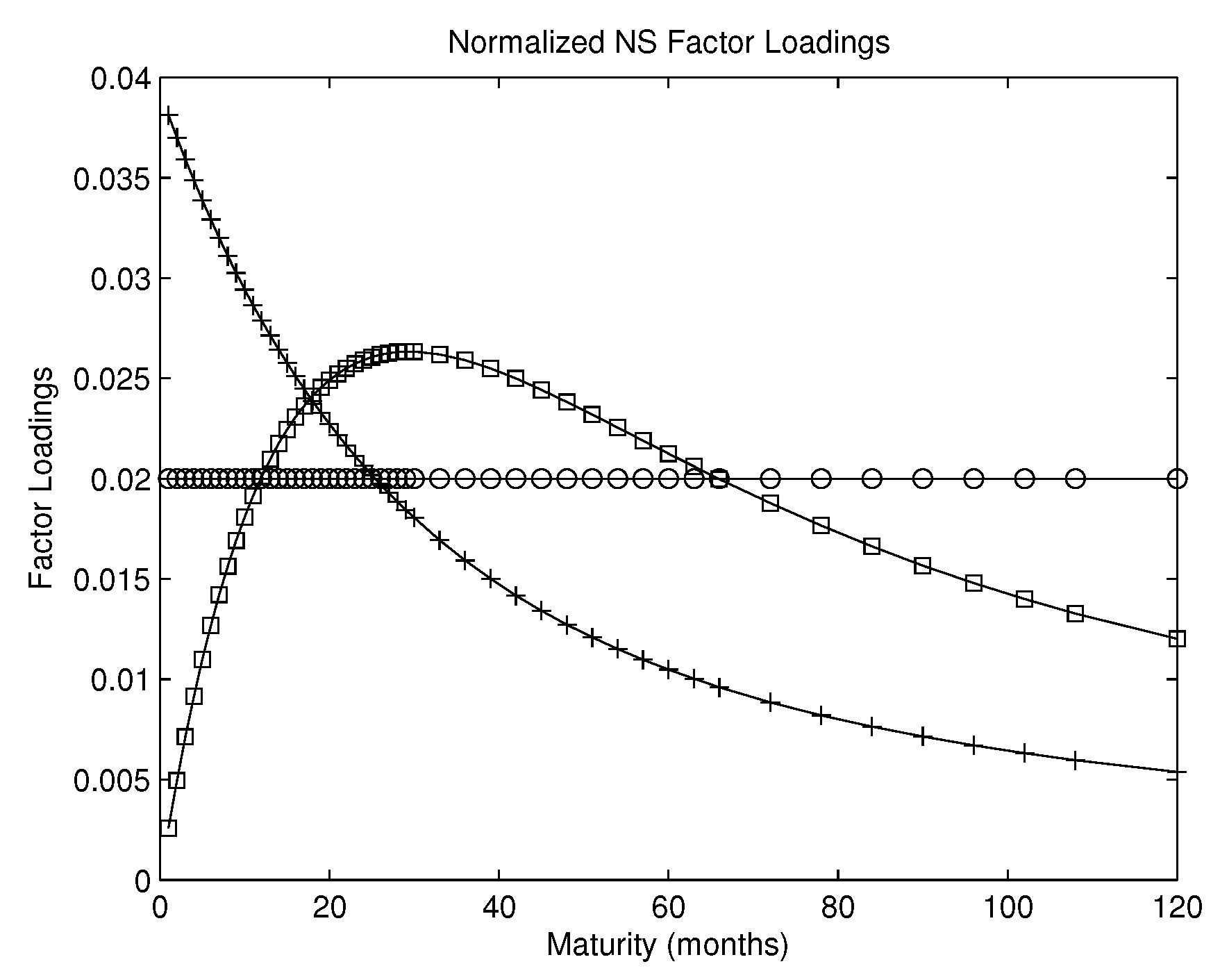
- Supervision is similar for CF-PC and CF-NS. The factor loadings for CF-NS and for CF-PC are similar as shown in Figure 5. Panel (c) of the figure plots three normalized NS exponential loadings in CF-NS that correspond respectively to the three NS factors. Note that the factor loadings in CF-NS are pre-specified while those in CF-PC are estimated from the N individual forecasts. Nevertheless, their shapes in panel (a) look very similar to those of the CF-PC loadings in panels (a) and (b) (apart from the signs). Accordingly, out-of-sample forecasting performance of CF-PC and CF-NS are very similar as shown in Panel A of Table 1 and Table 2.
- We often get the best supervised predictions with a single factor () with the CF-factor models.18 Since CF-NS is the equally weighted combined forecast as noted in Section 4.2.2, this is another case of the forecast combination puzzle discussed in Remark 3 that the equal-weighted forecast combination is hard to beat. Since CF-PC is numerically identical to CF-NS as shown in Figure 5, CF-PC is also effectively equally weighted forecast averaging.19
6. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
Appendix A. Calculation of Absolute and Relative Supervision in Example 1
References
- Ang, Andrew, and Monika Piazzesi. 2003. A No-Arbitrage Vector Autoregression of Term Structure Dynamics with Macroeconomic and Latent Variables. Journal of Monetary Economics 50: 745–87. [Google Scholar] [CrossRef]
- Ang, Andrew, Monika Piazzesi, and Min Wei. 2006. What Does the Yield Curve Tell Us about GDP Growth? Journal of Econometrics 131: 359–403. [Google Scholar] [CrossRef]
- Armah, Nii Ayi, and Norman R. Swanson. 2010. Seeing Inside the Black Box: Using Diffusion Index Methodology to Construct Factor Proxies in Large Scale Macroeconomic Time Series Environments. Econometric Reviews 29: 476–510. [Google Scholar] [CrossRef] [Green Version]
- Bai, Jushan. 2003. Inferential Theory for Factor Models of Large Dimensions. Econometrica 71: 135–71. [Google Scholar] [CrossRef]
- Bai, Jushan, and Serena Ng. 2006. Confidence Intervals for Diffusion Index Forecasts and Inference for Factor-Augmented Regressions. Econometrica 74: 1133–50. [Google Scholar] [CrossRef]
- Bai, Jushan, and Serena Ng. 2008. Forecasting Economic Time Series Using Targeted Predictors. Journal of Econometrics 146: 304–17. [Google Scholar] [CrossRef]
- Bair, Eric, Trevor Hastie, Debashis Paul, and Robert Tibshirani. 2006. Prediction by Supervised Principal Components. Journal of the American Statistical Association 101: 119–37. [Google Scholar] [CrossRef]
- Barndorff-Nielsen, Ole. 1978. Information and Exponential Families in Statistical Theory. New York: Wiley. [Google Scholar]
- Bernanke, Ben. 1990. On the Predictive Power of Interest Rates and Interest Rate Spreads, Federal Reserve Bank of Boston. New England Economic Review November/December: 51–68. [Google Scholar]
- Chan, Lewis, James Stock, and Mark Watson. 1999. A Dynamic Factor Model Framework for Forecast Combination. Spanish Economic Review 1: 91–121. [Google Scholar] [CrossRef]
- Christensen, Jens, Francis Diebold, and Glenn Rudebusch. 2009. An Arbitrage-free Generalized Nelson–Siegel Term Structure Model. Econometrics Journal 12: C33–C64. [Google Scholar] [CrossRef]
- De Jong, Sijmen. 1993. SIMPLS: An Alternative Approach to Partial Least Squares Regression. Chemometrics and Intelligent Laboratory Systems 18: 251–61. [Google Scholar] [CrossRef]
- De Jong, Sijmen, and Henk Kiers. 1992. Principal Covariate Regression: Part I. Theory. Chemometrics and Intelligent Laboratory Systems 14: 155–64. [Google Scholar] [CrossRef]
- Diebold, Francis, and Canlin Li. 2006. Forecasting the Term Structure of Government Bond Yields. Journal of Econometrics 130: 337–64. [Google Scholar] [CrossRef]
- Diebold, Francis, Monika Piazzesi, and Glenn Rudebusch. 2005. Modeling Bond Yields in Finance and Macroeconomics. American Economic Review 95: 415–20. [Google Scholar] [CrossRef]
- Diebold, Francis, Glenn Rudebusch, and Boragan Aruoba. 2006. The Macroeconomy and the Yield Curve: A Dynamic Latent Factor Approach. Journal of Econometrics 131: 309–38. [Google Scholar] [CrossRef]
- Engle, Robert, David Hendry, and Jean-Francois Richard. 1983. Exogeneity. Econometrica 51: 277–304. [Google Scholar] [CrossRef]
- Estrella, Arturo. 2005. Why Does the Yield Curve Predict Output and Inflation? The Economic Journal 115: 722–44. [Google Scholar] [CrossRef]
- Estrella, Arturo, and Gikas Hardouvelis. 1991. The Term Structure as a Predictor of Real Economic Activity. Journal of Finance 46: 555–76. [Google Scholar] [CrossRef]
- Fama, Eugene, and Robert Bliss. 1987. The Information in Long-maturity Forward Rates. American Economic Review 77: 680–92. [Google Scholar]
- Figlewski, Stephen, and Thomas Urich. 1983. Optimal Aggregation of Money Supply Forecasts: Accuracy, Profitability and Market Efficiency. Journal of Finance 38: 695–710. [Google Scholar] [CrossRef]
- Friedman, Benjamin, and Kenneth Kuttner. 1993. Why Does the Paper-Bill Spread Predict Real Economic Activity? In New Research on Business Cycles, Indicators and Forecasting. Edited by James Stock and Mark Watson. Chicago: University of Chicago Press, pp. 213–54. [Google Scholar]
- Gogas, Periklis, Theophilos Papadimitriou, and Efthymia Chrysanthidou. 2015. Yield Curve Point Triplets in Recession Forecasting. International Finance 18: 207–26. [Google Scholar] [CrossRef]
- Groen, Jan, and George Kapetanios. 2016. Revisiting Useful Approaches to Data-Rich Macroeconomic Forecasting. Computational Statistics & Data Analysis 100: 221–39. [Google Scholar]
- Hamilton, James, and Dong Heon Kim. 2002. A Reexamination of the Predictability of Economic Activity Using the Yield Spread. Journal of Money, Credit, and Banking 34: 340–60. [Google Scholar] [CrossRef]
- Huang, Huiyu, and Tae-Hwy Lee. 2010. To Combine Forecasts or To Combine Information? Econometric Reviews 29: 534–70. [Google Scholar] [CrossRef]
- Inoue, Atsushi, and Lutz Kilian. 2008. How Useful is Bagging in Forecasting Economic Time Series? A Case Study of U.S. CPI Inflation. Journal of the American Statistical Association 103: 511–22. [Google Scholar] [CrossRef]
- Kozicki, Sharon. 1997. Predicting Real Growth and Inflation with the Yield Spread, Federal Reserve Bank of Kansas City. Economic Review 82: 39–57. [Google Scholar]
- Lancaster, Tony. 2000. The incidental parameter problem since 1948. Journal of Econometrics 95: 391–413. [Google Scholar] [CrossRef] [Green Version]
- Litterman, Robert, and Jose Scheinkman. 1991. Common Factors Affecting Bond Returns. Journal of Fixed Income 1: 54–61. [Google Scholar] [CrossRef]
- Nelson, Charles, and Andrew Siegel. 1987. Parsimonious Modeling of Yield Curves. Journal of Business 60: 473–89. [Google Scholar] [CrossRef]
- Neyman, Jerzy, and Elizabeth Scott. 1948. Consistent Estimation from Partially Consistent Observations. Econometrica 16: 1–32. [Google Scholar] [CrossRef]
- Piazzesi, Monika. 2005. Bond Yields and the Federal Reserve. Journal of Political Economy 113: 311–44. [Google Scholar] [CrossRef]
- Rudebusch, Glenn, and Tao Wu. 2008. A Macro-Finance Model of the Term Structure, Monetary Policy, and the Economy. Economic Journal 118: 906–26. [Google Scholar] [CrossRef]
- Smith, Jeremy, and Kenneth Wallis. 2009. A Simple Explanation of the Forecast Combination Puzzle. Oxford Bulletin of Economics and Statistics 71: 331–55. [Google Scholar] [CrossRef]
- Stock, James, and Mark Watson. 1989. New Indexes of Coincident and Leading Indicators. In NBER Macroeconomic Annual. Edited by Olivier Blanchard and Stanley Fischer. Cambridge: MIT Press, vol. 4. [Google Scholar]
- Stock, James, and Mark Watson. 1999. Forecasting Inflation. Journal of Monetary Economics 44: 293–335. [Google Scholar] [CrossRef]
- Stock, James, and Mark Watson. 2002. Forecasting Using Principal Components from a Large Number of Predictors. Journal of the American Statistical Association 97: 1167–79. [Google Scholar] [CrossRef]
- Stock, James, and Mark Watson. 2004. Combination Forecasts of Output Growth in a Seven-country Data Set. Journal of Forecasting 23: 405–30. [Google Scholar] [CrossRef]
- Stock, James, and Mark Watson. 2007. Has Inflation Become Harder to Forecast? Journal of Money, Credit, and Banking 39: 3–34. [Google Scholar] [CrossRef]
- Stock, James, and Mark Watson. 2012. Generalized Shrinkage Methods for Forecasting Using Many Predictors. Journal of Business and Economic Statistics 30: 481–93. [Google Scholar] [CrossRef]
- Svensson, Lars. 1995. Estimating Forward Interest Rates with the Extended Nelson–Siegel Method. Quarterly Review 3: 13–26. [Google Scholar]
- Tibshirani, Robert. 1996. Regression Shrinkage and Selection via the Lasso. Journal of the Royal Statistical Society B 58: 267–88. [Google Scholar]
- Timmermann, Alan. 2006. Forecast Combinations. In Handbook of Economic Forecasting. Edited by Graham Elliott, Clive Granger and Alan Timmermann. Amsterdam: North-Holland, vol. 1, chp. 4. [Google Scholar]
- Wright, Jonathan. 2009. Forecasting US Inflation by Bayesian Model Averaging. Journal of Forecasting 28: 131–44. [Google Scholar] [CrossRef]
- Zou, Hui, Trevor Hastie, and Robert Tibshirani. 2006. Sparse Principal Component Analysis. Journal of Computational and Graphical Statistics 15: 262–86. [Google Scholar] [CrossRef]
| 1 | |
| 2 | Bai and Ng (2008) consider CI factor models with a selected subset (targeted predictors). |
| 3 | The suppressed time stamp of y and X captures the h-lag relation for the forecast horizon and we treat the data centered so that we do not include a constant term explicitly in the regression for notational simplicity. |
| 4 | Given the dependent nature of macroeconomic and financial time series, the forecasting equation can be extended to allow the supervision to be based on the relation between yt and some predictors after controlling for lagged dependent variables and to allow the dynamic factor structure, which we leave for future work. |
| 5 | |
| 6 | |
| 7 | In relation to the empirical application using the yield data in Section 5, we could have calibrated the simulation design to make the Monte Carlo more realistic for the empirical application in Section 5. Nevertheless, our Monte Carlo design covers wide ranges of the parameter values for the noise levels, correlation structures ( and ) in the yield data. Figure 2 shows that the supervision is smaller with larger noise levels, which may be rather obvious intuitively. Figure 4 shows that the advantage of supervision when the factors are persistence, which depends on the number of factors k relative to the true number of factors r. Particularly interesting is Figure 3 which shows that the advantage of supervision is smaller when the contemporaneous correlation between predictors is larger, which may be relevant for the yield data because the yields with different maturities may be moderately contemporaneously correlated. We thank a referee for pointing this out. |
| 8 | Diebold and Li (2006) show that fixing Nelson–Siegel decay parameter at maximizes the curvature loading at the two-year bond maturity and allows better identifications of the three NS factors. They also show that allowing the to be a free parameter does not improve the forecasting performance. Therefore, following their advice, we fix and did not estimate it. A small (for a slow decaying curve) fits the curve for long maturities better and a large (for a fast decaying curve) fits the curve for short maturities better. |
| 9 | is used in Bai and Ng (2008). |
| 10 | As a robust check, we apply our method to the original yield data of Diebold and Li (2006) and also to the sub-samples in our data set. The results are essentially the same as those summarized at the end of Section 5. |
| 11 | It may be interesting to explore whether different maturity yields might have different effects on the forecast outcome. However, the present paper is focused on the comparison between CF and CI, rather than a detailed CI-only analysis, e.g., to find the best maturity yield for the forecast outcome. Nevertheless, our CI-NS model has reflected such effects as the three NS factors (level, slope, and curvature) are different combinations of bond maturities as shown in Equation (55). The different coefficients on the NS factors suggest that different bond maturities have different effects on the forecast outcome, as Gogas et al. (2015) has found. |
| 12 | While not reported for space, we tried forecasting change in inflation and found forecasting inflation directly using all yield levels improves out-of-sample performances of most forecasting methods by a large margin. |
| 13 | As a robust check, we have also tried with different sample splits for the estimation and prediction periods, i.e., the number of in-sample regression observations and the out-of-sample evaluation observations. We find that the results are similar. |
| 14 | For different values of , the performances of CI-NS and CF-NS change only marginally. |
| 15 | While we report the results for for CF-PC, we do not report for for CF-NS. Svennsson (1995) and Christensen et al. (2009) (CDR 2009) extend the three factor NS model to four or five factor NS models. CDR’s dynamic generalized NS model has five factors with one level factor, two slope factors and two curvature factors. The Svensson and CDR extensions are useful to fit the yield curve at longer maturities (>10 years). Because we only used yields with maturities ≤10 years, the second curvature factor loadings will look similar to the slope factor loadings and we will have collinearity problem. CDR use yields up to 30 years. The 4th and 5th factors have no clear economic intrepretations and are hard to explain. For these reasons, we report results for for the CF-NS model. |
| 16 | For the statistical significance of the loss-difference (see Definition 2), the asymptotic p-values of the Diebold–Mariano statistics are all very close to zero especially for larger values of the forecast horizon |
| 17 | We conducted a Monte Carlo (not reported), which are consistent with the empirical results that the supervision is stronger for a longer forecast horizon |
| 18 | Figlewski and Urich (1983) talked about various constrained models in forming a combination of forecasts and examined when we need more than the simple averaging combined forecast. They discussed a sufficient condition when the simple average of forecasts is the optimal forecast combination: “Under the most extensive set of constraints, forecast errors are assumed to have zero mean and to be independent and identically distributed. In this case the optimal forecast is the simple average.” This corresponds to CF-PC() and CF-NS when the first factor in PC or NS is sufficient for the CF factor model. It is clearly the case in CF-NS as shown in Equation (55). One can show that the first PC (corresponding to the largest singular value) would also be the simple average. Hence, in terms of the CF-factor model, the forecast combination puzzle amounts to the fact that we often do not need the second PC factor. Interestingly, (Figlewski and Urich 1983, p. 696) continued to note the cases when the simple average is not optimal: “However, the hypothesis of independence among forecast errors is overwhelmingly rejected for our data-errors are highly positively correlated with one another.” On the other hand, they also noted other reasons why the simple average may still be preferred, as they wrote, “Because the estimated error structure was not completely stable over time, the models which adjusted for correlation did not achieve lower mean squared forecast error than the simple average in out-of-sample tests. Even so, we find...that forecasts from these models, while less accurate than the simple mean, do contain information which is not fully reflected in prices in the money market, and is therefore economically valuable.” We thank a referee for letting us know on this from Figlewski and Urich (1983). |
| 19 | While the simple equally weighted forecast combination can be implemented without the use of PCA or without making reference to the NS model, it is important to note that the simple average combined forecast indeed corresponds the first CF-PC factor (CF-PC) or the first CF-NS factor (CF-NS). In view of Figlewski and Urich (1983), it will be useful to know when the first factor is enough so that the simple average is good or when the higher order factors may be necessary as they contain more information in addition to the first CF-factor. This is important in understanding the forecast combination puzzle. The forecast combination puzzle is about whether to include only the first CF factor or more. |







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Panel A. Root Mean Squared Forecast Errors | ||||||||
| CI-PC() | 5.64 | 3.56 | 2.99 | 2.78 | 2.61 | 2.50 | 2.46 | 2.42 |
| CI-PC() | 5.67 | 3.64 | 3.12 | 3.00 | 2.81 | 2.66 | 2.55 | 2.45 |
| CI-PC() | 5.71 | 3.69 | 3.19 | 3.08 | 2.92 | 2.77 | 2.63 | 2.49 |
| CI-PC() | 5.72 | 3.76 | 3.23 | 3.12 | 2.93 | 2.77 | 2.58 | 2.36 |
| CI-PC() | 5.74 | 3.78 | 3.26 | 3.15 | 2.98 | 2.81 | 2.61 | 2.38 |
| CI-NS() | 5.84 | 3.84 | 3.28 | 3.06 | 2.86 | 2.69 | 2.53 | 2.41 |
| CI-NS() | 5.71 | 3.71 | 3.20 | 3.11 | 2.93 | 2.77 | 2.62 | 2.48 |
| CI-NS() | 5.72 | 3.69 | 3.19 | 3.09 | 2.93 | 2.78 | 2.63 | 2.47 |
| CF-PC() | 5.60 | 3.45 | 2.83 | 2.54 | 2.24 | 1.95 | 1.75 | 1.58 |
| CF-PC() | 5.56 | 3.43 | 2.83 | 2.62 | 2.31 | 1.93 | 1.76 | 1.61 |
| CF-PC() | 5.60 | 3.44 | 2.94 | 2.78 | 2.47 | 2.02 | 1.65 | 1.48 |
| CF-PC() | 5.63 | 3.60 | 3.08 | 2.83 | 2.39 | 1.97 | 1.67 | 1.45 |
| CF-PC() | 5.63 | 3.60 | 3.05 | 2.87 | 2.41 | 2.05 | 1.69 | 1.51 |
| CF-NS() | 5.60 | 3.45 | 2.83 | 2.54 | 2.24 | 1.95 | 1.75 | 1.58 |
| CF-NS() | 5.56 | 3.43 | 2.84 | 2.62 | 2.30 | 1.95 | 1.76 | 1.62 |
| CF-NS() | 5.59 | 3.44 | 2.94 | 2.79 | 2.47 | 2.02 | 1.64 | 1.48 |
| Panel B. Relative Supervision | ||||||||
| CI-PC() vs. CF-PC() | 1.01 | 1.06 | 1.12 | 1.20 | 1.36 | 1.64 | 1.98 | 2.35 |
| CI-PC() vs. CF-PC() | 1.04 | 1.13 | 1.22 | 1.31 | 1.48 | 1.90 | 2.10 | 2.32 |
| CI-PC() vs. CF-PC() | 1.04 | 1.15 | 1.18 | 1.23 | 1.40 | 1.88 | 2.54 | 2.83 |
| CI-PC() vs. CF-PC() | 1.03 | 1.09 | 1.10 | 1.22 | 1.50 | 1.98 | 2.39 | 2.65 |
| CI-PC() vs. CF-PC() | 1.04 | 1.10 | 1.14 | 1.20 | 1.53 | 1.88 | 2.39 | 2.48 |
| CI-NS() vs. CF-NS() | 1.09 | 1.24 | 1.34 | 1.45 | 1.63 | 1.90 | 2.09 | 2.33 |
| CI-NS() vs. CF-NS() | 1.05 | 1.17 | 1.27 | 1.41 | 1.62 | 2.02 | 2.22 | 2.34 |
| CI-NS() vs. CF-NS() | 1.05 | 1.15 | 1.18 | 1.23 | 1.41 | 1.89 | 2.57 | 2.79 |
| Panel A. Root Mean Squared Forecast Errors | ||||||||
| CI-PC() | 3.77 | 2.86 | 2.25 | 1.92 | 1.94 | 2.16 | 2.47 | 2.75 |
| CI-PC() | 4.21 | 3.45 | 2.96 | 2.76 | 2.77 | 2.84 | 2.96 | 3.08 |
| CI-PC() | 4.24 | 3.50 | 3.00 | 2.82 | 2.88 | 2.98 | 3.10 | 3.19 |
| CI-PC() | 4.31 | 3.57 | 3.05 | 2.87 | 2.91 | 3.00 | 3.12 | 3.18 |
| CI-PC() | 4.30 | 3.58 | 3.07 | 2.93 | 3.00 | 3.10 | 3.20 | 3.23 |
| CI-NS() | 3.95 | 3.12 | 2.62 | 2.48 | 2.60 | 2.79 | 2.97 | 3.10 |
| CI-NS() | 4.22 | 3.46 | 2.98 | 2.82 | 2.88 | 2.98 | 3.09 | 3.18 |
| CI-NS() | 4.24 | 3.50 | 3.01 | 2.83 | 2.89 | 2.99 | 3.11 | 3.20 |
| CF-PC() | 3.65 | 2.67 | 1.91 | 1.31 | 1.01 | 0.90 | 0.96 | 1.08 |
| CF-PC() | 3.66 | 2.70 | 1.93 | 1.35 | 1.10 | 1.05 | 1.11 | 1.19 |
| CF-PC() | 3.68 | 2.72 | 1.97 | 1.47 | 1.29 | 1.19 | 1.19 | 1.20 |
| CF-PC() | 3.74 | 2.80 | 2.01 | 1.47 | 1.22 | 1.14 | 1.15 | 1.17 |
| CF-PC() | 3.74 | 2.79 | 1.98 | 1.45 | 1.20 | 1.12 | 1.18 | 1.20 |
| CF-NS() | 3.65 | 2.68 | 1.91 | 1.31 | 1.02 | 0.90 | 0.96 | 1.08 |
| CF-NS() | 3.66 | 2.70 | 1.93 | 1.35 | 1.10 | 1.05 | 1.10 | 1.19 |
| CF-NS() | 3.68 | 2.73 | 1.97 | 1.47 | 1.29 | 1.20 | 1.19 | 1.20 |
| Panel B. Relative Supervision | ||||||||
| CI-PC() vs. CF-PC() | 1.07 | 1.15 | 1.39 | 2.15 | 3.69 | 5.76 | 6.62 | 6.48 |
| CI-PC() vs. CF-PC() | 1.32 | 1.63 | 2.35 | 4.18 | 6.34 | 7.32 | 7.11 | 6.70 |
| CI-PC() vs. CF-PC() | 1.33 | 1.66 | 2.32 | 3.68 | 4.98 | 6.27 | 6.79 | 7.07 |
| CI-PC() vs. CF-PC() | 1.33 | 1.63 | 2.30 | 3.81 | 5.69 | 6.93 | 7.36 | 7.39 |
| CI-PC() vs. CF-PC() | 1.32 | 1.65 | 2.40 | 4.08 | 6.25 | 7.66 | 7.35 | 7.25 |
| CI-NS() vs. CF-NS() | 1.17 | 1.36 | 1.88 | 3.58 | 6.50 | 9.61 | 9.57 | 8.24 |
| CI-NS() vs. CF-NS() | 1.33 | 1.64 | 2.38 | 4.36 | 6.85 | 8.05 | 7.89 | 7.14 |
| CI-NS() vs. CF-NS() | 1.33 | 1.64 | 2.33 | 3.71 | 5.02 | 6.21 | 6.83 | 7.11 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hillebrand, E.; Huang, H.; Lee, T.-H.; Li, C. Using the Entire Yield Curve in Forecasting Output and Inflation. Econometrics 2018, 6, 40. https://doi.org/10.3390/econometrics6030040
Hillebrand E, Huang H, Lee T-H, Li C. Using the Entire Yield Curve in Forecasting Output and Inflation. Econometrics. 2018; 6(3):40. https://doi.org/10.3390/econometrics6030040
Chicago/Turabian StyleHillebrand, Eric, Huiyu Huang, Tae-Hwy Lee, and Canlin Li. 2018. "Using the Entire Yield Curve in Forecasting Output and Inflation" Econometrics 6, no. 3: 40. https://doi.org/10.3390/econometrics6030040
APA StyleHillebrand, E., Huang, H., Lee, T. -H., & Li, C. (2018). Using the Entire Yield Curve in Forecasting Output and Inflation. Econometrics, 6(3), 40. https://doi.org/10.3390/econometrics6030040