1. Introduction
Economics is an odd discipline of science. It is common to have multiple, sometimes contradicting theories to explain observed phenomena. While this may not be too troubling for economic theorists, for empirical researchers it poses a considerable challenge to integrate diverse economic theories into one modelling framework. Moreover, not all aspects of econometric models can be derived from economic theories—many assumptions regarding, e.g., distribution of error terms or functional forms for conditional means are somewhat arbitrary. Since interpretable results are often sensitive to specifications of econometric models consequences of these assumptions should not be neglected.
Many approaches have been put forward to mitigate the problem—see, e.g., (
Steel 2019) and references therein—but one approach has caught attention in recent years. Bayesian model averaging (BMA hereafter), also known as Bayesian inference pooling, is a statistical method of pooling inference from different models in order to explain the observed economic process. Although BMA has been around for several decades, the reason it has been recently gaining popularity is not entirely due to its sound foundations rooted in statistics and probability theory. Its increasing popularity is also likely due to other reasons, e.g., (i) increased computation power; (ii), development of specific computation algorithms and (iii) scarcity of alternatives in the frequentist approach.
The core concept of BMA is to deal with model uncertainty by averaging the results from different models using the concept of mixture, with weights interpreted as posterior model probabilities. In cases where one model clearly dominates over others (which is more likely with increasing sample size) it is practically equivalent to Bayesian model selection (BMS). This technique amounts to choosing the model which is clearly favored by the data. In that sense, BMA/S can be viewed as tools for empirical validation of economic theories. BMA is undoubtedly very helpful to address model uncertainty, although some care needs to be taken when using it as it is sensitive to prior assumptions. Fortunately, at least for standard regression models, this has been well addressed in the literature (
Ley and Steel 2009,
2012).
We emphasize that although BMA is most often used for covariate selection problems, the approach is very general, and can be used to deal with uncertainty regarding all the aspects of model specification.
Steel (
2019) lists three types of uncertainty that need to be addressed, and our interest is in “specification uncertainty”. We focus on parametric models with known covariates, and the uncertainty here refers to the choice of the sampling model (in particular, its stochastic structure). Note, however, that in order for BMA to properly deal with this kind of uncertainty, certain conditions need to be met. The core idea of BMA is in pooling over a number of Bayesian models (and each Bayesian model consists of a likelihood and a prior). In order to be able to interpret the results of BMA as averaging over competing sampling models (likelihoods), we need to make sure that all the priors used reflect the same beliefs—this requirement is known as prior coherence. If prior coherence requirements are not met, BMA is feasible, but its results are driven not only by different performance of the sampling models under consideration, but also by differences in model-specific prior beliefs. In such cases, especially when prior incoherence is not explicitly discussed and justified, results are likely to be misinterpreted.
Two important aspects need to be mentioned. First, prior coherence is relatively easy to define for a class of nested sampling models. In such a framework, any sampling model under consideration is defined by a set of parametric restrictions imposed on the general model. Consequently, coherence requirement implies that it is necessary to set prior assumptions for the general sampling model only. Model-reducing restrictions need to be imposed on the prior in order to derive priors in all nested cases under consideration. Hence, in a nested family of sampling models prior elicitation is done only once, in the most general case. Second, even if prior coherence is met, the results of BMA still depend upon the chosen prior structure, and thus the prior needs to reflect reasonable (or justified) beliefs. Consequently, prior coherence is necessary but not sufficient when BMA is used to deal with model specification uncertainty. Note that prior incoherence is unlikely to be a problem in the usual application of BMA when the purpose is covariate selection.
Another requirement of BMA is that the priors for model-specific parameters have to be proper (hence ruling out many formal noninformative specifications), and even if prior coherence is met it is necessary to analyze sensitivity of BMA results with respect to the prior. However, without prior coherence, results of Bayesian model comparison or model averaging are difficult to interpret. Unfortunately, in many practical applications of BMA, prior coherence problems are implicit.
The practical use of BMA has often been concerned with rather simple models in terms of their stochastic structure. However, constant development in computational speed and algorithm design has made it possible for BMA to be applied in the areas which involve more complex stochastic model structures (e.g., complicated hierarchical priors). Still, two issues are of great importance here. First, increased model complexity with, e.g., many layers of latent variables or high-dimensional parameter spaces makes choice of priors more important (at least with fixed sample size). Obviously, such high-dimensional prior structures are difficult to investigate—hence the actual consequences of certain formally stated prior beliefs in terms of interpretable quantities are often unclear. Second, considerations regarding prior specification are still in practice motivated mostly by computational convenience. As priors are often restricted to certain parametric classes, the scope of sensitivity analysis is limited to disturbing the choice of hyperparameters (and even this is often neglected in empirical analyses), and then demonstrating some degree of robustness for selected characteristics of posterior distribution to changes in prior hyperparameters. However, it is well known that even if essential characteristics of a posterior distribution are robust to the choice of priors, the posterior model probabilities, crucial for BMA, are not; see, e.g., (
Osiewalski and Steel 1993). Moreover, such robustness is more likely to hold for model parameters and not necessarily for latent variables (as the latter increase in dimensionality with the sample size). If latent variables are the quantities of interest, prior assumptions might still have considerable influence upon the results. To summarize, whenever BMA is used and the quantities of interest are latent variables, it is essential to use priors that are coherent and well-specified (i.e., represent beliefs that are actually reasonable, given the problem at hand).
One prominent example where latent variables are of great interest is Stochastic Frontier Analysis (SFA hereafter). It is a method used to benchmark (in)efficiencies of decision-making units (DMUs) and these (in)efficiencies are treated as latent variables. Depending on how we frame the objective function, referred to as the frontier, the efficiency can be technical (pure analysis of production) or economic. Economic efficiency in turn can be, e.g., cost, revenue or profit efficiency; depending on the type of process we consider—cost, revenue or profit functions. The core difference between a stochastic frontier (SF) model and a “standard” regression input(s)-output model is that the stochastic component, usually denoted by ε, is compound in SFA. Traditionally to maintain identification we assume additive structure of ε’s sub-components; e.g.,
. Subcomponent
, which represents a random symmetric disturbance, is usually normally distributed, though new proposals emerge in this field (see, e.g.,
Tchumtchoua and Dey 2007;
Griffin and Steel 2007;
Wheat et al. 2019;
Stead et al. 2018,
2019;
Horrace and Parmeter 2018;
Florens et al. 2019). Subcomponent
represents inefficiency (latent variable), a nonnegative disturbance that results in asymmetry of the compound error ε and can only have a decreasing effect on the observed output. Given the traditional log-linear form of the frontier a simple transformation,
, produces standardized measures of efficiency
. Originally inefficiency has been assumed to follow either half-normal distribution in the normal-half-normal model (
Aigner et al. 1977) or exponential distribution in the normal-exponential model (
Meeusen and van den Broeck 1977). Many proposals about inefficiency distribution have been made since the introduction of SFA—see, e.g., (
Griffin and Steel 2008)—and SF models can currently have a complex structure with as many as four stochastic components (
Makieła 2017). However, the traditional normal-half-normal and normal-exponential SF models still dominate the applied research.
Efficiency estimates in SFA can vary depending on the distributional assumptions made about the compound error structure. The two most commonly used distributions of inefficiency—exponential and half-normal—have been reported to produce substantially different estimates; with gamma and truncated normal producing results somewhere “between” the two; see, e.g., (
Greene 2008). Since we do not know what the prior should look like it makes even more sense to “average” our results from different specifications in respect to
. BMA seems like a natural way to do so. Accurate inference about inefficiency is also important from the viewpoint of public policy (in the area of energy, education, health care, agriculture or finance, to mention some examples). Rankings of DMUs with respect to inefficiency are often used by public regulators. Moreover, extended stochastic frontier models might provide insights into sources of inefficiency. Proper application of BMA in SFA provides an important contribution into development of quantitative tools supporting policy-making.
Bayesian analysis of SF models was introduced in a seminal paper of (
van den Broeck et al. 1994). Despite limitations of computational power at the time, the authors clearly stated all the related inferential problems and managed to conduct inference using Monte Carlo–Importance Sampling (MC–IS), including inference pooling for latent variables. Moreover,
van den Broeck et al. (
1994) provided careful discussion of their prior assumptions, extended in subsequent papers e.g., (
Fernández et al. 1997). However, the actual popularity of Bayesian SFA followed the development of automated numerical methods, e.g., Gibbs sampling; see, e.g., (
Osiewalski and Steel 1998). It is perhaps a paradox that a more widespread use of Bayesian techniques was not accompanied by equally careful usage of Bayesian reasoning developed by van den
Broeck et al. (
1994) (
with a notable exception of Griffin and Steel 2008). Consequently, large part of the applied literature on Bayesian SFA is based on practical solutions that neglect the issue of model uncertainty or its linkage to prior elicitation. Thus, the purpose of this paper is to revisit the fundamental perspective outlined by
van den Broeck et al. (
1994) and to provide detailed discussion about the role of prior specification on model averaging in Bayesian SFA, using a somewhat more general model framework and advanced numerical methods.
Despite the contribution of
van den Broeck et al. (
1994), BMA/S usage in SFA has been infrequent at best. For example, (
Makieła 2014) used posterior odds but only to choose a particular model rather than average inference across inefficiency scores. Bayes factors have also been used, e.g., by (
Griffin and Steel 2008), or (
Tsionas and Kumbhakar 2014) to test alternative specifications. Probably the first use of BMA in Bayesian SFA on a large scale can be found in (
Makieła and Osiewalski 2018), who use this technique to find the optimal model in the sense of optimal set of explanatory variables. Although,
Makieła and Osiewalski (
2018) discuss the possibility of integrating different stochastic assumptions as regards inefficiency distribution for BMA, they stick to the normal-exponential model throughout the empirical study. One reason is that if we want to use different SFA specifications (in terms of inefficiency distribution) in BMA we need to be sure that we maintain prior coherence on inefficiency, and this may be a challenging task. In particular,
Makieła (
2014) reports substantial differences between the two popular normal-half-normal and normal-exponential models, some of which are likely due to incoherent priors. So this avenue is definitely worth exploring.
Our contribution to the literature is threefold. First, we propose a modelling framework that nests the two most commonly used SF models, that is, normal-half-normal and normal-exponential, so that formal comparative analysis is possible and effective. Second, we take the commonly used priors on inefficiency in the two models and review their impact on BMA in two scenarios: when prior coherence is neglected, and when it is accounted for. Third, we propose a prior which is intuitive and coherent, and thus allows us to effectively perform BMA across models with different distributional assumptions about inefficiency.
Griffin and Steel (
2008) have considered a framework with a generalized inefficiency distribution and prior coherence, but without explicit consideration of sensitivity to full range of alternative priors suggested in the literature. Furthermore, we note that our usage of BMA is nonstandard because we apply it to average results across different distributions of inefficiency within the aforementioned model class. Traditionally BMA is used to decide which covariates should enter the model, and thus which variables should be selected. We do not comment on the variable selection aspect of BMA in this paper. We feel that for SF models this has been already well addressed in (
Makieła and Osiewalski 2018).
The paper is structured as follows.
Section 2 discusses methodology for the comparative analysis.
Section 3 discusses results of prior and posterior analysis with respect BMA based on two datasets.
Section 4 concludes with a discussion.
2. Methodology
In order to reconsider issues of Bayesian model specification and inference pooling we make use of some of the results in (
Makieła and Mazur 2020), who have recently proposed a generalized framework for parametric analysis of stochastic frontier (SF) models based on generalizations discussed by (
Harvey and Lange 2017).
van den Broeck et al. (
1994) were the first to introduce Bayesian analysis of SF models along with an in-depth discussion of model uncertainty and inference pooling problems. However, some of their results reflect limitations of numerical methods available at the time. In the subsequent years, Bayesian applications of SF models had flourished following the successful use of the Gibbs sampling scheme (with full conditionals of the standard form, including the latent variables) as in (
Koop et al. 1999,
2000). Numerical convenience of the Gibbs algorithm resulted in abundance of empirical studies using the method, with normal-exponential and normal-half-normal models serving as the workhorse for the applied work. However, the convenience of the Gibbs sampling approach comes at a cost. First, as conjugate-type results are used, the priors are restricted to specific classes. As a result, the popular normal-exponential and normal-half-normal models have been used with priors that reflect beliefs which are not necessarily compatible. Second, the perspective of model averaging or inference pooling, emphasized in the original paper of
van den Broeck et al. (
1994), has not been pursued further in the mainstream applied work; exceptions include, e.g., (
Griffin and Steel 2007,
2008 and
Makieła and Osiewalski 2018). The two problems are related, as it is well-known that the results of Bayesian model comparison are likely to be sensitive to prior specification. Therefore, careful prior elicitation together with prior sensitivity analysis is essential for adequate Bayesian inference pooling.
The results in (
Makieła and Mazur 2020) imply that the two popular sampling models mentioned above are indeed nested within a broader model class, based on the Generalized Error Distribution (GED). Consequently, it is feasible to develop inference methods that do not require any particular form of priors, and thus to reconsider the original inference-pooling approach by
van den Broeck et al. (
1994). This can be now achieved based on various classes of priors that are coherent across sampling models and consequences for model comparison can be investigated.
Consider the counterpart of Equation (1) in
van den Broeck et al. (
1994), which defines the basic SF production model:
with
representing the
i.i.d. error term with symmetric and unimodal probability density function (pdf hereafter),
being an
i.i.d. latent variable, taking strictly positive values, representing the inefficiency term. Usually
represents the log of output while
denotes technology. The majority of practical applications assume that
follows Gaussian distribution, while
is half-normal or exponential. Our approach to statistical inference outlined below does not require the log transformation for
, nor the linear form of
with respect to
. However, in the empirical part of the paper we make use of the restrictions in order to compare our results to those reported in previous studies.
Statistical inference relies on properties of the compound error term
, with sampling distribution implied by properties of
, defined in the general case by the convolution of densities for
and
(denoted by
and
respectively):
Since u’s are treated as latent variables, the likelihood function based on (2) is sometimes referred to as integrated likelihood (emphasizing the fact that the latent variables are “integrated out”). Although in the general case this integral has no exact analytical solution it can be evaluated (using numerical methods) with arbitrary precision, at any point in the parameter space. One evaluation of the integrated likelihood requires computation of T univariate integrals, which can be parallelized easily (as the observations are assumed to be i.i.d.). In our view nonstochastic methods of numerical integration are sufficient for this purpose, although some fine-tuning of the numerical procedure is indeed required.
We assume that
follows the zero-mean GED distribution (
see Subbotin 1923) of the form:
where
denotes the Gamma function,
denotes the scale parameter and
controls shape, with special cases of
= 2 (Gaussian) and
= 1 (Laplace). For
we assume that it follows the distribution of
, i.e., half-GED:
. The same special cases induce half-normal and exponential distributions, respectively. The GED distribution is continuous, but not differentiable at the mode for some values of
(as it is “spiked” at the mode). However, the sum of a GED variable and a half-GED variable has smoother distribution, corresponding to a generalized four-parameter form of ‘skew GED’ (although it differs from some cases considered in the literature; see, e.g., (
Theodossiou et al. 2020); for a recent application). Hence the integrated likelihood function implied by (2) and (3) is regular (given the parameter space considered here). Some theoretical problems might occur for boundary values of parameter, though in our view they are of little practical importance for the Bayesian inference strategy outlined below.
Crucially, we assume that the shape parameters in the distributions of
and
are not the same. This is reflected below by subscripts
or
:
,
,
,
denoting parameters of the distribution of
and that of
. We assume that
,
≥ 1 if the parameters are not fixed. Compared to (
Griffin and Steel 2008) we assume a more general distributional form of
, although our assumption about
is somewhat more restrictive. The authors assume that
is distributed as generalized gamma following (
Stacy 1962), which implies somewhat different parametrization of the scale parameter in their restricted case corresponding to the half-GED distribution of
. The difference in parametrization leads to an observationally equivalent likelihood, but it might matter for prior specification, in particular the dependence between
and
. Our parametrization in (3) relies upon the fact that
itself is a scale parameter (
Makieła and Mazur 2020; demonstrate linkages with a more general formulation, which may also be of interest). This also means that our interpretation of the scale parameter of
does not change with
. Hence, the two approaches differ with respect to the assumptions regarding the prior dependence between
and
. We do not state that any of the two sets of assumptions is superior, though we indicate that the prior dependence should be somehow justified within the most general model used.
van den Broeck et al. (
1994) assume
to be Gaussian and
to be truncated-normal or Erlang-type (i.e., Gamma with the shape parameter equal to 1, 2 or 3). We prefer to restrict ourselves to cases where the distribution of
is characterized by a strictly decreasing pdf, therefore ruling out the Erlang-2 and Erlang-3 cases, as well as the truncated-normal one with truncation below 0. For the purpose of simplicity, we also rule out the truncated-normal case with positive truncation. It is important to note that it is possible to modify the above setup to encompass the fully general framework of
van den Broeck et al. (
1994). In this paper, however, we are motivated to remove the aforementioned cases for a number of reasons. First, we recognize that the SFA literature involving nonmonotonic distributions of
is quite large; see, e.g., (
Stevenson 1980;
van den Broeck et al. 1994;
Greene 2003;
Griffin and Steel 2004,
2008;
Tsionas 2006,
2007;
Hajargasht 2015) among others. Many studies find support for nonmonotonic densities of inefficiency. Unfortunately, these studies also assume
to be Gaussian. It may very well be that empirical evidence found in favor of nonmonotonic distributions is simply driven by, e.g., outliers and the restrictive assumption about
; see, e.g., (
Wheat et al. 2019;
Stead et al. 2018,
2019) for a series of discussions about outliers in SFA. Once the symmetric term is generalized to accommodate them the need for nonmonotonic distributions of inefficiency may no longer be supported by the data. Second, there is a more practical reason of statistical identification. Allowing for
with distribution that does not satisfy the aforementioned monotonicity condition provides very limited gain in terms of overall model flexibility at the cost of potentially leading to a likelihood that is empirically very close to nonidentification (i.e., approximately flat in certain directions). In other words, from the viewpoint of potential statistical fit (within the parametric approach), it is sufficient to consider flexible distributional forms for
and
that satisfy the conditions outlined above. Third, we wish to concentrate on the two most widely used SF models, i.e., normal-half-normal and normal-exponential. Both of them have a strictly decreasing distribution of inefficiency.
To sum up, we rule out the Erlang-2, Erlang-3 and truncated normal cases of
van den Broeck et al. (
1994), while encompass the two essential special cases (half-normal, exponential) and introduce extra flexibility by allowing for
and
1, 2. Furthermore, since it is possible for the model to encompass the fully general framework of
van den Broeck et al. (
1994) our main conclusions are likely to remain valid anyway.
Within the general structure we consider the following SF sampling models:
- (i)
normal-exponential, labelled NEX, with = 2, = 1 and statistical parameters: , , ,
- (ii)
normal-half-normal, NHN, with = 2, = 2 and statistical parameters: , , ,
- (iii)
normal-half-GED, NHG, with = 2 and statistical parameters: , , , ,
- (iv)
GED-half-GED, GHG, with statistical parameters , , , , .
The reader should note that the term “statistical parameters” is used throughout the paper to distinguish parameters from latent variables as well as strictly “statistical” parameters from “interpretable” parameters.
The GHG model (iv) nests the NHG case (iii), whereas the latter nests the NEX and NHN specifications. For the sequence of nested sampling models it is possible to develop a coherent Bayesian prior structure. The priors in the special cases (i)–(iii) are obtained from the prior in the general case (iv) by adequate conditioning, which reflects the model-reducing restrictions. Moreover, we also consider a model without inefficiency, i.e., a regression with i.i.d. GED errors, where the only statistical parameters are , and .
Crucially, our setup implies that is a common parameter in all SF models. This allows for a direct comparison of priors that have been proposed in the literature for the NHN and NEX models. For each of those models it is possible to analyze prior structures used in empirical applications by inducing the resulting prior on in our framework. Moreover, a prior that has been suggested for the NEX model can be used with NHN model and vice versa. This allows us to analyze consequences of applying “the usual” priors for model comparison.
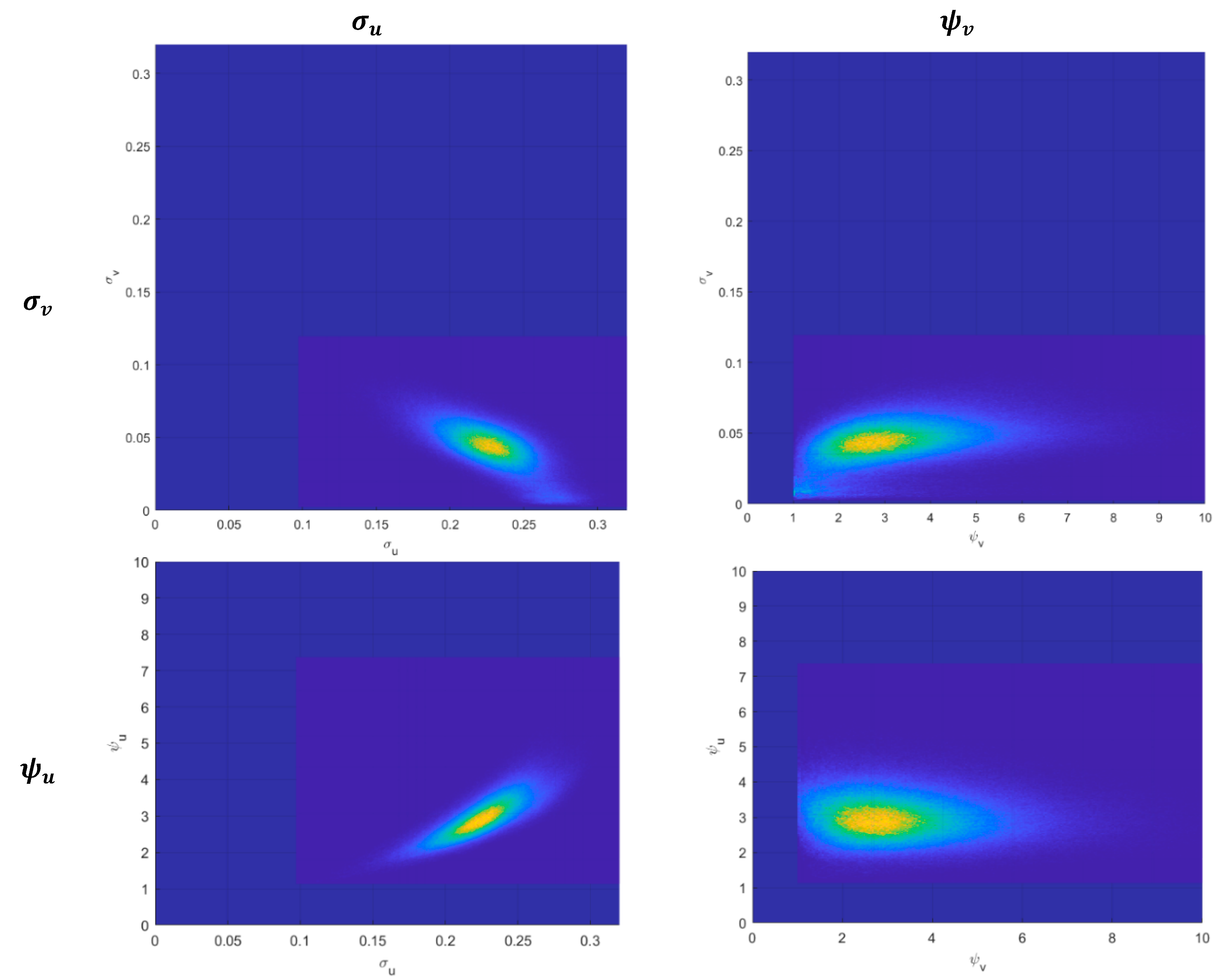
For the purpose of Bayesian estimation of the model class we suggest an approach that relies on a generalization of the popular Gibbs sampling. Gibbs sampling is based on the data augmentation technique, which requires drawing all statistical parameters and the latent variables (). However, it is usually required that priors are restricted to certain classes (otherwise, it is less attractive from the computational viewpoint). As the focus here is on prior sensitivity, we suggest a direct approach using likelihood function with latent variables integrated out (we refer to it as “integrated likelihood” throughout the paper) based on the implied density of the compound error term. Such integrated likelihood can be used with any prior structure in order to analyze the posterior of the statistical parameters (marginal with respect to latent variables). Within this approach, any general Bayesian algorithm can be applied and we make use of the Metropolis-Hastings (MH hereafter) algorithm with Random-Walk proposal (MH-RW hereafter). Furthermore, given the results from the full Markov Chain Monte Carlo (MCMC) chain that approximates the posterior draws of the statistical parameters (marginal with respect to latent variables), it is possible to draw the latent variables (inefficiencies ). The full conditional is nonstandard (as a product of two shifted densities of truncated-GED and half-GED form), but it is possible to develop an efficient MH algorithm to sample them. Note that, compared to the Gibbs sampling, the approach advocated here requires more computational power due to numerical integration, though it imposes no restrictions upon the prior structure and is likely to display better mixing properties. The latter is due to the fact that the parameters are drawn from the posterior distribution marginalized with respect to the latent variables. The usual Gibbs sampler used in a typical SF model draws parameters and latent variables jointly and relies upon conditioning on draws for all the ’s. This results in a potentially stronger dependence in the resulting Markov chain (making it likely that the effective sample size from a given number of MCMC repetitions decreases).
We transform all the statistical parameters into an unrestricted space (taking the implied priors into account), which allows for a smooth operation of the MH-RW sampler. In particular, we use and . We have compared the output from this algorithm to results obtained with Gibbs sampling (for special cases where the latter is available) and found practically identical characteristics of posterior draws of statistical parameters as well as latent variables.
The Bayesian model averaging relies upon estimation of posterior model probabilities, which in turn require the estimates of p(y), often referred to as marginal data density. The latter quantity is particularly difficult to estimate in a reliable manner. As our method relies upon direct use of the integrated likelihood, we rely on the Laplace approximation of the posterior for the statistical parameters, within the unrestricted parametrization in order to make the underlying multivariate Gaussian approximation more adequate. Laplace approximation has the advantage that the prior structure is explicitly taken into account. Some alternative methods like the popular variant of the harmonic mean estimator of (
Newton and Raftery 1994), depend upon priors only implicitly and therefore are likely to underestimate sensitivity of p(y) to changes in prior specification, which is of essential interest here. We are aware that a more advanced method could be used to estimate p(y); see, e.g., (
Pajor 2017). However we believe that the Laplace approximation is sufficient to demonstrate the degree of prior sensitivity.
We assume that the priors for all the model parameters are proper, with prior independence across all the parameters. We focus on model-specific parameters, which have to follow proper priors in order to average models in the standard way, because improper priors would result in ill-defined Bayes factors. As for prior independence, the general structure advocated here (the GHG form) allows us to relax this assumption. If a reasonable dependent prior is developed, the model can allow for a coherent prior specification of the nested cases as well. Nevertheless, the idea of prior coherence applied here assumes prior independence. As mentioned, (
Griffin and Steel 2008) have considered a model with inefficiency distribution of the generalized gamma class with prior dependence across its parameters. We do not adapt their prior structure here, although we note that it would be a feasible task as our approach allows for very general formulation of priors.
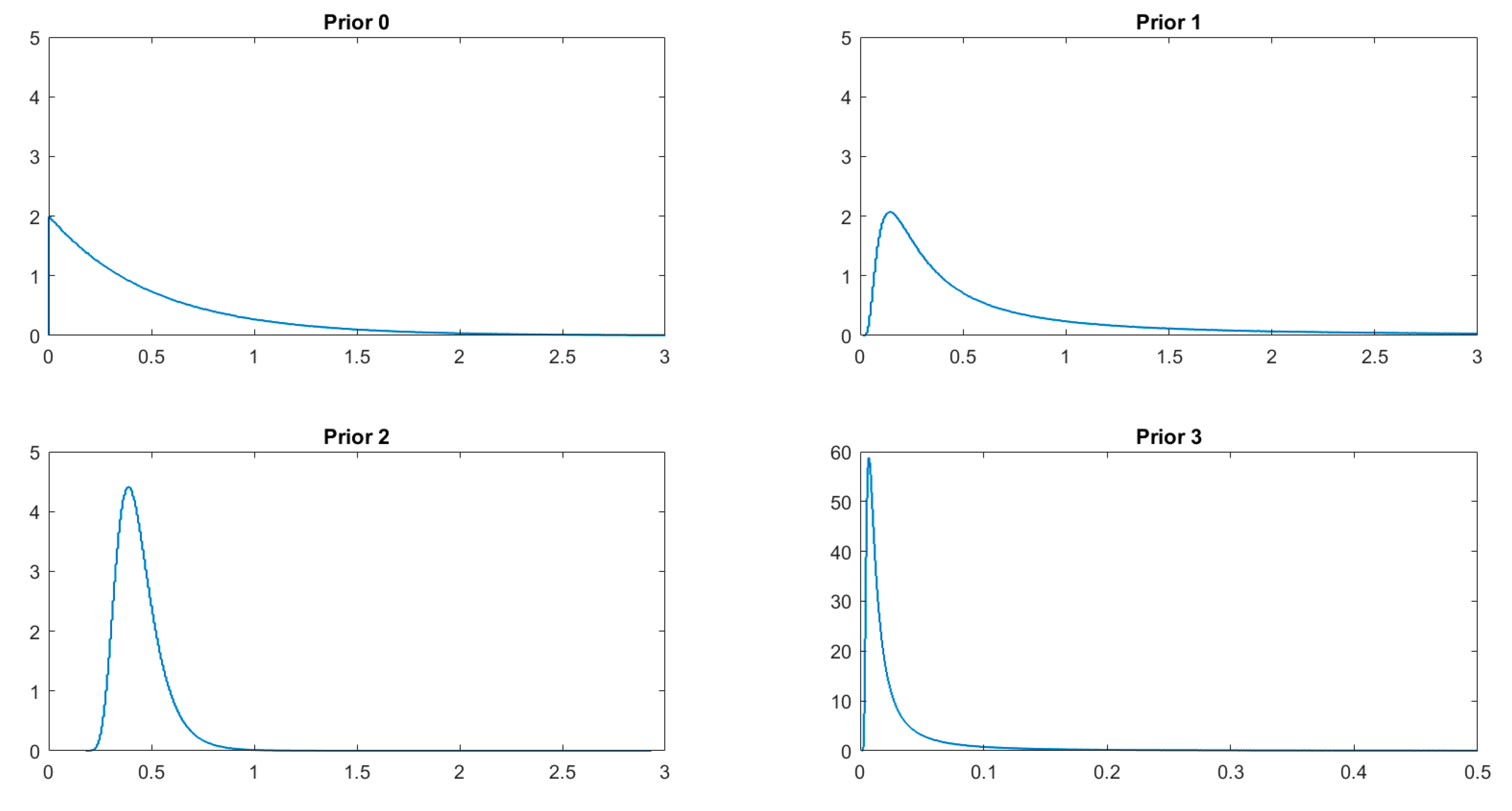
We assume that the priors in the general model (iv) are
, where
is multivariate Gaussian (with zero mean and covariance matrix 100
2Ik),
and
are of the same form, implying that
—consequently, we rule out
< 1, although this assumption might be relaxed. For
, we follow the suggestion of
Koop et al. (
2000), who elicit a Gamma-type prior that is assumed to mimic the traditional Jeffrey’s prior for precision in linear models (the latter is improper, so the interpretation is of course approximate). We take the prior
(0.5Q, 0.5Q) with Q = 10
−4 and make use of it in order to maintain comparability with the aforementioned papers. Though we leave the task to formulate adequate prior for
for further research, we have checked sensitivity with respect to changes in
and found our results to be quite robust.
4. Concluding Remarks
The paper discusses Bayesian model averaging, also known as Bayesian inference pooling, in Stochastic Frontier Analysis by making use of a generalized model structure introduced in (
Makieła and Mazur 2020). It is important to note that the use of BMA in this paper differs from standard applications which focus on covariate selection. We apply BMA to average over competing sampling models that differ with respect to the stochastic structure (distribution of the compound error term). We consider the two most popular SFA specifications, namely the normal-half-normal and normal-exponential models, and demonstrate that it is possible to nest them within GED-half-GED specification. We show that Bayesian model comparison or averaging can be used to deal with specification uncertainty. However, there are two important reservations. First, in order to interpret the results of BMA as averaging over competing sampling models, it is necessary to maintain prior coherence. Otherwise, the comparison is affected by differences in prior beliefs across models. Second, even if prior coherence holds, posterior model probabilities are likely to be sensitive to prior specification. Consequently, it is necessary to verify robustness to alternative priors. We introduce a framework that allows to consider prior coherence for most popular SFA models and show how the popular priors used in Bayesian SFA can affect the results of BMA.
Our approach to statistical inference within the new GED-half-GED model class is based on the use of integrated likelihood with the latent variables integrated out (using non-stochastic numerical integration). It is computationally more demanding, especially compared to traditional specifications suitable for Gibbs sampling, but it offers considerable advantages:
it allows for a formal model comparison within a broad, flexible parametric class;
it allows for an in-depth analysis of prior sensitivity, as the numerical methods used do not impose any particular class of priors (contrary to the Gibbs sampling approach).
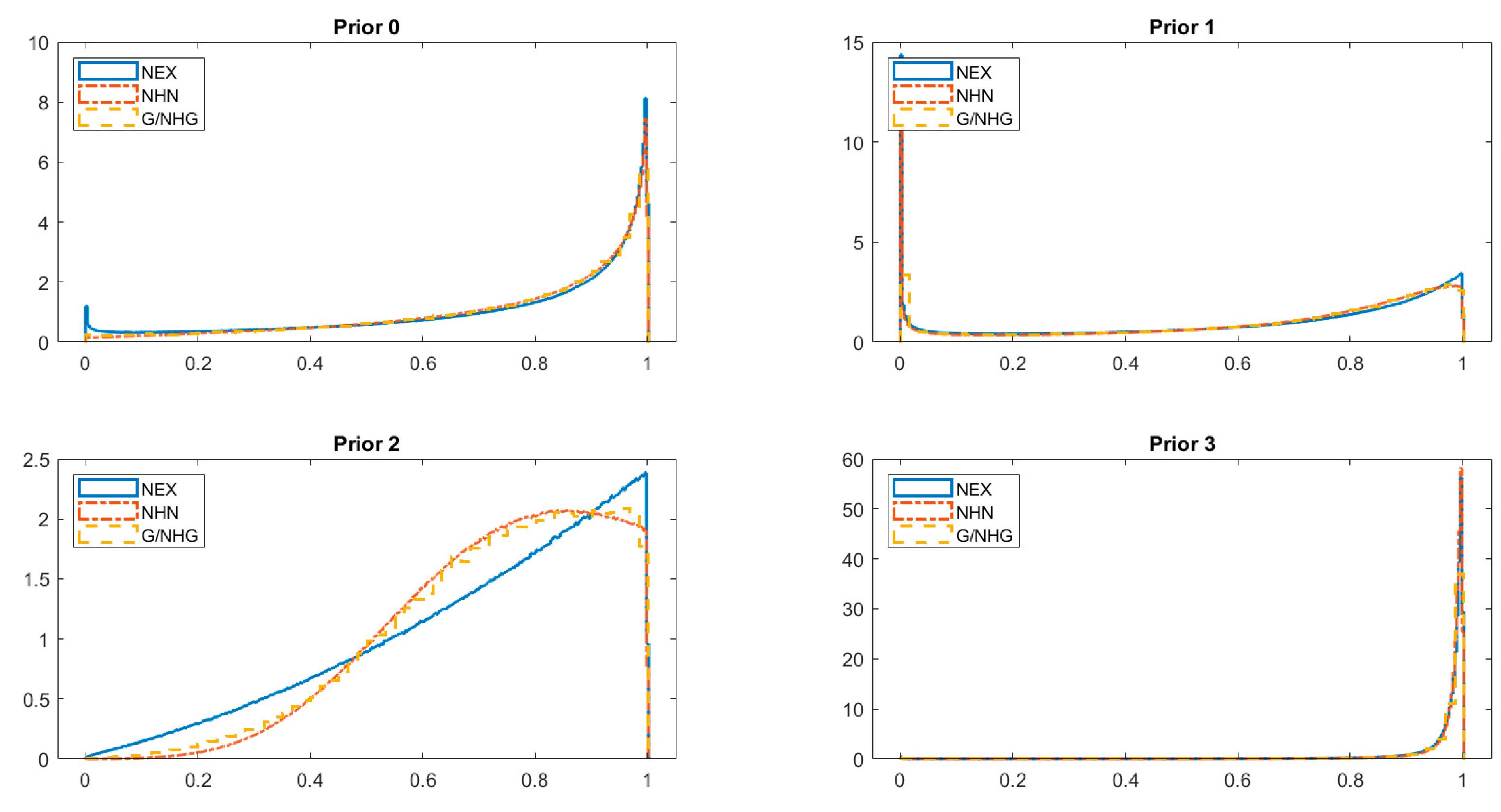
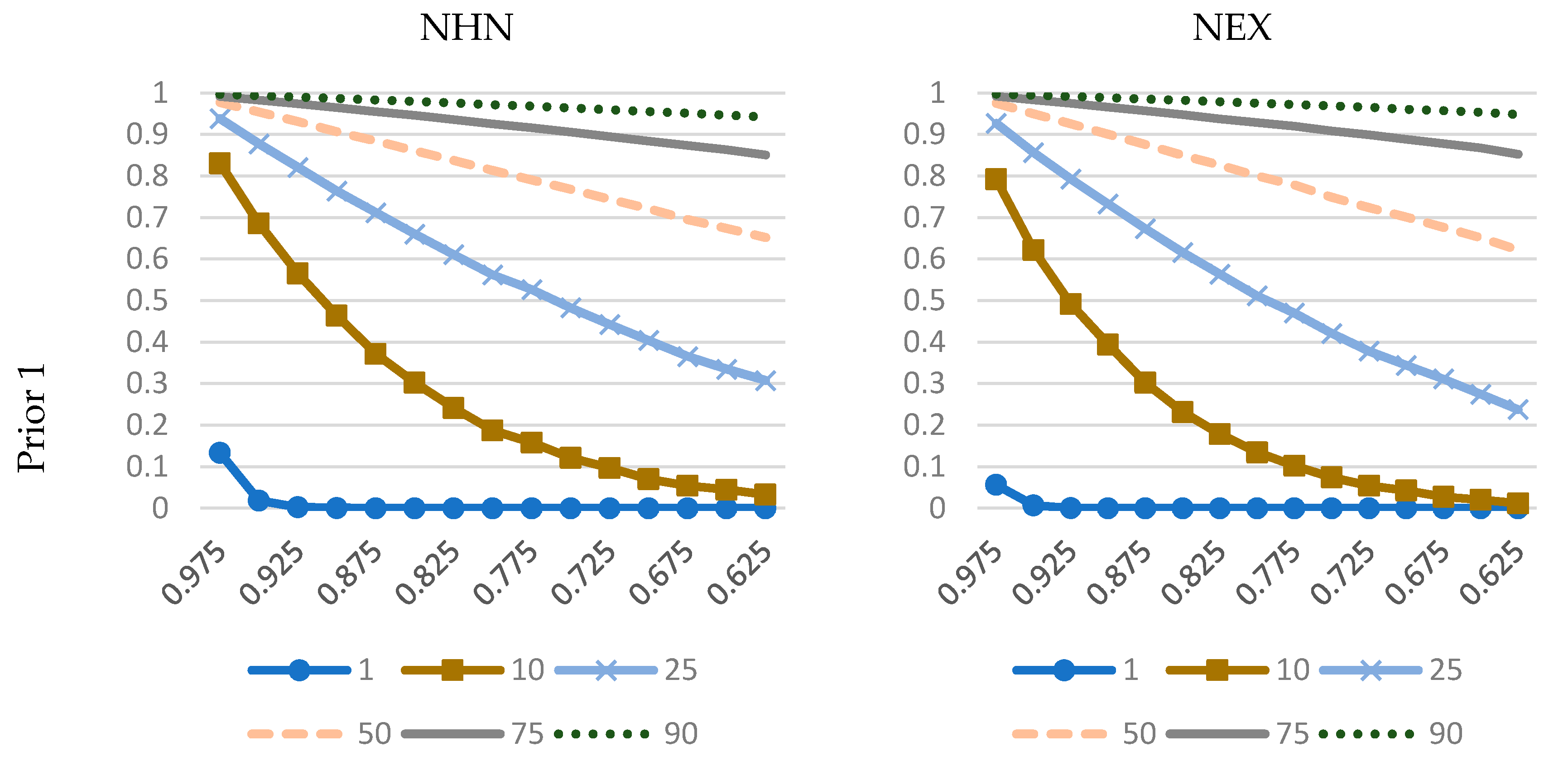
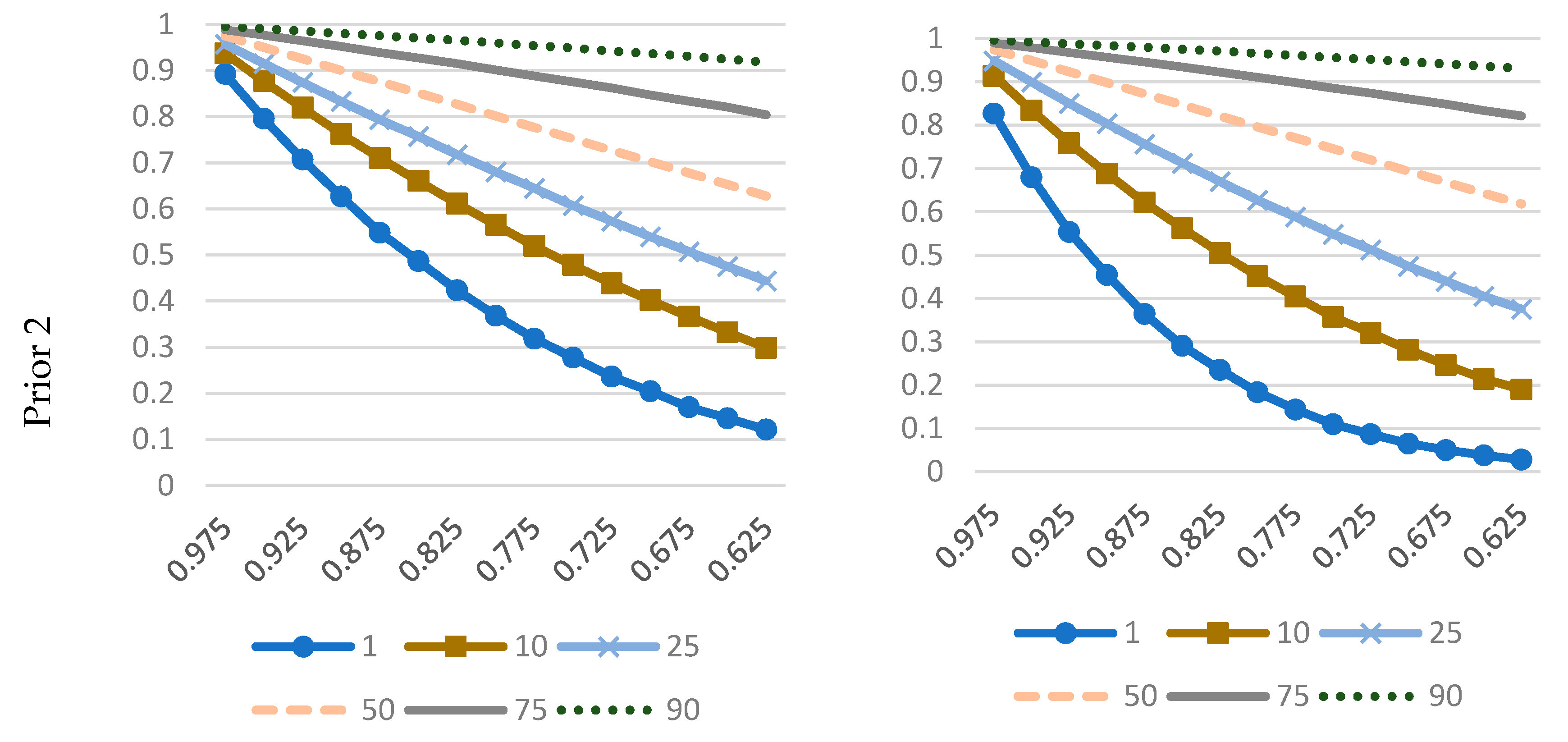
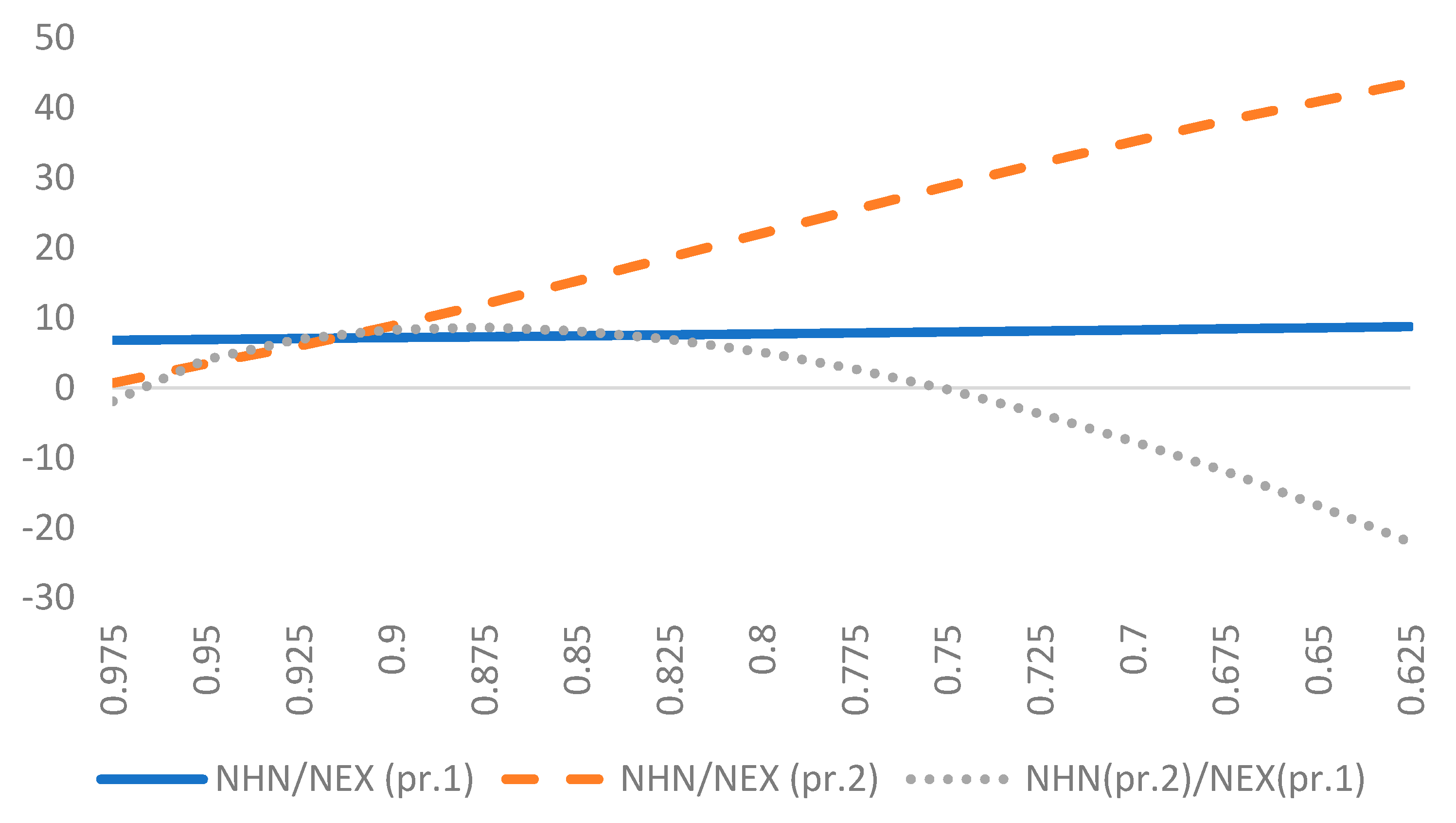
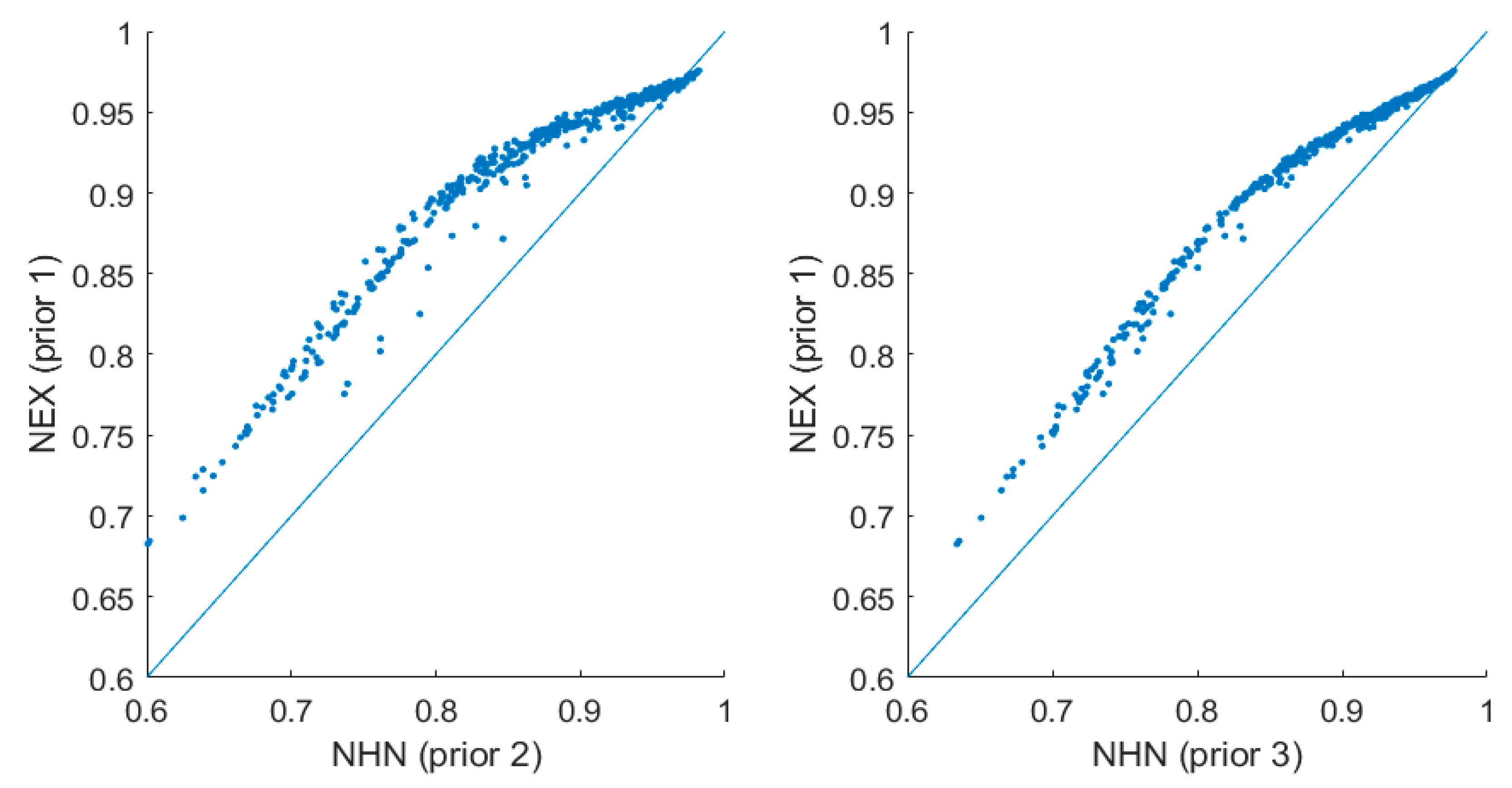
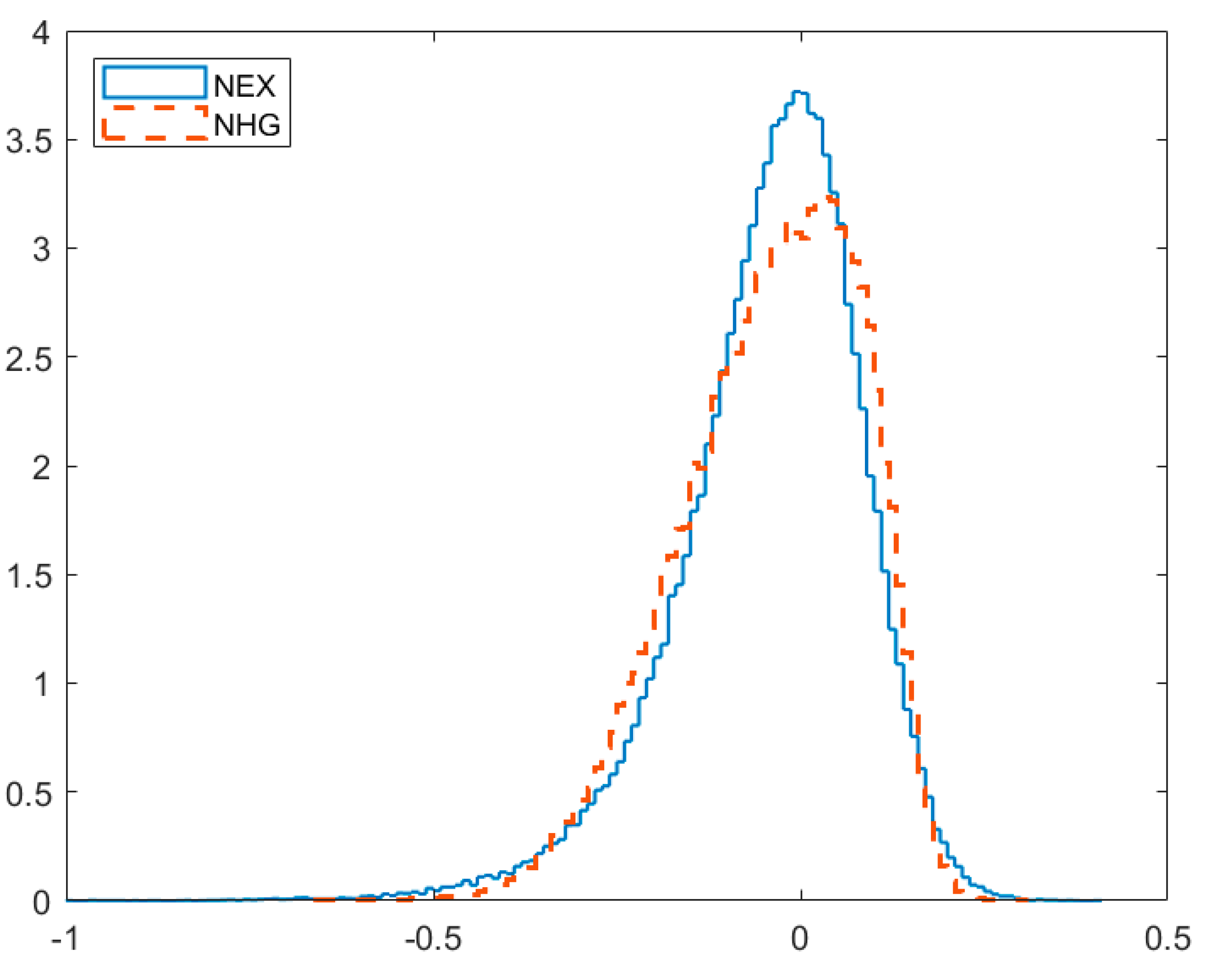
We indicate that the issue of prior elicitation is essential for two reasons. First, posterior model probabilities (crucial from the viewpoint of BMA) are likely to be sensitive to priors. Second, in SFA the quantities of interest are latent variables, which are generally less robust to changes in priors, e.g., compared to statistical parameters, for which dimensionality is independent of the sample size. In particular, we show that priors on , which are widely used in the applied Bayesian SFA, convey very specific (and potentially conflicting) information in certain cases, and this may affect the results of model comparison or inference pooling. We demonstrate that the two most popular models, NHN and NEX, when used with well-known and widely applied prior structures may produce distorted results. We suggest an alternative prior specification that is (informally) less informative. An in-depth analysis leads to the following conclusions about the prior on :
it has virtually no impact on the technology parameters;
it has some impact in terms of inference on the latent variables (i.e., the posterior efficiency estimates, especially in terms of “average” posterior mean and the relative spread of posterior means of efficiency);
it has substantial impact on posterior model probabilities, which are crucial in BMA.
So for the technology parameters the prior on does not really matter much in BMA. However, adequate BMA for latent variables (inefficiencies) requires a prior, which is not only coherent but also well thought through.
We indicate that the problem of adequate prior specification in the general model—the GHG model in this paper, or a more general formulation as in (
Makieła and Mazur 2020)—is still an open research problem. In our view it is reasonable to use proper priors (having the economic context in mind), though further research might lead to some form of relaxation of the prior independence assumption used here, e.g., along the direction proposed in (
Griffin and Steel 2008).
Models considered in this study fall into the so-called Common Efficiency Distribution (CED) class. For further research, it would be interesting to take a step further and consider prior coherence within the so called Varying Efficiency Distribution (VED) class, which allows us to introduce inefficiency determinants (
Koop et al. 1997,
2000). Although VED is traditionally used to extend the NEX it can be relatively easily adapted in NHN specification as well.
Makieła and Mazur (
2020) introduce a VED-type extension of a generalized CED model which nests the GHG specification. In principle it is possible to analyze prior coherence and prior sensitivity within this framework.
Panel data modelling is a large field in SFA. As noted in
Section 3.2.1, the lack of panel data context in the empirical example was to maintain a clear focus of the paper. Of course, accounting for panel structure of the data can bring some new insights as to the nature of inefficiency distribution, especially with regard to its transient and persistent components; see, e.g., (
Tsionas and Kumbhakar 2014;
Makieła 2017). For example, fixing
as constant over time and making it a “traditional” object-specific effect has some advantages over the
pooled estimator used here (italic is used on purpose; the exact form of a pooled estimator in panel data literature does not account for inefficiency). Inefficiency is estimated based on
t observations, which means there are more data points based on which the posterior is evaluated. This, in turn, may allow for a more accurate identification of the functional form of inefficiency distribution.
Although there is a considerable research that advocates non-monotonic (in)efficiency densities, (in)efficiency pdf’s considered in this study are monotonic. We feel this is reasonable in the presence of a generalized symmetric error (see discussion in
Section 2). The modelling framework proposed by (
Makieła and Mazur 2020), however, does not require monotonicity assumption of (in)efficiency. Hence, this avenue can be further researched based on the methodology presented here and in (
Makieła and Mazur 2020).
Last but not least, simulation-based analyses within this framework are compelling. The SFA literature would benefit greatly from examples based on multiple artificial datasets generated based on data generating processes (DGPs) that assume different (in)efficiency distributions. This way one could compare how various sampling models and prior assumptions perform under different DGPs. Moreover, it would be also beneficial to present results based on several hundred or even thousand realizations of a given dataset. This way one would be certain that the results are not, at least partially, due to the idiosyncrasies of a single artificial dataset. However, given that the estimation procedure for the SFA framework proposed by (
Makieła and Mazur 2020) is still at its infancy it would be extremely time-consuming to try such an endeavor now. Thus, we leave this for further research when the numerical procedures are fully developed (especially in terms of taking full advantage of parallelization) and packaged.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}