
Climate Finance: Mapping Air Pollution and Finance Market in Time Series


Abstract
:1. Introduction
2. Time Series Modeling
2.1. Box–Jenkins’s Method
2.2. Model Selection
- AIC = .
- BIC =
- HQ =
3. Methodology and Data
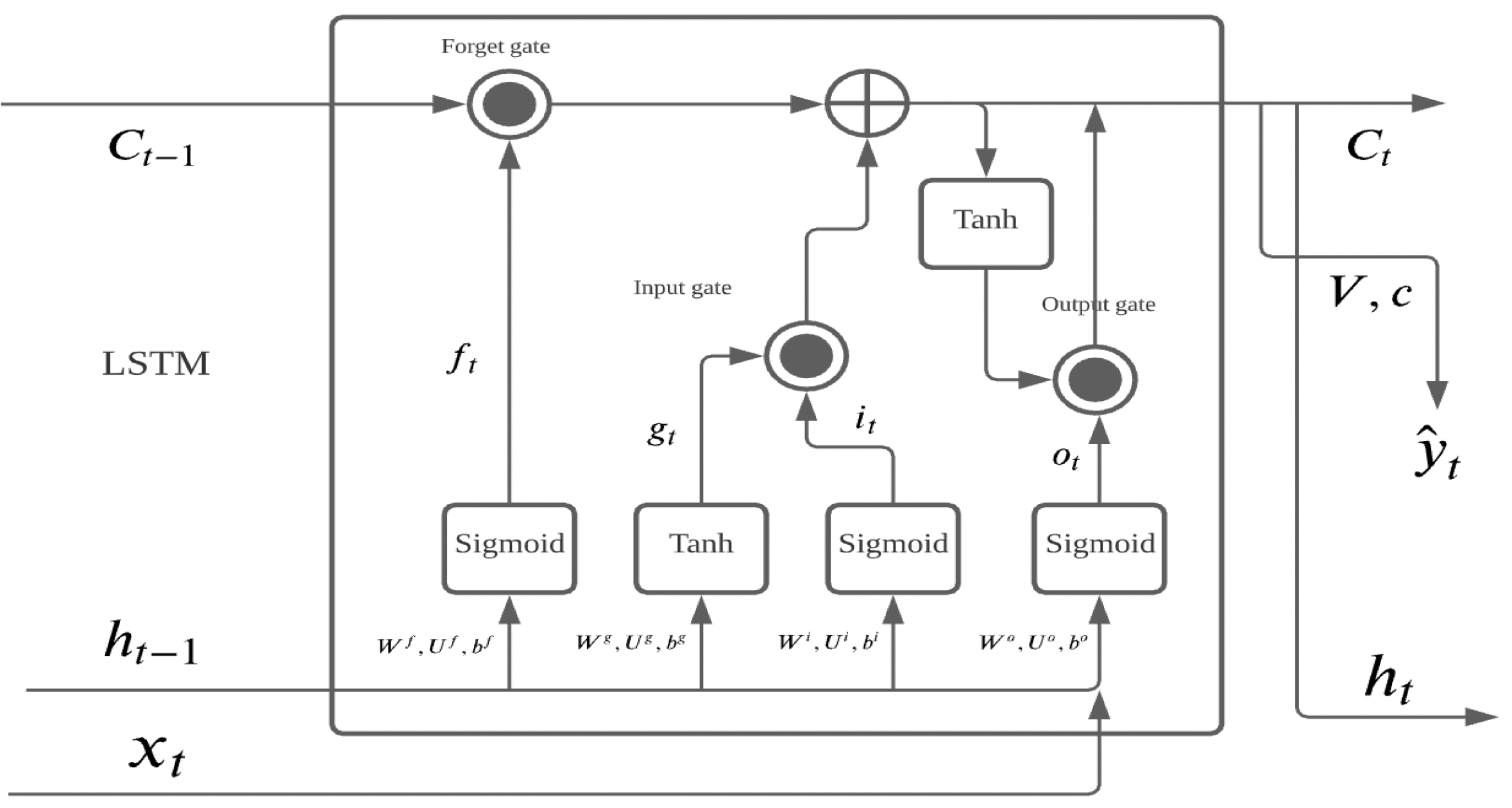
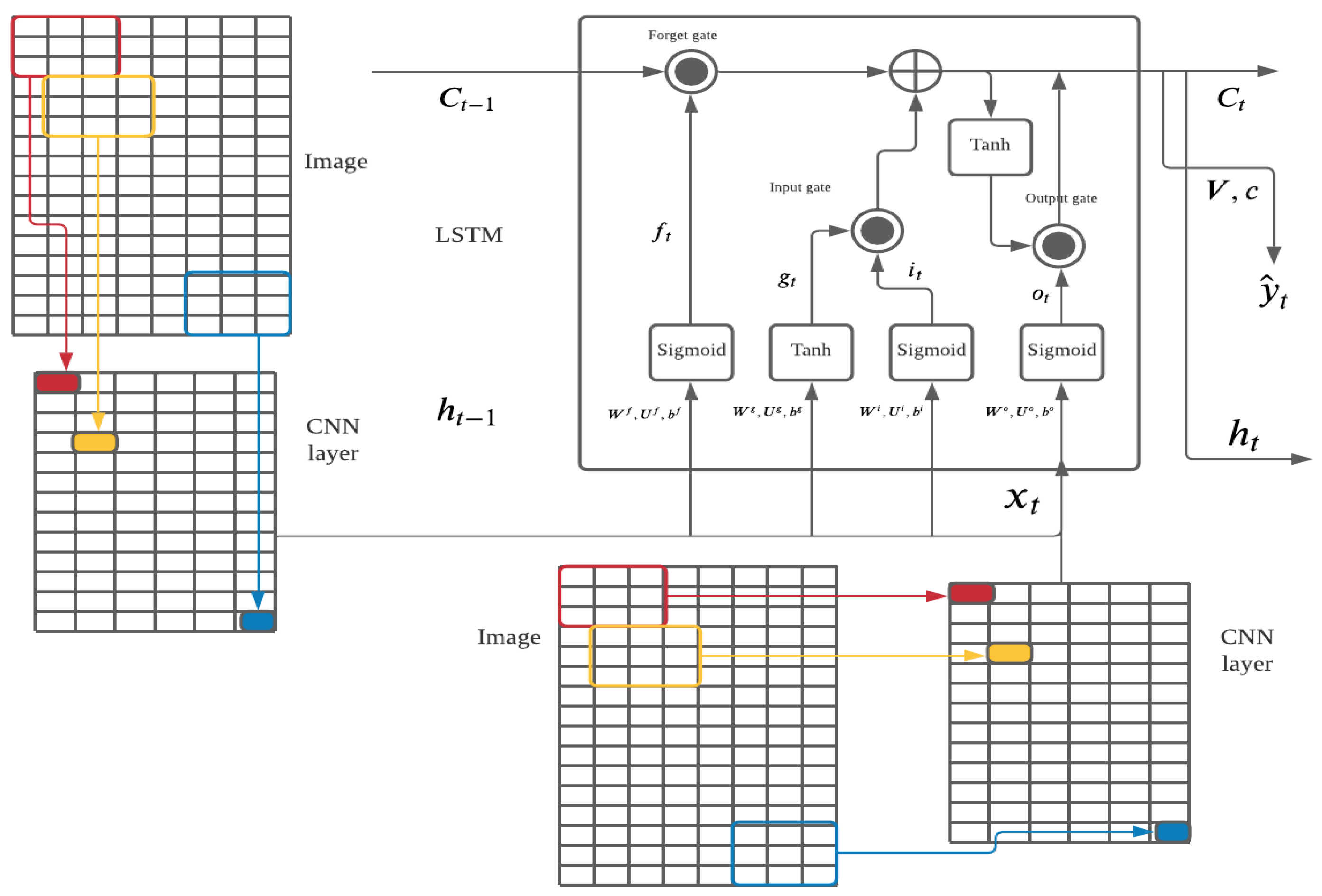
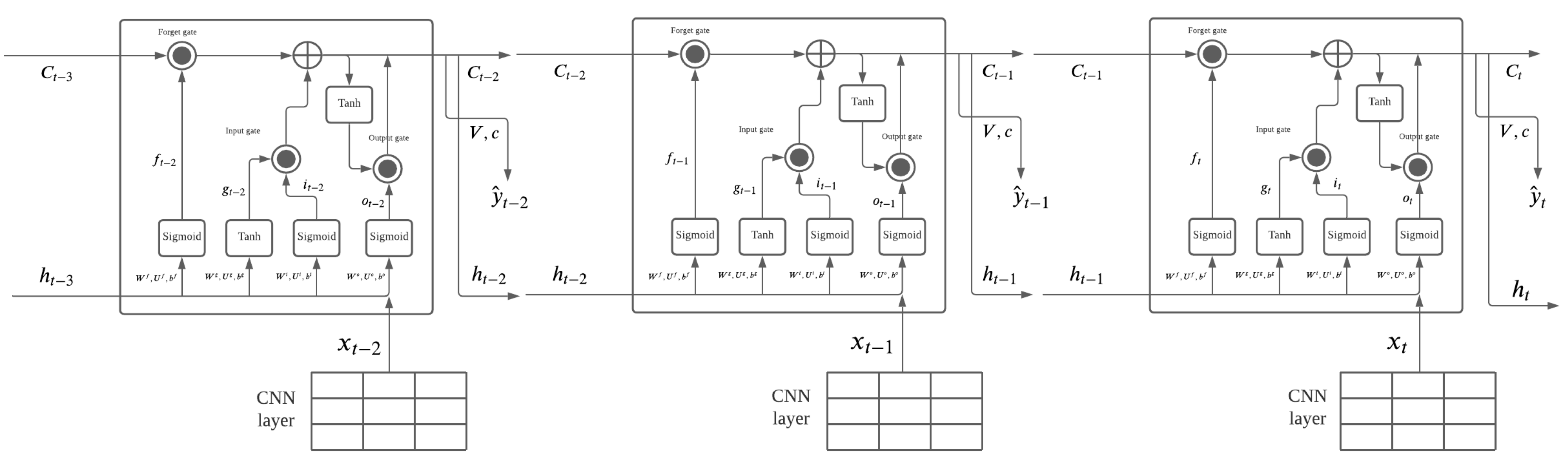
3.1. Methodology
- =
- Forget gate:
- Input gate:
- Long-term state:
- Output gate:
- Short-term state:
- Output:
| Algorithm 1 Algorithm with ConvLSTM2D Model |
| Require: number of epochs while i ≤ epochs do model.add(ConvLSTM2D(filters=64, kernel size=(3, 3), input shape=(batch size, number of frames, height, width, channels), padding= “same”, return sequences=True, activation=“relu”)) model.add(BatchNormalization()) model.add(ConvLSTM2D(filters=64, kernel size=(3, 3), padding=“same”, return sequences=True, activation=“relu")) model.add(Flatten()) model.add(Dense(256, activation=‘relu’)) model.add(Dense(1)) end while |
| Algorithm 2 Algorithm with updating feature term by using gradient descent |
| Require: number of epochs while i ≤ epochs do 1. Predicting the value of feature term from trained ConvLSTM2D model 2. Modeling the linear regression by ordinary least squares 3. Using gradient descent and hyperparameter of learning rate.to update the feature term 4. Train ConvLSTM2D model by new feature term end while |
3.2. Data
4. Experiment
4.1. Beijing
4.2. Taiyuan
4.3. Shijiazhuang
4.4. Changchun
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Adebiyi, Ayodele Ariyo, Aderemi Oluyinka Adewumi, and Charles Korede Ayo. 2014. Comparison of ARIMA and artificial neural networks models for stock price prediction. Journal of Applied Mathematics 2014: 137–45. [Google Scholar] [CrossRef] [Green Version]
- Agarap, Abien Fred. 2018. Deep learning using rectified linear units (relu). arXiv arXiv:1803.08375. [Google Scholar]
- Akaike, Hirotugu. 1974. A new look at the statistical model identification. IEEE Transactions on Automatic Control 19: 716–23. [Google Scholar] [CrossRef]
- Albawi, Saad, Tareq Abed Mohammed, and Saad Al-Zawi. 2017. Understanding of a convolutional neural network. Paper presented at 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, August 21–23; pp. 1–6. [Google Scholar]
- Alberg, Dima, Haim Shalit, and Rami Yosef. 2008. Estimating stock market volatility using asymmetric GARCH models. Applied Financial Economics 18: 1201–8. [Google Scholar] [CrossRef] [Green Version]
- Anwar, Muhammad Naveed, Muneeba Shabbir, Eza Tahir, Mahnoor Iftikhar, Hira Saif, Ajwa Tahir, Malik Ashir Murtaza, Muhammad Fahim Khokhar, Mohammad Rehan, Mortaza Aghbashlo, and et al. 2021. Emerging challenges of air pollution and particulate matter in China, India, and Pakistan and mitigating solutions. Journal of Hazardous Materials 416: 125851. [Google Scholar] [CrossRef] [PubMed]
- Banerjee, Suman, Vladimir A. Gatchev, and Paul A. Spindt. 2007. Stock market liquidity and firm dividend policy. Journal of Financial and Quantitative Analysis 42: 369–97. [Google Scholar] [CrossRef]
- Banga, Josué. 2019. The green bond market: A potential source of climate finance for developing countries. Journal of Sustainable Finance and Investment 9: 17–32. [Google Scholar] [CrossRef]
- Biau, David Jean, Brigitte M. Jolles, and Raphaël Porcher. 2010. P value and the theory of hypothesis testing: An explanation for new researchers. Clinical Orthopaedics and Related Research® 468: 885–92. [Google Scholar] [CrossRef] [Green Version]
- Bierens, H. J. 2004. Information Criteria and Model Selection. University Park: Penn State University. [Google Scholar]
- Bodansky, Daniel. 2016. The Paris climate change agreement: A new hope? American Journal of International Law 110: 288–319. [Google Scholar] [CrossRef] [Green Version]
- Box, George E. P., Gwilym M. Jenkins, and Gregory C. Reinsel. 1976. Time Series Analysis Prediction and Control. Hoboken: Wiley. [Google Scholar]
- Box, George E. P., Gwilym M. Jenkins, Gregory C. Reinsel, and Greta M. Ljung. 2015. Time Series Analysis, Control, and Forecasting. Hoboken: John Wiley & Sons. [Google Scholar]
- Box, George E. P., Gwilym M. Jenkins, Gregory C. Reinsel, and Greta M. Ljung. 2016. Time Series Analysis: Forecasting and Control. Hoboken: John Willey and Sons. [Google Scholar]
- Buchner, Barbara, Alex Clark, Angela Falconer, Rob Macquarie, Chavi Meattle, and Cooper Wetherbee. 2019. Global Landscape of Climate Finance. San Francisco: Climate Policy Initiative. [Google Scholar]
- Chen, Niya, Zheng Qian, Ian T. Nabney, and Xiaofeng Meng. 2013. Wind power forecasts using Gaussian processes and numerical weather prediction. IEEE Transactions on Power Systems 29: 656–65. [Google Scholar] [CrossRef] [Green Version]
- Emmert-Streib, Frank, and Matthias Dehmer. 2019. Understanding statistical hypothesis testing: The logic of statistical inference. Machine Learning and Knowledge Extraction 1: 945–61. [Google Scholar] [CrossRef] [Green Version]
- Fang, Zheng, David L. Dowe, Shelton Peiris, and Dedi Rosadi. 2021a. Minimum Message Length in Hybrid ARMA and LSTM Model Forecasting. Entropy 23: 1601. [Google Scholar] [CrossRef]
- Fang, Zheng, David L. Dowe, Shelton Peiris, and Dedi Rosadi. 2021b. Minimum Message Length Autoregressive Moving Average Model Order Selection. arXiv arXiv:2110.03250. [Google Scholar]
- Fitzgibbon, Leigh J., David L. Dowe, and Farshid Vahid. 2004. Minimum message length autoregressive model order selection. Paper presented at International Conference on Intelligent Sensing and Information Processing, Chennai, India, January 4–7; pp. 439–44. [Google Scholar]
- Grigoriu, Mircea. 2013. Stochastic Calculus: Applications in Science and Engineering. Berlin/Heidelberg: Springer Science and Business Media. [Google Scholar]
- Hochreiter, Sepp, and Jürgen Schmidhuber. 1997. Long short-term memory. Neural Computation 9: 1735–80. [Google Scholar] [CrossRef]
- Hong, Harrison, G. Andrew Karolyi, and José A. Scheinkman. 2020. Climate finance. The Review of Financial Studies 33: 1011–23. [Google Scholar] [CrossRef]
- Hyndman, R. J., G. Athanasopoulos, C. Bergmeir, G. Caceres, L. Chhay, M. O’Hara-Wild, Fotios Petropoulos, Slava Razbash, and E. Wang. 2020. Package ‘Forecast’. Available online: https://cran.r-project.org/web/packages/forecast/forecast.pdf (accessed on 3 November 2021).
- Jiang, Jing Jing, Bin Ye, and Xiao Ming Ma. 2014. The construction of Shenzhen carbon emission trading scheme. Energy Policy 75: 17–21. [Google Scholar] [CrossRef]
- Kelotra, Amit, and Prateek Pandey. 2020. Stock market prediction using optimized deep-convlstm model. Big Data 8: 5–24. [Google Scholar] [CrossRef] [Green Version]
- Kelp, Makoto M., Andrew P. Grieshop, Conor CO Reynolds, Jill Baumgartner, Grishma Jain, Karthik Sethuraman, and Julian D. Marshall. 2018. Real-time indoor measurement of health and climate-relevant air pollution concentrations during a carbon-finance-approved cookstove intervention in rural India. Development Engineering 3: 125–32. [Google Scholar] [CrossRef]
- Lelieveld, Jos, John S. Evans, Mohammed Fnais, Despina Giannadaki, and Andrea Pozzer. 2015. The contribution of outdoor air pollution sources to premature mortality on a global scale. Nature 525: 367–71. [Google Scholar] [CrossRef]
- Li, Jin, and Shanying Hu. 2017. History and future of the coal and coal chemical industry in China. Resources, Conservation and Recycling 124: 13–24. [Google Scholar] [CrossRef]
- Li, Li, Yalin Lei, Qun Xu, Sanmang Wu, Dan Yan, and Jiabin Chen. 2017. Crowding-out effect of coal industry investment in coal mining area: Taking Shanxi province in China as a case. Environmental Science and Pollution Research 24: 23290–98. [Google Scholar] [CrossRef] [PubMed]
- Liu, Yipeng, Haifeng Zheng, Xinxin Feng, and Zhonghui Chen. 2017. Short-term traffic flow prediction with Conv-LSTM. Paper presented at 2017 9th International Conference on Wireless Communications and Signal Processing (WCSP), Nanjing, China, October 11–13; pp. 1–6. [Google Scholar]
- Mehtab, Sidra, and Jaydip Sen. 2020. A time series analysis-based stock price prediction using machine learning and deep learning models. International Journal of Business Forecasting and Marketing Intelligence 6: 272–335. [Google Scholar] [CrossRef]
- Neath, Andrew A., and Joseph E. Cavanaugh. 2012. The Bayesian information criterion: Background, derivation, and applications. Wiley Interdisciplinary Reviews: Computational Statistics 4: 199–203. [Google Scholar] [CrossRef]
- Pang, Xiongwen, Yanqiang Zhou, Pan Wang, Weiwei Lin, and Victor Chang. 2020. An innovative neural network approach for stock market prediction. The Journal of Supercomputing 76: 2098–118. [Google Scholar] [CrossRef]
- Retta, Sivaji, Pavan Yarramsetti, and Sivalal Kethavath. 2021. Comprehensive Analysis of Deep Learning Approaches for PM2.5 Forecasting. In Proceedings of International Conference on Computational Intelligence and Data Engineering. Singapore: Springer, pp. 311–22. [Google Scholar]
- Sari, Anggraini Puspita, Hiroshi Suzuki, Takahiro Kitajima, Takashi Yasuno, Dwi Arman Prasetya, and Abd Rabi. 2020. Prediction of wind speed and direction using encoding-forecasting network with convolutional long short-term memory. Paper presented at 2020 59th Annual Conference of the Society of Instrument and Control Engineers of Japan (SICE), Chiang Mai, Thailand, September 23–26; pp. 958–63. [Google Scholar]
- Sakamoto, Yosiyuki, Makio Ishiguro, and Genshiro Kitagawa. 1986. Akaike Information Criterion Statistics. Dordrecht: D. Reidel, vol. 81, p. 26853. [Google Scholar]
- Sak, Mony, David L. Dowe, and Sid Ray. 2005. Minimum message length moving average time series data mining. Paper presented at 2005 ICSC Congress on Computational Intelligence Methods and Applications, Istanbul, Turkey, December 15–17; p. 6. [Google Scholar]
- Wooldridge, Jeffrey M. 2015. Introductory Econometrics: A Modern Approach. Boston: Cengage Learning. [Google Scholar]
- Xu, Z., and Y. Lv. 2019. Att-ConvLSTM: PM2.5 Prediction Model and Application. In Proceedings of International Conference on Natural Computation, Fuzzy Systems and Knowledge Discovery. Cham: Springer, pp. 30–40. [Google Scholar]
- Yonaba, H., F. Anctil, and V. Fortin. 2010. Comparing sigmoid transfer functions for neural network multistep ahead streamflow forecasting. Journal of Hydrologic Engineering 15: 275–83. [Google Scholar] [CrossRef]
- Zhao, Yongning, Lin Ye, Pierre Pinson, Yong Tang, and Peng Lu. 2018. Correlation-constrained and sparsity-controlled vector autoregressive model for spatio-temporal wind power forecasting. IEEE Transactions on Power Systems 33: 5029–40. [Google Scholar] [CrossRef] [Green Version]




{kind=link}
{kind=link}
{kind=link}
| Parameters of p in AR Selected by MML for Different Stock and Learning Rate Used in Different Stock | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Beijing | Taiyuan | Shijiazhuang | Changchun | |||||||
| Shougang | Shenhua | Sany | Datong Coal | Shanxi Coal | Sanxi Coking | Hbis | Maanshan Iron & Steel | FAW Jiefang | FAWAY | |
| p | 2 | 2 | 2 | 2 | 2 | 3 | 2 | 2 | 3 | 5 |
| 0.001 | 0.001 | 0.001 | 0.1 | 0.1 | 0.1 | 0.01 | 0.01 | 0.1 | 0.1 | |
| Model Comparison for the Stock Prices of Heavy Manufacturers in Beijing | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| MAE | 1.667209 | MAE | 3.225985 | MAE | 2.147781 | ||||
| Our model | Shougang | RMSE | 1.886901 | Shenhua | RMSE | 3.877564 | Sany | RMSE | 2.54785 |
| SSE | 192.2613 | SSE | 811.9173 | SSE | 350.5432 | ||||
| MAE | 1.910572 | MAE | 2.660931 | MAE | 2.502593 | ||||
| ARIMA | Shougang | RMSE | 2.137925 | Shenhua | RMSE | 3.16369 | Sany | RMSE | 2.967872 |
| SSE | 246.819 | SSE | 540.4825 | SSE | 475.6462 | ||||
| MAE | 2.678831 | MAE | 6.436293 | MAE | 14.61221 | ||||
| Historical mean | Shougang | RMSE | 2.853079 | Shenhua | RMSE | 6.844118 | Sany | RMSE | 14.79293 |
| SSE | 439.5633 | SSE | 2529.466 | SSE | 11816.86 | ||||
| Linear Regression Information | |||||
|---|---|---|---|---|---|
| Coefficients | Std. Error | t value | Pr(>t) | ||
| Intercept | 0.01068 | 0.03091 | 0.345 | 0.7298 | |
| Shougang | 0.52152 | 0.24484 | 2.130 | 0.0333 | |
| 0.45570 | 0.02264 | 20.131 | <2 | ||
| 0.53029 | 0.02267 | 23.395 | <2 | ||
| Coefficients | Std. Error | t value | Pr(>t) | ||
| Intercept | 0.29036 | 0.08952 | 3.244 | 0.00121 | |
| Shenhua | −1.34605 | 0.52752 | −2.552 | 0.01082 | |
| 0.12063 | 0.02525 | 4.777 | 1.95 | ||
| 0.86798 | 0.02526 | 34.367 | <2 | ||
| Coefficients | Std. Error | t value | Pr(>t) | ||
| Intercept | 0.37402 | 0.07062 | 5.296 | 1.35 | |
| Sany | −3.37391 | 0.63969 | −5.274 | 1.52 | |
| 0.02706 | 0.02532 | 1.069 | 0.285 | ||
| 0.96849 | 0.02535 | 38.208 | <2 | ||
| Model Comparison for the Stock Prices of Heavy Manufacturers in Taiyuan | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| MAE | 3.870204 | MAE | 3.09871 | MAE | 2.432536 | ||||
| Our model | Datong | RMSE | 4.493543 | Shanxi | RMSE | 3.737073 | Sanxi | RMSE | 2.984308 |
| SSE | 1090.364 | SSE | 754.1486 | SSE | 480.9291 | ||||
| MAE | 3.341736 | MAE | 2.864032 | MAE | 2.467751 | ||||
| ARIMA | Datong | RMSE | 3.941559 | Shanxi | RMSE | 3.501327 | Sanxi | RMSE | 3.004132 |
| SSE | 838.9378 | SSE | 662.0017 | SSE | 487.3397 | ||||
| MAE | 5.834804 | MAE | 5.004533 | MAE | 3.369719 | ||||
| Historical mean | Datong | RMSE | 6.262535 | Shanxi | RMSE | 5.529563 | Sanxi | RMSE | 3.838642 |
| SSE | 2117.845 | SSE | 1651.108 | SSE | 795.6992 | ||||
| Linear Regression Information | |||||
|---|---|---|---|---|---|
| Coefficients | Std. Error | t value | Pr(>t) | ||
| Intercept | −0.21564 | 0.03424 | −6.298 | 3.92 | |
| Datong | 1.98953 | 0.16299 | 12.207 | <2 | |
| −0.08842 | 0.02430 | −3.638 | 0.00283 | ||
| 0.11288 | 0.03054 | 3.696 | 0.000227 | ||
| 0.01822 | 0.03084 | 0.591 | 0.554809 | ||
| 0.17709 | 0.03053 | 5.800 | 8.03 | ||
| 0.75360 | 0.02432 | 30.992 | <2 | ||
| Coefficients | Std. Error | t value | Pr(>t) | ||
| Intercept | −0.96186 | 0.02383 | −40.362 | <2 | |
| Shanxi | 4.93618 | 0.10239 | 48.209 | <2 | |
| 0.16002 | 0.01605 | 9.971 | <2 | ||
| 0.83104 | 0.01605 | 51.778 | <2 | ||
| Coefficients | Std. Error | t value | Pr(>t) | ||
| Intercept | −0.41074 | 0.03359 | −12.228 | <2 | |
| Sanxi | 3.42941 | 0.15495 | 22.133 | <2 | |
| 0.12370 | 0.02206 | 5.609 | 2.41 | ||
| 0.25412 | 0.02522 | 10.078 | <2 | ||
| 0.57790 | 0.02210 | 26.155 | <2 | ||
| Model Comparison for the Stock Prices of Heavy Manufacturers in Shijiazhuang | ||||||
|---|---|---|---|---|---|---|
| MAE | 0.476300 | MAE | 1.330529 | |||
| Our model | Hbis | RMSE | 0.532923 | Maanshan | RMSE | 1.495913 |
| SSE | 15.33638 | SSE | 120.8388 | |||
| MAE | 0.516722 | MAE | 1.596509 | |||
| ARIMA | Hbis | RMSE | 0.571172 | Maanshan | RMSE | 1.742506 |
| SSE | 17.61684 | SSE | 163.9617 | |||
| MAE | 0.225341 | MAE | 2.35427 | |||
| Historical mean | Hbis | RMSE | 0.257499 | Maanshan | RMSE | 2.462239 |
| SSE | 3.580536 | SSE | 327.3815 | |||
| Linear Regression Information | |||||
|---|---|---|---|---|---|
| Coefficients | Std. Error | t value | Pr(>t) | ||
| Intercept | 0.002514 | 0.018013 | 0.140 | 0.8890 | |
| Hbis | 0.192569 | 0.093631 | 2.057 | 0.0399 | |
| 0.257325 | 0.024587 | 10.466 | <2 | ||
| 0.731314 | 0.024607 | 29.720 | <2 | ||
| Coefficients | Std. Error | t value | Pr(>t) | ||
| Intercept | 0.023264 | 0.016088 | 1.446 | 0.148 | |
| Maanshan | −0.062328 | 0.538827 | 2.198 | 0.0325 | |
| 0.004165 | 0.025510 | 0.163 | 0.870 | ||
| 0.985218 | 0.025493 | 38.647 | <2 | ||
| Model Comparison for the Stock Prices of Heavy Manufacturers in Changchun | ||||||
|---|---|---|---|---|---|---|
| MAE | 2.107585 | MAE | 1.227716 | |||
| Our model | FAW Jiefang | RMSE | 2.266491 | FAWAY | RMSE | 1.426226 |
| SSE | 277.3969 | SSE | 109.8424 | |||
| MAE | 5.223868 | MAE | 0.592963 | |||
| ARIMA | FAW Jiefang | RMSE | 5.270225 | FAWAY | RMSE | 0.632561 |
| SSE | 1499.864 | SSE | 21.6072 | |||
| MAE | 5.746878 | MAE | 0.738691 | |||
| Historical mean | FAW Jiefang | RMSE | 5.78802 | FAWAY | RMSE | 0.79334 |
| SSE | 1809.064 | SSE | 33.987 | |||
| Linear Regression Information | |||||
|---|---|---|---|---|---|
| Coefficients | Std. Error | t value | Pr(>t) | ||
| Intercept | −0.31293 | 0.03808 | −8.218 | 4.33 | |
| FAW Jiefang | 3.81093 | 0.19918 | 19.134 | <2 | |
| −0.08317 | 0.02279 | −3.649 | 0.00272 | ||
| 1.05703 | 0.02283 | 46.296 | <2 | ||
| Coefficients | Std. Error | t value | Pr(>t) | ||
| Intercept | −0.013665 | 0.038441 | −0.355 | 0.7223 | |
| 0.556075 | 0.111146 | 5.003 | 6.29 | ||
| 0.004234 | 0.025303 | 0.167 | 0.8671 | ||
| FAWAY | −0.030430 | 0.036429 | −0.835 | 0.4037 | |
| 0.058581 | 0.036462 | 1.607 | 0.1083 | ||
| −0.078380 | 0.036433 | −2.151 | 0.0316 | ||
| 1.036221 | 0.025285 | 40.981 | <2 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fang, Z.; Xie, J.; Peng, R.; Wang, S. Climate Finance: Mapping Air Pollution and Finance Market in Time Series. Econometrics 2021, 9, 43. https://doi.org/10.3390/econometrics9040043
Fang Z, Xie J, Peng R, Wang S. Climate Finance: Mapping Air Pollution and Finance Market in Time Series. Econometrics. 2021; 9(4):43. https://doi.org/10.3390/econometrics9040043
Chicago/Turabian StyleFang, Zheng, Jianying Xie, Ruiming Peng, and Sheng Wang. 2021. "Climate Finance: Mapping Air Pollution and Finance Market in Time Series" Econometrics 9, no. 4: 43. https://doi.org/10.3390/econometrics9040043
APA StyleFang, Z., Xie, J., Peng, R., & Wang, S. (2021). Climate Finance: Mapping Air Pollution and Finance Market in Time Series. Econometrics, 9(4), 43. https://doi.org/10.3390/econometrics9040043