1. Introduction
Stratospheric airships are a type of high-altitude aerostat that uses lighter-than-air gas as a lifting source and will drift with local wind or must expend energy to fight it. Stratospheric airships use a cyclic energy system, which primarily consists of a photovoltaic (PV) array, a DC/DC converter with maximum power point tracking (MPPT) functionality, and energy storage batteries to provide the energy required for flight, and can fly continuously for months or even years. Stratospheric airships have a high flight altitude, long float time, wide coverage, and monitoring range. Thus, they can be used for broad applications, such as communication relay, meteorological observation, and disaster warning [
1,
2,
3]. Stratospheric airships can also be used to form intelligent networked unmanned systems, further expanding their application range [
4]. Many technological powerhouses around the world are actively promoting the research and verification of stratospheric airship-related technologies [
5,
6,
7,
8].
Due to the current low conversion efficiency of solar cells and the low energy density of energy storage batteries, the energy balance of stratospheric airships during flight can only be maintained weakly and is easily broken, which is also the main challenge faced by stratospheric airships during long-term flight. Since the solar array provides all the energy required for airship flight, accurately and quickly predicting the output power of the array is critical to maintaining the energy balance of the airship.
In the initial research on the output characteristics of solar arrays, some scholars only focused on the influence of irradiation distribution on the output power of the solar array. For instance, Wang et al. [
9] and Shi et al. [
10] initially proposed a numerical computational method for assessing the solar radiation distribution on the PV array of a stratospheric airship. However, as research has increased in intensity, many studies have established high-precision simulation models for calculating the output power of stratospheric airship solar arrays. Sun et al. [
11] discussed existing photovoltaic modeling methods and divided them into circuit models, engineering models, and fitting models, providing a reference for selecting appropriate modeling methods based on the requirements for model accuracy and application scenarios. Pande et al. [
12] analyzed the impact of solar cell output characteristics and operating conditions of different material systems on the size of solar non-rigid airships. Tang et al. [
13] discussed the numerical calculation method for the output power of solar cell arrays in the optimization process of stratospheric airships. Song et al. [
14] considered the output characteristics of solar arrays under non- maximum power point tracking (MPPT) mode, which further improved the accuracy of the array power generation model. Liu et al. [
15] calculated the non-uniform irradiation and temperature in the solar array of a stratospheric airship and established a simulation model to analyze the mismatch loss of the array under different flight conditions. Shan et al. [
16] found that changes in the yaw and pitch angles of stratosphere airships are the main cause of solar array mismatch loss. In addition to reducing the maximum output power, mismatch losses can also mislead the MPPT process, further reducing the actual output power. Liu et al. [
17] proposed a solar array output power model that includes the insulation layer structure and analyzed the relationship between the thickness of the insulation layer and the array output power. Zhu et al. [
18] studied the effect of thermal effects on the output energy of the solar array on stratosphere airships and found that the temperature difference of photovoltaic modules at different positions in the array is significant, and the output power is significantly reduced compared with that without thermal effects.
In order to further enhance the energy acquisition during the operation of airships, some researchers are focusing on the design of flight strategies and attitude planning. Zhang et al. [
19] proposed an attitude angle planning strategy that integrates roll, yaw, and pitch controls to enhance the energy production of PV arrays and the wind resistance of airships. In addition, another factor cannot be ignored—namely shading (which is due to the installation of the top equipment or the flight attitude of the platform). Some existing research findings can serve as references for analyzing this issue. Belhachat et al. [
20] conducted a comprehensive analysis of the output characteristics of solar arrays under shading conditions, summarized the reconstruction strategies of photovoltaic arrays, and evaluated the advantages and disadvantages of different methods. Venkateswari et al. [
21] further tested and verified various shading situations by building a testing device.
For the application of traditional simulation models mentioned above, in order to improve model accuracy, it is necessary to consider more influencing factors during the modeling process and add more components according to the actual situation. This will inevitably increase the complexity of the model, leading to higher computational resource consumption. In recent years, data-driven surrogate modeling methods have been used more and more frequently. Surrogate models are machine learning methods that use sensor datasets to obtain a corresponding relationship through a certain learning method. The models are trained using only input–output data and do not involve calculating parameters, thereby greatly reducing run time. Surrogate models include two forms of offline learning and online learning. Offline learning divides the dataset into training and testing sets and obtains a model for prediction after training and testing. After the training is completed, the parameters in the model will be fixed. If new data types appear, the dataset needs to be imported to retrain the model. Online learning uses streaming data for training. By continuously sending newly generated data for training, the model is continuously refined, and the relevant parameters can be continuously updated. Currently, many studies use online learning models to solve real-time prediction problems in many fields. Luo et al. [
22] applied online incremental learning methods to precipitation nowcasting to adapt to real-time changes in precipitation data. Wu et al. [
23] proposed an online adaptation framework based on surrogate learning to deal with concept drift problems in time series prediction in the energy field. Compared with offline models, the accuracy was improved by more than 50%. Lu et al. [
24] proposed a flight training data prediction model based on incremental learning, which also provided high prediction accuracy and exceptional real-time performance. Liu et al. [
25] used online learning methods to update model parameters in the prediction of solar power generation, thereby avoiding the need for the entire retraining process and having the ability to maintain and enhance accuracy. Kraemer et al. [
26] used online machine learning methods to predict indoor photovoltaic energy within 24 h and found that simple machine learning methods are much better than persistence predictors. Puah et al. [
27] used a regression unsupervised incremental learning algorithm to predict solar irradiance, and incremental learning enables the model to address climate change and has good long-term predictive performance.
Regarding the solar array of a stratospheric airship, during its flight, the solar cells may experience attenuation or damage due to continuous exposure to sunlight, the aging of the film, hot spots, or wind vibration, which can lead to a decrease in conversion efficiency. If the model is not corrected to a certain extent, such errors will continue to accumulate and affect the prediction accuracy of the model. Online learning methods can effectively avoid this issue.
This paper proposes a surrogate modeling method based on online learning to predict the output power of the solar array on a stratospheric airship during flight. All the data required for training come from sensors mounted on the stratospheric airship itself, and the trained model can accurately predict the output power and adapt to abnormal states such as photovoltaic module attenuation or damage. Moreover, since the model consumes fewer computational resources, it can run on the stratospheric airship computers and provide guidance for autonomous flight.
Section 1 introduces the relevant background.
Section 2 introduces the online learning model and derives the relevant formulas.
Section 3 describes the process of training the online model, including specific parameters and data processing.
Section 4 presents the results and analyzes.
Section 5 is the conclusion.
2. Model Derivation
Considering that the online learning process is carried out on airship computers with limited computational resources, classification and regression models with lower complexity are needed to reduce power consumption. After comparing multiple models, the use of Naive Bayes classifiers and linear regression models balanced the prediction accuracy and complexity of the surrogate model in a better manner.
2.1. Gaussian Naive Bayes Classifier
The Naive Bayes classifier is a statistical generative model whose parameter estimation process is based on frequency statistics. It classifies data by Bayesian probability estimation and only needs to calculate the conditional probability distribution of the sample set to make predictions. It does not involve loss function optimization. The Naive Bayes classifier assumes that each feature is independent. Its advantages are fast training and good performance for high-dimensional and large-scale datasets. It has been proven to perform surprisingly well with very little training data [
28], while most other classifiers, especially artificial neural networks, find these data insufficient. For problems with continuous variable features, Gaussian Naive Bayes classifiers can be used, which assume that the feature distribution follows a Gaussian distribution. The mean and variance are calculated over the entire training set. When using Gaussian Naive Bayes classifiers for prediction, the model uses these parameters to estimate the conditional probability.
The idea of the Naive Bayes classifier is to calculate the posterior probability of each response category under the current input feature conditions. The largest one is used as the predicted category. The specific process is as follows:
Suppose a classification problem contains
n features and
m categories.
According to Bayesian theory, the posterior probability of a feature is represented by the following equation:
Due to the prior assumption that the features are independent of each other, the above equation can be written as:
where the denominator involves only the features of the input and is independent of the class, which can be simplified to mean that the final class output only needs to compare the size of the numerator. Thus, the expression for the result of the classification prediction is
In a Gaussian plain Bayes classifier, the conditional probability of each feature is assumed to follow a Gaussian distribution.
Its greatest likelihood estimate is:
The mean and variance in the above equation are obtained by counting the data corresponding to the training set.
It should be noted that for online learning, since training and prediction are continuously performed, the mean and variance are dynamically calculated as the training samples flow in.
2.2. Linear Regression Model
The idea of the linear regression model is to use a linear function to describe the relationship between the independent variable and the dependent variable. Then, according to the error between the predicted value and the actual value, the loss function is defined, and the weights in the function are calculated by minimizing the loss function.
It is assumed that the response to a regression problem consists of two parts. One part is affected by the features and the other part is affected by other factors, which can be considered as a kind of random error. Therefore, the model can be expressed as:
Linear regression models consider the relationship between features and response as a linear function.
In fact, the random error term can be merged into the zero-weight term. Thus, the loss function is defined as:
The weights are calculated as:
It should be noted that the formulas above are applicable to online learning, and only the current input sample is used to calculate the loss function, without retaining previous sample information. This form can be conveniently used to calculate weights using stochastic gradient descent. The weights are updated by continuously receiving individual new samples from the data stream, which can be understood as dividing the entire optimization problem into several independent sub-problems and combining the optimal solution of each sub-problem to obtain the optimal solution of the entire problem.
2.3. Online Learning Model
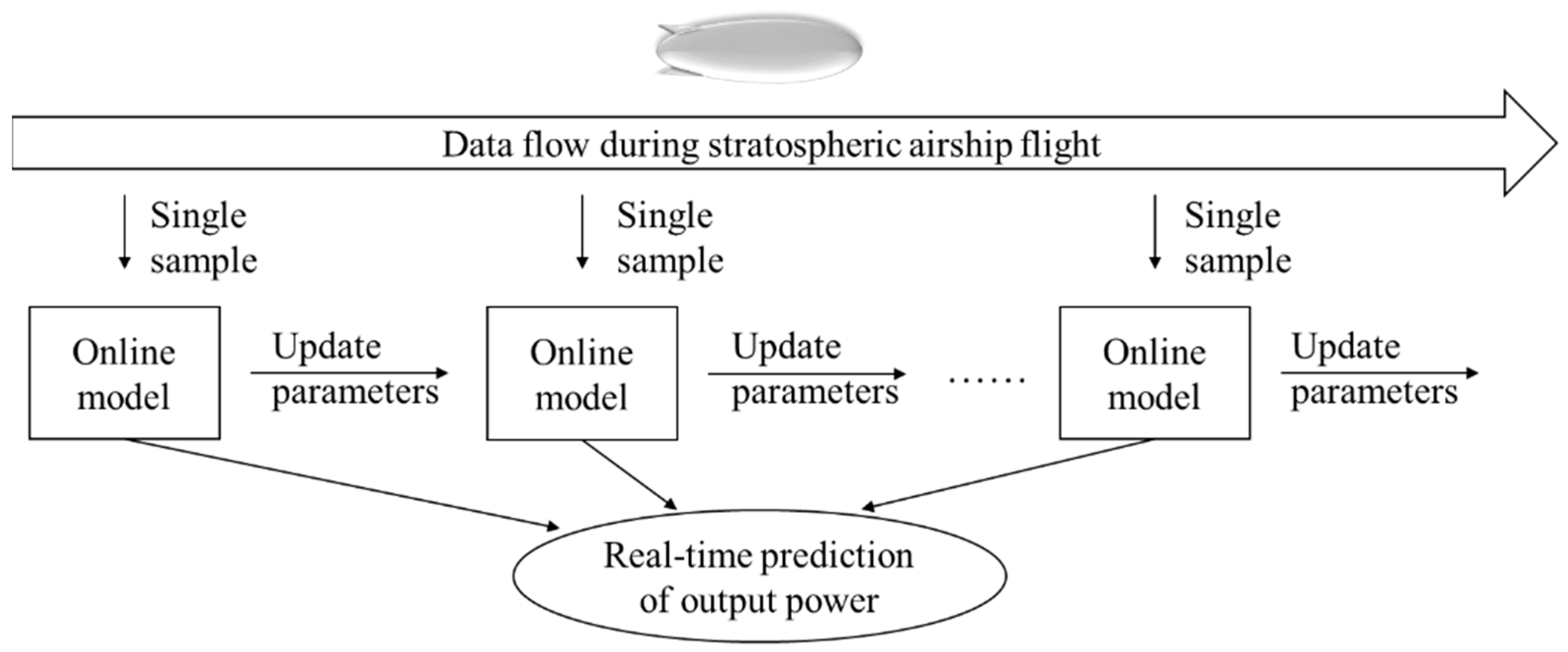
Online learning models are implemented using the River library in Python, which is a Python framework specifically designed for online incremental learning. It can handle data streams and dynamically train machine learning models. The established online learning model includes steps of data preprocessing, feature engineering, and parameter updating.
Data preprocessing: Since the relevant features and responses for training online models are collected through sensors arranged on the stratosphere airship, there may be problems such as abnormal, missing, or duplicate data. It is necessary to perform data cleaning on the training samples in advance to ensure the accuracy and consistency of the data.
Feature engineering: Feature engineering refers to the process of transforming or selecting original collected samples. Its purpose is to remove redundant features with low impact to improve model performance. In general, many factors will affect the response that needs to be predicted, and there are complex coupling effects between each factor. If all influencing factors are sent to the model for training, it will inevitably increase the complexity of the model and consume more computing resources. In addition, too many features will increase the risk of overfitting. When the number of features exceeds the actual information, the model may learn noise or irrelevant features in the data. This will cause the model to have high accuracy in the training set but poor accuracy in the new data.
Parameter updating: Unlike offline learning models, online learning models use data streams for training. This means that only one set of samples will be sent to the training model at the same time. The model uses this sample for incremental learning instead of learning on the entire dataset. After the parameter is updated, the next set of samples is sent in. The sample collection and model training are synchronized, and each set of samples will be discarded after training and not stored in the memory. This significantly reduces the consumption of computing resources.
Figure 1 shows the online learning process of training a solar array output power prediction model using data streams during stratospheric airship flight.
3. Research Sample
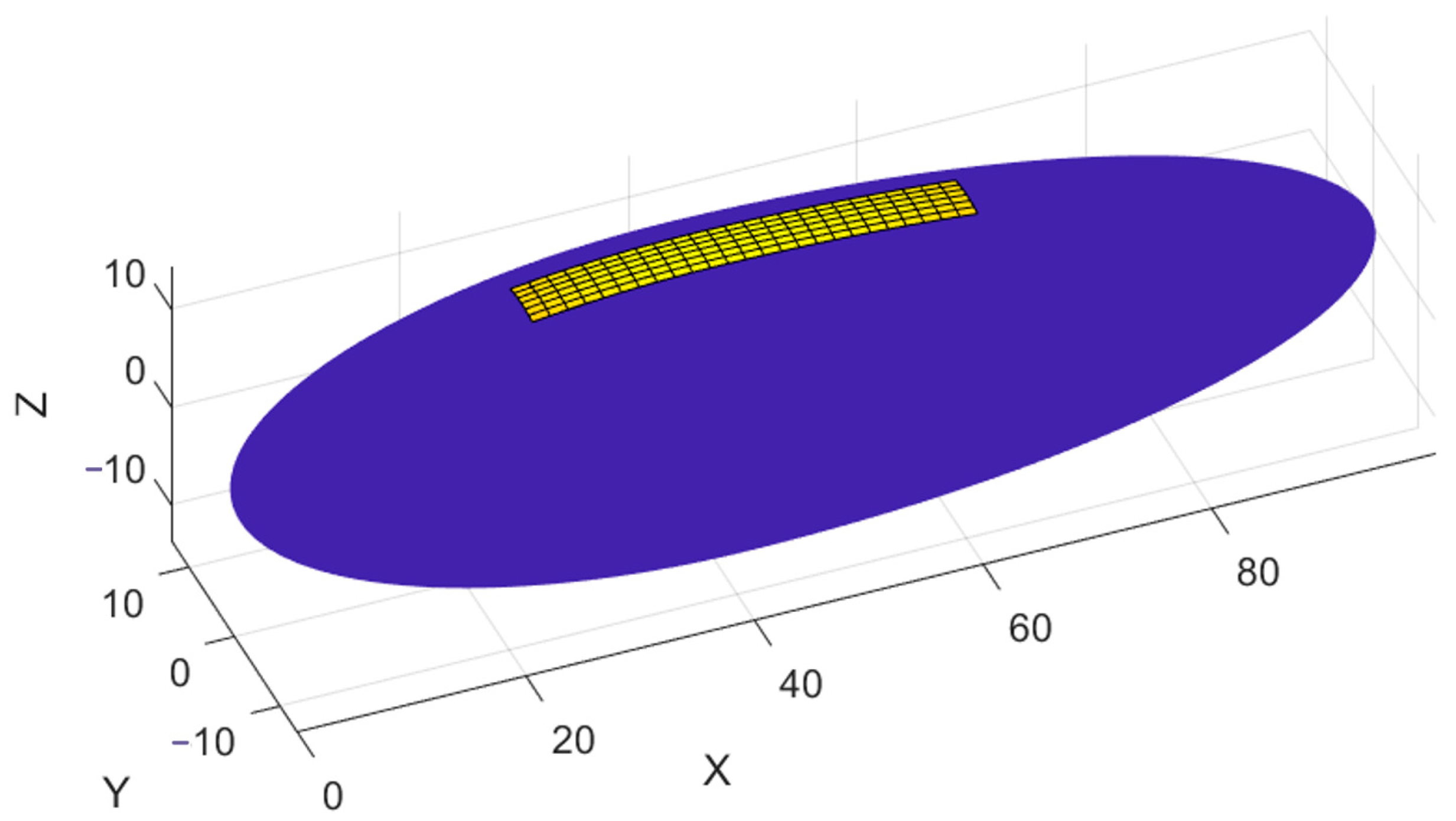
Due to the long flight test cycle and high cost, high-precision simulation models are used as research objects. As shown in
Figure 2, the airship adopts the National Physics Laboratory (NPL) configuration, and the photovoltaic modules use SunPower’s E20_245 [
29].
The specific parameters of the airship and array in the simulation model are shown in
Table 1.
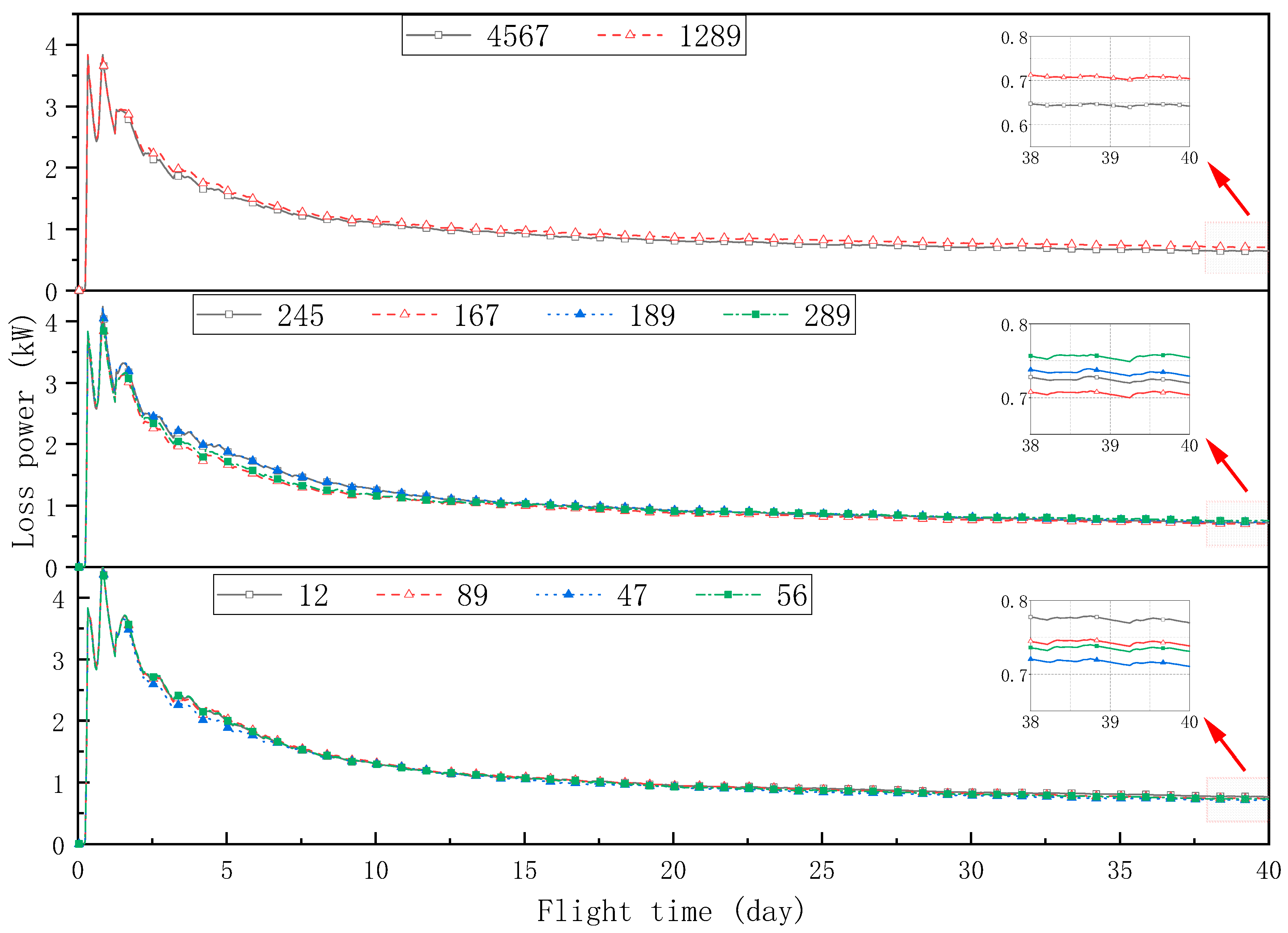
The output of the solar array is related to the received radiation intensity and temperature, and solar radiation intensity is the main influencing parameter. Radiation sensors are placed near the array to obtain radiation data. In addition, the solar panel array laid on the stratospheric airship has a large area. Due to the influence of the surface curvature of the airship, the positions of the photovoltaic modules on the airship are different, and the received radiation intensity is also different. Compared with uniform radiation, the total output power of the array will decrease, which is called mismatch loss [
30]. Therefore, a single radiation sensor may not accurately reflect the overall radiation received by the array, and it is necessary to arrange multiple sensors to collect radiation data.
Assuming that the radiation intensity at the very top of the airship is obtained, the direct radiation intensity received by the radiation meter arranged on the surface of the airship can be calculated using the following formula:
where
is the radiation intensity received by radiation sensor,
is the radiation intensity at the flight height,
is the incident light vector, and
is the normal vector of radiation sensor.
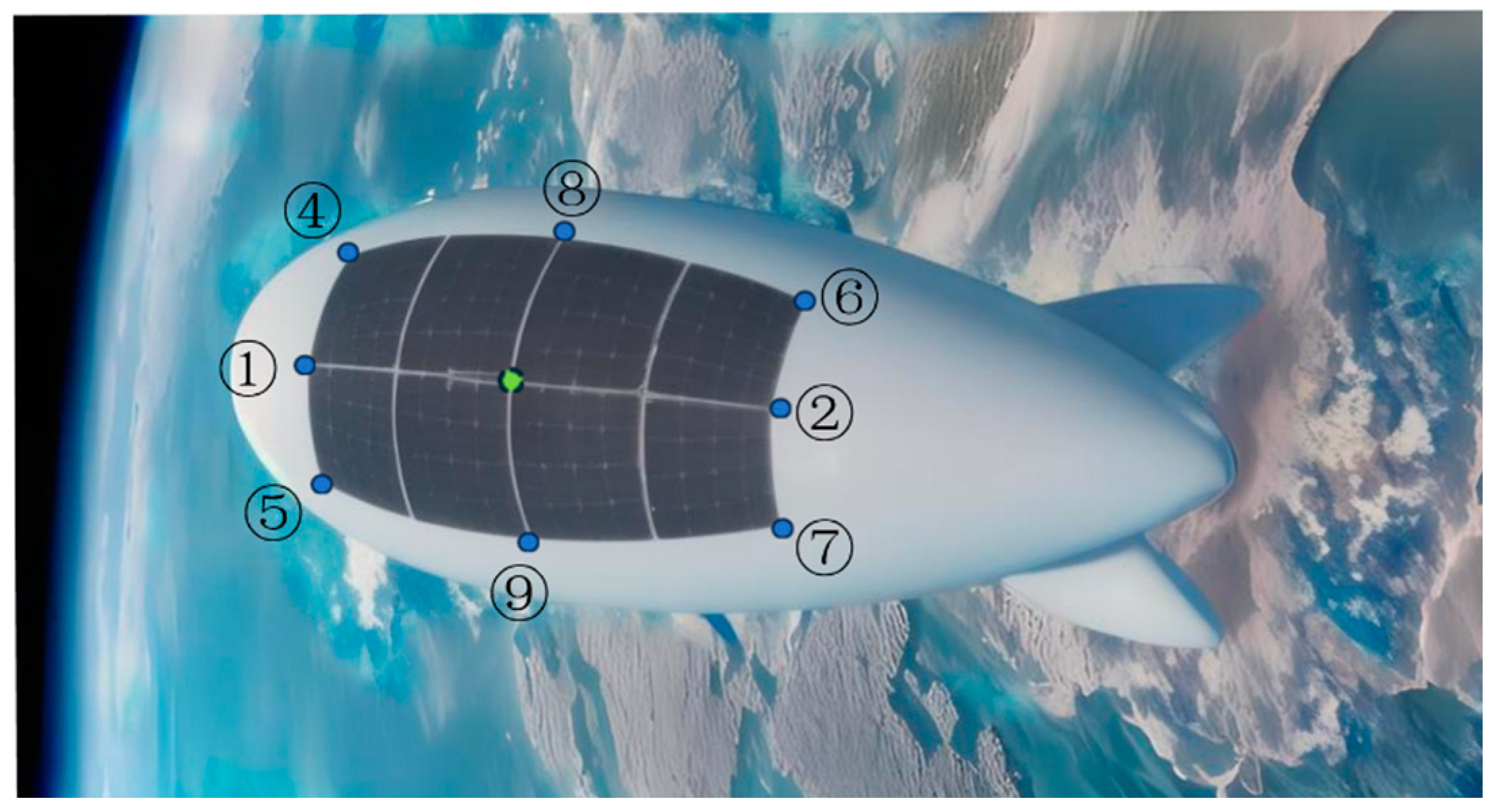
The
can be solved using three different positions of the radiometer.
Figure 3 shows the location of the sensors as they are arranged on the airship (although the No. 3 irradiation meter in the middle is not actually used, a position is still reserved for it here). Eight irradiation meters are located around the perimeter of the solar array to reflect the intensity of irradiation at each photovoltaic module in the array without affecting the operation of the solar array.
During the prediction process, after the flight mission of the airship is given, the radiation meter index at any time can be calculated by the solar radiation model and the geometric model of the airship and then input into the online model to predict the output power.
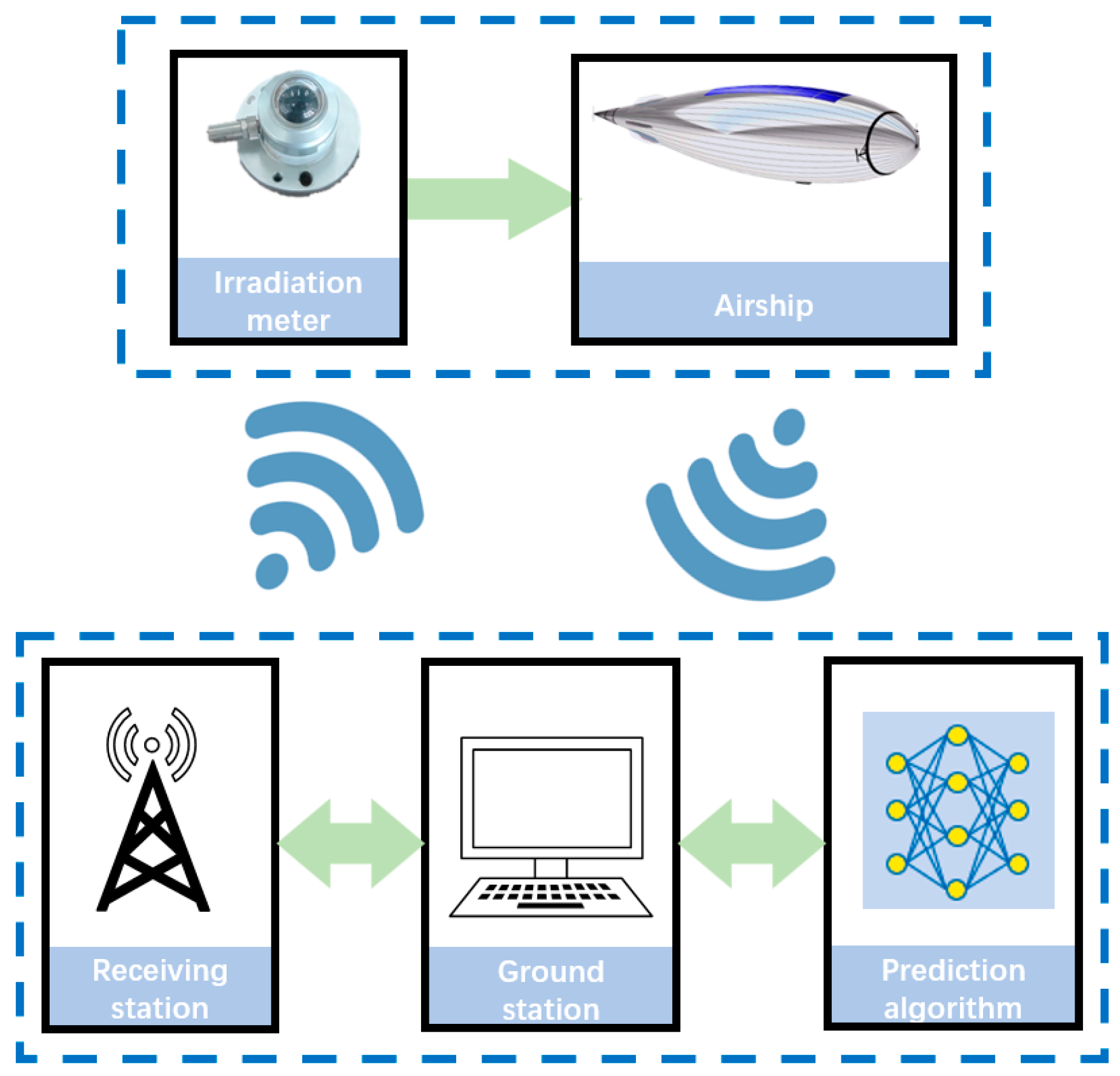
In order to facilitate a systematic analysis of the above design scheme, a ground physical principle verification system was constructed based on the correlation diagram in
Figure 4 (which is based on future data acquisition, analysis, and transmission scenarios), as shown in
Figure 5.
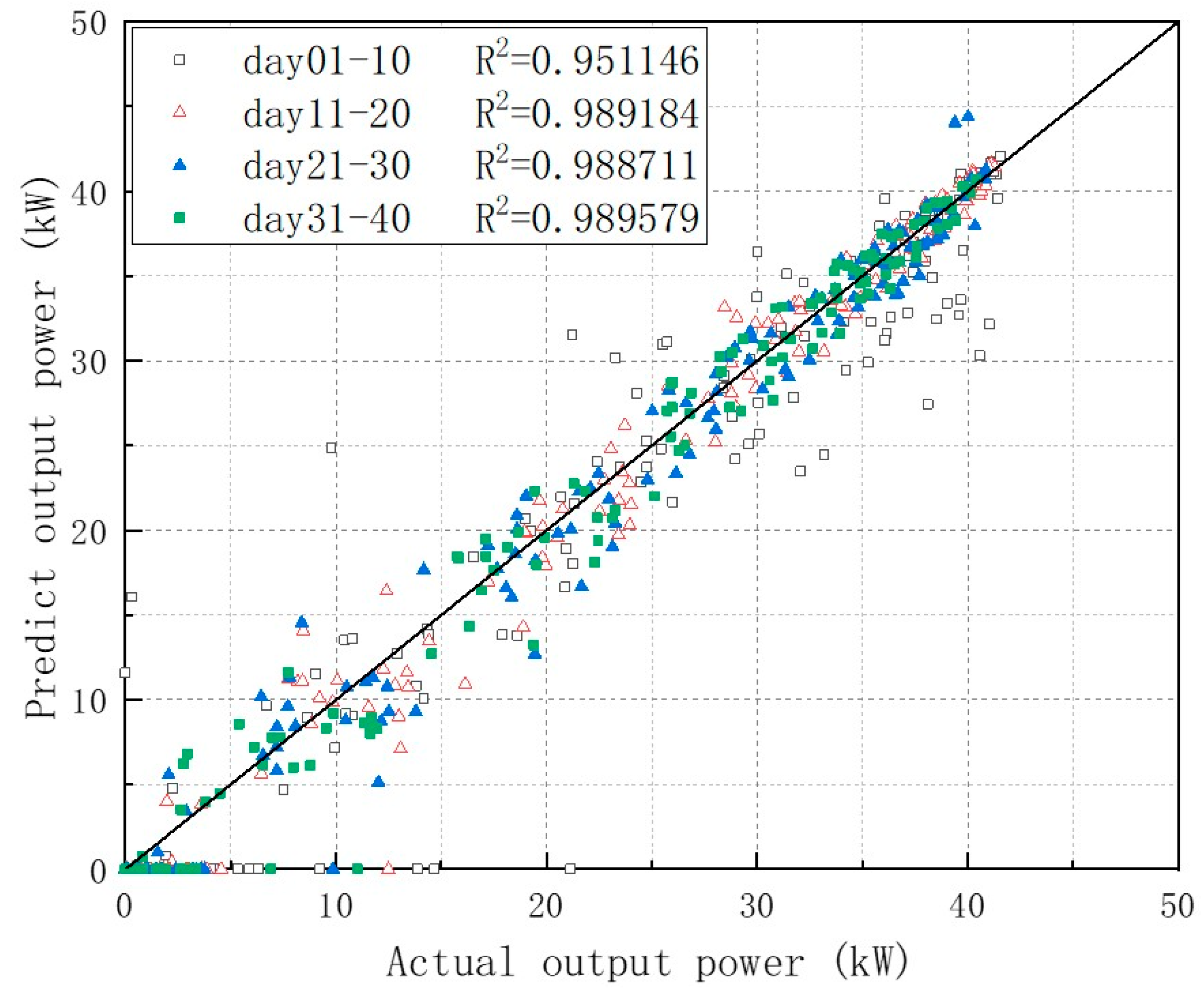
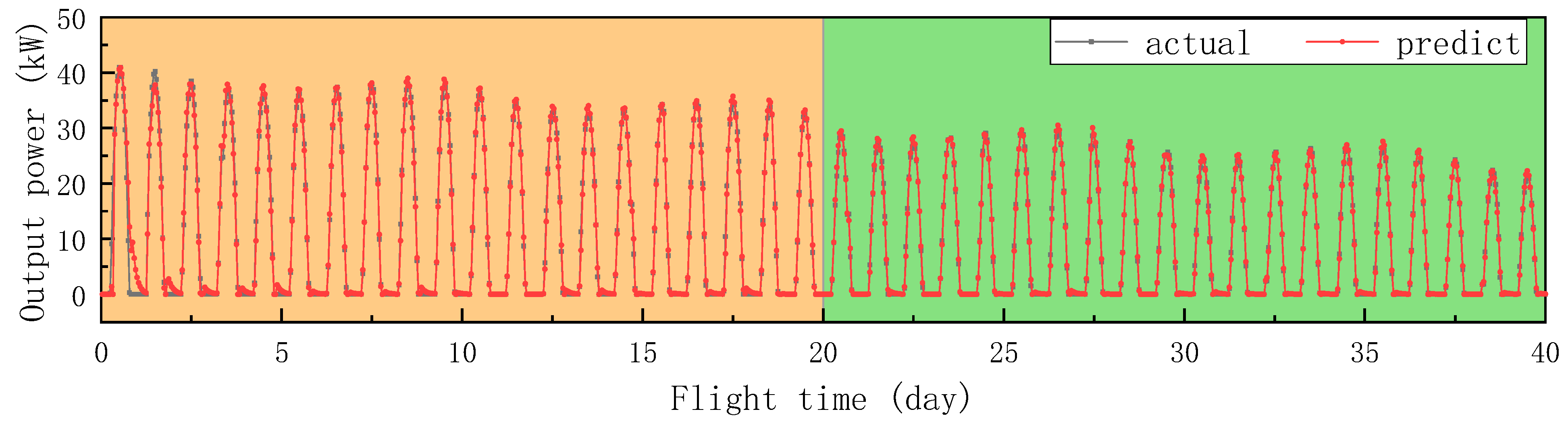
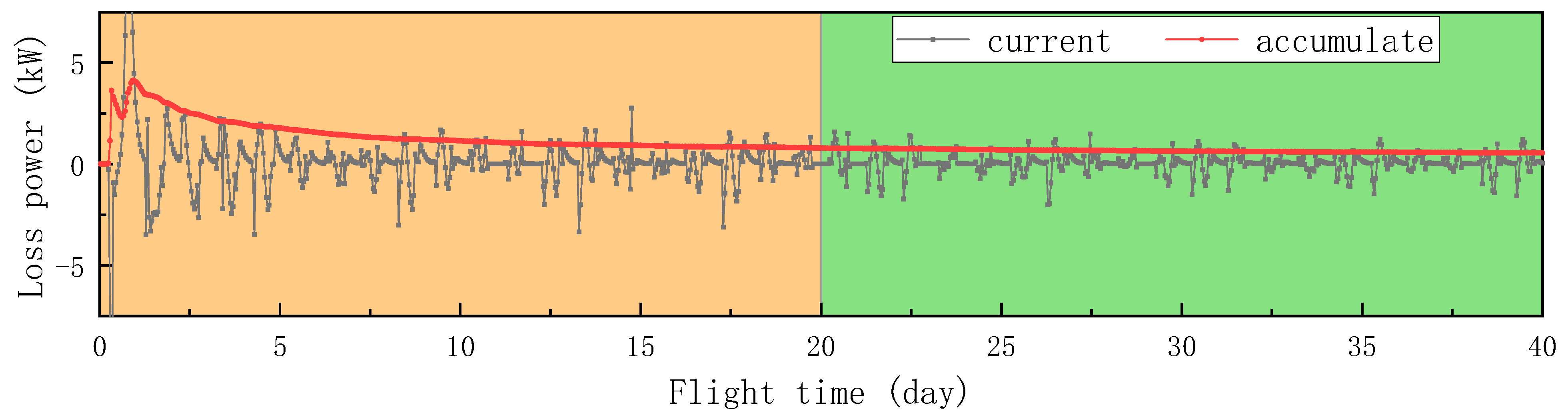
Assuming a flight mission for monitoring Australian wildfires, the airship will perform regional monitoring flight at a height of 20,000 m above Australia, with a flight radius of 900 km. The flight period is 40 days, from 31 January to 11 March. Samples are collected every hour, including sensor values and output power of solar array. To reflect the temporal characteristics and improve the prediction accuracy, in addition to using radiation values as input features, the output power and its first-order difference of the previous moment are also used. The performance indicator is evaluated using mean absolute error (MAE), which is consistent with the deviation of the actual output power in terms of order of magnitude.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}