
Modeling Heritage Language Phonetics and Phonology: Toward an Integrated Multilingual Sound System


Abstract
:1. Introduction
A heritage speaker (HS) is a bilingual who has acquired a family...and a majority societal language naturalistically in early childhood. To qualify as HS bilingualism, acquisition crucially must take place in a situation where the home language is decisively not the language of the greater society.
2. Theoretical Framework: Contrast, Features, and Levels of Representation
- Phonetics is typified by continuous, gradient properties, whereas the phonology consists of discrete, distinctive categories (Hall 2020, 2011). Therefore, each module deals in different representation types that reflect those properties (Purnell and Raimy 2015).
- Phonological representations are language-specific collections of relevant properties. They are not themselves percepts, sounds, nor abstractions of specific sounds like IPA symbols (Dresher 2014; Trubetzkoy 1939).
- Phonological representations constrain potential articulatory and acoustic realizations of speech sounds, of which there are often many potential variants (Avery and Rice 1989; Dresher 2009; Dresher et al. 1994; Natvig 2020).
- Phonetics is ‘richer’ than phonology, meaning that multiple acoustic cues may correspond to a single, relevant distinction. Accordingly, the phonology is underspecified relative to measurable outputs in speech production data.
2.1. Contrast and Representations
phonology takes substance from outside FLN [narrow faculty of language] and converts it to objects that can be manipulated by the linguistic computational system.
- (1)
- Example Contrastive Hierarchy

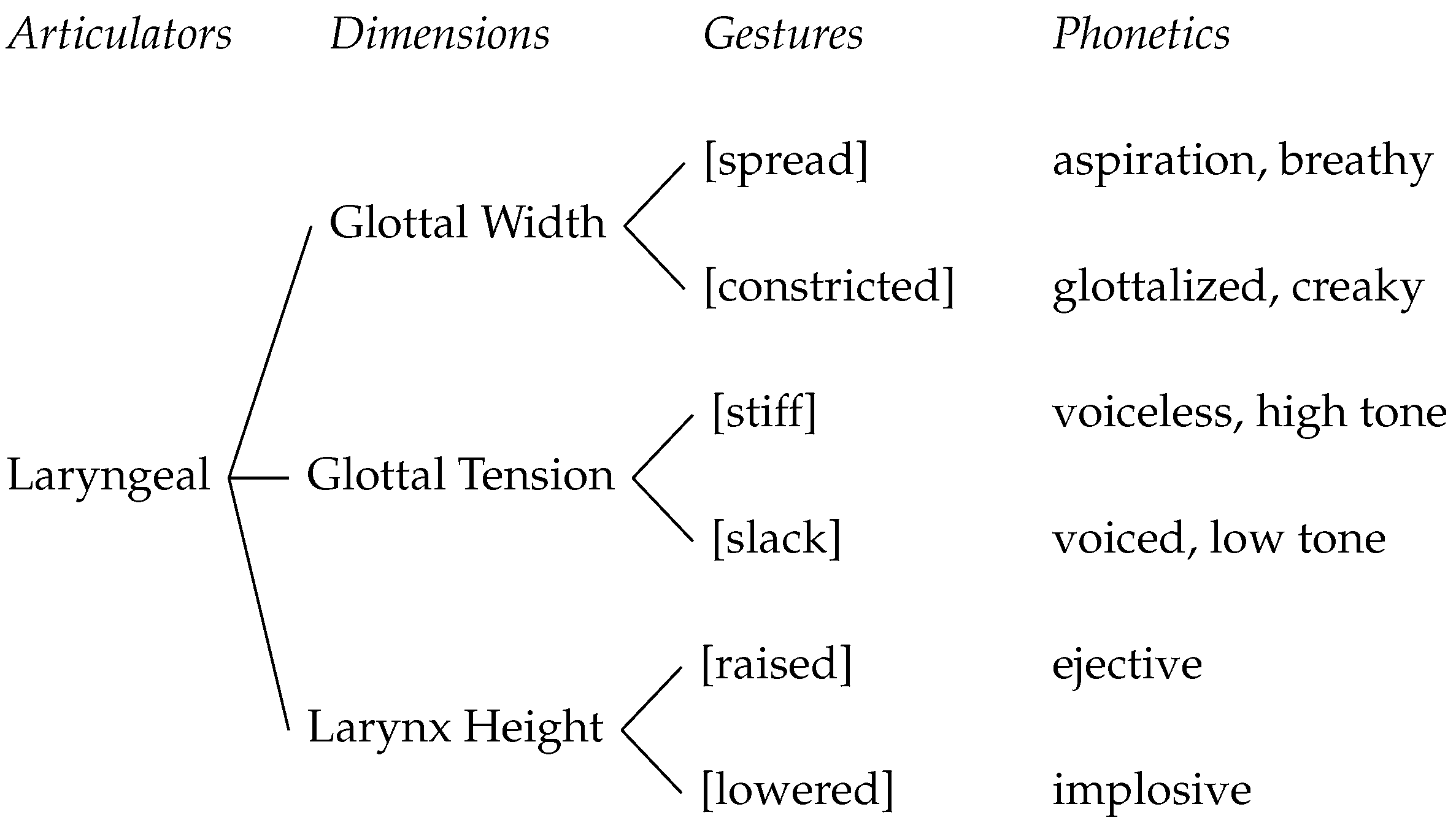
2.2. Feature Content
- (2)
- Voicing and Aspirating laryngeal representations

2.3. Levels of Representation and Contact Effects
3. Toward an Integrated Multilingual Sound System
- (3)
- Integrated Voicing and Aspirating laryngeal representations

- (4)
- Potential differentiations of structure for Voicing and Aspirating systems


- The sound system is modular and consists of at least the phonological, phonetic-phonological, and phonetic levels of representation.
- Phonological: Contrastive features are a shared set of abstract dimensions that divide a phonemic inventory following the Successive Division Algorithm. The representations necessary for one language may be a subset of the integrated system. These representations are furthermore underspecified relative to surface forms.
- Phonetic-phonological: Underspecified, contrastive representations are completed and/or enhanced with articulatory gestures. These processes may be shared or differentiated based on language, sociolect, register, etc.
- Phonetic: Articulatory gestures are implemented in real time. These processes may be highly variable and plastic.
- Speakers may have varying degrees of shared and differentiated operations at the phonetic-phonological and phonetic levels of representation based on experience with and in the particular languages in question.
4. Case Studies
4.1. Ambiguous Surface Patterns: Wisconsin Frisian
4.2. Ambiguous Phonological Processes: Toronto Polish Devoicing
- (5)
- Integrated Polish-English laryngeal representations

- Toronto Polish speakers implemented the devoicing rule at a higher rate than the homeland group (Homeland: 66%, Gen1: 67%, Gen2: 74%), and
- Gen2 devoiced less before voiceless obstruents than Gen1 and homeland speakers.
4.3. Asymmetric Outcomes across Dyads: Western Armenian
- WA Voicing system (2a):
- −
- WA undergoes no phonological change in contact with Arabic, but there is a loss of +[spread] enhancement (phonetic-phonological change);
- −
- WA and English are integrated into a Voicing-Aspirating system, with variable implementation of the English contrast (i.e., plain stops) or phonological change to Aspirating system, with variable +[slack] enhancement (a phonological dimension changes to a phonetic-phonological gesture);
- WA Aspirating system (2b):
- −
- Results show either an integrated WA-Arabic laryngeal system, with implementation of the GT-∅ subsystem in WA, or complete phonological change to the Arabic Voicing system;
- −
- No phonological change in contact with English; instead patterns show (variable) reduction of +[slack] enhancement (phonetic-phonological change);
- WA Overmarked (integrated) system (3):
- −
- Patterns in neither dyad distinguish between abstract representations or potential structural change. Rather, they demonstrate settings in which the implementations of contrastive subsets are modulated by MajL: Type (4a) for Arabic and type (4b) and/or type (4c) for English.
5. Discussion: Contextualizing Heritage Language Effects
5.1. Transfer
5.2. Attrition
Changes in category location and number are therefore expressions of essentially temporal developments in the process of updating this abstract knowledge from continuously varying input episodes. However, including time in phonology essentially makes phonology continuous, much like phonetics, rather than categorical, in contrast with much thought in phonological research.
5.3. Divergent Attainment
- (6)
- Example of cross-generational divergent attainment of laryngeal contrasts

The phonetic signal is accurately perceived by the listener but is intrinsically phonologically ambiguous, and the listener associates a phonological form with the utterance which differs from the phonological form in the speaker’s grammar.
6. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
| 1 | I refer to voiceless stops/obstruents as those that contrast with voiced ones and plain as those that contrast with aspirated ones. In a system where both voiced and aspirated classes are specified, voiceless and plain are synonymous with respect to the phonology. |
| 2 | See Purnell and Raimy (2015) and Natvig (2020) for a complete feature geometry of dimensions and their potential completions. |
| 3 | |
| 4 | There are many other paths to acquiring representations for the GT, GW, and ∅ classes. These may indeed turn out to be relevant factors for fine-grained differences in HSs’ production and comprehension of sound patterns. Here I only comment on differences in representation types (i.e., contrastive features, enhancements, timing, etc.), not all the permutations for how features may relate to each other in an integrated system. |
| 5 | Vanhecke and Hietpas (2021) likewise find ambiguity in cross-generational laryngeal patterns of Wisconsin Dutch speakers, another instance of contact in different laryngeal systems (Salmons 2020). |
| 6 | Such a system would suggest that WA phonology is already a subset of an integrated, multilingual system. Its status as a language spoken in a Turkish diaspora (Kelly and Keshishian 2021) may be consistent with this, although research into this specific question is necessary. |
References
- Ahn, Sang-cheol, and Gregory K. Iverson. 2004. Dimensions in Korean laryngeal phonology. Journal of East Asian Linguistics 13: 345–79. [Google Scholar] [CrossRef]
- Amengual, Mark. 2012. Interlingual influence in bilingual speech: Cognate status effect in a continuum of bilingualism. Bilingualism: Language and Cognition 15: 517–30. [Google Scholar] [CrossRef] [Green Version]
- Au, Terry Kit-fong, Leah M. Knightly, Sun-Ah Jun, and Janet S. Oh. 2002. Overhearing a language during childhood. Psychological Science 13: 238–43. [Google Scholar] [CrossRef] [PubMed]
- Avery, Peter, and William Idsardi. 2001. Laryngeal dimensions, completion and enhancement. In Distinctive Feature Theory. Edited by Tracy Alan Hall. Berlin: Mouton de Gruyter, pp. 41–70. [Google Scholar]
- Avery, Peter, and Keren Rice. 1989. Segment structure and coronal underspecification. Phonology 6: 179–200. [Google Scholar] [CrossRef]
- Baronian, Luc. 2017. Two problems in Armenian phonology. Language and Linguistic Compass 11: e12247. [Google Scholar] [CrossRef]
- Benmamoun, Elabbas, Silvina Montrul, and Maria Polinsky. 2013. Heritage languages and their speakers: Opportunities and challenges for linguistics. Theoretical Linguistics 39: 129–81. [Google Scholar] [CrossRef]
- Blevins, Juliette. 2004. Evolutionary Phonology: The Emergence of Sound Patterns. Cambridge: Cambridge University Press. [Google Scholar]
- Bousquette, Joshua, and Todd Ehresmann. 2010. West Frisian in Wisconsin: A historical profile of immigrant language use in Randolph Township. It Beaken 72: 247–78. [Google Scholar]
- Bullock, Barbara E., and Chip Gerfen. 2004a. Frenchville French: A case study in phonological attrition. International Journal of Bilingualism 8: 303–20. [Google Scholar] [CrossRef]
- Bullock, Barbara E., and Chip Gerfen. 2004b. Phonological convergence in a contracting language variety. Bilingualism: Language and Cognition 7: 95–104. [Google Scholar] [CrossRef]
- Bybee, Joan. 2001. Phonology and Language Use. Cambridge: Cambridge University Press. [Google Scholar]
- Casillas, Joseph V. 2020. The longitudinal development of fine-phonetic detail: Stop production in a domestic immersion program. Language Learning 70: 768–806. [Google Scholar] [CrossRef]
- Casillas, Joseph V., and Miquel Simonet. 2018. Perceptual categorization and bilingual language modes: Assessing the double phonemic boundary in early and late bilinguals. Journal of Phonetics 71: 51–64. [Google Scholar] [CrossRef]
- Celata, Chiara. 2019. Phonological attrition. In The Oxford Handbook of Language Attrition. Edited by Monika S. Schmid and Barbara Köpke. Oxford: Oxford University Press, pp. 218–27. [Google Scholar]
- Chang, Charles B. 2012. Rapid and multifaceted effects of second-language learning on first-language speech production. Journal of Phonetics 40: 249–68. [Google Scholar] [CrossRef]
- Chang, Charles B. 2013. A novelty effect in phonetic drift of the native language. Journal of Phonetics 41: 520–33. [Google Scholar] [CrossRef]
- Chang, Charles B. 2016. Bilingual perceptual benefits of experience with a heritage language. Bilingualism: Language and Cognition 19: 791–809. [Google Scholar] [CrossRef] [Green Version]
- Chang, Charles B. 2019a. Language change and linguistic inquiry in a world of multicompetence: Sustained phonetic drift and its implications for behavioral linguistic research. Journal of Phonetics 74: 96–113. [Google Scholar] [CrossRef] [Green Version]
- Chang, Charles B. 2019b. Phonetic drift. In The Oxford Handbook of Language Attrition. Edited by Monika S. Schmid and Barbara Köpke. Oxford: Oxford University Press, pp. 191–203. [Google Scholar]
- Chang, Charles B., and Yao Yao. 2016. Toward an Understanding of Heritage Prosody: Acoustic and Perceptual Properties of Tone Produced by Heritage, Native, and Second Language Speakers of Mandarin. Heritage Language Journal 13: 134–59. [Google Scholar] [CrossRef]
- Cook, Vivian. 2016. Language and cognition in bilinguals. In Premises of Multi-Competence. Edited by Vivian Cook and Li Wei. Cambridge: Cambridge University Press, pp. 1–25. [Google Scholar]
- D’Alessandro, Roberta, David Natvig, and Michael T. Putnam. 2021. Addressing challenges in formal research on moribund heritage languages: A path forward. Frontiers in Psychology 12: 700126. [Google Scholar] [CrossRef]
- de Groot, Annette M. B. 2016. Language and cognition in bilinguals. In The Cambridge Handbook of Linguistic Multi-Competence. Edited by Vivian Cook and Li Wei. Cambridge: Cambridge University Press, pp. 248–75. [Google Scholar]
- de Leeuw, Ester. 2019. Phonetic attrition. In The Oxford Handbook of Language Attrition. Edited by Monika S. Schmid and Barbara Köpke. Oxford: Oxford University Press, pp. 204–17. [Google Scholar]
- de Leeuw, Ester, and Chiara Celata. 2019. Plasticity of native phonetic and phonological domains in the context of bilingualism. Journal of Phonetics 75: 88–93. [Google Scholar] [CrossRef]
- Dorian, Nancy. 1993. Internally and externally motivated changes in language contact settings: Doubts about the dichotomy. In Historical Lingusitics: Problems and Perspectives. Edited by Charles Jones. London: Longman, pp. 131–55. [Google Scholar]
- Dresher, B. Elan. 2009. The Contrastive Hierarchy in Phonology. Oxford: Oxford University Press. [Google Scholar]
- Dresher, B. Elan. 2014. The arch not the stones: Universal feature theory without universal features. Nordlyd 41: 165–81. [Google Scholar] [CrossRef] [Green Version]
- Dresher, B. Elan, Glyne Piggott, and Keren Rice. 1994. Contrast in Phonology: Overview. In Toronto Working Papers in Linguistics. Edited by Carrie Dyck. Toronto: Department of Linguistics, University of Toronto, vol. 13, pp. iii–xvii. [Google Scholar]
- Ehresmann, Todd, and Joshua Bousquette. 2021. Laryngeal distinction in Wisconsin West Frisian: From privative to equipollent [voice]. Paper presented at 27th Germanic Linguistics Annual Conference, Madison, WI, USA, May 12–14. [Google Scholar]
- Flores, Cristina Maria Moreira, and Andreia Schurt Rauber. 2011. Perception of German vowels by bilingual Portuguese-German returnees: A case of phonological attrition? In The Development of Grammar: Language Acquisition and Diachronic Change—Volume in Honor of Jürgen M. Meisel. Edited by Esther Rinke and Tanja Kupisch. Amsterdam: John Benjamins, pp. 287–305. [Google Scholar]
- García-Sierra, Adrián, Nairán Ramírez-Esparza, Juan Silva-Pereyra, Jennifer Siard, and Craig A. Champlin. 2012. Assessing the double phonemic representation in bilingual speakers of Spanish and English: An electrophysiological study. Brain and Language 121: 194–205. [Google Scholar] [CrossRef]
- Godson, Linda. 2004. Vowel production in the speech of Western Armenian heritage speakers. Heritage Language Journal 2: 45–70. [Google Scholar] [CrossRef]
- Goldinger, Stephen D. 1996. Words and voices: Episodic traces in spoken word identification and recognition memory. Journal of Experimental Psychology: Learning, Memory, and Cognition 22: 1166–83. [Google Scholar] [CrossRef]
- Goldrick, Matthew, Michael T. Putnam, and Laura S. Schwarz. 2016. Co-activation in bilingual grammars: A computational account of code mixing. Bilingualism: Language an Cognition 19: 857–76. [Google Scholar] [CrossRef] [Green Version]
- Gonzales, Kalim, and Andrew J. Lotto. 2013. A Bafri, un Pafri: Bilinguals’ pseudoword identifications support language-specific phonetic systems. Psychological Science 24: 2135–42. [Google Scholar] [CrossRef]
- Grosjean, François. 1989. Neurolinguists, beware! The bilingual is not two monolinguals in one person. Brain and Language 35: 3–15. [Google Scholar] [CrossRef]
- Hale, Mark, and Charles Reiss. 2000. “Substance abuse” and “dysfunctionalism”: Current trends in phonology. Linguistic Inquiry 31: 157–69. [Google Scholar] [CrossRef]
- Hall, Daniel Currie. 2007. The Role and Representation of Contrast in Phonological Theory. Ph.D. thesis, University of Toronto, Toronto, ON, Canada. [Google Scholar]
- Hall, Daniel Currie. 2011. Phonological contrast and its phonetic enhancement: Dispersedness without dispersion. Phonology 28: 1–54. [Google Scholar] [CrossRef]
- Hall, Daniel Currie. 2020. Contrast is syntax and contrast in phonology: Same difference? In Contrast and Representations in Syntax. Edited by Bronwyn M. Bjorkman and Daniel Currie Hall. Oxford: Oxford University Press, pp. 247–71. [Google Scholar]
- Hartsuiker, Robert J., Martin J. Pickering, and Eline Veltkamp. 2004. Is syntax separate or shared between languages?: Cross-linguistic syntactic priming in Spanish-English bilinguals. Psychological Science 15: 409–14. [Google Scholar] [CrossRef] [PubMed]
- Hayes, Bruce, Robert Kirchner, and Donca Steriade, eds. 2004. Phonetically Based Phonology. Cambridge: Cambridge University Press. [Google Scholar]
- Hjelde, Arnstein. 1996. Some phonological changes in a Norwegian dialect in America. In Language Contact Across the North Atlantic. Edited by P. Sture Ureland and Iain Clarkson. Tübingen: Max Niemeyer, pp. 251–79. [Google Scholar]
- Hrycyna, Melania, Natalia Lapinskaya, Alexei Kochotev, and Naomi Nagy. 2011. VOT drift in 3 generations of heritage language speakers in Toronto. Canadian Acoustics 39: 166–67. [Google Scholar]
- Hsin, Lisa. 2014. Integrated Bilingual Grammatical Architecture: Insights from Syntactic Development. Ph.D. thesis, John Hopkins University, Baltimore, MD, USA. [Google Scholar]
- Hyltenstam, Kenneth, Emanuel Bylund, Niclas Abrahamsson, and Hyeon-Sook Park. 2009. Dominant-language replacement: The case of international adoptees. Bilingualism: Language and Cognition 2: 121–40. [Google Scholar] [CrossRef]
- Iverson, Gregory K., and Joseph Salmons. 1995. Aspiration and laryngeal representations in Germanic. Phonology 12: 369–96. [Google Scholar] [CrossRef]
- Iverson, Gregory K., and Joseph Salmons. 2011. Final laryngeal neutralization and final devoicing. In The Blackwell Companion to Phonology. Edited by Marc van Oostendorp, Colin J. Ewen, Elizabeth Hume and Keren Rice. Oxford: Blackwell, pp. 1622–43. [Google Scholar]
- Jacewicz, Ewa, Robert Allen Fox, and Samantha Lyle. 2009. Variation in stop consonant voicing in two regional varieties of American English. Journal of the International Phonetic Association 31: 313–34. [Google Scholar] [CrossRef] [PubMed]
- Joo, Hyoun-A, Lara Schwarz, and B. Richard Page. 2018. Nonconvergence and divergence in bilingual phonological and phonetic systems: Low back vowels in Moundridge Schweitzer German and English. Journal of Language Contact 11: 304–23. [Google Scholar] [CrossRef]
- Kang, Yoonjung, and Naomi Nagy. 2016. VOT merger in Heritage Korean in Toronto. Language Variation and Change 28: 249–72. [Google Scholar] [CrossRef]
- Kelly, Niamh E., and Lara Keshishian. 2021. Voicing patterns in stops among heritage speakers of Western Armenian in Lebanon and the US. Nordic Journal of Linguistics 44: 103–29. [Google Scholar] [CrossRef]
- Kim, Ji Young. 2011. L1–L2 phonetic interference in the production of Spanish heritage speakers in the US. The Korean Journal of Hispanic Studies 4: 1–28. [Google Scholar]
- Kingston, John, and Randy L. Diehl. 1994. Phonetic knowledge. Language 70: 419–54. [Google Scholar] [CrossRef]
- Kroll, Judith F., and Tamar H. Gollan. 2014. Speech planning in two languages: What bilinguals tell us about language production. In The Oxford Handbook of Language Production. Edited by Matthew Goldrick, Victor Ferreira and Michele Miozzo. Oxford: Oxford University Press, pp. 165–81. [Google Scholar]
- Kupisch, Tanja. 2020. Towards modelling heritage speakers’ sound systems. Bilingualism: Language and Cognition 23: 29–30. [Google Scholar] [CrossRef]
- Kupisch, Tanja, Dagmar Barton, Katja Hailer, Ewgenia Klaschik, Ilse Stangen, Tatjana Lein, and Joost van de Weijer. 2014. Foreign accent in adult simultaneous bilinguals. Heritage Language Journal 11: 123–50. [Google Scholar] [CrossRef]
- Kwon, Joy. 2021. The role of phonological representations in L2 perception: The case of English front vowels. Paper presented at the 25th Mid-Continental Phonetics & Phonology Conference, Urbana-Champaign, IL, USA, January 30. [Google Scholar]
- Ladd, D. Robert. 2014. Phonetics in phonology. In The Handbook of Phonological Theory, 2nd ed. Edited by John Goldsmith, Jason Riggle and Alan C. L. Yu. Malden: Wiley Blackwell, pp. 348–73. [Google Scholar]
- Ladefoged, Peter, and Ian Maddieson. 1996. The Sounds of the World’s Languages. Oxford: Blackwell. [Google Scholar]
- Llandos, Fernando, and Alexander L. Francis. 2017. The effects of language experience and speech context on the phonetic accommodation of English-accented Spanish voicing. Language and Speech 60: 3–26. [Google Scholar] [CrossRef]
- Lukyanchenko, Anna, and Kira Gor. 2011. Perceptual correlates of phonological representations in heritage speakers and L2 learners. In Proceedings of the Thirty-Fifth Annual Boston University Conference on Language Development. Sommerville: Cascadilla Press, pp. 414–26. [Google Scholar]
- Łyskawa, Paulina, Ruth Maddeaux, Emilia Melara, and Naomi Nagy. 2016. Heritage speakers follow all the rules: Language contact and convergence in Polish devoicing. Heritage Language Journal 13: 219–44. [Google Scholar] [CrossRef]
- Mackenzie, Sara. 2011. Contrast and the evaluation of similarity: Evidence from consonant harmony. Lingua 121: 1401–23. [Google Scholar] [CrossRef]
- Mackenzie, Sara. 2013. Laryngeal co-occurrence restrictions in Aymara: Contrastive representations and constraint interaction. Phonology 30: 297–45. [Google Scholar] [CrossRef]
- MacSwan, Jeff. 2017. A multilingual perspective on translanguaging. American Educational Research Journal 54: 167–201. [Google Scholar] [CrossRef] [Green Version]
- Major, Roy C. 1992. Losing English as a first language. The Modern Language Journal 76: 190–208. [Google Scholar] [CrossRef]
- Miller, David, and Jason Rothman. 2020. You win some, you lose some: Comprehension and event-related potential evidence for L1 attrition. Bilingualism: Language and Cognition 23: 869–83. [Google Scholar] [CrossRef]
- Nagy, Naomi, and Alexei Kochetov. 2013. Voice onset time across the generations: A corss-linguistic study of contact-induced change. In Mulilingualism and Language Contact in Urban Areas: Acquisition—Development—Teaching—Communication. Edited by Peter Siemund, Ingrid Gogolin, Monika Edith Schulz and Julia Davydova. Amsterdam: John Benhamins, pp. 19–38. [Google Scholar]
- Natvig, David. 2019. Levels of representation in phonetic and phonological contact. In Language Contact: An International Handbook. Edited by Jeroen Darquennes, Wim Vandenbussche and Joe Salmons. Berlin: De Gruyter Mouton, vol. 1, pp. 88–99. [Google Scholar] [CrossRef]
- Natvig, David. 2020. Rhotic underspecification: Deriving variability and arbitrariness through phonological representations. Glossa: A Journal of General Lingusitics 5: 48. [Google Scholar] [CrossRef]
- Natvig, David. 2021. Variation and stability of American Norwegian /r/ in contact. Linguistic Approaches to Bilingualism 29. [Google Scholar] [CrossRef]
- Natvig, David, and Joseph Salmons. 2021. Connecting variation and structure in sound change. Cadernos de Linguística 2: 1–20. [Google Scholar] [CrossRef]
- Nodari, Rosalba, Chiara Celata, and Naomi Nagy. 2019. Socio-indexical phonetic features in the heritage language context: Voiceless stop aspiration in the Calabrian community in Toronto. Journal of Phonetics 73: 91–112. [Google Scholar] [CrossRef]
- Oh, Janet S., Sun-Ah Jun, Leah M. Knightly, and Terry Kit-fong Au. 2003. Holding on to childhood language memory. Cognition 86: B53–B64. [Google Scholar] [CrossRef]
- Ohala, John J. 1981. The listener as a source of sound change. In Papers from the Parasession on Language and Behiavior. Edited by Carrie S. Masek, Roberta A. Hendrik and Mary Frances Miller. Chicago: Chicago Linguistics Society, pp. 178–203. [Google Scholar]
- Ohala, John J. 1990. There is no interface between phonology and phonetics: A personal view. Journal of Phonetics 18: 153–71. [Google Scholar] [CrossRef]
- Ohala, John J. 1993. Sound change as nature’s speech perception experiment. Speech Communication 13: 155–61. [Google Scholar] [CrossRef]
- Pascual y Cabo, Diego, and Jason Rothman. 2012. The (il)logical problem of heritage speaker bilingualism and incomplete acquisition. Applied Linguistics 33: 450–55. [Google Scholar] [CrossRef]
- Pickering, Martin J., and Simon Garrod. 2013. An integrated theory of language production and comprehension. Behavior and Brain Sciences 36: 329–47. [Google Scholar] [CrossRef] [Green Version]
- Pliatsikas, Christos. 2020. Understanding structural plasticity in the bilingual brain: The Dynamic Restructuring Model. Bilingualism: Language and Cognition 25: 459–71. [Google Scholar] [CrossRef] [Green Version]
- Polinsky, Maria. 2018. Heritage Languages and Their Speakers. Cambridge: Cambridge University Press. [Google Scholar]
- Polinsky, Maria, and Gregory Scontras. 2020. Understanding heritage languages. Bilingualism: Language and Cognition 23: 4–20. [Google Scholar] [CrossRef] [Green Version]
- Purnell, Thomas. 2009. Phonetic influence on phonological operations. In Contemporary Views on Architecture and Representations in Phonology. Edited by Eric Raimy and Charles Cairns. Cambridge: MIT Press, pp. 337–54. [Google Scholar]
- Purnell, Thomas. 2017. Rule-based phonology. In The Routledge Handbook of Phonology Theory. Edited by S. J. Hannahs and Anna R. K. Bosch. London: Routledge, pp. 135–66. [Google Scholar]
- Purnell, Thomas, and Eric Raimy. 2015. Distinctive features, levels of representation and historical phonology. In The Oxford Handbook of Historical Phonology. Edited by Patrick Honeybone and Joseph Salmons. Oxford: Oxford University Press, pp. 522–44. [Google Scholar] [CrossRef]
- Purnell, Thomas, Eric Raimy, and Joseph Salmons. 2019. Old English vowels: Diachrony, privativity, and phonological representations. Language 95: e447–e473. [Google Scholar] [CrossRef]
- Putnam, Michael, Matthew Carlson, and David Reitter. 2018. Integrated, not isolated: Defining typological proximity in an integrated multilingual architecture. Frontiers in Psychology 8: 2212. [Google Scholar] [CrossRef] [Green Version]
- Putnam, Michael, Sylvia Perez-Cortes, and Liliana Sánchez. 2019. Language attrition and the Feature Reassembly Hypothesis. In The Oxford Handbook of Language Attrition. Edited by Monika S. Schmid and Barbara Köpke. Oxford: Oxford University Press, pp. 18–24. [Google Scholar]
- Putnam, Michael T., Tanja Kupisch, and Diego Pascual y Cabo. 2018. Different situations, similar outcomes: Heritage grammars across the lifespan. In Bilingual Cognition and Language: The State of the Science across Its Subfields. Edited by David Miller, Fatih Bayram, Jason Rothman and Ludovica Serratrice. Amsterdam: John Benjamins, pp. 251–79. [Google Scholar]
- Putnam, Michael T., and Liliana Sánchez. 2013. What’s so incomplete about incomplete acquisition? A a prolegomenon to modeling heritage language grammars. Linguistic Approaches to Bilingualism 3: 478–508. [Google Scholar] [CrossRef]
- Reiss, Charles. 2017. Substance free phonology. In The Routledge Handbook of Phonology Theory. Edited by S. J. Hannahs and Anna R. K. Bosch. London: Routledge, pp. 425–52. [Google Scholar]
- Roeper, Thomas. 1999. Universal bilingualism. Bilingualism: Language and Cognition 2: 169–86. [Google Scholar] [CrossRef] [Green Version]
- Salmons, Joseph. 2020. Germanic laryngeal phonetics and phonology. In The Cambridge Handbook of Germanic Linguistics. Edited by Michael T. Putnam and B. Richard Page. Cambridge: Cambridge University Press, pp. 119–42. [Google Scholar] [CrossRef]
- Salmons, Joseph. 2021. Sound Change. Edinburgh: Edinburgh University Press. [Google Scholar]
- Salmons, Joseph, and Thomas Purnell. 2020. Contact and development of American English. In The Handbook of Language Contact, 2nd ed. Edited by Raymond Hickey. Oxford: Wiley Blackwell, pp. 361–383. [Google Scholar]
- Schmid, Monika. 2011. Language Attrition. Cambridge: Cambridge University Press. [Google Scholar]
- Scontras, Gregory, and Michael T. Putnam. 2020. Lesser-studied heritage languages: An appeal to the dyad. Heritage Language Journal 17: 152–54. [Google Scholar] [CrossRef]
- Smith, James. 2013. Sociophonetic variation of word-final stop voicing in Toronto English. Paper presented at Change and Variation in Canada, Toronto, ON, Canada, May 4–5. [Google Scholar]
- Sonderegger, Morgan, Jane Stuart-Smith, Thea Knowles, Rachel Macdonald, and Tamara Rathcke. 2020. Structured heterogeneity in Scottish stops over the twentieth century. Language 96: 94–125. [Google Scholar] [CrossRef]
- Stevens, Kenneth, Samuel Keyser, and Haruko Kawasaki. 1986. Toward a phonetic and phonological theory of redundant features. In Variance and Invariability in Speech Processes. Edited by Joseph S. Perkell and Dennis H. Klatt. Hillsdale: Erlbaum, pp. 426–49. [Google Scholar]
- Trubetzkoy, Nicolai S. 1969. Principles of Phonology [Grundzüge der Phonologie]. Berkeley: University of California Press. [Google Scholar]
- van Coetsem, Frans. 1988. Loan Phonology and the Two Transfer Types in Language Contact. Dordrecht: Foris. [Google Scholar]
- Vanhecke, Charlotte, and Rachyl Hietpas. 2021. Patterns of laryngeal contrast in Heritage Dutch speakers. Paper presented at the 27th Germanic Linguistics Annual Conference, Madison, WI, USA, May 12–14. [Google Scholar]
- Walker, Abby. 2020. Voiced stops in the command performance of Southern US English. Journal of the Acoustical Society of America 147: 606–15. [Google Scholar] [CrossRef]
- Weinreich, Uriel, Wiliiam Labov, and Marvin I. Herzog. 1968. Empirical Foundations for a Theory of Language Change. In Directions for Historical Linguistics: A Symposium. Edited by Winfred P. Lehmann and Yakov Malkiel. Austin: University of Texas Press, pp. 95–195. [Google Scholar]


{kind=link}
| (2a) Spanish Voicing | (2b) English Aspirating | |||
|---|---|---|---|---|
| /b d g/ | /p t k/ | /p t k/ | /ph th kh/ | |
| phonology | GT | ∅ | ∅ | GT |
| phon-phon | [slack] | [spread] | ||
| phonetics | voiced | plain | plain | aspirated |
| NAE | SAE | |||
|---|---|---|---|---|
| phonology | ∅ | GW | ∅ | GW |
| phon-phon | [spread] | +[slack] | [spread] | |
| phonetics | plain | aspirated | voiced | aspirated |
| (4a) Voicing | (4b) Hybrid | (4c) Aspirating | ||||
|---|---|---|---|---|---|---|
| phonology | GT | ∅ | GT | GW | ∅ | GW |
| phon-phon | [slack] | (+[spread]) | [slack] | [spread] | (+[slack]) | [spread] |
| phonetics | voiced | plain | voiced | aspirated | plain | aspirated |
| (aspirated) | (voiced) | |||||
| (4a) Voicing | (4b) Hybrid | (4c) Aspirating | ||||
|---|---|---|---|---|---|---|
| phonology | GT | ∅ | GT | GW | ∅ | GW |
| phon-phon | [slack] | +[spread] | [slack] | [spread] | +[slack] | [spread] |
| phonetics | voiced | aspirated | voiced | aspirated | voiced | aspirated |
| activity | Active | Inert | Active | Active | Inert | Active |
| Devoicing | Fortition | |||
|---|---|---|---|---|
| phonology | ∅ | ∅ | GW | |
| phon-phon | +[spread] | [spread] | ||
| phonetics | voiceless | voiceless | aspirated | aspirated |
| (2a) Voicing | (2b) Aspirating | (3) Hybrid | |||||
|---|---|---|---|---|---|---|---|
| phonology | GT | ∅ | ∅ | GW | GT | GW | ∅ |
| phon-phon | [slack] | +[spread] | +[slack] | [spread] | +[slack] | [spread] | — |
| phonetics | voiced | aspirated | voiced | aspirated | voiced | aspirated | — |
| (6a) GenX Voicing | ||||
|---|---|---|---|---|
| phonology | GT | ∅ | GT | ∅ |
| phon-phon | [slack] | [slack] | +[spread] | |
| phonetics | voiced | voiceless | voiced | aspirated |
| activity | Active | Inert | Active | Inert |
| (6b)GenX+1Aspirating | ||||
| phonology | ∅ | GW | ∅ | GW |
| phon-phon | [spread] | +[slack] | [spread] | |
| phonetics | voiceless | aspirated | voiced | aspirated |
| activity | Inert | Active | Inert | Active |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Natvig, D. Modeling Heritage Language Phonetics and Phonology: Toward an Integrated Multilingual Sound System. Languages 2021, 6, 209. https://doi.org/10.3390/languages6040209
Natvig D. Modeling Heritage Language Phonetics and Phonology: Toward an Integrated Multilingual Sound System. Languages. 2021; 6(4):209. https://doi.org/10.3390/languages6040209
Chicago/Turabian StyleNatvig, David. 2021. "Modeling Heritage Language Phonetics and Phonology: Toward an Integrated Multilingual Sound System" Languages 6, no. 4: 209. https://doi.org/10.3390/languages6040209
APA StyleNatvig, D. (2021). Modeling Heritage Language Phonetics and Phonology: Toward an Integrated Multilingual Sound System. Languages, 6(4), 209. https://doi.org/10.3390/languages6040209