1. Introduction
The present article investigates relative complementizer variation in Yucatecan Spanish, a variety of Spanish that is spoken in southeast Mexico and has been in long-term contact with Yucatec Maya. Relative complementizers are structures that connect a relative clause to a superordinate clause and are found in different sentence configurations, including clefts. A controversial topic in the discussion of complementizer variation in Spanish is the occurrence of bare
que (‘who, that’), where, according to reference grammars, standard varieties require other forms (e.g.,
el que ‘who, that’,
quien ‘who’,
en el que ‘in which’, etc.); this controversy has received a fair amount of attention among researchers. This phenomenon has been observed in a number of dialects of Spanish in regions such as in Colombia, Venezuela, the Antilles (
Henríquez Ureña 1921), and Argentina (
Butt and Benjamin 2000).
The present work has been motivated by an elicitation experiment conducted within a research project on language contact in Quintana Roo, México, where we found a notable degree of inter- and intra-speaker variation of bare
que and complex forms (i.e.,
en el/la que) in relative clauses in a naturalistic speech corpus (cf. 1a and 1b).
1| 1 | a. | ¿Por qué? Por el contexto en el que se encuentra... (elic03_nmc) |
| | | ‘Why? Because of the context in which [he] finds himself…’ |
| | b. | Hay un lugar en Veracruz que hablan con muchas groserías. (elic03_nmc) |
| | | ‘There is a place in Veracruz that [where] they speak in a vulgar manner.’ |
Furthermore, in other syntactic configurations involving relative complementation, namely, subject and object clefts, we observed a remarkable number of determiner-less
que in comparison to complex forms (
el/la que, quien) in both naturalistic and elicited data (cf. 2a and 2b).
| 2 | a. | No, es Cantinflas el que está bailando con su sombrero. (elic01_lydc) |
| | | ‘No, it is Cantinflas who is dancing with his hat.’ |
| | b. | No, es Cantinflas que está fumando un cigarro. (elic01_lydc) |
| | | ‘No, it is Cantinflas who is smoking a cigarette.’ |
In the literature, the discussion of determiner-less
que in clefts has primarily been restricted to clefts with focalized adverbial or causal preposition constituents, labeled as
que galicado constructions by
Cuervo (
1907) (cf., e.g.,
Dufter 2010 and the references cited therein). Structures in the form of (2b) are surprising, given that such determiner-less complementizers in subject or object clefts are either considered ungrammatical (
Di Tullio 1990,
2006) or have, to our knowledge, not been attested in any Spanish context so far. While one example of such a structure is cited in
Bentivoglio and Sedano (
2017, p. 113), the authors state that this single instance (across two corpora composed of literary works and samples of “habla culta”) comes from a work by the writer, Julio Cortázar. They further argue that, in this particular case, this (single) occurrence of bare
que may indeed be due to French influence, given that Cortázar spent a fair part of his life in France. Against this background, it is even more striking that the number of sentences containing bare
que accounts for around 50% of all cases in our data (see
Section 3.3 for details).
The reasons for such patterns are controversial in the literature, and various explanations have been put forward. In this context, it is opportune to note that cleft sentences of the type [copula + focal element +
que + predicate] are rarely included in discussions on determiner-less or bare
que complementizers in relative clauses, for theoretical reasons (
Brucart 2016), a fact that is reflected in the differing explanations given for to the occurrence of bare
que in cleft sentences, compared to the one in non-clefted relative clauses (see
Section 2). Nonetheless, previous researchers, such as
Borzi (
2018), argue that bare
que in clefts can be considered to be on par with bare
que in non-clefted relative clauses. In this paper, we will be following this assumption.
Turning back to the possible causes of the usage of determiner-less or bare
que relative complementizers in Spanish, we already mentioned the hypothesis that the use of bare
que in Spanish clefts, with focalized adverbs or causal prepositional constituents, may be due to the historic influence of the French language; hence, we see the label
que galicado (
Cuervo 1907), although such claims have been challenged in other studies (
Dufter 2010, see
Section 2 for details). Other researchers argue that such bare
que forms should be understood as processes of semantic bleaching or grammaticalization (
Alarcos 1963). In contrast, for non-clefted relative clauses, it has been shown in sociolinguistic diachronic research that relative complementizers with the determiner-less prepositional structure (PREPOSITION +
que) (e.g.,
en que) predate the complex prepositional complementizers of the type (PREPOSITION (PREP) + DETERMINER (DET) +
que) (e.g.,
en el que). While the form that has a determiner experiences an increase in usage in the 18th century (
Vellón Lahoz 2019), the determiner-less variant still outnumbers the alternative form, at least until the mid-19th century (
Blas Arroyo et al. 2019). From a broader historical perspective, then, the complex variant
with a determiner actually constitutes the innovative form. This, in turn, raises the question of what exactly motivates the usage of determiner-less or bare
que forms in Spanish relative clauses, synchronically: is it best considered as: (i) a historical remnant, or (ii) a dialectal recast, following the diachronic grammaticalization process that led to the above-mentioned complex forms? If it transpires that (ii) is more likely, what might be the reasons for the innovative reduction to a determiner-less
que: general cognitive (economy) principles, the context of massive bilingualism/language contact, or other reasons?
Obviously, these questions are complex and do, actually, require broad cross-dialectal comparisons. This paper aims to contribute one (modest) piece of the puzzle to this complex project by means of a pilot study on relative complementizer usage in Yucatecan Spanish, a Spanish dialect spoken on the Yucatán peninsula in southeast Mexico. Thus, as a first approach to the above-mentioned intricate questions, we will analyze the relative complementizers in a corpus containing both elicited and spontaneous speech data, against the background of the current state of research on complementizer variation in Spanish, focusing on a comparison between monolingual and bilingual speakers. For the purpose of obtaining a more comprehensive picture, we will also include clefts in our analysis, which have often been excluded in similar studies. That is to say, this paper primarily addresses the contrast between the use of: (i) complex prepositional complementizers ([PREP + DET + que]) and bare que, particularly in the locative domain, on the one hand, and (ii) complex complementizers in cleft sentences ([DET + que]) and bare que, on the other. When necessary, the determiner-less prepositional complementizers ([PREP + que]) will also briefly be touched upon.
The outline of the article is as follows: In
Section 2, we will delineate the theoretical background and depict the current state of research regarding relative complementizer variations in Spanish. In
Section 3, we will first introduce our research question and hypothesis (
Section 3.1), then describe our database and the methodology employed, in order to extract and annotate the relevant data (
Section 3.2), and, finally, present the results (
Section 3.3). In
Section 4, we will discuss our findings in the light of previous studies, in order to provide a first approach concerning the question of whether the complementizer patterns observed in our data of Yucatecan Spanish are best considered either as a historical remnant or as a distinct, innovative change. Finally,
Section 5 summarizes our main results and presents our conclusions.
2. Previous Accounts of Distributional Facts
As previously touched upon, relative complementizers are found in both non-clefted relative clauses and in clefts
2. However, in studies on complementizer variation in relative clauses, clefts are rarely included in this discussion for theoretical reasons (
Brucart 2016).
Borzi (
2018), however, suggests that bare
que in both clefted and non-clefted relative clauses can be treated on par since the selection of bare
que in both clause types seems to be governed by similar factors. More precisely, an identified antecedent favors the bare
que in both clefts and non-clefted relative clauses, as identification seems to render gender- and number-marked complementation obsolete (
Borzi 2018, p. 33).
In the discussion of relative complementizer variation, then, researchers have pursued different directions to account for determiner-less variants. One line of argument is the hypothesis that the use of bare
que can be attributed to an influence from the French language; hence, we see the label
que galicado, as coined by
Cuervo (
1907). In French cleft sentences that cleave an adverbial constituent,
que is the standard complementizer that connects the cleft to the main clause:
| 3 | Ce fut dans le XV siècle que l’Amérique fut découverte. (Cuervo 1907, §440) |
| | ‘It was in the 15th century that America was discovered.’ |
The fact that Spanish clefts, such as that in (4), follow the structure of the French example in (3) does, at first sight, seem to substantiate the assumption that the use of bare
que is due to an influence from French in this context.
| 4 | Fue en el siglo XV que se descubrió la América. (Dufter 2010, p. 254) |
| | ‘It was in the 15th century that America was discovered.’ |
However, the hypothesis that the Spanish bare
que traces back to a French influence has been challenged, for example, by
Dufter (
2010), who investigates the use of
que galicado in cleft sentences with adverbial antecedents. More specifically,
Dufter (
2010) suggests that such occurrences constitute a pan-Romance phenomenon, rather than a phenomenon in Spanish that was induced by a French influence. In order to test this hypothesis, he conducted a diachronic study, based on the FRANTEXT and CORDE corpora, to assess the development of bare
que usage from the 16th to the 20th century, in both French and Spanish. Additionally, he pursued a synchronic study, based on the CREA corpus, to map out in which Spanish-speaking regions bare
que finds the highest usage.
Dufter (
2010, p. 266) found that bare
que is used more often in Latin American Spanish than in peninsular Spanish (5.50 vs. 1.34 occurrences per 100,000 words) and that it seems to be most popular among speakers from Venezuela (9.43/100,000 words). Additionally, the results show that in the 16th century, there are more occurrences of bare
que in Spanish than in French (1.13 vs. 0.29 occurrences per 100,000 words). According to
Dufter (
2010), this contradicts the notion that bare
que in Spanish was adopted from the French language, as one would expect French to exhibit a higher degree of occurrences than Spanish in the latter case. In the 17th century, in turn, the data show a turnaround in the frequency rates. In the Spanish corpus, the frequency decreases to a rate of 0.80 per 100,000 words compared to 3.84 in French. According to
Dufter (
2010, pp. 268–69), this reversal coincides with both the increasingly stereotypical use of adverbial clefts
3 in French and the beginning of the refusal of the
que galicado in Spanish-speaking regions. In French, the use of adverbial clefts increases again in the 18th century (6.33/100,000 words), followed by a drop to 3.14 and 4.55 in the 19th and 20th centuries, respectively. In Spanish, a different developmental pattern can be observed. By the 18th century, there is a slight increase in bare
que usage (0.94/100,000 words), followed, again, by higher frequencies in the 19th and 20th centuries (2.96 and 1.69/100,000 words, respectively).
Dufter (
2010, p. 267) attributes the higher number of bare
que in the 19th and 20th centuries to the higher proportion of Latin American texts in the respective sections of the corpus. Based on these findings,
Dufter (
2010) concludes that, except for some specific instances, determiner-less or bare
que usage in adverbial clefts is not caused by a French influence.
Next to this, we note: (i) that determiner-less complementizers in relative complementation, other than cleft sentences, are widespread in medieval Spanish, with the combined forms (DET +
que) coming into being via reanalysis during the 13th to the 15th centuries only (
Mackenzie 2019, pp. 185–91), and (ii) that determiner-less complementizers in relative sentences other than clefts have also been attested far beyond that date in diachronic research. For example,
Vellón Lahoz (
2019) investigates the diachronic development of the use of determiner-less prepositional relative complementizers with the preposition
con (e.g.,
con (el) que) throughout the 18th century. The database is a corpus of ego-documents, i.e., texts of communicative immediacy, such as private letters from Spain to America and vice versa.
Vellón Lahoz (
2019) takes into account a whole range of possible influencing factors related to the antecedent and the complementizer, as well as to the clause itself, e.g., the presence of a determiner in the antecedent or the meaning or type of the relative clause, respectively. The results show that, at the beginning of the 18th century, the use of complex prepositional complementizers, i.e.,
con el que, was rather low compared to the use of the determiner-less variant,
con que, with a proportion of 8.5% for cases of
con el que in the second decade. However, in the final decade, the use of this variant reached a proportion of 21% in the data. This suggests that the determiner-less form actually predates the use of the complex prepositional complementizer with a determiner, suggesting that, diachronically, the latter (
con el que) constitutes the innovative form, whereas the former (
con que) seems to be a diachronic remnant of medieval/former stages of Spanish.
Studies on the use of determiner-less complementizers in the subsequent centuries seem to confirm this picture.
Blas Arroyo et al. (
2019) investigate the frequency of determiner omission in terms of relative complementizers from the 18th to the 20th centuries. They are concerned with the issue of whether the change from determiner-less (
en que) to complex prepositional complementizers (
en el que) constitutes an ongoing process of grammaticalization (of the
el que constituent). In order to answer this question, they employ an approach similar to the one pursued by
Vellón Lahoz (
2019), focusing on complementizers with the preposition
en ‘in’ (i.e.,
en (el) que ‘in that/which’). Their analysis is based on a corpus of texts of communicative immediacy, with over 3 million words, and considers the semantic, grammatical, and discursive variables pertaining to both the relative clause and the antecedent. The range of possible influencing factors considered by
Blas Arroyo et al. (
2019) is indeed very similar to those considered by
Vellón Lahoz (
2019), with relative clause type, relative clause meaning, and the type of determination of the antecedent being among the most important variables. Their results show, again, that the usage of complex prepositional relative complementizers, i.e.,
en el que, in this case, is low in the 18th century (17%), but increases in the following two centuries (24% and 29%, respectively). In comparison, the use of the determiner-less prepositional complementizer (
en que) is very high in the 18th century (80%) but decreases in the subsequent two centuries (73% and 59%, respectively). Still,
en que outnumbers
en el que, well into the 20th century. Although
Blas Arroyo et al. (
2019) assume a broader diachronic perspective on complementizer change, the results still corroborate
Vellón Lahoz’s (
2019) finding that the use of the determiner-less prepositional complementizers historically precedes that of the complex forms. Summing up the main results of the diachronic approaches, the cleft analysis by
Dufter (
2010) demonstrates that the occurrence of bare
que is not due to French influence because
que in the 16th century has a higher frequency in Spanish than in French clefts. Furthermore, the diachronic structural analysis by
Mackenzie (
2019) shows that the combined forms (DET +
que) come into being via reanalysis during the 13th to the 15th centuries only, and corpus analyses by
Blas Arroyo et al. (
2019) and
Vellón Lahoz (
2019) show that complex prepositional complementizers have been outnumbered by the determiner-less form until the 20th century. Coming back to the issue of complementizer variation in Yucatecan Spanish, it is important to note that the morphosyntactic particularities of Yucatecan Spanish are quite often considered to be “more attributable to archaism than to a Mayan substratum” (
Cotton and Sharp 1988, p. 166). According to this line of reasoning, the above-cited diachronic works on European Spanish determiner-less relative complementizers would suggest an analysis of the usage of determiner-less relative complementizers, including bare
que in cleft sentences, would find this in Yucatecan Spanish as a historical remnant of medieval Spanish.
However, it is important to also take into consideration the following: (i) Yucatecan Spanish has been in close contact with Yucatec Maya for more than 500 years, and (ii) Yucatec Maya is a typologically remote language that exhibits the following particularities with regard to relative complementation. First, Yucatec Maya lacks any “formal device for ‘which’” (
Andrade 1955, § 2.22), and has, instead, several “common verbal constructions” (ibid.) corresponding to those of the English relative clauses. Second, just as in Spanish, the interrogative pronouns:
baax, ‘what’;
máax, ‘who’;
bix, ‘how’;
tu’ux, ‘where’;
bahux, ‘how much’;
bik’ix, ‘when’, may “serve as relative pronouns and as initial components of relative clauses” (ibid.), as illustrated below in (5).
| 5 | Jach raro persona [CP[PP[NP máax] ti’] k-u | | si’ib-il] |
| | very rare person | who to hab-erg.3 | grant.pass-ind |
| | ‘It is a very rare person that (this power) is granted to.’ (Adapted from Gutiérrez Bravo 2012, p. 258) |
Nevertheless, note that the system of relative complementation of Yucatec Maya differs from the Spanish one in that is does not seem to provide any possibility to combine complementizers and definite determiners in the CP domain.
Another property of relative complementation in Yucatec Maya, which may possibly be related to the aforementioned characteristic, is that when complementizers with a preposition are raised into the CP domain, both the relative pronoun and the preposition undergo inversion. As can be seen in example (5), the order of the complementizer is máax ti’, i.e., [REL + PREP]. In contrast, the in situ word order of the corresponding prepositional phrase is ti’ máax.
Finally, another feature that sets the Yucatec Maya language apart from Spanish is the particular character of the relative pronoun
tu’ux, ‘where’. Consider, e.g., (6):
| 6 | Le tunich | [RC tu’ux | k-u | pak’-a’a-l | le graasia]-o’. |
| | the stones | where | aux-erg.3 | sow-pass-ind | the stuff |
| | ‘The stones between which the stuff (corn) is sowed.’ (Adapted from Gutiérrez Bravo 2012, p. 256) |
The complementizer
tu’ux in (6) expresses local information that in Spanish would translate to
entre las que ‘between which’. However, the complementizer is not modified by any preposition that expresses the semantic content of the preposition
entre. In fact, the adverbs
tu’un (i) and
tu’ux (i) have various translations—among others,
dónde,
en qué lugar, and
por dónde (
Martínez Huchim 2014). In Spanish, relative pronouns need to be preceded by a preposition if they are semantically or grammatically required (
Brucart 1999, p. 399), a feature that is lacking in relative complementizers in Yucatec Maya. Thus, it seems that the local relative adverb
tu’ux has a reduced expression of spatial or directional information, compared to the prepositional complementation in Spanish. Coming back to the issue of relative complementizer variations in Yucatecan Spanish, this phenomenon could, thus, possibly also be influenced by the less structurally complex complementizer system of Yucatec Maya. All in all, the findings considered thus far seem to point in two directions: the determiner-less complementizers in Yucatecan Spanish might either be a historical remnant from Medieval Spanish or are the result of an ongoing process of simplification, possibly driven by other factors, one of which could be the language contact with Yucatec Maya.
In order to approach this question in more detail, we conducted a corpus study that complements previous studies by contributing data from Yucatecan Spanish. Given that the studies described above cover information from the 18th to the 20th centuries, more recent data may contribute to the current body of knowledge on complementizer variation. Additionally, we not only consider relative clauses but also subject and object clefts, to which, according to the literature, bare
que usage has not yet been attested to any significant degree (see
Section 1) in any current variety of Spanish so far.
4. Discussion
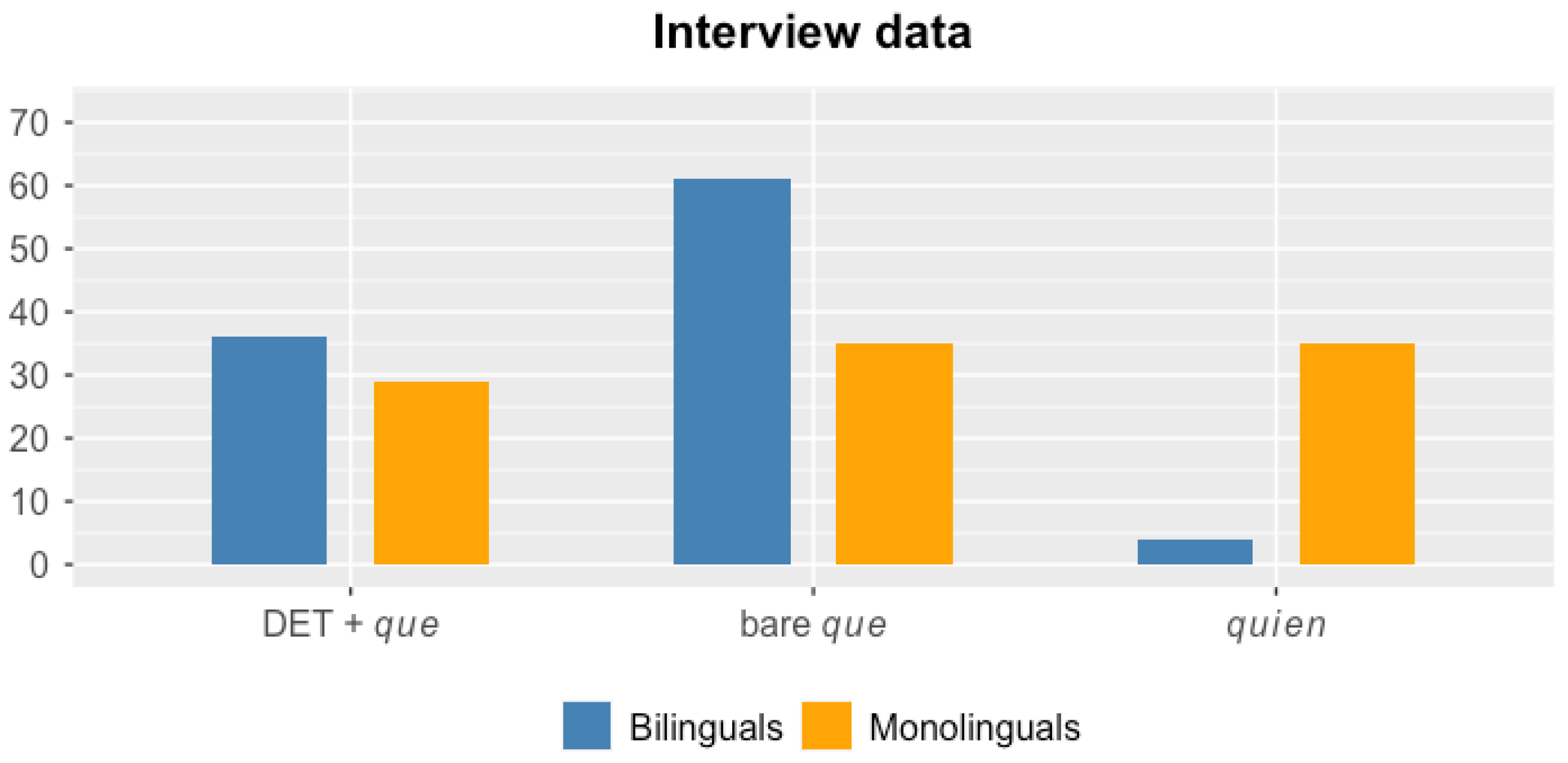
Taken altogether, our analyses of the databases have revealed a high degree of complementizer variation. With regard to the first research question, i.e., if our Quintana Roo Spanish data set exhibits a particularly high degree of bare
que usage, compared to what has been identified for other varieties, the data supports our affirmative hypothesis. We found a substantial number of bare
que in subject and object clefts, which have not so far been attested to (at least, to this degree) in other varieties. Additionally, in non-clefted relative clauses, we found that a considerable number of bare
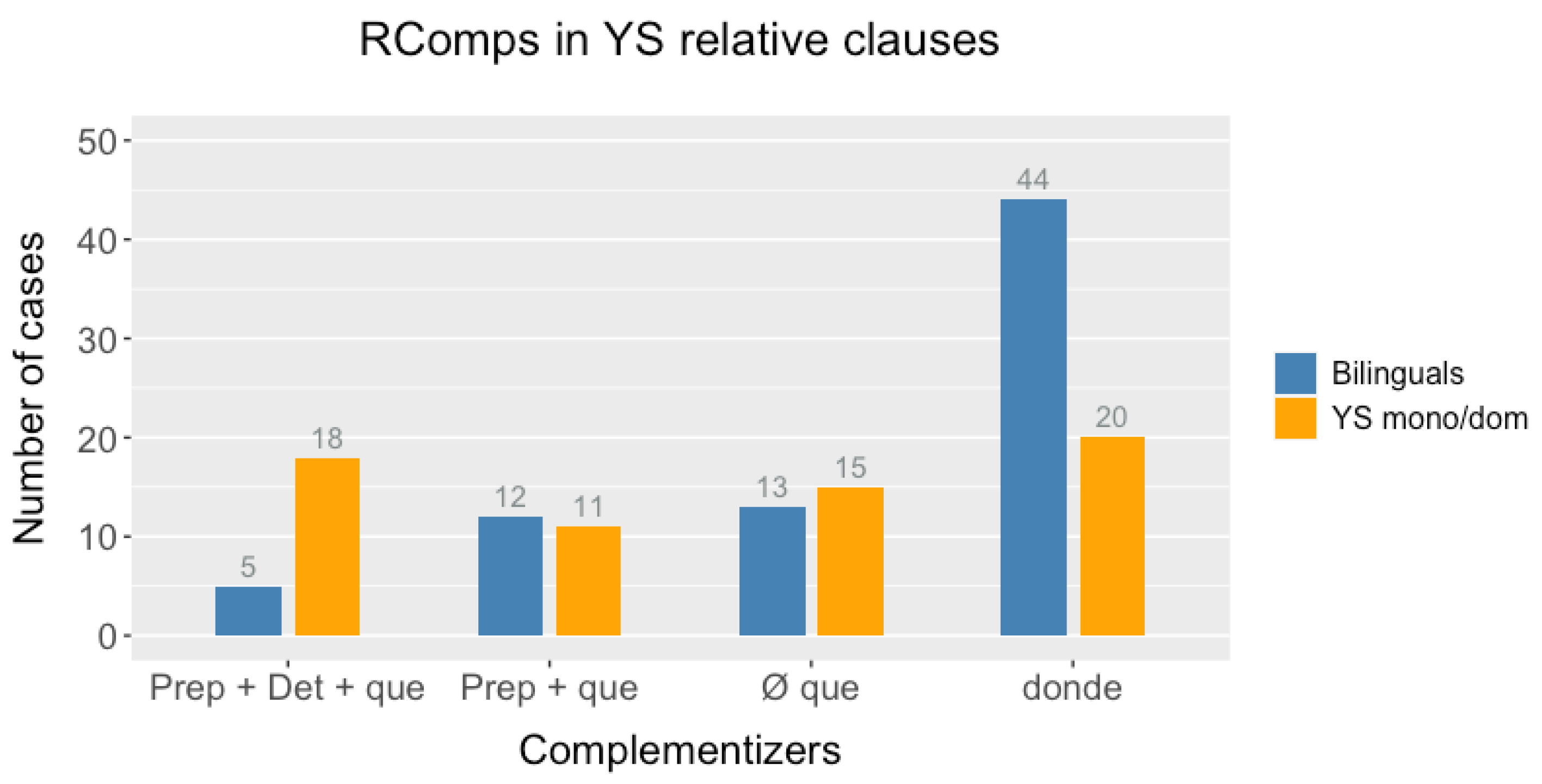
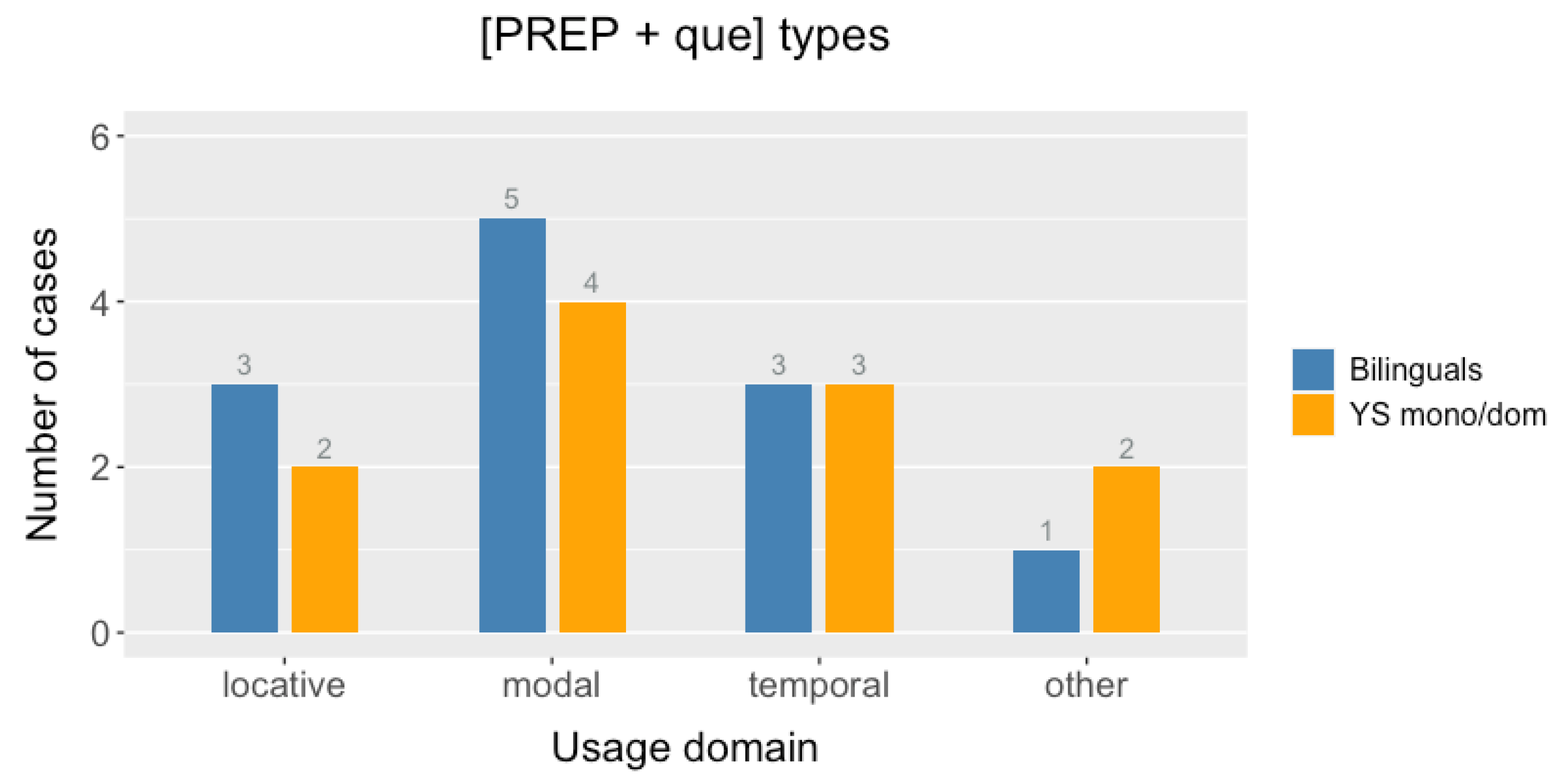
que co-occurs next to other relative complementizers. As concerns the question of whether the bilingual and monolingual speakers of Yucatecan Spanish in our database differ with respect to the patterns of relative complementizer usage, the data equally support our working hypothesis, in that the bilingual and the monolingual data do indeed exhibit differences with respect to the usage of +/− complex complementizers. As illustrated by
Figure 5 and
Figure 6 in
Section 3.3, the differences between the groups mainly arise in the domain of locative complementation, in that the YS-monolinguals and YS-dominant speakers produce the entire envelope of variation, whereas the bilingual speakers clearly prefer
donde for locative relative complementation, at the cost of the locative bare
que and locative complex prepositional complementizers (PREP + DET +
que). This finding corroborates the assumption of a dialectal recast, the causes of which remain to be investigated. The observation that these patterns are limited to locative complementation raises the possibility of the influence of the Yucatec Maya complementizer
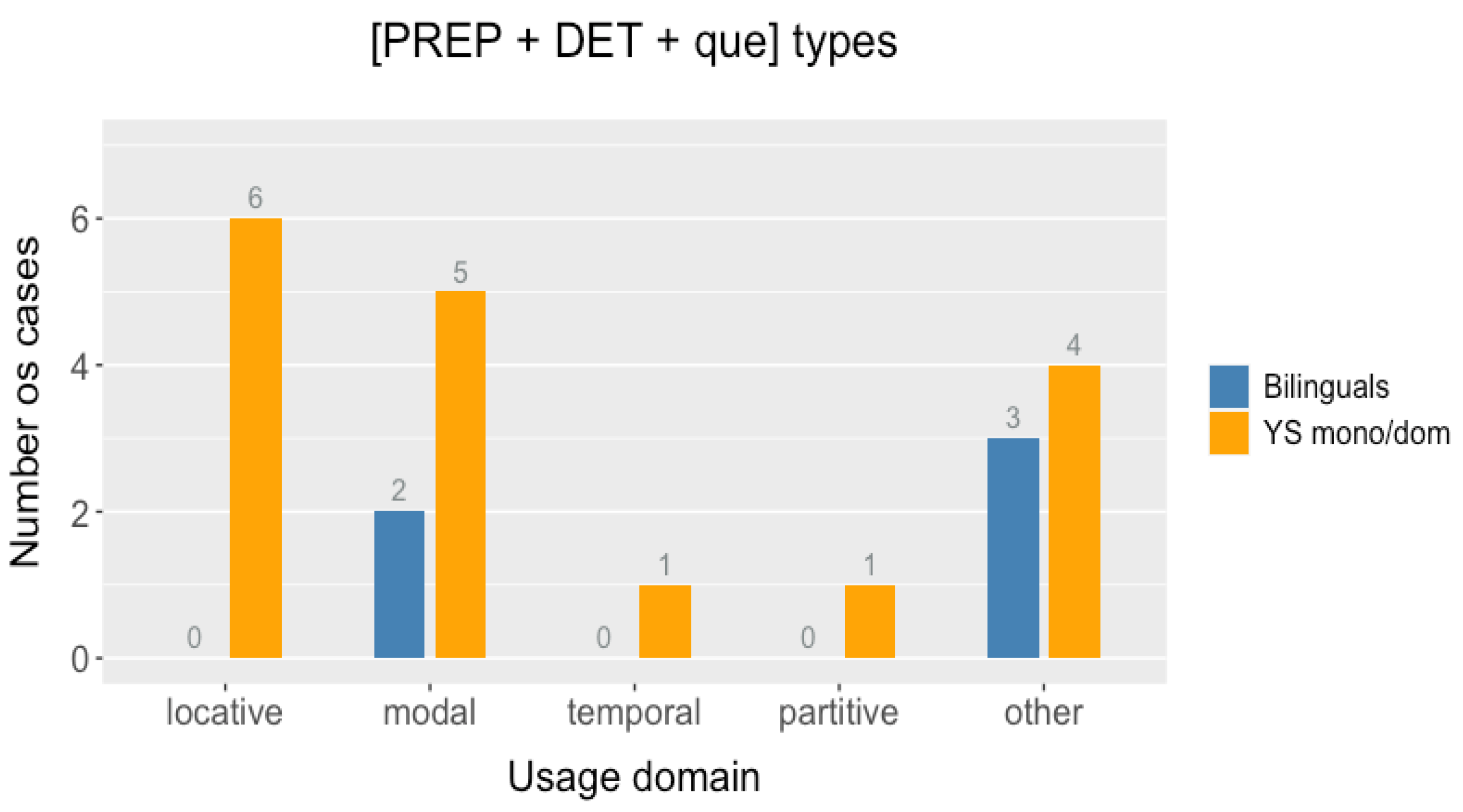
tu’ux on complementizer variations in bilingual speakers. A notable exception to this pattern was the locative determiner-less prepositional complementizers (PREP +
que), which were also produced by bilingual speakers, although the number of cases may have been too low to draw firm conclusions.
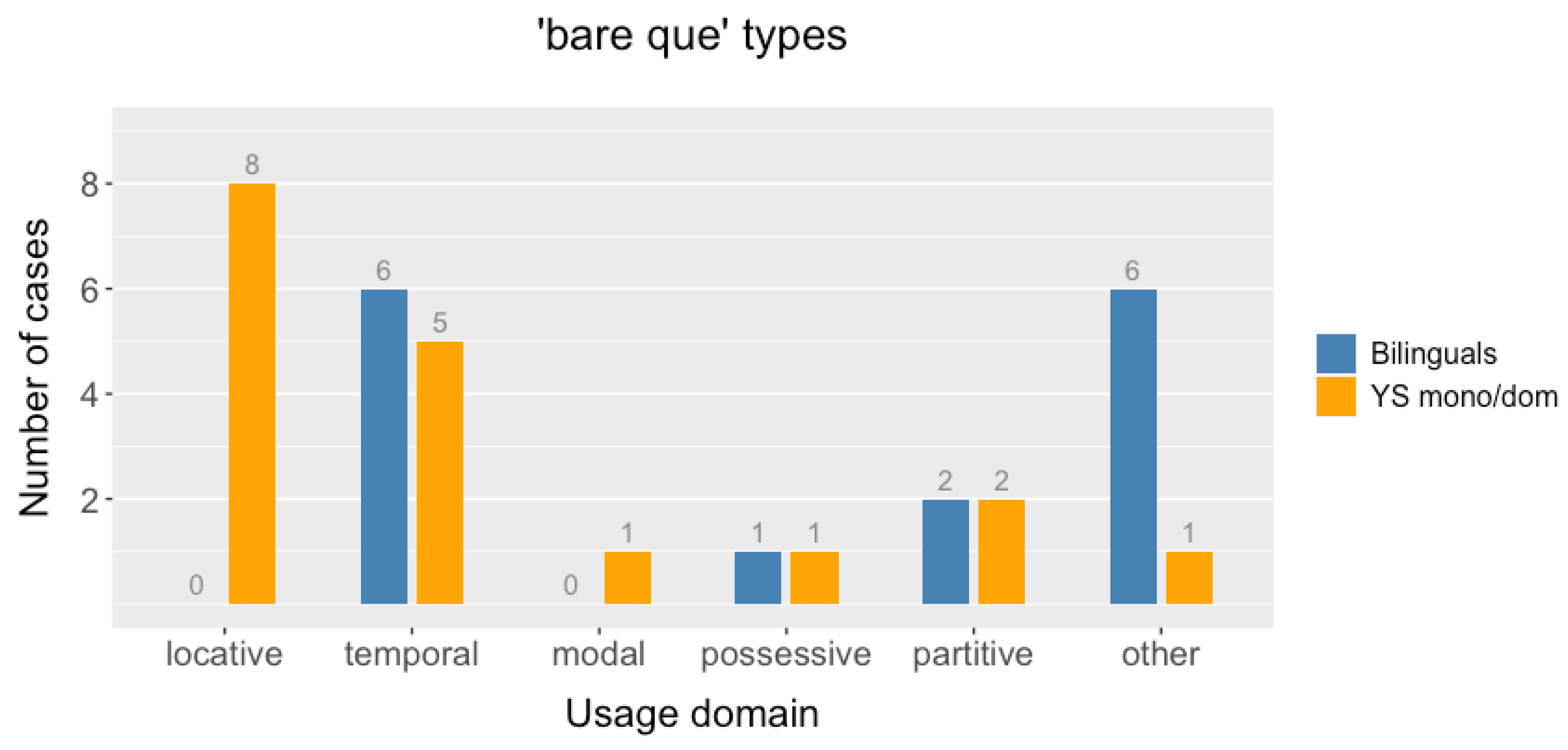
Nonetheless, it should also be noted that a fair degree of determiner-less
que and determiner-less prepositional complementizers, outside of the locative usage domain, was shared by both groups. This holds true not only for non-clefted relative clauses but also for clefts. For example, occurrences of bare
que can be observed in non-clefted relative clause data, with similar rates in both groups. Against the background of previous diachronic studies on relative complementation, the relative clause data are also quite intriguing, in that they, too, show the presence of both the determiner-less prepositional complementizer and diachronically innovative complex prepositional construction. The balanced number may be understood as a continuation of the trend that was observed by
Blas Arroyo et al. (
2019) and
Vellón Lahoz (
2019), namely, the increasing use of the innovative complex variant. However, this omits the role of
tu’ux, the influence of which may well have led to the previously described notable decrease in the use of locative complex prepositional complementizers in the bilingual group. Hence, our results on prepositional complementation with and without a determiner cannot be simply understood as a mere continuation of the development documented in previous studies. Rather, they point to a complex variational phenomenon unifying at least two types of triggers/motives or developments, respectively.
Another pattern shared by both groups, i.e., the usage of bare
que in subject and object clefts, seems to constitute a region-specific phenomenon as the particular pattern that emerged in our data has, so far, not generally been documented in the literature (see, again,
Section 1 for details). This phenomenon is striking in that it occurs in both the bilingual and the YS-monolingual/dominant group. The causes of this pattern are unclear at this point and need to be explored in future research. Another interesting effect that we observed, coincidentally, was that the numbers of bare
que seem to have been modulated by the task type: In the spontaneous speech data, the proportion of bare
que usage was higher overall than it was in the experimental data. While this may not be a surprising finding, in itself, we still consider it to be important, as it raises the possibility of cognitive economy in the context of non- or less formal speech as a factor in the variation of relative complementizer usage in Spanish, which should be considered in future research.
Summarizing our central findings, we found a two-way variational development: (i) the variational pattern exclusive to the bilingual group, i.e., the increased use of
donde, and the accompanying lowered production rate of locative complex prepositional complementizers and bare
que, which could eventually be attributed to the influence of the Mayan
tu’ux, and (ii) the patterns of complementizer usage shared by both groups, which can be observed in the presence of bare
que and determiner-less prepositional structures (PREP +
que). The causes of the latter are also difficult to pinpoint from our data sample, as the structural variation could be either due to diachronic archaism or could be a case of dialectal recast. We will briefly return to this issue in
Section 5.
Overall, the analysis has revealed a complex interplay of different strands of complementizer variation. On the one hand, we encountered complementizer preferences that are exclusive to the bilingual speakers, while on the other hand, we found dialect- or region-specific patterns in the form of bare que in both non-clefted relatives and clefts. Additionally, we also detected prepositional complementizers that are both with and without a determiner, the numbers of which are congruent with the pan-Hispanic developments worked out in previous studies, suggesting that the presence of the determiner-less variant may indeed constitute a historic remnant in these particular cases. These layers of variation do not exist in isolation but, instead, most probably interact with each other. For example, the region-specific usage of bare que in relative clauses could be influenced by the Mayan tu’ux in the bilingual group, to the extent that the bilingual speakers seem to gravitate toward donde at the cost of the locative bare que. This would suggest that donde and the locative bare que may be in competition with each other in the bilingual speakers. Similarly, donde also seems to have a siphoning effect on the historically innovative form (PREP + DET + que) in the bilinguals. As far as the question of grammaticalization is concerned, the presence of both the determiner-less as well as the complex prepositional complementizers suggests that the grammaticalization of (DET + que) is still not concluded. Additionally, these particular characteristics, in the form of bare que and the increased usage of donde in the bilingual group, may ultimately stall or alter the grammaticalization process.
Throughout the analysis, it has become apparent that disentangling the individual developments is a complex task, as both system-internal tendencies and externally induced changes seem to interact with each other. In view of the different tendencies observed between the groups, the question arises as to what exactly causes them. We would like to tentatively address the question of language contact, as this would be one candidate (among others) by which to explain at least some of these patterns, given the long-lasting presence of, and close interchange between, the two languages in one and the same region. Certain patterns in our data, at first glance, do indeed seem to point in this direction. For example, the increased use of
donde at the cost of other complementizer structures, as well as its usage patterns in the bilingual group, suggest the effect of
tu’ux. The (supposed) directionality of influence in this particular example lends itself to analysis along the lines followed by
van Coetsem (
1988,
2000),
Winford (
2005), or similar theoretical approaches (
Palacios Alcaine 2007;
Palacios 2011). In his framework,
van Coetsem (
1988,
2000) distinguishes between two types of transfer, which he labels
borrowing and
imposition. The difference between these two terms can be explained by referencing: (1) the direction in which the transfer takes place (from the source language to the recipient language) and (2) the agency of the speaker. Thus, borrowing is defined as a transfer where the agent is a speaker of the recipient language, whereas imposition is understood to be a transfer wherein the agent is a speaker of the source language (
van Coetsem 1988, p. 3). This approach has been expanded upon by
Winford (
2005), who crucially suggests that in a bilingual setting, one and the same speaker can be the agent of either type of transfer and can, thus, account for a variety of language-contact phenomena in a wide range of multilingual social configurations/settings. Coming back to the example of the increased use of
donde, it could be argued that this constitutes a case of imposition, i.e., a case of source language agentivity, given that it is the bilingual speaker group that seemingly transfers the properties of the Yucatec Maya complementizer
tu’ux onto the Spanish relativizer system. This analysis is far from in-depth, but more importantly, it needs to be ascertained as to whether this is indeed a case of cross-linguistic transfer at all. While our data, despite their limited sample size, reveal some notable tendencies that tend to suggest the possibility of linguistic transfer, they cannot, by themselves, answer the question if the patterns they exhibit are indeed due to language contact. Future research should thus focus on the comparison of complementizer preferences in other varieties of Spanish to confirm or rule out an impact of language contact in the case of our Quintana Roo data (and in the case of other varieties). Additionally, given the limited size of the corpus, the findings of this study should be verified by a larger study with a larger database.
5. Conclusions
This article set out to approach the issue of the high degree of relative complementizer variation that have we found in our elicited and naturalistic speech data analysis of Yucatecan Spanish. Previous diachronic research has shown that determiner-less complementizers actually predate relative complementizers with a determiner, which, thus, constitute an innovative variant (
Blas Arroyo et al. 2019;
Mackenzie 2019;
Vellón Lahoz 2019). A further important aspect of our research is that the Spanish variety investigated in this article, Yucatecan Spanish, has been in long-standing contact with Yucatec Maya. Relative complementation in Yucatec Maya differs from that in Spanish, in that the complementizer
tu’ux or ‘donde’ has a much broader usage than
donde in standard Spanish. Against this background, we investigated data from elicitation experiments and sociolinguistic interviews to approach the question of whether the determiner-less complementizers in our data should be considered to be historic remnants or rather as a case of dialectal recast, caused by entirely different factors. Our analysis suggests a complex picture: (i) usage of structurally less complex/determiner-less complementizers (PREP +
que; bare
que) that can be observed across both monolingual speakers of Spanish and Spanish Maya bilinguals, and (ii) a preference for
donde at the cost of locative bare
que and (PREP + DET +
que) in the bilingual group only. As regards the first finding: (a), the balanced number of complex and non-complex complementizers in our data may be understood as a continuation of the trend that was observed by
Blas Arroyo et al. (
2019) and
Vellón Lahoz (
2019), namely, the increasing use of the innovative complex variant, suggesting that we are faced with a historical remnant in this case. The second finding, (b), corroborates the assumption of a dialectal recast, the causes of which remain to be investigated. However, the observation that these patterns are limited to locative complementation raises the possibility of the influence of the Yucatec Maya complementizer
tu’ux on complementizer variations in bilingual speakers.
Our data not only complement previous findings on relative complementizer variation in Spanish but may also give new motivation for future research, given the broad envelope of variation in the usage investigated in this article. For example, it is noteworthy that the paradigm of relative complementizers in YS shows a donde-effect in the bilingual group, but not among the monolingual speakers, which could open up a window for a more fine-grained investigation of the reasons underlying this particular pattern, one of them possibly being language contact. Additionally, given the low numbers of (PREP + que) in our data, future research focusing on this particular configuration may provide new evidence: (i) whether (PREP + que) is indeed less susceptible to the influence of tu’ux, and, if so, (ii) due to what factors (e.g., processing-related mechanisms). Another complementizer that may benefit from further investigation is donde, which, in the bilingual data, seems to compete with both simple and complex locative prepositional complementizers. Finally, due to the limited scope, this article could not address the questions of intra-speaker variation and comparability to other dialects of Spanish. Future research should also focus on providing additional (comparative and experimental) data to complement the tendencies laid bare in this study. Nevertheless, our analysis revealed intriguing differences between the complementizer preferences of YS-monolingual/YS-dominant speakers, on the one hand, and bilingual speakers, on the other, suggesting that different variational patterns caused by different (socio-)linguistic factors can co-develop in parallel in one and the same region. The compelling findings of this early outline of complementizer variation in YS may hopefully serve to inspire more detailed cross-dialectal research along the lines proposed above.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






