

Robustness and Complexity in Italian Mid Vowel Contrasts


Abstract
:1. Introduction
1.1. The Multidimensional Model of Phonemic Robustness
1.2. Marginal Contrasts in Romance Languages
1.3. Sources and Evidence of Marginal Contrast in Italian
1.3.1. Regional Variation in Italy: Regiolects and the Construct of “Standard Italian”
1.3.2. Evidence for Marginal Contrast in Italian
- (1)
- Examples drawn from CLIPS, as transcribed in Crocco (2017, (1)). Bold indicates stressed mid vowels. The orthographic sentence is Maria dovrebbe stare più attenta a scuola, “Maria should pay more attention at school”.
[maˈria doˈvrɛbːe ˈstare ˈpju aˈtːɛnta a ˈskwɔla] Standard speaker [maˈria doˈvrɛbːe ˈstare ˈpju aˈtːenta a ˈskwɒla] Milanese speaker [maˈria doˈvrɛbːe ˈstare ˈɸju aˈtːɛnta a ˈskwɔla] Florentine speaker [maˈria doˈvrɛbːe ˈstare ˈp̬ju aˈtːɛnta a ˈskwɔla] Roman speaker [maˈria doˈvrebːe ˈstare ˈpːju aˈtːɛnta a ˈskwola] Neapolitan speaker - (2)
- Examples drawn from CLIPS, as transcribed in Crocco (2017, (2)). Bold indicates stressed mid vowels. The orthographic sentence is Un mese di vacanza passa in fretta, “A month of vacation passes quickly”.
[uˈmːeze di vaˈkanʦa ˈpasːa iɱ ˈfretːa] Standard speaker [uˈmːeze di vaˈkanʦa ˈpasːa iɱ ˈfrɛtːa] Milanese speaker [uˈmːeze di vaˈxanʦa ˈpasːa iɱ ˈfretːa] Florentine speaker [uˈmːese di vaˈk̬anʦa ˈpasːa iɱ ˈfretːa] Roman speaker [uˈmːese di vaˈkanʦa ˈpasːa iɱ ˈfretːa] Neapolitan speaker
1.4. Road Map: Sources of Mid Vowel Variation across Italy
2. Relative Frequencies and Functional Load of Italian Vowels
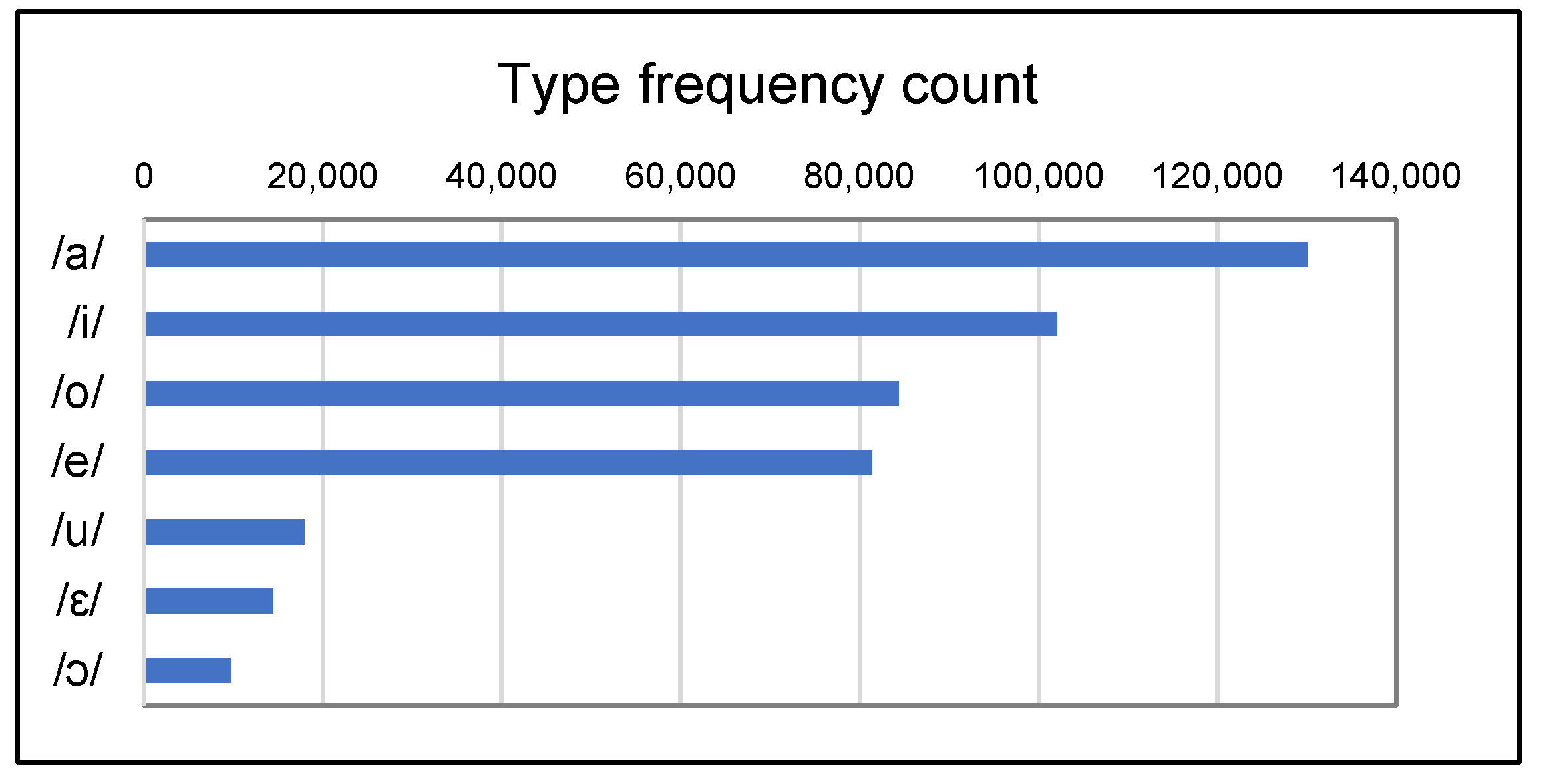
2.1. How Frequent Is Each Vowel across Italian Words?
2.2. Functional Loads of Italian Vowels
3. Corpus Analysis of Mid Vowel Variation: Methods and Predictors
3.1. Dataset and Acoustic Analysis
3.2. Systemic Factors for Italian Mid Vowels
3.3. Usage-Based Factor: Lexical Frequency
3.4. Phonetic Factor: Duration
4. Results of Corpus Study
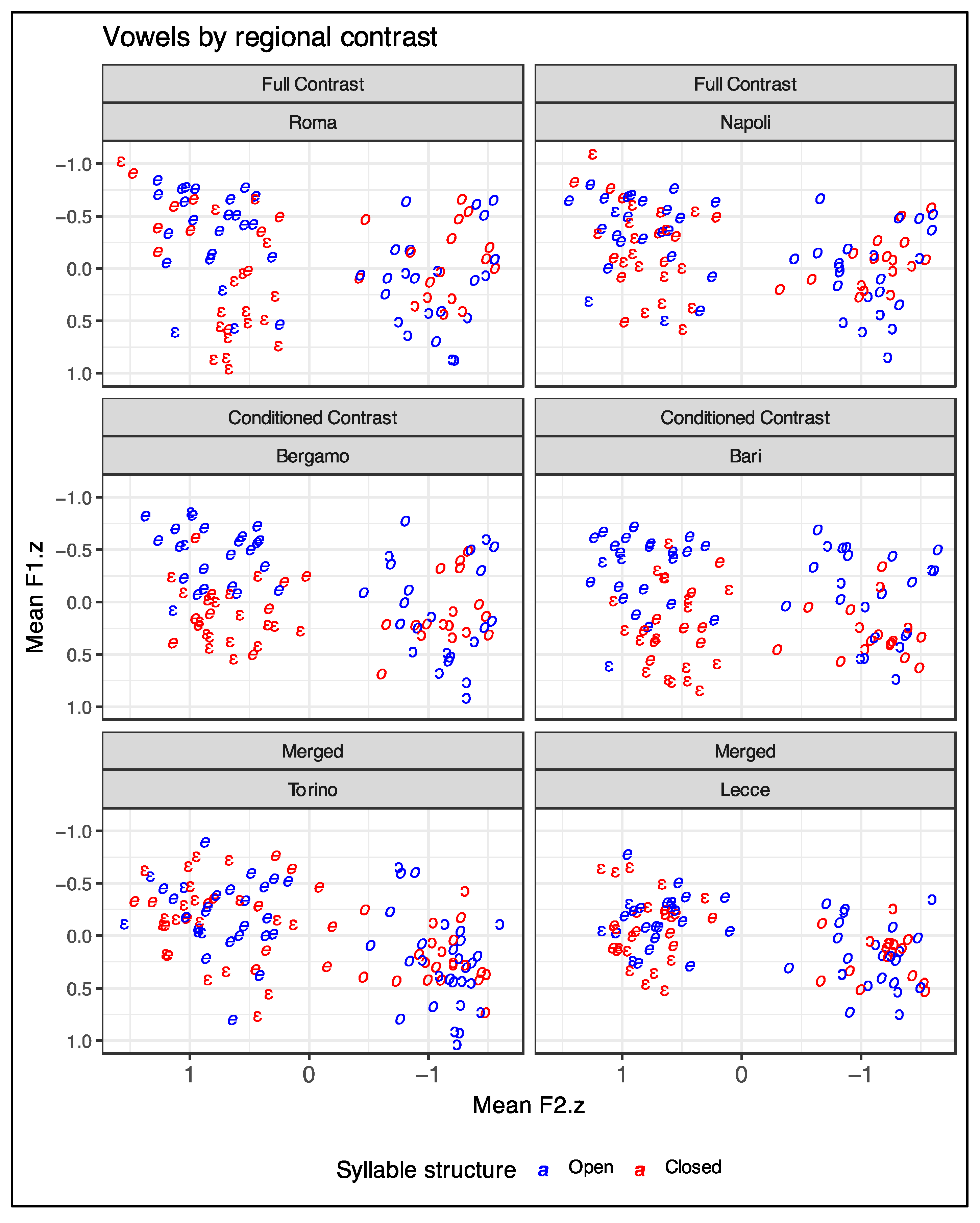
4.1. Lexical Specification vs. Regional Variation
4.2. Usage: Vowel Acoustics vs. Lexical Frequency
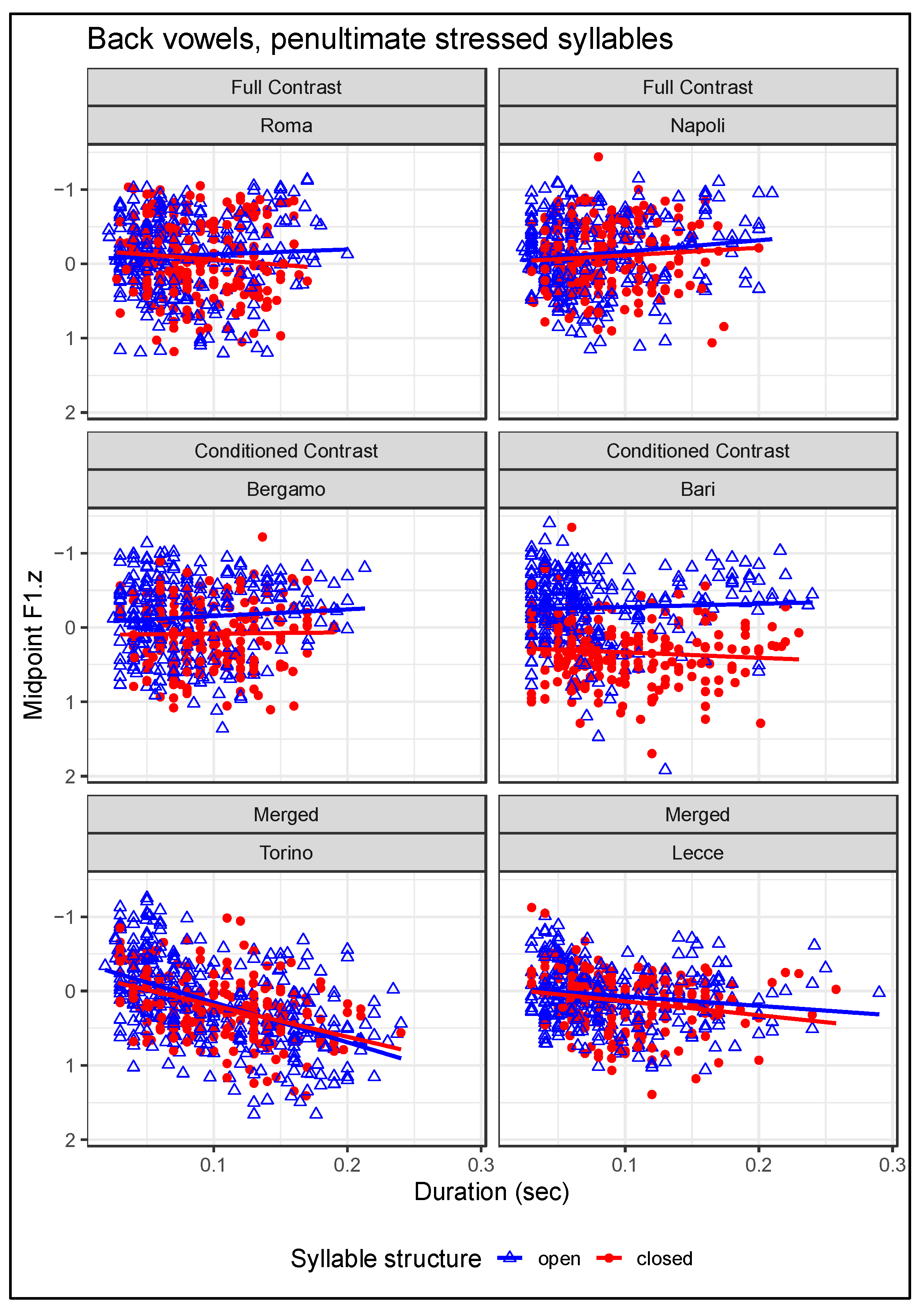
4.3. Phonetic Factors: Vowel Height vs. Duration
5. Modeling Mid Vowel Height with Linear Mixed-Effects Regression
- (3)
- Linear mixed-effects model structure
F1.z ~ # dependent variable F2.z + log10_frequency + # continuous fixed effects dictionary height + type + # categorical fixed effects duration*structure + # interaction term (1|City) + (1|Word) + (1|Speaker) # random intercept terms
Results of Linear Mixed-Effects Modeling
6. Discussion
6.1. Summary of Findings
6.2. Toward a Formalization of Italian Marginal Contrasts
7. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
| 1 | “Type frequency measures […] refer to the number of times a particular unit (phoneme, syllable, etc.) occurs within the words of the lexicon, with each word counted once. Token frequency (identified by the field TokenF, with the natural log of this value found in the field LnTokenF) refers to the number of times a unit occurs in the words of the language taking into account the frequency of the words” (Goslin et al. 2014, p. 875). |
| 2 | In PCT, functional load was calculated twice, using Algorithm: Change in Entropy and Minimal Pairs. All settings were identical across both algorithms as follows. Distinguished homophones: false. Minimal pair count: true minimal pairs. Transcription tier: transcription. Pronunciation variants: canonical form. Minimum word frequency: 0. Environments: none. For documentation, see: https://corpustools.readthedocs.io/en/latest/functional_load.html (accessed on 7 April 2024). |
| 3 | By comparison, the functional load for the marginal Romanian contrast /ɨ ʌ/ is 0.0004 (Renwick et al. 2016). |
| 4 | Penultimate syllables were modeled here because penultimate stress was the most common pattern in this dataset, representing stress patterns of Italian more broadly (Borrelli 2002), but also because previous exploratory analyses indicated that the relationship between F1 and duration was strongest in penultimate syllables (Renwick 2018). |
References
- Albano Leoni, Federico, Francesco Cutugno, Renata Savy, Valentina Caniparoli, Leandro D’Anna, Ester Paone, Rosa Giordano, Olga Manfrellotti, Massimo Petrillo, and Aurelio De Rosa. 2007. Corpora e Lessici dell’Italiano Parlato e Scritto. Available online: http://www.clips.unina.it/ (accessed on 7 April 2024).
- Alkire, Ti, and Carol Rosen. 2010. Romance Languages: A Historical Introduction. Cambridge: Cambridge University Press. [Google Scholar]
- Amengual, Mark, and Pilar Chamorro. 2015. The Effects of Language Dominance in the Perception and Production of the Galician Mid Vowel Contrasts. Phonetica 72: 207–36. [Google Scholar] [CrossRef] [PubMed]
- Auer, Edward T., Jr., and Paul A. Luce. 2005. Probabilistic Phonotactics in Spoken Word Recognition. In The Handbook of Speech Perception. Edited by David B. Pisoni and Robert E. Remez. Hoboken: John Wiley & Sons, pp. 610–30. [Google Scholar]
- Badia i Margarit, Antoni M. 1969. Algunes mostres de les igualacions E = e i O = o en el català parlat de Barcelona. In Sons i Fonemes de la Llengua Catalana. Barcelona: Publicacions de la Universitat de Barcelona, pp. 97–103. [Google Scholar]
- Barr, Dale J., Roger Levy, Christoph Scheepers, and Harry J. Tily. 2013. Random effects structure for confirmatory hypothesis testing: Keep it maximal. Journal of Memory and Language 68: 255–78. [Google Scholar] [CrossRef] [PubMed]
- Bates, David, and Martin Maechler. 2009. lme4: Linear Mixed-Effects Models Using S4 Classes. Available online: https://cran.r-project.org/web/packages/lme4/index.html (accessed on 7 April 2024).
- Bell, Alan, Jason M. Brenier, Michelle Gregory, Cynthia Girand, and Dan Jurafsky. 2009. Predictability effects on durations of content and function words in conversational English. Journal of Memory and Language 60: 92–111. [Google Scholar] [CrossRef]
- Bertinetto, Pier Marco, and Michele Loporcaro. 2005. The sound pattern of Standard Italian, as compared with the varieties spoken in Florence, Milan and Rome. Journal of the International Phonetic Association 35: 131–51. [Google Scholar] [CrossRef]
- Boersma, Paul, and David Weenink. 2021. Praat: Doing Phonetics by Computer [Computer Program], Version 6.2.03. Available online: http://www.praat.org (accessed on 7 April 2024).
- Borrelli, Doris Angel. 2002. Raddoppiamento Sintattico in Italian: A Synchronic and Diachronic Cross-Dialectical Study. Abingdon: Routledge. [Google Scholar]
- Bybee, Joan. 2003. Phonology and Language Use. Cambridge: Cambridge University Press. [Google Scholar]
- Calamai, Silvia. 2017. Tuscan between standard and vernacular: A sociophonetic perspective. In Towards a New Standard: Theoretical and Empirical Studies on the Restandardization of Italian. Edited by Massimo Cerruti, Claudia Crocco and Stefania Marzo. Boston: De Gruyter, pp. 213–41. [Google Scholar]
- Canepari, Luciano. 1980. Italiano Standard e Pronunce Regionali. Padua: CLUEP. [Google Scholar]
- Cerruti, Massimo. 2011. Regional varieties of Italian in the linguistic repertoire. International Journal of the Sociology of Language 210: 9–28. [Google Scholar] [CrossRef]
- Cerruti, Massimo, and Riccardo Regis. 2014. Standardization patterns and dialect/standard convergence: A northwestern Italian perspective. Language in Society 43: 83–111. [Google Scholar] [CrossRef]
- Cerruti, Massimo, Claudia Crocco, and Stefania Marzo. 2017. On the development of a new standard norm in Italian. In Towards a New Standard: Theoretical and Empirical Studies on the Restandardization of Italian. Edited by Massimo Cerruti, Claudia Crocco and Stefania Marzo. Boston: De Gruyter, pp. 3–28. [Google Scholar]
- Coetzee, Andries W. 2016. A comprehensive model of phonological variation: Grammatical and non-grammatical factors in variable nasal place assimilation. Phonology 33: 211–46. [Google Scholar] [CrossRef]
- Coetzee, Andries W., and Shigeto Kawahara. 2013. Frequency biases in phonological variation. Natural Language & Linguistic Theory 31: 47–89. [Google Scholar] [CrossRef]
- Cohn, Abigail C., and Margaret E. L. Renwick. 2021. Embracing multidimensionality in phonological analysis. The Linguistic Review 38: 101–39. [Google Scholar] [CrossRef]
- Crepaldi, Davide, Simone Amenta, Mandera Pawel, Emmanuel Keuleers, and Marc Brysbaert. 2015. SUBTLEX-IT. Subtitle-based word frequency estimates for Italian. Paper presented at the Annual Meeting of the Italian Association for Experimental Psychology, Rovereto, Italy, September 10–12. [Google Scholar]
- Crocco, Claudia. 2017. Everyone has an accent. Standard Italian and regional pronunciation. In Towards a New Standard: Theoretical and Empirical Studies on the Restandardization of Italian. Edited by Massimo Cerruti, Claudia Crocco and Stefania Marzo. Boston: De Gruyter, pp. 89–117. [Google Scholar]
- De Mauro, Tullio. 1976. Storia Linguistica dell’Italia unita. Roma and Bari: Laterza. [Google Scholar]
- De Mauro, Tullio. 2000. Il Dizionario della Lingua Italiana. Torino: Paravia. [Google Scholar]
- De Mauro, Tullio, and Marco Mancini. 2000. Dizionario Etimologico. Milan: Garzanti Linguistica. [Google Scholar]
- De Pascale, Stefano, Stefania Marzo, and Dirk Speelman. 2017. Evaluating regional variation in Italian: Towards a change in standard language ideology? In Towards a New Standard: Theoretical and Empirical Studies on the Restandardization of Italian. Edited by Massimo Cerruti, Claudia Crocco and Stefania Marzo. Boston: De Gruyter, pp. 118–41. [Google Scholar]
- D’Imperio, Mariapaola, and Sam Rosenthall. 1999. Phonetics and phonology of main stress in Italian. Phonology 16: 1–28. [Google Scholar] [CrossRef]
- Drager, Katie, and M. Joelle Kirtley. 2016. Awareness, salience, and stereotypes in exemplar-based models of speech production and perception. In Awareness and Control in Sociolinguistic Research. Edited by Anna Babel. Cambridge: Cambridge University Press, pp. 1–24. [Google Scholar]
- Esposito, Anna. 2002. On vowel height and consonantal voicing effects: Data from Italian. Phonetica 59: 197–231. [Google Scholar] [CrossRef] [PubMed]
- Farnetani, Edda, and Shiro Kori. 1986. Effects of syllable and word structure on segmental durations in spoken Italian. Speech Communication 5: 17–34. [Google Scholar] [CrossRef]
- Flemming, Edward. 2004. Contrast and perceptual distinctiveness. In Phonetically Based Phonology. Edited by Bruce Hayes, Robert Kirchner and Donca Steriade. Cambridge: Cambridge University Press, pp. 232–76. [Google Scholar]
- Goldsmith, John A. 1995. Phonological Theory. In The Handbook of Phonological Theory. Edited by John A. Goldsmith. Cambridge: Blackwell Publishers, pp. 1–23. [Google Scholar]
- Goldwater, Sharon, and Mark Johnson. 2003. Learning OT constraint rankings using a maximum entropy model. In Proceedings of the Stockholm Workshop on Variation within Optimality Theory. Edited by Jennifer Spenader, Aners Eriksson and Östen Dahl. Stockholm: Stockholm University Department of Linguistics, pp. 111–20. [Google Scholar]
- Gordon, Matthew. 2002. A Phonetically Driven Account of Syllable Weight. Language 78: 51–80. [Google Scholar] [CrossRef]
- Goslin, Jeremy, Claudia Galluzzi, and Cristina Romani. 2014. PhonItalia: A phonological lexicon for Italian. Behavior Research Methods 46: 872–86. [Google Scholar] [CrossRef] [PubMed]
- Griffiths, Joshua M. 2022. Competing repair strategies for word-final obstruent-liquid clusters in northern metropolitan French. Journal of French Language Studies 32: 1–24. [Google Scholar] [CrossRef]
- Hall, Daniel Currie, and Kathleen Currie Hall. 2016. Marginal contrasts and the Contrastivist Hypothesis. Glossa: A Journal of General Linguistics 1: 50. [Google Scholar] [CrossRef]
- Hall, Kathleen Currie. 2013. A typology of intermediate phonological relationships. The Linguistic Review 30: 215–75. [Google Scholar] [CrossRef]
- Hall, Kathleen Currie, Elizabeth Hume, T. Florian Jaeger, and Andrew Wedel. 2018. The role of predictability in shaping phonological patterns. Linguistics Vanguard 4: 20170027. [Google Scholar] [CrossRef]
- Hall, Kathleen Currie, J. Scott Mackie, and Roger Yu-Hsiang Lo. 2019. Phonological CorpusTools: Software for doing phonological analysis on transcribed corpora. International Journal of Corpus Linguistics 24: 522–35. [Google Scholar] [CrossRef]
- Hockett, Charles Francis. 1966. The Quantification of Functional Load: A Linguistic Problem. Oxford: Memorandum. [Google Scholar]
- Kisler, Thomas, Uwe D. Reichel, Florian Schiel, Christoph Draxler, Bernhard Jackl, and Nina Pörner. 2016. BAS Speech Science Web Services–An Update on Current Developments. Paper presented at the 10th International Conference on Language Resources and Evaluation (LREC 2016), Portorož, Slovenia, May 23–28; pp. 3880–85. [Google Scholar]
- Kuznetsova, Alexandra, Per Bruun Brockhoff, and Rune Haubo Bojesen Christensen. 2013. lmerTest: Tests for Random and Fixed Effects for Linear Mixed Effect Models (lmer Objects of lme4 Package). R Package Version 2–0. Available online: https://cran.r-project.org/web/packages/lmerTest/index.html (accessed on 7 April 2024).
- Labov, William, Ingrid Rosenfelder, and Josef Fruehwald. 2013. One hundred years of sound change in Philadelphia: Linear incrementation, reversal, and reanalysis. Language 89: 30–65. [Google Scholar] [CrossRef]
- Landick, Marie. 1995. The mid-vowels in figures: Hard facts. French Review 69: 88–102. [Google Scholar]
- Lobanov, Boris M. 1971. Classification of Russian vowels spoken by different speakers. The Journal of the Acoustical Society of America 49: 606–8. [Google Scholar] [CrossRef]
- Macklin-Cordes, Jayden L., and Erich R. Round. 2020. Re-evaluating Phoneme Frequencies. Frontiers in Psychology 11: 570895. [Google Scholar] [CrossRef] [PubMed]
- Mahalanobis, Prasanta Chandra. 1936. On the generalized distance in statistics. In Proceedings of the National Institute of Sciences of India. Calcutta: National Institute of Sciences, vol. 2, pp. 49–55. Available online: http://ci.nii.ac.jp/naid/10004710165/ (accessed on 7 April 2024).
- Maiden, Martin, and Mair Parry, eds. 1997. The Dialects of Italy. London: Routledge. [Google Scholar]
- Meunier, Christine, and Robert Espesser. 2011. Vowel reduction in conversational speech in French: The role of lexical factors. Journal of Phonetics 39: 271–78. [Google Scholar] [CrossRef]
- Mora, Joan C., and Marianna Nadeu. 2012. L2 effects on the perception and production of a native vowel contrast in early bilinguals. International Journal of Bilingualism 16: 484–500. [Google Scholar] [CrossRef]
- Nadeu, Marianna, and Margaret E. L. Renwick. 2016. Variation in the lexical distribution and implementation of phonetically similar phonemes in Catalan. Journal of Phonetics 58: 22–47. [Google Scholar] [CrossRef]
- Oh, Yoon Mi, Christophe Coupé, Egidio Marsico, and François Pellegrino. 2015. Bridging phonological system and lexicon: Insights from a corpus study of functional load. Journal of Phonetics 53: 153–76. [Google Scholar] [CrossRef]
- Pallier, Christophe, Laura Bosch, and Núria Sebastián-Gallés. 1997. A limit on behavioral plasticity in speech perception. Cognition 64: B9–B17. [Google Scholar] [CrossRef]
- Pater, Joe. 2009. Weighted Constraints in Generative Linguistics. Cognitive Science 33: 999–1035. [Google Scholar] [CrossRef]
- Peterson, Gordon E., and Ilse Lehiste. 1960. Duration of syllable nuclei in English. Journal of the Acoustical Society of America 32: 693–703. [Google Scholar] [CrossRef]
- Raymond, William D., and Esther L. Brown. 2012. Are effects of word frequency effects of context of use? An analysis of initial fricative reduction in Spanish. In Frequency Effects in Language Learning and Processing. Edited by Stefan Th Gries and Dagmar Divjak. Berlin: Walter de Gruyter, pp. 35–52. [Google Scholar]
- Rebora, Piero. 1958. Cassell’s Italian-English, English-Italian Dictionary. London: Cassell. [Google Scholar]
- Recasens, Daniel. 1993. Fonètica i Fonologia. Barcelona: Enciclopèdia Catalana. [Google Scholar]
- Renwick, Margaret E. L. 2012. Vowels of Romanian: Historical, Phonological and Phonetic Studies. Ph.D. dissertation, Cornell University, Ithaca, NY, USA. [Google Scholar]
- Renwick, Margaret E. L. 2014. The Phonetics and Phonology of Contrast: The Case of the Romanian Vowel System. Berlin and Boston: De Gruyter Mouton. [Google Scholar]
- Renwick, Margaret E. L. 2018. Phonetic Implementation of Mid Vowel Contrasts across Italian Varieties. Poster presented at BAAP 2018. Canterbury: British Association of Academic Phoneticians. [Google Scholar]
- Renwick, Margaret E. L. 2021. Mid vowel variation and contrast in regional Standard Italian. In Sound Change in Romance: Phonetic and Phonological Issues (LINCOM Studies in Romance Linguistics 84). Edited by Daniel Recasens and Fernando Sánchez-Miret. Munich: LINCOM Europa, pp. 115–37. [Google Scholar]
- Renwick, Margaret E. L., and D. Robert Ladd. 2016. Phonetic Distinctiveness vs. Lexical Contrastiveness in Non-Robust Phonemic Contrasts. Laboratory Phonology 7: 1–29. [Google Scholar] [CrossRef]
- Renwick, Margaret E. L., and Marianna Nadeu. 2018. A Survey of Phonological Mid Vowel Intuitions in Central Catalan. Language and Speech 62: 164–204. [Google Scholar] [CrossRef] [PubMed]
- Renwick, Margaret E. L., Ioana Vasilescu, Camille Dutrey, Lori Lamel, and Bianca Vieru. 2016. Marginal Contrast Among Romanian Vowels: Evidence from ASR and Functional Load. Proceedings of Interspeech 2016, 2433–37. [Google Scholar] [CrossRef]
- Rogers, Derek, and Luciana d’Arcangeli. 2004. Italian. Journal of the International Phonetic Association 34: 117–21. [Google Scholar] [CrossRef]
- Savy, Renata, and Francesco Cutugno. 1998. Hypospeech, vowel reduction, centralization: How do they interact in diaphasic variations. In Proceedings of the XVIth International Congress of Linguists. Oxford: Pergamon. [Google Scholar]
- Seidl, Amanda, and Alejandrina Cristia. 2012. Infants’ Learning of Phonological Status. Frontiers in Psychology 3: 448. [Google Scholar] [CrossRef] [PubMed]
- Silva, Daniel Márcio Rodrigues, and Rui Rothe-Neves. 2016. Perception of height and categorization of Brazilian Portuguese front vowels. DELTA: Documentação de Estudos em Lingüística Teórica e Aplicada 32: 355–73. [Google Scholar] [CrossRef]
- Simonet, Miquel. 2018. Phonetic behavior in proficient bilinguals: Insights from the Catalan–Spanish contact situation. In Romance Phonetics and Phonology. Edited by Mark Gibson and Juana Gil. Oxford: Oxford University Press, pp. 395–406. [Google Scholar] [CrossRef]
- Smith, Brian W., and Joe Pater. 2020. French schwa and gradient cumulativity. Glossa: A Journal of General Linguistics 5: 24. [Google Scholar] [CrossRef]
- Sobrero, Alberto. 2006. Definizione delle Caratteristiche Generali del Corpus: Informatori, Località. Available online: http://www.clips.unina.it/it/documenti/1_scelta_informatori_e_localita.pdf (accessed on 7 April 2024).
- Sonderegger, Morgan. 2023. Regression Modeling for Linguistic Data. Cambridge: MIT Press. [Google Scholar]
- Stevens, Kenneth Noble, and Samuel Jay Keyser. 2010. Quantal theory, enhancement and overlap. Journal of Phonetics 38: 10–19. [Google Scholar] [CrossRef]
- Stevenson, Sophia, and Tania Zamuner. 2017. Gradient phonological relationships: Evidence from vowels in French. Glossa: A Journal of General Linguistics 2: 58. [Google Scholar] [CrossRef]
- Storme, Benjamin. 2019. Contrast enhancement as motivation for closed syllable laxing and open syllable tensing. Phonology 36: 303–40. [Google Scholar] [CrossRef]
- Surendran, Dinoj, and Partha Niyogi. 2003. Measuring the Functional Load of Phonological Contrasts. arXiv arXiv:cs/0311036. [Google Scholar]
- Surendran, Dinoj, and Partha Niyogi. 2006. Quantifying the functional load of phonemic oppositions, distinctive features, and suprasegmentals. In Competing Models of Linguistic Change: Evolution and Beyond. Edited by Ole Nedergaard Thomsen. Amsterdam and Philadelphia: John Benjamins Publishing Company, pp. 43–58. [Google Scholar]
- Tiegs, Jessica. 2023. Processing Consequences of Marginal Contrastivity in Romance Phonology. Ph.D. thesis, The University of Arizona, Tucson, AZ, USA. [Google Scholar]
- Trubetzkoy, Nikolai Sergeevich. 1939. Principles of Phonology. Translated by Christiane Baltaxe. Berkeley: University of California Press. [Google Scholar]
- Vasilescu, Ioana, Margaret E. L. Renwick, Camille Dutrey, Lori Lamel, and Bianca Vieru. 2016. Réalisation phonétique et contraste phonologique marginal: Une étude automatique des voyelles du roumain. In Actes de la Conférence Conjointe JEP-TALN-RECITAL 2016. Paris: AFCP–ATALA, vol. 1, pp. 597–606. [Google Scholar]
- Vietti, Alessandro. 2019. Phonological Variation and Change in Italian. In Oxford Research Encyclopedia of Linguistics. Oxford: Oxford University Press. [Google Scholar] [CrossRef]
- Vietti, Alessandro, and Daniela Mereu. 2023. Mid vowels at the crossroads between standard and regional Italian. Sociolinguistica 37: 17–39. [Google Scholar] [CrossRef]
- Watt, Dominic, Margaret E. L. Renwick, and Joseph A. Stanley. 2023. Sociophonetics and dialectology. In The Routledge Handbook of Sociophonetics. Edited by Christopher Strelluf. London: Routledge, pp. 263–84. [Google Scholar]
- Wedel, Andrew, Abby Kaplan, and Scott Jackson. 2013. High functional load inhibits phonological contrast loss: A corpus study. Cognition 128: 179–86. [Google Scholar] [CrossRef]
- Wedel, Andrew, Noah Nelson, and Rebecca Sharp. 2018. The phonetic specificity of contrastive hyperarticulation in natural speech. Journal of Memory and Language 100: 61–88. [Google Scholar] [CrossRef]
- Wheeler, Max. 2005. The Phonology of Catalan. Oxford: Oxford University Press. [Google Scholar]
- Wright, Richard. 2004. Factors of lexical competition in vowel articulation. In Phonetic Interpretation: Papers in Laboratory Phonology VI. Edited by John Local, Richard Ogden and Rosalind Temple. Cambridge: Cambridge University Press, pp. 75–87. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Vowel | Type Frequency | Token Frequency | Example |
|---|---|---|---|
| /a/ | 0.168 | 0.161 | /ˈrata/ ‘installment’ |
| /i/ | 0.132 | 0.121 | /ˈmite/ ‘mild’ |
| /o/ | 0.109 | 0.114 | /ˈdove/ ‘where’ |
| /e/ | 0.105 | 0.126 | /ˈrete/ ‘net’ |
| /u/ | 0.023 | 0.031 | /ˈmuto/ ‘mute (m.sg.)’ |
| /ɛ/ | 0.019 | 0.028 | /ˈmɛta/ ‘destination’ |
| /ɔ/ | 0.012 | 0.016 | /ˈmɔto/ ‘motion’ |
| Vowels | e | ɛ | a | ɔ | o | u |
|---|---|---|---|---|---|---|
| i | 0.127 | 0.004 | 0.110 | 0.008 | 0.121 | 0.005 |
| e | 0.001 | 0.122 | 0.006 | 0.078 | 0.004 | |
| ɛ | 0.007 | 0.002 | 0.002 | 0.003 | ||
| a | 0.017 | 0.133 | 0.008 | |||
| ɔ | 0.006 | 0.003 |
| Vowels | e | ɛ | a | ɔ | o | u |
|---|---|---|---|---|---|---|
| i | 7872 | 251 | 6716 | 536 | 7516 | 333 |
| e | 70 | 7132 | 390 | 4895 | 277 | |
| ɛ | 455 | 146 | 130 | 164 | ||
| a | 1103 | 8224 | 489 | |||
| ɔ | 346 | 175 |
| City in CLIPS | Region | Regional Contrast Type |
|---|---|---|
| Cagliari | Sardegna | Full contrast |
| Firenze | Toscana | Full contrast |
| Genova 1 | Liguria | Full contrast |
| Napoli | Campania | Full contrast |
| Perugia | Umbria | Full contrast |
| Roma | Lazio | Full contrast |
| Venezia | Veneto | Full contrast |
| Bari | Puglia | Conditioned contrast |
| Bergamo | Lombardia | Conditioned contrast |
| Milano | Lombardia | Conditioned contrast |
| Parma | Emilia-Romagna | Conditioned contrast |
| Catanzaro | Calabria | Merged |
| Lecce | Puglia | Merged |
| Palermo | Sicilia | Merged |
| Torino | Piemonte | Merged |
| Full Contrast | Conditioned Contrast | Merged Contrast | ||||
|---|---|---|---|---|---|---|
| Predictor | β | SE | β | SE | β | SE |
| Intercept | 0.201 | 0.110 | –0.016 | 0.118 | –0.102 | 0.114 |
| Normalized F2 | –0.585 *** | 0.012 | –0.513 *** | 0.016 | –0.273 *** | 0.016 |
| Dictionary height = high mid | –0.297 ** | 0.093 | –0.116 | 0.098 | 0.029 | 0.088 |
| Duration (sec) | 3.609 *** | 0.244 | 3.062 *** | 0.322 | 3.486 *** | 0.270 |
| Structure = Closed | –0.040 | 0.087 | –0.080 | 0.094 | 0.055 | 0.085 |
| Log10 Frequency | 0.040 | 0.042 | 0.026 | 0.044 | 0.058 | 0.040 |
| Type = Function | –0.205 | 0.121 | –0.168 | 0.127 | –0.279 * | 0.115 |
| Duration × Structure = Closed | 1.349 *** | 0.366 | 3.344 *** | 0.488 | –0.156 | 0.419 |
| Full Contrast | Conditioned Contrast | Merged Contrast | ||||
|---|---|---|---|---|---|---|
| Predictor | β | SE | β | SE | β | SE |
| Intercept | 0.195 * | 0.089 | 0.243 * | 0.103 | –0.039 | 0.991 |
| Normalized F2 | 0.240 *** | 0.019 | 0.205 *** | 0.026 | 0.093 *** | 0.025 |
| Dictionary height = high mid | –0.432 *** | 0.069 | –0.533 *** | 0.079 | –0.042 | 0.075 |
| Duration (sec) | 2.414 *** | 0.264 | 1.447 *** | 0.326 | 2.051 *** | 0.275 |
| Structure = Closed | –0.096 | 0.079 | –0.001 | 0.093 | –0.087 | 0.086 |
| Log10 Frequency | –0.116 ** | 0.035 | –0.175 *** | 0.040 | –0.115 ** | 0.038 |
| Type = Function | 0.283 * | 0.138 | 0.262 | 0.157 | 0.153 | 0.148 |
| Duration × Structure = Closed | –0.262 | 0.405 | 0.487 | 0.503 | 0.215 | 0.430 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Renwick, M.E.L. Robustness and Complexity in Italian Mid Vowel Contrasts. Languages 2024, 9, 150. https://doi.org/10.3390/languages9040150
Renwick MEL. Robustness and Complexity in Italian Mid Vowel Contrasts. Languages. 2024; 9(4):150. https://doi.org/10.3390/languages9040150
Chicago/Turabian StyleRenwick, Margaret E. L. 2024. "Robustness and Complexity in Italian Mid Vowel Contrasts" Languages 9, no. 4: 150. https://doi.org/10.3390/languages9040150
APA StyleRenwick, M. E. L. (2024). Robustness and Complexity in Italian Mid Vowel Contrasts. Languages, 9(4), 150. https://doi.org/10.3390/languages9040150