

Closing the Gap: Automated Distractor Generation in Japanese Language Testing


Abstract
:1. Introduction
- RQ1:
- Are our generated distractors indistinguishable from human-made distractors?
- RQ2:
- Can we generate JLPT-level appropriate distractors?
- RQ3:
- Can we use NLP methods to attach a valid difficulty rank to generated questions?
- RQ4:
- Is there a preferred distractor type?
2. Background
2.1. Natural Language Processing
- Word2vec
- is a method built to understand semantic relations between words similarly to how humans understand the relations between words, e.g., “king” and “queen”. Since computers struggle with understanding human language, the method uses word embeddings, a vectorized representation of a word. Using “queen” as an example, the algebraic equation could look like . Note that the result would not necessarily equate to “queen” but a vector close to that word.
- Levenshtein distance
- measures the distance between two strings (a and b) by counting the number of operations required to transform string a into string b. The result is a numerical representation of the difference between the two strings, where a 0 represents that the two strings are the same.
- N-gram
- is an uninterrupted sequence of words or tokens in a document. The “N” represents the number of splits the N-gram makes when fed a string. For instance, a sentence like “I enjoy playing games” would produce four tokens when N = 1, three when N = 2, two when N = 3, and one when N = 4 (see Table 1).
- Bidirectional Encoder Representations from Transformers (BERT)
- is a language model for NLP that uses a bidirectional training of transformers to handle long-distance dependencies [28]. The model was released in 2018 by Google and has become ubiquitous within the NLP community. Only two years after its inception, over 150 studies had used BERT models in their work [29].
- Masked Language Model (MLM)
- is a language model inspired by the cloze task, which predicts a missing word from a sentence. The missing word is often represented by the [MASK] token, giving the model its name. The [MASK] token focuses the model on a single word in a sentence and uses the surrounding words for context. The model then returns possible words and scores that fit into the given sentence. The MLM is a bi-product of creating the BERT model, since the creators needed a method to train the model. The training method revolved around the random removal of 15% [28] of words in a training document. This allowed the model to consider surrounding words and learn more about the context of words thanks to the bidirectional access the BERT model allows.
2.2. The Japanese Language
2.2.1. Writing System
2.2.2. Japanese Grammar
2.3. Linguistic Terminology
- Synonym
- is a word or phrase that means the same as another word or phrase. The Japanese language has many synonyms since it uses many loan words from other languages, mainly Chinese and English. We can find synonyms between languages like Native 車(kuruma), Sino-Japanese 自動車(jidōsha), and Western カー (kaa), which all translate to “car” [32] as well as full-native synonyms such as 話す (hanasu) and 喋る (shaberu) which both mean to talk.
- Homonym
- is a word that does not share the same meaning as another word but is written or pronounced the same. When words are written the same, they are called homographs; when the pronunciation is the same, they are called homophones.Some English examples of homographs are “bat” (the animal and the one used in baseball), “letter” (a letter you send to someone, and the one of the alphabet). Examples of homophones is “one” and “won”, “two”, “to” and “too”. In Japanese, homographs are less common thanks to kanji in the written language. Some kanji have different meanings (which have different pronunciations) depending on the context, such as 金, “gold” and “money”, and 月, “month” and “moon”. However, since Japanese has fewer sounds than English, homophones are far more prevalent [33]. Words with entirely different meanings are written similarly, but thanks to kanji, meaning can more easily be conveyed. Examples of Japanese homophones are 会う (au, to meet), 合う (au, to fit), 感じ (kanji, feeling), 漢字(kanji, Chinese characters).
- Phono-semantic compounds
- Kanji is made of compounds of elements, radicals, and sometimes a combination of other kanji. The different parts of a kanji can often be split into two parts: the phono, the sound of the character, and the semantic, the meaning of the character.
- Part-of-speech (POS)
- is used to categorize and classify words according to their function in a sentence. Using the Universal Part-of-Speech Tagset as an example, there are 12 tags words that can be divided into [34]: (i) NOUN (nouns); (ii) VERB (verbs); (iii) ADJ (adjectives); (iv) ADV (adverbs); (v) PRON (pronouns); (vi) DET (determiners and articles); (vii) ADP (prepositions and postpositions); (viii) NUM (numerals); (ix) CONJ (conjunctions); (x) PRT (particles); (xi) ‘.’ (punctuation marks), and; (xii) X (a catch-all for other categories such as abbreviations or foreign words).
2.4. The Japanese Language Proficiency Test
2.5. Cloze Tests
3. Dataset
4. Automatic Cloze Test Generation
- Kanji reading 漢字読み (kanji yomi).
- A kanji reading test is a specialized test for the Japanese language since it relies on the swapping between different alphabets to create the distractors. The target in this question type must be a level-appropriate kanji, and the test uses the “Leave-in” focus area when creating the stem since the focus lies on the examinee’s ability to know the reading of the target kanji. The possible candidate distractors are synonyms, homonyms, and hiragana distractors.
- Orthography 表記 (hyouki).
- The kanji orthography test is similar to the kanji reading test, as it also relies on the swapping between alphabets. However, the focus area uses the “Hiragana” question type where the examinees are expected to read the target hiragana word and, through the context of the remaining stem, select the correct kanji provided in the keys. The possible candidate distractors are synonyms, homonyms, and phono-semantic distractors.
- Vocabulary 語彙 (goi).
- A standard vocabulary test which does not have any preferences or limitations on what words can be used as a target as long as they are a part of the level-appropriate JLPT vocabulary list. The focus area for this question type uses the “empty-style”, and its possible distractors are synonyms, homonyms, and POS.
4.1. Distractor Generation
4.2. Measuring the Difficulty
5. Evaluation
5.1. Question Generation and JLPT Levels
5.2. Difficulty
5.3. Candidate Creation Types
5.4. Cloze Test Examples
6. Discussion
6.1. RQ1: Are the Generated Distractors Indistinguishable from Human Made Distractors?
6.2. RQ2: Can We Generate JLPT Level Appropriate Distractors?
6.3. RQ3: Can We Use NLP Methods to Attach a Valid Difficulty Rank to Generated Questions?
6.4. RQ4: Is There a Preferred Distractor Type?
6.5. Limitations
7. Related Research
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. The Japanese Language

{kind=link}
| Type | Japanese | Translation |
|---|---|---|
| Name | ティム | Tim |
| Fruit or color | オレンジ | Orange |
| Location | イギリス | England |
| Type | Kanji | Parts |
|---|---|---|
| Elements | 空 | 工, 八, 冖, 宀, 穴 |
| Radicals | 空 | 穴, 工 |
| Type | Japanese | Translation |
|---|---|---|
| Hiragana | はは は はな が すき だ | My mother likes flowers |
| Kanji/Hiragana | 母は 花が 好き だ | My mother likes flowers |
| Learning Outcome | Question | JLPT Level | Generation Method | Correct | Wrong | Don’t Know |
|---|---|---|---|---|---|---|
| Vocabulary | 1 | N5 | NLP | 4 | 8 | 2 |
| 2 | N3 | NLP | 12 | 2 | 0 | |
| 3 | N1 | NLP | 6 | 6 | 2 | |
| 4 | N3 | NLP | 11 | 2 | 1 | |
| 5 | N2 | H | 12 | 2 | 0 | |
| 6 | N4 | NLP | 7 | 6 | 1 | |
| 7 | N2 | NLP | 2 | 9 | 3 | |
| 8 | N5 | NLP | 8 | 5 | 1 | |
| 9 | N5 | H | 10 | 3 | 1 | |
| 10 | N1 | H | 13 | 0 | 1 | |
| Kanji Reading | 1 | N4 | H | 7 | 5 | 2 |
| 2 | N3 | NLP | 10 | 3 | 1 | |
| 3 | N2 | H | 12 | 1 | 1 | |
| 4 | N3 | NLP | 11 | 1 | 2 | |
| 5 | N4 | NLP | 13 | 0 | 1 | |
| 6 | N3 | H | 13 | 1 | 0 | |
| 7 | N2 | H | 12 | 1 | 1 | |
| 8 | N5 | NLP | 10 | 2 | 2 | |
| 9 | N1 | NLP | 13 | 0 | 1 | |
| 10 | N3 | H | 11 | 1 | 2 | |
| Kanji Orthography | 1 | N3 | H | 8 | 4 | 2 |
| 2 | N2 | H | 9 | 3 | 2 | |
| 3 | N5 | H | 9 | 4 | 1 | |
| 4 | N5 | NLP | 13 | 0 | 1 | |
| 5 | N2 | NLP | 7 | 7 | 0 | |
| 6 | N2 | NLP | 5 | 7 | 2 | |
| 7 | N1 | NLP | 4 | 8 | 2 | |
| 8 | N3 | NLP | 9 | 4 | 1 | |
| 9 | N4 | NLP | 9 | 2 | 3 | |
| 10 | N3 | H | 10 | 2 | 2 |
| Learning Outcome | Question | JLPT Level | Too Easy | Just Right | Too Hard | Don’t Know |
|---|---|---|---|---|---|---|
| Vocabulary | 1 | N5 | 1 | 9 | 2 | 2 |
| 2 | N3 | 1 | 6 | 4 | 3 | |
| 3 | N1 | 1 | 11 | 2 | 0 | |
| 4 | N3 | 2 | 9 | 0 | 3 | |
| 5 | N2 | 2 | 12 | 0 | 0 | |
| 6 | N4 | 2 | 8 | 3 | 1 | |
| 7 | N2 | 2 | 8 | 2 | 2 | |
| 8 | N5 | 1 | 7 | 3 | 3 | |
| 9 | N5 | 3 | 9 | 1 | 1 | |
| 10 | N1 | 0 | 14 | 0 | 0 | |
| Kanji Reading | 1 | N4 | 1 | 8 | 4 | 1 |
| 2 | N3 | 7 | 6 | 0 | 1 | |
| 3 | N2 | 2 | 12 | 0 | 0 | |
| 4 | N3 | 12 | 1 | 0 | 1 | |
| 5 | N4 | 9 | 4 | 0 | 1 | |
| 6 | N3 | 0 | 13 | 1 | 0 | |
| 7 | N2 | 3 | 11 | 0 | 0 | |
| 8 | N5 | 3 | 7 | 2 | 2 | |
| 9 | N1 | 8 | 5 | 0 | 1 | |
| 10 | N3 | 2 | 10 | 2 | 0 | |
| Kanji Orthography | 1 | N3 | 0 | 12 | 1 | 1 |
| 2 | N2 | 2 | 11 | 1 | 0 | |
| 3 | N5 | 2 | 11 | 1 | 0 | |
| 4 | N5 | 7 | 1 | 4 | 2 | |
| 5 | N2 | 0 | 7 | 5 | 2 | |
| 6 | N2 | 9 | 5 | 0 | 0 | |
| 7 | N1 | 0 | 11 | 3 | 0 | |
| 8 | N3 | 1 | 10 | 1 | 2 | |
| 9 | N4 | 3 | 8 | 2 | 1 | |
| 10 | N3 | 0 | 8 | 5 | 1 |
| Learning Outcome | Question | JLPT Level | Distractor Type | Best | Avg. | Worst |
|---|---|---|---|---|---|---|
| Vocabulary | 1 | N4 | Synonym | 7 | 5 | 2 |
| Homonym | 4 | 8 | 2 | |||
| Part-of-Speech | 3 | 1 | 10 | |||
| 2 | N1 | Synonym | 5 | 6 | 3 | |
| Homonym | 5 | 6 | 3 | |||
| Part-of-Speech | 4 | 2 | 8 | |||
| 3 | N3 | Synonym | 10 | 3 | 1 | |
| Homonym | 2 | 9 | 3 | |||
| Part-of-Speech | 2 | 2 | 10 | |||
| Kanji Reading | 1 | N3 | Synonym | 5 | 3 | 6 |
| Homonym | 3 | 6 | 5 | |||
| Similar looking words | 6 | 5 | 3 | |||
| 2 | N3 | Synonym | 5 | 8 | 1 | |
| Homonym | 7 | 4 | 3 | |||
| Similar looking words | 2 | 2 | 10 | |||
| 3 | N4 | Synonym | 2 | 3 | 9 | |
| Homonym | 4 | 5 | 5 | |||
| Similar looking words | 8 | 6 | 0 | |||
| Kanji Orthography | 1 | N2 | Synonym | 3 | 8 | 3 |
| Homonym | 2 | 4 | 8 | |||
| Similar kanji | 9 | 2 | 3 | |||
| 2 | N4 | Synonym | 4 | 10 | 0 | |
| Homonym | 0 | 2 | 12 | |||
| Similar kanji | 10 | 2 | 2 | |||
| 3 | N3 | Synonym | 4 | 9 | 1 | |
| Homonym | 0 | 2 | 12 | |||
| Similar kanji | 10 | 3 | 1 |
References
- Araki, J.; Rajagopal, D.; Sankaranarayanan, S.; Holm, S.; Yamakawa, Y.; Mitamura, T. Generating Questions and Multiple-Choice Answers using Semantic Analysis of Texts. In Proceedings of the COLING, Osaka, Japan, 11 December 2016; pp. 1125–1136. [Google Scholar]
- Satria, A.Y.; Tokunaga, T. Automatic generation of english reference question by utilising nonrestrictive relative clause. In Proceedings of the CSEDU, Porto, Portugal, 21–23 April 2017; Volume 2, pp. 379–386. [Google Scholar]
- Susanti, Y.; Iida, R.; Tokunaga, T. Automatic Generation of English Vocabulary Tests. In Proceedings of the CSEDU, Lisbon, Portugal, 23–25 May 2015. [Google Scholar]
- Zhang, C.; Sun, Y.; Chen, H.; Wang, J. Generating Adequate Distractors for Multiple-Choice Questions. arXiv 2020, arXiv:2010.12658. [Google Scholar]
- Thalheimer, W. Learning Benefits of Questions, V2.0. 2014. Available online: https://www.worklearning.com/wp-content/uploads/2017/10/Learning-Benefits-of-Questions-2014-v2.0.pdf (accessed on 1 November 2023).
- Dave, N.; Bakes, R.; Pursel, B.; Giles, C.L. Math Multiple Choice Question Solving and Distractor Generation with Attentional GRU. In Proceedings of the EDM, Online, 29 June–2 July 2021. [Google Scholar]
- Bakes, R. Capabilities for Multiple Choice Question Distractor Generation and Elementary Mathematical Problem Solving by Recurrent Neural Networks. Bachelor’s Thesis, Pennsylvania State University, State College, PA, USA, 2020. [Google Scholar]
- Agarwal, M.; Mannem, P. Automatic Gap-fill Question Generation from Text Books. In Proceedings of the BEA, Portland, OR, USA, 24 June 2011; pp. 56–64. [Google Scholar]
- Maslak, H.; Mitkov, R. Paragraph Similarity Matches for Generating Multiple-choice Test Items. In Proceedings of the RANLP, Online, 6–8 September 2021; pp. 99–108. [Google Scholar]
- Sajjad, M.; Iltaf, S.; Khan, R.A. Nonfunctional distractor analysis: An indicator for quality of Multiple choice questions. Pak. J. Med. Sci. 2020, 36, 982. [Google Scholar] [CrossRef]
- Yeung, C.; Lee, J.; Tsou, B. Difficulty-aware Distractor Generation for Gap-Fill Items. In Proceedings of the ALTA, Perth, Australia, 23–25 May 2019; pp. 167–172. [Google Scholar]
- Labrak, Y.; Bazoge, A.; Dufour, R.; Daille, B.; Gourraud, P.A.; Morin, E.; Rouvier, M. FrenchMedMCQA: A French Multiple-Choice Question Answering Dataset for Medical domain. In Proceedings of the LOUHI, Abu Dhabi, United Arab Emirates, 30 May 2022; pp. 41–46. [Google Scholar]
- Nwafor, C.A.; Onyenwe, I.E. An automated multiple-choice question generation using natural language processing techniques. arXiv 2021, arXiv:2103.14757. [Google Scholar] [CrossRef]
- CH, D.R.; Saha, S.K. Automatic Multiple Choice Question Generation From Text: A Survey. IEEE Trans. Learn. Technol. 2020, 13, 14–25. [Google Scholar] [CrossRef]
- Kurdi, G.; Leo, J.; Parsia, B.; Sattler, U.; Al-Emari, S. A Systematic Review of Automatic Question Generation for Educational Purposes. Int. J. Artif. Intell. Educ. 2019, 30, 121–204. [Google Scholar] [CrossRef]
- Zhang, Z.; Mita, M.; Komachi, M. Cloze Quality Estimation for Language Assessment. In Proceedings of the EACL, Dubrovnik, Croatia, 2–6 May 2023; pp. 540–550. [Google Scholar]
- Huang, Y.T.; Mostow, J. Evaluating human and automated generation of distractors for diagnostic multiple-choice cloze questions to assess children’s reading comprehension. In Proceedings of the AIED, Madrid, Spain, 21–25 June 2015; pp. 155–164. [Google Scholar]
- Haladyna, T.M. Developing and Validating Multiple-Choice Test Items; Routledge: London, UK, 2004. [Google Scholar]
- Susanti, Y.; Tokunaga, T.; Nishikawa, H.; Obari, H. Automatic distractor generation for multiple-choice English vocabulary questions. Res. Pract. Technol. Enhanc. Learn. 2018, 13, 15. [Google Scholar] [CrossRef]
- Larrañaga, M.; Aldabe, I.; Arruarte, A.; Elorriaga, J.A.; Maritxalar, M. A Qualitative Case Study on the Validation of Automatically Generated Multiple-Choice Questions From Science Textbooks. IEEE Trans. Learn. Technol. 2022, 15, 338–349. [Google Scholar] [CrossRef]
- Hoshino, A.; Nakagawa, H. A Real-Time Multiple-Choice Question Generation For Language Testing: A Preliminary Study. In Proceedings of the BEA, Ann Arbor, MI, USA, 29 June 2005; pp. 17–20. [Google Scholar]
- Sumita, E.; Sugaya, F.; Yamamoto, S. Measuring Non-native Speakers’ Proficiency of English by Using a Test with Automatically-Generated Fill-in-the-Blank Questions. In Proceedings of the BEA, Ann Arbor, MI, USA, 29 June 2005; pp. 61–68. [Google Scholar]
- Liu, C.L.; Wang, C.H.; Gao, Z.M.; Huang, S.M. Applications of Lexical Information for Algorithmically Composing Multiple-Choice Cloze Items. In Proceedings of the BEA, Ann Arbor, MI, USA, 29 June 2005; pp. 1–8. [Google Scholar]
- Das, B.; Majumder, M.; Phadikar, S.; Sekh, A.A. Automatic generation of fill-in-the-blank question with corpus-based distractors for e-assessment to enhance learning. Comput. Appl. Eng. Educ. 2019, 27, 1485–1495. [Google Scholar] [CrossRef]
- Das, B.; Majumder, M.; Phadikar, S.; Sekh, A.A. Multiple-choice question generation with auto-generated distractors for computer-assisted educational assessment. Multimed. Tools Appl. 2021, 80, 31907–31925. [Google Scholar] [CrossRef]
- Panda, S.; Palma Gomez, F.; Flor, M.; Rozovskaya, A. Automatic Generation of Distractors for Fill-in-the-Blank Exercises with Round-Trip Neural Machine Translation. In Proceedings of the ACL, Dublin, Ireland, 22–27 May 2022; pp. 391–401. [Google Scholar]
- Hutchins, W.J. The Georgetown-IBM Experiment Demonstrated in January 1954. In Proceedings of the AMTA, Washington, DC, USA, 28 September–2 October 2004; Frederking, R.E., Taylor, K.B., Eds.; Springer: Berlin/Heidelberg, Germany, 2004; pp. 102–114. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the NAACL-HLT, Minneapolis, MN, USA, 2 June–7 June 2019; pp. 4171–4186. [Google Scholar]
- Rogers, A.; Kovaleva, O.; Rumshisky, A. A Primer in BERTology: What We Know About How BERT Works. Trans. Assoc. Comput. Linguist. 2020, 8, 842–866. [Google Scholar] [CrossRef]
- Hepburn, J.C. A Japanese-English and English-Japanese Dictionary; Trübner: London, UK; Maruya & Company: Tokyo, Japan, 1886. [Google Scholar]
- Kinsui, S. Virtual Japanese: Enigmas of Role Language; Osaka University Press: Suita, Japan, 2017. [Google Scholar]
- Hasegawa, Y. The Routledge Course in JAPANESE Translation; Routledge: London, UK, 2012. [Google Scholar]
- Trott, S.; Bergen, B. Why do human languages have homophones? Cognition 2020, 205, 104449. [Google Scholar] [CrossRef] [PubMed]
- Petrov, S.; Das, D.; McDonald, R. A Universal Part-of-Speech Tagset. In Proceedings of the LREC, Istanbul, Turkey, 21–27 May 2012; pp. 2089–2096. [Google Scholar]
- Foundation, J.; Exchanges, J.E.; Services. Japanese-Language Proficiency Test—Statistics. 2023. Available online: https://www.jlpt.jp/e/statistics/archive/202301.html (accessed on 27 February 2023).
- Objectives and History|JLPT Japanese-Language Proficiency Test. Available online: https://www.jlpt.jp/e/about/purpose.html (accessed on 25 August 2023).
- Foundation, J.; Exchanges, J.E.; Services. The New Japanese Language Proficiency Test Guidebook, Summarized Version. Available online: https://www.jlpt.jp/e/reference/pdf/guidebook_s_e.pdf (accessed on 27 February 2023).
- Composition of Test Sections and Items|JLPT Japanese-Language Proficiency Test. Available online: https://www.jlpt.jp/e/guideline/testsections.html (accessed on 25 August 2023).
- Nishizawa, H.; Isbell, D.R.; Suzuki, Y. Review of the Japanese-Language Proficiency Test. Lang. Test. 2022, 39, 494–503. [Google Scholar] [CrossRef]
- Iles, T.; Rojas-Lizana, S. ‘Changes’ to the new Japanese-Language Proficiency Test: Newly emerged language policies for non-Japanese and Japanese citizens. Electron. J. Contemp. Jpn. Stud. 2019, 9, 8. [Google Scholar]
- Raymond, M.R.; Stevens, C.; Bucak, S.D. The optimal number of options for multiple-choice questions on high-stakes tests: Application of a revised index for detecting nonfunctional distractors. Adv. Health Sci. Educ. 2019, 24, 141–150. [Google Scholar] [CrossRef] [PubMed]
- Guo, H.; Zu, J.; Kyllonen, P. A Simulation-Based Method for Finding the Optimal Number of Options for Multiple-Choice Items on a Test. ETS Res. Rep. Ser. 2018, 2018, 1–17. [Google Scholar] [CrossRef]
- Japanese NET (日本語NET). Available online: https://nihongokyoshi-net.com (accessed on 30 August 2023).
- Japanese Language Proficiency Test Resources. Available online: https://www.jlpt.jp/e/index.html (accessed on 30 August 2023).
- Japanese-English Dictionary. Available online: https://jisho.org (accessed on 30 August 2023).
- New Japanese-Language Proficiency Test Sample Questions|JLPT Japanese-Language Proficiency Test. Available online: https://www.jlpt.jp/e/samples/forlearners.html (accessed on 30 August 2023).
- Qiu, X.; Xue, H.; Liang, L.; Xie, Z.; Liao, S.; Shi, G. Automatic Generation of Multiple-choice Cloze-test Questions for Lao Language Learning. In Proceedings of the IALP, Singapore, 11–13 December 2021; pp. 125–130. [Google Scholar]
- Han, Z. Unsupervised Multilingual Distractor Generation for Fill-in-the-Blank Questions. Master’s Thesis, Uppsala University, Department of Linguistics and Philology, Uppsala, Sweden, 2022. [Google Scholar]
- Goodrich, H.C. Distractor efficiency in foreign language testing. In Tesol Quarterly; Teachers of English to Speakers of Other Languages, Inc.: Alexandria, VA, USA, 1977; pp. 69–78. [Google Scholar]
- Yujian, L.; Bo, L. A Normalized Levenshtein Distance Metric. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1091–1095. [Google Scholar] [CrossRef] [PubMed]
- Japanese N-gram (コーパス—日本語ウェブコーパス) 2010. Available online: https://www.s-yata.jp/corpus/nwc2010/ngrams/ (accessed on 30 August 2023).
- Ebel, R.L. Procedures for the Analysis of Classroom Tests. Educ. Psychol. Meas. 1954, 14, 352–364. [Google Scholar] [CrossRef]
- Trace, J.; Brown, J.D.; Janssen, G.; Kozhevnikova, L. Determining cloze item difficulty from item and passage characteristics across different learner backgrounds. Lang. Test. 2017, 34, 151–174. [Google Scholar] [CrossRef]
- Olney, A.M.; Pavlik, P.I., Jr.; Maass, J.K. Improving reading comprehension with automatically generated cloze item practice. In Proceedings of the AIED, Wuhan, China, 28 June–1 July 2017; pp. 262–273. [Google Scholar]
- Brown, J.D. Cloze Item Difficulty. Jpn. Assoc. Lang. Teach. J. 1989, 11, 46–67. [Google Scholar]
- Kudo, T. Mecab: Yet Another Part-of-Speech and Morphological Analyzer. 2005. Available online: http://mecab.sourceforge.net/ (accessed on 31 July 2023).
- Zhai, X.; Chu, X.; Chai, C.S.; Jong, M.S.Y.; Istenic, A.; Spector, M.; Liu, J.B.; Yuan, J.; Li, Y. A Review of Artificial Intelligence (AI) in Education from 2010 to 2020. Complexity 2021, 2021, 1–18. [Google Scholar] [CrossRef]
- Zawacki-Richter, O.; Marín, V.I.; Bond, M.; Gouverneur, F. Systematic review of research on artificial intelligence applications in higher education–where are the educators? Int. J. Educ. Technol. High. Educ. 2019, 16, 1–27. [Google Scholar] [CrossRef]
- Gardner, J.; O’Leary, M.; Yuan, L. Artificial intelligence in educational assessment: ‘Breakthrough? Or buncombe and ballyhoo?’. J. Comput. Assist. Learn. 2021, 37, 1207–1216. [Google Scholar] [CrossRef]
- Kurni, M.; Mohammed, M.S.; Srinivasa, K. Natural Language Processing for Education. In A Beginner’s Guide to Introduce Artificial Intelligence in Teaching and Learning; Springer: Berlin/Heidelberg, Germany, 2023; pp. 45–54. [Google Scholar]
- Shaik, T.; Tao, X.; Li, Y.; Dann, C.; McDonald, J.; Redmond, P.; Galligan, L. A review of the trends and challenges in adopting natural language processing methods for education feedback analysis. IEEE Access 2022, 10, 56720–56739. [Google Scholar] [CrossRef]
- Smith, G.G.; Haworth, R.; Žitnik, S. Computer science meets education: Natural language processing for automatic grading of open-ended questions in ebooks. J. Educ. Comput. Res. 2020, 58, 1227–1255. [Google Scholar] [CrossRef]
- Molnár, G.; Szüts, Z. The role of chatbots in formal education. In Proceedings of the 2018 IEEE 16th International Symposium on Intelligent Systems and Informatics (SISY), Subotica, Serbia, 13–15 September 2018; pp. 197–202. [Google Scholar]
- Pérez, J.Q.; Daradoumis, T.; Puig, J.M.M. Rediscovering the use of chatbots in education: A systematic literature review. Comput. Appl. Eng. Educ. 2020, 28, 1549–1565. [Google Scholar] [CrossRef]
- Mitkov, R.; Mitkov, R.; Ha, L.A. Computer-aided generation of multiple-choice tests. In Proceedings of the HLT-NAACL 03 Workshop on Building Educational Applications Using Natural Language Processing, Edmonton, AB, Canada, 31 May 2003; pp. 17–22. [Google Scholar]
- Brown, J.C.; Frishkoff, G.A.; Eskenazi, M. Automatic Question Generation for Vocabulary Assessment. In Proceedings of the HLT, Vancouver, BC, Canada, 6–8 October 2005; pp. 819–826. [Google Scholar]
- Zesch, T.; Melamud, O. Automatic Generation of Challenging Distractors Using Context-Sensitive Inference Rules. In Proceedings of the BEA, Baltimore, MD, USA, 26 June 2014; pp. 143–148. [Google Scholar]
- Hill, J.; Simha, R. Automatic Generation of Context-Based Fill-in-the-Blank Exercises Using Co-occurrence Likelihoods and Google n-grams. In Proceedings of the BEA, San Diego, CA, USA, 16 June 2016; pp. 23–30. [Google Scholar]

| N | N-Gram Type | N-Gram |
|---|---|---|
| 1 | Unigram | “I”, “enjoy”, “playing”, “games” |
| 2 | Bigram | “I enjoy”, “enjoy playing”, “playing games” |
| 3 | Trigram | “I enjoy playing”, “enjoy playing games” |
| 4 | Fourgram | “I enjoy playing games” |
| Type | Japanese | Translation |
|---|---|---|
| Base | 彼はボールを投げる | He is throwing a ball |
| Subject omitted | ボールを投げる | Throwing a ball |
| Hiragana | ははははながすきだ | My mother likes flowers |
| Level | Test Sections and Abilities (Time) | ||
|---|---|---|---|
| N1 | Vocabulary, Grammar, Reading (110 min) | Listening (55 min) | |
| N2 | Vocabulary, Grammar, Reading (105 min) | Listening (50 min) | |
| N3 | Vocabulary (30 min) | Grammar, Reading (70 min) | Listening (40 min) |
| N4 | Vocabulary (25 min) | Grammar, Reading (55 min) | Listening (35 min) |
| N5 | Vocabulary (20 min) | Grammar, Reading (40 min) | Listening (30 min) |
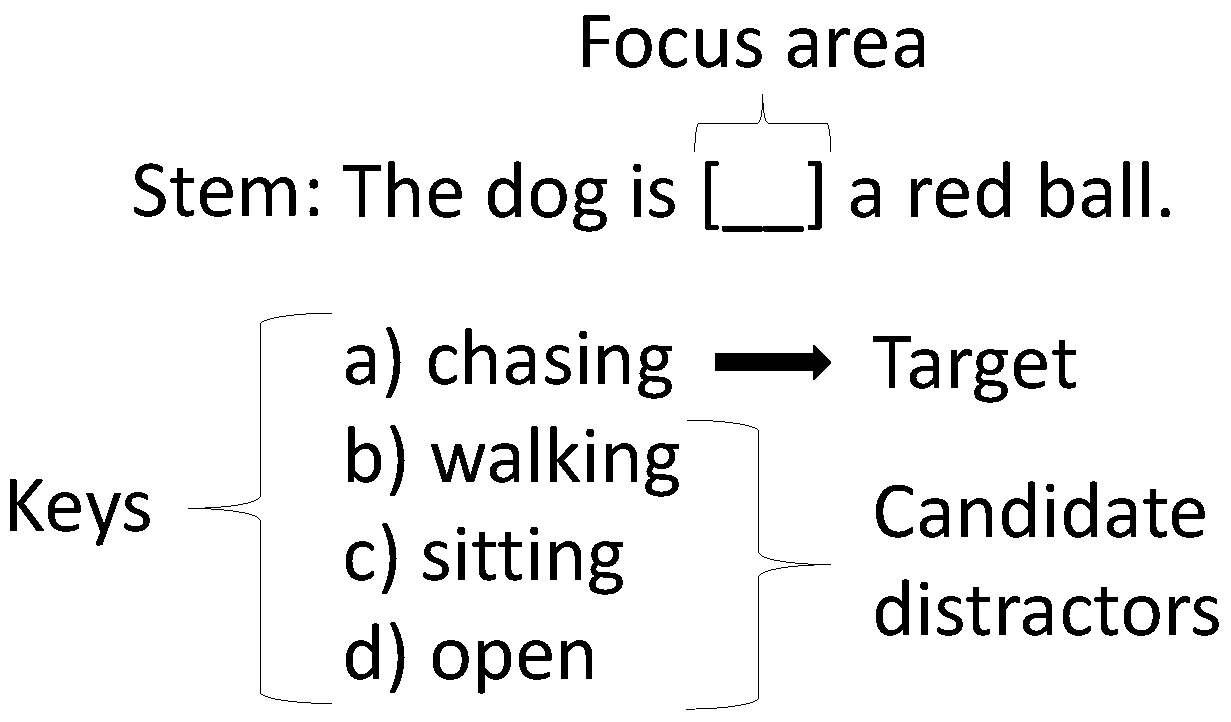
| Learning Outcome | Focus Area Type | Focus Area Example | Possible Distractor Types |
|---|---|---|---|
| Kanji Reading | Leave-in | [勉強] | Synonyms, Homonyms, Hiragana |
| Orthography | Hiragana | [べんきょう] | Synonyms, Homonyms, Phono-semantic |
| Vocabulary | Empty | [ ] | Synonyms, Homonyms, Part-of-speech |
| Kanji | Hiragana | Translation |
|---|---|---|
| 漢字 | かんじ | Chinese character |
| 感じ | かんじ | Feeling |
| 幹事 | かんじ | Secretary |
| Range | Level | Difficulty |
|---|---|---|
| More than 0.80 | 5 | Most Difficult |
| 0.60–0.80 | 4 | Difficult |
| 0.40–0.59 | 3 | Mid |
| 0.20–0.39 | 2 | Easy |
| Less than 0.20 | 1 | Easiest |
| Learning Outcome | Correct | Wrong | Don’t Know |
|---|---|---|---|
| Vocabulary | 85 (60%) | 43 (31%) | 12 (9%) |
| Kanji Reading | 112 (80%) | 15 (11%) | 13 (9%) |
| Kanji Orthography | 83 (59%) | 41 (29%) | 16 (12%) |
| Learning Outcome | Too Easy | Just Right | Too Hard | Don’t Know |
|---|---|---|---|---|
| Vocabulary | 15 (11%) | 93 (66%) | 17 (12%) | 15 (11%) |
| Kanji Reading | 47 (34%) | 77 (55%) | 9 (6%) | 7 (5%) |
| Kanji Orthography | 24 (17%) | 84 (60%) | 23 (17%) | 9 (6%) |
| Generation | Learning Outcome | Too Easy | Just Right | Too Hard | Don’t Know |
|---|---|---|---|---|---|
| Human | Vocabulary | 5 (12%) | 35 (83%) | 1 (2.5%) | 1 (2.5%) |
| Kanji Reading | 8 (10%) | 64 (80%) | 7 (9%) | 1 (1%) | |
| Kanji Orthography | 4 (7%) | 42 (75%) | 8 (14%) | 2 (4%) | |
| NLP | Vocabulary | 10 (10%) | 58 (60%) | 16 (16%) | 14 (14%) |
| Kanji Reading | 39 (57%) | 23 (34%) | 0 (0%) | 6 (9%) | |
| Kanji Orthography | 20 (24%) | 42 (50%) | 15 (18%) | 7 (8%) |
| Learning Outcome | Question | JLPT Level | Set of Keys | NLP (Difficulty) | Diff 1 | Diff 2 | Diff 3 | Diff 4 |
|---|---|---|---|---|---|---|---|---|
| Vocabulary | 1 | N5 | A | 3 | 4 | 5 | 5 | 0 |
| B | 2 | 7 | 4 | 2 | 1 | |||
| C | 1 | 6 | 4 | 3 | 1 | |||
| D | 4 | 4 | 1 | 2 | 7 | |||
| 2 | N2 | A | 1 | 7 | 4 | 3 | 0 | |
| B | 3 | 3 | 5 | 3 | 3 | |||
| C | 4 | 3 | 3 | 6 | 2 | |||
| D | 2 | 7 | 1 | 2 | 4 | |||
| 3 | N4 | A | 1 | 8 | 3 | 2 | 1 | |
| B | 2 | 6 | 2 | 3 | 3 | |||
| C | 3 | 3 | 2 | 5 | 4 | |||
| D ** | 4 | 9 | 4 | 0 | 1 | |||
| Kanji Reading | 1 | N4 | A | 2 | 5 | 2 | 2 | 5 |
| B ** | 4 | 5 | 5 | 3 | 1 | |||
| C ** | 3 | 6 | 4 | 1 | 3 | |||
| D | 1 | 5 | 2 | 5 | 2 | |||
| 2 | N5 | A | 1 | 10 | 1 | 2 | 1 | |
| B | 3 | 3 | 3 | 2 | 6 | |||
| C | 2 | 3 | 4 | 6 | 1 | |||
| D ** | 4 | 4 | 6 | 1 | 3 | |||
| 3 | N1 | A | 2 | 7 | 2 | 3 | 2 | |
| B ** | 1 | 4 | 3 | 2 | 5 | |||
| C ** | 4 | 5 | 4 | 4 | 1 | |||
| D ** | 3 | 7 | 2 | 2 | 3 | |||
| Kanji Orthography | 1 | N1 | A ** | 4 | 5 | 2 | 4 | 3 |
| B | 1 | 6 | 5 | 1 | 2 | |||
| C | 2 | 5 | 5 | 4 | 0 | |||
| D | 3 | 3 | 3 | 2 | 6 | |||
| 2 | N4 | A | 3 | 4 | 5 | 2 | 3 | |
| B | 1 | 5 | 4 | 4 | 1 | |||
| C | 2 | 6 | 2 | 3 | 3 | |||
| D | 4 | 5 | 0 | 3 | 6 | |||
| 3 | N2 | A | 1 | 7 | 3 | 1 | 3 | |
| B | 2 | 6 | 3 | 3 | 2 | |||
| C | 3 | 3 | 4 | 2 | 5 | |||
| D ** | 4 | 5 | 3 | 5 | 1 |
| Learning Outcome | Distractor Type | Best | Avg. | Worst |
|---|---|---|---|---|
| Vocabulary | Synonym | 22 (18%) | 14 (11%) | 6 (5%) |
| Homonym | 11 (9%) | 23 (18%) | 8 (6%) | |
| Part-of-Speech | 9 (7%) | 5 (4%) | 28 (22%) | |
| Kanji Reading | Synonym | 12 (10%) | 14 (11%) | 16 (13%) |
| Homonym | 14 (11%) | 15 (12%) | 13 (10%) | |
| Similar looking words | 16 (13%) | 13 (10%) | 13 (10%) | |
| Kanji Orthography | Synonym | 11 (9%) | 27 (21%) | 4 (3%) |
| Homonym | 2 (2%) | 8 (6%) | 32 (25%) | |
| Similar looking kanji | 29 (23%) | 7 (6%) | 6 (5%) |
| Question | Generation Method | Difficulty | |||||
|---|---|---|---|---|---|---|---|
| NLP | Human | Don’t Know | Too Easy | Just Right | Too Hard | Don’t Know | |
| 朝は何も食べません。牛乳だけ[__]ます。 | 4 (29%) | 8 (57%) | 2 (14%) | 1 (7%) | 9 (63%) | 2 (14%) | 2 (14%) |
| (I don’t eat anything in the morning. I only [__] milk) | |||||||
| a. 飲み (drink) | |||||||
| b. 着(wear) | |||||||
| c. 洗い (wash) | |||||||
| d. 寝(sleep) | |||||||
| アンジェラさんの走り[かた]はとてもかわいいです。 | 13 (93%) | 0 (0%) | 1 (7%) | 7 (50%) | 1 (7%) | 4 (29%) | 2 (14%) |
| (Angela’s running [style] is very cute.) | |||||||
| a. 方(style, manner of) | |||||||
| b. 地図(map) | |||||||
| c. 出(leave, exit) | |||||||
| d. 下手(poor, awkward) | |||||||
| Learning Outcome | Easy | Avg. | Hard | Don’t Know |
|---|---|---|---|---|
| Vocabulary | 2 (14%) | 4 (29%) | 8 (57%) | 0 (0%) |
| Kanji Reading | 6 (43%) | 7 (50%) | 1 (7%) | 0 (0%) |
| Kanji Orthography | 3 (21%) | 6 (43%) | 4 (29%) | 1 (7%) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Andersson, T.; Picazo-Sanchez, P. Closing the Gap: Automated Distractor Generation in Japanese Language Testing. Educ. Sci. 2023, 13, 1203. https://doi.org/10.3390/educsci13121203
Andersson T, Picazo-Sanchez P. Closing the Gap: Automated Distractor Generation in Japanese Language Testing. Education Sciences. 2023; 13(12):1203. https://doi.org/10.3390/educsci13121203
Chicago/Turabian StyleAndersson, Tim, and Pablo Picazo-Sanchez. 2023. "Closing the Gap: Automated Distractor Generation in Japanese Language Testing" Education Sciences 13, no. 12: 1203. https://doi.org/10.3390/educsci13121203
APA StyleAndersson, T., & Picazo-Sanchez, P. (2023). Closing the Gap: Automated Distractor Generation in Japanese Language Testing. Education Sciences, 13(12), 1203. https://doi.org/10.3390/educsci13121203