
Sharper Sub-Weibull Concentrations

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- (i)
- We review and present some new results for sub-Weibull r.v.s, including sharp concentration inequalities for weighted summations of independent sub-Weibull r.v.s and negative binomial r.v.s, which are useful in many statistical applications.
- (ii)
- Based on the generalized Bernstein-Orlicz norm, a sharper concentration for sub-Weibull summations is obtained in Theorem 1. Here we circumvent Stirling’s approximation and derive the inequalities more subtly. As a result, the confidence interval based on our result is sharper and more accurate than that in [6] (For example, see Remark 2) and [7] (see Proposition 1 with unknown constants) gave.
- (iii)
- By sharper sub-Weibull concentrations, we give two applications. First, from the proposed negative binomial concentration inequalities, we obtain the (up to some log factors) estimation error for the estimated coefficients in negative binomial regressions under the increasing-dimensional framework and heavy-tailed covariates. Second, we provide a non-asymptotic Bai-Yin’s theorem for sub-Weibull random matrices with exponential-decay high probability.
- (iv)
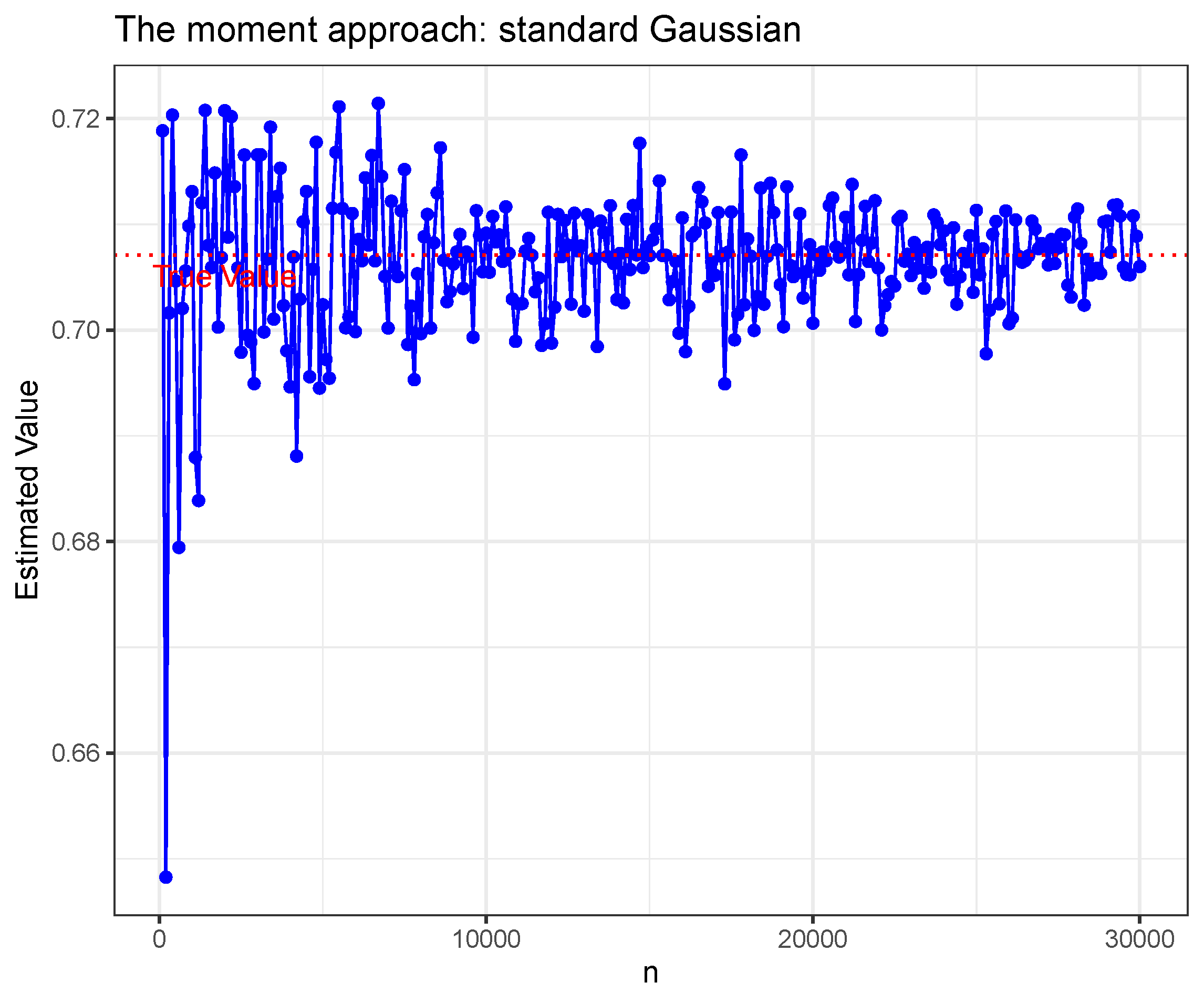
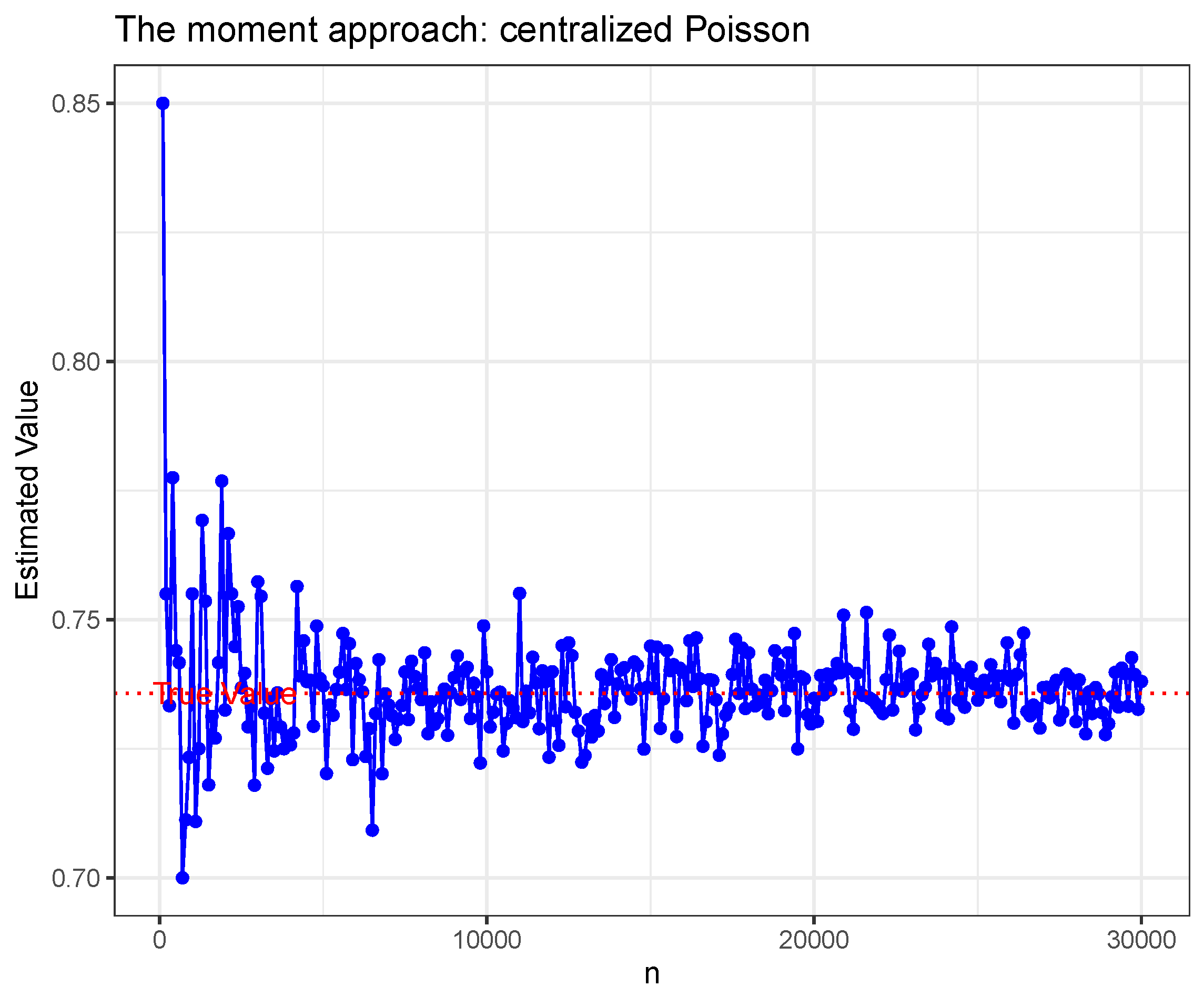
- We propose a new sub-Weibull parameters, which is enabled of recovering the tight concentration inequality for a single non-zero mean random vector. The simulation studies for estimating sub-Gaussian and sub-exponential parameters show these parameters could be estimated well.
- (v)
- We establish a unified non-asymptotic confidence region and the convergence rate for general log-truncated Z-estimator in Theorem 5. Moreover, we define a sub-Weibull type estimator for a sequence of independent observations without the second-moment condition, beyond the definition of the sub-Gaussian estimator.
2. Sharper Concentrations for Sub-Weibull Summation
2.1. Properties of Sub-Weibull norm and Orlicz-Type Norm
2.2. Main Results: Concentrations for Sub-Weibull Summation
- (a)
- If is concave, then .
- (b)
- For convex , denote the convex conjugate function and Then .
- (a)
- The estimate for GBO norm of the summation:,where , withand where and . For the case , β is the Hölder conjugate satisfying .
- (b)
- Concentration for sub-Weibull summation:
- (c)
- Another form of for :
2.3. Sub-Weibull Parameter
- Estimation procedure for and . Consideras a discrete optimization problem. We can take big enough to minimizeon .
3. Statistical Applications of Sub-Weibull Concentrations
3.1. Negative Binomial Regressions with Heavy-Tail Covariates
- •
- (C.1): For , assume and the heavy-tailed covariates are uniformly sub-Weibull with for .
- •
- (C.2): The vector is sparse or bounded. Let with a slowly increasing function , we have .
- •
- (C.3): Suppose that is satisfied for all .
3.2. Non-Asymptotic Bai-Yin’s Theorem
3.3. General Log-Truncated Z-Estimators and sub-Weibull Type Robust Estimators
- •
- (C.1): For a constant , the satisfies weak triangle inequality and scaling property,for satisfies(C.1.3): and are non-constant increasing functions and .
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
Appendix A
Appendix A.1
Appendix A.2
Appendix A.3
Appendix A.4
Appendix A.5
Appendix A.6
- (a)
- Without loss of generality, we assume . Define , then it is easy to check that implies . For independent Rademacher r.v. , the symmetrization inequality gives Note that is identically distributed as ,From Lemma 2, we are going to handle the first term in (A3) with the sum of symmetric r.v.s. Since , thenfor symmetric independent r.v.s satisfying and for all .Next, we proceed the proof by checking the moment conditions in Corollary 5.Case : is concave for . From Lemmas 2 and 3 (a), for ,where the last inequality we use HenceandUsing homogeneity, we can assume that . Then and . Therefore, for ,where the last inequality follows form the fact that for any . HenceFollowing Corollary 5, we havewhere , , and .Finally, take Indeed, the positive limit can be argued by (2.2) in [30]. Then by the monotonicity property of the GBO norm, it givesCase : In this case is convex with By Lemmas 2 and 3(b), for , we havewith mentioned in the statement. Therefore, for , Equation (A3) impliesThen the following result follows by Corollary 5,,where , , and .Note that , we can conclude (a).
- (b)
- It is followed from Proposition 5 and (a).
- (c)
- For easy notation, put in the proof. When , by the inequality for , we havePut , we haveFor , we obtain Let , it givesSimilarly, for , it impliesif ,and if . □
Appendix A.7
Appendix A.8
Appendix A.9
Appendix A.10
Appendix A.11
References
- Vershynin, R. High-Dimensional Probability: An Introduction with Applications in Data Science; Cambridge University Press: Cambridge, UK, 2018; Volume 47. [Google Scholar]
- Bai, Z.; Silverstein, J.W. Spectral Analysis of Large Dimensional Random Matrices; Springer: New York, NY, USA, 2010; Volume 20. [Google Scholar]
- Wainwright, M.J. High-Dimensional Statistics: A Non-Asymptotic Viewpoint; Cambridge University Press: Cambridge, UK, 2019; Volume 48. [Google Scholar]
- Zhang, H.; Chen, S.X. Concentration Inequalities for Statistical Inference. Commun. Math. Res. 2021, 37, 1–85. [Google Scholar]
- Tropp, J.A. An introduction to matrix concentration inequalities. Found. Trends Mach. Learn. 2015, 8, 1–230. [Google Scholar] [CrossRef]
- Kuchibhotla, A.K.; Chakrabortty, A. Moving beyond sub-Gaussianity in high-dimensional statistics: Applications in covariance estimation and linear regression. Inf. Inference J. Imag. 2022. ahead of print. [Google Scholar] [CrossRef]
- Hao, B.; Abbasi-Yadkori, Y.; Wen, Z.; Cheng, G. Bootstrapping Upper Confidence Bound. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Gbur, E.E.; Collins, R.A. Estimation of the Moment Generating Function. Commun. Stat. Simul. Comput. 1989, 18, 1113–1134. [Google Scholar] [CrossRef]
- Götze, F.; Sambale, H.; Sinulis, A. Concentration inequalities for polynomials in α-sub-exponential random variables. Electron. J. Probab. 2021, 26, 1–22. [Google Scholar] [CrossRef]
- Li, S.; Wei, H.; Lei, X. Heterogeneous Overdispersed Count Data Regressions via Double-Penalized Estimations. Mathematics 2022, 10, 1700. [Google Scholar] [CrossRef]
- Rigollet, P.; Hütter, J.C. High Dimensional Statistics. 2019. Available online: http://www-math.mit.edu/rigollet/PDFs/RigNotes17.pdf (accessed on 20 April 2022).
- Foss, S.; Korshunov, D.; Zachary, S. An Introduction to Heavy-Tailed and Subexponential Distributions; Springer: New York, NY, USA, 2011. [Google Scholar]
- De la Pena, V.; Gine, E. Decoupling: From Dependence to Independence; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Latala, R. Estimation of moments of sums of independent real random variables. Ann. Probab. 1997, 25, 1502–1513. [Google Scholar] [CrossRef]
- Kashlak, A.B. Measuring distributional asymmetry with Wasserstein distance and Rademacher symmetrization. Electron. J. Stat. 2018, 12, 2091–2113. [Google Scholar] [CrossRef]
- Vladimirova, M.; Girard, S.; Nguyen, H.; Arbel, J. Sub-Weibull distributions: Generalizing sub-Gaussian and sub-Exponential properties to heavier tailed distributions. Stat 2020, 9, e318. [Google Scholar] [CrossRef]
- Wong, K.C.; Li, Z.; Tewari, A. Lasso guarantees for β-mixing heavy-tailed time series. Ann. Stat. 2020, 48, 1124–1142. [Google Scholar] [CrossRef]
- Portnoy, S. Asymptotic behavior of likelihood methods for exponential families when the number of parameters tends to infinity. Ann. Stat. 1988, 16, 356–366. [Google Scholar] [CrossRef]
- Kuchibhotla, A.K. Deterministic inequalities for smooth m-estimators. arXiv 2018, arXiv:1809.05172. [Google Scholar]
- Zhang, H.; Jia, J. Elastic-net regularized high-dimensional negative binomial regression: Consistency and weak signals detection. Stat. Sin. 2022, 32, 181–207. [Google Scholar] [CrossRef]
- Bai, Z.D.; Yin, Y.Q. Limit of the smallest eigenvalue of a large dimensional sample covariance matrix. In Advances In Statistics; World Scientific: Singapore, 1993; pp. 1275–1294. [Google Scholar]
- Chen, P.; Jin, X.; Li, X.; Xu, L. A generalized catoni’s m-estimator under finite α-th moment assumption with α∈(1,2). Electron. J. Stat. 2021, 15, 5523–5544. [Google Scholar] [CrossRef]
- Xu, L.; Yao, F.; Yao, Q.; Zhang, H. Non-Asymptotic Guarantees for Robust Statistical Learning under (1+ε)-th Moment Assumption. arXiv 2022, arXiv:2201.03182. [Google Scholar]
- Lerasle, M. Lecture notes: Selected topics on robust statistical learning theory. arXiv 2019, arXiv:1908.10761. [Google Scholar]
- Devroye, L.; Lerasle, M.; Lugosi, G.; Oliveira, R.I. Sub-gaussian mean estimators. Ann. Stat. 2016, 44, 2695–2725. [Google Scholar] [CrossRef]
- Zhang, A.R.; Zhou, Y. On the non-asymptotic and sharp lower tail bounds of random variables. Stat 2020, 9, e314. [Google Scholar] [CrossRef]
- Zhang, H.; Tan, K.; Li, B. COM-negative binomial distribution: Modeling overdispersion and ultrahigh zero-inflated count data. Front. Math. China 2018, 13, 967–998. [Google Scholar] [CrossRef] [Green Version]
- Zajkowski, K. On norms in some class of exponential type Orlicz spaces of random variables. Positivity 2019, 24, 1231–1240. [Google Scholar] [CrossRef] [Green Version]
- Jameson, G.J. A simple proof of Stirling’s formula for the gamma function. Math. Gaz. 2015, 99, 68–74. [Google Scholar] [CrossRef] [Green Version]
- Alzer, H. On some inequalities for the gamma and psi functions. Math. Comput. 1997, 66, 373–389. [Google Scholar] [CrossRef] [Green Version]





Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Wei, H. Sharper Sub-Weibull Concentrations. Mathematics 2022, 10, 2252. https://doi.org/10.3390/math10132252
Zhang H, Wei H. Sharper Sub-Weibull Concentrations. Mathematics. 2022; 10(13):2252. https://doi.org/10.3390/math10132252
Chicago/Turabian StyleZhang, Huiming, and Haoyu Wei. 2022. "Sharper Sub-Weibull Concentrations" Mathematics 10, no. 13: 2252. https://doi.org/10.3390/math10132252
APA StyleZhang, H., & Wei, H. (2022). Sharper Sub-Weibull Concentrations. Mathematics, 10(13), 2252. https://doi.org/10.3390/math10132252