


Region Collaborative Network for Detection-Based Vision-Language Understanding

Abstract
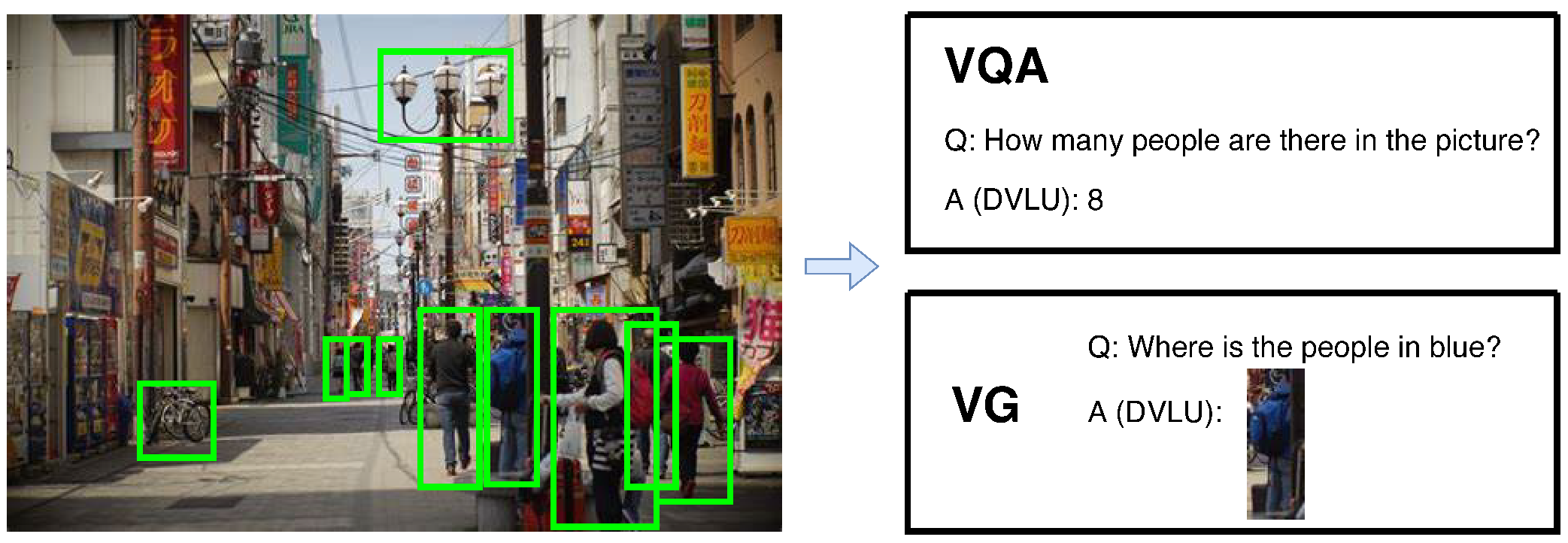
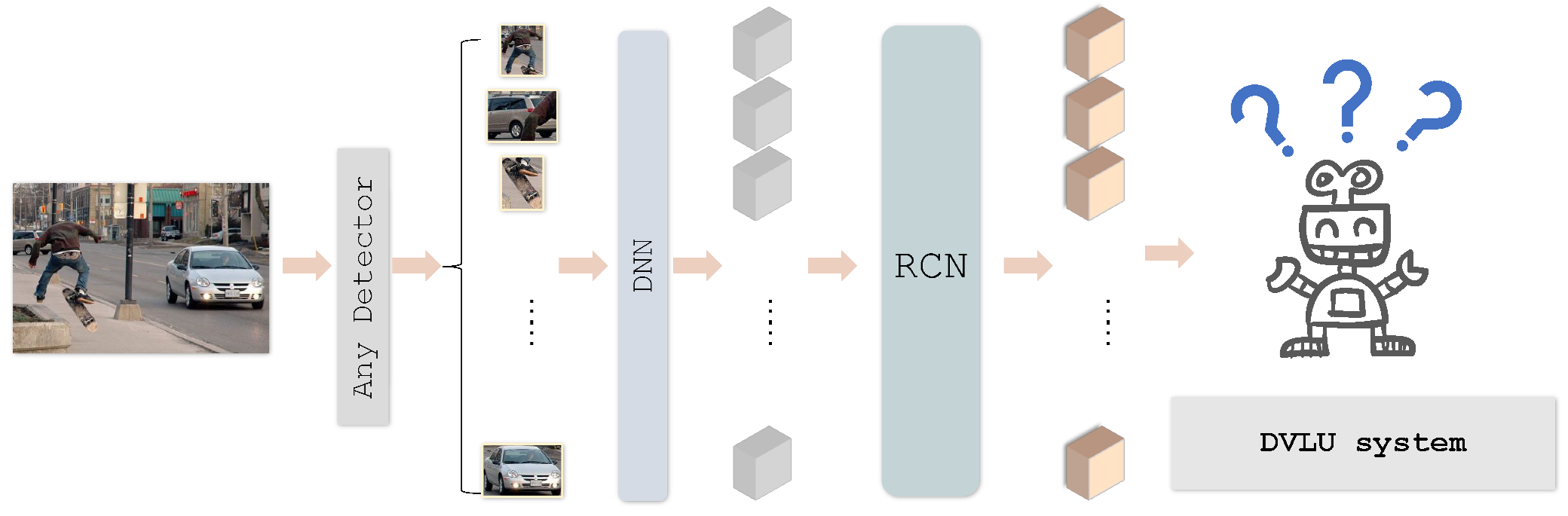
:1. Introduction
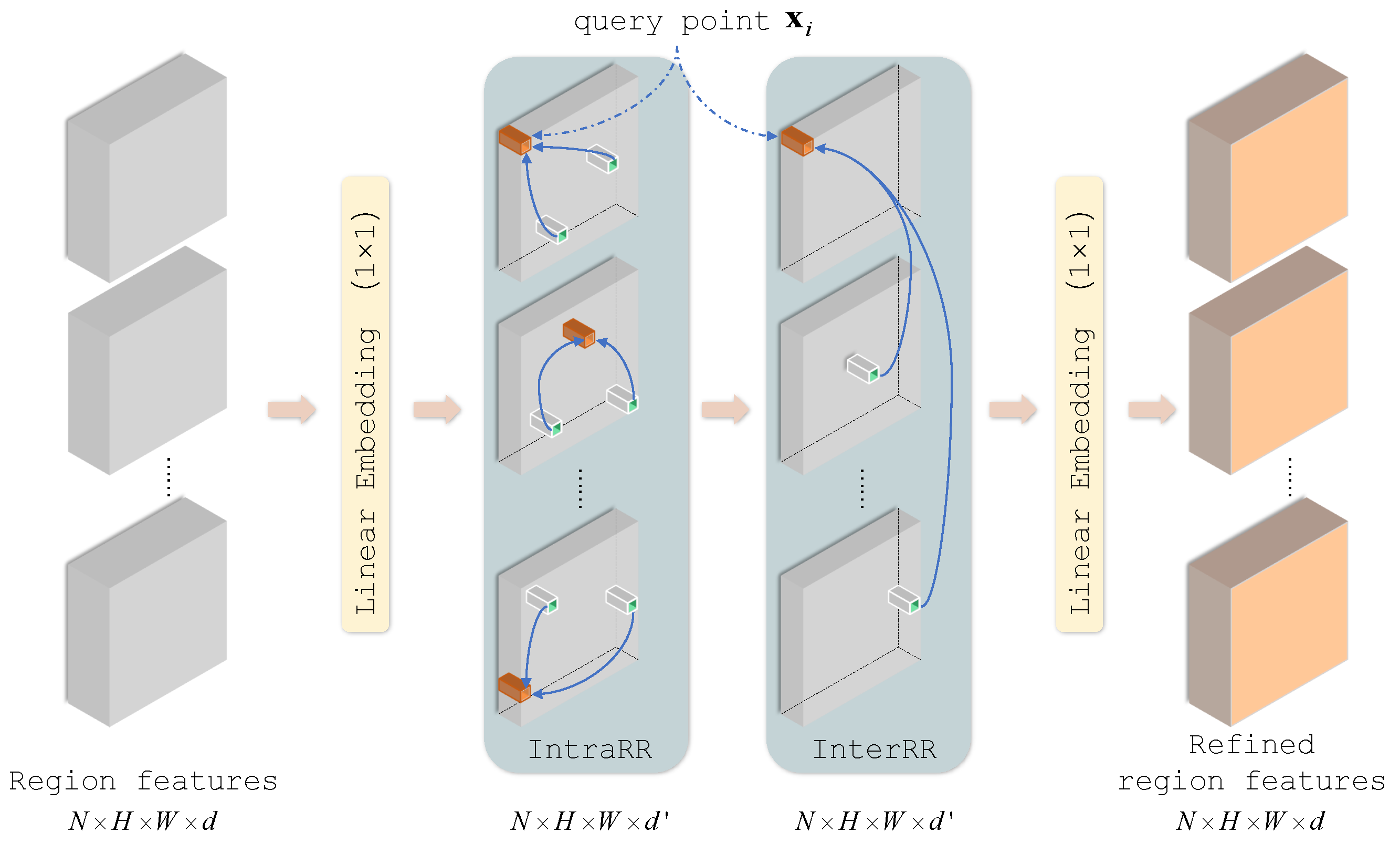
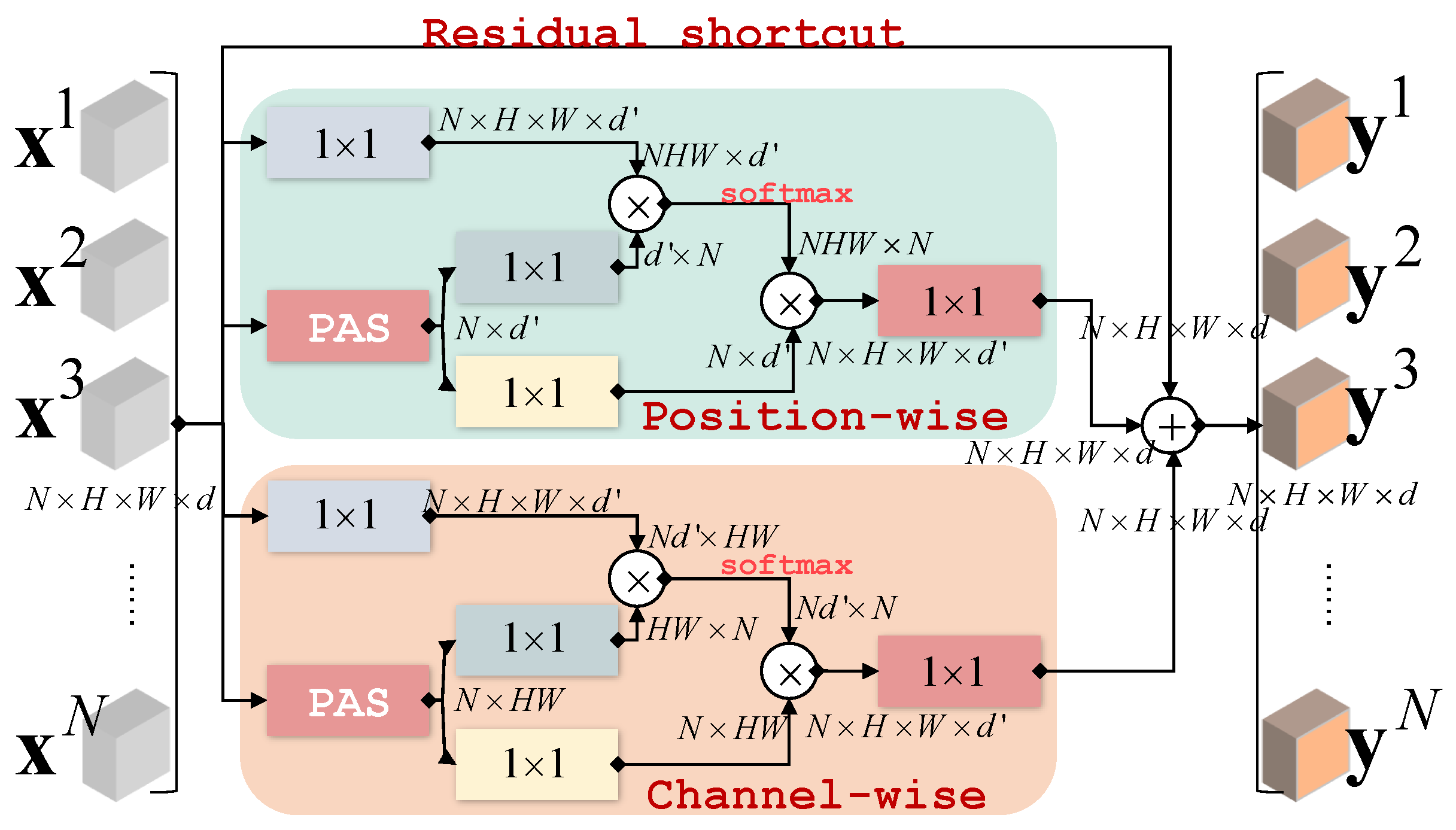
- In RCN, we propose to build Intra-Region Relation (IntraRR) across positions and channels to achieve self-enhancement.
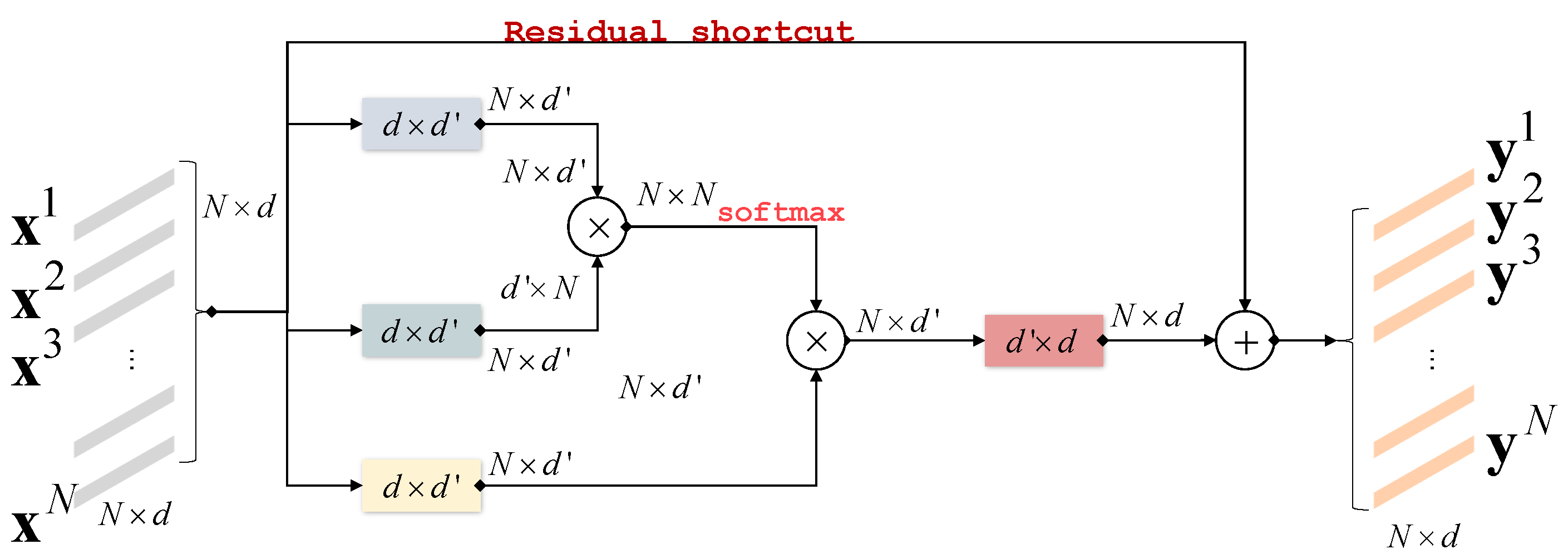
- We propose to build Inter-Region Relation (InterRR) to all regions across positions and channels for relationships among regions.
- We evaluate the effectiveness of RCN on VQA and VG, and the results show the proposed method can improve the performance of existing DVLU methods.
2. Related Work
2.1. Detection-Based Vision-Language Understanding
2.2. Region Relation Network
3. Method
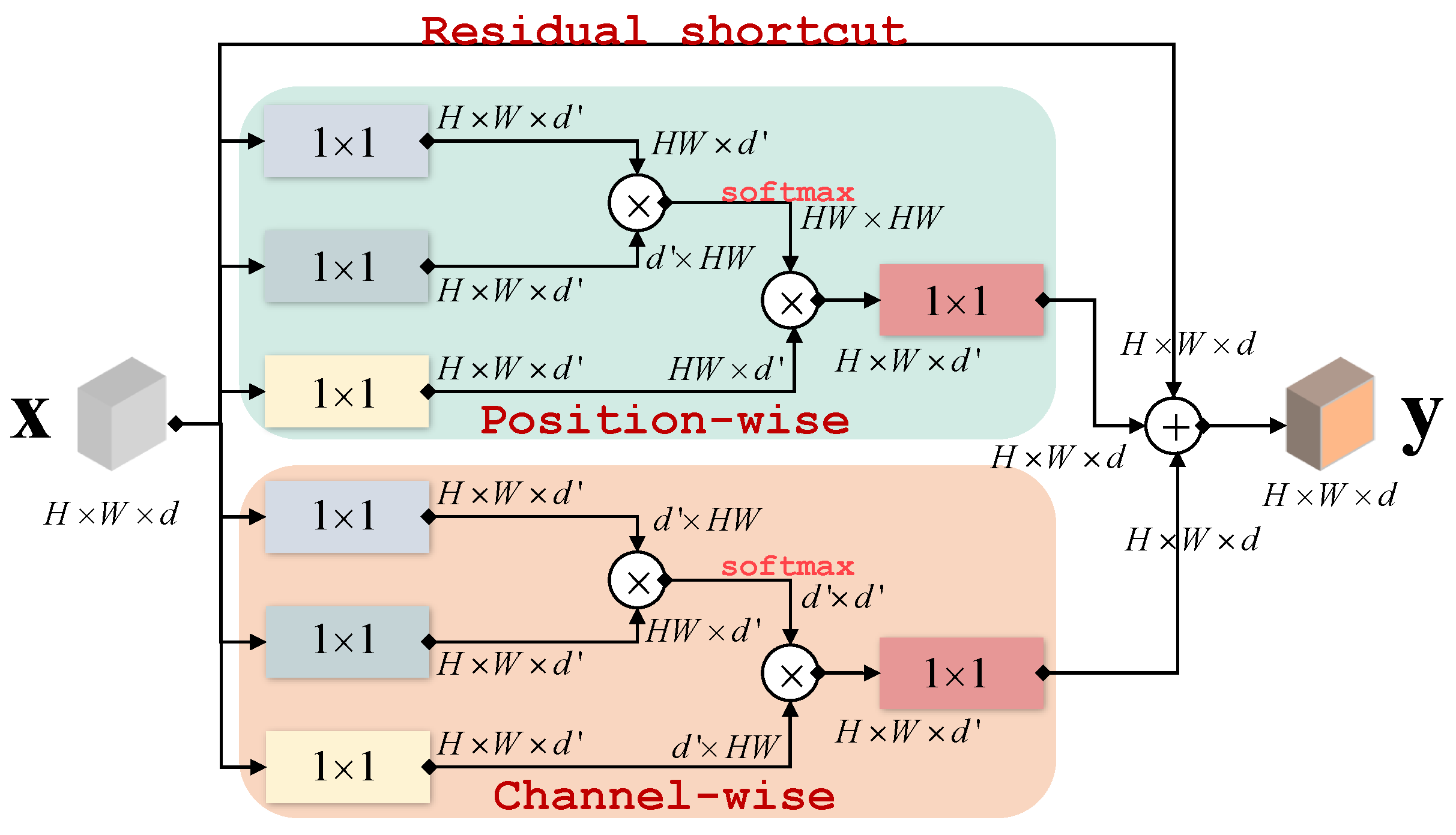
3.1. Review of Non-Local Network
3.2. Region Collaborative Network
3.2.1. Intra-Region Relation
3.2.2. Inter-Region Relation
3.2.3. RCN for Fully Connected Layer
4. Experiments
4.1. Implementation Detail
4.2. Bottom-Up Visual Question Answering
4.2.1. Dataset
4.2.2. Results
4.3. Visual Grounding
4.3.1. Dataset
4.3.2. Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.; Chen, J.; Liu, X.; Pietikäinen, M. Deep Learning for Generic Object Detection: A Survey. arXiv 2018, arXiv:1809.02165. [Google Scholar] [CrossRef]
- Peng, C.; Weiwei, Z.; Ziyao, X.; Yongxiang, T. Traffic Accident Detection Based on Deformable Frustum Proposal and Adaptive Space Segmentation. Comput. Model. Eng. Sci. 2022, 130, 97–109. [Google Scholar]
- Yunbo, R.; Hongyu, M.; Zeyu, Y.; Weibin, Z.; Faxin, W.; Jiansu, P.; Shaoning, Z. B-PesNet: Smoothly Propagating Semantics for Robust and Reliable Multi-Scale Object Detection for Secure Systems. Comput. Model. Eng. Sci. 2022, 132, 1039–1054. [Google Scholar]
- Johnson, J.; Krishna, R.; Stark, M.; Li, L.J.; Shamma, D.; Bernstein, M.; Fei-Fei, L. Image Retrieval using Scene Graphs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3668–3678. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; Zhang, L. Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6077–6086. [Google Scholar]
- Fu, K.; Jin, J.; Cui, R.; Sha, F.; Zhang, C. Aligning where to see and what to tell: Image captioning with region-based attention and scene-specific contexts. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 2321–2334. [Google Scholar] [CrossRef] [PubMed]
- Teney, D.; Anderson, P.; He, X.; van den Hengel, A. Tips and Tricks for Visual Question Answering: Learnings from the 2017 Challenge. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4223–4232. [Google Scholar]
- Jiang, Y.; Natarajan, V.; Chen, X.; Rohrbach, M.; Batra, D.; Parikh, D. Pythia v0. 1: The Winning Entry to the VQA Challenge 2018. arXiv 2018, arXiv:1807.09956. [Google Scholar]
- Biten, A.F.; Litman, R.; Xie, Y.; Appalaraju, S.; Manmatha, R. Latr: Layout-aware transformer for scene-text vqa. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 21–24 June 2022; pp. 16548–16558. [Google Scholar]
- Cascante-Bonilla, P.; Wu, H.; Wang, L.; Feris, R.S.; Ordonez, V. Simvqa: Exploring simulated environments for visual question answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 21–24 June 2022; pp. 5056–5066. [Google Scholar]
- Gupta, V.; Li, Z.; Kortylewski, A.; Zhang, C.; Li, Y.; Yuille, A. Swapmix: Diagnosing and regularizing the over-reliance on visual context in visual question answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 21–24 June 2022; pp. 5078–5088. [Google Scholar]
- Deng, C.; Wu, Q.; Wu, Q.; Hu, F.; Lyu, F.; Tan, M. Visual Grounding via Accumulated Attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7746–7755. [Google Scholar]
- Yu, L.; Lin, Z.; Shen, X.; Yang, J.; Lu, X.; Bansal, M.; Berg, T.L. Mattnet: Modular Attention Network for Referring Expression Comprehension. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1307–1315. [Google Scholar]
- Hu, R.; Rohrbach, M.; Andreas, J.; Darrell, T.; Saenko, K. Modeling Relationships in Referential Expressions with Compositional Modular Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1115–1124. [Google Scholar]
- Huang, S.; Chen, Y.; Jia, J.; Wang, L. Multi-View Transformer for 3D Visual Grounding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 21–24 June 2022; pp. 15524–15533. [Google Scholar]
- Yang, L.; Xu, Y.; Yuan, C.; Liu, W.; Li, B.; Hu, W. Improving Visual Grounding with Visual-Linguistic Verification and Iterative Reasoning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 21–24 June 2022; pp. 9499–9508. [Google Scholar]
- Dai, B.; Zhang, Y.; Lin, D. Detecting Visual Relationships with Deep Relational Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3076–3086. [Google Scholar]
- Lu, C.; Krishna, R.; Bernstein, M.S.; Li, F. Visual Relationship Detection with Language Priors. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 852–869. [Google Scholar]
- Xu, D.; Zhu, Y.; Choy, C.B.; Fei-Fei, L. Scene Graph Generation by Iterative Message Passing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5410–5419. [Google Scholar]
- Li, Y.; Ouyang, W.; Zhou, B.; Wang, K.; Wang, X. Scene Graph Generation from Objects, Phrases and Region Captions. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1261–1270. [Google Scholar]
- Zellers, R.; Yatskar, M.; Thomson, S.; Choi, Y. Neural Motifs: Scene Graph Parsing with Global Context. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5831–5840. [Google Scholar]
- Teng, Y.; Wang, L. Structured sparse r-cnn for direct scene graph generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 21–24 June 2022; pp. 19437–19446. [Google Scholar]
- Gao, K.; Chen, L.; Niu, Y.; Shao, J.; Xiao, J. Classification-then-grounding: Reformulating video scene graphs as temporal bipartite graphs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 21–24 June 2022; pp. 19497–19506. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Region-based Convolutional Networks for Accurate Object Detection and Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 142–158. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Chen, S.; Zhao, Q. REX: Reasoning-aware and Grounded Explanation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 21–24 June 2022; pp. 15586–15595. [Google Scholar]
- Li, G.; Wei, Y.; Tian, Y.; Xu, C.; Wen, J.R.; Hu, D. Learning to Answer Questions in Dynamic Audio-Visual Scenarios. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 21–24 June 2022; pp. 19108–19118. [Google Scholar]
- Cirik, V.; Berg-Kirkpatrick, T.; Morency, L.P. Using Syntax to Ground Referring Expressions in Natural Images. Proc. AAAI Conf. Artif. Intell. 2018, 32, 6756–6764. [Google Scholar] [CrossRef]
- Lyu, F.; Feng, W.; Wang, S. vtGraphNet: Learning weakly-supervised scene graph for complex visual grounding. Neurocomputing 2020, 413, 51–60. [Google Scholar] [CrossRef]
- Hinami, R.; Matsui, Y.; Satoh, S. Region-based Image Retrieval Revisited. In Proceedings of the ACM International Conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 528–536. [Google Scholar]
- Zhang, H.; Niu, Y.; Chang, S.F. Grounding referring expressions in images by variational context. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4158–4166. [Google Scholar]
- Yan, Y.; Ren, J.; Tschannerl, J.; Zhao, H.; Harrison, B.; Jack, F. Nondestructive phenolic compounds measurement and origin discrimination of peated barley malt using near-infrared hyperspectral imagery and machine learning. IEEE Trans. Instrum. Meas. 2021, 70, 5010715. [Google Scholar] [CrossRef]
- Sun, H.; Ren, J.; Zhao, H.; Yuen, P.; Tschannerl, J. Novel gumbel-softmax trick enabled concrete autoencoder with entropy constraints for unsupervised hyperspectral band selection. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5506413. [Google Scholar] [CrossRef]
- Sun, G.; Zhang, X.; Jia, X.; Ren, J.; Zhang, A.; Yao, Y.; Zhao, H. Deep fusion of localized spectral features and multi-scale spatial features for effective classification of hyperspectral images. Int. J. Appl. Earth Obs. Geoinf. 2020, 91, 102157. [Google Scholar] [CrossRef]
- Qiao, T.; Ren, J.; Wang, Z.; Zabalza, J.; Sun, M.; Zhao, H.; Li, S.; Benediktsson, J.A.; Dai, Q.; Marshall, S. Effective denoising and classification of hyperspectral images using curvelet transform and singular spectrum analysis. IEEE Trans. Geosci. Remote Sens. 2016, 55, 119–133. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; Volume 25. [Google Scholar]
- Lyu, F.; Wu, Q.; Hu, F.; Wu, Q.; Tan, M. Attend and Imagine: Multi-label Image Classification with Visual Attention and Recurrent Neural Networks. IEEE Trans. Multimed. 2019, 21, 1971–1981. [Google Scholar] [CrossRef]
- Du, K.; Lyu, F.; Hu, F.; Li, L.; Feng, W.; Xu, F.; Fu, Q. AGCN: Augmented Graph Convolutional Network for Lifelong Multi-label Image Recognition. arXiv 2022, arXiv:2203.05534. [Google Scholar]
- Mukhiddinov, M.; Cho, J. Smart glass system using deep learning for the blind and visually impaired. Electronics 2021, 10, 2756. [Google Scholar] [CrossRef]
- Zagoruyko, S.; Komodakis, N. Learning to Compare Image Patches via Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4353–4361. [Google Scholar]
- Tseng, S.Y.R.; Chen, H.T.; Tai, S.H.; Liu, T.L. Non-local RoI for Cross-Object Perception. arXiv 2018, arXiv:1811.10002. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-Local Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Buades, A.; Coll, B.; Morel, J.M. A Non-local Algorithm for Image Denoising. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; Volume 2, pp. 60–65. [Google Scholar]
- Ye, Z.; Hu, F.; Liu, Y.; Xia, Z.; Lyu, F.; Liu, P. Associating multi-scale receptive fields for fine-grained recognition. In Proceedings of the IEEE International Conference on Image Processing, Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 1851–1855. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Lu, J.; Yang, J.; Batra, D.; Parikh, D. Hierarchical Question-Image Co-Attention for Visual Question Answering. Adv. Neural Inf. Process. Syst. 2016, 29, 1–9. [Google Scholar]
- Wang, P.; Wu, Q.; Shen, C.; van den Hengel, A. The Vqa-Machine: Learning How to Use Existing Vision Algorithms to Answer New Questions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1173–1182. [Google Scholar]
- Fukui, A.; Park, D.H.; Yang, D.; Rohrbach, A.; Darrell, T.; Rohrbach, M. Multimodal Compact Bilinear Pooling for Visual Question Answering and Visual Grounding. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–4 November 2016; pp. 457–468. [Google Scholar]
- Luo, R.; Shakhnarovich, G. Comprehension-Guided Referring Expressions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7102–7111. [Google Scholar]
- Hu, R.; Xu, H.; Rohrbach, M.; Feng, J.; Saenko, K.; Darrell, T. Natural Language Object Retrieval. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4555–4564. [Google Scholar]
- Mao, J.; Huang, J.; Toshev, A.; Camburu, O.; Yuille, A.L.; Murphy, K. Generation and Comprehension of Unambiguous Object Descriptions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 11–20. [Google Scholar]
- Yu, L.; Poirson, P.; Yang, S.; Berg, A.C.; Berg, T.L. Modeling Context in Referring Expressions. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 69–85. [Google Scholar]
- Nagaraja, V.K.; Morariu, V.I.; Davis, L.S. Modeling Context between Objects for Referring Expression Understanding. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 792–807. [Google Scholar]
- Kazemzadeh, S.; Ordonez, V.; Matten, M.; Berg, T.L. ReferItGame: Referring to Objects in Photographs of Natural Scenes. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 787–798. [Google Scholar]
- Lin, T.; Maire, M.; Belongie, S.J.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 8–14 September 2014; pp. 740–755. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.j.; Li, K.; Fei-fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Yu, L.; Tan, H.; Bansal, M.; Berg, T.L. A Joint Speaker-Listener-Reinforcer Model for Referring Expressions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7282–7290. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Test-Dev |
|---|---|
| HieCoAtt-ResNet [50] | 61.80 |
| VQA-Machine-ResNet [51] | 63.10 |
| Ma et al. -ResNet [8] | 63.80 |
| MCB-ResNet [52] | 64.70 |
| up-down [8] (Champion of VQA Challenge 2017) | 65.32 |
| pythia [9] (Champion of VQA Challenge 2018) | 68.49 |
| pythia + RCN | 68.56 |
| Methods | Regions | ReferCOCO | ReferCOCO+ | ReferCOCOg | ||||
|---|---|---|---|---|---|---|---|---|
| Val | TestA | TestB | Val | TestA | TestB | Val | ||
| Luo et al. [53] | gt | - | 74.14 | 71.46 | - | 59.87 | 54.35 | 63.39 |
| Luo et al. (w2v) [53] | gt | - | 74.04 | 73.43 | - | 60.26 | 55.03 | 65.36 |
| speaker+listener+reinforcer+MMI [61] | gt | 79.56 | 78.95 | 80.22 | 62.26 | 64.60 | 59.62 | 72.63 |
| A-ATT-r4 [13] | gt | 81.27 | 81.17 | 80.01 | 65.56 | 68.76 | 60.63 | 73.18 |
| MAttN [14] | gt | 80.94 | 79.99 | 82.30 | 63.07 | 65.04 | 61.77 | 73.08 |
| VC [34] | gt | - | 78.98 | 82.39 | - | 62.56 | 62.90 | 73.98 |
| VC (Ours) | gt | - | 78.08 | 82.49 | - | 60.08 | 61.78 | 70.21 |
| VC+RCN | gt | 82.03 | 81.37 | 82.79 | 66.71 | 63.19 | 63.35 | 74.10 |
| Methods | Embedding Size | ReferCOCO | |
|---|---|---|---|
| TestA | TestB | ||
| VC [34] | - | 78.98 | 82.39 |
| VC (Ours) | - | 78.08 | 82.49 |
| VC+RCN | 256 | 79.12 | 82.40 |
| VC+RCN | 512 | 80.07 | 82.14 |
| VC+RCN | 1024 | 81.37 | 82.79 |
| VC+RCN | 2048 | 80.95 | 82.12 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, L.; Du, K.; Gu, M.; Hu, F.; Lyu, F. Region Collaborative Network for Detection-Based Vision-Language Understanding. Mathematics 2022, 10, 3110. https://doi.org/10.3390/math10173110
Li L, Du K, Gu M, Hu F, Lyu F. Region Collaborative Network for Detection-Based Vision-Language Understanding. Mathematics. 2022; 10(17):3110. https://doi.org/10.3390/math10173110
Chicago/Turabian StyleLi, Linyan, Kaile Du, Minming Gu, Fuyuan Hu, and Fan Lyu. 2022. "Region Collaborative Network for Detection-Based Vision-Language Understanding" Mathematics 10, no. 17: 3110. https://doi.org/10.3390/math10173110
APA StyleLi, L., Du, K., Gu, M., Hu, F., & Lyu, F. (2022). Region Collaborative Network for Detection-Based Vision-Language Understanding. Mathematics, 10(17), 3110. https://doi.org/10.3390/math10173110