
Teaching Probabilistic Graphical Models with OpenMarkov



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Background
2.1. Basic Definitions about Probability and Graphs
- 1.
- if the arrows that connect W with its two neighbors in the path converge in it (head-to-head trail), then W or at least one of its descendants is in ;
- 2.
- else (i.e., if W is the middle of a divergent or a sequential trail), then W is not in .
2.2. Probabilistic Graphical Models
2.2.1. Bayesian Networks
- Factorization of the probability: The joint probability is the product of the probability of each node conditioned on its parents, i.e.,(In this equation, the value x and the configuration in the right-hand side are given by the projection of onto X and respectively. The same holds for the equations in the next section.)
- Markov property. Each node is independent of its non-descendants given its parents, i.e., if is a set of nodes such that none of them is a descendant of X, then
- d-separation. If two nodes X and Y are d-separated in the graph given (cf. Definition 2), then they are probabilistically independent given :
2.2.2. Influence Diagrams
2.2.3. Arc Reversal Algorithm
2.3. OpenMarkov
3. Teaching Bayesian Networks
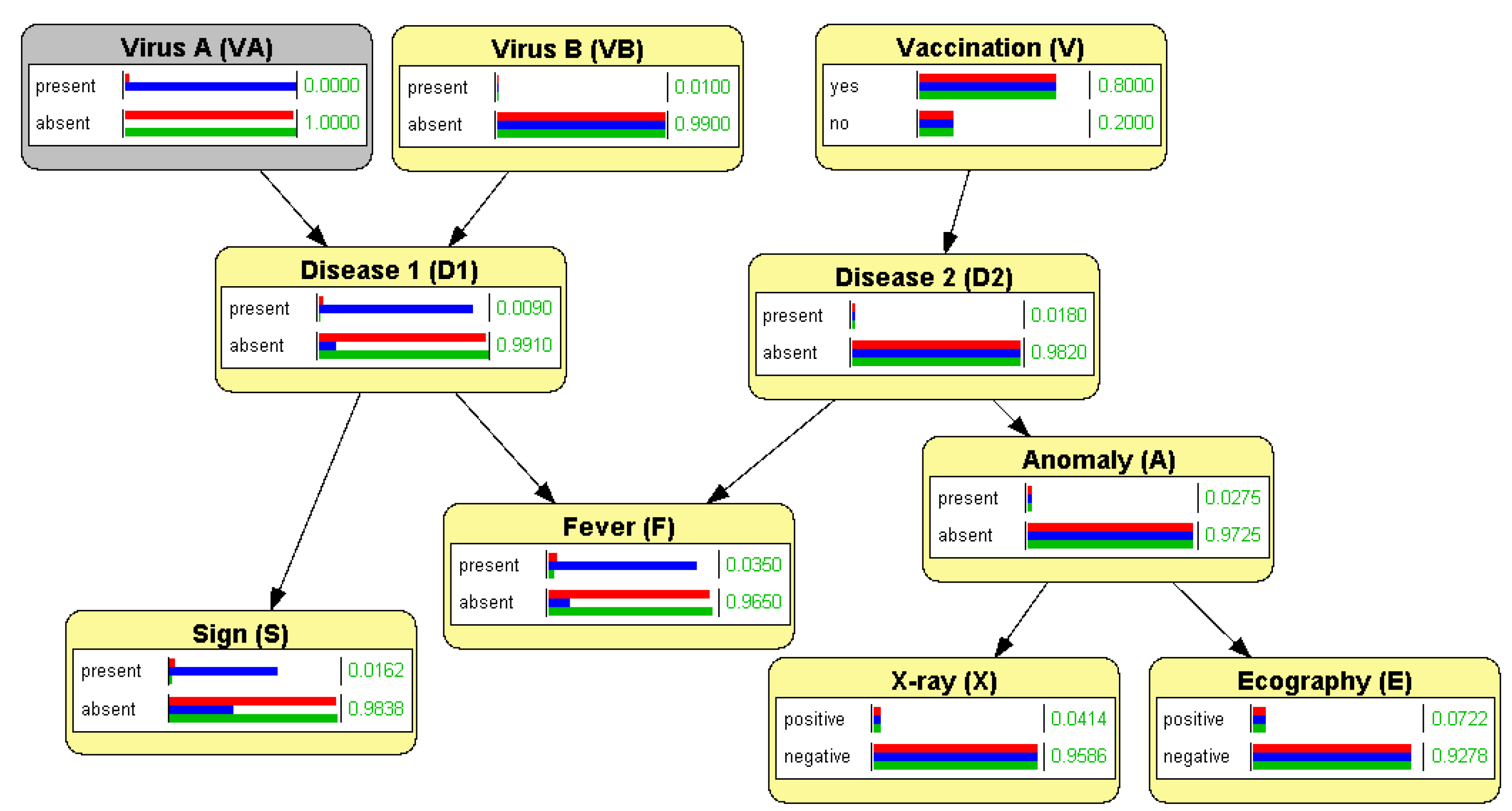
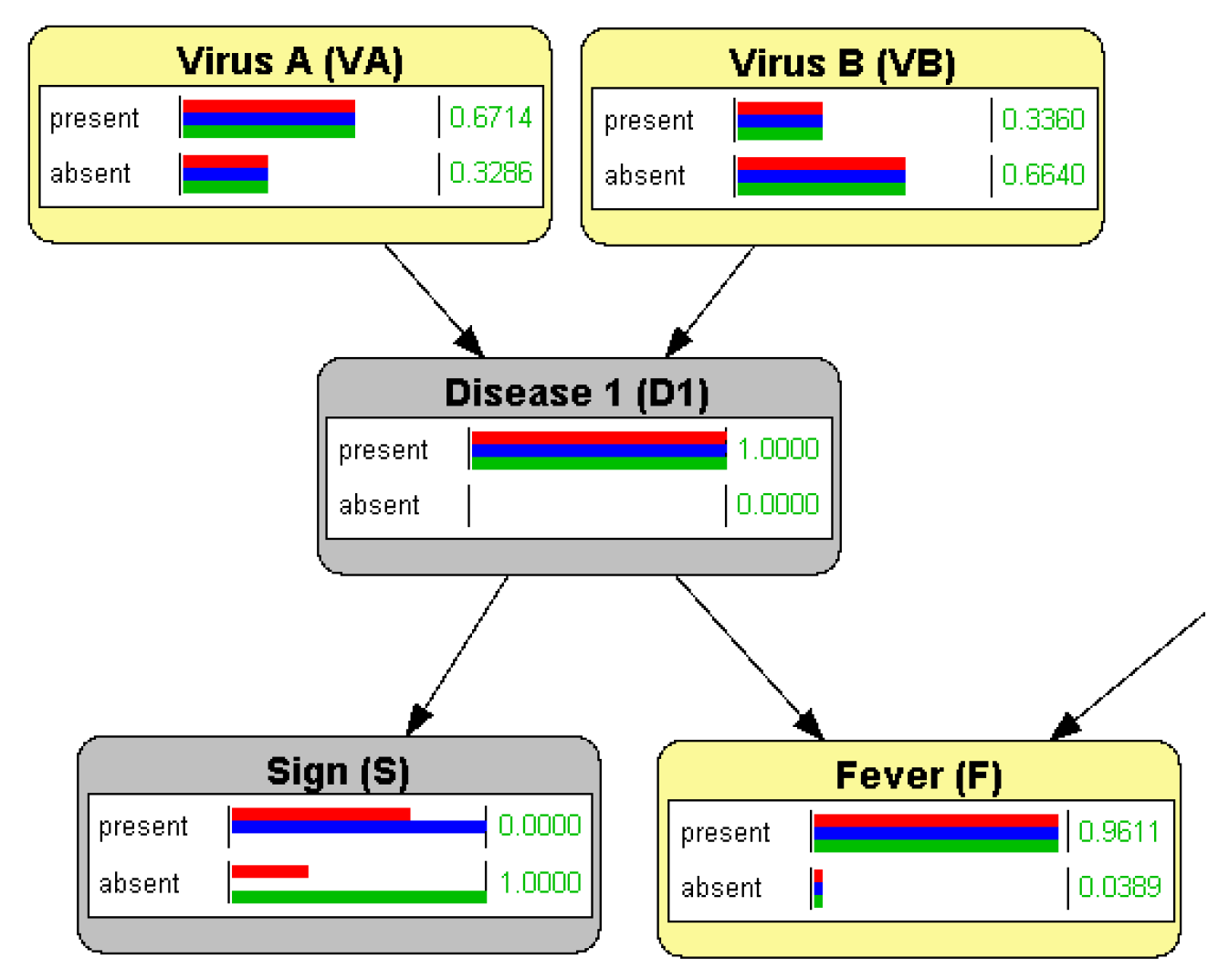
3.1. Evidence Propagation in BNs with OpenMarkov
3.2. Correlation and Independence
3.2.1. Conditional Independence
3.2.2. d-Separation
3.2.3. Markov Property and Markov Blankets
3.3. Inference Algorithms for Bayesian Networks
3.3.1. Arc Reversal for Bayesian Networks
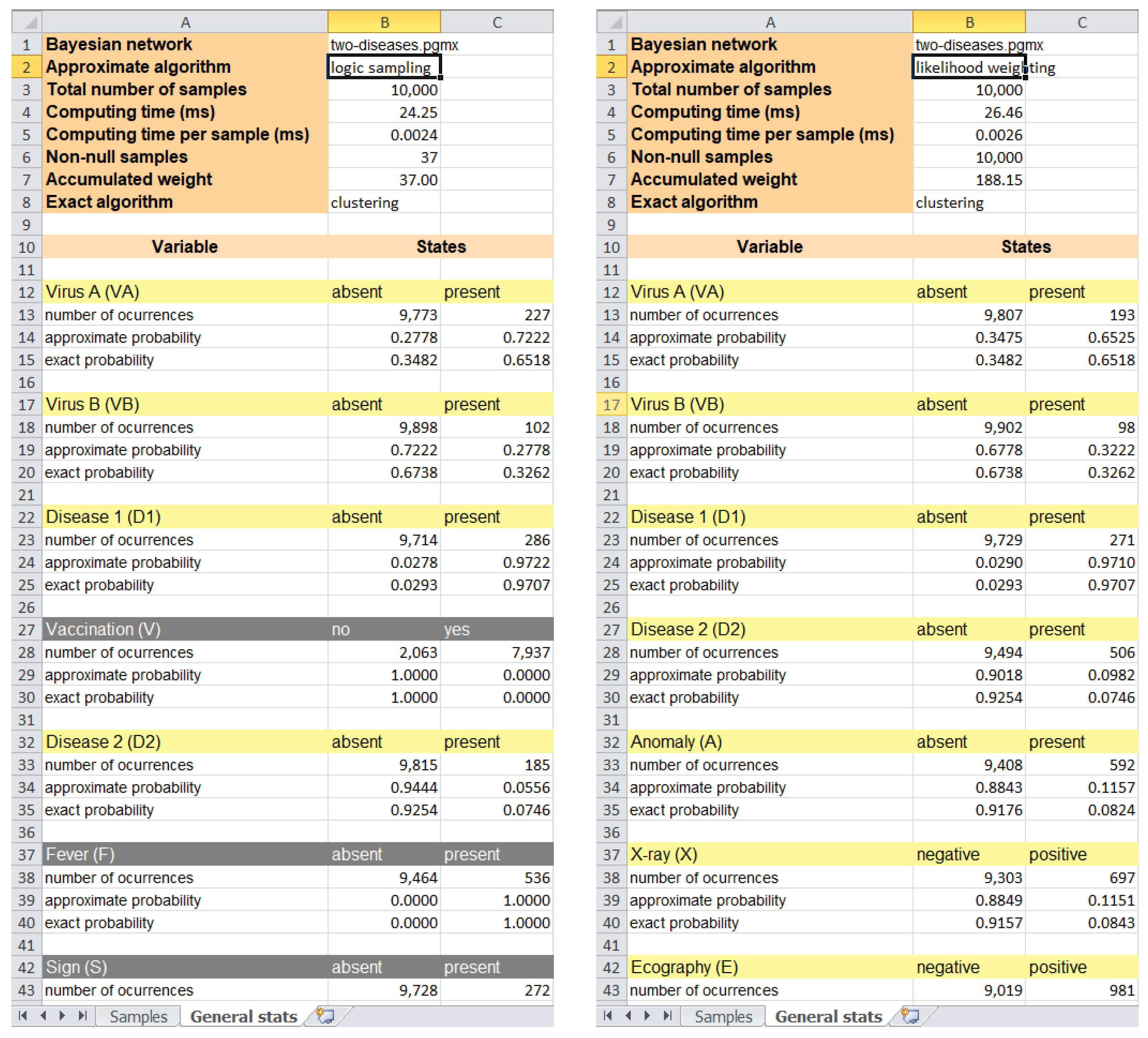
3.3.2. Stochastic Algorithms
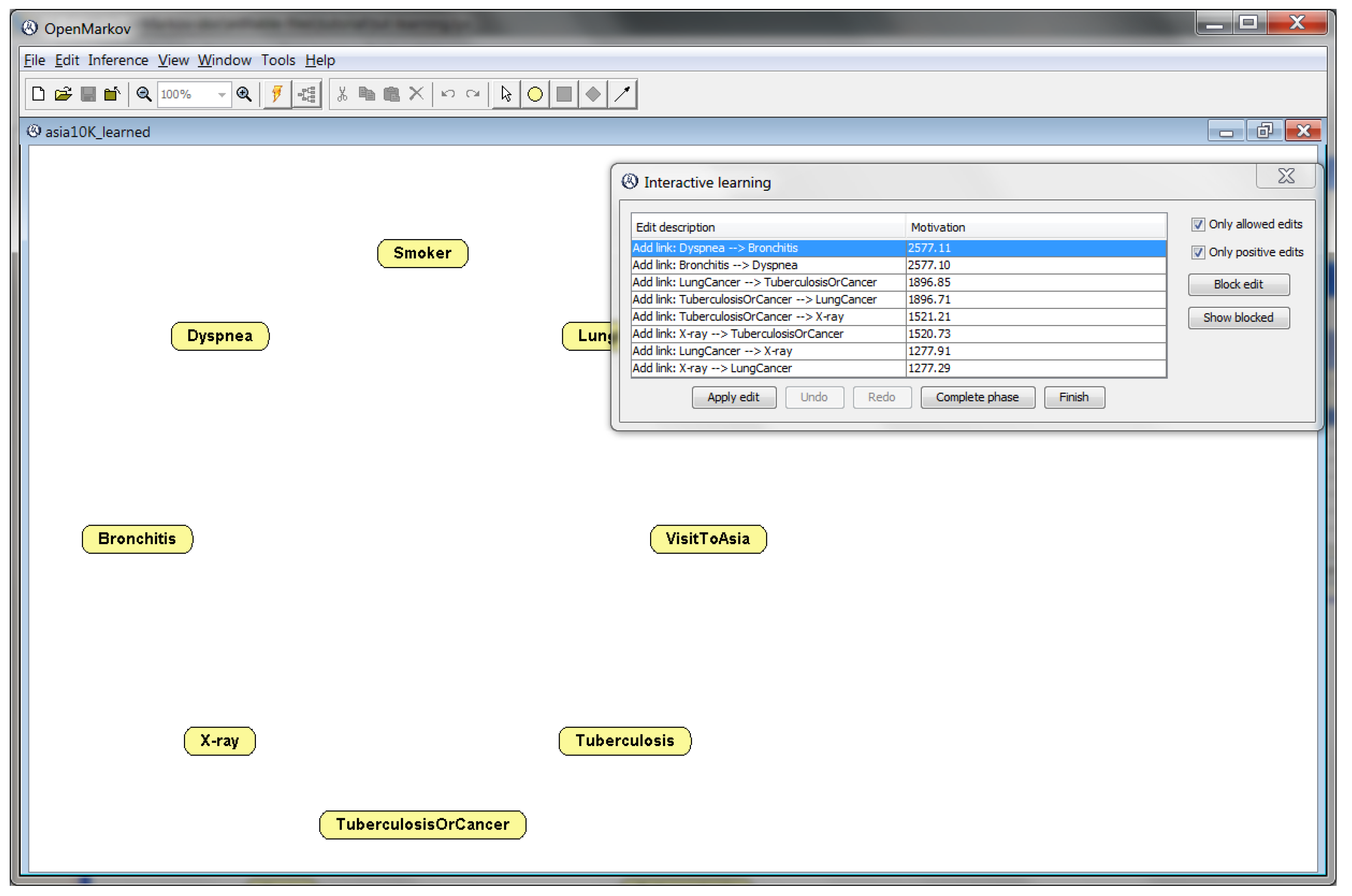
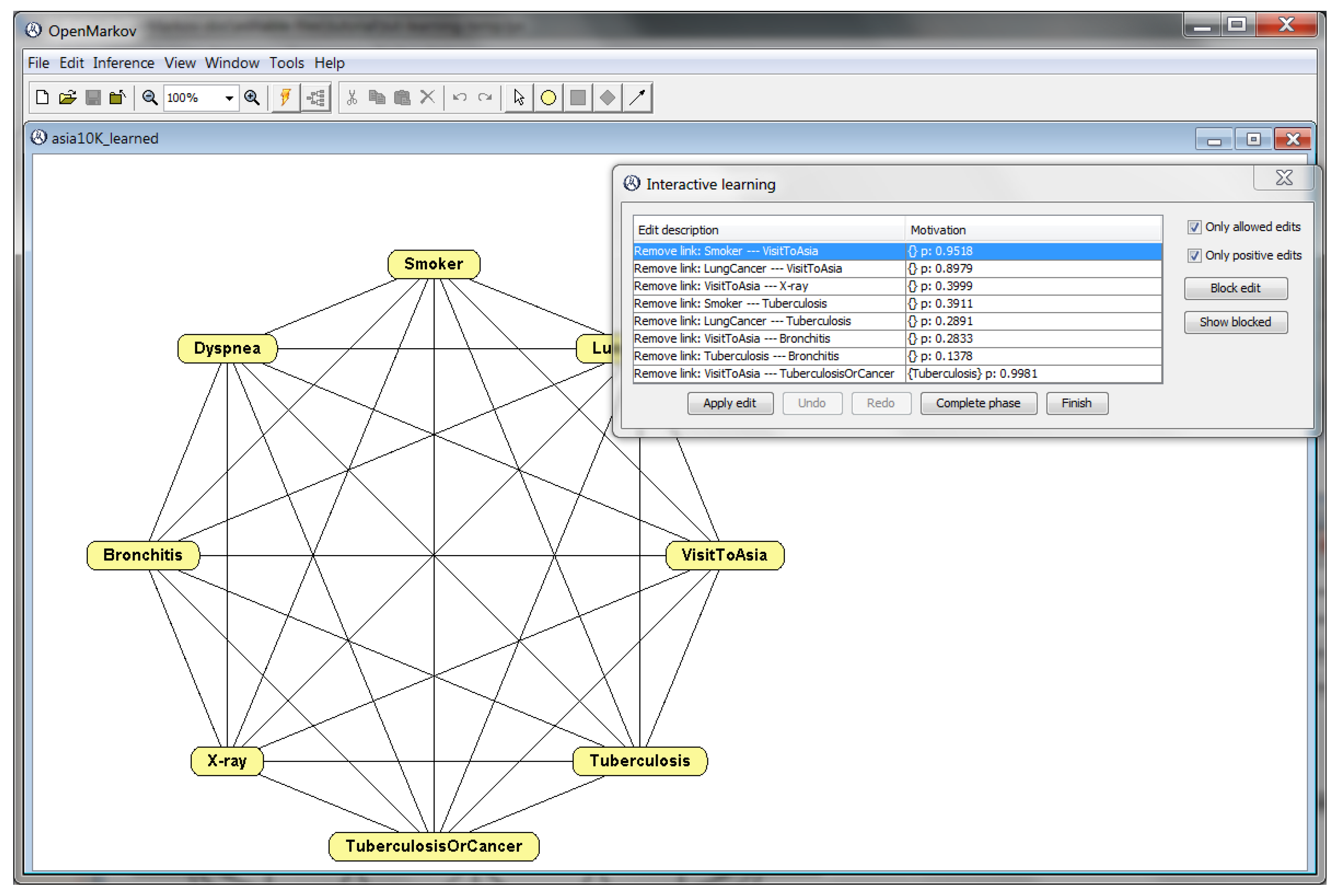
3.4. Learning Bayesian Networks
4. Teaching Influence Diagrams
4.1. Evaluation of Influence Diagrams
4.1.1. Expected Utility and Optimal Policies
4.1.2. Arc Reversal for Influence Diagrams
4.1.3. Expected Value of Perfect Information (EVPI)
4.2. Explanation of Reasoning
4.2.1. Imposing Policies for What-If Reasoning
4.2.2. Introducing Evidence
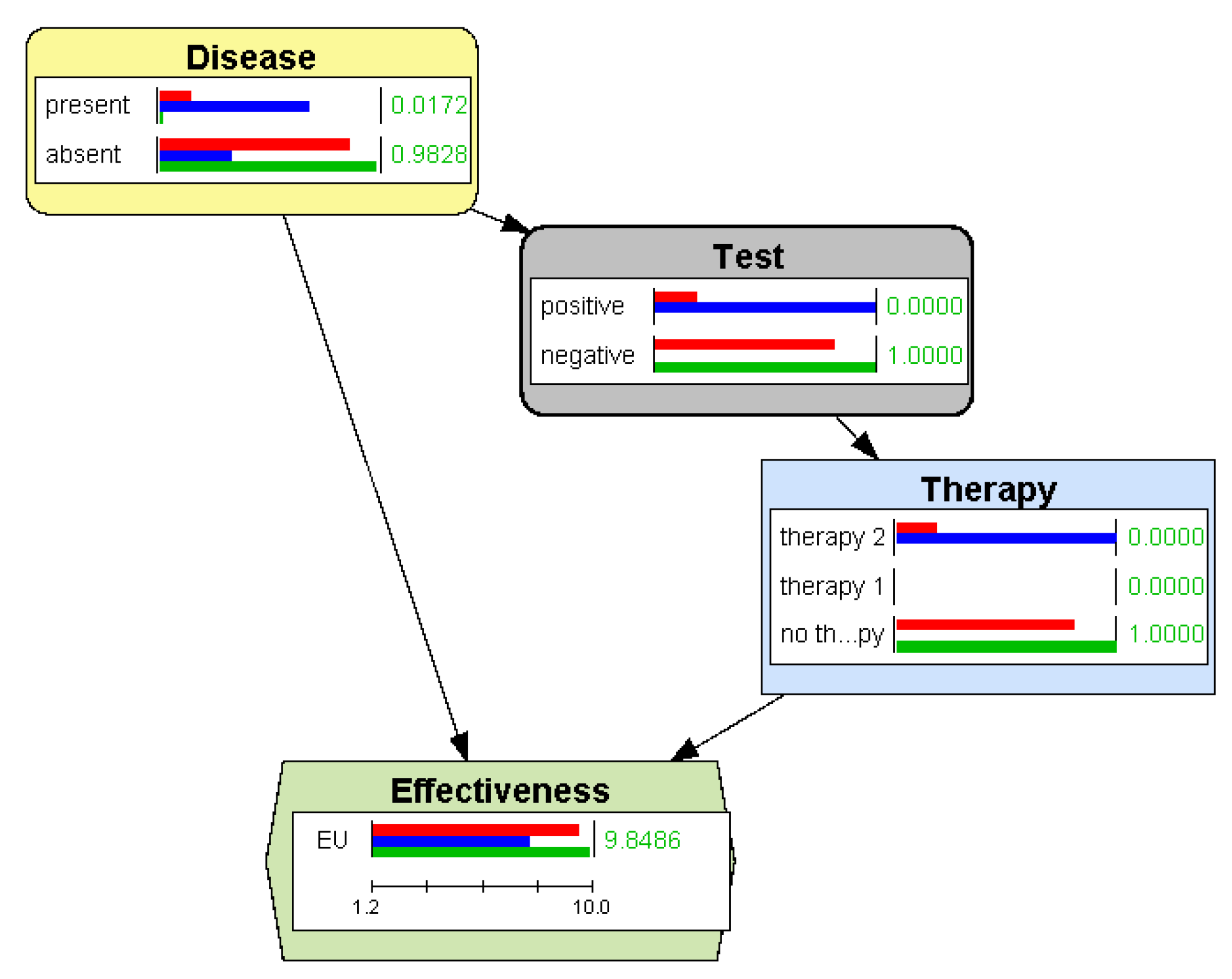
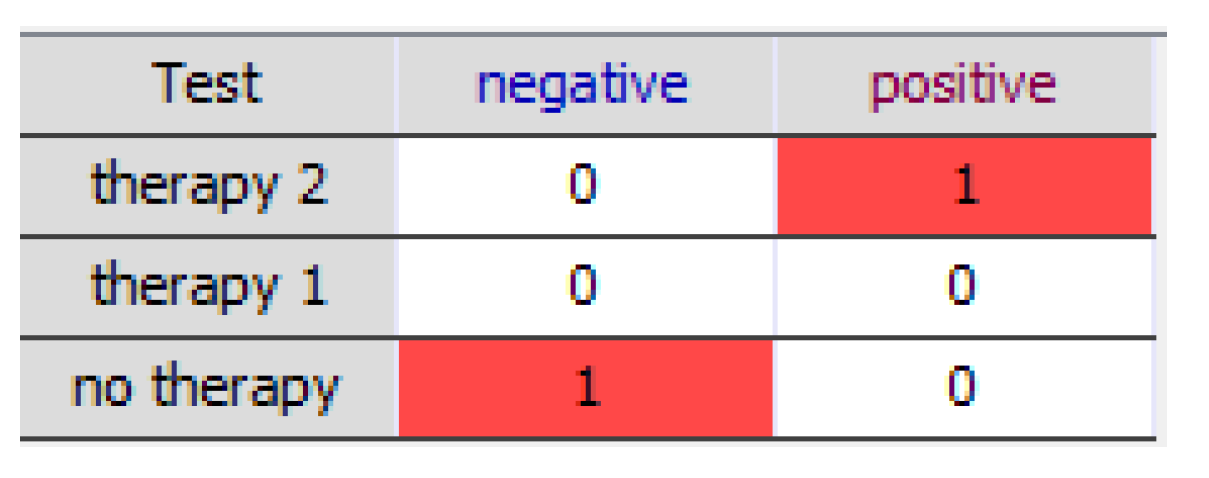
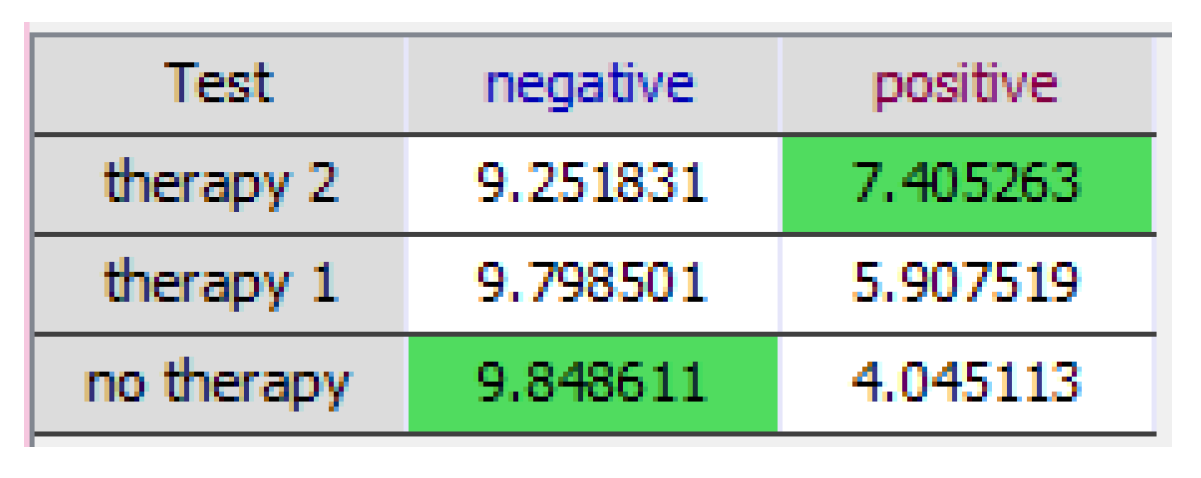
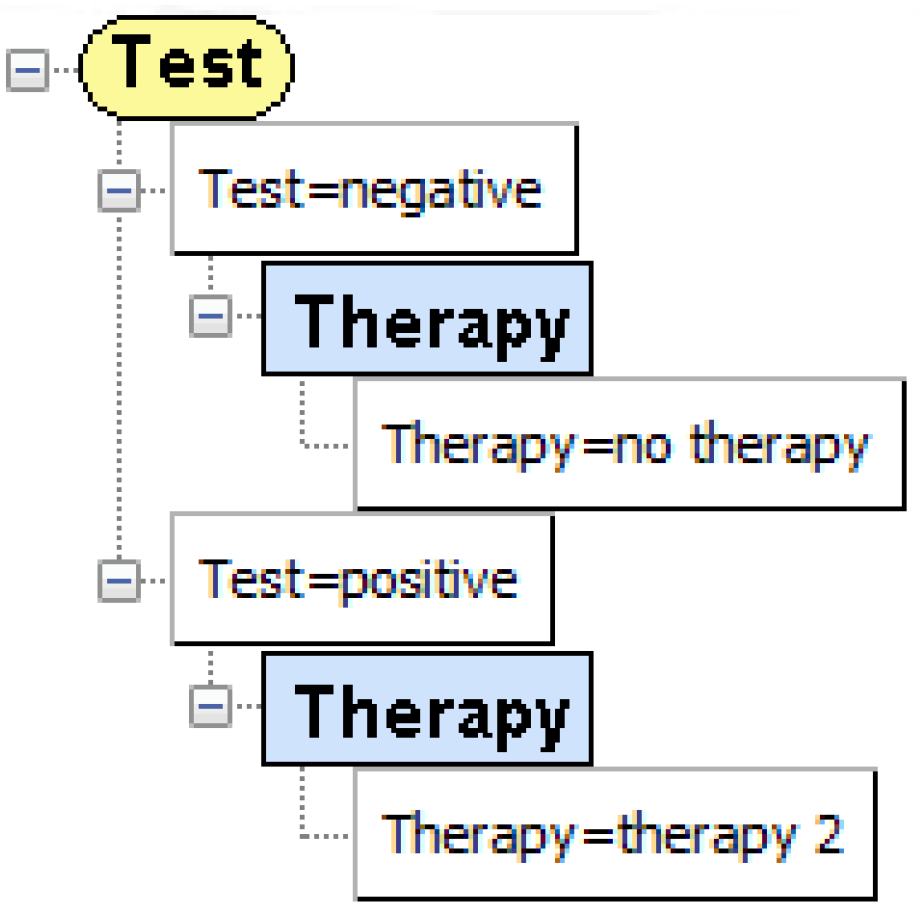
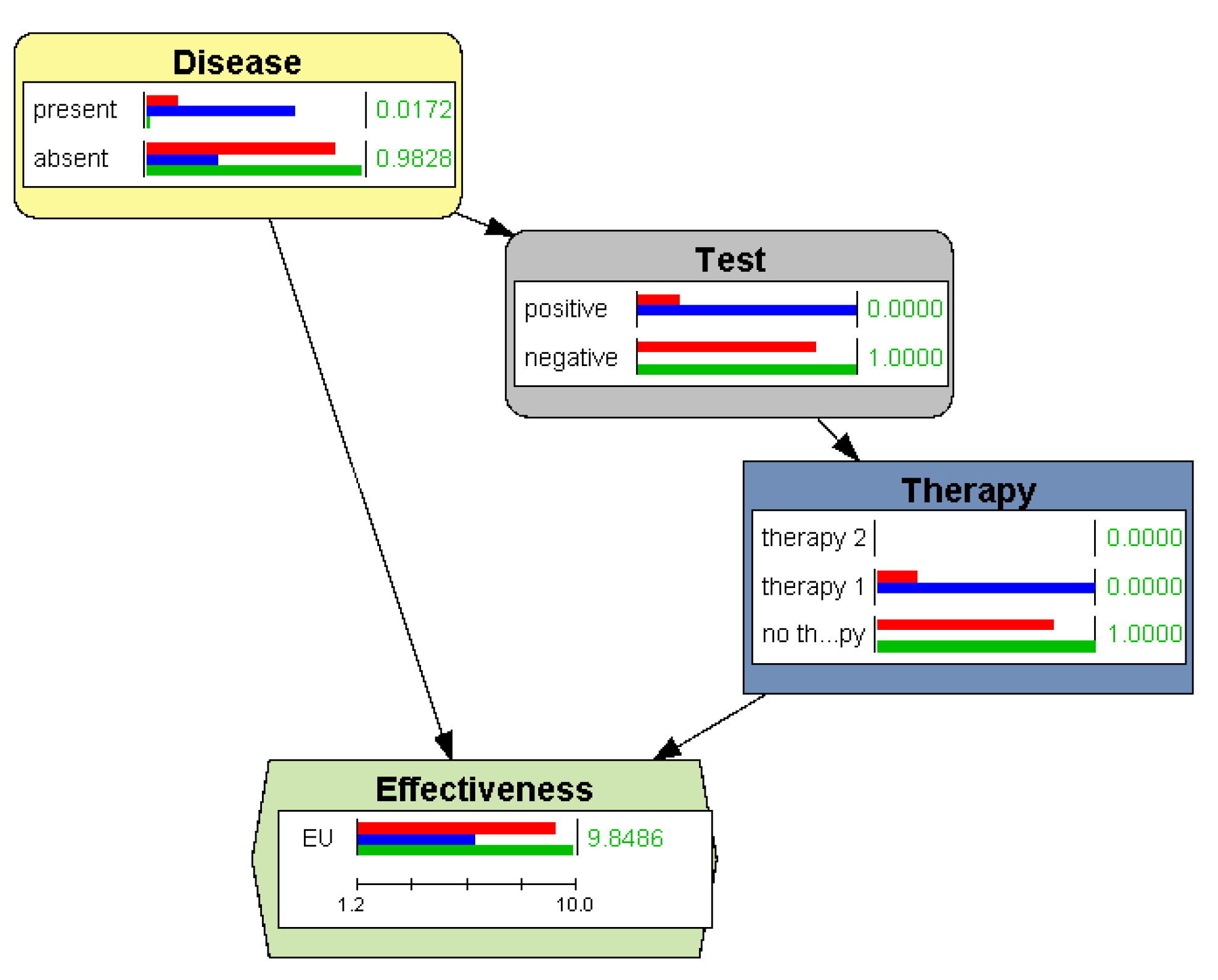
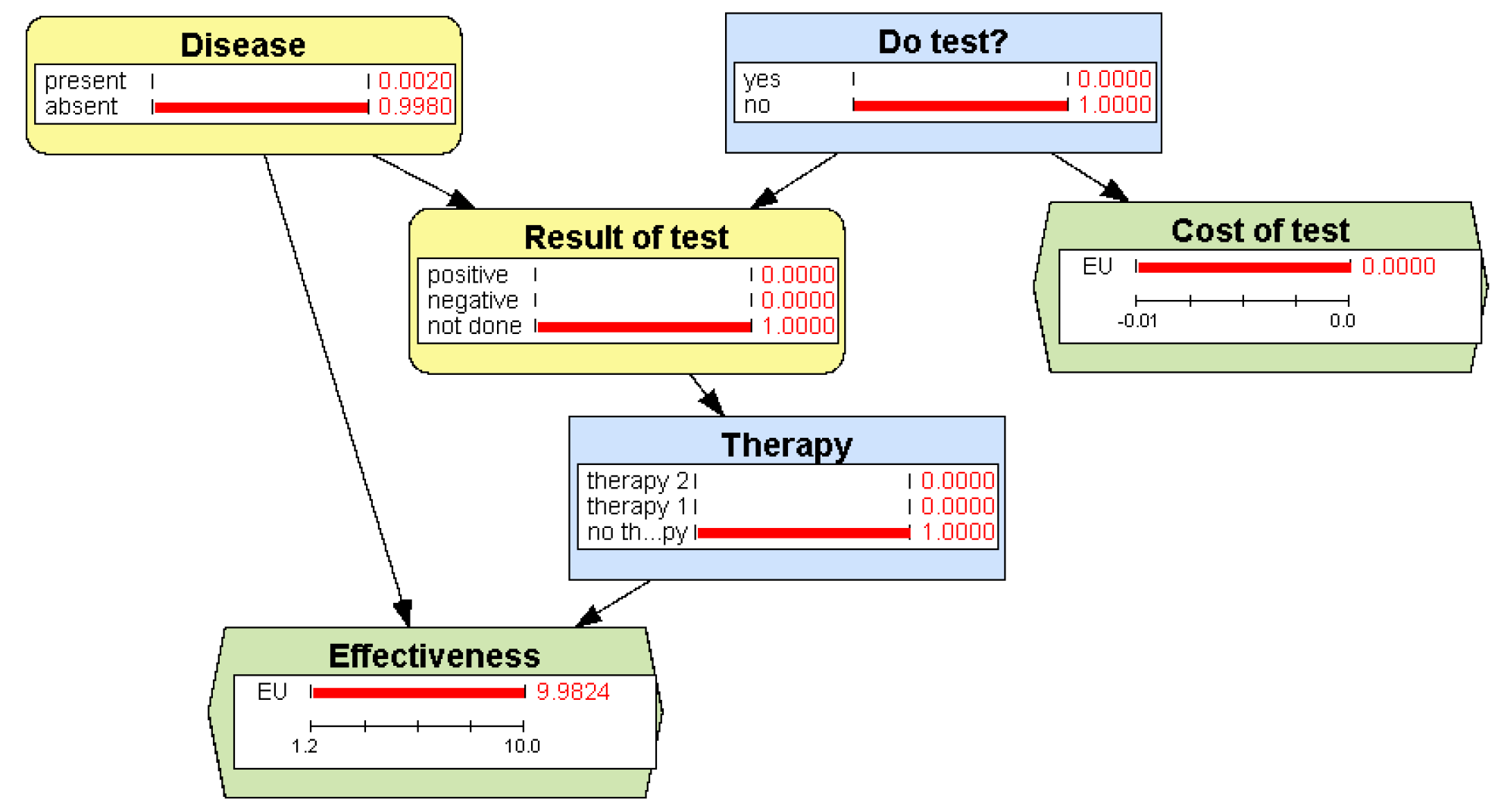
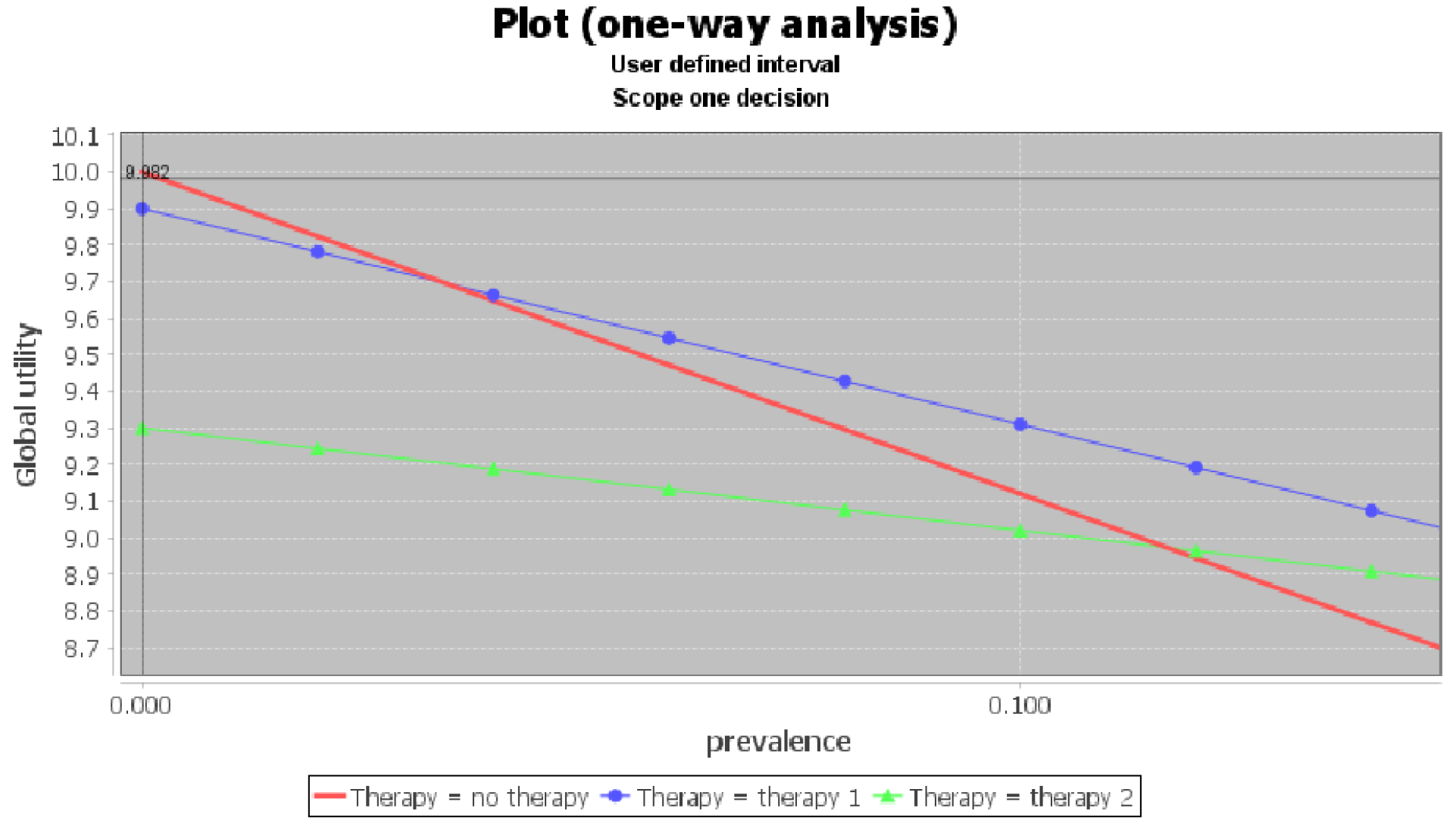
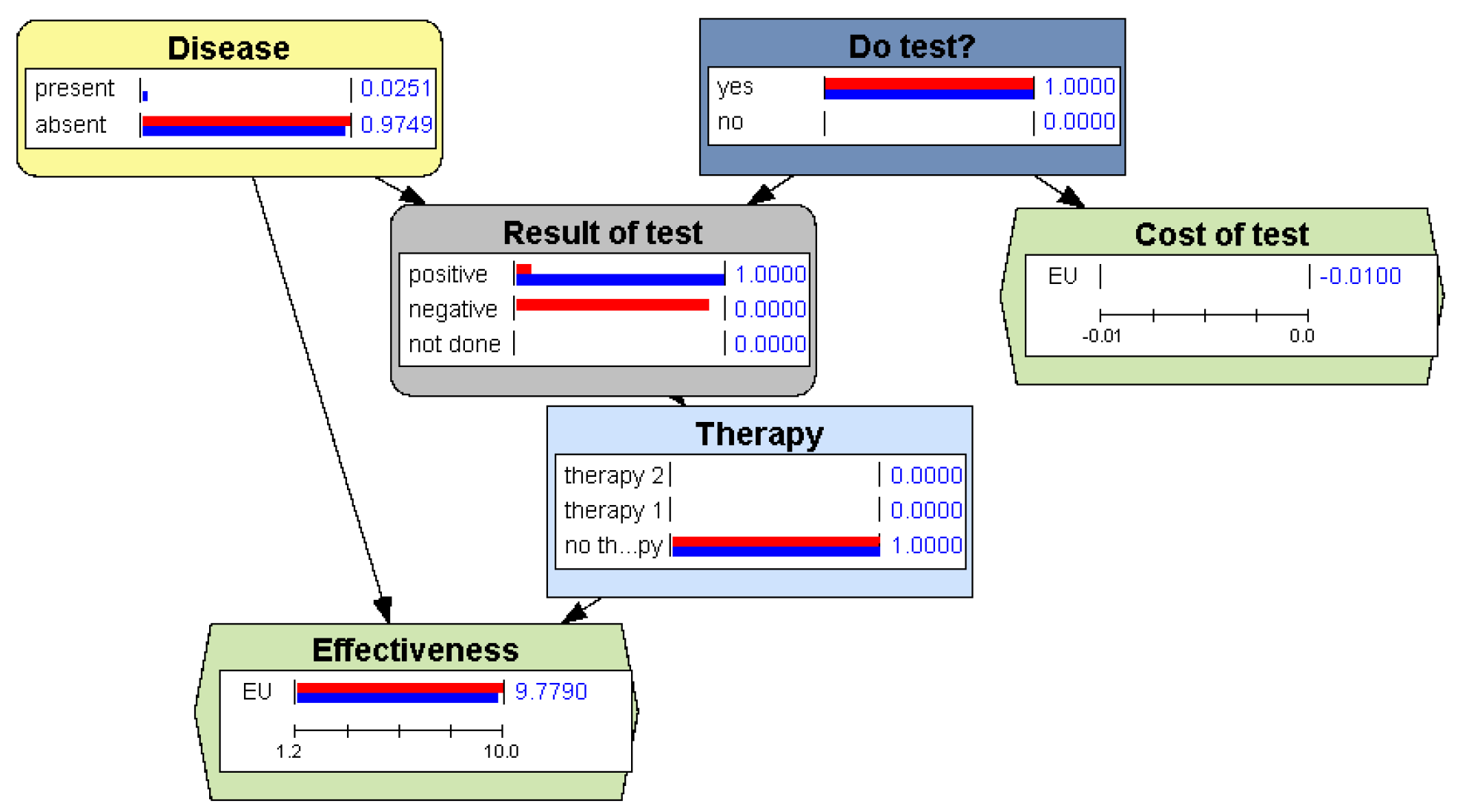
4.2.3. Example: Justifying a Policy
5. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| BN | Bayesian network |
| CPT | Conditional probability table |
| DT | Decision tree |
| GUI | Graphical user interface |
| ID | Influence diagram |
| MEU | Maximum expected utility |
| PGM | Probabilistic graphical model |
References
- Pearl, J. Fusion, propagation and structuring in belief networks. Artif. Intell. 1986, 29, 241–288. [Google Scholar] [CrossRef]
- Howard, R.A.; Matheson, J.E. Influence diagrams. In Readings on the Principles and Applications of Decision Analysis; Howard, R.A., Matheson, J.E., Eds.; Strategic Decisions Group: Menlo Park, CA, USA, 1984; pp. 719–762. [Google Scholar]
- Howard, R.A.; Matheson, J.E. Influence diagrams. Decis. Anal. 2005, 2, 127–143. [Google Scholar] [CrossRef]
- Pearl, J. Probabilistic Reasoning in Intelligent Systems: Networks of Plausible Inference; Morgan Kaufmann: San Mateo, CA, USA, 1988. [Google Scholar]
- Koller, D.; Friedman, N. Probabilistic Graphical Models: Principles and Techniques; The MIT Press: Cambridge, MA, USA, 2009. [Google Scholar]
- Sucar, L.E. Probabilistic Graphical Models. Principles and Applications; Springer: London, UK, 2015. [Google Scholar]
- Díez, F.J.; París, I.; Pérez-Martín, J.; Arias, M. Teaching Bayesian networks with OpenMarkov. In Proceedings of the Ninth European Workshop on Probabilistic Graphical Models (PGM’18), Prague, Czech Republic, 11–14 September 2018. [Google Scholar]
- Neapolitan, R.E. Probabilistic Reasoning in Expert Systems: Theory and Algorithms; Wiley-Interscience: New York, NY, USA, 1990. [Google Scholar]
- Luque, M.; Díez, F.J. Variable elimination for influence diagrams with super-value nodes. Int. J. Approx. Reason. 2010, 51, 615–631. [Google Scholar] [CrossRef]
- Nielsen, T.D.; Jensen, F.V. Welldefined decision scenarios. In Proceedings of the Fifteenth Conference on Uncertainty in Artificial Intelligence (UAI’99), Stockholm, Sweden, 30 July–1 August 1999; Laskey, K., Prade, H., Eds.; Morgan Kaufmann: San Francisco, CA, USA, 1999; pp. 502–511. [Google Scholar]
- Cowell, R.G.; Dawid, A.P.; Lauritzen, S.L.; Spiegelhalter, D.J. Probabilistic Networks and Expert Systems; Springer: New York, NY, USA, 1999. [Google Scholar]
- Olmsted, S.M. On Representing and Solving Decision Problems. Ph.D. Thesis, Dept. Engineering-Economic Systems, Stanford University, Stanford, CA, USA, 1983. [Google Scholar]
- Shachter, R.D. Evaluating influence diagrams. Oper. Res. 1986, 34, 871–882. [Google Scholar] [CrossRef]
- Díez, F.J.; Yebra, M.; Bermejo, I.; Palacios-Alonso, M.A.; Arias, M.; Luque, M.; Pérez-Martín, J. Markov influence diagrams: A graphical tool for cost-effectiveness analysis. Med. Decis. Mak. 2017, 37, 183–195. [Google Scholar] [CrossRef] [PubMed]
- Díez, F.J.; Luque, M.; Bermejo, I. Decision analysis networks. Int. J. Approx. Reason. 2018, 96, 1–17. [Google Scholar] [CrossRef]
- Lauritzen, S.L.; Nilsson, D. Representing and solving decision problems with limited information. Manag. Sci. 2001, 47, 1235–1251. [Google Scholar] [CrossRef]
- Dean, T.; Kanazawa, K. A model for reasoning about persistence and causation. Comput. Intell. 1989, 5, 142–150. [Google Scholar] [CrossRef]
- Boutilier, C.; Dearden, R.; Goldszmidt, M. Stochastic dynamic programming with factored representations. Artif. Intell. 2000, 121, 49–107. [Google Scholar] [CrossRef]
- Boutilier, C.; Poole, D. Computing optimal policies for partially observable decision processes using compact representations. In Proceedings of the Thirteenth National Conference on Artificial Intelligence (AAAI’96), Portland, OR, USA, 4–8 August 1996; Clancey, W.J., Weld, D.S., Eds.; AAAI Press/MIT Press: Portland, OR, USA, 1996; pp. 1168–1175. [Google Scholar]
- Díez, F.J.; van Gerven, M.A.J. Dynamic LIMIDs. In Decision Theory Models for Applications in Artificial Intelligence: Concepts and Solutions; Sucar, L.E., Hoey, J., Morales, E., Eds.; IGI Global: Hershey, PA, USA, 2011; pp. 164–189. [Google Scholar]
- Elvira Consortium. Elvira: An environment for creating and using probabilistic graphical models. In Proceedings of the First European Workshop on Probabilistic Graphical Models (PGM’02). In In Proceedings of the First European Workshop on Probabilistic Graphical Models (PGM’02), Cuenca, Spain, 6–8 November 2002; pp. 1–11. [Google Scholar]
- Oliehoek, F.A.; Spaan, M.T.J.; Terwijn, B.; Robbel, P.; Messias, J.V. The MADP Toolbox: An open source library for planning and learning in (multi-)agent systems. J. Mach. Learn. Res. 2017, 18, 1–5. [Google Scholar]
- Lacave, C.; Oniśko, A.; Díez, F.J. Use of Elvira’s explanation facilities for debugging probabilistic expert systems. Knowl.-Based Syst. 2006, 19, 730–738. [Google Scholar] [CrossRef]
- Lacave, C.; Luque, M.; Díez, F.J. Explanation of Bayesian networks and influence diagrams in Elvira. IEEE Trans. Syst. Man Cybern.—Part B Cybern. 2007, 37, 952–965. [Google Scholar] [CrossRef] [PubMed]
- Teach, R.L.; Shortliffe, E.H. An analysis of physician’s attitudes. In Rule-Based Expert Systems: The MYCIN Experiments of the Stanford Heuristic Programming Project; Addison-Wesley: Reading, MA, USA, 1984; pp. 635–652. [Google Scholar]
- Díez, F.J.; Druzdzel, M.J. Canonical Probabilistic Models for Knowledge Engineering; Technical Report CISIAD-06-01; UNED: Madrid, Spain, 2006. [Google Scholar]
- Henrion, M. Propagation of uncertainty by logic sampling in Bayes’ networks. In Proceedings of the Uncertainty in Artificial Intelligence 4 (UAI’88), Minneapolis, MN, USA, 10–12 July 1988; Shachter, R.D., Levitt, T., Kanal, L.N., Lemmer, J.F., Eds.; Elsevier Science Publishers: Amsterdam, The Netherlands, 1988; pp. 149–164. [Google Scholar]
- Fung, R.; Chang, K.C. Weighing and integrating evidence for stochastic simulation in Bayesian networks. In Proceedings of the Uncertainty in Artificial Intelligence 6 (UAI’90), Cambridge, MA, USA, 27–29 July 1990; Bonissone, P., Henrion, M., Kanal, L.N., Lemmer, J.F., Eds.; Elsevier Science Publishers: Amsterdam, The Netherlands, 1990; pp. 209–219. [Google Scholar]
- Cooper, G.F.; Herskovits, E. A Bayesian method for the induction of probabilistic networks from data. Mach. Learn. 1992, 9, 309–347. [Google Scholar] [CrossRef]
- Spirtes, P.; Glymour, C. An algorithm for fast recovery of sparse causal graphs. Soc. Sci. Comput. Rev. 1991, 9, 62–72. [Google Scholar] [CrossRef]
- Bermejo, I.; Oliva, J.; Díez, F.J.; Arias, M. Interactive learning of Bayesian networks with OpenMarkov. In Proceedings of the Sixth European Workshop on Probabilistic Graphical Models (PGM’12), Granada, Spain, 19–21 September 2012; pp. 27–34. [Google Scholar]
- Luque, M.; Díez, F.J.; Disdier, C. Optimal sequence of tests for the mediastinal staging of non-small cell lung cancer. BMC Med. Inform. Decis. Mak. 2016, 16, 9. [Google Scholar] [CrossRef] [PubMed]
- León, D. A Probabilistic Graphical Model for Total Knee Arthroplasty. Master’s Thesis, Department Artificial Intelligence, UNED, Madrid, Spain, 2011. [Google Scholar]
- Jensen, F.V.; Nielsen, T.D. Bayesian Networks and Decision Graphs, 2nd ed.; Springer: New York, NY, USA, 2007. [Google Scholar]
- Luque, M.; Arias, M.; Díez, F.J. Synthesis of strategies in influence diagrams. In Proceedings of the Thirty-third Conference on Uncertainty in Artificial Intelligence (UAI’17), Sydney, Australia, 11–15 August 2017; AUAI Press: Corvallis, OR, USA, 2017; pp. 1–9. [Google Scholar]
- Felli, J.C.; Hazen, G.B. Sensitivity Analysis and the Expected Value of Perfect Information. Med. Decis. Mak. 1998, 18, 95–109. [Google Scholar] [CrossRef] [PubMed]
- Ezawa, K.J. Value of evidence on influence diagrams. In Proceedings of the Tenth Conference on Uncertainty in Artificial Intelligence (UAI’94), Seattle, WA, USA, 29–31 July 1994; de Mántaras, R.L., Poole, D., Eds.; Morgan Kaufmann: San Francisco, CA, USA, 1994; pp. 212–220. [Google Scholar]
- Díez, F.J.; Galán, S.F. Efficient computation for the noisy MAX. Int. J. Intell. Syst. 2003, 18, 165–177. [Google Scholar] [CrossRef]
- Arias, M.; Díez, F.J. Cost-effectiveness analysis with influence diagrams. Methods Inf. Med. 2015, 54, 353–358. [Google Scholar] [CrossRef] [PubMed]
- Díez, F.J.; Luque, M.; Arias, M.; Pérez-Martín, J. Cost-effectiveness analysis with unordered decisions. Artif. Intell. Med. 2021, 117, 102064. [Google Scholar] [CrossRef] [PubMed]
- Li, L.; Ramadan, O.; Schmidt, P. Improving visual cues for the interactive learning of Bayesian networks. UC Berkeley. Available online: http://vis.berkeley.edu/courses/cs294-10-fa14/wiki/images/0/0a/Li_Ramadan_Schmidt_Paper.pdf (accessed on 20 September 2022).














Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Díez, F.J.; Arias, M.; Pérez-Martín, J.; Luque, M. Teaching Probabilistic Graphical Models with OpenMarkov. Mathematics 2022, 10, 3577. https://doi.org/10.3390/math10193577
Díez FJ, Arias M, Pérez-Martín J, Luque M. Teaching Probabilistic Graphical Models with OpenMarkov. Mathematics. 2022; 10(19):3577. https://doi.org/10.3390/math10193577
Chicago/Turabian StyleDíez, Francisco Javier, Manuel Arias, Jorge Pérez-Martín, and Manuel Luque. 2022. "Teaching Probabilistic Graphical Models with OpenMarkov" Mathematics 10, no. 19: 3577. https://doi.org/10.3390/math10193577
APA StyleDíez, F. J., Arias, M., Pérez-Martín, J., & Luque, M. (2022). Teaching Probabilistic Graphical Models with OpenMarkov. Mathematics, 10(19), 3577. https://doi.org/10.3390/math10193577