


High-Cardinality Categorical Attributes and Credit Card Fraud Detection
 ,
,  ,
,
Abstract
:1. Introduction
2. Fraud Detection System of a Major Brazilian Financial Institution
3. High-Cardinality Categorical Attributes
3.1. Numeric Encoding
3.2. Grouping
4. Materials and Methods
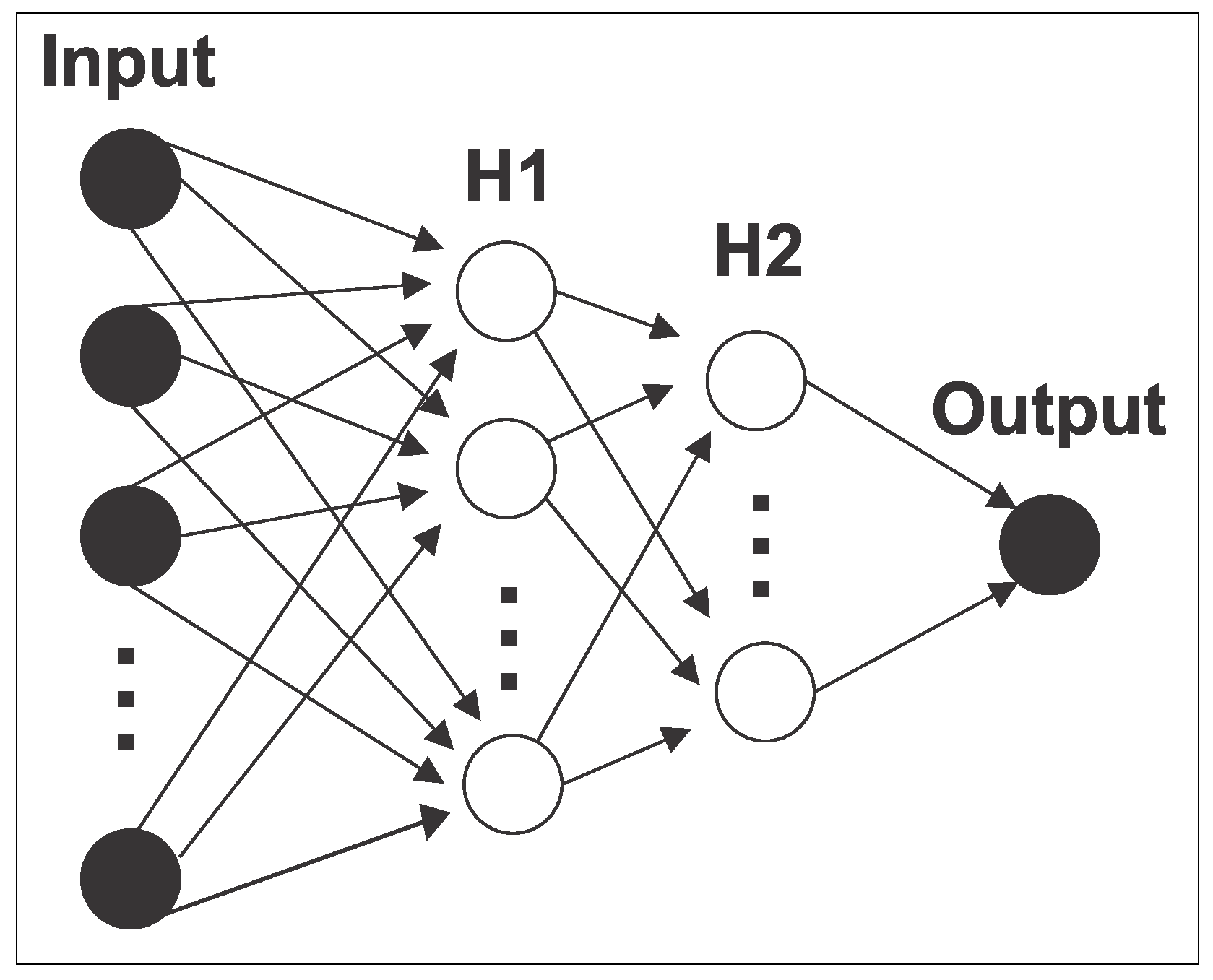
4.1. Techniques
4.2. The Proposed Algorithm of Value Clustering for Categorical Attributes
| Algorithm 1: The VCCA algorithm |
 |
4.3. Metrics
5. Results and Discussion
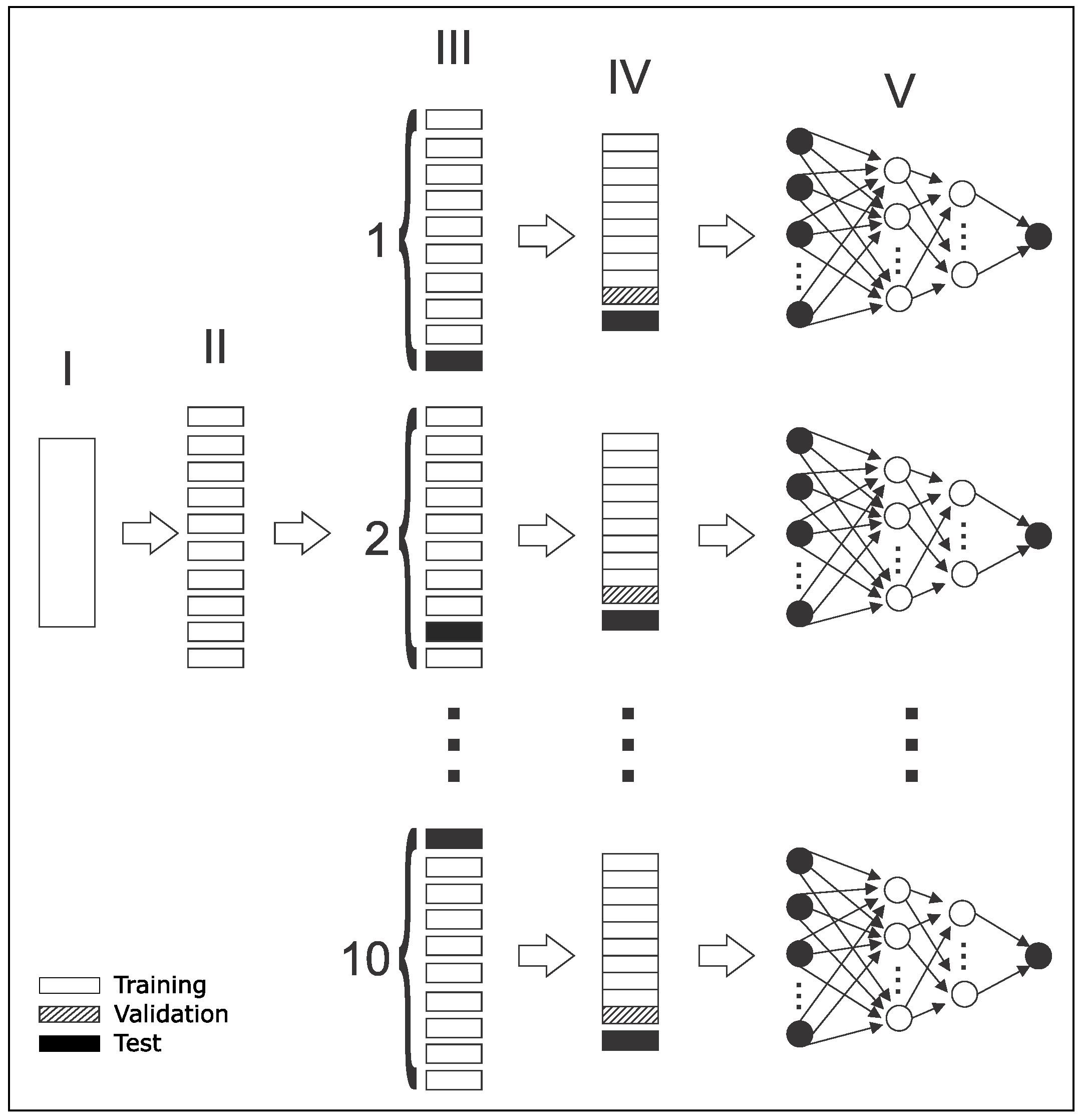
5.1. Experiments
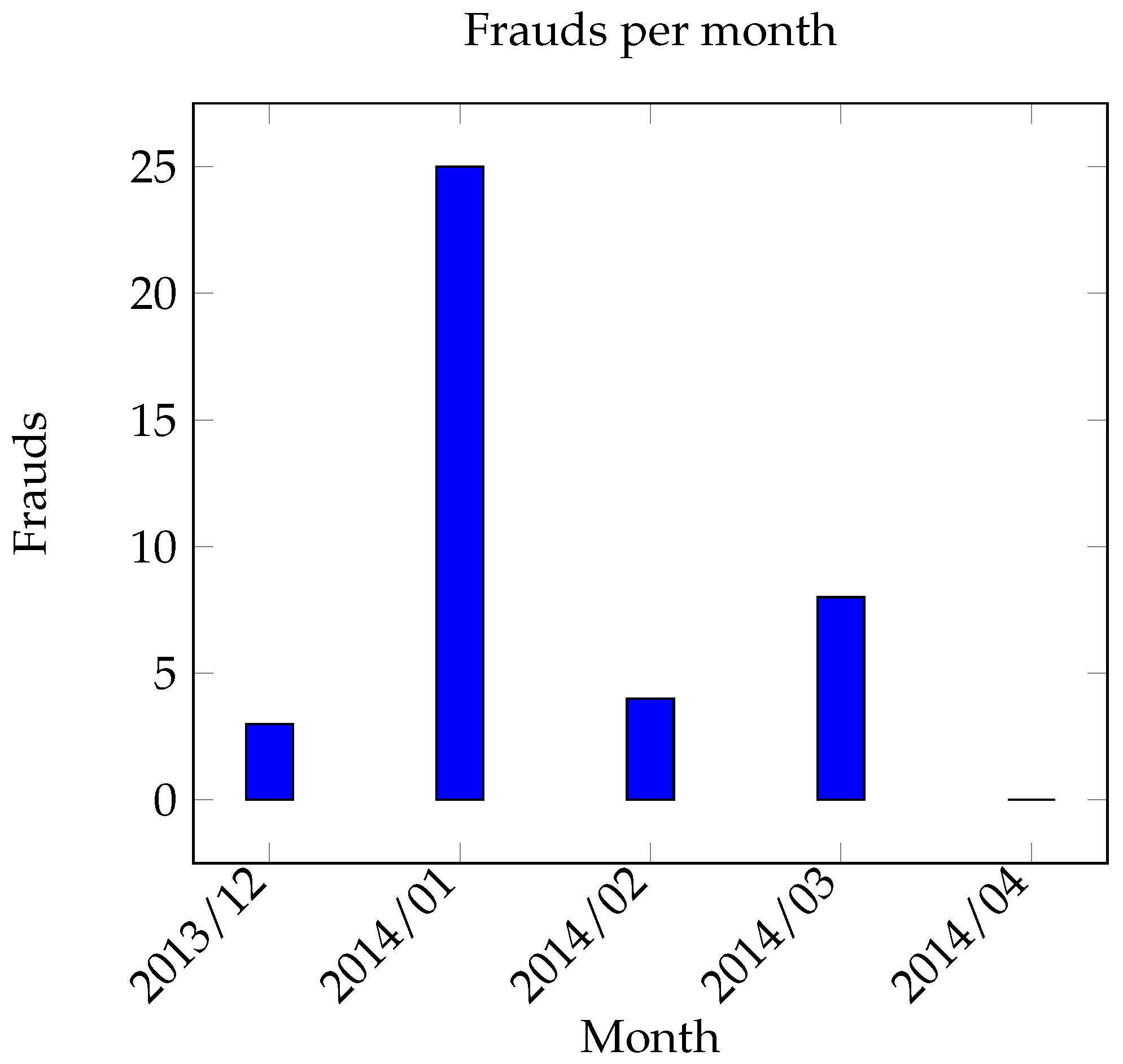
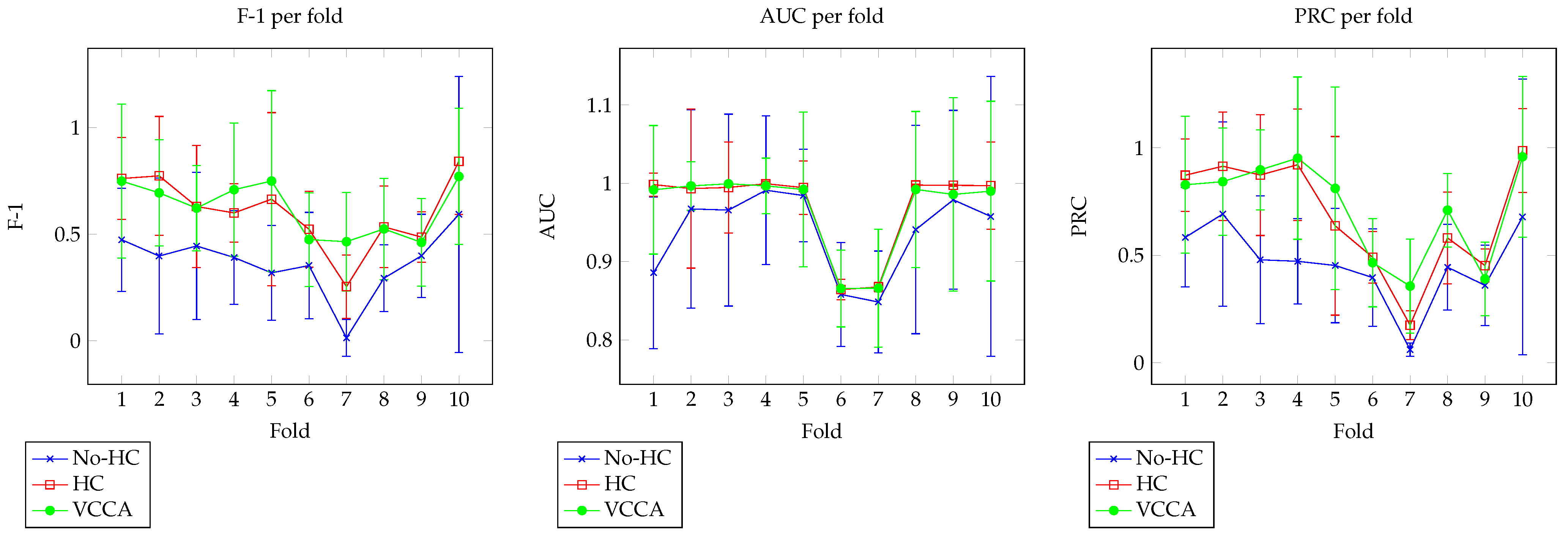
5.2. Dataset 1
Evaluation
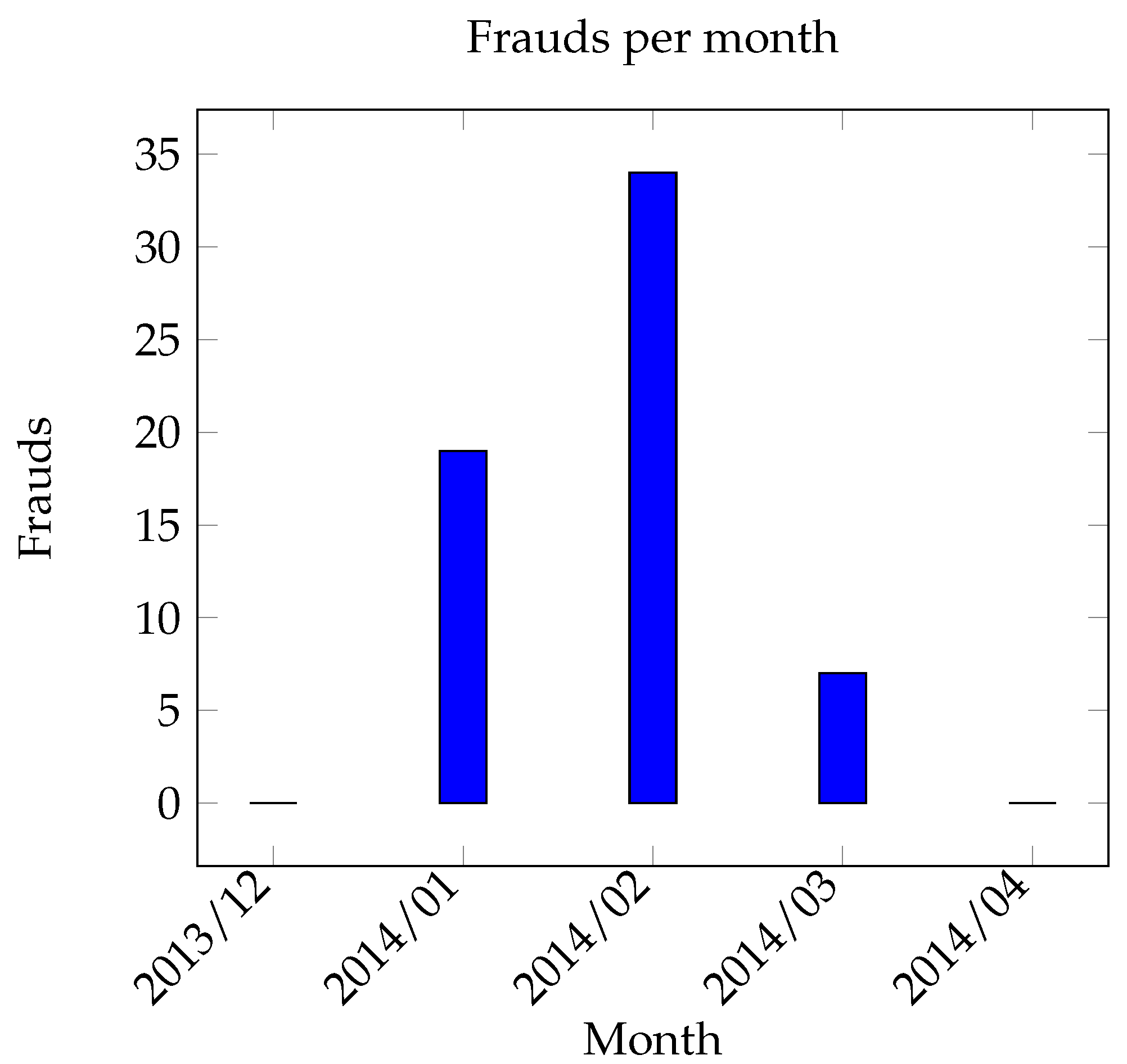
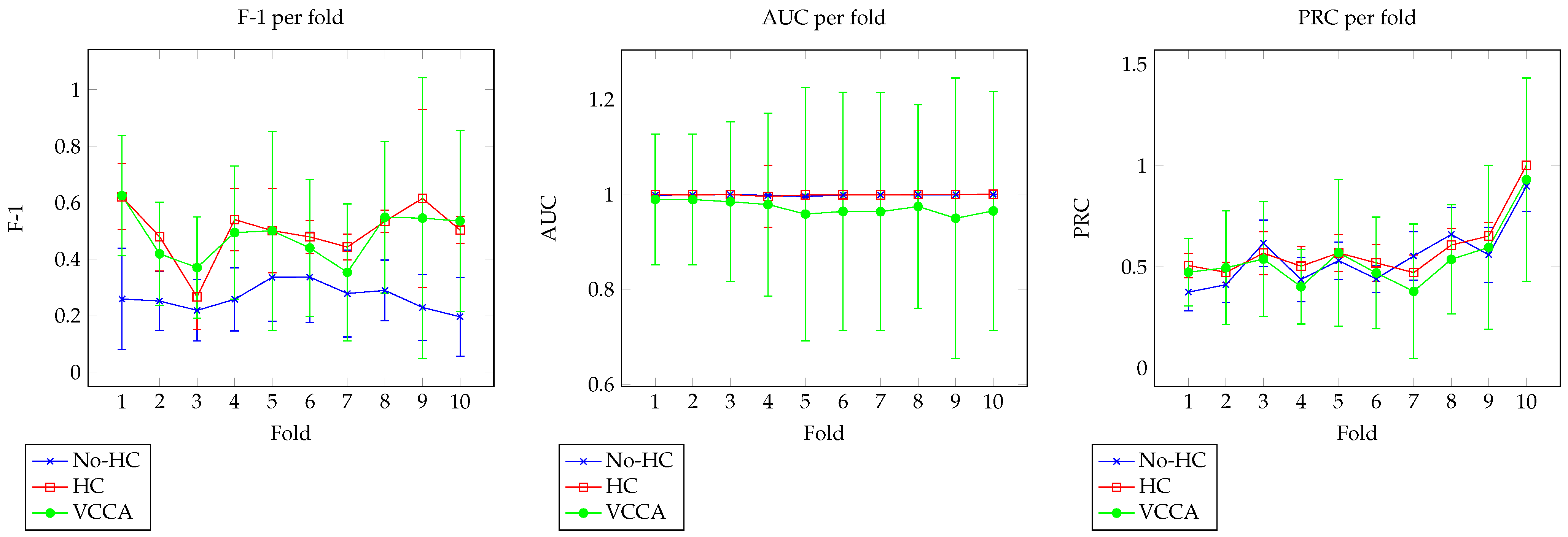
5.3. Dataset 2
Evaluation
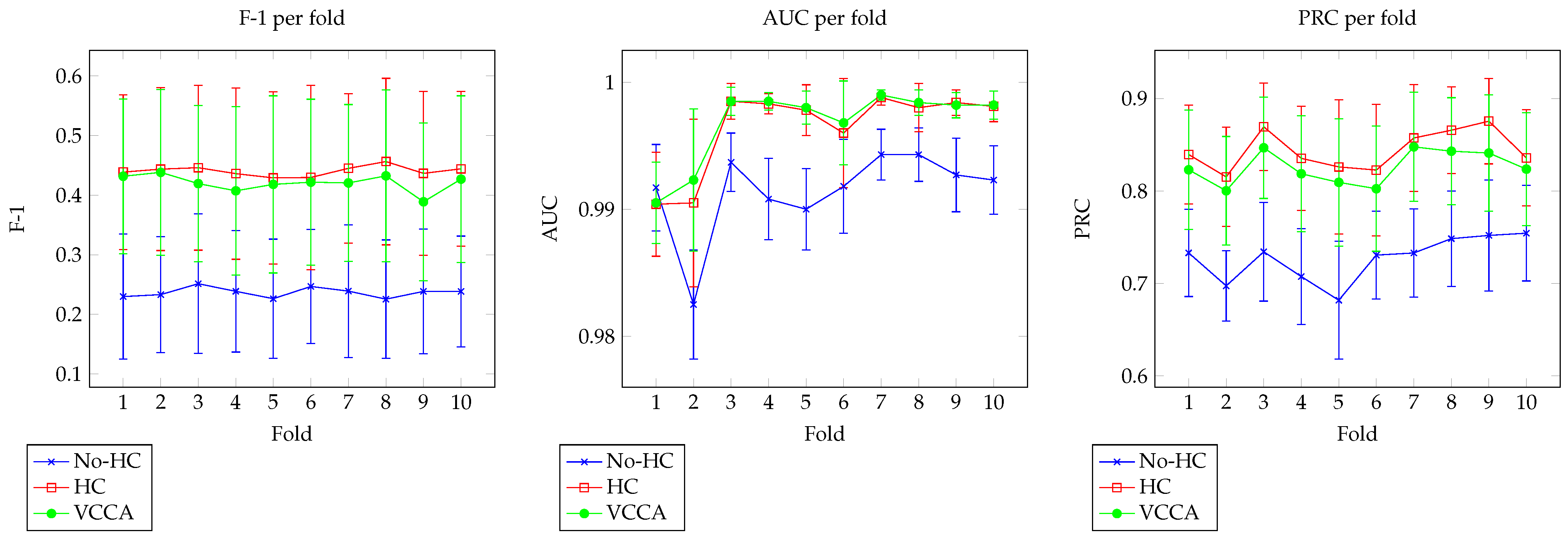
5.4. Dataset 3
Evaluation
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CNP | Card-Not-Present |
| ML | Machine Learning |
| MCC | Merchant Category Code |
| VCCA | Value Clustering for Categorical Attributes |
| PIN | Personal Identification Number |
| HC | High-Cardinality |
| CBM | Conjugate Bayesian Model |
| ANN | Artificial Neural Network |
| OFP | Optimal Family of Partitions |
| OSVP | Optimal Symbolic Value Partition |
| AVT | Attribute Value Taxonomy |
| NLP | Natural Language Processing |
| FFN | FeedForward Networks |
| MLP | MultiLayer Perceptron |
| ReLU | Rectified Linear Activation Function |
| IG | Information Gain |
| TPR | True Positive Rate |
| ROC | Receiver Operating Characteristic |
| FPR | False Positive Rate |
| AUC | Area Under the ROC Curve |
| PRC | Area Under the Precision-Recall Curve |
| ZIP | Zone Information Postal |
| NDA | Non-Disclosure Agreement |
References
- Jurgovsky, J.; Granitzer, M.; Ziegler, K.; Calabretto, S.; Portier, P.E.; He-Guelton, L.; Caelen, O. Sequence classification for credit-card fraud detection. Expert Syst. Appl. 2018, 100, 234–245. [Google Scholar] [CrossRef]
- HSN Consultants, Inc. Card Fraud Losses Reach $22.80 Billion; Technical Report 1118; The Nilson Report: Oxnard, CA, USA, 2017; Available online: https://nilsonreport.com/publication_newsletter_archive_issue.php?issue=1118 (accessed on 4 July 2022).
- Knieff, B. 2016 Global Consumer Card Fraud: Where Card Fraud Is Coming From; Technical Report; Aite Group LLC: Boston, MA, USA, 2016; Available online: https://aite-novarica.com/report/2016-global-consumer-card-fraud-where-card-fraud-coming (accessed on 4 July 2022).
- Sohony, I.; Pratap, R.; Nambiar, U. Ensemble Learning for Credit Card Fraud Detection. In Proceedings of the ACM India Joint International Conference on Data Science and Management of Data (CoDS-COMAD ’18), Goa, India, 11–13 January 2018; ACM: New York, NY, USA, 2018; pp. 289–294. [Google Scholar] [CrossRef]
- Gadi, M.F.A.; Wang, X.; do Lago, A.P. Credit Card Fraud Detection with Artificial Immune System. In Proceedings of the Artificial Immune Systems, Phuket, Thailand, 10–13 August 2008; Bentley, P.J., Lee, D., Jung, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; pp. 119–131. [Google Scholar]
- Singh, R.; Rani, R. Comparative Evaluation of Predictive Modeling Techniques on Credit Card Data. Int. J. Comput. Theory Eng. 2011, 598–603. [Google Scholar] [CrossRef]
- Ngai, E.W.T.; Hu, Y.; Wong, Y.H.; Chen, Y.; Sun, X. The Application of Data Mining Techniques in Financial Fraud Detection: A Classification Framework and an Academic Review of Literature. Decis. Support Syst. 2011, 50, 559–569. [Google Scholar] [CrossRef]
- Pozzolo, A.D.; Caelen, O.; Borgne, Y.A.L.; Waterschoot, S.; Bontempi, G. Learned lessons in credit card fraud detection from a practitioner perspective. Expert Syst. Appl. 2014, 41, 4915–4928. [Google Scholar] [CrossRef]
- Fadaei Noghani, F.; Moattar, M. Ensemble Classification and Extended Feature Selection for Credit Card Fraud Detection. J. AI Data Min. 2017, 5, 235–243. [Google Scholar] [CrossRef]
- Vlasselaer, V.V.; Bravo, C.; Caelen, O.; Eliassi-Rad, T.; Akoglu, L.; Snoeck, M.; Baesens, B. APATE: A novel approach for automated credit card transaction fraud detection using network-based extensions. Decis. Support Syst. 2015, 75, 38–48. [Google Scholar] [CrossRef] [Green Version]
- Bahnsen, A.C.; Aouada, D.; Stojanovic, A.; Ottersten, B. Feature engineering strategies for credit card fraud detection. Expert Syst. Appl. 2016, 51, 134–142. [Google Scholar] [CrossRef]
- Wang, C.; Han, D. Credit card fraud forecasting model based on clustering analysis and integrated support vector machine. Clust. Comput. 2018. [Google Scholar] [CrossRef]
- Somasundaram, A.; Reddy, S. Parallel and incremental credit card fraud detection model to handle concept drift and data imbalance. Neural Comput. Appl. 2018. [Google Scholar] [CrossRef]
- Mahmoudi, N.; Duman, E. Detecting credit card fraud by Modified Fisher Discriminant Analysis. Expert Syst. Appl. 2015, 42, 2510–2516. [Google Scholar] [CrossRef]
- Zareapoor, M.; Shamsolmoali, P. Application of Credit Card Fraud Detection: Based on Bagging Ensemble Classifier. Procedia Comput. Sci. 2015, 48, 679–685. [Google Scholar] [CrossRef] [Green Version]
- Bekirev, A.S.; Klimov, V.V.; Kuzin, M.V.; Shchukin, B.A. Payment card fraud detection using neural network committee and clustering. Opt. Mem. Neural Netw. 2015, 24, 193–200. [Google Scholar] [CrossRef]
- Juszczak, P.; Adams, N.M.; Hand, D.J.; Whitrow, C.; Weston, D.J. Off-the-peg and bespoke classifiers for fraud detection. Comput. Stat. Data Anal. 2008, 52, 4521–4532. [Google Scholar] [CrossRef]
- Moeyersoms, J.; Martens, D. Including high-cardinality attributes in predictive models: A case study in churn prediction in the energy sector. Decis. Support Syst. 2015, 72, 72–81. [Google Scholar] [CrossRef]
- Perlich, C.; Provost, F. Distribution-based aggregation for relational learning with identifier attributes. Mach. Learn. 2006, 62, 65–105. [Google Scholar] [CrossRef]
- Muto, Y.; Kudo, M.; Murai, T. Reduction of Attribute Values for Kansei Representation. JACIII 2006, 10, 666–672. [Google Scholar] [CrossRef]
- Min, F.; Liu, Q.; Fang, C.; Zhang, J. Reduction Based Symbolic Value Partition. In Proceedings of the Advances in Hybrid Information Technology, First International Conference, ICHIT 2006, Jeju Island, Korea, 9–11 November 2006; pp. 20–30. [Google Scholar] [CrossRef]
- Boullé, M. A robust method for partitioning the values of categorical attributes. In Proceedings of the Extraction et gestion des connaissances (EGC’2004), Clermont Ferrand, France, 20–23 January 2004; pp. 173–184. [Google Scholar]
- Micci-Barreca, D. A Preprocessing Scheme for High-Cardinality Categorical Attributes in Classification and Prediction Problems. SIGKDD Explor. Newsl. 2001, 3, 27–32. [Google Scholar] [CrossRef]
- Mougan, C.; Masip, D.; Nin, J.; Pujol, O. Quantile Encoder: Tackling High Cardinality Categorical Features in Regression Problems. In Proceedings of the Modeling Decisions for Artificial Intelligence: 18th International Conference, MDAI 2021, Umeå, Sweden, 27–30 September 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 168–180. [Google Scholar] [CrossRef]
- Slakey, A.; Salas, D.; Schamroth, Y. Encoding Categorical Variables with Conjugate Bayesian Models for WeWork Lead Scoring Engine. arXiv 2019, arXiv:1904.13001. [Google Scholar]
- Guo, C.; Berkhahn, F. Entity Embeddings of Categorical Variables. arXiv 2016, arXiv:1604.06737. [Google Scholar]
- Dahouda, M.K.; Joe, I. A Deep-Learned Embedding Technique for Categorical Features Encoding. IEEE Access 2021, 9, 114381–114391. [Google Scholar] [CrossRef]
- Arat, M.M. Learning From High-Cardinality Categorical Features in Deep Neural Networks. J. Adv. Res. Nat. Appl. Sci. 2022, 8, 222–236. [Google Scholar] [CrossRef]
- Nguyen, H.S. Discretization of Real Value Attributes, Boolean Reasoning Approach. Ph.D. Thesis, Warsaw University, Warsaw, Poland, 1997. [Google Scholar]
- Nguyen, S.H. Regularity Analysis and Its Applications in Data Mining. Ph.D. Thesis, Warsaw University, Warsaw, Poland, 1999. [Google Scholar]
- Min, F.; Liu, Q.; Fang, C. Rough sets approach to symbolic value partition. Int. J. Approx. Reason. 2008, 49, 689–700. [Google Scholar] [CrossRef] [Green Version]
- Ye, M.; Wu, X.; Hu, X.; Hu, D. Knowledge reduction for decision tables with attribute value taxonomies. Knowl.-Based Syst. 2014, 56, 68–78. [Google Scholar] [CrossRef]
- Wen, L.; Min, F. A Granular Computing Approach to Symbolic Value Partitioning. Fundam. Inform. 2015, 142, 337–371. [Google Scholar] [CrossRef]
- Cerda, P.; Varoquaux, G.; Kégl, B. Similarity Encoding for learning with dirty categorical variables. Mach. Learn. 2018, 107, 1477–1494. [Google Scholar] [CrossRef] [Green Version]
- Cerda, P.; Varoquaux, G. Encoding High-Cardinality String Categorical Variables. IEEE Trans. Knowl. Data Eng. 2022, 34, 1164–1176. [Google Scholar] [CrossRef]
- Weinberger, K.Q.; Dasgupta, A.; Attenberg, J.; Langford, J.; Smola, A.J. Feature Hashing for Large Scale Multitask Learning. In Proceedings of the 26th Annual International Conference on Machine Learning (ICML ’09), Montreal, QC, Canada, 14–18 June 2009; Association for Computing Machinery: New York, NY, USA; pp. 1113–1120. [Google Scholar] [CrossRef] [Green Version]
- Carneiro, E.M.; Dias, L.A.V.; Cunha, A.M.; Mialaret, L.F.S. Cluster Analysis and Artificial Neural Networks A Case Study in Credit Card Fraud Detection. In Proceedings of the 12th International Conference on Information Technology–New Generations, Las Vegas, NV, USA, 13–15 April 2015. [Google Scholar] [CrossRef]
- Hornik, K.; Stinchcombe, M.; White, H. Multilayer feedforward networks are universal approximators. Neural Netw. 1989, 2, 359–366. [Google Scholar] [CrossRef]
- Cybenko, G. Approximation by superpositions of a sigmoidal function. Math. Control. Signals Syst. (MCSS) 1989, 2, 303–314. [Google Scholar] [CrossRef]
- Haykin, S. Neural Networks: A Comprehensive Foundation, 2nd ed.; Prentice Hall: Englewood Cliffs, NJ, USA, 1998. [Google Scholar]
- Adewumi, A.O.; Akinyelu, A.A. A survey of machine-learning and nature-inspired based credit card fraud detection techniques. Int. J. Syst. Assur. Eng. Manag. 2017, 8, 937–953. [Google Scholar] [CrossRef]
- Al-Hashedi, K.G.; Magalingam, P. Financial fraud detection applying data mining techniques: A comprehensive review from 2009 to 2019. Comput. Sci. Rev. 2021, 40, 100402. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; Adaptive Computation and Machine Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Chollet, F. Keras. 2015. Available online: https://keras.io (accessed on 4 July 2022).
- Jarrett, K.; Kavukcuoglu, K.; Ranzato, M.; Lecun, Y. What is the Best Multi-Stage Architecture for Object Recognition? In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 27 September–4 October 2009; Volume 12. [Google Scholar] [CrossRef] [Green Version]
- Tikhonov, A.N.; Arsenin, V.Y. Solutions of Ill-Posed Problems; John, F., Translator; Scripta Series in Mathematics; V. H. Winston & Sons: Washington, DC, USA; John Wiley & Sons: New York, NY, USA, 1977; p. xiii+258. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Scripter, M.W. Nested-Means map classes for statistical maps. Ann. Assoc. Am. Geogr. 1970, 60, 385–392. [Google Scholar] [CrossRef]
- Lichman, M. [dataset] UCI Machine Learning Repository. 2013. Available online: https://archive.ics.uci.edu/ml/datasets/mushroom (accessed on 14 July 2022).
- Davis, J.; Goadrich, M. The relationship between Precision-Recall and ROC curves. In Proceedings of the ICML ’06: Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; ACM: New York, NY, USA, 2006; pp. 233–240. [Google Scholar] [CrossRef]
- Shenoy, K.; Brandon, H. [dataset] Credit Card Transactions Fraud Detection Dataset. 2020. Available online: https://www.kaggle.com/kartik2112/fraud-detection (accessed on 14 July 2022).
- Demšar, J. Statistical comparisons of classifiers over multiple data sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]
- Flexer, A. Statistical Evaluation of Neural Network Experiments: Minimum Requirements and Current Practice. In Proceedings of the 13th European Meeting on Cybernetics and Systems Research, Vienna, Austria, 9–12 April 1996; Volume 2. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations (ICLR 2015), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Tieleman, T.; Hinton, G. Lecture 6.5-Rmsprop: Divide the Gradient by a Running Average of Its Recent Magnitude. 2012. Available online: https://www.cs.toronto.edu/~tijmen/csc321/slides/lecture_slides_lec6.pdf (accessed on 14 July 2022).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Step | Expected Complexity |
|---|---|
| 1 | |
| 1.1 | |
| 2 | |
| 2.1 | |
| 2.2 | |
| 2.3 | |
| 2.3 | |
| 2.5 | |
| 2.5.1 | |
| 2.5.2 | |
| 2.5.3 |
| Name | Description | Type | Origin |
|---|---|---|---|
| gender | Card holder gender | Categorical | Dataset |
| age | Card holder age | Numerical | Calculated |
| job | Card holder job | Categorical | Dataset |
| city | Card holder city | Categorical | Dataset |
| city_pop | Card holder city population | Numerical | Dataset |
| state | Card holder state | Categorical | Dataset |
| lat | Card holder latitude | Numerical | Dataset |
| lon | Card holder longitude | Numerical | Dataset |
| category | Merchant category | Categorical | Dataset |
| merch_lat | Merchant latitude | Numerical | Dataset |
| merch_lon | Merchant longitude | Numerical | Dataset |
| amt | Transaction amount | Numerical | Dataset |
| trans_hour | Transaction hour | Numerical | Calculated |
| day_of_week | Transaction day of week | Categorical | Calculated |
| month | Transaction month | Numerical | Calculated |
| is_fraud | Transaction fraud flag | Categorical | Dataset |
| Attribute | ||||
|---|---|---|---|---|
| c | 587 | 0.020087454009060313 | 9 | 0.020087454009060313 |
| d | 199 | 0.01038105195206505 | 9 | 0.01038105195206505 |
| e | 20 | 0.005017041759478355 | 7 | 0.005017041759478355 |
| f | 2 | 0.0001723760259424098 | 2 | 0.0001723760259424098 |
| g | 13 | 0.013065745196519488 | 6 | 0.013065745196519488 |
| h | 18 | 0.010828126068959505 | 5 | 0.010828126068959505 |
| i | 185 | 0.012616077454649672 | 10 | 0.012616077454649668 |
| j | 4 | 0.0034157174977478555 | 4 | 0.0034157174977478555 |
| k | 428 | 0.018796128663501527 | 7 | 0.018796128663501527 |
| l | 25 | 0.003151780053255858 | 5 | 0.003151780053255858 |
| m | 1575 | 0.007888460862140696 | 4 | 0.007888460862140696 |
| o | 5 | 0.003897359833765539 | 4 | 0.003897359833765539 |
| p | 188 | 0.012821572812932829 | 11 | 0.012821572812932829 |
| q | 18 | 0.009203556840586557 | 5 | 0.00920355684058656 |
| r | 1578 | 0.007300173818738483 | 7 | 0.007300173818738483 |
| s | 26 | 0.0029986812882387 | 5 | 0.0029986812882387033 |
| t | 4 | 0.002688904270427419 | 4 | 0.002688904270427419 |
| No-HC | HC | VCCA | |
|---|---|---|---|
| First Hidden Layer Size | 64 | 32 | 64 |
| Second Hidden Layer Size | 16 | 32 | 8 |
| Optimizer | RMSProp | RMSProp | RMSProp |
| L2 Regularizer | 0.001 | 0.001 | 0.001 |
| Fold | F-1 | AUC | PRC | ||||||
|---|---|---|---|---|---|---|---|---|---|
| No-HC | HC | VCCA | No-HC | HC | VCCA | No-HC | HC | VCCA | |
| 1 | 0.4737 | 0.7607 | 0.7486 | 0.8858 | 0.9984 | 0.9917 | 0.5836 | 0.8724 | 0.8278 |
| 2 | 0.3973 | 0.7732 | 0.6936 | 0.9673 | 0.9933 | 0.9967 | 0.6919 | 0.9142 | 0.8425 |
| 3 | 0.4444 | 0.6295 | 0.6222 | 0.9658 | 0.9947 | 0.9994 | 0.479 | 0.8733 | 0.8974 |
| 4 | 0.3905 | 0.5994 | 0.7084 | 0.9912 | 0.9995 | 0.9967 | 0.4721 | 0.9214 | 0.9518 |
| 5 | 0.3184 | 0.6639 | 0.7489 | 0.9844 | 0.9945 | 0.9922 | 0.4526 | 0.637 | 0.8113 |
| 6 | 0.3526 | 0.523 | 0.4746 | 0.858 | 0.8642 | 0.8657 | 0.3964 | 0.4909 | 0.4658 |
| 7 | 0.0137 | 0.254 | 0.4646 | 0.8484 | 0.8676 | 0.8661 | 0.061 | 0.1754 | 0.3567 |
| 8 | 0.2935 | 0.534 | 0.5241 | 0.9409 | 0.9978 | 0.9922 | 0.4442 | 0.5807 | 0.7098 |
| 9 | 0.3982 | 0.4862 | 0.4614 | 0.9789 | 0.9974 | 0.9858 | 0.3601 | 0.4522 | 0.3901 |
| 10 | 0.5926 | 0.8416 | 0.7705 | 0.9577 | 0.9971 | 0.99 | 0.6779 | 0.9864 | 0.958 |
| Fold | F-1 | AUC | PRC | ||||||
|---|---|---|---|---|---|---|---|---|---|
| No-HC | HC | VCCA | No-HC | HC | VCCA | No-HC | HC | VCCA | |
| 1 | 0.0152 | 0.0096 | 0.0339 | 0.0025 | 0.0001 | 0.0018 | 0.0139 | 0.0074 | 0.0263 |
| 2 | 0.0347 | 0.0202 | 0.0161 | 0.0042 | 0.0027 | 0.0003 | 0.0478 | 0.0166 | 0.0163 |
| 3 | 0.031 | 0.0214 | 0.0104 | 0.0039 | 0.0009 | 0 | 0.0229 | 0.0206 | 0.009 |
| 4 | 0.0126 | 0.0048 | 0.0254 | 0.0023 | 0 | 0.0003 | 0.0102 | 0.0175 | 0.0371 |
| 5 | 0.0129 | 0.0428 | 0.0468 | 0.0009 | 0.0003 | 0.0025 | 0.0184 | 0.0449 | 0.0577 |
| 6 | 0.0162 | 0.0082 | 0.0126 | 0.0011 | 0 | 0.0006 | 0.0133 | 0.0038 | 0.011 |
| 7 | 0.002 | 0.0057 | 0.0139 | 0.0011 | 0 | 0.0015 | 0.0003 | 0.0012 | 0.0124 |
| 8 | 0.0064 | 0.0095 | 0.0147 | 0.0046 | 0 | 0.0026 | 0.0103 | 0.0118 | 0.0076 |
| 9 | 0.0099 | 0.0037 | 0.011 | 0.0034 | 0 | 0.004 | 0.0091 | 0.0015 | 0.0076 |
| 10 | 0.109 | 0.0161 | 0.0265 | 0.0083 | 0.0008 | 0.0034 | 0.107 | 0.0099 | 0.0363 |
| Fold | No-HC | HC | VCCA | VCCA (%) |
|---|---|---|---|---|
| 1 | 12.94 | 26.02 | 14.68 | 56.42 |
| 2 | 13.43 | 22.76 | 15.20 | 66.78 |
| 3 | 12.58 | 24.11 | 15.07 | 62.50 |
| 4 | 13.27 | 20.31 | 13.44 | 66.17 |
| 5 | 15.66 | 33.63 | 15.37 | 45.70 |
| 6 | 14.70 | 30.88 | 18.67 | 60.46 |
| 7 | 16.03 | 28.15 | 19.25 | 68.38 |
| 8 | 13.71 | 18.63 | 15.48 | 83.09 |
| 9 | 17.37 | 30.59 | 19.16 | 62.63 |
| 10 | 17.96 | 27.58 | 18.75 | 67.98 |
| Attribute | ||||
|---|---|---|---|---|
| a | 2 | 0.00019165172400172417 | 2 | 0.00019165172400172417 |
| b | 3 | 0.0005656457858254846 | 3 | 0.0005656457858254846 |
| c | 414 | 0.010965553523071556 | 6 | 0.010965553523071556 |
| d | 128 | 0.008359619642109994 | 6 | 0.008359619642109994 |
| e | 20 | 0.004630761867383492 | 4 | 0.004630761867383492 |
| f | 3 | 0.00028618741327195163 | 2 | 0.00028618741327195163 |
| g | 28 | 0.00395328094102812 | 3 | 0.00395328094102812 |
| h | 53 | 0.00625993642734945 | 5 | 0.006259936427349448 |
| i | 290 | 0.010018709402812331 | 9 | 0.010018709402812331 |
| j | 6 | 0.004324161191009918 | 3 | 0.004324161191009918 |
| k | 1295 | 0.010829713469237199 | 10 | 0.010829713469237199 |
| l | 26 | 0.004875998819042033 | 4 | 0.004875998819042033 |
| m | 3893 | 0.006676635146988344 | 6 | 0.006676635146988344 |
| n | 2 | 0.0000003671349237989452 | 2 | 0.0000003671349237989452 |
| o | 5 | 0.0005324192509037727 | 3 | 0.0005324192509037727 |
| p | 287 | 0.00850518645299473 | 13 | 0.00850518645299473 |
| q | 51 | 0.004936240899563283 | 5 | 0.004936240899563283 |
| r | 3844 | 0.006550636310641834 | 11 | 0.006550636310641832 |
| s | 27 | 0.004161004607392469 | 7 | 0.004161004607392469 |
| t | 7 | 0.0031338015517482255 | 4 | 0.0031338015517482255 |
| No-HC | HC | VCCA | |
|---|---|---|---|
| First Hidden Layer Size | 64 | 64 | 64 |
| Second Hidden Layer Size | 32 | 16 | 4 |
| Optimizer | RMSProp | adam | RMSProp |
| L2 Regularizer | 0.001 | 0.001 | 0.001 |
| Fold | F-1 | AUC | PRC | ||||||
|---|---|---|---|---|---|---|---|---|---|
| No-HC | HC | VCCA | No-HC | HC | VCCA | No-HC | HC | VCCA | |
| 1 | 0.2593 | 0.6212 | 0.6252 | 0.9981 | 0.9993 | 0.9892 | 0.3748 | 0.5059 | 0.473 |
| 2 | 0.2521 | 0.4798 | 0.4193 | 0.9987 | 0.9989 | 0.9889 | 0.4114 | 0.4724 | 0.4951 |
| 3 | 0.2191 | 0.2671 | 0.3705 | 0.9995 | 0.9994 | 0.9843 | 0.6161 | 0.5671 | 0.5381 |
| 4 | 0.2582 | 0.5402 | 0.4944 | 0.9977 | 0.9955 | 0.9785 | 0.4372 | 0.5029 | 0.401 |
| 5 | 0.3362 | 0.5012 | 0.5006 | 0.9954 | 0.9987 | 0.9583 | 0.53 | 0.5683 | 0.5691 |
| 6 | 0.3365 | 0.479 | 0.4398 | 0.9984 | 0.999 | 0.964 | 0.4404 | 0.5194 | 0.4698 |
| 7 | 0.2789 | 0.4431 | 0.3537 | 0.9989 | 0.9987 | 0.9633 | 0.5533 | 0.4712 | 0.379 |
| 8 | 0.2895 | 0.534 | 0.5486 | 0.9989 | 0.9993 | 0.9743 | 0.6592 | 0.6071 | 0.5366 |
| 9 | 0.2296 | 0.6152 | 0.5454 | 0.9992 | 0.9996 | 0.9496 | 0.559 | 0.6517 | 0.5958 |
| 10 | 0.1964 | 0.5033 | 0.5351 | 0.9999 | 1 | 0.965 | 0.8968 | 1 | 0.9299 |
| Fold | F-1 | AUC | PRC | ||||||
|---|---|---|---|---|---|---|---|---|---|
| No-HC | HC | VCCA | No-HC | HC | VCCA | No-HC | HC | VCCA | |
| 1 | 0.0084 | 0.0035 | 0.0117 | 0 | 0 | 0.0049 | 0.0022 | 0.0009 | 0.0072 |
| 2 | 0.0029 | 0.0038 | 0.0087 | 0 | 0 | 0.0049 | 0.002 | 0.0007 | 0.0205 |
| 3 | 0.003 | 0.0035 | 0.0084 | 0 | 0 | 0.0073 | 0.0034 | 0.0029 | 0.0209 |
| 4 | 0.0032 | 0.0032 | 0.0144 | 0 | 0.0011 | 0.0096 | 0.0031 | 0.0025 | 0.0088 |
| 5 | 0.0063 | 0.0058 | 0.0322 | 0 | 0 | 0.0185 | 0.0022 | 0.0022 | 0.0341 |
| 6 | 0.0066 | 0.0009 | 0.0154 | 0 | 0 | 0.0164 | 0.0011 | 0.0022 | 0.0197 |
| 7 | 0.0062 | 0.0005 | 0.0153 | 0 | 0 | 0.0163 | 0.0037 | 0.0019 | 0.0287 |
| 8 | 0.003 | 0.0004 | 0.0188 | 0 | 0 | 0.012 | 0.0047 | 0.0017 | 0.0189 |
| 9 | 0.0036 | 0.0258 | 0.0642 | 0 | 0 | 0.0227 | 0.0048 | 0.0012 | 0.0426 |
| 10 | 0.005 | 0.0006 | 0.0268 | 0 | 0 | 0.0164 | 0.004 | 0 | 0.0655 |
| Fold | No-HC | HC | VCCA | VCCA (%) |
|---|---|---|---|---|
| 1 | 14.71 | 116.47 | 18.20 | 15.63 |
| 2 | 10.14 | 44.74 | 14.04 | 31.38 |
| 3 | 15.56 | 55.40 | 15.71 | 28.36 |
| 4 | 17.46 | 78.39 | 20.66 | 26.36 |
| 5 | 18.45 | 106.61 | 22.38 | 20.99 |
| 6 | 18.46 | 79.64 | 19.87 | 24.95 |
| 7 | 22.53 | 85.16 | 25.43 | 29.86 |
| 8 | 21.76 | 92.89 | 24.14 | 25.99 |
| 9 | 19.66 | 56.55 | 20.08 | 35.51 |
| 10 | 20.46 | 45.92 | 19.72 | 42.94 |
| Attribute | ||||
|---|---|---|---|---|
| category | 14 | 0.0019799792770756885 | 14 | 0.0019799792770756885 |
| gender | 2 | 0.0000006409831799781 | 2 | 0.0000006409831799781 |
| city | 849 | 0.0103333005133997846 | 177 | 0.0103332999129037914 |
| state | 50 | 0.0006413767623995176 | 45 | 0.0006413767623995245 |
| job | 478 | 0.0060285748349879244 | 166 | 0.0060285744210841971 |
| day_of_week | 7 | 0.0001846527228808251 | 7 | 0.0001846527228808251 |
| No-HC | HC | VCCA | |
|---|---|---|---|
| First Hidden Layer Size | 64 | 32 | 32 |
| Second Hidden Layer Size | 16 | 16 | 16 |
| Optimizer | adam | adam | adam |
| L2 Regularizer | 0.001 | 0.001 | 0.001 |
| Fold | F-1 | AUC | PRC | ||||||
|---|---|---|---|---|---|---|---|---|---|
| No-HC | HC | VCCA | No-HC | HC | VCCA | No-HC | HC | VCCA | |
| 1 | 0.2298 | 0.4387 | 0.4317 | 0.9917 | 0.9904 | 0.9905 | 0.733 | 0.8394 | 0.8229 |
| 2 | 0.2331 | 0.4437 | 0.4383 | 0.9825 | 0.9905 | 0.9923 | 0.6973 | 0.8152 | 0.8002 |
| 3 | 0.2514 | 0.4461 | 0.4194 | 0.9937 | 0.9985 | 0.9985 | 0.7342 | 0.8694 | 0.8467 |
| 4 | 0.2386 | 0.4361 | 0.4073 | 0.9908 | 0.9983 | 0.9985 | 0.7074 | 0.8353 | 0.8186 |
| 5 | 0.2263 | 0.429 | 0.4181 | 0.99 | 0.9978 | 0.998 | 0.6818 | 0.826 | 0.8093 |
| 6 | 0.2468 | 0.4297 | 0.4218 | 0.9918 | 0.996 | 0.9968 | 0.7306 | 0.8226 | 0.8024 |
| 7 | 0.239 | 0.445 | 0.4205 | 0.9943 | 0.9988 | 0.999 | 0.7329 | 0.8573 | 0.8477 |
| 8 | 0.2255 | 0.4564 | 0.4324 | 0.9943 | 0.998 | 0.9984 | 0.7484 | 0.8657 | 0.843 |
| 9 | 0.2385 | 0.4366 | 0.3889 | 0.9927 | 0.9984 | 0.9982 | 0.7519 | 0.8755 | 0.841 |
| 10 | 0.2383 | 0.4442 | 0.4269 | 0.9923 | 0.9981 | 0.9982 | 0.7543 | 0.8358 | 0.8236 |
| Fold | F-1 | AUC | PRC | ||||||
|---|---|---|---|---|---|---|---|---|---|
| No-HC | HC | VCCA | No-HC | HC | VCCA | No-HC | HC | VCCA | |
| 1 | 0.0029 | 0.0044 | 0.0053 | 0 | 0 | 0 | 0.0006 | 0.0007 | 0.0011 |
| 2 | 0.0025 | 0.0049 | 0.005 | 0 | 0 | 0 | 0.0004 | 0.0008 | 0.0009 |
| 3 | 0.0036 | 0.005 | 0.0045 | 0 | 0 | 0 | 0.0007 | 0.0006 | 0.0008 |
| 4 | 0.0027 | 0.0054 | 0.0052 | 0 | 0 | 0 | 0.0007 | 0.0008 | 0.001 |
| 5 | 0.0026 | 0.0054 | 0.0058 | 0 | 0 | 0 | 0.0011 | 0.0014 | 0.0012 |
| 6 | 0.0024 | 0.0062 | 0.005 | 0 | 0 | 0 | 0.0006 | 0.0013 | 0.0012 |
| 7 | 0.0032 | 0.0041 | 0.0045 | 0 | 0 | 0 | 0.0006 | 0.0009 | 0.0009 |
| 8 | 0.0026 | 0.0051 | 0.0054 | 0 | 0 | 0 | 0.0007 | 0.0006 | 0.0009 |
| 9 | 0.0029 | 0.0049 | 0.0046 | 0 | 0 | 0 | 0.0009 | 0.0006 | 0.001 |
| 10 | 0.0023 | 0.0044 | 0.0051 | 0 | 0 | 0 | 0.0007 | 0.0007 | 0.001 |
| Fold | No-HC | HC | VCCA | VCCA (%) |
|---|---|---|---|---|
| 1 | 164.94 | 391.94 | 232.28 | 59.26 |
| 2 | 195.97 | 380.57 | 243.34 | 63.94 |
| 3 | 162.02 | 336.06 | 226.62 | 67.43 |
| 4 | 181.93 | 314.25 | 238.56 | 75.91 |
| 5 | 166.18 | 356.02 | 240.85 | 67.65 |
| 6 | 183.79 | 353.9 | 232.66 | 65.74 |
| 7 | 162.81 | 361.18 | 273.42 | 75.70 |
| 8 | 196.52 | 418.69 | 244.34 | 58.36 |
| 9 | 214.63 | 345.03 | 285.8 | 82.83 |
| 10 | 206.16 | 410.03 | 266.18 | 64.91 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Carneiro, E.M.; Forster, C.H.Q.; Mialaret, L.F.S.; Dias, L.A.V.; da Cunha, A.M. High-Cardinality Categorical Attributes and Credit Card Fraud Detection. Mathematics 2022, 10, 3808. https://doi.org/10.3390/math10203808
Carneiro EM, Forster CHQ, Mialaret LFS, Dias LAV, da Cunha AM. High-Cardinality Categorical Attributes and Credit Card Fraud Detection. Mathematics. 2022; 10(20):3808. https://doi.org/10.3390/math10203808
Chicago/Turabian StyleCarneiro, Emanuel Mineda, Carlos Henrique Quartucci Forster, Lineu Fernando Stege Mialaret, Luiz Alberto Vieira Dias, and Adilson Marques da Cunha. 2022. "High-Cardinality Categorical Attributes and Credit Card Fraud Detection" Mathematics 10, no. 20: 3808. https://doi.org/10.3390/math10203808
APA StyleCarneiro, E. M., Forster, C. H. Q., Mialaret, L. F. S., Dias, L. A. V., & da Cunha, A. M. (2022). High-Cardinality Categorical Attributes and Credit Card Fraud Detection. Mathematics, 10(20), 3808. https://doi.org/10.3390/math10203808