1. Introduction
The assessment of similarity or distance between two information entities is crucial for all information discovery tasks (whether Information Retrieval or Data mining). Appropriate measures are required for improving the quality of information selection and also for reducing the time and processing costs [
1].
Even if the concept of similarity originates from philosophy and psychology, its relevance arises in almost every scientific [
2]. This paper is focused on measuring similarity in the computer science domain, i.e., Information Retrieval, in images, video, and to some extent audio, respectively. In the paper domain, the similarity measure “is an algorithm that determines the degree of agreement between entities.” [
1].
The approaches for computing similarity or dissimilarity between various object representations can be classified [
2] in:
- (1)
distance-based similarity measures
This class includes the following models: Euclidean distance, Minkowski distance, Mahalanobis distance, Hamming distance, Manhattan/City block distance, Chebyshev distance, Jaccard distance, Levenshtein distance, Dice’s coefficient, cosine similarity, soundex distance.
- (2)
feature-based similarity measures (contrast model)
This method, proposed by Tversky in 1977, represents an alternate to distance-based similarity measures, based on computing similarity by common features of compared entities. Entities are more similar if they share more common features, while they are dissimilar in the case of more distinctive features. The similarity between entities A and B can be determined using the formula:
where:
- –
are used to define the respective weights of associated values,
- –
describes the common features in A and B,
- –
stands for the distinctive features of A
- –
means the distinctive features of the entity B.
- (3)
probabilistic similarity measures
For assessing the relevance among some complex data types, the following probabilistic similarity measures are necessary: maximum likelihood estimation, maximum a posteriori estimation.
- (4)
extended/ additional measures
Includes similarity measures based on fuzzy set theory [
3], similarity measures based on graph theory, similarity-based weighted nearest-neighbors [
4], similarity-based neural networks [
5].
A lot of algorithms and techniques like Classification [
6], Clustering, Regression [
7], Artificial Intelligence(AI), Neural Networks (NNs), Association Rules, Decision Trees, Genetic Algorithm, Nearest Neighbor method etc., are attempted [
2] for knowledge discovery from databases.
The Artificial Neural Networks (ANNs) are widely used in various fields of engineering and science. They generate useful tools in quantitative analysis, due to their unique feature of approximating complex and non-linear equations. Their performance and advantage consists in their ability to model both linear and non-linear relationships.
The Artificial Neural Networks are well-suited for a very broad class of nonlinear approximations and mappings. An Artificial Neural Network (ANN) with nonlinear activation functions is more effective than linear regression models in dealing with nonlinear relationships.
ANNs are regarded as one of the important components in AI. They have been studied [
8] for many years with the goal of achieving human-like performance in many branches, such as classification, clustering, and pattern recognition, speech and image recognition and Information Retrieval [
9] by modelling the human neural system.
IR “is different from data retrieval in databases using SQL queries because the data in databases are highly structured and stored in relational tables, while information in text is unstructured. There is no structured query language like SQL for text retrieval.” [
10].
Gonzales and Woods [
11] have developed Huffman Coding to remove coding redundancy, by yielding the smallest number of code symbols per source symbol.
Burgerr and Burge [
12] as well as Webb [
13] have developed several algorithms for Image Compression using Discrete Cosine Transformation.
The main objective of this paper consists in improving the performance of the Huffman Coding algorithm by achieving a minimum average length of the code word. Our new approach is important for removing more effectively the Coding Redundancy in Digital Image Processing.
The remainder of the paper is organized as follows. In
Section 2 we discuss some general aspects about the Poisson distribution and the data compression.
Then, in
Section 3 we introduce and analyze an approach to reduce the documents, entitled Discrete Cosine Transformation, in order to achieve the Latent Semantic Model.
We follow with the Fourier descriptor method in
Section 4 to describe the shape of an object by considering its boundaries.
We define some notions from the Information Theory in
Section 5 as they are useful to model the information generation like a probabilistic process.
The
Section 6 presents the Huffman Coding, which is built to remove the coding redundancy and to find the optimal code for an alphabet of symbols.
We introduce an experimental evaluation of the new model on the task of computing image entropy, the average length of the code words and the Huffman coding efficiency too in
Section 7.
We conclude in
Section 8 by highlighting that the scientific value added by our paper consists in the fact of computing the average length of the code words in the case of applying of the Poisson distribution.
2. Preliminaries
2.1. Discrete Random Variables and Distributions
By definition [
14], a random variable
X and its distribution are
discrete if the possible values of
X denoted
are finitely many or, at most, countably many values, with the probabilities
.
The Poisson Distribution
The
Poisson distribution (named after S.D. Poisson) is the discrete distribution which has infinite possible values and the probability function
The Poisson distribution is similar with the binomial distribution in the mean in that it is achieved as a limiting case of this distribution, for and , where the product is kept constant. As it is used for a rare occurrence of an event, the Poisson distribution is also called the distribution of the rare events that occur in order to achieve success in a sequence of some independent Bernoulli samples.
This distribution is frequently encountered in the study of some phenomena in biology, telecommunications, statistical quality control (when the probability of obtaining a defect is very small), in the study of phenomena that present some agglomerations (in the theory of threads of waiting).
The probability that of the
n drawn balls,
k are white is: [
15]
namely it results in the Equation (
2).
The simulation of
can be achieved [
16,
17]: using the Matlab generator, using the inverse transform method, using a binomial distribution.
In [
17] we generated a selection of volume 1000 on the random variable
X, having some continuous distributions (such as normal or exponential distribution) or discrete distributions (as the geometric or Poisson distribution). The methods used in the generation of the random variables
X are illustrated in the
Table 1.
The means and the variances corresponding to the resulting selections will be compared with the theoretical ones. In each case we build both the graphical histogram and the probability density of
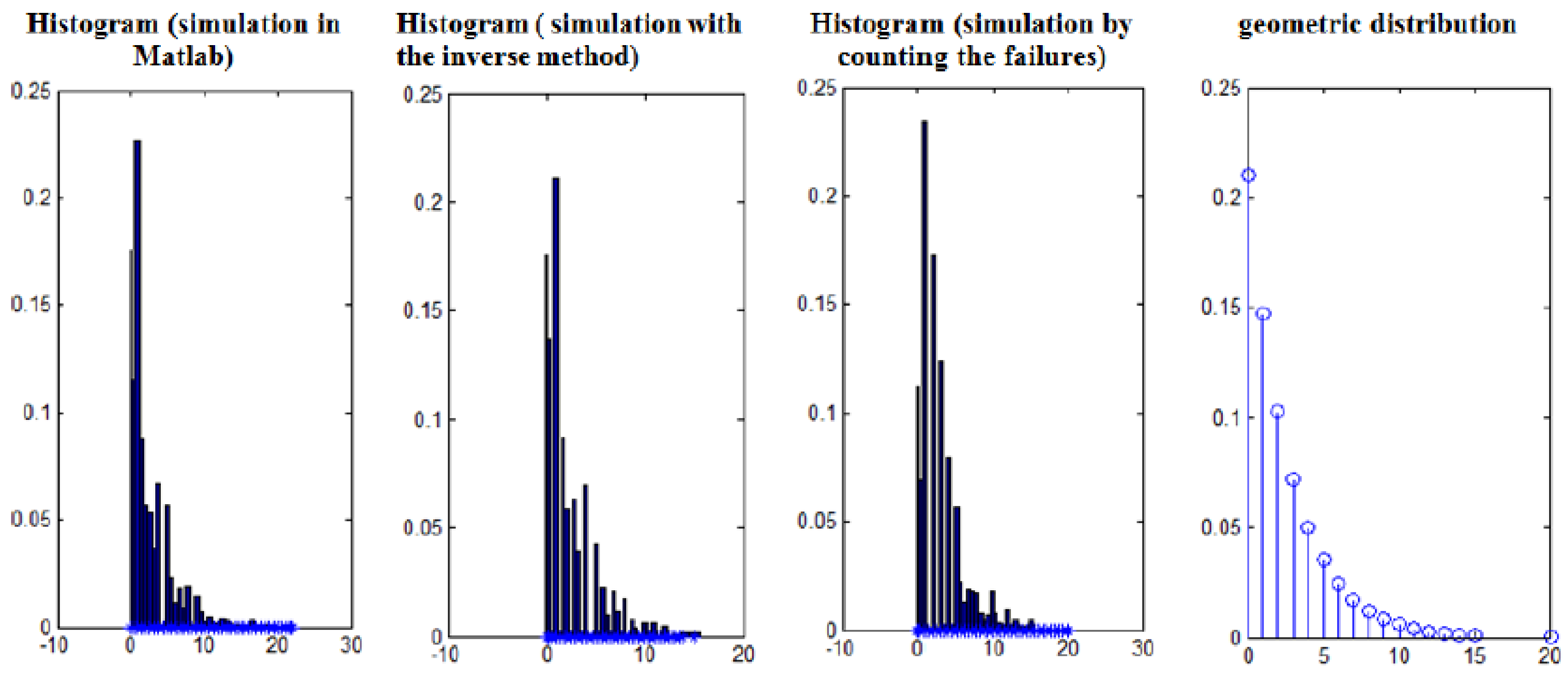
X too. For example, the
Figure 1 shows the histograms built for
, using three methods (Matlab generator, inverse transform method, by counting the failures) and the probability density of
X.
The statistics associated to the concordance tests are also computed in the
Table 1.
Example 1. Adjust the following empirical distribution, which is a discrete one, using the Poisson distribution:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 0.16 | 0.217 | 0.27 | 0.18 | 0.11 | 0.03 | 0.1 | 0.002 | 0.001 | 0.002 |
The resulting Poisson distribution will be:
| x | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 0.0799 | 0.2019 | 0.2551 | 0.2149 | 0.1358 | 0.0686 | 0.0289 | 0.0104 | 0.0033 | 0.0009 |
2.2. Data Compression
The concept of
data compression [
11,
18,
19,
20,
21,
22,
23,
24,
25,
26,
27,
28] means the reduction of that amount of data, which is used to represent a given quantity of information.
The data represent the way in which the information is transmitted, such that different amounts of data can be used to represent the same quantity of information.
For example, if
and
are the number of bits in two representations of the same information, then the
relative data redundancy of the representation with
bits can be defined as:
where
signifies the
compression ratio and has the expression:
There are the following three types of redundancies [
11] in the Digital Image Processing:
- (A)
Coding Redundancy- it is necessary to evaluate the optimal information coding by the average length of the code words (
) to remove this kind of redundancy:
where:
- ✓
L being the number of the intensity values associated to a an image;
- ✓
bits are necessary to represent the respective image;
- ✓
the discrete random variable represents the intensities of that image;
- ✓
is the absolute frequency of the k- th intensity ;
- ✓
means the number of bits that are used to represent each value of ;
- ✓
is the probability of the occurrence of the value;
- (B)
Interpixel Redundancy one refers to a reduction of the redundancy associated with spatially and temporally correlated pixels through mapping such as the run-lengths, differences between adjacent pixels and so on; reversible mapping implies the reconstruction without error;
- (C)
Psychovisual Redundancy is when certain information which has relatively less importance for the perception of the image quality; it is different from the Coding Redundancy and the Interpixel Redundancy by the fact that it is associated with the real information, which can be removed by a quantization method.
3. Discrete Cosine Transformation
The
appearance based approach constitutes [
2] one of the various approaches used to select the features from an image, by retaining the most important information of the image and rejecting the redundant information. This class includes Principal Component Analysis (PCA), Discrete Cosine Transformation (DCT) [
29], Independent Component Analysis (ICA) and Linear Discriminant Analysis (LDA).
In case of large document collections, the high dimension of the vector space matrix F generates problems in the text document set representation and induces high computing complexity in Information Retrieval.
The most often used methods for reducing the text document space dimension which have been applied in Information Retrieval are: Singular Value Decomposition (SVD) and PCA.
Our approach is based on using the Discrete Cosine Transformation for reducing the text documents. Thus, the set of keywords is reduced to the much smaller feature set. The resulting model represents the Latent Semantic Model.
The DCT [
30] represents an orthogonal transformation, similar with the PCA. The elements of the transformation matrix are obtained using the following formula:
n being the size of the transformation and
The DCT requires the transformation of the
n dimensional vectors
, where
N denotes the number of vectors that must be transformed), to the vectors
, using the formula:
meaning the transformation matrix.
We have to choose, between all the components of the vectors , a number of m components, corresponding to the positions which conduct to a mean square belonging to the first m mean squares, in descending order, while the other components will be cancelled.
The vector
, is defined through the formula (
8):
The mean square of the transformed vectors is given by:
where
The DCT application consists in determining the vectors corresponding to the m components of the vectors that do not cancel.
Image Compression Algorithm Using Discrete Cosine Transformation
Digital image processing represents [
11,
12,
13,
31,
32] a succession of hardware and software processing steps, as well as the implementation of several theoretical methods.
The first step of this process involves the image acquisition. It requires an image sensor for achieving a two-dimensional image, such as a video camera (for example, the Pinhole Camera Model, one of the simplest camera models).
The analog signal (which is continuous in time and values) [
33] resulted at the output of the video camera, must be converted into a digital signal, for its processing using the computer. This transformation involves the following steps [
12]:
- Step 1
(Spatial sampling). This step aims to achieve the spatial sampling of the continuous light distribution. The spatial sampling of an image represents the conversion of the continuous signal to its discrete representation and it depends on the geometry of the sensor elements associated to the acquisition device.
- Step 2
(Temporal sampling). In this stage, the resulting discrete function is sampled in the time domain to create a single image. The temporal sampling is achieved by measuring at regular intervals the amount of light incident on each individual sensor element.
- Step 3
(Quantization of pixel values). This step aims to quantize the resulting values of the image to a finite set of numeric values for storing and processing the image values on the computer.
Definition 1 ([
12]).
A digital image I represents a two-dimensional function of natural coordinates , which maps to a range of possible image values P, with the property that . The pixel values are described by binary words of length k (which define the depth of the image); therefore, a pixel can represent any of different values.
As an illustration, the pixels of the grayscale images:
are represented by using k = 8 bits (1 byte) per pixel;
have the intensity values belonging to the set , where the value 0 corresponds to the minimum brightness (black) and 255 represents the maximum brightness (white).
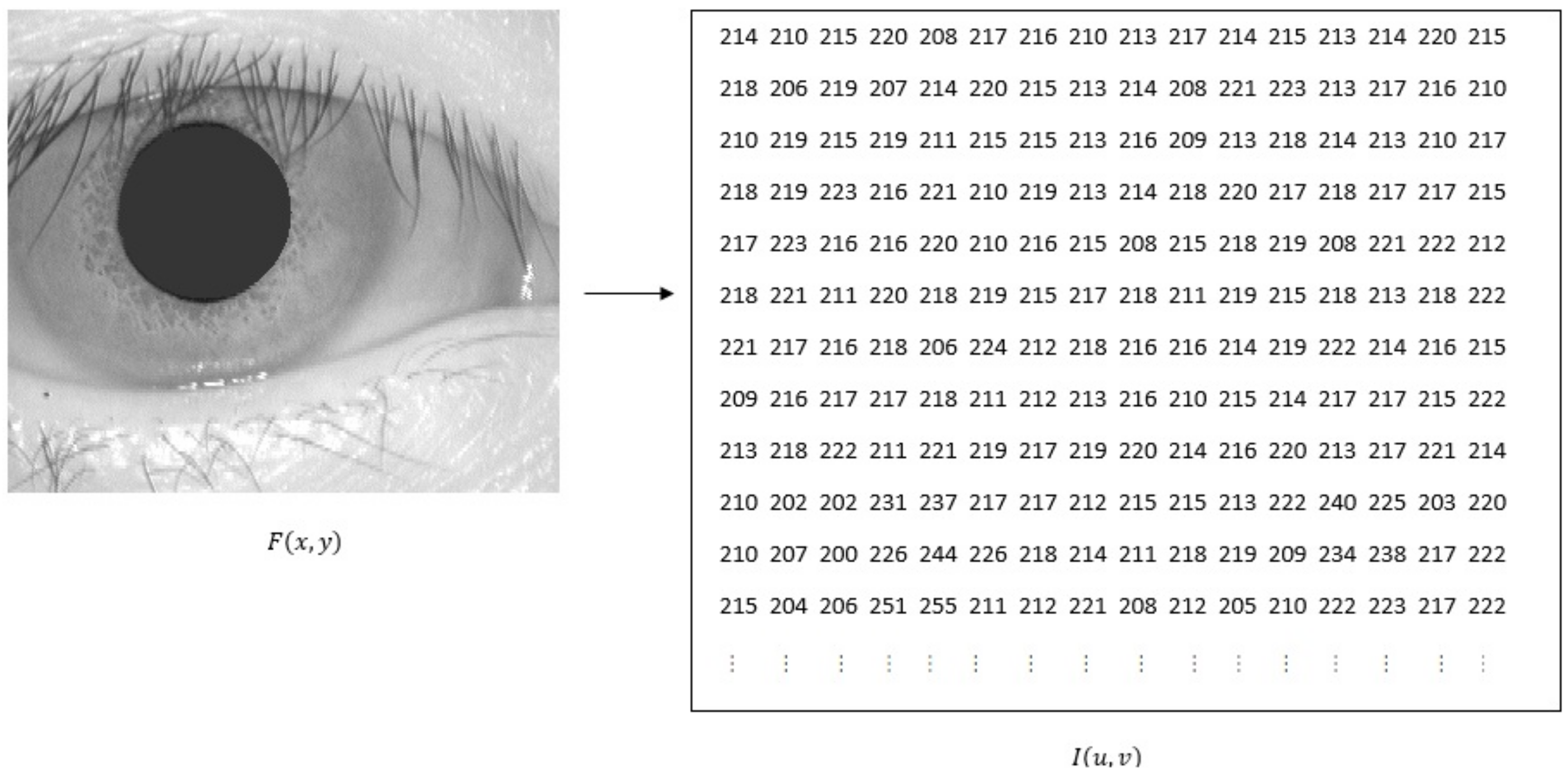
The result of performing the three steps
Step 1–
Step 3 is highlighted in a “description of the image in the form of a two-dimensional, ordered matrix of integers” [
12], illustrated in the
Figure 2.
CASIA Iris Image Database Ver 3.0 (or CASIA-IrisV3 for short) contains three subsets, totally 22,051 iris images of more than 700 subjects.
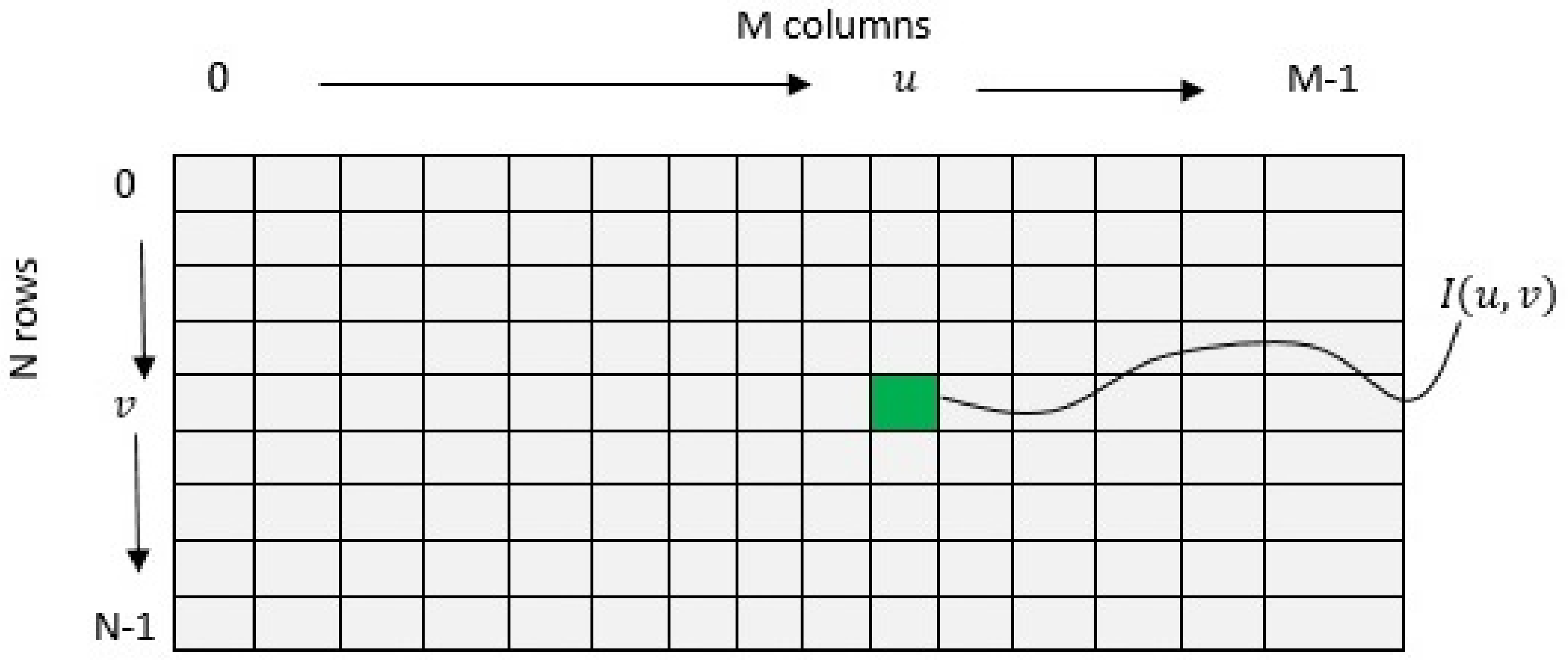
Figure 3 displays a coordinate system for image processing, which is flipped in the vertical direction, provided that the origin, defined by
and
lies in the upper left corner.
Another advantage of DCT in image compression consists in not depending on the input data.
The coordinates represent the columns and rows of the image, respectively. For an image with the resolution , the maximum column number is , while the maximum row number is .
After achieving the digital image, it is necessary to preprocess it in order to improve it; we can mention some examples of preprocessing image techniques:
image enhancement, which assumes the transformation of the images for highlighting some hidden or obscure details, interest features, etc.;
image compression, performed for reducing the amount of data needed to represent a given amount of information;
image restoration aims to correct those errors that appear at the image capture.
Among different methods for image compression, the DCT “achieves a good compromise between the ability of information compacting and the computational complexity” [
12]. Another advantage of using DCT in image compression consists in not depending on the input data.
The DCT algorithm is used for the compression of
matrix of integers
, where
means the original pixel values. The Algorithm 1 consists in performing the following steps [
2]:
We have performed the compression algorithm based on the DCT, using the Lena.bmp image [
2], which has
pixels and 256 levels of grey; it is represented in the
Figure 4.
The
Table 2 and
Figure 5 display the experimental results obtained by implementing the DCT compression algorithm, in Matlab.
| Algorithm 1: DCT compression algorithm. |
- Step 1
Split the initial image into pixel blocks (1024 image blocks). - Step 2
Process each block by applying the DCT, using relation ( 8). - Step 3
The first nine coefficients for each transformed block are retained in a zigzag fashion and the rest of ( ) the coefficients are cancelled (by making them equal to 0). This stage is illustrated in Figure 6. - Step 4
The inverse DCT is applied for each of the 1024 blocks resulted in the previous step. - Step 5
The compressed image represented by the matrix is achieved, where denotes the encoded pixel values. Then, the pixel values are converted into integer values. - Step 6
The performances of the DCT compression algorithm is evaluated in terms of the Peak Signal-to-Noise Ratio (PSNR), given by [ 34, 35]:
where the Mean Squared Error (MSE) is defined as follows [ 34, 35]:
where means the total number of pixels in the image (in our case ).
|
Figure 5.
Visual evaluation of the performances corresponding to the DCT compression algorithm.
Figure 5.
Visual evaluation of the performances corresponding to the DCT compression algorithm.
Figure 6.
Zigzag fashion to retain the first nine coefficients.
Figure 6.
Zigzag fashion to retain the first nine coefficients.
4. Fourier Descriptors
The descriptors of different objects can be compared for achieving [
36] a measurement of their similarity [
2].
The Fourier descriptors [
37,
38] show interesting properties in terms of the shape of an object, by considering its boundaries.
Let
be [
2,
35] a closed pattern, oriented counterclockwise, described by the parametric representation:
, where
l denotes the length of a circular arc, along the curve
, starting from an origin and
, where
L means the length of the boundary.
A point lying on the boundary generates the complex function . We note that is a periodic function, with period L.
Definition 2. The Fourier descriptors are the coefficients associated to the decomposition of the function in a complex Fourier series.
By using a similar approach of implementing a Fourier series for building a specific time signal, which consists of cosine/sine waves of different amplitude and frequency, “the Fourier descriptor method uses a series of circles with different sizes and frequencies to build up a two dimensional plot of a boundary” [
36] corresponding to an object.
The Fourier descriptors are computed using the formula [
2,
35]:
such that
In the case of a polygonal contour, depicted in the
Figure 7, we will derive [
2,
35] an equivalent formula to (
12).
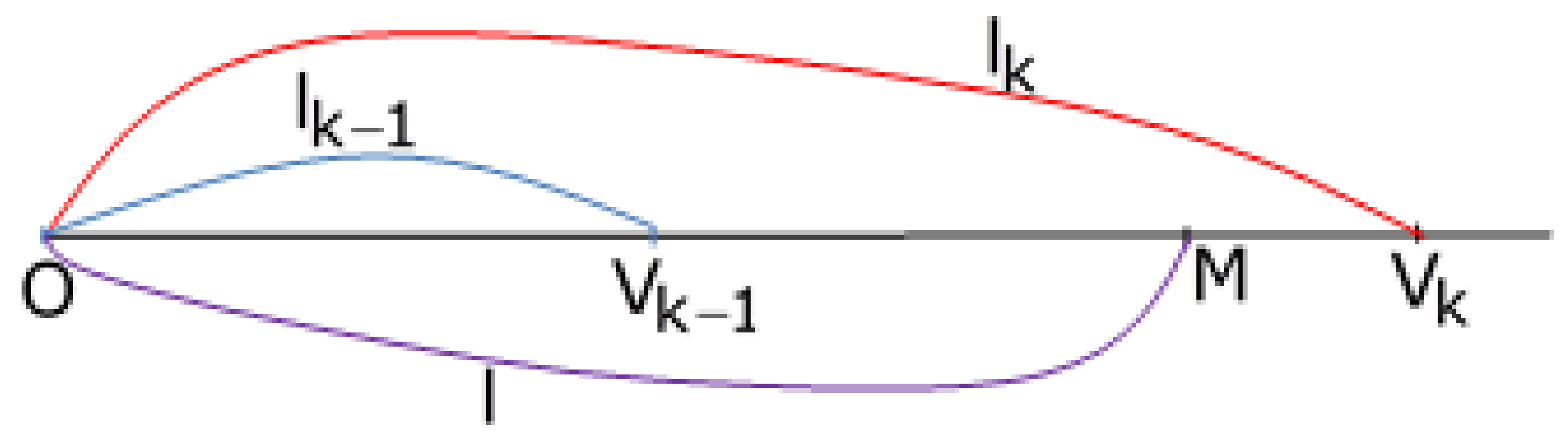
Denoting
namely (see the
Figure 8):
where
and
from (
12) it results:
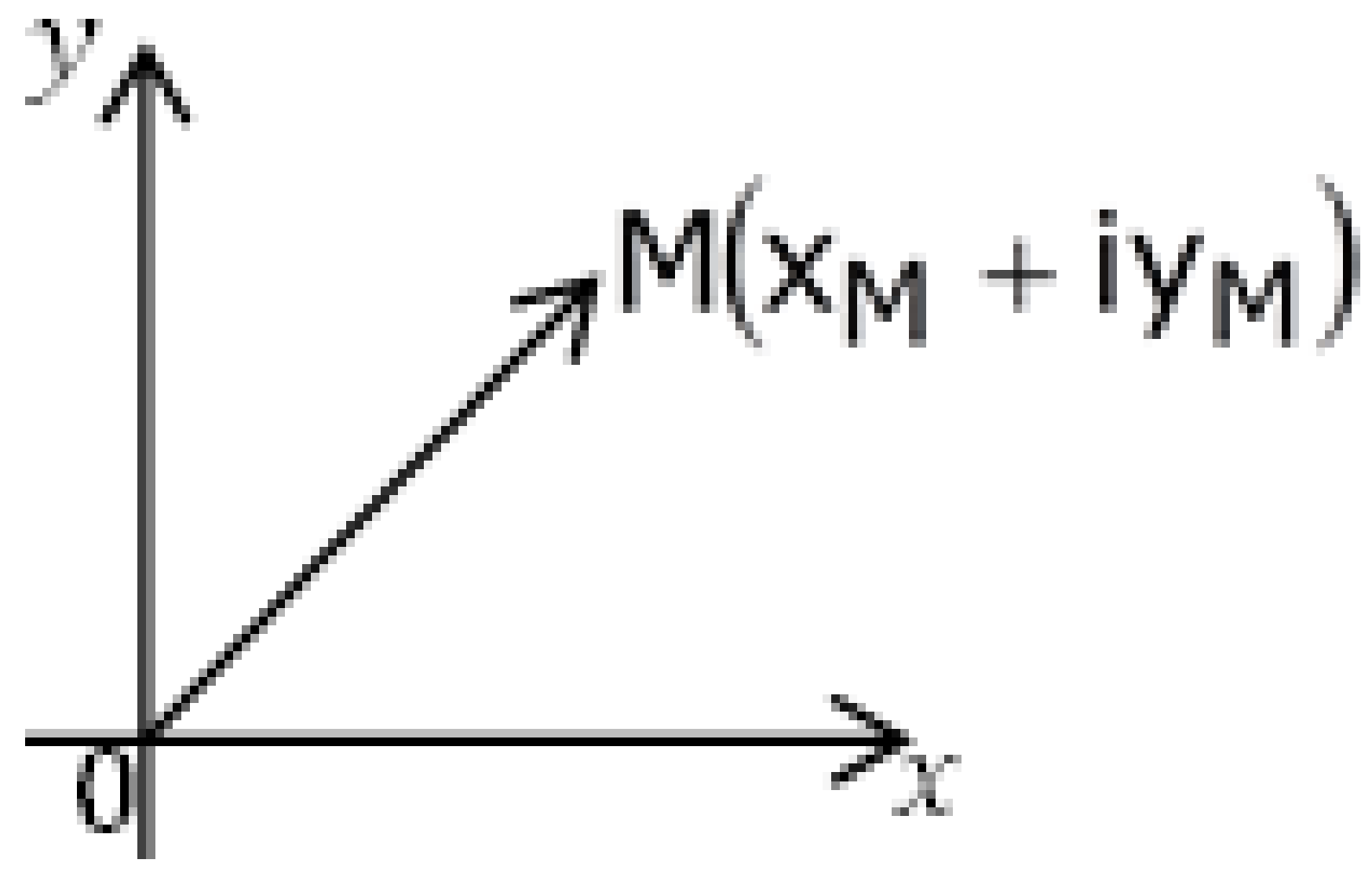
We will regard each coordinate pair as a complex number, as illustrated in the
Figure 9:
Taking into consideration the previous assumption and relationships (
18) and (
15) we get:
hence, the formula (
17) will become:
By computing
and substituting it into (
19) we shall achieve:
where
namely
Therefore, on the basis of the relations (
21) and (
16) from which it results
the formula (
20), which allows us the computation of the Fourier descriptors will be:
The principal advantages of the Fourier Descriptor method for object recognition consists in the invariance to translation, rotation and scale displayed by the Fourier descriptors are [
36].
5. Measuring Image Information
5.1. Entropy and Information
The fundamental premise in
Information Theory is that the information generation can be modeled like a probabilistic process [
39,
40,
41,
42,
43,
44,
45,
46,
47]
Hence, an event
E, which occurs with probability
will contain
information units, where [
11]:
There is the convention that the basis of the logarithm determines the unit used to measure the information. In the case when the basis is equal with two, then the information unit it is called a bit (binary digit).
Assuming a discrete set of symbols
, having the associated probabilities
we see that the entropy of the discrete distribution is [
11]:
where
.
We can note that the entropy from the Equation (
23) just depends on the probabilities of the symbols and it measures the randomness or unpredictability of the respective symbols drawn from a given sequence; in fact, the entropy defines the average amount of information that can be obtained by observing a single output of a primary source.
The information which is transferred to the receiver through an information transmission system is a random discrete set of symbols
too, with the corresponding probabilities
, where [
11]:
The Equation (
24) can be written in the matrix form [
11]:
where
is the probability distribution of the output alphabet ;
the matrix
means is associated with the information transmission system:
where
- (1)
the
conditional entropy:
where
means the joint probability, namely the probability of
occurring at the same time that
occurs:
- (2)
the mutual information between z and v, which expresses the reduction of uncertainty about z because of the knowledge of v:
Taking into account the Bayes Rule [
48]:
and from the Equation (
24) it will result that:
From the Equation (
30) we can deduce that the minimum value of
is 0 and can be achieved in the case when the input and the output alphabet are mutually independent [
48], i.e.,
5.2. The Case of the Binary Information Sources
Let a binary information source with the source alphabet
and let
be the probabilities that the source to produce the symbols
and
, such that [
11]:
By using the Equation (
23) it will result that the following entropy of the binary source [
11]:
where
, i.e., one achieves the binary entropy function [
11]:
having its maximum value (of 1 bit) when
.
If there is some noise during the data transmission then the matrix
Q from the Equation (
26) can be defined as [
11]:
being the probability of an error during the transmission of any symbol.
In the case when the output alphabet delivered at the receiver is the the set of symbols
one achieves that [
11]:
i.e., one can compute:
Hence, on the basis of the formula (
31), the
mutual information between
z and
v will be:
therefore [
11]:
From the Equation (
39) one can notice that:
when has the value 0 or 1;
the maximum value of is (it means the maximum amount of information that can be transferred, i.e., the capacity of the binary transmission system = BST) and can be achieved when the symbols of the binary source are equally likely to occur, namely . For one obtains the maximum capacity of the BST: , while for one deduces that , i.e., any information can not be transferred through the BST.
5.3. The Noiseless Coding Theorem
Let be a
zero-memory source , from the Equation (
23), which is an information source, having only statistically independent symbols. We suppose that the output of this source is a
n- tuple of symbols, then the output of the given zero-memory source is the set
has
possible values
, each of them consisting in
n symbols from the alphabet
A.
As there are the inequalities [
11]:
where
, introduced by the Equation (
5) is the length of the coding word used to represent
, one achieves:
therefore [
11]:
where
means the average number of code symbols required to represent all
n-symbol groups.
From the Equation (
42) one deduces the
Shannon’s first theorem (the noiseless coding theorem) [
11], which claims that the output of a zero-memory source can be represented with an average of
information units per source symbol:
namely:
or:
The Equation (
45) proves that the expression
can be approximated with
by encoding infinitely long extensions corresponding to the single-symbol source.
The efficiency of the coding strategy is given by [
11]:
6. Huffman Coding
Huffman Coding [
11] is an error-free compression method, designed to remove the coding redundancy, by yielding the smallest number of code symbols per source symbol, which in practice can be represented by the intensities of an image or the output of a mapping operation.
The Huffman algorithm finds the optimal code for an alphabet of symbols, taking into account the condition that the probabilities associated with the symbols have to be coded one at a time.
The approach of Huffman consists in following:
- Step 1
Approximate the given data with a Poisson distribution to avoid the undefined entropies.
- Step 2
Create a series of source reductions by sorting the probabilities of the respective symbols in a descending order in order to combine the lowest probability symbols into a single symbol, which replace them in the next source reduction. This process can be repeated as long as a source with two symbols is not reached.
- Step 3
Code each reduced source, by starting with the smallest source and then go back to the original source of this work, taking into account that the symbols 0 and 1 are the binary codes with minimal length for a two-symbol source.
The Huffman coding efficiency can be computed using the formula [
11]:
being the average length of the code words, defined in the relation (
5) and
being the entropy of the discrete distribution, introduced by the Equation (
23).
7. Experimental Evaluation
7.1. Data Sets
We will use [
2] the images from the PASCAL dataset for evaluating the performance of our method using Matlab.
In this paper we have used 10,102 images from the VOC data sets, which contain significant variability in terms of object size, orientation, pose, illumination, position and occlusion.
The database consists of 20 object classes: aeroplane, bicycle, bird, boat, bottle, bus, car, motorbike, train, sofa, table, chair, tv/monitor, potted plant, person, cat, cow, dog, horse and sheep.
We have used The ColorDescriptor engine [
49] for extracting the image descriptors from all the images.
The
Figure 10 shows 50 images from the VOC data base.
The performance of our method has been assessed using images from the PASCAL dataset The Pascal VOC challenge represents [
34] a benchmark in visual object category recognition and detection, as it provides the vision and machine learning communities with a standard data set of images and annotation.
Our approach uses 64 descriptors for each image belonging to the training and test set, therefore the number of symbols is 64.
7.2. Experimental Results
For our experiments, we used the descriptors corresponding to some images from the VOC data sets and after we approximated our data with a Poisson distribution, we computed the image entropy, the average length of the code words and the Huffman coding efficiency too. We have applied the following Algorithm:
- Step 1
Approximate the given data with a Poisson distribution.
- Step 2
Create a series of source reductions by sorting the probabilities of the respective symbols in a descending order in order to combine the lowest probability symbols into a single symbol, which replace them in the next source reduction. This process can be repeated as long as a source with two symbols is not reached.
- Step 3
Code each reduced source, by starting with the smallest source and then go back the original source of this work, taking into account that the symbols 0 and 1 are the binary codes with minimal length for a two-symbol source.
8. Conclusions
This paper proposes to improve the Huffman coding efficiency by adjusting the data using a Poisson distribution, which avoids the undefined entropies too. The performance of our method has been assessed in Matlab, by using a set of images from the PASCAL dataset.
The scientific value added of our paper consists in applying the Poisson distribution in order to minimize the average length of the Huffman code words.
The PASCAL VOC challenge represents [
34] a benchmark in visual object category recognition and detection as it provides the vision and machine learning communities with a standard data set of images and annotation.
In this paper we have used 10,102 images from the VOC data sets, which contain significant variability in terms of object size, orientation, pose, illumination, position and occlusion.
The database consists of 20 object classes: aeroplane, bicycle, bird, boat, bottle, bus, car, motorbike, train, sofa, table, chair, tv/monitor, potted plant, person, cat, cow, dog, horse and sheep.
The data of our information source are different from a finite memory source (Markov), where its output depends on a finite number of previous outputs.
Author Contributions
Conceptualization, I.I., M.D., S.D. and V.P.; Data curation, I.I. and M.D.; Formal analysis, M.D., S.D. and V.P.; Investigation, I.I., M.D., S.D. and V.P.; Methodology, I.I., M.D., S.D. and V.P.; Project administration, I.I. and V.P.; Resources, I.I.; Software, I.I. and M.D.; Supervision, I.I. and V.P.; Validation, I.I., M.D., S.D. and V.P.; Writing—original draft, I.I. and S.D.; Writing—review & editing, I.I., M.D., S.D. and V.P. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by a grant of the Romanian Ministery of Education and Research, CNCS—UEFISCDI, project number PN-III-P4-ID-PCE-2020-1112, within PNCDI III.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Zaka, B. Theory and Applications of Similarity Detection Techniques. 2009. Available online: http://www.iicm.tugraz.at/thesis/bilal_dissertation.pdf (accessed on 14 July 2022).
- Iatan, I.F. Issues in the Use of Neural Networks in Information Retrieval; Springer: Cham, Switzerland, 2017. [Google Scholar]
- Hwang, C.M.; Yang, M.S.; Hung, W.L.; Lee, M.L. A similarity measure of intuitionistic fuzzy sets based on the Sugeno integral with its application to pattern recognition. Inf. Sci. 2012, 189, 93–109. [Google Scholar] [CrossRef]
- Chen, Y.; Garcia, E.K.; Gupta, M.R.; Rahimi, A.; Cazzanti, L. Similarity-based Classification: Concepts and Algorithms. J. Mach. Learn. Res. 2009, 10, 747–776. [Google Scholar]
- Suzuki, K.; Yamada, H.; Hashimoto, S. A similarity-based neural network for facial expression analysis. Pattern Recognit. Lett. 2007, 28, 1104–1111. [Google Scholar] [CrossRef]
- Duda, D.O.; Hart, P.E.; Stork, D.G. Pattern Classification, 2nd ed.; John Wiley: New York, NY, USA, 2001. [Google Scholar]
- Andersson, J. Statistical Analysis with Swift; Apress: New York, NY, USA, 2021. [Google Scholar]
- Reshadat, V.; Feizi-Derakhshi, M.R. Neural network-based methods in information retrieval. Am. J. Sci. Res. 2012, 58, 33–43. [Google Scholar]
- Cai, F.; China, C.; de Rijke, M. A Survey of Query Auto Completion in Information Retrieval. Found. Trends R Signal Process. 2016, 10, 273–363. [Google Scholar]
- Liu, B. Web DataMining; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Gonzalez, R.C.; Woods, R.E. Digital Image Processing, 4th ed.; Pearson: New York, NY, USA, 2018. [Google Scholar]
- Burgerr, W.; Burge, M.J. Principles of Digital Image Processing; Fundamental Techniques; Springer: London, UK, 2009. [Google Scholar]
- Webb, A. Statistical Pattern Recognition, 2nd ed.; John Wiley and Sons: New York, NY, USA, 2002. [Google Scholar]
- Kreyszig, E. Advanced Engineering Mathematics; John Wiley and Sons: New York, NY, USA, 2006. [Google Scholar]
- Trandafir, R.; Iatan, I.F. Modelling and Simulation: Theoretical Notions and Applications; Conspress: Bucharest, Romania, 2013. [Google Scholar]
- Anastassiou, G.; Iatan, I. Modern Algorithms of Simulation for Getting Some Random Numbers. J. Comput. Anal. Appl. 2013, 15, 1211–1222. [Google Scholar]
- Iatan, I.F.; Trandafir, R. Validating in Matlab of some Algorithms to Simulate some Continuous and Discrete Random Variables. In Proceedings of the Mathematics and Educational Symposium of Department of Mathematics and Computer Science; Technical University of Civil Engineering Bucharest: București, Romania; MatrixRom: Bucharest, Romania, 2014; pp. 67–72. [Google Scholar]
- Kumar, P.; Parmar, A. Versatile Approaches for Medical Image Compression. Procedia Comput. Sci. 2020, 167, 1380–1389. [Google Scholar] [CrossRef]
- Wilhelmsson, D.; Mikkelsen, L.P.; Fæster, S.; Asp, L.E. X-ray tomography data of compression tested unidirectional fibre composites with different off-axis angles. Data Brief 2019, 25, 104263. [Google Scholar] [CrossRef]
- Wu, F.Y.; Yang, K.; Sheng, X. Optimized compression and recovery of electrocardiographic signal for IoT platform. Appl. Soft Comput. J. 2020, 96, 106659. [Google Scholar] [CrossRef]
- Norris, D.; Kalm, K. Chunking and data compression in verbal short-term memory. Cognition 2021, 208, 104534. [Google Scholar] [CrossRef]
- Peralta, M.; Jannin, P.; Haegelen, C.; Baxter, J.S.H. Data imputation and compression for Parkinson’s disease clinical questionnaires. Artif. Intell. Med. 2021, 114, 102051. [Google Scholar] [CrossRef]
- Calderoni, L.; Magnani, A. The impact of face image compression in future generation electronic identity documents. Forensic Sci. Int. Digit. Investig. 2022, 40, 301345. [Google Scholar] [CrossRef]
- Coutinho, V.A.; Cintra, R.J.; Bayer, F.B. Low-complexity three-dimensional discrete Hartley transform approximations for medical image compression. Comput. Biol. Med. 2021, 139, 3105018. [Google Scholar] [CrossRef]
- Ettaouil, M.; Ghanou, Y.; El Moutaouakil, K.; Lazaar, M. Image Medical Compression by a new Architecture Optimization Model for the Kohonen Networks. Int. J. Comput. Theory Eng. 2011, 3, 204–210. [Google Scholar] [CrossRef]
- Dokuchaev, N.G. On Data Compression and Recovery for Sequences Using Constraints on the Spectrum Range. Probl. Inf. Transm. 2021, 57, 368–372. [Google Scholar] [CrossRef]
- Du, Y.; Yu, H. Medical Data Compression and Sharing Technology Based on Blockchain. In International Conference on Algorithmic Applications in Management; Lecture Notes in Computer Science Book Series (LNTCS); Springer: Cham, Switzerland, 2020; Volume 12290, pp. 581–592. [Google Scholar]
- Ishikawa, M.; Kawakami, H. Compression-based distance between string data and its application to literary work classification based on authorship. Comput. Stat. 2013, 28, 851–878. [Google Scholar] [CrossRef]
- Jha, C.K.; Kolekar, M.H. Electrocardiogram data compression using DCT based discrete orthogonal Stockwell transform. Biomed. Signal Process. Control 2018, 46, 174–181. [Google Scholar] [CrossRef]
- Netravali, A.N.; Haskell, B.G. Digital Pictures: Representation and Compression; Springer: Cham, Switzerland, 2012. [Google Scholar]
- Vlaicu, A. Digital Image Processing; Microinformatica Group: Cluj-Napoca, Romania, 1997. (In Romanian) [Google Scholar]
- Shih, F.Y. Image Processing and Pattern Recognition; Fundamentals and Techniques; John Wiley and Sons: New York, NY, USA, 2010. [Google Scholar]
- Tuduce, R.A. Signal Theory; Bren: Bucharest, Romania, 1998. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. A Fuzzy Neural Network and its Application to Pattern Recognition. IEEE Trans. Fuzzy Syst. 2010, 88, 303–338. [Google Scholar]
- Neagoe, V.E.; Stǎnǎşilǎ, O. Pattern Recognition and Neural Networks; Matrix Rom: Bucharest, Romania, 1999. (In Romanian) [Google Scholar]
- Janse van Rensburg, F.J.; Treurnicht, J.; Fourie, C.J. The Use of Fourier Descriptors for Object Recogntion in Robotic Assembly. In Proceedings of the 5th CIRP International Seminar on Intelligent Computation in Manufacturing Engineering, Ischia, Italy, 25–28 July 2006. [Google Scholar]
- Yang, C.; Yu, Q. Multiscale Fourier descriptor based on triangular features for shape retrieval. Signal Process. Image Commun. 2019, 71, 110–119. [Google Scholar] [CrossRef]
- De, P.; Ghoshal, D. Recognition of Non Circular Iris Pattern of the Goat by Structural, Statistical and Fourier Descriptors. Procedia Comput. Sci. 2016, 89, 845–849. [Google Scholar] [CrossRef] [Green Version]
- Preda, V. Statistical Decision Theory; Romanian Academy: Bucharest, Romania, 1992. [Google Scholar]
- Preda, V.C. The Student distribution and the principle of maximum entropy. Ann. Inst. Stat. Math. 1982, 34, 335–338. [Google Scholar] [CrossRef]
- Preda, V.; Balcau, C.; Niculescu, C. Entropy optimization in phase determination with linear inequality constraints. Rev. Roum. Math. Pures Appl. 2010, 55, 327–340. [Google Scholar]
- Preda, V.; Dedu, S.; Sheraz, M. Second order entropy approach for risk models involving truncation and censoring. Proc. Rom.-Acad. Ser. Math. Phys. Tech. Sci. Inf. Sci. 2016, 17, 195–202. [Google Scholar]
- Preda, V.; Băncescu, I. Evolution of non-stationary processes and some maximum entropy principles. Ann. West Univ.-Timis.-Math. Comput. Sci. 2018, 56, 43–70. [Google Scholar] [CrossRef]
- Barbu, V.S.; Karagrigoriou, A.; Preda, V. Entropy and divergence rates for Markov chains: II. The weighted case. Proc. Rom.-Acad.-Ser. A 2018, 19, 3–10. [Google Scholar]
- Abdul-Sathar, E.I.; Sathyareji, G.S. Estimation of Dynamic Cumulative Past Entropy for Power Function Distribution. Statistica 2018, 78, 319–334. [Google Scholar]
- Sachlas, A.; Papaioannou, T. Residual and Past Entropy in Actuarial Science and Survival Models. Methodol. Comput. Appl. Probab. 2014, 16, 79–99. [Google Scholar] [CrossRef]
- Sheraz, M.; Dedu, S.; Preda, V. Entropy measures for assessing volatile markets. Procedia Econ. Financ. 2015, 22, 655–662. [Google Scholar] [CrossRef] [Green Version]
- Lehman, E.; Leighton, F.T.; Meyer, A.R. Mathematics for Computer Science; 12th Media Services: Suwanee, GA, USA, 2017. [Google Scholar]
- Van de Sande, K.E.A.; Gevers, T.; Snoek, C.G.M. Evaluating color descriptors for object and scene recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1582–1596. [Google Scholar] [CrossRef]
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
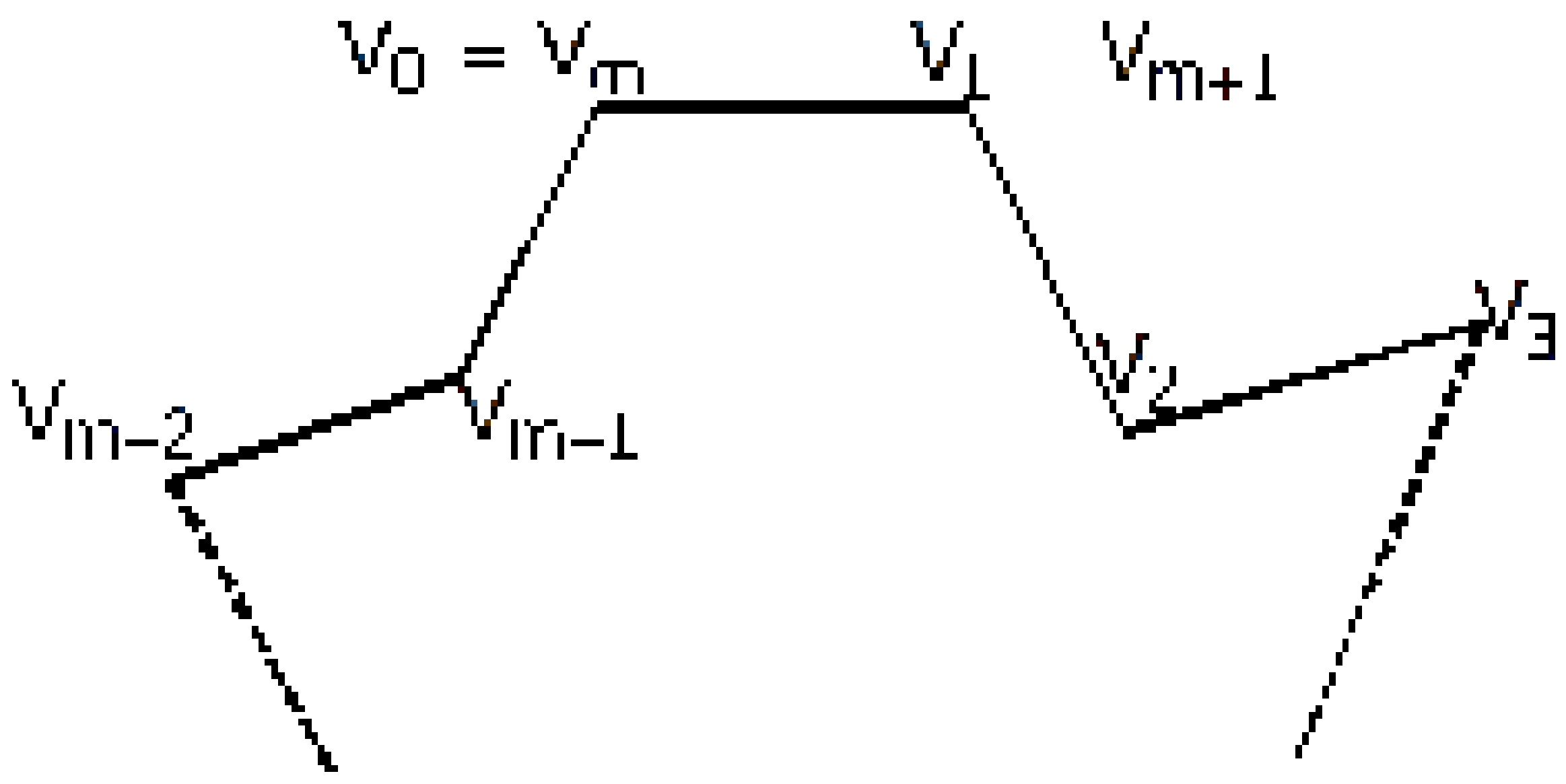{kind=link}
{kind=link}
{kind=link}
{kind=link}












































