
Cattle Number Estimation on Smart Pasture Based on Multi-Scale Information Fusion


Abstract
:1. Introduction
- Collect a novel herd image dataset in a variety of scenes and conditions.
- Train a multi-scale residual cattle density estimate network (MSRNet) for cattle number estimation on both public dataset and collected dataset, and demonstrate the interpretability.
- Identify three challenges on this dataset and utilize MSRNet to handle them. Conduct extensive experimentation to demonstrate the performance.
2. Related Work
2.1. Detection-Based Methods
2.2. Regression-Based Methods
2.3. Density Estimation-Based Methods
2.4. Common Public Datasets
3. Methodology
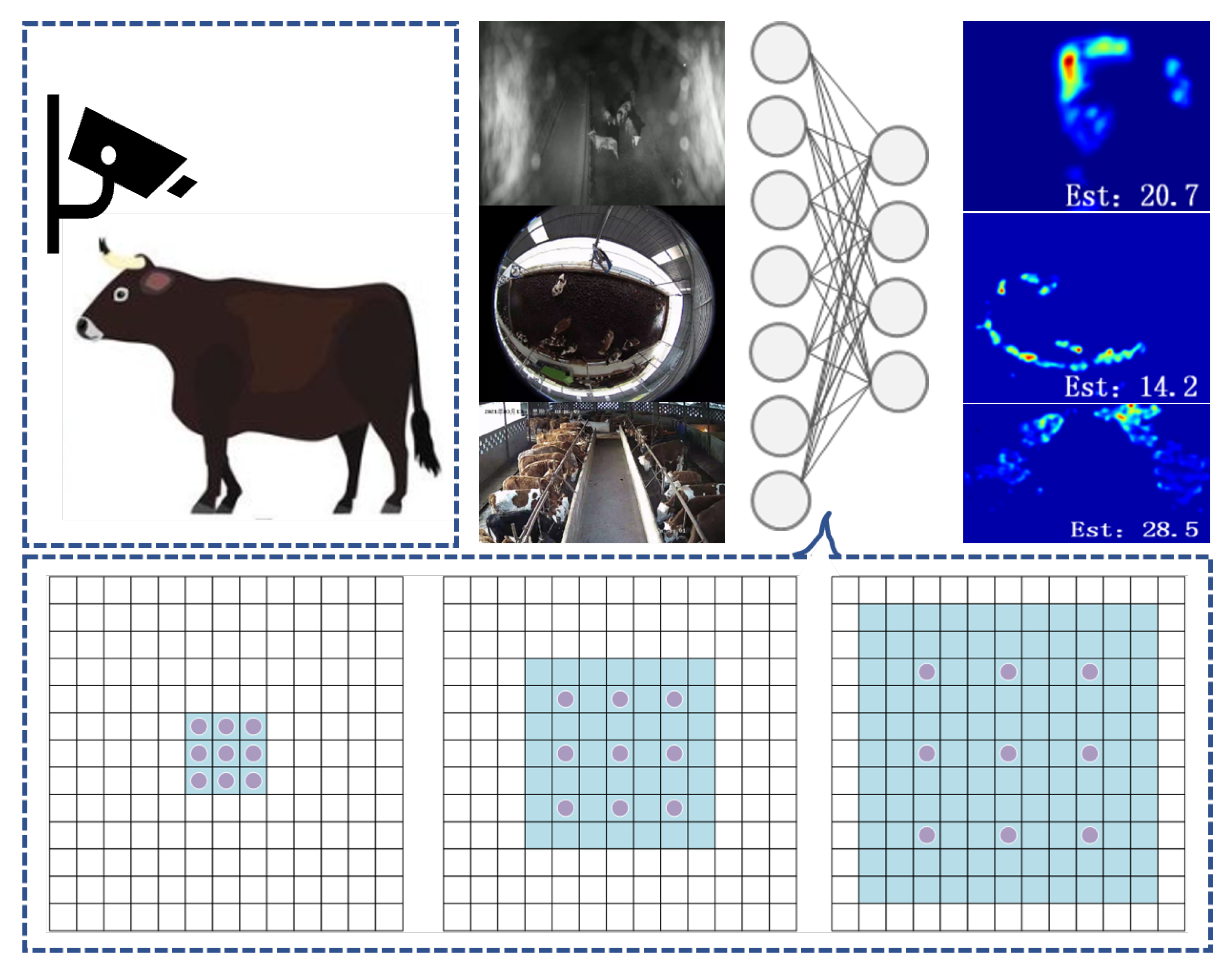
3.1. Formalization
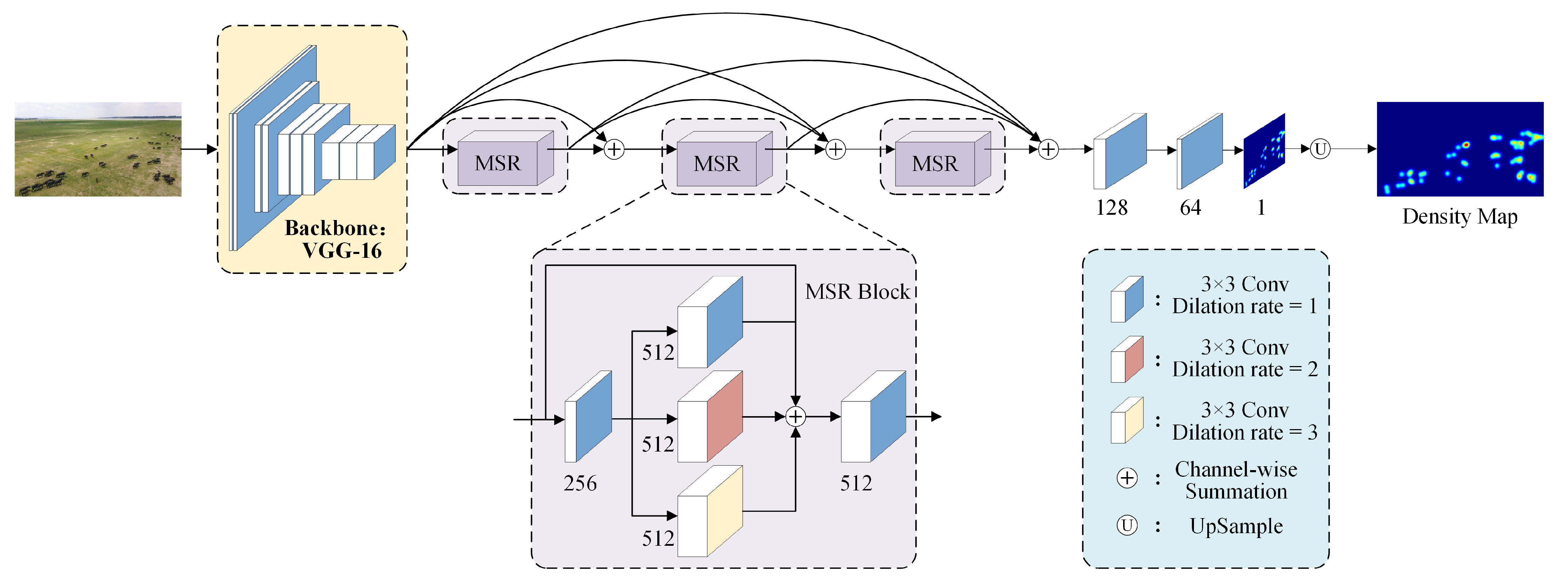
3.2. Multi-Scale Residual Cattle Density Estimation Methods
3.2.1. MSRNet Structure
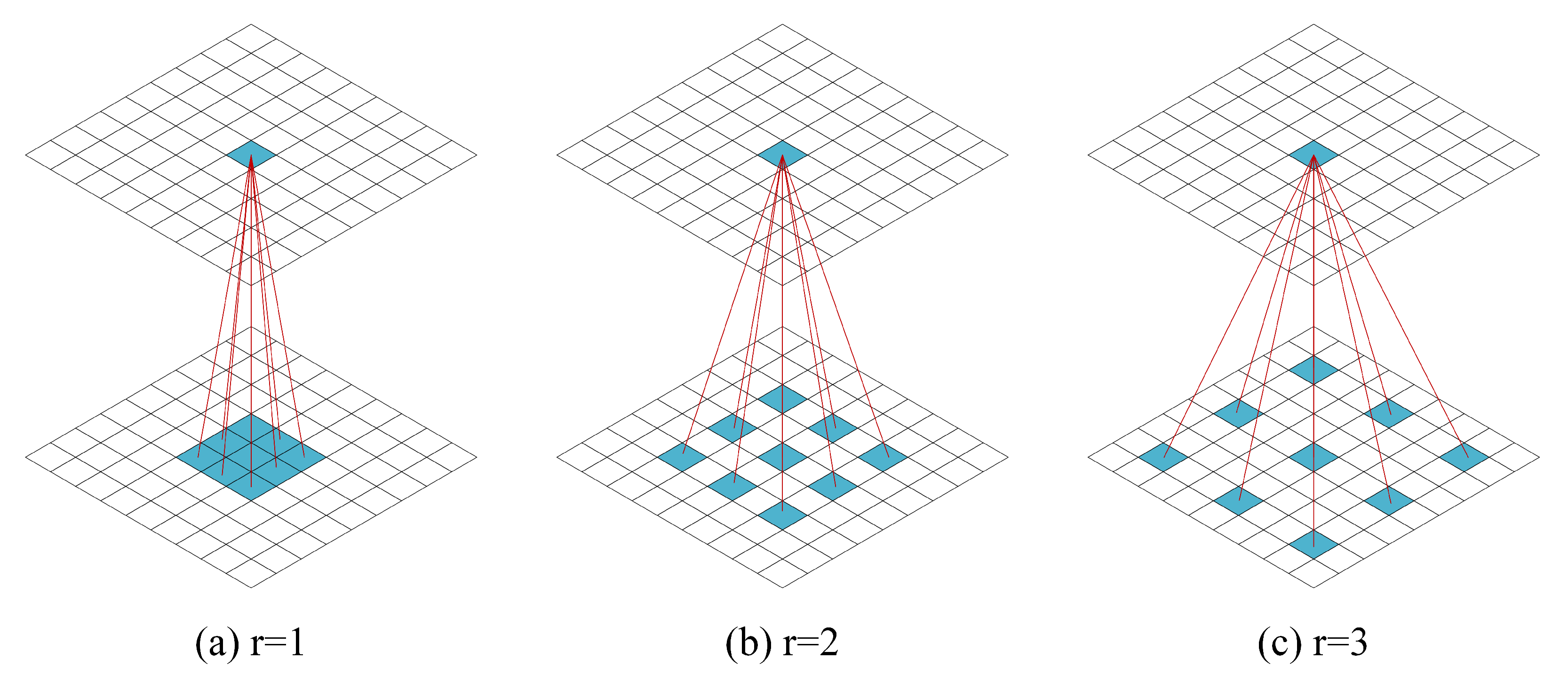
3.2.2. Multi-Scale Residual Feature Sensing Module (MSR)
3.2.3. Loss Function
| Algorithm 1 Multi-scale residual cattle density estimate network (MSRNet) algorithm | |
| Input: The input data: and ; | |
| Output: The well-trained MSRNet model ; | |
| 1: | Define the model function and initialize parameters ; |
| 2: | Define the loss function ; |
| 3: | The data augmentation from to get ; |
| 4: | fordo |
| 5: | for do |
| 6: | Calculate estimated density ; |
| 7: | Calculate ground truth ; |
| 8: | Calculate the ; |
| 9: | Update to minimize ; |
| 10: | end for |
| 11: | for do |
| 12: | Calculate estimated density ; |
| 13: | Calculate ground truth ; |
| 14: | end for |
| 15: | Calculate the ; |
| 16: | Calculate the ; |
| 17: | end for |
| 18: | Save the MSRNet model F; |
3.3. Herd Image Data Collection
4. Experiments
4.1. Setup
4.1.1. Model Training
- Randomly cropping the image to four non-overlapping image blocks of 1/4 the size of the image, or randomly cropping one image block of 1/4 the size of the image.
- Randomly flipping the image block, the possibility is 0.5.
- Randomly using gamma correction on image data considering variations in illumination, the possibility is 0.3, and the parameters for gamma correction are [0.5, 1.5].
4.1.2. Evaluation Criteria
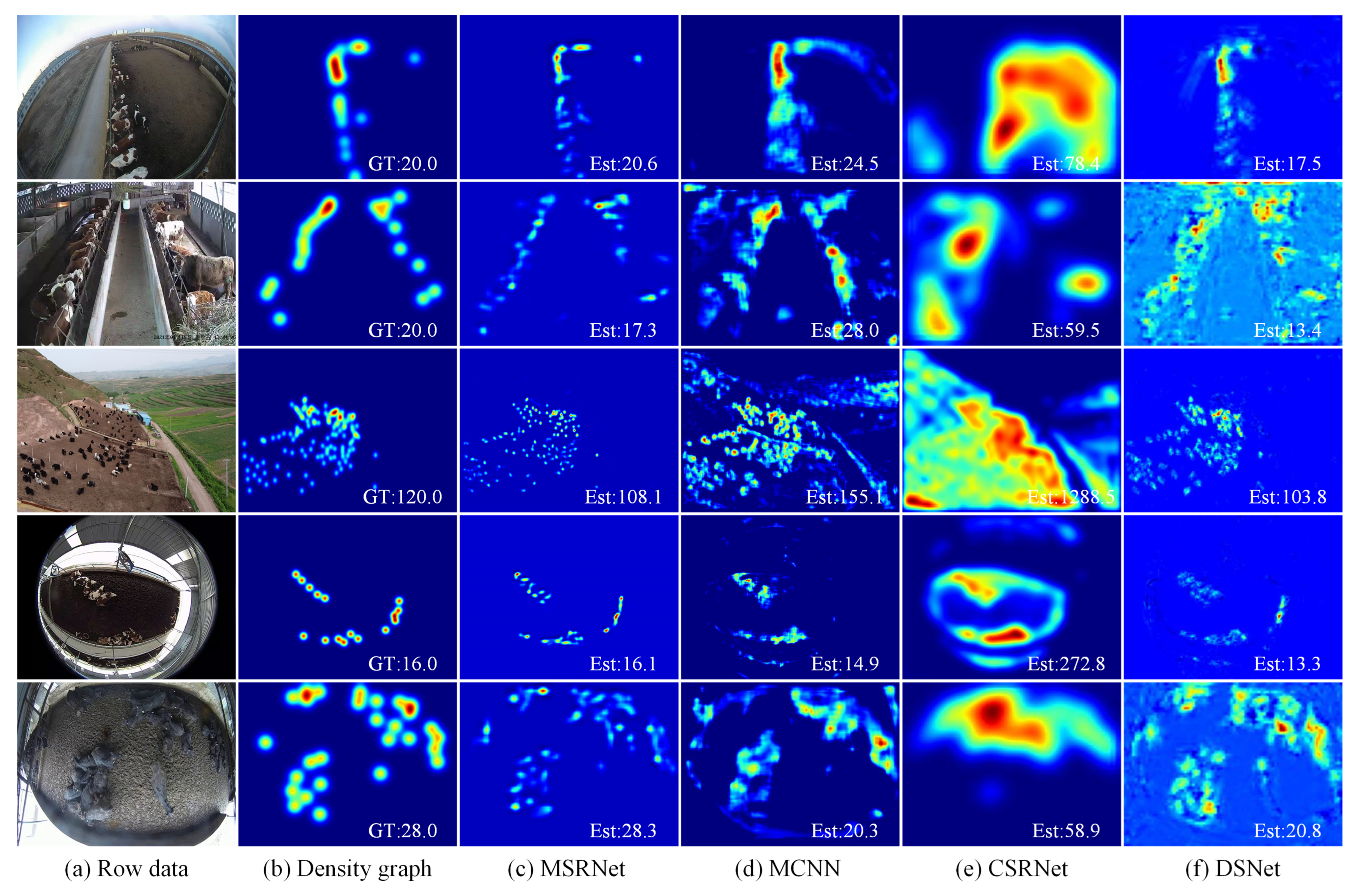
4.2. Main Result
4.2.1. Dataset Validity
4.2.2. Validity Test on ShanghaiTech Datasets
4.2.3. Ablation Experiments
4.3. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef] [Green Version]
- Ryan, D.; Denman, S.; Fookes, C.; Sridharan, S. Scene invariant multi camera crowd counting. Pattern Recognit. Lett. 2014, 44, 98–112. [Google Scholar] [CrossRef] [Green Version]
- Sang, J.; Wu, W.; Luo, H.; Xiang, H.; Zhang, Q.; Hu, H.; Xia, X. Improved crowd counting method based on scale-adaptive convolutional neural network. IEEE Access 2019, 7, 24411–24419. [Google Scholar] [CrossRef]
- Fu, H.; Ma, H.; Xiao, H. Scene-adaptive accurate and fast vertical crowd counting via joint using depth and color information. Multimed. Tools Appl. 2014, 73, 273–289. [Google Scholar] [CrossRef]
- Zhang, G. Current status and trends in the development of smart animal husbandry. China Status Quo 2019, 12, 33–35. [Google Scholar]
- Idrees, H.; Saleemi, I.; Seibert, C.; Shah, M. Multi-source multi-scale counting in extremely dense crowd images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2547–2554. [Google Scholar]
- Zhang, Y.; Zhou, D.; Chen, S.; Gao, S.; Ma, Y. Single-image crowd counting via multi-column convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 589–597. [Google Scholar]
- Li, Y.; Zhang, X.; Chen, D. Csrnet: Dilated convolutional neural networks for understanding the highly congested scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1091–1100. [Google Scholar]
- Dai, F.; Liu, H.; Ma, Y.; Zhang, X.; Zhao, Q. Dense scale network for crowd counting. In Proceedings of the 2021 International Conference on Multimedia Retrieval, Taipei, Taiwan, 21–24 August 2021; pp. 64–72. [Google Scholar]
- Shen, Z.; Xu, Y.; Ni, B.; Wang, M.; Hu, J.; Yang, X. Crowd counting via adversarial cross-scale consistency pursuit. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5245–5254. [Google Scholar]
- Cao, X.; Wang, Z.; Zhao, Y.; Su, F. Scale aggregation network for accurate and efficient crowd counting. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Huang, Z.; Li, Y. Contextual multiscale fusion-based algorithm for cotton boll counting. Appl. Res. Comput. 2021, 6, 1913–1916. [Google Scholar]
- Lu, H.; Cao, Z.; Xiao, Y.; Zhuang, B.; Shen, C. TasselNet: Counting maize tassels in the wild via local counts regression network. Plant Methods 2017, 13, 1–17. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, X. Deep Learning-Based Method for Automatic Cell Counting in Fluorescence Microscopy Imaging. Ph.D. Thesis, University of Electronic Science and Technology, Chengdu, China, 2020. [Google Scholar]
- Ma, Z.; Yu, L.; Chan, A.B. Small instance detection by integer programming on object density maps. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3689–3697. [Google Scholar]
- Sindagi, V.A.; Patel, V.M. A survey of recent advances in cnn-based single image crowd counting and density estimation. Pattern Recognit. Lett. 2018, 107, 3–16. [Google Scholar] [CrossRef] [Green Version]
- Cheng, D.; Rong, T.; Cao, G. Density map estimation for crowded chicken. In Proceedings of the International Conference on Image and Graphics, Beijing, China, 23–25 August 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 432–441. [Google Scholar]
- Hobbs, J.; Paull, R.; Markowicz, B.; Rose, G. Flowering density estimation from aerial imagery for automated pineapple flower counting. In Proceedings of the AI for Social Good Workshop, Virtual, 20–21 July 2020. [Google Scholar]
- Johnston, A.; Edwards, D. Welfare implications of identification of cattle by ear tags. Vet. Rec. 1996, 138, 612–614. [Google Scholar] [CrossRef] [PubMed]
- Xu, B.; Wang, W.; Falzon, G.; Kwan, P.; Schneider, D. Automated cattle counting using Mask R-CNN in quadcopter vision system. Comput. Electron. Agric. 2020, 171, 105300. [Google Scholar] [CrossRef]
- Li, Q.; Shang, J.; Li, B. Automatic counting method for grassland sheep based on head image features. China Meas. Test 2020, 46, 5. [Google Scholar]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Corfu, Greece, 20–25 September 1999; Volume 2, pp. 1150–1157. [Google Scholar]
- Tian, M.; Guo, H.; Chen, H.; Wang, Q.; Long, C.; Ma, Y. Automated pig counting using deep learning. Comput. Electron. Agric. 2019, 163, 104840. [Google Scholar] [CrossRef]
- Wan, J.; Wang, Q.; Chan, A.B. Kernel-based density map generation for dense object counting. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 1357–1370. [Google Scholar] [CrossRef] [PubMed]
- Chan, A.; Vasconcelos, N. Ucsd pedestrian dataset. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 2008, 30, 909–926. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, C.; Li, H.; Wang, X.; Yang, X. Cross-scene crowd counting via deep convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 833–841. [Google Scholar]
- Shao, W.; Kawakami, R.; Yoshihashi, R.; You, S.; Kawase, H.; Naemura, T. Cattle detection and counting in UAV images based on convolutional neural networks. Int. J. Remote. Sens. 2020, 41, 31–52. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Song, Q.; Wang, C.; Wang, Y.; Tai, Y.; Wang, C.; Li, J.; Wu, J.; Ma, J. To choose or to fuse? Scale selection for crowd counting. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 2576–2583. [Google Scholar]
- Cohen, T.; Welling, M. Group equivariant convolutional networks. In Proceedings of the International Conference on Machine Learning, PMLR, New York, NY, USA, 20–22 June 2016; pp. 2990–2999. [Google Scholar]
- Lagrave, P.Y.; Barbaresco, F. Hyperbolic Equivariant Convolutional Neural Networks for Fish-Eye Image Processing. Available online: https://hal.archives-ouvertes.fr/hal-03553274 (accessed on 25 February 2022).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Number of Images | Average Resolution | Count Statistics | |||
|---|---|---|---|---|---|---|
| Total | Min | Ave | Max | |||
| UCSD [25] | 2000 | 158 × 238 | 49,885 | 11 | 25 | 46 |
| UCF_CC_50 [6] | 50 | 2101 × 2888 | 63,974 | 94 | 1279 | 4543 |
| WorldExpo [26] | 3980 | 576 × 720 | 199,923 | 1 | 50 | 253 |
| ShanghaiTech_A [7] | 482 | 589 × 868 | 241,677 | 33 | 501 | 3139 |
| ShanghaiTech_B [7] | 716 | 768 × 1024 | 88,488 | 9 | 123 | 578 |
| Cattle dataset | 850 | 864 × 1317 | 18,403 | 3 | 22 | 129 |
| Models | MAE | RMSE |
|---|---|---|
| MCNN [7] | 6.57 | 10.25 |
| CSRet [8] | 11.57 | 14.61 |
| DSNet [9] | 2.14 | 3.31 |
| MSRNet | 1.85 | 2.64 |
| Models | ShanghaiTech_A | ShanghaiTech_B | ||
|---|---|---|---|---|
| MAE | RMSE | MAE | RMSE | |
| MCNN [7] | 110.2 | 173.2 | 26.4 | 33.4 |
| ACSCP [10] | 75.7 | 102.7 | 17.2 | 27.4 |
| CSRNet [8] | 68.2 | 115.0 | 10.6 | 16.0 |
| SANet [11] | 67.0 | 104.5 | 8.4 | 13.6 |
| KDMG [24] | 63.8 | 99.2 | 7.8 | 12.7 |
| MSRNet | 63.5 | 96.8 | 8.4 | 13.0 |
| Method | MAE | RMSE |
|---|---|---|
| VGG-16 | 5.34 | 8.86 |
| VGG-16 + MSR | 5.10 | 7.20 |
| VGG-16 + MSR + | 1.85 | 2.64 |
| ResNet-50 + MSR + | 8.64 | 12.65 |
| Value of Weight | MAE | RMSE |
|---|---|---|
| = 0 (w/o ) | 5.10 | 7.20 |
| = 10 | 2.02 | 2.88 |
| = 100 | 1.87 | 2.84 |
| = 1000 | 1.85 | 2.64 |
| = 10,000 | 1.90 | 2.81 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhong, M.; Tan, Y.; Li, J.; Zhang, H.; Yu, S. Cattle Number Estimation on Smart Pasture Based on Multi-Scale Information Fusion. Mathematics 2022, 10, 3856. https://doi.org/10.3390/math10203856
Zhong M, Tan Y, Li J, Zhang H, Yu S. Cattle Number Estimation on Smart Pasture Based on Multi-Scale Information Fusion. Mathematics. 2022; 10(20):3856. https://doi.org/10.3390/math10203856
Chicago/Turabian StyleZhong, Minyue, Yao Tan, Jie Li, Hongming Zhang, and Siyi Yu. 2022. "Cattle Number Estimation on Smart Pasture Based on Multi-Scale Information Fusion" Mathematics 10, no. 20: 3856. https://doi.org/10.3390/math10203856
APA StyleZhong, M., Tan, Y., Li, J., Zhang, H., & Yu, S. (2022). Cattle Number Estimation on Smart Pasture Based on Multi-Scale Information Fusion. Mathematics, 10(20), 3856. https://doi.org/10.3390/math10203856