


Neural Subspace Learning for Surface Defect Detection

Abstract
:1. Introduction
- A novel, non-rigid data augmentation method is proposed for surface defects detection. The proposed thin-plate-spline deformation method can generate more reliable training samples than rigid transformation based methods.
- A novel, unsupervised neural subspace learning method is proposed by combining the clear mathematical theory of traditional subspace learning and the powerful learning ability of DNNs.
- The proposed method achieves competitive performance and has better generalization than other methods.
2. Related Work
3. Methodology
3.1. Data Augmentation
3.2. Neural-Subspace Learning with Low-Rank and Sparse Representation Priors
4. Experiments
4.1. Implement Detail
4.1.1. SD-Saliency-900
4.1.2. CrackForest
4.2. Evaluation
4.3. Experimental Results
4.3.1. Comparison with Unsupervised Methods
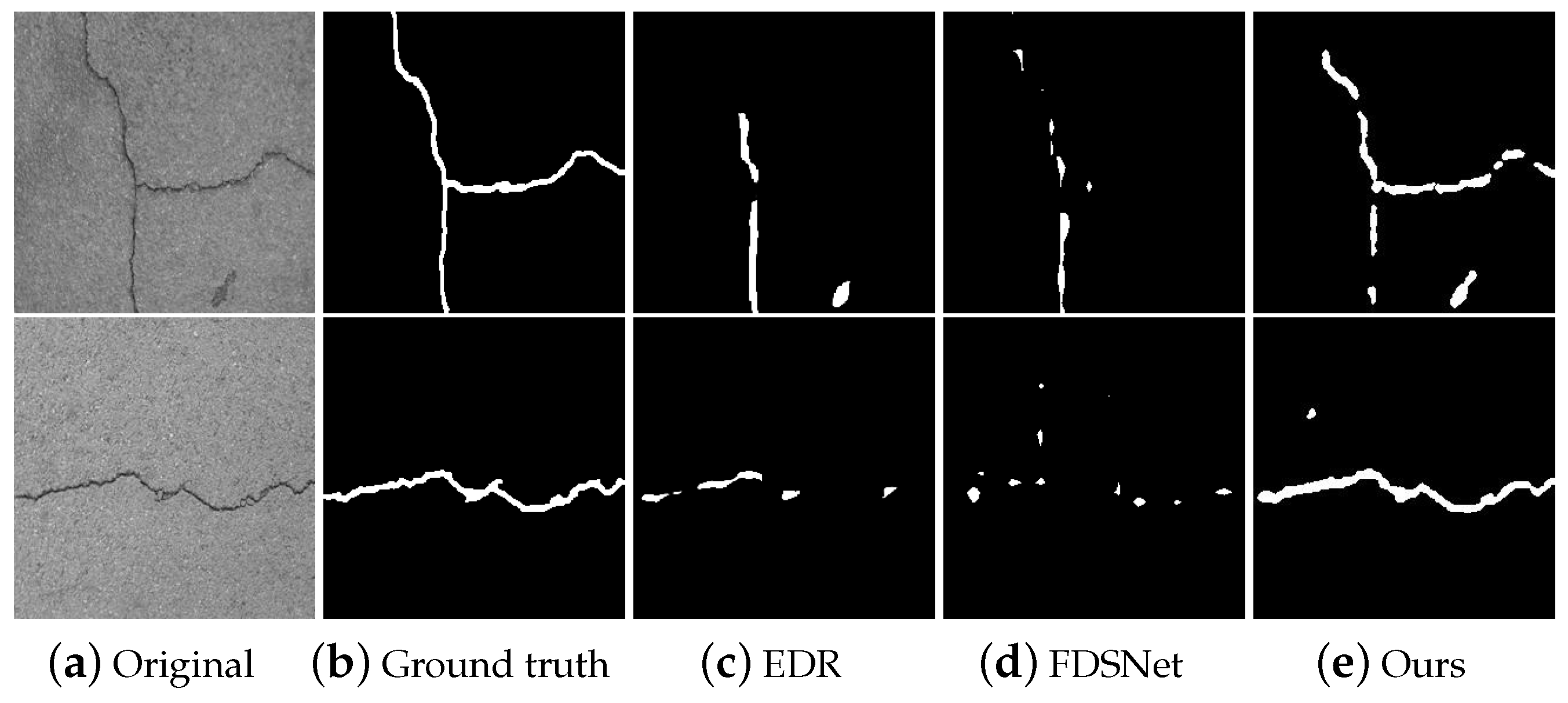
4.3.2. Comparison with Supervised Method
4.4. Comparison among Different Data Augmentation Strategy
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, P.C.; Pavlidis, T. Segmentation by texture using a co-occurrence matrix and a split-and-merge algorithm. Comput. Graph. Image Process. 1979, 10, 172–182. [Google Scholar] [CrossRef]
- Guo, Z.; Zhang, L.; Zhang, D. A completed modeling of local binary pattern operator for texture classification. IEEE Trans. Image Process. 2010, 19, 1657–1663. [Google Scholar] [PubMed] [Green Version]
- Comer, M.L.; Delp, E.J., III. Morphological operations for color image processing. J. Electron. Imaging 1999, 8, 279–289. [Google Scholar] [CrossRef]
- Shapley, R.; Lennie, P. Spatial frequency analysis in the visual system. Annu. Rev. Neurosci. 1985, 8, 547–581. [Google Scholar] [CrossRef] [PubMed]
- Majumdar, A.; Bhushan, B. Fractal model of elastic-plastic contact between rough surfaces. J. Tribol. 1991, 113, 1–11. [Google Scholar] [CrossRef]
- Bouman, C.A.; Shapiro, M. A multiscale random field model for Bayesian image segmentation. IEEE Trans. Image Process. 1994, 3, 162–177. [Google Scholar] [CrossRef] [Green Version]
- Xie, X.; Mirmehdi, M. Texture exemplars for defect detection on random textures. In Proceedings of the International Conference on Pattern Recognition and Image Analysis, Bath, UK, 22–25 August 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 404–413. [Google Scholar]
- Akaike, H. Fitting autoregressive models for prediction. Ann. Inst. Stat. Math. 1969, 21, 243–247. [Google Scholar] [CrossRef]
- Song, G.; Song, K.; Yan, Y. EDRNet: Encoder–decoder residual network for salient object detection of strip steel surface defects. IEEE Trans. Instrum. Meas. 2020, 69, 9709–9719. [Google Scholar] [CrossRef]
- Dong, H.; Song, K.; He, Y.; Xu, J.; Yan, Y.; Meng, Q. PGA-Net: Pyramid feature fusion and global context attention network for automated surface defect detection. IEEE Trans. Ind. Inform. 2019, 16, 7448–7458. [Google Scholar] [CrossRef]
- Mei, S.; Wang, Y.; Wen, G. Automatic fabric defect detection with a multi-scale convolutional denoising autoencoder network model. Sensors 2018, 18, 1064. [Google Scholar] [CrossRef]
- Khalilian, S.; Hallaj, Y.; Balouchestani, A.; Karshenas, H.; Mohammadi, A. PCB Defect Detection Using Denoising Convolutional Autoencoders. In Proceedings of the 2020 International Conference on Machine Vision and Image Processing (MVIP), Qom, Iran, 18–20 February 2020; pp. 1–5. [Google Scholar]
- Kang, G.; Gao, S.; Yu, L.; Zhang, D. Deep architecture for high-speed railway insulator surface defect detection: Denoising autoencoder with multitask learning. IEEE Trans. Instrum. Meas. 2018, 68, 2679–2690. [Google Scholar] [CrossRef]
- Yu, W.; Zhao, C. Robust monitoring and fault isolation of nonlinear industrial processes using denoising autoencoder and elastic net. IEEE Trans. Control Syst. Technol. 2019, 28, 1083–1091. [Google Scholar] [CrossRef]
- Ulutas, T.; Oz, M.A.N.; Mercimek, M.; Kaymakci, O.T. Split-Brain Autoencoder Approach for Surface Defect Detection. In Proceedings of the 2020 International Conference on Electrical, Communication, and Computer Engineering (ICECCE), Istanbul, Turkey, 12–13 June 2020; pp. 1–5. [Google Scholar]
- Bird, J.J.; Barnes, C.M.; Manso, L.J.; Ekárt, A.; Faria, D.R. Fruit quality and defect image classification with conditional GAN data augmentation. Sci. Hortic. 2022, 293, 110684. [Google Scholar] [CrossRef]
- Chou, Y.C.; Kuo, C.J.; Chen, T.T.; Horng, G.J.; Pai, M.Y.; Wu, M.E.; Lin, Y.C.; Hung, M.H.; Su, W.T.; Chen, Y.C.; et al. Deep-learning-based defective bean inspection with GAN-structured automated labeled data augmentation in coffee industry. Appl. Sci. 2019, 9, 4166. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.; Xiao, Z. Lychee surface defect detection based on deep convolutional neural networks with GAN-based data augmentation. Agronomy 2021, 11, 1500. [Google Scholar] [CrossRef]
- Zhang, Z.; Ganesh, A.; Xiao, L.; Yi, M. TILT: Transform Invariant Low-rank Textures. In Proceedings of the Asian Conference on Computer Vision, Queenstown, New Zealand, 8–12 November 2010. [Google Scholar]
- Peng, Y.; Ganesh, A.; Wright, J.; Xu, W.; Yi, M. RASL: Robust alignment by sparse and low-rank decomposition for linearly correlated images. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Candès, E.; Li, X.; Ma, Y.; Wright, J. Robust principal component analysis? J. ACM 2011, 58, 11:1–11:37. [Google Scholar] [CrossRef]
- Cao, J.; Wang, N.; Zhang, J.; Wen, Z.; Li, B.; Liu, X. Detection of varied defects in diverse fabric images via modified RPCA with noise term and defect prior. Int. J. Cloth. Sci. Technol. 2016, 28, 516–529. [Google Scholar] [CrossRef]
- Czimmermann, T.; Ciuti, G.; Milazzo, M.; Chiurazzi, M.; Roccella, S.; Oddo, C.M.; Dario, P. Visual-based defect detection and classification approaches for industrial applications—A survey. Sensors 2020, 20, 1459. [Google Scholar] [CrossRef] [Green Version]
- Niskanen, M.; Silvén, O.; Kauppinen, H. Color and texture based wood inspection with non-supervised clustering. In Proceedings of the Scandinavian Conference on Image Analysis, Bergen, Norway, 11–14 June 2001; pp. 336–342. [Google Scholar]
- Kittler, J.; Marik, R.; Mirmehdi, M.; Petrou, M.; Song, J. Detection of Defects in Colour Texture Surfaces. In Proceedings of the MVA, Kawasaki, Japan, 13–15 December 1994; pp. 558–567. [Google Scholar]
- Wen, W.; Xia, A. Verifying edges for visual inspection purposes. Pattern Recognit. Lett. 1999, 20, 315–328. [Google Scholar] [CrossRef]
- Chen, J.; Jain, A.K. A structural approach to identify defects in textured images. In Proceedings of the 1988 IEEE International Conference on Systems, Man, and Cybernetics, Beijing and Shenyang, China, 8–12 August 1988; Volume 1, pp. 29–32. [Google Scholar]
- Odemir, S.; Baykut, A.; Meylani, R.; Erçil, A.; Ertuzun, A. Comparative evaluation of texture analysis algorithms for defect inspection of textile products. In Proceedings of the Fourteenth International Conference on Pattern Recognition (Cat. No. 98EX170), Brisbane, QLD, Australia, 20 August 1998; Volume 2, pp. 1738–1740. [Google Scholar]
- Li, X.; Jiang, H.; Yin, G. Detection of surface crack defects on ferrite magnetic tile. NDT E Int. 2014, 62, 6–13. [Google Scholar] [CrossRef]
- Zhang, J.; Ding, R.; Ban, M.; Guo, T. FDSNeT: An Accurate Real-Time Surface Defect Segmentation Network. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 3803–3807. [Google Scholar]
- Augustauskas, R.; Lipnickas, A. Improved pixel-level pavement-defect segmentation using a deep autoencoder. Sensors 2020, 20, 2557. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.; Bengio, Y.; Courville, A.; Bengio, Y. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Chow, J.K.; Su, Z.; Wu, J.; Tan, P.S.; Mao, X.; Wang, Y.H. Anomaly detection of defects on concrete structures with the convolutional autoencoder. Adv. Eng. Inform. 2020, 45, 101105. [Google Scholar] [CrossRef]
- Mujeeb, A.; Dai, W.; Erdt, M.; Sourin, A. One class based feature learning approach for defect detection using deep autoencoders. Adv. Eng. Inform. 2019, 42, 100933. [Google Scholar] [CrossRef]
- Tian, H.; Li, F. Autoencoder-based fabric defect detection with cross-patch similarity. In Proceedings of the 2019 16th International Conference on Machine Vision Applications (MVA), Tokyo, Japan, 27–31 May 2019; pp. 1–6. [Google Scholar]
- Bergmann, P.; Löwe, S.; Fauser, M.; Sattlegger, D.; Steger, C. Improving unsupervised defect segmentation by applying structural similarity to autoencoders. arXiv 2018, arXiv:1807.02011. [Google Scholar]
- Yang, H.; Chen, Y.; Song, K.; Yin, Z. Multiscale feature-clustering-based fully convolutional autoencoder for fast accurate visual inspection of texture surface defects. IEEE Trans. Autom. Sci. Eng. 2019, 16, 1450–1467. [Google Scholar] [CrossRef]
- Dehaene, D.; Eline, P. Anomaly localization by modeling perceptual features. arXiv 2020, arXiv:2008.05369. [Google Scholar]
- Yan, H.; Yeh, H.M.; Sergin, N. Image-based process monitoring via adversarial autoencoder with applications to rolling defect detection. In Proceedings of the 2019 IEEE 15th International Conference on Automation Science and Engineering (CASE), Vancouver, BC, Canada, 22–26 August 2019; pp. 311–316. [Google Scholar]
- Powell, M. A thin plate spline method for mapping curves into curves in two dimensions. In Computational Techniques and Applications: CTAC95; World Scientific: Singapore, 1996; pp. 43–57. [Google Scholar]
- Donato, G.; Belongie, S. Approximate Thin Plate Spline Mappings. In Proceedings of the 7th European Conference on Computer Vision-Part III, Copenhagen, Denmark, 28–31 May 2002. [Google Scholar]
- Li, B.; Zhao, F.; Su, Z.; Liang, X.; Lai, Y.K.; Rosin, P.L. Example-Based Image Colorization Using Locality Consistent Sparse Representation. IEEE Trans. Image Process. 2017, 26, 5188–5202. [Google Scholar] [CrossRef] [Green Version]
- Li, B.; Liu, R.; Cao, J.; Zhang, J.; Lai, Y.K.; Liu, X. Online Low-Rank Representation Learning for Joint Multi-Subspace Recovery and Clustering. IEEE Trans. Image Process. 2018, 27, 335–348. [Google Scholar] [CrossRef] [Green Version]
- Liu, G.; Lin, Z.; Yan, S.; Sun, J.; Yu, Y.; Ma, Y. Robust recovery of subspace structures by low-rank representation. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 171–184. [Google Scholar] [CrossRef] [Green Version]
- Shi, J.; Yang, W.; Yong, L.; Zheng, X. Low-Rank Representation for Incomplete Data. Math. Probl. Eng. 2014, 2014, 439417. [Google Scholar]
- Zhao, Y.Q.; Yang, J. Hyperspectral Image Denoising via Sparse Representation and Low-Rank Constraint. IEEE Trans. Geosci. Remote Sens. 2014, 53, 296–308. [Google Scholar] [CrossRef]
- Xiong, L.; Chen, X.; Schneider, J. Direct robust matrix factorizatoin for anomaly detection. In Proceedings of the 2011 IEEE 11th International Conference on Data Mining, Vancouver, BC, Canada, 11–14 December 2011; pp. 844–853. [Google Scholar]
- van den Oord, A.; Vinyals, O.; Kavukcuoglu, K. Neural Discrete Representation Learning. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 3–9 December 2017; Curran Associates, Inc.: New York, NY, USA, 2017; Volume 30. [Google Scholar]
- Song, G.; Song, K.; Yan, Y. Saliency detection for strip steel surface defects using multiple constraints and improved texture features. Opt. Lasers Eng. 2020, 128, 106000. [Google Scholar] [CrossRef]
- Cui, L.; Qi, Z.; Chen, Z.; Meng, F.; Shi, Y. Pavement distress detection using random decision forests. In Proceedings of the International Conference on Data Science, Syd, Australia, 8–9 August 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 95–102. [Google Scholar]
- Abdel-Qader, I.; Pashaie-Rad, S.; Abudayyeh, O.; Yehia, S. PCA-based algorithm for unsupervised bridge crack detection. Adv. Eng. Softw. 2006, 37, 771–778. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SD-Saliency-900 | PCA | SSIMAE | FAVAE | Ours |
|---|---|---|---|---|
| Accuracy | 93.1 | 93.6 | 87.8 | 95.0 |
| Recall | 14.0 | 32.2 | 39.0 | 41.4 |
| Precision | 54.6 | 57.2 | 28.1 | 75.8 |
| F1-score | 22.3 | 41.2 | 32.6 | 53.6 |
| CrackForest | PCA | SSIMAE | FAVAE | Ours |
| Accuracy | 95.1 | 95.0 | 94.3 | 98.5 |
| Recall | 24.4 | 76.2 | 60.5 | 79.1 |
| Precision | 80.0 | 35.1 | 28.1 | 71.4 |
| F1-score | 37.4 | 48.1 | 38.4 | 75.1 |
| SD-Saliency-900 | Accuracy | Recall | Precision | F1-Score |
|---|---|---|---|---|
| EDR | 95.9 | 54.1 | 100 | 70.2 |
| FDSNet | 96.2 | 72.9 | 72.6 | 72.8 |
| Ours | 95.0 | 41.4 | 75.8 | 53.6 |
| CrackForest | Accuracy | Recall | Precision | F1-Score |
| EDR | 98.2 | 56.0 | 98.8 | 71.5 |
| Ours | 98.5 | 79.1 | 71.4 | 75.1 |
| Train on SD-Saliency-900, Test on CrackForest | Accuracy | Recall | Precision | F1-Score |
|---|---|---|---|---|
| EDR | 91.2 | 1.0 | 59.2 | 1.8 |
| FDSNet | 97.1 | 10.8 | 48.9 | 17.7 |
| Ours | 94.3 | 34.3 | 68.3 | 45.7 |
| Train on CrackForest, Test on SD-Saliency-900 | Accuracy | Recall | Precision | F1-Score |
| EDR | 97.3 | 4.9 | 95.9 | 9.4 |
| Ours | 94.7 | 7.1 | 97.4 | 13.2 |
| SD-Saliency-900 | Accuracy | Recall | Precision | F1-Score |
|---|---|---|---|---|
| TPS+Rigid | 95.0 | 41.6 | 76.0 | 53.8 |
| TPS | 95.0 | 41.4 | 75.8 | 53.6 |
| Rigid | 93.9 | 40.3 | 59.5 | 48.1 |
| w/o augmentation | 93.3 | 21.5 | 55.6 | 31.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, B.; Chen, W.; Li, B.; Liu, X. Neural Subspace Learning for Surface Defect Detection. Mathematics 2022, 10, 4351. https://doi.org/10.3390/math10224351
Liu B, Chen W, Li B, Liu X. Neural Subspace Learning for Surface Defect Detection. Mathematics. 2022; 10(22):4351. https://doi.org/10.3390/math10224351
Chicago/Turabian StyleLiu, Bin, Weifeng Chen, Bo Li, and Xiuping Liu. 2022. "Neural Subspace Learning for Surface Defect Detection" Mathematics 10, no. 22: 4351. https://doi.org/10.3390/math10224351
APA StyleLiu, B., Chen, W., Li, B., & Liu, X. (2022). Neural Subspace Learning for Surface Defect Detection. Mathematics, 10(22), 4351. https://doi.org/10.3390/math10224351