1. Introduction
Electricity consumption, production and supply are increasingly important areas that are being looked into seriously by governments, researchers and corporate companies due to the fact of their inevitable importance on livelihoods and economic development all around the world. Electricity is conventionally generated using sources of primary energy including fossil fuels, nuclear energy and renewable energy. However, a high percentage of electricity production comes from the burning of fossil fuels, leading to an increase in greenhouse gas emissions, which are harmful to the environment in the long run. One of the cruxes of the United Nation’s Sustainable Development Goals (UNSDGs) (
https://sdgs.un.org/goals, accessed on 5 November 2021) is to reduce greenhouse gases as an effective method to reduce carbon emissions worldwide and promote the use of renewable energy sources. Specifically, SDG 12 (
https://www.cdp.net/en/companies-discloser, accessed on 5 November 2021), which concerns “Responsible Consumption and Production”, aims to reduce greenhouse gases and carbon emissions worldwide. To effectively reduce carbon emissions, the solutions are to reduce electricity production from the burning of fossil fuels and to minimize the problems of electricity overproduction and oversupply.
Electricity consumption varies greatly from one region to another depending on the availability of electricity and the level of development of the region. One of the measures of the development of a country is the Human Development Index (HDI) (
https://hdr.undp.org/en/content/human-development-index-hdi, accessed on 5 November 2021). Countries with a higher HDI are considered more developed compared to countries with a lower HDI. Therefore, it is important to develop methods to accurately forecast electricity consumption in different geographical regions at different times so that we are able to produce and supply electricity in correct amounts. This would enable us to optimize electricity production and supply to match electricity demand. This would also ensure that all regions are supplied with adequate amounts of electricity supporting their livelihood and development. Forecasting electricity consumption accurately would help to prevent excessive burning of fossil fuels and is crucial for the strategic planning of electricity production and supply. Inefficiency in electricity production may cause a shortage or surplus of electricity supply. A shortage of electricity may affect a region’s development; meanwhile, a surplus of electricity would be a wastage.
There are many available methods in the relevant literature for forecasting electricity consumption. The most common models for this purpose are the autoregressive integrated moving average (ARIMA), the autoregressive moving average (ARMA), the grey models and the linear regression models [
1,
2,
3,
4,
5,
6]. In recent years, many methods that improve the forecasting ability of existing models have been introduced. However, a model developed for one region may not be appropriate for another region with different patterns of electricity consumption. Hence, in this study, we investigated the ability of the artificial neural network (ANN) [
1], the adaptive neuro-fuzzy inference system (ANFIS) [
2], the least squares support vector machines (LSSVMs) [
3] and the fuzzy time series model (FTS) [
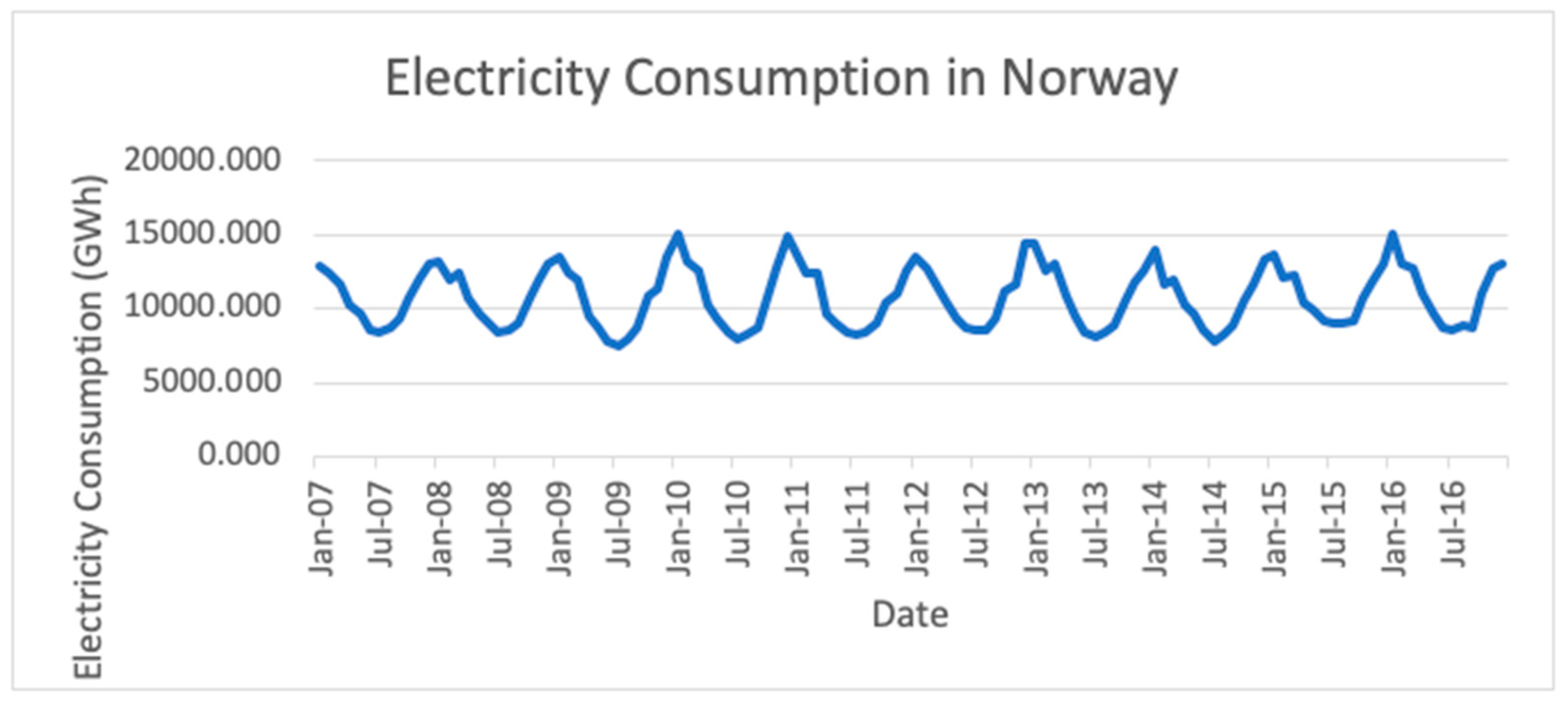
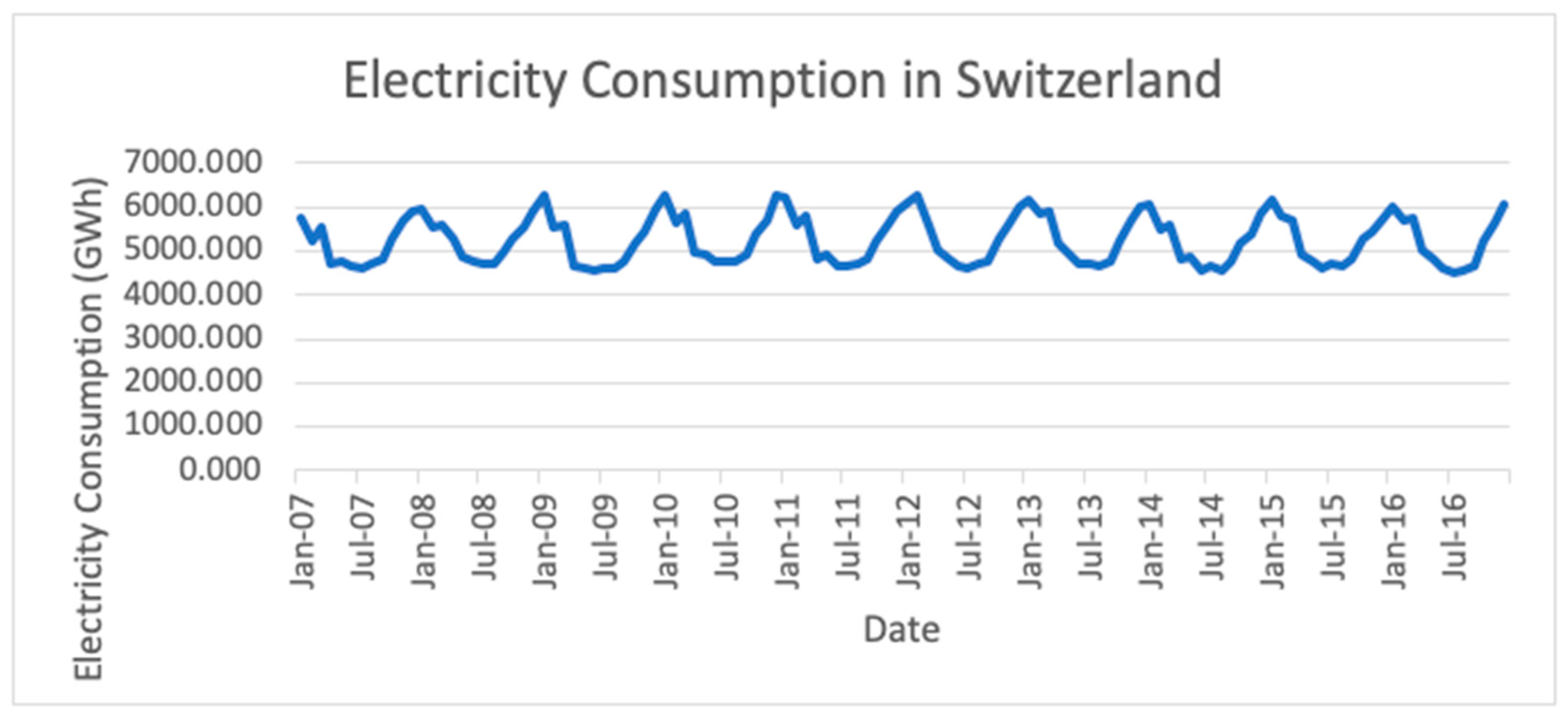
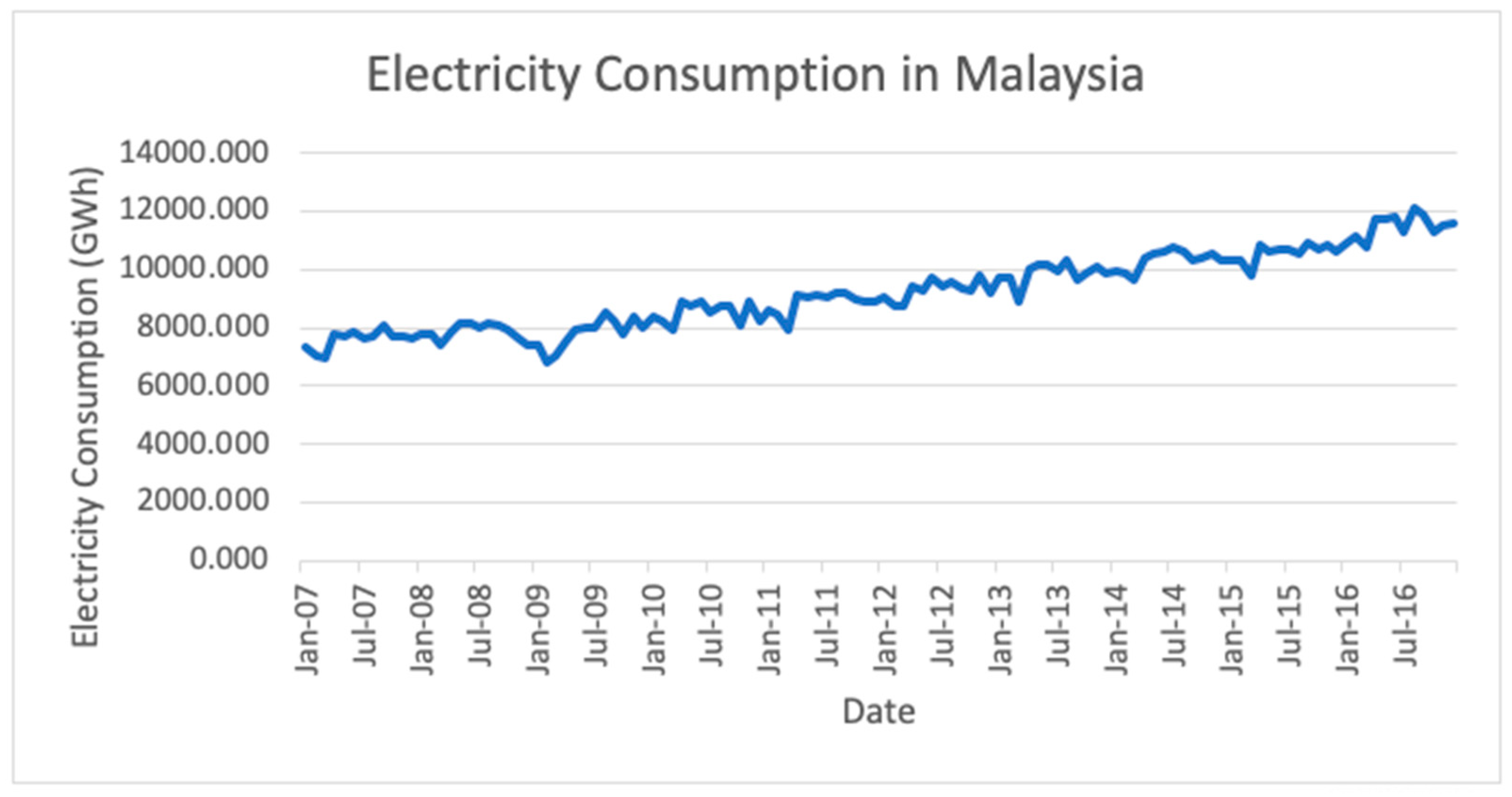
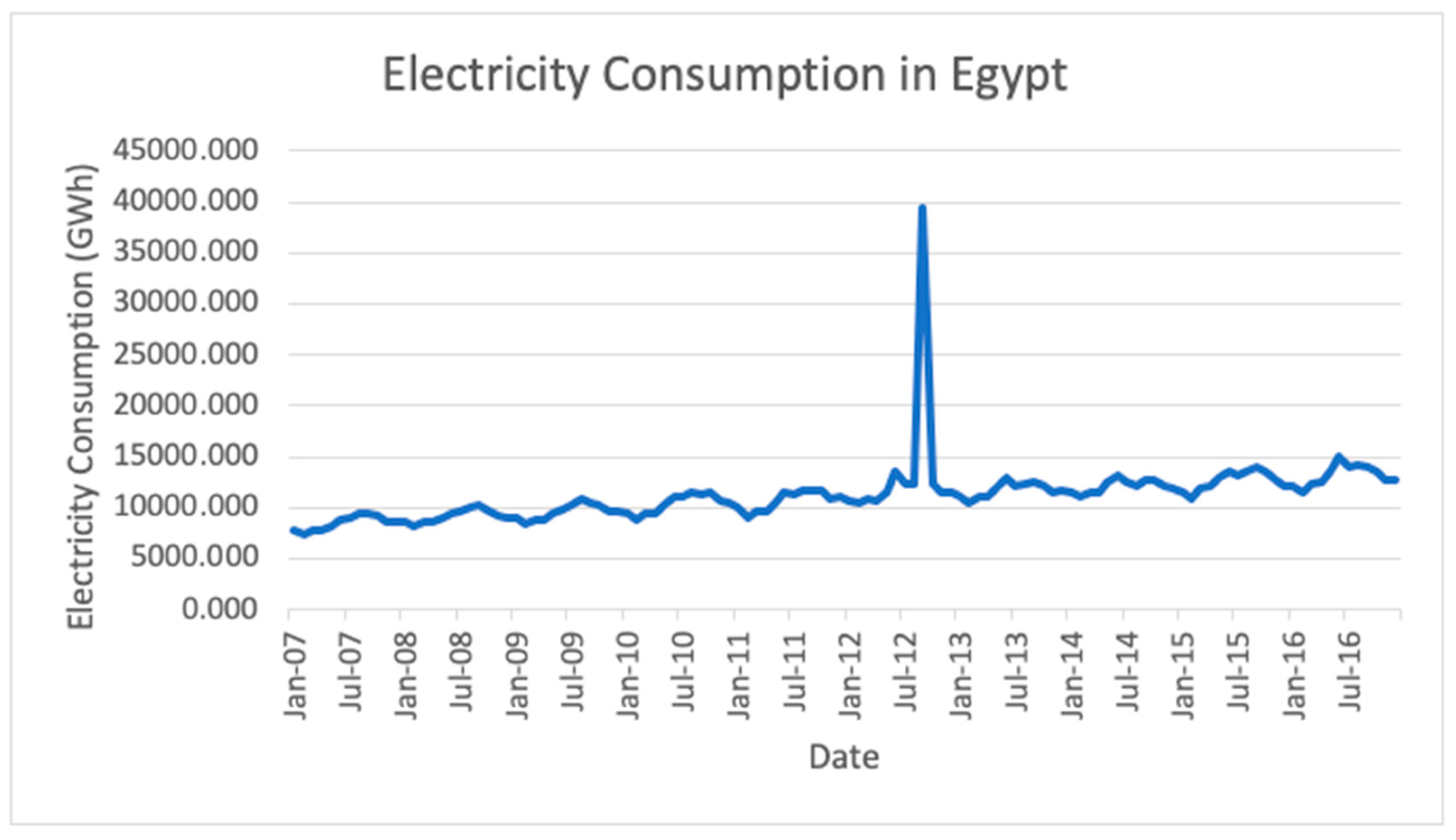
4] to forecast electricity consumption in different countries with different development levels. The forecasting accuracy of these models are also studied and analyzed. The variables considered in this research included the monthly electricity consumption in seven (7) countries: Norway, Switzerland, Malaysia, Egypt, Algeria, Bulgaria and Kenya. The selection of countries was mainly based on their development level, whereby Norway and Switzerland are developed countries; Malaysia, Egypt, Algeria and Bulgaria are developing countries; Kenya is an underdeveloped country.
There have been many research proposals for forecasting electricity consumption. Akdi, Gölveren and Okkaoğlu [
5] forecasted daily electricity consumption in Turkey using ARIMA and harmonic regression models. Cevik and Cunkas [
6,
7], Peng et al. [
8] and Tay et al. [
9] studied the application of the ANFIS model in forecasting short-term electricity load, while Al-Hamad and Qamber [
10] used the ANFIS model to forecast the long-term peak electricity loads of Gulf Cooperation Council member countries, and all of these studies found that the ANFIS model performed better than the other models. Koo and Park [
11] used the ANN model to forecast short-term electricity load, while Panklib et al. [
12], Ozoh et al. [
13] and Azadeh et al. [
14] applied the ANN model in forecasting electricity consumption, and all but [
11,
13] found that the ANN model performed the best compared to the other models. On the other hand, Rahman et al. [
15] studied the use of the ANN model for forecasting air quality in Malaysia, while Adebiyi et al. [
16] and Laboissiere et al. [
17] studied the application of the ANN model for forecasting stock prices, and these studies found that the ANN model produced the most accurate results.
Kaytez et al. [
18] applied the LSSVM model for forecasting electricity consumption in Turkey and found that this model performed better than the other models. Pham et al. [
19], Ahmadi et al. [
20], Kisi and Parmar [
21], Deo et al. [
22], and Arabloo et al. [
23] studied the LSSVM model in environmental forecasting, whereby all but [
19,
22] found that the LSSVM model performed the best. Efendi et al. [
24,
25] used the FTS model to forecast the electric load in Taiwan, using Taiwan’s regional electric load from 1981 to 2000, and in the forecasting of the electricity load demand in Malaysia using the daily electricity load data from the National Electricity Board of Malaysia (TNB) from January to August 2006 in [
24,
25], respectively. Chen [
26], Lee et al. [
27], and Sun et al. [
28] also used the FTS model in forecasting and all of the studies in [
24,
25,
26,
27,
28] found that the FTS model produced the best results.
There has been also massive research on the use of machine learning models in the area of forecasting, and this has led to an increase in the introduction of hybrid models that combine traditional statistical models with the latest machine learning models [
29]. Semero et al. [
30] used an integrated GA–PSO–ANFIS method to forecast electricity production, and Göçken et al. [
31] introduced a hybrid ANN model that used metaheuristic methods and applied this model to stock price prediction, whereas Shukur and Lee [
32] studied daily wind speed forecasting using a hybrid KF–ANN model that was based on the ARIMA model. Chaabane [
33] introduced a hybrid ARFIMA and neural network model to forecast electricity prices, while Cerjan et al. [
34] and Ardakani and Ardehali [
35] studied short-term and long-term electricity forecasting, respectively, using different types of dynamic hybrid models. Khandelwal et al. [
36] and Babu and Reddy [
37] studied time series forecasting using different types of hybrid ARIMA and ANN models. Kabran and Ünlü [
38], on the other hand, used a two-step machine learning approach on the support vector machine (SVM). Yuan et al. [
39], Zhu and Chevallier [
40], Jung et al. [
41] and Li et al. [
42] all used various types of hybrid LSSVM models and applied these to problems related to forecasting and prediction. Chen and Chen [
43], Dincer and Akkuş [
44] and Wang et al. [
45] used hybrid FTS models in forecasting stock prices and air pollution, respectively.
Even though studies exist regarding the application of machine learning models to the forecasting of electricity consumption, none have been published to validate and compare several typical forecasting methods within a concrete case study with real data. This paper is structured as follows. In
Section 2, we recapitulate the concepts related to the ANN, ANFIS, LSSVM and FTS models. In
Section 3, we introduce our proposed methodology on forecasting electricity consumption with the proposed models. In
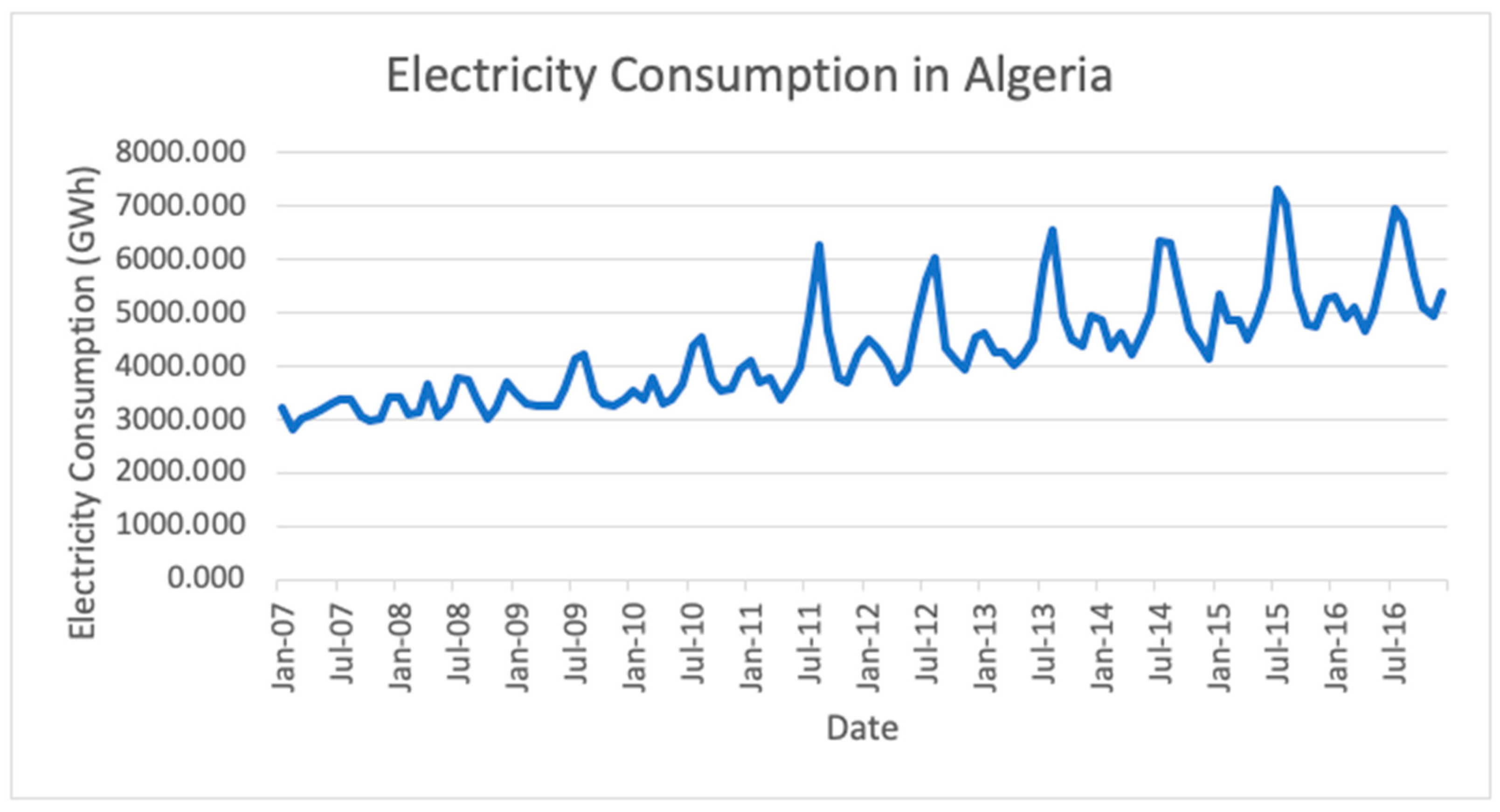
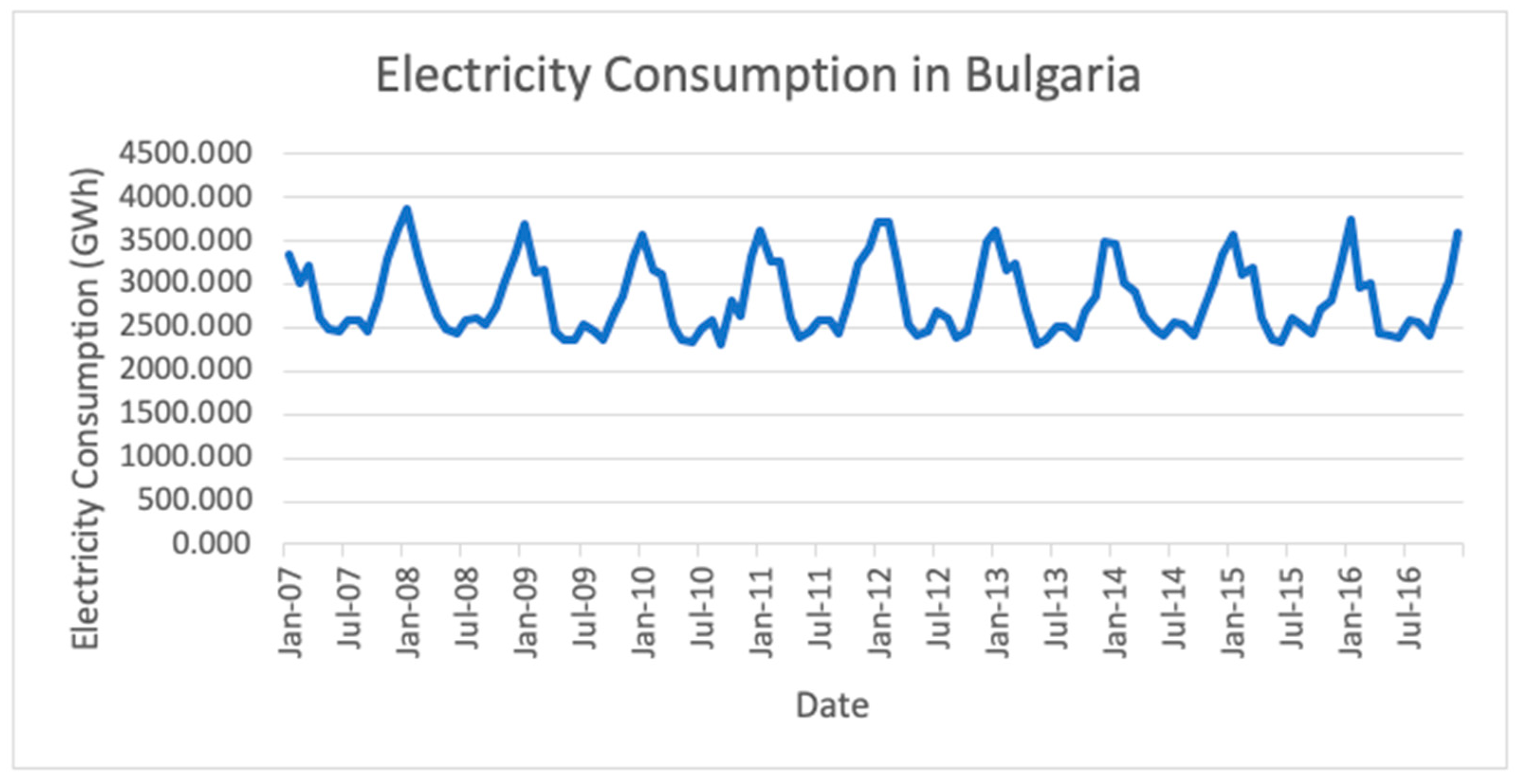
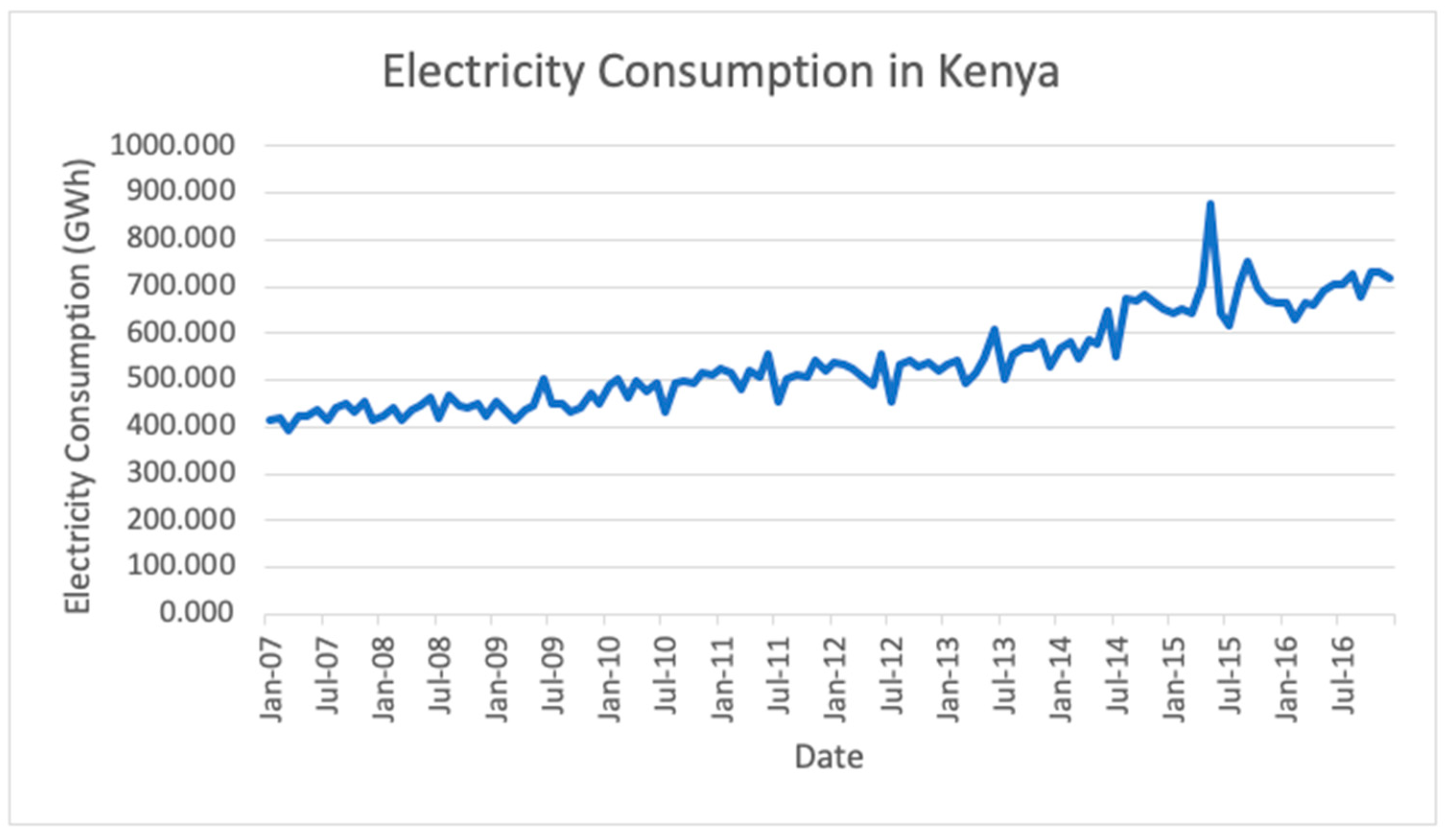
Section 4, the implementation of the methodology is described, and the results are analyzed. Electricity consumption data for the seven studied countries were obtained from ceicdata.com. In
Section 5, a summary of our findings is presented. In
Section 6, the limitations of this research are presented. Finally, Abbreviations section provides a table of the acronyms that are used throughout the present work and their descriptions.
2. Preliminaries
In this section, we briefly present an introduction to the concepts that are pertinent to the study presented in this paper.
2.1. Artificial Neural Network (ANN)
McCulloch and Pitts [
1] introduced this model whereby the neural network structure is based on the neurons in the human nervous system. The dendrites receive information from other neurons, which is processed through synapses and is sent to the axon for output.
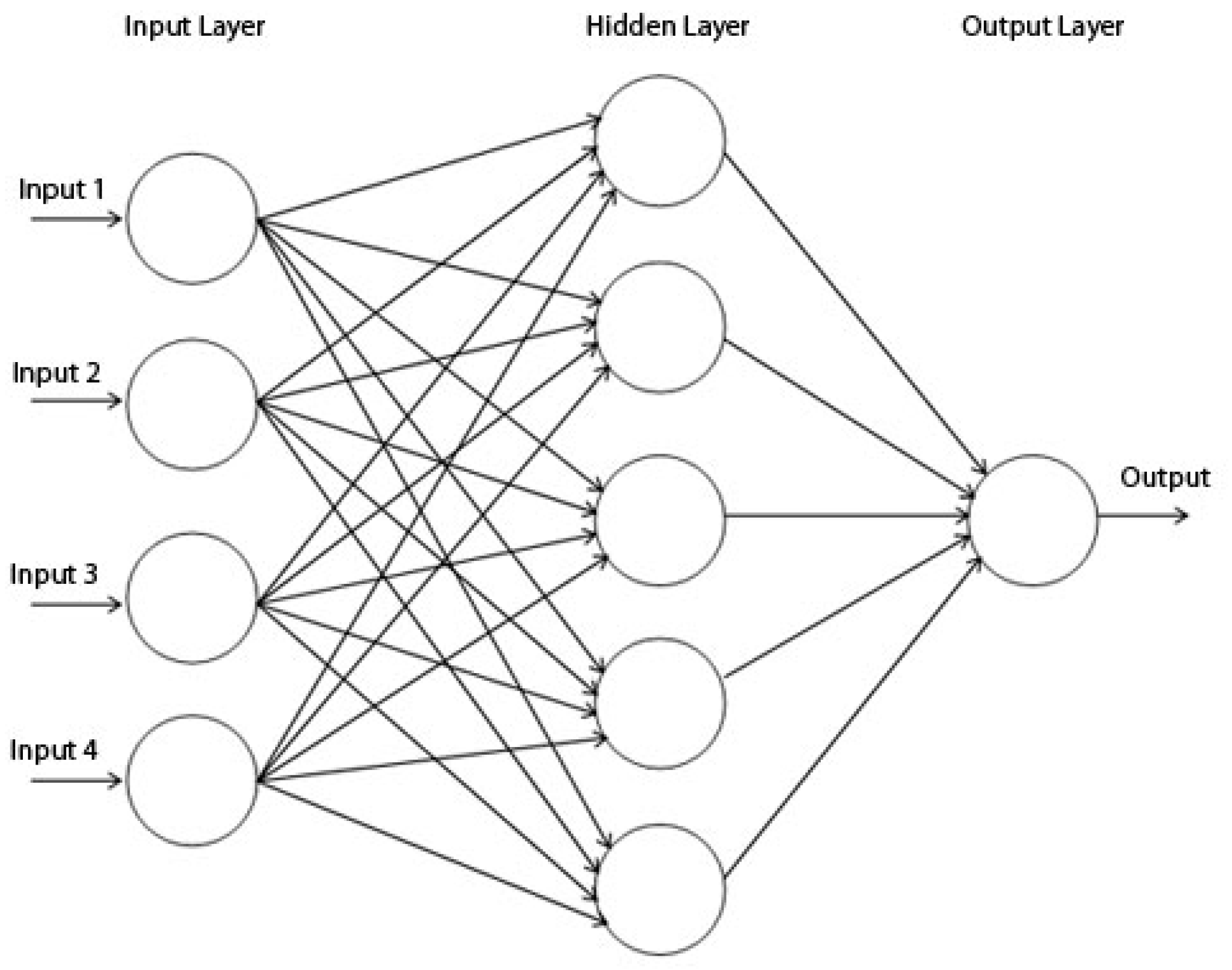
Figure 1 shows an example of the multilayer perceptron (MLP), which is the network structure of the ANN that consists of three layers: the input layer, the hidden layer, and the output layer, all of which are connected through weights. Every neuron in the hidden layer is connected to every neuron in the input layer and the output layer [
46]. External information is received from the input layer, and the result is sent out in the output layer. The parameters of the neural network structure are adjusted to identify which structure gives a more accurate result, thus increasing the performance of predicting the testing data [
47].
Generally, there is a transfer function that connects the hidden layer to the output, which is given by , where is the input.
The MLP with only the input layer and the hidden layer can be computed using the equation below:
where
is the output, and
denotes the connection weights. The function of the hidden layer is given by:
Referring to Equation (2), the connection weights are denoted as
and
, while
is the number of input nodes,
is the number of output nodes and
is the error term. Thus, Equation (2) maps a nonlinear equation based on the historical observations given by
, whereby
is the function formed by the connection weights, and
is a vector for all parameters [
48].
2.2. Adaptive Neuro-Fuzzy Inference System (ANFIS)
This model was introduced by Jang [
2], and it was based on the Takagi–Sugeno inference system. This model was proposed to overcome some of the weaknesses of the ANN model as well as some of the weaknesses of the fuzzy logic system. The ANFIS uses the hybrid learning method to decide the optimal distribution of membership functions in order to obtain the mapping relationship of the input and output data [
49].
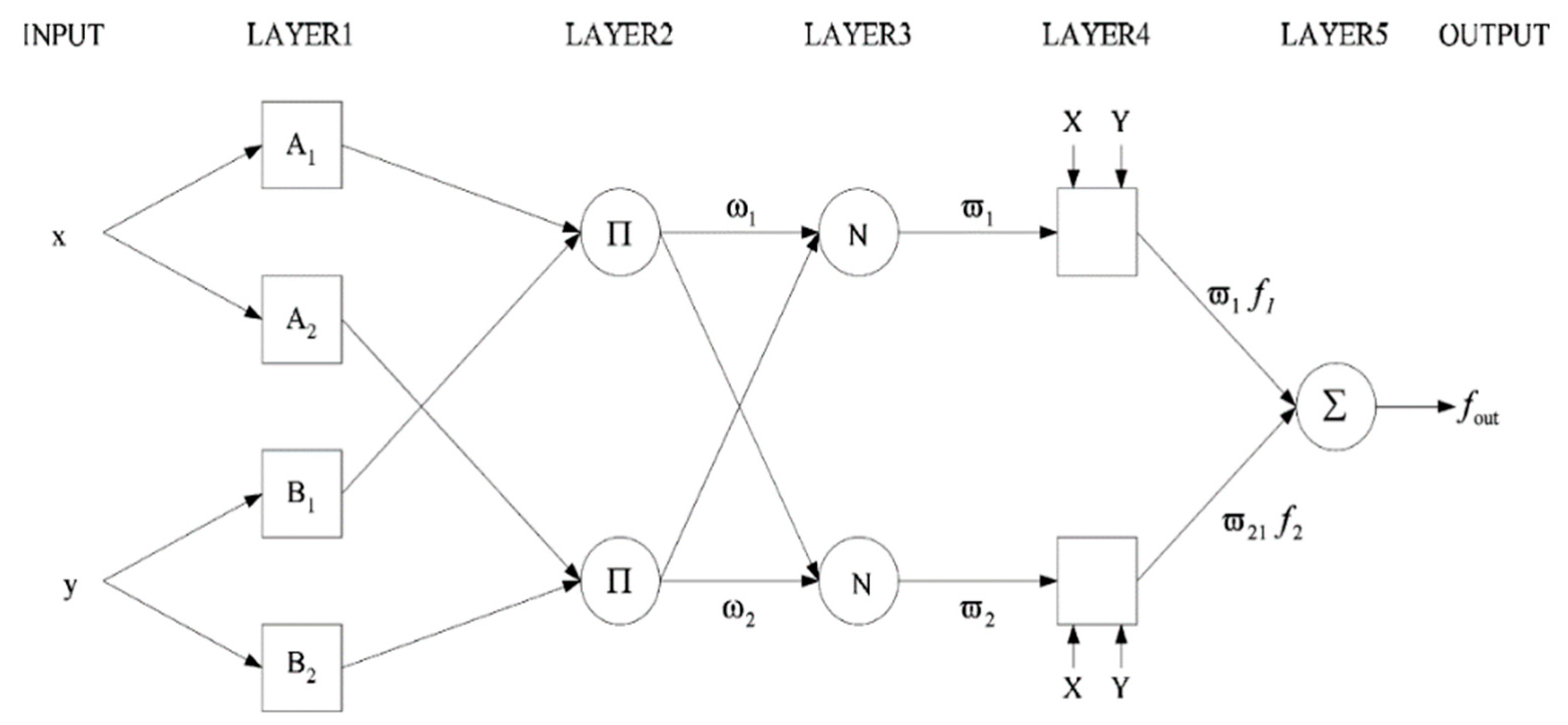
Figure 2 shows the basic ANFIS model consisting of two input data and one output. The rule base of the ANFIS contains the IF–THEN rules of the Sugeno type. The rules are as shown below:
where
and
are known as linguistic variables of the fuzzy sets;
and
are the input data;
,
and
are the output parameters. The ANFIS model consists of five layers, and they are explained below. Layer 1 can be known as the fuzzification layer. The nodes are fuzzified in the first layer to provide the output stated as
and
. Every node in this layer will have a bell function for fuzzification, which is:
where
is known as the input;
are the premise parameters of control;
is known as the output.
In Layer 2, every node will be multiplied by input signals to serve as output given as . The output, , is also known as the firing strength of rules.
Layer 3 is the normalization layer, also known as the normalization of the firing strength. The output of the third layer is denoted as .
Layer 4 is known as the defuzzification stage, where the firing strengths from the third layer are multiplied by the first-order polynomial of the Sugeno model and then normalized. The output is denoted as , where are the consequent parameters.
Layer 5 is where all input signals are summed to calculate the overall output of the ANFIS model. The output is denoted as , where is the first-order polynomial based on the first-order Sugeno model.
2.3. Least Squares Support Vector Machines (LSSVMs)
This model was proposed by Suykens and Vandewalles [
3] in order to solve quadratic programming (QP) problems faced by the support vector machines (SVMs). Instead of solving QP problems, LSSVMs solve a set of linear equations under the least squares cost function with equality constraints, thus reducing the complexity of computation [
51]. Wang and Yu [
52] used the LSSVM model to forecast electricity consumption. The modified LSSVM model introduced by Wang and Yu [
52] is presented below.
The modified LSSVM model by Wang and Yu [
52] supposing the extracted samples are
, where
is the number of samples and
is the extracted factor vector,
,
;
The electricity consumption model, , is derived from the data by minimizing the least squares cost function, . The regularization and error term are defined as and . Thus, the minimized cost function is , which is subjected to the constraint , where ;
The Lagrangian function, is constructed by introducing the Lagrange multipliers for equality constraints and taking the conditions for optimality to find the solution for the minimized cost function;
A linear Karush–Kuhn–Tucker (KKT) system, used to find the load model, is obtained in dual space as , where , , and ;
Mercer’s condition is applied within matrix results in . The possible kernel functions are linear kernel, and radial basis function (RBF) kernel, , where Mercer’s condition holds for all possible kernel parameters;
-
Then, the electricity consumption regressor is constructed as . The mapping relationship of electricity consumption and its extracted influence factors are obtained in this way.
2.4. Fuzzy Time Series (FTS)
In 1965, Zadeh [
4] developed the fuzzy set theory in order to solve the vagueness of the data by combining linguistic variables with the analysis process of applying fuzzy logic into time series. Song and Chissom [
53] further expanded the study of Zadeh’s fuzzy set theory in forecasting. In 1996, Chen [
54] improved the steps involved in the fuzzy time series (FTS) model using simple operations. The main characteristic of Chen’s model is that it uses simple calculations and can provide better forecasting results [
55]. The model begins with the process of fuzzification, developing fuzzy logical relationships (FLRs), forming the fuzzy logical group (FLG) and the defuzzification process [
25]. The definitions and concepts of FTS forecasting were developed by Song and Chissom [
56] as well as by Singh [
57].
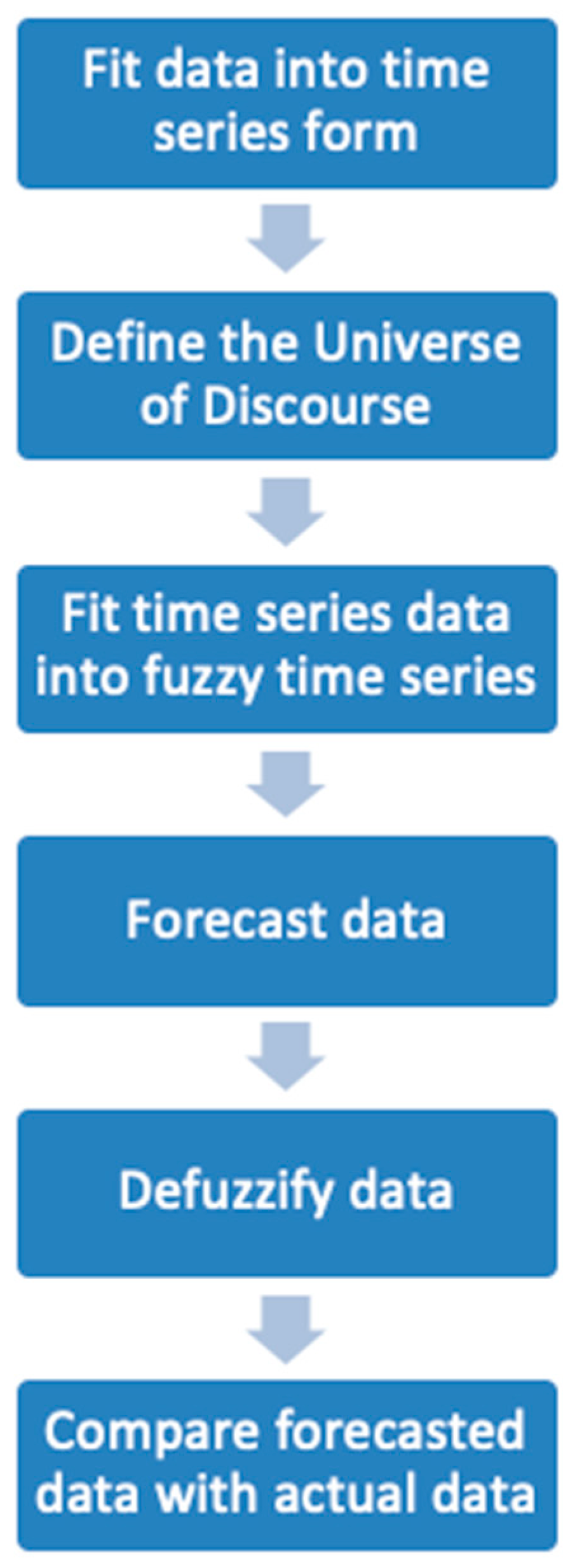
Singh [
57] developed a method for time series to solve real-life problems. The steps for FTS forecasting based on historical time series data that were introduced by Singh [
57] is presented below (
Figure 3):
Step 1: Define the universe of discourse (
).
Step 2: Divide the universe of discourse into equal-length intervals, , according to the number of linguistic variables, . The number of intervals is the same as the number of linguistics variable, which is .
Step 3: Define a fuzzy set for observation according to the intervals in Step 2. The triangular membership rule is applied to each interval in each fuzzy set that is constructed.
Step 4: Fuzzify the historical data.
Step 5: Establish FLRs by the following rule:
Rule: (current state) is a fuzzy production of year , (next state) is a fuzzy production of year ; then, the FLRs is denoted as .
Step 6: Determine the forecasting rule.


 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}