
Deep Learning Model for Multivariate High-Frequency Time-Series Data: Financial Market Index Prediction


Abstract
:1. Introduction
- The theme of our research is highly unprecedented in the financial field to the best of our knowledge. With three market index datasets with micro time interval time-series data, we validated our proposed end-to-end model for multivariate high-frequency data. Especially in the case of S&P 500, it exploits the whole 500 tickers’ hourly data as an input variable in the models.
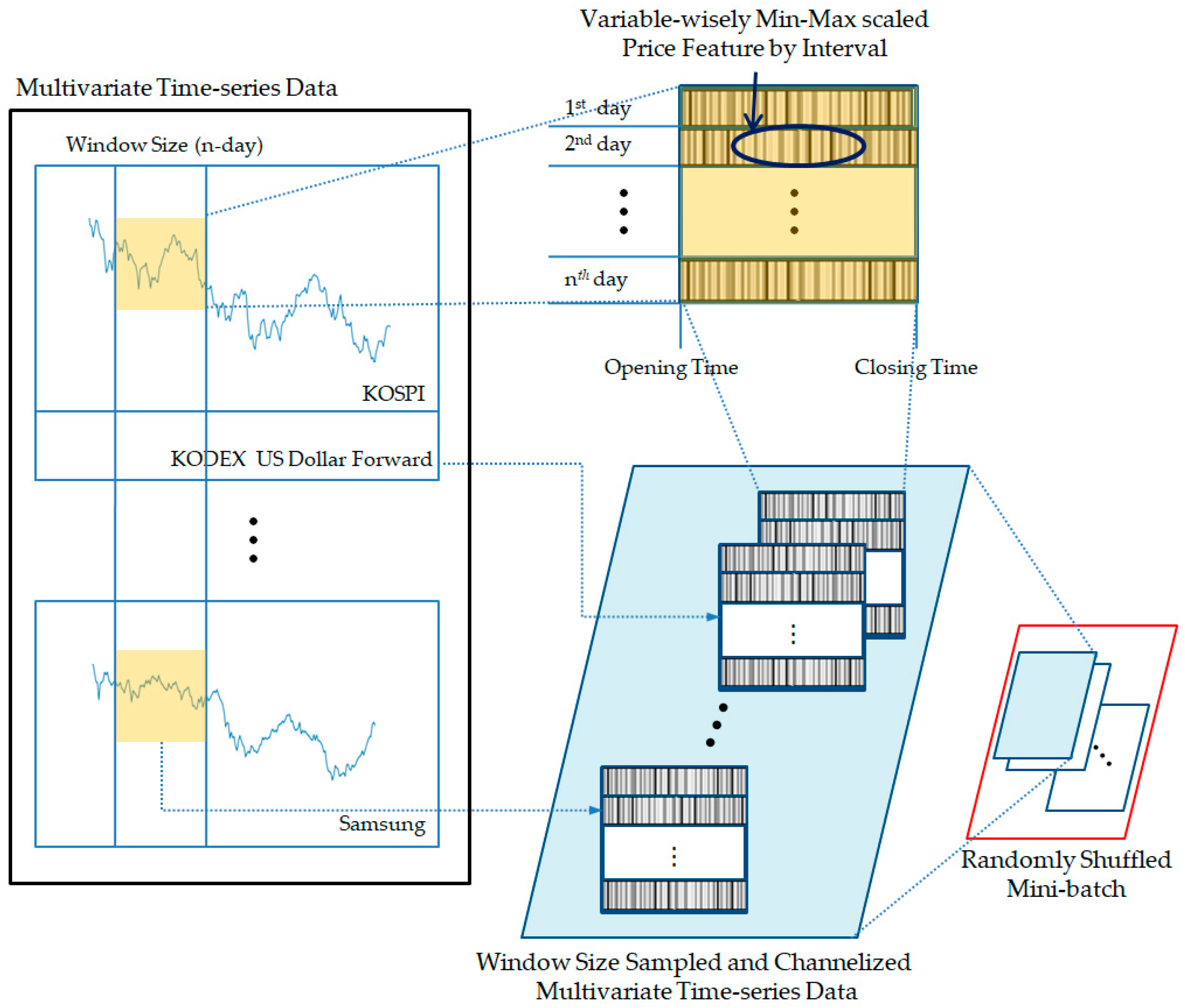
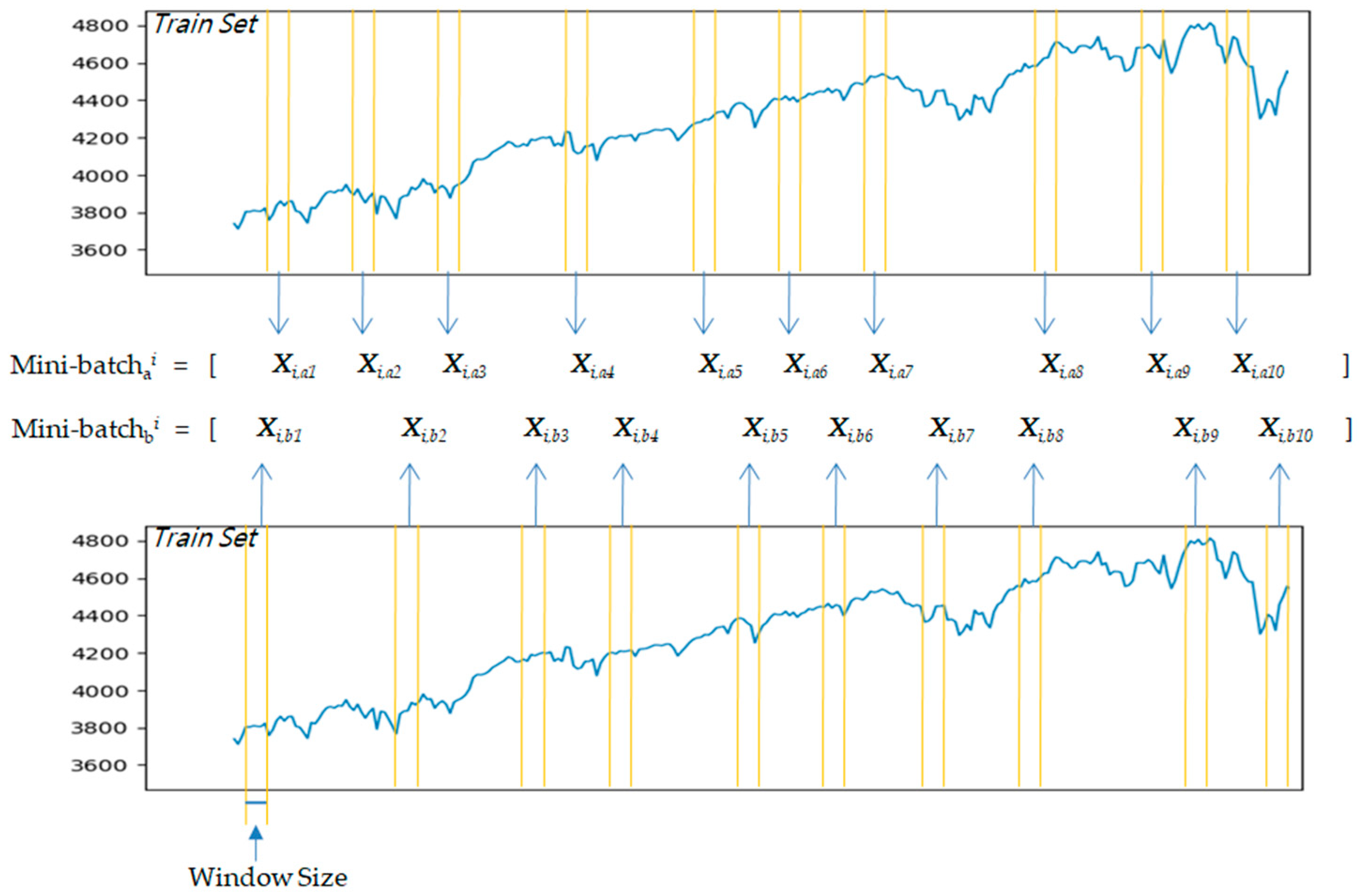
- We illustrated our data pipeline procedures for the proposed model in detail. This enables the model to train from batches of randomly shuffled samples. This approach positively affects the robustness of the model by updating the weights of the model from the entire period of the time-series during model training.
- The proposed model is a hybrid model that combines two state-of-the-art models, each of which has proven its performance in academic consensus. The algorithmic approach that enhances data features based on time-series context, alongside the algorithm focusing on extracting variable feature patterns, has facilitated performance enhancement in terms of accuracy, while concurrently reducing both model training duration and inference time.
2. Materials and Methods
2.1. Dataset
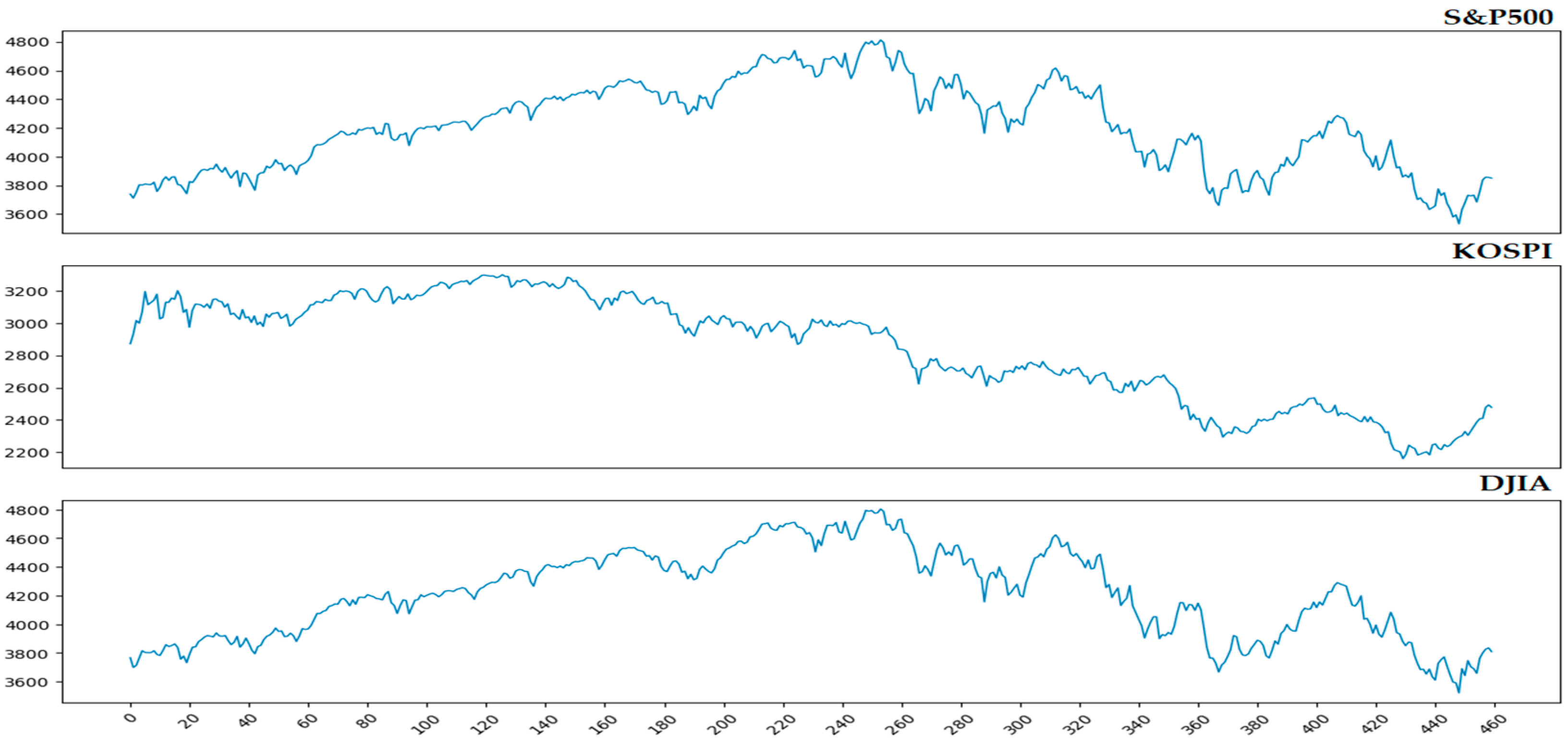
2.1.1. S&P 500
2.1.2. KOSPI
2.1.3. DJIA
2.2. Methods
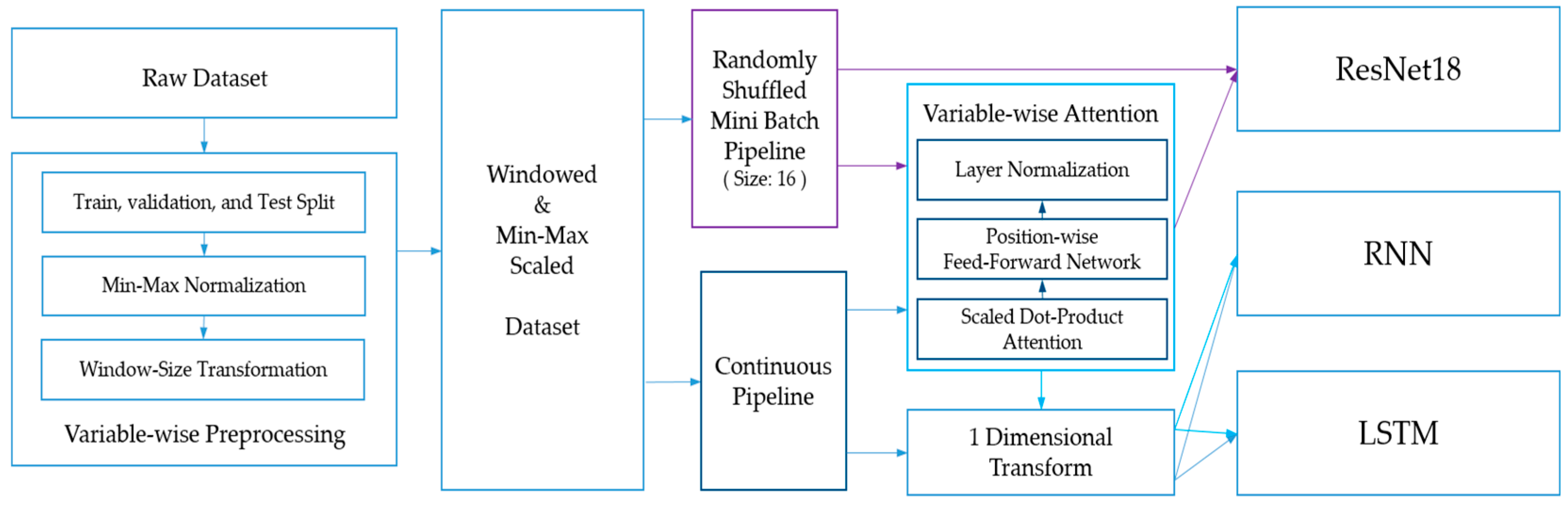
2.2.1. Data Preprocessing
- Min–max Normalization
- 2.
- Additional Preprocessing for Proposed Model
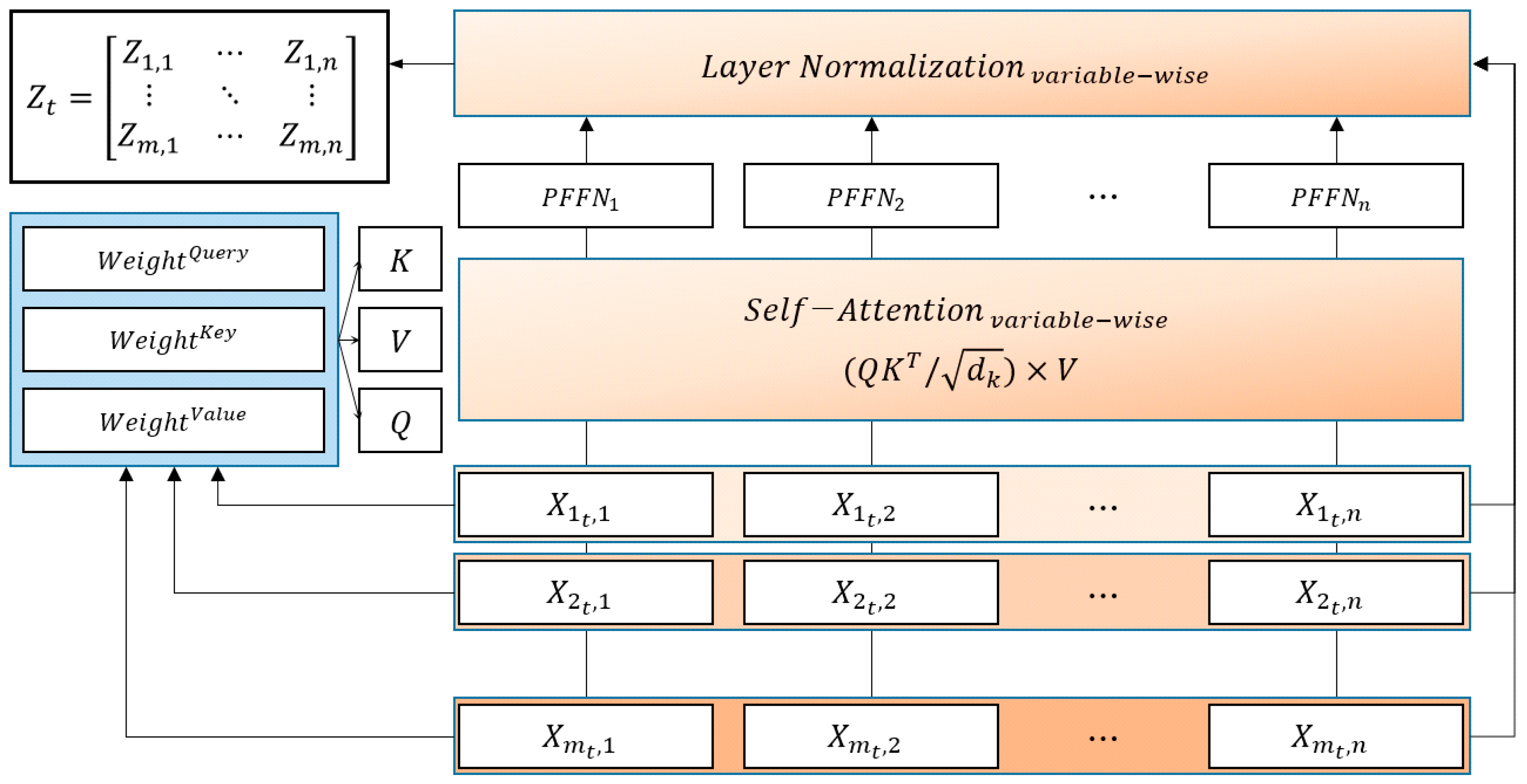
2.2.2. Attention Mechanism
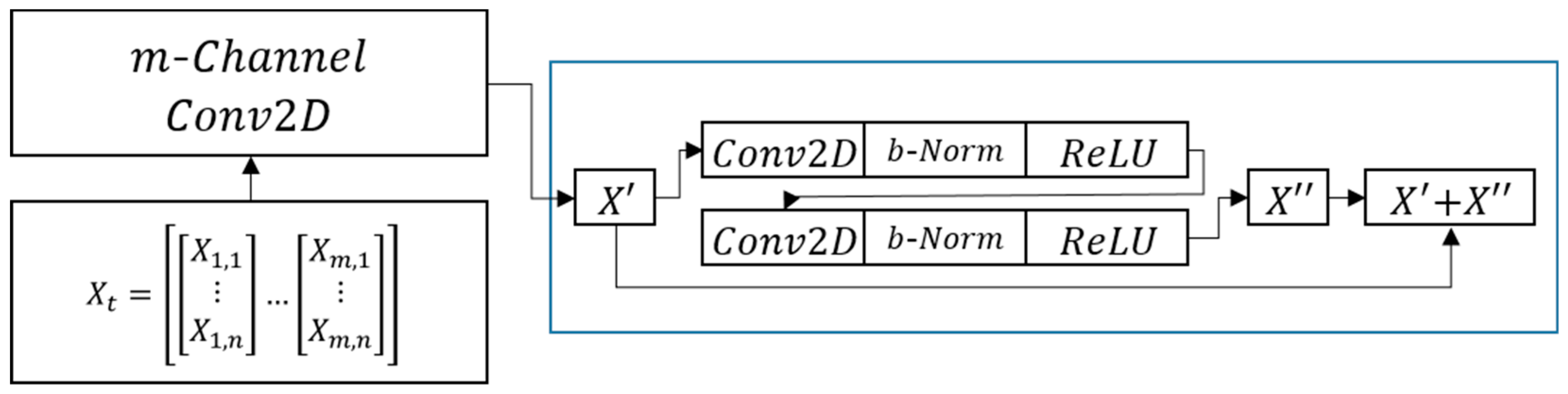
2.2.3. ResNet18
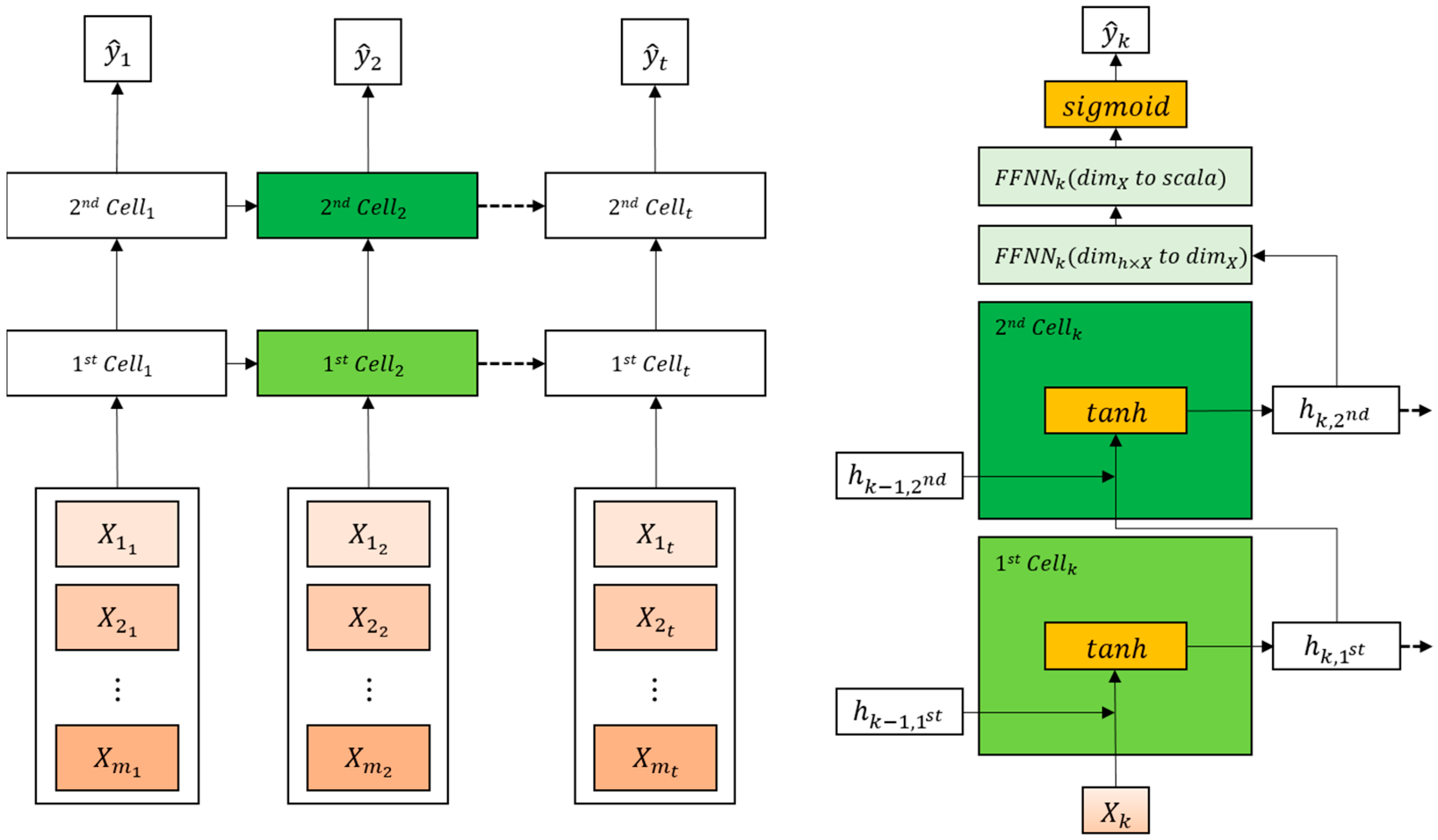
2.2.4. RNN
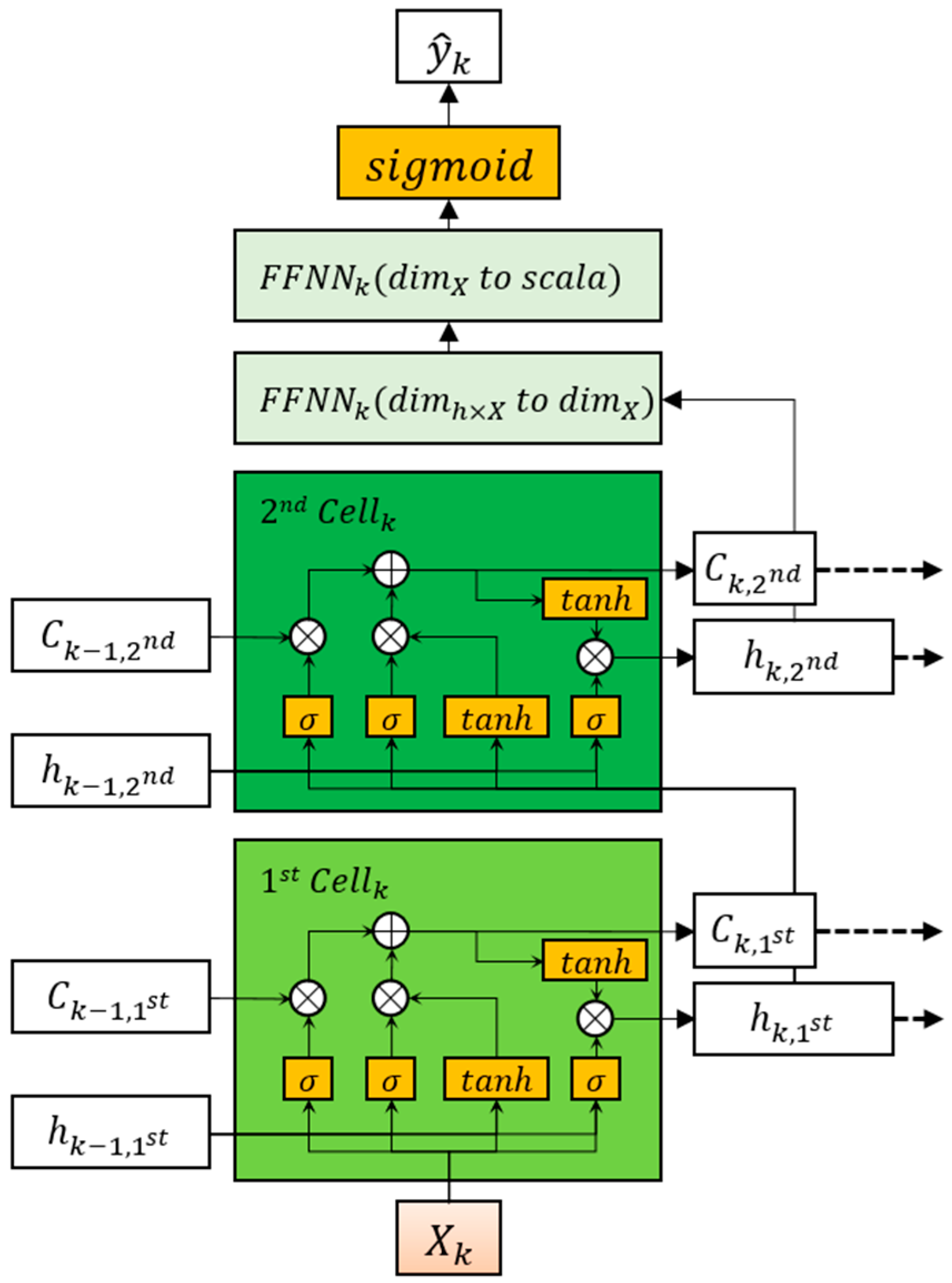
2.2.5. LSTM
2.3. Metrics of Performance: F1-Score
2.4. Research Design
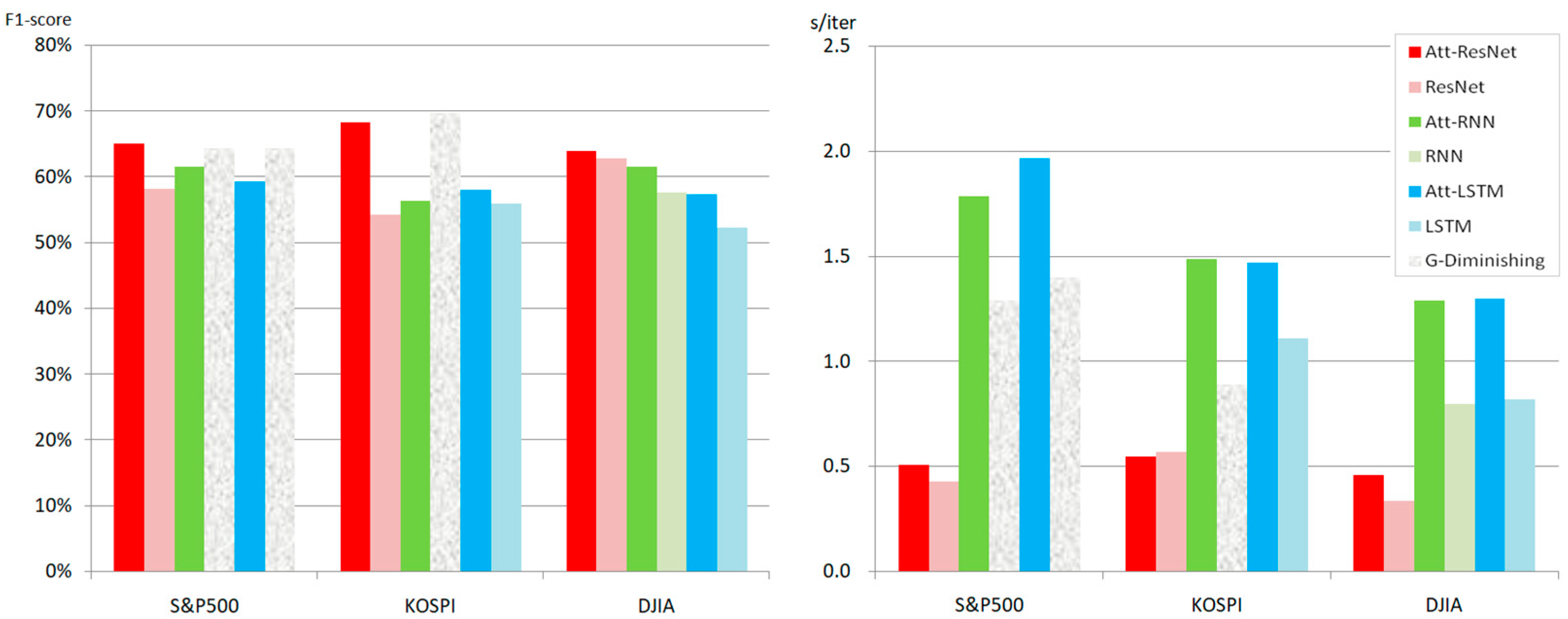
3. Results
3.1. S&P 500
3.2. KOSPI
3.3. DJIA
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviation
| X | one of the total dataset’ independent variables, such as S&P 500 with 504 variables, KOSPI with 13 variables, and DJIA with 12 variables |
| ith variable of X, where i = 1st, 2nd, …, mth variables | |
| scalar value of feature dimension, which is the number of time points in one day | |
| vector, which is the set of prices of th day of , where ∀, j = 1, 2, …, n | |
| w | size of window by the time interval, which is the size of the day |
| trainable weight vector of neural networks, where i = 1, 2, …, n | |
| trainable bias vector of neural networks, where i = 1, 2, …, n | |
| arbitrary vector |
References
- Fama, E.F. Efficient capital markets: A review of theory and empirical work. J. Financ. 1970, 25, 383–417. [Google Scholar] [CrossRef]
- Lakonishok, J.; Shleifer, A.; Vishny, R.W. Contrarian in-vestment, extrapolation, and risk. J. Financ. 1994, 49, 1541–1578. [Google Scholar] [CrossRef]
- Fama, E.F.; French, K.R. The cross-section of expected stock returns. J. Financ. 1992, 47, 427–465. [Google Scholar] [CrossRef]
- Fama, E.F.; French, K.R. Common risk factors in the returns on stocks and bonds. J. Financ. Econ. 1993, 33, 3–56. [Google Scholar] [CrossRef]
- Shiller, R.J. From efficient markets theory to behavioral finance. J. Econ. Perspect. 2003, 17, 83–104. [Google Scholar] [CrossRef]
- De Bondt, W.F.M.; Thaler, R. Does the stock market overreact? J. Financ. 1985, 40, 793–805. [Google Scholar] [CrossRef]
- Gallagher, L.A.; Taylor, M.P. Permanent and temporary components of stock prices: Evidence from assessing macroeconomic shocks. South. Econ. J. 2002, 69, 345–362. [Google Scholar]
- Engle, R.F. Autoregressive conditional heteroscedasticity with estimates of the variance of United Kingdom inflation. Econom. J. Econom. Soc. 1982, 50, 987–1007. [Google Scholar] [CrossRef]
- Bollerslev, T. Generalized autoregressive conditional heteroskedasticity. J. Econom. 1986, 31, 307–327. [Google Scholar] [CrossRef]
- Hörmann, S.; Horváth, L.; Reeder, R. A functional version of the ARCH model. Econom. Theory 2013, 29, 267–288. [Google Scholar] [CrossRef]
- Aue, A.; Horváth, L.; Pellatt, D.F. Functional generalized autoregressive conditional heteroskedasticity. J. Time Ser. Anal. 2017, 38, 3–21. [Google Scholar] [CrossRef]
- Kim, J.-M.; Jung, H. Time series forecasting using functional partial least square regression with stochastic volatility, GARCH, and exponential smoothing. J. Forecast. 2018, 37, 269–280. [Google Scholar] [CrossRef]
- Endri, E.; Abidin, Z.; Simanjuntak, T.; Nurhayati, I. Indonesian stock market volatility: GARCH model. Montenegrin J. Econ. 2020, 16, 7–17. [Google Scholar] [CrossRef]
- Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D.; Laboratories, H.Y.L.B.; Zhu, Z.; Cheng, J.; Zhao, Y.; et al. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar]
- Hinton, G.E. Learning multiple layers of representation. Trends Cogn. Sci. 2007, 11, 428–434. [Google Scholar] [CrossRef] [PubMed]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed]
- Cheng, J.-H.; Chen, H.-P.; Lin, Y.-M. A hybrid forecast marketing timing model based on probabilistic neural network, rough set and C4.5. Expert Syst. Appl. 2010, 37, 1814–1820. [Google Scholar] [CrossRef]
- Tsai, C.-F.; Lin, Y.-C.; Yen, D.C.; Chen, Y.-M. Predicting stock returns by classifier ensembles. Appl. Soft Comput. 2011, 11, 2452–2459. [Google Scholar] [CrossRef]
- Niaki, S.T.A.; Hoseinzade, S. Forecasting S&P 500 index using artificial neural networks and design of experiments. J. Ind. Eng. Int. 2013, 9, 1–9. [Google Scholar]
- Bao, W.; Yue, J.; Rao, Y. A deep learning framework for financial time series using stacked autoencoders and long-short term memory. PLoS ONE 2017, 12, e0180944. [Google Scholar] [CrossRef]
- Di Persio, L.; Honchar, O. Artificial neural networks architectures for stock price prediction: Comparisons and applications. Int. J. Circuits Syst. Signal Process. 2016, 10, 403–413. [Google Scholar]
- Chung, H.; Shin, K.-S. Genetic algorithm-optimized multi-channel convolutional neural network for stock market prediction. Neural Comput. Appl. 2020, 32, 7897–7914. [Google Scholar] [CrossRef]
- Zhong, X.; Enke, D. Forecasting daily stock market return using dimensionality reduction. Expert Syst. Appl. 2017, 67, 126–139. [Google Scholar] [CrossRef]
- Fischer, T.; Krauss, C. Deep learning with long short-term memory networks for financial market predictions. Eur. J. Oper. Res. 2018, 270, 654–669. [Google Scholar] [CrossRef]
- Cao, J.; Li, Z.; Li, J. Financial time series forecasting model based on CEEMDAN and LSTM. Phys. A Stat. Mech. Its Appl. 2019, 519, 127–139. [Google Scholar] [CrossRef]
- Kim, T.; Kim, H.Y. Forecasting stock prices with a feature fusion LSTM-CNN model using different representations of the same data. PLoS ONE 2019, 14, e0212320. [Google Scholar] [CrossRef]
- Yang, Y.; Yang, Y.; Wang, Z. Research on a hybrid prediction model for stock price based on long short-term memory and variational mode decomposition. Soft Comput. 2021, 25, 13513–13531. [Google Scholar]
- Wu, J.M.-T.; Li, Z.; Herencsar, N.; Vo, B.; Lin, J.C.-W. A graph-based CNN-LSTM stock price prediction algorithm with leading indicators. Multimed. Syst. 2021, 29, 1751–1770. [Google Scholar] [CrossRef]
- Fatima, S.; Uddin, M. On the forecasting of multivariate financial time series using hybridization of DCC-GARCH model and multivariate ANNs. Neural Comput. Appl. 2022, 34, 21911–21925. [Google Scholar] [CrossRef]
- Yin, C.; Dai, Q. A deep multivariate time series multistep forecasting network. Appl. Intell. 2022, 52, 8956–8974. [Google Scholar] [CrossRef]
- Oreshkin, B.N.; Carpov, D.; Chapados, N.; Bengio, Y. N-BEATS: Neural basis expansion analysis for interpretable time series forecasting. arXiv 2019, arXiv:1905.10437. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosudhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Qiu, J.; Wang, B.; Zhou, C. Forecasting stock prices with long-short term memory neural network based on attention mechanism. PLoS ONE 2020, 15, e0227222. [Google Scholar] [CrossRef]
- Zhang, X.; Huang, Y.; Xu, K.; Xing, L. Novel modelling strategies for high-frequency stock trading data. Financ. Innov. 2023, 9, 1–25. [Google Scholar] [CrossRef] [PubMed]
- Mikolov, T.; Karafiat, M.; Burget, L.; Honza, J.; Khudanpur, S. Recurrent neural network based language model. In Proceedings of the Interspeech, Chiba, Japan, 26–30 September 2010; pp. 1045–1048. [Google Scholar]
- Mittal, S.; Umesh, S. A survey on hardware accelerators and optimization techniques for RNNs. J. Syst. Archit. 2021, 112, 101839. [Google Scholar] [CrossRef]
- Pascanu, R.; Mikolov, T.; Bengio, Y. On the difficulty of training recurrent neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Atlanta, GA, USA, 17–19 June 2013; pp. 1310–1318. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Sharpe, W.F. Capital asset prices: A theory of market equilibrium under conditions of risk. J. Financ. 1964, 19, 425–442. [Google Scholar]
- Hwang, S.-S.; Lee, M.-W.; Lee, Y.-K. An empirical study of dynamic relationships between kospi 200 futures and ktb futures markets. J. Ind. Econ. Bus. 2020, 33, 1245–1263. [Google Scholar] [CrossRef]
- Jabbour, G.M. Prediction of future currency exchange rates from current currency futures prices: The case of GM and JY. J. Futures Mark. 1994, 44, 25. [Google Scholar] [CrossRef]
- Crain, S.J.; Lee, J.H. Intraday volatility in interest rate and foreign exchange spot and futures markets. J. Futures Mark. 1995, 15, 395. [Google Scholar]
- Kim, J.-I.; Soo, R.-K. A Study on Interrelation between Korea’s Global Company and KOSPI Index. J. CEO Manag. Stud. 2018, 21, 131–152. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Luong, M.-T.; Pham, H.; Manning, C.D. Effective approaches to attention-based neural machine translation. arXiv 2015, arXiv:1508.04025. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Singh, D.; Singh, B. Investigating the impact of data normalization on classification performance. Appl. Soft Comput. 2020, 97, 105524. [Google Scholar] [CrossRef]
- Liu, L.; Jiang, H.; He, P.; Chen, W.; Chen, W.; Liu, X.; Gao, J.; Han, J. On the variance of the adaptive learning rate and beyond. arXiv 2019, arXiv:1908.03265. [Google Scholar]
- Hochreiter, S.; Bengio, Y.; Frasconi, P.; Schmidhuber, J. Gradient Flow in Recurrent Nets: The Difficulty of Learning Long-Term Dependencies. 2001. Available online: https://ml.jku.at/publications/older/ch7.pdf (accessed on 2 August 2023).
- Liu, Y.; Di, H.; Bao, J.; Yong, Q. Multi-step ahead time series forecasting for different data patterns based on LSTM recurrent neural network. In Proceedings of the 2017 14th web information systems and applications conference (WISA), Liuzhou, China, 11–12 November 2017; IEEE: New York, NY, USA, 2017; pp. 305–310. [Google Scholar]
- Masters, D.; Luschi, C. Revisiting small batch training for deep neural networks. arXiv 2018, arXiv:1804.07612. [Google Scholar]
- Lundberg, S.M.; Lee, S.-I. A unified approach to interpreting model predictions. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should i trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Bach, S.; Binder, A.; Montavon, G.; Klauschen, F.; Müller, K.-R.; Samek, W. On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation. PLoS ONE 2015, 10, e0130140. [Google Scholar] [CrossRef] [PubMed]
- Endri, E.; Kasmir, K.; Syarif, A. Delisting sharia stock prediction model based on financial information: Support Vector Machine. Decis. Sci. Lett. 2020, 9, 207–214. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Time Points | Mean | Std | Min | Q1 | Median | Q3 | Max |
|---|---|---|---|---|---|---|---|---|
| S&P 500 | 3220 | 4211 | 302 | 3530 | 3934 | 4219 | 4452 | 4813 |
| KOSPI | 36,036 | 2848 | 324 | 2137 | 2613 | 2965 | 3132 | 3314 |
| DJIA | 3220 | 33,484 | 1838 | 28,767 | 28,767 | 33,964 | 34,899 | 36,947 |
| Dataset | Input Type | Attention | F1-Score | F1-Score (val) | AUC | Precision | Learning Time |
|---|---|---|---|---|---|---|---|
| ResNet18 | RS mini-batch | o | 65.07% | 65.97% | 57.07% | 51.89% | 0.51 s/iter |
| RS mini-batch | x | 58.26% | 68.68% | 51.98% | 46.25% | 0.43 s/iter | |
| RNN | Continuous | o | 61.65% | 67.92% | 50.34% | 47.67% | 1.79 s/iter |
| Continuous | x | 64.38% | 67.27% | 50% | 47.47% | 1.29 s/iter | |
| LSTM | Continuous | o | 59.42% | 68.23% | 54.46% | 45.05% | 1.97 s/iter |
| Continuous | x | 64.38% | 66.07% | 50% | 47.47% | 1.40 s/iter |
| Dataset | Input Type | Attention | F1-Score | F1-Score (val) | AUC | Precision | Learning Time |
|---|---|---|---|---|---|---|---|
| ResNet18 | RS mini-batch | o | 68.37% | 69.56% | 61.64% | 62.5% | 0.55 s/iter |
| RS mini-batch | x | 54.38% | 68.81% | 53.36% | 50.82% | 0.57 s/iter | |
| RNN | Continuous | o | 56.48% | 65.48% | 59.66% | 47.43% | 1.49 s/iter |
| Continuous | x | 69.73% | 62.81% | 50% | 53.53% | 0.89 s/iter | |
| LSTM | Continuous | o | 58.12% | 58.42% | 50.53% | 53.12% | 1.47 s/iter |
| Continuous | x | 56.07% | 63.86% | 52.21% | 55.55% | 1.11 s/iter |
| Dataset | Input Type | Attention | F1-Score | F1-Score (val) | AUC | Precision | Learning Time |
|---|---|---|---|---|---|---|---|
| ResNet18 | RS mini-batch | o | 64.07% | 61.72% | 59.19% | 62.26% | 0.46 s/iter |
| RS mini-batch | x | 62.90% | 64.64% | 52.66% | 52.70% | 0.34 s/iter | |
| RNN | Continuous | o | 61.68% | 65.42% | 54.42% | 57.89% | 1.29 s/iter |
| Continuous | x | 57.62% | 64.86% | 56.47% | 50% | 0.80 s/iter | |
| LSTM | Continuous | o | 57.39% | 67.34% | 55.09% | 50.76% | 1.30 s/iter |
| Continuous | x | 52.42% | 65.45% | 53.95% | 50.94% | 0.82 s/iter |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Noh, Y.; Kim, J.-M.; Hong, S.; Kim, S. Deep Learning Model for Multivariate High-Frequency Time-Series Data: Financial Market Index Prediction. Mathematics 2023, 11, 3603. https://doi.org/10.3390/math11163603
Noh Y, Kim J-M, Hong S, Kim S. Deep Learning Model for Multivariate High-Frequency Time-Series Data: Financial Market Index Prediction. Mathematics. 2023; 11(16):3603. https://doi.org/10.3390/math11163603
Chicago/Turabian StyleNoh, Yoonjae, Jong-Min Kim, Soongoo Hong, and Sangjin Kim. 2023. "Deep Learning Model for Multivariate High-Frequency Time-Series Data: Financial Market Index Prediction" Mathematics 11, no. 16: 3603. https://doi.org/10.3390/math11163603
APA StyleNoh, Y., Kim, J. -M., Hong, S., & Kim, S. (2023). Deep Learning Model for Multivariate High-Frequency Time-Series Data: Financial Market Index Prediction. Mathematics, 11(16), 3603. https://doi.org/10.3390/math11163603