
A Double-Layer Indemnity Enhancement Using LSTM and HASH Function Technique for Intrusion Detection System


Abstract
:1. Introduction
- (a)
- Data collecting is offered through the IoT network. The collected data should be normalized at the pre-processing stage.
- (b)
- To shorten training time and improve classification performance, it is necessary to provide an effective and ideal feature selection process for IDS using SSO.
- (c)
- Moreover, the deep LSTM method is used to classify packets (regular, malicious traffic).
- (d)
- The system classifies different kinds of attack packets as Denial of Service (DoS), User to Root (U2R), Probe, R2L, and Anomaly.
- (e)
- Also, a SHA3-256-based single-way hash function with Homomorphic Encryption (HE) method is designed for IoT intrusion prevention.
- (f)
- Assess the solution using suitable result parameters to determine the overall efficacy of the developed approach.
2. Related Work
3. Proposed Methodology
3.1. Data Pre-Processing
3.2. SSO for Feature Selection
| Algorithm 1. SSO pseudocode for feature selection |
Start
|
3.3. LSTM Classification
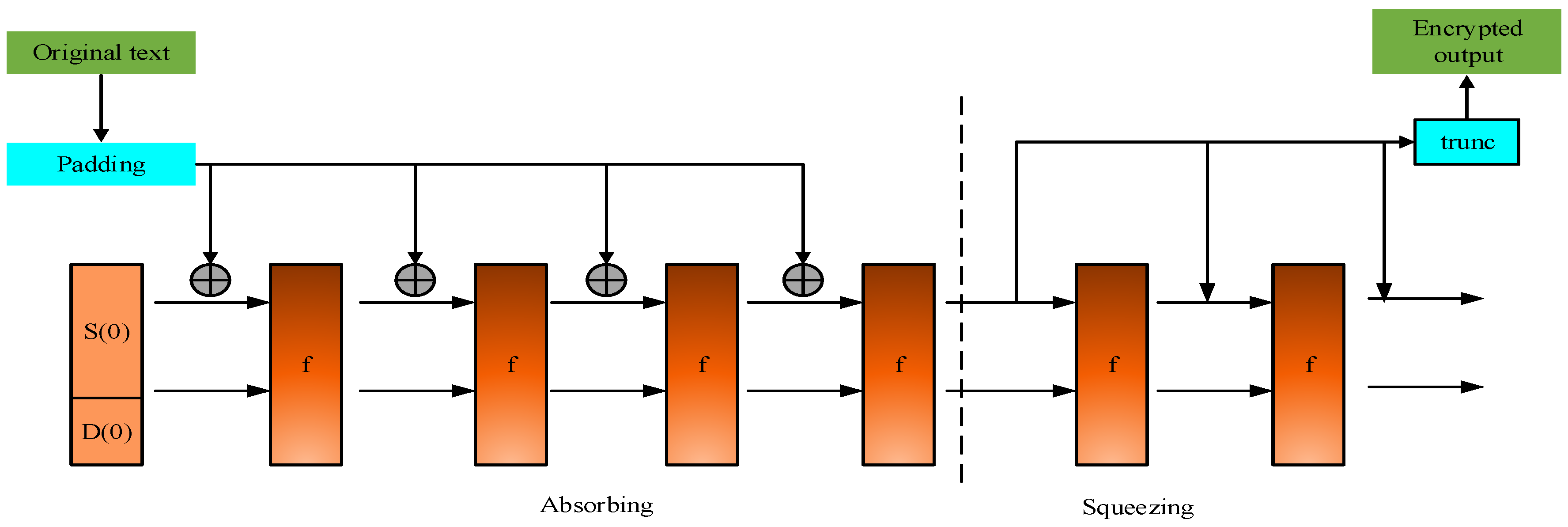
4. Intrusion Prevention
5. Results and Discussion
5.1. Dataset Description
5.2. Validation Parameters
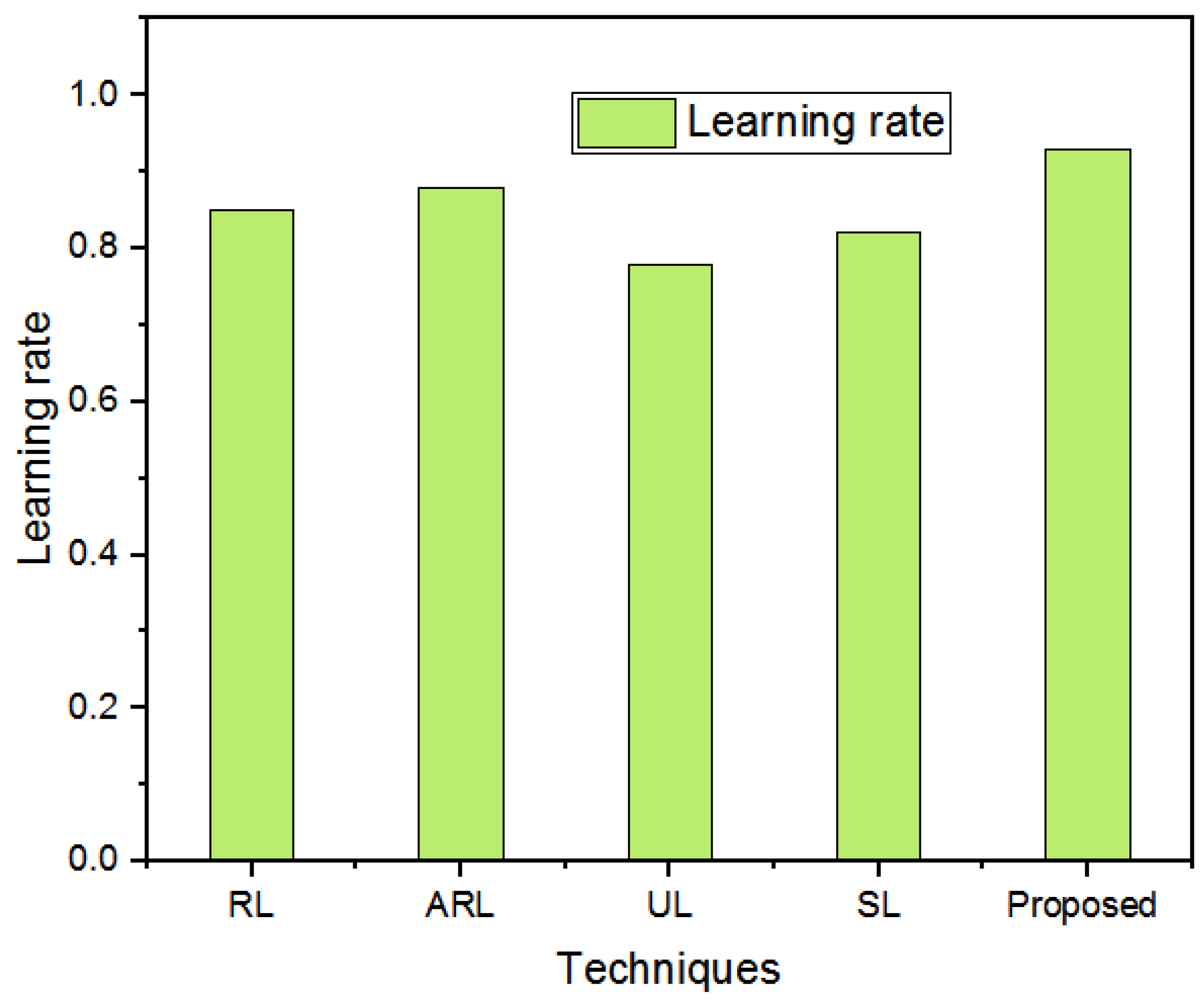
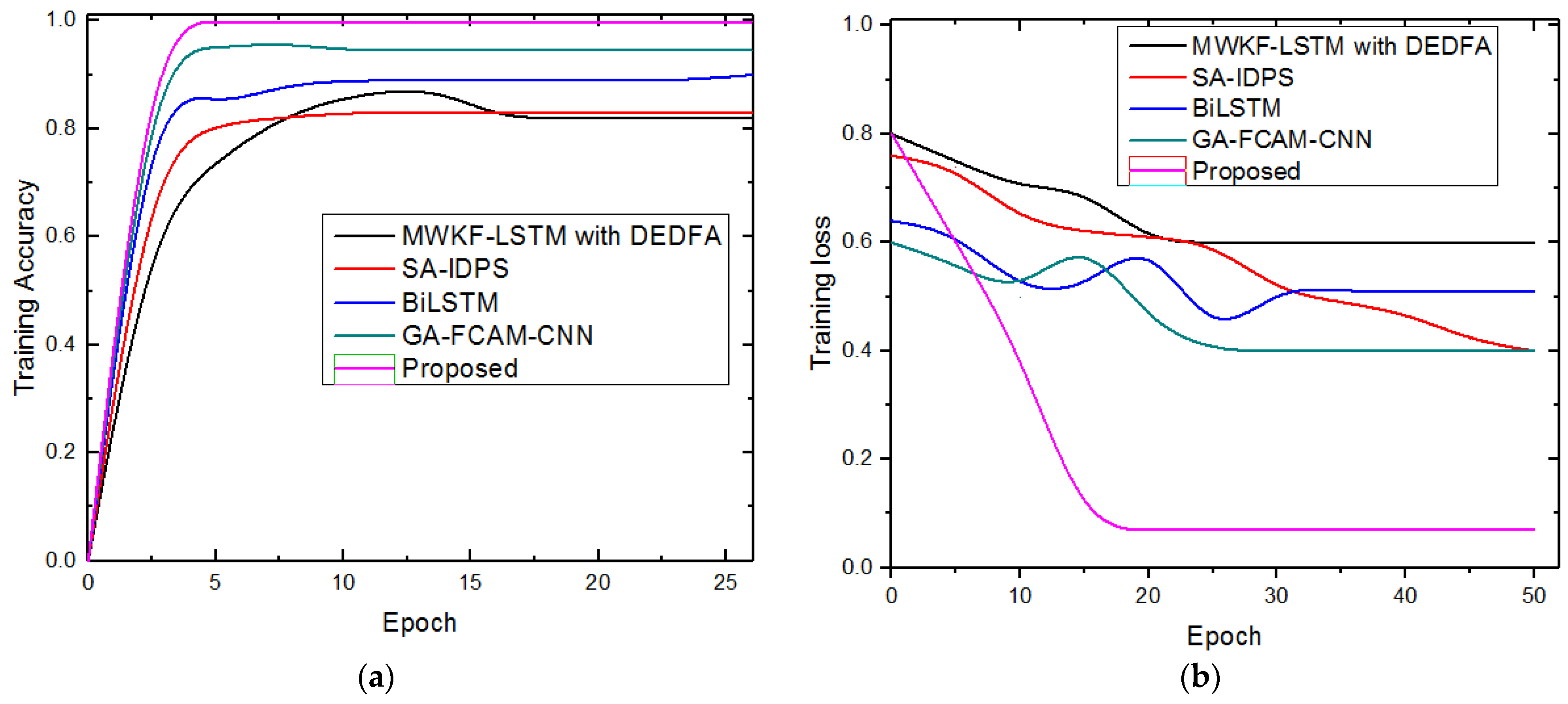
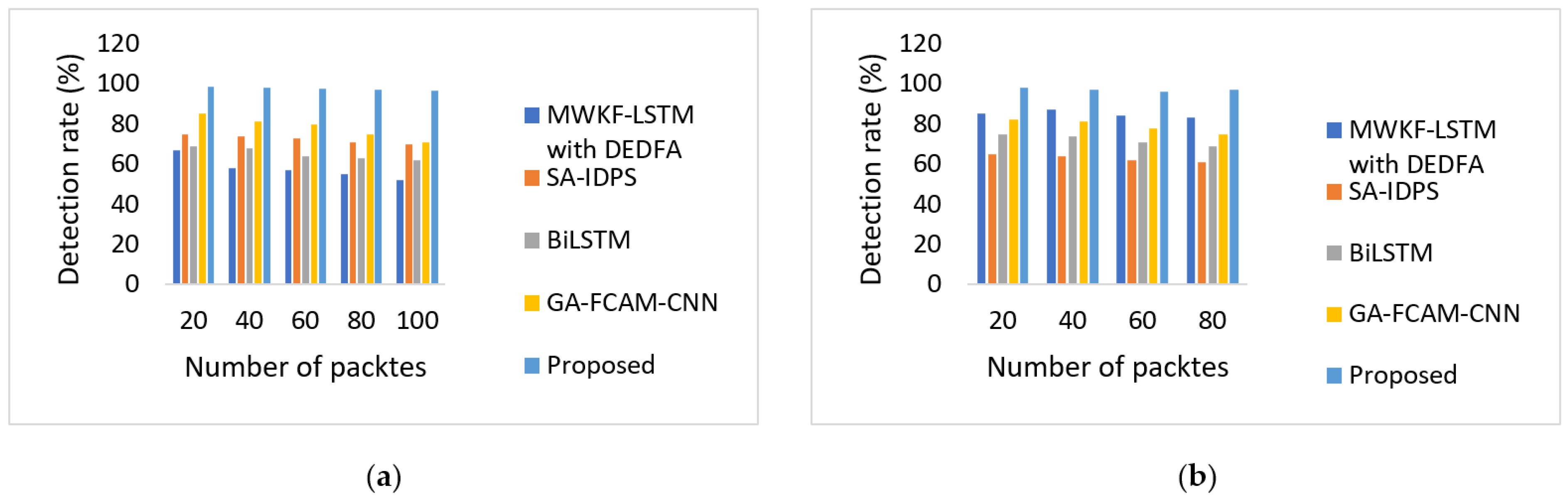
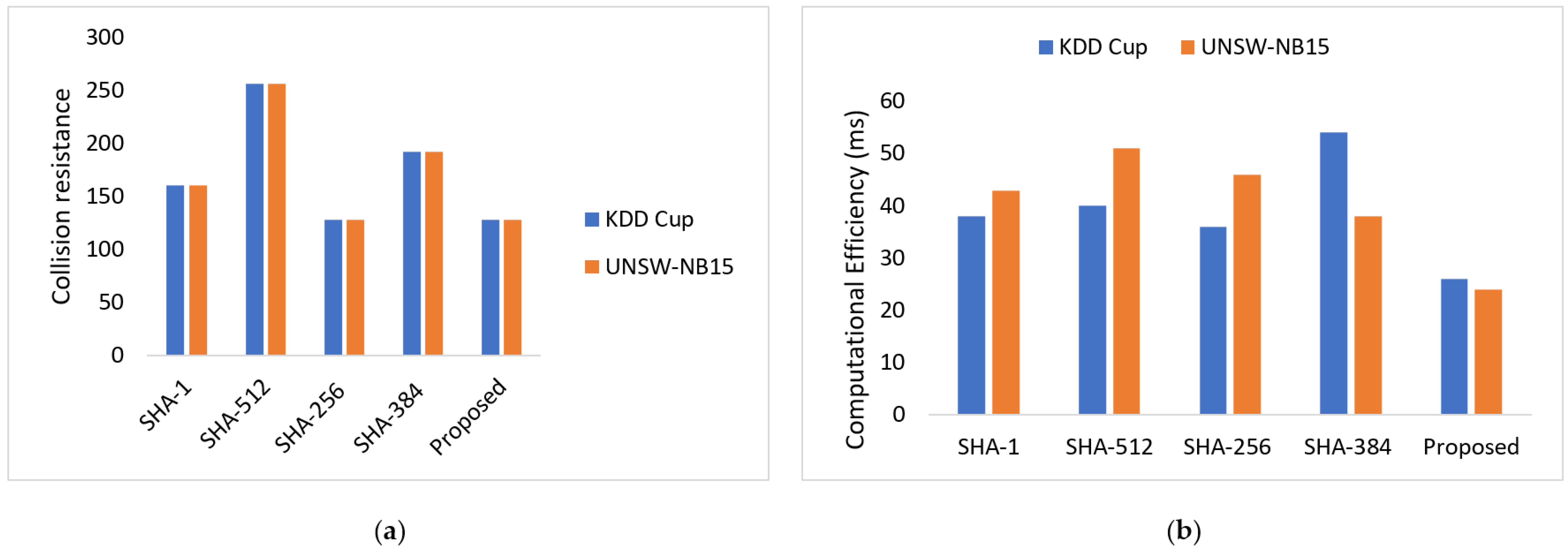
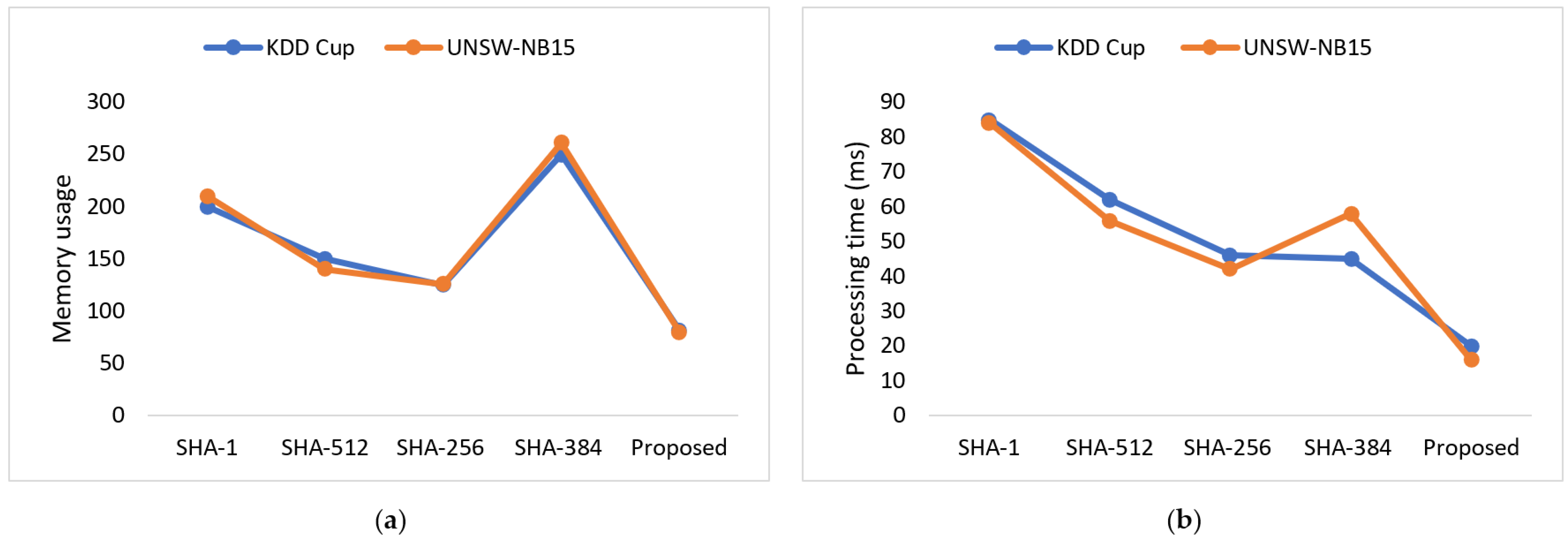
5.3. Performance Evaluation
5.4. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Nomenclature
| IoT | Internet of Things | |
| LSTM | Long Short-Term Memory | |
| SSO | Shuffle Shepherd Optimization | |
| IDS | Intrusion Detection System | |
| SHA3-256 | Secure Hash Algorithm 3 with a 256-bit hash value | |
| DoS | Denial of Service | |
| U2R | User to Root | |
| R2L | Remote to Local | |
| AI | Artificial Intelligence | |
| ML | Machine Learning | |
| CPU | Central Processing Unit | |
| SVM | Support Vector Machine | |
| KNN | K-nearest neighbor | |
| RF | Random Forest | |
| DNN | Deep neural network | |
| CNN | Convolutional neural network | |
| MACs | Message authentication codes | |
| HE | Homomorphic Encryption | |
| MWKF | Morlet Wavelet Kernel Function | |
| DEDFA | Differential Evaluation-based Dragonfly Algorithm | |
| E2CC | Enhanced Elliptical Curve Cryptography | |
| ANN | Artificial neural network | |
| CH | Cluster Heads | |
| HHO | Harris Hawks Optimization | |
| CSO | Chicken Swarm Optimization | |
| DBN | Deep Belief Network | |
| CAVO | Chronological Anticorona Virus Optimization | |
| IFS | Interplanetary File System | |
| FCM | Fuzzy C-means clustering | |
| GA | Genetic algorithm | |
| BiLSTM | Bidirectional Long Short-Term Memory | |
| MSE | Mean Square Error | |
| DPI | Deep Packet Inspection | |
| RAM | Random Access Memory | |
| FNR | False Negative Rate | |
| FPR | False Positive Rate | |
| Min-max normalization | ||
| Feature count | ||
| Variable assessment | ||
| Feature of | ||
| Quantity of training or testing set | ||
| Minimum rate of the column feature | ||
| Maximum rate of the column feature | ||
| Lowest archetypal parameter limits | ||
| Supreme archetypal parameter limits | ||
| Random number | ||
| Number of individuals in each collection | ||
| Entire number of collections | ||
| Index of the community | ||
| Index of the members within the community | ||
| Multi-community matrix | ||
| Possibility of looking into additional regions of the solution space | ||
| Ability to look around previously visited potential solution space regions | ||
| Step size | ||
| Objective function values | ||
| and | Random parameters | |
| Objective solution with the best parameter | ||
| Objective solution with worst parameter | ||
| Variable influencing explorations | ||
| Variable influencing exploitation | ||
| Input gate | ||
| Output gate | ||
| Hidden state weight | ||
| Concealed layer has a bias | ||
| tanh | Sigmoid layer function | |
| Potential parameter | ||
| New parameter | ||
| Weight matrices | ||
| Bias matrix | ||
| Output values | ||
| Output cell state | ||
| Output gate’s weight | ||
| Bias matrix | ||
| Permutation function | ||
| Rate | ||
| Capacity | ||
| Bit string | ||
| Input bit string | ||
| Padding task | ||
| Bit blocks size | ||
| Output length | ||
| Padded bit string |
References
- Park, S.; Choi, G.J.; Ko, H. Information technology-based tracing strategy in response to COVID-19 in South Korea—Privacy controversies. JAMA 2020, 323, 2129–2130. [Google Scholar] [CrossRef]
- Miśkiewicz, R. The impact of innovation and information technology on greenhouse gas emissions: A case of the Visegrád countries. J. Risk Financ. Manag. 2021, 14, 59. [Google Scholar] [CrossRef]
- Gopal, G.; Suter-Crazzolara, C.; Toldo, L.; Eberhardt, W. Digital transformation in healthcare-architectures of present and future information technologies. Clin. Chem. Lab. Med. (CCLM) 2021, 57, 328–335. [Google Scholar] [CrossRef]
- Mansour, R.F.; El Amraoui, A.; Nouaouri, I.; Diaz, V.G.; Gupta, D.; Kumar, S. Artificial intelligence and internet of things enabled disease diagnosis model for smart healthcare systems. IEEE Access 2021, 9, 45137–45146. [Google Scholar] [CrossRef]
- Chawla, N. AI, IOT and wearable technology for smart healthcare? A review. Int. J. Green Energy 2020, 7, 9–13. [Google Scholar]
- Kumar, S.; Raut, R.D.; Narkhede, B.E. A proposed collaborative framework by using artificial intelligence-internet of things (AI-IoT) in COVID-19 pandemic situation for healthcare workers. Int. J. Healthc. Manag. 2020, 13, 337–345. [Google Scholar] [CrossRef]
- Javaid, M.; Khan, I.H. Internet of Things (IoT) enabled healthcare helps to take the challenges of COVID-19 Pandemic. J. Oral Biol. Craniofacial Res. 2021, 11, 209–214. [Google Scholar] [CrossRef] [PubMed]
- Chaudhary, V.; Kaushik, A.; Furukawa, H.; Khosla, A. Review—Towards 5th Generation AI and IoT Driven Sustainable Intelligent Sensors Based on 2D MXenes and Borophene. ECS Sens. Plus 2022, 1, 013601. [Google Scholar] [CrossRef]
- Elvira, N.; Stehel, V. Internet of things sensing networks, artificial intelligence-based decision-making algorithms, and real-time process monitoring in sustainable industry 4.0. J. Self-Gov. Manag. Econ. 2021, 9, 35–47. [Google Scholar]
- Popa, A.; Hnatiuc, M.; Paun, M.; Geman, O.; Hemanth, D.J.; Dorcea, D.; Son, L.H.; Ghita, S. An intelligent IoT-base food quality monitoring approach using low-cost sensors. Symmetry 2019, 11, 374. [Google Scholar] [CrossRef]
- Greco, L.; Percannella, G.; Ritrovato, P.; Tortorella, F.; Vento, M. Trends in IoT based solutions for health care: Moving AI to the edge. Pattern Recognit. Lett. 2020, 135, 346–353. [Google Scholar] [CrossRef] [PubMed]
- Jain, A.; Singh, T.; Sharma, S.K. Security as a solution: An intrusion detection system using a neural network for IoT enabled healthcare ecosystem. Interdiscip. J. Inf. Knowl. Manag. 2021, 16, 331–369. [Google Scholar] [CrossRef] [PubMed]
- Eskandari, M.; Janjua, Z.H.; Vecchio, M.; Antonelli, F. Passban IDS: An intelligent anomaly-based intrusion detection system for IoT edge devices. IEEE Internet Things J. 2020, 7, 6882–6897. [Google Scholar] [CrossRef]
- Arisdakessian, S.; Wahab, O.A.; Mourad, A.; Otrok, H.; Guizani, M. A survey on iot intrusion detection: Federated learning, game theory, social psychology and explainable ai as future directions. IEEE Internet Things J. 2022, 10, 4059–4092. [Google Scholar] [CrossRef]
- Öztürk, T.; Turgut, Z.; Akgün, G.; Köse, C. Machine learning-based intrusion detection for SCADA systems in healthcare. Netw. Model. Anal. Health Inform. Bioinform. 2022, 11, 47. [Google Scholar] [CrossRef]
- Chen, S.; Webb, G.I.; Liu, L.; Ma, X. A novel selective naïve Bayes algorithm. Knowl.-Based Syst. 2020, 192, 105361. [Google Scholar] [CrossRef]
- Ponmalar, A.; Dhanakoti, V. An intrusion detection approach using ensemble support vector machine based chaos game optimization algorithm in big data platform. Appl. Soft Comput. 2022, 116, 108295. [Google Scholar] [CrossRef]
- Balyan, A.K.; Ahuja, S.; Lilhore, U.K.; Sharma, S.K.; Manoharan, P.; Algarni, A.D.; Elmannai, H.; Raahemifar, K. A hybrid intrusion detection model using ega-pso and improved random forest method. Sensors 2022, 22, 5986. [Google Scholar] [CrossRef]
- Wahab, O.A. Intrusion detection in the iot under data and concept drifts: Online deep learning approach. IEEE Internet Things J. 2022, 9, 19706–19716. [Google Scholar] [CrossRef]
- Mohammed, R.A.; Ali Alheeti, K.M. Intrusion detection system for Healthcare based on Convolutional Neural Networks. In Proceedings of the 2022 Iraqi International Conference on Communication and Information Technologies (IICCIT), Basrah, Iraq, 7–8 September 2022. [Google Scholar]
- Wahab, F.; Zhao, Y.; Javeed, D.; Al-Adhaileh, M.H.; Almaaytah, S.A.; Khan, W.; Saeed, M.S.; Shah, R.K. An AI-driven hybrid framework for intrusion detection in IoT-enabled E-health. Comput. Intell. Neurosci. 2022, 2022, 6096289. [Google Scholar] [CrossRef]
- Jayalaxmi, P.; Saha, R.; Kumar, G.; Conti, M.; Kim, T.H. Machine and Deep Learning Solutions for Intrusion Detection and Prevention in IoTs: A Survey. IEEE Access 2022, 10, 121173–121192. [Google Scholar] [CrossRef]
- Alsoufi, M.A.; Razak, S.; Siraj, M.M.; Nafea, I.; Ghaleb, F.A.; Saeed, F.; Nasser, M. Anomaly-based intrusion detection systems in iot using deep learning: A systematic literature review. Appl. Sci. 2021, 11, 8383. [Google Scholar] [CrossRef]
- Kumaar, M.A.; Samiayya, D.; Vincent, P.M.D.R.; Srinivasan, K.; Chang, C.-Y.; Ganesh, H. A Hybrid Framework for Intrusion Detection in Healthcare Systems Using Deep Learning. Front. Public Health 2022, 9, 2295. [Google Scholar]
- Asharf, J.; Moustafa, N.; Khurshid, H.; Debie, E.; Haider, W.; Wahab, A. A review of intrusion detection systems using machine and deep learning in internet of things: Challenges, solutions and future directions. Electronics 2022, 9, 1177. [Google Scholar] [CrossRef]
- Nave, O. Modification of semi-analytical method applied system of ODE. Mod. Appl. Sci. 2020, 14, 75. [Google Scholar] [CrossRef]
- Kumar, K.P.; Retnaswamy, B. A Novel MWKF-LSTM Based Intrusion Detection System for the IoT-Cloud Platform with Efficient User Authentication and Data Encryption Models. Res. Sq. 2022, preprint. [Google Scholar] [CrossRef]
- Pooja, T.S.; Shrinivasacharya, P. Evaluating neural networks using Bi-Directional LSTM for network IDS (intrusion detection systems) in cyber security. Glob. Transit. Proc. 2022, 2, 448–454. [Google Scholar]
- Islabudeen, M.; Devi, M.K.K. A smart approach for intrusion detection and prevention system in mobile ad hoc networks against security attacks. Wirel. Pers. Commun. 2022, 112, 193–224. [Google Scholar] [CrossRef]
- Alkadi, O.; Moustafa, N.; Turnbull, B.; Choo, K.K.R. A deep blockchain framework-enabled collaborative intrusion detection for protecting IoT and cloud networks. IEEE Internet Things J. 2022, 8, 9463–9472. [Google Scholar] [CrossRef]
- Mansour, R.F. Blockchain assisted clustering with Intrusion Detection System for Industrial Internet of Things environment. Expert Syst. Appl. 2022, 207, 117995. [Google Scholar] [CrossRef]
- Saviour, M.P.A.; Samiappan, D. IPFS based storage Authentication and access control model with optimization enabled deep learning for intrusion detection. Adv. Eng. Softw. 2023, 176, 103369. [Google Scholar] [CrossRef]
- Nguyen, M.T.; Kim, K. Genetic convolutional neural network for intrusion detection systems. Future Gener. Comput. Syst. 2022, 113, 418–427. [Google Scholar] [CrossRef]
- Almalawi, A.; Khan, A.I.; Alsolami, F.; Abushark, Y.B.; Alfakeeh, A.S. Managing Security of Healthcare Data for a Modern Healthcare System. Sensors 2023, 23, 3612. [Google Scholar] [CrossRef] [PubMed]
- Laghrissi, F.; Douzi, S.; Douzi, K.; Hssina, B. Intrusion detection systems using long short-term memory (LSTM). J. Big Data 2021, 8, 65. [Google Scholar] [CrossRef]
- Dao, P.N.; Liu, Y. Adaptive reinforcement learning in control design for cooperating manipulator systems. Asian J. Control 2022, 24, 1088–1103. [Google Scholar] [CrossRef]
- Chen, L.; Dai, S.-L.; Dong, C. Adaptive Optimal Tracking Control of an Underactuated Surface Vessel Using Actor-Critic Reinforcement Learning. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Fang, M.; Boutros, F.; Damer, N. Unsupervised face morphing attack detection via self-paced anomaly detection. In Proceedings of the 2022 IEEE International Joint Conference on Biometrics (IJCB), Abu Dhabi, United Arab Emirates, 10–13 October 2022. [Google Scholar]
- Aouedi, O.; Piamrat, K.; Muller, G.; Singh, K. Federated semisupervised learning for attack detection in industrial Internet of Things. IEEE Trans. Ind. Inform. 2022, 19, 286–295. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Dataset | Detection Method | Prevention Method | Key Findings | Limitation/Recommendation |
|---|---|---|---|---|---|
| Retnaswamy, Bharathi [27] | NSL-KDD | MWKF-LSTM with DEDFA | SHA-512 and E2CC | Low FPR and Detection delay | Accurate detection is not possible due to a high error rate |
| Pooja, T. S., and Purohit Shrinivasacharya [28] | KDDCUP99 and UNSW-NB15 | Bi-directional LSTM | - | 99% accuracy is achieved | Poor execution time and large amount of training time |
| Islabudeen, M., and M. K. Kavitha Devi [29] | NSL-KDD | SA-IDPS | SHA-256 | Assistance for a free environment with a high detection rate, FPR, and less energy consumption and delay | Large dataset processing is challenging |
| Alkadi, O., et al. [30] | UNSW-NB15 and BoT-IoT | BiLSTM | - | Effective in basic real-world scenarios | May not work for extended computations |
| Mansour, R. F. [31] | NSL-KDD2015 and CICIDS 2017 | BAC-IDS | - | Able to prevent end-to-end communication | More false positives compared to other approaches |
| Saviour, Mariya Princy Antony, et al. [32] | Network dataset | CACVO-based DRN | - | Flexible, in terms of features | The problem of uncertainty still needs to be resolved. Unsuitable for sophisticated applications, especially intrusion detection |
| Nguyen, Minh Tuan, and Kiseon Kim [33] | NSL-KDD | GA-FCAM-CNN | - | Additionally, the extremely trustworthy validation Performance results attained | IDS speed is a crucial statistic. However, it is extremely low, and any outside source does not update the trust calculation |
| Methods | Dataset | Features | Accuracy | Precision | Recall | F-Measure | FPR | FNR | Communication Delay (s) |
|---|---|---|---|---|---|---|---|---|---|
| DEDFA [27] | KDDCUP99 | 35 | 67 | 68 | 67 | 86 | 0.005 | 1.05 | 30.7 |
| UNSW-NB15 | 45 | 64 | 64 | 62 | 64 | 0.045 | 4.12 | 55.8 | |
| BOAT [28] | 99KDDCUP99 | 41 | 81 | 81 | 64 | 80 | 0.009 | 1.054 | 31.5 |
| UNSW-NB15 | 35 | 75 | 82 | 67 | 81 | 0.008 | 0.15 | 24.12 | |
| DFPFS [29] | KDDCUP99 | 42 | 76 | 81 | 68 | 64 | 0.00564 | 0.16 | 22.6 |
| UNSW-NB15 | 42 | 74 | 76 | 64 | 61 | 0.005 | 0.2 | 23.0 | |
| Feature fusion [32] | KDDCUP99 | 41 | 71 | 81 | 69 | 78 | 0.005 | 0.12 | 21.8 |
| UNSW-NB15 | 46 | 82 | 92 | 75 | 90 | 0.071 | 0.615 | 27.8 | |
| GA [33] | KDDCUP99 | 32 | 91 | 81 | 79 | 56 | 0.054 | 0.6 | 27.2 |
| UNSW-NB15 | 38 | 72 | 89 | 82 | 92 | 0.01 | 0.05 | 21.9 | |
| Proposed | KDDCUP99 | 40 | 99.92 | 98 | 95 | 98 | 0.09 | 0.015 | 7.23 |
| UNSW-NB15 | 49 | 99.91 | 97.4 | 96 | 94.5 | 0.091 | 0.011 | 6.02 |
| Tasks | Execution Time (ms) | |
|---|---|---|
| KDDCUP99 | UNSWNB-15 | |
| Data Pre-processing | 2.1 | 1.8 |
| Feature Extraction (SSO) | 3.5 | 3.2 |
| LSTM Training | 10.2 | 8.7 |
| Hash Function Calculation | 1.2 | 1.1 |
| Attack Prediction | 4.3 | 3.9 |
| Attack Mitigation | 2.8 | 2.5 |
| KDDCUP99 Dataset | |||||
|---|---|---|---|---|---|
| Metrics and Methods | MWKF-LSTM with DEDFA [26] | SA-IDPS [28] | BiLSTM [29] | GA-FCAM-CNN [32] | Proposed |
| Accuracy | 86 | 89 | 95.06 | 88 | 99.9 |
| Recall | 83 | 60 | 89 | 84 | 98.2 |
| Precision | 81 | 90 | 81.05 | 85 | 95 |
| F-measure | 82 | 59 | 84 | 82 | 98 |
| FPR | 0.001 | 0.045 | 0.005 | 0 | 0.09 |
| FNR | 1.34 | 0.91 | 0.65 | 1.85 | 0.001 |
| UNSW-NB15 dataset | |||||
| Accuracy | 86 | 89 | 95.06 | 88 | 99.9 |
| Recall | 83 | 60 | 89 | 84 | 98.2 |
| Precision | 81 | 90 | 81.05 | 85 | 95 |
| F-measure | 82 | 59 | 84 | 82 | 98 |
| FPR | 0.001 | 0.045 | 0.005 | 0 | 0.09 |
| FNR | 1.34 | 0.91 | 0.65 | 1.85 | 0.001 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ali, A.M.; Alqurashi, F.; Alsolami, F.J.; Qaiyum, S. A Double-Layer Indemnity Enhancement Using LSTM and HASH Function Technique for Intrusion Detection System. Mathematics 2023, 11, 3894. https://doi.org/10.3390/math11183894
Ali AM, Alqurashi F, Alsolami FJ, Qaiyum S. A Double-Layer Indemnity Enhancement Using LSTM and HASH Function Technique for Intrusion Detection System. Mathematics. 2023; 11(18):3894. https://doi.org/10.3390/math11183894
Chicago/Turabian StyleAli, Abdullah Marish, Fahad Alqurashi, Fawaz Jaber Alsolami, and Sana Qaiyum. 2023. "A Double-Layer Indemnity Enhancement Using LSTM and HASH Function Technique for Intrusion Detection System" Mathematics 11, no. 18: 3894. https://doi.org/10.3390/math11183894
APA StyleAli, A. M., Alqurashi, F., Alsolami, F. J., & Qaiyum, S. (2023). A Double-Layer Indemnity Enhancement Using LSTM and HASH Function Technique for Intrusion Detection System. Mathematics, 11(18), 3894. https://doi.org/10.3390/math11183894