


Self-Organizing Memory Based on Adaptive Resonance Theory for Vision and Language Navigation

Abstract
:1. Introduction
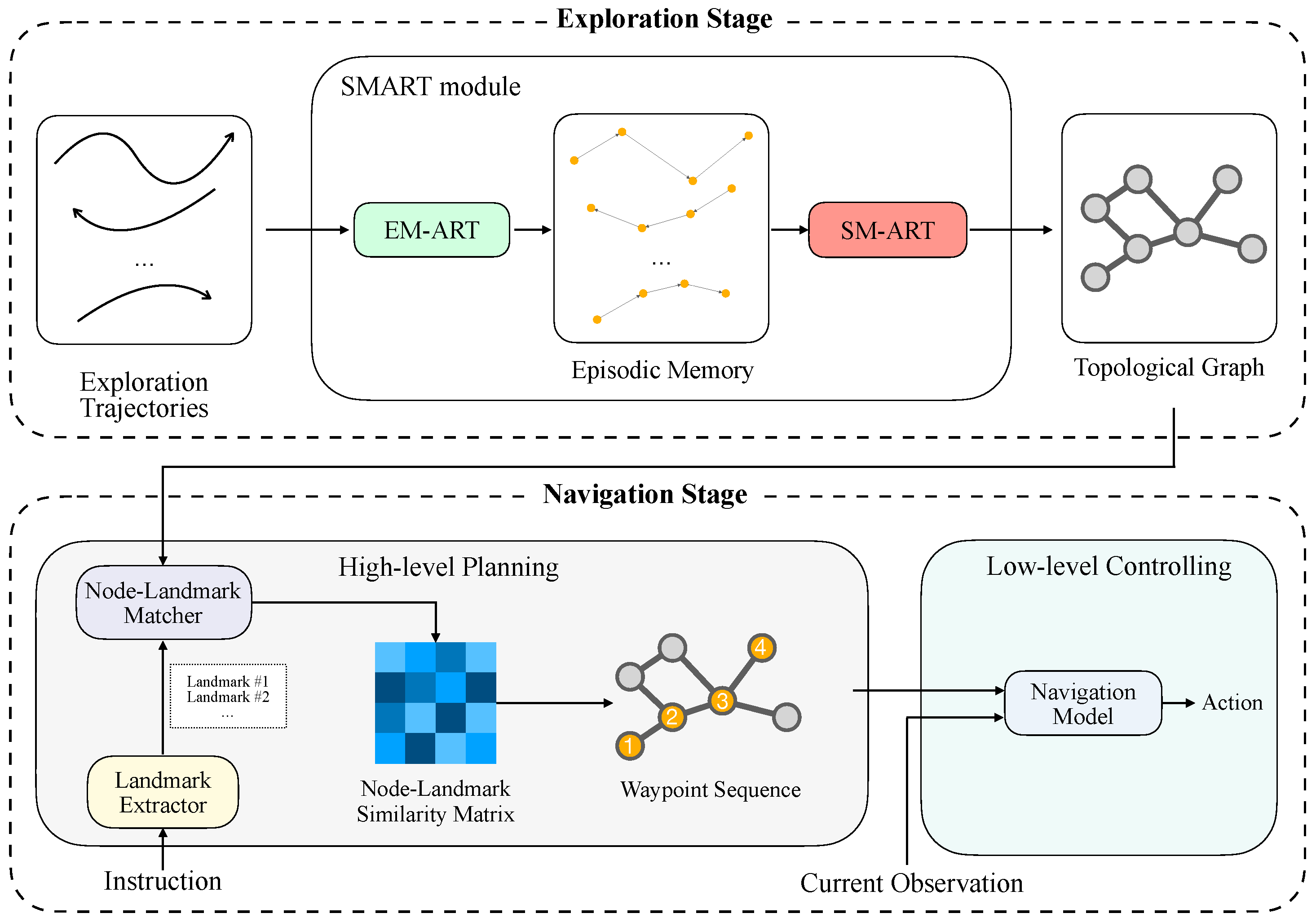
- We present the Self-organizing Memory based on the Adaptive Resonance Theory (SMART) module to address the topological mapping problem in a continuous state and action space.
- We also present a navigation framework that can utilize SMART to perform vision–language alignment for improving navigation performance, which incorporates three independent off-the-shelf pre-trained models without any fine-tuning.
- We conducted extensive experiments to validate the effectiveness of the SMART model. Experimental results show our approach has promising performance on the val-seen and test set, even compared against supervised models based on large-scale training, and show a good generalization performance.
2. Related Work
2.1. Vision and Language Navigation
2.2. Spatial Memory
2.3. Existing Memory Architectures in VLN
3. Method
3.1. Overview of Our Approach
3.2. Topological Mapping with Self-Organizing Memory
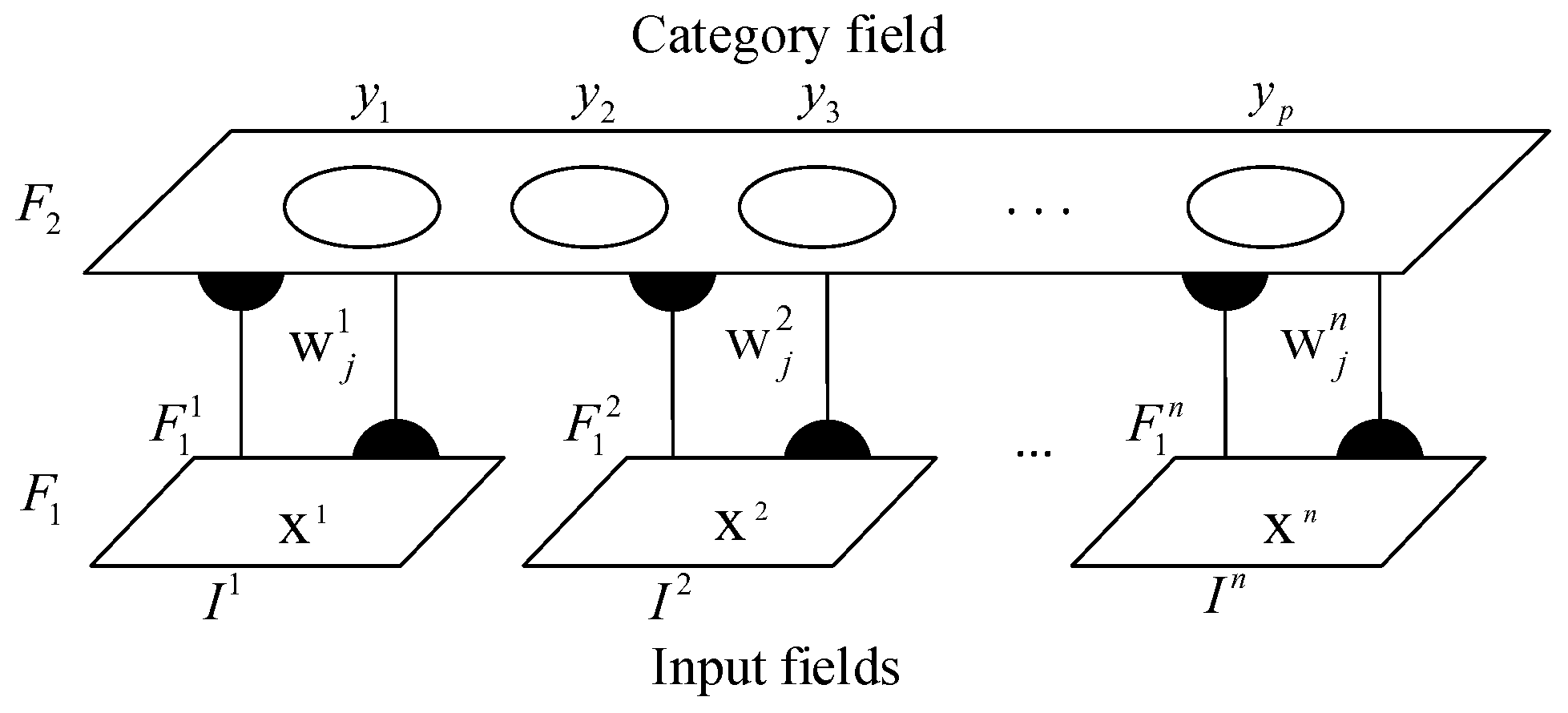
3.2.1. Fundamentals of Fusion ART
- Input Vectors: The input vector and the concatenation of input vectors of all channels can be denoted as and , respectively, where .
- Input Fields: is the k-th input field and is the activity vector after receiving .
- Category Fields: means one category field. is the activity vector of where p is the number of current learned categories.
- Weight Vectors: is denoted as the weight vector associated with the j-th node in for learning the input patterns of .
- Parameters: The parameters can affect the dynamics of each field, including choice parameters , learning rate parameters , contribution parameters , and vigilance parameters .
- The code activation process on the j-th node in is controlled by the choice:where the fuzzy AND operation ∧ is defined by , and the norm is defined by for vector p and q [13].
- A code competition process selects an node with the highest indexed at J and sets and for all .
- A template matching process checks if resonance occurs:This selection process will be repeated until a category with resonance is found. If no selected node in meets the vigilance, an uncommitted node is recruited in as a new category node.
- A template learning process is applied to the connection weights once resonance occurs
- Activity Readout: A chosen node J may perform a readout of its weight vectors to the input field such that .
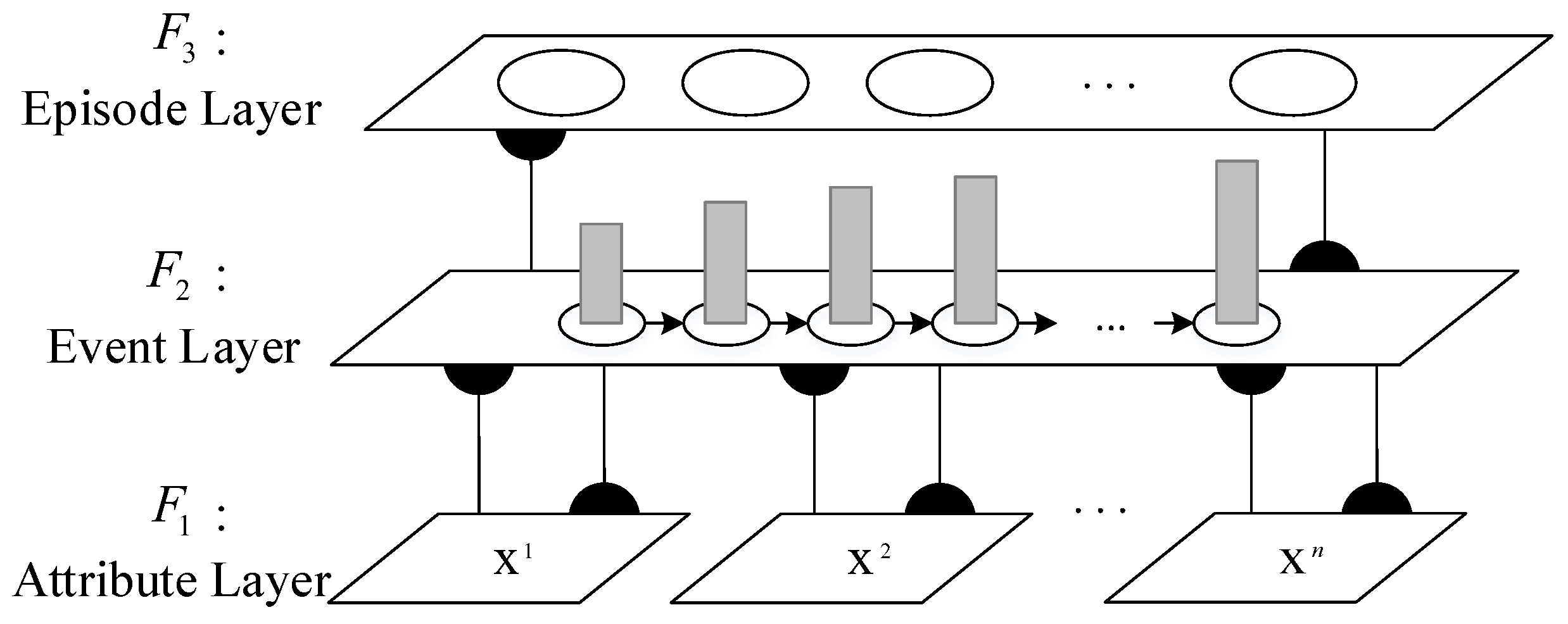
3.2.2. Episodic Memory Extraction from Exploration Trajectories
| Algorithm 1 Episodic memory modeling algorithm |
|
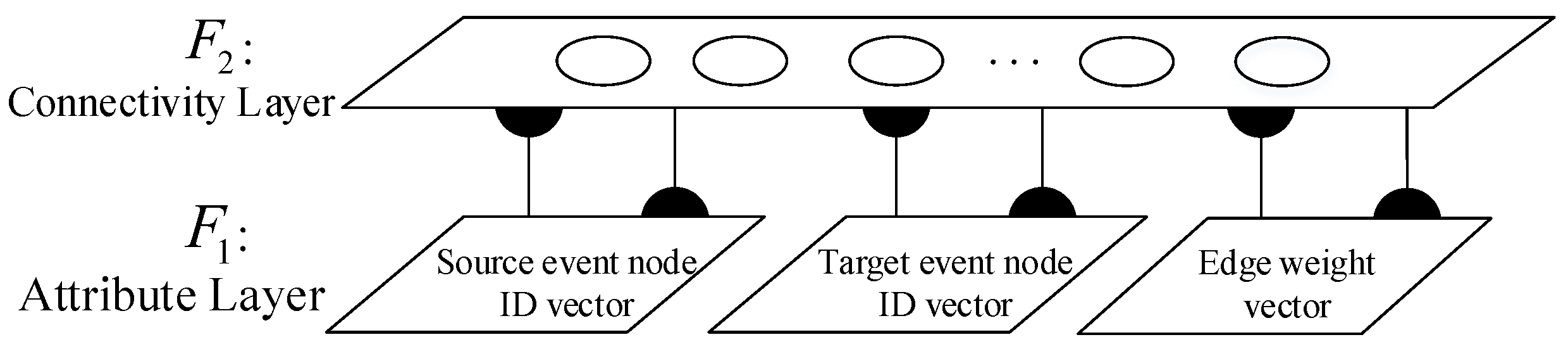
3.2.3. Spatial Memory Construction
| Algorithm 2 Spatial memory consolidating algorithm |
|
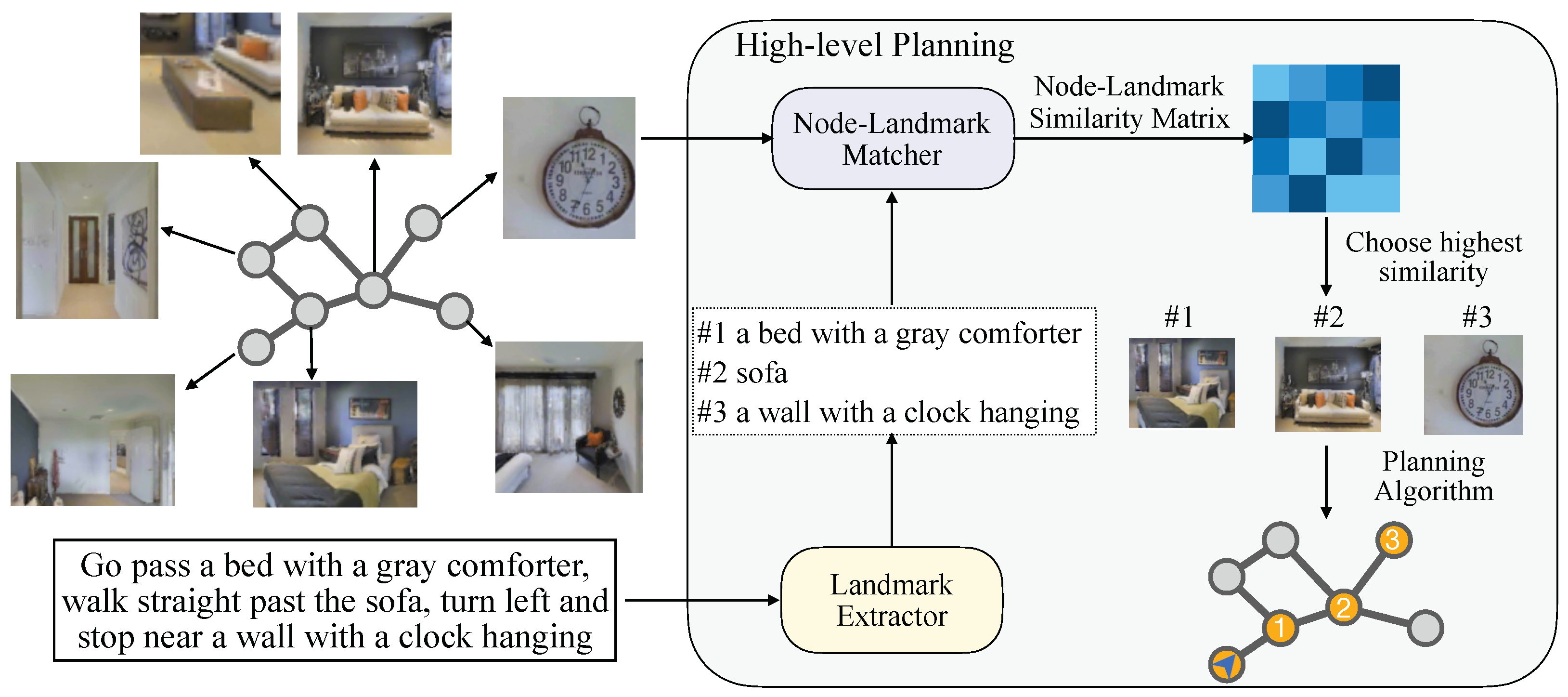
3.3. High-Level Planning
3.3.1. Landmark Extractor

3.3.2. Node–Landmark Matcher
3.4. Low-Level Controlling
4. Experiments
4.1. Dataset and Evaluation Metrics
4.2. Model Summary
- Non -topology-based models:
- Seq2Seq [8]: Proposes an end-to-end model that uses the LSTM network to predict actions directly from a language instruction and images.
- CMA+PM+DA+Aug [8]: Proposes a cross-modal attention model to grounding the language instruction to visual observation, combined with Progress Monitor techniques, imitation policy DAgger, and the Speaker–Follower data augmentation method.
- SARSA [44]: Proposes a hybrid transformer-recurrence model that focuses on combining classical semantic mapping techniques with a learning-based method.
- LAW [45]: Proposes a new supervision signal, which utilizes the nearest waypoint on the path as the supervision signal instead of the target position.
- Waypoint Model [46]: Proposes an end-to-end model that predicts relative waypoints directly from natural language instructions and panoramic RGB-D inputs.
- Topology-based models:
- CMTP [4]: Applies the most similar framework to ours among the baselines, which pre-builds a topological graph of the spatial layout. However, it uses a more complicated architecture for navigation planning, i.e,. a cross-modal transformer, which requires large-scale training. The authors have not released their source code, so we directly report the results shown in the paper.
4.3. Research Questions
- RQ1: What are the effects of different ART parameters on the composition of the topological map?
- RQ2: What is the effect of using different pre-trained models in the SMART framework on navigation performance?
- RQ3: Does SMART improve overall navigation performance compared to the baselines for the VLN-CE task?
5. Results and Discussion
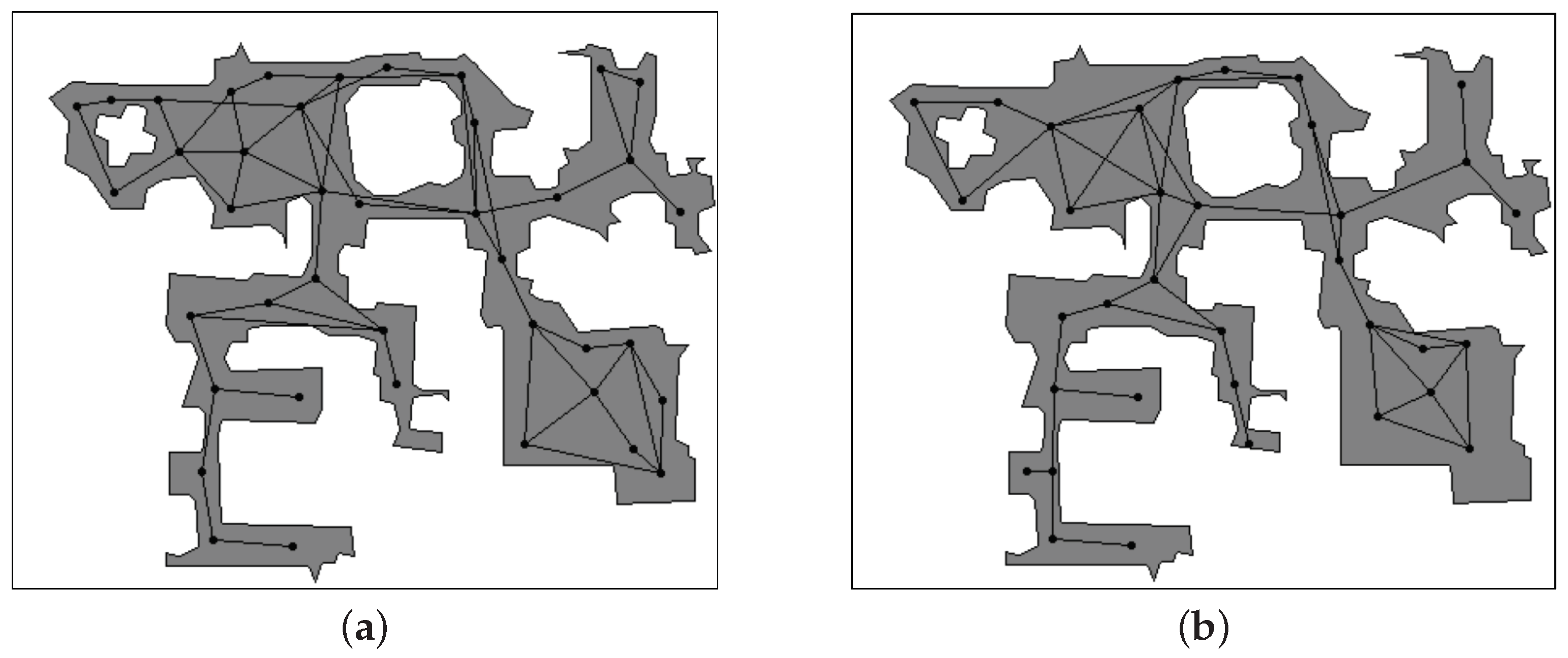
5.1. Results of Graph Construction
5.1.1. Effect of Different Input Patterns
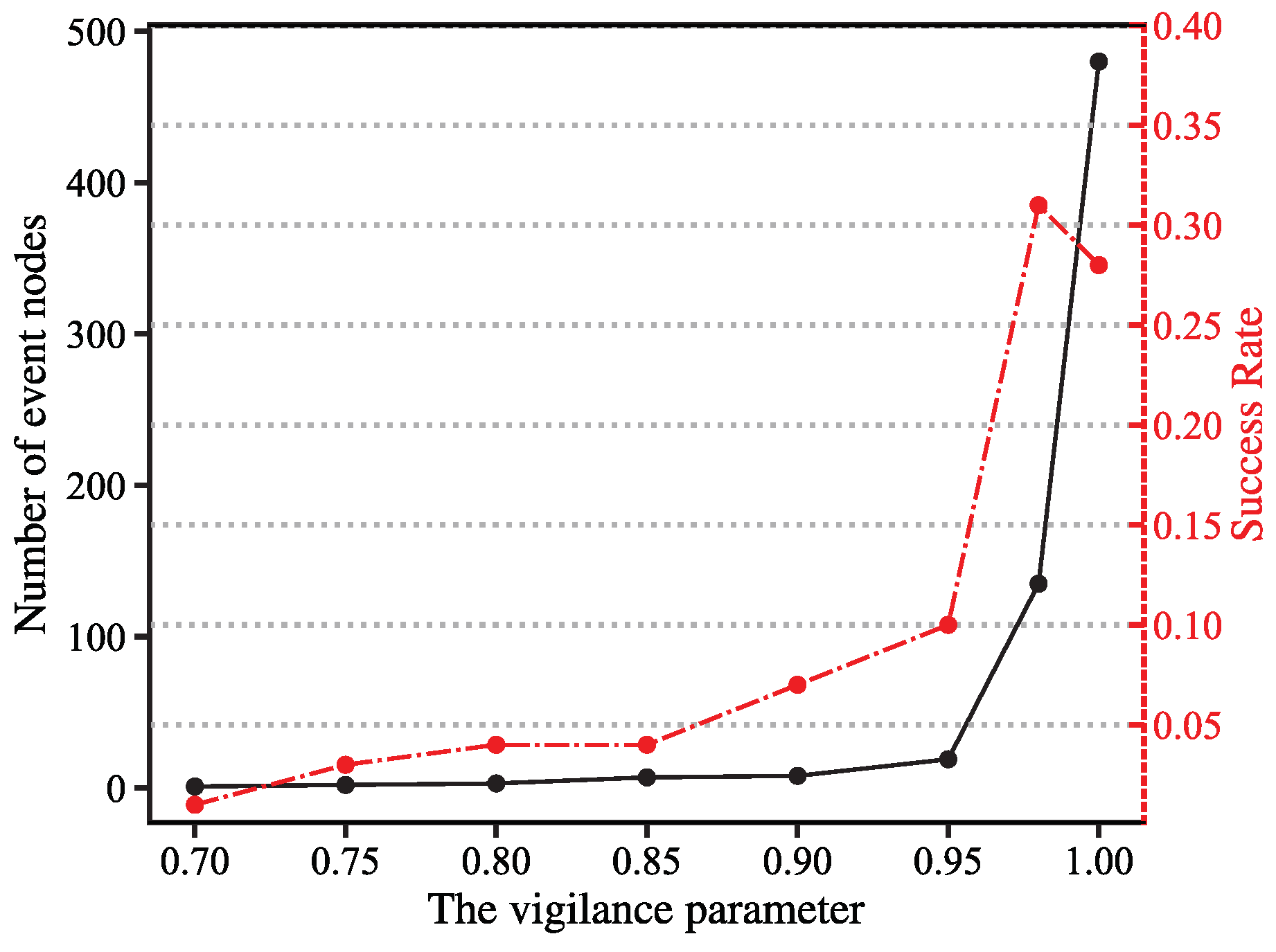
5.1.2. Effect of Different Vigilance Parameters
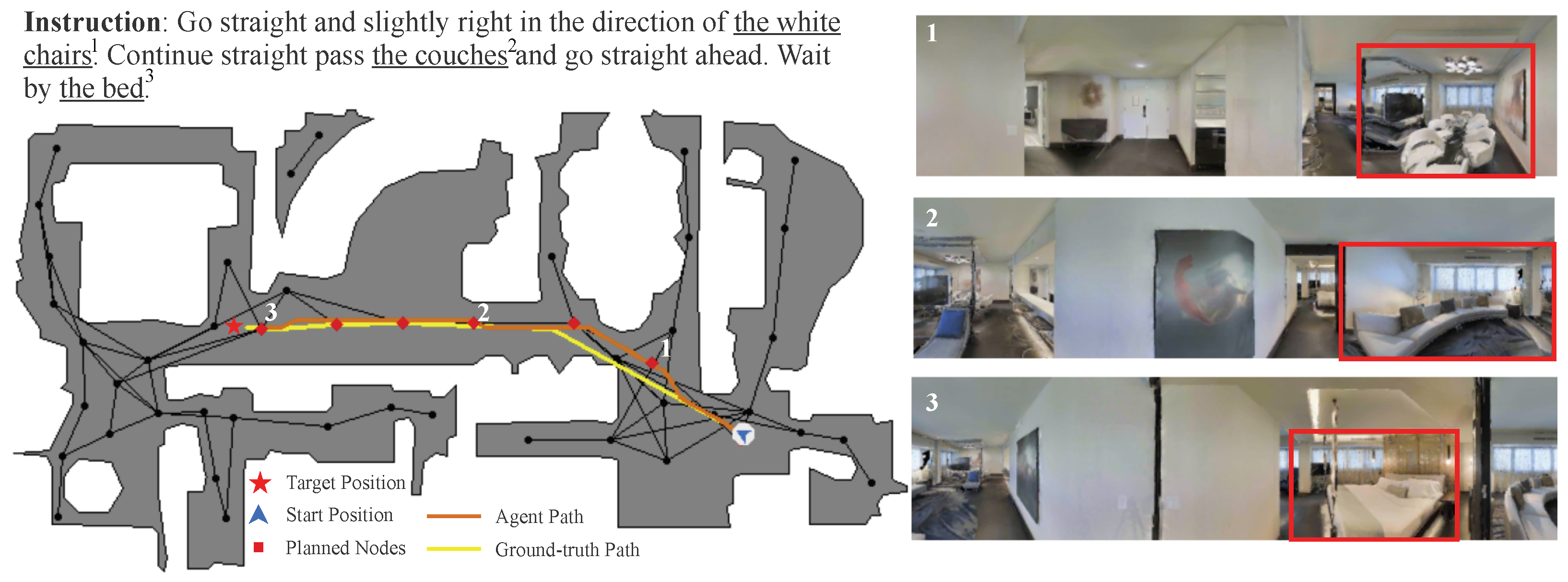
5.2. Results of Landmark Extraction
5.3. Evaluation on VLN-CE
5.4. Failure Analysis
- There are no obvious landmarks in some language instructions. For example, "Turn around, move forward 4 steps, stop" is an instruction from the training dataset. In this situation, the Landmark Extractor cannot extract any landmarks, so the episode fails directly.
- From the perspective of image-text matching, it may be walls or doors that occupy most of the area on the indoor panoramic image, but some salient landmarks may only occupy a small area on the image, which will greatly affect matching performance.
- The characteristics of the indoor environment might be one of the reasons for navigation failure. There could be many similar landmarks in the indoor scene, e.g., several beds or tables in the same house. During the node–landmark matching process, the agent struggles to distinguish which table or bed it corresponds to.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Anderson, P.; Wu, Q.; Teney, D.; Bruce, J.; Johnson, M.; Sünderhauf, N.; Reid, I.; Gould, S.; Van Den Hengel, A. Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3674–3683. [Google Scholar]
- Deng, Z.; Narasimhan, K.; Russakovsky, O. Evolving graphical planner: Contextual global planning for vision-and-language navigation. arXiv 2020, arXiv:2007.05655. [Google Scholar]
- Zhu, F.; Liang, X.; Zhu, Y.; Yu, Q.; Chang, X.; Liang, X. SOON: Scenario Oriented Object Navigation with Graph-based Exploration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtually, 19–25 June 2021; pp. 12689–12699. [Google Scholar]
- Chen, K.; Chen, J.K.; Chuang, J.; Vázquez, M.; Savarese, S. Topological Planning with Transformers for Vision-and-Language Navigation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11276–11286. [Google Scholar]
- Chen, S.; Guhur, P.L.; Schmid, C.; Laptev, I. History Aware Multimodal Transformer for Vision-and-Language Navigation. Adv. Neural Inf. Process. Syst. 2021, 34, 5834–5847. [Google Scholar]
- Hong, Y.; Wu, Q.; Qi, Y.; Opazo, C.R.; Gould, S. Vln bert: A recurrent vision-and-language bert for navigation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1643–1653. [Google Scholar]
- Hao, W.; Li, C.; Li, X.; Carin, L.; Gao, J. Towards learning a generic agent for vision-and-language navigation via pre-training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13137–13146. [Google Scholar]
- Krantz, J.; Wijmans, E.; Majumdar, A.; Batra, D.; Lee, S. Beyond the nav-graph: Vision-and-language navigation in continuous environments. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 104–120. [Google Scholar]
- Gillner, S.; Mallot, H.A. Navigation and acquisition of spatial knowledge in a virtual maze. J. Cogn. Neurosci. 1998, 10, 445–463. [Google Scholar] [CrossRef]
- Foo, P.; Warren, W.H.; Duchon, A.; Tarr, M.J. Do humans integrate routes into a cognitive map? Map-versus landmark-based navigation of novel shortcuts. J. Exp. Psychol. Learn. Mem. Cogn. 2005, 31, 195. [Google Scholar] [CrossRef] [PubMed]
- Lin, C.; Jiang, Y.; Cai, J.; Qu, L.; Haffari, G.; Yuan, Z. Multimodal Transformer with Variable-length Memory for Vision-and-Language Navigation. arXiv 2021, arXiv:2111.05759. [Google Scholar]
- Janzen, G.; Van Turennout, M. Selective neural representation of objects relevant for navigation. Nat. Neurosci. 2004, 7, 673–677. [Google Scholar] [CrossRef]
- Tan, A.H.; Carpenter, G.A.; Grossberg, S. Intelligence through interaction: Towards a unified theory for learning. In Proceedings of the International Symposium on Neural Networks, Nanjing, China, 3–7 June 2007; pp. 1094–1103. [Google Scholar]
- Tan, A.H.; Subagdja, B.; Wang, D.; Meng, L. Self-organizing neural networks for universal learning and multimodal memory encoding. Neural Netw. 2019, 120, 58–73. [Google Scholar] [CrossRef]
- Savva, M.; Kadian, A.; Maksymets, O.; Zhao, Y.; Wijmans, E.; Jain, B.; Straub, J.; Liu, J.; Koltun, V.; Malik, J.; et al. Habitat: A Platform for Embodied AI Research. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Wu, W.; Chang, T.; Li, X. Vision-and-language navigation: A survey and taxonomy. arXiv 2021, arXiv:2108.11544. [Google Scholar]
- Wang, H.; Wang, W.; Liang, W.; Xiong, C.; Shen, J. Structured Scene Memory for Vision-Language Navigation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8455–8464. [Google Scholar]
- Zhu, F.; Zhu, Y.; Chang, X.; Liang, X. Vision-Language Navigation With Self-Supervised Auxiliary Reasoning Tasks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Ma, C.Y.; Wu, Z.; AlRegib, G.; Xiong, C.; Kira, Z. The regretful agent: Heuristic-aided navigation through progress estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6732–6740. [Google Scholar]
- Wang, X.; Huang, Q.; Celikyilmaz, A.; Gao, J.; Shen, D.; Wang, Y.F.; Wang, W.Y.; Zhang, L. Reinforced cross-modal matching and self-supervised imitation learning for vision-language navigation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6629–6638. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Huggingface’s transformers: State-of-the-art natural language processing. arXiv 2019, arXiv:1910.03771. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Tolman, E.C. Cognitive maps in rats and men. Psychol. Rev. 1948, 55, 189. [Google Scholar] [CrossRef] [PubMed]
- Burgess, N.; Maguire, E.A.; O’Keefe, J. The human hippocampus and spatial and episodic memory. Neuron 2002, 35, 625–641. [Google Scholar] [CrossRef] [PubMed]
- Götze, J.; Boye, J. Learning landmark salience models from users’ route instructions. J. Locat. Based Serv. 2016, 10, 47–63. [Google Scholar] [CrossRef]
- Savinov, N.; Dosovitskiy, A.; Koltun, V. Semi-parametric topological memory for navigation. arXiv 2018, arXiv:1803.00653. [Google Scholar]
- Caduff, D.; Timpf, S. On the assessment of landmark salience for human navigation. Cogn. Process. 2008, 9, 249–267. [Google Scholar] [CrossRef] [PubMed]
- Gupta, S.; Fouhey, D.; Levine, S.; Malik, J. Unifying map and landmark based representations for visual navigation. arXiv 2017, arXiv:1712.08125. [Google Scholar]
- Hong, Y.; Rodriguez, C.; Qi, Y.; Wu, Q.; Gould, S. Language and visual entity relationship graph for agent navigation. Adv. Neural Inf. Process. Syst. 2020, 33, 7685–7696. [Google Scholar]
- Merity, S.; Keskar, N.S.; Socher, R. Regularizing and optimizing LSTM language models. arXiv 2017, arXiv:1708.02182. [Google Scholar]
- Mirowski, P.; Pascanu, R.; Viola, F.; Soyer, H.; Ballard, A.; Banino, A.; Denil, M.; Goroshin, R.; Sifre, L.; Kavukcuoglu, K.; et al. Learning to Navigate in Complex Environments. In Proceedings of the 5th International Conference on Learning Representations, ICLR, Toulon, France, 24–26 April 2017. [Google Scholar]
- Anderson, P.; Shrivastava, A.; Parikh, D.; Batra, D.; Lee, S. Chasing ghosts: Instruction following as bayesian state tracking. Adv. Neural Inf. Process. Syst. 2019, 32, 369–379. [Google Scholar]
- Gupta, S.; Davidson, J.; Levine, S.; Sukthankar, R.; Malik, J. Cognitive mapping and planning for visual navigation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2616–2625. [Google Scholar]
- Chaplot, D.S.; Salakhutdinov, R.; Gupta, A.; Gupta, S. Neural topological slam for visual navigation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12875–12884. [Google Scholar]
- Karkus, P.; Ma, X.; Hsu, D.; Kaelbling, L.P.; Lee, W.S.; Lozano-Pérez, T. Differentiable algorithm networks for composable robot learning. arXiv 2019, arXiv:1905.11602. [Google Scholar]
- Carpenter, G.A.; Grossberg, S. A massively parallel architecture for a self-organizing neural pattern recognition machine. Comput. Vision Graph. Image Process. 1987, 37, 54–115. [Google Scholar] [CrossRef]
- Wang, W.; Tan, A.H.; Teow, L.N. Semantic memory modeling and memory interaction in learning agents. IEEE Trans. Syst. Man Cybern. Syst. 2016, 47, 2882–2895. [Google Scholar] [CrossRef]
- Chaplot, D.S.; Gandhi, D.; Gupta, S.; Gupta, A.; Salakhutdinov, R. Learning To Explore Using Active Neural SLAM. In Proceedings of the 8th International Conference on Learning Representations, ICLR, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Wang, W.; Subagdja, B.; Tan, A.H.; Starzyk, J.A. Neural modeling of episodic memory: Encoding, retrieval, and forgetting. IEEE Trans. Neural Netw. Learn. Syst. 2012, 23, 1574–1586. [Google Scholar] [CrossRef]
- Hu, Y.; Subagdja, B.; Tan, A.H.; Yin, Q. Vision-Based Topological Mapping and Navigation with Self-Organizing Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 7101–7113. [Google Scholar] [CrossRef]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Wijmans, E.; Kadian, A.; Morcos, A.; Lee, S.; Essa, I.; Parikh, D.; Savva, M.; Batra, D. Dd-ppo: Learning near-perfect pointgoal navigators from 2.5 billion frames. arXiv 2019, arXiv:1911.00357. [Google Scholar]
- Anderson, P.; Chang, A.; Chaplot, D.S.; Dosovitskiy, A.; Gupta, S.; Koltun, V.; Kosecka, J.; Malik, J.; Mottaghi, R.; Savva, M.; et al. On evaluation of embodied navigation agents. arXiv 2018, arXiv:1807.06757. [Google Scholar]
- Irshad, M.Z.; Mithun, N.C.; Seymour, Z.; Chiu, H.P.; Samarasekera, S.; Kumar, R. Sasra: Semantically-aware spatio-temporal reasoning agent for vision-and-language navigation in continuous environments. arXiv 2021, arXiv:2108.11945. [Google Scholar]
- Raychaudhuri, S.; Wani, S.; Patel, S.; Jain, U.; Chang, A.X. Language-aligned waypoint (law) supervision for vision-and-language navigation in continuous environments. arXiv 2021, arXiv:2109.15207. [Google Scholar]
- Krantz, J.; Gokaslan, A.; Batra, D.; Lee, S.; Maksymets, O. Waypoint models for instruction-guided navigation in continuous environments. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 15162–15171. [Google Scholar]
- Hong, Y.; Wang, Z.; Wu, Q.; Gould, S. Bridging the Gap Between Learning in Discrete and Continuous Environments for Vision-and-Language Navigation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 15439–15449. [Google Scholar]
- Artetxe, M.; Bhosale, S.; Goyal, N.; Mihaylov, T.; Ott, M.; Shleifer, S.; Lin, X.V.; Du, J.; Iyer, S.; Pasunuru, R.; et al. Efficient large scale language modeling with mixtures of experts. arXiv 2021, arXiv:2112.10684. [Google Scholar]
- Wang, B.; Komatsuzaki, A. GPT-J-6B: A 6 Billion Parameter Autoregressive Language Model. May 2021. Available online: https://github.com/kingoflolz/mesh-transformer-jax (accessed on 1 September 2023).
- Black, S.; Biderman, S.; Hallahan, E.; Anthony, Q.; Gao, L.; Golding, L.; He, H.; Leahy, C.; McDonell, K.; Phang, J.; et al. Gpt-neox-20b: An open-source autoregressive language model. arXiv 2022, arXiv:2204.06745. [Google Scholar]
- Honnibal, M.; Montani, I.; Van Landeghem, S.; Boyd, A. spaCy: Industrial-Strength Natural Language Processing in Python. 2020. Available online: https://zenodo.org/record/8409320 (accessed on 1 September 2023).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Overall Nodes | Number of Edges per Scene | Number of Nodes per Scene | Average Edge Length | Average Edges of Each Node | |
|---|---|---|---|---|---|
| MP3D [1] | 10,559 | 218.7 | 117.3 | 1.87 | 4.07 |
| Hong2022 [47] | 13,358 | 245.9 | 148.4 | 2.26 | 3.31 |
| 12,150 | 226.5 | 135.0 | 2.35 | 3.15 | |
| 14,287 | 258.4 | 158.7 | 1.75 | 4.22 |
| Model Name | Extraction Success Rate |
|---|---|
| fairseq-125M | 0.105 |
| GPT-NeoX-20B | 0.271 |
| fairseq-13B | 0.323 |
| GPT-J-6B | 0.474 |
| spaCy | 0.704 |
| GPT-3 (text-davinci-002) | 0.837 |
| Models | Val-Unseen | Test | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| TL↓ | NE↓ | nDTW↑ | OSR↑ | SR↑ | SPL↑ | TL↓ | NE↓ | OSR↑ | SR↑ | SPL↑ | |
| Non-topology-based Methods | |||||||||||
| Seq2Seq [8] | 9.32 | 7.77 | – | 37 | 25 | 22 | 8.13 | 7.85 | 27 | 20 | 18 |
| CMA+PM+DA+Aug [8] | 8.64 | 7.37 | 51 | 40 | 32 | 30 | 8.85 | 7.91 | 36 | 28 | 25 |
| SASRA [44] | 7.89 | 8.32 | 47 | – | 24 | 22 | – | – | – | – | – |
| Waypoint Model [46] | 7.62 | 6.31 | – | 40 | 36 | 34 | 8.02 | 6.65 | 37 | 32 | 30 |
| LAW [45] | 8.89 | 6.83 | 54 | 44 | 35 | 31 | – | – | – | – | – |
| Topology-based Methods | |||||||||||
| CMTP [46] | – | 7.90 | – | 39 | 23 | 19 | – | – | – | – | – |
| Ours (SMART) | 10.90 | 6.35 | 52 | 42 | 31 | 27 | 9.85 | 6.62 | 40 | 32 | 28 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, W.; Hu, Y.; Xu, K.; Qin, L.; Yin, Q. Self-Organizing Memory Based on Adaptive Resonance Theory for Vision and Language Navigation. Mathematics 2023, 11, 4192. https://doi.org/10.3390/math11194192
Wu W, Hu Y, Xu K, Qin L, Yin Q. Self-Organizing Memory Based on Adaptive Resonance Theory for Vision and Language Navigation. Mathematics. 2023; 11(19):4192. https://doi.org/10.3390/math11194192
Chicago/Turabian StyleWu, Wansen, Yue Hu, Kai Xu, Long Qin, and Quanjun Yin. 2023. "Self-Organizing Memory Based on Adaptive Resonance Theory for Vision and Language Navigation" Mathematics 11, no. 19: 4192. https://doi.org/10.3390/math11194192
APA StyleWu, W., Hu, Y., Xu, K., Qin, L., & Yin, Q. (2023). Self-Organizing Memory Based on Adaptive Resonance Theory for Vision and Language Navigation. Mathematics, 11(19), 4192. https://doi.org/10.3390/math11194192