

Attention Knowledge Network Combining Explicit and Implicit Information
Abstract
:1. Introduction
- (1)
- We designed an ISL layer between KGE and recommendation tasks to connect KGE and recommendation tasks for feature sharing, automatically transfer interactive information during training, and obtain implicit semantics of entities and items. The ISL layer improves the model’s anti-noise and generalization capabilities.
- (2)
- We propose a cross feature fusion network that can explicitly extract features. This method can perform high-level explicit cross fusion of features, and the interaction of features occurs at the vector level, which reduces the number of parameters compared with the traditional neural network model that occurs at the element level. The network can retain the key information of each layer during the propagation process, preventing key information from being lost during the propagation process.
- (3)
- Based on the ISL layer, we designed a multilayered corrugated network based on multihead attention, which can consider the changes in users’ interests at different levels and achieve more accurate recommendations. Finally, combined with the cross feature fusion layer for high-order feature interaction, the shared information between KG entities and items can be fully utilized. We conducted experiments on multiple datasets, and good results were achieved on both large-scale and small datasets.
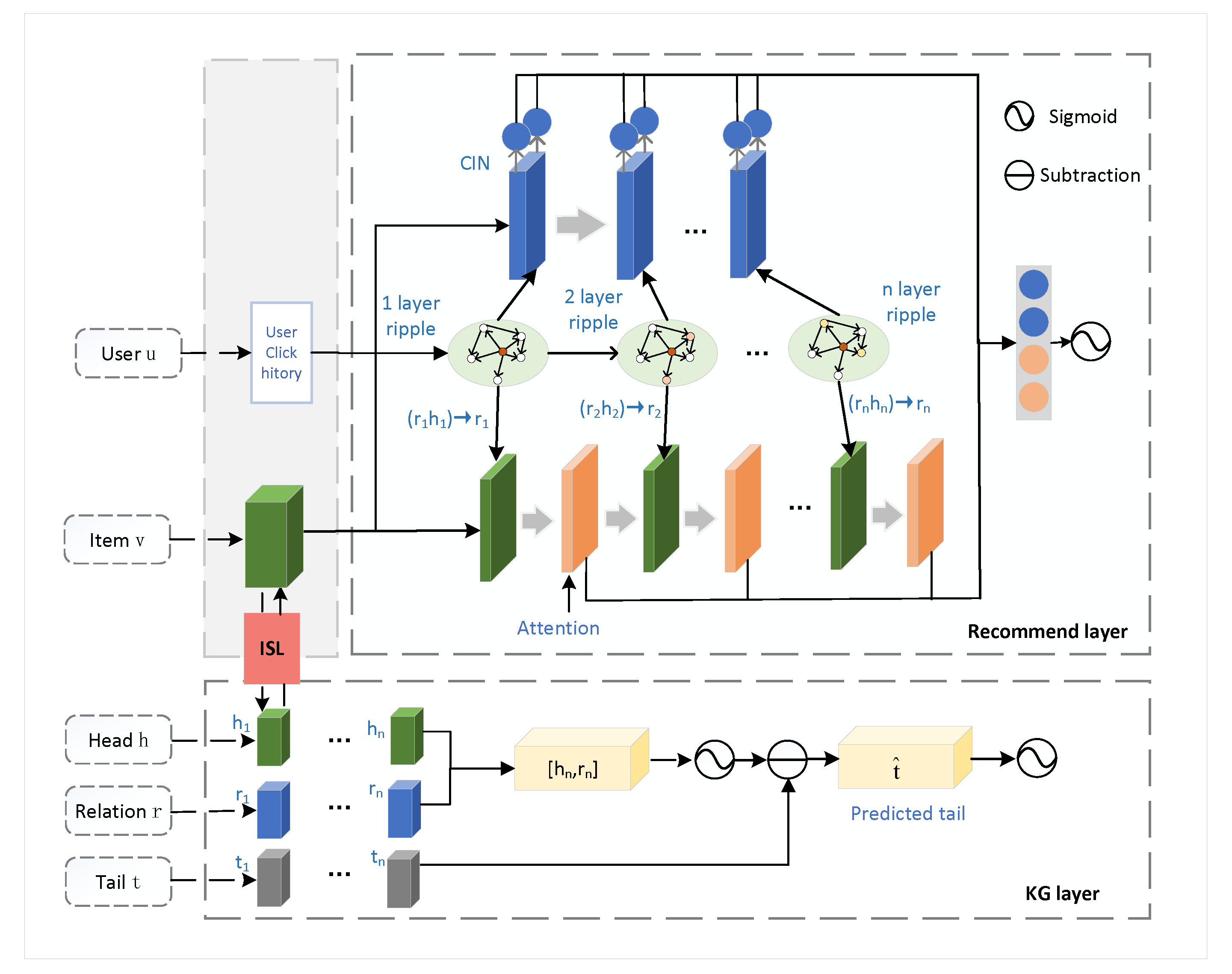
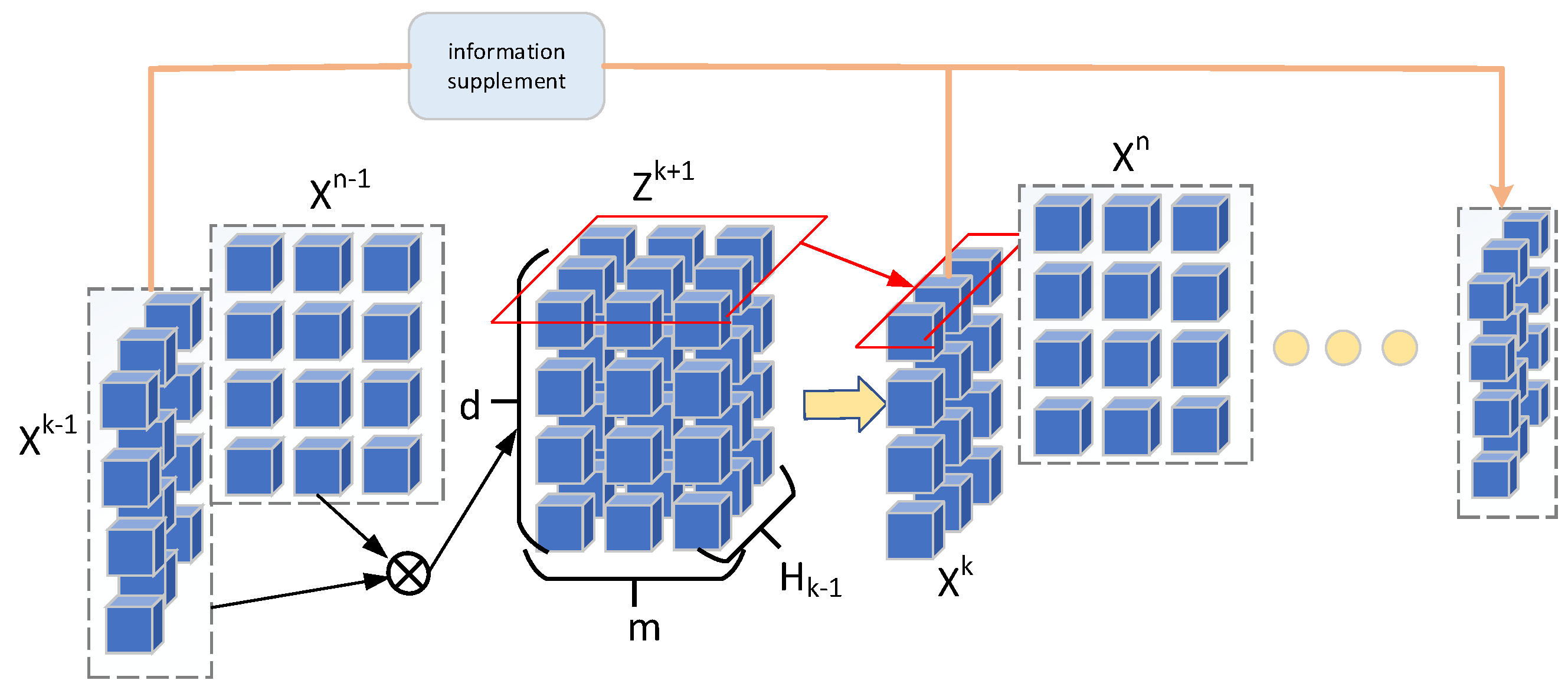
2. AKNEI Model
2.1. Problem Statement
2.2. Model Framework
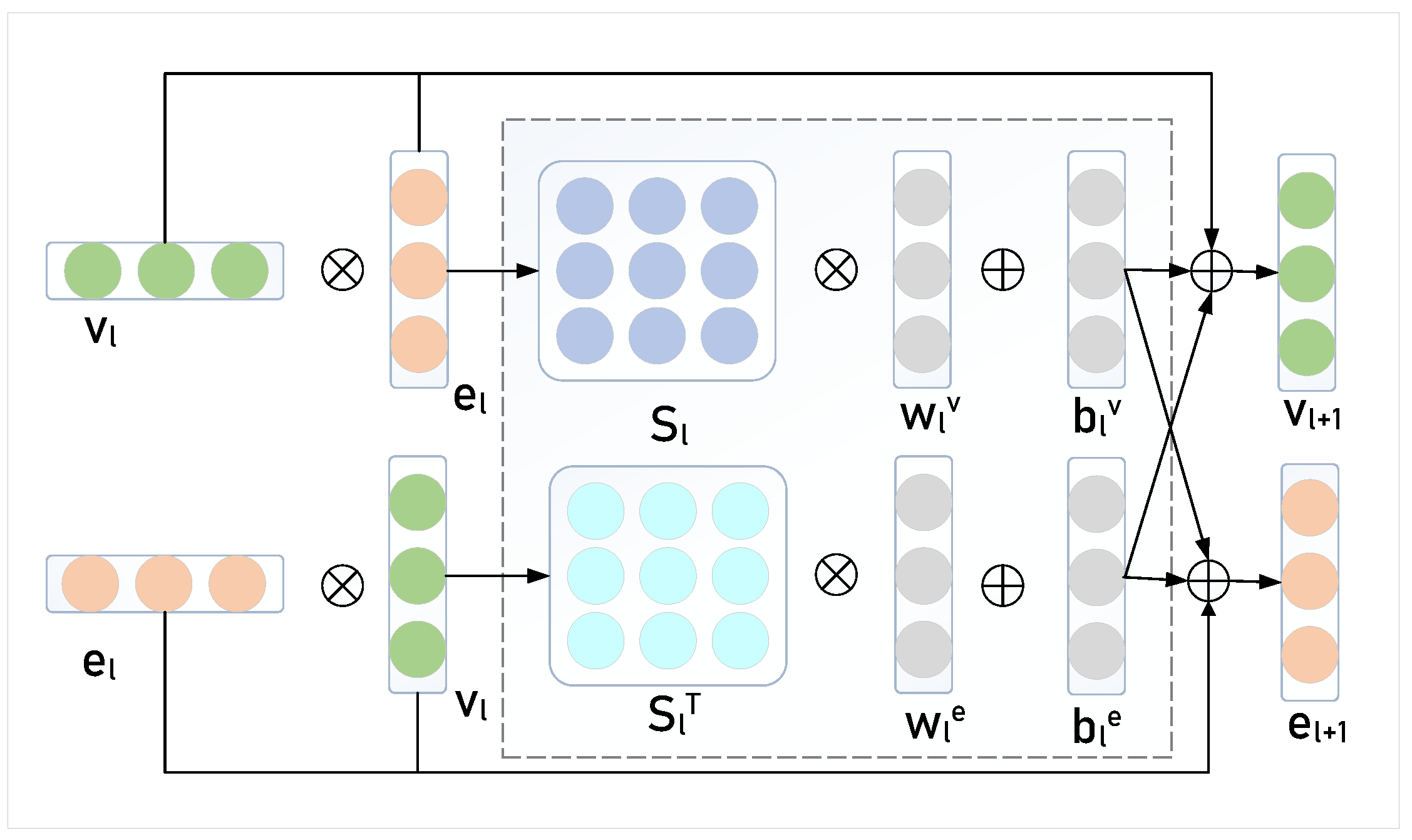
2.3. Information-Sharing Layer (ISL)
ISL Analysis
2.4. KG Layer
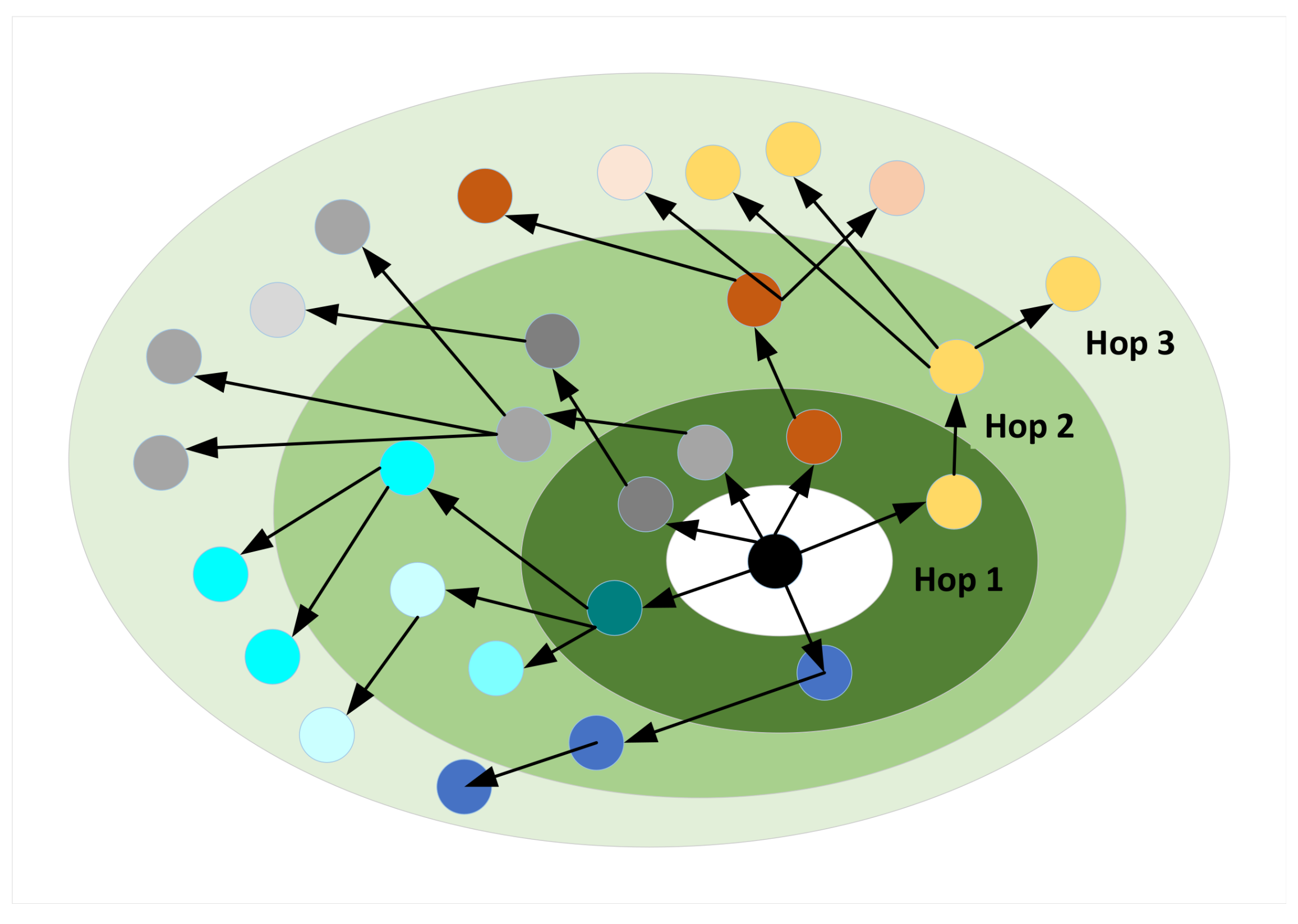
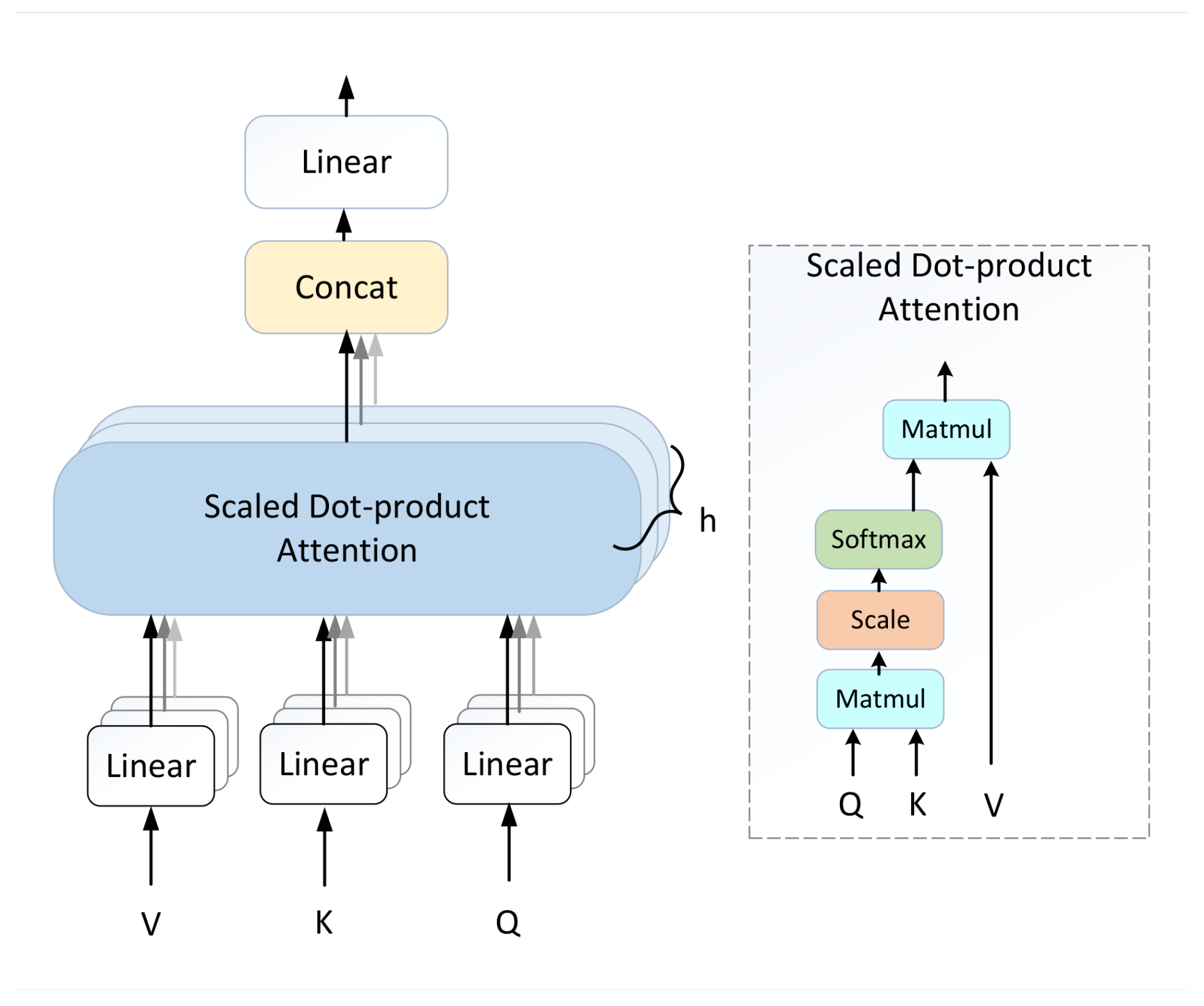
2.5. Attention Ripple Layer
2.6. Cross Feature Fusion Network (CFFN)
Cross Feature Fusion Network Analysis
2.7. Learning Algorithm
3. Links to Existing Work
4. Experiment
4.1. Public Datasets
- MovieLens-1M (https://grouplens.org/datasets/movielens/1m/ accessed on 1 December 2022): It is a widely used movie recommendation dataset. It includes approximately 1 million ratings from 6040 users on 3706 movies, with ratings ranging from 1 to 5.
- MovieLens-20M (https://grouplens.org/datasets/movielens/20m/ accessed on 1 December 2022): It is a dataset belonging to the MovieLens website, which contains the rating data of approximately 20 million users, with rating values ranging from 1 to 5.
- Book-Crossing (http://www2.informatik.uni-freiburg.de/cziegler/BX/ accessed on 1 December 2022): It is a benchmark dataset for book recommendation, which contains approximately 1.1 million ratings of 270,000 books by 90,000 users, with ratings ranging from 1 to 10.
- Last.FM (https://grouplens.org/datasets/hetrec-2011/ accessed on 1 December 2022): It is a dataset of an online music website that contains the listening information of 2000 users.
4.2. Baseline Model
- LibFM [37]: It combines general features with a near factorization model to make recommendations.
- PER [8]: A network that combines items and users and the interactive information between them.
- Wide & Deep [11]: A classic model combined with DNN neural network.
- DKN [7]: It is a news recommendation that uses multichannel and word-aligned methods to integrate CNNs.
- RippleNet [6]: The network forms a multi-layer knowledge graph network through the user’s interaction history through similar category information, and captures user preference information at different levels.
- MKR [35]: It is a feature model that combines multiple tasks, in which the KG is used as an auxiliary for recommendation tasks.
- KGCN [38]: It uses the relationship attributes of the KG to mine the associations of items to learn the potential interests of users.
- Ripp-MKR [39]: This model is an end-to-end recommendation method incorporating knowledge graph embeddings, which enhances the representation of latent information.
- CAKR [40]: A new method is designed to optimize the feature interaction between items and corresponding entities in knowledge graphs, and a feature intersection unit combined with the attention mechanism is proposed to enhance the recommendation effect.
4.3. Experimental Setup
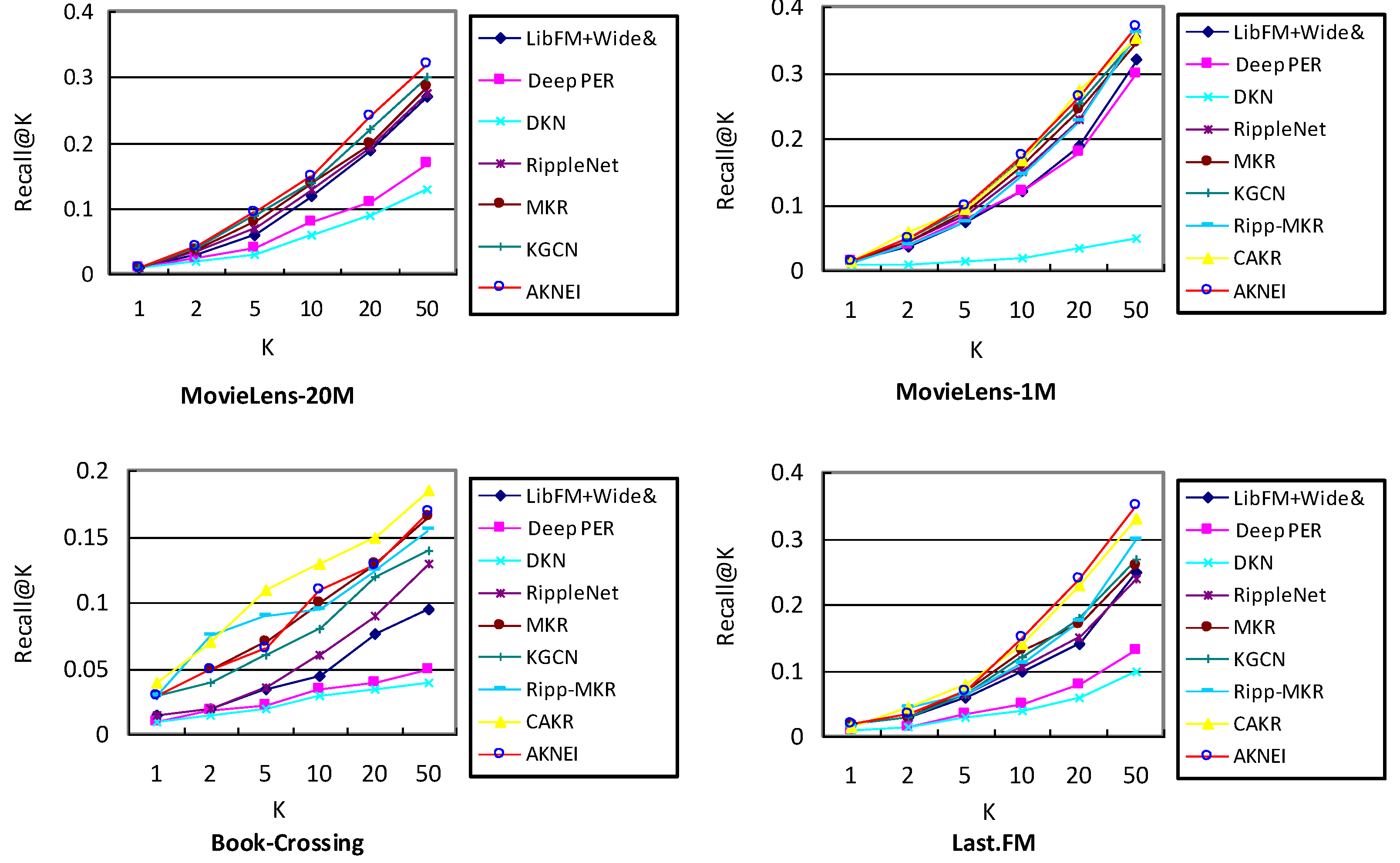
4.4. Experimental Results
- Compared with other baselines, DKN has the worst performance. Whether it is on movie data with large data volumes or small and sparse music and book datasets, its performance is not satisfactory. DKN entity embedding before input cannot participate in the learning process.
- From the comparison experiment, PER performs better than DKN on each dataset but the performance is not good enough compared to other baselines. The reason is that the metapath defined by the PER has difficulty achieving the optimal value and cannot integrate heterogeneous relationship information.
- The performance of LibFM and Wide&Deep is relatively good on the four datasets. It shows that the model has a high information utilization rate for KG, and can extract relevant information well to improve recommendation performance.
- RippleNet has shown excellent performance, which shows that it has a significant effect in capturing user preferences. From the comparison of the four datasets, RippleNet has reduced performance in the case of sparse data and has a strong dependence on data density.
- Compared with the MKR and the KGCN, the KGCN is more sensitive to the sparsity of data and performs weaker on sparse book datasets, but the KGCN performs better than the MKR on datasets with large data volumes, indicating that the KGCN is more suitable for obtaining large data on recommended occasions.
- CAKR benefits from its improved interaction module, and the feature intersection unit of the attention mechanism has certain advantages in complementing information. Therefore, the model performs better on sparse datasets.
- It can be seen from the experimental results that the AKNEI model proposed in this paper performs better than the baseline model mentioned above on the four datasets. In the MovieLens-20M dataset, the AUC increases by 1.1–18.6%, and the ACC increases by 2.3–19.9%. AUC in MovieLens-1M increases by 1.6–29.3%, ACC increases by 1.9–30.7%, AUC increases by 0.5–16.1% in Book-Crossing, ACC increases by 0.2–14.7%, Last.FM AUC increases by 3.1–26.6%, and ACC increases by 0.7–23.1%. This proves that our model has a higher utilization of user behavior data.
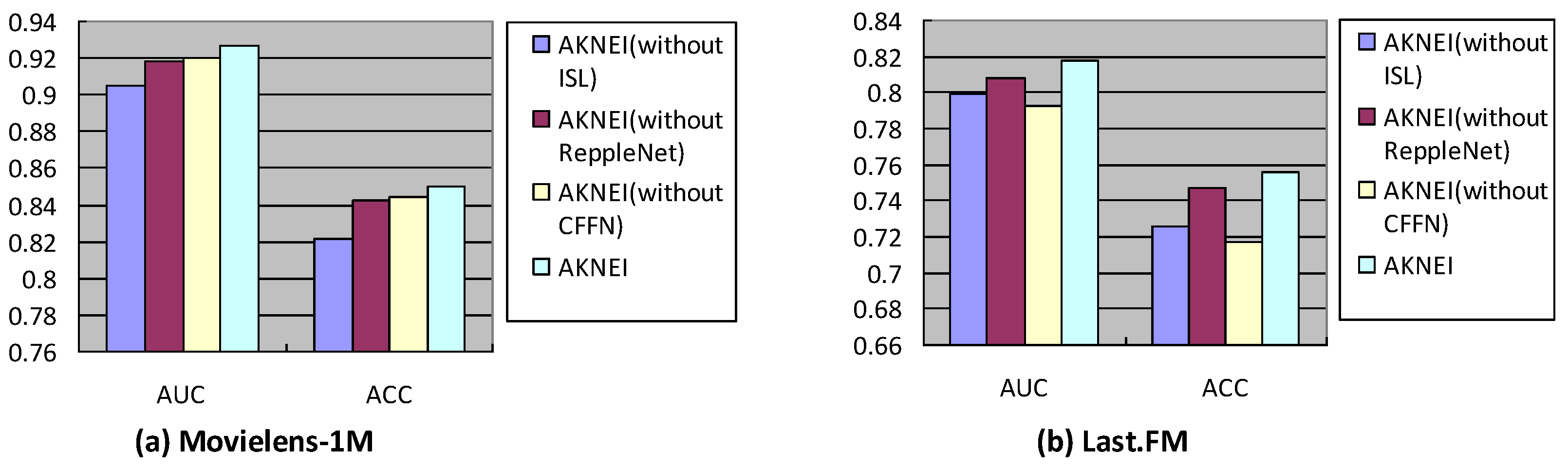
4.5. Influence of Different Modules
4.5.1. Impact of ISL Module, Cross Feature Fusion Network Module and RippleNet Module
4.5.2. Impact of RippleNet Layers and Attention Module
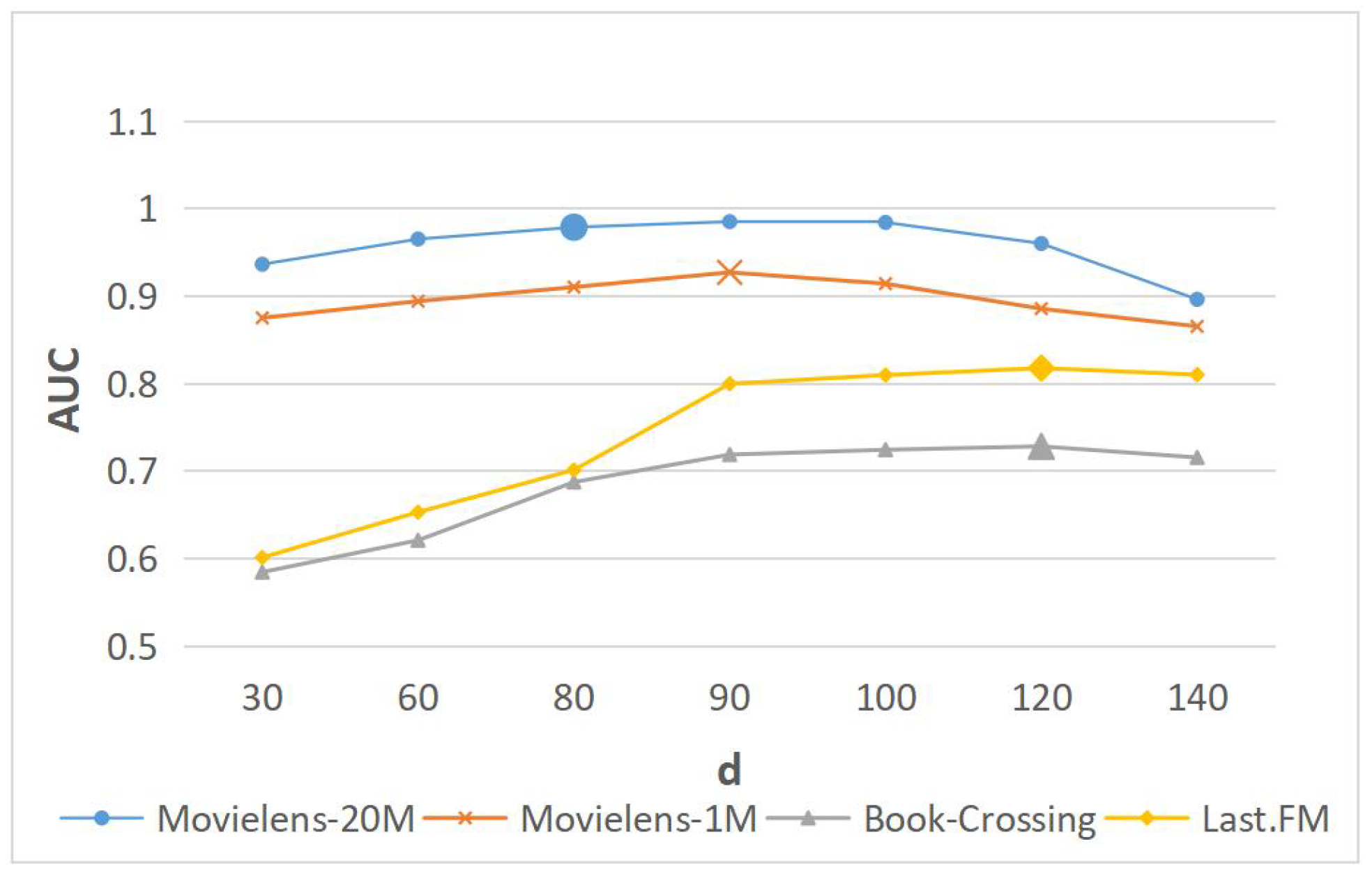
4.6. Parametric Analysis
4.6.1. Impact of Embedding Dimension
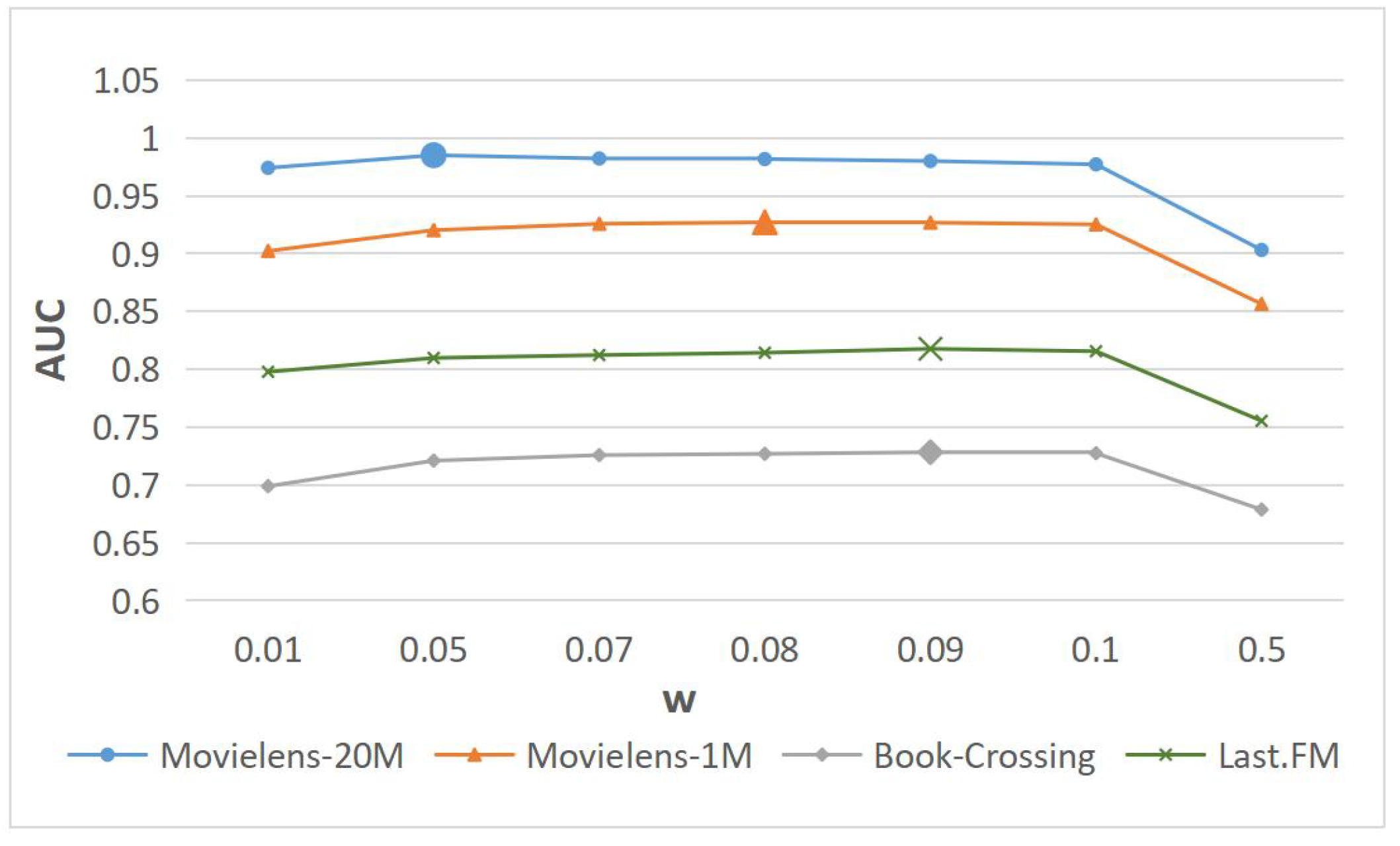
4.6.2. Impact of KEG Weight
4.7. Sensitivity Analysis of the Model to Data Sparseness
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Koren, Y.; Bell, R.; Volinsky, C. Matrix factorization techniques for recommender systems. Computer 2009, 42, 30–37. [Google Scholar] [CrossRef]
- Jamali, M.; Ester, M. A matrix factorization technique with trust propagation for recommendation in social networks. In Proceedings of the fourth ACM conference on Recommender Systems, Barcelona, Spain, 26–30 September 2010; pp. 135–142. [Google Scholar]
- Wang, H.; Zhang, F.; Hou, M.; Xie, X.; Guo, M.; Liu, Q. Shine: Signed heterogeneous information network embedding for sentiment link prediction. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, Marina Del Rey, CA, USA, 5–9 February 2018; pp. 592–600. [Google Scholar]
- Sun, Y.; Yuan, N.J.; Xie, X.; McDonald, K.; Zhang, R. Collaborative intent prediction with real-time contextual data. ACM Trans. Inf. Syst. (TOIS) 2017, 35, 1–33. [Google Scholar] [CrossRef]
- Huang, J.; Zhao, W.X.; Dou, H.; Wen, J.R.; Chang, E.Y. Improving sequential recommendation with knowledge-enhanced memory networks. In Proceedings of the The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, Ann Arbor, MI, USA, 8–12 July 2018; pp. 505–514. [Google Scholar]
- Wang, H.; Zhang, F.; Wang, J.; Zhao, M.; Li, W.; Xie, X.; Guo, M. Ripplenet: Propagating user preferences on the knowledge graph for recommender systems. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino, Italy, 22–26 October 2018; pp. 417–426. [Google Scholar]
- Wang, H.; Zhang, F.; Xie, X.; Guo, M. DKN: Deep knowledge-aware network for news recommendation. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 1835–1844. [Google Scholar]
- Yu, X.; Ren, X.; Sun, Y.; Gu, Q.; Sturt, B.; Khandelwal, U.; Norick, B.; Han, J. Personalized entity recommendation: A heterogeneous information network approach. In Proceedings of the 7th ACM International Conference on Web Search and Data Mining, New York, NY, USA, 24–28 February 2014; pp. 283–292. [Google Scholar]
- Zhao, H.; Yao, Q.; Li, J.; Song, Y.; Lee, D.L. Meta-graph based recommendation fusion over heterogeneous information networks. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 635–644. [Google Scholar]
- Wang, Q.; Mao, Z.; Wang, B.; Guo, L. Knowledge graph embedding: A survey of approaches and applications. IEEE Trans. Knowl. Data Eng. 2017, 29, 2724–2743. [Google Scholar] [CrossRef]
- Cheng, H.T.; Koc, L.; Harmsen, J.; Shaked, T.; Chandra, T.; Aradhye, H.; Anderson, G.; Corrado, G.; Chai, W.; Ispir, M.; et al. Wide & deep learning for recommender systems. In Proceedings of the 1st Workshop on Deep Learning for Recommender Systems, Boston, MA, USA, 15 September 2016; pp. 7–10. [Google Scholar]
- Misra, I.; Shrivastava, A.; Gupta, A.; Hebert, M. Cross-stitch networks for multi-task learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 July 2016; pp. 3994–4003. [Google Scholar]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? arXiv 2014, arXiv:1411.1792. [Google Scholar]
- Guo, H.; Tang, R.; Ye, Y.; Li, Z.; He, X. DeepFM: A factorization-machine based neural network for CTR prediction. arXiv 2017, arXiv:1703.04247. [Google Scholar]
- Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; Yakhnenko, O. Translating embeddings for modeling multi-relational data. In Proceedings of the NIPS’13: Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; Volume 26. [Google Scholar]
- Lin, Y.; Liu, Z.; Sun, M.; Liu, Y.; Zhu, X. Learning entity and relation embeddings for knowledge graph completion. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Liu, H.; Wu, Y.; Yang, Y. Analogical inference for multi-relational embeddings. In Proceedings of the International Conference on Machine Learning. PMLR, Sydney, Australia, 6–11 August 2017; pp. 2168–2178. [Google Scholar]
- Nickel, M.; Rosasco, L.; Poggio, T. Holographic embeddings of knowledge graphs. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–14 February 2016; Volume 30. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K.; et al. Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv 2016, arXiv:1609.08144. [Google Scholar]
- Rendle, S.; Freudenthaler, C.; Schmidt-Thieme, L. Factorizing personalized markov chains for next-basket recommendation. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; pp. 811–820. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Song, W.; Shi, C.; Xiao, Z.; Duan, Z.; Xu, Y.; Zhang, M.; Tang, J. Autoint: Automatic feature interaction learning via self-attentive neural networks. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 1161–1170. [Google Scholar]
- Kim, D.; Park, C.; Oh, J.; Lee, S.; Yu, H. Convolutional matrix factorization for document context-aware recommendation. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016; pp. 233–240. [Google Scholar]
- Zhang, W.; Du, T.; Wang, J. Deep learning over multi-field categorical data. In Proceedings of the European Conference on Information Retrieval, Padua, Italy, 20–23 March 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 45–57. [Google Scholar]
- Qu, Y.; Cai, H.; Ren, K.; Zhang, W.; Yu, Y.; Wen, Y.; Wang, J. Product-based neural networks for user response prediction. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining (ICDM), Barcelona, Spain, 12–15 December 2016; pp. 1149–1154. [Google Scholar]
- Lian, J.; Zhou, X.; Zhang, F.; Chen, Z.; Xie, X.; Sun, G. xdeepfm: Combining explicit and implicit feature interactions for recommender systems. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 1754–1763. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 3111–3119. [Google Scholar]
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Hu, X.; Chua, T.S. Neural collaborative filtering. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 173–182. [Google Scholar]
- Vig, J.; Sen, S.; Riedl, J. Tagsplanations: Explaining recommendations using tags. In Proceedings of the 14th International Conference on Intelligent User Interfaces, Sanibel Island, FL, USA, 8–11 February 2009; pp. 47–56. [Google Scholar]
- Sharma, A.; Cosley, D. Do social explanations work? Studying and modeling the effects of social explanations in recommender systems. In Proceedings of the 22nd international conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 1133–1144. [Google Scholar]
- Bauman, K.; Liu, B.; Tuzhilin, A. Aspect based recommendations: Recommending items with the most valuable aspects based on user reviews. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 717–725. [Google Scholar]
- Zhang, Y.; Lai, G.; Zhang, M.; Zhang, Y.; Liu, Y.; Ma, S. Explicit factor models for explainable recommendation based on phrase-level sentiment analysis. In Proceedings of the 37th International ACM SIGIR Conference on Research & Development in Information Retrieval, Gold Coast, Australia, 6–11 July 2014; pp. 83–92. [Google Scholar]
- Wang, H.; Zhang, F.; Zhao, M.; Li, W.; Xie, X.; Guo, M. Multi-task feature learning for knowledge graph enhanced recommendation. In Proceedings of the The World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 2000–2010. [Google Scholar]
- Ma, W.; Zhang, M.; Cao, Y.; Jin, W.; Wang, C.; Liu, Y.; Ma, S.; Ren, X. Jointly learning explainable rules for recommendation with knowledge graph. In Proceedings of the The World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 1210–1221. [Google Scholar]
- Rendle, S. Factorization machines with libfm. ACM Trans. Intell. Syst. Technol. (TIST) 2012, 3, 1–22. [Google Scholar] [CrossRef]
- Wang, H.; Zhao, M.; Xie, X.; Li, W.; Guo, M. Knowledge graph convolutional networks for recommender systems. In The World Wide Web Conference; ACM: New York, NY, USA, 2019; pp. 3307–3313. [Google Scholar] [CrossRef]
- Wang, Y.Q.; Dong, L.Y.; Li, Y.L.; Zhang, H. Multitask feature learning approach for knowledge graph enhanced recommendations with RippleNet. PLoS ONE 2021, 16, e0251162. [Google Scholar] [CrossRef] [PubMed]
- Huang, W.; Wu, J.; Song, W.; Wang, Z. Cross attention fusion for knowledge graph optimized recommendation. Appl. Intell. 2022, 52, 10297–10306. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MovieLens-20M | MovieLens-1M | Book-Crossing | Last.FM | |
|---|---|---|---|---|
| #user | 138,159 | 6036 | 17,860 | 1872 |
| #item | 16,954 | 2445 | 14,967 | 3846 |
| #interactions | 13,501,622 | 753,772 | 139,746 | 42,364 |
| #entities | 102,569 | 182,011 | 77,903 | 9366 |
| #relations | 32 | 12 | 25 | 60 |
| #KG triples | 499,474 | 20,782 | 19,876 | 15,518 |
| #sparsity level | 0.9947 | 0.9489 | 0.9994 | 0.9941 |
| Dataset | Parameters |
|---|---|
| MovieLens-20M | d = 90, H = 3, = 0.0005, = 0.05, = 6 × 10, = 0.05 |
| MovieLens-1M | d = 90, H = 3, = 0.0005, = 0.05, = 6 × 10, = 0.08 |
| Book-Crossing | d = 120, H = 3, = 4 × 10, = 0.5, = 5 × 10, = 0.09 |
| Last.FM | d = 120, H = 3, = 4 × 10, = 0.09, = 8 × 10, = 0.09 |
| Model | Movielens-20M | Movielens-1M | Book-Crossing | Last.FM | ||||
|---|---|---|---|---|---|---|---|---|
| AUC | ACC | AUC | ACC | AUC | ACC | AUC | ACC | |
| LibFM | 0.9587 | 0.9055 | 0.8921 | 0.8122 | 0.6855 | 0.6402 | 0.7774 | 0.7098 |
| PER | 0.8341 | 0.7893 | 0.7055 | 0.6621 | 0.6238 | 0.5884 | 0.6321 | 0.5963 |
| Wide&Deep | 0.9635 | 0.9221 | 0.8988 | 0.8203 | 0.7123 | 0.6245 | 0.7564 | 0.6887 |
| DKN | 0.8012 | 0.7565 | 0.6551 | 0.5892 | 0.6123 | 0.5878 | 0.6001 | 0.5812 |
| RippleNet | 0.9675 | 0.9122 | 0.9115 | 0.8323 | 0.7254 | 0.6501 | 0.7658 | 0.6891 |
| MKR | 0.9702 | 0.9198 | 0.9121 | 0.8334 | 0.7297 | 0.6767 | 0.7923 | 0.7501 |
| KGCN | 0.9742 | 0.9223 | 0.9105 | 0.8312 | 0.6753 | 0.6221 | 0.7932 | 0.7203 |
| Ripp-MKR | - | - | 0.9220 | 0.8450 | 0.7400 | 0.7120 | 0.7990 | 0.7500 |
| CAKR | - | - | 0.9240 | 0.8490 | 0.7460 | 0.7070 | 0.8020 | 0.7545 |
| AKNEI | 0.9851 | 0.9447 | 0.9271 | 0.8503 | 0.7283 | 0.6887 | 0.8177 | 0.7554 |
| H | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| Movielens-20M | 0.9824 | 0.9835 | 0.9851 | 0.9843 |
| Movielens-1M | 0.9223 | 0.9254 | 0.9271 | 0.9246 |
| Book-Crossing | 0.7246 | 0.7279 | 0.7283 | 0.7280 |
| Last.FM | 0.7167 | 0.8173 | 0.8177 | 0.8169 |
| AKNEI | AKNEI | |
|---|---|---|
| Movielens-20M | 0.9851 | 0.9810 |
| Movielens-1M | 0.9271 | 0.9237 |
| Book-Crossing | 0.7283 | 0.7163 |
| Last.FM | 0.8177 | 0.8097 |
| Model | 30% | 60% | 90% | |||
|---|---|---|---|---|---|---|
| AUC | ACC | AUC | ACC | AUC | ACC | |
| LibFM | 0.8165 | 0.7652 | 0.8501 | 0.7863 | 0.8864 | 0.8126 |
| PER | 0.6201 | 0.5842 | 0.6605 | 0.5889 | 0.7002 | 0.6118 |
| Wide & Deep | 0.8092 | 0.7542 | 0.8423 | 0.7818 | 0.8845 | 0.8105 |
| DKN | 0.5892 | 0.5231 | 0.6189 | 0.5767 | 0.6462 | 0.5997 |
| RippleNet | 0.8623 | 0.8012 | 0.8796 | 0.8155 | 0.9087 | 0.8305 |
| MKR | 0.8792 | 0.7952 | 0.8909 | 0.8123 | 0.9115 | 0.8313 |
| KGCN | 0.8766 | 0.8223 | 0.8902 | 0.8135 | 0.9089 | 0.8307 |
| AKNEI | 0.8953 | 0.8131 | 0.9032 | 0.8234 | 0.9225 | 0.8464 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, S.; Qin, J.; Wang, X.; Wang, R. Attention Knowledge Network Combining Explicit and Implicit Information. Mathematics 2023, 11, 724. https://doi.org/10.3390/math11030724
Deng S, Qin J, Wang X, Wang R. Attention Knowledge Network Combining Explicit and Implicit Information. Mathematics. 2023; 11(3):724. https://doi.org/10.3390/math11030724
Chicago/Turabian StyleDeng, Shangju, Jiwei Qin, Xiaole Wang, and Ruijin Wang. 2023. "Attention Knowledge Network Combining Explicit and Implicit Information" Mathematics 11, no. 3: 724. https://doi.org/10.3390/math11030724
APA StyleDeng, S., Qin, J., Wang, X., & Wang, R. (2023). Attention Knowledge Network Combining Explicit and Implicit Information. Mathematics, 11(3), 724. https://doi.org/10.3390/math11030724