

PCEP: Few-Shot Model-Based Source Camera Identification



Abstract
:1. Introduction
- We propose an ensemble learning projection method based on prototype set construction (PCEP). This method extracts multiple image features through semi-supervised learning, realizes prototype set construction and makes full use of the information of few-shot samples.
- We use the prototype sets to carry out ensemble learning projections and realize the transformation from image features to probability features.
- We introduce the ensemble learning voting strategy to obtain the final classification results. Our comprehensive experimental results show that this method is superior to many recent methods in a few-shot scenario.
2. Related Work
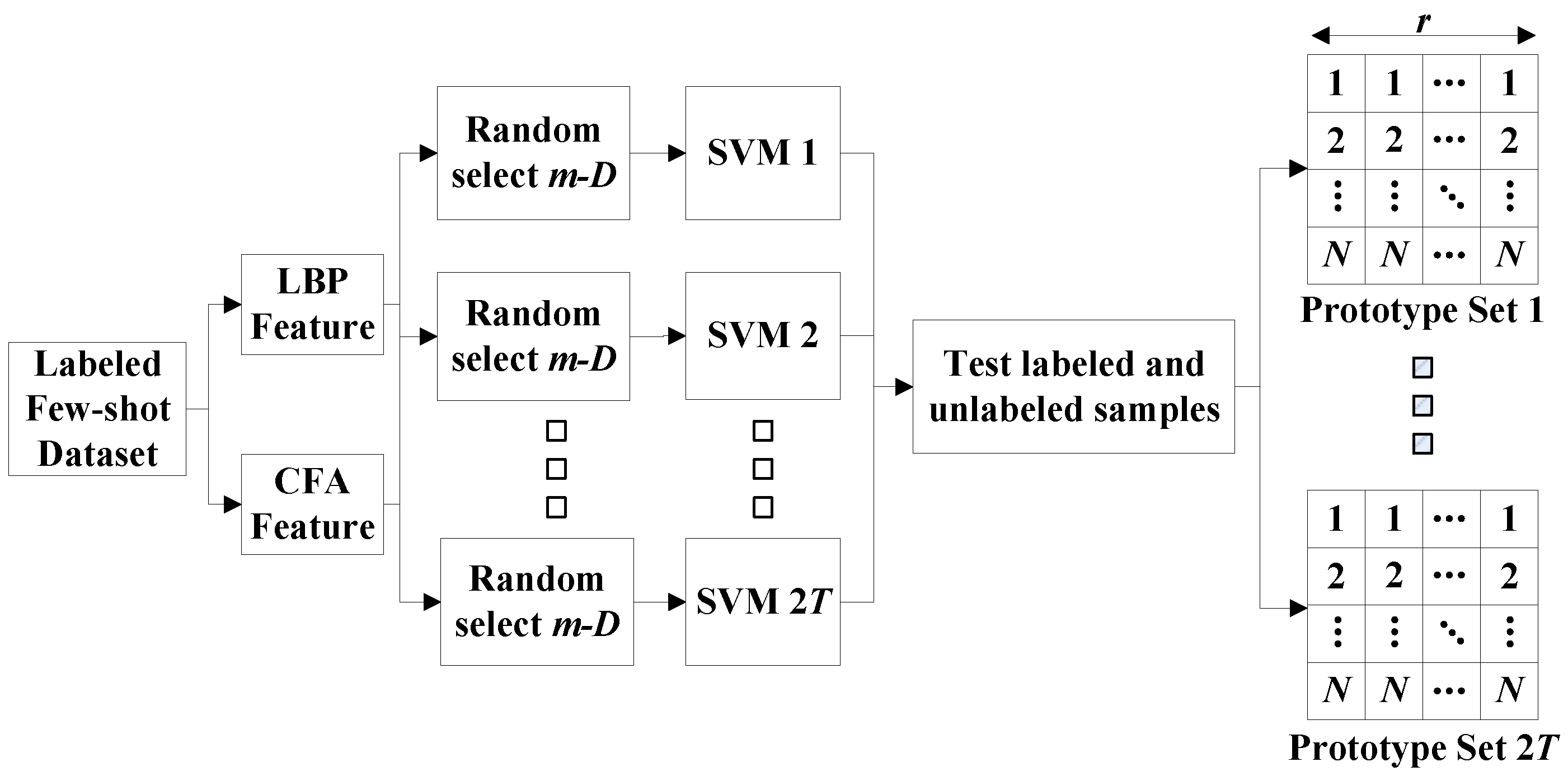
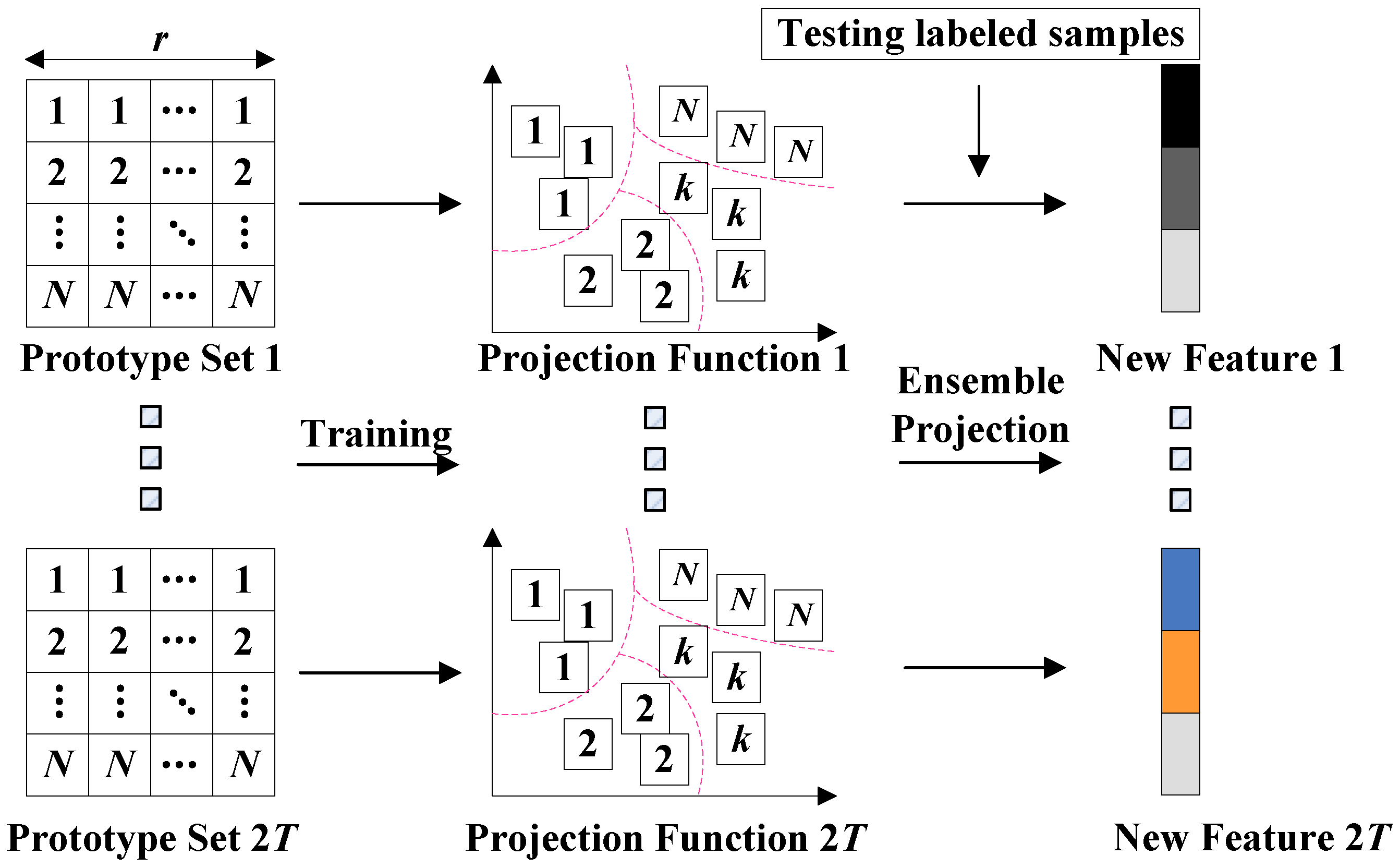
3. The PCEP Method
| Algorithm 1:Prototype construction with ensemble projection (PCEP) |
| Symbols: |
| : Labeled sample set; : Unlabeled sample set; : Labeled few-shot dataset; p: Posterior probability of the sample; P: Prototype set; E: Ensemble projection vector |
| Process: |
| 1. Extract CFA and LBP features from ; |
| 2. Train SVM classifiers based on partial feature information; |
| 3. Construct prototype sets: |
| fordo |
| Put s into SVM classifiers to obtain the posterior probability p |
| end for |
| Sort p in descending order and take the first r entries to form prototype sets P |
| 4. Obtain ensemble projection features: |
| for do |
| Train the projection function based on i |
| Put s () into the projection function to obtain the ensemble projection vector E |
| end for |
| 5. Obtain the final classification result: |
| for do |
| Train the weak classifier based on j |
| Put s () into the weak classifier to obtain the sub-classification result |
| end for |
| Obtain the final classification result using ensemble voting strategy. |
3.1. Constructing Prototype Set
3.2. Training Ensemble Projection Features and Voting Classification
4. Experiments
4.1. Experimental Settings
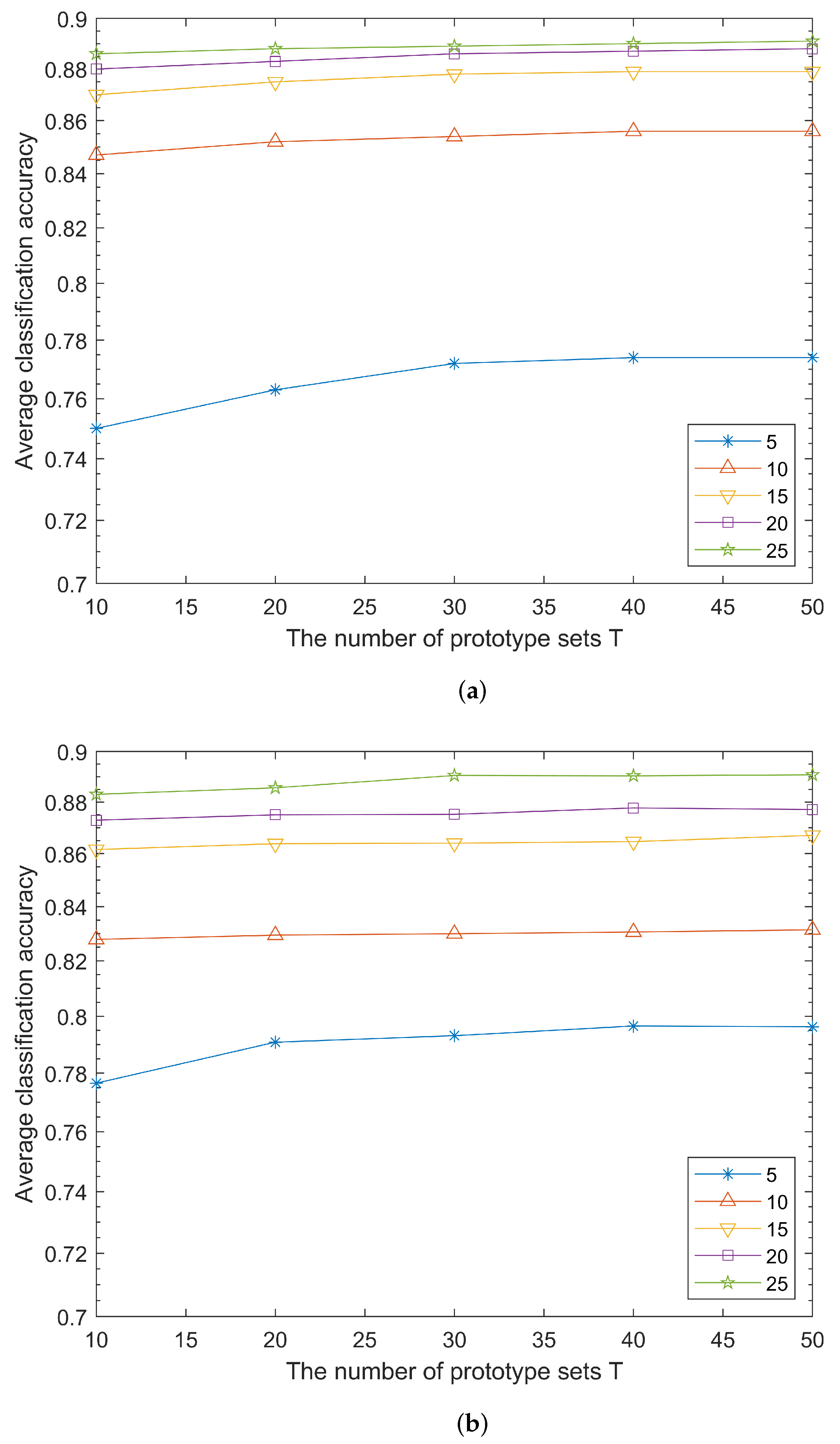
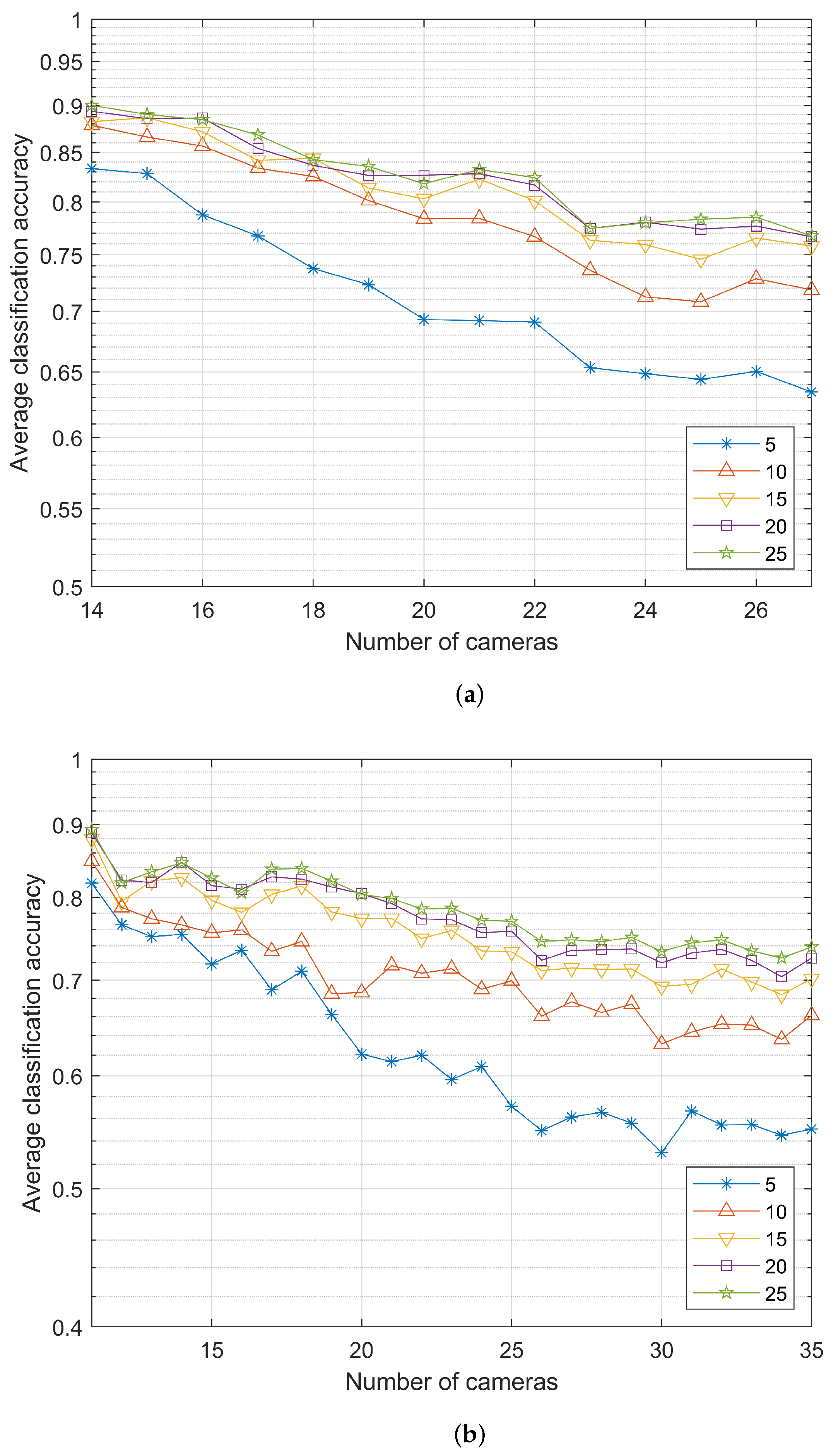
4.2. Experimental Results and Analysis
5. Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| PCEP | Prototype construction with ensemble projection |
| SCI | Source camera identification |
| SVM | Support vector machine |
| CFA | Color filter array |
| LBP | Local binary pattern |
References
- Fridrich, A.J.; Soukal, B.D.; Lukáš, A.J. Detection of copy-move forgery in digital images. In Proceedings of the Digital Forensic Research Workshop, Cleveland, OH, USA, 6–8 August 2003. [Google Scholar]
- Ho, A.T.; Li, S. Handbook of Digital Forensics of Multimedia Data and Devices; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Sandoval Orozco, A.L.; Corripio, J.R.; García Villalba, L.J.; Hernández Castro, J.C. Image source acquisition identification of mobile devices based on the use of features. Multimed. Tools Appl. 2016, 75, 7087–7111. [Google Scholar] [CrossRef]
- Pietikäinen, M.; Ojala, T.; Xu, Z. Rotation-invariant texture classification using feature distributions. Pattern Recognit. 2000, 33, 43–52. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Tan, X.; Triggs, B. Enhanced Local Texture Feature Sets for Face Recognition Under Difficult Lighting Conditions. IEEE Trans. Image Process. 2010, 19, 1635–1650. [Google Scholar] [PubMed]
- Guo, Z.; Zhang, L.; Zhang, D. A completed modeling of local binary pattern operator for texture classification. IEEE Trans. Image Process. 2010, 19, 1657–1663. [Google Scholar] [PubMed]
- Fekri-Ershad, S.; Ramakrishnan, S. Cervical cancer diagnosis based on modified uniform local ternary patterns and feed forward multilayer network optimized by genetic algorithm. Comput. Biol. Med. 2022, 144, 105392. [Google Scholar] [CrossRef] [PubMed]
- Pourkaramdel, Z.; Fekri-Ershad, S.; Nanni, L. Fabric defect detection based on completed local quartet patterns and majority decision algorithm. Expert Syst. Appl. 2022, 198, 116827. [Google Scholar] [CrossRef]
- Mahmmod, B.M.; Abdulhussain, S.H.; Suk, T.; Hussain, A. Fast computation of Hahn polynomials for high order moments. IEEE Access 2022, 10, 48719–48732. [Google Scholar] [CrossRef]
- Wang, Y.X.; Girshick, R.; Hebert, M.; Hariharan, B. Low-shot learning from imaginary data. In Proceedings of the IEEE conference on computer vision and pattern recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Hu, X.; Yang, Z.; Liu, G.; Liu, Q.; Wang, H. Virtual label expansion-Highlighted key features for few-shot learning. In Proceedings of the 2021 International Joint Conference on Neural Networks, Shenzhen, China, 18–22 July 2021. [Google Scholar]
- Wang, B.; Wu, S.; Wei, F.; Wang, Y.; Hou, J.; Sui, X. Virtual sample generation for few-shot source camera identification. J. Inf. Secur. Appl. 2022, 66, 103153. [Google Scholar] [CrossRef]
- Khodadadeh, S.; Boloni, L.; Shah, M. Unsupervised meta-learning for few-shot image classification. Adv. Neural Inf. Process. Syst. 2019, 32, 10132–10142. [Google Scholar]
- Xu, H.; Wang, J.; Li, H.; Ouyang, D.; Shao, J. Unsupervised meta-learning for few-shot learning. Pattern Recognit. 2021, 116, 107951. [Google Scholar] [CrossRef]
- Huang, K.; Geng, J.; Jiang, W.; Deng, X.; Xu, Z. Pseudo-loss confidence metric for semi-supervised few-shot learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Ling, J.; Liao, L.; Yang, M.; Shuai, J. Semi-Supervised Few-Shot Learning via Multi-Factor Clustering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Zhang, B.; Ye, H.; Yu, G.; Wang, B.; Wu, Y.; Fan, J.; Chen, T. Sample-Centric Feature Generation for Semi-Supervised Few-Shot Learning. IEEE Trans. Image Process. 2022, 31, 2309–2320. [Google Scholar] [CrossRef] [PubMed]
- Gidaris, S.; Komodakis, N. Dynamic few-shot visual learning without forgetting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Hou, R.; Chang, H.; Ma, B.; Shan, S.; Chen, X. Cross attention network for few-shot classification. Adv. Neural Inf. Process. Syst. 2019, 32, 4005–4016. [Google Scholar]
- Lukas, J.; Fridrich, J.; Goljan, M. Digital camera identification from sensor pattern noise. IEEE Trans. Inf. Forensics Secur. 2006, 1, 205–214. [Google Scholar] [CrossRef]
- Kang, X.; Li, Y.; Qu, Z.; Huang, J. Enhancing source camera identification performance with a camera reference phase sensor pattern noise. IEEE Trans. Inf. Forensics Secur. 2011, 7, 393–402. [Google Scholar] [CrossRef]
- Cozzolino, D.; Gragnaniello, D.; Verdoliva, L. Image forgery localization through the fusion of camera-based, feature-based and pixel-based techniques. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014. [Google Scholar]
- Li, R.; Li, C.T.; Guan, Y. A reference estimator based on composite sensor pattern noise for source device identification. In Proceedings of the Media Watermarking, Security, and Forensics, San Francisco, CA, USA, 2 February 2014. [Google Scholar]
- Kang, X.; Chen, J.; Lin, K.; Anjie, P. A context-adaptive SPN predictor for trustworthy source camera identification. EURASIP J. Image Video Process. 2014, 2014, 1–11. [Google Scholar] [CrossRef]
- Lawgaly, A.; Khelifi, F. Sensor pattern noise estimation based on improved locally adaptive DCT filtering and weighted averaging for source camera identification and verification. IEEE Trans. Inf. Forensics Secur. 2016, 12, 392–404. [Google Scholar] [CrossRef]
- Lin, X.; Li, C.T. Preprocessing reference sensor pattern noise via spectrum equalization. IEEE Trans. Inf. Forensics Secur. 2015, 11, 126–140. [Google Scholar] [CrossRef]
- Liu, Y.; Zou, Z.; Yang, Y.; Law, N.F.B.; Bharath, A.A. Efficient source camera identification with diversity-enhanced patch selection and deep residual prediction. Sensors 2021, 21, 4701. [Google Scholar] [CrossRef] [PubMed]
- Hui, C.; Jiang, F.; Liu, S.; Zhao, D. Source Camera Identification with Multi-Scale Feature Fusion Network. In Proceedings of the 2022 IEEE International Conference on Multimedia and Expo, Taipei, Taiwan, 18–22 July 2022. [Google Scholar]
- Zhang, W.N.; Liu, Y.X.; Zou, Z.Y.; Zang, Y.L.; Yang, Y.; Law, B.N.F. Effective source camera identification based on MSEPLL denoising applied to small image patches. In Proceedings of the 2019 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Lanzhou, China, 18–21 November 2019. [Google Scholar]
- Tan, Y.; Wang, B.; Li, M.; Guo, Y.; Kong, X.; Shi, Y. Camera source identification with limited labeled training set. In Proceedings of the International Workshop on Digital Watermarking, Tokyo, Japan, 7–10 October 2015. [Google Scholar]
- Boney, R.; Ilin, A. Semi-supervised few-shot learning with MAML. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Schwartz, E.; Karlinsky, L.; Shtok, J.; Harary, S.; Marder, M.; Kumar, A.; Feris, R.; Giryes, R.; Bronstein, A. Delta-encoder: An effective sample synthesis method for few-shot object recognition. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QB, Canada, 3–8 December 2018. [Google Scholar]
- Chen, Z.; Fu, Y.; Zhang, Y.; Jiang, Y.G.; Xue, X.; Sigal, L. Semantic feature augmentation in few-shot learning. arXiv 2018, arXiv:1804.05298. [Google Scholar]
- Gardenfors, P. Conceptual Spaces: The Geometry of Thought; MIT Press: Cambridge, MA, USA, 2004. [Google Scholar]
- Rosch, E.; Lloyd, B.B. Cognition and Categorization; Urban Ministried Inc.: Calumet City, IL, USA, 1978. [Google Scholar]
- Dai, D.; Van Gool, L. Ensemble projection for semi-supervised image classification. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013. [Google Scholar]
- Gloe, T.; Böhme, R. The ‘Dresden Image Database’ for benchmarking digital image forensics. In Proceedings of the 2010 ACM Symposium on Applied Computing, Sierre, Switzerland, 22–26 March 2010. [Google Scholar]
- Shullani, D.; Fontani, M.; Iuliani, M.; Al Shaya, O.; Piva, A. VISION: A video and image dataset for source identification. EURASIP J. Inf. Secur. 2017, 2017, 1–16. [Google Scholar] [CrossRef]
- Galdi, C.; Hartung, F.; Dugelay, J.L. SOCRatES: A Database of Realistic Data for Source Camera Recognition on Smartphones. In Proceedings of the 8th International Conference on Pattern Recognition Applications and Methods, Prague, Czech Republic, 19–21 February 2019. [Google Scholar]
- Sameer, V.U.; Naskar, R. Deep siamese network for limited labels classification in source camera identification. Multimed. Tools Appl. 2020, 79, 28079–28104. [Google Scholar] [CrossRef]
- Wang, B.; Hou, J.; Ma, Y.; Wang, F.; Wei, F. Multi-DS Strategy for Source Camera Identification in Few-Shot Sample Data Sets. Secur. Commun. Netw. 2022, 2022, 8716884. [Google Scholar] [CrossRef]
- Wu, S.; Wang, B.; Zhao, J.; Zhao, M.; Zhong, K.; Guo, Y. Virtual sample generation and ensemble learning based image source identification with small training samples. Int. J. Digit. Crime Forensics 2021, 13, 34–46. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Camera Model | Abbr. | Camera Model | Abbr. |
|---|---|---|---|
| Canon_Ixus70 | C1 | Panasonic_DMC-FZ50 | P1 |
| Casio_EX-Z150 | C2 | Praktica_DCZ5.9 | P2 |
| FujiFilm_FinePixJ50 | F1 | Rollei_RCP-7325XS | R1 |
| Kodak_M1063 | K1 | Samsung_L74wide | SL1 |
| Nikon_CoolPixS710 | N1 | Samsung_NV15 | SN1 |
| Nikon_D70 | N2 | Sony_DSC-H50 | SD1 |
| Nikon_D200 | N3 | Sony_DSC-T77 | SD2 |
| Olympus_mju_1050SW | O1 | Sony_DSC-W170 | SD3 |
| Camera Model | Abbr. | Camera Model | Abbr. |
|---|---|---|---|
| Samsung_GalaxyS3 | Sa1 | Apple_iPhone6 | Ap3 |
| Apple_iphone4s | Ap1 | Lenovo_P70A | Le1 |
| Huawei_P9 | Hu1 | Samsung_GalaxyTab3 | Sa2 |
| LG_D290 | Lg1 | Apple_iPhone4 | Ap4 |
| Apple_iPhone5c | Ap2 | Microsoft_Lumia640LTE | Mi1 |
| Camera Model | Abbr. | Camera Model | Abbr. |
|---|---|---|---|
| Apple iPhone 5s | A1 | LG G3 | L1 |
| Apple iPhone 6 | A2 | Motorola Moto G | M1 |
| Apple iPhone 6s | A3 | Samsung Galaxy A3 | SG1 |
| Apple iPhone 7 | A4 | Samsung GalaxyS5 | SG2 |
| Asus Zenfone 2 | As1 | Samsung Galaxy S7 Edge | SG3 |
| Method (%) | The Number of Training Samples per Class (L) | ||||
|---|---|---|---|---|---|
| 5 | 10 | 15 | 20 | 25 | |
| LBP-SVM | 45.64 | 71.24 | 78.97 | 83.29 | 85.45 |
| CFA-SVM | 49.75 | 69.99 | 78.67 | 82.68 | 84.89 |
| Multi-SVM | 64.36 | 78.64 | 81.67 | 84.26 | 86.13 |
| LBP-PCEP | 49.14 | 68.62 | 78.41 | 82.01 | 84.17 |
| CFA-PCEP | 67.83 | 77.15 | 80.36 | 81.92 | 82.79 |
| Multi-PCEP | 77.15 | 85.26 | 87.62 | 88.50 | 89.09 |
| Method (%) | The Number of Training Samples per Class (L) | ||||
|---|---|---|---|---|---|
| 5 | 10 | 15 | 20 | 25 | |
| LBP-SVM | 49.96 | 80.34 | 85.95 | 88.36 | 89.10 |
| CFA-SVM | 40.14 | 62.75 | 81.14 | 86.10 | 87.11 |
| Multi-SVM | 72.80 | 76.71 | 82.36 | 82.81 | 83.42 |
| Multi-PCEP | 74.94 | 83.99 | 86.59 | 88.46 | 90.51 |
| Method (%) | The Number of Training Samples per Class (L) | ||||
|---|---|---|---|---|---|
| 5 | 10 | 15 | 20 | 25 | |
| LBP-SVM | 38.56 | 67.24 | 76.06 | 79.67 | 81.78 |
| CFA-SVM | 20.11 | 57.13 | 66.76 | 74.04 | 77.06 |
| Multi-SVM | 49.66 | 57.53 | 67.45 | 73.13 | 75.81 |
| Multi-PCEP | 61.59 | 75.94 | 78.63 | 80.20 | 81.81 |
| Method (%) | Dresden | VISION | SOCRatES |
|---|---|---|---|
| EP [31] | 73.84 | 79.94 | 63.91 |
| MTDEM [43] | 75.16 | 80.49 | 64.84 |
| Deep Siamese Network [41] | 85.30 | 75.20 | \ |
| Multi-DS [42] | 86.08 | 85.56 | 67.00 |
| Multi-PCEP | 87.06 | 84.84 | 75.94 |
| Database(s) | L (the Number of Training Samples per Class) | ||||
|---|---|---|---|---|---|
| 5 | 10 | 15 | 20 | 25 | |
| Dresden (16 classes) | 155 | 247 | 406 | 596 | 853 |
| VISION (10 classes) | 62 | 103 | 165 | 238 | 341 |
| C1 | C2 | F1 | K1 | N1 | N2 | N3 | O1 | P1 | P2 | R1 | S1 | S2 | SD1 | SD2 | SD3 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| C1 | 99.2 | 0.2 | - | - | - | - | - | - | - | 0.6 | - | - | - | - | - | - |
| C2 | 0.8 | 95.9 | - | 0.2 | - | - | 0.1 | - | 0.2 | - | - | 2.8 | - | - | - | - |
| F1 | 0.1 | - | 91.7 | - | 0.2 | - | 0.5 | - | 0.1 | 0.2 | 3.8 | 1.8 | 0.4 | - | 1.2 | - |
| K1 | 0.5 | 2.3 | 0.2 | 92.1 | 0.1 | 3.1 | 0.3 | - | 0.1 | 0.6 | - | 0.4 | - | 0.1 | - | 0.2 |
| N1 | 1.7 | 1.8 | 0.1 | - | 92.4 | 0.3 | 0.4 | - | - | 0.7 | 0.2 | 2.4 | - | - | - | - |
| N2 | 0.3 | 1.0 | - | 1.4 | 0.4 | 90.6 | 3.7 | - | - | 1.0 | 0.2 | 0.2 | - | 0.4 | - | 0.8 |
| N3 | - | - | 0.3 | 1.2 | - | 5.4 | 92.3 | - | - | - | 0.2 | - | 0.6 | - | - | - |
| O1 | - | - | 0.1 | - | - | 0.2 | 0.9 | 96.5 | - | - | - | 2.3 | - | - | - | - |
| P1 | 0.2 | 0.5 | - | 0.5 | - | - | 0.3 | 0.2 | 95.8 | - | - | 2.0 | 0.5 | - | - | - |
| P2 | 1.5 | 0.4 | - | 0.3 | 0.2 | 0.4 | 0.5 | - | 1.0 | 93.6 | 0.1 | 0.7 | 0.5 | 0.3 | - | 0.5 |
| R1 | - | 0.1 | 4.8 | - | - | 0.2 | 0.3 | - | 0.1 | 0.1 | 91.7 | 2.3 | 0.4 | - | - | - |
| S1 | - | 2.3 | 1.3 | - | - | - | 0.4 | 0.1 | 0.1 | 0.7 | 0.3 | 94.7 | 0.1 | - | - | - |
| S2 | 0.5 | 0.2 | 0.3 | - | - | - | 0.1 | - | - | 1.8 | 1.0 | 0.5 | 95.2 | 0.2 | - | 0.2 |
| SD1 | 0.6 | 0.8 | - | 0.1 | - | 1.3 | 0.8 | - | - | 0.3 | - | - | 0.6 | 55.7 | 0.4 | 39.4 |
| SD2 | - | 1.2 | 0.3 | - | - | 0.2 | 0.2 | - | - | - | 0.1 | 0.9 | - | 0.2 | 96.7 | 0.2 |
| SD3 | - | 0.3 | - | 0.1 | - | 1.8 | 0.3 | - | - | 0.5 | 0.2 | - | 0.4 | 45.0 | - | 51.4 |
| Sa1 | Ap1 | Hu1 | Lg1 | Ap2 | Ap3 | Le1 | Sa2 | Ap4 | Mi1 | |
|---|---|---|---|---|---|---|---|---|---|---|
| Sa1 | 90.5 | - | 1.6 | 2.1 | - | 3.1 | 0.2 | 2.5 | - | - |
| Ap1 | 0.2 | 76.5 | 1.2 | 2.8 | 11.7 | 3.9 | 1.1 | - | 0.5 | 2.1 |
| Hu1 | 0.2 | 0.8 | 86.5 | 4.7 | 0.1 | 6.1 | 1.0 | - | - | 0.6 |
| Lg1 | - | - | 1.7 | 95.1 | 0.8 | 0.7 | 1.5 | - | - | 0.2 |
| Ap2 | - | 3.9 | 0.9 | 3.3 | 88.6 | 1.3 | 0.3 | 0.5 | - | 1.2 |
| Ap3 | 0.3 | 1.2 | 1.1 | 0.9 | 4.0 | 90.5 | 0.3 | 0.4 | - | 1.3 |
| Le1 | - | - | - | 3.7 | 0.8 | 0.1 | 94.8 | - | - | 0.6 |
| Sa2 | 0.5 | - | 0.9 | 1.6 | 0.2 | 0.2 | - | 96.6 | - | - |
| Ap4 | - | - | - | 0.7 | 0.1 | 0.1 | - | - | 99.1 | - |
| Mi1 | - | 6.6 | 0.2 | 3.0 | 0.3 | 1.8 | - | - | 1.0 | 87.1 |
| A1 | A2 | A3 | A4 | As1 | L1 | M1 | S1 | S2 | S3 | |
|---|---|---|---|---|---|---|---|---|---|---|
| A1 | 82.7 | 6.3 | 4.0 | 0.9 | 2.4 | 0.8 | 0.1 | - | 2.8 | - |
| A2 | 6.4 | 74.8 | 6.5 | 4.2 | 1.8 | 0.4 | 3.2 | 1.1 | 0.8 | 0.8 |
| A3 | 5.4 | 8.1 | 75.8 | 7.2 | 1.6 | 0.1 | 1.4 | 0.1 | 0.1 | 0.2 |
| A4 | 3.9 | 5.7 | 9.2 | 73.7 | 3.3 | 0.2 | 1.8 | 0.8 | 1.4 | - |
| As1 | 4.0 | 0.4 | 2.4 | 3.2 | 85.6 | 0.3 | 1.1 | 0.7 | 2.3 | - |
| L1 | 0.3 | 0.8 | - | 4.5 | 5.1 | 83.1 | 3.2 | 1.0 | 2.0 | - |
| M1 | 0.2 | 0.6 | 2.6 | 4.5 | 6.6 | 1.4 | 81.3 | 0.6 | 2.1 | 0.1 |
| S1 | - | 1.2 | 0.5 | 0.4 | 2.4 | 0.1 | 0.8 | 91.2 | 1.9 | 1.5 |
| S2 | 4.7 | 0.8 | 1.0 | 2.2 | 2.4 | 2.7 | 1.9 | 0.6 | 82.9 | 0.8 |
| S3 | 1.0 | 0.7 | 1.6 | 1.4 | 4.3 | 0.8 | 1.2 | 1.6 | 0.3 | 87.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, B.; Yu, F.; Ma, Y.; Zhao, H.; Hou, J.; Zheng, W. PCEP: Few-Shot Model-Based Source Camera Identification. Mathematics 2023, 11, 803. https://doi.org/10.3390/math11040803
Wang B, Yu F, Ma Y, Zhao H, Hou J, Zheng W. PCEP: Few-Shot Model-Based Source Camera Identification. Mathematics. 2023; 11(4):803. https://doi.org/10.3390/math11040803
Chicago/Turabian StyleWang, Bo, Fei Yu, Yanyan Ma, Haining Zhao, Jiayao Hou, and Weiming Zheng. 2023. "PCEP: Few-Shot Model-Based Source Camera Identification" Mathematics 11, no. 4: 803. https://doi.org/10.3390/math11040803
APA StyleWang, B., Yu, F., Ma, Y., Zhao, H., Hou, J., & Zheng, W. (2023). PCEP: Few-Shot Model-Based Source Camera Identification. Mathematics, 11(4), 803. https://doi.org/10.3390/math11040803