

Multimodal Movie Recommendation System Using Deep Learning

Abstract
:1. Introduction
- (1)
- Introducing a novel movie recommendation system through the combination of the deep-learning technology and the multimodal data analysis.
- (2)
- Experimental results for the proposed recommendation system using the MovieLens 100 K and 1 M datasets have been reported, which have achieved good performance.
- (3)
- We suggest that multimodal data, such as movie posters, could improve the performance of the recommendation system.
2. Related Works
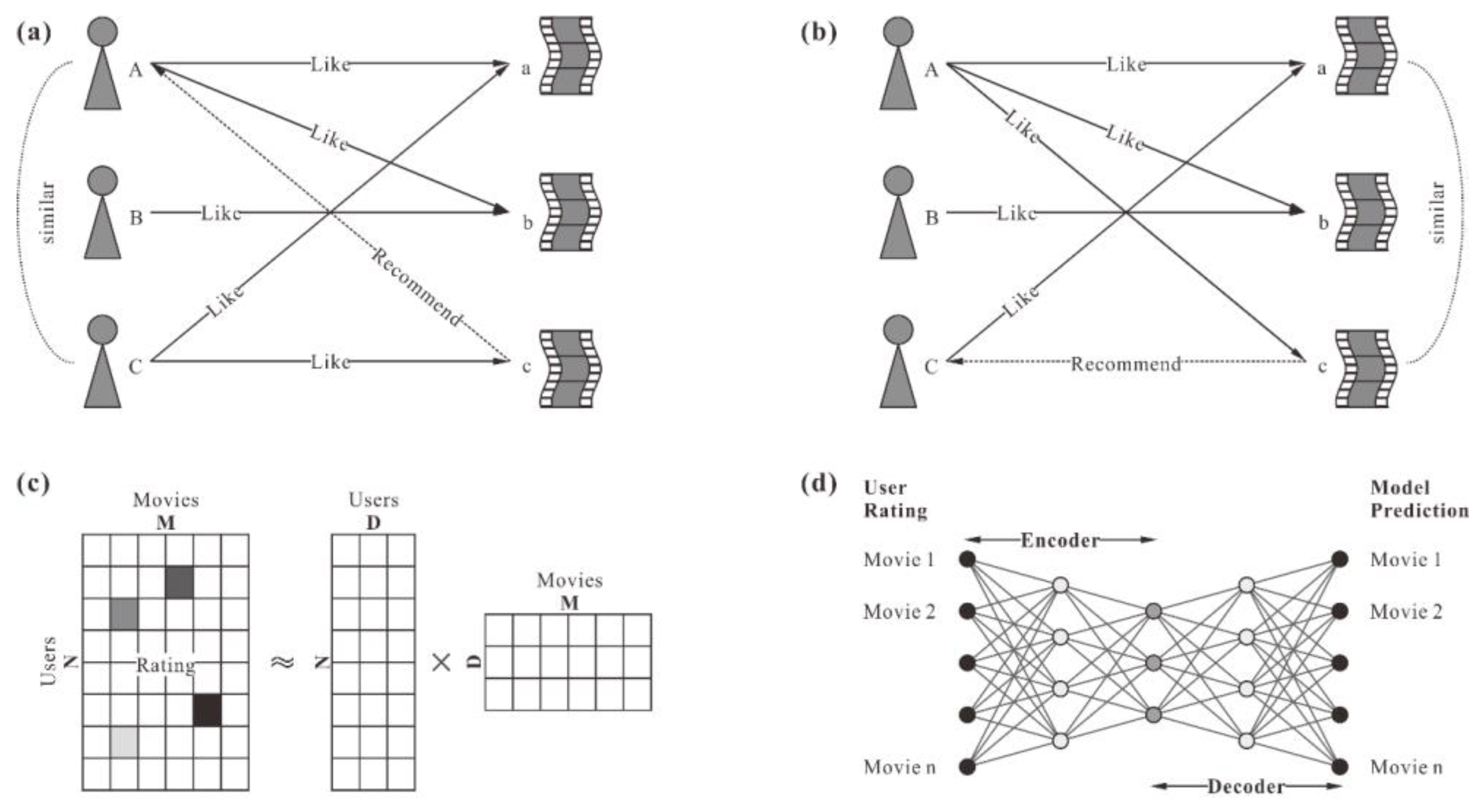
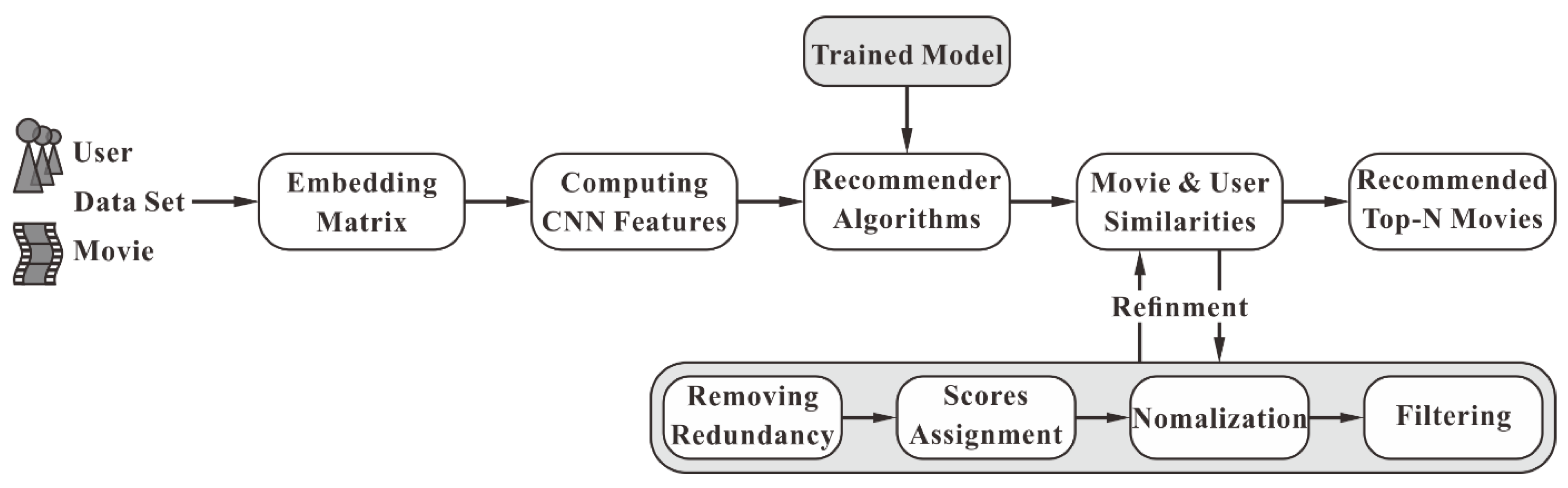
3. Proposed Recommendation System
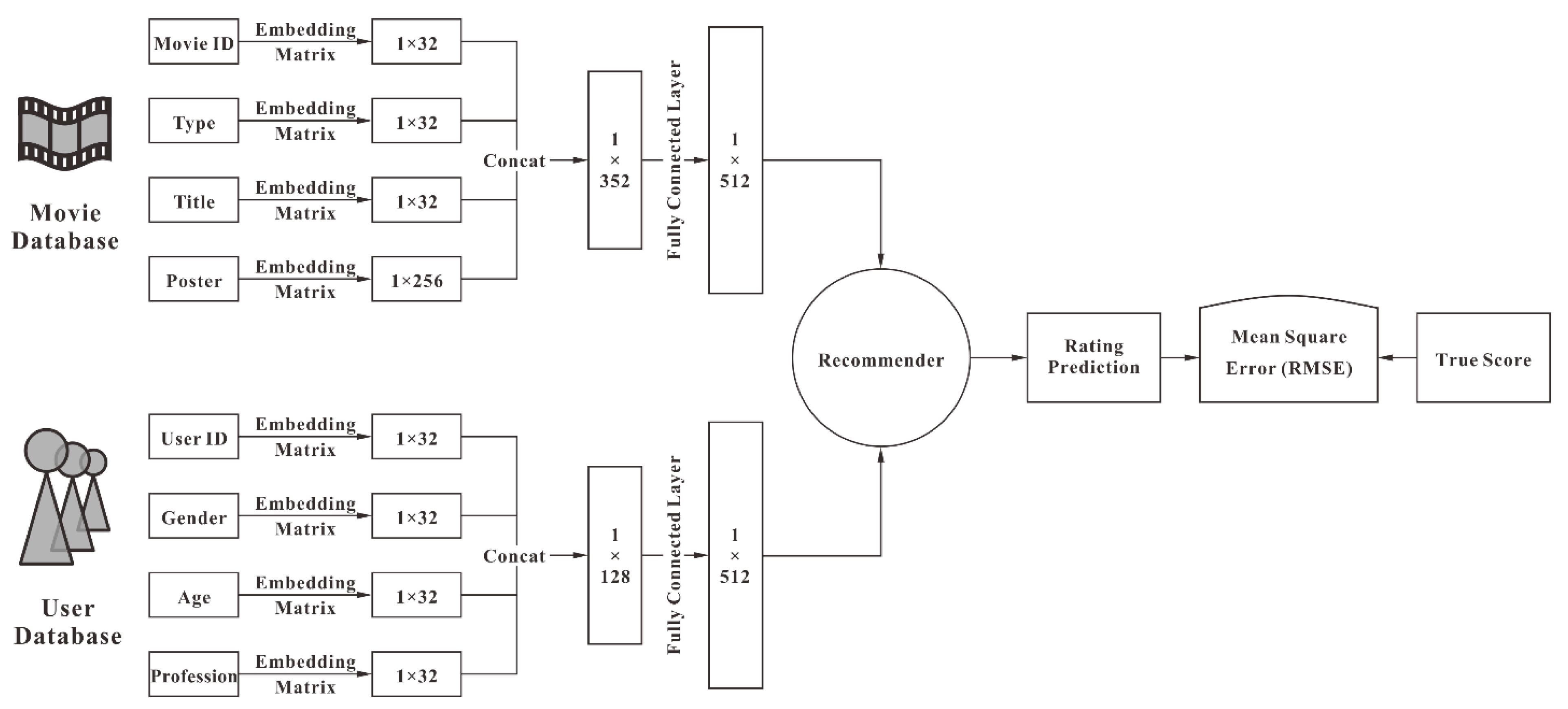
3.1. Framework of the Proposed Model
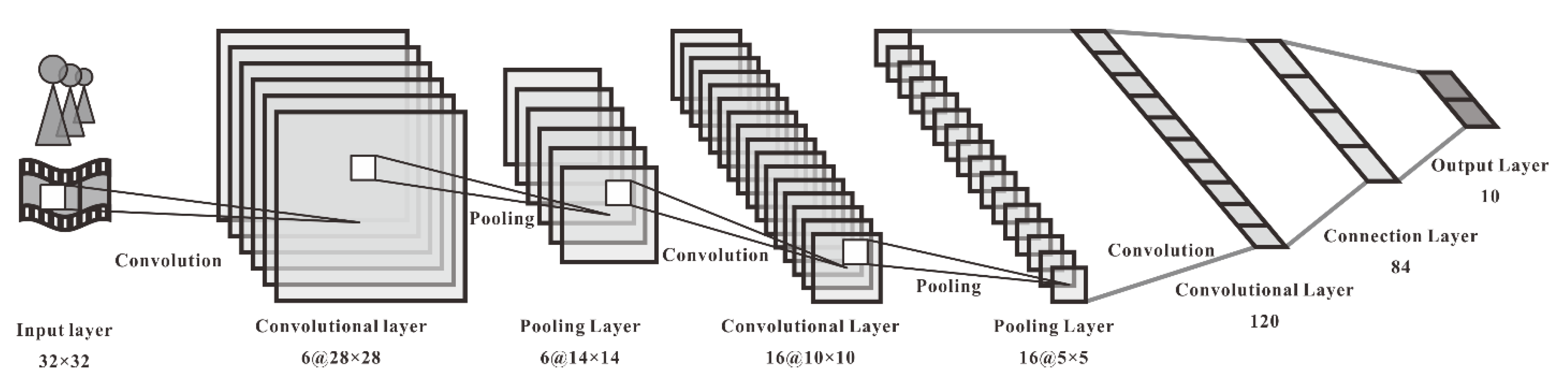
3.2. Feature Extraction
4. Experiments
4.1. Dataset Introduction
4.2. Evaluation Indicators
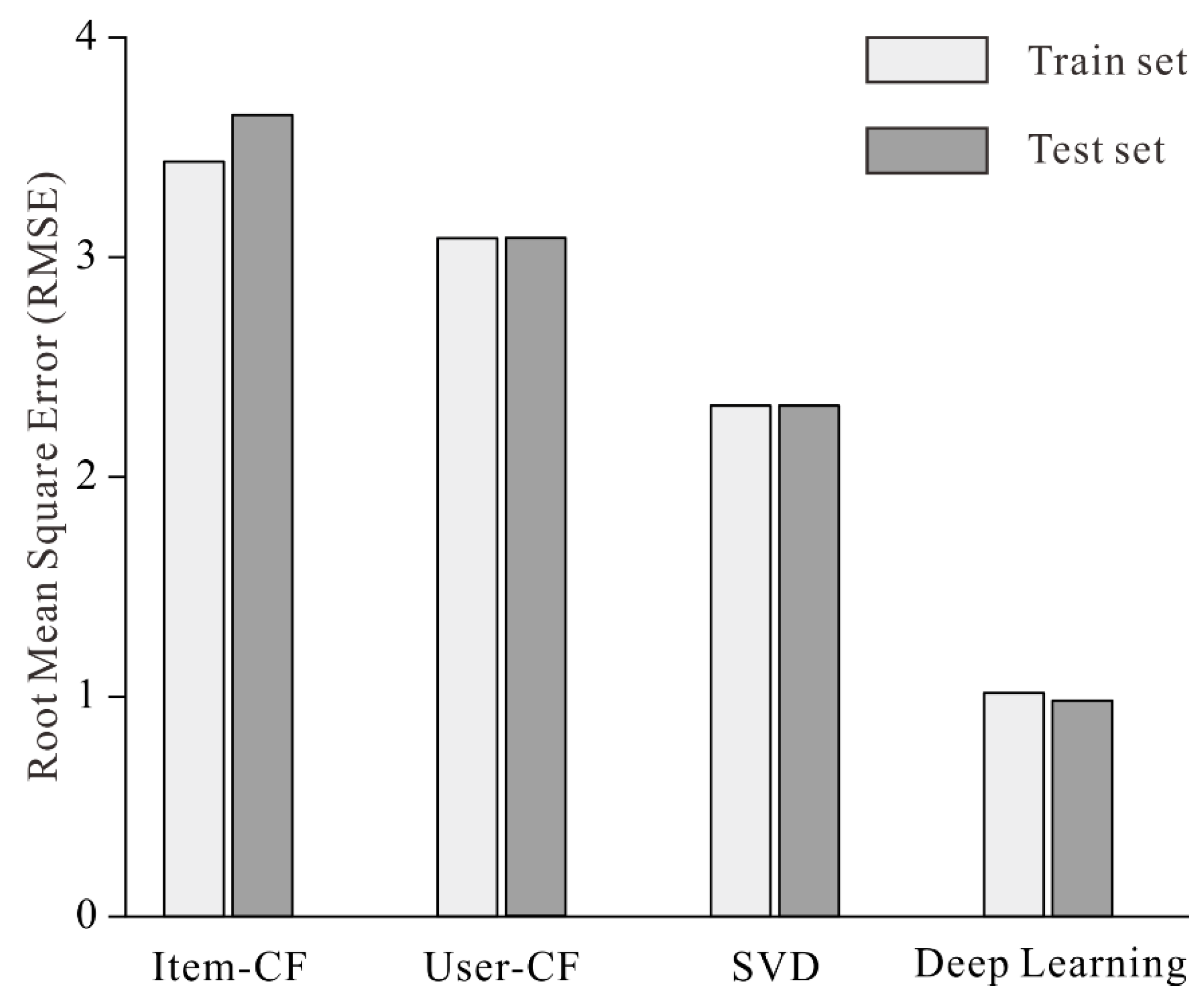
4.3. Comparing Deep Learning Algorithm with Others
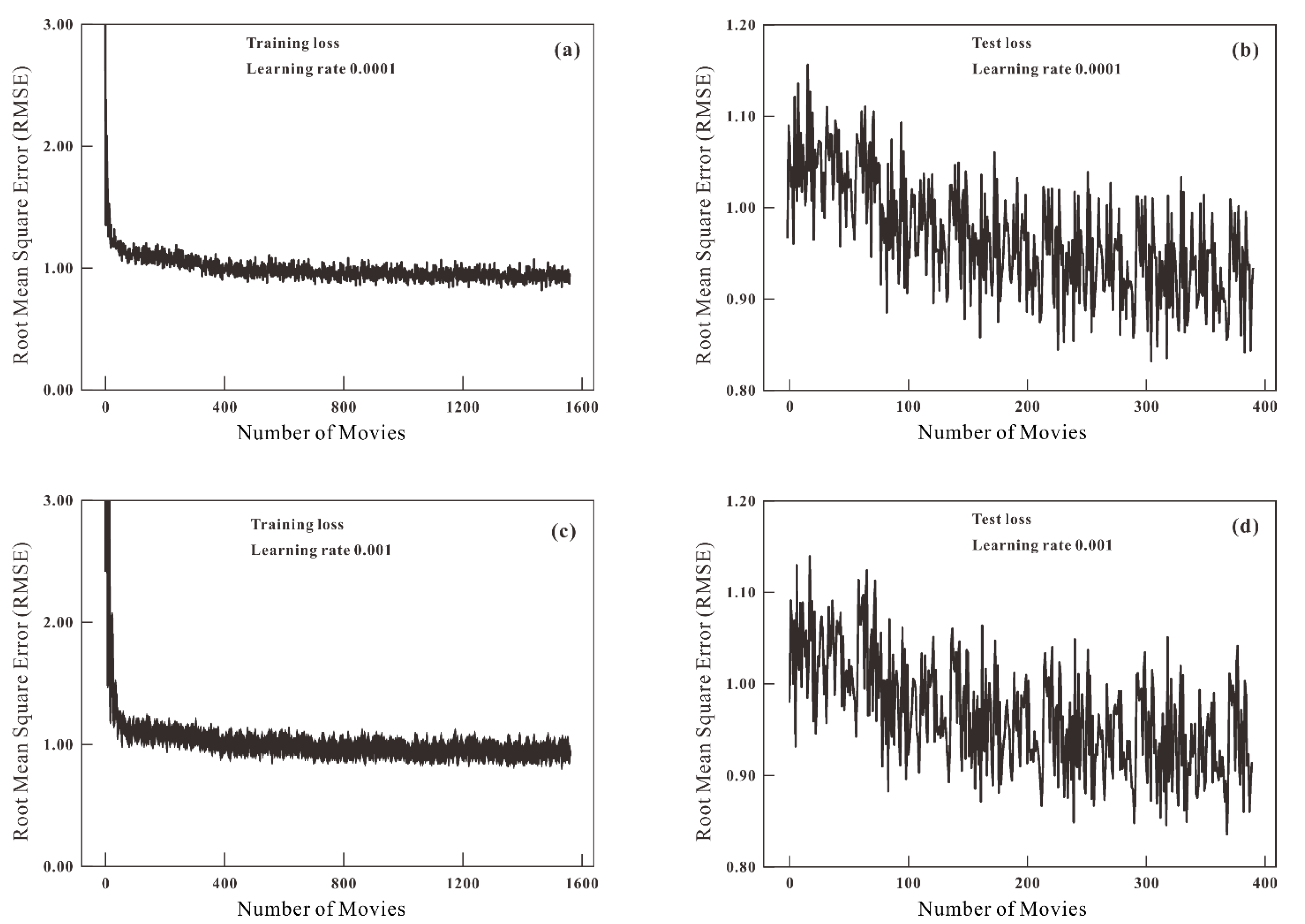
4.4. Influence of the Data Size and the Learning Rate
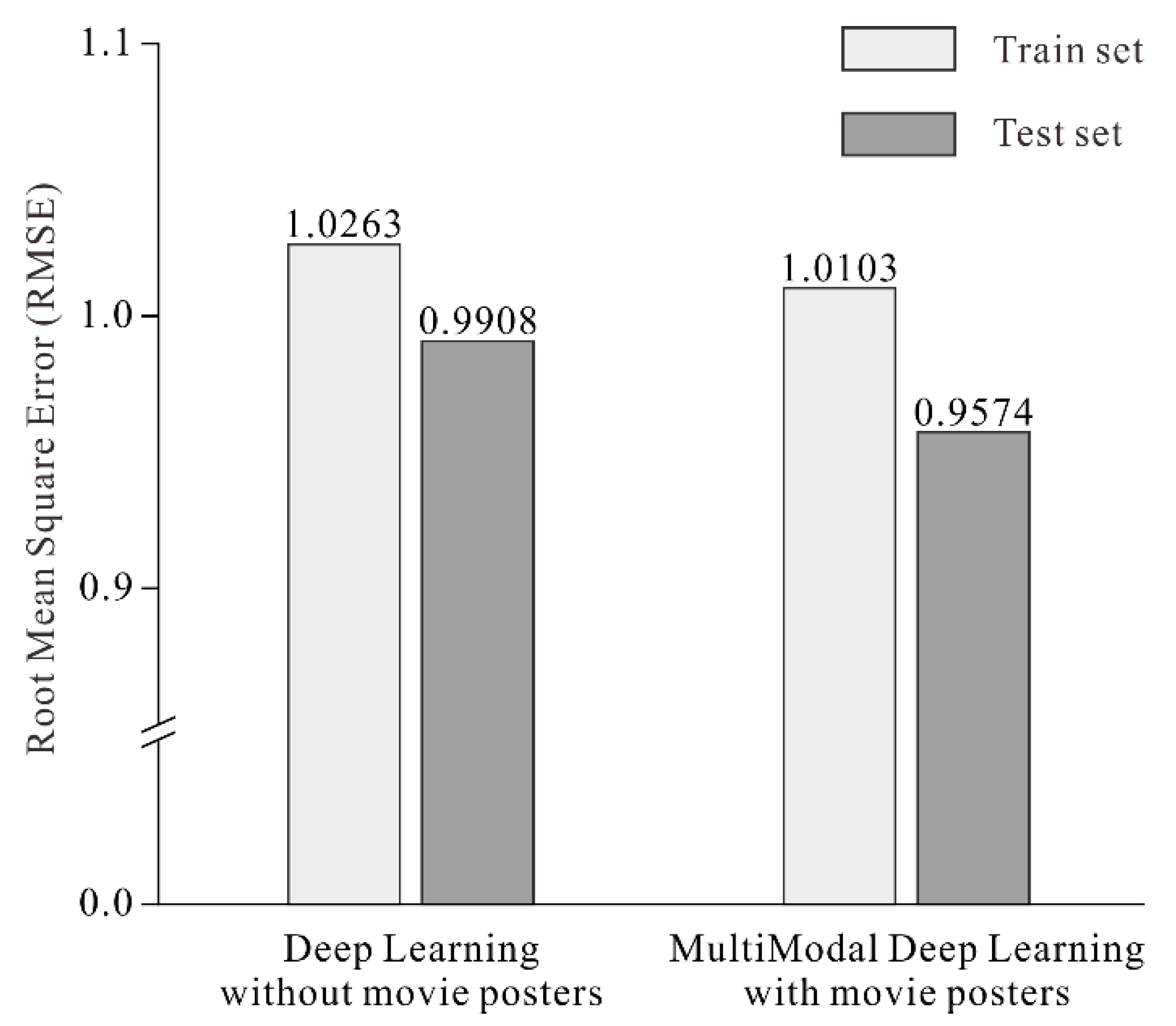
4.5. Influence of Multimodal Data Analysis
5. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jacoby, J.; Speller, D.E.; Berning, C.K. Brand Choice Behavior as a Function of Information Load: Replication and Extension. J. Consum. Res. 1974, 1, 33–42. [Google Scholar] [CrossRef]
- Schwartz, B. The Paradox of Choice: Why More is Less; HarperCollins Publishers: New York, NY, USA, 2004; p. 304. [Google Scholar]
- Chen, Y.; Shang, R.; Kao, C. The Effects of Information Overload on Consumers’ Subjective State Towards Buying Decision in the Internet Shopping Environment. Electron. Commer. Res. Appl. 2009, 8, 48–58. [Google Scholar] [CrossRef]
- Resnick, P.; Varian, H.R. Recommender Systems. Commun. ACM 1997, 40, 56–58. [Google Scholar] [CrossRef]
- Isinkaye, F.O.; Folajimi, Y.O.; Ojokoh, B.A. Recommendation Systems: Principles, Methods and Evaluation. Egypt. Inform. J. 2015, 16, 261–273. [Google Scholar] [CrossRef]
- Kane, F. Building Recommender Systems with Machine Learning and AI, 2nd ed.; Sundog Education: Winter Springs, FL, USA, 2021; p. 503. [Google Scholar]
- Aggarwal, C.C. Recommender Systems: The Textbook; Springer: Berlin/Heidelberg, Germany, 2016; p. 498. [Google Scholar]
- Adomavicius, G.; Tuzhilin, A. Toward the Next Generation of Recommender Systems: A Survey of the State-of-the-Art and Possible Extensions. IEEE Trans. Knowl. Data Eng. 2005, 17, 734–749. [Google Scholar] [CrossRef]
- Lu, J.; Wu, D.; Mao, M.; Wang, W.; Zhang, G. Recommender System Application Developments: A Survey. Decis. Support Syst. 2015, 74, 12–32. [Google Scholar] [CrossRef]
- Liu, J.; Choi, W.; Liu, J. Personalized Movie Recommendation Method Based on Deep Learning. Math. Probl. Eng. 2021, 2021, 6694237. [Google Scholar] [CrossRef]
- Lund, J.; Ng, Y. Movie Recommendations Using the Deep Learning Approach. In Proceedings of the 2018 IEEE International Conference on Communications (ICC), Kansas City, MO, USA, 20–24 May 2018; pp. 47–54. [Google Scholar]
- Chavare, S.R.; Awati, C.J.; Shirgave, S.K. Smart Recommender System Using Deep Learning. In Proceedings of the 2021 IEEE International Conference on Communications, Montreal, QC, Canada, 14–23 June 2021; pp. 590–594. [Google Scholar]
- Gopi, P.S.S.; Karthikeyan, M. Multimodal Machine Learning Based Crop Recommendation and Yield Prediction Model. Intell. Autom. Soft Comput. 2023, 36, 313–326. [Google Scholar] [CrossRef]
- Blake, R.; Frajtova Michalikova, K. Deep Learning-Based Sensing Technologies, Artificial Intelligence-Based Decision-Making Algorithms, and Big Geospatial Data Analytics in Cognitive Internet of Things. Anal. Metaphys. 2021, 20, 159–173. [Google Scholar] [CrossRef]
- Watson, R. The Virtual Economy of the Metaverse: Computer Vision and Deep Learning Algorithms, Customer Engagement Tools, and Behavioral Predictive Analytics. Linguist. Philos. Investig. 2022, 21, 41–56. [Google Scholar] [CrossRef]
- Zauskova, A.; Miklencicova, R.; Popescu, G.H.; Abualhaj, M.M. Visual Imagery and Geospatial Mapping Tools, Virtual Simulation Algorithms, and Deep Learning-Based Sensing Technologies in the Metaverse Interactive Environment. Rev. Contemp. Philos. 2022, 21, 122–137. [Google Scholar] [CrossRef]
- Cai, J.J.; Tang, J.; Chen, Q.G.; Hu, Y.; Wang, X.B.; Huang, S.J. Multi-View Active Learning for Video Recommendation. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence (IJCAI-19), Macao, China, 10–16 August 2019; pp. 2053–2059. [Google Scholar]
- Qin, Z.T.; Zhang, M.J. Towards a Personalized Movie Recommendation System: A Deep Learning Approach. In Proceedings of the 2021 2nd International Conference on Artificial Intelligence and Information Systems (ICAIIS’21), Montreal, QC, Canada, 19–27 August 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Siersdorfer, S.; San Pedro, J.; Sanderson, M. Automatic Video Tagging Using Content Redundancy. In Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Boston MA, USA, 19–23 July 2009; pp. 395–402. [Google Scholar]
- Fang, W.; Sha, Y.; Qi, M.; Sheng, V.S. Movie Recommendation Algorithm Based on Ensemble Learning. Intell. Autom. Soft Comput. 2022, 34, 609–622. [Google Scholar] [CrossRef]
- Khan, U.A.; Martinez-Del-Amor, M.A.; Altowaijri, S.M.; Ahmed, A.; Rahman, A.U.; Sama, N.U.; Haseeb, K.; Islam, N. Movie Tags Prediction and Segmentation Using Deep Learning. IEEE Access. 2020, 8, 6071–6086. [Google Scholar] [CrossRef]
- Zhang, F.; Lee, V.E.; Jin, R.; Garg, S.; Choo, K.R.; Maasberg, M.; Dong, L.; Cheng, C. Privacy-Aware Smart City: A Case Study in Collaborative Filtering Recommender Systems. J. Parallel Distrib. Comput. 2019, 127, 145–159. [Google Scholar] [CrossRef]
- Sridhar, S.; Dhanasekaran, D.; Charlyn Pushpa Latha, G. Content-Based Movie Recommendation System Using Mbo with Dbn. Intell. Autom. Soft Comput. 2023, 35, 3241–3257. [Google Scholar] [CrossRef]
- Wei, J.; He, J.; Chen, K.; Zhou, Y.; Tang, Z. Collaborative Filtering and Deep Learning Based Recommendation System for Cold Start Items. Expert Syst. Appl. 2017, 69, 29–39. [Google Scholar] [CrossRef]
- Hussein, A.H.; Kharma, Q.M.; Taweel, F.M.; Abualhaj, M.M.; Shambour, Q.Y. A Hybrid Multi-Criteria Collaborative Filtering Model for Effective Personalized Recommendations. Intell. Autom. Soft Comput. 2022, 31, 661–675. [Google Scholar] [CrossRef]
- Duan, R.; Jiang, C.; Jain, H.K. Combining Review-Based Collaborative Filtering and Matrix Factorization: A Solution to Rating’s Sparsity Problem. Decis. Support Syst. 2022, 156, 113748. [Google Scholar] [CrossRef]
- Da’’U, A.; Salim, N. Recommendation System Based on Deep Learning Methods: A Systematic Review and New Directions. Artif. Intell. Rev. 2020, 53, 2709–2748. [Google Scholar] [CrossRef]
- Zuo, M.; Dai, G. P-Lsgof: A Parallel Learning-Selection-Based Global Optimization Framework. J. Intell. Fuzzy Syst. 2020, 39, 7333–7361. [Google Scholar] [CrossRef]
- Covington, P.; Adams, J.; Sargin, E. Deep Neural Networks for Youtube Recommendations. In Proceedings of the 2016 ACM Conference on Innovation and Technology in Computer Science Education, New York, NY, USA, 11–13 July 2016; pp. 191–198. [Google Scholar]
- Ramachandram, D.; Taylor, G.W. Deep Multimodal Learning: A Survey on Recent Advances and Trends. IEEE Signal Process. Mag. 2017, 34, 96–108. [Google Scholar] [CrossRef]
- Yang, B.; Mei, T.; Hua, X.; Yang, L.; Yang, S.; Li, M. Online Video Recommendation Based on Multimodal Fusion and Relevance Feedback; ACM: New York, NY, USA, 2007; pp. 73–80. [Google Scholar]
- Fan, Y.; Wang, Y.; Yu, H.; Liu, B. Movie Recommendation Based on Visual Features of Trailers. In Innovative Mobile and Internet Services in Ubiquitous Computing, Advances in Intelligent Systems and Computing 612; Springer International Publishing: Manhattan, NY, USA, 2017; pp. 242–253. [Google Scholar] [CrossRef]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural Language Processing (Almost) From Scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Rassweiler Filho, R.J.; Wehrmann, J.; Barros, R.C. Leveraging Deep Visual Features for Content-Based Movie Recommender Systems. In Proceedings of the 2017 IEEE International Ultrasonics Symposium, Washington, DC, USA, 6–9 September 2017; pp. 604–611. [Google Scholar]
- Roy, D.; Ding, C. Movie Recommendation Using Youtube Movie Trailer Data as the Side Information. In Proceedings of the 2020 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), The Hague, The Netherlands, 7–10 December 2020; pp. 275–279. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Parameters | Value |
|---|---|---|
| MovieLens 100 K | #Users | 943 |
| #Movies | 1682 | |
| #Ratings | 100,000 | |
| Sparsity | 93.695% | |
| MovieLens 1 M | #Users | 6040 |
| #Items | 3883 | |
| #Ratings | 1,000,209 | |
| Sparsity | 95.359% |
| MovieLens 100 K | MovieLens 1 M | |||
|---|---|---|---|---|
| Learning rate | 0.001 | 0.0001 | 0.001 | 0.0001 |
| RMSE of Train set | 1.0263 | 1.1319 | 0.9264 | 0.9967 |
| RMSE of Test set | 0.9908 | 1.0877 | 0.9096 | 0.9807 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mu, Y.; Wu, Y. Multimodal Movie Recommendation System Using Deep Learning. Mathematics 2023, 11, 895. https://doi.org/10.3390/math11040895
Mu Y, Wu Y. Multimodal Movie Recommendation System Using Deep Learning. Mathematics. 2023; 11(4):895. https://doi.org/10.3390/math11040895
Chicago/Turabian StyleMu, Yongheng, and Yun Wu. 2023. "Multimodal Movie Recommendation System Using Deep Learning" Mathematics 11, no. 4: 895. https://doi.org/10.3390/math11040895
APA StyleMu, Y., & Wu, Y. (2023). Multimodal Movie Recommendation System Using Deep Learning. Mathematics, 11(4), 895. https://doi.org/10.3390/math11040895