


Evaluating the Privacy and Utility of Time-Series Data Perturbation Algorithms

Abstract
:1. Introduction
- A systematic procedure for evaluating the utility and privacy of perturbation algorithms. The approach is sensor-type-independent, algorithm-independent, and data-independent.
- A methodology for comparing data perturbation methods.
- We demonstrate applicability by assessing the impact of data integrity attacks on perturbed data.
- We analyze the approach on actual driving data and build the dataset following the stated requirements.
2. Background and Related Work
2.1. Time-Series Data Privacy Techniques
2.2. Privacy and Utility Metrics for Data Perturbation
2.3. Cyber Attack Impact Assessment (CAIA) Methodology
3. Proposed Approach
3.1. Perturbation System Architecture and Design Consideration
- the type of data leaving the system and the potentially sensitive information they carry;
- the amount of information to be hidden considering possible sensitive information or other external factors;
- utility restrictions (how much information about the data should still be available after perturbation);
- the processing power of the equipment.
3.2. Formal Description
3.3. Comparing Perturbation Methods
- : if provides higher utility than ;
- : if provides higher privacy than ;
- : if provides higher utility than and provides higher privacy than .
| Algorithm 1: Comparison of Perturbation Methods |
 |
3.4. Evaluation of the Utility of a Perturbation Method in Case of Data Interventions
| Algorithm 2: Intervention Impact on Perturbed Data Algorithm |
 |
4. Experimental Results
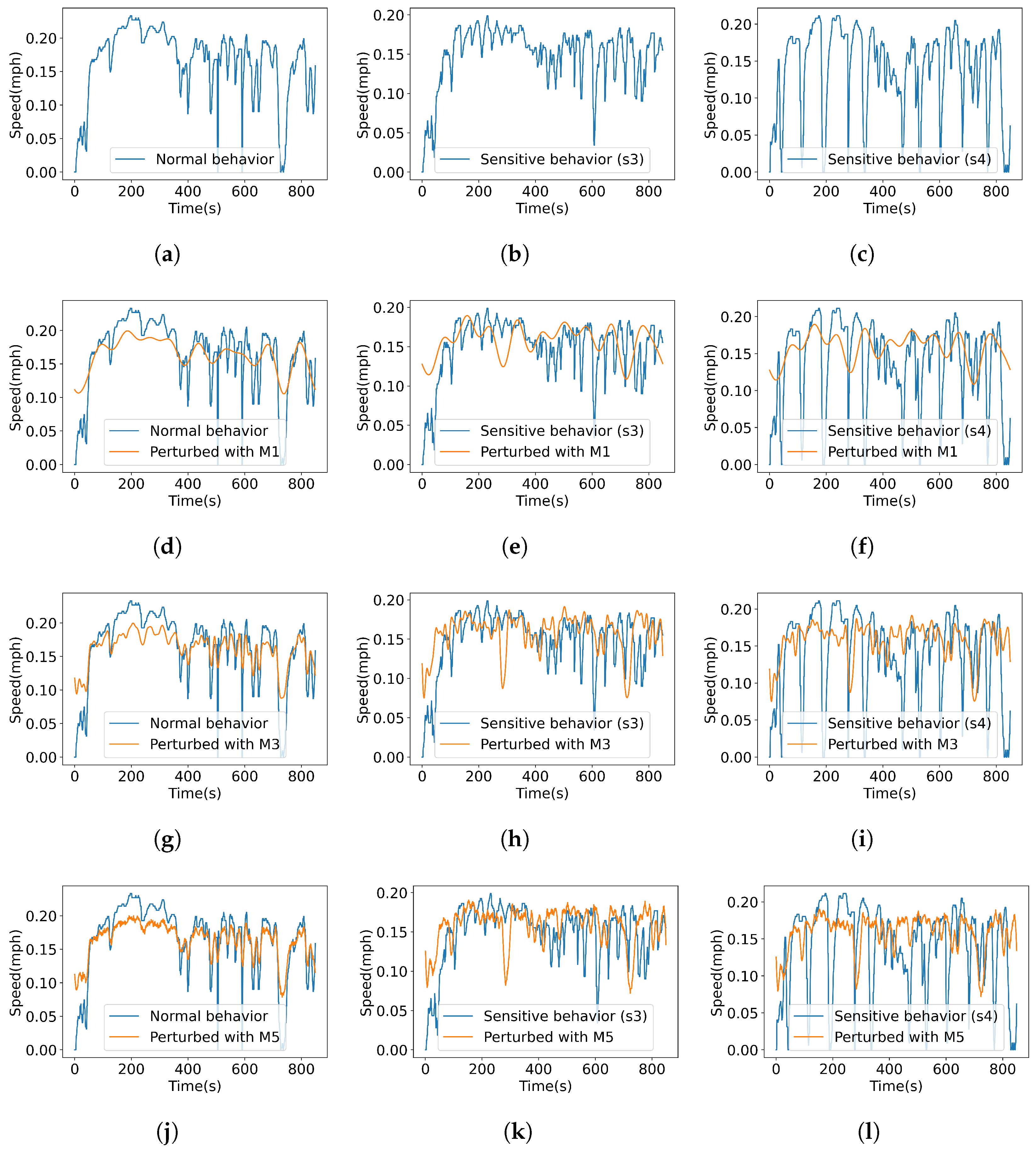
4.1. Data Collection and Intervention Generation
- Step 1: Collect several normal behavior time-series data, compute the standard deviation for each one, and identify , the interval of minimum and maximum standard deviation possible for normal behavior.
- Step 2: Choose the landmark normal behavior (), the data further used for computing impact coefficients and for attack generation. For instance, choose the normal behavior that has the standard deviation closest to the middle of the interval.
- Step 3: Identify possible sensitive behaviors and collect the corresponding data. The collected data qualifies as sensitive behavior if its standard deviation is outside the interval , according to Definition 2.
- Pulse attack: In this case the altered value is obtained by dividing the value of the attribute j at time t, , by an attack parameter : with t in the attack interval ;
- Scaling attack: The value is scaled by attack parameter : , for ;
- Ramp attack: This type of attack adds values from a ramp function , for , where ;
- Random attack: Here, a random value selected from a uniform distribution interval is added: , for ;
- Step attack: This attack involves setting values to the attack parameter is added: , for .
4.2. Experiments
4.2.1. Compare Perturbation Methods
4.2.2. Evaluate the Utility of a Perturbation Module for Detecting Data Interventions/Attacks
5. Discussion
- Compared to the other mechanisms, the proposed approach measures both privacy and utility;
- Various distortion and perturbation methods can be compared, no matter how different they are;
- An evaluation of the impact of various data integrity attacks on perturbed data is possible.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hallac, D.; Sharang, A.; Stahlmann, R.; Lamprecht, A.; Huber, M.; Roehder, M.; Leskovec, J. Driver identification using automobile sensor data from a single turn. In Proceedings of the 2016 IEEE 19th International Conference on Intelligent Transportation Systems (ITSC), Rio de Janeiro, Brazil, 1–4 November 2016; IEEE: New York, NY, USA, 2016; pp. 953–958. [Google Scholar]
- Mekruksavanich, S.; Jitpattanakul, A. Biometric user identification based on human activity recognition using wearable sensors: An experiment using deep learning models. Electronics 2021, 10, 308. [Google Scholar] [CrossRef]
- Lako, F.L.; Lajoie-Mazenc, P.; Laurent, M. Privacy-Preserving Publication of Time-Series Data in Smart Grid. Secur. Commun. Netw. 2021, 2021, 6643566. [Google Scholar]
- Agrawal, R.; Srikant, R. Privacy-Preserving Data Mining. In Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, Dallas, TX, USA, 15–18 May 2000; Association for Computing Machinery: New York, NY, USA, 2000; pp. 439–450. [Google Scholar] [CrossRef]
- Bingham, E.; Mannila, H. Random Projection in Dimensionality Reduction: Applications to Image and Text Data. In Proceedings of the Seventh ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 26–29 August 2001; Association for Computing Machinery: New York, NY, USA, 2001; pp. 245–250. [Google Scholar] [CrossRef]
- Chen, K.; Liu, L. Privacy preserving data classification with rotation perturbation. In Proceedings of the Fifth IEEE International Conference on Data Mining (ICDM’05), Houston, TX, USA, 27–30 November 2005; p. 4. [Google Scholar] [CrossRef]
- Mukherjee, S.; Chen, Z.; Gangopadhyay, A. A privacy-preserving technique for Euclidean distance-based mining algorithms using Fourier-related transforms. VLDB J. 2006, 15, 293–315. [Google Scholar] [CrossRef]
- Papadimitriou, S.; Li, F.; Kollios, G.; Yu, P.S. Time Series Compressibility and Privacy. In Proceedings of the 33rd International Conference on Very Large Data Bases—VLDB Endowment, Vienna, Austria, 23–27 September 2007; pp. 459–470. [Google Scholar]
- Rastogi, V.; Nath, S. Differentially Private Aggregation of Distributed Time-Series with Transformation and Encryption. In Proceedings of the 2010 ACM SIGMOD International Conference on Management of Data, Indianapolis, IN, USA, 6–10 June 2010; pp. 735–746. [Google Scholar]
- Lyu, L.; He, X.; Law, Y.W.; Palaniswami, M. Privacy-Preserving Collaborative Deep Learning with Application to Human Activity Recognition. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 1219–1228. [Google Scholar] [CrossRef]
- Genge, B.; Kiss, I.; Haller, P. A system dynamics approach for assessing the impact of cyber attacks on critical infrastructures. Int. J. Crit. Infrastruct. Prot. 2015, 10, 3–17. [Google Scholar] [CrossRef]
- Ford, D.N. A behavioral approach to feedback loop dominance analysis. Syst. Dyn. Rev. J. Syst. Dyn. Soc. 1999, 15, 3–36. [Google Scholar] [CrossRef]
- Wang, H.; Xu, Z. CTS-DP: Publishing correlated time-series data via differential privacy. Knowl. Based Syst. 2017, 122, 167–179. [Google Scholar] [CrossRef]
- Roman, A.S.; Genge, B.; Duka, A.V.; Haller, P. Privacy-Preserving Tampering Detection in Automotive Systems. Electronics 2021, 10, 3161. [Google Scholar] [CrossRef]
- Hassan, M.U.; Rehmani, M.H.; Chen, J. Differential Privacy Techniques for Cyber Physical Systems: A Survey. IEEE Commun. Surv. Tutor. 2020, 22, 746–789. [Google Scholar] [CrossRef] [Green Version]
- Liu, X.; Zheng, Y.; Yi, X.; Nepal, S. Privacy-preserving collaborative analytics on medical time series data. IEEE Trans. Dependable Secur. Comput. 2020, 19, 1687–1702. [Google Scholar] [CrossRef]
- Katsomallos, M.; Tzompanaki, K.; Kotzinos, D. Privacy, space and time: A survey on privacy-preserving continuous data publishing. J. Spat. Inf. Sci. 2019, 2019, 57–103. [Google Scholar] [CrossRef]
- Wang, T.; Zheng, Z.; Rehmani, M.H.; Yao, S.; Huo, Z. Privacy Preservation in Big Data From the Communication Perspective—A Survey. IEEE Commun. Surv. Tutor. 2019, 21, 753–778. [Google Scholar] [CrossRef]
- Sweeney, L. k-Anonymity: A Model for Protecting Privacy. IEEE Secur. Priv. 2002, 10, 557–570. [Google Scholar] [CrossRef] [Green Version]
- Machanavajjhala, A.; Gehrke, J.; Kifer, D.; Venkitasubramaniam, M. L-Diversity: Privacy Beyond k-Anonymity. Acm Trans. Knowl. Discov. Data 2006, 1, 24. [Google Scholar]
- Li, N.; Li, T.; Venkatasubramanian, S. t-Closeness: Privacy Beyond k-Anonymity and l-Diversity. In Proceedings of the 2007 IEEE 23rd International Conference on Data Engineering, Istanbul, Turkey, 17–20 April 2007; Volume 2, pp. 106–115. [Google Scholar]
- Bhaduri, K.; Stefanski, M.D.; Srivastava, A.N. Privacy-Preserving Outlier Detection Through Random Nonlinear Data Distortion. IEEE Trans. Syst. Man Cybern. Part B 2011, 41, 260–272. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dwork, C. Differential privacy: A survey of results. In Proceedings of the International Conference on Theory and Applications of Models of Computation, Xi’an, China, 25–29 April 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 1–19. [Google Scholar]
- Dwork, C.; McSherry, F.; Nissim, K.; Smith, A. Calibrating noise to sensitivity in private data analysis. In Theory of Cryptography Conference; Springer: Berlin/Heidelberg, Germany, 2006; pp. 265–284. [Google Scholar]
- Arcolezi, H.H.; Couchot, J.F.; Renaud, D.; Al Bouna, B.; Xiao, X. Differentially private multivariate time series forecasting of aggregated human mobility with deep learning: Input or gradient perturbation? Neural Comput. Appl. 2022, 34, 13355–13369. [Google Scholar] [CrossRef]
- Wu, T.; Wang, X.; Qiao, S.; Xian, X.; Liu, Y.; Zhang, L. Small perturbations are enough: Adversarial attacks on time series prediction. Inf. Sci. 2022, 587, 794–812. [Google Scholar] [CrossRef]
- Dwork, C.; Kohli, N.; Mulligan, D. Differential privacy in practice: Expose your epsilons! J. Priv. Confid. 2019, 9, 1–22. [Google Scholar] [CrossRef] [Green Version]
- Yang, E.; Parvathy, V.S.; Selvi, P.P.; Shankar, K.; Seo, C.; Joshi, G.P.; Yi, O. Privacy Preservation in Edge Consumer Electronics by Combining Anomaly Detection with Dynamic Attribute-Based Re-Encryption. Mathematics 2020, 8, 1871. [Google Scholar] [CrossRef]
- De Canditiis, D.; De Feis, I. Anomaly detection in multichannel data using sparse representation in RADWT frames. Mathematics 2021, 9, 1288. [Google Scholar] [CrossRef]
- Bolboacă, R. Adaptive Ensemble Methods for Tampering Detection in Automotive Aftertreatment Systems. IEEE Access 2022, 10, 105497–105517. [Google Scholar] [CrossRef]
- Geng, Q.; Viswanath, P. The optimal noise-adding mechanism in differential privacy. IEEE Trans. Inf. Theory 2015, 62, 925–951. [Google Scholar] [CrossRef]
- Soria-Comas, J.; Domingo-Ferrer, J. Optimal data-independent noise for differential privacy. Inf. Sci. 2013, 250, 200–214. [Google Scholar] [CrossRef]
- Xiao, X.; Bender, G.; Hay, M.; Gehrke, J. iReduct: Differential privacy with reduced relative errors. In Proceedings of the 2011 ACM SIGMOD International Conference on Management of Data, Athens, Greece, 12–16 June 2011; pp. 229–240. [Google Scholar]
- Yang, X.; Ren, X.; Lin, J.; Yu, W. On binary decomposition based privacy-preserving aggregation schemes in real-time monitoring systems. IEEE Trans. Parallel Distrib. Syst. 2016, 27, 2967–2983. [Google Scholar] [CrossRef]
- Kellaris, G.; Papadopoulos, S. Practical differential privacy via grouping and smoothing. Proc. VLDB Endow. 2013, 6, 301–312. [Google Scholar] [CrossRef] [Green Version]
- Acs, G.; Castelluccia, C.; Chen, R. Differentially private histogram publishing through lossy compression. In Proceedings of the 2012 IEEE 12th International Conference on Data Mining, Brussels, Belgium, 10–13 December 2012; IEEE: New Yok, NY, USA, 2012; pp. 1–10. [Google Scholar]
- Zhu, T.; Xiong, P.; Li, G.; Zhou, W. Correlated differential privacy: Hiding information in non-IID data set. IEEE Trans. Inf. Forensics Secur. 2014, 10, 229–242. [Google Scholar]
- Agrawal, D.; Aggarwal, C.C. On the Design and Quantification of Privacy Preserving Data Mining Algorithms. In Proceedings of the 20th ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems, Santa Barbara, CA, USA, 21–23 May 2001; pp. 247–255. [Google Scholar]
- Evfimievski, A.; Srikant, R.; Agrawal, R.; Gehrke, J. Privacy preserving mining of association rules. In Proceedings of the 8th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Edmonton, AB, Canada, 23–26 July 2002; pp. 217–228. [Google Scholar]
- Huang, J.; Howley, E.; Duggan, J. The Ford Method: A sensitivity analysis approach. In Proceedings of the 27th International Conference of the System Dynamics Society, Albuquerque, NM, USA, 26–30 July 2009; The System Dynamics Society: Littleton, MA, USA, 2009. [Google Scholar]
- European Data Protection Board. Guidelines 1/2020 on Processing Personal Data in the Context of Connected Vehicles and Mobility Related Applications; European Data Protection Board: Brussels, Belgium, 2020. [Google Scholar]
- Ntalampiras, S. Detection of integrity attacks in cyber-physical critical infrastructures using ensemble modeling. IEEE Trans. Ind. Inform. 2014, 11, 104–111. [Google Scholar] [CrossRef]
- Haller, P.; Genge, B. Using sensitivity analysis and cross-association for the design of intrusion detection systems in industrial cyber-physical systems. IEEE Access 2017, 5, 9336–9347. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description |
|---|---|
| R | Set of collected regular (typical) user behavior data |
| S | Set of collected sensitive user behavior data |
| B | Set of collected user behavior data (regular and sensitive), |
| and | |
| A | Set of intervention data (integrity attacks), |
| Standard deviation | |
| Minimum standard deviation of regular user behavior data, | |
| Maximum standard deviation of regular user behavior data, | |
| Standard deviation of a regular user behavior data, | |
| Standard deviation of a sensitive user behavior data, | |
| Standard deviation of an intervention data (integrity attacks), | |
| Regular user behavior data, | |
| Landmark regular user behavior data | |
| Sensitive user behavior data, | |
| Regular or sensitive user behavior data, | |
| Intervention (attack) data, | |
| Perturbation method | |
| , , , , | Perturbed data, , , , |
| , | |
| C | Cross-covariance |
| Relative impact of a behavior data on the observed variable (attribute) | |
| Mean relative impact of a behavior data on the observed | |
| variable (attribute) | |
| Behavior-privacy parameter | |
| Behavior-utility parameter |
| Time-Series Data | Description | Standard Deviation () |
|---|---|---|
| Regular behavior () | Vehicle usage under regular driving | 0.0539 |
| Regular behavior () | Vehicle usage under regular driving | 0.0474 |
| Regular behavior () | Vehicle usage under regular driving | 0.0463 |
| Regular behavior () | Vehicle usage under regular driving | 0.0495 |
| Regular behavior ()—landmark () | Vehicle usage under regular driving | 0.0500 |
| Sensitive behavior () | Break pressed with a random intensity every 30 s | 0.0376 |
| Sensitive behavior () | Stop and go every 60 s | 0.0598 |
| Sensitive behavior () | Accelerate with a random intensity every 60 s | 0.0557 |
| Sensitive behavior () | Break and accelerate alternatively every 60 s | 0.0678 |
| Sensitive behavior () | Stop and go and accelerate alternatively every 60 s | 0.0569 |
| Intervention/attack () | Pulse attack (attack window size = 7, ) | 0.0701 |
| Intervention/attack () | Scaling attack (attack window size = 7, ) | 0.0816 |
| Intervention/attack () | Ramp attack (attack window size = 35, ) | 0.0860 |
| Intervention/attack () | Random attack (attack window size = 7, ) | 0.0762 |
| Intervention/attack () | Step attack (attack window size = 10, ) | 0.0906 |
| Distortion/Perturbation Method | Notation | Number of Fourier Coefficients | Noise Size/Privacy Budget |
|---|---|---|---|
| No distortion/perturbation | - | - | |
| Filtered FFT | - | ||
| Filtered FFT | - | ||
| CPA Algorithm | |||
| CPA Algorithm | |||
| FPA Algorithm | |||
| FPA Algorithm |
| Sensitive Behavior | |||||||
|---|---|---|---|---|---|---|---|
| Break/30 s () | 1.0 | 0.205 | 0.217 | 0.194 | 0.255 | 0.236 | 0.228 |
| Stop/60 s () | 1.0 | 0.266 | 0.205 | 0.353 | 0.202 | 0.235 | 0.259 |
| Acceleration/60 s () | 1.0 | 0.251 | 0.238 | 0.208 | 0.232 | 0.239 | 0.243 |
| Break and acceleration | |||||||
| (alternatively)/60 s () | 1.0 | 0.184 | 0.218 | 0.364 | 0.105 | 0.228 | 0.240 |
| Stop and go and acceleration | |||||||
| (alternatively)/60 s () | 1.0 | 0.257 | 0.256 | 0.334 | 0.216 | 0.245 | 0.249 |
| Intervention/Attack | |||||||
|---|---|---|---|---|---|---|---|
| Intervention/attack () | 1.0 | 0.157 | |||||
| Intervention/attack () | 1.0 | 0.140 | |||||
| Intervention/attack () | 1.0 | 0.134 | 0.231 | ||||
| Intervention/attack () | 1.0 | 0.138 | 0.263 | ||||
| Intervention/attack () | 1.0 | 0.132 | 0.261 | 0.230 | |||
| 1.0 | 0.184 | 0.205 | 0.194 | 0.105 | 0.228 | 0.228 | |
| 1.0 | 0.266 | 0.256 | 0.364 | 0.255 | 0.245 | 0.259 |
| Sensitive Behavior | |||||||
|---|---|---|---|---|---|---|---|
| Break/30 s () | 0.0 | 1.977 | 1.601 | 1.518 | 1.775 | 1.486 | 1.486 |
| Stop/60 s () | 0.0 | 3.977 | 2.832 | 2.668 | 2.650 | 2.568 | 2.577 |
| Acceleration/60 s () | 0.0 | 2.744 | 2.359 | 2.266 | 2.519 | 2.162 | 2.176 |
| Break and acceleration | |||||||
| (alternatively)/60 s () | 0.0 | 3.541 | 3.027 | 3.072 | 3.028 | 2.849 | 2.796 |
| Stop and go and acceleration | |||||||
| (alternatively)/60 s () | 0.0 | 3.218 | 2.454 | 2.197 | 2.276 | 2.273 | 2.248 |
| Sensitive Behavior | ||||
|---|---|---|---|---|
| Break/30 s () | ||||
| Stop/60 s () | ||||
| Acceleration/60 s () | ||||
| Break and acceleration | ||||
| (alternatively)/60 s () | ||||
| Stop and go and | ||||
| acceleration/60 s () |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Roman, A.-S. Evaluating the Privacy and Utility of Time-Series Data Perturbation Algorithms. Mathematics 2023, 11, 1260. https://doi.org/10.3390/math11051260
Roman A-S. Evaluating the Privacy and Utility of Time-Series Data Perturbation Algorithms. Mathematics. 2023; 11(5):1260. https://doi.org/10.3390/math11051260
Chicago/Turabian StyleRoman, Adrian-Silviu. 2023. "Evaluating the Privacy and Utility of Time-Series Data Perturbation Algorithms" Mathematics 11, no. 5: 1260. https://doi.org/10.3390/math11051260
APA StyleRoman, A. -S. (2023). Evaluating the Privacy and Utility of Time-Series Data Perturbation Algorithms. Mathematics, 11(5), 1260. https://doi.org/10.3390/math11051260