1. Introduction
Functional Data Analysis (FDA) is a branch of statistics that has played a growing role since the book by [
1] due to its multiple applications [
2,
3,
4,
5,
6,
7,
8]. In fact, according to [
9], the term Functional Data Analysis is due to [
10,
11], although some previous work on the subject is credited to [
12,
13]. FDA takes, as a starting point, discrete measurements of a continuous phenomenon to construct smooth curves using modified numerical analysis techniques. With these, the set of scalar data is converted into a new object called a functional datum, which is a continuous function [
8,
14]. This allows us to bring into statistical analysis some theoretical aspects from functional analysis, where some sets of functions with certain characteristics can form algebraic structures [
15,
16]. These structures can provide optimal properties for the analysis and measurement of continuous function curves. The Hilbert space, which is formed by square-integrable functions in a closed interval
;
, is a structure that plays a key role in this context. It is usually denoted as
and the main reason for playing such an important role is because Hilbert spaces are usually seen as extensions of the Euclidean space [
15,
17] (pages 249 and 19, respectively) because they have distance and size measures [
18], which are desirable properties.
Until now, most existing FDA theory has been constructed based on the extension of scalar statistics concepts to functions, giving functional objects as a result. For instance, a widely accepted definition of summary statistics for functional data is given in [
1], who define the sample functional mean, variance, covariance and correlation as continuous functions in
, as shown in Definition 1.
Definition 1. Measures in Functional Data: Given the sets of functional data and defined in , the summary functions are defined as:
In Definition 1, we show an expression for the covariance between and , which is usually defined in the literature as “cross-covariance”. This name is suggested by Ramsay and Silverman in their 2005 book because they define the covariance as a summary of the dependence of records across different argument values.
It should be noted, however, that functions and scalars are different mathematical objects with different properties, which generates some conceptual discussions. Let us consider in the first place the functional mean. As is very well known for scalar data [
19] (pp. 15–18), the Arithmetic Mean is a central tendency indicator that must be interpretable in the same context as the data. In this sense, the fact that the functional mean is a function results in a conceptually coherent concept of “tendency” because the functional mean describes the expected behavior of a set of functions related to a functional random variable. Moreover, it also has the property of “centrality” [
20] (p. 76), which can be described in its functional form with the fulfilment of Equation (
1), where
is the null function in the definition interval of the functional dataset
.
However, if we follow the approach of [
1], proving this fact requires an exhaustive walkthrough of the infinite points of the function’s definition interval, which adds complexity to a proof that would become simpler upon performing the new approach we propose in this paper.
Let us consider now the functional variance. It should be considered that the usual motivation for the concept of variance is as a measure of dispersion [
21] (p. 309), whose initial intention is to bring a comparative way for the use of consistency and efficiency concepts [
22,
23], whose definition is based on the basic premise that the sum of the squares of the deviations from the mean is a minimum [
19] (pp. 555–557). Namely, given a set of scalar data
,
, associated with the random variable
X and whose arithmetic mean is
, the sum of Expression (
2) is minimum value when
[
20] (p. 84), so that the variance in Expression (
3) is also minimum value because it reflects the expected behavior of the deviations from the mean.
Similarly, given a functional dataset
and a functional datum
, the sum in Expression (
4) must be minimum value when
, where
is the functional mean of
.
However, Ramsay and Silverman’s functional variance given in Definition 1 does not comply with this functional version of such property. This is true because the concept of a “minimum” function lacks validity due to the functional character of the objects and that the functions do not form a well ordered set [
24,
25,
26].
Furthermore, a conceptual problem seems to be associated with the fact that the variance itself gives a measure of the distance from the values to the mean [
21]. According to [
17], a measure always has to be a nonnegative real number; therefore, the functional variance given in Definition 1 is not truly a measure of dispersion of the functional data but rather a curve that offers point-to-point variances within the functional data definition interval.
Another important flaw of the variance curve is that, due to the lack of order inside a functional space, if there are two sets of curves, it is hard to decide which of the two sets has a larger dispersion. This is possible, however, with a point-to-point comparison, as is done if we look at the functional variance as a curve of point-to-point variances.
On the other hand, on the functional covariance and correlation, while the concept of covariance is not thought of as a measure, it is expected to be an indicator of the joint variation of two random variables [
27,
28]. It maintains a close relation to the concept of variance because the variance is a very particular case of the covariance [
19] (pp. 126–128). Therefore, if the functional variance is a real number, the covariance must also be because there should be coherence between the concepts. However, covariance in Definition 1 is just a point-to-point covariance function whose interpretation gives an idea of the regions where there is a larger or a smaller joint variation of the curves within the definition interval of the functional data, but it is not an indicator of the joint variation of two functional random variables.
In turn, correlation is defined as a coefficient that is linked to the concept of covariance [
19] (pp. 115–119) and for that reason, it must be defined as a real number, even in functional data. However, it is important to point out that the concept of “linear” correlation within functional data does not become clearly visible and its “linear” interpretation needs further study.
In this sense, we present a new approach for the treatment of functional data that attempts to provide summary statistics for functional data with conceptual coherence and operational advantages, defining the variance, covariance and correlation for functional data as real numbers. For this, we use one of the most notable particularities of the Hilbert spaces like vector space because, as claimed by [
29,
30,
31,
32], the elements of a vector space can be uniquely completely described by a linear combination of a set of orthogonal elements called a basis. However, for
, this set is infinite. For that reason, all FDA theory is not performed over the entire
but over a subspace of finite dimension [
33] because the number of functions used as a basis for the construction of the functional data is finite [
1,
34].
Thus far, this fact has been little explored in FDA theoretical development, although there are recent works, such as [
35], that estimate a test statistic using the basis coefficients, the use of coefficients in the homogeneity problem by [
36], and also [
37] who use the basis coefficients for estimating functional PLS regression, or even previously, with the use of principal components of functional logistic regression the authors of [
38] deal with some aspects of the subject. However, our approach addresses the functional data from a vector perspective because each functional datum corresponds to a single coefficient vector that characterizes it, which allows transferring some operations between functions to operations between coefficient vectors, component-by-component, providing operational advantages in formal proofs.
It is important to point out that our approach is based on the representation of a continuous function within an arbitrary subspace of finite dimension of
and therefore the results obtained can be applied without loss of generality to any type of orthonormal basis and of any finite dimension. Thus, in addition to the theory proposed, a simulation study with curves represented in a subspace spanned by an orthonormal basis of cosines in the [0, 1] interval is presented briefly and two implementation examples are described in the final section. In the first example, we implement our correlation proposition to determine whether there is independence between the functional random variables, used by [
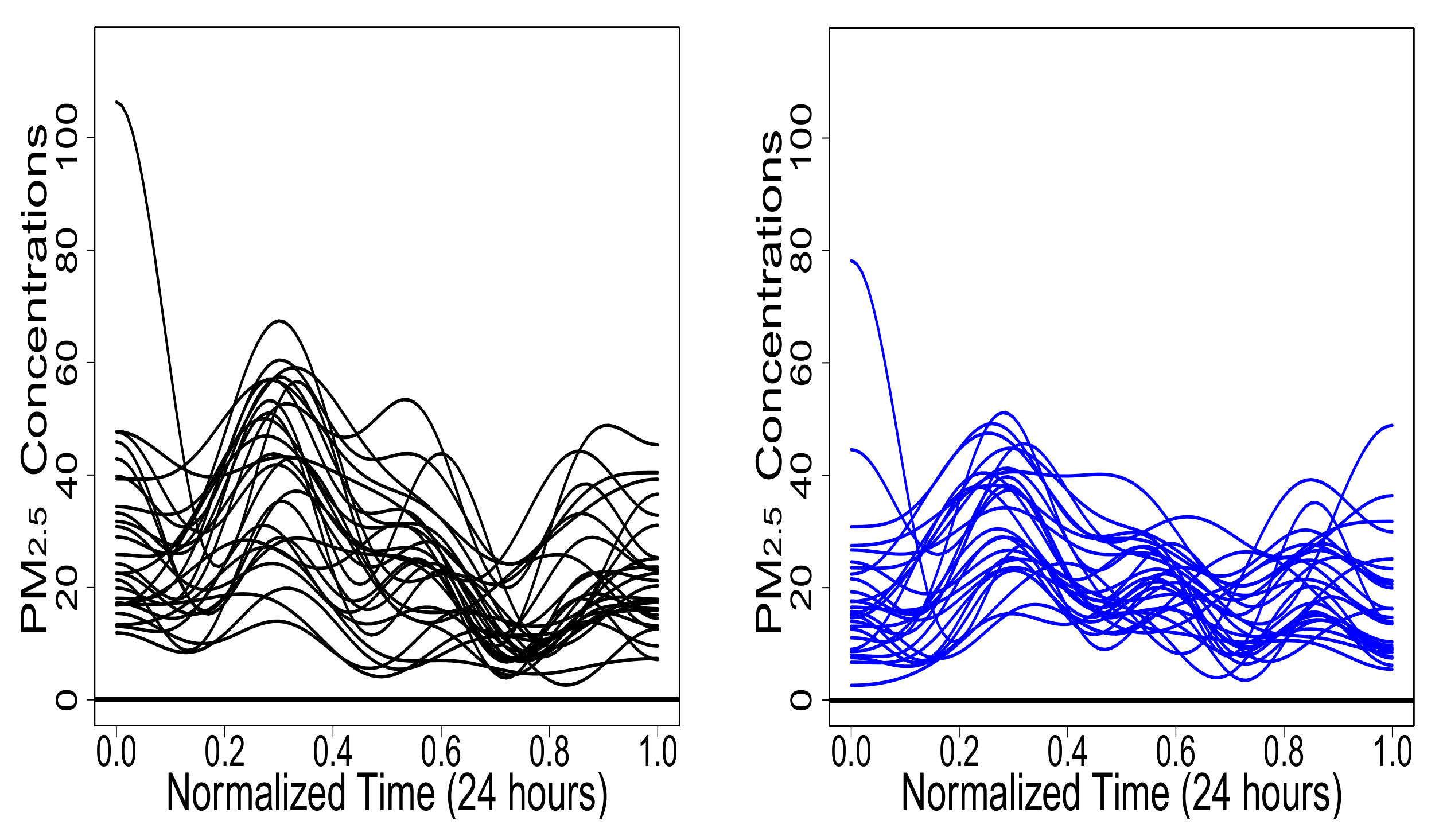
1] when constructing a functional analysis of variance (FANOVA) of the Canadian average annual temperature in four of its regions. This is done because the analysis does not specify the existence of independence between the functional random variables. The second example describes the use of our variance and functional correlation proposition as part of a functional and descriptive data analysis on particulate matter from two air quality monitoring stations in Cali, Colombia.
At this point, we recall some very well known background information, which we will need to present the new summary statistics definitions.
Definition 2. System of Generators, Basis and Dimension:
Given a vector space over a field and given , it is decided that is spanned by S if every element of can be written as a linear combination of the elements of S [32]. A vector space is said to be of finite dimension if it can be generated by a finite set of elements [39]. A set is a basis for if B spans and is also linearly independent [32].
Definition 3. Hilbert Space: In a very general manner, a Hilbert space is a vector space over the field of real numbers in which a norm and an inner product have been defined [34,40]. Definition 4. Functional Space: A functional space is a vector space whose elements are functions.
Definition 5. The Functional Hilbert Space: The space is a vector space over the field of real numbers whose elements are square-integrable functions in the closed interval ; and where given , an inner product, a norm and a distance are defined as:
Inner product: .
Norm:
Distance:
With this, the space is a functional Hilbert space [29,41]. Definition 6. Orthonormal and Orthogonal Bases: Two elements of a vector space are orthogonal if and only if the inner product between them is zero. In the same way, an element of a vector space is said to be normal if and only if its norm value is equal to 1. Thus, a basis is said to be orthogonal if and only if it is composed of elements that are orthogonal two-by-two. If, in addition, such elements satisfy the condition of normality, the basis is said to be orthonormal [30,42]. Definition 7. Functional Random Variable: A functional random variable is a random variable that takes values in a functional space, where an observation of is called a functional datum [43]. 2. Summary Statistics for Functional Data
With the motivation of providing FDA theory with summary statistics that have interpretive and operational advantages, in this section, we propose a new approach for the treatment of functional data that considers them as elements of the same functional subspace
of finite dimension of the Hilbert space
, which allows transforming operations between functions to operations between elements of vectors of coefficients component-by-component because the
space is in particular a vector space and therefore if
is a finite basis of
and
, defined on Equation (
5), is a functional datum,
where
is a linear combination of the elements of
and therefore
is uniquely completely determined by the vector
, which is called the
basis representation vector.
As mentioned, Ref. [
35] estimate a test statistic using the basis coefficients. Previously, on a density estimation problem, Ref. [
33] used a finite-dimensional approximation of the functional data, just like the one we propose here. However, none of them moved toward the representation of summary statistics for functional data using the vectors of coefficients used for the functional data representation shown in Equation (
5). Next, the new definitions of summary statistics are proposed, as well as their properties.
2.1. Sum of Functional Data
As observed in works by [
44,
45] and in most of the textbooks on linear algebra and functional analysis, the sum of the elements of a space of finite dimension can be defined by the sum of their representation coefficients in the same basis, as is presented in Proposition 1 and whose proof is immediate, using the representation of each functional datum and the association and commutation properties of
under the sum.
Proposition 1. Let be a subspace of finite dimension p of the Hilbert space with basis and a set of n functional data with representation vectors , for some with and . Then, the sum is an element of with representation vector: Proof. Given that
with
,
and
are representation vectors,
Therefore, given
for every
, then
and its representation vector is
□
Proposition 1 indicates that the sum of the n functional data is completely determined by the sum of the representation vectors component-by-component.
2.2. Mean of Functional Data
It is possible to obtain a definition of the mean for functional data from the representation coefficients, as we show in Proposition 2 and whose proof applies Proposition 1 as well as the representation coefficients.
Proposition 2. Let be a subspace of finite dimension p of the Hilbert space with basis and a set of n functional data with representation vectors for with and . Then, the functional mean for the functional dataset is given by:where for Proof. Given
is the mean of the
coefficients with
, then:
□
Proposition 2 indicates that the representation vector of the functional mean is completely determined by the representation vector of component-by-component mean coefficients. Namely, for a set of n functional data whose representation vectors are with , the functional mean is another functional datum, whose representation vector is .
In addition, it should be noted that the functional mean of Proposition 2 and the one in Definition 1 are the same functions because, as mentioned above, it is coherent with the concept of tendency. However, under this new approach, the functional mean has operational advantages, some of which are immediately observed in the proof of the functional version of the property of centrality (p. 76, [
20]), illustrated by Proposition 3.
Proposition 3. Let be a subspace of finite dimension p of the Hilbert space , a set of n functional data and its functional mean, then:where is the null function in . Proof. Let
be a basis of
. Therefore, there are
such that
for every
. In addition, by Proposition 2,
, where
; then, by Proposition 1:
because
for
, “
” and “
” are scalars and therefore satisfy the property of centrality. □
2.3. Variance for Functional Data
We define the variance for functional data as the average of the squared distances of each function to the functional mean. The distance used is the distance between the functions of , shown above in Definition 5, which gives a scalar number as a result and therefore the variance of Definition 8 is a scalar and maintains the concept of the variance as a measure of dispersion because it is the expected behavior of the distances of the functions to the functional mean, whose interpretation is performed in a general manner over the entire set of functions.
Definition 8. Variance for Functional Data: Let be a subspace of finite dimension p of the Hilbert space and let be a set of n functional data associated with the functional random variable ; then, the scalar variance for this functional data set is defined as: This definition allows having a scalar measure of dispersion, around the functional mean, of a set of functions. The most notable operational advantage of Definition 8 is given by Theorem 1.
Theorem 1. Let be a subspace of finite dimension p of the Hilbert space , an orthonormal basis of and a set of n functional data associated with the functional random variable , with representation vectors , then:where . Theorem 1 indicates that if the representation basis is orthonormal, the variance for the functional data can be simply calculated as the sum of the variances of the coefficients, component-by-component.
To prove Theorem 1, we need first to prove a couple of very important results presented in Lemmas 1 and 2.
Lemma 1. Let be a subspace of finite dimension p of , a basis of , a set of functional data with representation vectors and a functional datum with representation vector , then:The proof of Lemma 1 follows from the representation of each of the elements of on the selected basis and from the properties of summation. Proof. Given that
for every
, then:
□
If in Lemma 1 we replace by the functional mean of , the Lemma 2 is obtained.
Lemma 2. Let be a subspace of finite dimension p of , a basis of , a set of functional data with representation vectors and the functional mean of ; then, if , for , the mean difference of squares can be decomposed as:where and . Proof. By Lemma 1:
but
and
, with which:
□
We thus provide a proof of Theorem 1.
Proof. By Definition 8:
and by the integral’s properties, we know that:
but from Lemma 2, we have that:
By hypothesis,
is an orthonormal basis; that is,
and
; for each
, therefore, we have that:
□
We highlight that as part of the proof of Theorem 1, the Equation (
9) is obtained:
which means that we can apply the result to a nonnormal basis and even to generator sets that are not necessarily orthogonal.
Let us display now some properties of the functional variance under this new approach, which satisfies the same properties of a variance for scalar data because it inherits them from the variances of coefficients, as shown below.
Proposition 4. Let be a subspace of finite dimension p of the Hilbert space , an orthonormal basis of and a set of n functional data associated with the functional random variable , with representation vectors . Then, the following properties for the functional variance are followed:
- 1
.
- 2
is of minimum value.
- 3
If have the same representation vectors, then .
Proof. Properties
Given that and that for every , .
Given that and that each is of minimum value for every , then is of minimum value.
Given
functional data, such that their representation vectors are equal, then:
Then, for every
,
and
Therefore,
for each
and consequently
.
□
The fulfilment of this last property shows that, in fact, measures the dispersion of the functional data.
2.4. Covariance and Correlation in Functional Data
Following the same line of reasoning as for the variance for functional data associated with Definition 8, the covariance for functional data is shown in Definition 9.
Definition 9. Covariance in Functional Data: Let be a subspace of finite dimension p of the Hilbert space and and two sets of n functional data associated with the functional random variables and , respectively. Then the scalar covariance for these two sets of functional data is defined as: Like the variance case, this definition allows having a scalar value of the joint variability of two functional random variables in relation to the functional mean in each case and presents the operational advantage given by Theorem 2.
Theorem 2. Let be a subspace of finite dimension p of the Hilbert space , an orthonormal basis of and and two sets of n functional data associated with the functional random variables and , with representation vectors and , respectively. Then:where , being and for each Proof. By definition, we have that:
and by the integral’s properties, we know that:
Because of Lemma 1, we have that:
By applying the integral, we obtain:
where
and
. However, because the basis is orthonormal, we have that:
□
We notice that under this approach, it makes sense that and that , by virtue of Theorem 2, as well as , by virtue of Theorem 1, inherit the properties of the classical covariance in scalar data through their coefficients, but even more so, it is possible to define a correlation coefficient, as shown in Definition 10.
Definition 10. Correlation in Functional Data: Let be a subspace of dimension p of and two sets of functional data associated with the functional random variables and , whose scalar variances are and , respectively, and with scalar covariance ; then the scalar correlation coefficient is defined by the expression: As a result of the proposed approach, it can be seen that
and that
. In addition, under the compliance of the hypothesis of Theorems 1 and 2, the calculation of the correlation can be performed with the expression:
5. Conclusions
Because of the functional character of objects in FDA, it is reasonable to believe that a first approach would be the extension of concepts in their functional form. However, scalars and functions do not have the same properties or interpretations. Therefore, it is necessary to create treatment methods that are coherent according to the nature of the objects. In this sense, the proposed treatment method has important advantages because it puts aside the point-to-point treatment of the curve to treat the functional datum as a complete unit by means of the representation coefficients, given that each coefficient modifies a characteristic of the function and not just a point of it.
Some of the most important advantages provided by this approach are:
It maintains the concepts of tendency, centrality, dispersion and association coherently, which results in an interpretive advantage.
Given that each coefficient oversees a specific characteristic of the curve, when taking the arithmetic mean of the functional data through the coefficients per group of components, what is being taken is an “expected behavior” of each of the characteristics, which is conceptually coherent in terms of tendency.
It offers operational advantages, given that the set of representation coefficients is finite and their elements are scalars, which facilitates the treatment of functional data because many of the operations with them can be transferred to the coefficients.
The proposed variance allows the comparison of the variability of two groups of functional data in such a way that it is easy to calculate and interpret in terms of the “amount”.
It allows knowing how strong the joint variability of two datasets of functional data is, with interpretive and operational ease.
It allows characterizing the functional data in terms of a probability distribution function for the coefficients, component-by-component, which facilitates the controlled simulation of the functional data and their analysis.
Our new proposition of variance for functional data is also useful to determine which functional estimators are consistent within a set, i.e., which one decreases its variance when the number of functional observations increases. Furthermore, our proposition helps to determine which estimator shows less variance for the same number of functional observations; i.e., which one is more efficient.
To use our summary statistics, it is necessary that the functional data can be represented by a function basis, which limits its use to only functional data that have this characteristic. Moreover, all functional data must be represented with the same basis and function number.
Another limitation is that, because it is a new proposal, we still do not know how to assess the confidence of the estimates, which requires new simulation experiments.
To conclude, it is important to point out the need to create a theory based on methods for the analysis of functional data and to take advantage of the mathematical richness of continuous functions. Therefore, we present a formal theory to validate the proposed approach that can be taken as a starting point for future works, hoping that FDA can be transformed into a new form of statistics, say functional statistics.

 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}