
An Analysis of PISA 2018 Mathematics Assessment for Asia-Pacific Countries Using Educational Data Mining

Abstract
:1. Introduction
- In this study, we compared three EDM algorithms (LR, RF and SVM) in their performance in predicting the PISA 2018 mathematical achievement for each of the Asia-pacific countries. Then, through these models, we determined the important variables affecting the PISA 2018 mathematics achievement for each of the twelve Asia-Pacific countries we considered in this study. Determining these variables reveals which variables should be focused on in order to increase the mathematics achievement of the countries.
- We clustered Asia-Pacific countries separately using PISA 2018 mathematics achievement and socio-economic features of these countries. We examined the similarities and differences between these two clusters and to test whether a relationship between the PISA 2018 results and the socio-economic levels of the countries can be found.
2. Related Works
3. Materials and Methods
3.1. Data
3.1.1. PISA Data
3.1.2. Socio-Economic Data
- Gross Domestic Product per Capita (GDP-PPP): GDP is used to determine the average living standards of nations and for measuring their economic well-being [59]. GDP is obtained by dividing the GDP by the population of the country. Purchasing power parity (PPP) is a measure to compare the value of money in different countries by accounting for differences in the cost of living and inflation rates between them. PPP can be used to convert one country’s economic statistics, such as GDP or income, into a common currency to facilitate cross-country comparisons. GDP adjusted by purchasing power parity (PPP) accounts for the variations in the cost of living between countries and reflects the actual value of goods and services produced in a particular country [60].
- Economic Freedom Index: Economic freedom refers to the economic activities of each individual without the interference of government and other individuals. Economic freedom is also an important determinant of growth, efficiency, and welfare [61]. In the index prepared by the Heritage Foundation, 12 sub-components were analyzed under four main titles [62].
- Gender Inequality (GII): The Gender Inequality Index measures gender inequality. Published by the United Nations Development Program, it is a composite measure that uses the three dimensions of gender inequality: empowerment, economic activity, and reproductive health. It ranges from 0, where men and women are equal, to 1, where inequality is greatest [63].
- Human Development Index (HDI): The human development index aims to compare the welfare and relative development of nations by bringing together indicators related to income, education and living standards, such as the average literacy rate of people living in any country, per capita income, and life expectancy [64]. Index is calculated by taking into account the features which are important in terms of economic and social aspects, such as adult literacy rate, average life expectancy and GDP per capita by purchasing parity.
3.2. Classification and Clustering Algorithms
3.2.1. Logistic Regression Classifier (LR)
3.2.2. Random Forest Classifier (RF)
3.2.3. Support Vector Machine Classifier (SVM)
- Linear Support Vector Machine: This method tries to find an optimal hyperplane whose limit is the maximum among the infinite number of hyperplanes that separate samples in the input space.
- Non-Linear Support Vector Machine: Data that cannot be separated linearly are transformed into a linearly separable form with the help of kernel functions. The purpose of kernel functions is to extend the feature space to create nonlinear boundaries between classes.
3.2.4. Hierarchical Clustering Algorithm
3.3. Feature Selection
- Inputs: trained model m, evaluation data set D (data not used in training the model).
- Calculate the reference score s of the model m on data D (for example the accuracy for a classifier).
- For each feature j (column of D):
- ○
- For each repetition k in 1, ..., K:
- ▪
- A new modified data set named is created by randomly shuffling column j in data set D.
- ▪
- , score is calculated on model m for modified data set.
- ○
- Importance for feature fi is defined as
3.4. Metrics and Classification Criteria
3.4.1. Kullback–Leibler Divergence (KL Divergence)
3.4.2. Accuracy
3.4.3. Precision
3.4.4. Recall
3.4.5. F-Measure
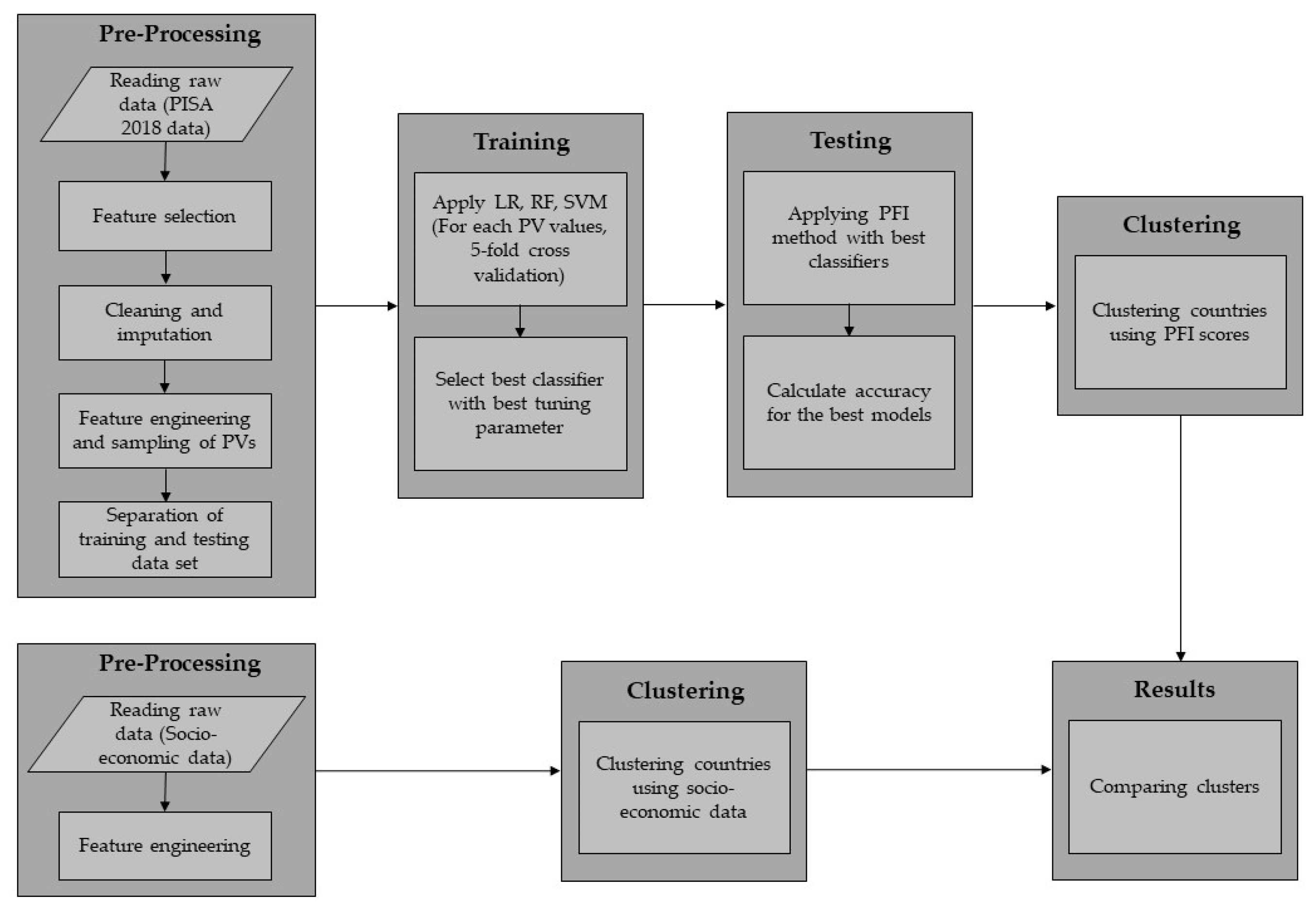
4. Application
4.1. Pre-Processing
4.2. Classification
4.3. Clustering of PISA Data
4.4. Clustering of Socio-Economic Data
5. Results
5.1. Results of Classification Algorithms
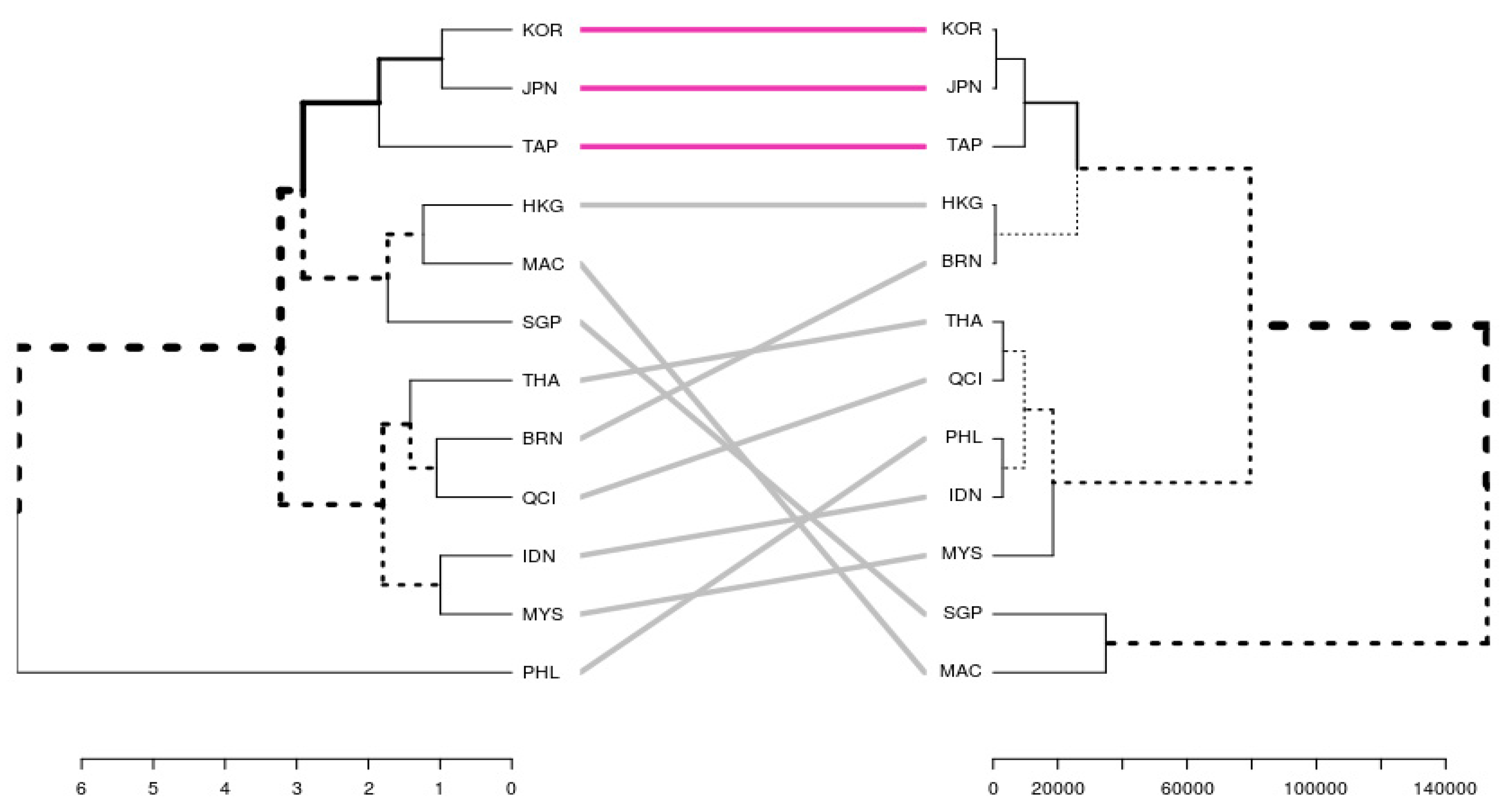
5.2. Results of the Clustering Algorithms
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Romero, C.; Ventura, S.; Pechenizkiy, M.; Baker, R.S. Handbook of Educational Data Mining; CRC Press: Boca Raton, FL, USA, 2010. [Google Scholar]
- Baradwaj, B.K.; Pal, S. Mining educational data to analyze students’ performance. Int. J. Adv. Comput. Sci. Appl. 2011, 2, 63–69. [Google Scholar]
- Witten, I.H.; Frank, E.; Hall, M.A.; Pal, C.J. Data Mining: Practical Machine Learning Tools and Techniques; Morgan Kaufmann Publishers: Burlington, MA, USA, 2005; Volume 2, No. 4. [Google Scholar]
- Maimon, O.; Rokach, L. (Eds.) Data Mining and Knowledge Discovery Handbook; Springer: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- Han, J.; Kamber, M.; Pei, J. Data Mining Concepts and Techniques, 3rd ed.; University of Illinois at Urbana-Champaign Micheline Kamber Jian Pei Simon Fraser University: Champaign, IL, USA, 2012. [Google Scholar]
- Ranjan, J.; Malik, K. Effective educational process: A data-mining approach. Vine 2007, 37, 502–515. [Google Scholar] [CrossRef]
- Siemens, G.; Baker, R.S.D. Learning analytics and educational data mining: Towards communication and collaboration. In Proceedings of the 2nd International Conference on Learning Analytics and Knowledge, Vancouver, BC, Canada, 29 April–2 May 2012; pp. 252–254. [Google Scholar]
- Viberg, O.; Hatakka, M.; Bälter, O.; Mavroudi, A. The current landscape of learning analytics in higher education. Comput. Hum. Behav. 2018, 89, 98–110. [Google Scholar] [CrossRef]
- Thakar, P.; Mehta, A. Performance analysis and prediction in educational data mining: A research travelogue. arXiv 2015, preprint. arXiv:1509.05176. [Google Scholar]
- Bulut, O.; Yavuz, H.C. Educational data mining: A tutorial for the rattle package in R. Int. J. Assess. Tools Educ. 2019, 6, 20–36. [Google Scholar] [CrossRef] [Green Version]
- Romero, C.; Ventura, S. Educational data mining: A review of the state of the art. IEEE Trans. Syst. Man Cybern. Part C 2010, 40, 601–618. [Google Scholar] [CrossRef]
- Kumar, A.D.; Selvam, R.P.; Kumar, K.S. Review on prediction algorithms in educational data mining. Int. J. Pure Appl. Math. 2018, 118, 531–537. [Google Scholar]
- Peña-Ayala, A. Educational data mining: A survey and a data mining-based analysis of recent works. Expert Syst. Appl. 2014, 41, 1432–1462. [Google Scholar] [CrossRef]
- Yağcı, M. Educational data mining: Prediction of students’ academic performance using machine learning algorithms. Smart Learn. Environ. 2022, 9, 11. [Google Scholar] [CrossRef]
- Baker, R.S.; Yacef, K. The state of educational data mining in 2009: A review and future visions. J. Educ. Data Min. 2009, 1, 3–17. [Google Scholar]
- Cheng, J. Data-mining research in education. arXiv 2017, arXiv:1703.10117. [Google Scholar]
- Dutt, A.; Ismail, M.A.; Herawan, T. A systematic review on educational data mining. IEEE Access 2017, 5, 15991–16005. [Google Scholar] [CrossRef]
- MoNE (Ministry of National Education). PISA 2018 Türkiye ön Raporu; Eğitim Analiz ve Değerlendirme Raporları Serisi; MEB Publishing: Ankara, Turkey, 2019; Volume 10. [Google Scholar]
- OECD. PISA Web Site, Next Steps. 2022. Available online: https://www.oecd.org/pisa/ (accessed on 9 August 2022).
- Özer, Y.; Anil, D. Examining the factors affecting students’science and mathematics achievement with structural equation modeling. Hacettepe Universitesi Egitim Fakultesi Dergisi-Hacettepe. Univ. J. Educ. 2011, 41, 313–324. [Google Scholar]
- OECD. PISA 2018 Results (Volume I): What Students Know and Can Do; PISA, OECD Publishing: Paris, France, 2019. [Google Scholar] [CrossRef]
- Baker, R.S.J.D. Data mining for education. Int. Encycl. Educ. 2010, 7, 112–118. [Google Scholar]
- Pai, P.F.; Chen, C.T.; Hung, Y.M.; Hung, W.Z.; Chang, Y.C. A group decision classifier with particle swarm optimization and decision tree for analyzing achievements in mathematics and science. Neural Comput. Appl. 2014, 25, 2011–2023. [Google Scholar] [CrossRef]
- Aksu, G.; Guzeller, C.O. Classification of PISA 2012 mathematical literacy scores using decision-tree method: Turkey sampling. Eğitim Ve Bilim 2016, 41, 185. [Google Scholar] [CrossRef] [Green Version]
- Filiz, E.; Öz, E. Finding the Best Algorithms and Effective Factors in Classification of Turkish Science Student Success. J. Balt. Sci. Educ. 2019, 18, 239–253. [Google Scholar] [CrossRef]
- Mutluer, C.; Büyükkidik, S. PISA 2012 verilerine göre matematik okuryazarlığının lojistik regresyon ile kestirilmesi. Marmara Üniversitesi Atatürk Eğitim Fakültesi Eğitim Bilim. Derg. 2017, 46, 97–112. [Google Scholar] [CrossRef] [Green Version]
- De Witte, K.; Kortelainen, M. What explains the performance of students in a heterogeneous environment? Conditional efficiency estimation with continuous and discrete environmental variables. Appl. Econ. 2013, 45, 2401–2412. [Google Scholar] [CrossRef]
- Martinez Abad, F.; Chaparro Caso López, A.A. Data-mining techniques in detecting factors linked to academic achievement. Sch. Eff. Sch. Improv. 2017, 28, 39–55. [Google Scholar] [CrossRef]
- Cruz-Jesus, F.; Castelli, M.; Oliveira, T.; Mendes, R.; Nunes, C.; Sa-Velho, M.; Rosa-Louro, A. Using artificial intelligence methods to assess academic achievement in public high schools of a European Union country. Heliyon 2020, 6, e04081. [Google Scholar] [CrossRef]
- Jalota, C.; Agrawal, R. Analysis of educational data mining using classification. In Proceedings of the 2019 International Conference on Machine Learning, Big Data, Cloud and Parallel Computing (COMITCon), Faridabad, India, 14–16 February 2019; pp. 243–247. [Google Scholar] [CrossRef]
- Chiu, M.M.; Xihua, Z. Family and motivation effects on mathematics achievement: Analyses of students in 41 countries. Learn. Instr. 2008, 18, 321–336. [Google Scholar] [CrossRef]
- Güre, Ö.B.; Kayri, M.; Erdoğan, F. Analysis of Factors Effecting PISA 2015 Mathematics Literacy via Educational Data Mining. Educ. Sci. 2020, 45, 202. [Google Scholar] [CrossRef]
- Gürsakal, S. PISA 2009 öğrenci başari düzeylerini etkileyen faktörlerin değerlendirilmesi. Suleyman Demirel Univ. J. Fac. Econ. Adm. Sci. 2012, 17, 441–452. [Google Scholar]
- Savaş, E.; Taş, S.; Duru, A. Factors affecting students’ achievement in mathematics. Math. Learn. 2010, 11, 113–132. [Google Scholar]
- Özkan, Y.Ö.; Güvendir, M.A. Socioeconomic Factors of Students’ Relation to Mathematic Achievement: Comparison of PISA and ÖBBS. Int. Online J. Educ. Sci. 2014, 6, 776–789. [Google Scholar] [CrossRef]
- Wang, Y.; King, R.; Haw, J.; Leung, S.O. What explains Macau students’ achievement? An integrative perspective using a machine learning approach. J. Study Educ. Dev. 2022, 46, 71–108. [Google Scholar] [CrossRef]
- Bernardo, A.B.; Cordel, M.O.; Lucas RI, G.; Teves JM, M.; Yap, S.A.; Chua, U.C. Using machine learning approaches to explore non-cognitive variables influencing reading proficiency in English among Filipino learners. Educ. Sci. 2021, 11, 628. [Google Scholar] [CrossRef]
- Sanchez EM, T.; Miguelanez, S.O.; Abad, F.M. Explanatory factors as predictors of academic achievement in PISA tests. An analysis of the moderating effect of gender. Int. J. Educ. Res. 2019, 96, 111–119. [Google Scholar] [CrossRef]
- Ding, H.; Homer, M. Interpreting mathematics performance in PISA: Taking account of reading performance. Int. J. Educ. Res. 2020, 102, 101566. [Google Scholar] [CrossRef]
- Caso Niebla, J.; Hernández Guzmán, L. Modelo explicativo del bajo rendimiento escolar: Un estudio con adolescentes mexicanos. RIEE. Rev. Iberoam. De Evaluación Educ. 2010, 3, 145–159. [Google Scholar]
- Strayhorn, T.L. Factors influencing the academic achievement of first-generation college students. J. Stud. Aff. Res. Pract. 2007, 43, 1278–1307. [Google Scholar] [CrossRef]
- Aydın, A.; Sarıer, Y.; Uysal, Ş. Sosyoekonomik ve sosyokültürel değişkenler açısından PISA matematik sonuçlarının karşılaştırılması. Eğitim Ve Bilim 2012, 37, 20–30. [Google Scholar]
- Dutt, A.; Aghabozrgi, S.; Ismail, M.A.B.; Mahroeian, H. Clustering algorithms applied in educational data mining. Int. J. Inf. Electron. Eng. 2015, 5, 112. [Google Scholar] [CrossRef] [Green Version]
- Mazurek, J.; Mielcová, E. On the relationship between selected-socio-economic indicators and student performances in the PISA 2015 study. Economics 2019, XXII, 2. [Google Scholar] [CrossRef]
- Acemoglu, D.; Pischke, J.-S. Changes in the wage structure, family income, and children’s education. Eur. Econ. Rev. 2001, 45, 890–904. [Google Scholar] [CrossRef] [Green Version]
- Ellwood, D.; Kane, T.J. Who Is Getting a College Education? Family Background and the Growing Gaps in Enrollment. In Securing the Future: Investing in Children from Birth to College; Russell Sage: New York, NY, USA, 2000; pp. 283–324. [Google Scholar]
- Kaynak, S.; Rashid, Y. Sosyo-Ekonomik Göstergelerine Göre Eco Üyesi Ülkelerin Hiyerarşik Kümeleme Metoduyla Kümelenmesi. Hitit Üniversitesi Sos. Bilim. Enstitüsü Derg. 2020, 13, 69–81. [Google Scholar] [CrossRef]
- Şahin, D. Kümelenme Analizi ile Doğu Avrupa Ülkelerinin Ekonomik Özgürlükler Açısından Değerlendirilmesi. Hitit Üniversitesi Sos. Bilim. Enstitüsü Derg. 2017, 10, 1299–1314. [Google Scholar]
- Kangalli, S.; Umut, U.Y.A.R.; Buyrukoğlu, S. OECD ülkelerinde ekonomik özgürlük: Bir kümeleme analizi. Uluslararası Alanya İşletme Fakültesi Derg. 2014, 6, 95–109. [Google Scholar]
- Aksu, G.; Güzeller, C.; Eser, M. Clustering Study of PISA 2012 Results According to Affective Attributes. Hacet. Univ. Egit. Fak. Derg. Hacet. Univ. J. Educ. 2017, 32, 838–862. [Google Scholar] [CrossRef]
- OECD. PISA 2018 Database [Data Set]. 2020. Available online: http://www.oecd.org/pisa/data/2018database/ (accessed on 9 August 2022).
- World Bank. GDP per Capita (Current US$). 2018. Available online: http://databank.worldbank.org (accessed on 23 November 2022).
- The Heritage Foundation. Index of Economic Freedom. Available online: http://www.heritage.org/Index/about (accessed on 23 November 2022).
- UNDP. Human Development Data (1990–2018). 2019. Available online: http://hdr.undp.org/en/data (accessed on 24 November 2022).
- United Nations Development Programme. Human Development Report. 2019. “Human Development Index”. Available online: http://hdr.undp.org/en/composite/HDI (accessed on 22 November 2022).
- Monseur, C.; Adams, R. Plausible values: How to deal with their limitations. J. Appl. Meas. 2009, 10, 320–334. [Google Scholar]
- Von Davier, M.; Gonzalez, E.; Mislevy, R. What are plausible values and why are they useful. IERI Monogr. Ser. 2009, 2, 9–36. [Google Scholar]
- OECD. PISA Data Analysis Manual: SPSS and SAS, 2nd ed.; OECD Publishing: Paris, France, 2009. [Google Scholar] [CrossRef]
- OECD Publishing; Organisation for Economic Co-Operation and Development Staff. National Accounts of OECD Countries 2002; OECD Publishing: Paris, France, 2002; Volume I. [Google Scholar]
- Mankiw, N.G.; Taylor, M.P.; Ashwin, A.K. Economics, 3rd ed.; Cengage Learning: Boston, MA, USA, 2014. [Google Scholar]
- Tunçsiper, B.; Biçen, Ö.F. Ekonomik özgürlükler ve ekonomik büyüme arasındaki ilişkinin panel regresyon yöntemiyle incelenmesi. Eskişehir Osman. Üniversitesi İktisadi Ve İdari Bilim. Derg. 2014, 9, 25–46. [Google Scholar]
- Miller, T.; Kim, A.B.; Roberts, J.M. Index of Economic Freedom; The Heritage Foundation: Washington, DC, USA, 2019. [Google Scholar]
- Miščević, N. United Nations development programme, human development report 2020. The next frontier human development and the anthropocene. Croat. J. Philos. 2021, 21, 231–235. [Google Scholar]
- United Nations Development Programme (UNDP). Human Development Indices and Indicators: 2018 Statistical Update, Published for the United Nations Development Programme; United Nations Development Programme (UNDP): Washington, DC, USA, 2018. [Google Scholar]
- Hou, J.; Walsh, P.P.; Zhang, J. The dynamics of human development index. Soc. Sci. J. 2015, 52, 331–347. [Google Scholar] [CrossRef]
- Hosmer, D.W., Jr.; Lemeshow, S.; Sturdivant, R.X. Applied Logistic Regression; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- Dayton, C. Mitchell. Logistic regression analysis. Stat 1992, 474, 574. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Biau, G.; Scornet, E. A random forest guided tour. Test 2016, 25, 197–227. [Google Scholar] [CrossRef] [Green Version]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Noble, W.S. What is a support vector machine? Nat. Biotechnol. 2006, 24, 1565–1567. [Google Scholar] [CrossRef]
- Alp, S.; Öz, E. Makine Öğrenmesinde Sınıflandırma Yöntemleri ve R Uygulamaları; Nobel Akademik Yayıncılık: Ankara, Turkey, 2019. [Google Scholar]
- Güzel, İ.; Kaygun, A. A new non-archimedean metric on persistent homology. Comput. Stat. 2022, 37, 1963–1983. [Google Scholar] [CrossRef]
- Nielsen, F.; Nielsen, F. Hierarchical clustering. In Introduction to HPC with MPI for Data Science; Springer: Berlin/Heidelberg, Germany, 2016; pp. 195–211. [Google Scholar]
- Murtagh, F.; Contreras, P. Algorithms for hierarchical clustering: An overview. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2012, 2, 86–97. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar] [CrossRef]
- Martins, A.M.; Neto, A.D.; de Melo, J.D.; Costa, J.A.F. Clustering Using Neural Networks and Kullback-Leibler Divergency. In Proceedings of the 2004 IEEE International Joint Conference on Neural Networks, Budapest, Hungary, 25–29 July 2014; IEEE: Piscataway, NJ, USA, 2004; pp. 2813–2817. [Google Scholar] [CrossRef]
- Japkowicz, N.; Shah, M. Evaluating Learning Algorithms: A Classification Perspective; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Brownlee, J. Machine Learning Mastery; 2022. Available online: http//machinelearningmastery.com (accessed on 21 September 2022).
- Galili, T. Dendextend: An R package for visualizing, adjusting and comparing trees of hierarchical clustering. Bioinformatics 2015, 31, 3718–3720. [Google Scholar] [CrossRef] [Green Version]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2021. [Google Scholar]
- Chawla, N.V.; Japkowicz, N.; Kolcz, A. Workshop on learning from imbalanced datasets II. In Proceedings of the 20th International Conference on Machine Learning, Washington, DC, USA, 21–24 August 2003. [Google Scholar]
- Kubat, M.; Matwin, S. Addressing the curse of imbalanced training sets. In Proceedings of the International Conference on Machine Learning, San Francisco, CA, USA, 8–12 July 1997; pp. 179–186. [Google Scholar]
- Laurikkaka, J. Improving Identification of Difficult Small Classes by Balancing Class Distribution; Technical Report; Department of Computer and Information Science, University of Tampere: Tampere, Finland, 2001. [Google Scholar]
- Japkowicz, N.; Stephen, S. The class imbalance problem: A systematic study. Intell. Data Anal. 2002, 6, 429–450. [Google Scholar] [CrossRef]
- Lee, S. Noisy replication in skewed binary classification. Comput. Stat. Data Anal. 2000, 34, 165–191. [Google Scholar] [CrossRef]
- Liu, Y.; Chawla, N.V.; Harper, M.P.; Shriberg, E.; Stolcke, A. A study in machine learning from imbalanced data for sentence boundary detection in speech. Comput. Speech Lang. 2006, 20, 468–494. [Google Scholar] [CrossRef]
- Wongvorachan, T.; He, S.; Bulut, O. A Comparison of Undersampling, Oversampling, and SMOTE Methods for Dealing with Imbalanced Classification in Educational Data Mining. Information 2023, 14, 54. [Google Scholar] [CrossRef]
- Molnar, C. Interpretable Machine Learning. 2020. Available online: https://originalstatic.aminer.cn/misc/pdf/Molnar-interpretable-machine-learning_compressed.pdf (accessed on 17 September 2022).
- Hastie, T.; Tibshirani, R.; Friedman, J.H.; Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: New York, NY, USA, 2009; Volume 2, pp. 1–758. [Google Scholar]
- SHARMA, S. Applied Multivariate Techniques; John Wiley & Sons., Inc: New York, NY, USA, 1996. [Google Scholar]
- Depren, S.K.; Aşkin, Ö.E.; Öz, E. Identifying the classification performances of educational data mining methods: A case study for TIMSS. Educ. Sci. Theory Pract. 2017, 17. [Google Scholar] [CrossRef] [Green Version]
- Fernández-Delgado, M. Do we need hundreds of classifiers to solve real world classification problems? J. Mach. Learn. Res. 2014, 15, 3133–3181. [Google Scholar]
- Büyükkıdık, S.; Bakırarar, B.; Bulut, O. Comparing the Performance of Data Mining Methods in Classifying Successful Students with Scientific Literacy in PISA 2015. Comput. Sci. 2018, 68–75. [Google Scholar] [CrossRef]
- Huebener, M.; Kuger, S.; Marcus, J. Increased instruction hours and the widening gap in student performance. Labour Econ. 2017, 47, 15–34. [Google Scholar] [CrossRef]
- Martínez-Abad, F.; Gamazo, A.; Rodriguez-Conde, M.J. Educational Data Mining: Identification of factors associated with school effectiveness in PISA assessment. Stud. Educ. Eval. 2020, 66, 100875. [Google Scholar] [CrossRef]
- Gamazo, A.; Martínez-Abad, F. An exploration of factors linked to academic performance in PISA 2018 through data mining techniques. Front. Psychol. 2020, 11, 575167. [Google Scholar] [CrossRef]
- Blau, D.; Currie, J. Pre-School, Day Care, and After-School Care: Who’s Minding the Kids? In Handbook of the Economics of Education; Elsevier: Amsterdam, The Netherlands, 2006; Volume 2, pp. 1163–1278. [Google Scholar] [CrossRef]
- Topçu, M.S.; Erbilgin, E.; Arikan, S. Factors predicting Turkish and Korean students’ science and mathematics achievement in TIMSS 2011. EURASIA J. Math. Sci. Tech. Ed. 2016, 12, 1711–1737. [Google Scholar] [CrossRef]
- Koçak, G. The Comparison of Variables Effecting Success in Turkey, Singapore, Canada and Estonia in Pisa 2018. Master Thesis, Hacettepe University, Ankara, Turkey, 2022. [Google Scholar]
- Depren, S.K. Prediction of students’science achievement: An application of multivariate adaptive regression splines and regression trees. J. Balt. Sci. Educ. 2018, 17, 887–903. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Country | Total Student | Female | Male |
|---|---|---|---|
| Brunei Darussalam (BRN) | 5374 | 2654 | 2720 |
| Hong Kong (HKG) | 5659 | 2786 | 2873 |
| Indonesia (IDN) | 12,023 | 6198 | 5825 |
| Japan (JPN) | 6054 | 3088 | 2966 |
| Korea (KOR) | 6636 | 3185 | 3451 |
| Macao (MAC) | 3769 | 1860 | 1909 |
| Malaysia (MYS) | 6036 | 3088 | 2948 |
| Philippines (PHL) | 7118 | 3806 | 3312 |
| B-S-J-Z China (QCI) | 11,989 | 5740 | 6249 |
| Singapore (SGP) | 6556 | 3210 | 3346 |
| Thailand (THA) | 8511 | 4621 | 3890 |
| Chinese Taipei (TAP) | 7161 | 3581 | 3580 |
| Variable | Description in Research | PISA Survey Code | |
|---|---|---|---|
| Age | Age | Age | |
| Gender | Gender | ST004D01T | |
| Mothers’ and fathers’ education level | Mothers’ Education and Fathers’ Education | ST005Q01TA, ST007Q01TA | |
| Mothers and Fathers’ qualifications by ISCED level | Mother qualifications, Father qualifications | ST006Q01TA, ST006Q02TA, ST006Q03TA, ST008Q01TA, ST008Q02TA, ST008Q03TA | |
| How old were you when you started ISCED 0? | ISCED0 | ST125Q01NA | |
| Mothers’ and Fathers’ Education (ISCED) | MISCED, FISCED | MISCED, FISCED | |
| Highest Education of parents (ISCED) | HISCED | HISCED | |
| In your home: | A desk to study at | Desk, Room, Quite Place, PC for School, Edu Software, Internet, Classic literature, Books of poetry, Works of art, Books for school, Technical books, Dictionary, Art Books | ST011Q01TA, ST011Q02TA, ST011Q03TA, ST011Q04TA, ST011Q05TA, ST011Q06TA, ST011Q07TA, ST011Q08TA, ST011Q09TA, ST011Q10TA, ST011Q11TA, ST011Q12TA, ST011Q16NA |
| A room of your own | |||
| A quiet place to study | |||
| A computer you can use for schoolwork | |||
| Educational software | |||
| A link to the Internet | |||
| Classic literature | |||
| Books of poetry | |||
| Works of art | |||
| Books to help with your schoolwork | |||
| Technical reference books | |||
| A dictionary | |||
| Books on art, music, or design | |||
| How many in your home: | Televisions | TV, Cars, Bath, Smartphones, Computers, Tablet, E-book, Musical instruments, Books | ST012Q01TA, ST012Q02TA, ST012Q03TA, ST012Q05NA, ST012Q06NA, ST012Q07NA, ST012Q08NA, ST012Q09NA, ST013Q01TA |
| Cars | |||
| Rooms with a bath or shower | |||
| Smartphones | |||
| Computers | |||
| Tablet computers | |||
| E-book readers | |||
| Musical instruments | |||
| Books | |||
| Thinking about (this academic year): | My parents support my educational efforts and achievements. | Support achievements, Support difficulties, Encourage. | ST123Q02NA, ST123Q03NA, ST123Q04NA |
| My parents support me when I am facing difficulties at school. | |||
| My parents encourage me to be confident. | |||
| Typically required to attend: Number of class periods per week in: | Test language lessons | PerWeek_TLanguage, PerWeek_Math, PerWeek_Science, PerWeek_FLanguage | ST059Q01TA, ST059Q02TA, ST059Q03TA, ST059Q04HA |
| Mathematics | |||
| Science | |||
| Foreign language | |||
| Plausible Values in Global Competency | PV1SCIE-PV10SCIE | PV1SCIE-PV10SCIE | |
| Response Variable | |||
| Mathematics Achievement | RS1-RS5 | Randomly selected 5 PVs | |
| Country | GDP PPP (Per Capita) | Economic Freedom | Human Development Index (HDI) | Gender Inequality (GII) |
|---|---|---|---|---|
| Brunei Darussalam (BRN) | 61,831 | 64.2 | 0.83 | 0.255 |
| Hong Kong (HKG) | 62,513 | 90.2 | 0.949 | 0.466 |
| Indonesia (IDN) | 11,643 | 64.2 | 0.71 | 0.453 |
| Japan (JPN) | 42,116 | 72.3 | 0.923 | 0.466 |
| Korea (KOR) | 43,044 | 73.8 | 0.919 | 0.087 |
| Macao (MAC) | 135,535 | 70.9 | 0.922 | 0.466 |
| Malaysia (MYS) | 28,236 | 74.5 | 0.807 | 0.225 |
| Philippines (PHL) | 8719 | 65 | 0.71 | 0.422 |
| B-S-J-Z China (QCI) | 15,495 | 57.8 | 0.755 | 0.206 |
| Singapore (SGP) | 100,686 | 88.8 | 0.94 | 0.049 |
| Thailand (THA) | 18,533 | 67.1 | 0.795 | 0.405 |
| Chinese Taipei (TAP) | 51,011 | 76.6 | 0.916 | 0.466 |
| Predicted Condition | ||
|---|---|---|
| Actual condition | True Positive-TP | False Negative-FN |
| False Positive-FP | True Negative-TN | |
| Logistic Regression | Random Forest | SVM | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Country | Accuracy (95% CI) | Precision | Recall | F-Score | Accuracy (95% CI) | Precision | Recall | F-Score | Accuracy (95% CI) | Precision | Recall | F-Score |
| BRN | 0.757 [0.72, 0.79] | 0.747 | 0.778 | 0.762 | 0.741 [0.71, 0.77] | 0.742 | 0.737 | 0.739 | 0.768 [0.76, 0.78] | 0.766 | 0.776 | 0.770 |
| HKG | 0.659 [0.63, 0.69] | 0.648 | 0.697 | 0.671 | 0.661 [0.61, 0.72] | 0.650 | 0.696 | 0.672 | 0.663 [0.64, 0.69] | 0.660 | 0.676 | 0.667 |
| IDN | 0.764 [0.74, 0.79] | 0.768 | 0.757 | 0.762 | 0.751 [0.74, 0.77] | 0.744 | 0.765 | 0.754 | 0.758 [0.72, 0.8] | 0.744 | 0.788 | 0.765 |
| JPN | 0.704 [0.68, 0.73] | 0.71 | 0.696 | 0.701 | 0.7 [0.67, 0.73] | 0.710 | 0.675 | 0.692 | 0.679 [0.66, 0.7] | 0.677 | 0.685 | 0.681 |
| KOR | 0.683 [0.64, 0.73] | 0.677 | 0.701 | 0.689 | 0.671 [0.63, 0.71] | 0.671 | 0.676 | 0.673 | 0.659 [0.64, 0.68] | 0.658 | 0.667 | 0.662 |
| MAC | 0.633 [0.61, 0.66] | 0.636 | 0.633 | 0.633 | 0.651 [0.62, 0.68] | 0.668 | 0.605 | 0.634 | 0.639 [0.56, 0.72] | 0.639 | 0.644 | 0.641 |
| MYS | 0.697 [0.67, 0.73] | 0.691 | 0.713 | 0.702 | 0.7 [0.67, 0.72] | 0.721 | 0.649 | 0.683 | 0.712 [0.67, 0.75] | 0.721 | 0.700 | 0.71 |
| PHL | 0.774 [0.73, 0.82] | 0.784 | 0.763 | 0.770 | 0.788 [0.74, 0.84] | 0.796 | 0.781 | 0.787 | 0.824 [0.77, 0.88] | 0.802 | 0.863 | 0.831 |
| QCI | 0.740 [0.7, 0.78] | 0.743 | 0.737 | 0.738 | 0.741 [0.72, 0.76] | 0.763 | 0.701 | 0.730 | 0.753 [0.72, 0.79] | 0.756 | 0.749 | 0.752 |
| SGP | 0.734 [0.69, 0.78] | 0.757 | 0.696 | 0.724 | 0.75 [0.68, 0.81] | 0.769 | 0.714 | 0.74 | 0.733 [0.69, 0.78] | 0.736 | 0.735 | 0.735 |
| THA | 0.790 [0.75, 0.83] | 0.815 | 0.755 | 0.783 | 0.796 [0.79, 0.8] | 0.811 | 0.775 | 0.792 | 0.787 [0.76, 0.82] | 0.803 | 0.762 | 0.782 |
| TAP | 0.684 [0.65, 0.72] | 0.683 | 0.688 | 0.685 | 0.685 [0.65, 0.72] | 0.684 | 0.690 | 0.686 | 0.705 [0.68, 0.73] | 0.698 | 0.724 | 0.711 |
| Mean of Performance Measures (95% CI) | ||||||||||||
| 0.718 [0.69, 0.75] | 0.722 [0.69, 0.76] | 0.718 [0.69, 0.74] | 0.718 [0.69, 0.75] | 0.717 [0.69, 0.75] | 0.73 [0.69, 0.76] | 0.705 [0.67, 0.74] | 0.715 [0.68, 0.75] | 0.73 [0.69, 0.76] | 0.722 [0.69, 0.76] | 0.731 [0.69, 0.77] | 0.726 [0.69, 0.76] | |
| Country | LR Algorithm | RF Algorithm | SVM |
|---|---|---|---|
| BRN | PerWeek_Science, TV, Smartphones, FatherHighestSchooling, ISCED0, FISCED, HISCED, Support_Difficulties, Support_Achievements | PerWeek_Science, ISCED0, Smartphones, TV, PerWeek_TLanguage, Computers, PerWeek_Math, Age, PerWeek_FLanguage, Technical_Books, Support_Achievements | PerWeek_Science, ISCED0, Computers, Support_Achievements, TV, FISCED, FatherHighestSchooling, Books, Support_Difficulties, MISCED, Smartphones, MotherHighestSchooling |
| HKG | Books, E-Book, PerWeek_Science, Smartphones, FISCED, Tablet, Cars, Musical_instruments, Art_Books, FatherHighestSchooling | PerWeek_Science, Books, Art_Books PerWeek_FLanguage, Age, ISCED0, PerWeek_TLanguage, Smartphones, PerWeek_Math, InYourHome_ArtWorks, | Books, PerWeek_Science, E-Book, Musical_instruments, MotherHighestSchooling, FISCED, Cars, Tablet, FatherHighestSchooling |
| IDN | MISCED, MotherHighestSchooling, PerWeek_Science, Computers, Tablet, PerWeek_Math, Musical_instruments, Support_Achievements, Smartphones, FatherHighestSchooling, PerWeek_FLanguage, Bath | Computers, PerWeek_Science, PerWeek_Math, PerWeek_FLanguage, ISCED0, PerWeek_TLanguage, Age, InYourHome_Internet, FatherHighestSchooling, Smartphones | PerWeek_Science, MISCED, MotherHighestSchooling, Computers, Tablet, ISCED0, Bath, Support_Achievements, PerWeek_FLanguage, Smartphones, Encourage |
| JPN | PerWeek_FLanguage, MISCED, HISCED, Encourage, MotherHighestSchooling, MotherQualification, E-Book, Books, Classic_literature, PerWeek_TLanguage, FatherQualification, PerWeek_Math | PerWeek_FLanguage, PerWeek_Math, Classic_literature, Age, E-Book, ISCED0, PerWeek_Science, HISCED, Technical_Books, PerWeek_TLanguage, Musical_instruments, TV | PerWeek_FLanguage, E-Book, FISCED, Support_Achievements, MISCED, PerWeek_TLanguage, Books, HISCED, Classic_literature, MotherHighestSchooling, Encourage, PerWeek_Math |
| KOR | Support_Achievements, FISCED, Books, MISCED, PerWeek_FLanguage, Bath, MotherQualification, PerWeek_Science, E-Book, Support_Difficulties, Art_Books, MotherHighestSchooling, Smartphones | PerWeek_FLanguage, Age, Musical_instruments, PerWeek_Science, Classic_literature, Books, ISCED0, Support_Achievements, Smartphones, PerWeek_TLanguage, PerWeek_Math, Bath | FISCED, Support_Achievements, MotherQualification, E-Book, MISCED, Books, PerWeek_FLanguage, PerWeek_Science, Smartphones, Encourage |
| MAC | PerWeek_Science, E-Book, ISCED0, PerWeek_Math, MISCED, FISCED, Books, Smartphones, TV, Bath, HISCED, Computers, Tablet | PerWeek_Science, PerWeek_Math, PerWeek_FLanguage, Age, ISCED0, Classic_literature, PerWeek_TLanguage, Technical_Books, MotherHighestSchooling, Books, FatherHighestSchooling | PerWeek_Science, PerWeek_Math, Books, HISCED, Bath, FatherHighestSchooling, Age, E-Book, InYourHome_ArtWorks, TV, MotherQualification, Classic_literature |
| MYS | PerWeek_Science, FISCED, MISCED, PerWeek_TLanguage, HISCED, Support_Achievements, Smartphones, Computers, PerWeek_FLanguage, FatherQualification, Classic_literature | PerWeek_Science, PerWeek_FLanguage, Smartphones, PerWeek_Math, Computers, PerWeek_TLanguage, Age, MotherHighestSchooling, ISCED0, Support_Achievements, Books | PerWeek_Science, FISCED, MISCED, Smartphones, PerWeek_FLanguage, FatherQualification, Bath, Tablet, Support_Difficulties, Support_Achievements, Computers, MotherQualification |
| PHL | Books, Smartphones, Musical_instruments, MotherHighestSchooling, HISCED, Bath, Classic_literature, Support_Achievements, Encourage, MotherQualification, FISCED | Musical_instruments, Smartphones, Books, ISCED0, Computers, HISCED, Age, PerWeek_FLanguage, InYourHome_Internet, Bath, MISCED | Computers, Tablet, TV, Musical_instruments, Classic_literature, MotherHighestSchooling, Cars, Support_Difficulties, Encourage, InYourHome_OwnRoom, Books, InYourHome_Desk, FatherHighestSchooling |
| QCI | PerWeek_Science, FatherQualification, FISCED, Support_Achievements, Books, Smartphones, MotherHighestSchooling, Tablet, ISCED0, MISCED, PerWeek_TLanguage | PerWeek_Science, PerWeek_TLanguage, ISCED0, Age, PerWeek_FLanguage, PerWeek_Math, MotherHighestSchooling, Books, FatherHighestSchooling, Smartphones, Support_Achievements, TV | PerWeek_Science, Books, FISCED, MISCED, MotherHighestSchooling, FatherQualification, ISCED0, PerWeek_TLanguage, Support_Achievements, Tablet |
| SGP | PerWeek_Science, PerWeek_TLanguage, FatherQualification, FISCED, HISCED, Encourage, Support_Achievements, Books, MISCED, FatherHighestSchooling, MotherHighestSchooling, TV | PerWeek_Science, PerWeek_TLanguage, PerWeek_FLanguage, Books, ISCED0, PerWeek_Math, Age, FatherQualification, Art_Books, Musical_instruments, Computers | PerWeek_Science, PerWeek_TLanguage, Books, FatherQualification, HISCED, FISCED, MotherHighestSchooling, Art_Books, Encourage, Cars, MISCED |
| THA | PerWeek_Science Support_Achievements, PerWeek_FLanguage, Encourage, Books, PerWeek_TLanguage, Musical_instruments, PerWeek_Math, FatherHighestSchooling, MISCED, FISCED, Computers, E-Book | PerWeek_Science, PerWeek_FLanguage, PerWeek_Math, HISCED, Age, PerWeek_TLanguage, Computers, MISCED, ISCED0, Books, Smartphones, Support_Achievements | PerWeek_Science, Support_Achievements, PerWeek_FLanguage, PerWeek_TLanguage, FISCED, PerWeek_Math, MISCED, MotherHighestSchooling, Encourage, Books, Computers, E-Book |
| TAP | Support_Achievements, Books, FatherHighestSchooling, Smartphones, FISCED, MotherHighestSchooling, PerWeek_Science, PerWeek_Math, Encourage | Books, PerWeek_Math, PerWeek_Science, PerWeek_FLanguage, Musical_instruments, Age, ISCED0, MotherHighestSchooling, Support_Achievements, PerWeek_TLanguage, FatherHighestSchooling, Classic_literature | Support_Achievements, Books, MotherHighestSchooling, PerWeek_Science, FatherHighestSchooling, FISCED, PerWeek_Math, Encourage, HISCED, Age, ISCED0, Smartphones |
| LR Algorithm | RF Algorithm | SVM Algorithm | ||||
|---|---|---|---|---|---|---|
| All F. | Imp. F. | All F. | Imp. F. | All F. | Imp. F. | |
| BRN | 0.757 | 0.738 | 0.741 | 0.738 | 0.768 | 0.712 |
| HKG | 0.659 | 0.638 | 0.661 | 0.654 | 0.663 | 0.629 |
| IDN | 0.764 | 0.748 | 0.751 | 0.751 | 0.758 | 0.706 |
| JPN | 0.704 | 0.68 | 0.67 | 0.700 | 0.679 | 0.64 |
| KOR | 0.683 | 0.646 | 0.671 | 0.669 | 0.659 | 0.611 |
| MAC | 0.633 | 0.615 | 0.651 | 0.645 | 0.639 | 0.609 |
| MYS | 0.697 | 0.677 | 0.699 | 0.694 | 0.712 | 0.656 |
| PHL | 0.774 | 0.682 | 0.788 | 0.744 | 0.824 | 0.679 |
| QCI | 0.740 | 0.728 | 0.741 | 0.751 | 0.753 | 0.738 |
| SGP | 0.734 | 0.726 | 0.749 | 0.757 | 0.733 | 0.692 |
| THA | 0.790 | 0.771 | 0.796 | 0.797 | 0.787 | 0.773 |
| TAP | 0.684 | 0.663 | 0.685 | 0.685 | 0.705 | 0.681 |
| Mean of Accuracies (95% CI) | ||||||
| 0.718 [0.69, 0.75] | 0.693 [0.66, 0.72] | 0.717 [0.69, 0.75] | 0.715 [0.69, 0.75] | 0.73 [0.69, 0.76] | 0.677 [0.64, 0.71] 1 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bayirli, E.G.; Kaygun, A.; Öz, E. An Analysis of PISA 2018 Mathematics Assessment for Asia-Pacific Countries Using Educational Data Mining. Mathematics 2023, 11, 1318. https://doi.org/10.3390/math11061318
Bayirli EG, Kaygun A, Öz E. An Analysis of PISA 2018 Mathematics Assessment for Asia-Pacific Countries Using Educational Data Mining. Mathematics. 2023; 11(6):1318. https://doi.org/10.3390/math11061318
Chicago/Turabian StyleBayirli, Ezgi Gülenç, Atabey Kaygun, and Ersoy Öz. 2023. "An Analysis of PISA 2018 Mathematics Assessment for Asia-Pacific Countries Using Educational Data Mining" Mathematics 11, no. 6: 1318. https://doi.org/10.3390/math11061318
APA StyleBayirli, E. G., Kaygun, A., & Öz, E. (2023). An Analysis of PISA 2018 Mathematics Assessment for Asia-Pacific Countries Using Educational Data Mining. Mathematics, 11(6), 1318. https://doi.org/10.3390/math11061318