

Reinforcement-Learning-Based Level Controller for Separator Drum Unit in Refinery System

 ,
,  ,
,  and
and
Abstract
:1. Introduction
- To emulate the performance of the RD5204 system, it was mathematically modeled depending on the information of the existing system in the Basrah Refinery. Further, the system performance was evaluated in the case of using a conventional PI controller, and its parameters were evaluated by trial and error.
- The auto-tuning method was used to evaluate the optimal PI parameters that achieve a performance improvement.
- The reinforcement learning approach (as an offline tuner) was proposed to evaluate the optimal PI parameters that will increase the robustness of the system controller against perturbation.
- Reinforcement learning (as an online tuner) was used as an adaptive PI-like controller; in this case, the system performance will be more robust against perturbation and noise.
2. Background
3. Mathematical Model
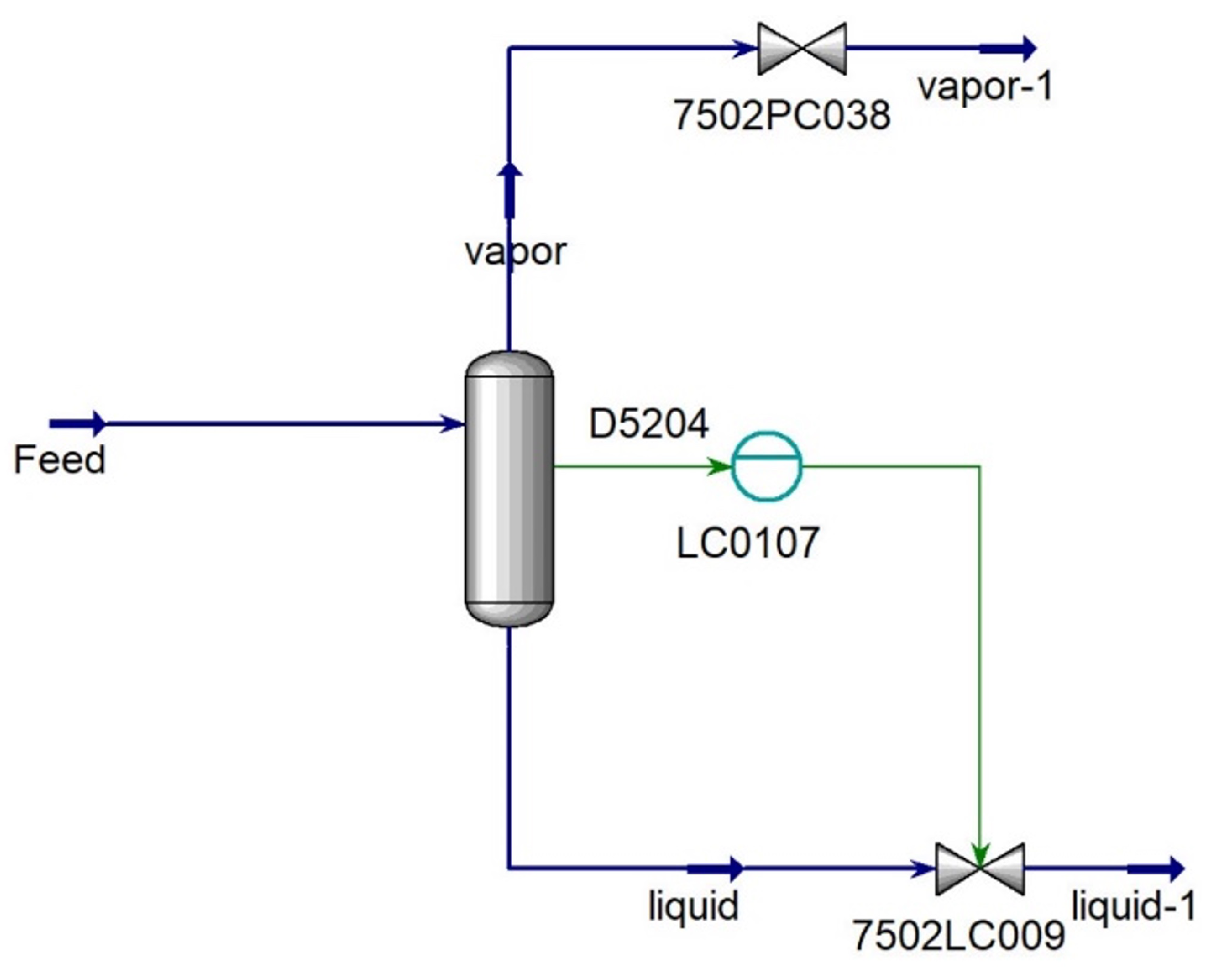
3.1. RD 5204 Mathematical Model
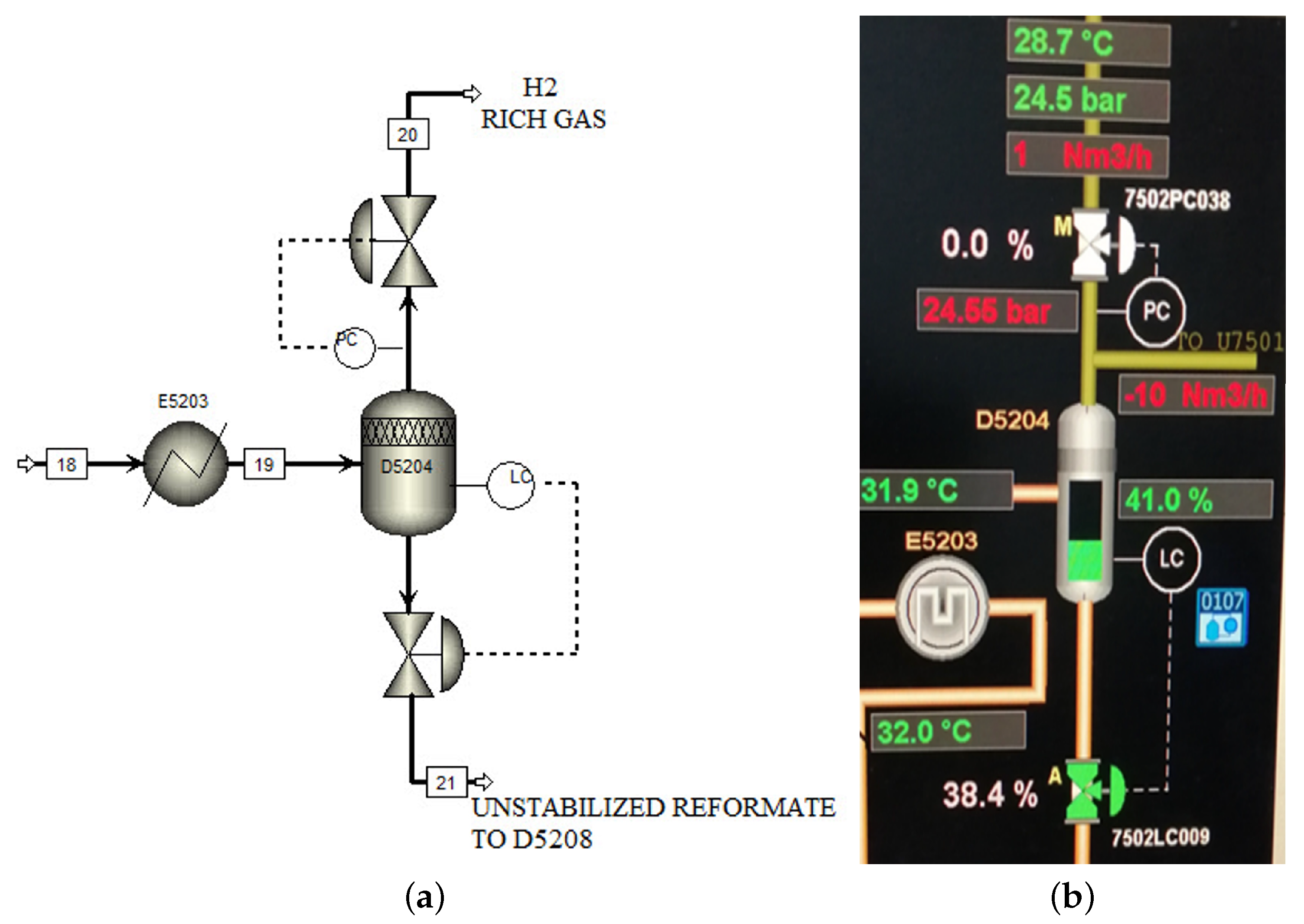
- Item: 7502-D5204.
- The mixture is readily accessible at (45) C, (25) bar.
- The gravity 759 kg/m and molar inlet is 48,141 kg/h or (1159.01) kmole/h (constant pressure).
- With pressure (25), this stream will be split into two phases, with 85% liquid and 15% vapor.
- The physical separation is occurring in a flash drum with a height is 5.2 m and a diameter is 1.6 m.
- In the flash drum, liquid–vapor equilibrium is achieved because the relative volatility of the liquids is sufficiently different.
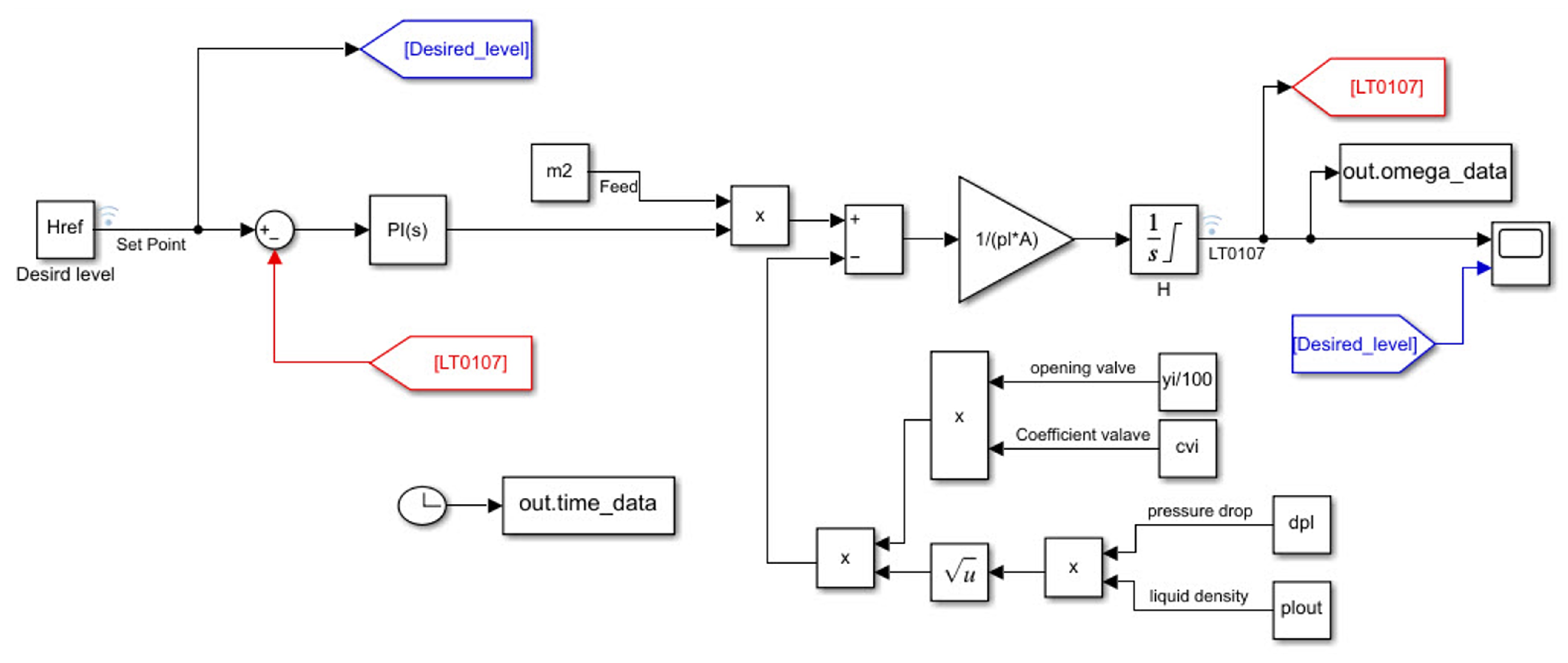
- Balance over Total PS:
- –
- Total mass balance:where M is the total mass, is the current mass flow i, subscript V is the vapor, and L is the liquid in multiphase currents.
- –
- Energy balance:with as the heat flow and as the work flow of the system, and () is the specific enthalpy of current , the total energy of total PS.
- Balance over Liquid Process System (PS liquid):
- –
- Total mass balance:with as the liquid level in the tank, as the phase density i (vapor or liquid), and r is the tank radius.
- Balance over Vapor Process System (PS vapor):
- –
- Total mass balance:
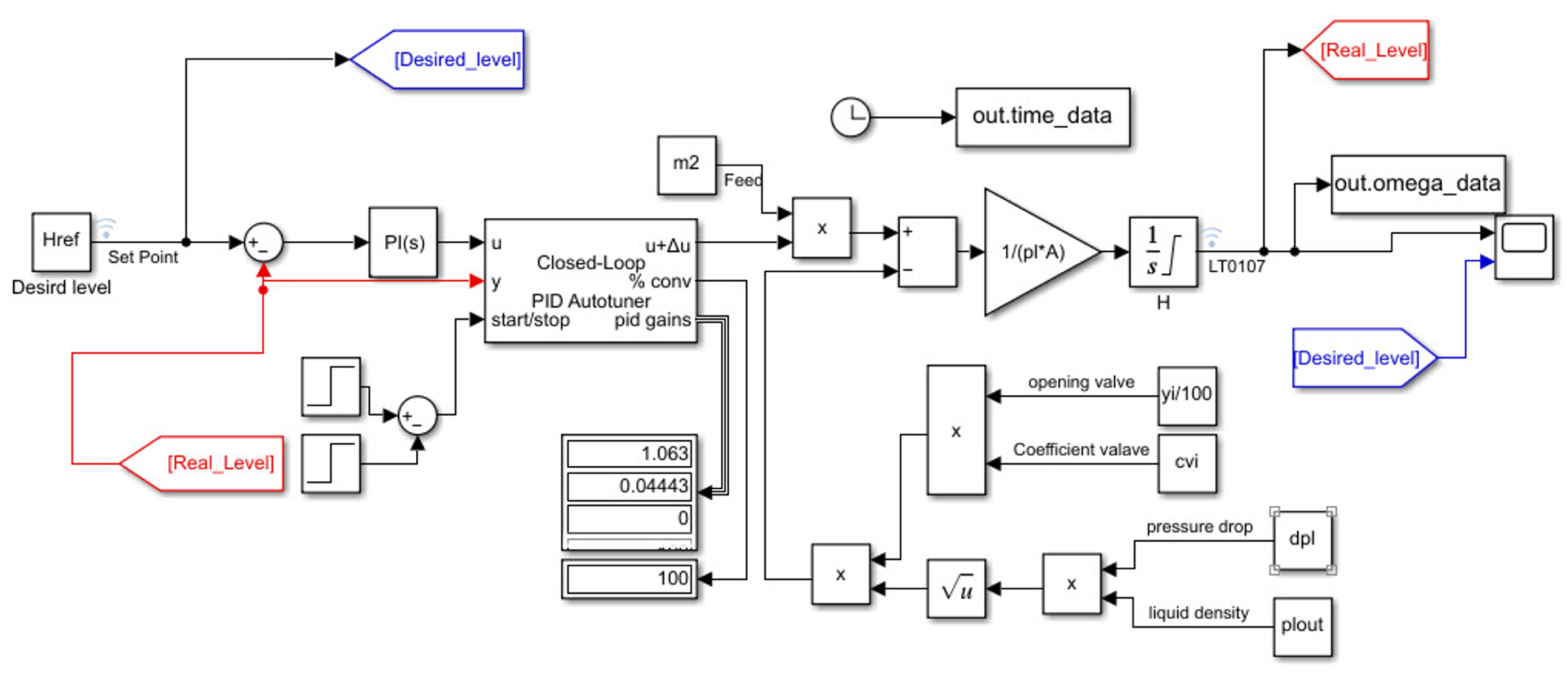
where P is the pressure of the vapor phase inside the tank, R is the universal gas constant and the operating temperature, is the molecular mass of vapor, and is the volume of vapor phase inside the flash tank.For liquid or vapor flow through the output flash tank valve, it is necessary to calculate () and (), and the vapor and liquid flows exiting the flash tank arewhere is the coefficient of the valve for phase i, is the valve opening percentage, and is the pressure drop through the valve acting over phase i. In valve sizing, is taken equal to 50% for a nominal or design flow.
3.2. Auto-Tuning PID Mathematical Model
- At the normal operating range, we inject sine wave test signals into the plant.
- We collect data on the reaction of the plant’s performance.
- We estimate the frequency.
3.3. The Twin-Delayed Deep Deterministic Policy Gradient (TD3) Algorithm
- The TD3 agent learns two Q-value functions and changes policies based on the estimated minimum value function.
- In contrast to Q functions, TD3 agents modify their policies and targets more slowly.
- When the policy is updated, a TD3 agent introduces noise into the target action, making it less likely to exploit actions with high Q-value estimations.
- Initialize each critic Qk(S, A) with random parameter values , and initialize each target critic with the same random parameter values: .
- Initialize the actor with random parameter values , and initialize the target actor with the same parameter values: .
- For the current monitoring S, select action , where N denotes stochastic noise as defined by the noise model.
- Run action A. Observe the benefit R and next monitoring S’.
- Store the knowledge () in the knowledge buffer.
- Sample a random mini-batch of M knowledge () from the knowledge buffer.
- If is a terminal state, set the value function target to . Otherwise, set it to
- Update the parameters of each critic at each time training step by minimizing the loss over all sampled experiences.
- At every D1 step, update the actor parameters using the following sampled policy gradient to maximize the expected discounted reward.where A =where is the gradient of the minimum critic output with respect to the action computed by the actor network, and is the gradient of the actor output with respect to the actor parameters. Both gradients are evaluated for observation .
- At every D2 step, update the target actor and critics based on the technique used to update the target.
4. Experiments and Results
- Analyzing the performance of the D5204 system with a PI controller in which the PI parameters are manually tuned in the case of effect factors (inlet feed and opening valve);
- Analyzing the performance of the D5204 system with a PI controller in which the PI parameters are optimized by an auto-tuner in the case of effect factors (inlet feed and opening valve);
- Analyzing the performance of the D5204 system with a PI controller in which the PI parameters are optimized by the RL approach in the case of effect factors (inlet feed and opening valve);
- Using an RL controller as a PI-like controller and analyzing the performance of the D5204 system in the case of effect factors (inlet feed and opening valve).
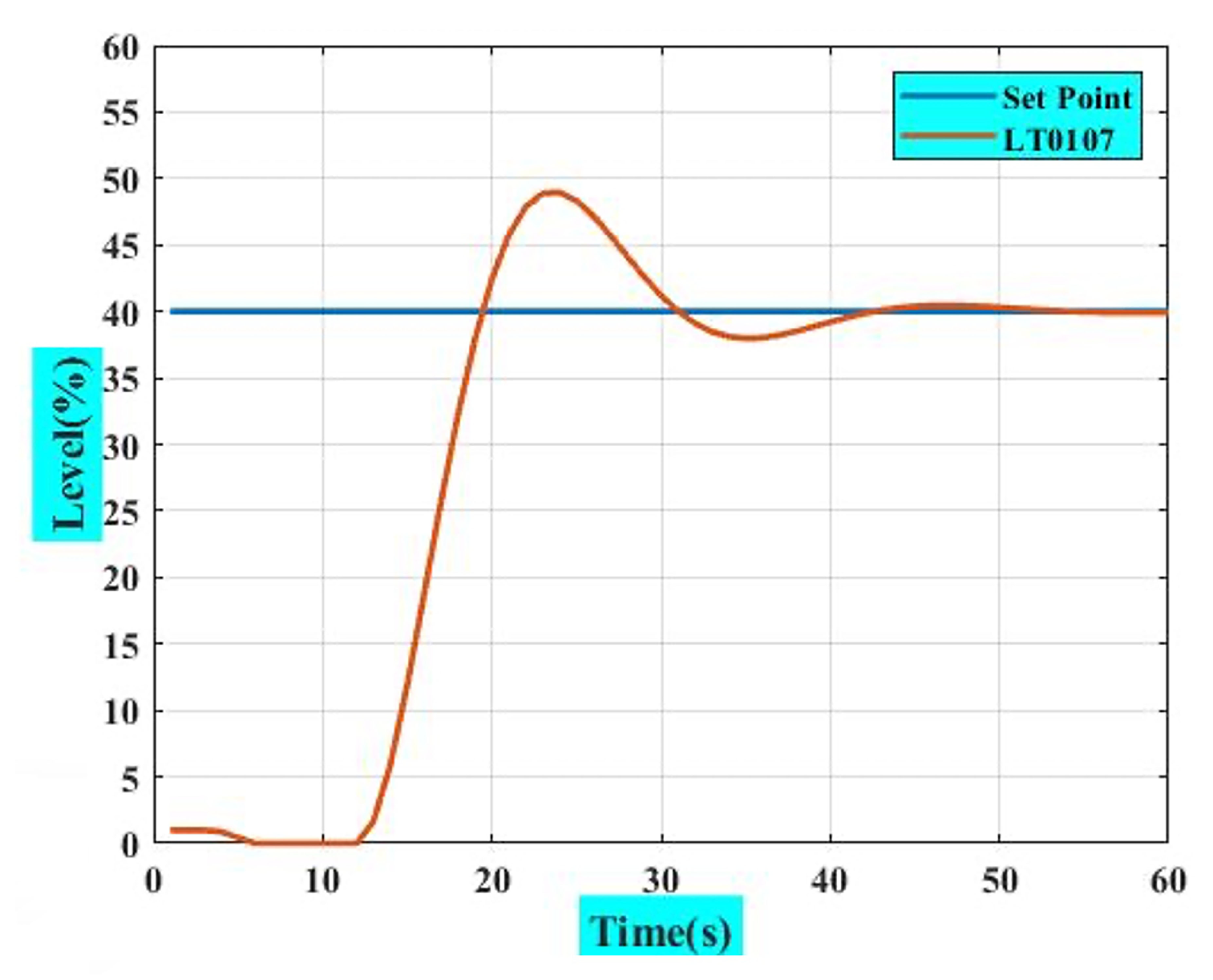
4.1. PI Controller (Evaluating PI Parameters by Manual Tuning) [7]
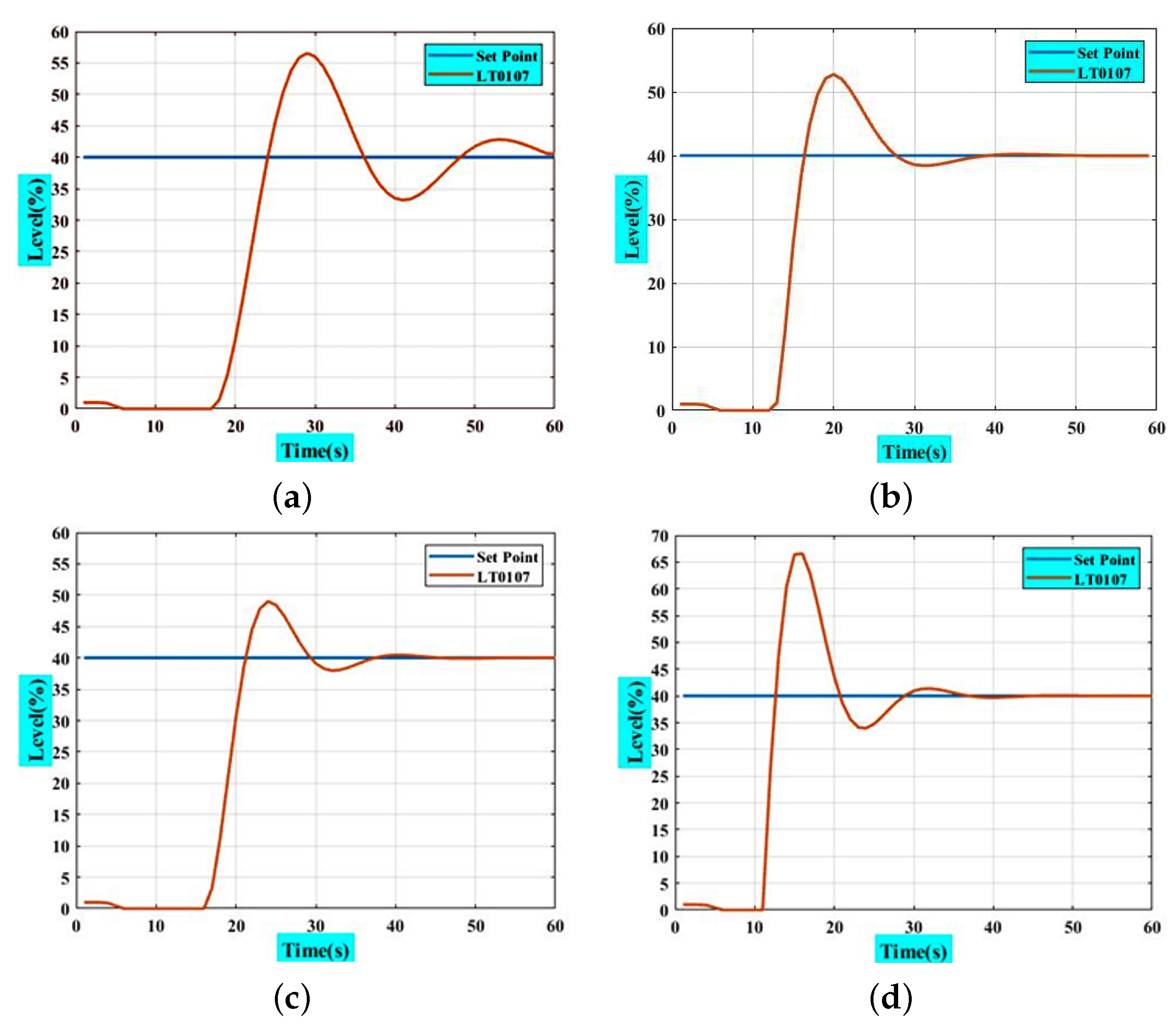
4.2. PI Controller (Estimating PI Parameters by Auto-Tuning) [7]
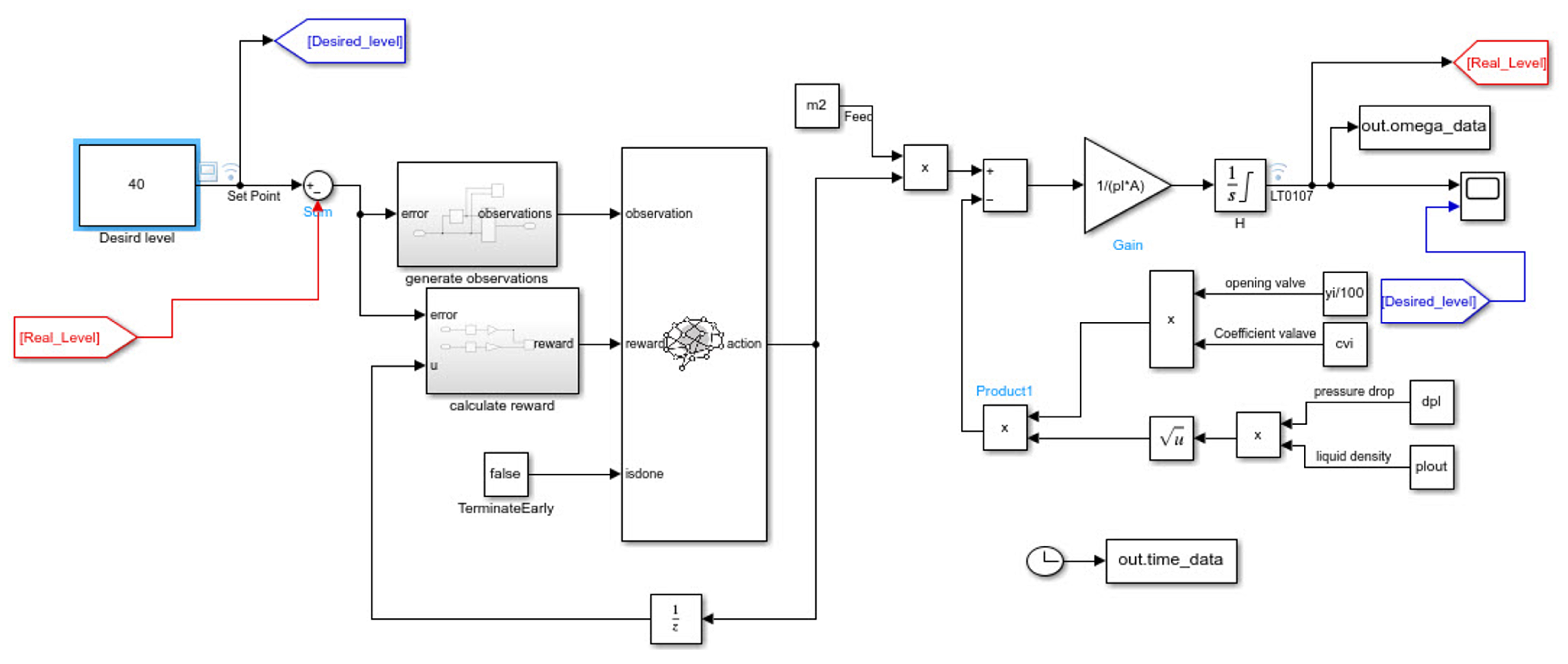
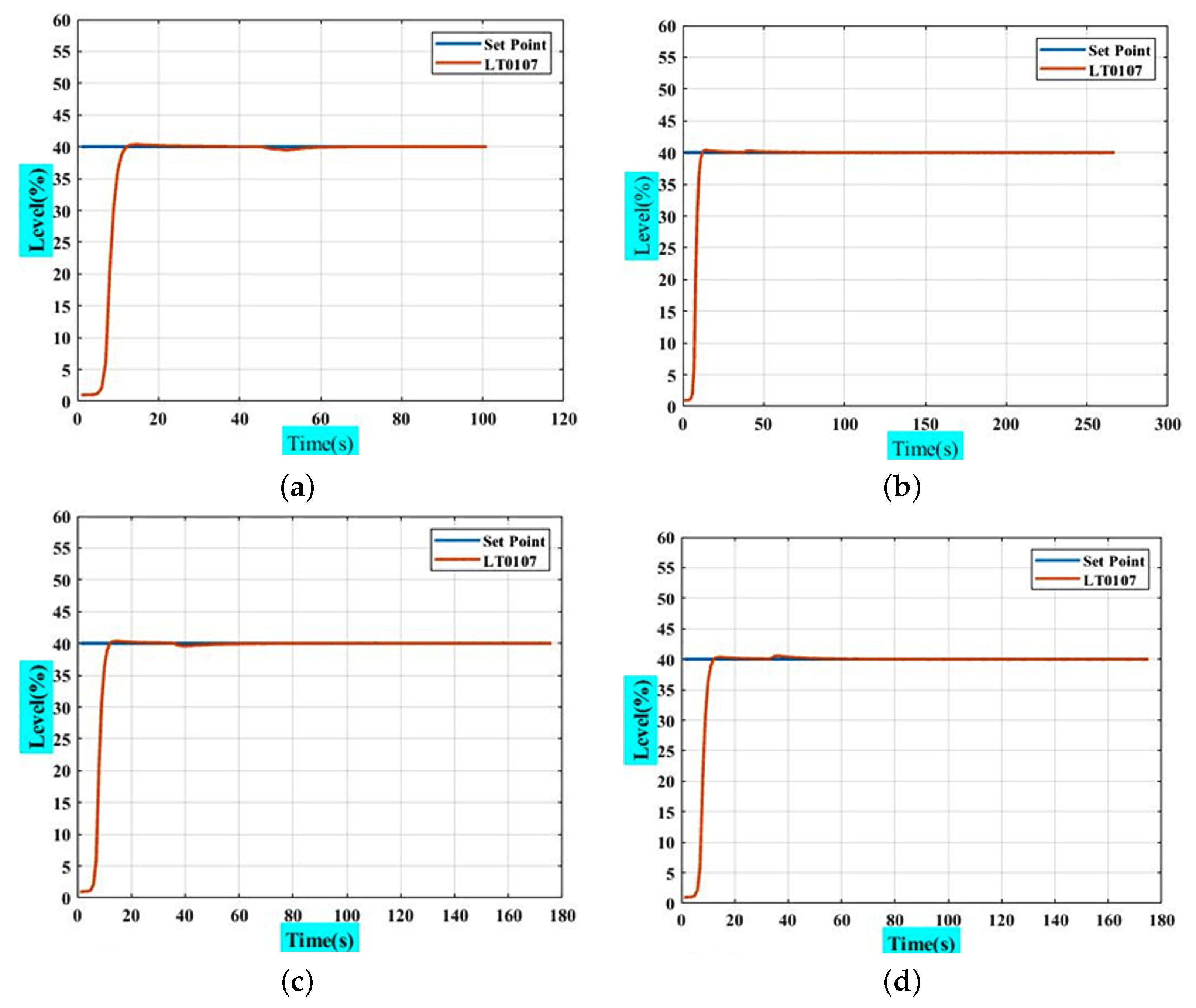
4.3. PI Controller (Estimating PI Parameters by RL Approach)
- Delete the PI controller.
- Insert an RL agent block.
- Create the observation vector , where is the height of the tank, and r is the reference height. Connect the observation signal to the RL agent block.
- Define the reward function for the RL agent as the negative, i.e.,
4.3.1. Create TD3 Agent
- U is the outlet of the actor NN.
- and are the absolute values of the neural network weights.
- is the height of the tank, and r is the reference height.
- Set the agent to use the controller sample time Ts;
- Set the mini-batch size to 128 experience samples;
- Set the experience buffer length to ;
- Set the exploration model and target policy smoothing model to use Gaussian noise with variance of 0.1.
4.3.2. Train Agent
- Run each training step for at most 1000 episodes, with every episode enduring at most 100 schedule steps.
- Show the training headway in the episode manager (set the plots option) and consult the command-line display.
- Stop training when the agent receives an average cumulative reward greater than −200 over 100 consecutive episodes.
- At this point, the agent can control the level in the tank.
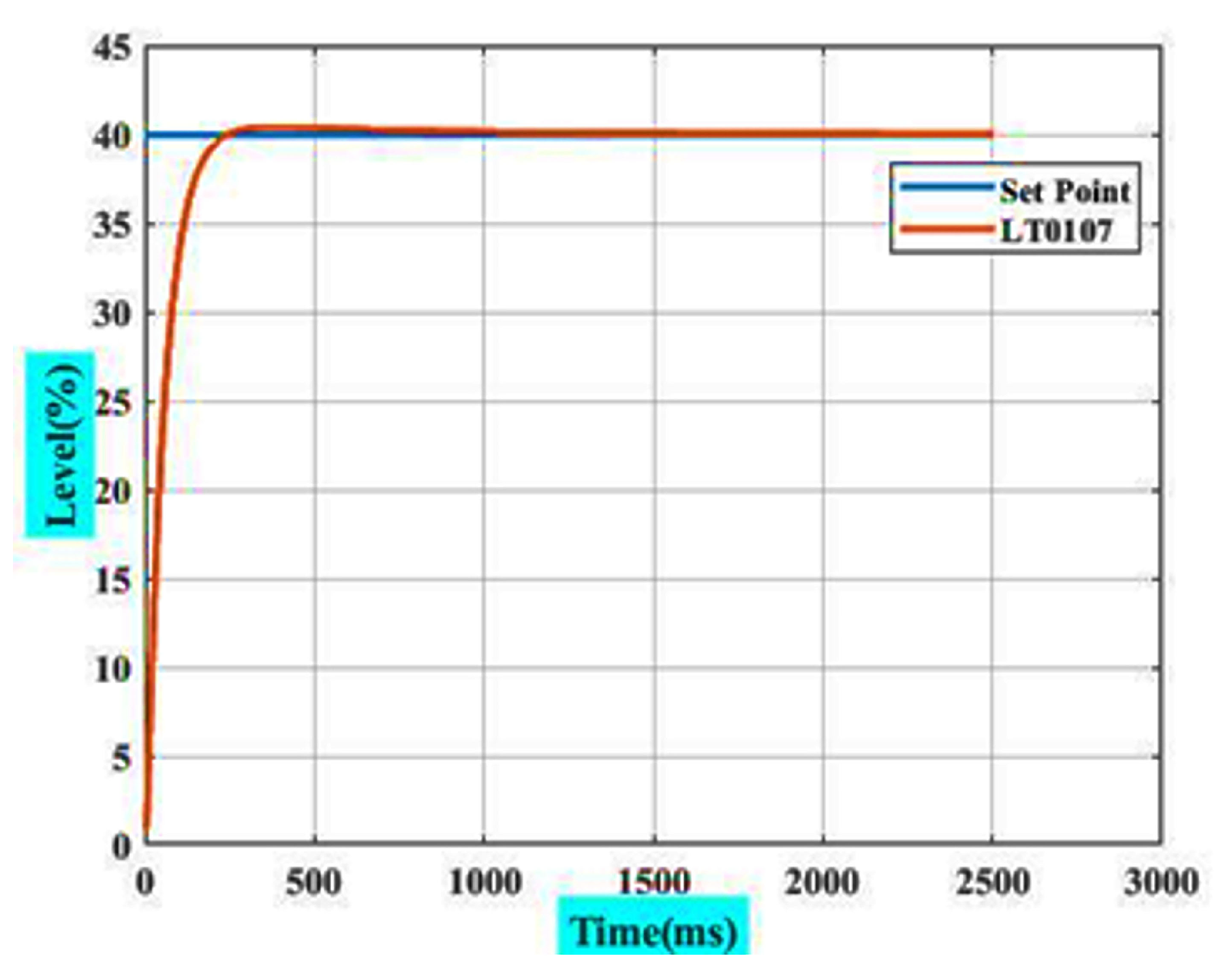
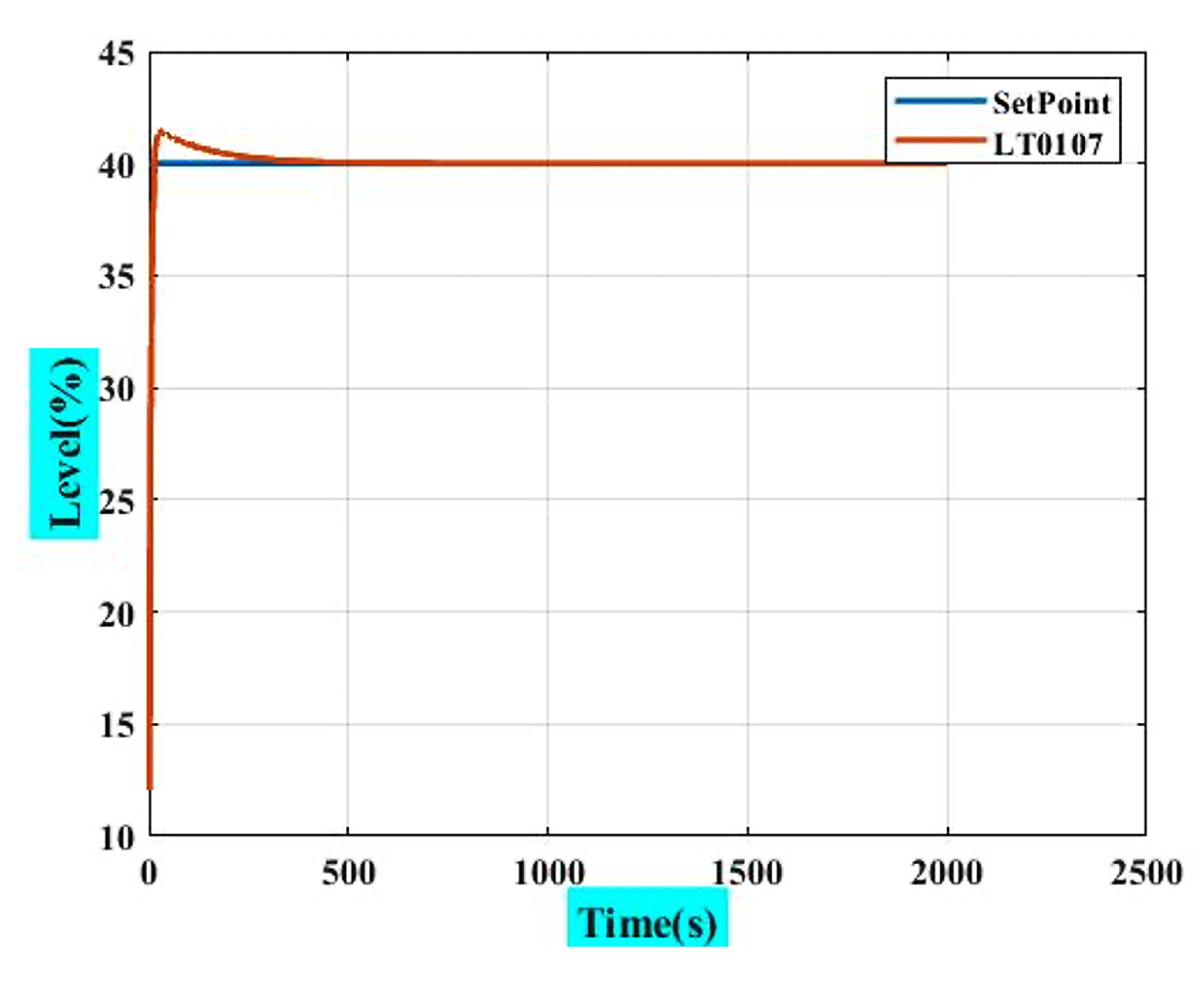
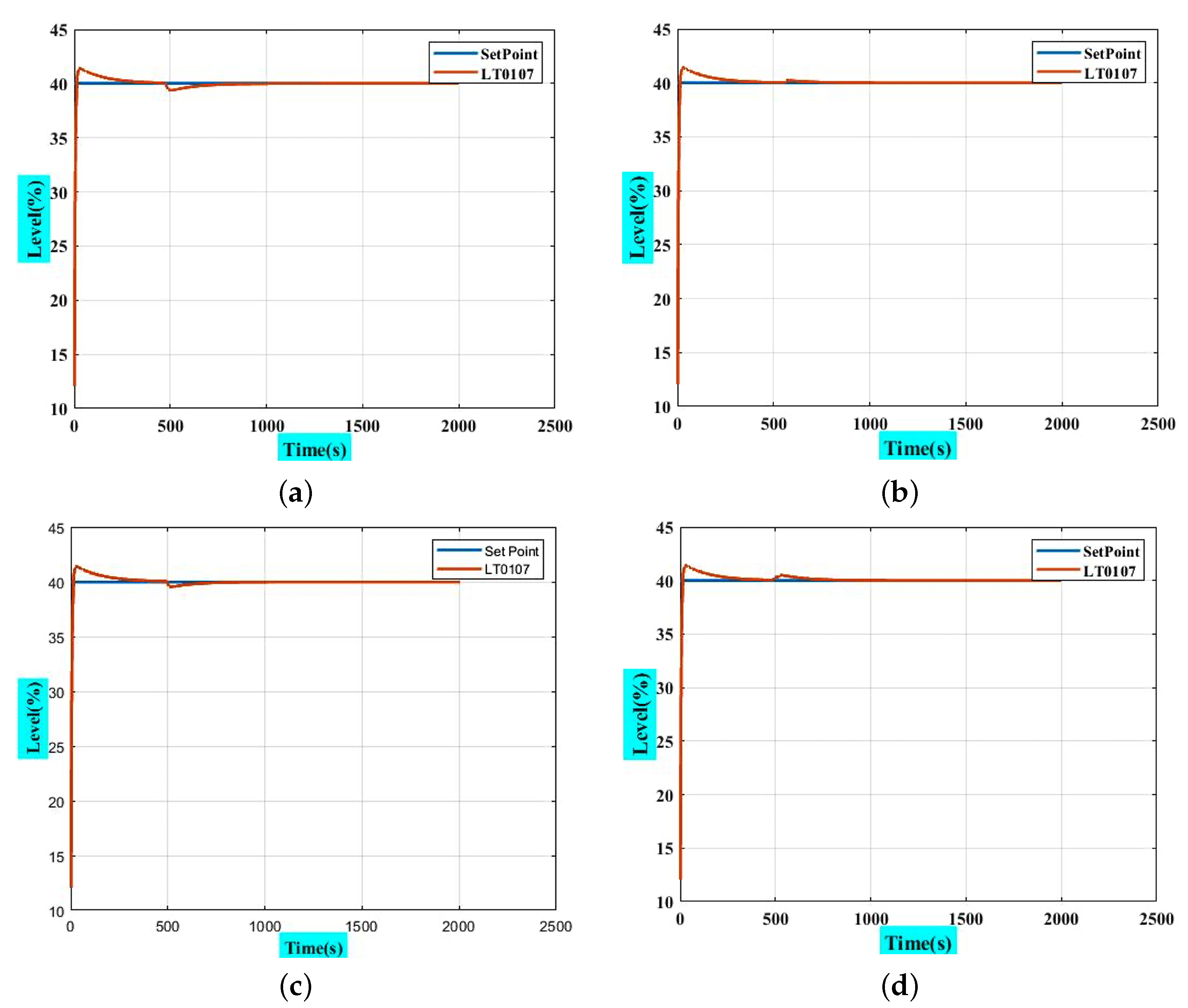
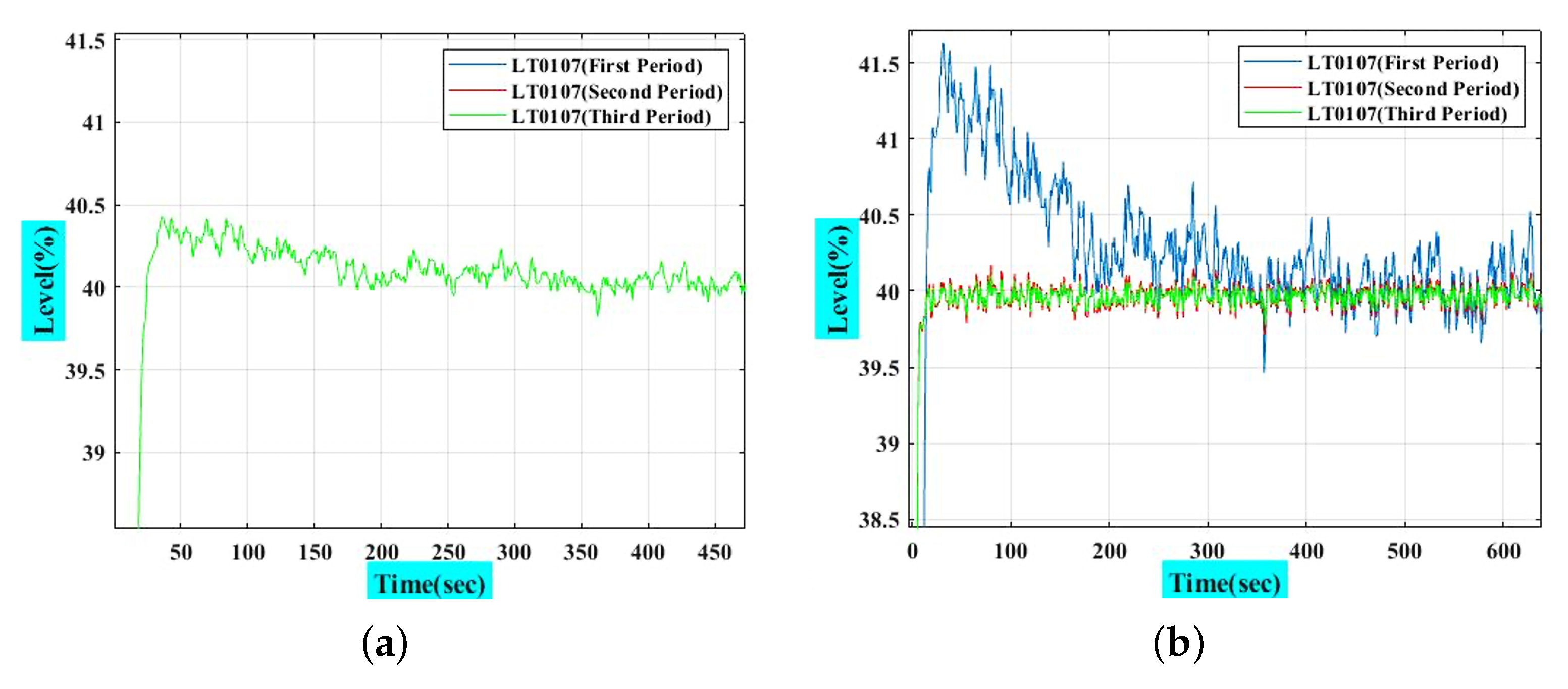
4.4. RL Agent as PI-like Controller
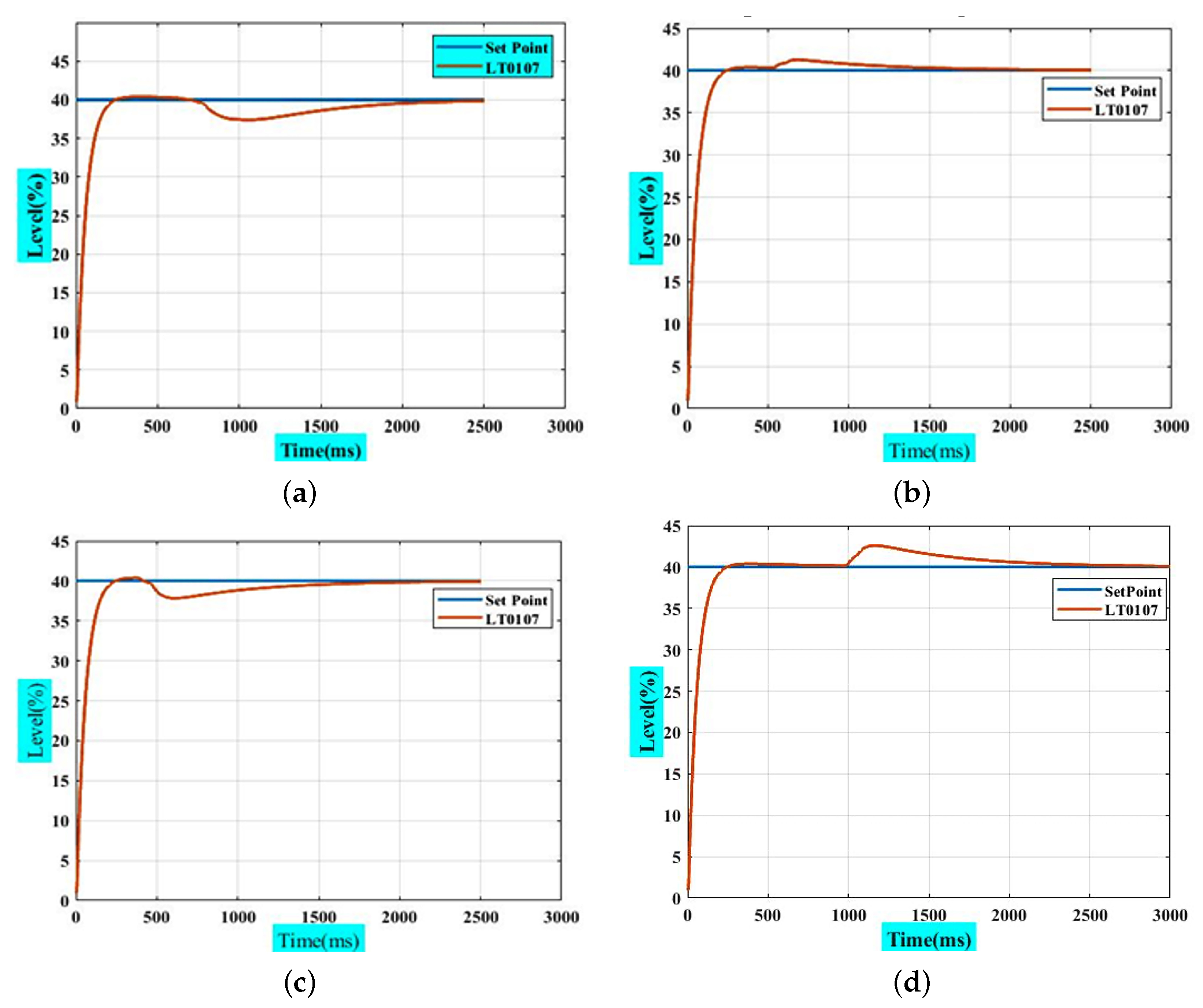
4.5. Comparison of Use of RL as an Offline Tuner and PI-like Controller
- The values extracted from the offline tuner are fixed for a conventional PI controller during operation, but the values that are evaluated by the online tuner are changeable and improved during operation; therefore, it is more resistant to external noise due to continuous learning, improvement, exploration, and event anticipation.
- Due to the additional complexity of the online tuner, the offline tuner has a faster reaction time than its online counterpart.
- In the case of offline training, the duration of training is less than that of online training; thus, the best option is determined based on the requirements.
- In certain industrial applications that require an auto-stop, the system’s reaction speed is necessary; therefore, the online tuner is unsuitable in comparison to the offline case.
- Economically, the offline tuner is more costly than the online tuner due to the increase in complexity and, thus, the need for more devices and capabilities, particularly in applications with a large number of control paths.
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Chirita, D.; Florescu, A.; Florea, B.C.; Ene, R.; Stoichescu, D.A. Liquid level control for industrial three tanks system based on sliding mode control. Rev. Roum. Sci. Technol. Électrotechnol. Énerg. 2015, 60, 437–446. [Google Scholar]
- Dorf, R.C.; Bishop, R.H. Modern Control Systems; Prentice-Hall: Englewood Cliffs, NJ, USA, 2004. [Google Scholar]
- Liptak, B.G. Instrument Engineers, Volume Two: Process Control and Optimization; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]
- Smith, R.S.; Doylel, J. The Two Tank Experiment: A Benchmark Control Problem. In Proceedings of the American Control Conference, Milwaukee, WI, USA, 27–29 June 2018. [Google Scholar]
- Zhao, Z.; Zhang, X.; Li, Z. Tank-Level Control of Liquefied Natural Gas Carrier Based on Gaussian Function Nonlinear Decoration. J. Mar. Sci. Eng. 2020, 8, 695. [Google Scholar] [CrossRef]
- Short, M.; Selvakumar, A.A. Non-Linear Tank Level Control for Industrial Applications. Appl. Math. 2020, 11, 876. [Google Scholar] [CrossRef]
- Ali, A.A.; Rashid, M.T. Design PI Controller for Tank Level in Industrial Process. Iraqi J. Electr. Electron. Eng. 2022, 18, 82–92. [Google Scholar] [CrossRef]
- Ademola, O.; Akpa, J.; Dagde, K. Modeling and Simulation of Two-Staged Separation Process for an Onshore Early Production Facility. Adv. Chem. Eng. Sci. 2019, 9, 127. [Google Scholar] [CrossRef] [Green Version]
- Mokhatab, S.; Poe, W.A. Handbook of Natural Gas Transmission and Processing; Gulf Professional Publishing: Houston, TX, USA, 2012. [Google Scholar]
- Keidy, R.; Morales, L.; Alvarez, H. Flash distillation modeling and a multiloop control proposal. In Proceedings of the IEEE 2nd Colombian Conference on Automatic Control (CCAC), Manizales, Colombia, 14–16 October 2015. [Google Scholar]
- Seames, W. Designing Controls for the Process Industries; CRC Press: Boca Raton, FL, USA, 2017. [Google Scholar]
- Marlin, T.E. Process Control; McGraw-Hill International Editions: New York, NY, USA, 2018. [Google Scholar]
- Zhang, Z.; Wu, Z.; Dur, H.; Albalawi, F.; Christofides, P.D. On integration of feedback control and safety systems: Analyzing two chemical process applications. Int. J. Control. Autom. Syst. 2020, 132, 616–626. [Google Scholar] [CrossRef] [Green Version]
- Xu, J.; Shao, H. A novel method of PID tuning for integrating processes. In Proceedings of the 42nd IEEE International Conference on Decision and Control, Maui, HI, USA, 9–12 December 2004. [Google Scholar]
- Bucz, Š.; Kozáková, A. Advanced methods of PID controller tuning for specified performance. In PID Control for Industrial Processes; InTech Open: London, UK, 2018; pp. 73–119. [Google Scholar]
- Chidambaram, M.; Saxena, N. Relay Tuning of PID Controllers; Springer: Tamil Nadu, India, 2018. [Google Scholar]
- Pandey, S.K.; Veeranna, K.; Kumai, B.; Deshmukh, K.U. A Robust Auto-tuning Scheme for PID Controllers. In Proceedings of the 46th Annual Conference of the IEEE Industrial Electronics Society, Singapore, 18–21 October 2020. [Google Scholar]
- Vilanova, R.; Arrieta, O.; Ponsa, P. Robust PI/PID controllers for load disturbance based on direct synthesis. ISA Trans. 2018, 81, 177–196. [Google Scholar] [CrossRef] [PubMed]
- Singh, A.P.; Mukherjee, S.; Nikolaou, M. Debottlenecking level control for tanks in series. J. Process. Control. 2014, 24, 158–171. [Google Scholar] [CrossRef]
- Jáuregui, C.; Duarte-Mermoud, M.A.; Oróstica, R.; Travieso-Torres, J.C.; Beytía, O. Conical tank level control using fractional order PID controllers: A simulated and experimental study. Control. Theory Technol. 2016, 14, 369–384. [Google Scholar] [CrossRef]
- Backi, C.J.; Skogestad, S. A simple dynamic gravity separator model for separation efficiency evaluation incorporating level and pressure control. In Proceedings of the American Control Conference (ACC), Seattle, WA, USA, 24–26 May 2017. [Google Scholar]
- Sásig, R.; Naranjo, C.; Pruna, E.; Chicaiza, W.D.; Chicaiza, F.A.; Carvajal, C.P.; Andaluz, V.H. An Implementation on Matlab Software for Non-linear Controller Design Based on Linear Algebra for Quadruple Tank Process. In Proceedings of the World Conference on Information Systems and Technologies, Naples, Italy, 27–29 March 2018. [Google Scholar]
- Reyes-Lúa, A.; Backi, C.J.; Skogestad, S. Improved PI control for a surge tank satisfying level constraints. IFAC-PapersOnLine 2018, 51, 835–840. [Google Scholar] [CrossRef]
- Sathasivam, L.; Elamvazuthi, I.; Ahamed Khan, M.K.A.; Parasuraman, S. Tuning a three-phase separator level controller via particle swarm optimizationalgorithm. In Proceedings of the International Conference on Recent Trends in Electrical, Control and Communication (RTECC), Malaysia, Malaysia, 20–22 March 2018. [Google Scholar]
- Yu, S.; Lu, X.; Zhou, Y.; Feng, Y.; Qu, T.; Chen, H. Liquid level tracking control of three-tank systems. Int. J. Control. Autom. Syst. 2020, 18, 2630–2640. [Google Scholar] [CrossRef]
- Nath, U.M.; Dey, C.; Mudi, R.K. Fuzzy tuned model based control for level and temperature processes. Microsyst. Technol. 2019, 25, 819–827. [Google Scholar] [CrossRef]
- Ye, J.; Zhang, X.; Lv, C.; Wang, P.; Lv, H. Design of liquid level control system for double tank. IOP Conf. Ser. Mater. Sci. Eng. 2020, 740, 012097. [Google Scholar] [CrossRef]
- Nath, U.M.; Dey, C.; Mudi, R.K. Desired characteristic equation based PID controller tuning for lag-dominating processes with real-time realization on level control system. IEEE Control. Syst. Lett. 2020, 5, 1255–1260. [Google Scholar] [CrossRef]
- Singh, V.P.; Patnana, N.; Singh, S. PID controller tuning using hybrid optimisation technique based on Box’s evolutionary optimisation and teacher-learner-based-optimisation. Int. J. Comput. Aided Eng. Technol. 2020, 13, 258–270. [Google Scholar] [CrossRef]
- Kos, T.; Huba, M.; Vrančić, D. Parametric and Nonparametric PID controller tuning method for integrating processes based on Magnitude Optimum. Appl. Sci. 2020, 10, 6012. [Google Scholar] [CrossRef]
- Mary, A.H.; Miry, A.H.; Miry, M.H. ANFIS based reinforcement learning strategy for control a nonlinear coupled tanks system. J. Electr. Eng. Technol. 2022, 17, 1921–1929. [Google Scholar] [CrossRef]
- Ziegler, J.G.; Nichols, N.B. Optimum settings for automatic controllers. J. Dyn. Syst. Meas. Control. 1993, 115, 759–765. [Google Scholar] [CrossRef] [Green Version]
- Available online: http://www.src.gov.iq/en/about_us (accessed on 15 March 2023).
- McDonald, K.A.; McAvoy, T.J. Decoupling Dual Composition Controllers 1. Steady State Results. In Proceedings of the American Control Conference, San Francisco, CA, USA, 22–24 June 1983. [Google Scholar]
- Davis, M.; Vinter, R. Minimum-Variance and Self-Tuning Control. In Stochastic Modelling and Control; Springer: Berlin/Heidelberg, Germany, 1985. [Google Scholar]
- Haykin, S. Recursive least squares adaptive filters. In Adaptive Filter Theory; Pearson Education India: Delhi, India, 2002; pp. 436–447. [Google Scholar]
- Monson, H.H. Recursive Least Squares. Statistical Digital Signal Processing and Modelling; Wiley: Hoboken, NJ, USA, 1996. [Google Scholar]
- Available online: https://en.wikipedia.org/w/index.php?title=Recursive_least_squares_filter&oldid=1059014247 (accessed on 20 February 2023).
- Scott, F.; Hoof, H.; Meger, D. Addressing function approximation error in actor-critic methods. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Height: | 5200 mm tang to tang |
| Diameter: | 1600 mm |
| Total volume: | 11.5 m |
| Operation pressure: | 25 bar |
| Operation temperature: | 45 C |
| Liquid density at 45 C: | 759 kg/m |
| Liquid operation density for inlet stream: | 650.52 kg/m |
| Liquid operation density for output stream: | 722.8 kg/m |
| The level control valve coefficient: | cvi = 44.6 |
| The pressure drop through the valve acting: | 10 bar |
| Inlet liquid flow rate to tank m2: | 600 Kmole/h |
| Valve opening in % yi: | 50% |
| Desired level set point: | 40% |
| Parameters | m2 = 250 kmole/h | m2 = 1000 kmole/h | yi = 100% | yi = 0% |
|---|---|---|---|---|
| Rise Time | 4.9 | 1.42 | 3.57 | 1.03 |
| Transient Time | 57.46 | 25.15 | 35.6 | 35.49 |
| Settling Time | 57.46 | 25.15 | 35.6 | 35.49 |
| SettlingMin | 33.10 | 38.28 | 37.97 | 34.23 |
| SettlingMax | 56.61 | 53.98 | 49.1 | 66.56 |
| Overshoot | 38.98% | 34.96% | 22.5% | 86.46% |
| Undershoot | 0 | 0 | 0 | 0 |
| Peak | 56.61 | 53.98 | 49.1 | 66.56 |
| Peak Time | 29 | 20 | 24 | 16 |
| Parameters | m2 = 250 kmole/h | m2 = 1000 kmole/h | yi = 100% | yi = 0% |
|---|---|---|---|---|
| Rise Time | 116.54 | 116.54 | 116.54 | 116.54 |
| Transient Time | 2637.5 | 194.44 | 1642.7 | 5780 |
| Settling Time | 2626.3 | 193.60 | 1629 | 5766.1 |
| SettlingMin | 36.00 | 36.00 | 36.00 | 36.00 |
| SettlingMax | 41.04 | 40.72 | 40.39 | 42.39 |
| Overshoot | 0.98% | 1.82% | 0.98% | 5.98% |
| Undershoot | 0 | 0 | 0 | 0 |
| Peak | 40.39 | 40.72 | 40.39 | 42.39 |
| Peak Time | 388 | 6193 | 388 | 7633 |
| Parameters | m2 = 250 kmole/h | m2 = 1000 kmole/h | yi = 100% | yi = 0% |
|---|---|---|---|---|
| Rise Time | 3.46 | 3.46 | 3.46 | 3.46 |
| Transient Time | 11.31 | 11.30 | 11.31 | 11.30 |
| Settling Time | 11.29 | 11.28 | 11.29 | 11.28 |
| SettlingMin | 36.27 | 36.27 | 36.27 | 36.27 |
| SettlingMax | 40.35 | 40.35 | 40.35 | 40.40 |
| Overshoot | 0.86% | 0.88% | 0.85% | 0.93% |
| Undershoot | 0 | 0 | 0 | 0 |
| Peak | 40.35 | 40.35 | 40.35 | 40.40 |
| Peak Time | 14 | 14 | 14 | 14 |
| Parameters | m2 = 250 kmole/h | m2 = 1000 kmole/h | yi = 100% | yi = 0% |
|---|---|---|---|---|
| Rise Time | 7.47 | 7.47 | 7.47 | 7.47 |
| Transient Time | 158.77 | 158.77 | 158.77 | 158.77 |
| Settling Time | 112.09 | 112.09 | 112.09 | 112.09 |
| SettlingMin | 36.57 | 36.57 | 36.57 | 36.57 |
| SettlingMax | 41.40 | 41.40 | 41.40 | 41.40 |
| Overshoot | 3.50% | 3.50% | 3.50% | 3.50% |
| Undershoot | 0 | 0 | 0 | 0 |
| Peak | 41.40 | 41.40 | 41.40 | 41.40 |
| Peak Time | 32 | 32 | 32 | 32 |
| Parameters | RL as Offline Tuner | RL as Online Tuner |
|---|---|---|
| Rise Time (s) | 8.7 | 7.47 |
| Transient Time (s) | 20.08 | 158.77 |
| Settling Time (s) | 20 | 112.09 |
| SettlingMin (%) | 36.87 | 36.57 |
| SettlingMax (%) | 40.35 | 41.40 |
| Overshoot (%) | 0.88% | 3.50% |
| Undershoot (%) | 0 | 0 |
| Peak (0–100)% | 40.35 | 41.40 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ali, A.A.; Rashid, M.T.; Alhasnawi, B.N.; Bureš, V.; Mikulecký, P. Reinforcement-Learning-Based Level Controller for Separator Drum Unit in Refinery System. Mathematics 2023, 11, 1746. https://doi.org/10.3390/math11071746
Ali AA, Rashid MT, Alhasnawi BN, Bureš V, Mikulecký P. Reinforcement-Learning-Based Level Controller for Separator Drum Unit in Refinery System. Mathematics. 2023; 11(7):1746. https://doi.org/10.3390/math11071746
Chicago/Turabian StyleAli, Anwer Abdulkareem, Mofeed Turky Rashid, Bilal Naji Alhasnawi, Vladimír Bureš, and Peter Mikulecký. 2023. "Reinforcement-Learning-Based Level Controller for Separator Drum Unit in Refinery System" Mathematics 11, no. 7: 1746. https://doi.org/10.3390/math11071746
APA StyleAli, A. A., Rashid, M. T., Alhasnawi, B. N., Bureš, V., & Mikulecký, P. (2023). Reinforcement-Learning-Based Level Controller for Separator Drum Unit in Refinery System. Mathematics, 11(7), 1746. https://doi.org/10.3390/math11071746