An important limitation in describing the Chilean economy is the unavailability of a sufficient number of observations for estimating a reliable econometric model. Among the economic variables, the gross domestic product (GDP) is one of the most important indexes for describing the country’s economy. It constitutes the broadest measure of the country’s economy, containing a wide range of constitutive factors representing different areas of economic activity. It can be defined as the total value of products and services produced by a nation in a specific period of time, usually a year or a quarter. The frequency with which GDP is calculated is of particular interest since the low number of data (for example, yearly) could cause serious problems in terms of the quality of quantitative analysis. However, for this variable, in Chile, there is no quarterly information before 1986 (only annual information is available), and there is not a formally recognized procedure for reconstructing it. The Benchmarking or disaggregation methods allow disaggregating or interpolating a low frequency to a higher frequency time series, while the sum remains consistent with the low-frequency series. The most used disaggregation methods in the literature for estimating the GDP of different countries have been proposed by [
1,
2,
3,
4,
5,
6]. In summary, a two-step procedure can be used to describe all these methods. First, a preliminary high-frequency series is evaluated by using indicators with the same frequency. Second, the differences between the preliminary low-frequency series and the observed series are distributed among the high-frequency series. The resulting estimated high-frequency series is obtained by the sum of the preliminary high-frequency series and distributed annual residuals. While the methods of Denton [
4] and Denton–Cholette [
3] attempt to preserve the movements by using a single indicator as their preliminary series (which is not necessarily correlated with the low-frequency series), Chow–Lin [
2], Fernandez [
5], and Litterman [
6] performed a Generalized Least Squares Regression (GLS) of the low-frequency series on the high-frequency one for evaluating the preliminary series, which is obtained by the fitted values of the GLS regression. In the second step, the distribution matrix of all temporal disaggregation methods (except for the Denton–Cholette method) is a function of the variance-covariance matrix, as shown in Table 2 of [
7]. While Denton proposed to minimize the squared absolute or relative deviations from a (differenced) indicator series, Denton–Cholette introduced a modification of Denton’s original method, which removes spurious transient movement at the beginning of the resulting series ([
7,
8]). Instead, Chow–Lin [
2] assumed that the high-frequency residuals follow a stationary autoregressive process of order 1, AR(1), while Fernandez [
5] and Litterman [
6] suppose that the quarterly residuals follow a nonstationary process where the residual term is an AR(1). In particular, Fernandez’s method is a special case of Litterman where the autoregression parameter is equal to zero, and the high-frequency residuals follow a random walk process. Several methods have been proposed for estimating the autoregressive parameter (denoted by
) of the residuals in the Chow–Lin and Litterman methods. Chow and Lin (1971) proposed an iterative procedure that infers the parameter from the observed autocorrelation of the low-frequency residuals. Bournay and Laroque [
9] suggested the maximization of the likelihood of the GLS regression, and Barbone et al. [
10] proposed the minimization of the weighted residual sum of squares (RSS). Two variants of minimization of the residual sum of squares of the Chow–Lin method have been proposed: one of these was originally implemented in the software Ecotrim introduced by Barcellan et al. [
1], which used the correlation matrix instead of the variance-covariance matrix, and the other one in Matlab, by Quilis [
11], which multiplied the correlation matrix by a factor of
. All the above methods are now implemented in the
tempdisagg R package [
7]. Further, some works compare the above-mentioned methods using some traditional accuracy prediction metrics, such as Root Mean Squared Error (RMSE), Absolute Mean Difference (MAD), and Theil’s inequality coefficient (see, for example, [
12,
13,
14]). In particular, Ajao et al. [
14] compared the results of disaggregating techniques (Denton, Denton–Cholette, Chow–Lin, and Fernandez, and Litterman) for studying the Annual Gross Domestic Product (GDP) for Nigeria in the period 1981–2012 using quarterly export and import as the indicator variables. Some of these methods are also compared by Islaqm [
12] for disaggregating the yearly export of Bangladesh to quarterly export in the period 2004–2012. In [
13], different methods were used to disaggregate the annual series for personal consumption using the quarterly disposable income as an indicator.
Extensions to a dynamic framework have been considered by Guay and Maurin [
15,
16,
17]. In particular, [
16] extended the Chow–Lin procedure to flexible dynamic setting taking into account seasonality or calendar effects. Reference [
15] presented a temporal disaggregation technique concerning the extension from static to dynamic autoregressive distributed lag regressions in a state-space framework with application to the Italian quarterly accounts. In [
17], a state space approach is proposed for the temporal disaggregation problem by considering dynamic regression models with a particular concentration on the exact initialization of the different models. A set of annual series and the corresponding quarterly indicators, available by the Italian National Statistical Institute, Istat, are considered for real case studies. A different approach based on a two-step procedure (cointegration and state space regression) has been proposed by [
18] for estimating the Brazilian GDP quarterly series in the period between 1960 and 1996. A different type of two-step procedure based on regression and Benchmarking has been proposed by [
19] for the temporal disaggregation of quarterly GDP, and a novel sparse temporal-disaggregation procedure with an application to the UK gross domestic product data has been introduced by [
20].
GPD is important because it represents an image of how a country’s finances are doing and which areas are growing or shrinking. The growth of the PIB, which compares one quarter or one year with another, provides a reference to know if the economic situation is improving or worsening. PIB may be affected by many factors, such as public spending, trade, foreign investment, and productivity, and is a good financial indicator. When the PIB of a country grows, it means that its economy is prosperous. Companies are more profitable, they hire more people, and the investors will want to invest in the companies of the country. On the contrary, when the gross domestic product of a nation decreases, it means that its economy is experiencing a slowdown. The economic slowdown translates into less hiring of personnel, thus increases the unemployment rate. In addition, the profits of many companies decrease, so the distribution of dividends and the prices of their shares can also fall. The availability of official information produced by the state covers from 1940 to the present. The systematic construction of national accounts begins in CORFO (1957), which represents series prior to 1940–1954. This is followed by the accounts prepared by the Planning Office (ODEPLAN), which basically cover the decade of the nineteen-sixties. Finally, to this day, it is the Central Bank of Chile that is in charge of this task. The Central Bank of Chile has calculated the national accounts using 1977, 1986, 1996, and 2003 as base years. [
21]).
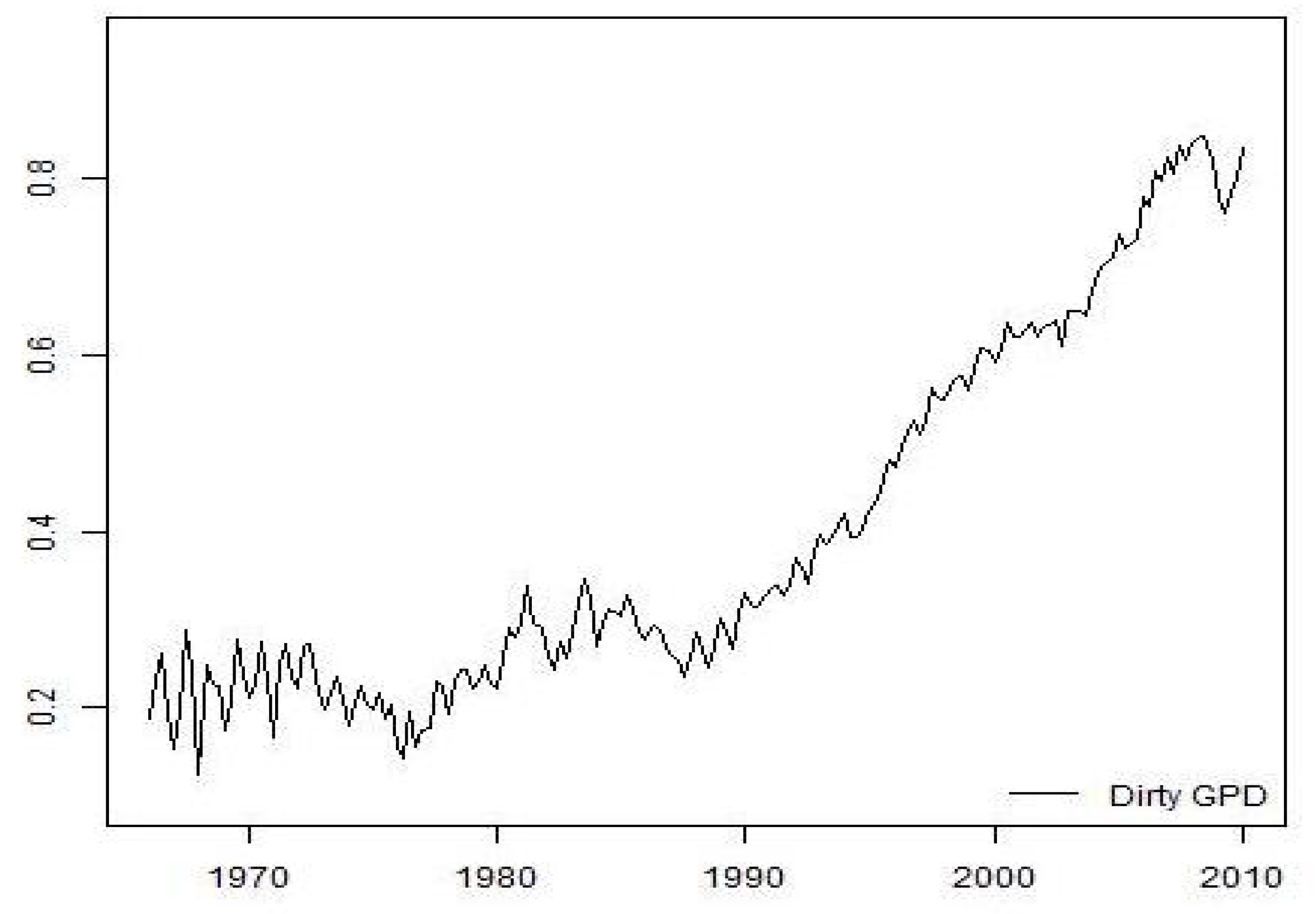
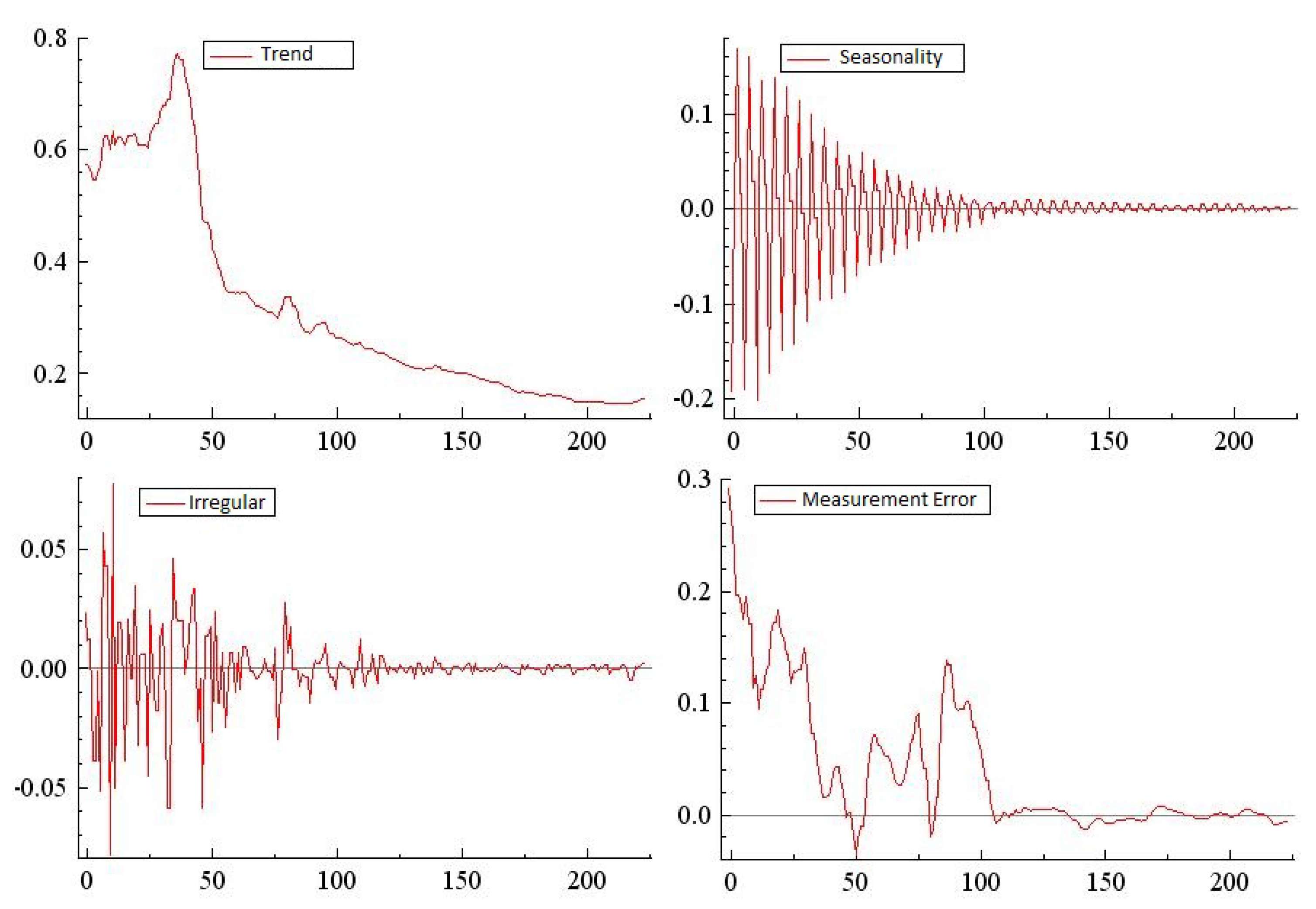
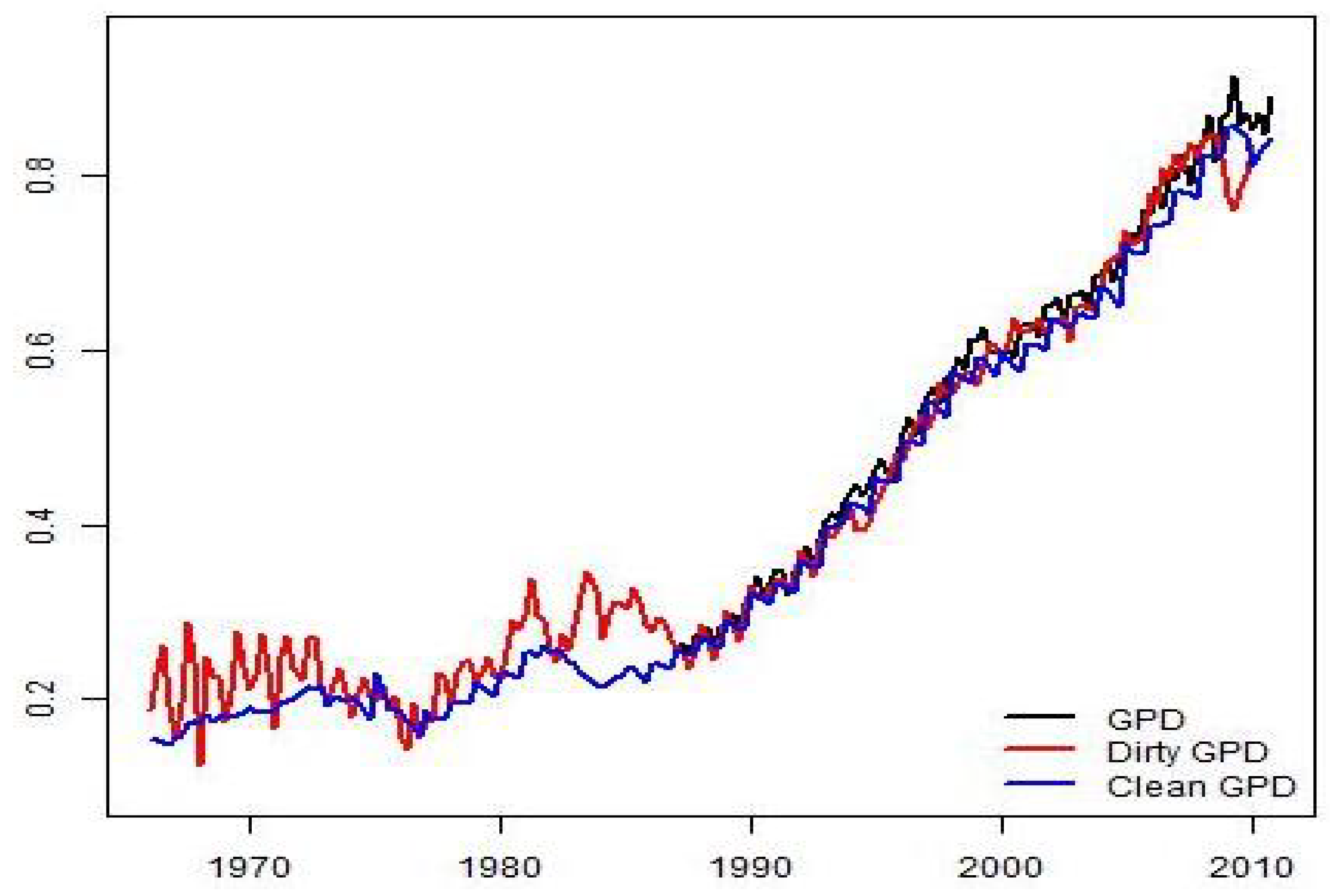
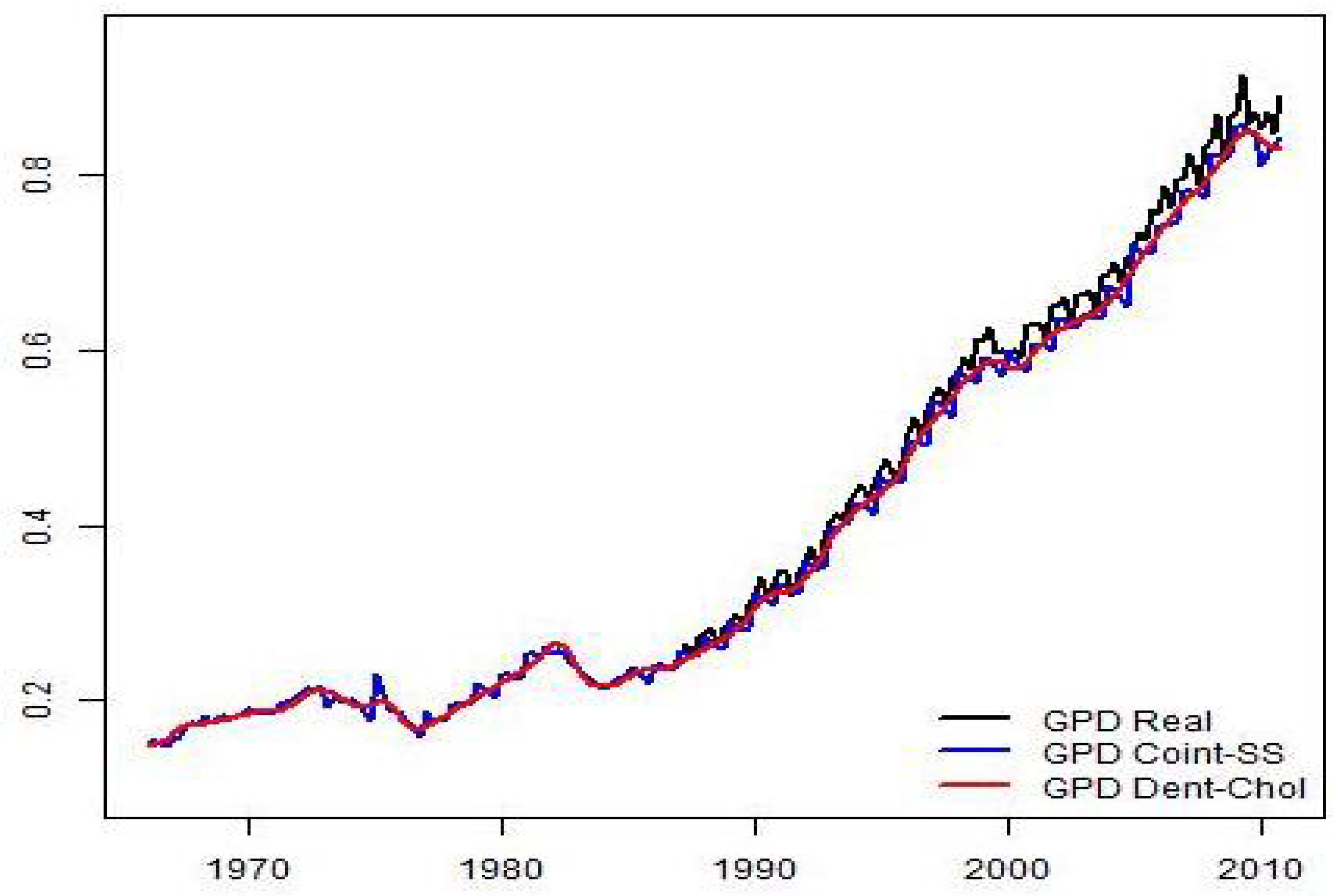
The main objective of this work is to propose a methodology for the estimation of Chilean quarterly GDP from 1965 to 2009. The procedure consists of an initial estimate of the quarterly GDP, which is obtained through the static Engle–Granger equation (see [
22,
23]) or cointegration analysis using the annual GDP data and variables related to GDP. The estimated coefficients of this regression are used to construct a quarterly equation between GDP and related variables by interpolating the estimated coefficients with the quarterly data of the aforementioned variables. This equation produces a first estimate of the quarterly GDP, called dirty GDP, due to the presence of errors. The second stage is to improve the estimates by minimizing the measurement errors and considering that the estimated measurements should be consistent with the annual GDP calculated by the Central Bank of Chile; that is, the sum of the quarterly estimates should be equal to the total annual GDP. The process of harmonization of quarterly and annual estimates is known, in the literature, as Benchmarking, and in this paper, it is addressed using the state space approach (see [
24,
25]). Important economical Chilean variables, such as the monetary aggregate, the price of copper, the terms of trade, the exports of goods and services and the mining production index, are used in the model to improve the estimation of the quarterly data. The application of the proposed method for reconstructing the quarterly Chilean GDP series constitutes a new contribution, which could be helpful to better understand the history of the Chilean economy additionally to the possibility of applying econometric models for predicting its future behavior. In summary, the main contributions of this work can be described as follows.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}